This is the multi-page printable view of this section. Click here to print.
Pigsty Blog Articles
- Featured
- Scaling Postgres to the Next Level at OpenAI
- Self-Hosting Supabase on PostgreSQL
- PostgreSQL is Eating the Database World
- Database in K8S: Pros & Cons
- Pigsty
- Pigsty v4.0: Victoria Stack + Security Hardening
- Pigsty v3.7: PostgreSQL Magneto Award, PG18 Deep Support
- Pigsty v3.6: The Ultimate PostgreSQL Distribution
- Pigsty v3.5: 4K Stars, PG18 Beta, 421 Extensions
- Pigsty v3.4: PITR Enhancement, Locale Best Practices, Auto Certificates
- Pigsty v3.3: 404 Extensions, Turnkey Apps, New Website
- Pigsty v3.2: The pig CLI, Full ARM Support, Supabase & Grafana Enhancements
- Pigsty v3.1: One-Click Supabase, PG17 Default, ARM & Ubuntu 24
- Pigsty v3.0: Pluggable Kernels & 340 Extensions
- Pigsty v2.7: The Extension Superpack
- Pigsty v2.6: PostgreSQL Crashes the OLAP Party
- Pigsty v2.5: Ubuntu & PG16
- Pigsty v2.4: Monitor Cloud RDS
- Pigsty v2.3: Richer App Ecosystem
- Pigsty v2.2: Monitoring System Reborn
- Pigsty v2.1: Vector + Full PG Version Support!
- Pigsty v2.0: Open-Source RDS PostgreSQL Alternative
- Pigsty v1.5: Docker Application Support, Infrastructure Self-Monitoring
- Pigsty v1.4: Modular Architecture, MatrixDB Data Warehouse Support
- Pigsty v1.3: Redis Support, PGCAT Overhaul, PGSQL Enhancements
- Pigsty v1.2: PG14 Default, Monitor Existing PG
- Pigsty v1.1: Homepage, Jupyter, Pev2, PgBadger
- Pigsty v1.0: GA Release with Monitoring Overhaul
- Pigsty v0.9: CLI + Logs
- Pigsty v0.8: Service Provisioning
- Pigsty v0.7: Monitor-Only Deployments
- Pigsty v0.6: Provisioning Upgrades
- Pigsty v0.5: Declarative DB Templates
- Pigsty v0.4: PG13 and Better Docs
- Pigsty v0.3: First Public Beta
- Cloud
- Did RedNote Exit the Cloud?
- Alipay, Taobao, Xianyu Went Dark. Smells Like a Message Queue Meltdown.
- Cloudflare’s Nov 18 Outage, Translated and Dissected
- Alicloud “Borrowed” Supabase. This Is What Happens When Giants Strip-Mine Open-Source.
- AWS’s Official DynamoDB Outage Postmortem
- How One AWS DNS Failure Cascaded Across Half the Internet
- Column: Cloud-Exit
- KubeSphere: Trust Crisis Behind Open-Source Supply Cut
- Alicloud’s rds_duckdb: Tribute or Rip-Off?
- Escaping Cloud Computing Scam Mills: The Big Fool Paying for Pain
- OpenAI Global Outage Postmortem: K8S Circular Dependencies
- WordPress Community Civil War: On Community Boundary Demarcation
- Cloud Database: Michelin Prices for Cafeteria Pre-made Meals
- Alibaba-Cloud: High Availability Disaster Recovery Myth Shattered
- Amateur Hour Opera: Alibaba-Cloud PostgreSQL Disaster Chronicle
- What Can We Learn from NetEase Cloud Music's Outage?
- Blue Screen Friday: Amateur Hour on Both Sides
- How Ahrefs Saved US$400M by NOT Going to the Cloud
- Database Deletion Supreme - Google Cloud Nuked a Major Fund's Entire Cloud Account
- Cloud Dark Forest: Exploding Cloud Bills with Just S3 Bucket Names
- Cloudflare Roundtable Interview and Q&A Record
- What Can We Learn from Tencent Cloud's Major Outage?
- Cloudflare - The Cyber Buddha That Destroys Public Cloud
- Can Luo Yonghao Save Toothpaste Cloud?
- Analyzing Alibaba-Cloud Server Computing Cost
- Will DBAs Be Eliminated by Cloud?
- Cloud-Exit High Availability Secret: Rejecting Complexity Masturbation
- S3: Elite to Mediocre
- Cloud Exit FAQ: DHH Saves Millions
- From Cost-Reduction Jokes to Real Cost Reduction and Efficiency
- Reclaim Hardware Bonus from the Cloud
- What Can We Learn from Alibaba-Cloud's Global Outage?
- Harvesting Alibaba-Cloud Wool, Building Your Digital Homestead
- Cloud Computing Mudslide: Deconstructing Public Cloud with Data
- Cloud Exit Odyssey: Time to Leave Cloud?
- DHH: Cloud-Exit Saves Over Ten Million, More Than Expected!
- FinOps: Endgame Cloud-Exit
- Why Isn't Cloud Computing More Profitable Than Sand Mining?
- SLA: Placebo or Insurance?
- EBS: Pig Slaughter Scam
- Garbage QCloud CDN: From Getting Started to Giving Up?
- Refuting "Why You Still Shouldn't Hire a DBA"
- Paradigm Shift: From Cloud to Local-First
- Are Cloud Databases an IQ Tax?
- Cloud RDS: From Database Drop to Exit
- Is DBA Still a Good Job?
- PostgreSQL
- Why PostgreSQL Will Dominate the AI Era
- Forging a China-Rooted, Global PostgreSQL Distro
- PG Extension Cloud: Unlocking PostgreSQL’s Entire Ecosystem
- The PostgreSQL 'Supply Cut' and Trust Issues in Software Supply Chain
- PostgreSQL Dominates Database World, but Who Will Devour PG?
- PostgreSQL Has Dominated the Database World
- PGDG Cuts Off Mirror Sync Channel
- Postgres Extension Day - See You There!
- OrioleDB is Coming! 4x Performance, Eliminates Pain Points, Storage-Compute Separation
- OpenHalo: MySQL Wire-Compatible PostgreSQL is Here!
- PGFS: Using Database as a Filesystem
- PostgreSQL Ecosystem Frontier Developments
- Pig, The Postgres Extension Wizard
- Don't Upgrade! Released and Immediately Pulled - Even PostgreSQL Isn't Immune to Epic Fails
- PostgreSQL 12 End-of-Life, PG 17 Takes the Throne
- The ideal way to deliver PostgreSQL Extensions
- PostgreSQL Convention 2024
- PostgreSQL 17 Released: No More Pretending!
- Can PostgreSQL Replace Microsoft SQL Server?
- Whoever Integrates DuckDB Best Wins the OLAP World
- StackOverflow 2024 Survey: PostgreSQL Has Gone Completely Berserk
- Self-Hosting Dify with PG, PGVector, and Pigsty
- PGCon.Dev 2024, The conf that shutdown PG for a week
- PostgreSQL 17 Beta1 Released!
- Why PostgreSQL is the Future Standard?
- Will PostgreSQL Change Its License?
- Postgres is eating the database world
- Technical Minimalism: Just Use PostgreSQL for Everything
- New PostgreSQL Ecosystem Player: ParadeDB
- PostgreSQL's Impressive Scalability
- PostgreSQL Outlook for 2024
- PostgreSQL Wins 2024 Database of the Year Award! (Fifth Time)
- PostgreSQL Macro Query Optimization with pg_stat_statements
- FerretDB: PostgreSQL Disguised as MongoDB
- How to Use pg_filedump for Data Recovery?
- Vector is the New JSON
- PostgreSQL, The most successful database
- AI Large Models and Vector Database PGVector
- How Powerful is PostgreSQL Really?
- Why PostgreSQL is the Most Successful Database?
- Ready-to-Use PostgreSQL Distribution: Pigsty
- Why Does PostgreSQL Have a Bright Future?
- Implementing Advanced Fuzzy Search
- Localization and Collation Rules in PostgreSQL
- PG Replica Identity Explained
- PostgreSQL Logical Replication Deep Dive
- A Methodology for Diagnosing PostgreSQL Slow Queries
- Incident-Report: Patroni Failure Due to Time Travel
- Online Primary Key Column Type Change
- Golden Monitoring Metrics: Errors, Latency, Throughput, Saturation
- Database Cluster Management Concepts and Entity Naming Conventions
- PostgreSQL's KPI
- Online PostgreSQL Column Type Migration
- Frontend-Backend Communication Wire Protocol
- Transaction Isolation Level Considerations
- Incident: PostgreSQL Extension Installation Causes Connection Failure
- CDC Change Data Capture Mechanisms
- Locks in PostgreSQL
- O(n2) Complexity of GIN Search
- PostgreSQL Common Replication Topology Plans
- Warm Standby: Using pg_receivewal
- Incident-Report: Connection-Pool Contamination Caused by pg_dump
- PostgreSQL Data Page Corruption Repair
- Relation Bloat Monitoring and Management
- Getting Started with PipelineDB
- TimescaleDB Quick Start
- Incident-Report: Integer Overflow from Rapid Sequence Number Consumption
- Incident-Report: PostgreSQL Transaction ID Wraparound
- GeoIP Geographic Reverse Lookup Optimization
- PostgreSQL Trigger Usage Considerations
- PostgreSQL Development Convention (2018 Edition)
- What Are PostgreSQL's Advantages?
- Efficient Administrative Region Lookup with PostGIS
- KNN Ultimate Optimization: From RDS to PostGIS
- Monitoring Table Size in PostgreSQL
- PgAdmin Installation and Configuration
- Incident-Report: Uneven Load Avalanche
- Bash and psql Tips
- Distinct On: Remove Duplicate Data
- Function Volatility Classification Levels
- Implementing Mutual Exclusion Constraints with Exclude
- PostgreSQL Routine Maintenance
- Backup and Recovery Methods Overview
- PgBackRest2 Documentation
- Pgbouncer Quick Start
- PostgreSQL Server Log Regular Configuration
- Testing Disk Performance with FIO
- Using sysbench to Test PostgreSQL Performance
- Changing Engines Mid-Flight — PostgreSQL Zero-Downtime Data Migration
- Finding Unused Indexes
- Batch Configure SSH Passwordless Login
- Wireshark Packet Capture Protocol Analysis
- The Versatile file_fdw — Reading System Information from Your Database
- Common Linux Statistics CLI Tools
- Installing PostGIS from Source
- Go Database Tutorial: database/sql
- Implementing Cache Synchronization with Go and PostgreSQL
- Auditing Data Changes with Triggers
- Building an ItemCF Recommender in Pure SQL
- UUID Properties, Principles and Applications
- PostgreSQL MongoFDW Installation and Deployment
- Database
- Data 2025: Year in Review with Mike Stonebraker
- What Database Does AI Agent Need?
- MySQL and Baijiu: The Internet’s Obedience Test
- Victoria: The Observability Stack That Slaps the Industry
- MinIO Is Dead. Who Picks Up the Pieces?
- MinIO is Dead
- When Answers Become Abundant, Questions Become the New Currency
- On Trusting Open-Source Supply Chains
- Don't Run Docker Postgres for Production!
- DDIA 2nd Edition, Chinese Translation
- Column: Database Guru
- Dongchedi Just Exposed “Smart Driving.” Where’s Our Dongku-Di?
- Google AI Toolbox: Production-Ready Database MCP is Here?
- Where Will Databases and DBAs Go in the AI Era?
- Stop Arguing, The AI Era Database Has Been Settled
- Open Data Standards: Postgres, OTel, and Iceberg
- The Lost Decade of Small Data
- Scaling Postgres to the Next Level at OpenAI
- How Many Shops Has etcd Torched?
- In the AI Era, Software Starts at the Database
- MySQL vs. PostgreSQL @ 2025
- Database Planet Collision: When PG Falls for DuckDB
- Comparing Oracle and PostgreSQL Transaction Systems
- Database as Business Architecture
- 7 Databases in 7 Weeks (2025)
- Solving Poker 24 with a Single SQL Query
- Self-Hosting Supabase on PostgreSQL
- Modern Hardware for Future Databases
- Can MySQL Still Catch Up with PostgreSQL?
- Open-Source "Tyrant" Linus's Purge
- Optimize Bio Cores First, CPU Cores Second
- MongoDB Has No Future: Good Marketing Can't Save a Rotten Mango
- MongoDB: Now Powered by PostgreSQL?
- Switzerland Mandates Open-Source for Government Software
- MySQL is dead, Long live PostgreSQL!
- CVE-2024-6387 SSH Vulnerability Fix
- Can Oracle Still Save MySQL?
- Oracle Finally Killed MySQL
- MySQL Performance Declining: Where is Sakila Going?
- Can Chinese Domestic Databases Really Compete?
- The $20 Brother PolarDB: What Should Databases Actually Cost?
- Redis Going Non-Open-Source is a Disgrace to "Open-Source" and Public Cloud
- How Can MySQL's Correctness Be This Garbage?
- Database in K8S: Pros & Cons
- Are Specialized Vector Databases Dead?
- Are Databases Really Being Strangled?
- Which EL-Series OS Distribution Is Best?
- What Kind of Self-Reliance Do Infrastructure Software Need?
- Back to Basics: Tech Reflection Chronicles
- Database Demand Hierarchy Pyramid
- Are Microservices a Bad Idea?
- NewSQL: Distributive Nonsens
- Time to Say Goodbye to GPL
- Is running postgres in docker a good idea?
- Understanding Time - Leap Years, Leap Seconds, Time and Time Zones
- Understanding Character Encoding Principles
- Concurrency Anomalies Explained
- Blockchain and Distributed Databases
- Consistency: An Overloaded Term
- Why Study Database Principles
Featured
Scaling Postgres to the Next Level at OpenAI

At PGConf.Dev 2025, Bohan Zhang from OpenAI shared how they scale PostgreSQL to millions of QPS using a single-primary, multi-replica architecture—proving that PostgreSQL can handle massive read workloads without sharding. Read more
Self-Hosting Supabase on PostgreSQL

Supabase is great, owning your own Supabase is even better! This tutorial covers how to self-host production-grade Supabase on local/cloud VMs using Pigsty. Read more
PostgreSQL is Eating the Database World

PostgreSQL is not just a simple relational database, but an abstract framework for data management with the power to devour the entire database world. “Just use Postgres for everything” has become a mainstream best practice. Read more
Database in K8S: Pros & Cons

Whether databases should be housed in Kubernetes/Docker remains highly controversial. While K8s excels in managing stateless applications, it has fundamental drawbacks with stateful services like databases. Read more
Pigsty
Pigsty v4.0: Victoria Stack + Security Hardening

VictoriaMetrics/Logs replace Prometheus/Loki for 10x observability performance, Vector handles logs, unified UI, firewall/SELinux/credential hardening. Read more
Pigsty v3.7: PostgreSQL Magneto Award, PG18 Deep Support

PostgreSQL 18 becomes the default version, EL10 and Debian 13 support added, extensions reach 437, and Pigsty wins the PostgreSQL Magneto Award. Read more
Pigsty v3.6: The Ultimate PostgreSQL Distribution

New doc site, PITR playbook, Percona PG TDE kernel support, and Supabase self-hosting optimization make v3.6 the last major release before 4.0. Read more
Pigsty v3.5: 4K Stars, PG18 Beta, 421 Extensions

Pigsty crosses 4K GitHub stars, adds PG18 beta support, pushes extensions to 421, ships new doc site, and completes OrioleDB/OpenHalo full-platform support. Read more
Pigsty v3.4: PITR Enhancement, Locale Best Practices, Auto Certificates

Pigsty v3.4 adds pgBackRest backup monitoring, cross-cluster PITR restore, automated HTTPS certificates, locale best practices, and full-platform IvorySQL and Apache AGE support. Read more
Pigsty v3.3: 404 Extensions, Turnkey Apps, New Website

Pigsty v3.3 pushes available extensions to 404, adds turnkey app deployment with app.yml, delivers Certbot integration for automated HTTPS, and launches a redesigned website. Read more
Pigsty v3.2: The pig CLI, Full ARM Support, Supabase & Grafana Enhancements

Pigsty v3.2 introduces the pig CLI for PostgreSQL package management, complete ARM64 extension repository support, and Supabase & Grafana enhancements. Read more
Pigsty v3.1: One-Click Supabase, PG17 Default, ARM & Ubuntu 24

Pigsty v3.1 makes PostgreSQL 17 the default, delivers one-click Supabase self-hosting, adds ARM64 and Ubuntu 24.04 support, and simplifies configuration management. Read more
Pigsty v3.0: Pluggable Kernels & 340 Extensions

Pigsty v3.0 ships 340 extensions across EL/Deb with full parity, adds pluggable kernels (Babelfish, IvorySQL, PolarDB) for MSSQL/Oracle compatibility, and delivers a local-first state-of-the-art RDS experience. Read more
Pigsty v2.7: The Extension Superpack

Pigsty v2.7 bundles 255 PostgreSQL extensions, plus Docker templates for Odoo, Supabase, PolarDB, and Jupyter, with new PITR dashboards. Read more
Pigsty v2.6: PostgreSQL Crashes the OLAP Party

Pigsty v2.6 makes PostgreSQL 16.2 the default, introduces ParadeDB and DuckDB support, and brings epic-level OLAP improvements. Read more
Pigsty v2.5: Ubuntu & PG16

Pigsty v2.5 adds Ubuntu/Debian support (bullseye, bookworm, jammy, focal), new extensions including pointcloud and imgsmlr, and redesigned monitoring dashboards. Read more
Pigsty v2.4: Monitor Cloud RDS

Pigsty v2.4 delivers PostgreSQL 16 GA support, RDS/PolarDB monitoring, Redis Sentinel HA, and a wave of new extensions including Apache AGE, zhparser, and pg_embedding. Read more
Pigsty v2.3: Richer App Ecosystem

Pigsty v2.3 adds FerretDB MongoDB support, NocoDB integration, L2 VIP for node clusters, PostgreSQL security patches, and Redis 7.2. Read more
Pigsty v2.2: Monitoring System Reborn

Pigsty v2.2 delivers a complete monitoring dashboard overhaul built on Grafana 10, a 42-node production simulation sandbox, Pigsty’s own RPM repos, and UOS compatibility. Read more
Pigsty v2.1: Vector + Full PG Version Support!

Pigsty v2.1 provides support for PostgreSQL 12 through 16, with PGVector for AI embeddings. Read more
Pigsty v2.0: Open-Source RDS PostgreSQL Alternative

Pigsty v2.0 delivers major improvements in security, compatibility, and feature integration — truly becoming a local open-source RDS alternative. Read more
Pigsty v1.5: Docker Application Support, Infrastructure Self-Monitoring

Complete Docker support, infrastructure self-monitoring, ETCD as DCS, better cold backup support, and CMDB improvements. Read more
Pigsty v1.4: Modular Architecture, MatrixDB Data Warehouse Support

Pigsty v1.4 introduces a modular architecture with four independent modules, adds MatrixDB time-series data warehouse support, and delivers global CDN acceleration. Read more
Pigsty v1.3: Redis Support, PGCAT Overhaul, PGSQL Enhancements

Pigsty v1.3 adds Redis support with three deployment modes, rebuilds the PGCAT catalog explorer, and enhances PGSQL monitoring dashboards. Read more
Pigsty v1.2: PG14 Default, Monitor Existing PG

Pigsty v1.2 makes PostgreSQL 14 the default version and adds support for monitoring existing database instances independently. Read more
Pigsty v1.1: Homepage, Jupyter, Pev2, PgBadger

Pigsty v1.1.0 ships with a redesigned homepage, plus JupyterLab, PGWeb, Pev2 & PgBadger integrations. Read more
Pigsty v1.0: GA Release with Monitoring Overhaul

Pigsty v1.0.0 GA is here — a batteries-included, open-source PostgreSQL distribution ready for production. Read more
Pigsty v0.9: CLI + Logs

One-click installs, a beta CLI, and Loki-based logging make Pigsty easier to land. Read more
Pigsty v0.8: Service Provisioning

Services are now first-class objects, so you can define any routing policy—built-in HAProxy, L4 VIPs, or your own balancer. Read more
Pigsty v0.7: Monitor-Only Deployments

Monitor-only deployments unlock hybrid fleets, while DB/user provisioning APIs get a serious cleanup. Read more
Pigsty v0.6: Provisioning Upgrades

v0.6 reworks the provisioning flow, adds exporter toggles, and makes the monitoring stack portable across environments. Read more
Pigsty v0.5: Declarative DB Templates

Pigsty v0.5 introduces declarative database templates so roles, schemas, extensions, and ACLs can be described entirely in YAML. Read more
Pigsty v0.4: PG13 and Better Docs

Pigsty v0.4 ships PG13 support, a Grafana 7.3 refresh, and a cleaned-up docs site for the second public beta. Read more
Pigsty v0.3: First Public Beta

Pigsty v0.3.0, the first public beta, lands with eight battle-tested dashboards and an offline bundle. Read more
Cloud
Did RedNote Exit the Cloud?

When a company that was “born on the cloud” goes “self-host first,” does that count as cloud exit? A repost of a deleted piece on the infrastructure coming-of-age for Chinas internet giants. Read more
Alipay, Taobao, Xianyu Went Dark. Smells Like a Message Queue Meltdown.

Dec 4, 2025, Taobao, Alipay, and Xianyu all cratered. Users got charged while orders still showed “unpaid,” a carbon copy of the 2024 Double-11 fiasco. Read more
Cloudflare’s Nov 18 Outage, Translated and Dissected

A ClickHouse permission tweak doubled a feature file, tripped a Rust hard limit, and froze Cloudflare’s core traffic for six hours—their worst outage since 2019. Here’s the full translation plus commentary. Read more
Alicloud “Borrowed” Supabase. This Is What Happens When Giants Strip-Mine Open-Source.

Founders here get asked the same question over and over: what if Alibaba builds the same thing? Alicloud RDS just launched Supabase as a managed service. Exhibit A. Read more
AWS’s Official DynamoDB Outage Postmortem

AWS finally published the Oct 20 us-east-1 postmortem. I translated the key parts and added commentary on how one DNS bug toppled half the internet. Read more
How One AWS DNS Failure Cascaded Across Half the Internet

us-east-1’s DNS control plane faceplanted for 15 hours and dragged 142 AWS services—and a good chunk of the public internet—down with it. Here’s the forensic tour. Read more
Column: Cloud-Exit

A whole generation of developers has been told “cloud-first.” This column collects data, case studies, and analysis on the cloud exit movement. Read more
KubeSphere: Trust Crisis Behind Open-Source Supply Cut

Deleting images and running away - this isn’t about commercial closed-source issues, but supply cut problems that directly destroy years of accumulated community trust. Read more
Alicloud’s rds_duckdb: Tribute or Rip-Off?

Does bolting DuckDB onto RDS suddenly make open-source Postgres ‘trash’? Business and open source should be symbiotic. If a vendor only extracts without giving back, the community will spit it out." Read more
Escaping Cloud Computing Scam Mills: The Big Fool Paying for Pain

A user consulted about distributed databases, but he wasn’t dealing with data bursting through server cabinet doors—rather, he’d fallen into another cloud computing pig-butchering scam. Read more
OpenAI Global Outage Postmortem: K8S Circular Dependencies

Even trillion-dollar unicorns can be a house of cards when operating outside their core expertise. Read more
WordPress Community Civil War: On Community Boundary Demarcation

When open source ideals meet commercial conflicts, what insights can this conflict between open source software communities and cloud vendors bring? On the importance of community boundary demarcation. Read more
Cloud Database: Michelin Prices for Cafeteria Pre-made Meals

The paradigm shift brought by RDS, whether cloud databases are overpriced cafeteria meals. Quality, security, efficiency, and cost analysis, cloud exit database self-building: how to implement in practice! Read more
Alibaba-Cloud: High Availability Disaster Recovery Myth Shattered

Seven days after Singapore Zone C failure, availability not even reaching 8, let alone multiple 9s. But compared to data loss, availability is just a minor issue Read more
Amateur Hour Opera: Alibaba-Cloud PostgreSQL Disaster Chronicle

A customer experienced an outrageous cascade of failures on cloud database last week: a high-availability PG RDS cluster went down completely - both primary and replica servers - after attempting a simple memory expansion, troubleshooting until dawn. Poor recommendations abounded during the incident, and the postmortem was equally perfunctory. I share this case study here for reference and review. Read more
What Can We Learn from NetEase Cloud Music's Outage?

NetEase Cloud Music experienced a two-and-a-half-hour outage this afternoon. Based on circulating online clues, we can deduce that the real cause behind this incident was… Read more
Blue Screen Friday: Amateur Hour on Both Sides

Both client and vendor failed to control blast radius, leading to this epic global security incident that will greatly benefit local-first software philosophy. Read more
How Ahrefs Saved US$400M by NOT Going to the Cloud

After Alibaba-Cloud’s epic global outage on Double 11, setting industry records, how should we evaluate this incident and what lessons can we learn from it? Read more
Database Deletion Supreme - Google Cloud Nuked a Major Fund's Entire Cloud Account

Due to an “unprecedented configuration error,” Google Cloud mistakenly deleted trillion-RMB fund giant UniSuper’s entire cloud account, cloud environment and all off-site backups, setting a new record in cloud computing history! Read more
Cloud Dark Forest: Exploding Cloud Bills with Just S3 Bucket Names

The dark forest law has emerged on public cloud: Anyone who knows your S3 object storage bucket name can explode your cloud bill. Read more
Cloudflare Roundtable Interview and Q&A Record

As a roundtable guest, I was invited to participate in Cloudflare’s Immerse conference in Shenzhen. During the dinner, I had in-depth discussions with Cloudflare’s APAC CMO, Greater China Technical Director, and front-line engineers about many questions of interest to netizens. Read more
What Can We Learn from Tencent Cloud's Major Outage?

Tencent Cloud’s epic global outage after Double 11 set industry records. How should we evaluate and view this failure, and what lessons can we learn from it? Read more
Cloudflare - The Cyber Buddha That Destroys Public Cloud

While I’ve always advocated for cloud exit, if it’s about adopting a cyber bodhisattva cloud like Cloudflare, I’m all in with both hands raised. Read more
Can Luo Yonghao Save Toothpaste Cloud?

Luo Yonghao’s livestream first spent half an hour selling robot vacuums, then Luo himself belatedly appeared to read scripts selling “cloud computing” for forty minutes — before seamlessly transitioning to selling Colgate enzyme-free toothpaste — leaving viewers bewildered between toothpaste and cloud computing. Read more
Analyzing Alibaba-Cloud Server Computing Cost

Alibaba-Cloud claimed major price cuts, but a detailed analysis of cloud server costs reveals that cloud computing and storage remain outrageously expensive. Read more
Will DBAs Be Eliminated by Cloud?

Two days ago, the ninth episode of Open-Source Talks had the theme “Will DBAs Be Eliminated by Cloud?” As the host, I restrained myself from jumping into the debate throughout, so I’m writing this article to discuss this question: Will DBAs be eliminated by cloud? Read more
Cloud-Exit High Availability Secret: Rejecting Complexity Masturbation

Programmers are drawn to complexity like moths to flame. The more complex the system architecture diagram, the greater the intellectual masturbation high. Steadfast resistance to this behavior is a key reason for DHH’s success in cloud-free availability. Read more
S3: Elite to Mediocre

S3 is no longer “cheap” with the evolution of hardware, and other challengers such as cloudflare R2. Read more
Cloud Exit FAQ: DHH Saves Millions
Author: DHH (David Heinemeier Hansson) | Original: Cloud Exit FAQ

DHH’s cloud exit journey has reached a new stage, saving nearly a million dollars so far with potential savings of nearly ten million over the next five years. Read more
From Cost-Reduction Jokes to Real Cost Reduction and Efficiency
Alibaba-Cloud and Didi had major outages one after another. This article discusses how to move from cost-reduction jokes to real cost reduction and efficiency — what costs should we really reduce, what efficiency should we improve? Read more
Reclaim Hardware Bonus from the Cloud

Hardware is interesting again, developments in CPUs and SSDs remain largely unnoticed by the majority of devs. A whole generation of developers is obscured by cloud hype and marketing noise. Read more
What Can We Learn from Alibaba-Cloud's Global Outage?

Alibaba-Cloud’s epic global outage after Double 11 set an industry record. How should we evaluate this incident, and what lessons can we learn from it? Read more
Harvesting Alibaba-Cloud Wool, Building Your Digital Homestead

Alibaba-Cloud’s Double 11 offered a great deal: 2C2G3M ECS servers for ¥99/year, low price for three years. This article shows how to use this decent ECS to build your own digital homestead. Read more
Cloud Computing Mudslide: Deconstructing Public Cloud with Data

Once upon a time, “going to cloud” was almost politically correct in tech circles, but few people use hard data to analyze the trade-offs involved. I’m willing to be this skeptic: let me use hard data and personal stories to explain the traps and value of public cloud rental models. Read more
Cloud Exit Odyssey: Time to Leave Cloud?
Author: DHH (David Heinemeier Hansson) | Original: DHH’s Hey Blog

This article chronicles the complete journey of 37Signals moving off the cloud, led by DHH. Valuable reference for both cloud-bound and cloud-native enterprises. Read more
DHH: Cloud-Exit Saves Over Ten Million, More Than Expected!

DHH migrated their seven cloud applications from AWS to their own hardware. 2024 is the first year of full savings realization. They’re delighted to find the savings exceed initial estimates. Read more
FinOps: Endgame Cloud-Exit

At the SACC 2023 FinOps session, I fiercely criticized cloud vendors. This is a transcript of my speech, introducing the ultimate FinOps concept — Cloud-Exit and its implementation path. Read more
Why Isn't Cloud Computing More Profitable Than Sand Mining?

Public cloud margins worse than sand mining—why are pig-butchering schemes losing money? Resource-selling models heading toward price wars, open source alternatives breaking monopoly dreams! Service competitiveness gradually neutralized—where is the cloud computing industry heading? How did domestic cloud vendors make a business with 30-40% pure profit less profitable than sand mining? Read more
SLA: Placebo or Insurance?

SLA is a marketing tool rather than insurance. In the worst-case scenario, it’s an unavoidable loss; at best, it provides emotional comfort. Read more
EBS: Pig Slaughter Scam

The real business model of cloud: “Cheap” EC2/S3 to attract customers, and fleece with “Expensive” EBS/RDS Read more
Garbage QCloud CDN: From Getting Started to Giving Up?

I originally believed that at least in IaaS fundamentals — storage, compute, and networking — public cloud vendors could still make significant contributions. However, my personal experience with Tencent Cloud CDN shook that belief: domestic cloud vendors’ products and services are truly unbearable. Read more
Refuting "Why You Still Shouldn't Hire a DBA"

Guo Degang has a comedy routine: “Say I tell a rocket scientist, your rocket is no good, the fuel is wrong. I think it should burn wood, better yet coal, and it has to be premium coal, not washed coal. If that scientist takes me seriously, he loses.” Read more
Paradigm Shift: From Cloud to Local-First

Cloud databases’ exorbitant markups—sometimes 10x or more—are undoubtedly a scam for users outside the applicable spectrum. But we can dig deeper: why are public clouds, especially cloud databases, like this? And based on their underlying logic, make predictions about the industry’s future. Read more
Are Cloud Databases an IQ Tax?

Winter is coming, tech giants are laying off workers entering cost-reduction mode. Can cloud databases, the number one public cloud cash cow, still tell their story? The money you spend on cloud databases for one year is enough to buy several or even dozens of higher-performing servers. Are you paying an IQ tax by using cloud databases? Read more
Cloud RDS: From Database Drop to Exit

I recently witnessed a live cloud database drop-and-run incident. This article discusses how to handle accidentally deleted data when using PostgreSQL in production environments. Read more
Is DBA Still a Good Job?

Ant Financial had a self-deprecating joke: besides regulation, only DBAs could bring down Alipay. Although DBA sounds like a profession with glorious history and dim prospects, who knows if it might become trendy again after a few terrifying major cloud database incidents? Read more
PostgreSQL
Why PostgreSQL Will Dominate the AI Era

Context window economics, the polyglot persistence problem, and the triumph of zero-glue architecture make PostgreSQL the database king of the AI era. Read more
Forging a China-Rooted, Global PostgreSQL Distro

PostgreSQL already won. The real battle is the distro layer. Will Chinese developers watch from the sideline or craft a PG “Ubuntu” for the world? Read more
PG Extension Cloud: Unlocking PostgreSQL’s Entire Ecosystem

Free, open, no VPN. Install PostgreSQL and 431 extensions on 14 Linux distros × 6 PG versions via native RPM/DEB—and a tiny CLI. Read more
The PostgreSQL 'Supply Cut' and Trust Issues in Software Supply Chain

PostgreSQL official repos cut off global mirror sync channels, open-source binaries supply disrupted, revealing the true colors of various database and cloud vendors. Read more
PostgreSQL Dominates Database World, but Who Will Devour PG?

The same forces that once led MongoDB and MySQL toward closure are now at work in the PostgreSQL ecosystem. The PG world needs a distribution that represents “software freedom” values. Read more
PostgreSQL Has Dominated the Database World

The 2025 SO global developer survey results are fresh out, and PostgreSQL has become the most popular, most loved, and most wanted database for the third consecutive year. Nothing can stop PostgreSQL from consolidating the entire database world! Read more
PGDG Cuts Off Mirror Sync Channel

PGDG cuts off FTP rsync sync channels, global mirror sites universally disconnected - this time they really strangled global users’ supply chain. Read more
Postgres Extension Day - See You There!

The annual PostgreSQL developer conference will be held in Montreal in May. Like the first PG Con.Dev, there’s also an additional dedicated event - Postgres Extensions Day Read more
OrioleDB is Coming! 4x Performance, Eliminates Pain Points, Storage-Compute Separation

A PG kernel fork acquired by Supabase, claiming to solve PG’s XID wraparound problem, eliminate table bloat issues, improve performance by 4x, and support cloud-native storage. Now part of the Pigsty family. Read more
OpenHalo: MySQL Wire-Compatible PostgreSQL is Here!

What? PostgreSQL can now be accessed using MySQL clients? That’s right, openHalo, which was open-sourced on April Fool’s Day, provides exactly this capability and has now joined the Pigsty kernel family. Read more
PGFS: Using Database as a Filesystem

Leverage JuiceFS to turn PostgreSQL into a filesystem with PITR capabilities! Read more
PostgreSQL Ecosystem Frontier Developments

Sharing some interesting recent developments in the PG ecosystem. Read more
Pig, The Postgres Extension Wizard

Why would we need yet another package manager for PostgreSQL & extensions? Read more
Don't Upgrade! Released and Immediately Pulled - Even PostgreSQL Isn't Immune to Epic Fails

Never deploy on Friday, or you’ll be working all weekend! PostgreSQL minor releases were pulled on the day of release, requiring emergency rollback. Read more
PostgreSQL 12 End-of-Life, PG 17 Takes the Throne

PG17 achieved extension ecosystem adaptation in half the time of PG16, with 300 available extensions ready for production use. PG 12 officially exits support lifecycle. Read more
The ideal way to deliver PostgreSQL Extensions

PostgreSQL Is Eating the Database World through the power of extensibility. With 390 extensions powering PG, we may not say it’s invincible, but it’s definitely getting much closer. Read more
PostgreSQL Convention 2024

No rules, no standards. Some developer conventions for PostgreSQL 16. Read more
PostgreSQL 17 Released: No More Pretending!

PostgreSQL is now the world’s most advanced open-source database and has become the preferred open-source database for organizations of all sizes, matching or exceeding top commercial databases. Read more
Can PostgreSQL Replace Microsoft SQL Server?

PostgreSQL can directly replace Oracle, SQL Server, and MongoDB at the kernel level. Of course, the most thorough replacement is SQL Server - AWS’s Babelfish provides wire-protocol-level compatibility. Read more
Whoever Integrates DuckDB Best Wins the OLAP World

Just like the vector database extension race two years ago, the current PostgreSQL ecosystem extension competition has begun revolving around DuckDB. MotherDuck’s official entry into the PostgreSQL extension space undoubtedly signals that competition has entered white-hot territory. Read more
StackOverflow 2024 Survey: PostgreSQL Has Gone Completely Berserk
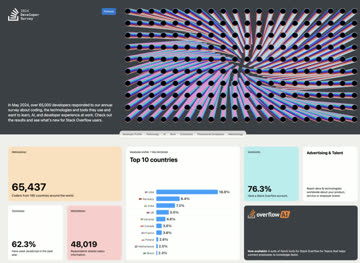
The 2024 StackOverflow Global Developer Survey results are fresh out, and PostgreSQL has become the most popular, most loved, and most wanted database globally for the second consecutive year. Nothing can stop PostgreSQL from devouring the entire database world anymore! Read more
Self-Hosting Dify with PG, PGVector, and Pigsty
Dify is an open-source LLM app development platform. This article explains how to self-host Dify using Pigsty. Read more
PGCon.Dev 2024, The conf that shutdown PG for a week

Experience & Feeling on the PGCon.Dev 2024 Read more
PostgreSQL 17 Beta1 Released!

The PostgreSQL Global Development Group announces PostgreSQL 17’s first Beta version is now available. This time, PostgreSQL has truly burst the toothpaste tube! Read more
Why PostgreSQL is the Future Standard?
Author: Ajay Kulkarni (TimescaleDB CEO) | Original: Why PostgreSQL Is the Bedrock for the Future of Data

One of the biggest trends in software development today is PostgreSQL becoming the de facto database standard. This article explains why. Read more
Will PostgreSQL Change Its License?
Author: Jonathan Katz (PostgreSQL Core Team) | Original: PostgreSQL Will Not Change Its License

PostgreSQL will not change its license. This article is a response from PostgreSQL core team members on this question. Read more
Postgres is eating the database world
PostgreSQL isn’t just a simple relational database; it’s a data management framework with the potential to engulf the entire database realm. The trend of “Using Postgres for Everything” is no longer limited to a few elite teams but is becoming a mainstream best practice.
OLAP’s New Challenger
In a 2016 database meetup, I argued that a significant gap in the PostgreSQL ecosystem was the lack of a sufficiently good columnar storage engine for OLAP workloads. While PostgreSQL itself offers lots of analysis features, its performance in full-scale analysis on larger datasets doesn’t quite measure up to dedicated real-time data warehouses.
Consider ClickBench, an analytics performance benchmark, where we’ve documented the performance of PostgreSQL, its ecosystem extensions, and derivative databases. The untuned PostgreSQL performs poorly (x1050), but it can reach (x47) with optimization. Additionally, there are three analysis-related extensions: columnar store Hydra (x42), time-series TimescaleDB (x103), and distributed Citus (x262).

ClickBench c6a.4xlarge, 500gb gp2 results in relative time
This performance can’t be considered bad, especially compared to pure OLTP databases like MySQL and MariaDB (x3065, x19700); however, its third-tier performance is not “good enough,” lagging behind the first-tier OLAP components like Umbra, ClickHouse, Databend, SelectDB (x3~x4) by an order of magnitude. It’s a tough spot - not satisfying enough to use, but too good to discard.
However, the arrival of ParadeDB and DuckDB changed the game!
ParadeDB’s native PG extension pg_analytics achieves second-tier performance (x10), narrowing the gap to the top tier to just 3–4x. Given the additional benefits, this level of performance discrepancy is often acceptable - ACID, freshness and real-time data without ETL, no additional learning curve, no maintenance of separate services, not to mention its ElasticSearch grade full-text search capabilities.
DuckDB focuses on pure OLAP, pushing analysis performance to the extreme (x3.2) — excluding the academically focused, closed-source database Umbra, DuckDB is arguably the fastest for practical OLAP performance. It’s not a PG extension, but PostgreSQL can fully leverage DuckDB’s analysis performance boost as an embedded file database through projects like DuckDB FDW and pg_quack.
The emergence of ParadeDB and DuckDB propels PostgreSQL’s analysis capabilities to the top tier of OLAP, filling the last crucial gap in its analytic performance.
The Pendulum of Database Realm
The distinction between OLTP and OLAP didn’t exist at the inception of databases. The separation of OLAP data warehouses from databases emerged in the 1990s due to traditional OLTP databases struggling to support analytics scenarios’ query patterns and performance demands.
For a long time, best practice in data processing involved using MySQL/PostgreSQL for OLTP workloads and syncing data to specialized OLAP systems like Greenplum, ClickHouse, Doris, Snowflake, etc., through ETL processes.

DDIA, Martin Kleppmann, ch3, The republic of OLTP & Kingdom of OLAP
Like many “specialized databases,” the strength of dedicated OLAP systems often lies in performance — achieving 1-3 orders of magnitude improvement over native PG or MySQL. The cost, however, is redundant data, excessive data movement, lack of agreement on data values among distributed components, extra labor expense for specialized skills, extra licensing costs, limited query language power, programmability and extensibility, limited tool integration, poor data integrity and availability compared with a complete DMBS.
However, as the saying goes, “What goes around comes around”. With hardware improving over thirty years following Moore’s Law, performance has increased exponentially while costs have plummeted. In 2024, a single x86 machine can have hundreds of cores (512 vCPU EPYC 9754x2), several TBs of RAM, a single NVMe SSD can hold up to 64TB, and a single all-flash rack can reach 2PB; object storage like S3 offers virtually unlimited storage.

Hardware advancements have solved the data volume and performance issue, while database software developments (PostgreSQL, ParadeDB, DuckDB) have addressed access method challenges. This puts the fundamental assumptions of the analytics sector — the so-called “big data” industry — under scrutiny.
As DuckDB’s manifesto "Big Data is Dead" suggests, the era of big data is over. Most people don’t have that much data, and most data is seldom queried. The frontier of big data recedes as hardware and software evolve, rendering “big data” unnecessary for 99% of scenarios.
If 99% of use cases can now be handled on a single machine with standalone DuckDB or PostgreSQL (and its replicas), what’s the point of using dedicated analytics components? If every smartphone can send and receive texts freely, what’s the point of pagers? (With the caveat that North American hospitals still use pagers, indicating that maybe less than 1% of scenarios might genuinely need “big data.”)
The shift in fundamental assumptions is steering the database world from a phase of diversification back to convergence, from a big bang to a mass extinction. In this process, a new era of unified, multi-modeled, super-converged databases will emerge, reuniting OLTP and OLAP. But who will lead this monumental task of reconsolidating the database field?
PostgreSQL: The Database World Eater
There are a plethora of niches in the database realm: time-series, geospatial, document, search, graph, vector databases, message queues, and object databases. PostgreSQL makes its presence felt across all these domains.
A case in point is the PostGIS extension, which sets the de facto standard in geospatial databases; the TimescaleDB extension awkwardly positions “generic” time-series databases; and the vector extension, PGVector, turns the dedicated vector database niche into a punchline.
This isn’t the first time; we’re witnessing it again in the oldest and largest subdomain: OLAP analytics. But PostgreSQL’s ambition doesn’t stop at OLAP; it’s eyeing the entire database world!

What makes PostgreSQL so capable? Sure, it’s advanced, but so is Oracle; it’s open-source, as is MySQL. PostgreSQL’s edge comes from being both advanced and open-source, allowing it to compete with Oracle/MySQL. But its true uniqueness lies in its extreme extensibility and thriving extension ecosystem.

TimescaleDB survey: what is the main reason you choose to use PostgreSQL
PostgreSQL isn’t just a relational database; it’s a data management framework capable of engulfing the entire database galaxy. Besides being open-source and advanced, its core competitiveness stems from extensibility, i.e., its infra’s reusability and extension’s composability.
The Magic of Extreme Extensibility
PostgreSQL allows users to develop extensions, leveraging the database’s common infra to deliver features at minimal cost. For instance, the vector database extension pgvector, with just several thousand lines of code, is negligible in complexity compared to PostgreSQL’s millions of lines. Yet, this “insignificant” extension achieves complete vector data types and indexing capabilities, outperforming lots of specialized vector databases.
Why? Because pgvector’s creators didn’t need to worry about the database’s general additional complexities: ACID, recovery, backup & PITR, high availability, access control, monitoring, deployment, 3rd-party ecosystem tools, client drivers, etc., which require millions of lines of code to solve well. They only focused on the essential complexity of their problem.
For example, ElasticSearch was developed on the Lucene search library, while the Rust ecosystem has an improved next-gen full-text search library, Tantivy, as a Lucene alternative. ParadeDB only needs to wrap and connect it to PostgreSQL’s interface to offer search services comparable to ElasticSearch. More importantly, it can stand on the shoulders of PostgreSQL, leveraging the entire PG ecosystem’s united strength (e.g., mixed searches with PG Vector) to “unfairly” compete with another dedicated database.
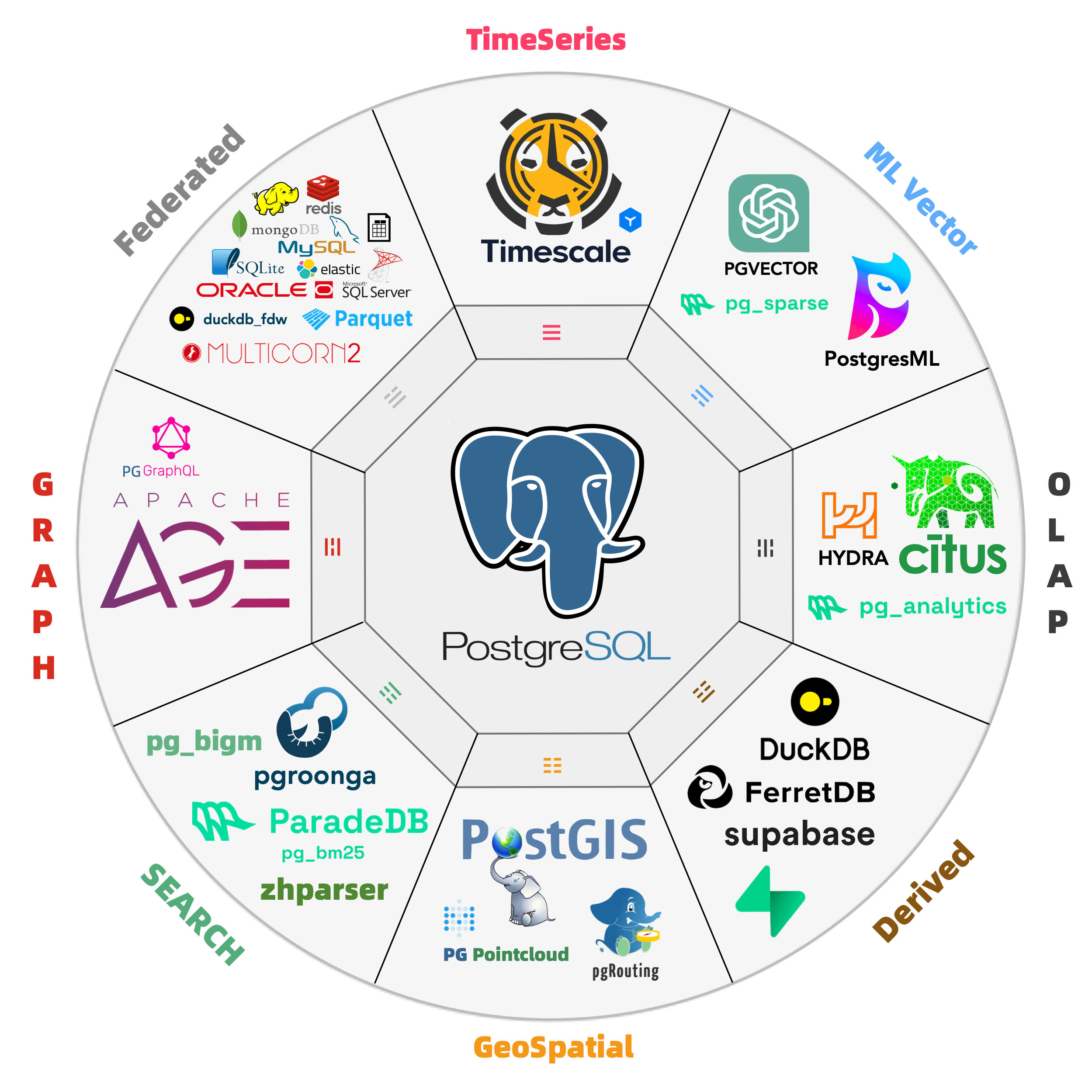
Pigsty has 255 extensions available. And there are 1000+ more in the ecosystem
The extensibility brings another huge advantage: the composability of extensions, allowing different extensions to work together, creating a synergistic effect where 1+1 » 2. For instance, TimescaleDB can be combined with PostGIS for spatio-temporal data support; the BM25 extension for full-text search can be combined with the PGVector extension, providing hybrid search capabilities.
Furthermore, the distributive extension Citus can transparently transform a standalone cluster into a horizontally partitioned distributed database cluster. This capability can be orthogonally combined with other features, making PostGIS a distributed geospatial database, PGVector a distributed vector database, ParadeDB a distributed full-text search database, and so on.
What’s more powerful is that extensions evolve independently, without the cumbersome need for main branch merges and coordination. This allows for scaling — PG’s extensibility lets numerous teams explore database possibilities in parallel, with all extensions being optional, not affecting the core functionality’s reliability. Those features that are mature and robust have the chance to be stably integrated into the main branch.
PostgreSQL achieves both foundational reliability and agile functionality through the magic of extreme extensibility, making it an outlier in the database world and changing the game rules of the database landscape.
Game Changer in the DB Arena
The emergence of PostgreSQL has shifted the paradigms in the database domain: Teams endeavoring to craft a “new database kernel” now face a formidable trial — how to stand out against the open-source, feature-rich Postgres. What’s their unique value proposition?
Until a revolutionary hardware breakthrough occurs, the advent of practical, new, general-purpose database kernels seems unlikely. No singular database can match the overall prowess of PG, bolstered by all its extensions — not even Oracle, given PG’s ace of being open-source and free.
A niche database product might carve out a space for itself if it can outperform PostgreSQL by an order of magnitude in specific aspects (typically performance). However, it usually doesn’t take long before the PostgreSQL ecosystem spawns open-source extension alternatives. Opting to develop a PG extension rather than a whole new database gives teams a crushing speed advantage in playing catch-up!
Following this logic, the PostgreSQL ecosystem is poised to snowball, accruing advantages and inevitably moving towards a monopoly, mirroring the Linux kernel’s status in server OS within a few years. Developer surveys and database trend reports confirm this trajectory.


PostgreSQL has long been the favorite database in HackerNews & StackOverflow. Many new open-source projects default to PostgreSQL as their primary, if not only, database choice. And many new-gen companies are going All in PostgreSQL.
As “Radical Simplicity: Just Use Postgres” says, Simplifying tech stacks, reducing components, accelerating development, lowering risks, and adding more features can be achieved by “Just Use Postgres.” Postgres can replace many backend technologies, including MySQL, Kafka, RabbitMQ, ElasticSearch, Mongo, and Redis, effortlessly serving millions of users. Just Use Postgres is no longer limited to a few elite teams but becoming a mainstream best practice.
What Else Can Be Done?
The endgame for the database domain seems predictable. But what can we do, and what should we do?
PostgreSQL is already a near-perfect database kernel for the vast majority of scenarios, making the idea of a kernel “bottleneck” absurd. Forks of PostgreSQL and MySQL that tout kernel modifications as selling points are essentially going nowhere.
This is similar to the situation with the Linux OS kernel today; despite the plethora of Linux distros, everyone opts for the same kernel. Forking the Linux kernel is seen as creating unnecessary difficulties, and the industry frowns upon it.
Accordingly, the main conflict is no longer the database kernel itself but two directions— database extensions and services! The former pertains to internal extensibility, while the latter relates to external composability. Much like the OS ecosystem, the competitive landscape will concentrate on database distributions. In the database domain, only those distributions centered around extensions and services stand a chance for ultimate success.
Kernel remains lukewarm, with MariaDB, the fork of MySQL’s parent, nearing delisting, while AWS, profiting from offering services and extensions on top of the free kernel, thrives. Investment has flowed into numerous PG ecosystem extensions and service distributions: Citus, TimescaleDB, Hydra, PostgresML, ParadeDB, FerretDB, StackGres, Aiven, Neon, Supabase, Tembo, PostgresAI, and our own PG distro — — Pigsty.

A dilemma within the PostgreSQL ecosystem is the independent evolution of many extensions and tools, lacking a unifier to synergize them. For instance, Hydra releases its own package and Docker image, and so does PostgresML, each distributing PostgreSQL images with their own extensions and only their own. These images and packages are far from comprehensive database services like AWS RDS.
Even service providers and ecosystem integrators like AWS fall short in front of numerous extensions, unable to include many due to various reasons (AGPLv3 license, security challenges with multi-tenancy), thus failing to leverage the synergistic amplification potential of PostgreSQL ecosystem extensions.
Extesion Category Pigsty RDS & PGDG AWS RDS PG Aliyun RDS PG Add Extension Free to Install Not Allowed Not Allowed Geo Spatial PostGIS 3.4.2 PostGIS 3.4.1 PostGIS 3.3.4 Time Series TimescaleDB 2.14.2 Distributive Citus 12.1 AI / ML PostgresML 2.8.1 Columnar Hydra 1.1.1 Vector PGVector 0.6 PGVector 0.6 pase 0.0.1 Sparse Vector PG Sparse 0.5.6 Full-Text Search pg_bm25 0.5.6 Graph Apache AGE 1.5.0 GraphQL PG GraphQL 1.5.0 Message Queue pgq 3.5.0 OLAP pg_analytics 0.5.6 DuckDB duckdb_fdw 1.1 CDC wal2json 2.5.3 wal2json 2.5 Bloat Control pg_repack 1.5.0 pg_repack 1.5.0 pg_repack 1.4.8 Point Cloud PG PointCloud 1.2.5 Ganos PointCloud 6.1 Many important extensions are not available on Cloud RDS (PG 16, 2024-02-29)
Extensions are the soul of PostgreSQL. A Postgres without the freedom to use extensions is like cooking without salt, a giant constrained.
Addressing this issue is one of our primary goals.
Our Resolution: Pigsty
Despite earlier exposure to MySQL Oracle, and MSSQL, when I first used PostgreSQL in 2015, I was convinced of its future dominance in the database realm. Nearly a decade later, I’ve transitioned from a user and administrator to a contributor and developer, witnessing PG’s march toward that goal.
Interactions with diverse users revealed that the database field’s shortcoming isn’t the kernel anymore — PostgreSQL is already sufficient. The real issue is leveraging the kernel’s capabilities, which is the reason behind RDS’s booming success.
However, I believe this capability should be as accessible as free software, like the PostgreSQL kernel itself — available to every user, not just renting from cyber feudal lords.
Thus, I created Pigsty, a battery-included, local-first PostgreSQL distribution as an open-source RDS Alternative, which aims to harness the collective power of PostgreSQL ecosystem extensions and democratize access to production-grade database services.
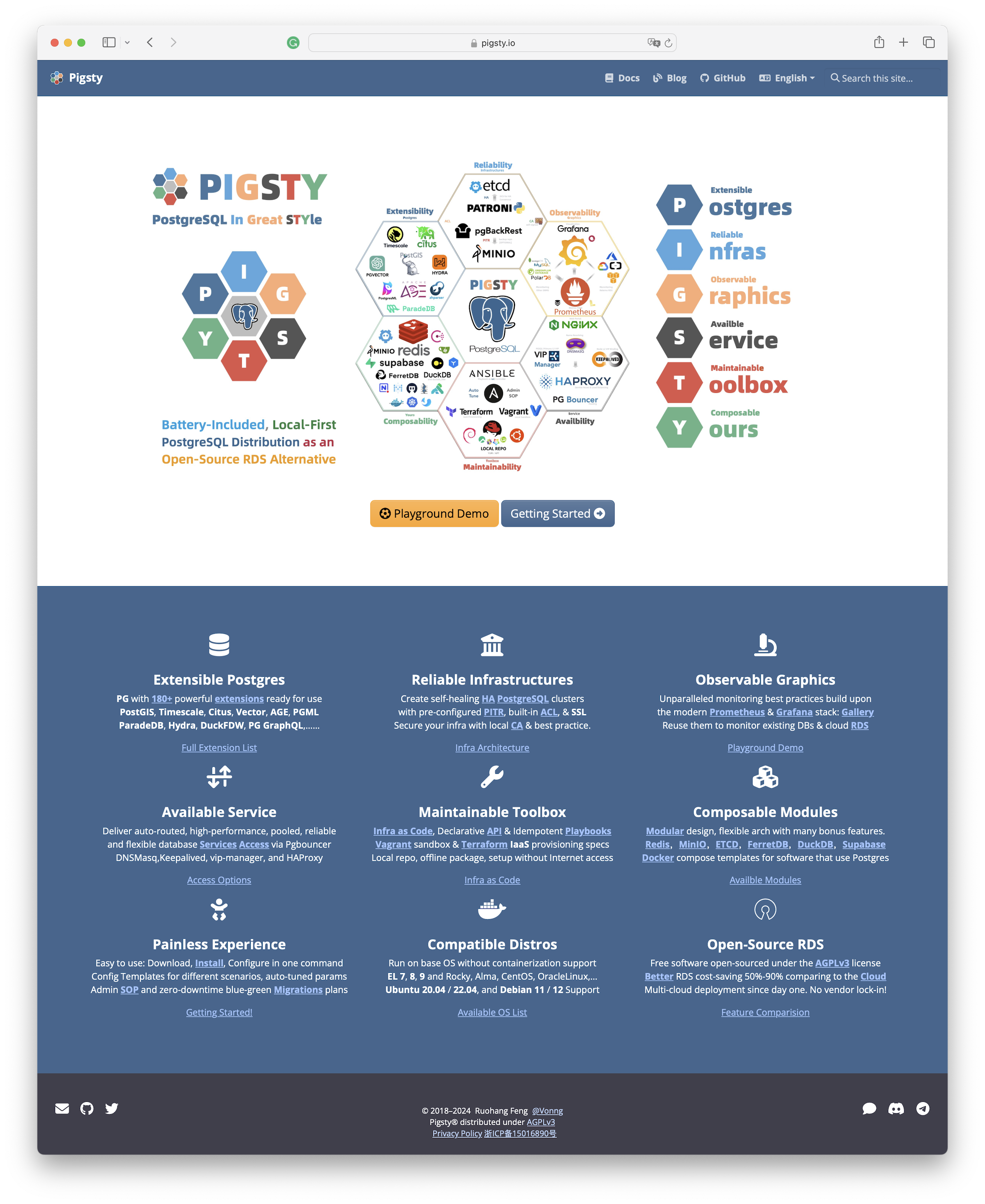
Pigsty stands for PostgreSQL in Great STYle, representing the zenith of PostgreSQL.
We’ve defined six core propositions addressing the central issues in PostgreSQL database services:
Extensible Postgres, Reliable Infras, Observable Graphics, Available Services, Maintainable Toolbox, and Composable Modules.
The initials of these value propositions offer another acronym for Pigsty:
Postgres, Infras, Graphics, Service, Toolbox, Yours.
Your graphical Postgres infrastructure service toolbox.
Extensible PostgreSQL is the linchpin of this distribution. In the recently launched Pigsty v2.6, we integrated DuckDB FDW and ParadeDB extensions, massively boosting PostgreSQL’s analytical capabilities and ensuring every user can easily harness this power.
Our aim is to integrate the strengths within the PostgreSQL ecosystem, creating a synergistic force akin to the Ubuntu of the database world. I believe the kernel debate is settled, and the real competitive frontier lies here.
- PostGIS: Provides geospatial data types and indexes, the de facto standard for GIS (& pgPointCloud, pgRouting).
- TimescaleDB: Adds time-series, continuous aggregates, distributed, columnar storage, and automatic compression capabilities.
- PGVector: Support AI vectors/embeddings and ivfflat, hnsw vector indexes (& pg_sparse for sparse vectors).
- Citus: Transforms classic master-slave PG clusters into horizontally partitioned distributed database clusters.
- Hydra: Adds columnar storage and analytics, rivaling ClickHouse’s analytic capabilities.
- ParadeDB: Elevates full-text search and mixed retrieval to ElasticSearch levels (& zhparser for Chinese tokenization).
- Apache AGE: Graph database extension, adding Neo4J-like OpenCypher query support to PostgreSQL.
- PG GraphQL: Adds native built-in GraphQL query language support to PostgreSQL.
- DuckDB FDW: Enables direct access to DuckDB’s powerful embedded analytic database files through PostgreSQL (& DuckDB CLI).
- Supabase: An open-source Firebase alternative based on PostgreSQL, providing a complete app development storage solution.
- FerretDB: An open-source MongoDB alternative based on PostgreSQL, compatible with MongoDB APIs/drivers.
- PostgresML: Facilitates classic machine learning algorithms, calling, deploying, and training AI models with SQL.
Developers, your choices will shape the future of the database world. I hope my work helps you better utilize the world’s most advanced open-source database kernel: PostgreSQL.
Read in Pigsty’s Blog | GitHub Repo: Pigsty | Official Website
Technical Minimalism: Just Use PostgreSQL for Everything

Whether production databases should be containerized remains a controversial topic. From a DBA’s perspective, I believe that currently, putting production databases in Docker is still a bad idea. Read more
New PostgreSQL Ecosystem Player: ParadeDB

ParadeDB aims to be an Elasticsearch alternative: “Modern Elasticsearch Alternative built on Postgres” — PostgreSQL for search and analytics. Read more
PostgreSQL's Impressive Scalability

This article describes how Cloudflare scaled to support 55 million requests per second using 15 PostgreSQL clusters, and PostgreSQL’s scalability performance. Read more
PostgreSQL Outlook for 2024
Author: Jonathan Katz (PostgreSQL Core Team) | Original: PostgreSQL 2024

PostgreSQL core team member Jonathan Katz’s outlook for PostgreSQL in 2024, reviewing the progress made over the past few years. Read more
PostgreSQL Wins 2024 Database of the Year Award! (Fifth Time)

DB-Engines officially announced today that PostgreSQL has once again been crowned “Database of the Year.” This is the fifth time PG has received this honor in the past seven years. If not for Snowflake stealing the spotlight for two years, the database world would have almost become a PostgreSQL solo show. Read more
PostgreSQL Macro Query Optimization with pg_stat_statements
pg_stat_statements for macro-level PostgreSQL query optimization.
Query optimization is one of the core responsibilities of DBAs. This article introduces how to use metrics provided by pg_stat_statements for macro-level PostgreSQL query optimization. Read more
FerretDB: PostgreSQL Disguised as MongoDB

FerretDB aims to provide a truly open-source MongoDB alternative based on PostgreSQL. Read more
How to Use pg_filedump for Data Recovery?
pg_filedump can help you!
Backups are a DBA’s lifeline — but what if your PostgreSQL database has already exploded and you have no backups? Maybe pg_filedump can help you! Read more
Vector is the New JSON
Author: Jonathan Katz (PostgreSQL Core Team) | Original: Vectors are the new JSON in PostgreSQL

Vectors will become a key element in building applications, just like JSON historically. PostgreSQL leads the AI era with vector extensions. Read more
PostgreSQL, The most successful database

StackOverflow 2023 Survey shows PostgreSQL is the most popular, loved, and wanted database, solidifying its status as the ‘Linux of Database’. Read more
AI Large Models and Vector Database PGVector
This article focuses on vector databases hyped by AI, introduces the basic principles of AI embeddings and vector storage/retrieval, and demonstrates the functionality, performance, acquisition, and application of the vector database extension PGVECTOR through a concrete knowledge base retrieval case study. Read more
How Powerful is PostgreSQL Really?

Let performance data speak: Why PostgreSQL is the world’s most advanced open-source relational database, aka the world’s most successful database. MySQL vs PostgreSQL performance showdown and distributed database reality check. Read more
Why PostgreSQL is the Most Successful Database?

Database users are developers, but what about developers’ preferences, likes, and choices? Looking at StackOverflow survey results over the past six years, it’s clear that in 2022, PostgreSQL has won all three categories, becoming literally the “most successful database” Read more
Ready-to-Use PostgreSQL Distribution: Pigsty

Yesterday I gave a live presentation in the PostgreSQL Chinese community, introducing the open-source PostgreSQL full-stack solution — Pigsty Read more
Why Does PostgreSQL Have a Bright Future?

Databases are the core component of information systems, relational databases are the absolute backbone of databases, and PostgreSQL is the world’s most advanced open source relational database. With such favorable timing and positioning, how can it not achieve great success? Read more
Implementing Advanced Fuzzy Search

How to implement relatively complex fuzzy search logic in PostgreSQL? Read more
Localization and Collation Rules in PostgreSQL

What? Don’t know what COLLATION is? Remember one thing: using C COLLATE is always the right choice! Read more
PG Replica Identity Explained

Replica identity is important - it determines the success or failure of logical replication Read more
PostgreSQL Logical Replication Deep Dive

This article introduces the principles and best practices of logical replication in PostgreSQL 13. Read more
A Methodology for Diagnosing PostgreSQL Slow Queries

Slow queries are the sworn enemy of OLTP databases. Here’s how to identify, analyze, and fix them using metrics (Pigsty dashboards), pg_stat_statements, and logs. Read more
Incident-Report: Patroni Failure Due to Time Travel

Machine restarted due to failure, NTP service corrected PG time after PG startup, causing Patroni to fail to start. Read more
Online Primary Key Column Type Change

How to change column types online, such as upgrading from INT to BIGINT? Read more
Golden Monitoring Metrics: Errors, Latency, Throughput, Saturation

Understanding the golden monitoring metrics in PostgreSQL Read more
Database Cluster Management Concepts and Entity Naming Conventions

Concepts and their naming are very important. Naming style reflects an engineer’s understanding of system architecture. Poorly defined concepts lead to communication confusion, while carelessly set names create unexpected additional burden. Therefore, they need careful design. Read more
PostgreSQL's KPI

Managing databases is similar to managing people - both need KPIs (Key Performance Indicators). So what are database KPIs? This article introduces a way to measure PostgreSQL load: using a single horizontally comparable metric that is basically independent of workload type and machine type, called PG Load. Read more
Online PostgreSQL Column Type Migration

How to modify PostgreSQL column types online? A general approach Read more
Frontend-Backend Communication Wire Protocol

Understanding the TCP protocol used for communication between PostgreSQL server and client, and printing messages using Go Read more
Transaction Isolation Level Considerations

PostgreSQL actually has only two transaction isolation levels: Read Committed and Serializable Read more
Incident: PostgreSQL Extension Installation Causes Connection Failure

Today encountered an interesting case where a customer reported database connection issues caused by extensions. Read more
CDC Change Data Capture Mechanisms

Change Data Capture is an interesting ETL alternative solution. Read more
Locks in PostgreSQL
pg_locks.
Snapshot isolation does most of the heavy lifting in PG, but locks still matter. Here’s a practical guide to table locks, row locks, intention locks, and pg_locks. Read more
O(n2) Complexity of GIN Search

When GIN indexes are used to search with very long keyword lists, performance degrades significantly. This article explains why GIN index keyword search has O(n^2) time complexity. Read more
PostgreSQL Common Replication Topology Plans
Replication is one of the core issues in system architecture. Read more
Warm Standby: Using pg_receivewal

There are various backup strategies. Physical backups can usually be divided into four types. Read more
Incident-Report: Connection-Pool Contamination Caused by pg_dump

Sometimes, interactions between components manifest in subtle ways. For example, using pg_dump to export data from a connection pool can cause connection pool contamination issues. Read more
PostgreSQL Data Page Corruption Repair

Using binary editing to repair PostgreSQL data pages, and how to make a primary key query return two records. Read more
Relation Bloat Monitoring and Management

PostgreSQL uses MVCC as its primary concurrency control technology. While it has many benefits, it also brings other effects, such as relation bloat. Read more
Getting Started with PipelineDB

PipelineDB is a PostgreSQL extension for streaming analytics. Here’s how to install it and build continuous views over live data. Read more
TimescaleDB Quick Start

TimescaleDB is a PostgreSQL extension plugin that provides time-series database functionality. Read more
Incident-Report: Integer Overflow from Rapid Sequence Number Consumption

If you use Integer sequences on tables, you should consider potential overflow scenarios. Read more
Incident-Report: PostgreSQL Transaction ID Wraparound

XID WrapAround is perhaps a unique type of failure specific to PostgreSQL Read more
GeoIP Geographic Reverse Lookup Optimization

A common requirement in application development is GeoIP conversion - converting source IP addresses to geographic coordinates or administrative divisions (country-state-city-county-town-village) Read more
PostgreSQL Trigger Usage Considerations

Detailed understanding of trigger management and usage in PostgreSQL Read more
PostgreSQL Development Convention (2018 Edition)

Without rules, there can be no order. This article compiles a development specification for PostgreSQL database principles and features, which can reduce confusion encountered when using PostgreSQL. Read more
What Are PostgreSQL's Advantages?

PostgreSQL’s slogan is “The World’s Most Advanced Open-Source Relational Database,” but I think the most vivid characterization should be: The Full-Stack Database That Does It All - one tool to rule them all. Read more
Efficient Administrative Region Lookup with PostGIS
How to efficiently solve the typical reverse geocoding problem: determining administrative regions based on user coordinates. Read more
KNN Ultimate Optimization: From RDS to PostGIS

Ultimate optimization of KNN problems, from traditional relational design to PostGIS Read more
Monitoring Table Size in PostgreSQL

Tables in PostgreSQL correspond to many physical files. This article explains how to calculate the actual size of a table in PostgreSQL. Read more
PgAdmin Installation and Configuration

PgAdmin is a GUI program for managing PostgreSQL, written in Python, but it’s quite dated and requires some additional configuration. Read more
Incident-Report: Uneven Load Avalanche

Recently there was a perplexing incident where a database had half its data volume and load migrated away, but ended up being overwhelmed due to increased load. Read more
Bash and psql Tips

Some tips for interacting between PostgreSQL and Bash. Read more
Distinct On: Remove Duplicate Data

Use Distinct On extension clause to quickly find records with maximum/minimum values within groups Read more
Function Volatility Classification Levels

PostgreSQL functions have three volatility levels by default. Proper use can significantly improve performance. Read more
Implementing Mutual Exclusion Constraints with Exclude

Exclude constraint is a PostgreSQL extension that can implement more advanced and sophisticated database constraints. Read more
PostgreSQL Routine Maintenance

Cars need oil changes, databases need maintenance. For PG, three important maintenance tasks: backup, repack, vacuum Read more
Backup and Recovery Methods Overview

Backup is the foundation of a DBA’s livelihood. With backups, there’s no need to panic. Read more
PgBackRest2 Documentation

PgBackRest is a set of PostgreSQL backup tools written in Perl Read more
Pgbouncer Quick Start

Pgbouncer is a lightweight database connection pool. This guide covers basic Pgbouncer configuration, management, and usage. Read more
PostgreSQL Server Log Regular Configuration

It’s recommended to configure PostgreSQL’s log format as CSV for easy analysis, and it can be directly imported into PostgreSQL data tables. Read more
Testing Disk Performance with FIO

FIO is a convenient tool for testing disk I/O performance Read more
Using sysbench to Test PostgreSQL Performance

Although PostgreSQL provides pgbench, sometimes you need sysbench to outperform MySQL. Read more
Changing Engines Mid-Flight — PostgreSQL Zero-Downtime Data Migration

Data migration typically involves stopping services for updates. Zero-downtime data migration is a relatively advanced operation. Read more
Finding Unused Indexes

Indexes are useful, but they’re not free. Unused indexes are a waste. Use these methods to identify unused indexes. Read more
Batch Configure SSH Passwordless Login

Quick configuration for passwordless login to all machines Read more
Wireshark Packet Capture Protocol Analysis

Wireshark is a very useful tool, especially suitable for analyzing network protocols. Here’s a simple introduction to using Wireshark for packet capture and PostgreSQL protocol analysis. Read more
The Versatile file_fdw — Reading System Information from Your Database
file_fdw, you can easily view operating system information, fetch network data, and feed various data sources into your database for unified viewing and management.
With file_fdw, you can easily view operating system information, fetch network data, and feed various data sources into your database for unified viewing and management. Read more
Common Linux Statistics CLI Tools

top, free, vmstat, iostat: Quick reference for four commonly used CLI tools Read more
Installing PostGIS from Source

PostGIS is PostgreSQL’s killer extension, but compiling and installing it isn’t easy. Read more
Go Database Tutorial: database/sql

Similar to JDBC, Go also has a standard database access interface. This article details how to use database/sql in Go and important considerations. Read more
Implementing Cache Synchronization with Go and PostgreSQL

Cleverly utilizing PostgreSQL’s Notify feature, you can conveniently notify applications of metadata changes and implement trigger-based logical replication. Read more
Auditing Data Changes with Triggers

Sometimes we want to record important metadata changes for audit purposes. PostgreSQL triggers can conveniently solve this need automatically. Read more
Building an ItemCF Recommender in Pure SQL

Five minutes, PostgreSQL, and the MovieLens dataset—that’s all you need to implement a classic item-based collaborative filtering recommender. Read more
UUID Properties, Principles and Applications

UUID properties, principles and applications, and how to manipulate UUIDs using PostgreSQL stored procedures. Read more
PostgreSQL MongoFDW Installation and Deployment

Recently had business requirements to access MongoDB through PostgreSQL FDW, but compiling MongoDB FDW is really a nightmare. Read more
Database
Data 2025: Year in Review with Mike Stonebraker

A conversation between Mike Stonebraker (Turing Award Winner, Creator of PostgreSQL), Andy Pavlo (Carnegie Mellon), and the DBOS team. Read more
What Database Does AI Agent Need?

The bottleneck for AI Agents isnt in database engines but in upper-layer integration. Muscle memory, associative memory, and trial-and-error courage will be key. Read more
MySQL and Baijiu: The Internet’s Obedience Test

MySQL is to the internet what baijiu is to China: harsh, hard to swallow, yet worshipped because culture demands obedience. Both are loyalty tests—will you endure discomfort to fit in? Read more
Victoria: The Observability Stack That Slaps the Industry

VictoriaMetrics is brutally efficient—using a fraction of Prometheus + Loki’s resources for multiples of the performance. Pigsty v4 swaps to the Victoria stack; here’s the beta for anyone eager to try it. Read more
MinIO Is Dead. Who Picks Up the Pieces?

MinIO just entered maintenance mode. What replaces it? Can RustFS step in? I tested the contenders so you don’t have to. Read more
MinIO is Dead

MinIO announces it is entering maintenance mode, the dragon-slayer has become the dragon – how MinIO transformed from an open-source S3 alternative to just another commercial software company Read more
When Answers Become Abundant, Questions Become the New Currency

Your ability to ask questions—and your taste in what to ask—determines your position in the AI era. When answers become commodities, good questions become the new wealth. We are living in the moment this prophecy comes true. Read more
On Trusting Open-Source Supply Chains

In serious production you can’t rely on an upstream that explicitly says “no guarantees.” When someone says “don’t count on me,” the right answer is “then I’ll run it myself.” Read more
Don't Run Docker Postgres for Production!

Tons of users running the official docker postgres image got burned during recent minor version upgrades. A friendly reminder: think twice before containerizing production databases. Read more
DDIA 2nd Edition, Chinese Translation

The second edition of Designing Data-Intensive Applications has released ten chapters. I translated them into Chinese and rebuilt a clean Hugo/Hextra web version for the community. Read more
Column: Database Guru

The database world is full of hype and marketing fog. This column cuts through it with blunt commentary on industry trends and product reality. Read more
Dongchedi Just Exposed “Smart Driving.” Where’s Our Dongku-Di?

Imagine a “closed-course” shootout for domestic databases and clouds, the way Dongchedi just humiliated 30+ autonomous cars. This industry needs its own stress test. Read more
Google AI Toolbox: Production-Ready Database MCP is Here?

Google recently launched a database MCP toolbox, perhaps the first production-ready solution. Read more
Where Will Databases and DBAs Go in the AI Era?

Who will be revolutionized first - OLTP or OLAP? Integration vs specialization, how to choose? Where will DBAs go in the AI era? Feng’s views from the HOW 2025 conference roundtable, organized and published. Read more
Stop Arguing, The AI Era Database Has Been Settled

The database for the AI era has been settled. Capital markets are making intensive moves on PostgreSQL targets, with PG having become the default database for the AI era. Read more
Open Data Standards: Postgres, OTel, and Iceberg
Author: Paul Copplestone (Supabase CEO) | Original: Open Data Standards: Postgres, OTel, and Iceberg

Three emerging standards in the data world: Postgres, OpenTelemetry, and Iceberg. Postgres is already the de facto standard. Read more
The Lost Decade of Small Data
Author: Hannes Mühleisen (DuckDB Labs) | Original: The Lost Decade of Small Data

If DuckDB had launched in 2012, the great migration to distributed analytics might never have happened. Data isn’t that big after all. Read more
Scaling Postgres to the Next Level at OpenAI
At PGConf.Dev 2025, Bohan Zhang from OpenAI presented a session titled “Scaling Postgres to the Next Level at OpenAI”, giving us a peek into database operations at one of the world’s most prominent AI companies.
OpenAI has successfully demonstrated that PostgreSQL can scale to support massive read-heavy workloads—even without sharding—using a single primary writer with dozens of read replicas.
Architecture Foundation
OpenAI operates PostgreSQL on Azure using a classic primary-replica replication model. The infrastructure includes one primary database and over a dozen read replicas distributed across regions. This approach supports several hundred million active users while maintaining critical system reliability.
The key insight here is that sharding is not necessary for scaling reads—you can scale horizontally by adding more replicas. The single primary handles all writes, while read traffic is distributed across replicas.
Key Challenges Identified
Write Bottlenecks
The primary challenge centers on write request limitations. While read scalability performs well through replication, write operations remain constrained to the single primary instance. This is the fundamental trade-off of the single-primary architecture.
MVCC Design Issues
PostgreSQL’s multi-version concurrency control creates table and index bloat concerns. Every write generates a new row version, requiring additional heap fetches for visibility checks during index access. Autovacuum tuning becomes critical at scale.
Replication Lag
Increased WAL (write-ahead logging) correlates with greater replication lag, and expanding replica count increases network bandwidth demands. Managing this becomes crucial as you add more replicas.
Optimization Strategies Implemented
Load Reduction
OpenAI systematically offloads writes where possible:
- Minimize unnecessary application-level writes
- Implement lazy write patterns
- Control data backfill rates
- Move read requests to replicas whenever feasible
- Only read-write transaction queries remain on the primary
Query Optimization
The team employs aggressive timeout settings to prevent “idle in transaction” states:
- Session, statement, and client-level timeouts prevent resource exhaustion
- Multi-table joins receive special attention (ORMs frequently generate inefficient queries)
- Long-running queries are strictly controlled
Failure Mitigation
Recognizing the primary as a single point of failure, OpenAI:
- Segregates high-priority requests onto dedicated read-only replicas
- Prevents low-priority workloads from impacting critical operations
- Maintains separate replica pools for different workload types
Schema Management Restrictions
The cluster operates under strict schema change limitations:
- Operations requiring full table rewrites are forbidden
- Index operations must use the
CONCURRENTLYsyntax - Column additions or removals require a 5-second timeout maximum
- No heavy DDL during business hours
Results Achieved
The approach has proven highly successful:
- Millions of QPS: Scaled PostgreSQL to handle millions of queries per second
- Dozens of replicas: Added dozens of replicas without increasing replication lag
- Geographic distribution: Deployed geo-distributed read replicas with maintained low latency
- High reliability: Only one SEV0 (highest severity) PostgreSQL-related incident in nine months
- Headroom remaining: Substantial capacity for future growth
Feature Requests to PostgreSQL Community
OpenAI raised several enhancement suggestions for the PostgreSQL community:
Index Disabling
Request a formal capability to disable indexes while maintaining them during DML operations. This allows safe validation before deletion—currently requires superuser access to manipulate pg_index.indisvalid.
Real-Time Observability
Current pg_stat_statements provides average metrics but lacks percentile latency distributions (p95, p99). Histogram-style latency metrics would dramatically improve monitoring capabilities.
Schema Change History
SQL-queryable views tracking DDL operations would improve audit and historical reference capabilities. Currently requires parsing logs or using EVENT TRIGGERs.
Monitoring View Semantics
Clarification needed regarding session states reporting “active” while waiting for client I/O, particularly regarding idle_in_transaction_timeout applicability.
Default Parameters
Request for heuristic-based default configuration detection based on hardware specifications—smarter out-of-the-box settings.
Commentary
Having managed comparable infrastructure at Tantan (supporting approximately 2.5 million QPS across multiple clusters, with individual primary instances handling 400K QPS using 33 read replicas), I can contextualize OpenAI’s experience within broader PostgreSQL deployment history.
The difference reflects hardware advancement over eight years, enabling modern startups to serve entire operations through single PostgreSQL instances. What required dozens of clusters in 2016 can now be handled by a single, well-tuned PostgreSQL deployment.
Most features OpenAI requested already exist within the PostgreSQL ecosystem but remain unavailable in either vanilla PostgreSQL or managed cloud database environments:
- Index disabling: Manipulate
pg_index.indisvalidcatalog field (requires superuser) - Query latency percentiles: Use
pg_stat_monitorextension or calculate frompg_stat_statementsstandard deviation - DDL history tracking: Enable
log_statement = 'ddl'or use EVENT TRIGGER mechanisms - Connection timeout management: Configure at load balancer (PgBouncer/HAProxy) or application connection pool level
- Parameter optimization: Use initialization tools with hardware detection
The presentation demonstrates that despite cloud database management limitations, successful extreme-scale PostgreSQL operations require substantial operational expertise and DBA capabilities—even with premier cloud provider support.
Infrastructure Insights
During conference discussions, OpenAI revealed:
- Reliance on Azure’s highest-specification managed PostgreSQL service
- Dedicated engineering support from Azure
- Database access routes through Kubernetes via application-side PgBouncer connection pooling
- Monitoring utilizes Datadog for observability across the deployment
This confirms that even at the highest cloud tiers, organizations still need deep PostgreSQL expertise to succeed at scale.
References
How Many Shops Has etcd Torched?

Plenty. If you’re rolling your own Kubernetes, odds are you’ll crash because etcd ships with a 2 GB time bomb. Read more
In the AI Era, Software Starts at the Database

Future software = Agent + Database. No middle tiers, just agents issuing CRUD. Database skills age well, and PostgreSQL is poised to be the agent-era default. Read more
MySQL vs. PostgreSQL @ 2025

A 2025 reality check on where PostgreSQL stands relative to MySQL across features, performance, quality, and ecosystem. Read more
Database Planet Collision: When PG Falls for DuckDB

If you ask me, we’re on the brink of a cosmic collision in database-land, and Postgres + DuckDB is the meteor we should all be watching. Read more
Comparing Oracle and PostgreSQL Transaction Systems

The PG community has started punching up: Cybertec’s Laurenz Albe breaks down how Oracle’s transaction system stacks against PostgreSQL. Read more
Database as Business Architecture

Databases are the core of business architecture, but what happens if we go further and let databases become the business architecture itself? Read more
7 Databases in 7 Weeks (2025)

Is PostgreSQL the king of boring databases? Here are seven databases worth studying in 2025: PostgreSQL, SQLite, DuckDB, ClickHouse, FoundationDB, TigerBeetle, and CockroachDB—each deserving a week of deep exploration. Read more
Solving Poker 24 with a Single SQL Query

An interesting but tricky puzzle: solving the 24 game with SQL. The PostgreSQL solution. Read more
Self-Hosting Supabase on PostgreSQL
Supabase is great, own your own Supabase is even better. Here’s a comprehensive tutorial for self-hosting production-grade supabase on local/cloud VM/BMs.
What is Supabase?
Supabase is an open-source Firebase alternative, a Backend as a Service (BaaS).
Supabase wraps PostgreSQL kernel and vector extensions, alone with authentication, realtime subscriptions, edge functions, object storage, and instant REST and GraphQL APIs from your postgres schema. It let you skip most backend work, requiring only database design and frontend skills to ship quickly.
Currently, Supabase may be the most popular open-source project in the PostgreSQL ecosystem, boasting over 74,000 stars on GitHub. And become quite popular among developers, and startups, since they have a generous free plan, just like cloudflare & neon.
Why Self-Hosting?
Supabase’s slogan is: “Build in a weekend, Scale to millions”. It has great cost-effectiveness in small scales (4c8g) indeed. But there is no doubt that when you really grow to millions of users, some may choose to self-hosting their own Supabase —— for functionality, performance, cost, and other reasons.
That’s where Pigsty comes in. Pigsty provides a complete one-click self-hosting solution for Supabase. Self-hosted Supabase can enjoy full PostgreSQL monitoring, IaC, PITR, and high availability capability,
You can run the latest PostgreSQL 17(,16,15,14) kernels, (supabase is using the 15 currently), alone with 390 PostgreSQL extensions out-of-the-box. Run on mainstream Linus OS distros with production grade HA PostgreSQL, MinIO, Prometheus & Grafana Stack for observability, and Nginx for reverse proxy.
TIME: timescaledb timescaledb_toolkit timeseries periods temporal_tables emaj table_version pg_cron pg_later pg_background
GIS: postgis postgis_topology postgis_raster postgis_sfcgal postgis_tiger_geocoder address_standardizer address_standardizer_data_us pgrouting pointcloud pointcloud_postgis h3 h3_postgis q3c ogr_fdw geoip pg_polyline pg_geohash mobilitydb earthdistance
RAG: vector vectorscale vectorize pg_similarity smlar pg_summarize pg_tiktoken pgml pg4ml
FTS: pg_search pg_bigm zhparser hunspell_cs_cz hunspell_de_de hunspell_en_us hunspell_fr hunspell_ne_np hunspell_nl_nl hunspell_nn_no hunspell_pt_pt hunspell_ru_ru hunspell_ru_ru_aot fuzzystrmatch pg_trgm
OLAP: citus citus_columnar columnar pg_analytics pg_duckdb pg_mooncake duckdb_fdw pg_parquet pg_fkpart pg_partman plproxy pg_strom tablefunc
FEAT: age hll rum pg_graphql pg_jsonschema jsquery pg_hint_plan hypopg index_advisor plan_filter imgsmlr pg_ivm pgmq pgq pg_cardano rdkit bloom
LANG: pg_tle plv8 pllua hstore_pllua plluau hstore_plluau plprql pldbgapi plpgsql_check plprofiler plsh pljava plr pgtap faker dbt2 pltcl pltclu plperl bool_plperl hstore_plperl jsonb_plperl plperlu bool_plperlu jsonb_plperlu hstore_plperlu plpgsql plpython3u jsonb_plpython3u ltree_plpython3u hstore_plpython3u
TYPE: prefix semver unit md5hash asn1oid roaringbitmap pgfaceting pg_sphere country currency pgmp numeral pg_rational uint uint128 ip4r uri pgemailaddr acl debversion pg_rrule timestamp9 chkpass isn seg cube ltree hstore citext xml2
FUNC: topn gzip zstd http pg_net pg_smtp_client pg_html5_email_address pgsql_tweaks pg_extra_time timeit count_distinct extra_window_functions first_last_agg tdigest aggs_for_vecs aggs_for_arrays arraymath quantile lower_quantile pg_idkit pg_uuidv7 permuteseq pg_hashids sequential_uuids pg_math random base36 base62 pg_base58 floatvec financial pgjwt pg_hashlib shacrypt cryptint pguecc pgpcre icu_ext pgqr envvar pg_protobuf url_encode refint autoinc insert_username moddatetime tsm_system_time dict_xsyn tsm_system_rows tcn uuid-ossp btree_gist btree_gin intarray intagg dict_int unaccent
ADMIN: pg_repack pg_squeeze pg_dirtyread pgfincore pgdd ddlx prioritize pg_checksums pg_readonly safeupdate pg_permissions pgautofailover pg_catcheck pre_prepare pgcozy pg_orphaned pg_crash pg_cheat_funcs pg_savior table_log pg_fio pgpool_adm pgpool_recovery pgpool_regclass pgagent vacuumlo pg_prewarm oid2name lo basic_archive basebackup_to_shell old_snapshot adminpack amcheck pg_surgery
STAT: pg_profile pg_show_plans pg_stat_kcache pg_stat_monitor pg_qualstats pg_store_plans pg_track_settings pg_wait_sampling system_stats meta pgnodemx pg_proctab pg_sqlog bgw_replstatus pgmeminfo toastinfo explain_ui pg_relusage pg_top pagevis powa pageinspect pgrowlocks sslinfo pg_buffercache pg_walinspect pg_freespacemap pg_visibility pgstattuple auto_explain pg_stat_statements
SEC: passwordcheck_cracklib supautils pgsodium supabase_vault pg_session_jwt anon pg_tde pgsmcrypto pgaudit pgauditlogtofile pg_auth_mon credcheck pgcryptokey pg_jobmon logerrors login_hook set_user pg_snakeoil pgextwlist pg_auditor sslutils noset sepgsql auth_delay pgcrypto passwordcheck
FDW: wrappers multicorn odbc_fdw jdbc_fdw mysql_fdw oracle_fdw tds_fdw db2_fdw sqlite_fdw pgbouncer_fdw mongo_fdw redis_fdw redis kafka_fdw hdfs_fdw firebird_fdw aws_s3 log_fdw dblink file_fdw postgres_fdw
SIM: orafce pgtt session_variable pg_statement_rollback pg_dbms_metadata pg_dbms_lock pg_dbms_job babelfishpg_common babelfishpg_tsql babelfishpg_tds babelfishpg_money pgmemcache
ETL: pglogical pglogical_origin pglogical_ticker pgl_ddl_deploy pg_failover_slots wal2json wal2mongo decoderbufs decoder_raw test_decoding mimeo repmgr pg_fact_loader pg_bulkload
Since most of the supabase maintained extensions are not available in the official PGDG repo, we have compiled all the RPM/DEBs for these extensions and put them in the Pigsty repo: pg_graphql, pg_jsonschema, wrappers, index_advisor, pg_net, vault, pgjwt, supautils, pg_plan_filter,
Everything is under your control, you have the ability and freedom to scale PGSQL, MinIO, and Supabase itself. And take full advantage of the performance and cost advantages of modern hardware like Gen5 NVMe SSD.
All you need is prepare a VM with several commands and wait for 10 minutes….
Get Started
First, download & install pigsty as usual, with the supa config template:
curl -fsSL https://repo.pigsty.io/get | bash
./bootstrap # install deps (ansible)
./configure -c supa # use supa config template (IMPORTANT: CHANGE PASSWORDS!)
./install.yml # install pigsty, create ha postgres & minio clusters
Please change the
pigsty.ymlconfig file according to your need before deploying Supabase. (Credentials) For dev/test/demo purposes, we will just skip that, and comes back later.
Then, run the supabase.yml to launch stateless part of supabase.
./supabase.yml # launch stateless supabase containers with docker compose
You can access the supabase API / Web UI through the 8000/8443 directly.
with configured DNS, or a local /etc/hosts entry, you can also use the default supa.pigsty domain name via the 80/443 infra portal.
Credentials for Supabase Studio:
supabase:pigsty

Architecture
Pigsty’s supabase is based on the Supabase Docker Compose Template, with some slight modifications to fit-in Pigsty’s default ACL model.
The stateful part of this template is replaced by Pigsty’s managed PostgreSQL cluster and MinIO cluster. The container part are stateless, so you can launch / destroy / run multiple supabase containers on the same stateful PGSQL / MINIO cluster simultaneously to scale out.

The built-in supa.yml config template will create a single-node supabase, with a singleton PostgreSQL and SNSD MinIO server.
You can use Multinode PostgreSQL Clusters and MNMD MinIO Clusters / external S3 service instead in production, we will cover that later.
Config Detail
Here are checklists for self-hosting
- Hardware: necessary VM/BM resources, one node at least, 3-4 are recommended for HA.
- Linux OS: Linux x86_64 server with fresh installed Linux, check compatible distro
- Network: Static IPv4 address which can be used as node identity
- Admin User: nopass ssh & sudo are recommended for admin user
- Conf Template: Use the
supaconfig template, if you don’t know how to manually configure pigsty
The built-in supa.yml config template is shown below.
The supa Config Template
all:
children:
# infra cluster for proxy, monitor, alert, etc..
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
# etcd cluster for ha postgres
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
# minio cluster, s3 compatible object storage
minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
# pg-meta, the underlying postgres database for supabase
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users:
# supabase roles: anon, authenticated, dashboard_user
- { name: anon ,login: false }
- { name: authenticated ,login: false }
- { name: dashboard_user ,login: false ,replication: true ,createdb: true ,createrole: true }
- { name: service_role ,login: false ,bypassrls: true }
# supabase users: please use the same password
- { name: supabase_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: true ,roles: [ dbrole_admin ] ,superuser: true ,replication: true ,createdb: true ,createrole: true ,bypassrls: true }
- { name: authenticator ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] }
- { name: supabase_auth_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_storage_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] ,createrole: true }
- { name: supabase_functions_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_replication_admin ,password: 'DBUser.Supa' ,replication: true ,roles: [ dbrole_admin ]}
- { name: supabase_read_only_user ,password: 'DBUser.Supa' ,bypassrls: true ,roles: [ dbrole_readonly, pg_read_all_data ] }
pg_databases:
- name: postgres
baseline: supabase.sql
owner: supabase_admin
comment: supabase postgres database
schemas: [ extensions ,auth ,realtime ,storage ,graphql_public ,supabase_functions ,_analytics ,_realtime ]
extensions:
- { name: pgcrypto ,schema: extensions } # 1.3 : cryptographic functions
- { name: pg_net ,schema: extensions } # 0.9.2 : async HTTP
- { name: pgjwt ,schema: extensions } # 0.2.0 : json web token API for postgres
- { name: uuid-ossp ,schema: extensions } # 1.1 : generate universally unique identifiers (UUIDs)
- { name: pgsodium } # 3.1.9 : pgsodium is a modern cryptography library for Postgres.
- { name: supabase_vault } # 0.2.8 : Supabase Vault Extension
- { name: pg_graphql } # 1.5.9 : pg_graphql: GraphQL support
- { name: pg_jsonschema } # 0.3.3 : pg_jsonschema: Validate json schema
- { name: wrappers } # 0.4.3 : wrappers: FDW collections
- { name: http } # 1.6 : http: allows web page retrieval inside the database.
- { name: pg_cron } # 1.6 : pg_cron: Job scheduler for PostgreSQL
- { name: timescaledb } # 2.17 : timescaledb: Enables scalable inserts and complex queries for time-series data
- { name: pg_tle } # 1.2 : pg_tle: Trusted Language Extensions for PostgreSQL
- { name: vector } # 0.8.0 : pgvector: the vector similarity search
# supabase required extensions
pg_libs: 'pg_stat_statements, plpgsql, plpgsql_check, pg_cron, pg_net, timescaledb, auto_explain, pg_tle, plan_filter'
pg_extensions: # extensions to be installed on this cluster
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
pg_parameters:
cron.database_name: postgres
pgsodium.enable_event_trigger: off
pg_hba_rules: # supabase hba rules, require access from docker network
- { user: all ,db: postgres ,addr: intra ,auth: pwd ,title: 'allow supabase access from intranet' }
- { user: all ,db: postgres ,addr: 172.17.0.0/16 ,auth: pwd ,title: 'allow access from local docker network' }
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # make a full backup every 1am
# launch supabase stateless part with docker compose: ./supabase.yml
supabase:
hosts:
10.10.10.10: { supa_seq: 1 } # instance id
vars:
supa_cluster: supa # cluster name
docker_enabled: true # enable docker
# use these to pull docker images via proxy and mirror registries
#docker_registry_mirrors: ['https://docker.xxxxx.io']
#proxy_env: # add [OPTIONAL] proxy env to /etc/docker/daemon.json configuration file
# no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"
# #all_proxy: http://user:pass@host:port
# these configuration entries will OVERWRITE or APPEND to /opt/supabase/.env file (src template: app/supabase/.env)
# check https://github.com/Vonng/pigsty/blob/main/app/supabase/.env for default values
supa_config:
# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!
# https://supabase.com/docs/guides/self-hosting/docker#securing-your-services
jwt_secret: your-super-secret-jwt-token-with-at-least-32-characters-long
anon_key: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GE
service_role_key: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Q
dashboard_username: supabase
dashboard_password: pigsty
# postgres connection string (use the correct ip and port)
postgres_host: 10.10.10.10
postgres_port: 5436 # access via the 'default' service, which always route to the primary postgres
postgres_db: postgres
postgres_password: DBUser.Supa # password for supabase_admin and multiple supabase users
# expose supabase via domain name
site_url: http://supa.pigsty
api_external_url: http://supa.pigsty
supabase_public_url: http://supa.pigsty
# if using s3/minio as file storage
s3_bucket: supa
s3_endpoint: https://sss.pigsty:9000
s3_access_key: supabase
s3_secret_key: S3User.Supabase
s3_force_path_style: true
s3_protocol: https
s3_region: stub
minio_domain_ip: 10.10.10.10 # sss.pigsty domain name will resolve to this ip statically
# if using SMTP (optional)
#smtp_admin_email: [email protected]
#smtp_host: supabase-mail
#smtp_port: 2500
#smtp_user: fake_mail_user
#smtp_pass: fake_mail_password
#smtp_sender_name: fake_sender
#enable_anonymous_users: false
vars:
version: v3.1.0 # pigsty version string
admin_ip: 10.10.10.10 # admin node ip address
region: default # upstream mirror region: default|china|europe
node_tune: oltp # node tuning specs: oltp,olap,tiny,crit
pg_conf: oltp.yml # pgsql tuning specs: {oltp,olap,tiny,crit}.yml
infra_portal: # domain names and upstream servers
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus : { domain: p.pigsty ,endpoint: "${admin_ip}:9090" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9093" }
minio : { domain: m.pigsty ,endpoint: "10.10.10.10:9001", https: true, websocket: true }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" } # expose supa studio UI and API via nginx
supa : { domain: supa.pigsty ,endpoint: "10.10.10.10:8000", websocket: true }
#----------------------------------#
# Credential: CHANGE THESE PASSWORDS
#----------------------------------#
#grafana_admin_username: admin
grafana_admin_password: pigsty
#pg_admin_username: dbuser_dba
pg_admin_password: DBUser.DBA
#pg_monitor_username: dbuser_monitor
pg_monitor_password: DBUser.Monitor
#pg_replication_username: replicator
pg_replication_password: DBUser.Replicator
#patroni_username: postgres
patroni_password: Patroni.API
#haproxy_admin_username: admin
haproxy_admin_password: pigsty
# use minio as supabase file storage, single node single driver mode for demonstration purpose
minio_access_key: minioadmin # root access key, `minioadmin` by default
minio_secret_key: minioadmin # root secret key, `minioadmin` by default
minio_buckets: [ { name: pgsql }, { name: supa } ]
minio_users:
- { access_key: dba , secret_key: S3User.DBA, policy: consoleAdmin }
- { access_key: pgbackrest , secret_key: S3User.Backup, policy: readwrite }
- { access_key: supabase , secret_key: S3User.Supabase, policy: readwrite }
minio_endpoint: https://sss.pigsty:9000 # explicit overwrite minio endpoint with haproxy port
node_etc_hosts: ["10.10.10.10 sss.pigsty"] # domain name to access minio from all nodes (required)
# use minio as default backup repo for PostgreSQL
pgbackrest_method: minio # pgbackrest repo method: local,minio,[user-defined...]
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
s3_endpoint: sss.pigsty # minio endpoint domain name, `sss.pigsty` by default
s3_region: us-east-1 # minio region, us-east-1 by default, useless for minio
s3_bucket: pgsql # minio bucket name, `pgsql` by default
s3_key: pgbackrest # minio user access key for pgbackrest
s3_key_secret: S3User.Backup # minio user secret key for pgbackrest
s3_uri_style: path # use path style uri for minio rather than host style
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9000 # minio port, 9000 by default
storage_ca_file: /pg/cert/ca.crt # minio ca file path, `/pg/cert/ca.crt` by default
bundle: y # bundle small files into a single file
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
# download docker and supabase related extensions
pg_version: 17
repo_modules: node,pgsql,infra,docker
repo_packages: [node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility, docker ]
repo_extra_packages:
- pgsql-main
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
For advanced topics, we may need to modify the configuration file to fit our needs.
- Security Enhancement
- Domain Name and HTTPS
- Sending Mail with SMTP
- MinIO or External S3
- True High Availability
Security Enhancement
For security reasons, you should change the default passwords in the pigsty.yml config file.
grafana_admin_password:pigsty, Grafana admin passwordpg_admin_password:DBUser.DBA, PGSQL superuser passwordpg_monitor_password:DBUser.Monitor, PGSQL monitor user passwordpg_replication_password:DBUser.Replicator, PGSQL replication user passwordpatroni_password:Patroni.API, Patroni HA Agent Passwordhaproxy_admin_password:pigsty, Load balancer admin passwordminio_access_key:minioadmin, MinIO root usernameminio_secret_key:minioadmin, MinIO root password
Supabase will use PostgreSQL & MinIO as its backend, so also change the following passwords for supabase business users:
pg_users: password for supabase business users in postgresminio_users:minioadmin, MinIO business user’s password
The pgbackrest will take backups and WALs to MinIO, so also change the following passwords reference
pgbackrest_repo: refer to the
PLEASE check the Supabase Self-Hosting: Generate API Keys to generate supabase credentials:
jwt_secret: a secret key with at least 40 charactersanon_key: a jwt token generate for anonymous users, based onjwt_secretservice_role_key: a jwt token generate for elevated service roles, based onjwt_secretdashboard_username: supabase studio web portal username,supabaseby defaultdashboard_password: supabase studio web portal password,pigstyby default
If you have chanaged the default password for PostgreSQL and MinIO, you have to update the following parameters as well:
postgres_password, according topg_userss3_access_keyands3_secret_key, according tominio_users
Domain Name and HTTPS
For local or intranet use, you can connect directly to Kong port on http://<IP>:8000 or 8443 for https.
This works but isn’t ideal. Using a domain with HTTPS is strongly recommended when serving Supabase to the public.
Pigsty has a Nginx server installed & configured on the admin node to act as a reverse proxy for all web based service. which is configured via the infra_portal parameter.
all:
vars: # global vars
#.....
infra_portal: # domain names and upstream servers
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus : { domain: p.pigsty ,endpoint: "${admin_ip}:9090" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9093" }
minio : { domain: m.pigsty ,endpoint: "10.10.10.10:9001", https: true, websocket: true }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" } # expose supa studio UI and API via nginx
supa : { domain: supa.pigsty ,endpoint: "10.10.10.10:8000", websocket: true }
On the client side, you can use the domain supa.pigsty to access the Supabase Studio management interface.
You can add this domain to your local /etc/hosts file or use a local DNS server to resolve it to the server’s external IP address.
To use a real domain with HTTPS, you will need to modify the all.vars.infra_portal.supa with updated domain name (such as supa.pigsty.cc here).
You can obtain a free HTTPS certificate from Let’s Encrypt, and just put the cert/key files in the specified path.
#supa : { domain: supa.pigsty ,endpoint: "10.10.10.10:8000", websocket: true } # add your HTTPS certs/keys and specify the path
supa : { domain: supa.pigsty.cc ,endpoint: "10.10.10.10:8000", websocket: true ,cert: /etc/cert/suap.pigsty.cc.crt ,key: /etc/cert/supa.pigsty.cc.key }
To reload the new configuration after installation, use the infra.yml playbook:
./infra.yml -t nginx_config,nginx_launch # reload nginx config
You also have to update the all.children.supabase.vars.supa_config to tell supabase to use the new domain name:
all:
children: # clusters
supabase: # supabase group
vars: # supabase param
supa_config: # supabase config
# update supabase domain names here
site_url: http://supa.pigsty.cc
api_external_url: http://supa.pigsty.cc
supabase_public_url: http://supa.pigsty.cc
And reload the supabase service to apply the new configuration:
./supabase.yml -t supa_config,supa_launch # reload supabase config
Sending Mail with SMTP
Some Supabase features require email. For production use, I’d recommend using an external SMTP service. Since self-hosted SMTP servers often result in rejected or spam-flagged emails.
To do this, modify the Supabase configuration and add SMTP credentials:
all:
children:
supabase:
vars:
supa_config:
smtp_host: smtpdm.aliyun.com:80
smtp_port: 80
smtp_user: [email protected]
smtp_pass: your_email_user_password
smtp_sender_name: MySupabase
smtp_admin_email: [email protected]
enable_anonymous_users: false
And don’t forget to reload the supabase service with ./supabase.yml -t supa_config,supa_launch
MinIO or External S3
Pigsty’s self-hosting supabase will use a local SNSD MinIO server, which is used by Supabase itself for object storage, and by PostgreSQL for backups. For production use, you should consider using a HA MNMD MinIO cluster or an external S3 compatible service instead.
We recommend using an external S3 when:
- you just have one single server available, then external s3 gives you a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
- you are operating in the cloud, then using S3 directly is recommended rather than wrap expensively EBS with MinIO
The
terraform/spec/aliyun-meta-s3.tfprovides an example of how to provision a single node alone with an S3 bucket.
To use an external S3 compatible service, you’ll have to update two related references in the pigsty.yml config.
For example, to use Aliyun OSS as the object storage for Supabase, you can modify the all.children.supabase.vars.supa_config to point to the Aliyun OSS bucket:
all:
children:
supabase:
vars:
supa_config:
s3_bucket: pigsty-oss
s3_endpoint: https://oss-cn-beijing-internal.aliyuncs.com
s3_access_key: xxxxxxxxxxxxxxxx
s3_secret_key: xxxxxxxxxxxxxxxx
s3_force_path_style: false
s3_protocol: https
s3_region: oss-cn-beijing
Reload the supabase service with ./supabase.yml -t supa_config,supa_launch again.
The next reference is in the PostgreSQL backup repo:
all:
vars:
# use minio as default backup repo for PostgreSQL
pgbackrest_method: minio # pgbackrest repo method: local,minio,[user-defined...]
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
# update your credentials here
s3_endpoint: oss-cn-beijing-internal.aliyuncs.com
s3_region: oss-cn-beijing
s3_bucket: pigsty-oss
s3_key: xxxxxxxxxxxxxx
s3_key_secret: xxxxxxxx
s3_uri_style: host
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9000 # minio port, 9000 by default
storage_ca_file: /pg/cert/ca.crt # minio ca file path, `/pg/cert/ca.crt` by default
bundle: y # bundle small files into a single file
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
After updating the pgbackrest_repo, you can reset the pgBackrest backup with ./pgsql.yml -t pgbackrest.
True High Availability
The default single-node deployment (with external S3) provide a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
To achieve RTO < 30s and zero data loss, you need a multi-node high availability cluster with at least 3-nodes.
Which involves high availability for these components:
- ETCD: DCS requires at least three nodes to tolerate one node failure.
- PGSQL: PGSQL synchronous commit mode recommends at least three nodes.
- INFRA: It’s good to have two or three copies of observability stack.
- Supabase itself can also have multiple replicas to achieve high availability.
We recommend you to refer to the trio and safe config to upgrade your cluster to three nodes or more.
In this case, you also need to modify the access points for PostgreSQL and MinIO to use the DNS / L2 VIP / HAProxy HA access points.
all:
children:
supabase:
hosts:
10.10.10.10: { supa_seq: 1 }
10.10.10.11: { supa_seq: 2 }
10.10.10.12: { supa_seq: 3 }
vars:
supa_cluster: supa # cluster name
supa_config:
postgres_host: 10.10.10.2 # use the PG L2 VIP
postgres_port: 5433 # use the 5433 port to access the primary instance through pgbouncer
s3_endpoint: https://sss.pigsty:9002 # If you are using MinIO through the haproxy lb port 9002
minio_domain_ip: 10.10.10.3 # use the L2 VIP binds to all proxy nodes
The 3-Node HA Supabase Config Template
all:
#==============================================================#
# Clusters, Nodes, and Modules
#==============================================================#
children:
# infra cluster for proxy, monitor, alert, etc..
infra:
hosts:
10.10.10.10: { infra_seq: 1 ,nodename: infra-1 }
10.10.10.11: { infra_seq: 2 ,nodename: infra-2, repo_enabled: false, grafana_enabled: false }
10.10.10.12: { infra_seq: 3 ,nodename: infra-3, repo_enabled: false, grafana_enabled: false }
vars:
vip_enabled: true
vip_vrid: 128
vip_address: 10.10.10.3
vip_interface: eth1
haproxy_services:
- name: minio # [REQUIRED] service name, unique
port: 9002 # [REQUIRED] service port, unique
balance: leastconn # [OPTIONAL] load balancer algorithm
options: # [OPTIONAL] minio health check
- option httpchk
- option http-keep-alive
- http-check send meth OPTIONS uri /minio/health/live
- http-check expect status 200
servers:
- { name: minio-1 ,ip: 10.10.10.10 ,port: 9000 ,options: 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
- { name: minio-2 ,ip: 10.10.10.11 ,port: 9000 ,options: 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
- { name: minio-3 ,ip: 10.10.10.12 ,port: 9000 ,options: 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
etcd: # dcs service for postgres/patroni ha consensus
hosts: # 1 node for testing, 3 or 5 for production
10.10.10.10: { etcd_seq: 1 } # etcd_seq required
10.10.10.11: { etcd_seq: 2 } # assign from 1 ~ n
10.10.10.12: { etcd_seq: 3 } # odd number please
vars: # cluster level parameter override roles/etcd
etcd_cluster: etcd # mark etcd cluster name etcd
etcd_safeguard: false # safeguard against purging
etcd_clean: true # purge etcd during init process
# minio cluster 4-node
minio:
hosts:
10.10.10.10: { minio_seq: 1 , nodename: minio-1 }
10.10.10.11: { minio_seq: 2 , nodename: minio-2 }
10.10.10.12: { minio_seq: 3 , nodename: minio-3 }
vars:
minio_cluster: minio
minio_data: '/data{1...4}'
minio_buckets: [ { name: pgsql }, { name: supa } ]
minio_users:
- { access_key: dba , secret_key: S3User.DBA, policy: consoleAdmin }
- { access_key: pgbackrest , secret_key: S3User.Backup, policy: readwrite }
- { access_key: supabase , secret_key: S3User.Supabase, policy: readwrite }
# pg-meta, the underlying postgres database for supabase
pg-meta:
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary }
10.10.10.11: { pg_seq: 2, pg_role: replica }
10.10.10.12: { pg_seq: 3, pg_role: replica }
vars:
pg_cluster: pg-meta
pg_users:
# supabase roles: anon, authenticated, dashboard_user
- { name: anon ,login: false }
- { name: authenticated ,login: false }
- { name: dashboard_user ,login: false ,replication: true ,createdb: true ,createrole: true }
- { name: service_role ,login: false ,bypassrls: true }
# supabase users: please use the same password
- { name: supabase_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: true ,roles: [ dbrole_admin ] ,superuser: true ,replication: true ,createdb: true ,createrole: true ,bypassrls: true }
- { name: authenticator ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] }
- { name: supabase_auth_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_storage_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] ,createrole: true }
- { name: supabase_functions_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_replication_admin ,password: 'DBUser.Supa' ,replication: true ,roles: [ dbrole_admin ]}
- { name: supabase_read_only_user ,password: 'DBUser.Supa' ,bypassrls: true ,roles: [ dbrole_readonly, pg_read_all_data ] }
pg_databases:
- name: postgres
baseline: supabase.sql
owner: supabase_admin
comment: supabase postgres database
schemas: [ extensions ,auth ,realtime ,storage ,graphql_public ,supabase_functions ,_analytics ,_realtime ]
extensions:
- { name: pgcrypto ,schema: extensions } # 1.3 : cryptographic functions
- { name: pg_net ,schema: extensions } # 0.9.2 : async HTTP
- { name: pgjwt ,schema: extensions } # 0.2.0 : json web token API for postgres
- { name: uuid-ossp ,schema: extensions } # 1.1 : generate universally unique identifiers (UUIDs)
- { name: pgsodium } # 3.1.9 : pgsodium is a modern cryptography library for Postgres.
- { name: supabase_vault } # 0.2.8 : Supabase Vault Extension
- { name: pg_graphql } # 1.5.9 : pg_graphql: GraphQL support
- { name: pg_jsonschema } # 0.3.3 : pg_jsonschema: Validate json schema
- { name: wrappers } # 0.4.3 : wrappers: FDW collections
- { name: http } # 1.6 : http: allows web page retrieval inside the database.
- { name: pg_cron } # 1.6 : pg_cron: Job scheduler for PostgreSQL
- { name: timescaledb } # 2.17 : timescaledb: Enables scalable inserts and complex queries for time-series data
- { name: pg_tle } # 1.2 : pg_tle: Trusted Language Extensions for PostgreSQL
- { name: vector } # 0.8.0 : pgvector: the vector similarity search
# supabase required extensions
pg_libs: 'pg_stat_statements, plpgsql, plpgsql_check, pg_cron, pg_net, timescaledb, auto_explain, pg_tle, plan_filter'
pg_extensions: # extensions to be installed on this cluster
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
pg_parameters:
cron.database_name: postgres
pgsodium.enable_event_trigger: off
pg_hba_rules: # supabase hba rules, require access from docker network
- { user: all ,db: postgres ,addr: intra ,auth: pwd ,title: 'allow supabase access from intranet' }
- { user: all ,db: postgres ,addr: 172.17.0.0/16 ,auth: pwd ,title: 'allow access from local docker network' }
pg_vip_enabled: true
pg_vip_address: 10.10.10.2/24
pg_vip_interface: eth1
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # make a full backup every 1am
# launch supabase stateless part with docker compose: ./supabase.yml
supabase:
hosts:
10.10.10.10: { supa_seq: 1 } # instance 1
10.10.10.11: { supa_seq: 2 } # instance 2
10.10.10.12: { supa_seq: 3 } # instance 3
vars:
supa_cluster: supa # cluster name
docker_enabled: true # enable docker
# use these to pull docker images via proxy and mirror registries
#docker_registry_mirrors: ['https://docker.xxxxx.io']
#proxy_env: # add [OPTIONAL] proxy env to /etc/docker/daemon.json configuration file
# no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"
# #all_proxy: http://user:pass@host:port
# these configuration entries will OVERWRITE or APPEND to /opt/supabase/.env file (src template: app/supabase/.env)
# check https://github.com/Vonng/pigsty/blob/main/app/supabase/.env for default values
supa_config:
# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!
# https://supabase.com/docs/guides/self-hosting/docker#securing-your-services
jwt_secret: your-super-secret-jwt-token-with-at-least-32-characters-long
anon_key: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GE
service_role_key: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Q
dashboard_username: supabase
dashboard_password: pigsty
# postgres connection string (use the correct ip and port)
postgres_host: 10.10.10.3 # use the pg_vip_address rather than single node ip
postgres_port: 5433 # access via the 'default' service, which always route to the primary postgres
postgres_db: postgres
postgres_password: DBUser.Supa # password for supabase_admin and multiple supabase users
# expose supabase via domain name
site_url: http://supa.pigsty
api_external_url: http://supa.pigsty
supabase_public_url: http://supa.pigsty
# if using s3/minio as file storage
s3_bucket: supa
s3_endpoint: https://sss.pigsty:9002
s3_access_key: supabase
s3_secret_key: S3User.Supabase
s3_force_path_style: true
s3_protocol: https
s3_region: stub
minio_domain_ip: 10.10.10.3 # sss.pigsty domain name will resolve to this l2 vip that bind to all nodes
# if using SMTP (optional)
#smtp_admin_email: [email protected]
#smtp_host: supabase-mail
#smtp_port: 2500
#smtp_user: fake_mail_user
#smtp_pass: fake_mail_password
#smtp_sender_name: fake_sender
#enable_anonymous_users: false
#==============================================================#
# Global Parameters
#==============================================================#
vars:
version: v3.1.0 # pigsty version string
admin_ip: 10.10.10.10 # admin node ip address
region: china # upstream mirror region: default|china|europe
node_tune: oltp # node tuning specs: oltp,olap,tiny,crit
pg_conf: oltp.yml # pgsql tuning specs: {oltp,olap,tiny,crit}.yml
infra_portal: # domain names and upstream servers
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus : { domain: p.pigsty ,endpoint: "${admin_ip}:9090" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9093" }
minio : { domain: m.pigsty ,endpoint: "10.10.10.10:9001", https: true, websocket: true }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" } # expose supa studio UI and API via nginx
supa : { domain: supa.pigsty ,endpoint: "10.10.10.10:8000", websocket: true }
#----------------------------------#
# Credential: CHANGE THESE PASSWORDS
#----------------------------------#
#grafana_admin_username: admin
grafana_admin_password: pigsty
#pg_admin_username: dbuser_dba
pg_admin_password: DBUser.DBA
#pg_monitor_username: dbuser_monitor
pg_monitor_password: DBUser.Monitor
#pg_replication_username: replicator
pg_replication_password: DBUser.Replicator
#patroni_username: postgres
patroni_password: Patroni.API
#haproxy_admin_username: admin
haproxy_admin_password: pigsty
# use minio as supabase file storage, single node single driver mode for demonstration purpose
minio_access_key: minioadmin # root access key, `minioadmin` by default
minio_secret_key: minioadmin # root secret key, `minioadmin` by default
minio_buckets: [ { name: pgsql }, { name: supa } ]
minio_users:
- { access_key: dba , secret_key: S3User.DBA, policy: consoleAdmin }
- { access_key: pgbackrest , secret_key: S3User.Backup, policy: readwrite }
- { access_key: supabase , secret_key: S3User.Supabase, policy: readwrite }
minio_endpoint: https://sss.pigsty:9000 # explicit overwrite minio endpoint with haproxy port
node_etc_hosts: ["10.10.10.3 sss.pigsty"] # domain name to access minio from all nodes (required)
# use minio as default backup repo for PostgreSQL
pgbackrest_method: minio # pgbackrest repo method: local,minio,[user-defined...]
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
s3_endpoint: sss.pigsty # minio endpoint domain name, `sss.pigsty` by default
s3_region: us-east-1 # minio region, us-east-1 by default, useless for minio
s3_bucket: pgsql # minio bucket name, `pgsql` by default
s3_key: pgbackrest # minio user access key for pgbackrest
s3_key_secret: S3User.Backup # minio user secret key for pgbackrest
s3_uri_style: path # use path style uri for minio rather than host style
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9002 # minio port, 9000 by default
storage_ca_file: /pg/cert/ca.crt # minio ca file path, `/pg/cert/ca.crt` by default
bundle: y # bundle small files into a single file
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
# download docker and supabase related extensions
pg_version: 17
repo_modules: node,pgsql,infra,docker
repo_packages: [node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility, docker ]
repo_extra_packages:
- pgsql-main
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
Modern Hardware for Future Databases
Author: Alex Miller (Snowflake, Apple, Google) | Original: Modern Hardware for Future Databases

A survey on how hardware developments affect database design, covering key advancements in networking, storage, and computing. Read more
Can MySQL Still Catch Up with PostgreSQL?
Author: Peter Zaitsev (Percona Founder) | Original: Can MySQL Catch Up with PostgreSQL?

Percona founder Peter Zaitsev discusses whether MySQL can still keep up with PostgreSQL. His views largely represent the MySQL community’s perspective. Read more
Open-Source "Tyrant" Linus's Purge

The Linux community is essentially imperial — and Linus himself is the earliest and most successful technical dictator. People are used to Linus’s generosity but forget this point. Read more
Optimize Bio Cores First, CPU Cores Second

Programmers are expensive, scarce biological computing cores, the anchor point of software costs — please prioritize optimizing biological cores before optimizing CPU cores. Read more
MongoDB Has No Future: Good Marketing Can't Save a Rotten Mango

MongoDB has a terrible track record on integrity, lackluster products and technology, gets beaten by PG in correctness, performance, and functionality, with collapsing developer reputation, declining popularity, stock price halving, and expanding losses. Provocative marketing against PG can’t save it with “good marketing.” Read more
MongoDB: Now Powered by PostgreSQL?

MongoDB 3.2’s analytics subsystem turned out to be an embedded PostgreSQL database? A whistleblowing story from MongoDB’s partner about betrayal and disillusionment. Read more
Switzerland Mandates Open-Source for Government Software

Switzerland’s government leads the way with open source legislation, showing IT developing countries how to ensure software sovereignty and control. True autonomy and control stem from “open source communities,” not some “nationalist” style “domestic software.” Read more
MySQL is dead, Long live PostgreSQL!

This July, MySQL 9.0 was finally released—a full eight years after its last major version, 8.0 (@2016-09). Read more
CVE-2024-6387 SSH Vulnerability Fix
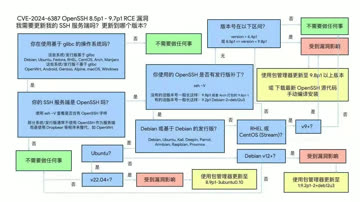
This vulnerability affects EL9, Ubuntu 22.04, Debian 12. Users should promptly update OpenSSH to fix this vulnerability. Read more
Can Oracle Still Save MySQL?
Author: Peter Zaitsev (Percona Founder) | Original: Can Oracle Save MySQL?

Percona founder Peter Zaitsev publicly expressed disappointment with MySQL and Oracle, criticizing the declining performance with newer versions. Read more
Oracle Finally Killed MySQL
Author: Peter Zaitsev (Percona Founder) | Original: Is Oracle Finally Killing MySQL?

Peter Zaitsev, founder of Percona, criticizes how Oracle’s actions and inactions have killed MySQL. About 15 years after acquiring Sun and MySQL. Read more
MySQL Performance Declining: Where is Sakila Going?
Author: Marco Tusa (Percona) | Original: Sakila, Where Are You Going?

Higher MySQL versions mean worse performance? Percona monitoring shows slow migration from 5.7 to 8.x. PostgreSQL is pulling ahead. Read more
Can Chinese Domestic Databases Really Compete?

Friends often ask me, can Chinese domestic databases really compete? To be honest, it’s a question that offends people. So let’s try speaking with data - I hope the charts provided in this article can help readers understand the database ecosystem landscape and establish more accurate proportional awareness. Read more
The $20 Brother PolarDB: What Should Databases Actually Cost?

Today we discuss the fair pricing of commercial databases, open-source databases, cloud databases, and domestic Chinese databases. Read more
Redis Going Non-Open-Source is a Disgrace to "Open-Source" and Public Cloud

Redis “going non-open source” is not a disgrace to Redis, but a disgrace to “open source/OSI” and even more so to public cloud. What truly matters has always been software freedom, while open source is just one means to achieve software freedom. Read more
How Can MySQL's Correctness Be This Garbage?

MySQL’s transaction ACID has flaws and doesn’t match documentation promises. This may lead to serious correctness issues - use with caution. Read more
Database in K8S: Pros & Cons
Whether databases should be housed in Kubernetes/Docker remains highly controversial. While Kubernetes (k8s) excels in managing stateless applications, it has fundamental drawbacks with stateful services, especially databases like PostgreSQL and MySQL.
In the previous article, “Databases in Docker: Good or Bad,” we discussed the pros and cons of containerizing databases. Today, let’s delve into the trade-offs in orchestrating databases in K8S and explore why it’s not a wise decision.
Summary
Kubernetes (k8s) is an exceptional container orchestration tool aimed at helping developers better manage a vast array of complex stateless applications. Despite its offerings like StatefulSet, PV, PVC, and LocalhostPV for supporting stateful services (i.e., databases), these features are still insufficient for running production-level databases that demand higher reliability.
Databases are more like “pets” than “cattle” and require careful nurturing. Treating databases as “cattle” in K8S essentially turns external disk/file system/storage services into new “database pets.” Running databases on EBS/network storage presents significant disadvantages in reliability and performance. However, using high-performance local NVMe disks will make the database bound to nodes and non-schedulable, negating the primary purpose of putting them in K8S.
Placing databases in K8S results in a “lose-lose” situation - K8S loses its simplicity in statelessness, lacking the flexibility to quickly relocate, schedule, destroy, and rebuild like purely stateless use. On the other hand, databases suffer several crucial attributes: reliability, security, performance, and complexity costs, in exchange for limited “elasticity” and utilization - something virtual machines can also achieve. For users outside public cloud vendors, the disadvantages far outweigh the benefits.
The “cloud-native frenzy,” exemplified by K8S, has become a distorted phenomenon: adopting k8s for the sake of k8s. Engineers add extra complexity to increase their irreplaceability, while managers fear being left behind by the industry and getting caught up in deployment races. Using tanks for tasks that could be done with bicycles, to gain experience or prove oneself, without considering if the problem needs such “dragon-slaying” techniques - this kind of architectural juggling will eventually lead to adverse outcomes.
Until the reliability and performance of the network storage surpass local storage, placing databases in K8S is an unwise choice. There are other ways to seal the complexity of database management, such as RDS and open-source RDS solutions like Pigsty, which are based on bare Metal or bare OS. Users should make wise decisions based on their situations and needs, carefully weighing the pros and cons.
The Status Quo
K8S excels in orchestrating stateless application services but was initially limited to stateful services. Despite not being the intended purpose of K8S and Docker, the community’s zeal for expansion has been unstoppable. Evangelists depict K8S as the next-generation cloud operating system, asserting that databases will inevitably become regular applications within Kubernetes. Various abstractions have emerged to support stateful services: StatefulSet, PV, PVC, and LocalhostPV.
Countless cloud-native enthusiasts have attempted to migrate existing databases into K8S, resulting in a proliferation of CRDs and Operators for databases. Taking PostgreSQL as an example, there are already more than ten different K8S deployment solutions available: PGO, StackGres, CloudNativePG, PostgresOperator, PerconaOperator, CYBERTEC-pg-operator, TemboOperator, Kubegres, KubeDB, KubeBlocks, and so on. The CNCF landscape rapidly expands, turning into a playground of complexity.
However, complexity is a cost. With “cost reduction” becoming mainstream, voices of reflection have begun to emerge. Could-Exit Pioneers like DHH, who deeply utilized K8S in public clouds, abandoned it due to its excessive complexity during the transition to self-hosted open-source solutions, relying only on Docker and a Ruby tool named Kamal as alternatives. Many began to question whether stateful services like databases suit Kubernetes.
K8S itself, in its effort to support stateful applications, has become increasingly complex, straying from its original intention as a container orchestration platform. Tim Hockin, a co-founder of Kubernetes, also voiced his rare concerns at this year’s KubeCon in “K8s is Cannibalizing Itself!”: “Kubernetes has become too complex; it needs to learn restraint, or it will stop innovating and lose its base.”
Lose-Lose Situation
In the cloud-native realm, the analogy of “pets” versus “cattle” is often used for illustrating stateful services. “Pets,” like databases, need careful and individual care, while “cattle” represent disposable, stateless applications (Disposability).
Cloud Native Applications 12 Factors: Disposability
One of the leading architectural goals of K8S is to treat what can be treated as cattle as cattle. The attempt to “separate storage from computation” in databases follows this strategy: splitting stateful database services into state storage outside K8S and pure computation inside K8S. The state is stored on the EBS/cloud disk/distributed storage service, allowing the “stateless” database part to be freely created, destroyed, and scheduled in K8S.
Unfortunately, databases, especially OLTP databases, heavily depend on disk hardware, and network storage’s reliability and performance still lag behind local disks by orders of magnitude. Thus, K8S offers the LocalhostPV option, allowing containers to use data volumes directly lies on the host operating system, utilizing high-performance/high-reliability local NVMe disk storage.
However, this presents a dilemma: should one use subpar cloud disks and tolerate poor database reliability/performance for K8S’s scheduling and orchestration capabilities? Or use high-performance local disks tied to host nodes, virtually losing all flexible scheduling abilities? The former is like stuffing an anchor into K8S’s small boat, slowing overall speed and agility; the latter is like anchoring and pinning the ship to a specific point.
Running a stateless K8S cluster is simple and reliable, as is running a stateful database on a physical machine’s bare operating system. Mixing the two, however, results in a lose-lose situation: K8S loses its stateless flexibility and casual scheduling abilities, while the database sacrifices core attributes like reliability, security, efficiency, and simplicity in exchange for elasticity, resource utilization, and Day1 delivery speed that are not fundamentally important to databases.
A vivid example of the former is the performance optimization of PostgreSQL@K8S, which KubeBlocks contributed. K8S experts employed various advanced methods to solve performance issues that did not exist on bare metal/bare OS at all. A fresh case of the latter is Didi’s K8S architecture juggling disaster; if it weren’t for putting the stateful MySQL in K8S, would rebuilding a stateless K8S cluster and redeploying applications take 12 hours to recover?
Pros and Cons
For serious technology decisions, the most crucial aspect is weighing the pros and cons. Here, in the order of “quality, security, performance, cost,” let’s discuss the technical trade-offs of placing databases in K8S versus classic bare metal/VM deployments. I don’t want to write a comprehensive paper that covers everything. Instead, I’ll throw some specific questions for consideration and discussion.
Quality
K8S, compared to physical deployments, introduces additional failure points and architectural complexity, increasing the blast radius and significantly prolonging the average recovery time of failures. In “Is it a Good Idea to Put Databases into Docker?”, we provided an argument about reliability, which can also apply to Kubernetes — K8S and Docker introduce additional and unnecessary dependencies and failure points to databases, lacking community failure knowledge accumulation and reliability track record (MTTR/MTBF).
In the cloud vendor classification system, K8S belongs to PaaS, while RDS belongs to a more fundamental layer, IaaS. Database services have higher reliability requirements than K8S; for instance, many companies’ cloud management platforms rely on an additional CMDB database. Where should this database be placed? You shouldn’t let K8S manage things it depends on, nor should you add unnecessary extra dependencies. The Alibaba Cloud global epic failure and Didi’s K8S architecture juggling disaster have taught us this lesson. Moreover, maintaining a separate database system inside K8S when there’s already one outside is even more unjustifiable.
Security
The database in a multi-tenant environment introduces additional attack surfaces, bringing higher risks and more complex audit compliance challenges. Does K8S make your database more secure? Maybe the complexity of K8S architecture juggling will deter script kiddies unfamiliar with K8S, but for real attackers, more components and dependencies often mean a broader attack surface.
In “BrokenSesame Alibaba Cloud PostgreSQL Vulnerability Technical Details”, security personnel escaped to the K8S host node using their own PostgreSQL container and accessed the K8S API and other tenants’ containers and data. This is clearly a K8S-specific issue — the risk is real, such attacks have occurred, and even Alibaba Cloud, a local cloud industry leader, has been compromised.
Source: The Attacker Perspective - Insights From Hacking Alibaba Cloud
Performance
As stated in “Is it a Good Idea to Put Databases into Docker?”, whether it’s additional network overhead, Ingress bottlenecks, or underperforming cloud disks, all negatively impact database performance. For example, as revealed in “PostgreSQL@K8s Performance Optimization” — you need a considerable level of technical prowess to make database performance in K8S barely match that on bare metal.
Note: Latency is measured in ms, not µs — a significant performance difference.
Another misconception about efficiency is resource utilization. Unlike offline analytical businesses, critical online OLTP databases should not aim to increase resource utilization but rather deliberately lower it to enhance system reliability and user experience. If there are many fragmented businesses, resource utilization can be improved through PDB/shared database clusters. K8S’s advocated elasticity efficiency is not unique to it — KVM/EC2 can also effectively address this issue.
In terms of cost, K8S and various Operators provide a decent abstraction, encapsulating some of the complexity of database management, which is attractive for teams without DBAs. However, the complexity reduced by using it to manage databases pales in comparison to the complexity introduced by using K8S itself. For instance, random IP address drifts and automatic Pod restarts may not be a big issue for stateless applications, but for databases, they are intolerable — many companies have had to attempt to modify kubelet to avoid this behavior, thereby introducing more complexity and maintenance costs.
As stated in “From Reducing Costs and Smiles to Reducing Costs and Efficiency” “Reducing Complexity Costs” section: Intellectual power is hard to accumulate spatially: when a database encounters problems, it needs database experts to solve them; when Kubernetes has problems, it needs K8S experts to look into them; however, when you put a database into Kubernetes, complexities combine, the state space explodes, but the intellectual bandwidth of individual database experts and K8S experts is hard to stack — you need a dual expert to solve the problem, and such experts are undoubtedly much rarer and more expensive than pure database experts. Such architectural juggling is enough to cause major setbacks for most teams, including top public clouds/big companies, in the event of a failure.
The Cloud-Native Frenzy
An interesting question arises: if K8S is unsuitable for stateful databases, why are so many companies, including big players, rushing to do this? The reasons are not technical.
Google open-sourced its K8S battleship, modeled after its internal Borg spaceship, and managers, fearing being left behind, rushed to adopt it, thinking using K8S would put them on par with Google. Ironically, Google doesn’t use K8S; it was more likely to disrupt AWS and mislead the industry. However, most companies don’t have the manpower like Google to operate such a battleship. More importantly, their problems might need a simple vessel. Running MySQL + PHP, PostgreSQL + Go/Python on bare metal has already taken many companies to IPO.
Under modern hardware conditions, the complexity of most applications throughout their lifecycle doesn’t justify using K8S. Yet, the “cloud-native” frenzy, epitomized by K8S, has become a distorted phenomenon: adopting k8s just for the sake of k8s. Some engineers are looking for “advanced” and “cool” technologies used by big companies to fulfill their personal goals like job hopping or promotions or to increase their job security by adding complexity, not considering if these “dragon-slaying” techniques are necessary for solving their problems.
The cloud-native landscape is filled with fancy projects. Every new development team wants to introduce something new: Helm today, Kubevela tomorrow. They talk big about bright futures and peak efficiency, but in reality, they create a mountain of architectural complexities and a playground for “YAML Boys” - tinkering with the latest tech, inventing concepts, earning experience and reputation at the expense of users who bear the complexity and maintenance costs.
CNCF Landscape: A sprawling ecosystem of complexity
The cloud-native movement’s philosophy is compelling - democratizing the elastic scheduling capabilities of public clouds for every user. K8S indeed excels in stateless applications. However, excessive enthusiasm has led K8S astray from its original intent and direction - simply doing well in orchestrating stateless applications, burdened by the ill-conceived support for stateful applications.
Making Wise Decisions
Years ago, when I first encountered K8S, I too was fervent —— It was at TanTan. We had over twenty thousand cores and hundreds of database clusters, and I was eager to try putting databases in Kubernetes and testing all the available Operators. However, after two to three years of extensive research and architectural design, I calmed down and abandoned this madness. Instead, I architected our database service based on bare metal/operating systems. For us, the benefits K8S brought to databases were negligible compared to the problems and hassles it introduced.
Should databases be put into K8S? It depends: for public cloud vendors who thrive on overselling resources, elasticity and utilization are crucial, which are directly linked to revenue and profit, While reliability and performance take a back seat - after all, an availability below three nines means compensating 25% monthly credit. But for most user, including ourselves, these trade-offs hold different: One-time Day1 Setup, elasticity, and resource utilization aren’t their primary concerns; reliability, performance, Day2 Operation costs, these core database attributes are what matter most.
We open-sourced our database service architecture — an out-of-the-box PostgreSQL distribution and a local-first RDS alternative: Pigsty. We didn’t choose the so-called “build once, run anywhere” approach of K8S and Docker. Instead, we adapted to different OS distros & major versions, and used Ansible to achieve a K8S CRD IaC-like API to seal management complexity. This was arduous, but it was the right thing to do - the world does not need another clumsy attempt at putting PostgreSQL into K8S. Still, it does need a production database service architecture that maximizes hardware performance and reliability.
Pigsty vs StackGres: Different approaches to PostgreSQL deployment
Perhaps one day, when the reliability and performance of distributed network storage surpass local storage and mainstream databases have some native support for storage-computation separation, things might change again — K8S might become suitable for databases. But for now, I believe putting serious production OLTP databases into K8S is immature and inappropriate. I hope readers will make wise choices on this matter.
Reference
Database in Docker: Is that a good idea?
《What can we learn from DiDi’s Epic k8s Failure》
Are Specialized Vector Databases Dead?

Vector storage and retrieval is a real need, but specialized vector databases are already dead. Small needs are solved by OpenAI directly, standard needs are captured by existing mature databases with vector extensions. The ecological niche left for specialized vector databases might support one company, but trying to build an industry around AI stories is impossible. Read more
Are Databases Really Being Strangled?

Many “domestic databases” are just shoddy, inferior products that can’t be helped. Xinchuang domestic OS/databases are essentially IT pre-made meals in schools. Users hold their noses while migrating, developers pretend to work hard, and everyone plays along with leaders who neither understand nor care about technology. The infrastructure software industry isn’t being strangled by anyone - the real chokehold comes from the so-called “insiders.” Read more
Which EL-Series OS Distribution Is Best?

RHEL-series OS distribution compatibility level: RHEL = Rocky ≈ Anolis > Alma > Oracle » Euler. Recommend using RockyLinux 8.8, or Anolis 8.8 for domestic requirements. Read more
What Kind of Self-Reliance Do Infrastructure Software Need?

When we talk about self-reliance and control, what are we really talking about? Operational self-reliance vs. R&D self-reliance - what nations/users truly need is the former, not flashy “self-research”. Read more
Back to Basics: Tech Reflection Chronicles

The cost-cutting imperative has triggered a reevaluation of all technologies, including databases. This series critiques hot DB technologies and poses fundamental questions about their trade-offs: Are cloud databases, distributed databases, microservices, and containerization real needs or false hype? Read more
Database Demand Hierarchy Pyramid

Similar to Maslow’s hierarchy of needs, user demands for databases also have a progressive hierarchy: physiological needs, safety needs, belonging needs, esteem needs, cognitive needs, aesthetic needs, self-actualization needs, and transcendence needs. Read more
Are Microservices a Bad Idea?
Author: DHH (David Heinemeier Hansson) | Original: Even Amazon can’t make sense of serverless or microservices

Even Amazon’s SOA paradigm team admits microservices and Serverless have problems. Prime Video team switched to monolith, saving 90% operational costs. Read more
NewSQL: Distributive Nonsens

As hardware technology advances, the capacity and performance of standalone databases have reached unprecedented heights. which makes distributed (TP) databases appear utterly powerless, much like the “data middle platform,” donning the emperor’s new clothes in a state of self-deception. Read more
Time to Say Goodbye to GPL
Author: Martin Kleppmann (DDIA Author) | Original: It’s time to say goodbye to the GPL

DDIA author Martin Kleppmann argues we should move away from GPL licenses. In the 2020s, the enemy of computing freedom is cloud software. Read more
Is running postgres in docker a good idea?

Thou shalt not run a prod database inside a container Read more
Understanding Time - Leap Years, Leap Seconds, Time and Time Zones

A proper understanding of time is very helpful for correctly handling time-related issues in work and life. For example, time representation and processing in computers, as well as time handling in databases and programming languages. Read more
Understanding Character Encoding Principles

Without understanding the basic principles of character encoding, even simple string operations like comparison, sorting, and random access can easily lead you into pitfalls. This article attempts to clarify these issues through a comprehensive explanation. Read more
Concurrency Anomalies Explained

Concurrent programs are hard to write correctly and even harder to write well. Many programmers simply throw these problems at the database… But even the most sophisticated databases won’t help if you don’t understand concurrency anomalies and isolation levels. Read more
Blockchain and Distributed Databases

The technical essence, functionality, and evolution of blockchain is distributed databases. Specifically, it’s a Byzantine Fault Tolerant (resistant to malicious node attacks) distributed (leaderless replication) database. Read more
Consistency: An Overloaded Term

The term “consistency” is heavily overloaded, representing different concepts in different contexts. For example, the C in ACID and the C in CAP actually refer to different concepts. Read more
Why Study Database Principles

Those who only know how to code are just programmers; learn databases well, and you can at least make a living; but for excellent engineers, merely using databases is far from enough. Read more