Monitoring
Built-in Console
MinIO has a built-in management console. By default, you can access this interface via HTTPS through the admin port (minio_admin_port, default 9001) of any MinIO instance.
In most configuration templates that provide MinIO services, MinIO is exposed as a custom service at m.pigsty. After configuring domain name resolution, you can access the MinIO console at https://m.pigsty.
Log in with the admin credentials configured by minio_access_key and minio_secret_key (default minioadmin / S3User.MinIO).
The MinIO console requires HTTPS access. If you use Pigsty’s self-signed CA, you need to trust the CA certificate in your browser, or manually accept the security warning.
Pigsty Monitoring
Pigsty provides two monitoring dashboards related to the MINIO module:
- MinIO Overview: Displays overall monitoring metrics for the MinIO cluster, including cluster status, storage usage, request rates, etc.
- MinIO Instance: Displays monitoring metrics details for a single MinIO instance, including CPU, memory, network, disk, etc.
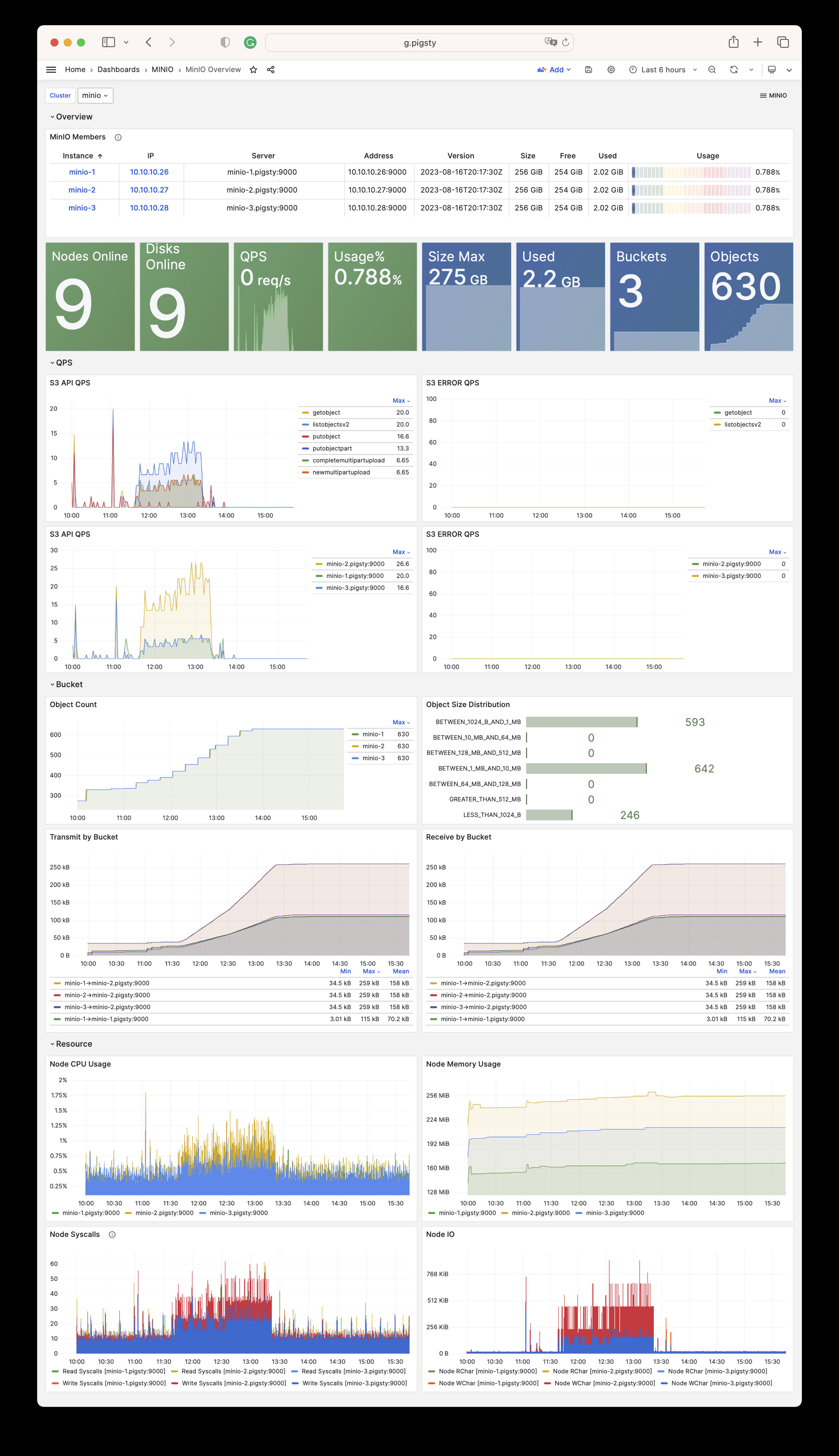
MinIO monitoring metrics are collected through MinIO’s native Prometheus endpoint (/minio/v2/metrics/cluster), and by default are scraped and stored by Victoria Metrics.
Pigsty Alerting
Pigsty provides the following three alerting rules for MinIO:
- MinIO Server Down
- MinIO Node Offline
- MinIO Disk Offline
#==============================================================#
# Aliveness #
#==============================================================#
# MinIO server instance down
- alert: MinioServerDown
expr: minio_up < 1
for: 1m
labels: { level: 0, severity: CRIT, category: minio }
annotations:
summary: "CRIT MinioServerDown {{ $labels.ins }}@{{ $labels.instance }}"
description: |
minio_up[ins={{ $labels.ins }}, instance={{ $labels.instance }}] = {{ $value }} < 1
http://g.pigsty/d/minio-overview
#==============================================================#
# Error #
#==============================================================#
# MinIO node offline triggers a p1 alert
- alert: MinioNodeOffline
expr: avg_over_time(minio_cluster_nodes_offline_total{job="minio"}[5m]) > 0
for: 3m
labels: { level: 1, severity: WARN, category: minio }
annotations:
summary: "WARN MinioNodeOffline: {{ $labels.cls }} {{ $value }}"
description: |
minio_cluster_nodes_offline_total[cls={{ $labels.cls }}] = {{ $value }} > 0
http://g.pigsty/d/minio-overview?from=now-5m&to=now&var-cls={{$labels.cls}}
# MinIO disk offline triggers a p1 alert
- alert: MinioDiskOffline
expr: avg_over_time(minio_cluster_disk_offline_total{job="minio"}[5m]) > 0
for: 3m
labels: { level: 1, severity: WARN, category: minio }
annotations:
summary: "WARN MinioDiskOffline: {{ $labels.cls }} {{ $value }}"
description: |
minio_cluster_disk_offline_total[cls={{ $labels.cls }}] = {{ $value }} > 0
http://g.pigsty/d/minio-overview?from=now-5m&to=now&var-cls={{$labels.cls}}
Feedback
Was this page helpful?
Thanks for the feedback! Please let us know how we can improve.
Sorry to hear that. Please let us know how we can improve.