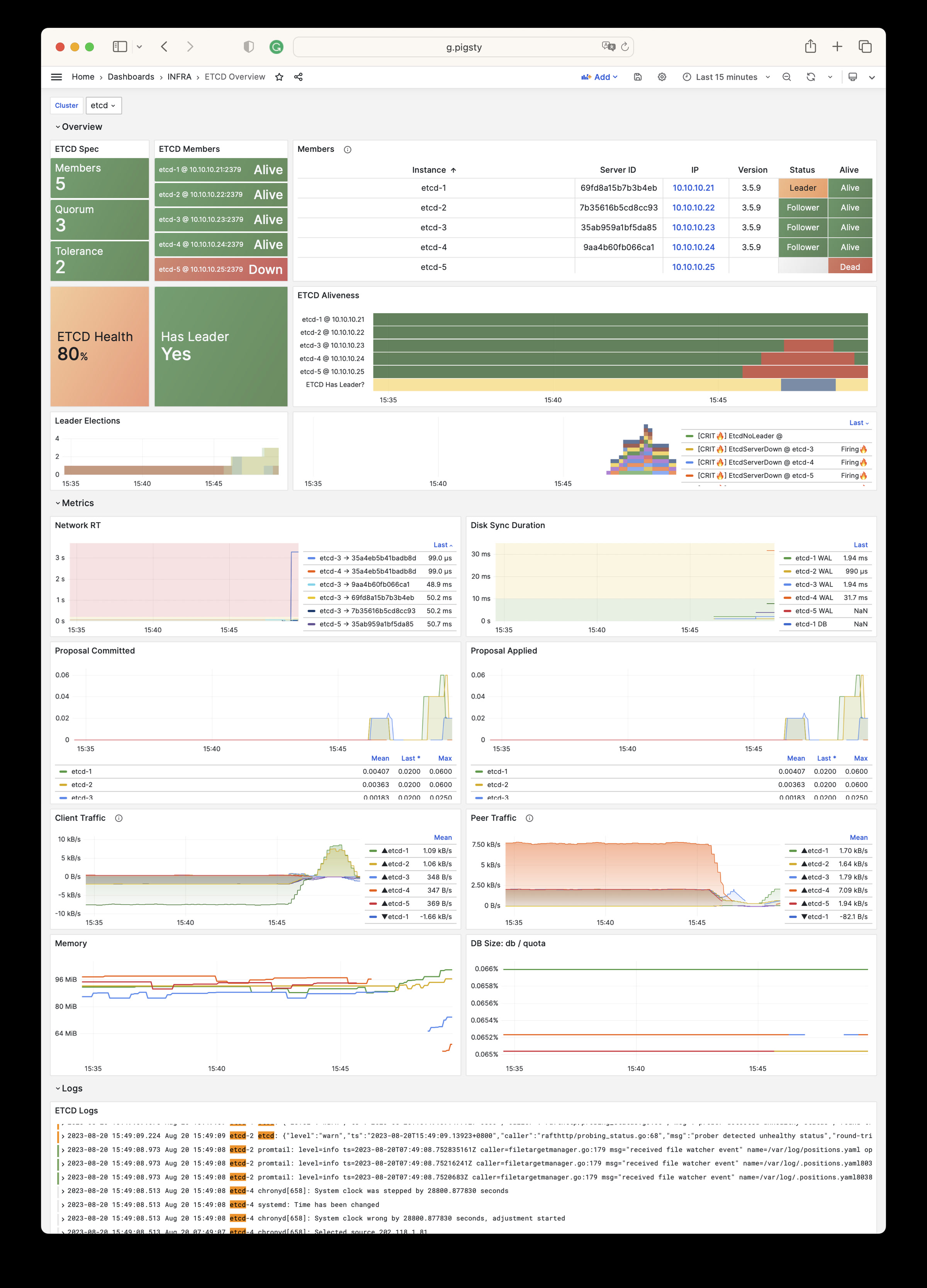
| etcd:ins:backend_commit_rt_p99_5m |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd:ins:disk_fsync_rt_p99_5m |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd:ins:network_peer_rt_p99_1m |
Unknown |
cls, To, ins, instance, job, ip |
N/A |
| etcd_cluster_version |
gauge |
cls, cluster_version, ins, instance, job, ip |
Which version is running. 1 for ‘cluster_version’ label with current cluster version |
| etcd_debugging_auth_revision |
gauge |
cls, ins, instance, job, ip |
The current revision of auth store. |
| etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_disk_backend_commit_rebalance_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_disk_backend_commit_rebalance_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_disk_backend_commit_spill_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_disk_backend_commit_spill_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_disk_backend_commit_spill_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_disk_backend_commit_write_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_disk_backend_commit_write_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_disk_backend_commit_write_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_lease_granted_total |
counter |
cls, ins, instance, job, ip |
The total number of granted leases. |
| etcd_debugging_lease_renewed_total |
counter |
cls, ins, instance, job, ip |
The number of renewed leases seen by the leader. |
| etcd_debugging_lease_revoked_total |
counter |
cls, ins, instance, job, ip |
The total number of revoked leases. |
| etcd_debugging_lease_ttl_total_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_lease_ttl_total_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_lease_ttl_total_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_mvcc_compact_revision |
gauge |
cls, ins, instance, job, ip |
The revision of the last compaction in store. |
| etcd_debugging_mvcc_current_revision |
gauge |
cls, ins, instance, job, ip |
The current revision of store. |
| etcd_debugging_mvcc_db_compaction_keys_total |
counter |
cls, ins, instance, job, ip |
Total number of db keys compacted. |
| etcd_debugging_mvcc_db_compaction_last |
gauge |
cls, ins, instance, job, ip |
The unix time of the last db compaction. Resets to 0 on start. |
| etcd_debugging_mvcc_db_compaction_pause_duration_milliseconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_mvcc_db_compaction_pause_duration_milliseconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_mvcc_db_compaction_pause_duration_milliseconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_mvcc_db_compaction_total_duration_milliseconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_mvcc_db_compaction_total_duration_milliseconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_mvcc_db_compaction_total_duration_milliseconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_mvcc_events_total |
counter |
cls, ins, instance, job, ip |
Total number of events sent by this member. |
| etcd_debugging_mvcc_index_compaction_pause_duration_milliseconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_mvcc_index_compaction_pause_duration_milliseconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_mvcc_index_compaction_pause_duration_milliseconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_mvcc_keys_total |
gauge |
cls, ins, instance, job, ip |
Total number of keys. |
| etcd_debugging_mvcc_pending_events_total |
gauge |
cls, ins, instance, job, ip |
Total number of pending events to be sent. |
| etcd_debugging_mvcc_range_total |
counter |
cls, ins, instance, job, ip |
Total number of ranges seen by this member. |
| etcd_debugging_mvcc_slow_watcher_total |
gauge |
cls, ins, instance, job, ip |
Total number of unsynced slow watchers. |
| etcd_debugging_mvcc_total_put_size_in_bytes |
gauge |
cls, ins, instance, job, ip |
The total size of put kv pairs seen by this member. |
| etcd_debugging_mvcc_watch_stream_total |
gauge |
cls, ins, instance, job, ip |
Total number of watch streams. |
| etcd_debugging_mvcc_watcher_total |
gauge |
cls, ins, instance, job, ip |
Total number of watchers. |
| etcd_debugging_server_lease_expired_total |
counter |
cls, ins, instance, job, ip |
The total number of expired leases. |
| etcd_debugging_snap_save_marshalling_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_snap_save_marshalling_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_snap_save_marshalling_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_snap_save_total_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_debugging_snap_save_total_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_snap_save_total_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_debugging_store_expires_total |
counter |
cls, ins, instance, job, ip |
Total number of expired keys. |
| etcd_debugging_store_reads_total |
counter |
cls, action, ins, instance, job, ip |
Total number of reads action by (get/getRecursive), local to this member. |
| etcd_debugging_store_watch_requests_total |
counter |
cls, ins, instance, job, ip |
Total number of incoming watch requests (new or reestablished). |
| etcd_debugging_store_watchers |
gauge |
cls, ins, instance, job, ip |
Count of currently active watchers. |
| etcd_debugging_store_writes_total |
counter |
cls, action, ins, instance, job, ip |
Total number of writes (e.g. set/compareAndDelete) seen by this member. |
| etcd_disk_backend_commit_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_disk_backend_commit_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_backend_commit_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_backend_defrag_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_disk_backend_defrag_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_backend_defrag_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_backend_snapshot_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_disk_backend_snapshot_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_backend_snapshot_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_defrag_inflight |
gauge |
cls, ins, instance, job, ip |
Whether or not defrag is active on the member. 1 means active, 0 means not. |
| etcd_disk_wal_fsync_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_disk_wal_fsync_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_wal_fsync_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_disk_wal_write_bytes_total |
gauge |
cls, ins, instance, job, ip |
Total number of bytes written in WAL. |
| etcd_grpc_proxy_cache_hits_total |
gauge |
cls, ins, instance, job, ip |
Total number of cache hits |
| etcd_grpc_proxy_cache_keys_total |
gauge |
cls, ins, instance, job, ip |
Total number of keys/ranges cached |
| etcd_grpc_proxy_cache_misses_total |
gauge |
cls, ins, instance, job, ip |
Total number of cache misses |
| etcd_grpc_proxy_events_coalescing_total |
counter |
cls, ins, instance, job, ip |
Total number of events coalescing |
| etcd_grpc_proxy_watchers_coalescing_total |
gauge |
cls, ins, instance, job, ip |
Total number of current watchers coalescing |
| etcd_mvcc_db_open_read_transactions |
gauge |
cls, ins, instance, job, ip |
The number of currently open read transactions |
| etcd_mvcc_db_total_size_in_bytes |
gauge |
cls, ins, instance, job, ip |
Total size of the underlying database physically allocated in bytes. |
| etcd_mvcc_db_total_size_in_use_in_bytes |
gauge |
cls, ins, instance, job, ip |
Total size of the underlying database logically in use in bytes. |
| etcd_mvcc_delete_total |
counter |
cls, ins, instance, job, ip |
Total number of deletes seen by this member. |
| etcd_mvcc_hash_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_mvcc_hash_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_mvcc_hash_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_mvcc_hash_rev_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_mvcc_hash_rev_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_mvcc_hash_rev_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_mvcc_put_total |
counter |
cls, ins, instance, job, ip |
Total number of puts seen by this member. |
| etcd_mvcc_range_total |
counter |
cls, ins, instance, job, ip |
Total number of ranges seen by this member. |
| etcd_mvcc_txn_total |
counter |
cls, ins, instance, job, ip |
Total number of txns seen by this member. |
| etcd_network_active_peers |
gauge |
cls, ins, Local, instance, job, ip, Remote |
The current number of active peer connections. |
| etcd_network_client_grpc_received_bytes_total |
counter |
cls, ins, instance, job, ip |
The total number of bytes received from grpc clients. |
| etcd_network_client_grpc_sent_bytes_total |
counter |
cls, ins, instance, job, ip |
The total number of bytes sent to grpc clients. |
| etcd_network_peer_received_bytes_total |
counter |
cls, ins, instance, job, ip, From |
The total number of bytes received from peers. |
| etcd_network_peer_round_trip_time_seconds_bucket |
Unknown |
cls, To, ins, instance, job, le, ip |
N/A |
| etcd_network_peer_round_trip_time_seconds_count |
Unknown |
cls, To, ins, instance, job, ip |
N/A |
| etcd_network_peer_round_trip_time_seconds_sum |
Unknown |
cls, To, ins, instance, job, ip |
N/A |
| etcd_network_peer_sent_bytes_total |
counter |
cls, To, ins, instance, job, ip |
The total number of bytes sent to peers. |
| etcd_server_apply_duration_seconds_bucket |
Unknown |
cls, version, ins, instance, job, le, success, ip, op |
N/A |
| etcd_server_apply_duration_seconds_count |
Unknown |
cls, version, ins, instance, job, success, ip, op |
N/A |
| etcd_server_apply_duration_seconds_sum |
Unknown |
cls, version, ins, instance, job, success, ip, op |
N/A |
| etcd_server_client_requests_total |
counter |
client_api_version, cls, ins, instance, type, job, ip |
The total number of client requests per client version. |
| etcd_server_go_version |
gauge |
cls, ins, instance, job, server_go_version, ip |
Which Go version server is running with. 1 for ‘server_go_version’ label with current version. |
| etcd_server_has_leader |
gauge |
cls, ins, instance, job, ip |
Whether or not a leader exists. 1 is existence, 0 is not. |
| etcd_server_health_failures |
counter |
cls, ins, instance, job, ip |
The total number of failed health checks |
| etcd_server_health_success |
counter |
cls, ins, instance, job, ip |
The total number of successful health checks |
| etcd_server_heartbeat_send_failures_total |
counter |
cls, ins, instance, job, ip |
The total number of leader heartbeat send failures (likely overloaded from slow disk). |
| etcd_server_id |
gauge |
cls, ins, instance, job, server_id, ip |
Server or member ID in hexadecimal format. 1 for ‘server_id’ label with current ID. |
| etcd_server_is_leader |
gauge |
cls, ins, instance, job, ip |
Whether or not this member is a leader. 1 if is, 0 otherwise. |
| etcd_server_is_learner |
gauge |
cls, ins, instance, job, ip |
Whether or not this member is a learner. 1 if is, 0 otherwise. |
| etcd_server_leader_changes_seen_total |
counter |
cls, ins, instance, job, ip |
The number of leader changes seen. |
| etcd_server_learner_promote_successes |
counter |
cls, ins, instance, job, ip |
The total number of successful learner promotions while this member is leader. |
| etcd_server_proposals_applied_total |
gauge |
cls, ins, instance, job, ip |
The total number of consensus proposals applied. |
| etcd_server_proposals_committed_total |
gauge |
cls, ins, instance, job, ip |
The total number of consensus proposals committed. |
| etcd_server_proposals_failed_total |
counter |
cls, ins, instance, job, ip |
The total number of failed proposals seen. |
| etcd_server_proposals_pending |
gauge |
cls, ins, instance, job, ip |
The current number of pending proposals to commit. |
| etcd_server_quota_backend_bytes |
gauge |
cls, ins, instance, job, ip |
Current backend storage quota size in bytes. |
| etcd_server_read_indexes_failed_total |
counter |
cls, ins, instance, job, ip |
The total number of failed read indexes seen. |
| etcd_server_slow_apply_total |
counter |
cls, ins, instance, job, ip |
The total number of slow apply requests (likely overloaded from slow disk). |
| etcd_server_slow_read_indexes_total |
counter |
cls, ins, instance, job, ip |
The total number of pending read indexes not in sync with leader’s or timed out read index requests. |
| etcd_server_snapshot_apply_in_progress_total |
gauge |
cls, ins, instance, job, ip |
1 if the server is applying the incoming snapshot. 0 if none. |
| etcd_server_version |
gauge |
cls, server_version, ins, instance, job, ip |
Which version is running. 1 for ‘server_version’ label with current version. |
| etcd_snap_db_fsync_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_snap_db_fsync_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_snap_db_fsync_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_snap_db_save_total_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_snap_db_save_total_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_snap_db_save_total_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_snap_fsync_duration_seconds_bucket |
Unknown |
cls, ins, instance, job, le, ip |
N/A |
| etcd_snap_fsync_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_snap_fsync_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| etcd_up |
Unknown |
cls, ins, instance, job, ip |
N/A |
| go_gc_duration_seconds |
summary |
cls, ins, instance, quantile, job, ip |
A summary of the pause duration of garbage collection cycles. |
| go_gc_duration_seconds_count |
Unknown |
cls, ins, instance, job, ip |
N/A |
| go_gc_duration_seconds_sum |
Unknown |
cls, ins, instance, job, ip |
N/A |
| go_goroutines |
gauge |
cls, ins, instance, job, ip |
Number of goroutines that currently exist. |
| go_info |
gauge |
cls, version, ins, instance, job, ip |
Information about the Go environment. |
| go_memstats_alloc_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes allocated and still in use. |
| go_memstats_alloc_bytes_total |
counter |
cls, ins, instance, job, ip |
Total number of bytes allocated, even if freed. |
| go_memstats_buck_hash_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes used by the profiling bucket hash table. |
| go_memstats_frees_total |
counter |
cls, ins, instance, job, ip |
Total number of frees. |
| go_memstats_gc_cpu_fraction |
gauge |
cls, ins, instance, job, ip |
The fraction of this program’s available CPU time used by the GC since the program started. |
| go_memstats_gc_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes used for garbage collection system metadata. |
| go_memstats_heap_alloc_bytes |
gauge |
cls, ins, instance, job, ip |
Number of heap bytes allocated and still in use. |
| go_memstats_heap_idle_bytes |
gauge |
cls, ins, instance, job, ip |
Number of heap bytes waiting to be used. |
| go_memstats_heap_inuse_bytes |
gauge |
cls, ins, instance, job, ip |
Number of heap bytes that are in use. |
| go_memstats_heap_objects |
gauge |
cls, ins, instance, job, ip |
Number of allocated objects. |
| go_memstats_heap_released_bytes |
gauge |
cls, ins, instance, job, ip |
Number of heap bytes released to OS. |
| go_memstats_heap_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of heap bytes obtained from system. |
| go_memstats_last_gc_time_seconds |
gauge |
cls, ins, instance, job, ip |
Number of seconds since 1970 of last garbage collection. |
| go_memstats_lookups_total |
counter |
cls, ins, instance, job, ip |
Total number of pointer lookups. |
| go_memstats_mallocs_total |
counter |
cls, ins, instance, job, ip |
Total number of mallocs. |
| go_memstats_mcache_inuse_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes in use by mcache structures. |
| go_memstats_mcache_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes used for mcache structures obtained from system. |
| go_memstats_mspan_inuse_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes in use by mspan structures. |
| go_memstats_mspan_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes used for mspan structures obtained from system. |
| go_memstats_next_gc_bytes |
gauge |
cls, ins, instance, job, ip |
Number of heap bytes when next garbage collection will take place. |
| go_memstats_other_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes used for other system allocations. |
| go_memstats_stack_inuse_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes in use by the stack allocator. |
| go_memstats_stack_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes obtained from system for stack allocator. |
| go_memstats_sys_bytes |
gauge |
cls, ins, instance, job, ip |
Number of bytes obtained from system. |
| go_threads |
gauge |
cls, ins, instance, job, ip |
Number of OS threads created. |
| grpc_server_handled_total |
counter |
cls, ins, instance, grpc_code, job, grpc_method, grpc_type, ip, grpc_service |
Total number of RPCs completed on the server, regardless of success or failure. |
| grpc_server_msg_received_total |
counter |
cls, ins, instance, job, grpc_type, grpc_method, ip, grpc_service |
Total number of RPC stream messages received on the server. |
| grpc_server_msg_sent_total |
counter |
cls, ins, instance, job, grpc_type, grpc_method, ip, grpc_service |
Total number of gRPC stream messages sent by the server. |
| grpc_server_started_total |
counter |
cls, ins, instance, job, grpc_type, grpc_method, ip, grpc_service |
Total number of RPCs started on the server. |
| os_fd_limit |
gauge |
cls, ins, instance, job, ip |
The file descriptor limit. |
| os_fd_used |
gauge |
cls, ins, instance, job, ip |
The number of used file descriptors. |
| process_cpu_seconds_total |
counter |
cls, ins, instance, job, ip |
Total user and system CPU time spent in seconds. |
| process_max_fds |
gauge |
cls, ins, instance, job, ip |
Maximum number of open file descriptors. |
| process_open_fds |
gauge |
cls, ins, instance, job, ip |
Number of open file descriptors. |
| process_resident_memory_bytes |
gauge |
cls, ins, instance, job, ip |
Resident memory size in bytes. |
| process_start_time_seconds |
gauge |
cls, ins, instance, job, ip |
Start time of the process since unix epoch in seconds. |
| process_virtual_memory_bytes |
gauge |
cls, ins, instance, job, ip |
Virtual memory size in bytes. |
| process_virtual_memory_max_bytes |
gauge |
cls, ins, instance, job, ip |
Maximum amount of virtual memory available in bytes. |
| promhttp_metric_handler_requests_in_flight |
gauge |
cls, ins, instance, job, ip |
Current number of scrapes being served. |
| promhttp_metric_handler_requests_total |
counter |
cls, ins, instance, job, ip, code |
Total number of scrapes by HTTP status code. |
| scrape_duration_seconds |
Unknown |
cls, ins, instance, job, ip |
N/A |
| scrape_samples_post_metric_relabeling |
Unknown |
cls, ins, instance, job, ip |
N/A |
| scrape_samples_scraped |
Unknown |
cls, ins, instance, job, ip |
N/A |
| scrape_series_added |
Unknown |
cls, ins, instance, job, ip |
N/A |
| up |
Unknown |
cls, ins, instance, job, ip |
N/A |