故障档案:快慢不匀雪崩
最近发生了一起匪夷所思的故障,某数据库切走了一半的数据量和负载。
其他什么都没变,本来还好;压力减小,却在高峰期陷入濒死状态,完全不符合直觉。
但正如福尔摩斯所说,当你排除掉一切不可能之后,剩下的即使再离奇,也是事实。
一、摘要
某日凌晨4点,进行了核心库进行分库迁移,拆走一半的表和一半的查询负载,原库节点规模不变。
当日晚高峰核心库所有热备库(15台)出现连接堆积,压力暴涨,针对性地清理慢查询不再起效。
无差别持续杀查询,有立竿见影的救火效果(22:30后),且暂停后故障立刻重现(22:48),杀至高峰期结束。
匪夷所思的是,移走了表(数据量减半),移走了负载(TPS减半),其他什么都没变竟然会导致压力上升?
二、现象
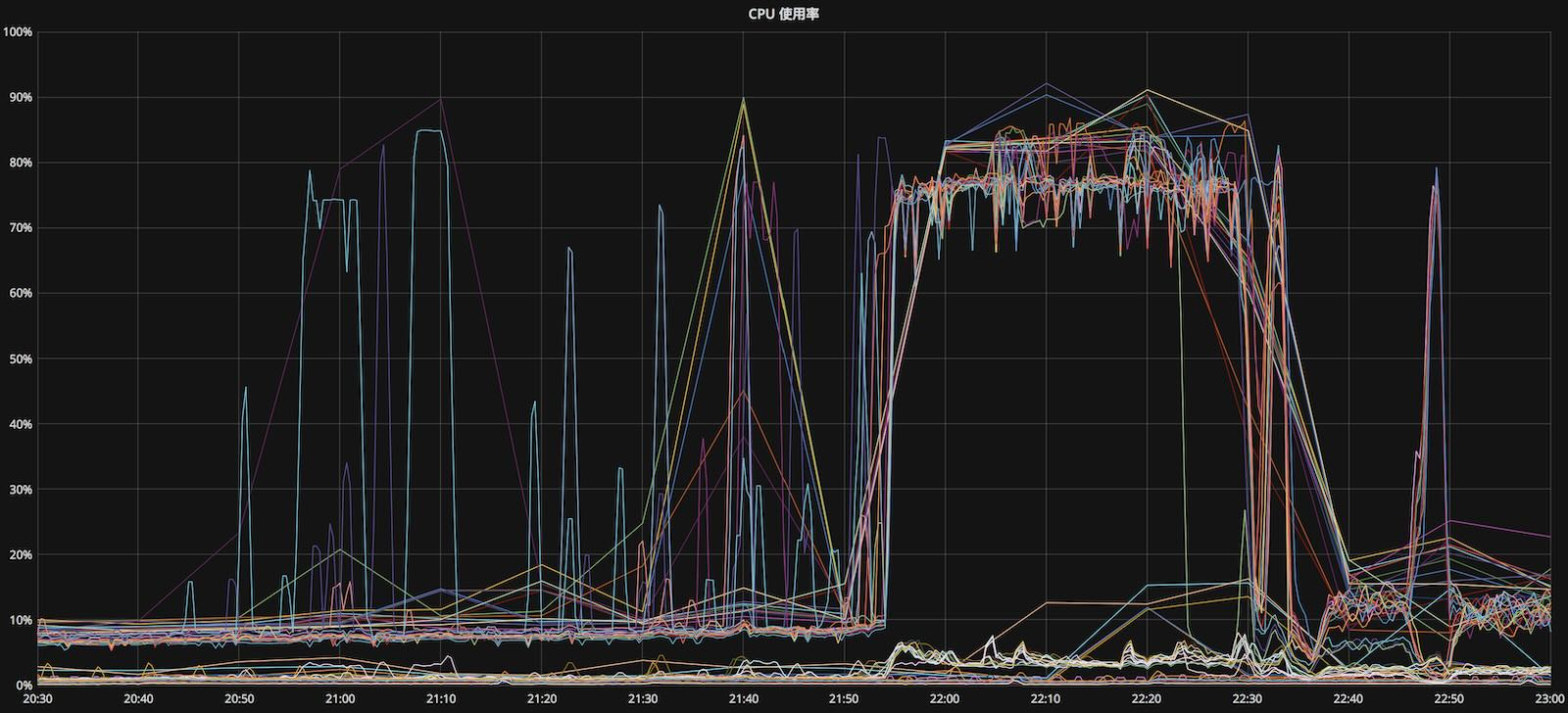
CPU使用率的正常水位在25%,警戒水位在45%,极限水位在80%。故障期间所有从库飙升至极限水位。
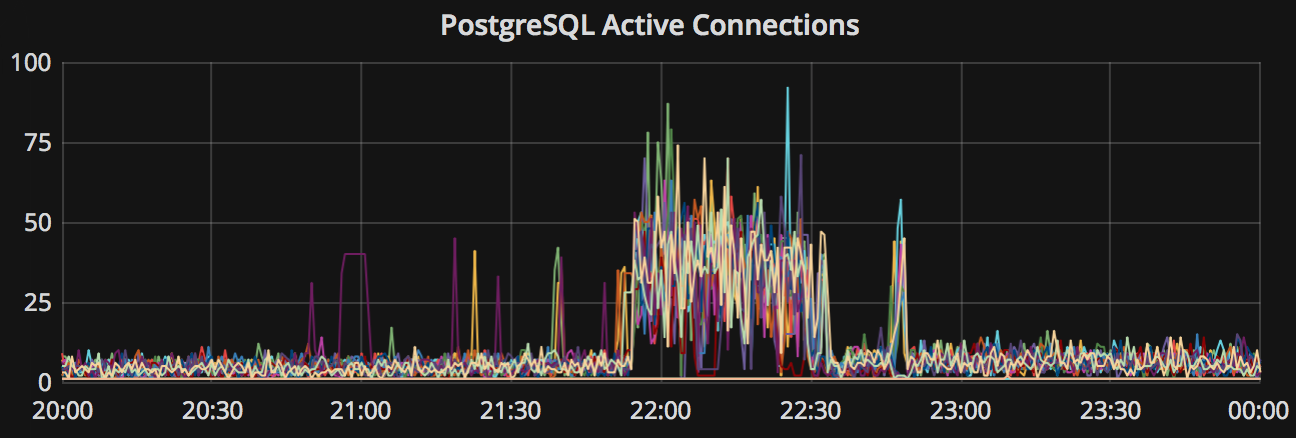
PostgreSQL连接数发生暴涨,通常5~10个左右的数据库连接就足够撑起所有流量,连接池的最大连接数为100。
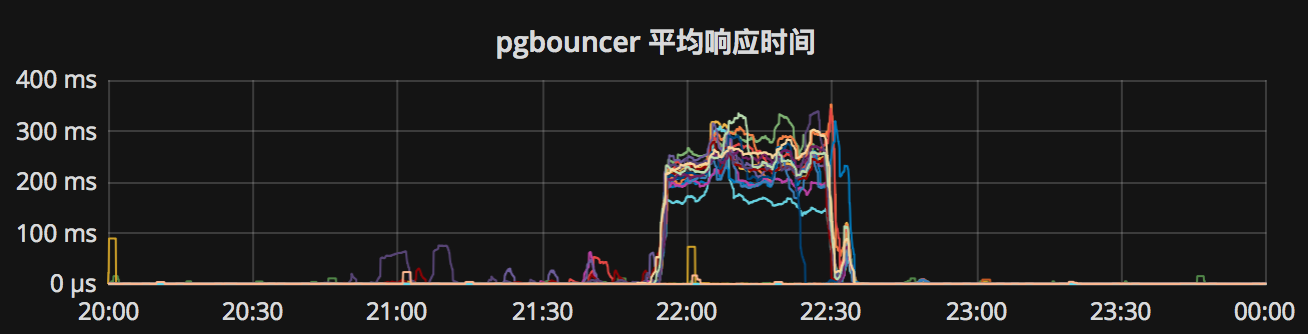
pgbouncer连接池平均响应时间平时在500μs左右,故障期间飙升至百毫秒级别。
故障期间,数据库TPS发生显著下滑。进行杀查询抢救后恢复,但处于剧烈抖动状态。

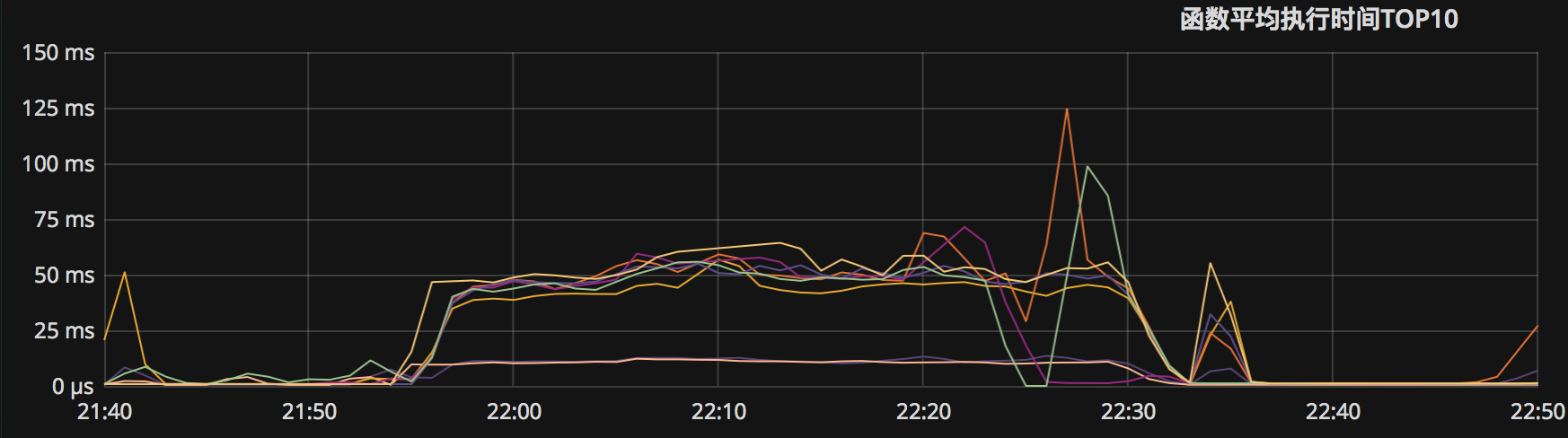
故障期间,两个函数的执行时间发生显著恶化,从几百微秒劣化至几十毫秒。
故障期间,复制延迟显著上升,开始出现GB级别的复制延迟,业务指标出现显著下滑。
开始杀查询后,大部分指标恢复,但一旦停止马上重新开始出现(22:48尝试性停止故障恢复)。
三、原因分析
【表因】:所有从库连接池被打满,连接被慢查询占据,快查询无法执行,发生连接堆积。
【主内因】:两个函数的并发数增大到30左右时,性能会发生急剧劣化,变为慢查询(500μs到100ms)。
【副内因】:后端与数据库没有合理的超时取消机制,断路器会放大故障。
【外因】:分库后,快查询比例下降,导致特定查询的相对比例上升,并发数增大至临界点。恶化为慢查询。
表因:连接打满
故障的表因是数据库连接池被打满,产生大量堆积连接。进而新连接无法建立,拒绝服务。
原理
数据库配置的最大连接数max_connections = 100,一个连接实质上就是一个数据库进程。机器能够负载的实际数据库进程数目与查询类型高度相关:如果全是在1ms内的快查询,几百上千个链接都是可以的(生产环境中的正常情况)。而如果全都是CPU和IO密集的慢查询,则最大支持的连接数可能只有(48 * 80% ≈ 38)个左右。
在生产环境中使用了连接池,正常情况下5~10个实际数据库连接就可以支撑起所有快查询。然而一旦有大量慢查询持续进入,长期占用了活跃连接,那么快查询就会排队等待发生堆积,连接池进而启动更多实际数据库的连接,而这些连接上的快查询很快就会执行完毕,最终仍然会被不断进入的慢查询占据。最终导致约100个实际数据库连接都在执行CPU/IO密集的慢查询(max_pool_size=100),CPU暴涨,进一步恶化情况。
证据
连接池活跃连接数
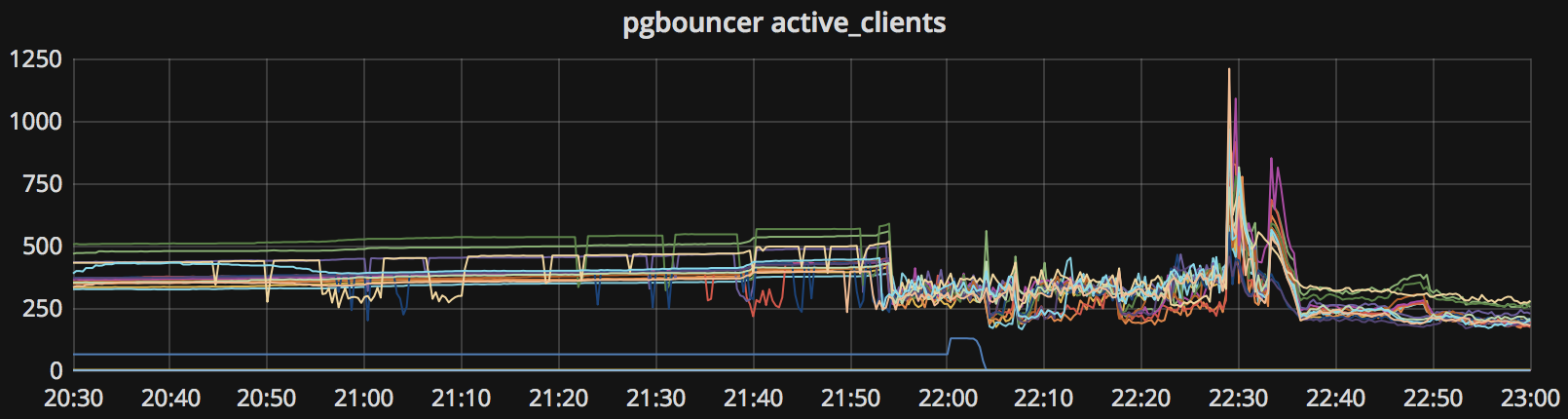
连接池排队连接数
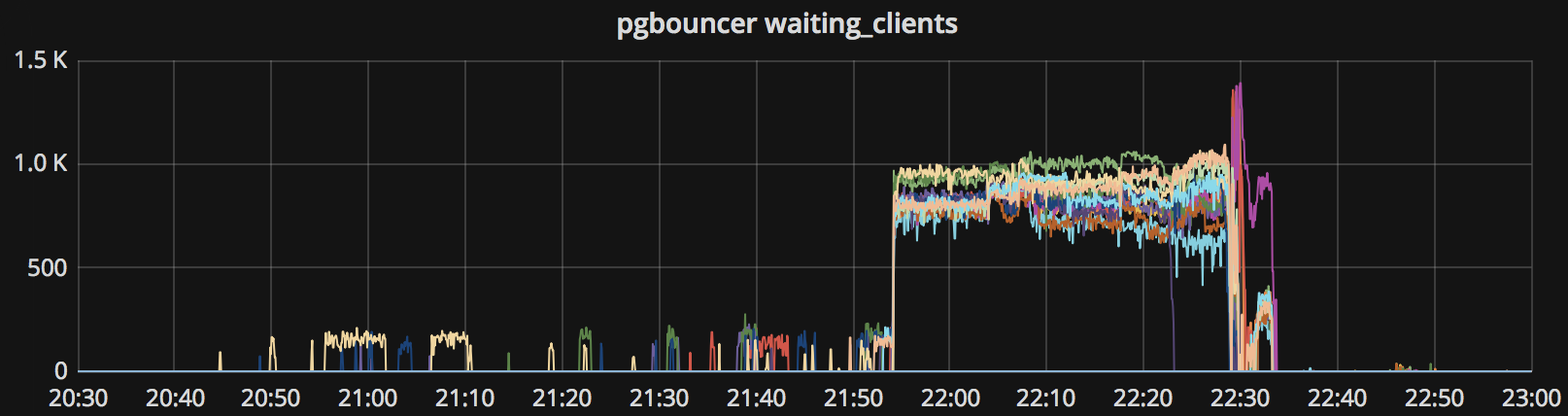
数据库后端连接数
修复
持续地无差别杀掉所有数据库活跃连接,能起到很好的治标效果,且对业务指标影响很小。
但杀掉连接(pg_terminate_backend)会导致连接池重连,更好的做法是取消查询(pg_cancel_backend)
因为快查询走的快,卡在后端实际连接上执行的查询极大概率都是慢查询,这时候无差别取消所有查询命中的绝大多数都是慢查询。杀查询能将连接释放给快查询使用,让应用苟活下去,但必须持续不断的杀才有效果,因为用不了零点几秒,慢查询就会重新占据活跃连接。
使用psql执行以下SQL,每隔0.5秒取消所有活跃查询。
SELECT pg_cancel_backend(pid) FROM pg_stat_activity WHERE application_name != 'psql' \watch 0.5
解决方案:调整了连接池的后端最大连接数,进行快慢分离,强制所有批量任务与慢查询走离线从库。
主内因:并行恶化
故障的主内因是两个函数的执行时间在并行数增大时发生恶化。
原理
故障的直接导火索是这两个函数劣化为慢查询。经过单独的压力测试,这两个函数随着并行执行数增高,发生急剧的性能劣化,阈值点为约30个并发进程。(因为所有进程只执行同一个查询,所以可认为并行数等于并发数)
证据
图:故障期间函数平均执行时间出现明显飙升
图:在不同并行数下压测该函数能达到的最大QPS
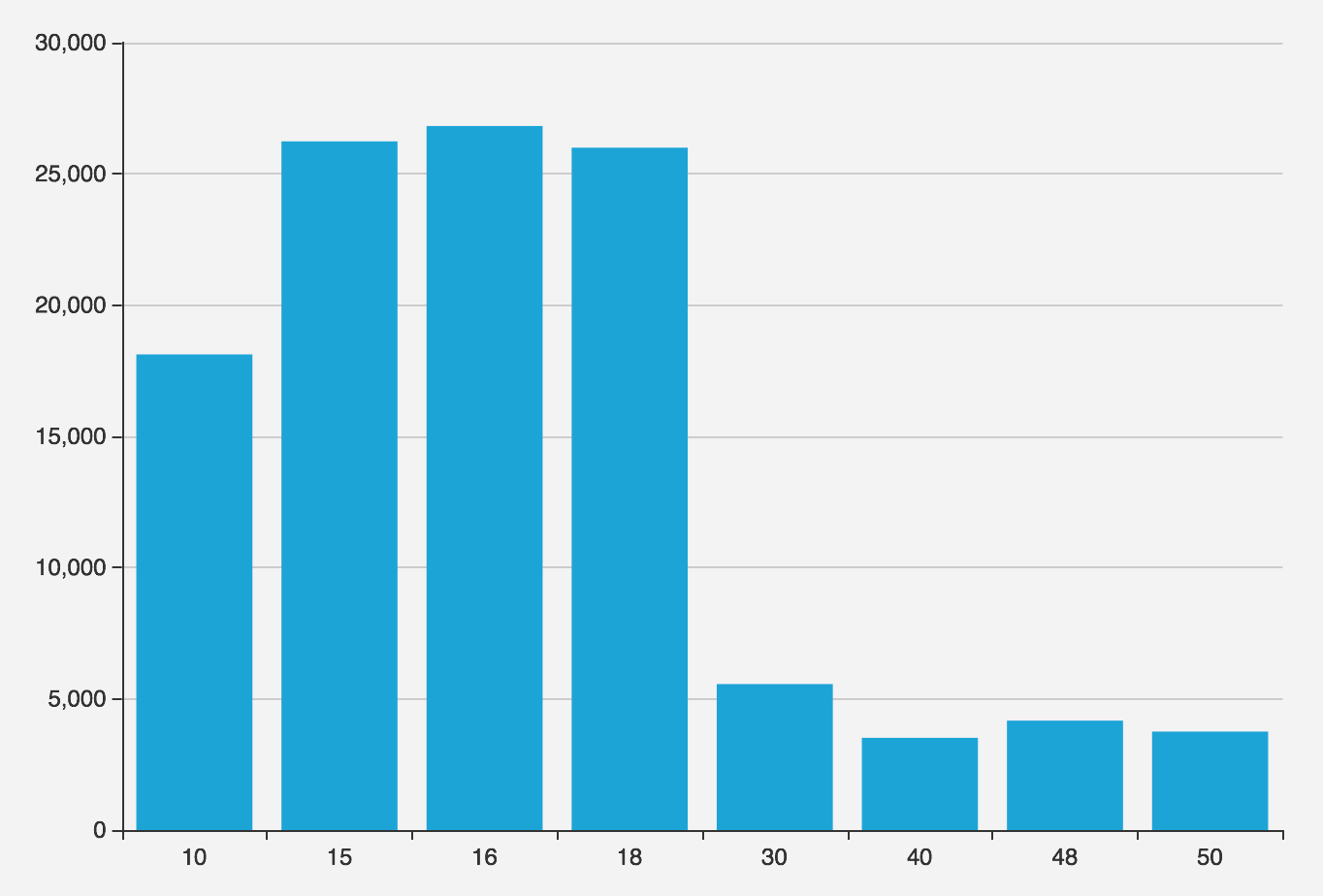
修复
- 优化函数执行逻辑,将该函数的执行时间优化至原来的一半(最大QPS翻倍)。
- 新增五台从库,进一步降低单机负载。
副内因:没有超时
故障的副内因在于没有合理的超时取消机制,查询不会因为超时被取消,是发生堆积的必要条件。
原理
发生查询超时时,应用层的合理行为是
- 直接返回,报错。
- 进行若干次重试(在高峰期可以考虑直接返回错误)
查询等待超出合理范围的时间却不取消,就会导致连接堆积。抛弃返回结果并无法取消已经发出的查询,客户端需要主动Cancel Request。Go1.7后的标准实践是通过context包与database/sql提供的QueryContext/ExecContext进行超时控制。
数据库端和连接池端可以配置语句超时(statement_timeout),但实践表明这样的操作很容易误杀查询。
手动杀灭能够立竿见影地治标,但它本质上是一种人工超时取消机制。稳健的系统应当有自动化的超时取消机制,这需要在数据库、连接池、应用多个层次协同解决。
检视后端使用的驱动代码,发现pg.v3 pg.v5并没有真正意义上的查询超时机制,超时参数不过是为net.Conn加上的TCP超时(通常在分钟级别)。
修复
- 建议使用
github.com/jackc/pgx与github.com/go-pg/pg第六版驱动替代现有驱动 - 使用circuit-breaker会导致故障效应被放大,建议后端使用主动超时替代断路器。
- 建议在应用层面对连接的使用进行更精细的控制。
外因:分库迁移
分库导致了原库中的快慢查询比例发生变化,诱发了两个函数的劣化。
问题函数在迁移前后的全局调用次数占比由1/6 变为1/2,导致问题函数的并行数增大。
原理
- 迁走的函数全都是快查询,原本问题函数:普通函数的比例为1:5
- 迁移负载后,快查询迁走了大半。问题函数:普通函数超过1:1
- 问题函数的比例大幅升高,导致高峰期其并发数超出阈值点,出现劣化。
证据
通过分析分库迁移前后的数据库全量日志,回放查询流量进行压测,重现了现象,确认了问题原因。
| 指标 | 迁移前 | 迁移后 |
|---|---|---|
| 问题函数占比 | 1/6 | 5/9 |
| 最大QPS | 40k | 8k |
QPS/TPS是一个极具误导性的指标,只有在负载类型不变的清空下,比较QPS才有意义。当系统负载类型发生变化时,QPS的水位点也需要重新进行评估测试。
在本例中,在负载变化后,系统的最大QPS水位点已经发生了戏剧性的变化,因为问题函数并发劣化,最大QPS变为原来的五分之一。
修复
对问题函数进行了改写优化,提高了一倍的性能。
通过测试,确定了迁移后的系统水位值,并进行了相应的优化与容量调整。
四、经验与教训
在故障排查中,走了一些弯路。比如一开始认为是某个离线批量任务拖慢了查询(根据日志中观察到的前后相关性),也排查了API调用量突增,外部恶意访问,其他变更因素,未知线上操作等。虽然分库迁移被列入怀疑对象,但因为直觉上认为负载小了,系统的Capacity怎么可能会下降?就没有列为优先排查对象。现实马上就给我们上了一课:
当你排除掉一切不可能之后,剩下的即使再离奇,也是事实。