驳《再论为什么你不应该招DBA》
郭德纲有一段相声:比如我和火箭专家说,你那火箭不行,燃料不好,我认为得烧柴,最好是烧煤,煤还得精选煤,水洗煤不行。如果那科学家拿正眼看我一眼,那他就输了。
但不管怎么说,马工也还是一位体面的瑞典研发工程师。没有做过DBA就敢大放厥词,开地图炮拉仇恨,实在勇气可嘉。之前在《你怎么还在招聘DBA》,以及回应文《云数据库是不是智商税》中,我们便已交锋过。
当别人把屎盆子扣在这个行业所有人头上时,还是需要人来站出来说几句的。因此今天特此撰文以驳斥马工的谬论:《再论为什么你不应该招DBA》。

马工的论点有三:
-
DBA妨碍了研发交付新特性
-
DBA威胁了企业数据安全
-
人工DBA需要被基于代码的软件所取代
我的看法是:
-
第一点属于无效输出,DBA本来就是在稳定性侧制衡研发的存在。
-
第二点则是完全扯淡,DBA本来就是类似于财务的关健岗位,需要信任。
-
第三点属于部分事实,但严重高估了短期变化,且云数据库并非唯一的路。
且听我一一道来:
DBA 对稳定性负责
关于信息系统的一个基本原理是:安全性与活性相互抵触,过于强调安全稳定,则活性受损;过于强调活性,则难以稳定。任何组织都要在两者中间找到一个平衡点。而研发与运维,就是两者的职能化身。
研发对新功负责,而 SRE/DBA 对稳定性负责,一个开创,一个守成,两者相互协作,但也是相互制衡。马工作为研发,特别还是创业公司的研发,主张功能活性很重要,从立场上来说是无可厚非的。但在更广大的组织中,稳定性的地位往往是高于新功能的,成熟的组织如银行,大型互联网平台,从来都是稳定性压倒一切。毕竟,新功能的收益是不确定的,而大故障的损失是肉眼可见的。每天发10个新版本不见得能带来多少增长,但一次大故障也许就能让几个月的努力付之东流。
“在高速上开两百迈的阻碍从来都不是车的性能,而是司机的胆量”。站在更高位的管理者角度来说,马工强调的 “开掉DBA得到更快的DB交付速度”,纯粹属于研发者的一厢情愿:用云把运维职能外包出去, 无人制衡,我想怎样就怎样。这样的想法如果落地,最终必将在某个时刻以惨痛的教训收场。
笔者曾是 DBA,但也没少干 Dev。关于研发和 DBA 的心态,都有亲身的体会。我在刚入行当研发的时候,在“PostgreSQL数据库里”跑神经网络,推荐系统,Web服务器和爬虫,用FDW接了 MongoDB 和 HBase以及一堆外部系统,什么稳定性?跑的不是挺好吗?直到没有运维与DBA愿意接手维护,我不得不亲自干起了 DBA 的活自己狗食背起锅来,才能设身处地的对DBA / 运维有同理心,谨慎选择有所为有所不为。
交付速度谁在乎?
评价一款数据库需要从许多维度出发:稳定性,可靠性,安全性,简单性,可伸缩性,可扩展性,可观测性,可维护性,成本性价比,等等等等。交付速度这件事勉强属于“可伸缩性”里一个比较次要的附属维度,在数据库系统需要关注的属性中,压根排不上号。
更重要的是,性价比才是第一产品力,对比方案却对成本闭而不提,是一种耍流氓的行为。笔者对研发人员的这种心理非常了解:花的是公司的钱,省的是自己事儿,自然没有几个人会有动机为公司去省钱。你的数据库花半个小时交付,还是花三四天交付,老板与领导不会 Care 这些。但是,你的老板会很在乎你花30分钟拉起了一个数据库,然后每个月账单多出来几十万元。

以 AWS 上 64核256GB的 db.m5.16xlarge RDS 为例,用一个月价格 $25,817 / 月,折合约 18 万元人民币,一个月的租金,够你把两台性能比这还要好的多得多的服务器直接买下来了,任何理智的企业用户都看得明白这里面的道理:如果采购这种服务不是为了短期的,临时性的需求,那么绝对算得上是重大的财务失当行为。
比交付速度也不怵
但即使我们退一万步讲,交付速度真的重要,马工的论证用例也是破绽百出。
马工假想了一个数据库上线的案例:PG新版本,两地三中心,同城HA,异地灾备,数据加密,自动备份,自带监控,App与DB独立网段,DBA也无法删库。然后得意洋洋的宣称:”使用 Terraform,我只要28分钟就可以完成满足需要的配置!比拉DBA搭建数据库快几个数量级!“
实际上只要你的机器就绪,网络打通,规划完毕:使用 Pigsty 部署一套满足这些需求的数据库系统,执行耗时也就是十几分钟。自建机房且不提,Pigsty 完全可以使用同样的逻辑:基于Terraform 一键拉起EC2、存储、网络,然后在这个基础上额外执行一条命令部署数据库,耗费的时间说不定比 Terraform 还短一点,更重要的是,还能省掉百分之八九十的天价 RDS 智商税。
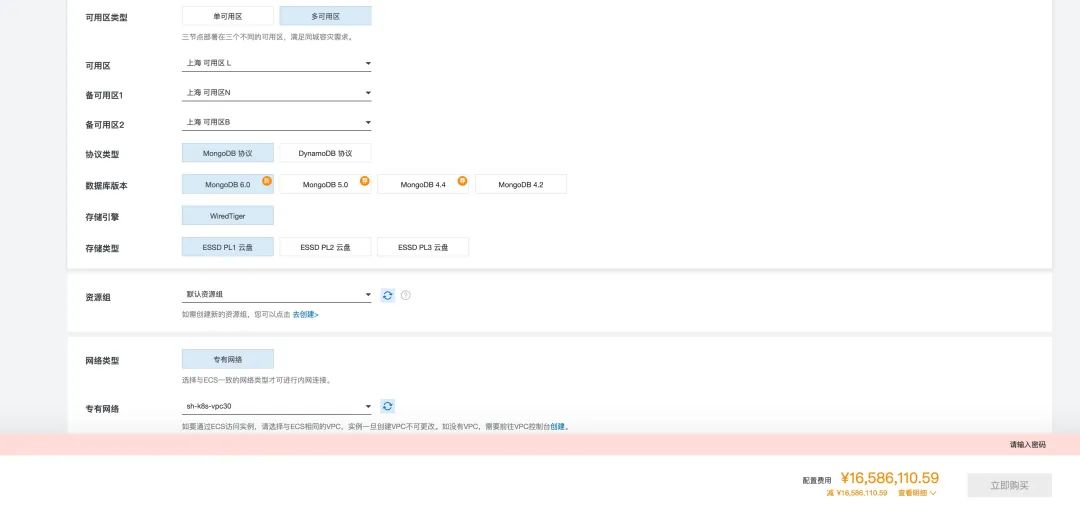
能想出这种定价的云数据库产品经理脑袋一定被门夹了
分库分表的稻草人靶子
马工提出,分库分表是DBA自抬身价的一种工具。
在今天,数据库的能力已经得到了极大的发展,给应用开发者带来巨大管理成本的分库分表已经没必要了。凡是在用分库分表的系统, 都可以用分布式数据库或者NoSQL数据库替换掉。几乎可以说,分库分表不过是DBA自抬身价的一种工具。
时至今日,硬件存储技术的发展已经让很多老同志跟不上新形势了。家用 PCI-E NVME SSD 2TB的价格已经进入了三位数,常用的企业级 3.2TB MLC NVME SSD也不过六七千,最大几十TB的单卡容量,已经完爆了很多中大型企业的所有 TB 数据量,七位数的IOPS让几千/几万IOPS还卖天价的 云 EBS 恨不得找个地缝钻进去。
软件方面,以 PostgreSQL 为例,使用堆表存储的单表容量十几TB千亿量级数据一点儿不成问题,还有 Citus 插件可以原地改造为分布式数据库。各种分布式数据库的卖点也是 “不用分库分表”。这都已经是老黄历问题了。除了极个别场景,恐怕也只有原教旨 MySQL 用户还守着 “单表不能超过 2000w 记录” 去玩分表了。
当然,分布式数据库对于 DBA 的水平要求不会更低只会更高;所以这里马工主要想说的还是 NoSQL ,更具体的讲,就是 DynamoDB 这种所谓“不需要” DBA运维的数据库直接干翻 DBA。不过,一个平均延迟在 10ms 的数据库,一个抽象程度只是等同于文件系统的扁平 KV 存储的数据库,光是杀猪程度要比 RDS 还要狠毒的 RCU / WCU 计费方式,就足够用户喝上一壶,有何德何能敢标榜自己能替掉 DBA ?
指望用NoSQL替代DBA是做梦
互联网应用大多属于数据密集型应用,对于真实世界的数据密集型应用而言,除非你准备从基础组件的轮子造起,不然根本没那么多机会去摆弄花哨的数据结构和算法。实际生产中,数据表就是数据结构,索引与查询就是算法。而应用研发写的代码往往扮演的是胶水的角色,处理IO与业务逻辑,其他大部分工作都是在数据系统之间搬运数据。
在最宽泛的意义上,有状态的地方就有数据库。它无所不在,网站的背后、应用的内部,单机软件,区块链里。有。关系型数据库只是数据系统的冰山一角(或者说冰山之巅),实际上存在着各种各样的数据系统组件:
- 数据库:存储数据,以便自己或其他应用程序之后能再次找到(PostgreSQL,MySQL,Oracle)
- 缓存:记住开销昂贵操作的结果,加快读取速度(Redis,Memcached)
- 搜索索引:允许用户按关键字搜索数据,或以各种方式对数据进行过滤(ElasticSearch)
- 流处理:向其他进程发送消息,进行异步处理(Kafka,Flink,Storm)
- 批处理:定期处理累积的大批量数据(Hadoop)
状态管理是信息系统的永恒问题,马工以为的 DBA 是抱着祖传 Oracle 手册的打字员,实际上互联网公司的 DBA 已经是十八班武艺样样精通的 数据架构师 了。架构师最重要的能力之一,就是了解这些组件的性能特点与应用场景,能够灵活地权衡取舍、集成拼接这些数据系统。 他们上要 Push 业务落地最佳实践指导模式设计,下要深入操作系统与硬件排查问题优化性能,中间要掌握无数种数据组件的使用方式。君子不器,关系型数据库的知识,只是其中最为核心重要的一种。
正如我在《为什么要学习数据库原理和设计》所说, 只会写代码的是码农;学好数据库,基本能混口饭吃;在此基础上再学好操作系统和计算机网络,就能当一个不错的程序员。可惜的是,数据建模和SQL几乎快成为一门失传的艺术:这类基础知识逐渐为新一代工程师遗忘,他们设计出离谱的模式,不懂得正确地创建索引,然后草率得出结论:关系型数据库和SQL都是垃圾,我们必须使用糙猛快的NoSQL来省时间。然而人们总是需要可靠的系统来处理关键业务数据:在许多企业中,核心数据仍然是一个常规关系型数据库作为Source of Truth,NoSQL数据库仅用于非关键数据。某个研发跳出来说 DynamoDB / Redis / MongoDB / HBase 太牛逼了,我所有的状态都能放在这里,而且再也不需要 DBA 了,毫无疑问是滑稽可笑的。
DBA 是企业数据库的守护者
马工的最后一炮,直指 DBA 的职业道德 :DBA想删库,谁也拦不住。
这话倒是没有错,DBA和财务一样,都属于能对企业造成致命杀伤的关键岗位:用人不疑,疑人不用。但这句话同样也绕开了一个重要事实:没有DBA守门,人人都能删库。在马工举的微盟和百度删库跑路的两个例子中,主犯都是普通的研发与运维人员,正是因为没有称职的 DBA 把关,才有删库跑路的可趁之机。
合格的 DBA 可以有效减少有能力对企业进行致命一击的人群范围,从所有的研发与运维收敛到DBA本身。至于 DBA 本身如何制衡,要么是两个 DBA 互为备份,要么是由运维/安全团队管理冷备份的删除权限。马工举的,腾讯云不让手工删例行备份的例子,实属对业内实践少见多怪。
对于给 DBA 群体泼脏水的行为,本人表示鄙视愤慨 😄。按照这个逻辑,我也完全可以认为马工喜爱的公有云厂商,才是对数据安全最大的威胁:用云不过是把运维和DBA外包给了云厂商,而你完全阻碍不了某个云厂商中有权限的研发/运维/DBA,在心血来潮的情况下来你的库里里逛逛。或者干脆脱个备份裤子赏玩一下,你压根不可能追索,不可能取证,当然核心原因是你压根没有能力知道这一点。而这样的人许许多多,一个运维的脚本出岔子就会爆破一大片,你能指望的赔偿也只有不痛不痒的时长代金券。
参考阅读:《云RDS:从删库到跑路》
DBA要退出历史舞台?
作为一个整体行业, DBA 确实在走下坡路, 但人们总是会过高估短期影响而低估长期趋势。许多大型组织都雇用DBA,DBA类似于 Cobol 程序员,那些听上去不那么Fancy的制造业,银行保险证券、以及大量运行本地软件的党政军部门,大量使用了关系型数据库。在可预见的未来,DBA在某个地方找工作是不会有什么问题的。
但大的趋势是,数据库本身会越来越智能,易用性越来越好,而各式各样的工具、SaaS、PaaS不断涌出,也会进一步压低数据库的使用门槛。公有云/私有云DBasS的出现更是让数据库的管理门槛进一步下降。数据库的专业技术门槛降低,将导致DBA的不可替代性降低:安装一套软件收费十几万,做一次数据恢复上百万的好日子肯定是一去不复返了。但在另一种意义上讲,这也将 DBA 从运维性的琐事中解放出来,他们可以把更多时间投身于更有价值的性能优化,隐患排查,制度建设工作之中。
无论是公有云厂商,还是以Kubernetes为代表的云原生/私有云,其核心价值都在于尽可能多地使用软件,而不是人来应对系统复杂度。但是不要指望这些能完全替代 DBA:云并不是什么都不用管的运维外包魔法。根据复杂度守恒定律,无论是系统管理员还是数据库管理员,管理员这个岗位消失的唯一方式是,它们被重命名为“DevOps Engineer”或SRE/DRE。好的云软件可以帮你屏蔽运维杂活,解决70%的日常高频问题,然而总是会有那么一些复杂问题只有人才能处理。你可能需要更少的人手来打理这些云软件,但总归还是需要人来管理。毕竟:
你也需要懂行的人来协调处理,才不至于被云厂商嘎嘎割韭菜当傻逼。
题外话:有那么一些研发,总想着通过云这种运维外包外援,用云数据库,云XX砸掉 DBA 的饭碗。我们做了一个开箱即用的 云数据库 RDS PostgreSQL 本地开源替代 Pigsty ,最近刚发布了 2.0,监控/数据库开箱即用 HA/PITR/IaC一应俱全。允许您在缺乏数据库专家的情况下,用接近硬件的成本运行企业级数据库服务,省掉50%~90%上贡给RDS的“无专家税”,让 RDS 除了它引以为傲的弹性,在各个方面都像是一个大笑话。对于广大 DBA 来说,这就是一件怼回去的武器。咱们明人不说暗话,就是要砸了云数据库的饭碗,并断了研发的这种痴念。https://pigsty.cc/zh/docs/feature
最后,让我们用某个 Notion AI 生成的无版权提词小笑话结束今天的主题。
