为什么要学习数据库原理
我们学校开了数据库系统原理课程。但是我还是很迷茫,这几节课老师一上来就讲一堆令人头大的名词概念,我以为我们知道“如何设计构建表”,“如何mysql增删改查”就行了……那为什么还要了解关系模式的表示方法,计算,规范化……概念模型……各种模型的相互转换,为什么还要了解什么关系代数,什么笛卡尔积……这些的理论知识。我十分困惑,通过这些理论概念,该课的目的或者说该书的目的究竟是想让学生学会什么呢?

只会写代码的是码农;学好数据库,基本能混口饭吃;在此基础上再学好操作系统和计算机网络,就能当一个不错的程序员。如果能再把离散数学、数字电路、体系结构、数据结构/算法、编译原理学通透,再加上丰富的实践经验与领域特定知识,就能算是一个优秀的工程师了。(前端算IO密集型应用就别抬杠了)
计算机其实就是存储/IO/CPU三大件; 而计算说穿了就是两个东西:数据与算法(状态与转移函数)。常见的软件应用,除了各种模拟仿真、模型训练、视频游戏这些属于计算密集型应用外,绝大多数都属于数据密集型应用。从最抽象的意义上讲,这些应用干的事儿就是把数据拿进来,存进数据库,需要的时候再拿出来。
抽象是应对复杂度的最强武器。操作系统提供了对存储的基本抽象:内存寻址空间与磁盘逻辑块号。文件系统在此基础上提供了文件名到地址空间的KV存储抽象。而数据库则在其基础上提供了对应用通用存储需求的高级抽象。
在真实世界中,除非准备从基础组件的轮子造起,不然根本没那么多机会去摆弄花哨的数据结构和算法(对数据密集型应用而言)。甚至写代码的本事可能也没那么重要:可能只会有那么一两个Ad Hoc算法需要在应用层实现,大部分需求都有现成的轮子可以使用,主要的创造性工作往往是在数据模型设计上。实际生产中,数据表就是数据结构,索引与查询就是算法。而应用代码往往扮演的是胶水的角色,处理IO与业务逻辑,其他大部分的工作都是在数据系统之间搬运数据。
在最宽泛的意义上,有状态的地方就有数据库。它无所不在,网站的背后、应用的内部,单机软件,区块链里,甚至在离数据库最远的Web浏览器中,也逐渐出现了其雏形:各类状态管理框架与本地存储。“数据库”可以简单地只是内存中的哈希表/磁盘上的日志,也可以复杂到由多种数据系统集成而来。关系型数据库只是数据系统的冰山一角(或者说冰山之巅),实际上存在着各种各样的数据系统组件:
- 数据库:存储数据,以便自己或其他应用程序之后能再次找到(PostgreSQL,MySQL,Oracle)
- 缓存:记住开销昂贵操作的结果,加快读取速度(Redis,Memcached)
- 搜索索引:允许用户按关键字搜索数据,或以各种方式对数据进行过滤(ElasticSearch)
- 流处理:向其他进程发送消息,进行异步处理(Kafka,Flink)
- 批处理:定期处理累积的大批量数据(Hadoop)
架构师最重要的能力之一,就是了解这些组件的性能特点与应用场景,能够灵活地权衡取舍、集成拼接这些数据系统。绝大多数工程师都不会去从零开始编写存储引擎,因为在开发应用时,数据库已经是足够完美的工具了。关系型数据库则是目前所有数据系统中使用最广泛的组件,可以说是程序员吃饭的主要家伙,重要性不言而喻。
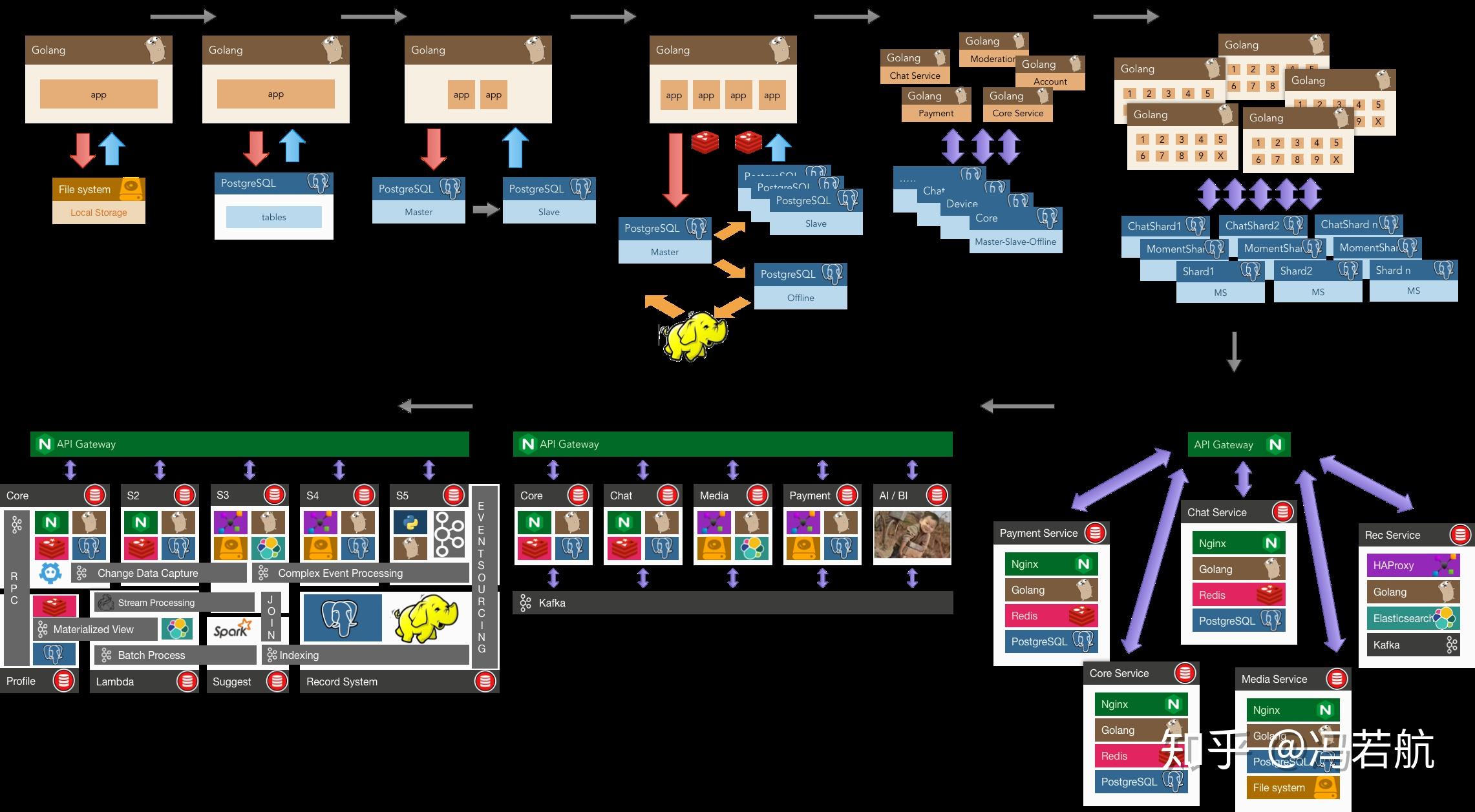
了解意义(WHY)比了解方法(HOW)更重要。但一个很遗憾的现实是,以大多数学生,甚至相当一部分公司能够接触到的现实问题而言,拿几个文件甚至在内存里放着估计都能应付大多数场景了(需求简单到低级抽象就可以Handle)。没什么机会接触到数据库真正要解决的问题,也就难有真正使用与学习数据库的驱动力,更别提数据库原理了。当软硬件故障把数据搞成一团浆糊(可靠性);当单表超出了内存大小,并发访问的用户增多(可扩展性),当代码的复杂度发生爆炸,开发陷入泥潭(可维护性),人们才会真正意识到数据库的重要性。所以我也理解当前这种填鸭教学现状的苦衷:工作之后很难有这么大把的完整时间来学习原理了,所以老师只好先使劲灌输,多少让学生对这些知识有个印象。等学生参加工作后真正遇到这些问题,也许会想起大学好像还学了个叫数据库的东西,这些知识就会开始反刍。
数据库,尤其是关系型数据库,非常重要。那为什么要学习其原理呢?
对优秀的工程师来说,只会用数据库是远远不够的。学习原理对于当CRUD BOY搬砖收益并不大,但当通用组件真的无解需要自己撸起袖子上时,没有金坷垃怎么种庄稼?设计系统时,理解原理能让你以最少的复杂度代价写出更可靠高效的代码;遇到疑难杂症需要排查时,理解原理能带来精准的直觉与深刻的洞察。
数据库是一个博大精深的领域,存储I/O计算无所不包。其主要原理也可以粗略分为几个部分:数据模型设计原理(应用)、存储引擎原理(基础)、索引与查询优化器的原理(性能)、事务与并发控制的原理(正确性)、故障恢复与复制系统的原理(可靠性)。所有的原理都有其存在意义:为了解决实际问题。
例如数据模型设计中的范式理论,就是为了解决数据冗余这一问题而提出的,它是为了把事情做漂亮(可维护)。它是模型设计中一个很重要的设计权衡:通常而言,冗余少则复杂度小/可维护性强,冗余高则性能好。比如用了冗余字段,那更新时原本一条SQL就搞定的事情,现在现在就要用两条SQL更新两个地方,需要考虑多对象事务,以及并发执行时可能的竞态条件。这就需要仔细权衡利弊,选择合适的规范化等级。数据模型设计,就是生产中的数据结构设计。不了解这些原理,就难以提取良好的抽象,其他工作也就无从谈起。
而关系代数与索引的原理,则在查询优化中扮演重要的角色,它是为了把事情做得快(性能,可扩展) 。当数据量越来越大,SQL写的越来越复杂时,它的意义就会体现出来:怎样写出等价但是更高效的查询? 当查询优化器没那么智能时,就需要人来干这件事。这种优化往往成本极小而收益巨大,比如一个需要几秒的KNN查询,如果知道R树索引的原理,就可以通过改写查询,创建GIST索引优化到1毫秒内,千倍的性能提升。不了解索引与查询设计原理,就难以充分发挥数据库的性能。
事务与并发控制的原理,是为了把事情做正确(可靠性) 。事务是数据处理领域最伟大的抽象之一,它提供了很多有用的保证(ACID),但这些保证到底意味着什么?事务的原子性让你在提交前能随时中止事务并丢弃所有写入,相应地,事务的 持久性 则承诺一旦事务成功提交,即使发生硬件故障或数据库崩溃,写入的任何数据也不会丢失。这让错误处理变得无比简单:要么成功完事,要么失败重试。有了后悔药,程序员不用再担心半路翻车会留下惨不忍睹的车祸现场了。
另一方面,事务的隔离性则保证同时执行的事务无法相互影响(Serializable), 数据库提供了不同的隔离等级保证,以供程序员在性能与正确性之间进行权衡。编写并发程序并不容易,在几万TPS的负载下,各种极低概率,匪夷所思的问题都会出现:事务之间相互踩踏,丢失更新,幻读与写入偏差,慢查询拖慢快查询导致连接堆积,单表数据库并发增大后的性能急剧恶化,甚至快慢查询都减少但因比例变化导致的灵异抽风。这些问题,在低负载的情况下会潜伏着,随着规模量级增长突然跳出来,给你一个大大的惊喜。现实中真正可能出现的各类异常,也绝非SQL标准中简单的几种异常能说清的。不理解事务的原理,意味着应用的正确性与数据的完整性可能遭受不必要的损失。
故障恢复与复制的原理,可能对于程序员没有那么重要,但架构师与DBA必须清楚。高可用是很多应用的追求目标,但什么是高可用,高可用怎么保证?读写分离?快慢分离?异地多活?x地x中心?说穿了底下的核心技术其实就是复制(Replication)(或再加上自动故障切换(Failover))。这里有无穷无尽的坑:复制延迟带来的各种灵异现象,网络分区与脑裂,存疑事务blahblah。不理解复制的原理,高可用就无从谈起。
对于一些程序员而言,可能数据库就是“增删改查”,包一包接口,原理似乎属于“屠龙之技”。如果止步于此,那原理确实没什么好学的,但有志者应当打破砂锅问到底的精神。私认为只了解自己本领域知识是不够的,只有把当前领域赖以建立的上层领域摸清楚,才能称为专家。在数据库面前,后端也是前端;对于程序员知识栈而言,数据库是一个合适的栈底。
上面讲了WHY,下面就说一下 HOW
数据库教学的一个矛盾是:如果连数据库都不会用,那学数据库原理有个卵用呢?
学数据库的原则是学以致用。只有实践,才能带来对问题的深刻理解;只有先知其然,才有条件去知其所以然。教材可以先草草的过一遍,然后直接去看数据库文档,上手去把数据库用起来,做个东西出来。通过实践掌握数据库的使用,再去学习原理就会事半功倍(以及充满动力)。对于学习而言,有条件去实习当然最好,没有条件那最好的办法就是自己创造场景,自己挖掘需求。
比如,从解决个人需求开始:管理个人密码,体重跟踪,记账,做个小网站、在线聊天小程序。当它演化的越来越复杂,开始有多个用户,出现各种蛋疼问题之后,你就会开始意识到事务的意义。
再比如,结合爬虫,抓一些房价、股价、地理、社交网络的数据存在数据库里,做一些挖掘与分析。当你积累的数据越来越多,分析查询越来越复杂;SQL长得没法读,跑起来慢出猪叫,这时候关系代数的理论就能指导你进一步进行优化。
当你意识到这些设计都是为了解决现实生产中的问题,并亲自遇到过这些问题之后,再去学习原理,才能相互印证,并知其所以然。当你发现查询时间随数据增长而指数增长时;当你遇到成千上万的用户同时读写为并发控制焦头烂额时;当你碰上软硬件故障把数据搅得稀巴烂时;当你发现数据冗余让代码复杂度快速爆炸时;你就会发现这些设计存在的意义。
教材、书籍、文档、视频、邮件组、博客都是很好的学习资源。教材的话华章的黑皮系列教材都还不错,《数据库系统概念》这本就挺好的。但我推荐先看看这本书:《设计数据密集型应用》 ,写的非常好,我觉得不错就义务翻译了一下。纸上得来终觉浅,绝知此事要躬行。实践方能出真知,新手上路选哪家?个人推荐世界上最先进的开源关系型数据库PostgreSQL,设计优雅,功能强大。传教就有请德哥出场了:https://github.com/digoal/blog 。有时间的话可以再看看Redis,源码简单易读,实践中也很常用,非关系型数据库也应当多了解一下。
最后,关系型数据库虽然强大,却绝非数据处理的终章,尽可能多地去尝试各种各样的数据库吧。
知乎原题:计算机系为什么要学数据库原理和设计?