第十一章 流复制
PostgreSQL在9.1版本中实现了流复制。它属于所谓的一主多从类型的复制,而这两个术语 —— 主(master)和从(slave),在PostgreSQL中通常分别被称为主(primary)和备(standby)。
译注:存储数据库副本的每个节点称为副本(replica)。每一次对数据库的写入操作都需要传播到所有副本上,否则副本就会包含不一样的数据。最常见的解决方案被称为基于领导者的复制(leader-based replication),也称主动/被动(active/passive) 或 主/从(master/slave)复制。其中,副本之一被指定为领导者(leader),也称为 主库(master) ,首要(primary)。当客户端要向数据库写入时,它必须将请求发送给领导者,领导者会将新数据写入其本地存储。其他副本被称为追随者(followers),亦称为只读副本(read replicas),从库(slaves),次要( sencondaries),热备(hot-standby)。
这种原生复制功能是基于日志传输实现的,这是一种通用的复制技术:主库不断发送WAL数据,而每个备库接受WAL数据,并立即重放日志。
本章将介绍以下主题,重点介绍流复制的工作原理:
- 流复制是如何启动的
- 数据是如何在主备之间传递的
- 主库如何管理多个备库
- 主库如何检测到备库的失效
尽管在9.0版本中最初实现的复制功能只能进行异步复制,它很快就在9.1版中被新的实现(如今采用的)所替代,可以支持同步复制。
11.1 流复制的启动
在流复制中,有三种进程协同工作。首先,主库上的walsender(WAL发送器)进程将WAL数据发送到备库;同时,备库上的walreceiver(WAL接收器)在接收这些数据,而备库上的startup进程可以重放这些数据。 其中walsender和walreceiver 之间使用单条TCP连接进行通信。
在本节中,我们将探讨流复制的启动顺序,以了解这些进程如何启动并且它们之间是如何建立连接的。图11.1显示了流复制的启动顺序图:
图11.1 流复制的启动顺序
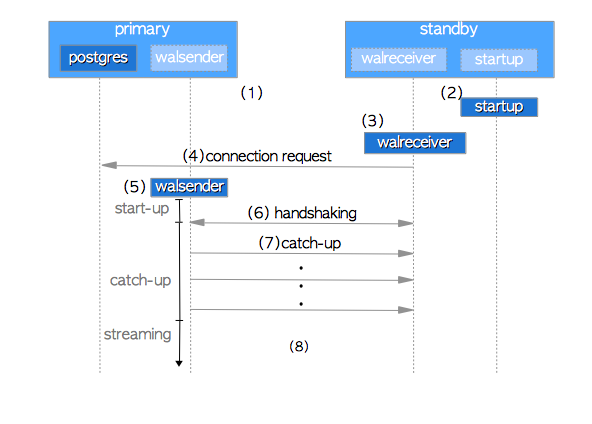
- 启动主库服务器和备库服务器。
- 备库服务器启动一个startup进程。
- 备库服务器启动一个walreceiver进程。
- walreceiver向主库服务器发送连接请求。如果主库尚未启动,walreceiver会定期重发该请求。
- 当主库服务器收到连接请求时,将启动walsender进程,并建立walsender和walreceiver之间的TCP连接。
- walreceiver发送备库数据库集簇上最新的LSN。在IT领域中通常将该阶段称作握手(handshaking)。
- 如果备库最新的LSN小于主库最新的LSN(备库的LSN < 主库的LSN),则walsender会将前一个LSN到后一个LSN之间的WAL数据发送到walreceiver。这些WAL数据由存储在主库
pg_xlog子目录(版本号为10+的更名为pg_wal)中的WAL段提供。最终,备库重放接收到的WAL数据。在这一阶段,备库在追赶主库,因此被称为**追赶(catch-up)**阶段。 - 最终,流复制开始工作。
每个walsender进程都维护了连接上的walreceiver或其他应用程序的复制进度状态(请注意,不是连接到walsender的walreceiver或应用程序的本身的状态)。如下是其可能的状态:
- 启动(start-up) —— 从启动walsender到握手结束。如图11.1(5)-(6)。
- 追赶(catch-up) —— 处于追赶期间,如图11.1(7)。
- 流复制(streaming)—— 正在运行流复制。如图11.1(8)。
- 备份(backup)—— 处于向
pg_basebackup等备份工具发送整个数据库集簇文件的过程中。
系统视图pg_stat_replication显示了所有正在运行的walsenders的状态,如下例所示:
testdb=# SELECT application_name,state FROM pg_stat_replication;
application_name | state
------------------+-----------
standby1 | streaming
standby2 | streaming
pg_basebackup | backup
(3 rows)
如上结果所示,有两个walsender正在运行,其正在向连接的备库发送WAL数据,另一个walsender在向pg_basebackup应用发送所有数据库集簇中的文件。
### 在备库长时间停机后,如果重启会发生什么?
在9.3版及更早版本中,如果备库所需的WAL段在主库上已经被回收了,备库就无法追上主库了。这一问题并没有可靠的解决方案,只能为参数
wal_keep_segments配置一个较大的值,以减少这种情况发生的可能性,但这只是权宜之计。在9.4及后续版本中,可以使用**复制槽(replications slot)来预防此问题发生。复制槽是一项提高WAL数据发送灵活性的功能。主要是为逻辑复制(logical replication)**而提出的,同时也能解决这类问题 ——复制槽通过暂停回收过程,从而保留
pg_xlog(10及后续版本的pg_wal)中含有未发送数据的的WAL段文件,详情请参阅官方文档。
11.2 如何实施流复制
流复制有两个方面:日志传输和数据库同步。因为流复制基于日志,日志传送显然是其中的一个方面 —— 主库会在写入日志记录时,将WAL数据发送到连接的备库。同步复制中需要数据库同步 —— 主库与多个备库通信,从而同步整个数据库集簇。
为准确理解流复制的工作原理,我们应该探究下主库如何管理多个备库。为了尽可能简化问题,本节描述了一个特例(即单主单备系统),而下一节将描述一般情况(单主多备系统)。
11.2.1 主从间的通信
假设备库处于同步复制模式,但配置参数hot-standby已禁用,且wal_level为'archive'。主库的主要参数如下所示:
synchronous_standby_names = 'standby1'
hot_standby = off
wal_level = archive
另外,在9.5节中提到,有三个情况触发写WAL数据,这里我们只关注事务提交。
假设主库上的一个后端进程在自动提交模式下发出一个简单的INSERT语句。后端启动事务,发出INSERT语句,然后立即提交事务。让我们进一步探讨此提交操作如何完成的。如图11.2中的序列图:
图11.2 流复制的通信序列图
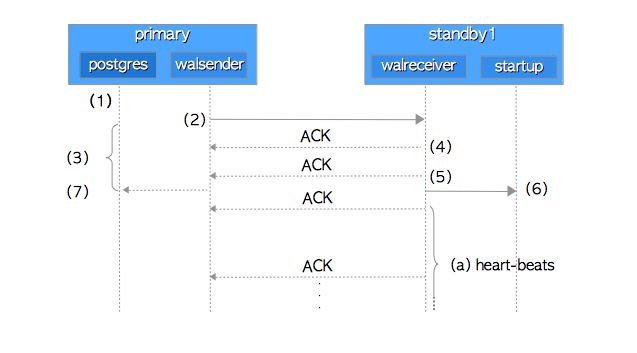
- 后端进程通过执行函数
XLogInsert()和XLogFlush(),将WAL数据写入并刷新到WAL段文件中。 - walsender进程将写入WAL段文件的WAL数据发送到walreceiver进程。
- 在发送WAL数据之后,后端进程继续等待来自备库的ACK响应。更确切地说,后端进程通过执行内部函数
SyncRepWaitForLSN()来获取锁存器(latch),并等待它被释放。 - 备库上的walreceiver通过
write()系统调用,将接收到的WAL数据写入备库的WAL段,并向walsender返回ACK响应。 - walreceiver通过系统调用(例如
fsync())将WAL数据刷新到WAL段中,向walsender返回另一个ACK响应,并通知**启动进程(startup process )**相关WAL数据的更新。 - 启动进程重放已写入WAL段的WAL数据。
- walsender在收到来自walreceiver的ACK响应后释放后端进程的锁存器,然后,后端进程完成
commit或abort动作。 锁存器释放的时间取决于参数synchronous_commit。如果它是'on'(默认),当接收到步骤(5)的ACK时,锁存器被释放。而当它是'remote_write'时,接收到步骤(4)的ACK时,即被释放。
如果配置参数
wal_level是'hot_standby'或'logical',则PostgreSQL会根据COMMIT或ABORT操作的记录,写入热备功能相关的WAL记录。(在这个例子中,PostgreSQL不写那些记录,因为它是'archive'。)
每个ACK响应将备库的内部信息通知给主库。包含以下四个项目:
- 已写入最新WAL数据的LSN位置。
- 已刷新最新WAL数据的LSN位置。
- 启动进程已经重放最新的WAL数据的LSN。
- 发送此响应的时间戳。
walreceiver不仅在写入和刷新WAL数据时返回ACK响应,而且还定期发送备库的心跳响应。因此,主库始终掌握所有连接备库的状态。
执行如下查询,可以显示所连接备库的相关LSN信息。
testdb=# SELECT application_name AS host,
write_location AS write_LSN, flush_location AS flush_LSN,
replay_location AS replay_LSN FROM pg_stat_replication;
host | write_lsn | flush_lsn | replay_lsn
----------+-----------+-----------+------------
standby1 | 0/5000280 | 0/5000280 | 0/5000280
standby2 | 0/5000280 | 0/5000280 | 0/5000280
(2 rows)
心跳的间隔设置为参数
wal_receiver_status_interval,默认为10秒。
11.2.2 发生故障时的行为
在本小节中,将介绍在同步备库发生故障时,主库的行为方式,以及主库会如何处理该情况。
即使同步备库发生故障,且不再能够返回ACK响应,主库也会继续等待响应。因此,正在运行的事务无法提交,而后续查询也无法启动。换而言之,实际上主库的所有操作都已停止(流复制不支持发生超时时自动降级回滚到异步模式的功能)。
有两种方法可以避免这种情况。其中之一是使用多个备库来提高系统可用性,另一个是通过手动执行以下步骤从同步模式切换到异步模式。
-
将参数
synchronous_standby_names的值设置为空字符串。synchronous_standby_names = '' -
使用
reload选项执行pg_ctl命令。postgres> pg_ctl -D $PGDATA reload
上述过程不会影响连接的客户端。主库继续事务处理,以及会保持客户端与相应的后端进程之间的所有会话。
11.2 流复制如何实施
流式复制有两个部分:日志传输与数据库同步。日志传输是很明显的部分,因为流复制正是基于此的 —— 每当主库发生写入时,它会向所有连接着的备库发送WAL数据。数据库同步对于同步复制而言则是必需的 —— 主库与多个备库中的每一个相互沟通,以便各自的数据库集簇保持同步。
为了准确理解流复制的工作原理,我们应当研究主库是如何管理多个备库的。为了简单起见,下面的小节将会描述一种特殊场景(即一主一从的情况),而通用的场景(一主多从)会在更后面一个小节中描述。
11.2.1 主库与同步备库之间的通信
假设备库处于同步复制模式,但参数hot_standby被配置为禁用,而wal_level被配置为archive,而主库上的主要参数如下所示:
synchronous_standby_names = 'standby1'
hot_standby = off
wal_level = archive
除了在9.5节中提到过的三种操作外,我们在这里主要关注事务的提交。
假设主库上一个后端进程在自动提交模式中发起了一条INSERT语句。首先,后端进程开启了一个事务,执行INSERT语句,然后立即提交。让我们深入研究一下这个提交动作是如何完成的,如下面的序列图11.2。
- 后端进程通过执行函数
XLogInsert()和XLogFlush()将WAL数据刷写入WAL段文件中。 - walsender进程将写入WAL段的WAL数据发送到walreceiver进程。
- 在发送WAL数据之后,后端进程继续等待来自备库的ACK响应。更确切地说,后端进程通过执行内部函数
SyncRepWaitForLSN()来获取锁存器(latch),并等待它被释放。 - 备库上的walreceiver使用
write()系统调用将接收到的WAL数据写入备库的WAL段,并向walsender返回ACK响应。 - 备库上的walreceiver使用诸如
fsync()的系统调用将WAL数据刷入WAL段中,向walsender返回另一个ACK响应,并通知startup进程WAL数据已经更新。 - startup进程重放已经被写入WAL段文件中的WAL数据。
- walsender在收到来自walreceiver的ACK响应后,释放后端进程的锁存器,然后后端进程的提交或中止动作就会完成。释放锁存器的时机取决于参数
synchronous_commit,其默认是on,也就是当收到步骤(5)中的确认(远端刷入)时,而当其值为remote_write时,则是在步骤(4)(远端写入)时。
如果配置参数
wal_level是hot_standby或logical,PostgreSQL会按照热备功能来写WAL记录,并写入提交或终止的记录(在本例中PostgreSQL不会写这些记录,因为它被配置为archive)
每一个ACK响应都会告知主库一些关于备库的信息,包含下列四个项目:
- 最近被**写入(write)**的WAL数据的LSN位置。
- 最近被**刷盘(flush)**的WAL数据的LSN位置。
- 最近被**重放(replay)**的WAL数据的LSN位置。
- 响应发送的时间戳。
/* XLogWalRcvSendReply(void) */
/* src/backend/replication/walreceiver.c */
/* 构造一条新消息 */
reply_message.write = LogstreamResult.Write;
reply_message.flush = LogstreamResult.Flush;
reply_message.apply = GetXLogReplayRecPtr();
reply_message.sendTime = now;
/* 为消息添加消息类型,并执行发送 */
buf[0] = 'r';
memcpy(&buf[1], &reply_message, sizeof(StandbyReplyMessage));
walrcv_send(buf, sizeof(StandbyReplyMessage) + 1);
walreceiver不仅仅在写入和刷盘WAL数据时返回ACK响应,也会周期性地发送ACK,作为备库的心跳。因此主库能掌控所有连接到自己的备库的状态。
在主库上执行下面的查询,可以显示所有关联的备库与LSN相关的信息。
testdb=# SELECT application_name AS host,
write_location AS write_LSN, flush_location AS flush_LSN,
replay_location AS replay_LSN FROM pg_stat_replication;
host | write_lsn | flush_lsn | replay_lsn
----------+-----------+-----------+------------
standby1 | 0/5000280 | 0/5000280 | 0/5000280
standby2 | 0/5000280 | 0/5000280 | 0/5000280
(2 rows)
心跳频率是由参数
wal_receiver_status_interval决定的,默认为10秒。
11.2.2 失效时的行为
本节将介绍当备库失效时主库的行为,以及如何处理这种情况。
当备库发生故障且不再能返回ACK响应,主库也会继续并永远等待响应。导致运行中的事务无法提交,而后续的查询处理也无法开始。换而言之,主库上的所有操作实际上都停止了(流复制并不支持这种功能:通过超时将同步提交模式降级为异步提交模式)
有两种方法能避免这种情况,一种是使用多个备库,以提高系统的可用性;另一种方法是通过手动执行下列步骤,将同步提交模式改为**异步提交(Asynchronous)**模式:
-
将参数
synchronous_standby_names的值配置为空字符串synchronous_standby_names = '' -
使用
pg_ctl执行reload。postgres> pg_ctl -D $PGDATA reload
上述过程不会影响连接着的客户端,主库会继续进行事务处理,所有客户端与后端进程之间的会话也会被保留。
11.3 管理多个备库
本节描述了存在多个备库时,流复制是如何工作的。
11.3.1 同步优先级与同步状态
主库为自己管理的每一个备库指定一个同步优先级(sync_priority) 与 同步状态(sync_state) 。(上一节并没有提到这一点,即使主库只管理一个备库,也会指定这些值)。
**同步优先级(sync_priority)**表示备库在同步模式下的优先级,它是一个固定值。较小的值表示较高的优先级,而0是一个特殊值,表示“异步模式”。备库优先级是一个有序列表,在主库配置参数 synchronous_standby_names中依序给出。例如在以下配置中,standby1和standby2的优先级分别为1和2。
synchronous_standby_names = 'standby1, standby2'
(未列于此参数中的备库处于异步模式,优先级为0)
**同步状态(sync_state)**是备库的状态,它因所有在列备库的运行状态及其优先级而异,以下是可能的状态:
- **同步(Sync)**状态的备库,是所有正在工作中的备库中,具有最高优先级的同步备库的状态(异步模式除外)。
- 潜在(Potential) 状态的备库,是所有工作备库(异步备库除外)中,优先级等于或低于2的闲置同步备库。如果同步备库失效,潜在备库中有着最高优先级的那个将替换为同步备库。
- 异步(Async) 状态的备库是固定的。主库以与潜在备库相同的方式处理异步备库,只是它们的
sync_state永远不会是sync或potential。
执行以下查询来显示备库的优先级和状态:
testdb=# SELECT application_name AS host,
sync_priority, sync_state FROM pg_stat_replication;
host | sync_priority | sync_state
----------+---------------+------------
standby1 | 1 | sync
standby2 | 2 | potential
(2 rows)
最近有几个开发者尝试实现“多个同步备库”。详情参见此处。
11.3.2 主库如何管理多个备库
主库仅等待来自同步备库的ACK响应。换句话说,主库仅确保同步备库写入并刷新WAL数据。因此在流复制中,只有同步备库的状态是与主库始终一致且同步的。
图11.3展示了潜在备库的ACK响应早于首要备库ACK响应的情况。这时主库并不会完成当前事务的COMMIT操作,而是继续等待首要备库的ACK响应。而当收到首要备库的响应时,后端进程释放锁存器并完成当前事务的处理。
图11.3 管理多个备库
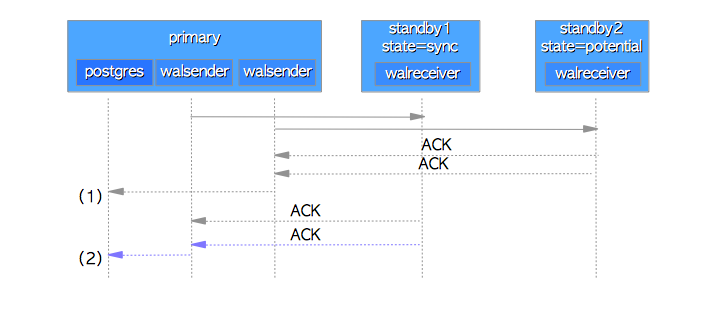
备库1与备库2的同步状态分别为
sync和potential。
- 尽管从潜在备库接收到ACK响应,但主库的后端进程会继续等待来自同步备库的ACK响应。
- 主库的后端进程释放锁存器,完成当前的事务处理。
在相反的情况下(即首要从库的ACK响应返回早于潜在从库的响应),主库会立即完成当前事务的COMMIT操作,而不会去确认潜在从库是否已经写入和刷盘了WAL数据。
11.3.3 发生故障时的行为
我们再来看看当从库发生故障时主库的表现。
当潜在或异步备库发生故障时,主库会终止连接到故障备库的walsender进程,并继续进行所有处理。换而言之,主库上的事务处理不会受到这两种备库的影响。
当同步备库发生故障时,主库将终止连接到故障备库的walsender进程,并使用具有最高优先级的潜在备库替换首要同步备库,如图11.4。与上述的故障相反,主库将会暂停从失效点到成功替换同步备库之间的查询处理。(因此备库的故障检测对于提高复制系统可用性至关重要,故障检测将在下一节介绍)
图11.4 更换同步备库
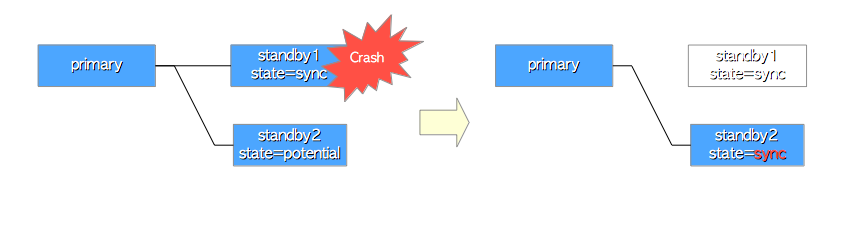
在任何情况下,如果一个或多个备库在同步模式下运行,主库始终只会保留一个同步备库,而同步备库始终与主库保持一致且同步的状态。
11.4 备库的故障检测
流复制使用两种常见的故障检测过程,不需要任何特别的硬件。
-
备库服务器的失效检测
当检测到walsender和walreceiver之间的连接断开时,主库立即判定备库或walreceiver进程出现故障。当底层网络函数由于未能成功读写walreceiver的套接字接口而返回错误时,主库也会立即判定其失效。
-
硬件与网络的失效检测
如果walreceiver在参数
wal_sender_timeout(默认为60秒)配置的时间段内没有返回任何结果,则主库会判定备库出现故障。相对于上面的故障而言,尽管从库可能因为一些失效原因(例如备库上的硬件失效,网络失效等),已经无法发送任何响应,但主库仍需要耗费特定的时间 —— 最大为wal_sender_timeout,来确认备库的死亡。
取决于失效的类型,一些失效可以在失效发生时被立即检测到,而有时候则可能在出现失效与检测到失效之间存在一段时间延迟。如果在同步从库上出现后一种失效,那么即使有多个潜在备库正常工作,直到检测到同步备库失效了,主库仍然可能会停止一段时间的事务处理。
在9.2或更早版本中,参数
wal_sender_timeout被称为replication_timeout。