系统架构
Module:
Categories:
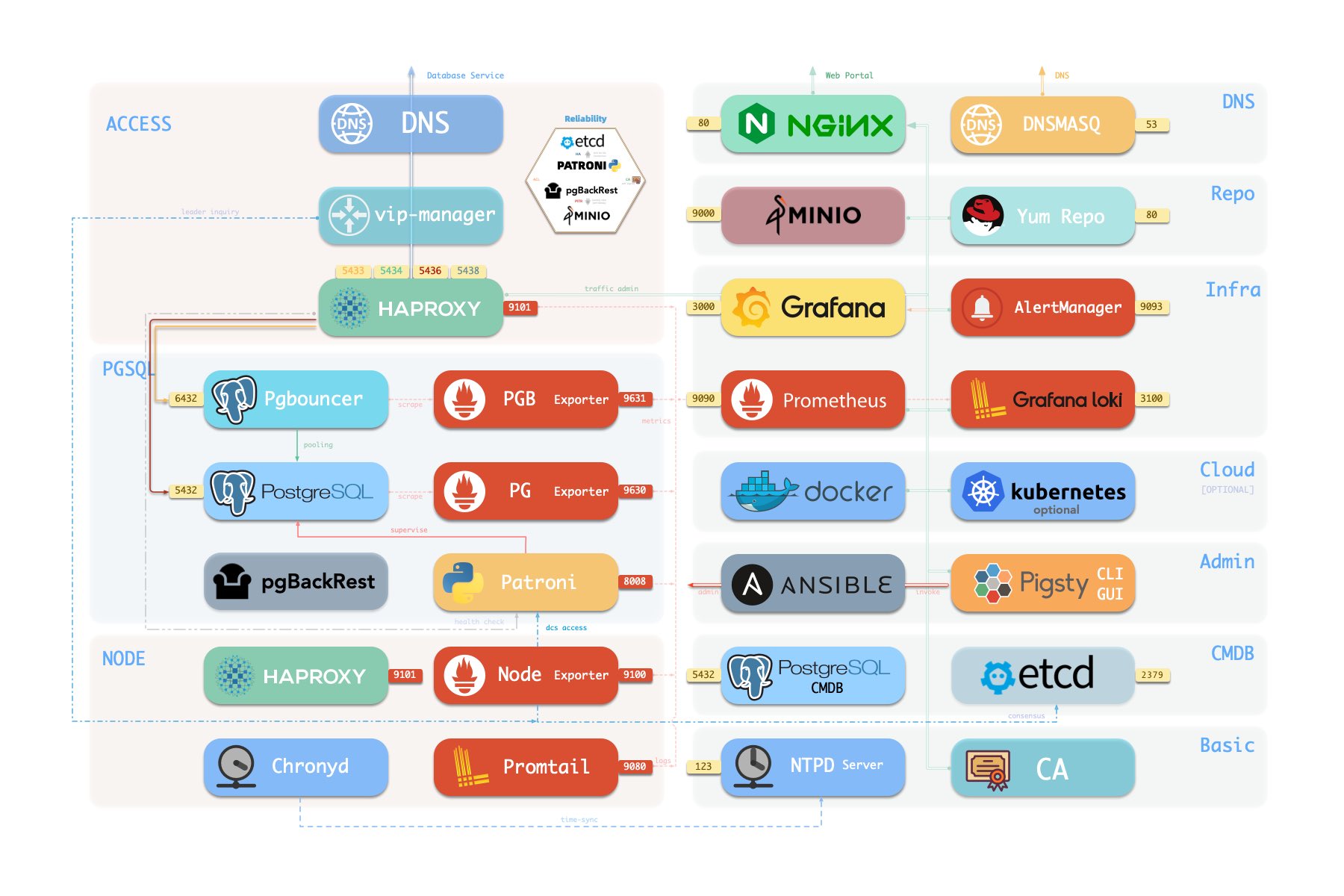
PGSQL 模块总览:关键概念与架构细节
组件概览
以下是 PostgreSQL 模块组件及其相互作用的详细描述,从上至下分别为:
- 集群 DNS 由 infra 节点上的 DNSMASQ 负责解析
- 集群 VIP 由
vip-manager组件管理,它负责将pg_vip_address绑定到集群主库节点上。vip-manager从etcd集群获取由patroni写入的集群领导者信息
- 集群服务由节点上的 Haproxy 对外暴露,不同服务通过节点的不同端口(543x)区分。
- Pgbouncer 是一个连接池中间件,默认监听6432端口,可以缓冲连接、暴露额外的指标,并提供额外的灵活性。
- Pgbouncer 是无状态的,并通过本地 Unix 套接字以 1:1 的方式与 Postgres 服务器部署。
- 生产流量(主/从)将默认通过 pgbouncer(可以通过
pg_default_service_dest指定跳过) - 默认/离线服务将始终绕过 pgbouncer ,并直接连接到目标 Postgres。
- PostgreSQL 监听5432端口,提供关系型数据库服务
- 在多个节点上安装 PGSQL 模块,并使用同一集群名,将自动基于流式复制组成高可用集群
- PostgreSQL 进程默认由
patroni管理。
- Patroni 默认监听端口 8008,监管着 PostgreSQL 服务器进程
- Patroni 将 Postgres 服务器作为子进程启动
- Patroni 使用
etcd作为 DCS:存储配置、故障检测和领导者选举。 - Patroni 通过健康检查提供 Postgres 信息(比如主/从),HAProxy 通过健康检查使用该信息分发服务流量
- Patroni 指标将被 infra 节点上的 Prometheus 抓取
- PG Exporter 在 9630 端口对外暴露 postgres 架空指标
- PostgreSQL 指标将被 infra 节点上的 Prometheus 抓取
- Pgbouncer Exporter 在端口 9631 暴露 pgbouncer 指标
- Pgbouncer 指标将被 infra 节点上的 Prometheus 抓取
- pgBackRest 默认在使用本地备份仓库 (
pgbackrest_method=local)- 如果使用
local(默认)作为备份仓库,pgBackRest 将在主库节点的pg_fs_bkup下创建本地仓库 - 如果使用
minio作为备份仓库,pgBackRest 将在专用的 MinIO 集群上创建备份仓库:pgbackrest_repo.minio
- 如果使用
- Postgres 相关日志(postgres, pgbouncer, patroni, pgbackrest)由 promtail 负责收集
- Promtail 监听 9080 端口,也对 infra 节点上的 Prometheus 暴露自身的监控指标
- Promtail 将日志发送至 infra 节点上的 Loki
高可用
主库故障恢复时间目标 (RTO) ≈ 30s,数据恢复点目标 (RPO) < 1MB,从库故障 RTO ≈ 0 (重置当前连接)
Pigsty 的 PostgreSQL 集群带有开箱即用的高可用方案,由 patroni、etcd 和 haproxy 强力驱动。
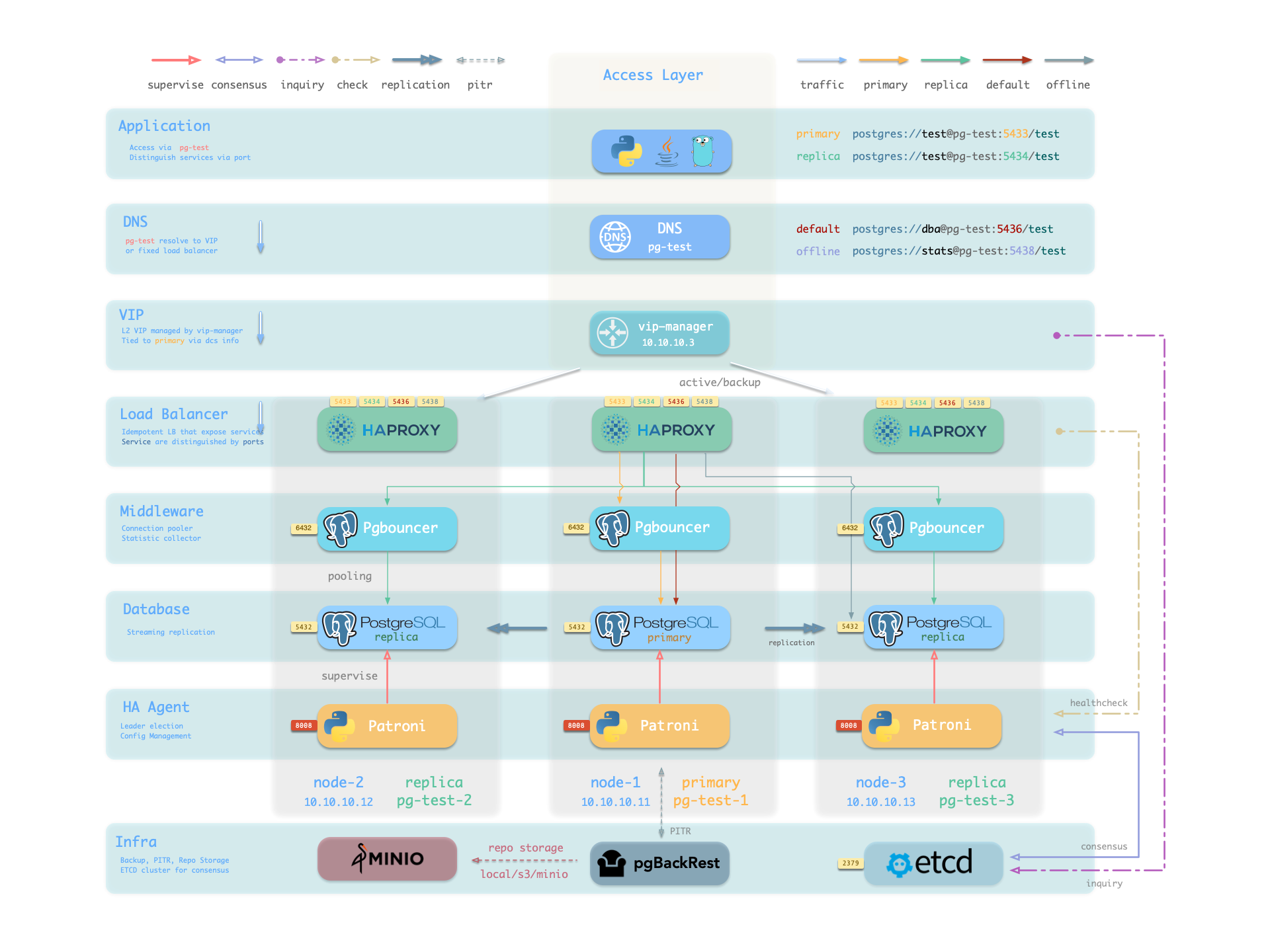
当主库故障时,将触发新一轮领导者竞选,集群中最为健康的从库将胜出,并被提升为新的主库。读写流量将立即路由至新的主库。主库故障影响是:默认情况下写入查询将被阻塞 15 ~ 40s,直到选出新的领导者来。
当从库故障时,只读流量将路由至其他从库,如果所有从库都故障,只读流量才会最终由主库承载。从库故障的影响非常小:查询闪断:该从库上正在运行查询将由于连接重置而中止。
故障检测由 patroni 和 etcd 完成,集群领导者将持有一个租约,如果它因为故障而没有及时续租(10s),租约将会被释放,新一轮集群选举会被触发。
您可以使用 pg_rto 参数调整集群的 TTL,默认 RTO 配置为 30s,增大它将导致更长的故障转移等待时间,而减少它将增加误报故障转移率(例如,网络抖动)。
Pigsty 默认使用可用性优先模式,这意味着当主库故障时,它将尽快进行故障转移,尚未复制到从库的数据可能会丢失(常规万兆网络下,复制延迟在通常在几KB到100KB)。
最大潜在数据丢失由 pg_rpo 控制,默认为 1MB,减小这个值将会减少故障恢复时的可能数据损失,但也会增加故障时因为从库不够健康(落后太久)而拒绝自动切换的概率。
RTO 与 RPO 是高可用集群设计时需要仔细权衡的两个参数,您应当根据您的硬件水平,网络质量,业务需求来合理调整它们。
时间点恢复
您可以将集群恢复回滚至过去任意时刻,避免软件缺陷与人为失误导致的数据损失。
Pigsty 的 PostgreSQL 集群带有自动配置的时间点恢复(PITR)方案,基于 pgBackRest 与可选的 MinIO。
高可用可以解决硬件故障,软件缺陷与人为失误导致的数据删除/覆盖写入却无能为力:因为变更操作会立即同步至从库应用。时间点恢复(Point in Time Recovery, PITR)可以解决这个问题。此外当您只有单个实例时,PITR也可以代替高可用,为最坏的情况兜底。
如果想将集群恢复至某个备份,用户需要提前定期做好基础备份,如果想将集群恢复至任意时间点,用户还需要从备份时刻迄今的 WAL归档。这两项工作 Pigsty 为您自动进行了兜底配置。
Pigsty 使用 pgBackRest 管理备份,接受WAL归档,执行PITR。备份仓库可以进行灵活配置(pgbackrest_repo):默认使用主库本地文件系统(local),但也可以使用其他磁盘路径,或使用自带的可选 MinIO 服务(minio)与云上 S3 服务。
pgbackrest_enabled: true # 在 pgsql 主机上启用 pgBackRest 吗?
pgbackrest_clean: true # 初始化时删除 pg 备份数据?
pgbackrest_log_dir: /pg/log/pgbackrest # pgbackrest 日志目录,默认为 `/pg/log/pgbackrest`
pgbackrest_method: local # pgbackrest 仓库方法:local, minio, [用户定义...]
pgbackrest_repo: # pgbackrest 仓库:https://pgbackrest.org/configuration.html#section-repository
local: # 默认使用本地 posix 文件系统的 pgbackrest 仓库
path: /pg/backup # 本地备份目录,默认为 `/pg/backup`
retention_full_type: count # 按计数保留完整备份
retention_full: 2 # 使用本地文件系统仓库时,最多保留 3 个完整备份,至少保留 2 个
minio: # pgbackrest 的可选 minio 仓库
type: s3 # minio 是与 s3 兼容的,所以使用 s3
s3_endpoint: sss.pigsty # minio 端点域名,默认为 `sss.pigsty`
s3_region: us-east-1 # minio 区域,默认为 us-east-1,对 minio 无效
s3_bucket: pgsql # minio 桶名称,默认为 `pgsql`
s3_key: pgbackrest # pgbackrest 的 minio 用户访问密钥
s3_key_secret: S3User.Backup # pgbackrest 的 minio 用户秘密密钥
s3_uri_style: path # 对 minio 使用路径风格的 uri,而不是主机风格
path: /pgbackrest # minio 备份路径,默认为 `/pgbackrest`
storage_port: 9000 # minio 端口,默认为 9000
storage_ca_file: /etc/pki/ca.crt # minio ca 文件路径,默认为 `/etc/pki/ca.crt`
bundle: y # 将小文件打包成一个文件
cipher_type: aes-256-cbc # 为远程备份仓库启用 AES 加密
cipher_pass: pgBackRest # AES 加密密码,默认为 'pgBackRest'
retention_full_type: time # 在 minio 仓库上按时间保留完整备份
retention_full: 14 # 保留过去 14 天的完整备份
默认情况下,Pigsty提供了两种预置备份策略:默认使用本地文件系统备份仓库,在这种情况下每天进行一次全量备份,确保用户任何时候都能回滚至一天内的任意时间点。备选策略使用专用的 MinIO 集群或S3存储备份,每周一全备,每天一增备,默认保留两周的备份与WAL归档。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.