This is the multi-page printable view of this section. Click here to print.
Cloud Exit
- S3: Elite to Mediocre
- Reclaim Hardware Bonus from the Cloud
- FinOps: Endgame Cloud-Exit
- SLA: Placebo or Insurance?
- EBS: Pig Slaughter Scam
- RDS: The Idiot Tax
S3: Elite to Mediocre
Object storage (S3) has been a defining service of cloud computing, once hailed as a paragon of cost reduction in the cloud era. Unfortunately, with the evolution of hardware and the emergence of resources cloud (Cloudflare R2) and open-source alternatives (MinIO), the once “cost-effective” object storage services have lost their value for money, becoming as much a “cash cow” as EBS. In our “Mudslide of Cloud Computing” series, we’ve already delved into the cost structure of cloud-based EC2 compute power, EBS disks, and RDS databases. Today, let’s examine the anchor of cloud services—object storage.

From Cost Reduction to Cash Cow
Object Storage, also known as Simple Storage Service (abbreviated as S3, hereafter referred to as S3), was once the flagship product for its cost-effectiveness in the cloud.
A decade ago, hardware was expensive; managing to use a bunch of several hundred GB mechanical hard drives to build a reliable storage service and design an elegant HTTP API was a significant barrier. Therefore, compared to those “enterprise IT” storage solutions, the cost-effective S3 seemed very attractive.
However, the field of computer hardware is quite unique—with a Moore’s Law that sees prices halve every two years. AWS S3 has indeed seen several price reductions in its history. The table below organizes the main post-reduction prices for S3 standard tier storage, along with the reference unit prices for enterprise-grade HDD/SSD in the corresponding years.
| Date | $/GB·Month | ¥/TB·5年 | HDD ¥/TB | SSD ¥/TB |
|---|---|---|---|---|
| 2006.03 | 0.150 | 63000 | 2800 | |
| 2010.11 | 0.140 | 58800 | 1680 | |
| 2012.12 | 0.095 | 39900 | 420 | 15400 |
| 2014.04 | 0.030 | 12600 | 371 | 9051 |
| 2016.12 | 0.023 | 9660 | 245 | 3766 |
| 2023.12 | 0.023 | 9660 | 105 | 280 |
| Price Ref | EBS | All Upfront | Buy NVMe SSD | Price Ref |
|---|---|---|---|---|
| S3 Express | 0.160 | 67200 | DHH 12T | 1400 |
| EBS io2 | 0.125 + IOPS | 114000 | Shannon 3.2T | 900 |
It’s not hard to see that the unit price of S3’s standard tier dropped from $0.15/GB·month in 2006 to $0.023/GB·month in 2023, a reduction to 15% of the original or a 6-fold decrease, which sounds good. However, when you consider that the price of the underlying HDDs for S3 dropped to 3.7% of their original, a whopping 26-fold decrease, the trickery becomes apparent.
The resource premium multiple of S3 increased from 7 times in 2006 to 30 times today!
In 2023, when we re-calculate the costs, it’s clear that the value for money of storage services like S3/EBS has changed dramatically—cloud computing power EC2 compared to building one’s own servers has a 5 – 10 times premium, while cloud block storage EBS has a several dozen to a hundred times premium compared to local SSDs. Cloud-based S3 compared to ordinary HDDs also has about a thirty times resource premium. And as the anchor of cloud services, the prices of S3/EBS/EC2 are passed on to almost all cloud services—completely stripping cloud services of their cost-effectiveness.
The core issue here is: The price of hardware resources drops exponentially according to Moore’s Law, but the savings are not passed through the cloud providers’ intermediary layer to the end-user service prices. To not advance is to go back; failing to reduce prices at the pace of Moore’s Law is effectively a price increase. Taking S3 as an example, over the past decade, cloud providers’ S3 has nominally reduced prices by 6-fold, but hardware resources have become 26 times cheaper, so how should we view this pricing now?
Cost, Performance, Throughput
Despite the high premiums of cloud services, if it represents an irreplaceable best choice, the use by high-value, price-insensitive top-tier customers is not affected even with a high premium and low cost-effectiveness. However, it’s not just about cost; the performance of storage hardware also follows Moore’s Law. Over time, building one’s own S3 has started to show a significant advantage in performance.
The performance of S3 is mainly reflected in its throughput. AWS S3’s 100 Gb/s network provides up to 12.5 GB/s of access bandwidth, which is indeed commendable. Such throughput was undoubtedly impressive a decade ago. However, today, an enterprise-level 12 TB NVMe SSD, costing less than $20,000, can achieve 14 GB/s of read/write bandwidth. 100Gb switches and network cards have also become very common, making such performance readily achievable.
In another key performance indicator, “latency,” S3 is significantly outperformed by local disks. The first-byte latency of the S3 standard tier is quite poor, ranging between 100-200ms according to the documentation. Of course, AWS has just launched “High-Performance S3” — S3 Express One Zone at 2023 Re:Invent, which can achieve millisecond-level latency, addressing this shortcoming. However, it still falls far short of the NVMe’s 4K random read/write latency of 55µs/9µs.
S3 Express’s millisecond-level latency sounds good, but when we compare it to a self-built NVMe SSD + MinIO setup, this “millisecond-level” performance is embarrassingly inadequate. Modern NVMe SSDs achieve 4K random read/write latencies of 55µs/9µs. With a thin layer of MinIO forwarding, the first-byte output latency is at least an order of magnitude better than S3 Express. If standard tier S3 is used for comparison, the performance gap widens to three orders of magnitude.
The gap in performance is just one aspect; the cost is even more crucial. The price of standard tier S3 has remained unchanged since 2016 at $0.023/GB·month, equating to 161 RMB/TB·month. The higher-tier S3 Express One Zone is an order of magnitude more expensive, at $0.16/GB·month, equating to 1120 RMB/TB·month. For reference, we can compare the data from “Reclaiming the Dividends of Computer Hardware” and “Is Cloud Storage a Cash Cow?”:
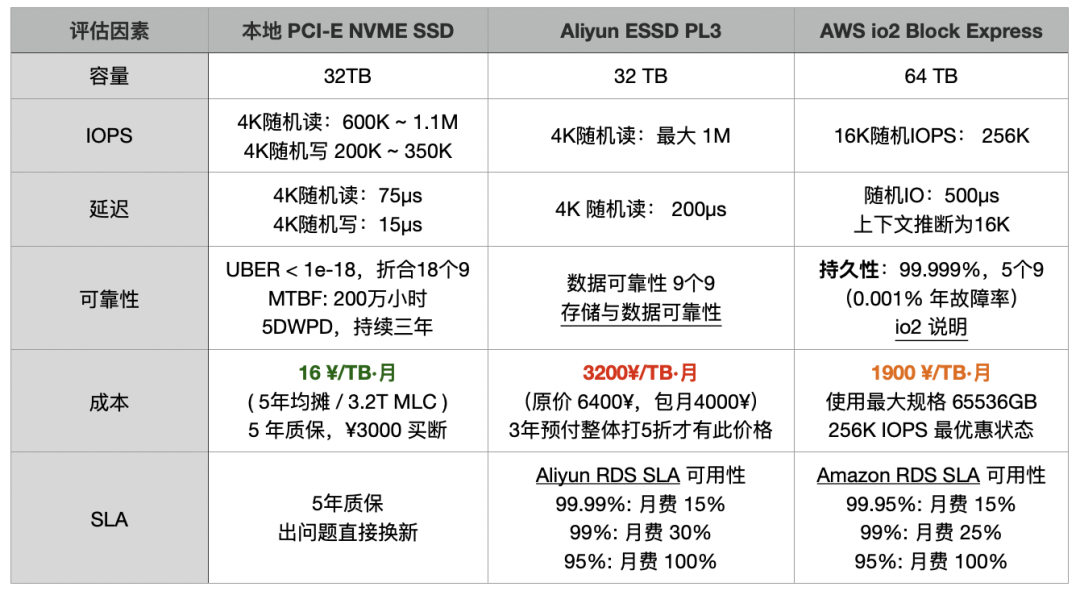
| Factor | Local PCI-E NVME SSD | Aliyun ESSD PL3 | AWS io2 Block Express |
|---|---|---|---|
| Cost | 14.5 RMB/TB·month (5-year amortization / 3.2T MLC) 5-year warranty, ¥3000 retail | 3200 RMB/TB·month (Original price 6400 RMB, monthly package 4000 RMB) 50% discount for 3-year upfront payment | 1900 RMB/TB·month Best discount for the largest specification 65536GB 256K IOPS |
| Capacity | 32TB | 32 TB | 64 TB |
| IOPS | 4K random read: 600K ~ 1.1M 4K random write 200K ~ 350K | Max 4K random read: 1M | 16K random IOPS: 256K |
| Latency | 4K random read: 75µs 4K random write: 15µs | 4K random read: 200µs | Random IO: 500µs (assumed 16K) |
| Reliability | UBER < 1e-18, equivalent to 18 nines MTBF: 2 million hours 5DWPD, over three years | Data reliability: 9 nines Storage and Data Reliability | Durability: 99.999%, 5 nines (0.001% annual failure rate) io2 details |
| SLA | 5-year warranty, direct replacement for issues | Aliyun RDS SLA Availability 99.99%: 15% monthly fee 99%: 30% monthly fee 95%: 100% monthly fee | Amazon RDS SLA Availability 99.95%: 15% monthly fee 99%: 25% monthly fee 95%: 100% monthly fee |
e local NVMe SSD example used here is the Shannon DirectIO G5i 3.2TB MLC particle enterprise-level SSD, extensively used by us. Brand new, disassembled retail pieces are priced at ¥2788 (available on Xianyu!), translating to a monthly cost per TB of 14.5 RMB over 60 months (5 years). Even if we calculate using the Inspur list price of ¥4388, the cost per TB·month is only 22.8. If this example is not convincing enough, we can refer to the 12 TB Gen4 NVMe enterprise-level SSDs purchased by DHH in “Is It Time to Give Up on Cloud Computing?”, priced at $2390 each, with a cost per TB·month of exactly 23 RMB.
So, why are NVMe SSDs, which outperform by several orders of magnitude, priced an order of magnitude cheaper than standard tier S3 (161 vs 23) and two orders of magnitude cheaper than S3 Express (1120 vs 23 x3)? If I were to use such hardware (even accounting for triple replication) + open-source software to build an object storage service, could I achieve a three orders of magnitude improvement in cost-effectiveness? (This doesn’t even account for the reliability advantages of SSDs over HDDs.)
It’s worth noting that the comparison above focuses solely on the cost of storage space. The cost of data transfer in and out of object storage is also a significant expense, with some tiers charging not for storage but for retrieval traffic. Additionally, there are issues of SSD reliability compared to HDD, data sovereignty in the cloud, etc., which will not be elaborated further here.
Of course, cloud providers might argue that their S3 service is not just about storage hardware resources but an out-of-the-box service. This includes software intellectual property and maintenance labor costs. They may claim that self-hosting has a higher failure rate, is riskier, and incurs significant operational labor costs. Unfortunately, these arguments might have been valid in 2006 or 2013, but they seem rather ludicrous today.
Self-Hosted OSS S3
A decade and a half ago, the vast majority of users lacked the IT capabilities to self-host, and there were no mature open-source alternatives to S3. Users could tolerate the premium for this high technology. However, as various cloud providers and IDCs began offering object storage, and even open-source free object storage solutions like MinIO emerged, the market shifted from a seller’s to a buyer’s market. The logic of value pricing turned into cost pricing, and the unyielding premium on resources naturally faced scrutiny — what extra value does it actually provide to justify such significant costs?
Proponents of cloud storage claim that moving to the cloud is cheaper, simpler, and faster than self-hosting. For individual webmasters and small to medium-sized internet companies within the cloud’s suitable spectrum, this claim certainly holds. If your data scale is only a few dozen GBs, or you have some medium-scale overseas business and CDN needs, I would not recommend jumping on the bandwagon to self-host object storage. You should instead turn to Cloudflare and use R2 — perhaps the best solution.
However, for the truly high-value, medium-to-large scale customers who contribute the majority of revenue, these value propositions do not necessarily hold. If you are primarily using local storage for TB/PB scale data, then you should seriously consider the cost and benefits of self-hosting object storage services — which has become very simple, stable, and mature with open-source software. Storage service reliability mainly depends on disk redundancy: apart from occasional hard drive failures (HDD AFR 1%, SSD 0.2-0.3%), requiring you (or a maintenance service provider) to replace parts, there isn’t much additional burden.
If the open-source Ceph, which mixes EBS/S3 capabilities, is considered somewhat operationally complex and not fully feature-complete; then the fully S3-compatible object storage service MinIO can be considered truly plug-and-play — a standalone binary without external dependencies, requiring only a few configuration parameters to quickly set up, transforming server disk arrays into a standard local S3-compatible service, even integrating AWS’s AK/SK/IAM compatible implementations!
From an operational management perspective, the operational complexity of Redis is an order of magnitude lower than PostgreSQL, and MinIO’s operational complexity is another order of magnitude lower than Redis. It’s so simple that I could spend less than a week to integrate MinIO deployment/monitoring as an add-on into our open-source PostgreSQL RDS solution, serving as an optional central backup storage repository.
At Tantan, several MinIO clusters were built and maintained this way: holding 25PB of data, possibly the largest scale of MinIO deployment in China at the time. How many people were needed for maintenance? Just a fraction of one operations engineer’s working time was enough, and the overall self-hosting cost was about half of the cloud list price. Practice proves the point, if anyone tells you that self-hosting object storage is difficult and expensive, you can try it yourself — in just a few hours, these sales FUD tactics will fall apart.
For object storage services, the cloud’s three core value propositions: “cheaper, simpler, faster”, the “simpler” part may not hold up, “cheaper” has turned the other way, probably only leaving “faster” — indeed, no one can beat the cloud on this point. You can apply for PB-level storage services across all regions of the world in less than a minute on the cloud, which is amazing! However, you also have to pay a high premium, several times to dozens of times over for this privilege.
Therefore, for object storage services, among the cloud’s three core value propositions: “cheaper, simpler, faster”, the “simpler” part may not hold, and “cheaper” has gone in the opposite direction, probably only leaving “faster” — indeed, no one can beat the cloud on this point. You can indeed apply for PB-level storage services across all regions of the world in less than a minute on the cloud, which is amazing! However, you also have to pay a high premium for this privilege, several to dozens of times over. For enterprises of a certain scale, compared to the cost of operations increasing several times, waiting a couple of weeks or making a one-time capital investment is not a big deal.
Summary
The exponential decline in hardware costs has not been fully reflected in the service prices of cloud providers, turning public clouds from universally beneficial infrastructure into monopolistic profit centers.
However, the tide is turning. Hardware is becoming interesting again, and cloud providers can no longer indefinitely hide this advantage. The savvy are starting to crunch the numbers, and the bold have already taken action. Pioneers like Elon Musk and DHH have fully realized this, moving away from the cloud to reap millions in financial benefits, enjoy performance gains, and gain more operational independence. More and more people are beginning to notice this, following in the footsteps of these pioneers to make the wise choice and reclaim their hardware dividends.
References
[1] 2006: https://aws.amazon.com/cn/blogs/aws/amazon_s3/
[2] 2010: http://aws.typepad.com/aws/2010/11/what-can-i-say-another-amazon-s3-price-reduction.html
[3] 2012: http://aws.typepad.com/aws/2012/11/amazon-s3-price-reduction-december-1-2012.html
[5] 2016: https://aws.amazon.com/ru/blogs/aws/aws-storage-update-s3-glacier-price-reductions/
[6] 2023: https://aws.amazon.com/cn/s3/pricing
[7] First-byte Latency: https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance.html
[8] Storage & Reliability: https://help.aliyun.com/document_detail/476273.html
[9] EBS io2 Spec: https://aws.amazon.com/cn/blogs/storage/achieve-higher-database-performance-using-amazon-ebs-io2-block-express-volumes/
[10] Aliyun RDS SLA: https://terms.aliyun.com/legal-agreement/terms/suit_bu1_ali_cloud/suit_bu1_ali_cloud201910310944_35008.html?spm=a2c4g.11186623.0.0.270e6e37n8Exh5
[11] Amazon RDS SLA: https://d1.awsstatic.com/legal/amazonrdsservice/Amazon-RDS-Service-Level-Agreement-Chinese.pdf
Reclaim Hardware Bonus from the Cloud
Hardware is interesting again, with the AI wave fueling a GPU frenzy. However, the intrigue isn’t limited to GPUs —— developments in CPUs and SSDs remain largely unnoticed by the majority of devs. A whole generation of developers is obscured by cloud hype and marketing noise.
Hardware performance is skyrocketing, and costs are plummeting, turning the public cloud from a decent service into a cash cow. These shifts necessitate a reevaluation of technology and software. It’s time to get back to basics and reclaim the hardware dividend that belongs to users.

Revolutionary New Hardware
If you’ve been unaware of computer hardware for a while, the specs of the latest gear might shock you.
Once, Intel’s CPUs saw marginal gains each generation, allowing old PCs to remain viable year after year. However, CPU evolution has recently accelerated, with significant leaps in core counts and regular 20-30% improvements in single-core performance.
For instance, AMD’s recently released desktop CPU, the Threadripper 7995WX, is a performance beast with 96 cores and 192 threads at speeds ranging from 2.5 to 5.1 GHz, retailing on Amazon for $5600. The server CPU series, EPYC, includes the previous generation EPYC Genoa 9654, with 96 cores and 192 threads at speeds ranging from 2.4 to 3.55 GHz, priced at $3940 on Amazon. This year’s new EPYC 9754 goes even further, offering a single CPU with 128 cores and 256 threads. This means a standard dual-socket server could have an astonishing 512 threads! If we consider cloud computing/container platforms’ 500% overselling rate, this could virtualize more than two thousand five hundred 1-core virtual machines.
Take AMD’s new Threadripper 7995WX, a 96-core, 192-thread behemoth clocked at 2.5 to 5.1 GHz, retailing at $5600 on Amazon. On the server side, the previous-gen EPYC Genoa 9654 offered 96 cores and 192 threads at 2.4 to 3.55 GHz, priced at $3940. The latest EPYC 9754 pushes boundaries further with 128 cores and 256 threads, enabling a dual-socket server to boast a staggering 512 vCPUs — enough to oversubscribe and virtualize over 2500+ 1c VMs at 500% oversell rates.
SSD/NVMe storage has seen even more dramatic generational jumps. Speeds have escalated from Gen2’s 500MB/s to Gen3’s 2.5GB/s, and now Gen4’s mainstream 7GB/s, with Gen5 at 14GB/s emerging. Gen6 is released, with Gen7 on the horizon, as I/O bandwidth doubles exponentially.
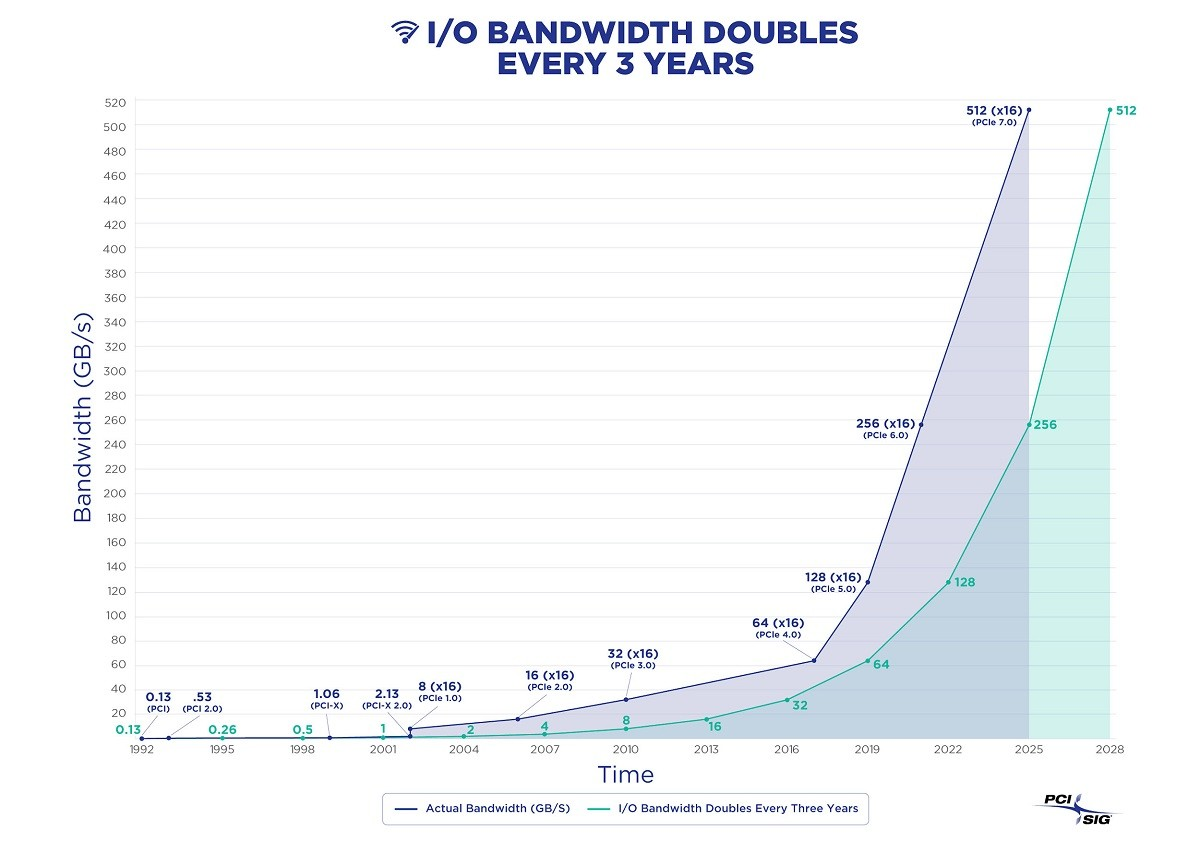
Consider the Gen5 NVMe SSD: KIOXIA CM7, which offers 128K sequential read bandwidth of 14GB/s and write bandwidth of 7GB/s, with 4K random IOPS of 2.7M for reads and 600K for writes. It’s doubtful that many database software packages can fully utilize this insane read/write bandwidth and IOPS. For context, HDD generally fluctuates around a read/write bandwidth of a few hundred MB/s, with 7200 RPM drives achieving IOPS in the tens and 15000 RPM drives in the low hundreds. NVMe SSDs’ I/O bandwidth rates are already four orders of magnitude better than HDD — 10,000x better.
In terms of 4K RankRW response times, which are of utmost concern for databases, NVMe SSDs have achieved 55/9 µs for reads & writes since several generations ago. Meanwhile, HDD seek time usually measures around 10ms, with an average rotational latency depending on speed between 2ms and 4ms, meaning a single I/O operation typically takes over a dozen milliseconds. Comparing dozens of milliseconds to 55/9µs, NVMe SSDs are three orders of magnitude faster than mechanical disks — 1000x faster!
Besides computing and storage, network hardware has also improved significantly. 40GbE and 100GbE are now commonplace — a 100GbE optical module network card costs just about several hundred dollars, offering a network transfer speed of 12 GB/s, a hundred times faster than the gigabit network cards familiar to older programmers.
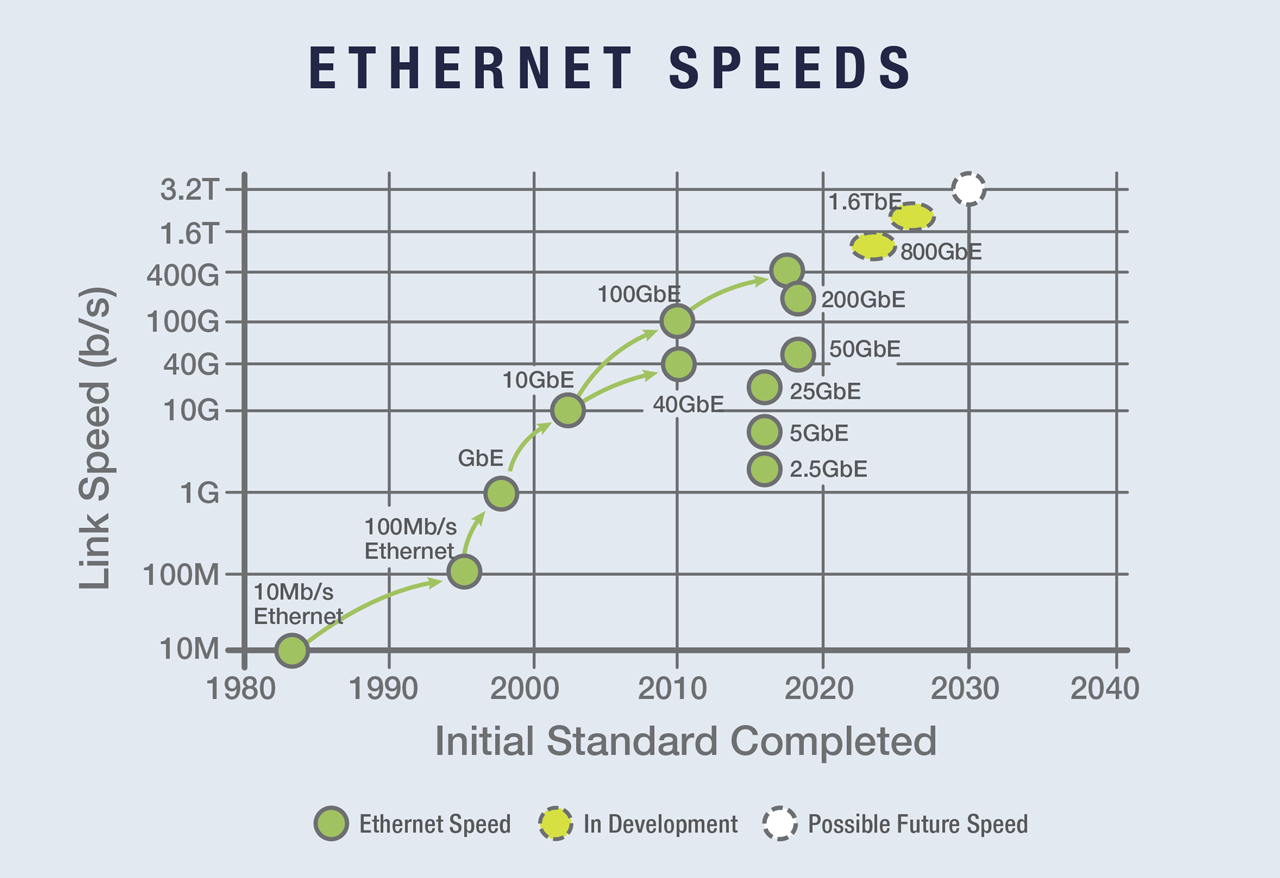
1.6T Ethernet is already on the radar.
As computing, storage, and networking hardware evolve exponentially following Moore’s Law, hardware becomes fascinating again. But the real intrigue lies in how these technological leaps will impact the world.
Distributed Losing Favor
The landscape of hardware has undergone monumental changes over the past decade, rendering many assumptions in the software realm obsolete, such as those concerning distributed databases.
Today, the capabilities of a standard x86 server have reached astonishing levels. An intriguing draft calculation roughly demonstrates the feasibility of running the entirety of Twitter on a modern server (Dell PowerEdge R740xd, with 32 cores, 768GB RAM, 6TB NVMe, 360TB HDD, GPU slots, and 4x40Gbe networking). While you wouldn’t do this for production redundancy (using two or three servers might be safer), this calculation indeed raises an interesting question — Is scalability still a real issue?
At the turn of the century, an Apache server could barely handle a few hundred concurrent requests. The best software struggled with tens of thousands of concurrent connections — the industry’s notorious C10K problem, where handling several thousand connections was seen as a feat. However, with the advent of Epoll and Nginx in 2003/2004, “high concurrency” ceased to be a challenge — any novice who learned to configure Nginx could achieve what masters only dreamed of a few years earlier. “Customers in the Eyes of Cloud Providers: Poor, Idle, and Lacking Love” details this evolution.
As of 2023, the impact of hardware has once again revolutionized distributed databases: Scalability, much like the C10K problem two decades ago, has become a solved issue of the past. If a service like Twitter can run on a single server, then 99.xxxx+% of services will not exceed the scalability needs that such a server can provide throughout their entire lifecycle. This means the once-prized “distributed” technology boasted by big tech companies has become redundant with the advent of new hardware — Anyone still discussing partitioning, distributed databases, and high concurrency on a massive scale is living in the past, having ceased to learn and grow over the past decade.
The foundational assumption of distributed databases — that a single machine’s processing power is insufficient to support the load — has been shattered by contemporary hardware. Centralized databases don’t even need to lift a finger; their capacity automatically scales to meet demands that most services will never reach in their lifetime. Some might argue that services like WeChat or Alipay require distributed databases, but setting aside whether distributed databases are the only solution, assuming these rare extreme cases can sustain a couple of distributed TP kernels, distributed OLTP databases will no longer be the main direction for database development as network hardware becomes more cost-effective than disk storage. Alibaba’s choice of a distributed path for its database progeny, OceanBase, versus its current preference for centralized architectures with PolarDB, serves as a telling example.
In the realm of big data analytics (OLAP), distributed systems might have been essential, but now even this is questionable — for the majority of companies, their entire database volume could potentially be processed on a single server. Scenarios that previously demanded “distributed data warehouses” might now be addressed by running PostgreSQL or DuckDB on a modern server. True, large internet companies may have PB/ZB-level data scenarios, but even for core internet services, it’s rare for a single service’s data volume to exceed a single machine’s processing limits. For instance, BreachForums’ recent leak of 5 years of Taobao shopping records (2015-2020, 8.2 billion records) compressed to 600GB, and similarly, the data sizes for JD.com’s billions and Pinduoduo’s 14.5 billion records are on par. Moreover, companies like Dell or Inspur offer PB-level NVMe all-flash storage cabinets, capable of housing the entire U.S. insurance industry’s historical data and analysis tasks in a single box for less than $200,000.
The core trade-off of distributed databases is “quality for quantity,” sacrificing functionality, performance, complexity, and reliability in exchange for greater data capacity and throughput. However, “premature optimization is the root of all evil,” and designing for unnecessary scale is futile. If scale is no longer an issue, then sacrificing other attributes for unneeded capacity, incurring extra complexity and costs, becomes utterly pointless.
Cost of Owning Servers
With new hardware boasting such powerful performance, what about the cost? Moore’s Law states that every 18 to 24 months, processor performance doubles while the cost halves. Compared to a decade ago, new hardware is not only more powerful but also cheaper.
In “DHH: The Cloud-Exit Odyssey”, we have a fresh example of a public procurement. DHH and 37 Signals purchased a batch of physical machines for their move away from the cloud in 2023: they bought 20 servers from Dell, totaling 4,000-core vCPUs, 7,680GB of memory, and 384TB of NVMe storage, among other things, for a total expenditure of $500,000.
The specific configuration of each server was as follows: Dell R7625 server, 192 vCPU / 384 GB memory: two AMD EPYC 9454 processors (48 cores/96 threads, 2.75 GHz), equipped with 2x vCPU memory (16 x 32GB memory), a 12 TB NVMe Gen4 SSD, plus other components, at a cost of $20,000 per server ($\19,980), amortized over five years is $333 per month.
To verify the validity of this quote, we can directly refer to the retail market prices of the core components: the CPU is the EPYC 9654, with a current retail price of $3,725 each, totaling $7,450 for two. 32GB DDR5 ECC server memory, retailing at $128 per stick, 16 sticks total $2,048. Enterprise-grade NVMe SSD 12TB, priced at $2,390. 100G optical module 100GbE QSFP28 priced at $1,804, adding up to around $13,692, plus the server barebone, power supply, system disk, RAID card, fans, etc., the total price of $20,000 is reasonable.
Of course, a server is not just made up of CPUs, memory, hard drives, and network cards; we also need to consider the total cost of ownership. Data centers need to provide these machines with electricity, rack space, and networking, maintenance fees, and reserve redundancy (prices in the US). After accounting for these costs, they are basically on par with the monthly hardware amortization cost, so the comprehensive monthly cost of a server with 192C / 384G / 12T NVMe storage is $666, which is about $3.5 / vCPU·month.
I believe DHH’s figures are accurate, as at Tantan, from day one, we chose to build our IDC / resource cloud, and after several rounds of cost optimization, we achieved a similar price — our database server model (Dell R730, 64 vCPU / 512GB / 3.2 TB NVMe SSD) plus the cost of manpower, maintenance, electricity, and internet, the TCO was about $10,400 , with a core-month cost of $2.71 / vCPU·month. Here is a table for reference on the price per unit of computing power:
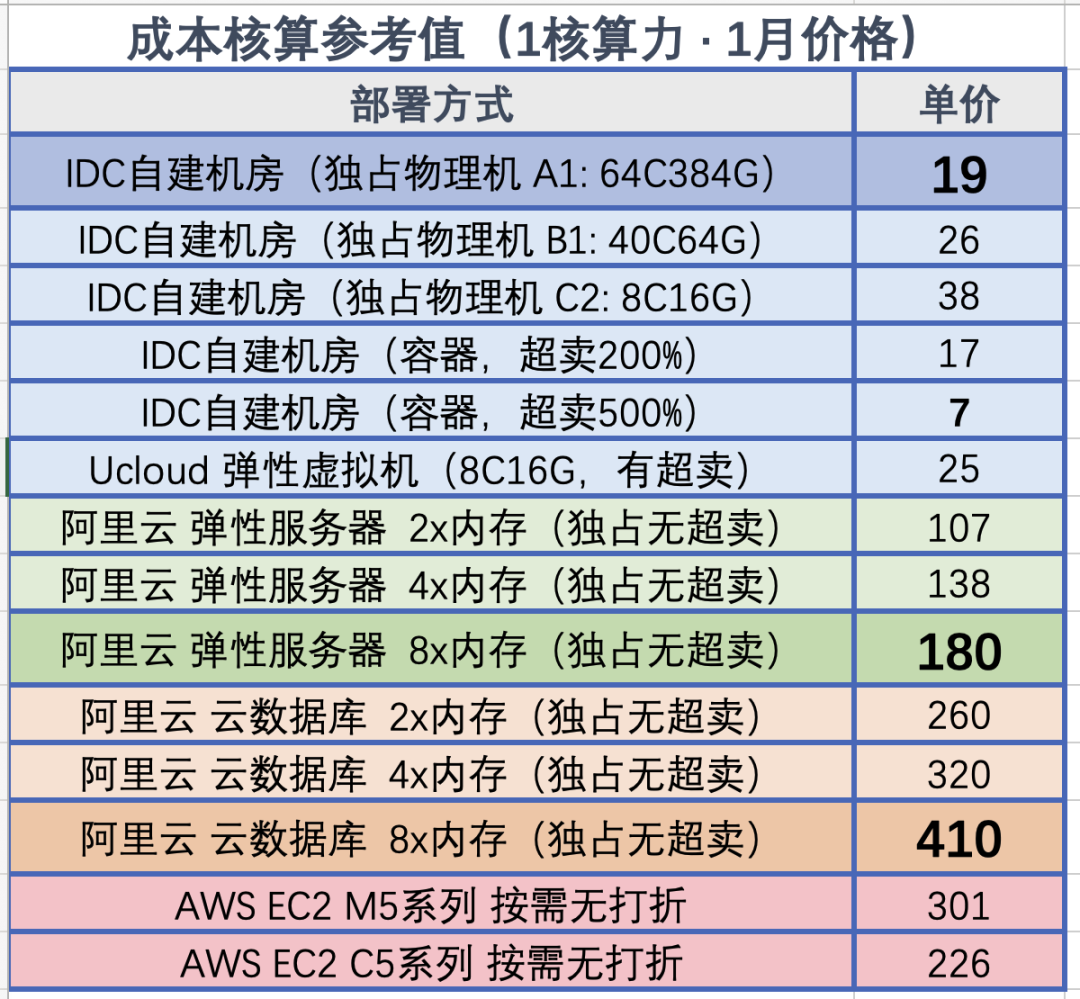
| BM / EC2 / ECS Specs | $ / vCPU·Month |
|---|---|
| DHH’s self-hosted vCPU·Month Price (192C 384G) | 3.5 |
| TanTan IDC self-hosted DC (64C 384G) | 2.7 |
| TanTan container platform (container, oversold 500%) | 1.0 |
| Aliyun ECS family c 2x (us-east-1), hourly | 23.8 |
| Aliyun ECS family c 2x (us-east-1), monthly | 18.2 |
| Aliyun ECS family c 2x (us-east-1), yearly | 15.6 |
| Aliyun ECS family c 2x (us-east-1), 3-year upfront | 10.0 |
| Aliyun ECS family c 2x (us-east-1), 5-year upfront | 6.9 |
| AWS C5N.METAL 96C (On Demand) | 35.0 |
| AWS C5N.METAL 96C (1y Reserve, All Upfront) | 20.6 |
| AWS C5N.METAL 96C (3y Reserve, All Upfront) | 12.8 |
Cloud Rental Price
For reference, we can compare the cost to leasing compute power from AWS EC2. A monthly expense of $666 can get you the best specification without storage, the c6in.4xlarge on-demand instance (16 cores, 32G x 3.5GHz); while the on-demand cost for a c7a.metal instance, which has similar compute and memory specification (192C/384G) but excludes EBS storage, is $7,200 per month, which is 10.8 times the comprehensive local build cost; the lowest monthly cost for a 3-year reserved instance can go down to $2,756, which is still 4.1 times the cost of building your own server. If we calculate the cost per core-month, the price for the majority of AWS EC2 instances ranges between $10 ~ $30, which is roughly a hundred to a few hundred dollars, leading us to a rough conclusion: the unit price of cloud compute is 5 to 10 times that of self-built solutions.
Note that these prices do not include the hundredfold premium for EBS cloud storage. In “Is Cloud Disk a Rip-off?”, we’ve already detailed the cost comparison between enterprise SSDs and equivalent cloud disks. Here, we can provide two updated reference values: the cost per TB-month for the 12TB enterprise NVMe SSD purchased by DHH (with a five-year warranty) is 24 CNY, while the cost per TB-month for a retail Samsung consumer SSD 990Pro on GameStop can reach an astonishing 6.6 CNY… Meanwhile, the corresponding block storage TB-month cost on AWS and Alibaba Cloud, even after full discounts, is respectively 1,900 and 3,200 CNY. In the most outrageous scenarios (6400 vs 6.6), the premium can even reach a thousandfold. However, a more apples-to-apples comparison results in: the unit price of cloud block storage is 100 to 200 times that of self-built solutions (and the performance is not as good as local disks).
EC2 and EBS prices can be considered the anchor of cloud service pricing, for example, the premium rate of cloud databases RDS that mainly use EC2 and EBS compared to local self-built solutions fluctuates between the two, depending on your storage usage: the unit price of cloud databases is dozens of times that of self-built solutions. For more details, refer to “Is Cloud Database a Dumb Tax?”.
Of course, we can’t deny the cost advantages of public clouds for micro instances and startups — for example, the nano instances on public clouds used to patch together 12C, 0.52G configurations really can be offered to users at a core-month cost of a few dollars. In “Exploiting Alibaba Cloud ECS for a Digital Homestead,” I recommended exploiting Alibaba Cloud’s Double 11 virtual machine deals for this reason. For instance, a 2C 2G server’s compute cost, calculated with a 500% overselling, is 84 CNY per year, and the cost for 40G cloud disk storage, calculated with triple replication, is about 20 CNY per year, making the annual cost for these two parts over a hundred CNY. This doesn’t include the cost of a public IP or the more valuable 3M bandwidth (for example, if you could fully utilize 3M bandwidth 24 hours a day, that would mean 32G of data per day, costing about 25 CNY). The list price for such cloud servers is ¥1500 per year, so the 99¥ price allowing for a low-cost renewal for four years indeed can be considered a loss-leading benefit.
However, when your business can no longer be covered by a bunch of micro instances, you really should do the math again carefully: in several key examples, the cost of cloud services is extremely high — whether for large physical machine databases, large NVMe storage, or just the latest and fastest compute. The rental price for such production-grade resources is so high — that a few months’ rent could equal the cost of buying it outright. In such cases, you really should just buy the donkey!
Reclaim Hardware Bonus from Cloud
I still remember on April 1, 2019, when the domestic value-added tax in China was officially reduced from 16% to 13%, Apple’s official website immediately implemented a price reduction across the board, with the maximum discount reaching 8% — several iconic iPhone models were reduced by 500 yuan, effectively passing the tax cut benefits to the users. However, many manufacturers chose to turn a deaf ear and maintain their original prices, pocketing the benefits for themselves — why would they want to distribute this newfound wealth to the less fortunate? A similar situation has occurred in the cloud computing domain — the exponential decrease in hardware costs has not been fully reflected in the service prices of cloud providers, gradually turning public cloud from a universally accessible infrastructure into a monopolistic cash cow.
In the old days, developers had to deeply understand hardware to write code. However, the older generation of engineers and programmers, who had a keen sense of hardware, have mostly retired, changed positions, moved into management, or stopped learning. Subsequently, as operating systems and compiler technologies advanced and various VM programming languages emerged, software no longer needed to concern itself with how hardware executed instructions. Then came services like EC2, which encapsulated computing power, and S3/EBS, which encapsulated storage, leading applications to interact with HTTP APIs rather than system calls. Software and hardware diverged into two separate realms, each going its own way. An entire new generation of engineers grew up in the cloud environment, shielded from an understanding of computer hardware.
However, things are beginning to change, with hardware becoming interesting again, and cloud providers are unable to perpetually hide this dividend — the wise are starting to crunch the numbers, and the brave have already taken action. Pioneers like Musk and DHH have fully recognized this, moving off the cloud and onto solid ground — directly generating tens of millions of dollars in financial benefits, with returns in performance, and gaining more independence in operations. More and more people will come to the same realization, following in the footsteps of these trailblazers to make the wise choice of reclaiming their hardware bonus from the cloud.
FinOps: Endgame Cloud-Exit
At the SACC 2023 FinOps session, I fiercely criticized cloud vendors. This is a transcript of my speech, introducing the ultimate FinOps concept — cloud-exit and its best practice.
TL; DR
Misaligned FinOps Focus: Total Cost = Unit Price x Quantity. FinOps efforts are centered around reducing the quantity of wasted resources, deliberately ignoring the elephant in the room — cloud resource unit price.
Public Cloud as a Slaughterhouse: Attract customers with cheap EC2/S3, then slaughter them with EBS/RDS. The cost of cloud compute is five times that of in-house, while block storage costs can be over a hundred times more, making it the ultimate cost assassin.
The Endgame of FinOps is Going Off-Cloud: For enterprises of a certain scale, the cost of in-house IDC is around 10% of the list price of cloud services. Going off-cloud is both the endgame of orthodox FinOps and the starting point of true FinOps.
In-house Capabilities Determine Bargaining Power: Users with in-house capabilities can negotiate extremely low discounts even without going off-cloud, while companies without in-house capabilities can only pay a high “no-expert tax” to public cloud vendors.
Databases are Key to In-House Transition: Migrating stateless applications on K8S and data warehouses is relatively easy. The real challenge is building databases in-house without compromising quality and security.
Misaligned FinOps Focus
Compared to the amount of waste, the unit price of resources is the key point.
The FinOps Foundation states that FinOps focuses on “cloud cost optimization”. However, we believe that emphasizing only public clouds deliberately narrows this concept — the focus should be on the cost control and optimization of all resources, not just those on public clouds — including “hybrid clouds” and “private clouds”. Even without using public clouds, some FinOps methodologies can still be applied to the entire K8S cloud-native ecosystem. Because of this, many involved in FinOps are led astray — their focus is limited to reducing the quantity of cloud resource waste, neglecting a very important issue: unit price.
Total cost depends on two factors: Quantity ✖️ Unit Price. Compared to quantity, unit price might be the key to cost reduction and efficiency improvement. Previous speakers mentioned that about 1/3 of cloud resources are wasted on average, which is the optimization space for FinOps. However, if you use non-elastic services on public clouds, the unit price of the resources you use is already several to dozens of times higher, making the wasted portion negligible in comparison.
In the first stop of my career, I experienced a FinOps movement firsthand. Our BU was among the first internal users of Alibaba Cloud and also where the “data middle platform” concept originated. Alibaba Cloud sent over a dozen engineers to help us migrate to the cloud. After migrating to ODPS, our annual storage and computing costs were 70 million, and through FinOps methods like health scoring, we did optimize and save tens of millions. However, running the same services with an in-house Hadoop suite in our data center cost less than 10 million annually — savings are good, but they’re nothing compared to the multiplied resource costs.
As cost reduction and efficiency become the main theme, cloud repatriation is becoming a trend. Alibaba, the inventor of the middle platform concept, has already started dismantling its own middle platform. Yet, many companies are still falling into the trap of the slaughterhouse, repeating the old path of cloud migration - cloud repatriation.
Public Clouds: A Slaughterhouse in Disguise
Attract customers with cheap EC2/S3, then slaughter them with EBS/RDS pricing.
The elasticity touted by public clouds is designed for their business model: low startup costs, exorbitant maintenance costs. Low initial costs lure users onto the cloud, and its good elasticity can adapt to business growth at any time. However, once the business stabilizes, vendor lock-in occurs, making it difficult to switch providers without incurring high costs, turning maintenance into a financial nightmare for users. This model is colloquially known as a pig slaughterhouse.
To slaughter pigs, one must first raise them. You can’t catch a wolf without putting your child at risk. Hence, for new users, startups, and small businesses, public clouds offer sweet deals, even at a loss, to make noise and attract business. New users get first-time discounts, startups receive free or half-price credits, and there’s a sophisticated pricing strategy. Taking AWS RDS pricing as an example, the mini models with 1 or 2 cores are priced at just a few dollars per core per month, translating to a few hundred yuan per year (excluding storage). This is an affordable option for those needing a low-usage database for small data storage.
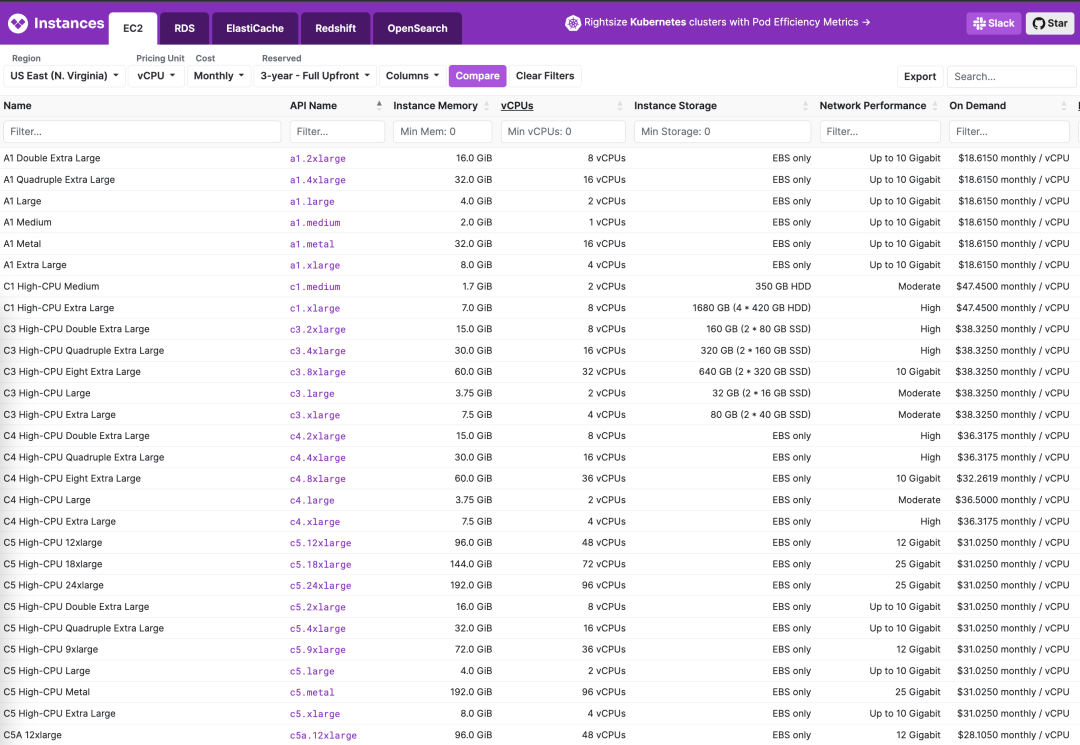
However, even a slight increase in configuration leads to a magnitude increase in the price per core month, skyrocketing to twenty or thirty to a hundred dollars, sometimes even more — not to mention the shocking EBS prices. Users may only realize what has happened when they see the exorbitant bill suddenly appearing.
Compared to in-house solutions, the price of cloud resources is generally several to more than ten times higher, with a rent-to-buy ratio ranging from a few days to several months. For example, the cost of a physical server core month in an IDC, including all costs for network, electricity, maintenance, and IT staff, is about 19 yuan. Using a K8S container private cloud, the cost of a virtual core month is only 7 yuan.
In contrast, the price per core month for Alibaba Cloud’s ECS is a couple of hundred yuan, and for AWS EC2, it’s two to three hundred yuan. If you “don’t care about elasticity” and prepay for three years, you can usually get a discount of about 50-60%. But no matter how you calculate it, the price difference between cloud computing power and local in-house computing power is there and significant.
The pricing of cloud storage resources is even more outrageous. A common 3.2 TB enterprise-grade NVMe SSD, with its formidable performance, reliability, and cost-effectiveness, has a wholesale price of just over ¥3000, significantly outperforming older storage solutions. However, for the same storage on the cloud, providers dare to charge 100 times the price. Compared to direct hardware procurement, the cost of AWS EBS io2 is 120 times higher, while Alibaba Cloud’s ESSD PL3 is 200 times higher.
Using a 3.2TB enterprise-grade PCI-E SSD card as a benchmark, the rent-to-buy ratio on AWS is 15 days, while on Alibaba Cloud it’s less than 5 days, meaning renting for this period allows you to purchase the entire disk outright. If you opt for a three-year prepaid purchase on Alibaba Cloud with the maximum discount of 50%, the three-year rental fee could buy over 120 similar disks.
The price markup ratio of cloud databases (RDS) falls between that of cloud disks and cloud servers. For example, using RDS for PostgreSQL on AWS, a 64C / 256GB RDS costs $25,817 per month, equivalent to 180,000 yuan per month. One month’s rent is enough to purchase two servers with much better performance for in-house use. The rent-to-buy ratio is not even a month; renting for just over ten days would be enough to purchase an entire server.
Any rational enterprise user can see the folly in this: If the procurement of such services is not for short-term, temporary needs, then it definitely qualifies as a significant financial misjudgment.
| Payment Model | Price | Cost Per Year (¥10k) |
|---|---|---|
| Self-hosted IDC (Single Physical Server) | ¥75k / 5 years | 1.5 |
| Self-hosted IDC (2-3 Server HA Cluster) | ¥150k / 5 years | 3.0 ~ 4.5 |
| Alibaba Cloud RDS (On-demand) | ¥87.36/hour | 76.5 |
| Alibaba Cloud RDS (Monthly) | ¥42k / month | 50 |
| Alibaba Cloud RDS (Yearly, 15% off) | ¥425,095 / year | 42.5 |
| Alibaba Cloud RDS (3-year, 50% off) | ¥750,168 / 3 years | 25 |
| AWS (On-demand) | $25,817 / month | 217 |
| AWS (1-year, no upfront) | $22,827 / month | 191.7 |
| AWS (3-year, full upfront) | $120k + $17.5k/month | 175 |
| AWS China/Ningxia (On-demand) | ¥197,489 / month | 237 |
| AWS China/Ningxia (1-year, no upfront) | ¥143,176 / month | 171 |
| AWS China/Ningxia (3-year, full upfront) | ¥647k + ¥116k/month | 160.6 |
Comparing the costs of self-hosting versus using a cloud database:
| Method | Cost Per Year (¥10k) |
|---|---|
| Self-hosted Servers 64C / 384G / 3.2TB NVME SSD 660K IOPS (2-3 servers) | 3.0 ~ 4.5 |
| Alibaba Cloud RDS PG High-Availability pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG High-Availability db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
RDS pricing compared to self-hosting, see “Is Cloud Database an idiot Tax?”
Any meaningful cost reduction and efficiency increase initiative cannot ignore this issue: if there’s potential to slash resource prices by 50% to 200%, then focusing on a 30% reduction in waste is not a priority. As long as your main business is on the cloud, traditional FinOps is like scratching an itch through a boot — migrating off the cloud is the focal point of FinOps.
The Endgame of FinOps is Exiting from the Cloud
The well-fed do not understand the pangs of hunger, human joys and sorrows are not universally shared.
I spent five years at Tantan — a Nordic-style internet startup founded by a Swede. Nordic engineers have a characteristic pragmatism. When it comes to choosing between cloud and on-premise solutions, they are not swayed by hype or marketing but rather make decisions based on quantitative analysis of pros and cons. We meticulously calculated the costs of building our own infrastructure versus using the cloud — the straightforward conclusion was that the total cost of on-premise solutions (including labor) generally fluctuates between 10% to 100% of the list price for cloud services.
Thus, from its inception, Tantan chose to build its own infrastructure. Apart from overseas compliance businesses, CDN, and a very small amount of elastic services using public clouds, the main part of our operations was entirely hosted in IDC-managed data centers. Our database was not small, with 13K cores for PostgreSQL and 12K cores for Redis, 4.5 million QPS, and 300TB of unique transactional data. The annual cost for these two parts was less than 10 million yuan: including salaries for two DBAs, one network engineer, network and electricity, managed hosting fees, and hardware amortized over five years. However, for such a scale, if we were to use cloud databases, even with significant discounts, the starting cost would be between 50 to 60 million yuan, not to mention the even more expensive big data sector.
However, digitalization in enterprises is phased, and different companies are at different stages. For many internet companies, they have reached the stage where they are fully engaged with building cloud-native K8S ecosystems. At this stage, focusing on resource utilization, mixed online and offline deployments, and reducing waste are reasonable demands and directions where FinOps should concentrate its efforts. Yet, for the vast majority of enterprises outside the digital realm, the urgent need is not reducing waste but lowering the unit cost of resources — Dell servers can be discounted by 50%, IDC virtual machines by 50%, and even cloud services can be heavily discounted. Are these companies still paying the list price, or even facing several times the markup in rebates? A great many companies are still being severely exploited due to information asymmetry and lack of capability.
Enterprises should evaluate their scale and stage, assess their business, and weigh the pros and cons accordingly. For small-scale startups, the cloud can indeed save a lot of manpower costs, which is very attractive — but please be cautious not to be locked in by vendors due to the convenience offered. If your annual cloud expenditure has already exceeded 1 million yuan, it’s time to seriously consider the benefits of descending from the cloud — many businesses do not require the elasticity for massive concurrent spikes or training AI models. Paying a premium for temporary/sudden needs or overseas compliance is reasonable, but paying several times to tens of times more for unnecessary elasticity is wasteful. You can keep the truly elastic parts of your operations on the public cloud and transfer those parts that do not require elasticity to IDCs. Just by doing this, the cost savings could be astonishing.
Descending from the cloud is the ultimate goal of traditional FinOps and the starting point of true FinOps.
Self-Hosting Matters
“To seek peace through struggle is to preserve peace; to seek peace through compromise is to lose peace.”
When the times are favorable, the world joins forces; when fortune fades, even heroes lose their freedom: During the bubble phase, it was easy to disregard spending heavily in the cloud. However, in an economic downturn, cost reduction and efficiency become central themes. An increasing number of companies are realizing that using cloud services is essentially paying a “no-expert tax” and “protection money”. Consequently, a trend of “cloud repatriation” has emerged, with 37Signals’ DHH being one of the most notable proponents. Correspondingly, the revenue growth rate of major cloud providers worldwide has been experiencing a continuous decline, with Alibaba Cloud’s revenue even starting to shrink in the first quarter of 2023.
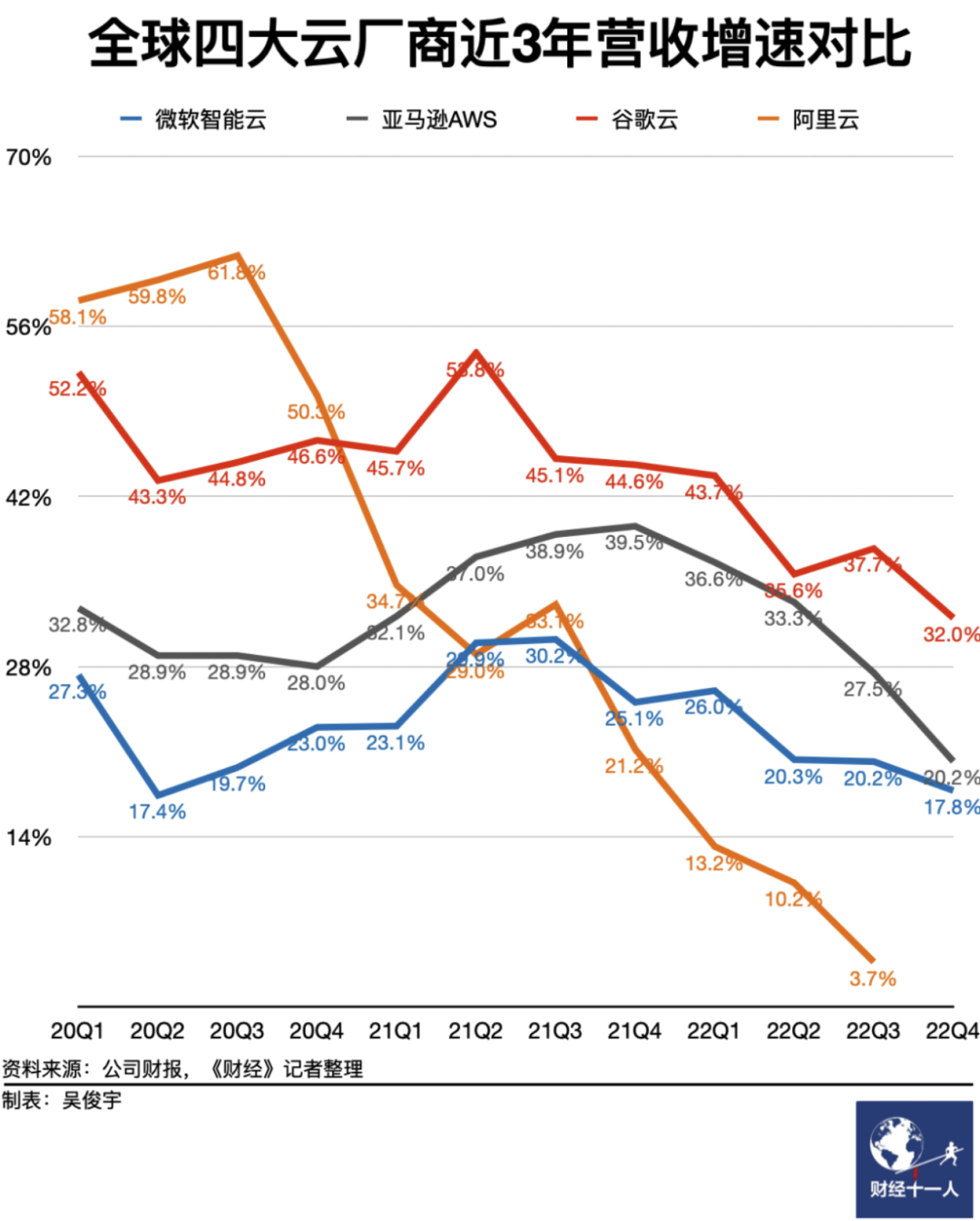
《“Why Cloud Computing Hasn’t Yet Hit Its Stride in Earning Profits”》
The underlying trend is the emergence of open-source alternatives, breaking down the technical barriers of public clouds; the advent of resource clouds/IDC2.0, offering a cost-effective alternative to public cloud resources; and the release of technical talents from large layoffs, along with the future of AI models, giving every industry the opportunity to possess the expert knowledge and capability required for self-hosting. Combining these trends, the combination of IDC2.0 + open-source self-hosting is becoming increasingly competitive: Bypassing the public cloud intermediaries and working directly with IDCs is clearly a more economical choice.
Public cloud providers are not incapable of engaging in the business of selling IDC resources profitably. Given their higher level of expertise compared to IDCs, they should, in theory, leverage their technological advantages and economies of scale to offer cheaper resources than IDC self-hosting. However, the harsh reality is that resource clouds can offer users virtual machines at a 80% discount, while public clouds cannot. Even considering the exponential growth law of Moore’s Law in the storage and computing industry, public clouds are actually increasing their prices every year!
Well-informed major clients, especially those capable of migrating at will, can indeed negotiate for 80% off the list prices with public clouds, a feat unlikely for smaller clients — in this sense, clouds are essentially subsidizing large clients by bleeding small and medium-sized clients dry. Cloud vendors offer massive discounts to large clients while fleecing small and medium-sized clients and developers, completely contradicting the original intention and vision of cloud computing.
Clouds lure in users with low initial prices, but once users are deeply locked in, the slaughter begins — the previously discussed discounts and benefits disappear at each renewal. Escaping the cloud entails a significant cost, leaving users in a dilemma between a rock and a hard place, forced to continue paying protection money.
However, for users with the capability to self-host, capable of flexibly moving between multi-cloud and on-premises hybrid clouds, this is not an issue: The trump card in negotiations is the ability to go off-cloud or migrate to another cloud at any time. This is more effective than any argument — as the saying goes, “To seek peace through struggle is to preserve peace; to seek peace through compromise is to lose peace.” The extent of cost reduction depends on your bargaining power, which in turn depends on your ability to self-host.
Self-hosting might seem daunting, but it is not difficult for those who know how. The key is addressing the core issues of resources and capabilities. In 2023, due to the emergence of resource clouds and open-source alternatives, these issues have become much simpler than before.
In terms of resources, IDC and resource clouds have solved the problem adequately. The aforementioned IDC self-hosting doesn’t mean buying land and building data centers from scratch but directly using the hosting services of resource clouds/IDCs — you might only need a network engineer to plan the network, with other maintenance tasks managed by the provider.
If you prefer not to hassle, IDCs can directly sell you virtual machines at 20% of the list price, or you can rent a physical server with 64C/256G for a couple thousand a month; whether renting an entire data center or just a single colocation space, it’s all feasible. A retail colocation space with comprehensive services can be settled for about five thousand a year, running a K8S or virtualization on a couple of hundred-core physical servers, why bother with flexible ECS?
FinOps Leads to CLoud-Exit
Building your own infrastructure comes with the added perk of extreme FinOps—utilizing out-of-warranty or even second-hand servers. Servers are typically depreciated over three to five years, yet it’s not rare to see them operational for eight to ten years. This contrasts with cloud services, where you’re just consuming resources; owning your server translates to tangible assets, making any extended use essentially a gain.
For instance, a new 64-core, 256GB server could cost around $7,000, but after a year or two, the price for such “electronic waste” drops to merely $400. By replacing the most failure-prone components with brand new enterprise-grade 3.2TB NVMe SSDs (costing $390), you could secure the entire setup for just $800.
In such scenarios, your vCPU·Month price could plummet to less than $0.15, a figure legendary in the gaming industry, where server costs can dip to mere cents. With Kubernetes (K8S) orchestration and database high-availability switching, reliability can be assured through parallel operation of multiple such servers, achieving an astonishing cost-efficiency ratio.
In terms of capability, with the emergence of sufficiently robust open-source alternatives, the difficulty of self-hosting has dramatically decreased compared to a few years ago.
For example, Kubernetes/OpenStack/SealOS are open-source alternatives to cloud providers’ EC2/ECS/VPS management software; MinIO/Ceph aim to replace S3/OSS; while Pigsty and various database operators serve as open-source substitutes for RDS cloud database management. There’s a plethora of open-source software available for effectively utilizing these resources, along with numerous commercial entities offering transparently priced support services.
Your operations should ideally converge to using just virtual machines and object storage, the lowest common denominator across all cloud providers. Ideally, all applications should run on Kubernetes, which can operate in any environment—be it a cloud-hosted K8S, ECS, dedicated servers, or your own data center. External states like database backups and big data warehouses should be managed with compute-storage separation, using MinIO/S3 storage.
Such a CloudNative tech stack theoretically enables operation and flexible migration across any resource environment, thus avoiding vendor lock-in and maintaining control. This allows you to either significantly cut costs by moving off the cloud or leverage it to negotiate discounts with public cloud providers.
However, self-hosting isn’t without risks, with RDS representing a major potential vulnerability.
Database: The Biggest Risk Factor
Cloud databases may not be the most expensive line item, but they are definitely the most deeply locked-in and challenging to migrate.
Quality, security, efficiency, and cost represent different levels of a hierarchical pyramid of needs. The goal of FinOps is to reduce costs and increase efficiency without compromising quality and security.
Stateless apps on K8S or offline big data platforms pose little fatal risk when migrating. Especially if you have already achieved big data compute-storage separation and stateless app cloud-native transformation, moving these components is generally not too troublesome. The former can afford a few hours of downtime, while the latter can be updated through blue-green deployments and canary releases. The database, serving as the working memory, is prone to major issues when migrated.
Most IT system architectures are centered around the database, making it the key risk point in cloud migration, particularly with OLTP databases/RDS. Many users hesitate to move off the cloud and self-host due to the lack of reliable database services — traditional Kubernetes Operators don’t fully replicate the cloud database experience: hosting OLTP databases on K8S/containers with EBS is not yet a mature practice.
There’s a growing demand for a viable open-source alternative to RDS, and that’s precisely what we aim to address: enabling users to establish a local RDS service in any environment that matches or exceeds cloud databases — Pigsty, a free open-source alternative to RDS PG. It empowers users to effectively utilize PostgreSQL, the world’s most advanced and successful database.
Pigsty is a non-profit, open-source software powered by community love. It offers a ready-to-use, feature-rich PostgreSQL distribution with automatic high availability, PITR, top-tier monitoring systems, Infrastructure as Code, cloud-based Terraform templates, local Vagrant sandbox for one-click installation, and SOP manuals for various operations, enabling quick RDS self-setup without needing a professional DBA.
Although Pigsty is a database distribution, it enables users to practice ultimate FinOps—running production-level PostgreSQL RDS services anywhere (ECS, resource clouds, data center servers, or even local laptop VMs) at almost pure resource cost. It turns the cost of cloud database capabilities from being proportional to marginal resource costs to nearly zero in fixed learning costs.
Perhaps it’s the socialist ethos of Nordic companies that nurtures such pure free software. Our goal isn’t profit but to promote a philosophy: to democratize the expertise of using the advanced open-source database PostgreSQL for everyone, not just cloud monopolies. Cloud providers monopolize open-source expertise and roles, exploiting free open-source software, and we aim to break this monopoly—Freedom is not free. You shouldn’t concede the world to those you despise but rather overturn their table.
This is the essence of FinOps—empowering users with viable alternatives and the ability to self-host, thus negotiating with cloud providers from a position of strength.
References
[1] 云计算为啥还没挖沙子赚钱?
[2] 云数据库是不是智商税?
[3] 云SLA是不是安慰剂?
[4] 云盘是不是杀猪盘?
[5] 范式转移:从云到本地优先
[6] 杀猪盘真的降价了吗?
[8] 垃圾腾讯云CDN:从入门到放弃
[9] 云RDS:从删库到跑路
[10] 分布式数据库是伪需求吗?
[11] 微服务是不是个蠢主意?
[12] 更好的开源RDS替代:Pigsty
SLA: Placebo or Insurance?
In the world of cloud computing, Service Level Agreements (SLAs) are seen as a cloud provider’s commitment to the quality of its services. However, a closer examination of these SLAs reveals that they might not offer the safety net one might expect: you might think you’ve insured your database for peace of mind, but in reality, you’ve bought a placebo that provides emotional comfort rather than actual coverage.
Insurance Policy or Placebo?
One of the reasons many users opt for cloud services is for the “safety net” they supposedly provide, often referring to the SLA when asked what this “safety net” entails. Cloud experts liken purchasing cloud services to buying insurance: certain failures might never occur throughout many companies’ lifespans, but should they happen, the consequences could be catastrophic. In such cases, a cloud service provider’s SLA is supposed to act as this safety net. Yet, when we actually review these SLAs, we find that this “policy” isn’t as useful as one might think.
Data is the lifeline of many businesses, and cloud storage serves as the foundation for nearly all data storage on the public cloud. Let’s take cloud storage services as an example. Many cloud service providers boast of their cloud storage services having nine nines of data reliability [1]. However, upon examining their SLAs, we find that these crucial promises are conspicuously absent from the SLAs [2].
What is typically included in the SLAs is the service’s availability. Even this promised availability is superficial, paling in comparison to the core business reliability metrics in the real world, with compensation schemes that are practically negligible in the face of common downtime losses. Compared to an insurance policy, SLAs more closely resemble placebos that offer emotional value.
Subpar Availability
The key metric used in cloud SLAs is availability. Cloud service availability is typically represented as the proportion of time a resource can be accessed from the outside, usually over a one-month period. If a user cannot access the resource over the Internet due to a problem on the cloud provider’s end, the resource is considered unavailable/down.
Taking the industry benchmark AWS as an example, most of its services use a similar SLA template [3]. The SLA for a single virtual machine on AWS is as follows [4]. This means that in the best-case scenario, if an EC2 instance on AWS is unavailable for less than 21 minutes in a month (99.9% availability), AWS compensates nothing. In the worst-case scenario, only when the unavailability exceeds 36 hours (95% availability) can you receive a 100% credit return.
Instance-Level SLA
For each individual Amazon EC2 instance (“Single EC2 Instance”), AWS will use commercially reasonable efforts to make the Single EC2 Instance available with an Instance-Level Uptime Percentage of at least 99.5%, in each case during any monthly billing cycle (the “Instance-Level SLA”). In the event any Single EC2 Instance does not meet the Instance-Level SLA, you will be eligible to receive a Service Credit as described below.
Instance-Level Uptime Percentage Service Credit Percentage Less than 99.5% but equal to or greater than 99.0% 10% Less than 99.0% but equal to or greater than 95.0% 30% Less than 95.0% 100% Note: In addition to the Instance-Level SLA, AWS will not charge you for any Single EC2 Instance that is Unavailable for more than six minutes of a clockhour. This applies automatically and you do not need to request credit for any such hour with more than six minutes of Unavailability.
For some internet companies, a 15-minute service outage is enough to jeopardize bonuses, and a 30-minute outage is sufficient for leadership changes. The actual availability of core systems running most of the time might have five nines, six nines, or even infinite nines. Cloud providers, incubated from major internet companies, using such inferior availability metrics is indeed disappointing.
What’s more outrageous is that these compensations are not automatically provided to you after a failure occurs. Users are required to measure downtime themselves, submit evidence for claims within a specific timeframe (usually two months), and request compensation to receive any. This requires users to collect monitoring metrics and log evidence to negotiate with cloud providers, and the compensation returned is not in cash but in vouchers/duration compensations — meaning virtually no real loss for the cloud providers and no actual value for the users, with almost no chance of compensating for the actual losses incurred during service interruptions.
Is the “Safety Net” Meaningful?
For businesses, a “safety net” means minimizing losses as much as possible when failures occur. Unfortunately, SLAs are of little help in this regard.
The impact of service unavailability on business varies by industry, time, and duration. A brief outage of a few seconds to minutes might not significantly affect general industries, however, long-term outages (several hours to several days) can severely affect revenue and reputation.
In the Uptime Institute’s 2021 data center survey [5], several of the most severe outages cost respondents an average of nearly $1 million, not including the worst 2% of cases, which suffered losses exceeding $40 million.

However, SLA compensations are a drop in the ocean compared to these business losses. Taking the t4g.nano virtual machine instance in the us-east-1 region as an example, priced at about $3 per month. If the unavailability is less than 7 hours and 18 minutes (99% monthly availability), AWS will pay 10% of the monthly cost of that virtual machine, a total compensation of 30 cents. If the virtual machine is unavailable for less than 36 hours (95% availability within a month), the compensation is only 30% — less than $1. Only if the unavailability exceeds a day and a half, can users receive a full refund for the month — $3. Even if compensating for thousands of instances, this is virtually negligible compared to the losses.
In contrast, the traditional insurance industry genuinely provides coverage for its customers. For instance, SF Express charges 1% of the item’s value for insurance, but if the item is lost, they compensate the full amount. Similarly, commercial health insurance costing tens of thousands yearly can cover millions in medical expenses. “Insurance” in this industry truly means you get what you pay for.
Cloud service providers charge far more than the BOM for their expensive services (see: “Are Public Clouds a Pig Butchering Scam?” [7]), but when service issues arise, their so-called “safety net” compensation is merely vouchers, which is clearly unfair.
Vanished Reliability
Some people use cloud services to “pass the buck,” absolving themselves of responsibility. However, some critical responsibilities cannot be shifted to external IT suppliers, such as data security. Users might tolerate temporary service unavailability, but the damage caused by lost or corrupted data is often unacceptable. Blindly trusting exaggerated promises can have severe consequences, potentially a matter of life and death for a startup.
In storage products offered by various cloud providers, it’s common to see promises of nine nines of reliability [1], implying a one in a billion chance of data loss when using cloud disks. Examining actual reports on cloud provider disk failure rates [6] casts doubt on these figures. However, as long as providers are bold enough to make, stand by, and honor such claims, there shouldn’t be an issue.
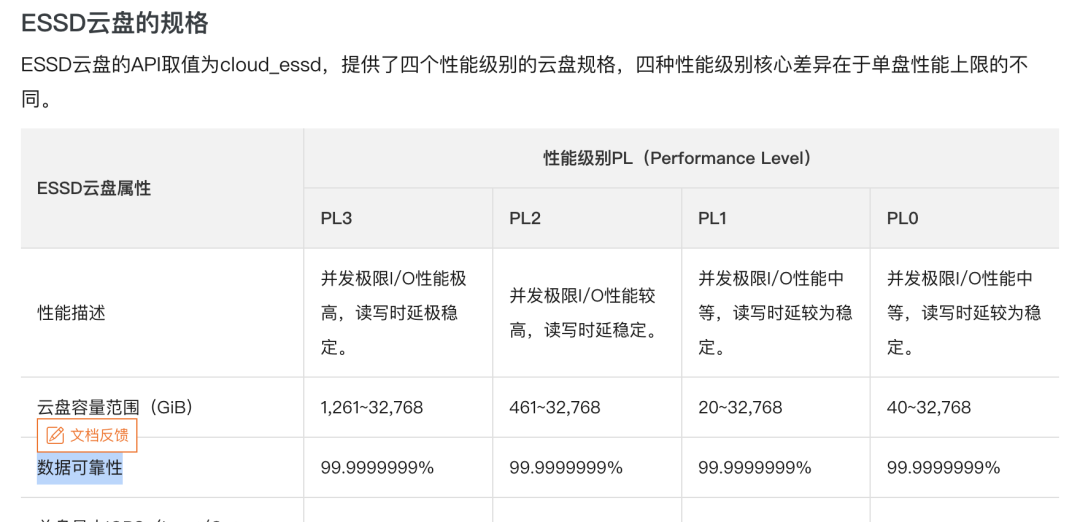
Yet, upon examining the SLAs of various cloud providers, this promise disappears! [2]
In the 2018 sensational case “The Disaster Tencent Cloud Brought to a Startup Company!” [8], the startup believed the cloud provider’s promises and stored data on server hard drives, only to encounter what was termed “silent disk errors”: “Years of accumulated data were lost, causing nearly ten million yuan in losses.” Tencent Cloud expressed apologies to the company, willing to compensate the actual expenses incurred on Tencent Cloud totaling 3,569 yuan and, with the aim of helping the business quickly recover, promised an additional compensation of 132,900 yuan
What Exactly is an SLA
Having discussed this far, proponents of cloud services might play their last card: although the post-failure “safety net” is a facade, what users need is to avoid failures as much as possible. According to the SLA promises, there is a 99.99% probability of avoiding failures, which is of the most value to users.
However, SLAs are deliberately confused with the actual reliability of the service: Users should not consider SLAs as reliable indicators of service availability — not even as accurate records of past availability levels. For providers, an SLA is not a real commitment to reliability or a track record but a marketing tool designed to convince buyers that the cloud provider can host critical business applications.
The UPTIME INSTITUTE’s annual data center failure analysis report shows that many cloud services perform below their published SLAs. The analysis of failures in 2022 found that efforts to contain the frequency of failures have failed, and the cost and consequences of failures are worsening [9].
Key Findings Include:
- High outage rates haven’t changed significantly. One in five organizations report experiencing a “serious” or “severe” outage (involving significant financial losses, reputational damage, compliance breaches and in some severe cases, loss of life) in the past three years, marking a slight upward trend in the prevalence of major outages. According to Uptime’s 2022 Data Center Resiliency Survey, 80% of data center managers and operators have experienced some type of outage in the past three years – a marginal increase over the norm, which has fluctuated between 70% and 80%.
- The proportion of outages costing over $100,000 has soared in recent years. Over 60% of failures result in at least $100,000 in total losses, up substantially from 39% in 2019. The share of outages that cost upwards of $1 million increased from 11% to 15% over that same period.
- Power-related problems continue to dog data center operators. Power-related outages account for 43% of outages that are classified as significant (causing downtime and financial loss). The single biggest cause of power incidents is uninterruptible power supply (UPS) failures.
- Networking issues are causing a large portion of IT outages. According to Uptime’s 2022 Data Center Resiliency Survey, networking-related problems have been the single biggest cause of all IT service downtime incidents – regardless of severity – over the past three years. Outages attributed to software, network and systems issues are on the rise due to complexities from the increasing use of cloud technologies, software-defined architectures and hybrid, distributed architectures.
- The overwhelming majority of human error-related outages involve ignored or inadequate procedures. Nearly 40% of organizations have suffered a major outage caused by human error over the past three years. Of these incidents, 85% stem from staff failing to follow procedures or from flaws in the processes and procedures themselves.
- External IT providers cause most major public outages. The more workloads that are outsourced to external providers, the more these operators account for high-profile, public outages. Third-party, commercial IT operators (including cloud, hosting, colocation, telecommunication providers, etc.) account for 63% of all publicly reported outages that Uptime has tracked since 2016. In 2021, commercial operators caused 70% of all outages.
- Prolonged downtime is becoming more common in publicly reported outages. The gap between the beginning of a major public outage and full recovery has stretched significantly over the last five years. Nearly 30% of these outages in 2021 lasted more than 24 hours, a disturbing increase from just 8% in 2017.
- Public outage trends suggest there will be at least 20 serious, high-profile IT outages worldwide each year. Of the 108 publicly reported outages in 2021, 27 were serious or severe. This ratio has been fairly consistent since the Uptime Intelligence team began cataloging major outages in 2016, indicating that roughly one-fourth of publicly recorded outages each year are likely to be serious or severe.
Rather than compensating users, SLAs are more of a “punishment” for cloud providers when their service quality fails to meet standards. The deterrent effect of the punishment depends on the certainty and severity of the punishment. Monthly duration/voucher compensations impose virtually no real cost on cloud providers, making the severity of the punishment nearly zero; compensation also requires users to submit evidence and get approval from the cloud provider, meaning the certainty is not high either.
Compared to experts and engineers who might lose bonuses and jobs due to failures, the punishment of SLAs for cloud providers is akin to a slap on the wrist. If the punishment is meaningless, then cloud providers have no incentive to improve service quality. When users encounter problems, they can only wait and die, and the service attitude towards small customers, in particular, is arrogantly dismissive compared to self-built/third-party service companies.
More subtly, cloud providers have absolute power over the SLA agreement: they reserve the right to unilaterally adjust and revise SLAs and inform users of their effectiveness, leaving users with only the right to choose not to use the service, without any participation or choice. As a default “take-it-or-leave-it” clause, it blocks any possibility for users to seek meaningful compensation.
Thus, SLAs are not an insurance policy against losses for users. In the worst-case scenario, it’s an unavoidable loss; at best, it provides emotional comfort. Therefore, when choosing cloud services, we need to be vigilant and fully understand the contents of their SLAs to make informed decisions.
Reference
【1】阿里云 ESSD云盘
【2】阿里云 SLA 汇总页
【3】AWS SLA 汇总页
【7】公有云是不是杀猪盘
EBS: Pig Slaughter Scam
We already answer the question: Is RDS an Idiot Tax?. But when compared to the hundredfold markup of public cloud block storage, cloud databases seem almost reasonable. This article uses real data to reveal the true business model of public cloud: “Cheap” EC2/S3 to attract customers, and fleece with “Expensive” EBS/RDS. Such practices have led public clouds to diverge from their original mission and vision.

TL; DR
EC2/S3/EBS pricing serves as the anchor for all cloud services pricing. While the pricing for EC2/S3 might still be considered reasonable, EBS pricing is outright extortionate. The best block storage services offered by public cloud providers are essentially on par with off-the-shelf PCI-E NVMe SSDs in terms of performance specifications. Yet, compared to direct hardware purchases, the cost of AWS EBS can be up to 60 times higher, and Alibaba Cloud’s ESSD can reach up to 100 times higher.
Why is there such a staggering markup for plug-and-play disk hardware? Cloud providers fail to justify the exorbitant prices. When considering the design and pricing models of other cloud storage services, there’s only one plausible explanation: The high markup on EBS is a deliberately set barrier, intended to fleece cloud database customers.
With EC2 and EBS serving as the pricing anchors for cloud databases, their markups are several and several dozen times higher, respectively, thus supporting the exorbitant profit margins of cloud databases. However, such monopolistic profits are unsustainable: the impact of IDC 2.0/telecom/national cloud on IaaS; private cloud/cloud-native/open source as alternatives to PaaS; and the tech industry’s massive layoffs, AI disruption, and the impact of China’s low labor costs on cloud services (through IT outsourcing/shared expertise). If public clouds continue to adhere to their current fleecing model, diverging from their original mission of providing fundamental compute and storage infrastructure, they will inevitably face increasingly severe competition and challenges from the aforementioned forces.
WHAT a Scam!
When you use a microwave at home to heat up a ready-to-eat braised chicken rice meal costing 10 yuan, you wouldn’t mind if a restaurant charges you 30 yuan for microwaving the same meal and serving it to you, considering the costs of rent, utilities, labor, and service. But what if the restaurant charges you 1000 yuan for the same dish, claiming: “What we offer is not just braised chicken rice, but a reliable and flexible dining service”, with the chef controlling the quality and cooking time, pay-per-portion so you get exactly as much as you want, pay-per-need so you get as much as you eat, with options to switch to hot and spicy soup or skewers if you don’t feel like chicken, claiming it’s all worth the price. Wouldn’t you feel the urge to give the owner a piece of your mind? This is exactly what’s happening with block storage!
With hardware technology evolving rapidly, PCI-E NVMe SSDs have reached a new level of performance across various metrics. A common 3.2 TB enterprise-grade MLC SSD offers incredible performance, reliability, and value for money, costing less than ¥3000, significantly outperforming older storage solutions.
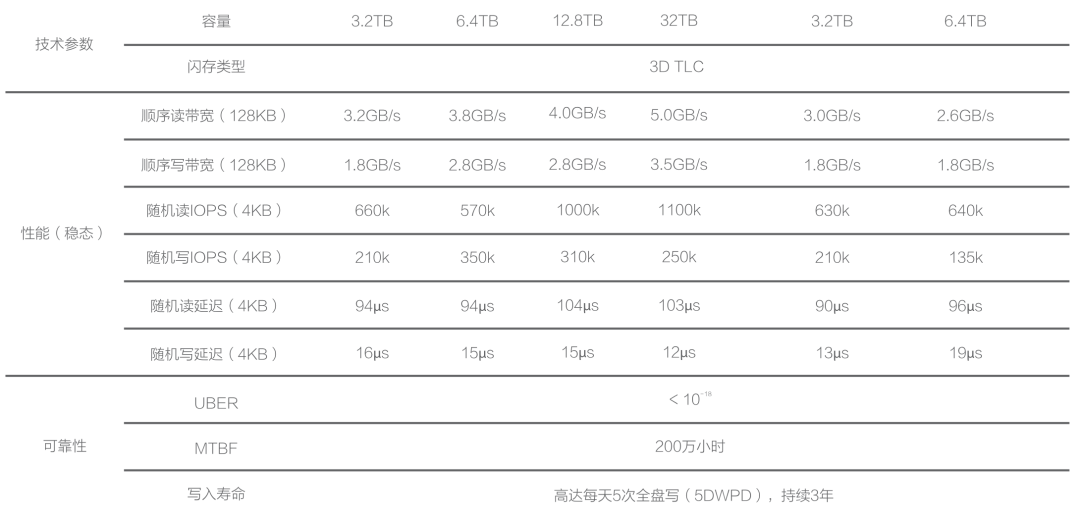
Aliyun ESSD PL3 and our own IDC’s procured PCI-E NVMe SSDs come from the same supplier. Hence, their maximum capacity and IOPS limitations are identical. AWS’s top-tier block storage solution, io2 Block Express, also shares similar specifications and metrics. Cloud providers’ highest-end storage solutions utilize these 32TB single cards, leading to a maximum capacity limit of 32TB (64TB for AWS), which suggests a high degree of hardware consistency underneath.
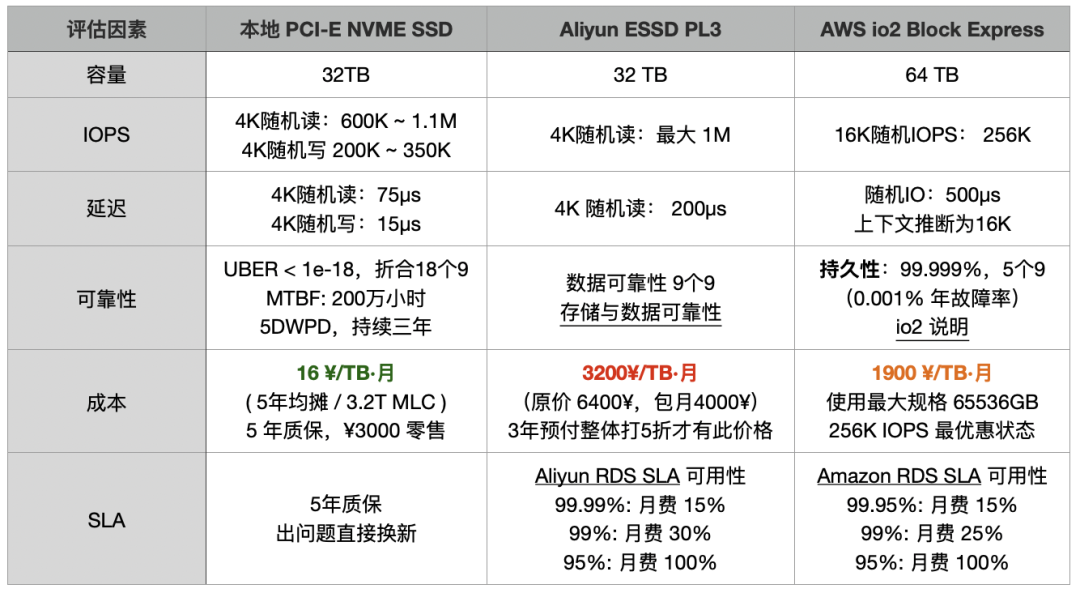
However, compared to direct hardware procurement, the cost of AWS EBS io2 is up to 120 times higher, while Aliyun’s ESSD PL3 is up to 200 times higher. Taking a 3.2TB enterprise-grade PCI-E SSD card as a reference, the ratio of on-demand rental to purchase price is 15 days on AWS and less than 5 days on Aliyun, meaning you could own the entire disk after renting it for this duration. If you opt for a three-year prepaid purchase on Aliyun, taking advantage of the maximum 50% discount, the rental fees over three years could buy over 120 disks of the same model.

Is that SSD made of gold ?
Cloud providers argue that block storage should be compared to SAN rather than local DAS, which should be compared to instance storage (Host Storage) on the cloud. However, public cloud instance storage is generally ephemeral (Ephemeral Storage), with data being wiped once the instance is paused/stopped【7,11】, making it unsuitable for serious production databases. Cloud providers themselves advise against storing critical data on it. Therefore, the only viable option for database storage is EBS block storage. Products like DBFS, which have similar performance and cost metrics to EBS, are also included in this category.
Ultimately, users care not about whether the underlying hardware is SAN, SSD, or HDD; the real priorities are tangible metrics: latency, IOPS, reliability, and cost. Comparing local options with the best cloud solutions poses no issue, especially when the top-tier cloud storage uses the same local disks.
Some “experts” claim that cloud block storage is stable and reliable, offering multi-replica redundancy and error correction. In the past, Share Everything databases required SAN storage, but many databases now operate on a Share Nothing architecture. Redundancy is managed at the database instance level, eliminating the need for triple-replica storage redundancy, especially since enterprise-grade disks already possess strong self-correction capabilities and safety redundancy (UBER < 1e-18). With redundancy already in place at the database level, multi-replica block storage becomes an unnecessary waste for databases. Even if cloud providers did use two additional replicas for redundancy, it would only reduce the markup from 200x to 66x, without fundamentally changing the situation.
“Experts” also liken purchasing “cloud services” to buying insurance: “An annual failure rate of 0.02% may seem negligible to most, but a single incident can be devastating, with the cloud provider offering a safety net.” This sounds appealing, but a closer look at cloud providers’ EBS SLAs reveals no guarantees for reliability. ESSD cloud disk promotions mention 9 nines of data reliability, but such claims are conspicuously absent from the SLAs. Cloud providers only guarantee availability, and even then, the guarantees are modest, as illustrated by the AWS EBS SLA:

In plain language: if the service is down for a day and a half in a month (95% availability), you get a 100% coupon for that month’s service fee; seven hours of downtime (99%) yields a 30% coupon; and a few minutes of downtime (99.9% for a single disk, 99.99% for a region) earns a 10% coupon. Cloud providers charge a hundredfold more, yet offer mere coupons as compensation for significant outages. Applications that can’t tolerate even a few minutes of downtime wouldn’t benefit from these meager coupons, reminiscent of the past incident, “The Disaster Tencent Cloud Brought to a Startup Company.”
SF Express offers 1% insurance for parcels, compensating for losses with real money. Annual commercial health insurance plans costing tens of thousands can cover millions in expenses when issues arise. The insurance industry should not be insulted; it operates on a principle of value for money. Thus, an SLA is not an insurance policy against losses for users. At worst, it’s a bitter pill to swallow without recourse; at best, it provides emotional comfort.
The premium charged for cloud database services might be justified by “expert manpower,” but this rationale falls flat for plug-and-play disks, with cloud providers unable to explain the exorbitant price markup. When pressed, their engineers might only say:
“We’re just following AWS; that’s how they designed it.”
WHY so Pricing?
Even engineers within public cloud services may not fully grasp the rationale behind their pricing strategies, and those who do are unlikely to share. However, this does not prevent us from deducing the reasoning behind such decisions from the design of the product itself.
Storage follows a de facto standard: POSIX file system + block storage. Whether it’s database files, images, audio, or video, they all use the same file system interface to store data on disks. But AWS’s “divine intervention” splits this into two distinct services: S3 (Simple Storage Service) and EBS (Elastic Block Store). Many “followers” have imitated AWS’s product design and pricing model, yet the logic and principles behind such actions remain elusive.
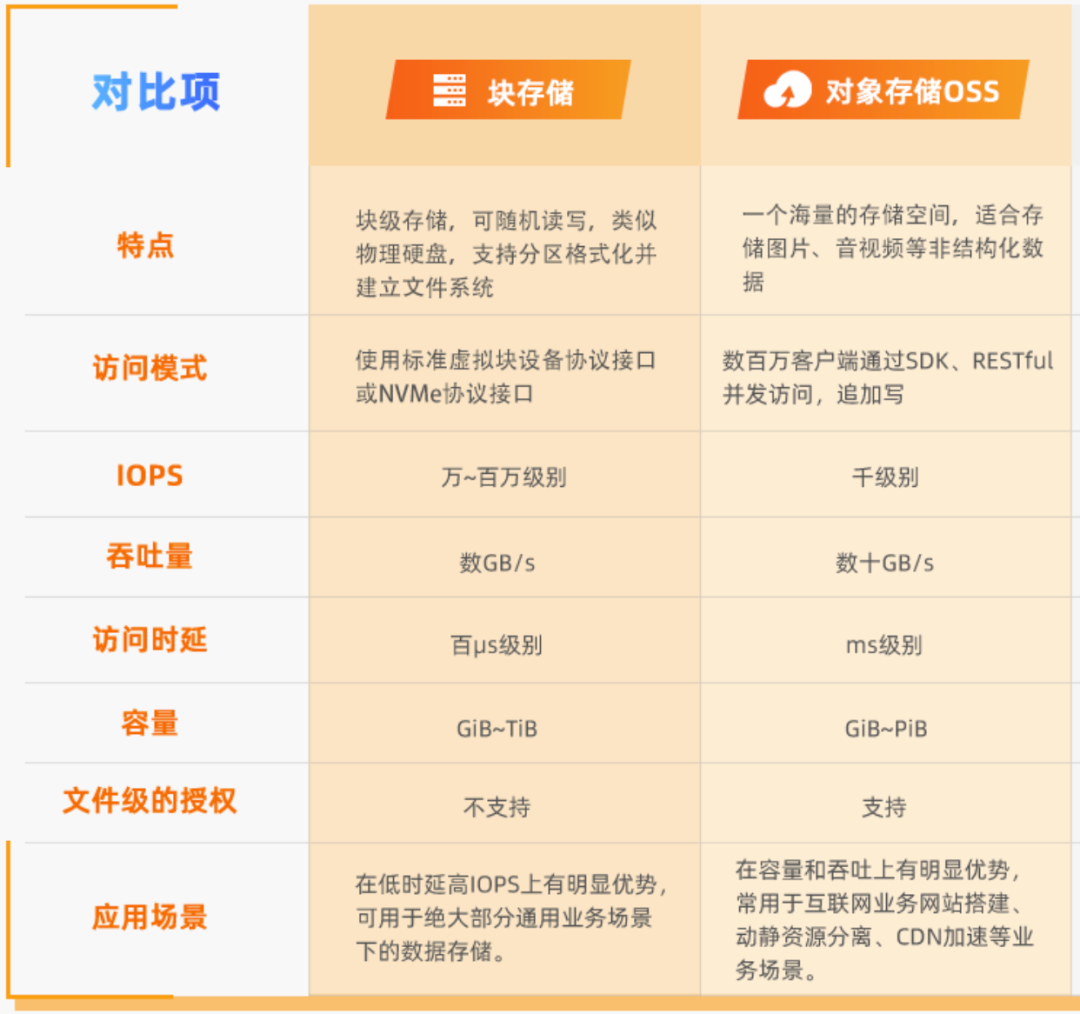
Aliyun EBS OSS Compare
S3, standing for Simple Storage Service, is a simplified alternative to file system/storage: sacrificing strong consistency, directory management, and access latency for the sake of low cost and massive scalability. It offers a simple, high-latency, high-throughput flat KV storage service, detached from standard storage services. This aspect, being cost-effective, serves as a major allure for users to migrate to the cloud, thus becoming possibly the only de facto cloud computing standard across all public cloud providers.
Databases, on the other hand, require low latency, strong consistency, high quality, high performance, and random read/write block storage, which is encapsulated in the EBS service: Elastic Block Store. This segment becomes the forbidden fruit for cloud providers: reluctant to let users dabble. Because EBS serves as the pricing anchor for RDS — the barrier and moat for cloud databases.
For IaaS providers, who make their living by selling resources, there’s not much room for price inflation, as costs can be precisely calculated against the BOM. However, for PaaS services like cloud databases, which include “services,” labor/development costs are significantly marked up, allowing for astronomical pricing and high profits. Despite storage, computing, and networking making up half of the revenue for domestic public cloud IaaS, their gross margin stands only at 15% to 20%. In contrast, public cloud PaaS, represented by cloud databases, can achieve gross margins of 50% or higher, vastly outperforming the IaaS model.
If users opt to use IaaS resources (EC2/EBS) to build their own databases, it represents a significant loss of profit for cloud providers. Thus, cloud providers go to great lengths to prevent this scenario. But how is such a product designed to meet this need?
Firstly, instance storage, which is best suited for self-hosted databases, must come with various restrictions: instances that are hibernated/stopped are reclaimed and wiped, preventing serious production database services from running on EC2’s built-in disks. Although EBS’s performance and reliability might slightly lag behind local NVMe SSD storage, it’s still viable for database operations, hence the restrictions: but not without giving users an option, hence the exorbitant pricing! As compensation, the secondary, cheaper, and massive storage option, S3, can be priced more affordably to lure customers.
Of course, to make customers bite, some cloud computing KOLs promote the accompanying “public cloud-native” philosophy: “EC2 is not suitable for stateful applications. Please store state in S3 or RDS and other managed services, as these are the ‘best practices’ for using our cloud.”

These four points are well summarized, but what public clouds will not disclose is the cost of these “best practices.” To put these four points in layman’s terms, they form a carefully designed trap for customers:
Dump ordinary files in S3! (With such cost-effective S3, who needs EBS?)
Don’t build your own database! (Forget about tinkering with open-source alternatives using instance storage)
Please deeply use the vendor’s proprietary identity system (vendor lock-in)
Faithfully contribute to the cloud database! (Once users are locked in, the time to “slaughter” arrives)
HOW to Do that
The business model of public clouds can be summarized as: Attract customers with cheap EC2/S3, make a killing with EBS/RDS.
To slaughter the pig, you first need to raise it. No pains, no gains. Thus, for new users, startups, and small-to-medium enterprises, public clouds spare no effort in offering sweeteners, even at a loss, to drum up business. New users enjoy a significant discount on their first order, startups receive free or half-price credits, and the pricing strategy is subtly crafted.
Taking AWS RDS pricing as an example, the unit price for mini models with 1 to 2 cores is only a few dollars per core per month, which translates to three to four hundred yuan per year (excluding storage): If you need a low-usage database for minor storage, this might be the most straightforward and affordable choice.
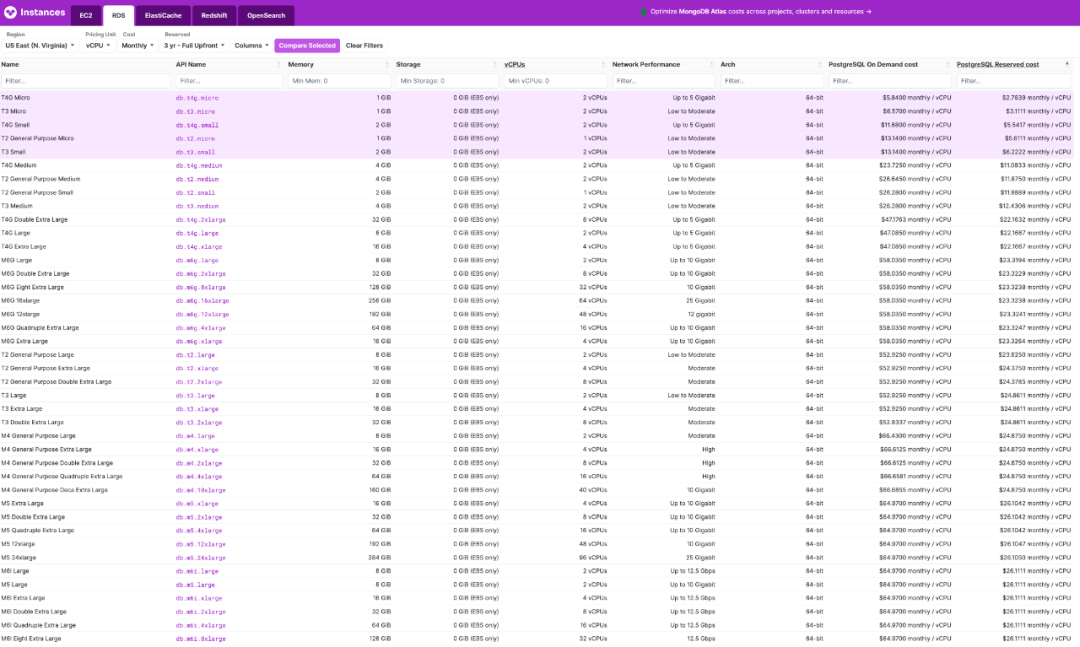
However, as soon as you slightly increase the configuration, even by just a little, the price per core per month jumps by orders of magnitude, reaching twenty to a hundred dollars, with the potential to skyrocket by dozens of times — and that’s before the doubling effect of the astonishing EBS prices. Users only realize what has happened when they are faced with a suddenly astronomical bill.
For instance, using RDS for PostgreSQL on AWS, the price for a 64C / 256GB db.m5.16xlarge RDS for one month is $25,817, which is equivalent to about 180,000 yuan per month. The monthly rent is enough for you to buy two servers with even better performance and set them up on your own. The rent-to-buy ratio doesn’t even last a month; renting for just over ten days is enough to buy the whole server for yourself.
| Payment Model | Price | Cost Per Year (¥10k) |
|---|---|---|
| Self-hosted IDC (Single Physical Server) | ¥75k / 5 years | 1.5 |
| Self-hosted IDC (2-3 Server HA Cluster) | ¥150k / 5 years | 3.0 ~ 4.5 |
| Alibaba Cloud RDS (On-demand) | ¥87.36/hour | 76.5 |
| Alibaba Cloud RDS (Monthly) | ¥42k / month | 50 |
| Alibaba Cloud RDS (Yearly, 15% off) | ¥425,095 / year | 42.5 |
| Alibaba Cloud RDS (3-year, 50% off) | ¥750,168 / 3 years | 25 |
| AWS (On-demand) | $25,817 / month | 217 |
| AWS (1-year, no upfront) | $22,827 / month | 191.7 |
| AWS (3-year, full upfront) | $120k + $17.5k/month | 175 |
| AWS China/Ningxia (On-demand) | ¥197,489 / month | 237 |
| AWS China/Ningxia (1-year, no upfront) | ¥143,176 / month | 171 |
| AWS China/Ningxia (3-year, full upfront) | ¥647k + ¥116k/month | 160.6 |
Comparing the costs of self-hosting versus using a cloud database:
| Method | Cost Per Year (¥10k) |
|---|---|
| Self-hosted Servers 64C / 384G / 3.2TB NVME SSD 660K IOPS (2-3 servers) | 3.0 ~ 4.5 |
| Alibaba Cloud RDS PG High-Availability pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG High-Availability db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
RDS pricing compared to self-hosting, see “Is Cloud Database an idiot Tax?”
Any rational business user can see the logic here: **If the purchase of such a service is not for short-term, temporary needs, then it is definitely considered a major financial misstep.
This is not just the case with Relational Database Services / RDS, but with all sorts of cloud databases. MongoDB, ClickHouse, Cassandra, if it uses EC2 / EBS, they are all doing the same. Take the popular NoSQL document database MongoDB as an example:
This kind of pricing could only come from a product manager without a decade-long cerebral thrombosis
Five years is the typical depreciation period for servers, and with the maximum discount, a 12-node (64C 512G) configuration is priced at twenty-three million. The minor part of this quote alone could easily cover the five-year hardware maintenance, plus you could afford a team of MongoDB experts to customize and set up as you wish.
Fine dining restaurants charge a 15% service fee on dishes, and users can understand and support this reasonable profit margin. If cloud databases charge a few tens of percent on top of hardware resources for service fees and elasticity premiums (let’s not even start on software costs for cloud services that piggyback on open-source), it can be justified as pricing for productive elements, with the problems solved and services provided being worth the money.
However, charging several hundred or even thousands of percent as a premium falls into the category of destructive element distribution: cloud providers bank on the fact that once users are onboard, they have no alternatives, and migration would incur significant costs, so they can confidently proceed with the slaughter! In this sense, the money users pay is not for the service, but rather a compulsory levy of a “no-expert tax” and “protection money”.
The Forgotten Vision
Facing accusations of “slaughtering the pig,” cloud vendors often defend themselves by saying: “Oh, what you’re seeing is the list price. Sure, it’s said to be a minimum of 50% off, but for major customers, there are no limits to the discounts.” As a rule of thumb: the cost of self-hosting fluctuates around 5% to 10% of the current cloud service list prices. If such discounts can be maintained long-term, cloud services become more competitive than self-hosting.
Professional and knowledgeable large customers, especially those capable of migrating at any time, can indeed negotiate steep discounts of up to 80% with public clouds, while smaller customers naturally lack bargaining power and are unlikely to secure such deals.
However, cloud computing should not turn into ‘calculating clouds’: if cloud providers can only offer massive discounts to large enterprises while “shearing the sheep” and “slaughtering the pig” when dealing with small and medium-sized customers and developers, they are essentially robbing the poor to subsidize the rich. This practice completely contradicts the original intent and vision of cloud computing and is unsustainable in the long run.
When cloud computing first emerged, the focus was on the cloud hardware / IaaS layer: computing power, storage, bandwidth. Cloud hardware represents the founding story of cloud vendors: to make computing and storage resources as accessible as utilities, with themselves playing the role of infrastructure providers. This is a compelling vision: public cloud vendors can reduce hardware costs and spread labor costs through economies of scale; ideally, while keeping a profit for themselves, they can offer storage and computing power that is more cost-effective and flexible than IDC prices.
On the other hand, cloud software (PaaS / SaaS) follows a fundamentally different business logic: cloud hardware relies on economies of scale to optimize overall efficiency and earn money through resource pooling and overselling, which represents a progress in efficiency. Cloud software, however, relies on sharing expertise and charging service fees for outsourced operations and maintenance. Many services on the public cloud are essentially wrappers around free open-source software, relying on monopolizing expertise and exploiting information asymmetry to charge exorbitant insurance fees, which constitutes a transfer of value.
Unfortunately, for the sake of obfuscation, both cloud software and cloud hardware are branded under the “cloud” title. Thus, the narrative of cloud computing mixes breaking resource monopolies with establishing expertise monopolies: it combines the idealistic glow of democratizing computing power across millions of households with the greed of monopolizing and unethically profiting from it.
Public cloud providers that abandon platform neutrality and their original intent of being infrastructure providers, indulging in PaaS / SaaS / and even application layer profiteering, will sink in a bottomless competition.
Where to Go
Monopolistic profits vanish as competition emerges, plunging public cloud providers into a grueling battle.
At the infrastructure level, telecom operators, state-owned clouds, and IDC 1.5/2.0 have entered the fray, offering highly competitive IaaS services. These services include turnkey network and electricity hosting and maintenance, with high-end servers available for either purchase and hosting or direct rental at actual prices, showing no fear in terms of flexibility.
IDC 2.0’s new server rental model: Actual price rental, ownership transfers to the user after a full term
On the software front, what once were the technical barriers of public clouds, various management software / PaaS solutions, have seen excellent open-source alternatives emerge. OpenStack / Kubernetes have replaced EC2, MinIO / Ceph have taken the place of S3, and on RDS, open-source alternatives like Pigsty and various K8S Operators have appeared.
The whole “cloud-native” movement, in essence, is the open-source ecosystem’s response to the challenge of public cloud “freeloading”: users and developers have created a complete set of local-priority public cloud open-source alternatives to avoid being exploited by public cloud providers.
The term “CloudNative” is aptly named, reflecting different perspectives: public clouds see it as being “born on the public cloud,” while private clouds think of it as “running cloud-like services locally.” Ironically, the biggest proponents of Kubernetes are the public clouds themselves, akin to a salesman crafting his own noose.
In the context of economic downturn, cost reduction and efficiency gains have become the main theme. Massive layoffs in the tech sector, coupled with the future large-scale impact of AI on intellectual industries, will release a large amount of related talent. Additionally, the low-wage advantage in our era will significantly alleviate the scarcity and high cost of building one’s own talent pool. Labor costs, in comparison to cloud service costs, offer much more advantage.
Considering these trends, the combination of IDC2.0 and open-source self-building is becoming increasingly competitive: for organizations with a bit of scale and talent reserves, bypassing public clouds as middlemen and directly collaborating with IDCs is clearly a more economical choice.
Staying true to the original mission is essential. Public clouds do an admirable job at the cloud hardware / IaaS level, except for being outrageously expensive, there aren’t many issues, and the offerings are indeed solid. If they could return to their original vision and truly excel as providers of basic infrastructure, akin to utilities, selling resources might not offer high margins, but it would allow them to earn money standing up. Continuing down the path of exploitation, however, will ultimately lead customers to vote with their feet.
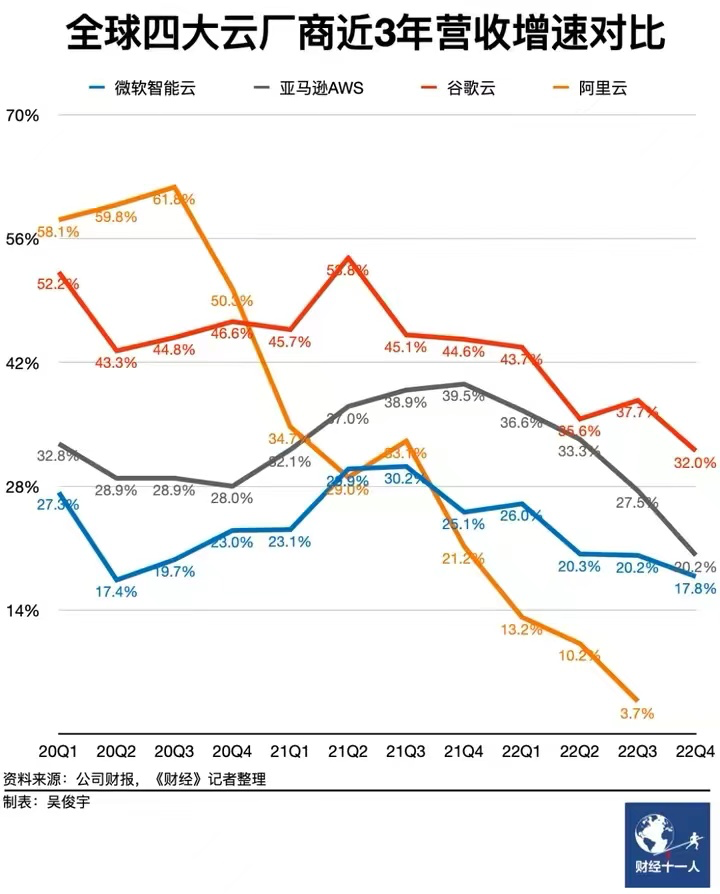
References
【2】云数据库是不是智商税
【3】范式转移:从云到本地优先
【7】AWS实例存储
【9】AWS EBS SLA
【12】阿里云:云盘概述
【13】图说块存储与云盘
【15】云计算为啥还没挖沙子赚钱?
RDS: The Idiot Tax
As the season of layoffs hits big tech companies, cost-cutting and efficiency are top of mind. Public cloud databases, often referred to as the “slaughterhouse knives” of the cloud, are under increasing scrutiny. The question now is: Can their dominance continue?
Recently, DHH (David Heinemeier Hansson), co-founder of Basecamp and HEY, published a thought-provoking piece that has sparked a lot of debate. His core message is succinct:
“We spend $500,000 a year on cloud databases (RDS/ES). Do you know how many powerful servers that kind of money could buy?
We’re off the cloud. Goodbye!”
So, How Many Powerful Servers Could $500,000 Buy?

Absurd Pricing
Sharpening the knives for the sheep and pigs
Let’s rephrase the question: how much do servers and RDS (Relational Database Service) cost?
Taking the physical server model we heavily use as an example: Dell R730, 64 cores, 384GB of memory, equipped with a 3.2 TB MLC NVME SSD. A server like this, running a standard production-level PostgreSQL, can handle up to hundreds of thousands of TPS (Transactions Per Second), and read-only queries can reach four to five hundred thousand. How much does it cost? Including electricity, internet, IDC (Internet Data Center) hosting, and maintenance fees, and amortizing the cost over a 5-year depreciation period, the total lifecycle cost is around seventy-five thousand, or fifteen thousand per year. Of course, for production use, high availability is a must, so a typical database cluster would need two to three physical servers, amounting to an annual cost of thirty to forty-five thousand dollars.
This calculation does not include the cost of DBA (Database Administrator) salaries: managing tens of thousands of cores with just two or three people is not that expensive.
If you directly purchase a cloud database of this specification, what would the cost be? Let’s look at the pricing from Alibaba Cloud in China. Since the basic version is practically unusable for production (for reference, see: “Cloud Database: From Deletion to Desertion”), we’ll choose the high-availability version, which usually involves two to three instances. Opting for a yearly or monthly subscription, for an exclusive use of a 64-core, 256GB instance with PostgreSQL 15 on x86 in East China 1 availability zone, and adding a 3.2TB ESSD PL3 cloud disk, the annual cost ranges from 250,000 (for a 3-year contract) to 750,000 (on-demand), with storage costs accounting for about a third.
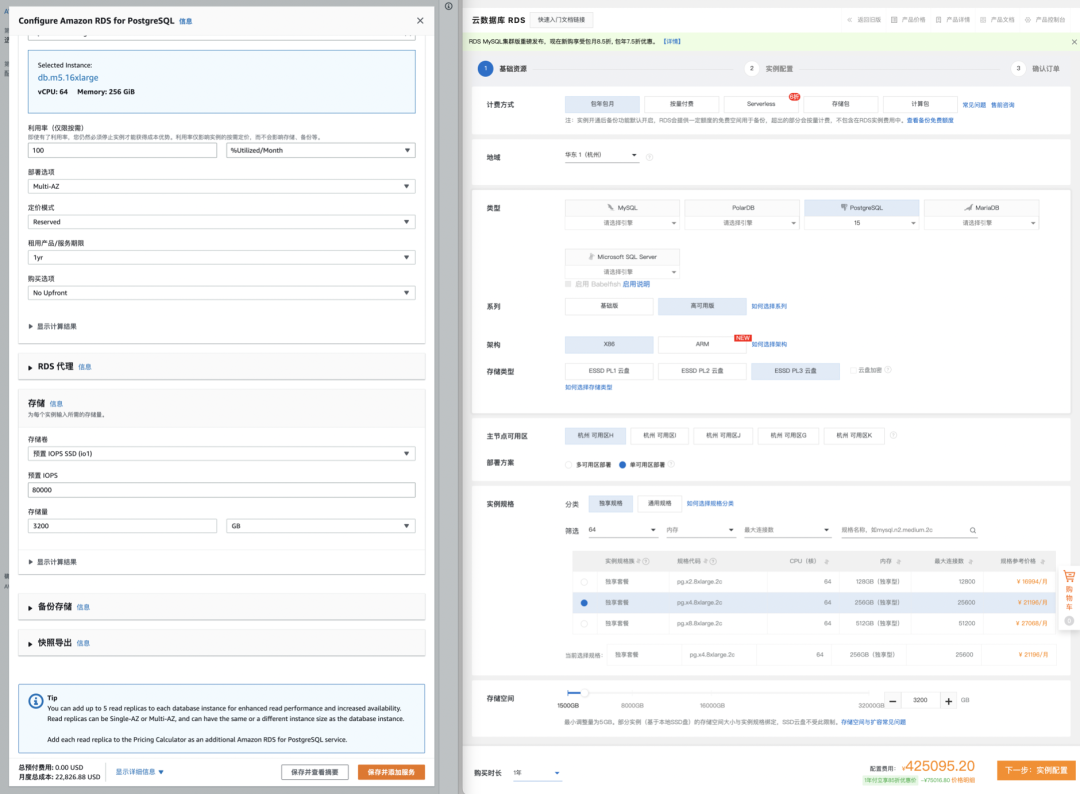
Let’s also consider AWS, the leading public cloud provider. The closest equivalent on AWS is the db.m5.16xlarge, also with 64 cores and 256GB across multiple availability zones. Similarly, we add a 3.2TB io1 SSD disk with up to 80,000 IOPS, and review the global and China-specific pricing from AWS. The overall cost ranges from 1.6 million to 2.17 million yuan per year, with storage costs accounting for about half. The table below summarizes the costs:
| Payment Model | Price | Cost Per Year (¥10k) |
|---|---|---|
| Self-hosted IDC (Single Physical Server) | ¥75k / 5 years | 1.5 |
| Self-hosted IDC (2-3 Server HA Cluster) | ¥150k / 5 years | 3.0 ~ 4.5 |
| AWS (On-demand) | $25,817 / month | 217 |
| AWS (1-year, no upfront) | $22,827 / month | 191.7 |
| AWS (3-year, full upfront) | $120k + $17.5k/month | 175 |
| AWS China/Ningxia (On-demand) | ¥197,489 / month | 237 |
| AWS China/Ningxia (1-year, no upfront) | ¥143,176 / month | 171 |
| AWS China/Ningxia (3-year, full upfront) | ¥647k + ¥116k/month | 160.6 |
Comparing the costs of self-hosting versus using a cloud database:
| Method | Cost Per Year (¥10k) |
|---|---|
| Self-hosted Servers 64C / 384G / 3.2TB NVME SSD 660K IOPS (2-3 servers) | 3.0 ~ 4.5 |
| Alibaba Cloud RDS PG High-Availability pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG High-Availability db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
So, the question arises, if the cost of using a cloud database for one year is enough to buy several or even more than a dozen better-performing servers, what then is the real benefit of using a cloud database? Of course, large public cloud customers can usually receive business discounts, but even with discounts, the magnitude of the cost difference is hard to ignore.
Is using a cloud database essentially paying a “tax” for lack of better judgment?
Comfort Zone
No Silver Bullet
Databases are the heart of data-intensive applications, and since applications follow the lead of databases, choosing the right database requires great care. Evaluating a database involves many dimensions: reliability, security, simplicity, scalability, extensibility, observability, maintainability, cost-effectiveness, and more. What clients truly care about are these attributes, not the fluffy tech hype: decoupling of compute and storage, Serverless, HTAP, cloud-native, hyper-converged… These must be translated into the language of engineering: what is sacrificed for what is gained to be meaningful.
Public cloud proponents like to gild it: cost-saving, flexible elasticity, reliable security, a panacea for enterprise digital transformation, a revolution from horse-drawn carriage to automobile, good, fast, and cheap, and so on. Unfortunately, few of these claims are realistic. Cutting through the fluff, the only real advantage of cloud databases over professional database services is elasticity, specifically in two aspects: low startup costs and strong scalability.
Low startup costs mean that users don’t need to build data centers, hire and train personnel, or purchase servers to get started; strong scalability refers to the ease of upgrading or downgrading configurations and scaling capacity. Thus, the core scenarios where public cloud truly fits are these two:
- Initial stages, simple applications with minimal traffic
- Workloads with no predictable pattern, experiencing drastic fluctuations
The former mainly includes simple websites, personal blogs, small apps and tools, demos/PoC, and the latter includes low-frequency data analysis/model training, sudden spike sales or ticket grabs, celebrity concurrent affairs, and other special scenarios.
The business model of the public cloud is essentially renting: renting servers, bandwidth, storage, experts. It’s fundamentally no different from renting houses, cars, or power banks. Of course, renting servers and outsourcing operations doesn’t sound very appealing, hence the term “cloud” sounds more like a cyber landlord. The characteristic of the renting model is its elasticity.
The renting model has its benefits, for example, shared power banks can meet the temporary, small-scale charging needs when out and about. However, for many people who travel daily between home and work, using shared power banks to charge phones and computers every day is undoubtedly absurd, especially when renting a power bank for an hour costs about the same as buying one outright after just a few hours. Renting a car can perfectly meet temporary, emergency, or one-off transportation needs: traveling or hauling goods on short notice. But if your travel needs are frequent and local, purchasing an autonomous car might be the most convenient and cost-effective choice.
The key issue is the rent-to-own ratio, with houses taking decades, cars a few years, but public cloud servers usually only a few months. If your business can sustain for more than a few months, why rent instead of buying outright?
Thus, the money cloud vendors make comes either from VC-funded tech startups seeking explosive growth, from entities in gray areas where the rent-seeking space exceeds the cloud premium, from the foolishly wealthy, or from a mishmash of webmasters, students, VPN individual users. Smart, high-net-worth enterprise customers, who could enjoy a comfortable, affordable big house, why would they choose to squeeze into rental cube apartments?
If your business fits within the suitable spectrum for the public cloud, that’s fantastic; but paying several times or even more than a tenfold premium for unnecessary flexibility and elasticity is purely a tax on lack of intelligence.
The Cost Assassin
Profit margins lie in information asymmetry, but you can’t fool everyone forever.
The elasticity of public clouds is designed for their business model: low startup costs, high maintenance costs. Low startup costs lure users to the cloud, and the excellent elasticity adapts to business growth at any time. However, once the business stabilizes, vendor lock-in occurs, making it difficult to switch providers, and the high maintenance costs become unbearable for users. This model is colloquially known as the pig slaughtering scam.

In the first stop of my career, I had such a pig slaughtering experience that remains vivid in my memory. As one of the first internal BUs forced onto A Cloud, A Cloud directly sent engineers to handhold us through the cloud migration process. We replaced our self-built big data/database suite with ODPS. The service was indeed decent, but the annual cost of storage and computing soared from tens of millions to nearly a hundred million, almost transferring all profits to A Cloud, making it the ultimate cost assassin.

At my next stop, the situation was entirely different. We managed a PostgreSQL and Redis database cluster with 25,000 cores and 4.5 million QPS. For databases of this size, if charged by AWS RCU/WCU, the cost would be billions annually; even with a long-term, yearly subscription and a substantial business discount, it would still cost at least fifty to sixty million. Yet, we had only two or three DBAs and a few hundred servers, with a total annual cost of manpower and assets of less than ten million.
Here, we can calculate the unit cost in a simple way: the comprehensive cost of using one core (including memory/disk) for a month, termed as core·month. We have calculated the costs of self-built server types and compared them with the quotes from cloud providers, with the following rough results:
| 硬件算力 | 单价 |
|---|---|
| IDC自建机房(独占物理机 A1: 64C384G) | 19 |
| IDC自建机房(独占物理机 B1: 40C64G) | 26 |
| IDC自建机房(独占物理机 C2: 8C16G) | 38 |
| IDC自建机房(容器,超卖200%) | 17 |
| IDC自建机房(容器,超卖500%) | 7 |
| UCloud 弹性虚拟机(8C16G,有超卖) | 25 |
| 阿里云 弹性服务器 2x内存(独占无超卖) | 107 |
| 阿里云 弹性服务器 4x内存(独占无超卖) | 138 |
| 阿里云 弹性服务器 8x内存(独占无超卖) | 180 |
| AWS C5D.METAL 96C 200G (按月无预付) | 100 |
| AWS C5D.METAL 96C 200G(预付3年) | 80 |
| 数据库 | |
| AWS RDS PostgreSQL db.T2 (4x) | 440 |
| AWS RDS PostgreSQL db.M5 (4x) | 611 |
| AWS RDS PostgreSQL db.R6G (8x) | 786 |
| AWS RDS PostgreSQL db.M5 24xlarge | 1328 |
| 阿里云 RDS PG 2x内存(独占) | 260 |
| 阿里云 RDS PG 4x内存(独占) | 320 |
| 阿里云 RDS PG 8x内存(独占) | 410 |
| ORACLE数据库授权 | 10000 |
So, the question arises, why can server hardware priced at twenty units be sold for hundreds, and why does installing cloud database software on it multiply the price? Is it because the operations are made of gold, or is the server made of gold?
A common response is: Databases are the crown jewels of foundational software, embodying countless intangible intellectual properties BlahBlah. Thus, it’s reasonable for the software to be priced much higher than the hardware. This reasoning might be acceptable for top-tier commercial databases like Oracle, or console games from Sony and Nintendo.
But for cloud databases (RDS for PostgreSQL/MySQL/…) on public clouds, which are essentially rebranded and modified open-source database kernels with added control software and shared DBA services, this markup is absurd: the database kernel is free. Is your control software made of gold, or are your DBAs made of gold?
The secret of public clouds lies here: they acquire customers with ‘cheap’ S3 and EC2, then “slaughter the pig” with RDS.
Although nearly half of the revenue of domestic public cloud IaaS (storage, computing, network) comes with only a 15% to 20% gross margin, the revenue from public cloud PaaS may be lower, but its gross margin can reach 50%, utterly outperforming the resource-selling IaaS. And the most representative of PaaS services is the cloud database.
Normally, if you’re not using public cloud as just an IDC 2.0 or CDN provider, the most expensive service would be the database. Are the storage, computing, and networking resources on the public cloud expensive? Strictly speaking, not outrageously so. The cost of hosting and maintaining a physical machine in an IDC is about twenty to thirty units per core·month, while the price of using one CPU core for a month on the public cloud ranges from seventy to two hundred units, considering various discounts and activities, as well as the premium for elasticity, it’s barely within an acceptable range.
However, cloud databases are outrageously expensive, with the price for the same computing power per month being several times to over ten times higher than the corresponding hardware. For the cheaper Alibaba Cloud, the price per core·month ranges from two hundred to four hundred units, and for the more expensive AWS, it can reach seven to eight hundred or even more than a thousand.
If you’re only using one or two cores of RDS, then it might not be worth the hassle to switch, just consider it a tax. But if your business scales up and you’re still not moving away from the cloud, then you’re really paying a tax on intelligence.
Good Enough?
Make no mistake, RDS are just mediocre solutions.
When it comes to the cost of cloud databases/cloud servers, if you manage to bring this up with a sales representative, their pitch usually shifts to: Yes, we are expensive, but we are good!
But, is RDS really that good?
It could be argued that for toy applications, small websites, personal hosting, and self-built databases by those without technical knowledge, RDS might be good enough. However, from the perspective of high-value clients and database experts, RDS is seen as nothing more than a barely passable, communal pot meal.
At its core, the public cloud stems from the operational capabilities that overflowed from major tech companies. People within these companies are well aware of their own technological capabilities, so there’s no need for any undue idolization. (Google might be an exception).
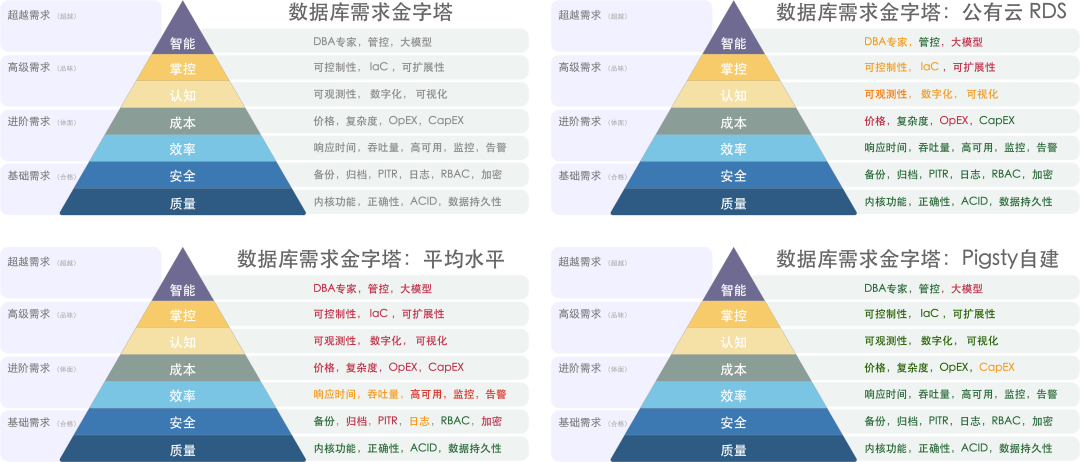
Take performance as an example, where the core metric is latency/response time, especially tail latency, which directly impacts user experience: nobody wants to wait several seconds for a screen swipe to register. Here, disks play a crucial role.
In our production environment, we use local NVME SSDs, with a typical 4K write latency of 15µs and read latency of 94µs. Consequently, the response time for a simple query on PostgreSQL is usually between 100 ~ 300µs, and the response time on the application side typically ranges from 200 ~ 600µs; for simple queries, our SLO is to achieve within 1ms for hits, and within 10ms for misses, with anything over 10ms considered a slow query that needs optimization.
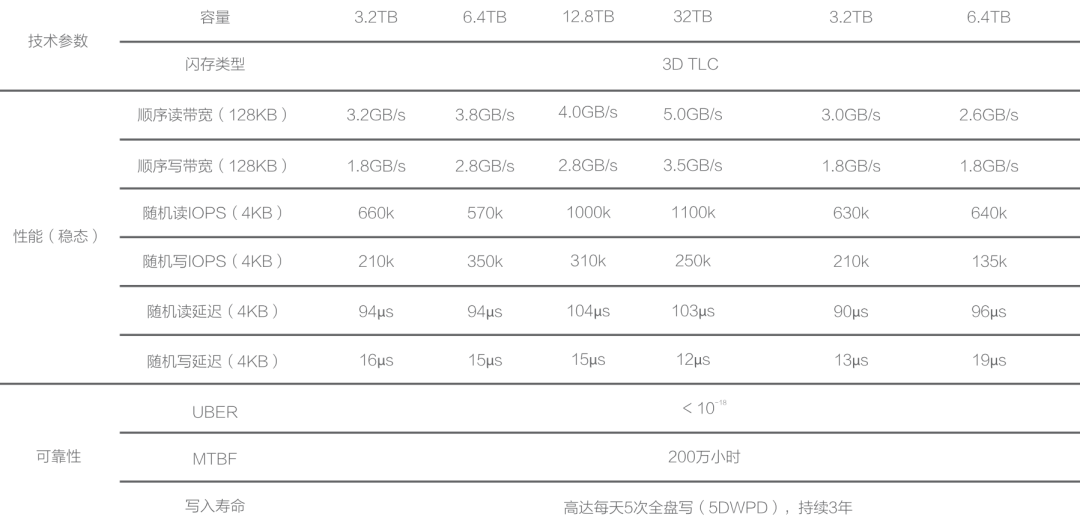
AWS’s EBS service, when tested with fio, shows disastrously poor performance【6】, with default gp3 read/write latencies at 40ms and io1 at 10ms, a difference of nearly three orders of magnitude. Moreover, the maximum IOPS is only eighty thousand. RDS uses EBS for storage, and if even a single disk access takes 10ms, it’s just not workable. io2 does use the same kind of NVMe SSDs as we do, but remote block storage has double the latency compared to local disks.

Indeed, sometimes cloud providers do offer sufficiently good local NVMe SSDs, but they cunningly impose various restrictions to prevent users from using EC2 to build their own databases. AWS restricts this by offering NVMe SSD Ephemeral Storage, which is wiped clean upon EC2 restart, rendering it unusable. Alibaba Cloud, on the other hand, sells at exorbitant prices, with Alibaba Cloud’s ESSD PL3 being 200 times more expensive compared to direct hardware purchases. For a reference, a 3.2TB enterprise-grade PCI-E SSD card, AWS’s rental ratio is one month, while Alibaba Cloud’s is nine days, meaning the cost of renting for this period is equivalent to purchasing the entire disk. If purchasing on Alibaba Cloud with a three-year maximum discount at 50% off, the cost of three years of rent could buy 123 of the same disks, nearly 400TB in total ownership.
Observability is another example where no RDS monitoring can be considered “good”. Just looking at the number of monitoring metrics, while knowing whether a service is dead or alive may require only a few metrics, fault root cause analysis benefits from as many monitoring metrics as possible to build a good context. Most RDS services only provide basic monitoring metrics and rudimentary dashboards. For example, Alibaba Cloud RDS PG【7】’s so-called “enhanced monitoring” includes only a few pitiful metrics. AWS and PG database-related metrics are also less than 100, while our own monitoring system includes over 800 types of host metrics, 610 types for PGSQL database, 257 types for REDIS, totaling around three thousand metrics, dwarfing those of RDS.

Public Demo: https://demo.pigsty.io
As for reliability, I used to have basic trust in the reliability of RDS, until the scandal in A Cloud’s Hong Kong data center a month ago. The rented data center had a fire suppression incident with water spraying, OSS malfunction, and numerous RDS services became unusable and could not be switched over; then, A Cloud’s entire Region’s control services crashed due to a single AZ failure, making a mockery of the idea of remote disaster recovery for cloud databases.
Of course, this is not to say that self-hosting would not have these issues, but a somewhat reliable IDC hosting would not commit such egregious errors. Security needs no further discussion; recent high-profile incidents, such as the infamous SHGA; hardcoding AK/SK in a bunch of sample codes, is cloud RDS more secure? Don’t make me laugh. At least traditional architecture has a VPN bastion as a layer of protection, while databases exposed on the public network with weak passwords are all too common, undeniably increasing the attack surface.
Another widespread criticism of cloud databases is their extensibility. RDS does not grant users dbsu permissions, meaning users cannot install extension plugins in the database. PostgreSQL’s charm lies in its extensions; without extensions, PostgreSQL is like cola without ice, yogurt without sugar. A more severe issue is that in some failure scenarios, users even lose the ability to help themselves, as seen in the real case of “Cloud Database: From Deleting Databases to Running Away”: WAL archiving and PITR, basic functionalities, are charged features in RDS. Regarding maintainability, some say cloud databases are convenient as they can be created and destroyed with just a few clicks, but those people have likely never experienced the ordeal of receiving SMS verification codes for restarting each database. With Database as Code style management tools, true engineers would never resort to such “ClickOps”.
However, everything has its rationale for existence, and cloud databases are not entirely without merit. In terms of scalability, cloud databases have indeed reached new heights, such as various Serverless offerings, but this is more about saving money and overselling for cloud providers, offering little real benefit to users.
The Obsolescence of DBAs?
Dominated by cloud vendors, hard to hire, and now obsolete?
Another pitch from cloud databases is that with RDS, you don’t need a DBA anymore!
For instance, this infamous article, “Why Are You Still Hiring DBAs?”, argues: We have autonomous database services! RDS and DAS can solve these database-related issues for you, making DBAs redundant, haha. I believe anyone who seriously reviews these so-called “autonomous services” or “AI4DB” official documents will not buy into this nonsense: Can a module, hardly a decent monitoring system, truly autonomize database management? This is simply a pipe dream.
DBA, Database Administrator, historically also known as database coordinators or database programmers, is a role that spans across development and operations teams, covering responsibilities related to DA, SA, Dev, Ops, and SRE. They manage everything related to data and databases: setting management policies and operational standards, planning hardware and software architecture, coordinating database management, verifying table schema designs, optimizing SQL queries, analyzing execution plans, and even handling emergencies and data recovery.
The first value of a DBA is in security fallback: They are the guardians of a company’s core data assets and can potentially inflict fatal damage on the company. There’s a joke at Ant Financial that besides regulatory bodies, DBAs could bring Alipay down. Executives often fail to recognize the importance of DBAs until a database incident occurs, and a group of CXOs anxiously watches the DBA firefighting and fixing… Compared to the cost of avoiding a database failure, such as a nationwide flight halt, Youtube downtime, or a factory’s day-long shutdown, hiring a DBA seems trivial.
The second value of a DBA is in model design and optimization. Many companies do not care if their queries perform poorly, thinking “hardware is cheap,” and solve problems by throwing money at hardware. However, improperly tuned queries/SQL or poorly designed data models and table structures can degrade performance by orders of magnitude. At some scale, the cost of stacking hardware becomes prohibitively expensive compared to hiring a competent DBA. Frankly, I believe the largest IT expenditure in most companies is due to developers not using databases correctly.
A DBA’s basic skill is managing DBs, but their essence lies in Administration: managing the entropy created by developers requires more than just technical skills. “Autonomous databases” might help analyze loads and create indexes, but they cannot understand business needs or push for table structure optimization, and this is something unlikely to be replaced by cloud services in the next two to three decades.
Whether it’s public cloud vendors, cloud-native/private clouds represented by Kubernetes, or local open-source RDS alternatives like Pigsty, their core value is to use software as much as possible, not manpower, to deal with system complexity. So, will cloud software revolutionize operations and DBA roles?
Cloud is not a maintenance-free outsourcing magic. According to the law of complexity conservation, the only way for the roles of system administrators or database administrators to disappear is for them to be rebranded as “DevOps Engineers” or SREs. Good cloud software can shield you from mundane operational tasks and solve 70% of routine issues, but there will always be complex problems that only humans can handle. You might need fewer people to manage these cloud services, but you still need people【12】. After all, you need knowledgeable individuals to coordinate and manage, so you don’t get exploited by cloud vendors.
In large organizations, a good DBA is crucial. However, excellent DBAs are quite rare and in high demand, leading to this role being outsourced in most organizations: either to professional database service companies or to cloud database RDS service teams. Organizations unable to find DBA providers must internally assign this responsibility to their development/operations staff, until the company grows large enough or suffers enough setbacks for some Dev/Ops to develop the necessary skills.
DBAs won’t become obsolete; they will just be monopolized by cloud vendors to provide services.
The Shadow of Monopoly
In 2020, the adversary of computing freedom was cloud computing software.
Beyond the “obsolescence of DBAs,” the emergence of the cloud harbors a larger threat. We should be concerned about a scenario where public clouds (or “Fruit Clouds”) grow dominant, controlling both hardware and operators up and down the stream, monopolizing computation, storage, networking, and top-tier expert resources to become the de facto standards. If all top-tier DBAs are poached by cloud vendors to provide centralized shared expert services, ordinary business organizations will completely lose the capability to utilize databases effectively, eventually left with no choice but to be “taxed” by public clouds. Ultimately, all IT resources would be concentrated in the hands of cloud vendors, who, by controlling a critical few, could control the entire internet. This is undeniably contrary to the original intent behind the creation of the internet.
Let me reference Martin Kelppmann:
In the 2020s, the enemy of freedom in computing is cloud software
i.e. software that runs primarily on the vendor’s servers, with all your data also stored on those servers. This cloud software may have a client-side component (a mobile app, or the JavaScript running in your web browser), but it only works in conjunction with the vendor’s server. And there are lots of problems with cloud software:
- If the company providing the cloud software goes out of business or decides to discontinue a product, the software stops working, and you are locked out of the documents and data you created with that software. This is an especially common problem with software made by a startup, which may get acquired by a bigger company that has no interest in continuing to maintain the startup’s product.
- Google and other cloud services may suddenly suspend your account with no warning and no recourse, for example if an automated system thinks you have violated its terms of service. Even if your own behaviour has been faultless, someone else may have hacked into your account and used it to send malware or phishing emails without your knowledge, triggering a terms of service violation. Thus, you could suddenly find yourself permanently locked out of every document you ever created on Google Docs or another app.
- With software that runs on your own computer, even if the software vendor goes bust, you can continue running it forever (in a VM/emulator if it’s no longer compatible with your OS, and assuming it doesn’t need to contact a server to check for a license check). For example, the Internet Archive has a collection of over 100,000 historical software titles that you can run in an emulator inside your web browser! In contrast, if cloud software gets shut down, there is no way for you to preserve it, because you never had a copy of the server-side software, neither as source code nor in compiled form.
- The 1990s problem of not being able to customise or extend software you use is aggravated further in cloud software. With closed-source software that runs on your own computer, at least someone could reverse-engineer the file format it uses to store its data, so that you could load it into alternative software (think pre-OOXML Microsoft Office file formats, or Photoshop files before the spec was published). With cloud software, not even that is possible, since the data is only stored in the cloud, not in files on your own computer.
If all software was free and open source, these problems would all be solved. However, making the source code available is not actually necessary to solve the problems with cloud software; even closed-source software avoids the aforementioned problems, as long as it is running on your own computer rather than the vendor’s cloud server. Note that the Internet Archive is able to keep historical software working without ever having its source code: for purposes of preservation, running the compiled machine code in an emulator is just fine. Maybe having the source code would make it a little easier, but it’s not crucial. The important thing is having a copy of the software at all.
My collaborators and I have previously argued for local-first software, which is a response to these problems with cloud software. Local-first software runs on your own computer, and stores its data on your local hard drive, while also retaining the convenience of cloud software, such as real-time collaboration and syncing your data across all of your devices. It is nice for local-first software to also be open source, but this is not necessary: 90% of its benefits apply equally to closed-source local-first software.
Cloud software, not closed-source software, is the real threat to software freedom, because the harm from being suddenly locked out of all of your data at the whim of a cloud provider is much greater than the harm from not being able to view and modify the source code of your software. For that reason, it is much more important and pressing that we make local-first software ubiquitous. If, in that process, we can also make more software open-source, then that would be nice, but that is less critical. Focus on the biggest and most urgent challenges first.
However, where there is action, there is reaction; local-first software began to emerge as a countermeasure to cloud software. For instance, the Cloud Native movement, represented by Kubernetes, is a prime example. “Cloud Native,” as interpreted by cloud vendors, means “software that is natively developed in a public cloud environment”; but its real significance should be “local,” as in the opposite of “Cloud” — “Local” cloud / private cloud / proprietary cloud / native cloud, the name doesn’t matter. What matters is that it can run anywhere the user desires (including on cloud servers), not just exclusively in public clouds!
Open-source projects, like Kubernetes, have democratized resource scheduling/smart operations capabilities previously unique to public clouds, enabling enterprises to run ‘cloud’-like capabilities locally. For stateless applications, it already serves as a sufficiently robust “cloud operating system” kernel. Open-source alternatives like Ceph/Minio offer S3 object storage solutions, leaving only one question unanswered: how to manage and deploy stateful, production-grade database services?
The era is calling for an open-source alternative to RDS.
Answer & Solution
Pigsty —— Battery-Included, Local-First PostgreSQL Distribution as an Open-Source RDS Alternative
I envision a future where everyone has the factual right to freely use superior services, not confined within the pens (Pigsty) provided by a few public cloud vendors, feeding on subpar offerings. This is why I created Pigsty — a better, open-source, free alternative to PostgreSQL RDS. It enables users to launch a database service better than cloud RDS with just one click, anywhere (including on cloud servers).
Pigsty is a comprehensive complement to PostgreSQL, and a spicy critique of cloud databases. Its name signifies “pigpen,” but it also stands for Postgres In Great STYle, symbolizing PostgreSQL at its peak. It is a solution distilled from best practices in managing and using PostgreSQL, entirely based on open source software and capable of running anywhere. Born from real-world, high-standard PostgreSQL clusters, it was developed to fulfill the database management needs of Tantan, performing valuable work across eight dimensions:
Observability is akin to heaven; as heaven maintains vigor through movement, a gentleman should constantly strive for self-improvement; Pigsty utilizes a modern observability tech stack to create an unparalleled monitoring system for PostgreSQL, offering a comprehensive overview from global dashboards to granular historical metrics for individual tables/indexes/functions, enabling users to see through the system and control everything. Additionally, Pigsty’s monitoring system can operate independently to monitor third-party database instances.
Controllability is akin to earth; as earth’s nature is broad and bearing, a gentleman should carry the world with broad virtue; Pigsty provides Database as Code capabilities: describing the state of database clusters through expressive declarative interfaces and employing idempotent scripts for deployment and adjustments. This allows users to customize finely without worrying about implementation details, freeing their mental capacity and lowering the barrier from expert to novice level in database operations and management.
Scalability is like water; as water flows and encompasses all, a gentleman should maintain virtue consistently; Pigsty offers pre-configured tuning templates (OLTP / OLAP / CRIT / TINY), automatically optimizes system parameters, and can infinitely scale read capabilities through cascading replication. It also utilizes Pgbouncer for connection pool optimization to handle massive concurrent connections; Pigsty ensures PostgreSQL’s performance is maximized under modern hardware conditions: achieving tens of thousands of concurrent connections, million-level single-point query QPS, and hundred thousand-level single transaction TPS.
Maintainability is like fire; as fire illuminates, a great person should illuminate the surroundings; Pigsty allows for online instance addition or removal for scaling, Switchover/rolling upgrades for scaling up or down, and offers a downtime-free migration solution based on logical replication, minimizing maintenance windows to sub-second levels, thus enhancing the system’s evolvability, availability, and maintainability to a new standard.
Security is like thunder; as thunder signifies awe, a gentleman should reflect and be cautious; Pigsty offers an access control model following the principle of least privilege, along with various security features: synchronous commit for replication to prevent data loss, data directory checksums to prevent corruption, SSL encryption for network traffic to prevent eavesdropping, and AES-256 for remote backups to prevent data leaks. As long as physical hardware and passwords are secure, users need not worry about database security.
Simplicity is like wind; as wind follows its path, a gentleman should decree and act accordingly; Using Pigsty is no more difficult than any cloud database. It aims to deliver complete RDS functionality with the least complexity, allowing users to choose and combine modules as needed. Pigsty offers a Vagrant-based local development testing sandbox and Terraform cloud IaC for one-click deployment templates, enabling offline installation on any new EL node and complete environment replication.
Reliability is like a mountain; as a mountain stands firm, a gentleman should be steadfast in thought; Pigsty provides a high-availability architecture with self-healing capabilities to address hardware issues and offers out-of-the-box PITR for recovery from accidental data deletion and software flaws, verified through long-term, large-scale production environment operation and high-availability drills.
Extensibility is like a lake; as a lake reflects beauty, a gentleman should discuss and practice with friends; Pigsty deeply integrates core PostgreSQL ecosystem extensions like PostGIS, TimescaleDB, Citus, PGVector, and numerous extension plugins. It offers a modular design of the Prometheus/Grafana observability tech stack, and high-availability deployment of MINIO, ETCD, Redis, Greenplum, etc., in combination with PostgreSQL.

More importantly, Pigsty is entirely open-source and free software, licensed under AGPL v3.0. Powered by passion, you can run a fully functional, even superior RDS service at the cost of mere hardware expenses per month. Whether you are a beginner or a seasoned DBA, managing a massive cluster or a small setup, whether you’re already using RDS or have set up databases locally, if you are a PostgreSQL user, Pigsty will be beneficial to you, completely free. You can focus on the most interesting or valuable parts of your business and leave the routine tasks to the software.
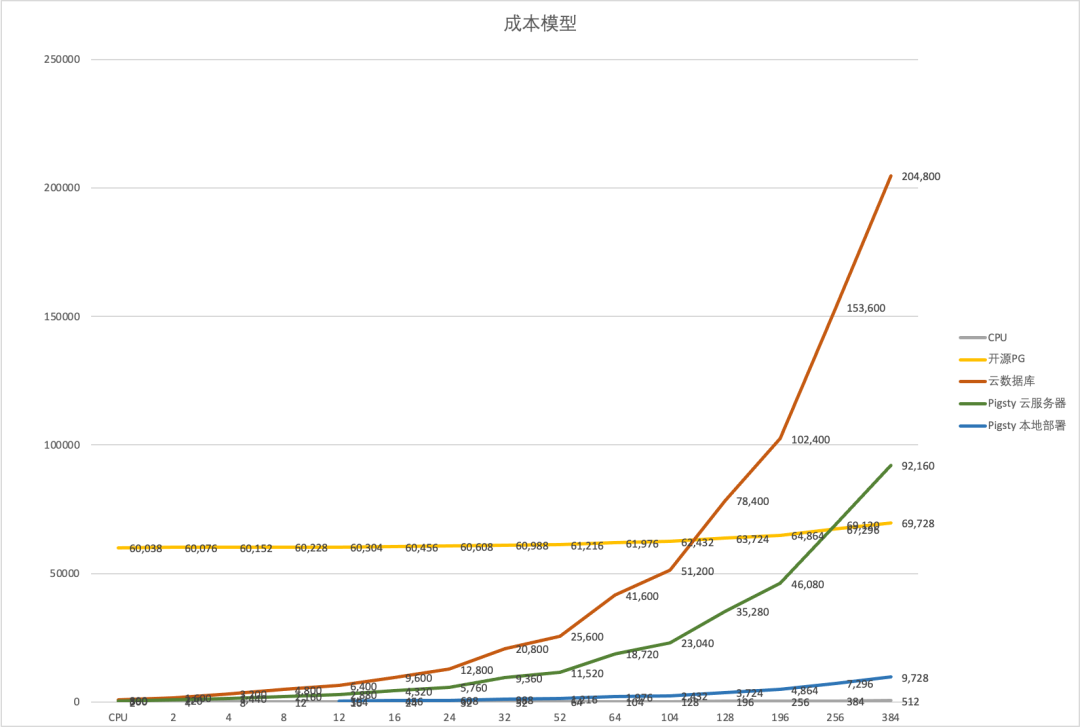
RDS Cost and Scale Cost Curve
Pigsty allows you to practice the ultimate FinOps principle — running production-level PostgreSQL RDS database services anywhere (ECS, resource cloud, data center servers, even local notebook virtual machines) at prices close to pure resource costs. Turning the cost capability of cloud databases from being proportional to marginal resource costs to virtually zero fixed learning costs.
If you can use a better RDS service at a fraction of the cost, then continuing to use cloud databases is truly just a tax on your intellect.
Reference
【1】Why we’re leaving the cloud
【2】上云“被坑”十年终放弃,寒冬里第一轮“下云潮”要来了?
【3】Aliyun RDS for PostgreSQL Pricing
【5】 AWS Pricing Calculator (China NingXia)