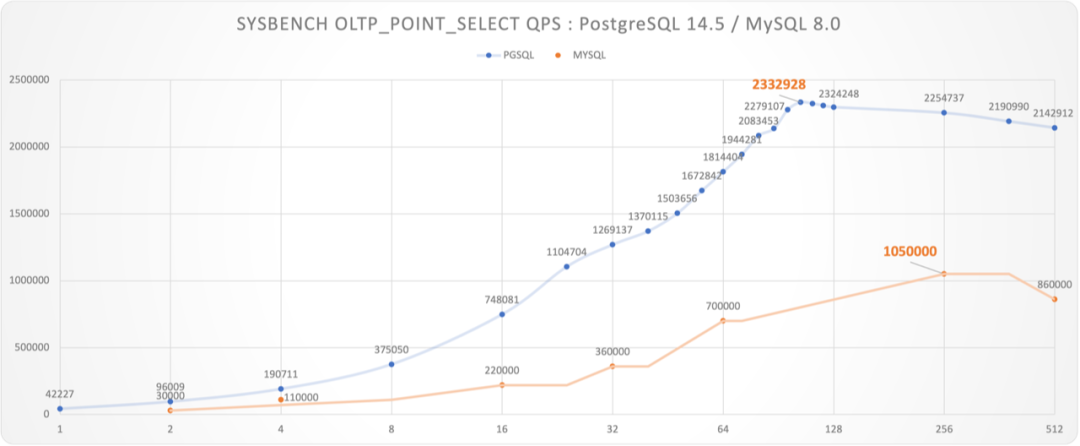
Great Performance: Hardware Fully Harnessed
Amazing scalability, fully utilizing top-tier hardware performance
No OLTP workload is too large for a single PG node, if there is, use more!
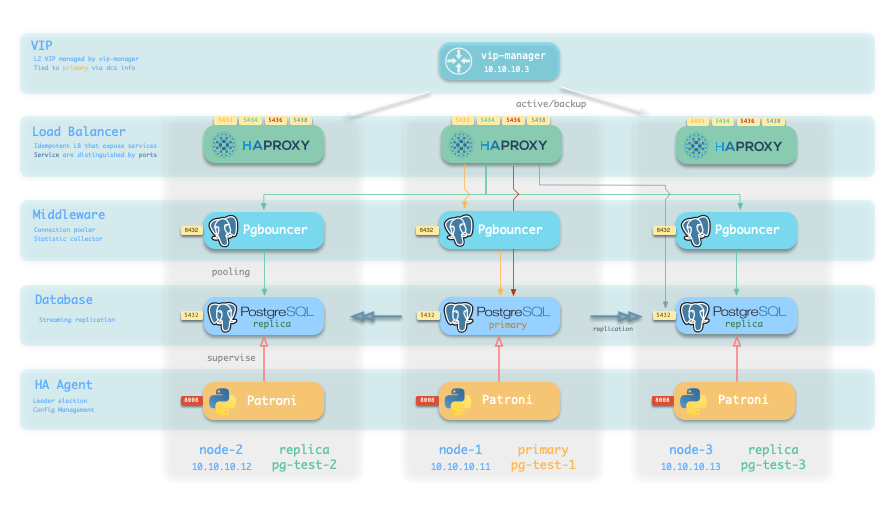
R/W Separation: Unlimited Read scaling
Have unlimited replicas through cascading replication, with auto traffic routing
Dedicated instances for analytics/ETL, separation of fast and slow queries
- Read-only Service: Route to read-only replicas with primary as backup
- Offline Service: Route to special analytics instance with replicas as backup
- Production Case: One primary with 34+ replicas through cascading bridges
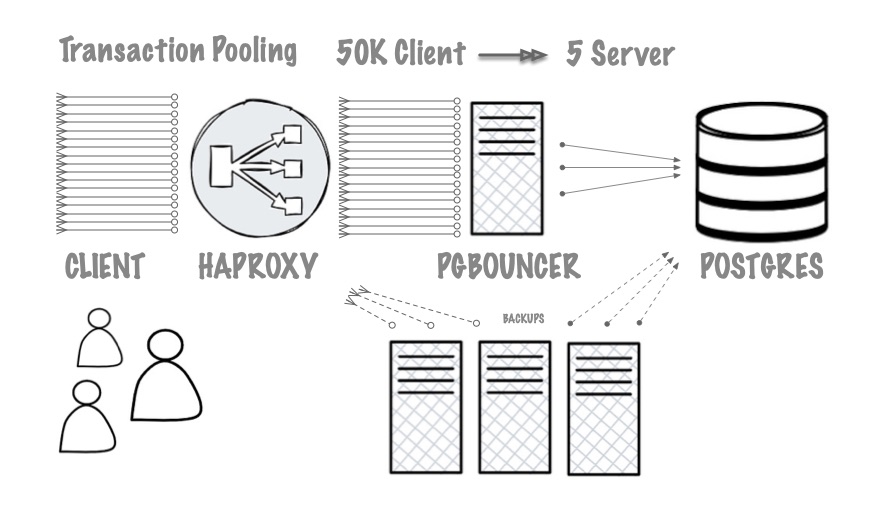
Connection Pooling: High concurrency made easy
Built-in PGBouncer connection pool, ready out of the box, sync with postgres
Transaction pooling by default, reducing conns while improving throughput
- Xact pooling converts 20000+ client conns to several active server conns
- Enabled by default, automatically syncing db/user with postgres
- Deploy multiple pgbouncer instances to circumvent its own bottlenecks
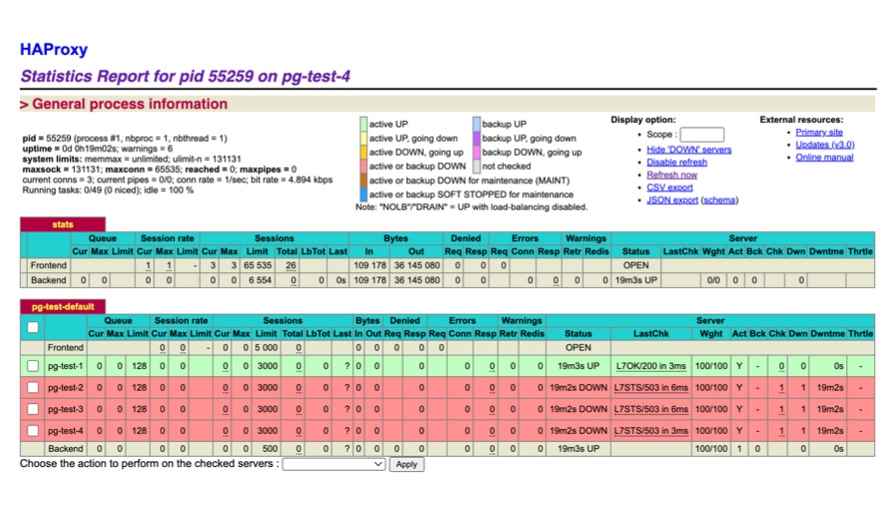
Load Balancing: Traffic Control with HAProxy
Monitor and schedule request traffic in real-time with Haproxy console
Seamless online migration with conn draining, fast takeover in emergencies
- Stateless HAProxy can be scaled at will or deployed on dedicated servers
- Weights can be adjusted via CLI, draining or warming up instances gracefully
- Password-protected HAProxy GUI exposed uniformly through Nginx
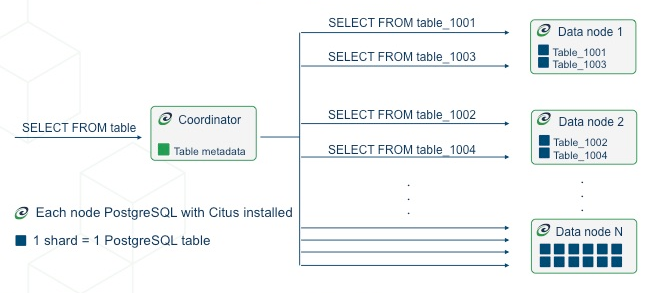
Horizontal Scaling: In-place Distributive Extension
Citus with multi-write and multi-tenant capabilities, a native postgres extension
Turn existing clusters into distributed in-place for more throughput and storage
- Accelerate real-time OLAP analytics using multi-node parallel processing
- Shard by row key or by schema, easily supporting multi-tenant scenarios
- Online partition rebalancing, adjusting throughput capacity as needed
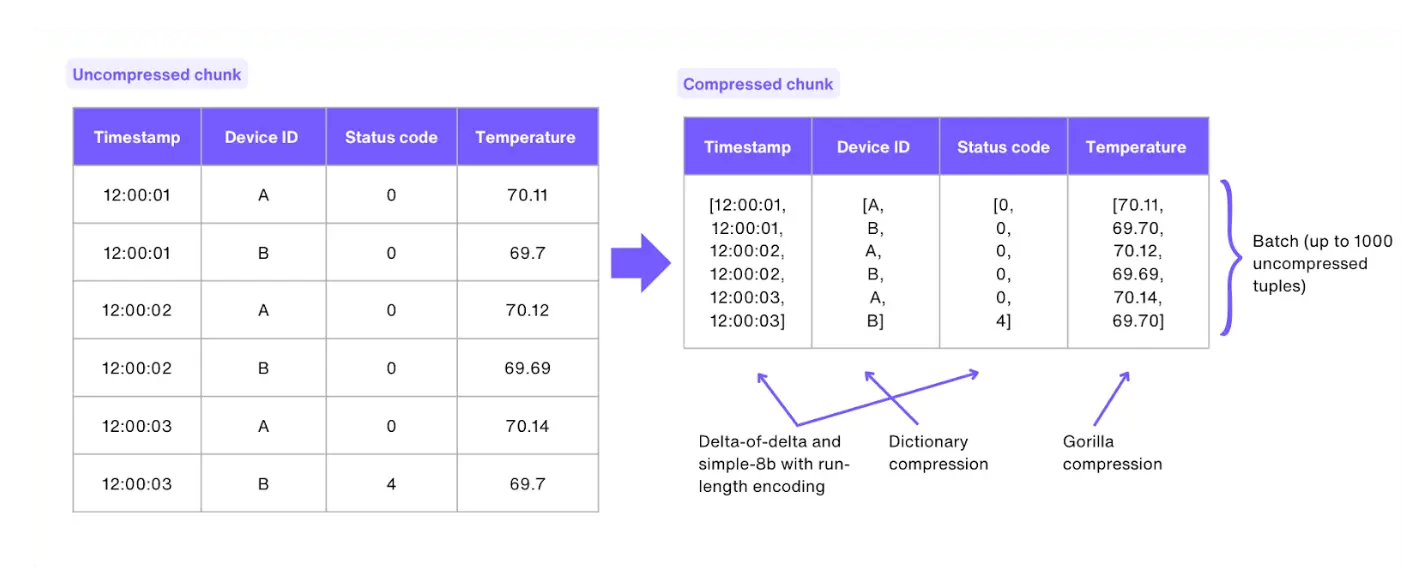
Storage Expansion: Transparent Compression
Achieve 10:1 or even higher compression ratios with colunmar and other exts
R/W data in S3 with FDW, hot/cold separation and unlimited capacity expansion
- Use timescaledb, pg_mooncake, pg_duckdb for columnar compression
- Use duckdb_fdw, pg_parquet, pg_analytics to read/write object storage tables
- Expand or contract storage with S/H RAID, ZFS, and PG tablespaces
Mass Deployment: Large clusters made easy
Designed for extreme scale - flexible for 25K vCPU clusters or 1c1m node
No limit on nodes per deployment - soft constrained only by monitoring capacity
- Batch Ops at scale through Ansible, saying goodbye to console ClickOps
- Largest production deployment record: 25,000 vCPU, 3,000+ instances
- Scale monitoring system with optional Distributed VictoriaMetrics
Elasticity: Cloud-like Elasticity
Supports cloud EC2 deployment, fully leveraging the elastic advantages of cloud
Flexible multi-cloud strategies - enjoy RDS elasticity with EC2/EBS prices
- Pigsty only needs cloud servers, works the same across any cloud provider
- Seamless switching between public, private, hybrid, and multi-cloud
- Scale compute and storage as needed: buy the baseline, rent the peak
PIGSTY