You can use different “flavors” of PostgreSQL branches, forks and derivatives to replace the “native PG kernel” in Pigsty.
This is the multi-page printable view of this section. Click here to print.
Kernel Forks
How to use another PostgreSQL “kernel” in Pigsty, such as Citus, Babelfish, IvorySQL, PolarDB, Neon, and Greenplum
- 1: Citus (Distributive)
- 2: WiltonDB (MSSQL)
- 3: IvorySQL (Oracle)
- 4: OpenHalo (MySQL)
- 5: OrioleDB (OLTP)
- 6: PolarDB PG (RAC)
- 7: PolarDB O(racle)
- 8: Supabase (Firebase)
- 9: Greenplum (MPP)
- 10: Cloudberry (MPP)
- 11: Neon (Serverless)
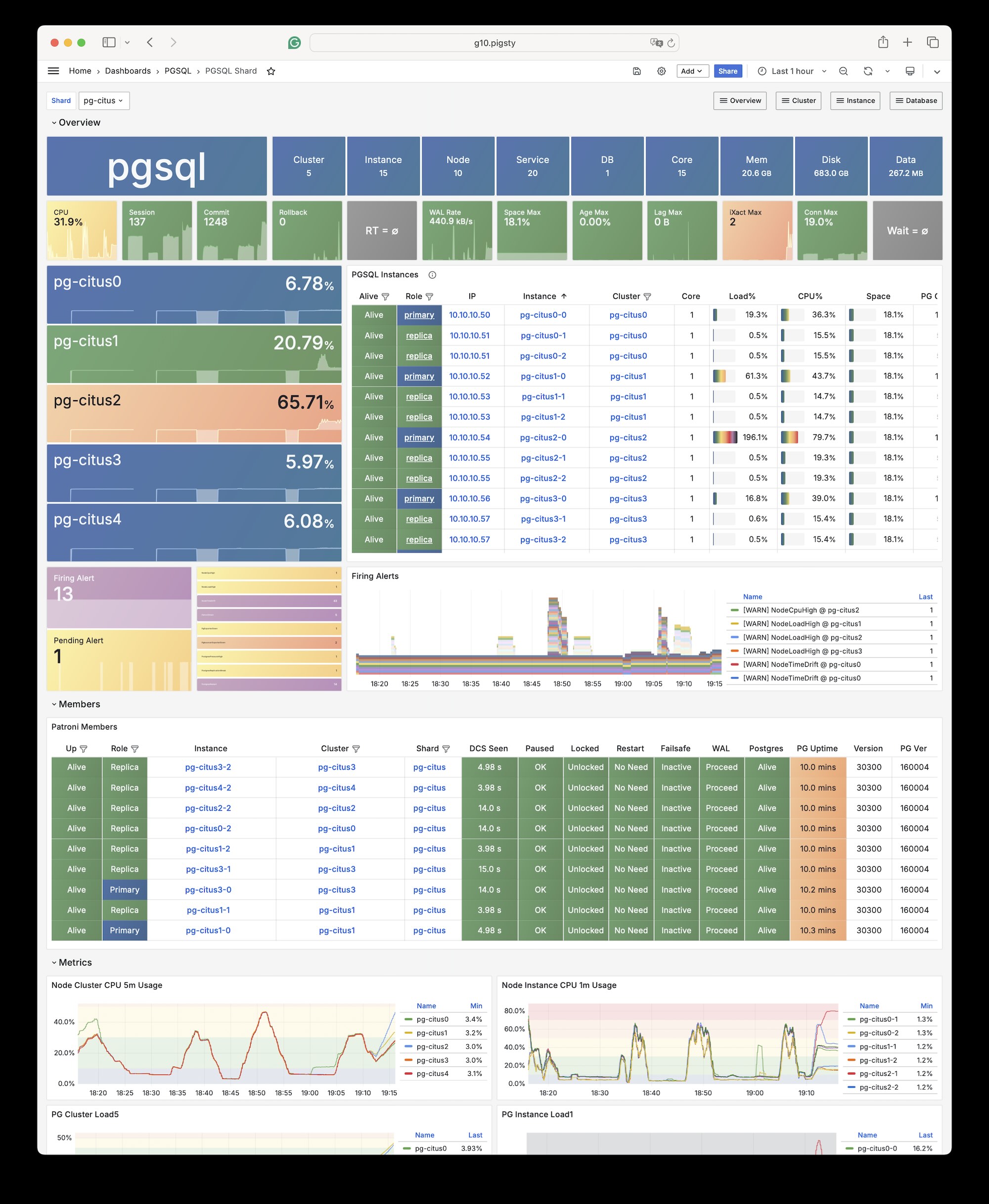
1 - Citus (Distributive)
Deploy native HA citus cluster with Pigsty, horizontal scaling PostgreSQL with better throughput and performance.
Beware that citus for the latest major version PostgreSQL 17 support is still WIP
Pigsty has native citus support:
Install
Citus is a standard PostgreSQL extension, which can be installed and enabled on a native PostgreSQL cluster by following the standard plugin installation process.
To install it manually, you can run the following command:
./pgsql.yml -t pg_extension -e '{"pg_extensions":["citus"]}'
Configuration
To define a citus cluster, you have to specify the following parameters:
pg_modehas to be set tocitusinstead of defaultpgsqlpg_shard&pg_grouphas to be defined on each sharding clusterpg_primary_dbhas to be defined to specify the database to be managedpg_dbsu_passwordhas to be set to a non-empty string plain password if you want to use thepg_dbsupostgresrather than defaultpg_admin_usernameto perform admin commands
Besides, extra hba rules that allow ssl access from local & other data nodes are required. Which may looks like this
You can define each citus cluster separately within a group, like conf/dbms/citus.yml :
all:
children:
pg-citus0: # citus data node 0
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus0 , pg_group: 0 }
pg-citus1: # citus data node 1
hosts: { 10.10.10.11: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus1 , pg_group: 1 }
pg-citus2: # citus data node 2
hosts: { 10.10.10.12: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus2 , pg_group: 2 }
pg-citus3: # citus data node 3, with an extra replica
hosts:
10.10.10.13: { pg_seq: 1, pg_role: primary }
10.10.10.14: { pg_seq: 2, pg_role: replica }
vars: { pg_cluster: pg-citus3 , pg_group: 3 }
vars: # global parameters for all citus clusters
pg_mode: citus # pgsql cluster mode: citus
pg_shard: pg-citus # citus shard name: pg-citus
patroni_citus_db: meta # citus distributed database name
pg_dbsu_password: DBUser.Postgres # all dbsu password access for citus cluster
pg_users: [ { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [ dbrole_admin ] } ]
pg_databases: [ { name: meta ,extensions: [ { name: citus }, { name: postgis }, { name: timescaledb } ] } ]
pg_hba_rules:
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title: 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'all user ssl access from intranet' }
You can also specify all citus cluster members within a group, take prod.yml for example.
#==========================================================#
# pg-citus: 10 node citus cluster (5 x primary-replica pair)
#==========================================================#
pg-citus: # citus group
hosts:
10.10.10.50: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 0, pg_role: primary }
10.10.10.51: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 1, pg_role: replica }
10.10.10.52: { pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 0, pg_role: primary }
10.10.10.53: { pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 1, pg_role: replica }
10.10.10.54: { pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 0, pg_role: primary }
10.10.10.55: { pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 1, pg_role: replica }
10.10.10.56: { pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 0, pg_role: primary }
10.10.10.57: { pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 1, pg_role: replica }
10.10.10.58: { pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 0, pg_role: primary }
10.10.10.59: { pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 1, pg_role: replica }
vars:
pg_mode: citus # pgsql cluster mode: citus
pg_shard: pg-citus # citus shard name: pg-citus
pg_primary_db: test # primary database used by citus
pg_dbsu_password: DBUser.Postgres # all dbsu password access for citus cluster
pg_vip_enabled: true
pg_vip_interface: eth1
pg_extensions: [ 'citus postgis timescaledb pgvector' ]
pg_libs: 'citus, timescaledb, pg_stat_statements, auto_explain' # citus will be added by patroni automatically
pg_users: [ { name: test ,password: test ,pgbouncer: true ,roles: [ dbrole_admin ] } ]
pg_databases: [ { name: test ,owner: test ,extensions: [ { name: citus }, { name: postgis } ] } ]
pg_hba_rules:
- { user: 'all' ,db: all ,addr: 10.10.10.0/24 ,auth: trust ,title: 'trust citus cluster members' }
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title: 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'all user ssl access from intranet' }
And you can create distributed table & reference table on the coordinator node. Any data node can be used as the coordinator node since citus 11.2.
Usage
You can access any (primary) node in the cluster as you would with a regular cluster:
pgbench -i postgres://test:test@pg-citus0/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus0/test
By default, any changes you make to a shard only occur on that cluster, not on other shards.
If you want to distribute a table, you can use the following command:
psql -h pg-citus0 -d test -c "SELECT create_distributed_table('pgbench_accounts', 'aid'); SELECT truncate_local_data_after_distributing_table('public.pgbench_accounts');"
psql -h pg-citus0 -d test -c "SELECT create_reference_table('pgbench_branches') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_branches');"
psql -h pg-citus0 -d test -c "SELECT create_reference_table('pgbench_history') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_history');"
psql -h pg-citus0 -d test -c "SELECT create_reference_table('pgbench_tellers') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_tellers');"
There are two types of tables you can create:
- distributed tables (automatic partitioning, need to specify partition key)
- reference tables (full replication: no need to specify partition key)
Starting from Citus 11.2, any Citus database node can act as a coordinator, meaning any primary node can write.
For example, your changes will be visible on other nodes:
psql -h pg-citus1 -d test -c '\dt+'
And your scan will be distributed:
vagrant@meta-1:~$ psql -h pg-citus3 -d test -c 'explain select * from pgbench_accounts'
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=352)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.10.10.52 port=5432 dbname=test
-> Seq Scan on pgbench_accounts_102008 pgbench_accounts (cost=0.00..81.66 rows=3066 width=97)
(6 rows)
You can issue writes from different primary nodes:
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus1/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus2/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus3/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus4/test
And in case of primary node failure, the replica will take over with native patroni support:
test=# select * from pg_dist_node;
nodeid | groupid | nodename | nodeport | noderack | hasmetadata | isactive | noderole | nodecluster | metadatasynced | shouldhaveshards
--------+---------+-------------+----------+----------+-------------+----------+----------+-------------+----------------+------------------
1 | 0 | 10.10.10.51 | 5432 | default | t | t | primary | default | t | f
2 | 2 | 10.10.10.54 | 5432 | default | t | t | primary | default | t | t
5 | 1 | 10.10.10.52 | 5432 | default | t | t | primary | default | t | t
3 | 4 | 10.10.10.58 | 5432 | default | t | t | primary | default | t | t
4 | 3 | 10.10.10.56 | 5432 | default | t | t | primary | default | t | t
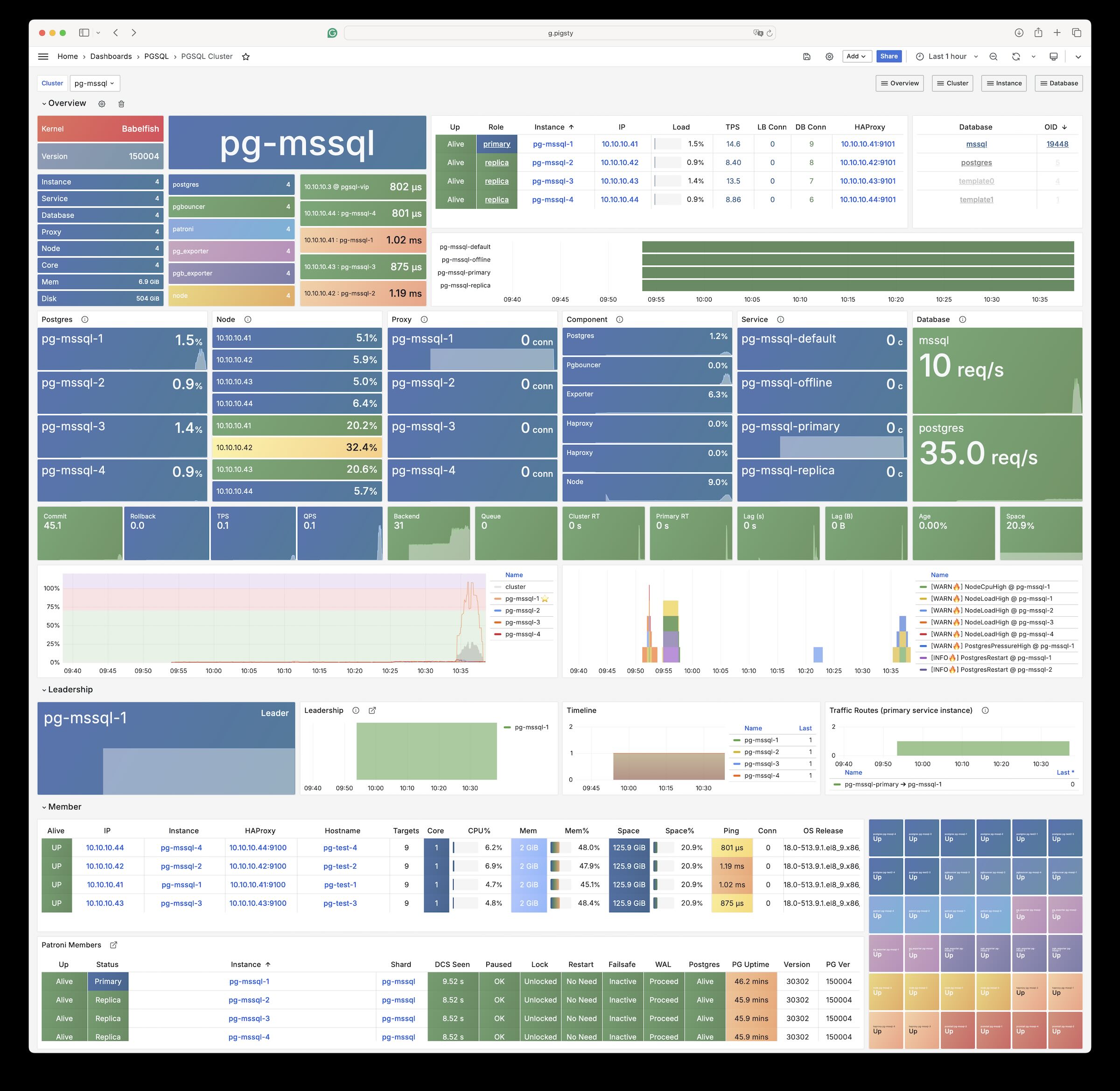
2 - WiltonDB (MSSQL)
Create SQL Server Compatible PostgreSQL cluster with WiltonDB and Babelfish (Wire Protocol Level)
Pigsty allows users to create a Microsoft SQL Server compatible PostgreSQL cluster using Babelfish and WiltonDB!
- Babelfish: An open-source MSSQL (Microsoft SQL Server) compatibility extension Open Sourced by AWS
- WiltonDB: A PostgreSQL kernel distribution focusing on integrating Babelfish
Babelfish is a PostgreSQL extension, but it works on a slightly modified PostgreSQL kernel Fork, WiltonDB provides compiled kernel binaries and extension binary packages on EL/Ubuntu systems.
Pigsty can replace the native PostgreSQL kernel with WiltonDB, providing an out-of-the-box MSSQL compatible cluster along with all the supported by common PostgreSQL clusters, such as HA, PITR, IaC, monitoring, etc.
WiltonDB is very similar to PostgreSQL 15, but it can not use vanilla PostgreSQL extensions directly. WiltonDB has several re-compiled extensions such as system_stats, pg_hint_plan and tds_fdw.
The cluster will listen on the default PostgreSQL port and the default MSSQL 1433 port, providing MSSQL services via the TDS WireProtocol on this port.
You can connect to the MSSQL service provided by Pigsty using any MSSQL client, such as SQL Server Management Studio, or using the sqlcmd command-line tool.
Get Started
install Pigsty’s with the mssql config template.
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # Prepare Pigsty Dependencies
./configure -c mssql # Use mssql (babelfish) template
./install.yml # Run Deployment Playbook
For production deployments, make sure to modify the password parameters in the pigsty.yml config before running the install playbook.
Notes
When installing and deploying the MSSQL module, please pay special attention to the following points:
- WiltonDB is available on EL (7/8/9) and Ubuntu (20.04/22.04) but not available on Debian systems.
- WiltonDB is currently compiled based on PostgreSQL 15, so you need to specify
pg_version: 15. - On EL systems, the
wiltondbbinary is installed by default in the/usr/bin/directory, while on Ubuntu systems, it is installed in the/usr/lib/postgresql/15/bin/directory, which is different from the official PostgreSQL binary location. - In WiltonDB compatibility mode, the HBA password authentication rule needs to use
md5instead ofscram-sha-256. Therefore, you need to override Pigsty’s default HBA rule set and insert themd5authentication rule required by SQL Server before thedbrole_readonlywildcard authentication rule. - WiltonDB can only be enabled for a primary database, and you should designate a user as the Babelfish superuser, allowing Babelfish to create databases and users. The default is
mssqlanddbuser_myssql. If you change this, you should also modify the user infiles/mssql.sql. - The WiltonDB TDS cable protocol compatibility plugin
babelfishpg_tdsneeds to be enabled inshared_preload_libraries. - After enabling the WiltonDB extension, it listens on the default MSSQL port
1433. You can override Pigsty’s default service definitions to redirect theprimaryandreplicaservices to port1433instead of the5432/6432ports.
The following parameters need to be configured for the MSSQL database cluster:
#----------------------------------#
# PGSQL & MSSQL (Babelfish & Wilton)
#----------------------------------#
# PG Installation
node_repo_modules: local,node,mssql # add mssql and os upstream repos
pg_mode: mssql # Microsoft SQL Server Compatible Mode
pg_libs: 'babelfishpg_tds, pg_stat_statements, auto_explain' # add timescaledb to shared_preload_libraries
pg_version: 15 # The current WiltonDB major version is 15
pg_packages:
- wiltondb # install forked version of postgresql with babelfishpg support
- patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager
pg_extensions: [] # do not install any vanilla postgresql extensions
# PG Provision
pg_default_hba_rules: # overwrite default HBA rules for babelfish cluster
- {user: '${dbsu}' ,db: all ,addr: local ,auth: ident ,title: 'dbsu access via local os user ident' }
- {user: '${dbsu}' ,db: replication ,addr: local ,auth: ident ,title: 'dbsu replication from local os ident' }
- {user: '${repl}' ,db: replication ,addr: localhost ,auth: pwd ,title: 'replicator replication from localhost'}
- {user: '${repl}' ,db: replication ,addr: intra ,auth: pwd ,title: 'replicator replication from intranet' }
- {user: '${repl}' ,db: postgres ,addr: intra ,auth: pwd ,title: 'replicator postgres db from intranet' }
- {user: '${monitor}' ,db: all ,addr: localhost ,auth: pwd ,title: 'monitor from localhost with password' }
- {user: '${monitor}' ,db: all ,addr: infra ,auth: pwd ,title: 'monitor from infra host with password'}
- {user: '${admin}' ,db: all ,addr: infra ,auth: ssl ,title: 'admin @ infra nodes with pwd & ssl' }
- {user: '${admin}' ,db: all ,addr: world ,auth: ssl ,title: 'admin @ everywhere with ssl & pwd' }
- {user: dbuser_mssql ,db: mssql ,addr: intra ,auth: md5 ,title: 'allow mssql dbsu intranet access' } # <--- use md5 auth method for mssql user
- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: pwd ,title: 'pgbouncer read/write via local socket'}
- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: pwd ,title: 'read/write biz user via password' }
- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: pwd ,title: 'allow etl offline tasks from intranet'}
pg_default_services: # route primary & replica service to mssql port 1433
- { name: primary ,port: 5433 ,dest: 1433 ,check: /primary ,selector: "[]" }
- { name: replica ,port: 5434 ,dest: 1433 ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
- { name: default ,port: 5436 ,dest: postgres ,check: /primary ,selector: "[]" }
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
You can define business database & users in the pg_databases and pg_users section:
#----------------------------------#
# pgsql (singleton on current node)
#----------------------------------#
# this is an example single-node postgres cluster with postgis & timescaledb installed, with one biz database & two biz users
pg-meta:
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary } # <---- primary instance with read-write capability
vars:
pg_cluster: pg-test
pg_users: # create MSSQL superuser
- {name: dbuser_mssql ,password: DBUser.MSSQL ,superuser: true, pgbouncer: true ,roles: [dbrole_admin], comment: superuser & owner for babelfish }
pg_primary_db: mssql # use `mssql` as the primary sql server database
pg_databases:
- name: mssql
baseline: mssql.sql # init babelfish database & user
extensions:
- { name: uuid-ossp }
- { name: babelfishpg_common }
- { name: babelfishpg_tsql }
- { name: babelfishpg_tds }
- { name: babelfishpg_money }
- { name: pg_hint_plan }
- { name: system_stats }
- { name: tds_fdw }
owner: dbuser_mssql
parameters: { 'babelfishpg_tsql.migration_mode' : 'multi-db' }
comment: babelfish cluster, a MSSQL compatible pg cluster
Client Access
You can use any SQL Server compatible client tool to access this database cluster.
Microsoft provides sqlcmd as the official command-line tool.
Besides, they have a go version cli tool: go-sqlcmd
Install go-sqlcmd:
curl -LO https://github.com/microsoft/go-sqlcmd/releases/download/v1.4.0/sqlcmd-v1.4.0-linux-amd64.tar.bz2
tar xjvf sqlcmd-v1.4.0-linux-amd64.tar.bz2
sudo mv sqlcmd* /usr/bin/
Get started with go-sqlcmd
$ sqlcmd -S 10.10.10.10,1433 -U dbuser_mssql -P DBUser.MSSQL
1> select @@version
2> go
version
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Babelfish for PostgreSQL with SQL Server Compatibility - 12.0.2000.8
Oct 22 2023 17:48:32
Copyright (c) Amazon Web Services
PostgreSQL 15.4 (EL 1:15.4.wiltondb3.3_2-2.el8) on x86_64-redhat-linux-gnu (Babelfish 3.3.0)
(1 row affected)
You can route service traffic to MSSQL 1433 port instead of 5433/5434:
# route 5433 on all members to 1433 on primary
sqlcmd -S 10.10.10.11,5433 -U dbuser_mssql -P DBUser.MSSQL
# route 5434 on all members to 1433 on replicas
sqlcmd -S 10.10.10.11,5434 -U dbuser_mssql -P DBUser.MSSQL
Install
If you have the Internet access, you can add the WiltonDB repository to the node and install it as a node package directly:
node_repo_modules: local,node,pgsql,mssql
node_packages: [ wiltondb ]
Install wiltondb with the following command:
./node.yml -t node_repo,node_pkg
It’s OK to install vanilla PostgreSQL and WiltonDB on the same node, but you can only run one of them at a time, and this is not recommended for production environments.
Extensions
Most of the PGSQL module’s extensions (non-SQL class) cannot be used directly on the WiltonDB core of the MSSQL module and need to be recompiled.
WiltonDB currently comes with the following extension plugins:
| Name | Version | Comment |
|---|---|---|
| dblink | 1.2 | connect to other PostgreSQL databases from within a database |
| adminpack | 2.1 | administrative functions for PostgreSQL |
| dict_int | 1.0 | text search dictionary template for integers |
| intagg | 1.1 | integer aggregator and enumerator (obsolete) |
| dict_xsyn | 1.0 | text search dictionary template for extended synonym processing |
| amcheck | 1.3 | functions for verifying relation integrity |
| autoinc | 1.0 | functions for autoincrementing fields |
| bloom | 1.0 | bloom access method - signature file based index |
| fuzzystrmatch | 1.1 | determine similarities and distance between strings |
| intarray | 1.5 | functions, operators, and index support for 1-D arrays of integers |
| btree_gin | 1.3 | support for indexing common datatypes in GIN |
| btree_gist | 1.7 | support for indexing common datatypes in GiST |
| hstore | 1.8 | data type for storing sets of (key, value) pairs |
| hstore_plperl | 1.0 | transform between hstore and plperl |
| isn | 1.2 | data types for international product numbering standards |
| hstore_plperlu | 1.0 | transform between hstore and plperlu |
| jsonb_plperl | 1.0 | transform between jsonb and plperl |
| citext | 1.6 | data type for case-insensitive character strings |
| jsonb_plperlu | 1.0 | transform between jsonb and plperlu |
| jsonb_plpython3u | 1.0 | transform between jsonb and plpython3u |
| cube | 1.5 | data type for multidimensional cubes |
| hstore_plpython3u | 1.0 | transform between hstore and plpython3u |
| earthdistance | 1.1 | calculate great-circle distances on the surface of the Earth |
| lo | 1.1 | Large Object maintenance |
| file_fdw | 1.0 | foreign-data wrapper for flat file access |
| insert_username | 1.0 | functions for tracking who changed a table |
| ltree | 1.2 | data type for hierarchical tree-like structures |
| ltree_plpython3u | 1.0 | transform between ltree and plpython3u |
| pg_walinspect | 1.0 | functions to inspect contents of PostgreSQL Write-Ahead Log |
| moddatetime | 1.0 | functions for tracking last modification time |
| old_snapshot | 1.0 | utilities in support of old_snapshot_threshold |
| pgcrypto | 1.3 | cryptographic functions |
| pgrowlocks | 1.2 | show row-level locking information |
| pageinspect | 1.11 | inspect the contents of database pages at a low level |
| pg_surgery | 1.0 | extension to perform surgery on a damaged relation |
| seg | 1.4 | data type for representing line segments or floating-point intervals |
| pgstattuple | 1.5 | show tuple-level statistics |
| pg_buffercache | 1.3 | examine the shared buffer cache |
| pg_freespacemap | 1.2 | examine the free space map (FSM) |
| postgres_fdw | 1.1 | foreign-data wrapper for remote PostgreSQL servers |
| pg_prewarm | 1.2 | prewarm relation data |
| tcn | 1.0 | Triggered change notifications |
| pg_trgm | 1.6 | text similarity measurement and index searching based on trigrams |
| xml2 | 1.1 | XPath querying and XSLT |
| refint | 1.0 | functions for implementing referential integrity (obsolete) |
| pg_visibility | 1.2 | examine the visibility map (VM) and page-level visibility info |
| pg_stat_statements | 1.10 | track planning and execution statistics of all SQL statements executed |
| sslinfo | 1.2 | information about SSL certificates |
| tablefunc | 1.0 | functions that manipulate whole tables, including crosstab |
| tsm_system_rows | 1.0 | TABLESAMPLE method which accepts number of rows as a limit |
| tsm_system_time | 1.0 | TABLESAMPLE method which accepts time in milliseconds as a limit |
| unaccent | 1.1 | text search dictionary that removes accents |
| uuid-ossp | 1.1 | generate universally unique identifiers (UUIDs) |
| plpgsql | 1.0 | PL/pgSQL procedural language |
| babelfishpg_money | 1.1.0 | babelfishpg_money |
| system_stats | 2.0 | EnterpriseDB system statistics for PostgreSQL |
| tds_fdw | 2.0.3 | Foreign data wrapper for querying a TDS database (Sybase or Microsoft SQL Server) |
| babelfishpg_common | 3.3.3 | Transact SQL Datatype Support |
| babelfishpg_tds | 1.0.0 | TDS protocol extension |
| pg_hint_plan | 1.5.1 | |
| babelfishpg_tsql | 3.3.1 | Transact SQL compatibility |
- Pigsty Pro offers the offline installation ability for MSSQL compatible extensions
- Pigsty Pro offers MSSQL compatible extension porting services, which can port available extensions in the PGSQL module to the MSSQL cluster.
3 - IvorySQL (Oracle)
Run “Oracle-Compatible” PostgreSQL cluster with the IvorySQL Kernel open sourced by HighGo
IvorySQL is an open-source “Oracle-compatible” PostgreSQL kernel, developed by HighGo, licensed under Apache 2.0.
The Oracle compatibility here refers to compatibility at the PL/SQL, syntax, built-in functions, data types, system views, MERGE, and GUC parameter levels. It’s not a wire protocol compatibility like Babelfish, openHalo, or FerretDB that allows using the original client drivers. Users still need to use PostgreSQL client tools to access IvorySQL, but can use Oracle-compatible syntax.
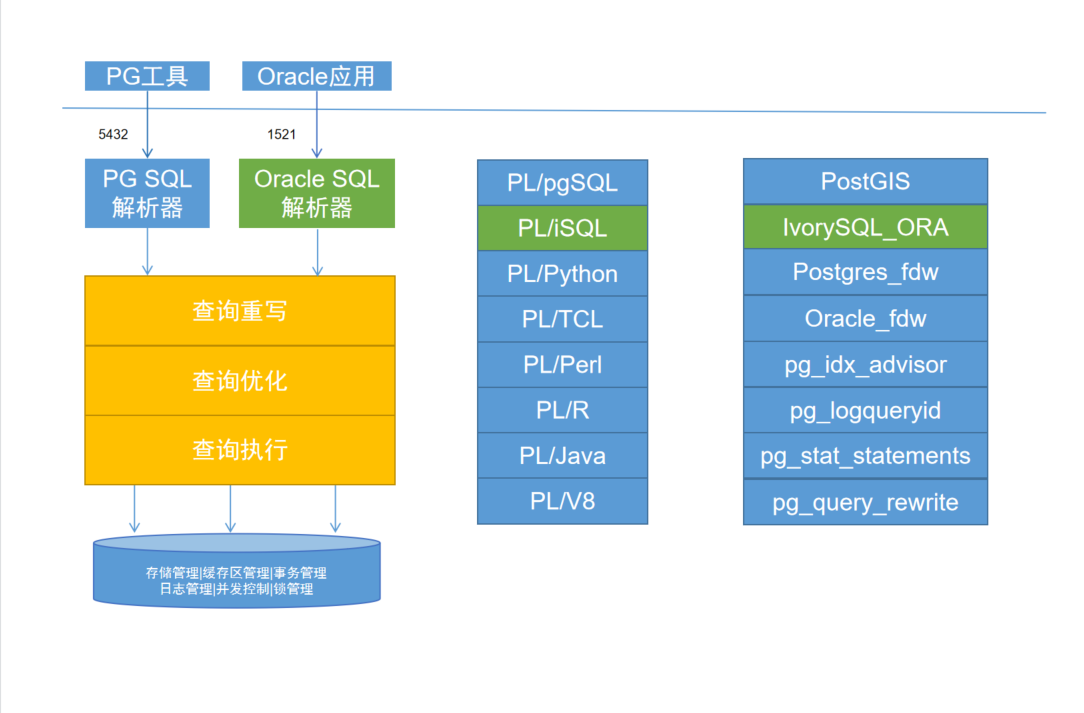
Currently, IvorySQL’s latest version 4.4 maintains compatibility with PostgreSQL’s latest minor version 17.4, and provides binary RPM/DEB packages for mainstream Linux distributions. Pigsty offers the option to replace the native PostgreSQL with the IvorySQL kernel in PG RDS.
Quick Start
Use the standard procedure to install Pigsty with the ivory configuration template:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # Install Pigsty dependencies
./configure -c ivory # Use IvorySQL configuration template
./install.yml # Execute deployment using playbook
For production deployments, you should edit the auto-generated pigsty.yml configuration file to modify parameters like passwords before executing ./install.yml for deployment.
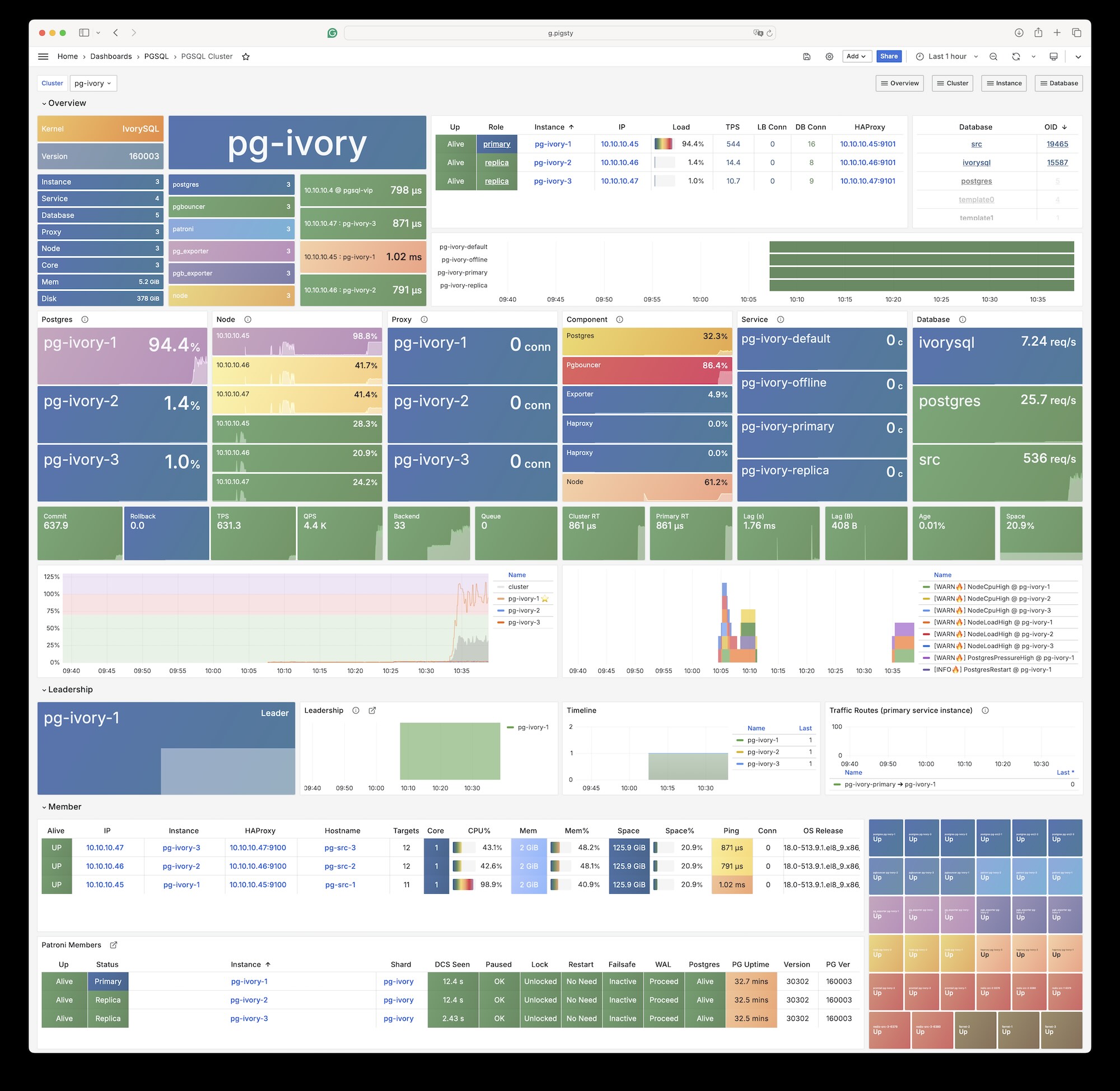
The latest IvorySQL 4.4 is equivalent to PostgreSQL 17. Any client tool compatible with PostgreSQL’s wire protocol can access IvorySQL clusters.
By default, you can use a PostgreSQL client to access through the alternative 1521 port, which enables Oracle compatibility mode by default.
Configuration Instructions
To use the IvorySQL kernel in Pigsty, modify the following four configuration parameters:
pg_mode: Useivorycompatibility moderepo_extra_packages: Downloadivorysqlpackagespg_packages: Installivorysqlpackagespg_libs: Load Oracle syntax compatibility extensions
It’s that simple - just add these four lines to the global variables in the configuration file, and Pigsty will replace the native PostgreSQL kernel with IvorySQL:
pg_mode: ivory # IvorySQL compatibility mode, uses IvorySQL binaries
pg_packages: [ ivorysql, pgsql-common ] # Install ivorysql, replacing pgsql-main kernel
pg_libs: 'liboracle_parser, pg_stat_statements, auto_explain' # Load Oracle compatibility extensions
repo_extra_packages: [ ivorysql ] # Download ivorysql packages
IvorySQL also provides a series of new GUC parameters that can be specified in pg_parameters.
Extensions
Most of the PGSQL modules’ extension (non-SQL classes) cannot be used directly on the IvorySQL kernel. If you need to use them, you need to recompile and install from source code for the new kernel.
Currently, the IvorySQL kernel comes with the following 109 extension plugins:
IvorySQL Available Extensions
| Name | Version | Description |
|---|---|---|
| amcheck | 1.4 | functions for verifying relation integrity |
| autoinc | 1.0 | functions for autoincrementing fields |
| bloom | 1.0 | bloom access method - signature file based index |
| bool_plperl | 1.0 | transform between bool and plperl |
| bool_plperlu | 1.0 | transform between bool and plperlu |
| btree_gin | 1.3 | support for indexing common datatypes in GIN |
| btree_gist | 1.7 | support for indexing common datatypes in GiST |
| citext | 1.6 | data type for case-insensitive character strings |
| cube | 1.5 | data type for multidimensional cubes |
| dblink | 1.2 | connect to other PostgreSQL databases from within a database |
| dict_int | 1.0 | text search dictionary template for integers |
| dict_xsyn | 1.0 | text search dictionary template for extended synonym processing |
| dummy_index_am | 1.0 | dummy_index_am - index access method template |
| dummy_seclabel | 1.0 | Test code for SECURITY LABEL feature |
| earthdistance | 1.2 | calculate great-circle distances on the surface of the Earth |
| file_fdw | 1.0 | foreign-data wrapper for flat file access |
| fuzzystrmatch | 1.2 | determine similarities and distance between strings |
| hstore | 1.8 | data type for storing sets of (key, value) pairs |
| hstore_plperl | 1.0 | transform between hstore and plperl |
| hstore_plperlu | 1.0 | transform between hstore and plperlu |
| hstore_plpython3u | 1.0 | transform between hstore and plpython3u |
| injection_points | 1.0 | Test code for injection points |
| insert_username | 1.0 | functions for tracking who changed a table |
| intagg | 1.1 | integer aggregator and enumerator (obsolete) |
| intarray | 1.5 | functions, operators, and index support for 1-D arrays of integers |
| isn | 1.2 | data types for international product numbering standards |
| ivorysql_ora | 1.0 | Oracle Compatible extenison on Postgres Database |
| jsonb_plperl | 1.0 | transform between jsonb and plperl |
| jsonb_plperlu | 1.0 | transform between jsonb and plperlu |
| jsonb_plpython3u | 1.0 | transform between jsonb and plpython3u |
| lo | 1.1 | Large Object maintenance |
| ltree | 1.3 | data type for hierarchical tree-like structures |
| ltree_plpython3u | 1.0 | transform between ltree and plpython3u |
| moddatetime | 1.0 | functions for tracking last modification time |
| ora_btree_gin | 1.0 | support for indexing oracle datatypes in GIN |
| ora_btree_gist | 1.0 | support for oracle indexing common datatypes in GiST |
| pageinspect | 1.12 | inspect the contents of database pages at a low level |
| pg_buffercache | 1.5 | examine the shared buffer cache |
| pg_freespacemap | 1.2 | examine the free space map (FSM) |
| pg_get_functiondef | 1.0 | Get function’s definition |
| pg_prewarm | 1.2 | prewarm relation data |
| pg_stat_statements | 1.11 | track planning and execution statistics of all SQL statements executed |
| pg_surgery | 1.0 | extension to perform surgery on a damaged relation |
| pg_trgm | 1.6 | text similarity measurement and index searching based on trigrams |
| pg_visibility | 1.2 | examine the visibility map (VM) and page-level visibility info |
| pg_walinspect | 1.1 | functions to inspect contents of PostgreSQL Write-Ahead Log |
| pgcrypto | 1.3 | cryptographic functions |
| pgrowlocks | 1.2 | show row-level locking information |
| pgstattuple | 1.5 | show tuple-level statistics |
| plisql | 1.0 | PL/iSQL procedural language |
| plperl | 1.0 | PL/Perl procedural language |
| plperlu | 1.0 | PL/PerlU untrusted procedural language |
| plpgsql | 1.0 | PL/pgSQL procedural language |
| plpython3u | 1.0 | PL/Python3U untrusted procedural language |
| plsample | 1.0 | PL/Sample |
| pltcl | 1.0 | PL/Tcl procedural language |
| pltclu | 1.0 | PL/TclU untrusted procedural language |
| postgres_fdw | 1.1 | foreign-data wrapper for remote PostgreSQL servers |
| refint | 1.0 | functions for implementing referential integrity (obsolete) |
| seg | 1.4 | data type for representing line segments or floating-point intervals |
| spgist_name_ops | 1.0 | Test opclass for SP-GiST |
| sslinfo | 1.2 | information about SSL certificates |
| tablefunc | 1.0 | functions that manipulate whole tables, including crosstab |
| tcn | 1.0 | Triggered change notifications |
| test_bloomfilter | 1.0 | Test code for Bloom filter library |
| test_copy_callbacks | 1.0 | Test code for COPY callbacks |
| test_custom_rmgrs | 1.0 | Test code for custom WAL resource managers |
| test_ddl_deparse | 1.0 | Test code for DDL deparse feature |
| test_dsa | 1.0 | Test code for dynamic shared memory areas |
| test_dsm_registry | 1.0 | Test code for the DSM registry |
| test_ext1 | 1.0 | Test extension 1 |
| test_ext2 | 1.0 | Test extension 2 |
| test_ext3 | 1.0 | Test extension 3 |
| test_ext4 | 1.0 | Test extension 4 |
| test_ext5 | 1.0 | Test extension 5 |
| test_ext6 | 1.0 | test_ext6 |
| test_ext7 | 1.0 | Test extension 7 |
| test_ext8 | 1.0 | Test extension 8 |
| test_ext9 | 1.0 | test_ext9 |
| test_ext_cine | 1.0 | Test extension using CREATE IF NOT EXISTS |
| test_ext_cor | 1.0 | Test extension using CREATE OR REPLACE |
| test_ext_cyclic1 | 1.0 | Test extension cyclic 1 |
| test_ext_cyclic2 | 1.0 | Test extension cyclic 2 |
| test_ext_evttrig | 1.0 | Test extension - event trigger |
| test_ext_extschema | 1.0 | test @extschema@ |
| test_ext_req_schema1 | 1.0 | Required extension to be referenced |
| test_ext_req_schema2 | 1.0 | Test schema referencing of required extensions |
| test_ext_req_schema3 | 1.0 | Test schema referencing of 2 required extensions |
| test_ext_set_schema | 1.0 | Test ALTER EXTENSION SET SCHEMA |
| test_ginpostinglist | 1.0 | Test code for ginpostinglist.c |
| test_integerset | 1.0 | Test code for integerset |
| test_lfind | 1.0 | Test code for optimized linear search functions |
| test_parser | 1.0 | example of a custom parser for full-text search |
| test_pg_dump | 1.0 | Test pg_dump with an extension |
| test_predtest | 1.0 | Test code for optimizer/util/predtest.c |
| test_radixtree | 1.0 | Test code for radix tree |
| test_rbtree | 1.0 | Test code for red-black tree library |
| test_regex | 1.0 | Test code for backend/regex/ |
| test_resowner | 1.0 | Test code for ResourceOwners |
| test_shm_mq | 1.0 | Test code for shared memory message queues |
| test_slru | 1.0 | Test code for SLRU |
| test_tidstore | 1.0 | Test code for tidstore |
| tsm_system_rows | 1.0 | TABLESAMPLE method which accepts number of rows as a limit |
| tsm_system_time | 1.0 | TABLESAMPLE method which accepts time in milliseconds as a limit |
| unaccent | 1.1 | text search dictionary that removes accents |
| uuid-ossp | 1.1 | generate universally unique identifiers (UUIDs) |
| worker_spi | 1.0 | Sample background worker |
| xid_wraparound | 1.0 | Tests for XID wraparound |
| xml2 | 1.1 | XPath querying and XSLT |
Caveats
-
The IvorySQL software package is located in the
pigsty-infrarepository, not inpigsty-pgsqlorpigsty-ivoryrepositories. -
The default FHS of IvorySQL 4.4 has changed, please pay attention to users upgrading from older versions.
-
IvorySQL 4.4 requires gibc version >= 2.17, which is currently supported by Pigsty.
-
The last IvorySQL version supporting EL7 is 3.3, corresponding to PostgreSQL 16.3, and IvorySQL 4.x no longer supports EL7.
-
Pigsty does not assume any warranty for using the IvorySQL kernel, and any issues or requests should be addressed to the manufacturer.
4 - OpenHalo (MySQL)
The OpenHalo kernel provides a MySQL-compatible PostgreSQL kernel, which can be accessed using the MySQL client.
OpenHalo is an open-source PostgreSQL kernel that provides MySQL wire protocol compatibility.
OpenHalo is based on PostgreSQL 14.10 kernel version and provides wire protocol compatibility with MySQL 5.7.32-log / 8.0 version.
Currently, Pigsty provides deployment support for OpenHalo on EL systems, with Debian/Ubuntu system support planned for future releases.
Get Started
Use Pigsty’s standard installation process with the mysql configuration template.
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # Prepare Pigsty dependencies
./configure -c mysql # Use MySQL (openHalo) configuration template
./install.yml # Install, for production deployment please modify passwords in pigsty.yml first
For production deployment, please ensure to modify the password parameters in the pigsty.yml configuration file before running the installation playbook.
Usage
When accessing MySQL, the actual connection uses the postgres database.
Please note that the concept of “database” in MySQL actually corresponds to “Schema” in PostgreSQL.
Therefore, use mysql actually uses the mysql Schema within the postgres database.
The usernames and passwords used for MySQL are the same as those in PostgreSQL. You can manage users and permissions using the standard PostgreSQL approach.
Client Access
OpenHalo provides MySQL wire protocol compatibility, listening on port 3306 by default, allowing direct connections from MySQL clients and drivers.
Pigsty’s conf/mysql configuration installs the mysql client tool by default.
You can access MySQL using the following command:
mysql -h 127.0.0.1 -u dbuser_dba
Currently, OpenHalo officially ensures that Navicat can access this MySQL port normally, but Intellij IDEA’s DataGrip access will result in errors.
Modification
The OpenHalo kernel installed by Pigsty is based on the HaloTech-Co-Ltd/openHalo kernel with minor modifications:
- Changed the default database name from
halo0rootback topostgres - Removed the
1.0.prefix from the default version number, reverting to14.10 - Modified the default configuration file to enable MySQL compatibility and listen on port
3306by default
Please note that Pigsty does not provide any warranty for using the OpenHalo kernel. Any issues or requirements encountered while using this kernel should be addressed with the original vendor.
5 - OrioleDB (OLTP)
A PostgreSQL storage engine optimized for OLTP workloads, without xid wrapround & table bloat, and put data on S3
OrioleDB is a PostgreSQL storage engine extension that delivers 4x OLTP performance without xid wraparound & table bloat, and “cloud native” (data on s3) capabilities.
The latest version of OrioleDB is based on a Patched PostgreSQL 17.0 with additional extension
Currently, Pigsty has OrioleDB RDS support on EL 8/9 systems. Support for Debian/Ubuntu systems will be available in future releases.
Get Started
Follow the Pigsty standard installation and use the oriole config template.
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # Prepare Pigsty dependencies
./configure -c oriole # Use the OrioleDB configuration template
./install.yml # Install Pigsty with OrioleDB
For production deployments, make sure to modify the password parameters in the pigsty.yml config before running the install playbook.
Configuration
all:
children:
pg-orio:
vars:
pg_databases:
- {name: meta ,extensions: [orioledb]}
vars:
pg_mode: oriole
pg_version: 17
pg_packages: [ orioledb, pgsql-common ]
pg_libs: 'orioledb.so, pg_stat_statements, auto_explain'
repo_extra_packages: [ orioledb ]
Usage
To use OrioleDB, you need to install the orioledb_17 and oriolepg_17 packages (currently only available as RPMs).
Initialize TPC-B-like tables with 100 warehouses using pgbench:
pgbench -is 100 meta
pgbench -nv -P1 -c10 -S -T1000 meta
pgbench -nv -P1 -c50 -S -T1000 meta
pgbench -nv -P1 -c10 -T1000 meta
pgbench -nv -P1 -c50 -T1000 meta
Next, you can rebuild these tables using the orioledb storage engine and observe the performance differences:
-- Create OrioleDB tables
CREATE TABLE pgbench_accounts_o (LIKE pgbench_accounts INCLUDING ALL) USING orioledb;
CREATE TABLE pgbench_branches_o (LIKE pgbench_branches INCLUDING ALL) USING orioledb;
CREATE TABLE pgbench_history_o (LIKE pgbench_history INCLUDING ALL) USING orioledb;
CREATE TABLE pgbench_tellers_o (LIKE pgbench_tellers INCLUDING ALL) USING orioledb;
-- Copy data from regular tables to OrioleDB tables
INSERT INTO pgbench_accounts_o SELECT * FROM pgbench_accounts;
INSERT INTO pgbench_branches_o SELECT * FROM pgbench_branches;
INSERT INTO pgbench_history_o SELECT * FROM pgbench_history;
INSERT INTO pgbench_tellers_o SELECT * FROM pgbench_tellers;
-- Drop original tables and rename OrioleDB tables
DROP TABLE pgbench_accounts, pgbench_branches, pgbench_history, pgbench_tellers;
ALTER TABLE pgbench_accounts_o RENAME TO pgbench_accounts;
ALTER TABLE pgbench_branches_o RENAME TO pgbench_branches;
ALTER TABLE pgbench_history_o RENAME TO pgbench_history;
ALTER TABLE pgbench_tellers_o RENAME TO pgbench_tellers;
6 - PolarDB PG (RAC)
Replace vanilla PostgreSQL with PolarDB PG, which is an OSS Aurora similar to Oracle RAC
You can deploy an Aurora flavor of PostgreSQL, PolarDB, in Pigsty.
PolarDB is a distributed, shared-nothing, and high-availability database system that is compatible with PostgreSQL 15, open sourced by Aliyun.
Get Started
install Pigsty’s with the mssql config template.
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # Prepare Pigsty Dependencies
./configure -c polar # Use polar (PolarDB) template
./install.yml # Run Deployment Playbook
For production deployments, make sure to modify the password parameters in the pigsty.yml config before running the install playbook.
Notes
The following parameters need to be tuned to deploy a PolarDB cluster:
#----------------------------------#
# PGSQL & PolarDB
#----------------------------------#
pg_version: 15
pg_packages: [ 'polardb patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager' ]
pg_extensions: [ ] # do not install any vanilla postgresql extensions
pg_mode: polar # PolarDB Compatible Mode
pg_default_roles: # default roles and users in postgres cluster
- { name: dbrole_readonly ,login: false ,comment: role for global read-only access }
- { name: dbrole_offline ,login: false ,comment: role for restricted read-only access }
- { name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment: role for global read-write access }
- { name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment: role for object creation }
- { name: postgres ,superuser: true ,comment: system superuser }
- { name: replicator ,superuser: true ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator } # <- superuser is required for replication
- { name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 ,comment: pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor] ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
Client Access
PolarDB for PostgreSQL is essentially equivalent to PostgreSQL 11, and any client tools compatible with the PostgreSQL wire protocol can access the PolarDB cluster.
Installation
If your environment has internet access, you can directly add the PolarDB repository to the node and install it as a node package:
node_repo_modules: local,node,pgsql
node_packages: [ polardb ]
ånd then install the PolarDB kernel pacakge with the following command:
./node.yml -t node_repo,node_pkg
Extensions
Most of the PGSQL module’s extension (non pure-SQL) cannot be used directly on the PolarDB kernel. If you need to use them, you need to recompile and install from source code for the new kernel.
Currently, the PolarDB kernel comes with the following 61 extension plugins. In addition to Contrib extensions, the additional extensions provided include:
polar_csn1.0 : polar_csnpolar_monitor1.2 : examine the polardb informationpolar_monitor_preload1.1 : examine the polardb informationpolar_parameter_check1.0 : kernel extension for parameter validationpolar_px1.0 : Parallel Execution extensionpolar_stat_env1.0 : env stat functions for PolarDBpolar_stat_sql1.3 : Kernel statistics gathering, and sql plan nodes information gatheringpolar_tde_utils1.0 : Internal extension for TDEpolar_vfs1.0 : polar_vfspolar_worker1.0 : polar_workertimetravel1.0 : functions for implementing time travelvector0.5.1 : vector data type and ivfflat and hnsw access methodssmlar1.0 : compute similary of any one-dimensional arrays
Here is the list of extensions provided by the PolarDB kernel:
| name | version | comment |
|---|---|---|
| hstore_plpython2u | 1.0 | transform between hstore and plpython2u |
| dict_int | 1.0 | text search dictionary template for integers |
| adminpack | 2.0 | administrative functions for PostgreSQL |
| hstore_plpython3u | 1.0 | transform between hstore and plpython3u |
| amcheck | 1.1 | functions for verifying relation integrity |
| hstore_plpythonu | 1.0 | transform between hstore and plpythonu |
| autoinc | 1.0 | functions for autoincrementing fields |
| insert_username | 1.0 | functions for tracking who changed a table |
| bloom | 1.0 | bloom access method - signature file based index |
| file_fdw | 1.0 | foreign-data wrapper for flat file access |
| dblink | 1.2 | connect to other PostgreSQL databases from within a database |
| btree_gin | 1.3 | support for indexing common datatypes in GIN |
| fuzzystrmatch | 1.1 | determine similarities and distance between strings |
| lo | 1.1 | Large Object maintenance |
| intagg | 1.1 | integer aggregator and enumerator (obsolete) |
| btree_gist | 1.5 | support for indexing common datatypes in GiST |
| hstore | 1.5 | data type for storing sets of (key, value) pairs |
| intarray | 1.2 | functions, operators, and index support for 1-D arrays of integers |
| citext | 1.5 | data type for case-insensitive character strings |
| cube | 1.4 | data type for multidimensional cubes |
| hstore_plperl | 1.0 | transform between hstore and plperl |
| isn | 1.2 | data types for international product numbering standards |
| jsonb_plperl | 1.0 | transform between jsonb and plperl |
| dict_xsyn | 1.0 | text search dictionary template for extended synonym processing |
| hstore_plperlu | 1.0 | transform between hstore and plperlu |
| earthdistance | 1.1 | calculate great-circle distances on the surface of the Earth |
| pg_prewarm | 1.2 | prewarm relation data |
| jsonb_plperlu | 1.0 | transform between jsonb and plperlu |
| pg_stat_statements | 1.6 | track execution statistics of all SQL statements executed |
| jsonb_plpython2u | 1.0 | transform between jsonb and plpython2u |
| jsonb_plpython3u | 1.0 | transform between jsonb and plpython3u |
| jsonb_plpythonu | 1.0 | transform between jsonb and plpythonu |
| pg_trgm | 1.4 | text similarity measurement and index searching based on trigrams |
| pgstattuple | 1.5 | show tuple-level statistics |
| ltree | 1.1 | data type for hierarchical tree-like structures |
| ltree_plpython2u | 1.0 | transform between ltree and plpython2u |
| pg_visibility | 1.2 | examine the visibility map (VM) and page-level visibility info |
| ltree_plpython3u | 1.0 | transform between ltree and plpython3u |
| ltree_plpythonu | 1.0 | transform between ltree and plpythonu |
| seg | 1.3 | data type for representing line segments or floating-point intervals |
| moddatetime | 1.0 | functions for tracking last modification time |
| pgcrypto | 1.3 | cryptographic functions |
| pgrowlocks | 1.2 | show row-level locking information |
| pageinspect | 1.7 | inspect the contents of database pages at a low level |
| pg_buffercache | 1.3 | examine the shared buffer cache |
| pg_freespacemap | 1.2 | examine the free space map (FSM) |
| tcn | 1.0 | Triggered change notifications |
| plperl | 1.0 | PL/Perl procedural language |
| uuid-ossp | 1.1 | generate universally unique identifiers (UUIDs) |
| plperlu | 1.0 | PL/PerlU untrusted procedural language |
| refint | 1.0 | functions for implementing referential integrity (obsolete) |
| xml2 | 1.1 | XPath querying and XSLT |
| plpgsql | 1.0 | PL/pgSQL procedural language |
| plpython3u | 1.0 | PL/Python3U untrusted procedural language |
| pltcl | 1.0 | PL/Tcl procedural language |
| pltclu | 1.0 | PL/TclU untrusted procedural language |
| polar_csn | 1.0 | polar_csn |
| sslinfo | 1.2 | information about SSL certificates |
| polar_monitor | 1.2 | examine the polardb information |
| polar_monitor_preload | 1.1 | examine the polardb information |
| polar_parameter_check | 1.0 | kernel extension for parameter validation |
| polar_px | 1.0 | Parallel Execution extension |
| tablefunc | 1.0 | functions that manipulate whole tables, including crosstab |
| polar_stat_env | 1.0 | env stat functions for PolarDB |
| smlar | 1.0 | compute similary of any one-dimensional arrays |
| timetravel | 1.0 | functions for implementing time travel |
| tsm_system_rows | 1.0 | TABLESAMPLE method which accepts number of rows as a limit |
| polar_stat_sql | 1.3 | Kernel statistics gathering, and sql plan nodes information gathering |
| tsm_system_time | 1.0 | TABLESAMPLE method which accepts time in milliseconds as a limit |
| polar_tde_utils | 1.0 | Internal extension for TDE |
| polar_vfs | 1.0 | polar_vfs |
| polar_worker | 1.0 | polar_worker |
| unaccent | 1.1 | text search dictionary that removes accents |
| postgres_fdw | 1.0 | foreign-data wrapper for remote PostgreSQL servers |
- Pigsty Pro has offline installation support for PolarDB and its extensions
- Pigsty has partnership with Aliyun and can provide PolarDB kernel enterprise support for enterprise users
7 - PolarDB O(racle)
The commercial version of PolarDB for Oracle, only available in Pigsty Enterprise Edition.
Oracle Compatible version, Fork of PolarDB PG.
This is not available in OSS version. But quite similar to the PolarDB PG kernel
8 - Supabase (Firebase)
How to self-host Supabase with existing managed HA PostgreSQL cluster, and launch the stateless part with docker-compose?
Supabase —— Build in a weekend, Scale to millions
Supabase is the open-source Firebase alternative built upon PostgreSQL. It provides authentication, API, edge functions, real-time subscriptions, object storage, and vector embedding capabilities out of the box. All you need to do is to design the database schema and frontend, and you can quickly get things done without worrying about the backend development.
Supabase’s slogan is: “Build in a weekend, Scale to millions”. Supabase has great cost-effectiveness in small scales (4c8g) indeed. But there is no doubt that when you really grow to millions of users, some may choose to self-hosting their own Supabase —— for functionality, performance, cost, and other reasons.
That’s where Pigsty comes in. Pigsty provides a complete one-click self-hosting solution for Supabase. Self-hosted Supabase can enjoy full PostgreSQL monitoring, IaC, PITR, and high availability, the new PG 17 kernels (and 14-16), and 400 PostgreSQL extensions ready to use, and can take full advantage of the performance and cost advantages of modern hardware.
Quick Start
First, download & install pigsty as usual, with the supa config template:
curl -fsSL https://repo.pigsty.io/get | bash
./bootstrap # install deps (ansible)
./configure -c app/supa # use supa config template (IMPORTANT: CHANGE PASSWORDS!)
./install.yml # install pigsty, create ha postgres & minio clusters
./docker.yml
./app.yml
Please change the pigsty.yml config file according to your need before deploying Supabase. (Credentials)
Then, run the supabase.yml to launch stateless part of supabase.
./supabase.yml # launch stateless supabase containers with docker compose
You can access the supabase API / Web UI through the 80/443 infra portal,
with configured DNS for public domain, or a local /etc/hosts record with supa.pigsty pointing to the node also works.
Default username & password:
supabase:pigsty

Architecture
Pigsty’s supabase is based on the Supabase Docker Compose Template, with some slight modifications to fit-in Pigsty’s default ACL model.
The stateful part of this template is replaced by Pigsty’s managed HA PostgreSQL cluster and MinIO service. And the container part are stateless, so you can launch / destroy / run multiple supabase containers on the same PGSQL/MINIO cluster simultaneously to scale out.

The built-in supa.yml config template will create a single-node supabase, with a singleton PostgreSQL and SNSD MinIO server.
You can use Multinode PostgreSQL Clusters and MNMD MinIO Clusters / external S3 service instead in production, we will cover that later.
Config Details
When running the install.yml playbook, pigsty will prepare the MinIO & PostgreSQL according to the first part of supa.yml config template:
Usually the only thing that you need to change is the password part. Don’t forget to change other passwords (haproxy, grafana, patroni) in a real prod env!
PostgreSQL & MinIO Cluster Definition
all:
children:
# infra cluster for proxy, monitor, alert, etc..
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
# etcd cluster for ha postgres
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
# minio cluster, s3 compatible object storage
minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
# pg-meta, the underlying postgres database for supabase
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users:
# supabase roles: anon, authenticated, dashboard_user
- { name: anon ,login: false }
- { name: authenticated ,login: false }
- { name: dashboard_user ,login: false ,replication: true ,createdb: true ,createrole: true }
- { name: service_role ,login: false ,bypassrls: true }
# supabase users: please use the same password
- { name: supabase_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: true ,roles: [ dbrole_admin ] ,superuser: true ,replication: true ,createdb: true ,createrole: true ,bypassrls: true }
- { name: authenticator ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] }
- { name: supabase_auth_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_storage_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] ,createrole: true }
- { name: supabase_functions_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_replication_admin ,password: 'DBUser.Supa' ,replication: true ,roles: [ dbrole_admin ]}
- { name: supabase_read_only_user ,password: 'DBUser.Supa' ,bypassrls: true ,roles: [ dbrole_readonly, pg_read_all_data ] }
pg_databases:
- name: postgres
baseline: supabase.sql
owner: supabase_admin
comment: supabase postgres database
schemas: [ extensions ,auth ,realtime ,storage ,graphql_public ,supabase_functions ,_analytics ,_realtime ]
extensions:
- { name: pgcrypto ,schema: extensions } # 1.3 : cryptographic functions
- { name: pg_net ,schema: extensions } # 0.9.2 : async HTTP
- { name: pgjwt ,schema: extensions } # 0.2.0 : json web token API for postgres
- { name: uuid-ossp ,schema: extensions } # 1.1 : generate universally unique identifiers (UUIDs)
- { name: pgsodium } # 3.1.9 : pgsodium is a modern cryptography library for Postgres.
- { name: supabase_vault } # 0.2.8 : Supabase Vault Extension
- { name: pg_graphql } # 1.5.9 : pg_graphql: GraphQL support
- { name: pg_jsonschema } # 0.3.3 : pg_jsonschema: Validate json schema
- { name: wrappers } # 0.4.3 : wrappers: FDW collections
- { name: http } # 1.6 : http: allows web page retrieval inside the database.
- { name: pg_cron } # 1.6 : pg_cron: Job scheduler for PostgreSQL
- { name: timescaledb } # 2.17 : timescaledb: Enables scalable inserts and complex queries for time-series data
- { name: pg_tle } # 1.2 : pg_tle: Trusted Language Extensions for PostgreSQL
- { name: vector } # 0.8.0 : pgvector: the vector similarity search
# supabase required extensions
pg_libs: 'pg_stat_statements, plpgsql, plpgsql_check, pg_cron, pg_net, timescaledb, auto_explain, pg_tle, plan_filter'
pg_extensions: # extensions to be installed on this cluster
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
pg_parameters:
cron.database_name: postgres
pgsodium.enable_event_trigger: off
pg_hba_rules: # supabase hba rules, require access from docker network
- { user: all ,db: postgres ,addr: intra ,auth: pwd ,title: 'allow supabase access from intranet' }
- { user: all ,db: postgres ,addr: 172.17.0.0/16 ,auth: pwd ,title: 'allow access from local docker network' }
pg_vip_enabled: true
pg_vip_address: 10.10.10.2/24
pg_vip_interface: eth1
When you run the supabase.yml playbook, The resource folder app/supabase will be copy to /opt/supabase on target nodes (the supabase group).
With the default parameters file: .env and docker-compose.yml template.
# launch supabase stateless part with docker compose:
# ./supabase.yml
supabase:
hosts:
10.10.10.10: { supa_seq: 1 } # instance id
vars:
supa_cluster: supa # cluster name
docker_enabled: true # enable docker
# use these to pull docker images via proxy and mirror registries
#docker_registry_mirrors: ['https://docker.xxxxx.io']
#proxy_env: # add [OPTIONAL] proxy env to /etc/docker/daemon.json configuration file
# no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"
# #all_proxy: http://user:pass@host:port
# these configuration entries will OVERWRITE or APPEND to /opt/supabase/.env file (src template: app/supabase/.env)
# check https://github.com/pgsty/pigsty/blob/main/app/supabase/.env for default values
supa_config:
# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!
# https://supabase.com/docs/guides/self-hosting/docker#securing-your-services
jwt_secret: your-super-secret-jwt-token-with-at-least-32-characters-long
anon_key: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GE
service_role_key: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Q
dashboard_username: supabase
dashboard_password: pigsty
# postgres connection string (use the correct ip and port)
postgres_host: 10.10.10.10
postgres_port: 5436 # access via the 'default' service, which always route to the primary postgres
postgres_db: postgres
postgres_password: DBUser.Supa # password for supabase_admin and multiple supabase users
# expose supabase via domain name
site_url: http://supa.pigsty
api_external_url: http://supa.pigsty
supabase_public_url: http://supa.pigsty
# if using s3/minio as file storage
s3_bucket: supa
s3_endpoint: https://sss.pigsty:9000
s3_access_key: supabase
s3_secret_key: S3User.Supabase
s3_force_path_style: true
s3_protocol: https
s3_region: stub
minio_domain_ip: 10.10.10.10 # sss.pigsty domain name will resolve to this ip statically
# if using SMTP (optional)
#smtp_admin_email: [email protected]
#smtp_host: supabase-mail
#smtp_port: 2500
#smtp_user: fake_mail_user
#smtp_pass: fake_mail_password
#smtp_sender_name: fake_sender
#enable_anonymous_users: false
And the most important part is the supa_config parameter, it will be used to overwrite or append to the .env file in the /opt/supabase directory.
The most critical parameter is jwt_secret, and the corresponding anon_key and service_role_key.
For serious production use, please refer to the Supabase self-hosting guide and use their tools to generate these keys accordingly.
Pigsty uses local MinIO and PostgreSQL by default. You can overwrite the PostgreSQL connection string with postgres_host, postgres_port, postgres_db, and postgres_password.
if you want to use S3 or MinIO as file storage, you need to configure s3_bucket, s3_endpoint, s3_access_key, s3_secret_key, and other parameters accordingly.
Usually you also need to use an external SMTP service to send emails, consider using mature 3rd-party services such as Mailchimp, etc…
Expose Service
If you wish to expose service to the Internet, A public DNS will be required, please add your domain name to the infra_portal and update site_url, api_external_url, and supabase_public_url in supa_config as well:
# ./infra.yml -t nginx # domain names and upstream servers
infra_portal:
# ...
supa : { domain: supa.pigsty ,endpoint: "10.10.10.10:8000", websocket: true }
Make sure supa.pigsty or your own domain is resolvable to the infra_portal server, and you can access the supabase studio dashboard via https://supa.pigsty.
9 - Greenplum (MPP)
Deploy and monitoring Greenplum/YMatrix MPP clusters with Pigsty
Pigsty has native support for Greenplum and its derivative distribution YMatrixDB.
It can deploy Greenplum clusters and monitor them with Pigsty.
To define a Greenplum cluster, you need to specify the following parameters:
Set pg_mode = gpsql and the extra identity parameters pg_shard and gp_role.
#================================================================#
# GPSQL Clusters #
#================================================================#
#----------------------------------#
# cluster: mx-mdw (gp master)
#----------------------------------#
mx-mdw:
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary , nodename: mx-mdw-1 }
vars:
gp_role: master # this cluster is used as greenplum master
pg_shard: mx # pgsql sharding name & gpsql deployment name
pg_cluster: mx-mdw # this master cluster name is mx-mdw
pg_databases:
- { name: matrixmgr , extensions: [ { name: matrixdbts } ] }
- { name: meta }
pg_users:
- { name: meta , password: DBUser.Meta , pgbouncer: true }
- { name: dbuser_monitor , password: DBUser.Monitor , roles: [ dbrole_readonly ], superuser: true }
pgbouncer_enabled: true # enable pgbouncer for greenplum master
pgbouncer_exporter_enabled: false # enable pgbouncer_exporter for greenplum master
pg_exporter_params: 'host=127.0.0.1&sslmode=disable' # use 127.0.0.1 as local monitor host
#----------------------------------#
# cluster: mx-sdw (gp master)
#----------------------------------#
mx-sdw:
hosts:
10.10.10.11:
nodename: mx-sdw-1 # greenplum segment node
pg_instances: # greenplum segment instances
6000: { pg_cluster: mx-seg1, pg_seq: 1, pg_role: primary , pg_exporter_port: 9633 }
6001: { pg_cluster: mx-seg2, pg_seq: 2, pg_role: replica , pg_exporter_port: 9634 }
10.10.10.12:
nodename: mx-sdw-2
pg_instances:
6000: { pg_cluster: mx-seg2, pg_seq: 1, pg_role: primary , pg_exporter_port: 9633 }
6001: { pg_cluster: mx-seg3, pg_seq: 2, pg_role: replica , pg_exporter_port: 9634 }
10.10.10.13:
nodename: mx-sdw-3
pg_instances:
6000: { pg_cluster: mx-seg3, pg_seq: 1, pg_role: primary , pg_exporter_port: 9633 }
6001: { pg_cluster: mx-seg1, pg_seq: 2, pg_role: replica , pg_exporter_port: 9634 }
vars:
gp_role: segment # these are nodes for gp segments
pg_shard: mx # pgsql sharding name & gpsql deployment name
pg_cluster: mx-sdw # these segment clusters name is mx-sdw
pg_preflight_skip: true # skip preflight check (since pg_seq & pg_role & pg_cluster not exists)
pg_exporter_config: pg_exporter_basic.yml # use basic config to avoid segment server crash
pg_exporter_params: 'options=-c%20gp_role%3Dutility&sslmode=disable' # use gp_role = utility to connect to segments
Besides, you’ll need extra parameters to connect to Greenplum Segment instances for monitoring.
Since Greenplum is no longer Open-Sourced, this feature is only available in the Professional/Enterprise version and is not open-sourced at this time.
10 - Cloudberry (MPP)
Deploy Cloudberry MPP cluster, which is forked from Greenplum.
Install
Pigsty has cloudberry packages for EL 7/8/9:
./node.yml -t node_install -e '{"node_repo_modules":"pgsql","node_packages":["cloudberrydb"]}'
11 - Neon (Serverless)
Self-Hosting serverless version of PostgreSQL from Neon, which is a powerful, truly scalable, and elastic service.
Neon adopts a storage and compute separation architecture, offering seamless features such as auto-scaling, Scale to Zero, and unique capabilities like database version branching.
Neon official website: https://neon.tech/
Due to the substantial size of Neon’s compiled binaries, they are not currently available to open-source users. If you need them, please contact Pigsty sales.