This is the multi-page printable view of this section. Click here to print.
Concept
- 1: Architecture
- 2: Cluster Model
- 3: Monitor System
- 4: Self-Signed CA
- 5: Infra as Code
- 6: High Availability
- 7: Point-in-Time Recovery
- 8: Services & Access
- 9: Access Control
1 - Architecture
Modular Architecture and Declarative Interface!
- Pigsty deployment is described by config inventory and materialized with ansible playbooks.
- Pigsty works on Linux x86_64 common nodes, i.e., bare metals or virtual machines.
- Pigsty uses a modular design that can be freely composed for different scenarios.
- The config controls where & how to install modules with parameters
- The playbooks will adjust nodes into the desired status in an idempotent manner.
Modules
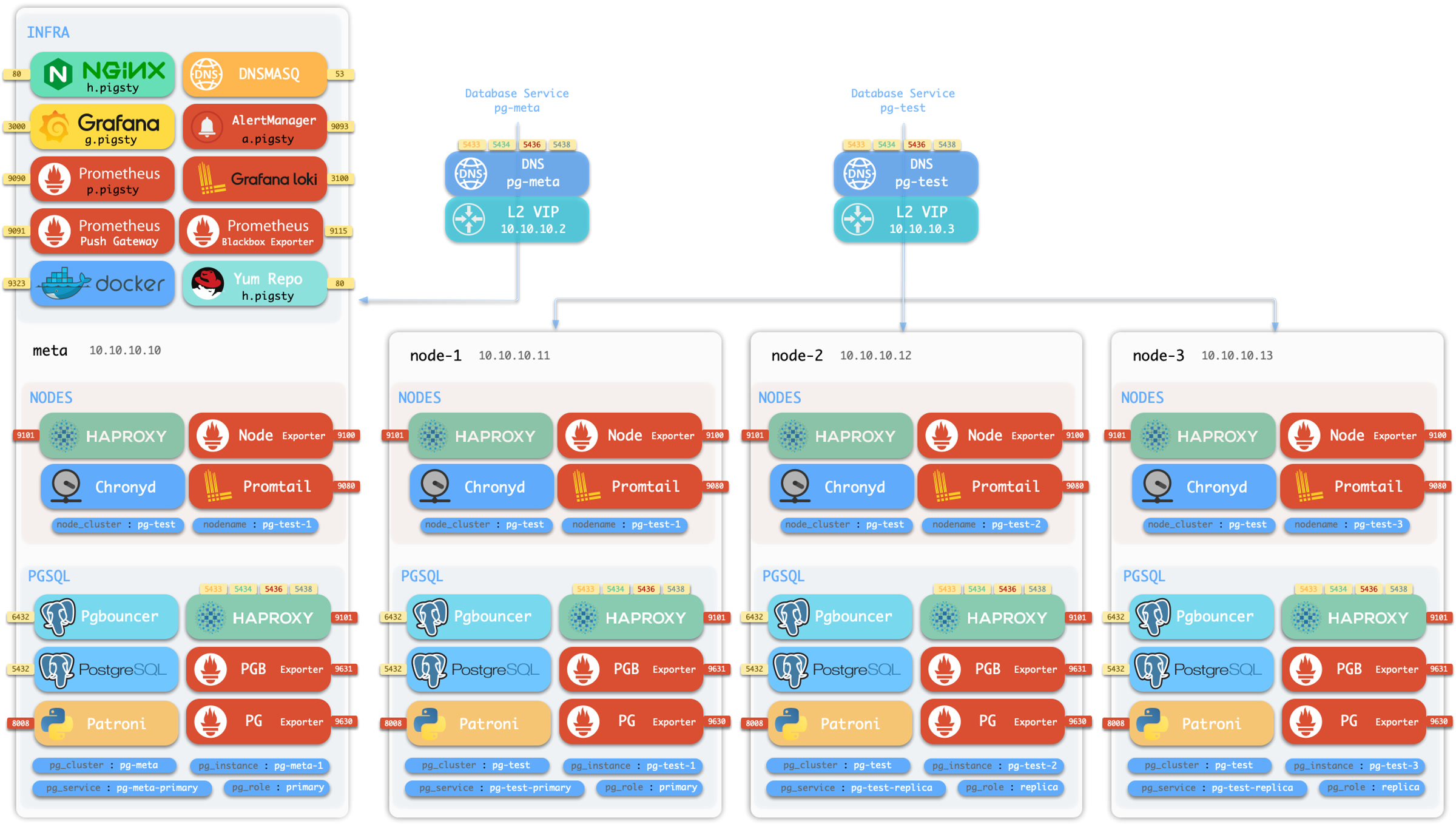
Pigsty uses a modular design, and there are six default modules: PGSQL, INFRA, NODE, ETCD, REDIS, and MINIO.
PGSQL: Autonomous ha Postgres cluster powered by Patroni, Pgbouncer, HAproxy, PgBackrest, etc…INFRA: Local yum/apt repo, Prometheus, Grafana, Loki, AlertManager, PushGateway, Blackbox Exporter…NODE: Tune node to desired state, name, timezone, NTP, ssh, sudo, haproxy, docker, promtail, keepalivedETCD: Distributed key-value store will be used as DCS for high-available Postgres clusters.REDIS: Redis servers in standalone master-replica, sentinel, cluster mode with Redis exporter.MINIO: S3 compatible simple object storage server, can be used as an optional backup center for Postgres.
You can compose them freely in a declarative manner. If you want host monitoring, INFRA & NODE will suffice. Add additional ETCD and PGSQL are used for HA PG Clusters. Deploying them on multiple nodes will form a ha cluster. You can reuse pigsty infra and develop your modules, considering optional REDIS and MINIO as examples.
Singleton Meta
Pigsty will install on a single node (BareMetal / VirtualMachine) by default. The install.yml playbook will install INFRA, ETCD, PGSQL, and optional MINIO modules on the current node, which will give you a full-featured observability infrastructure (Prometheus, Grafana, Loki, AlertManager, PushGateway, BlackboxExporter, etc… ) and a battery-included PostgreSQL Singleton Instance (Named meta).
This node now has a self-monitoring system, visualization toolsets, and a Postgres database with autoconfigured PITR. You can use this node for devbox, testing, running demos, and doing data visualization & analysis. Or, furthermore, adding more nodes to it!
Monitoring
The installed Singleton Meta can be use as an admin node and monitoring center, to take more nodes & Database servers under it’s surveillance & control.
If you want to install the Prometheus / Grafana observability stack, Pigsty just deliver the best practice for you! It has fine-grained dashboards for Nodes & PostgreSQL, no matter these nodes or PostgreSQL servers are managed by Pigsty or not, you can have a production-grade monitoring & alerting immediately with simple configuration.

HA PG Cluster
With Pigsty, you can have your own local production-grade HA PostgreSQL RDS as much as you want.
And to create such a HA PostgreSQL cluster, All you have to do is describe it & run the playbook:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica }
vars: { pg_cluster: pg-test }
$ bin/pgsql-add pg-test # init cluster 'pg-test'
Which will gives you a following cluster with monitoring , replica, backup all set.
Hardware failures are covered by self-healing HA architecture powered by patroni, etcd, and haproxy, which will perform auto failover in case of leader failure under 30 seconds. With the self-healing traffic control powered by haproxy, the client may not even notice there’s a failure at all, in case of a switchover or replica failure.
Software Failures, human errors, and DC Failure are covered by pgbackrest, and optional MinIO clusters. Which gives you the ability to perform point-in-time recovery to anytime (as long as your storage is capable)
Database as Code
Pigsty follows IaC & GitOPS philosophy: Pigsty deployment is described by declarative Config Inventory and materialized with idempotent playbooks.
The user describes the desired status with Parameters in a declarative manner, and the playbooks tune target nodes into that status in an idempotent manner. It’s like Kubernetes CRD & Operator but works on Bare Metals & Virtual Machines.

Take the default config snippet as an example, which describes a node 10.10.10.10 with modules INFRA, NODE, ETCD, and PGSQL installed.
# infra cluster for proxy, monitor, alert, etc...
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
# minio cluster, s3 compatible object storage
minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
# etcd cluster for ha postgres DCS
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
# postgres example cluster: pg-meta
pg-meta: { hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary }, vars: { pg_cluster: pg-meta } }
To materialize it, use the following playbooks:
./infra.yml -l infra # init infra module on group 'infra'
./etcd.yml -l etcd # init etcd module on group 'etcd'
./minio.yml -l minio # init minio module on group 'minio'
./pgsql.yml -l pg-meta # init pgsql module on group 'pgsql'
It would be straightforward to perform regular administration tasks. For example, if you wish to add a new replica/database/user to an existing HA PostgreSQL cluster, all you need to do is add a host in config & run that playbook on it, such as:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica } # <-- add new instance
vars: { pg_cluster: pg-test }
$ bin/pgsql-add pg-test 10.10.10.13
You can even manage many PostgreSQL Entities using this approach: User/Role, Database, Service, HBA Rules, Extensions, Schemas, etc…
Check PGSQL Conf for details.
2 - Cluster Model
PGSQL for production environments is organized in clusters, which clusters are logical entities consisting of a set of database instances associated by primary-replica. Each database cluster is an autonomous serving unit consisting of at least one database instance (primary).
ER Diagram
Let’s get started with ER diagram. There are four types of core entities in Pigsty’s PGSQL module:
- PGSQL Cluster: An autonomous PostgreSQL business unit, used as the top-level namespace for other entities.
- PGSQL Service: A named abstraction of cluster ability, route traffics, and expose postgres services with node ports.
- PGSQL Instance: A single postgres server which is a group of running processes & database files on a single node.
- PGSQL Node: An abstraction of hardware resources, which can be bare metal, virtual machine, or even k8s pods.
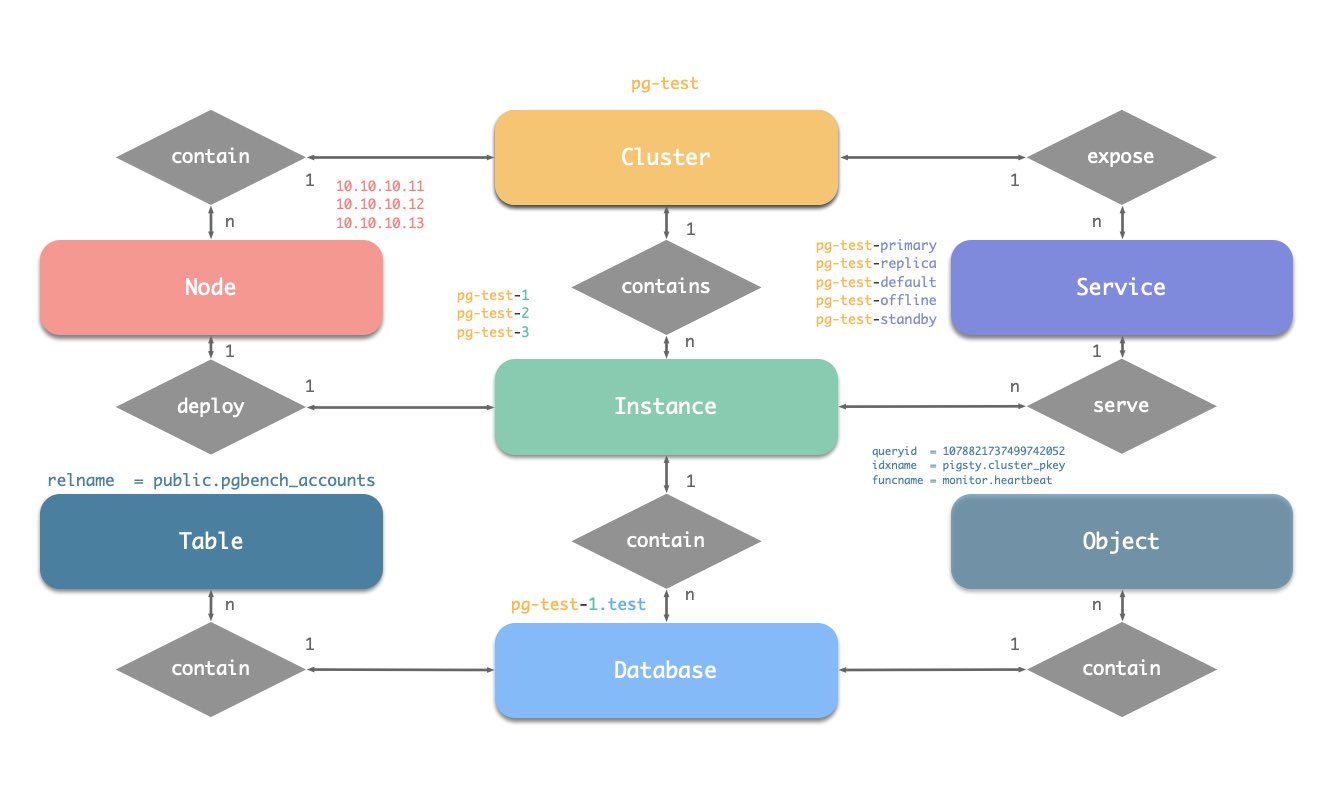
Naming Convention
- The cluster name should be a valid domain name, without any dot:
[a-zA-Z0-9-]+ - Service name should be prefixed with cluster name, and suffixed with a single word: such as
primary,replica,offline,delayed, join by- - Instance name is prefixed with cluster name and suffixed with an integer, join by
-, e.g.,${cluster}-${seq}. - Node is identified by its IP address, and its hostname is usually the same as the instance name since they are 1:1 deployed.
Identity Parameter
Pigsty uses identity parameters to identify entities: PG_ID.
In addition to the node IP address, three parameters: pg_cluster, pg_role, and pg_seq are the minimum set of parameters necessary to define a postgres cluster.
Take the sandbox testing cluster pg-test as an example:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica }
vars:
pg_cluster: pg-test
The three members of the cluster are identified as follows.
| cluster | seq | role | host / ip | instance | service | nodename |
|---|---|---|---|---|---|---|
pg-test |
1 |
primary |
10.10.10.11 |
pg-test-1 |
pg-test-primary |
pg-test-1 |
pg-test |
2 |
replica |
10.10.10.12 |
pg-test-2 |
pg-test-replica |
pg-test-2 |
pg-test |
3 |
replica |
10.10.10.13 |
pg-test-3 |
pg-test-replica |
pg-test-3 |
There are:
- One Cluster: The cluster is named as
pg-test. - Two Roles:
primaryandreplica. - Three Instances: The cluster consists of three instances:
pg-test-1,pg-test-2,pg-test-3. - Three Nodes: The cluster is deployed on three nodes:
10.10.10.11,10.10.10.12, and10.10.10.13. - Four services:
- read-write service:
pg-test-primary - read-only service:
pg-test-replica - directly connected management service:
pg-test-default - offline read service:
pg-test-offline
- read-write service:
And in the monitoring system (Prometheus/Grafana/Loki), corresponding metrics will be labeled with these identities:
pg_up{cls="pg-meta", ins="pg-meta-1", ip="10.10.10.10", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", job="pgsql"}
3 - Monitor System
4 - Self-Signed CA
Pigsty has some security best practices: encrypting network traffic with SSL and encrypting the Web interface with HTTPS.
To achieve this, Pigsty comes with a built-in local self-signed Certificate Authority (CA) for issuing SSL certificates to encrypt network communication.
By default, SSL and HTTPS are enabled but not enforced. For environments with higher security requirements, you can enforce the use of SSL and HTTPS.
Local CA
Pigsty, by default, generates a self-signed CA in the Pigsty source code directory (~/pigsty) on the ADMIN node during initialization. This CA is used when SSL, HTTPS, digital signatures, issuing database client certificates, and advanced security features are needed.
Hence, each Pigsty deployment uses a unique CA, and CAs from different Pigsty deployments do not trust each other.
The local CA consists of two files, typically located in the files/pki/ca directory:
ca.crt: The self-signed root CA certificate, which should be distributed and installed on all managed nodes for certificate verification.ca.key: The CA private key, used to issue certificates and verify CA identity. It should be securely stored to prevent leaks!
Protect Your CA Private Key File
Please securely store the CA private key file, do not lose it or let it leak. We recommend encrypting and backing up this file after completing the Pigsty installation.Using an Existing CA
If you already have a CA public and private key infrastructure, Pigsty can also be configured to use an existing CA.
Simply place your CA public and private key files in the files/pki/ca directory.
files/pki/ca/ca.key # The essential CA private key file, must exist; if not, a new one will be randomly generated by default
files/pki/ca/ca.crt # If a certificate file is absent, Pigsty will automatically generate a new root certificate file from the CA private key
When Pigsty executes the install.yml and infra.yml playbooks for installation, if the ca.key private key file is found in the files/pki/ca directory, the existing CA will be used. The ca.crt file can be generated from the ca.key private key, so if there is no certificate file, Pigsty will automatically generate a new root certificate file from the CA private key.
Note When Using an Existing CA
You can configure theca_method parameter as copy to ensure that Pigsty reports an error and halts if it cannot find the local CA, rather than automatically regenerating a new self-signed CA.
Trust CA
During the Pigsty installation, ca.crt is distributed to all nodes under the /etc/pki/ca.crt path during the node_ca task in the node.yml playbook.
The default paths for trusted CA root certificates differ between EL family and Debian family operating systems, hence the distribution path and update methods also vary.
rm -rf /etc/pki/ca-trust/source/anchors/ca.crt
ln -s /etc/pki/ca.crt /etc/pki/ca-trust/source/anchors/ca.crt
/bin/update-ca-trustrm -rf /usr/local/share/ca-certificates/ca.crt
ln -s /etc/pki/ca.crt /usr/local/share/ca-certificates/ca.crt
/usr/sbin/update-ca-certificatesBy default, Pigsty will issue HTTPS certificates for domain names used by web systems on infrastructure nodes, allowing you to access Pigsty’s web systems via HTTPS.
If you do not want your browser on the client computer to display “untrusted CA certificate” messages, you can distribute ca.crt to the trusted certificate directory on the client computer.
You can double-click the ca.crt file to add it to the system keychain, for example, on macOS systems, you need to open “Keychain Access,” search for pigsty-ca, and then “trust” this root certificate.
Check Cert
Use the following command to view the contents of the Pigsty CA certificate
openssl x509 -text -in /etc/pki/ca.crt
Local CA Root Cert Content
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
50:29:e3:60:96:93:f4:85:14:fe:44:81:73:b5:e1:09:2a:a8:5c:0a
Signature Algorithm: sha256WithRSAEncryption
Issuer: O=pigsty, OU=ca, CN=pigsty-ca
Validity
Not Before: Feb 7 00:56:27 2023 GMT
Not After : Jan 14 00:56:27 2123 GMT
Subject: O=pigsty, OU=ca, CN=pigsty-ca
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
Modulus:
00:c1:41:74:4f:28:c3:3c:2b:13:a2:37:05:87:31:
....
e6:bd:69:a5:5b:e3:b4:c0:65:09:6e:84:14:e9:eb:
90:f7:61
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Alternative Name:
DNS:pigsty-ca
X509v3 Key Usage:
Digital Signature, Certificate Sign, CRL Sign
X509v3 Basic Constraints: critical
CA:TRUE, pathlen:1
X509v3 Subject Key Identifier:
C5:F6:23:CE:BA:F3:96:F6:4B:48:A5:B1:CD:D4:FA:2B:BD:6F:A6:9C
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
89:9d:21:35:59:6b:2c:9b:c7:6d:26:5b:a9:49:80:93:81:18:
....
9e:dd:87:88:0d:c4:29:9e
-----BEGIN CERTIFICATE-----
...
cXyWAYcvfPae3YeIDcQpng==
-----END CERTIFICATE-----
Issue Database Client Certs
If you wish to authenticate via client certificates, you can manually issue PostgreSQL client certificates using the local CA and the cert.yml playbook.
Set the certificate’s CN field to the database username:
./cert.yml -e cn=dbuser_dba
./cert.yml -e cn=dbuser_monitor
The issued certificates will default to being generated in the files/pki/misc/<cn>.{key,crt} path.
5 - Infra as Code
Infra as Code, Database as Code, Declarative API & Idempotent Playbooks, GitOPS works like a charm.
Pigsty provides a declarative interface: Describe everything in a config file, and Pigsty operates it to the desired state with idempotent playbooks. It works like Kubernetes CRDs & Operators but for databases and infrastructures on any nodes: bare metal or virtual machines.
Declare Module
Take the default config snippet as an example, which describes a node 10.10.10.10 with modules INFRA, NODE, ETCD, and PGSQL installed.
# infra cluster for proxy, monitor, alert, etc...
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
# minio cluster, s3 compatible object storage
minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
# etcd cluster for ha postgres DCS
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
# postgres example cluster: pg-meta
pg-meta: { hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary }, vars: { pg_cluster: pg-meta } }
To materialize it, use the following playbooks:
./infra.yml -l infra # init infra module on node 10.10.10.10
./etcd.yml -l etcd # init etcd module on node 10.10.10.10
./minio.yml -l minio # init minio module on node 10.10.10.10
./pgsql.yml -l pg-meta # init pgsql module on node 10.10.10.10
Declare Cluster
You can declare the PGSQL module on multiple nodes, and form a cluster.
For example, to create a three-node HA cluster based on streaming replication, just adding the following definition to the all.children section of the config file pigsty.yml:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica } # <-- add new instance
vars: { pg_cluster: pg-test }
Then create the cluster with the pgsql.yml Playbook.
$ bin/pgsql-add pg-test 10.10.10.13
You can deploy different kinds of instance roles such as
primary, replica, offline, delayed, sync standby, and different kinds of clusters, such as standby clusters, Citus clusters, and even Redis / MinIO / Etcd clusters.
Declare Cluster Internal
Not only can you define clusters in a declarative manner, but you can also specify the databases, users, services, and HBA rules within the cluster. For example, the following configuration file deeply customizes the content of the default pg-meta single-node database cluster:
This includes declaring six business databases and seven business users, adding an additional standby service (a synchronous replica providing read capabilities with no replication delay), defining some extra pg_hba rules, an L2 VIP address pointing to the cluster’s primary database, and a customized backup strategy.
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary , pg_offline_query: true } }
vars:
pg_cluster: pg-meta
pg_databases: # define business databases on this cluster, array of database definition
- name: meta # REQUIRED, `name` is the only mandatory field of a database definition
baseline: cmdb.sql # optional, database sql baseline path, (relative path among ansible search path, e.g files/)
pgbouncer: true # optional, add this database to pgbouncer database list? true by default
schemas: [pigsty] # optional, additional schemas to be created, array of schema names
extensions: # optional, additional extensions to be installed: array of `{name[,schema]}`
- { name: postgis , schema: public }
- { name: timescaledb }
comment: pigsty meta database # optional, comment string for this database
owner: postgres # optional, database owner, postgres by default
template: template1 # optional, which template to use, template1 by default
encoding: UTF8 # optional, database encoding, UTF8 by default. (MUST same as template database)
locale: C # optional, database locale, C by default. (MUST same as template database)
lc_collate: C # optional, database collate, C by default. (MUST same as template database)
lc_ctype: C # optional, database ctype, C by default. (MUST same as template database)
tablespace: pg_default # optional, default tablespace, 'pg_default' by default.
allowconn: true # optional, allow connection, true by default. false will disable connect at all
revokeconn: false # optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)
register_datasource: true # optional, register this database to grafana datasources? true by default
connlimit: -1 # optional, database connection limit, default -1 disable limit
pool_auth_user: dbuser_meta # optional, all connection to this pgbouncer database will be authenticated by this user
pool_mode: transaction # optional, pgbouncer pool mode at database level, default transaction
pool_size: 64 # optional, pgbouncer pool size at database level, default 64
pool_size_reserve: 32 # optional, pgbouncer pool size reserve at database level, default 32
pool_size_min: 0 # optional, pgbouncer pool size min at database level, default 0
pool_max_db_conn: 100 # optional, max database connections at database level, default 100
- { name: grafana ,owner: dbuser_grafana ,revokeconn: true ,comment: grafana primary database }
- { name: bytebase ,owner: dbuser_bytebase ,revokeconn: true ,comment: bytebase primary database }
- { name: kong ,owner: dbuser_kong ,revokeconn: true ,comment: kong the api gateway database }
- { name: gitea ,owner: dbuser_gitea ,revokeconn: true ,comment: gitea meta database }
- { name: wiki ,owner: dbuser_wiki ,revokeconn: true ,comment: wiki meta database }
pg_users: # define business users/roles on this cluster, array of user definition
- name: dbuser_meta # REQUIRED, `name` is the only mandatory field of a user definition
password: DBUser.Meta # optional, password, can be a scram-sha-256 hash string or plain text
login: true # optional, can log in, true by default (new biz ROLE should be false)
superuser: false # optional, is superuser? false by default
createdb: false # optional, can create database? false by default
createrole: false # optional, can create role? false by default
inherit: true # optional, can this role use inherited privileges? true by default
replication: false # optional, can this role do replication? false by default
bypassrls: false # optional, can this role bypass row level security? false by default
pgbouncer: true # optional, add this user to pgbouncer user-list? false by default (production user should be true explicitly)
connlimit: -1 # optional, user connection limit, default -1 disable limit
expire_in: 3650 # optional, now + n days when this role is expired (OVERWRITE expire_at)
expire_at: '2030-12-31' # optional, YYYY-MM-DD 'timestamp' when this role is expired (OVERWRITTEN by expire_in)
comment: pigsty admin user # optional, comment string for this user/role
roles: [dbrole_admin] # optional, belonged roles. default roles are: dbrole_{admin,readonly,readwrite,offline}
parameters: {} # optional, role level parameters with `ALTER ROLE SET`
pool_mode: transaction # optional, pgbouncer pool mode at user level, transaction by default
pool_connlimit: -1 # optional, max database connections at user level, default -1 disable limit
- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly], comment: read-only viewer for meta database}
- {name: dbuser_grafana ,password: DBUser.Grafana ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for grafana database }
- {name: dbuser_bytebase ,password: DBUser.Bytebase ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for bytebase database }
- {name: dbuser_kong ,password: DBUser.Kong ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for kong api gateway }
- {name: dbuser_gitea ,password: DBUser.Gitea ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for gitea service }
- {name: dbuser_wiki ,password: DBUser.Wiki ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for wiki.js service }
pg_services: # extra services in addition to pg_default_services, array of service definition
# standby service will route {ip|name}:5435 to sync replica's pgbouncer (5435->6432 standby)
- name: standby # required, service name, the actual svc name will be prefixed with `pg_cluster`, e.g: pg-meta-standby
port: 5435 # required, service exposed port (work as kubernetes service node port mode)
ip: "*" # optional, service bind ip address, `*` for all ip by default
selector: "[]" # required, service member selector, use JMESPath to filter inventory
dest: default # optional, destination port, default|postgres|pgbouncer|<port_number>, 'default' by default
check: /sync # optional, health check url path, / by default
backup: "[? pg_role == `primary`]" # backup server selector
maxconn: 3000 # optional, max allowed front-end connection
balance: roundrobin # optional, haproxy load balance algorithm (roundrobin by default, other: leastconn)
options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
pg_hba_rules:
- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title: 'allow grafana dashboard access cmdb from infra nodes'}
pg_vip_enabled: true
pg_vip_address: 10.10.10.2/24
pg_vip_interface: eth1
node_crontab: # make a full backup 1 am everyday
- '00 01 * * * postgres /pg/bin/pg-backup full'
Declare Access Control
You can also deeply customize Pigsty’s access control capabilities through declarative configuration. For example, the following configuration file provides deep security customization for the pg-meta cluster:
- Utilizes a three-node core cluster template:
crit.yml, to ensure data consistency is prioritized, with zero data loss during failover. - Enables L2 VIP, and restricts the database and connection pool listening addresses to three specific addresses: local loopback IP, internal network IP, and VIP.
- The template mandatorily enables SSL API for Patroni and SSL for Pgbouncer, and in the HBA rules, it enforces SSL usage for accessing the database cluster.
- Additionally, the
$libdir/passwordcheckextension is enabled inpg_libsto enforce a password strength security policy.
Lastly, a separate pg-meta-delay cluster is declared as a delayed replica of pg-meta from one hour ago, for use in emergency data deletion recovery.
pg-meta: # 3 instance postgres cluster `pg-meta`
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary }
10.10.10.11: { pg_seq: 2, pg_role: replica }
10.10.10.12: { pg_seq: 3, pg_role: replica , pg_offline_query: true }
vars:
pg_cluster: pg-meta
pg_conf: crit.yml
pg_users:
- { name: dbuser_meta , password: DBUser.Meta , pgbouncer: true , roles: [ dbrole_admin ] , comment: pigsty admin user }
- { name: dbuser_view , password: DBUser.Viewer , pgbouncer: true , roles: [ dbrole_readonly ] , comment: read-only viewer for meta database }
pg_databases:
- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions: [{name: postgis, schema: public}, {name: timescaledb}]}
pg_default_service_dest: postgres
pg_services:
- { name: standby ,src_ip: "*" ,port: 5435 , dest: default ,selector: "[]" , backup: "[? pg_role == `primary`]" }
pg_vip_enabled: true
pg_vip_address: 10.10.10.2/24
pg_vip_interface: eth1
pg_listen: '${ip},${vip},${lo}'
patroni_ssl_enabled: true
pgbouncer_sslmode: require
pgbackrest_method: minio
pg_libs: 'timescaledb, $libdir/passwordcheck, pg_stat_statements, auto_explain' # add passwordcheck extension to enforce strong password
pg_default_roles: # default roles and users in postgres cluster
- { name: dbrole_readonly ,login: false ,comment: role for global read-only access }
- { name: dbrole_offline ,login: false ,comment: role for restricted read-only access }
- { name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment: role for global read-write access }
- { name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment: role for object creation }
- { name: postgres ,superuser: true ,expire_in: 7300 ,comment: system superuser }
- { name: replicator ,replication: true ,expire_in: 7300 ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator }
- { name: dbuser_dba ,superuser: true ,expire_in: 7300 ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment: pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor] ,expire_in: 7300 ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
pg_default_hba_rules: # postgres host-based auth rules by default
- {user: '${dbsu}' ,db: all ,addr: local ,auth: ident ,title: 'dbsu access via local os user ident' }
- {user: '${dbsu}' ,db: replication ,addr: local ,auth: ident ,title: 'dbsu replication from local os ident' }
- {user: '${repl}' ,db: replication ,addr: localhost ,auth: ssl ,title: 'replicator replication from localhost'}
- {user: '${repl}' ,db: replication ,addr: intra ,auth: ssl ,title: 'replicator replication from intranet' }
- {user: '${repl}' ,db: postgres ,addr: intra ,auth: ssl ,title: 'replicator postgres db from intranet' }
- {user: '${monitor}' ,db: all ,addr: localhost ,auth: pwd ,title: 'monitor from localhost with password' }
- {user: '${monitor}' ,db: all ,addr: infra ,auth: ssl ,title: 'monitor from infra host with password'}
- {user: '${admin}' ,db: all ,addr: infra ,auth: ssl ,title: 'admin @ infra nodes with pwd & ssl' }
- {user: '${admin}' ,db: all ,addr: world ,auth: cert ,title: 'admin @ everywhere with ssl & cert' }
- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: ssl ,title: 'pgbouncer read/write via local socket'}
- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: ssl ,title: 'read/write biz user via password' }
- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: ssl ,title: 'allow etl offline tasks from intranet'}
pgb_default_hba_rules: # pgbouncer host-based authentication rules
- {user: '${dbsu}' ,db: pgbouncer ,addr: local ,auth: peer ,title: 'dbsu local admin access with os ident'}
- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title: 'allow all user local access with pwd' }
- {user: '${monitor}' ,db: pgbouncer ,addr: intra ,auth: ssl ,title: 'monitor access via intranet with pwd' }
- {user: '${monitor}' ,db: all ,addr: world ,auth: deny ,title: 'reject all other monitor access addr' }
- {user: '${admin}' ,db: all ,addr: intra ,auth: ssl ,title: 'admin access via intranet with pwd' }
- {user: '${admin}' ,db: all ,addr: world ,auth: deny ,title: 'reject all other admin access addr' }
- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'allow all user intra access with pwd' }
# OPTIONAL delayed cluster for pg-meta
pg-meta-delay: # delayed instance for pg-meta (1 hour ago)
hosts: { 10.10.10.13: { pg_seq: 1, pg_role: primary, pg_upstream: 10.10.10.10, pg_delay: 1h } }
vars: { pg_cluster: pg-meta-delay }
Citus Distributive Cluster
Example: Citus Distributed Cluster: 5 Nodes
all:
children:
pg-citus0: # citus coordinator, pg_group = 0
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus0 , pg_group: 0 }
pg-citus1: # citus data node 1
hosts: { 10.10.10.11: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus1 , pg_group: 1 }
pg-citus2: # citus data node 2
hosts: { 10.10.10.12: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus2 , pg_group: 2 }
pg-citus3: # citus data node 3, with an extra replica
hosts:
10.10.10.13: { pg_seq: 1, pg_role: primary }
10.10.10.14: { pg_seq: 2, pg_role: replica }
vars: { pg_cluster: pg-citus3 , pg_group: 3 }
vars: # global parameters for all citus clusters
pg_mode: citus # pgsql cluster mode: citus
pg_shard: pg-citus # citus shard name: pg-citus
patroni_citus_db: meta # citus distributed database name
pg_dbsu_password: DBUser.Postgres # all dbsu password access for citus cluster
pg_libs: 'citus, timescaledb, pg_stat_statements, auto_explain' # citus will be added by patroni automatically
pg_extensions:
- postgis34_${ pg_version }* timescaledb-2-postgresql-${ pg_version }* pgvector_${ pg_version }* citus_${ pg_version }*
pg_users: [ { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [ dbrole_admin ] } ]
pg_databases: [ { name: meta ,extensions: [ { name: citus }, { name: postgis }, { name: timescaledb } ] } ]
pg_hba_rules:
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title: 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'all user ssl access from intranet' }
Redis Clusters
Example: Redis Cluster/Sentinel/Standalone
redis-ms: # redis classic primary & replica
hosts: { 10.10.10.10: { redis_node: 1 , redis_instances: { 6379: { }, 6380: { replica_of: '10.10.10.10 6379' } } } }
vars: { redis_cluster: redis-ms ,redis_password: 'redis.ms' ,redis_max_memory: 64MB }
redis-meta: # redis sentinel x 3
hosts: { 10.10.10.11: { redis_node: 1 , redis_instances: { 26379: { } ,26380: { } ,26381: { } } } }
vars:
redis_cluster: redis-meta
redis_password: 'redis.meta'
redis_mode: sentinel
redis_max_memory: 16MB
redis_sentinel_monitor: # primary list for redis sentinel, use cls as name, primary ip:port
- { name: redis-ms, host: 10.10.10.10, port: 6379 ,password: redis.ms, quorum: 2 }
redis-test: # redis native cluster: 3m x 3s
hosts:
10.10.10.12: { redis_node: 1 ,redis_instances: { 6379: { } ,6380: { } ,6381: { } } }
10.10.10.13: { redis_node: 2 ,redis_instances: { 6379: { } ,6380: { } ,6381: { } } }
vars: { redis_cluster: redis-test ,redis_password: 'redis.test' ,redis_mode: cluster, redis_max_memory: 32MB }
Etcd Cluster
Example: ETCD 3 Node Cluster
etcd: # dcs service for postgres/patroni ha consensus
hosts: # 1 node for testing, 3 or 5 for production
10.10.10.10: { etcd_seq: 1 } # etcd_seq required
10.10.10.11: { etcd_seq: 2 } # assign from 1 ~ n
10.10.10.12: { etcd_seq: 3 } # odd number please
vars: # cluster level parameter override roles/etcd
etcd_cluster: etcd # mark etcd cluster name etcd
etcd_safeguard: false # safeguard against purging
etcd_clean: true # purge etcd during init process
MinIO Cluster
Example: Minio 3 Node Deployment
minio:
hosts:
10.10.10.10: { minio_seq: 1 }
10.10.10.11: { minio_seq: 2 }
10.10.10.12: { minio_seq: 3 }
vars:
minio_cluster: minio
minio_data: '/data{1...2}' # use two disk per node
minio_node: '${minio_cluster}-${minio_seq}.pigsty' # minio node name pattern
haproxy_services:
- name: minio # [REQUIRED] service name, unique
port: 9002 # [REQUIRED] service port, unique
options:
- option httpchk
- option http-keep-alive
- http-check send meth OPTIONS uri /minio/health/live
- http-check expect status 200
servers:
- { name: minio-1 ,ip: 10.10.10.10 , port: 9000 , options: 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
- { name: minio-2 ,ip: 10.10.10.11 , port: 9000 , options: 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
- { name: minio-3 ,ip: 10.10.10.12 , port: 9000 , options: 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
6 - High Availability
Overview
Primary Failure RTO ≈ 30s, RPO < 1MB, Replica Failure RTO≈0 (reset current conn)
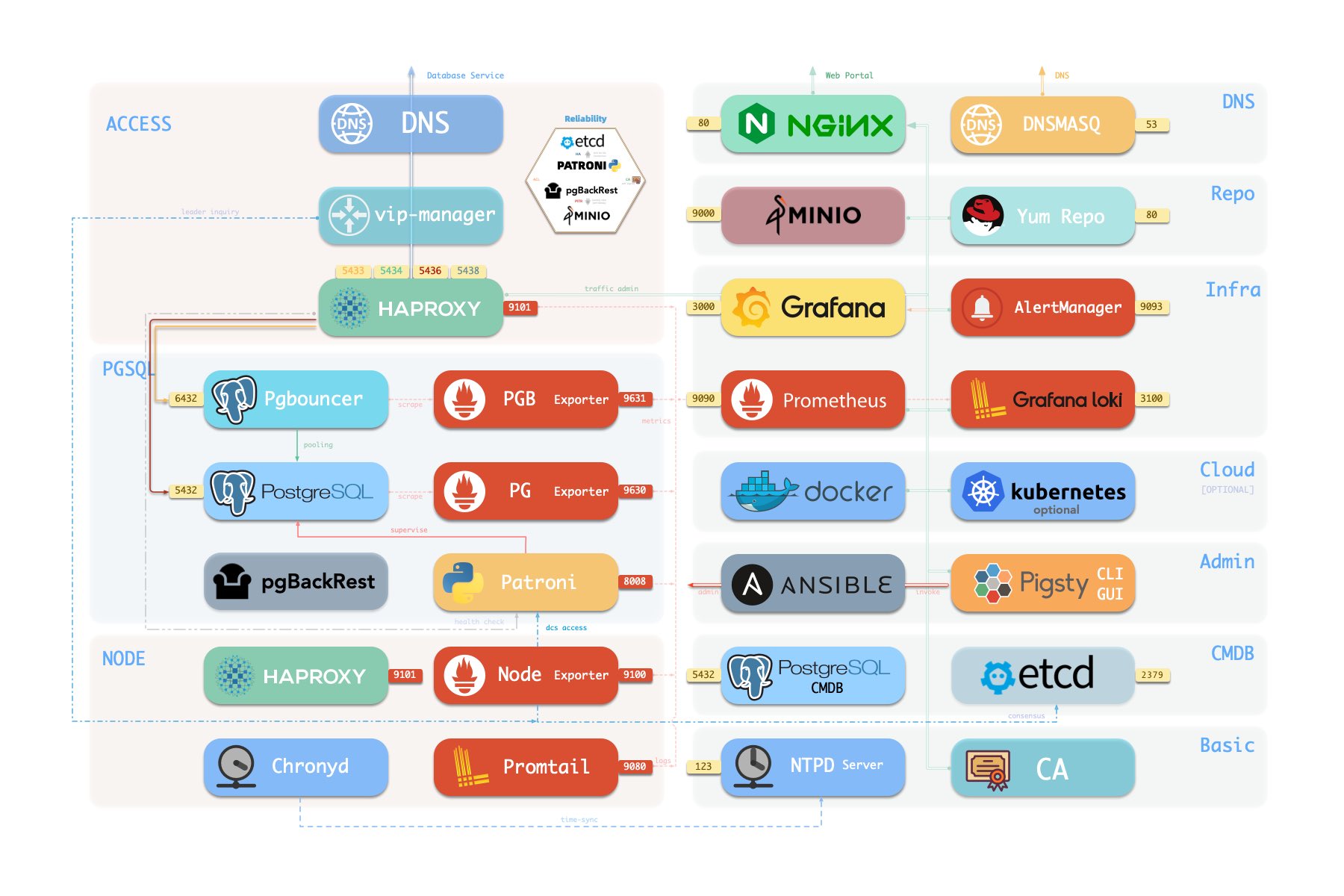
Pigsty’s PostgreSQL cluster has battery-included high-availability powered by Patroni, Etcd, and HAProxy
When your have two or more instances in the PostgreSQL cluster, you have the ability to self-healing from hardware failures without any further configuration — as long as any instance within the cluster survives, the cluster can serve its services. Clients simply need to connect to any node in the cluster to obtain full services without worrying about replication topology changes.
By default, the recovery time objective (RTO) for primary failure is approximately 30s ~ 60s, and the data recovery point objective (RPO) is < 1MB; for standby failure, RPO = 0, RTO ≈ 0 (instantaneous). In consistency-first mode, zero data loss during failover is guaranteed: RPO = 0. These metrics can be configured as needed based on your actual hardware conditions and reliability requirements.
Pigsty incorporates an HAProxy load balancer for automatic traffic switching, offering multiple access methods for clients such as DNS/VIP/LVS. Failovers and switchover are almost imperceptible to the business side except for sporadic interruptions, meaning applications do not need connection string modifications or restarts.
What problems does High-Availability solve?
- Elevates the availability aspect of data safety C/IA to a new height: RPO ≈ 0, RTO < 30s.
- Enables seamless rolling maintenance capabilities, minimizing maintenance window requirements for great convenience.
- Hardware failures can self-heal immediately without human intervention, allowing operations DBAs to sleep soundly.
- Standbys can carry read-only requests, sharing the load with the primary to make full use of resources.
What are the costs of High Availability?
- Infrastructure dependency: High availability relies on DCS (etcd/zk/consul) for consensus.
- Increased entry barrier: A meaningful high-availability deployment environment requires at least three nodes.
- Additional resource consumption: Each new standby consumes additional resources, which isn’t a major issue.
- Significantly higher complexity costs: Backup costs significantly increase, requiring tools to manage complexity.
Limitations of High Availability
Since replication is real-time, all changes are immediately applied to the standby. Thus, high-availability solutions based on streaming replication cannot address human errors and software defects that cause data deletions or modifications. (e.g., DROP TABLE, or DELETE data)
Such failures require the use of Delayed Clusters or Point-In-Time Recovery using previous base backups and WAL archives.
| Strategy | RTO (Time to Recover) | RPO (Max Data Loss) |
|---|---|---|
| Standalone + Do Nothing | Permanent data loss, irrecoverable | Total data loss |
| Standalone + Basic Backup | Depends on backup size and bandwidth (hours) | Loss of data since last backup (hours to days) |
| Standalone + Basic Backup + WAL Archiving |
Depends on backup size and bandwidth (hours) | Loss of last unarchived data (tens of MB) |
| Primary-Replica + Manual Failover | Dozens of minutes | Replication Lag (about 100KB) |
| Primary-Replica + Auto Failover | Within a minute | Replication Lag (about 100KB) |
| Primary-Replica + Auto Failover + Synchronous Commit |
Within a minute | No data loss |
Implementation
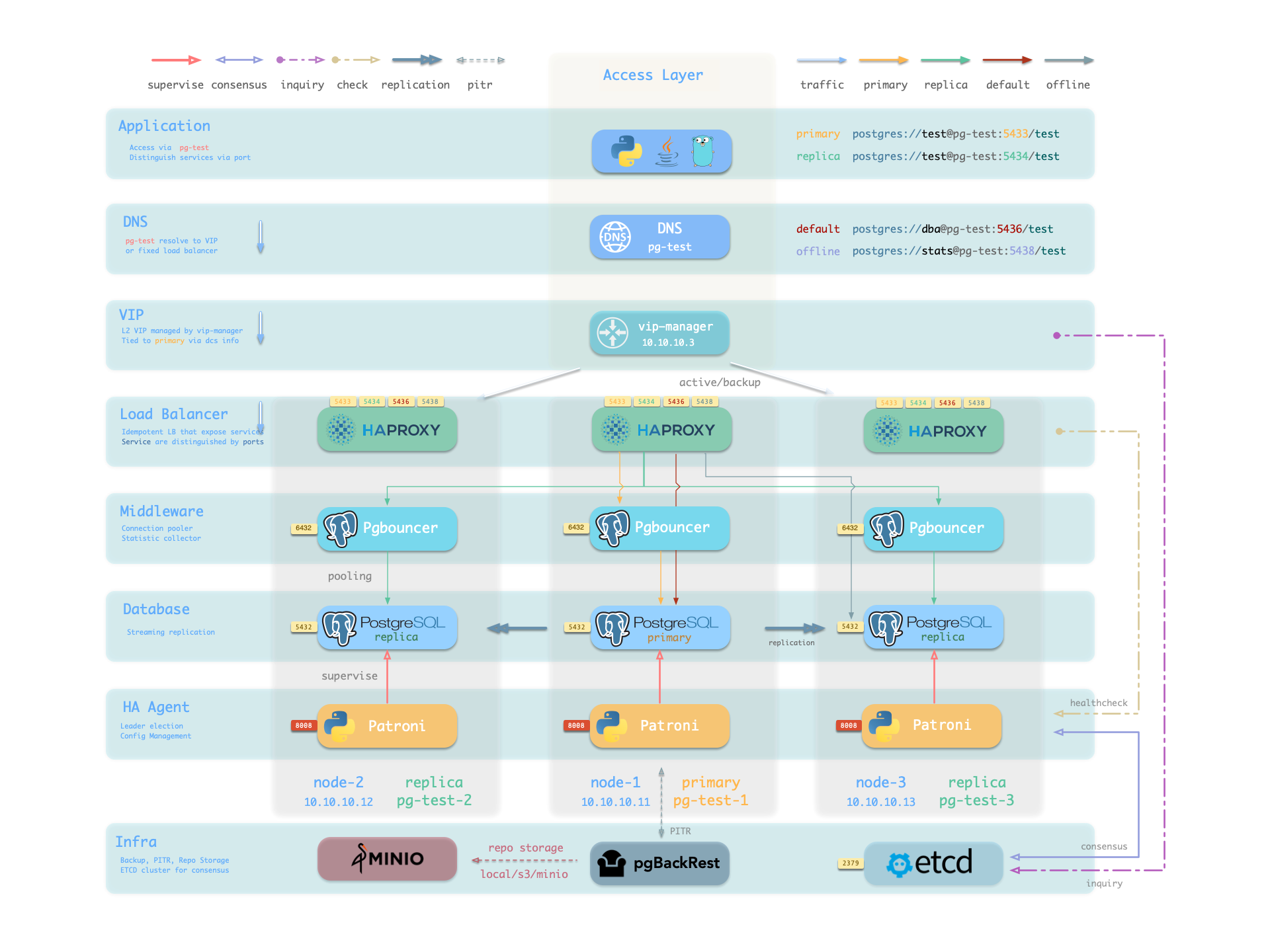
In Pigsty, the high-availability architecture works as follows:
- PostgreSQL uses standard streaming replication to set up physical standby databases. In case of a primary database failure, the standby takes over.
- Patroni is responsible for managing PostgreSQL server processes and handles high-availability-related matters.
- Etcd provides Distributed Configuration Store (DCS) capabilities and is used for leader election after a failure.
- Patroni relies on Etcd to reach a consensus on cluster leadership and offers a health check interface to the outside.
- HAProxy exposes cluster services externally and utilizes the Patroni health check interface to automatically route traffic to healthy nodes.
- vip-manager offers an optional layer 2 VIP, retrieves leader information from Etcd, and binds the VIP to the node hosting the primary database.
Upon primary database failure, a new round of leader election is triggered. The healthiest standby in the cluster (with the highest LSN and least data loss) wins and is promoted to the new primary. After the promotion of the winning standby, read-write traffic is immediately routed to the new primary. The impact of a primary failure is temporary unavailability of write services: from the primary’s failure to the promotion of a new primary, write requests will be blocked or directly fail, typically lasting 15 to 30 seconds, usually not exceeding 1 minute.
When a standby fails, read-only traffic is routed to other standbys. If all standbys fail, the primary will eventually carry the read-only traffic. The impact of a standby failure is partial read-only query interruption: queries currently running on the failed standby will be aborted due to connection reset and immediately taken over by another available standby.
Failure detection is jointly completed by Patroni and Etcd. The cluster leader holds a lease, if the cluster leader fails to renew the lease in time (10s) due to a failure, the lease will be released, triggering a failover and a new round of cluster elections.
Even without any failures, you can still proactively perform a Switchover to change the primary of the cluster. In this case, write queries on the primary will be interrupted and immediately routed to the new primary for execution. This operation can typically be used for rolling maintenance/upgrades of the database server.
Trade Offs
The ttl can be tuned with pg_rto, which is 30s by default, increasing it will cause longer failover wait time, while decreasing it will increase the false-positive failover rate (e.g. network jitter).
Pigsty will use availability first mode by default, which means when primary fails, it will try to failover ASAP, data not replicated to the replica may be lost (usually 100KB), and the max potential data loss is controlled by pg_rpo, which is 1MB by default.
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are two parameters that need careful consideration when designing a high-availability cluster.
The default values of RTO and RPO used by Pigsty meet the reliability requirements for most scenarios. You can adjust them based on your hardware level, network quality, and business needs.
Smaller RTO and RPO are not always better!
A smaller RTO increases the likelihood of false positives, and a smaller RPO reduces the probability of successful automatic failovers.The maximum duration of unavailability during a failover is controlled by the pg_rto parameter, with a default value of 30s. Increasing it will lead to a longer duration of unavailability for write operations during primary failover, while decreasing it will increase the rate of false failovers (e.g., due to brief network jitters).
The upper limit of potential data loss is controlled by the pg_rpo parameter, defaulting to 1MB. Lowering this value can reduce the upper limit of data loss during failovers but also increases the likelihood of refusing automatic failovers due to insufficiently healthy standbys (too far behind).
Pigsty defaults to an availability-first mode, meaning that it will proceed with a failover as quickly as possible when the primary fails, and data not yet replicated to the standby might be lost (under regular ten-gigabit networks, replication delay is usually between a few KB to 100KB).
If you need to ensure no data loss during failovers, you can use the crit.yml template to ensure no data loss during failovers, but this will come at the cost of some performance.
Parameters
pg_rto
name: pg_rto, type: int, level: C
recovery time objective in seconds, This will be used as Patroni TTL value, 30s by default.
If a primary instance is missing for such a long time, a new leader election will be triggered.
Decrease the value can reduce the unavailable time (unable to write) of the cluster during failover, but it will make the cluster more sensitive to network jitter, thus increase the chance of false-positive failover.
Config this according to your network condition and expectation to trade-off between chance and impact, the default value is 30s, and it will be populated to the following patroni parameters:
# the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30
ttl: {{ pg_rto }}
# the number of seconds the loop will sleep. Default value: 10 , this is patroni check loop interval
loop_wait: {{ (pg_rto / 3)|round(0, 'ceil')|int }}
# timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10
retry_timeout: {{ (pg_rto / 3)|round(0, 'ceil')|int }}
# the amount of time a primary is allowed to recover from failures before failover is triggered (in seconds), Max RTO: 2 loop wait + primary_start_timeout
primary_start_timeout: {{ (pg_rto / 3)|round(0, 'ceil')|int }}
pg_rpo
name: pg_rpo, type: int, level: C
recovery point objective in bytes, 1MiB at most by default
default values: 1048576, which will tolerate at most 1MiB data loss during failover.
when the primary is down and all replicas are lagged, you have to make a tough choice to trade off between Availability and Consistency:
- Promote a replica to be the new primary and bring system back online ASAP, with the price of an acceptable data loss (e.g. less than 1MB).
- Wait for the primary to come back (which may never be) or human intervention to avoid any data loss.
You can use crit.yml crit.yml template to ensure no data loss during failover, but it will sacrifice some performance.
7 - Point-in-Time Recovery
Overview
You can roll back your cluster to any point in time, avoiding data loss caused by software defects and human errors.
Pigsty’s PostgreSQL clusters come with an automatically configured Point in Time Recovery (PITR) solution, based on the backup component pgBackRest and the optional object storage repository MinIO.
High Availability solutions can address hardware failures, but they are powerless against data deletions/overwrites/deletions caused by software defects and human errors. For such scenarios, Pigsty offers an out-of-the-box Point in Time Recovery (PITR) capability, enabled by default without any additional configuration.
Pigsty provides you with the default configuration for base backups and WAL archiving, allowing you to use local directories and disks, or dedicated MinIO clusters or S3 object storage services to store backups and achieve off-site disaster recovery. When using local disks, by default, you retain the ability to recover to any point in time within the past day. When using MinIO or S3, by default, you retain the ability to recover to any point in time within the past week. As long as storage space permits, you can keep a recoverable time span as long as desired, based on your budget.
What problems does Point in Time Recovery (PITR) solve?
- Enhanced disaster recovery capability: RPO reduces from ∞ to a few MBs, RTO from ∞ to a few hours/minutes.
- Ensures data security: Data Integrity among C/I/A: avoids data consistency issues caused by accidental deletions.
- Ensures data security: Data Availability among C/I/A: provides a safety net for “permanently unavailable” disasters.
| Singleton Strategy | Event | RTO | RPO |
|---|---|---|---|
| Do nothing | Crash | Permanently lost | All lost |
| Basic backup | Crash | Depends on backup size and bandwidth (a few hours) | Loss of data after the last backup (a few hours to days) |
| Basic backup + WAL Archiving | Crash | Depends on backup size and bandwidth (a few hours) | Loss of data not yet archived (a few dozen MBs) |
What are the costs of Point in Time Recovery?
- Reduced C in data security: Confidentiality, creating additional leakage points, requiring extra protection for backups.
- Additional resource consumption: local storage or network traffic/bandwidth costs, usually not a problem.
- Increased complexity cost: users need to invest in backup management.
Limitations of Point in Time Recovery
If PITR is the only method for fault recovery, the RTO and RPO metrics are inferior compared to High Availability solutions, and it’s usually best to use both in combination.
- RTO: With only a single machine + PITR, recovery time depends on backup size and network/disk bandwidth, ranging from tens of minutes to several hours or days.
- RPO: With only a single machine + PITR, a crash might result in the loss of a small amount of data, as one or several WAL log segments might not yet be archived, losing between 16 MB to several dozen MBs of data.
Apart from PITR, you can also use Delayed Clusters in Pigsty to address data deletion or alteration issues caused by human errors or software defects.
How does PITR works?
Point in Time Recovery allows you to roll back your cluster to any “specific moment” in the past, avoiding data loss caused by software defects and human errors. To achieve this, two key preparations are necessary: Base Backups and WAL Archiving. Having a Base Backup allows users to restore the database to the state at the time of the backup, while having WAL Archiving from a certain base backup enables users to restore the database to any point in time after the base backup.
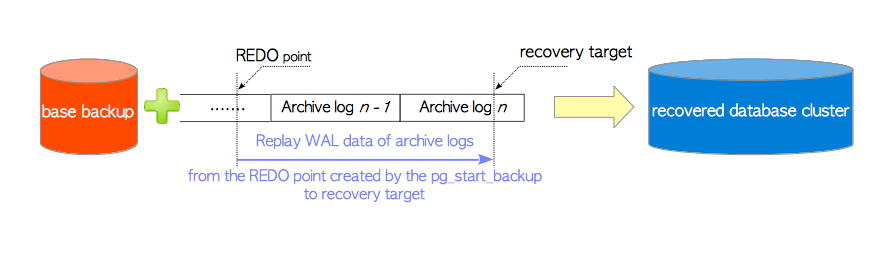
For a detailed principle, refer to: Base Backups and Point in Time Recovery; for specific operations, refer to PGSQL Management: Backup and Restore.
Base Backups
Pigsty uses pgBackRest to manage PostgreSQL backups. pgBackRest will initialize an empty repository on all cluster instances, but it will only use the repository on the primary instance.
pgBackRest supports three backup modes: Full Backup, Incremental Backup, and Differential Backup, with the first two being the most commonly used. A Full Backup takes a complete physical snapshot of the database cluster at a current moment, while an Incremental Backup records the differences between the current database cluster and the last full backup.
Pigsty provides a wrapper command for backups: /pg/bin/pg-backup [full|incr]. You can make base backups periodically as needed through Crontab or any other task scheduling system.
WAL Archiving
By default, Pigsty enables WAL archiving on the primary instance of the cluster and continuously pushes WAL segment files to the backup repository using the pgbackrest command-line tool.
pgBackRest automatically manages the required WAL files and promptly cleans up expired backups and their corresponding WAL archive files according to the backup retention policy.
If you do not need PITR functionality, you can disable WAL archiving by configuring the cluster: archive_mode: off, and remove node_crontab to stop periodic backup tasks.
Implementation
By default, Pigsty provides two preset backup strategies: using the local filesystem backup repository by default, where a full backup is taken daily to ensure users can roll back to any point within a day at any time. The alternative strategy uses a dedicated MinIO cluster or S3 storage for backups, with a full backup on Monday and incremental backups daily, keeping two weeks of backups and WAL archives by default.
Pigsty uses pgBackRest to manage backups, receive WAL archives, and perform PITR. The backup repository can be flexibly configured (pgbackrest_repo): by default, it uses the local filesystem (local) of the primary instance, but it can also use other disk paths, or the optional MinIO service (minio) and cloud-based S3 services.
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
s3_endpoint: sss.pigsty # minio endpoint domain name, `sss.pigsty` by default
s3_region: us-east-1 # minio region, us-east-1 by default, useless for minio
s3_bucket: pgsql # minio bucket name, `pgsql` by default
s3_key: pgbackrest # minio user access key for pgbackrest
s3_key_secret: S3User.Backup # minio user secret key for pgbackrest
s3_uri_style: path # use path style uri for minio rather than host style
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9000 # minio port, 9000 by default
storage_ca_file: /etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by default
bundle: y # bundle small files into a single file
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
Pigsty has two built-in backup options: local file system repository with daily full backups or dedicated MinIO/S3 storage with weekly full and daily incremental backups, retaining two weeks’ worth by default.
The target repositories in Pigsty parameter pgbackrest_repo are translated into repository definitions in the /etc/pgbackrest/pgbackrest.conf configuration file.
For example, if you define a West US region S3 repository for cold backups, you could use the following reference configuration.
s3: # ------> /etc/pgbackrest/pgbackrest.conf
repo1-type: s3 # ----> repo1-type=s3
repo1-s3-region: us-west-1 # ----> repo1-s3-region=us-west-1
repo1-s3-endpoint: s3-us-west-1.amazonaws.com # ----> repo1-s3-endpoint=s3-us-west-1.amazonaws.com
repo1-s3-key: '<your_access_key>' # ----> repo1-s3-key=<your_access_key>
repo1-s3-key-secret: '<your_secret_key>' # ----> repo1-s3-key-secret=<your_secret_key>
repo1-s3-bucket: pgsql # ----> repo1-s3-bucket=pgsql
repo1-s3-uri-style: host # ----> repo1-s3-uri-style=host
repo1-path: /pgbackrest # ----> repo1-path=/pgbackrest
repo1-bundle: y # ----> repo1-bundle=y
repo1-cipher-type: aes-256-cbc # ----> repo1-cipher-type=aes-256-cbc
repo1-cipher-pass: pgBackRest # ----> repo1-cipher-pass=pgBackRest
repo1-retention-full-type: time # ----> repo1-retention-full-type=time
repo1-retention-full: 90 # ----> repo1-retention-full=90
Recovery
You can use the following encapsulated commands for Point in Time Recovery of the PostgreSQL database cluster.
By default, Pigsty uses incremental, differential, parallel recovery, allowing you to restore to a specified point in time as quickly as possible.
pg-pitr # restore to wal archive stream end (e.g. used in case of entire DC failure)
pg-pitr -i # restore to the time of latest backup complete (not often used)
pg-pitr --time="2022-12-30 14:44:44+08" # restore to specific time point (in case of drop db, drop table)
pg-pitr --name="my-restore-point" # restore TO a named restore point create by pg_create_restore_point
pg-pitr --lsn="0/7C82CB8" -X # restore right BEFORE a LSN
pg-pitr --xid="1234567" -X -P # restore right BEFORE a specific transaction id, then promote
pg-pitr --backup=latest # restore to latest backup set
pg-pitr --backup=20221108-105325 # restore to a specific backup set, which can be checked with pgbackrest info
pg-pitr # pgbackrest --stanza=pg-meta restore
pg-pitr -i # pgbackrest --stanza=pg-meta --type=immediate restore
pg-pitr -t "2022-12-30 14:44:44+08" # pgbackrest --stanza=pg-meta --type=time --target="2022-12-30 14:44:44+08" restore
pg-pitr -n "my-restore-point" # pgbackrest --stanza=pg-meta --type=name --target=my-restore-point restore
pg-pitr -b 20221108-105325F # pgbackrest --stanza=pg-meta --type=name --set=20221230-120101F restore
pg-pitr -l "0/7C82CB8" -X # pgbackrest --stanza=pg-meta --type=lsn --target="0/7C82CB8" --target-exclusive restore
pg-pitr -x 1234567 -X -P # pgbackrest --stanza=pg-meta --type=xid --target="0/7C82CB8" --target-exclusive --target-action=promote restore
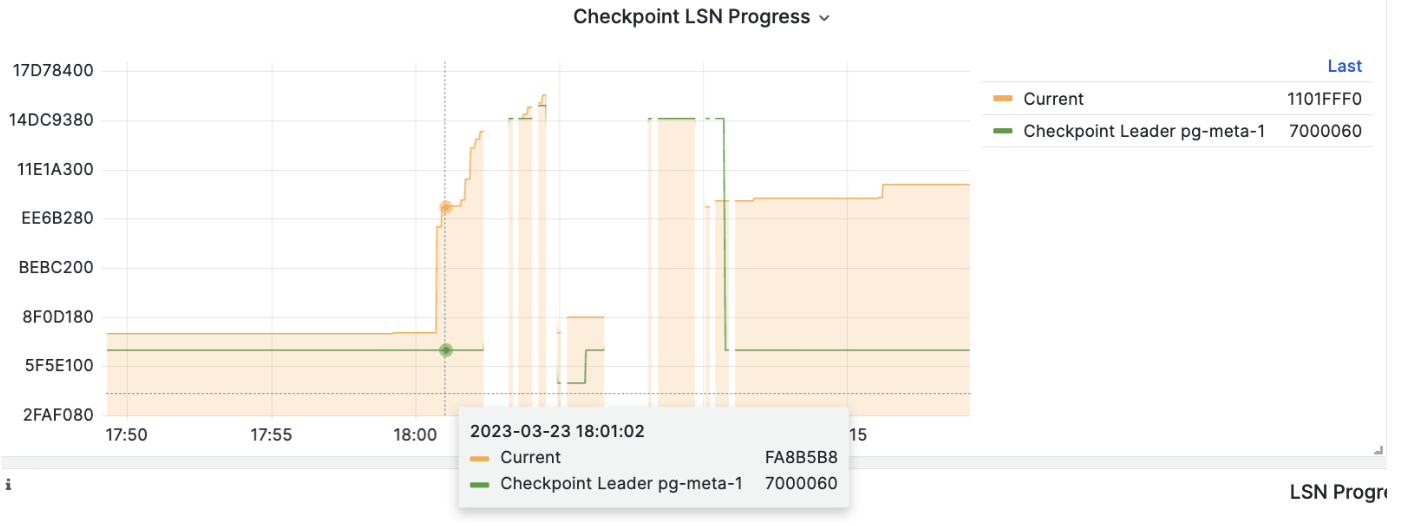
During PITR, you can observe the LSN point status of the cluster using the Pigsty monitoring system to determine if it has successfully restored to the specified time point, transaction point, LSN point, or other points.
8 - Services & Access
Split read & write, route traffic to the right place, and achieve stable & reliable access to the PostgreSQL cluster.
Service is an abstraction to seal the details of the underlying cluster, especially during cluster failover/switchover.
Personal User
Service is meaningless to personal users. You can access the database with raw IP address or whatever method you like.
psql postgres://dbuser_dba:[email protected]/meta # dbsu direct connect
psql postgres://dbuser_meta:[email protected]/meta # default business admin user
psql postgres://dbuser_view:DBUser.View@pg-meta/meta # default read-only user
Service Overview
We utilize a PostgreSQL database cluster based on replication in real-world production environments. Within the cluster, only one instance is the leader (primary) that can accept writes. Other instances (replicas) continuously fetch WAL from the leader to stay synchronized. Additionally, replicas can handle read-only queries and offload the primary in read-heavy, write-light scenarios. Thus, distinguishing between write and read-only requests is a common practice.
Moreover, we pool requests through a connection pooling middleware (Pgbouncer) for high-frequency, short-lived connections to reduce the overhead of connection and backend process creation. And, for scenarios like ETL and change execution, we need to bypass the connection pool and directly access the database servers. Furthermore, high-availability clusters may undergo failover during failures, causing a change in the cluster leadership. Therefore, the RW requests should be re-routed automatically to the new leader.
These varied requirements (read-write separation, pooling vs. direct connection, and client request failover) have led to the abstraction of the service concept.
Typically, a database cluster must provide this basic service:
- Read-write service (primary): Can read and write to the database.
For production database clusters, at least these two services should be provided:
- Read-write service (primary): Write data: Only carried by the primary.
- Read-only service (replica): Read data: Can be carried by replicas, but fallback to the primary if no replicas are available.
Additionally, there might be other services, such as:
- Direct access service (default): Allows (admin) users to bypass the connection pool and directly access the database.
- Offline replica service (offline): A dedicated replica that doesn’t handle online read traffic, used for ETL and analytical queries.
- Synchronous replica service (standby): A read-only service with no replication delay, handled by synchronous standby/primary for read queries.
- Delayed replica service (delayed): Accesses older data from the same cluster from a certain time ago, handled by delayed replicas.
Default Service
Pigsty will enable four default services for each PostgreSQL cluster:
| service | port | description |
|---|---|---|
| primary | 5433 | pgbouncer read/write, connect to primary 5432 or 6432 |
| replica | 5434 | pgbouncer read-only, connect to replicas 5432/6432 |
| default | 5436 | admin or direct access to primary |
| offline | 5438 | OLAP, ETL, personal user, interactive queries |
Take the default pg-meta cluster as an example, you can access these services in the following ways:
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5433/meta # pg-meta-primary : production read/write via primary pgbouncer(6432)
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5434/meta # pg-meta-replica : production read-only via replica pgbouncer(6432)
psql postgres://dbuser_dba:DBUser.DBA@pg-meta:5436/meta # pg-meta-default : Direct connect primary via primary postgres(5432)
psql postgres://dbuser_stats:DBUser.Stats@pg-meta:5438/meta # pg-meta-offline : Direct connect offline via offline postgres(5432)
Here the pg-meta domain name point to the cluster’s L2 VIP, which in turn points to the haproxy load balancer on the primary instance. It is responsible for routing traffic to different instances, check Access Services for details.
Primary Service
The primary service may be the most critical service for production usage.
It will route traffic to the primary instance, depending on pg_default_service_dest:
pgbouncer: route traffic to primary pgbouncer port (6432), which is the default behaviorpostgres: route traffic to primary postgres port (5432) directly if you don’t want to use pgbouncer
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
It means all cluster members will be included in the primary service (selector: "[]"), but the one and only one instance that past health check (check: /primary) will be used as the primary instance.
Patroni will guarantee that only one instance is primary at any time, so the primary service will always route traffic to THE primary instance.
Example: pg-test-primary haproxy config
listen pg-test-primary
bind *:5433
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Replica Service
The replica service is used for production read-only traffic.
There may be many more read-only queries than read-write queries in real-world scenarios. You may have many replicas.
The replica service will route traffic to Pgbouncer or postgres depending on pg_default_service_dest, just like the primary service.
- { name: replica ,port: 5434 ,dest: default ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
The replica service traffic will try to use common pg instances with pg_role = replica to alleviate the load on the primary instance as much as possible. It will try NOT to use instances with pg_role = offline to avoid mixing OLAP & OLTP queries as much as possible.
All cluster members will be included in the replica service (selector: "[]") when it passes the read-only health check (check: /read-only).
primary and offline instances are used as backup servers, which will take over in case of all replica instances are down.
Example: pg-test-replica haproxy config
listen pg-test-replica
bind *:5434
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /read-only
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backup
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Default Service
The default service will route to primary postgres (5432) by default.
It is quite like the primary service, except it will always bypass pgbouncer, regardless of pg_default_service_dest.
Which is useful for administration connection, ETL writes, CDC changing data capture, etc…
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
Example: pg-test-default haproxy config
listen pg-test-default
bind *:5436
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:5432 check port 8008 weight 100
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100
Offline Service
The Offline service will route traffic to dedicate postgres instance directly.
Which could be a pg_role = offline instance, or a pg_offline_query flagged instance.
If no such instance is found, it will fall back to any replica instances. the bottom line is: it will never route traffic to the primary instance.
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
listen pg-test-offline
bind *:5438
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /replica
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100 backup
Access Service
Pigsty expose service with haproxy. Which is enabled on all nodes by default.
haproxy load balancers are idempotent among same pg cluster by default, you use ANY / ALL of them by all means.
The typical method is access via cluster domain name, which resolve to cluster L2 VIP, or all instances ip address in a round-robin manner.
Service can be implemented in different ways, You can even implement you own access method such as L4 LVS, F5, etc… instead of haproxy.
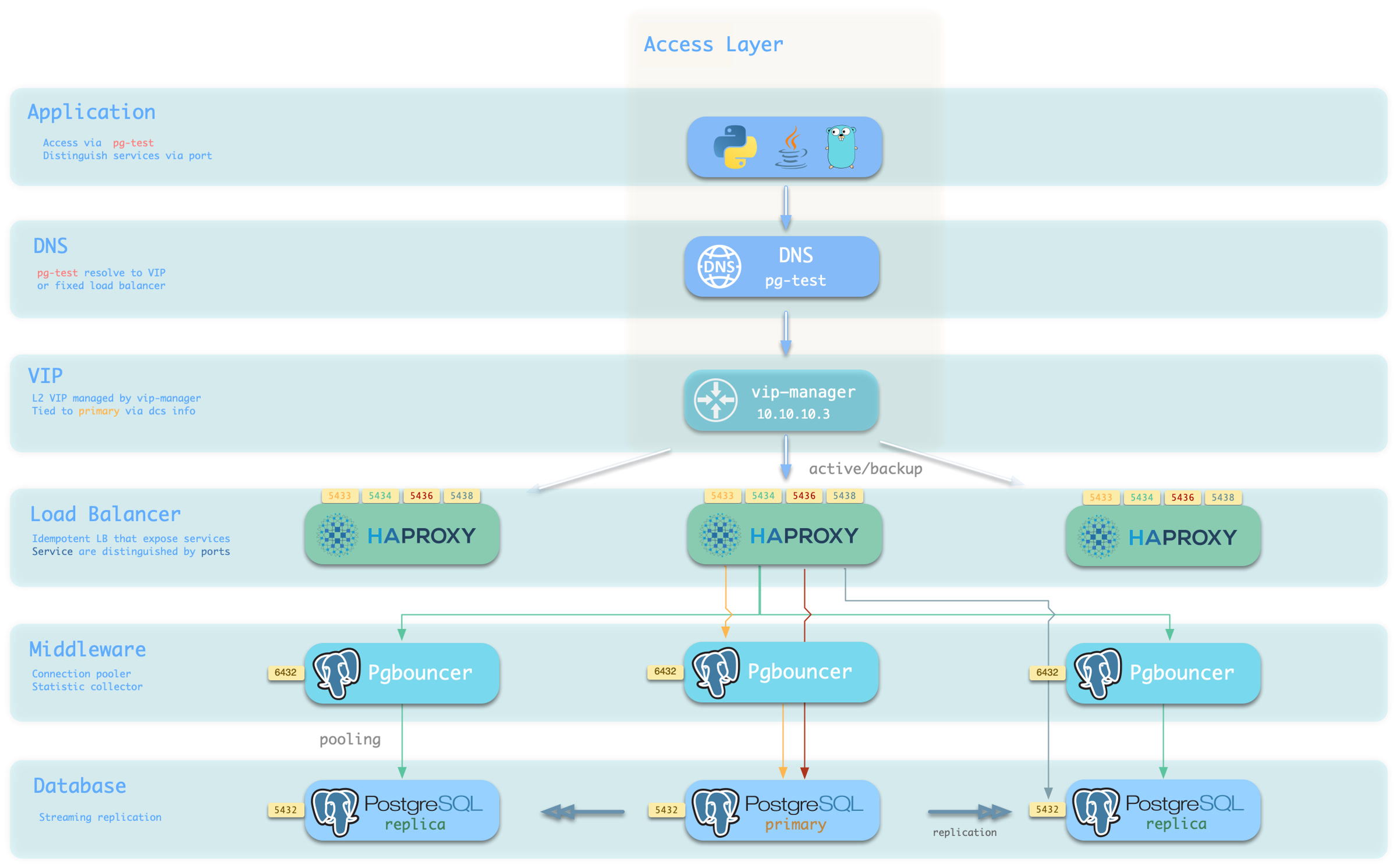
You can use different combination of host & port, they are provide PostgreSQL service in different ways.
Host
| type | sample | description |
|---|---|---|
| Cluster Domain Name | pg-test |
via cluster domain name (resolved by dnsmasq @ infra nodes) |
| Cluster VIP Address | 10.10.10.3 |
via a L2 VIP address managed by vip-manager, bind to primary |
| Instance Hostname | pg-test-1 |
Access via any instance hostname (resolved by dnsmasq @ infra nodes) |
| Instance IP Address | 10.10.10.11 |
Access any instance ip address |
Port
Pigsty uses different ports to distinguish between pg services:
| port | service | type | description |
|---|---|---|---|
| 5432 | postgres | database | Direct access to postgres server |
| 6432 | pgbouncer | middleware | Go through connection pool middleware before postgres |
| 5433 | primary | service | Access primary pgbouncer (or postgres) |
| 5434 | replica | service | Access replica pgbouncer (or postgres) |
| 5436 | default | service | Access primary postgres |
| 5438 | offline | service | Access offline postgres |
Combinations
# Access via cluster domain
postgres://test@pg-test:5432/test # DNS -> L2 VIP -> primary direct connection
postgres://test@pg-test:6432/test # DNS -> L2 VIP -> primary connection pool -> primary
postgres://test@pg-test:5433/test # DNS -> L2 VIP -> HAProxy -> Primary Connection Pool -> Primary
postgres://test@pg-test:5434/test # DNS -> L2 VIP -> HAProxy -> Replica Connection Pool -> Replica
postgres://dbuser_dba@pg-test:5436/test # DNS -> L2 VIP -> HAProxy -> Primary direct connection (for Admin)
postgres://dbuser_stats@pg-test:5438/test # DNS -> L2 VIP -> HAProxy -> offline direct connection (for ETL/personal queries)
# Direct access via cluster VIP
postgres://[email protected]:5432/test # L2 VIP -> Primary direct access
postgres://[email protected]:6432/test # L2 VIP -> Primary Connection Pool -> Primary
postgres://[email protected]:5433/test # L2 VIP -> HAProxy -> Primary Connection Pool -> Primary
postgres://[email protected]:5434/test # L2 VIP -> HAProxy -> Repilca Connection Pool -> Replica
postgres://[email protected]:5436/test # L2 VIP -> HAProxy -> Primary direct connection (for Admin)
postgres://[email protected]::5438/test # L2 VIP -> HAProxy -> offline direct connect (for ETL/personal queries)
# Specify any cluster instance name directly
postgres://test@pg-test-1:5432/test # DNS -> Database Instance Direct Connect (singleton access)
postgres://test@pg-test-1:6432/test # DNS -> connection pool -> database
postgres://test@pg-test-1:5433/test # DNS -> HAProxy -> connection pool -> database read/write
postgres://test@pg-test-1:5434/test # DNS -> HAProxy -> connection pool -> database read-only
postgres://dbuser_dba@pg-test-1:5436/test # DNS -> HAProxy -> database direct connect
postgres://dbuser_stats@pg-test-1:5438/test # DNS -> HAProxy -> database offline read/write
# Directly specify any cluster instance IP access
postgres://[email protected]:5432/test # Database instance direct connection (directly specify instance, no automatic traffic distribution)
postgres://[email protected]:6432/test # Connection Pool -> Database
postgres://[email protected]:5433/test # HAProxy -> connection pool -> database read/write
postgres://[email protected]:5434/test # HAProxy -> connection pool -> database read-only
postgres://[email protected]:5436/test # HAProxy -> Database Direct Connections
postgres://[email protected]:5438/test # HAProxy -> database offline read-write
# Smart client automatic read/write separation (connection pooling)
postgres://[email protected]:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=primary
postgres://[email protected]:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=prefer-standby
9 - Access Control
Pigsty has a battery-included access control model based on Role System and Privileges.
Role System
Pigsty has a default role system consist of four default roles and four default users:
| Role name | Attributes | Member of | Description |
|---|---|---|---|
dbrole_readonly |
NOLOGIN |
role for global read-only access | |
dbrole_readwrite |
NOLOGIN |
dbrole_readonly | role for global read-write access |
dbrole_admin |
NOLOGIN |
pg_monitor,dbrole_readwrite | role for object creation |
dbrole_offline |
NOLOGIN |
role for restricted read-only access | |
postgres |
SUPERUSER |
system superuser | |
replicator |
REPLICATION |
pg_monitor,dbrole_readonly | system replicator |
dbuser_dba |
SUPERUSER |
dbrole_admin | pgsql admin user |
dbuser_monitor |
pg_monitor | pgsql monitor user |
pg_default_roles: # default roles and users in postgres cluster
- { name: dbrole_readonly ,login: false ,comment: role for global read-only access }
- { name: dbrole_offline ,login: false ,comment: role for restricted read-only access }
- { name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment: role for global read-write access }
- { name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment: role for object creation }
- { name: postgres ,superuser: true ,comment: system superuser }
- { name: replicator ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator }
- { name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 ,comment: pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor] ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
Default Roles
There are four default roles in pigsty:
- Read Only (
dbrole_readonly): Role for global read-only access - Read Write (
dbrole_readwrite): Role for global read-write access, inheritsdbrole_readonly. - Admin (
dbrole_admin): Role for DDL commands, inheritsdbrole_readwrite. - Offline (
dbrole_offline): Role for restricted read-only access (offline instance)
Default roles are defined in pg_default_roles, change default roles is not recommended.
- { name: dbrole_readonly , login: false , comment: role for global read-only access } # production read-only role
- { name: dbrole_offline , login: false , comment: role for restricted read-only access (offline instance) } # restricted-read-only role
- { name: dbrole_readwrite , login: false , roles: [dbrole_readonly], comment: role for global read-write access } # production read-write role
- { name: dbrole_admin , login: false , roles: [pg_monitor, dbrole_readwrite] , comment: role for object creation } # production DDL change role
Default Users
There are four default users in pigsty, too.
- Superuser (
postgres), the owner and creator of the cluster, same as the OS dbsu. - Replication user (
replicator), the system user used for primary-replica. - Monitor user (
dbuser_monitor), a user used to monitor database and connection pool metrics. - Admin user (
dbuser_dba), the admin user who performs daily operations and database changes.
Default users’ username/password are defined with dedicate parameters (except for dbsu password):
pg_dbsu: os dbsu name, postgres by default, better not change itpg_replication_username: postgres replication username,replicatorby defaultpg_replication_password: postgres replication password,DBUser.Replicatorby defaultpg_admin_username: postgres admin username,dbuser_dbaby defaultpg_admin_password: postgres admin password in plain text,DBUser.DBAby defaultpg_monitor_username: postgres monitor username,dbuser_monitorby defaultpg_monitor_password: postgres monitor password,DBUser.Monitorby default
!> Remember to change these password in production deployment !
pg_dbsu: postgres # os user for the database
pg_replication_username: replicator # system replication user
pg_replication_password: DBUser.Replicator # system replication password
pg_monitor_username: dbuser_monitor # system monitor user
pg_monitor_password: DBUser.Monitor # system monitor password
pg_admin_username: dbuser_dba # system admin user
pg_admin_password: DBUser.DBA # system admin password
To define extra options, specify them in pg_default_roles:
- { name: postgres ,superuser: true ,comment: system superuser }
- { name: replicator ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator }
- { name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment: pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor, dbrole_readonly] ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
Privileges
Pigsty has a battery-included privilege model that works with default roles.
- All users have access to all schemas.
- Read-Only user can read from all tables. (SELECT, EXECUTE)
- Read-Write user can write to all tables run DML. (INSERT, UPDATE, DELETE).
- Admin user can create object and run DDL (CREATE, USAGE, TRUNCATE, REFERENCES, TRIGGER).
- Offline user is Read-Only user with limited access on offline instance (
pg_role = 'offline'orpg_offline_query = true) - Object created by admin users will have correct privilege.
- Default privileges are installed on all databases, including template database.
- Database connect privilege is covered by database definition
CREATEprivileges of database & public schema are revoked fromPUBLICby default
Object Privilege
Default object privileges are defined in pg_default_privileges.
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
- GRANT SELECT ON TABLES TO dbrole_readonly
- GRANT SELECT ON SEQUENCES TO dbrole_readonly
- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
- GRANT USAGE ON SCHEMAS TO dbrole_offline
- GRANT SELECT ON TABLES TO dbrole_offline
- GRANT SELECT ON SEQUENCES TO dbrole_offline
- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline
- GRANT INSERT ON TABLES TO dbrole_readwrite
- GRANT UPDATE ON TABLES TO dbrole_readwrite
- GRANT DELETE ON TABLES TO dbrole_readwrite
- GRANT USAGE ON SEQUENCES TO dbrole_readwrite
- GRANT UPDATE ON SEQUENCES TO dbrole_readwrite
- GRANT TRUNCATE ON TABLES TO dbrole_admin
- GRANT REFERENCES ON TABLES TO dbrole_admin
- GRANT TRIGGER ON TABLES TO dbrole_admin
- GRANT CREATE ON SCHEMAS TO dbrole_admin
Newly created objects will have corresponding privileges when it is created by admin users
The \ddp+ may looks like:
| Type | Access privileges |
|---|---|
| function | =X |
| dbrole_readonly=X | |
| dbrole_offline=X | |
| dbrole_admin=X | |
| schema | dbrole_readonly=U |
| dbrole_offline=U | |
| dbrole_admin=UC | |
| sequence | dbrole_readonly=r |
| dbrole_offline=r | |
| dbrole_readwrite=wU | |
| dbrole_admin=rwU | |
| table | dbrole_readonly=r |
| dbrole_offline=r | |
| dbrole_readwrite=awd | |
| dbrole_admin=arwdDxt |
Default Privilege
ALTER DEFAULT PRIVILEGES allows you to set the privileges that will be applied to objects created in the future.
It does not affect privileges assigned to already-existing objects, and objects created by non-admin users.
Pigsty will use the following default privileges:
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_dbsu }} {{ priv }};
{% endfor %}
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_admin_username }} {{ priv }};
{% endfor %}
-- for additional business admin, they can SET ROLE to dbrole_admin
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" {{ priv }};
{% endfor %}
Which will be rendered in pg-init-template.sql alone with ALTER DEFAULT PRIVILEGES statement for admin users.
These SQL command will be executed on postgres & template1 during cluster bootstrap, and newly created database will inherit it from tempalte1 by default.
That is to say, to maintain the correct object privilege, you have to run DDL with admin users, which could be:
{{ pg_dbsu }},postgresby default{{ pg_admin_username }},dbuser_dbaby default- Business admin user granted with
dbrole_admin
It’s wise to use postgres as global object owner to perform DDL changes.
If you wish to create objects with business admin user, YOU MUST USE SET ROLE dbrole_admin before running that DDL to maintain the correct privileges.
You can also ALTER DEFAULT PRIVILEGE FOR ROLE <some_biz_admin> XXX to grant default privilege to business admin user, too.
Database Privilege
Database privilege is covered by database definition.
There are 3 database level privileges: CONNECT, CREATE, TEMP, and a special ‘privilege’: OWNERSHIP.
- name: meta # required, `name` is the only mandatory field of a database definition
owner: postgres # optional, specify a database owner, {{ pg_dbsu }} by default
allowconn: true # optional, allow connection, true by default. false will disable connect at all
revokeconn: false # optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)
- If
ownerexists, it will be used as database owner instead of default{{ pg_dbsu }} - If
revokeconnisfalse, all users have theCONNECTprivilege of the database, this is the default behavior. - If
revokeconnis set totrueexplicitly:CONNECTprivilege of the database will be revoked fromPUBLICCONNECTprivilege will be granted to{{ pg_replication_username }},{{ pg_monitor_username }}and{{ pg_admin_username }}CONNECTprivilege will be granted to database owner withGRANT OPTION
revokeconn flag can be used for database access isolation, you can create different business users as the owners for each database and set the revokeconn option for all of them.
Example: Database Isolation
pg-infra:
hosts:
10.10.10.40: { pg_seq: 1, pg_role: primary }
10.10.10.41: { pg_seq: 2, pg_role: replica , pg_offline_query: true }
vars:
pg_cluster: pg-infra
pg_users:
- { name: dbuser_confluence, password: mc2iohos , pgbouncer: true, roles: [ dbrole_admin ] }
- { name: dbuser_gitlab, password: sdf23g22sfdd , pgbouncer: true, roles: [ dbrole_readwrite ] }
- { name: dbuser_jira, password: sdpijfsfdsfdfs , pgbouncer: true, roles: [ dbrole_admin ] }
pg_databases:
- { name: confluence , revokeconn: true, owner: dbuser_confluence , connlimit: 100 }
- { name: gitlab , revokeconn: true, owner: dbuser_gitlab, connlimit: 100 }
- { name: jira , revokeconn: true, owner: dbuser_jira , connlimit: 100 }
Create Privilege
Pigsty revokes the CREATE privilege on database from PUBLIC by default, for security consideration.
And this is the default behavior since PostgreSQL 15.
The database owner have the full capability to adjust these privileges as they see fit.