RPO Trade-offs
Trade-off analysis for RPO (Recovery Point Objective), finding the optimal balance between availability and data loss.
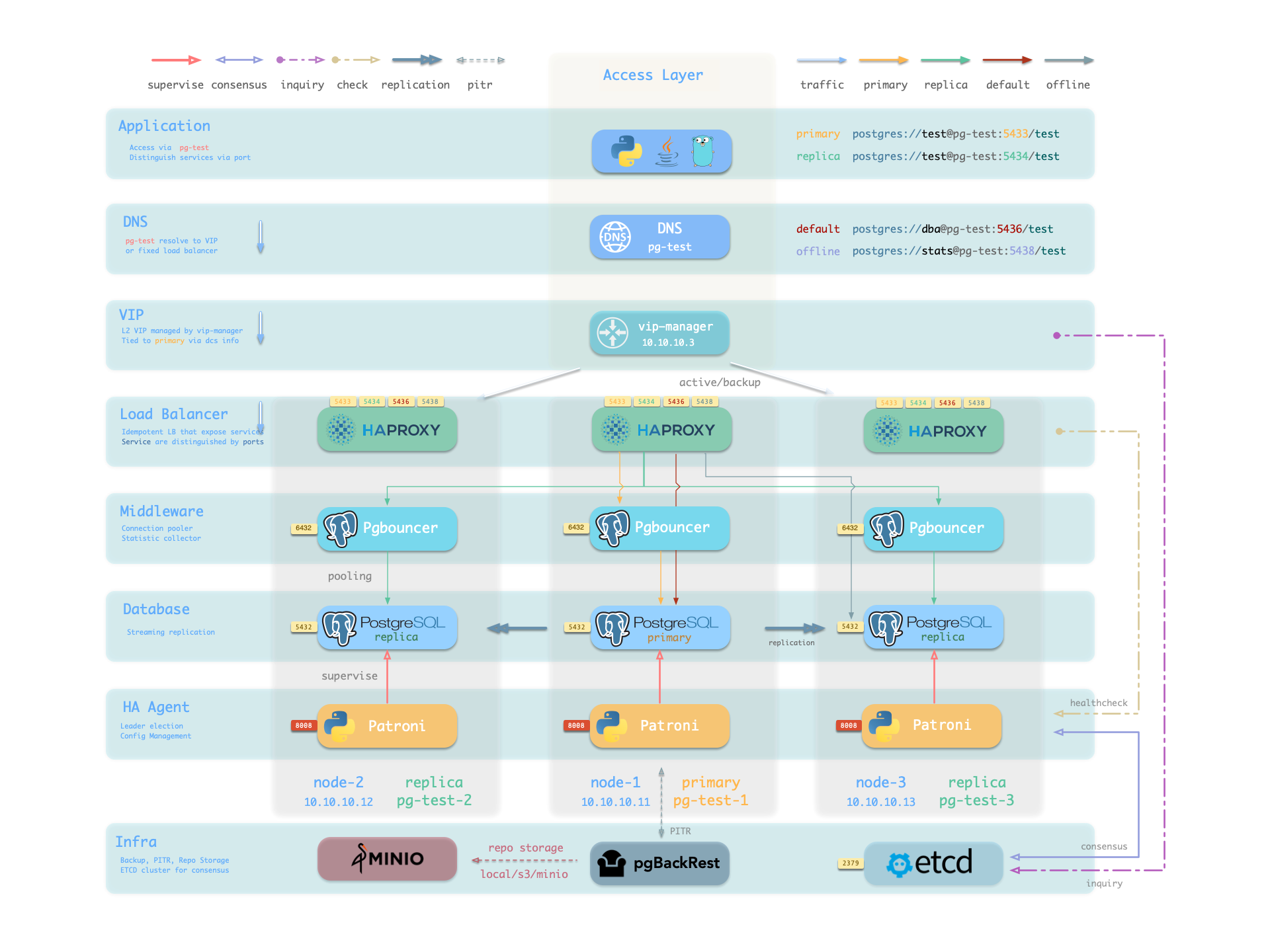
Pigsty’s PostgreSQL clusters come with out-of-the-box high availability, powered by Patroni, Etcd, and HAProxy.
When your PostgreSQL cluster has two or more instances, you automatically have self-healing database high availability without any additional configuration — as long as any instance in the cluster survives, the cluster can provide complete service. Clients only need to connect to any node in the cluster to get full service without worrying about primary-replica topology changes.
With default configuration, the primary failure Recovery Time Objective (RTO) ≈ 45s, and Recovery Point Objective (RPO) < 1MB; for replica failures, RPO = 0 and RTO ≈ 0 (brief interruption). In consistency-first mode, failover can guarantee zero data loss: RPO = 0. All these metrics can be configured as needed based on your actual hardware conditions and reliability requirements.
Pigsty includes built-in HAProxy load balancers for automatic traffic switching, providing DNS/VIP/LVS and other access methods for clients. Failover and switchover are almost transparent to the business side except for brief interruptions - applications don’t need to modify connection strings or restart. The minimal maintenance window requirements bring great flexibility and convenience: you can perform rolling maintenance and upgrades on the entire cluster without application coordination. The feature that hardware failures can wait until the next day to handle lets developers, operations, and DBAs sleep well during incidents.
Many large organizations and core institutions have been using Pigsty in production for extended periods. The largest deployment has 25K CPU cores and 220+ PostgreSQL ultra-large instances (64c / 512g / 3TB NVMe SSD). In this deployment case, dozens of hardware failures and various incidents occurred over five years, yet overall availability of over 99.999% was maintained.
What problems does High Availability solve?
What are the costs of High Availability?
Limitations of High Availability
Since replication happens in real-time, all changes are immediately applied to replicas. Therefore, streaming replication-based HA solutions cannot handle data deletion or modification caused by human errors and software defects. (e.g., DROP TABLE or DELETE data)
Such failures require using delayed clusters or performing point-in-time recovery using previous base backups and WAL archives.
| Configuration Strategy | RTO | RPO |
|---|---|---|
| Standalone + Nothing | Data permanently lost, unrecoverable | All data lost |
| Standalone + Base Backup | Depends on backup size and bandwidth (hours) | Lose data since last backup (hours to days) |
| Standalone + Base Backup + WAL Archive | Depends on backup size and bandwidth (hours) | Lose unarchived data (tens of MB) |
| Primary-Replica + Manual Failover | ~10 minutes | Lose data in replication lag (~100KB) |
| Primary-Replica + Auto Failover | Within 1 minute | Lose data in replication lag (~100KB) |
| Primary-Replica + Auto Failover + Sync Commit | Within 1 minute | No data loss |
In Pigsty, the high availability architecture works as follows:
When the primary fails, a new round of leader election is triggered. The healthiest replica in the cluster (highest LSN position, minimum data loss) wins and is promoted to the new primary. After the winning replica is promoted, read-write traffic is immediately routed to the new primary. The impact of primary failure is brief write service unavailability: write requests will be blocked or fail directly from primary failure until new primary promotion, with unavailability typically lasting 15 to 30 seconds, usually not exceeding 1 minute.
When a replica fails, read-only traffic is routed to other replicas. Only when all replicas fail will read-only traffic ultimately be handled by the primary. The impact of replica failure is partial read-only query interruption: queries currently running on that replica will abort due to connection reset and be immediately taken over by other available replicas.
Failure detection is performed jointly by Patroni and Etcd. The cluster leader holds a lease; if the cluster leader fails to renew the lease in time (10s) due to failure, the lease is released, triggering a Failover and new cluster election.
Even without any failures, you can proactively change the cluster primary through Switchover. In this case, write queries on the primary will experience a brief interruption and be immediately routed to the new primary. This operation is typically used for rolling maintenance/upgrades of database servers.
Trade-off analysis for RPO (Recovery Point Objective), finding the optimal balance between availability and data loss.
Detailed analysis of worst-case, best-case, and average RTO calculation logic and results across three classic failure detection/recovery paths
Trade-off analysis for RTO (Recovery Time Objective), finding the optimal balance between recovery speed and false failover risk.
Pigsty uses HAProxy to provide service access, with optional pgBouncer for connection pooling, and optional L2 VIP and DNS access.
Was this page helpful?
Thanks for the feedback! Please let us know how we can improve.
Sorry to hear that. Please let us know how we can improve.