This is the multi-page printable view of this section. Click here to print.
Database
- Scaling Postgres to the next level at OpenAI
- Database Planet Collision: When PG Falls for DuckDB
- Self-Hosting Supabase on PostgreSQL
- MySQL is dead, Long live PostgreSQL!
- MySQL's Terrible ACID
- Database in K8S: Pros & Cons
- NewSQL: Distributive Nonsens
- Is running postgres in docker a good idea?
Scaling Postgres to the next level at OpenAI
At PGConf.Dev 2025, Bohan Zhang from OpenAI shared a session titled Scaling Postgres to the next level at OpenAI, giving us a peek into the database usage of a top-tier unicorn.
“At OpenAl, we’ve proven that PostgreSQL can scale to support massive read-heavy workloads - even without sharding - using a single primary writer”
—— Bohan Zhang from OpenAI, PGConf.Dev 2025

Bohan Zhang is a member of the OpenAI Infra team, student of Andy Pavlo, and co-found OtterTune with him.
This article is based on Bohan’s presentation at the conference. with chinese translation/commentary by Ruohang Feng (Vonng): Author of Pigsty. The original chinese version is available on WeChat Column and Pigsty CN Blog.
Hacker News Discussion: OpenAI: Scaling Postgres to the Next Level
Background
Postgres is the backbone of our most critical systems at OpenAl. If Postgres goes down, many of OpenAI’s key features go down with it — and there’s plenty of precedent for this. PostgreSQL-related failures have caused several ChatGPT outages in the past.

OpenAI uses managed PostgreSQL databases on Azure, without sharding. Instead, they employ a classic primary-replica replication architecture with one primary and over dozens of read replicas. For a service with several hundred million active users like OpenAI, scalability is a major concern.
Challenges
In OpenAI’s PostgreSQL architecture, read scalability is excellent, but “write requests” have become the primary bottleneck. OpenAI has already made many optimizations here, such as offloading write workloads wherever possible and avoiding placing new business logic into the main database.

PostgreSQL’s MVCC design has some known issues, such as table and index bloat. Tuning autovacuum is complex, and every write generates a completely new version of a row. Index access might also require additional heap fetches for visibility checks. These design choices create challenges for scaling read replicas: for instance, more WAL typically leads to greater replication lag, and as the number of replicas grows, network bandwidth can become the new bottleneck.
Measures
To tackle these issues, we’ve made efforts on multiple fronts:
Reduce Load on Primary
The first optimization is to smooth out write spikes on the primary and minimize its load as much as possible, for example:
- Offloading all possible writes.
- Avoiding unnecessary writes at the application level.
- Using lazy writes to smooth out write bursts.
- Controlling the rate of data backfilling.
Additionally, OpenAI offloads as many read requests as possible to replicas. The few read requests that cannot be moved from the primary because they are part of read-write transactions are required to be as efficient as possible.

Query Optimization
The second area is query-level optimization. Since long-running transactions can block garbage collection and consume resources, they use timeout settings to prevent long “idle in transaction” states and set session, statement, and client-level timeouts. They also optimized some multi-way JOIN queries (e.g., joining 12 tables at once). The talk specifically mentioned that using ORMs can easily lead to inefficient queries and should be used with caution.

Mitigating Single Points of Failure
The primary is a single point of failure; if it goes down, writes are blocked. In contrast, we have many read-only replicas. If one fails, applications can still read from others. In fact, many critical requests are read-only, so even if the primary goes down, they can continue to serve reads.
Furthermore, we’ve distinguished between low-priority and high-priority requests. For high-priority requests, OpenAI allocates dedicated read-only replicas to prevent them from being impacted by low-priority ones.

Schema Management
The fourth measure is to allow only lightweight schema changes on this cluster. This means:
- Creating new tables or adding new workloads to it is not allowed.
- Adding or removing columns is allowed (with a 5-second timeout), but any operation that requires a full table rewrite is forbidden.
- Creating or removing indexes is allowed, but must be done using
CONCURRENTLY.
Another issue mentioned was that persistent long-running queries (>1s) would continuously block schema changes, eventually causing them to fail. The solution was to have the application optimize or move these slow queries to replicas.

Results
- Scaled PostgreSQL on Azure to millions of QPS, supporting OpenAI’s critical services.
- Added dozens of replicas without increasing replication lag.
- Deployed read-only replicas to different geographical regions while maintaining low latency.
- Only one SEV0 incident related to PostgreSQL in the past nine months.
- Still have plenty of room for future growth.

“At OpenAl, we’ve proven that PostgreSQL can scale to support massive read-heavy workloads - even without sharding - using a single primary writer”
Case Studies
OpenAI also shared a few case studies of failures they’ve faced. The first was a cascading failure caused by a redis outage.

The second incident was more interesting: extremely high CPU usage triggered a bug where the WALSender process kept spin-looping instead of sending WAL to replicas, even after CPU levels returned to normal. This led to increased replication lag.

Feature Suggestions
Finally, Bohan raised some questions and feature suggestions to the PostgreSQL developer community:
First, regarding disabling indexes. Unused indexes cause write amplification and extra maintenance overhead. They want to remove useless indexes, but to minimize risk, they wish for a feature to “disable” an index. This would allow them to monitor performance metrics to ensure everything is fine before actually dropping it.

Second is about RT observability. Currently, pg_stat_statement only provides the average response time for each query type, but doesn’t directly offer latency metrics like p95 or p99. They hope for more histogram-like and percentile latency metrics.

The third point is about schema changes. They want PostgreSQL to record a history of schema change events, such as adding/removing columns and other DDL operations.

The fourth case is about the semantics of monitoring views. They found a session with state = 'active' and wait_event = 'ClientRead' that lasted for over two hours. This means a connection remained active long after query_start, and such connections can’t be killed by the idle_in_transaction_timeout. They wanted to know if this is a bug and how to resolve it.

Finally, a suggestion for optimizing PostgreSQL’s default parameters. The default values are too conservative. Could better defaults be used, or perhaps a heuristic-based configuration rule?
Vonng’s Commentary
Although PGConf.Dev 2025 is primarily focused on development, you often see use case presentations from users, like this one from OpenAI on their PostgreSQL scaling practices. These topics are actually quite interesting for core developers, as many of them don’t have a clear picture of how PostgreSQL is used in extreme scenarios, and these talks are very helpful.

Since late 2017, I managed dozens of PostgreSQL clusters at Tantan, which was one of the largest and most complex PG deployments in the Chinese internet scene: dozens of PG clusters with around 2.5 million QPS. Back then, our largest core primary had a 1-primary-33-replica setup, with a single cluster handling around 400K QPS. The bottleneck was also on single-database writes, which we eventually solved with application-side sharding, similar to Instagram’s approach.
You could say I’ve encountered all the problems and used all the solutions OpenAI mentioned in their talk. Of course, the difference is that today’s top-tier hardware is orders of magnitude better than it was eight years ago. This allows a startup like OpenAI to serve its entire business with a single PostgreSQL cluster without sharding. This is undoubtedly another powerful piece of evidence for the argument that “Distributed Databases Are a False Need”.
During the Q&A, I learned that OpenAI uses managed PostgreSQL on Azure with the highest available server hardware specs. They have dozens of replicas, including some in different geographical regions, and this behemoth cluster handles a total of about millions QPS. They use Datadog for monitoring, and the services access the RDS cluster from Kubernetes through a business-side PgBouncer connection pool.
As a strategic customer, the Azure PostgreSQL team provides them with dedicated support. But it’s clear that even with top-tier cloud database services, the customer needs to have sufficient knowledge and skill on the application and operations side. Even with the brainpower of OpenAI, they still stumble on some of the practical driving lessons of PostgreSQL.
During the social event after the conference, I had a great chat with Bohan and two other database founders until the wee hours. The off-the-record discussions were fascinating, but I can’t disclose more here, haha.

Vonng’s Q&A
Regarding the questions and feature requests Bohan raised, I can offer some answers here.
Most of the features OpenAI wants already exist in the PostgreSQL ecosystem, they just might not be available in the vanilla PG kernel or in a managed cloud database environment.
On Disabling Indexes
PostgreSQL actually has a “feature” to disable indexes. You just need to update the indisvalid field in the pg_index system catalog to false.
The planner will then stop using the index, but it will continue to be maintained during DML operations. In principle, there’s nothing wrong with this, as concurrent index creation uses these two flags (isready, isvalid). It’s not black magic.
However, I can understand why OpenAI can’t use this method: it’s an undocumented “internal detail” rather than a formal feature. But more importantly, cloud databases usually don’t grant superuser privileges, so you just can’t update the system catalog like this.
But back to the original need — fear of accidentally deleting an index.
There’s a simpler solution: just confirm from monitoring view (pg_stat_all_indexes) that the index isn’t being used on either the primary or the replicas.
If you know an index hasn’t been used for a long time, you can safely delete it.
Monitoring index switch with Pigsty PGSQL TABLES Dashboard
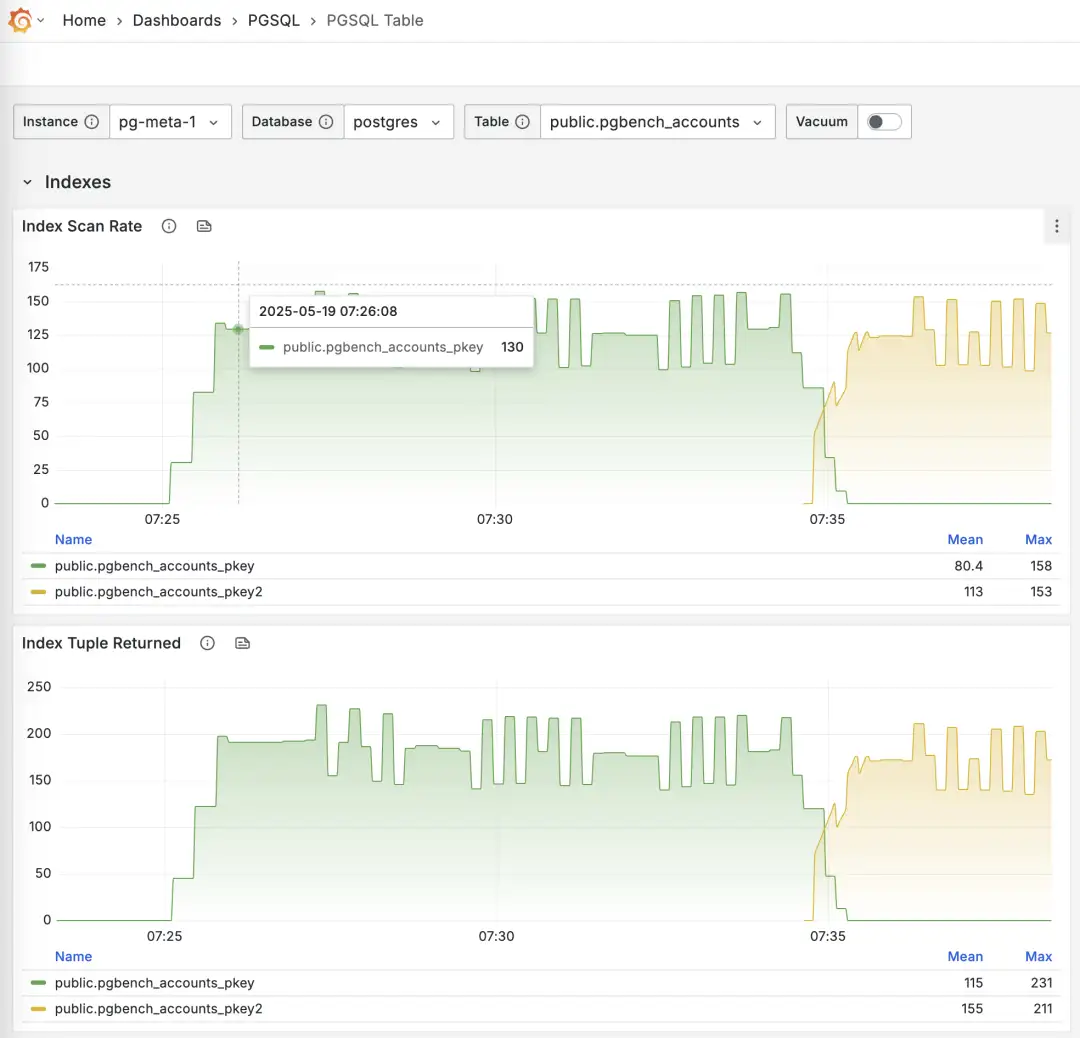
-- Create a new index
CREATE UNIQUE INDEX CONCURRENTLY pgbench_accounts_pkey2 ON pgbench_accounts USING BTREE(aid);
-- Mark the original index as invalid (not used), but still maintained. planner will not use it.
UPDATE pg_index SET indisvalid = false WHERE indexrelid = 'pgbench_accounts_pkey'::regclass;
On Observability
Actually, pg_stat_statements provides the mean and stddev metrics, which you can use with properties of the normal distribution to estimate percentile metrics.
But this is only a rough estimate, and you need to reset the counters periodically, otherwise the effectiveness of the full historical statistics will degrade over time.
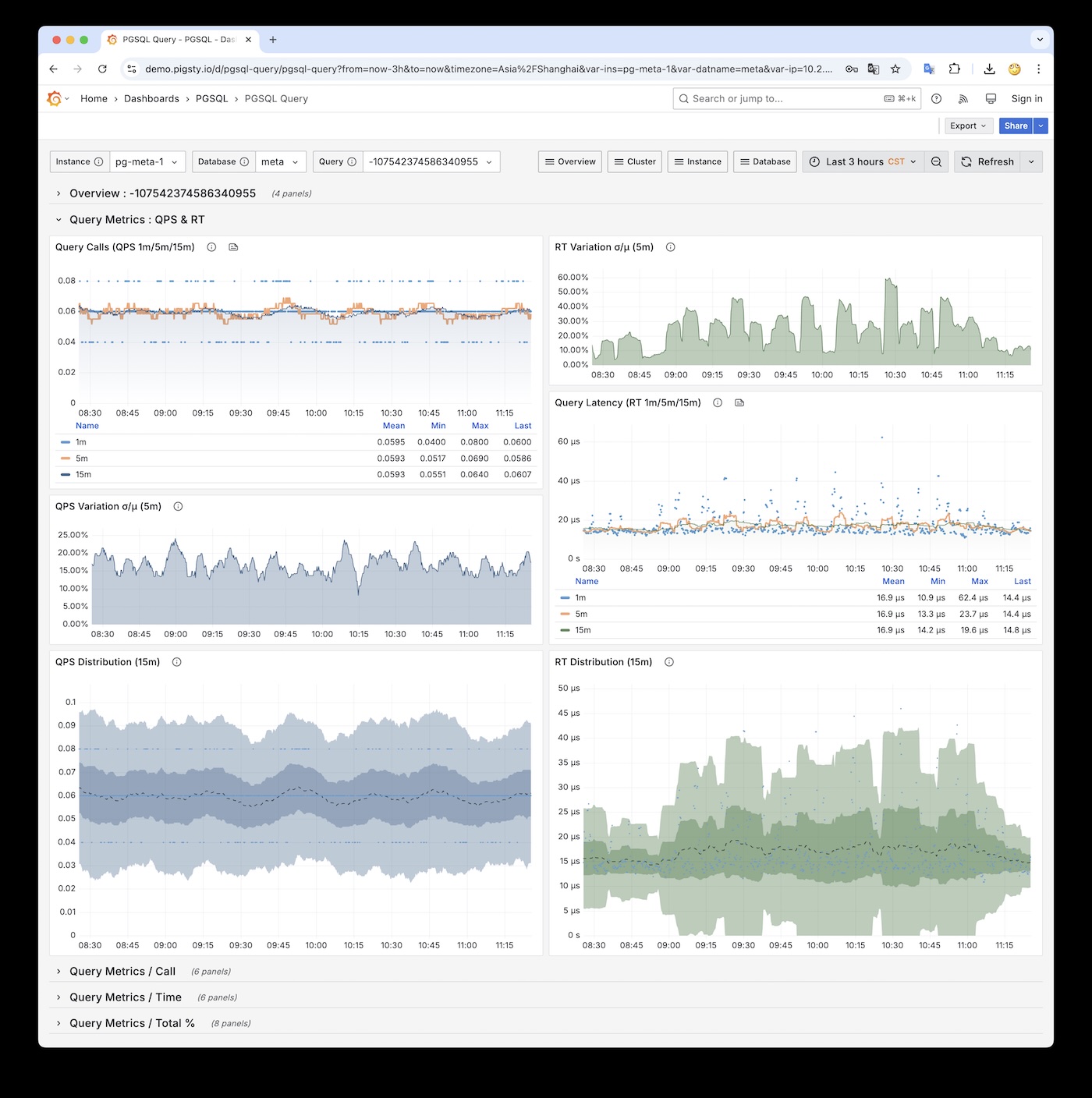
RT Distribution with PGSQL QUERY Dashboard from PGSS
PGSS is unlikely to provide P95, P99 RT percentile metrics anytime soon, because it would increase the extension’s memory footprint by several dozen times. While that’s not a big deal for modern servers, it could be an issue in extremely conservative environments. I asked the maintainer of PGSS about this at the Unconference, and it’s unlikely to happen in the short term. I also asked Jelte, the maintainer of Pgbouncer, if this could be solved at the connection pool level, and a feature like that is not coming soon either.
However, there are other solutions to this problem. First, the pg_stat_monitor extension explicitly provides detailed percentile RT metrics,
but you have to consider the performance impact of collecting these metrics on the cluster.
A universal, non-intrusive method with no database performance overhead is to add query RT monitoring directly at the application’s Data Access Layer (DAL), but this requires cooperation and effort from the application side.
Also, using eBPF for side-channel collection of RT metrics is a great idea, but considering they’re using managed PostgreSQL on Azure, they won’t have server access, so that path is likely blocked.
On Schema Change History
Actually, PostgreSQL’s logging already provides this option. You just need to set log_statement to ddl (or the more advanced mod or all),
and all DDL logs will be preserved. The pgaudit extension also provides similar functionality.
But I suspect what they really want isn’t DDL logs, but something like a system view that can be queried via SQL.
In that case, another option is CREATE EVENT TRIGGER.
You can use an event trigger to log DDL events directly into a data table.
The pg_ddl_historization extension provides a more convenient way to do this, and I’ve compiled and packaged this extension as well.
Creating an event trigger also requires superuser privileges. AWS RDS has some special handling to allow this, but it seems that PostgreSQL on Azure does not support it.
On Monitoring View Semantics
In OpenAI’s example, pg_stat_activity.state = active means the backend process is still within the lifecycle of a single SQL statement.
The WaitEvent = ClientRead means the process is on the CPU waiting for data from the client.
When both appear together, a typical example is an idle COPY FROM STDIN, but it could also be TCP blocking or being stuck between BIND / EXECUTE. So it’s hard to say if it’s a bug without knowing what the connection is actually doing.
Some might argue that waiting for client I/O should be considered “idle” from a CPU perspective. But state tracks the execution state of the statement itself, not whether the CPU is busy.
state = 'active' means the PostgreSQL backend considers “this statement is not yet finished.” Resources like row locks, buffer pins, snapshots, and file handles are considered “in use.”
This doesn’t mean it’s running on the CPU. When the process is running on the CPU in a loop waiting for client data, the wait event is ClientRead. When it yields the CPU and “waits” in the background, the wait event is NULL.
But back to the problem itself, there are other solutions. For example, in Pigsty, when accessing PostgreSQL through HAProxy, we set a connection timeout at the LB level for the primary service,
defaulting to 24 hours. More stringent environments would have a shorter timeout, like 1 hour. This means any connection lasting over an hour would be terminated.
Of course, this also needs to be configured with a corresponding max lifetime in the application-side connection pool, to proactively close connections rather than having them be cut off.
For offline, read-only services, this parameter can be omitted to allow for ultra-long queries that might run for two or three days. This provides a safety net for these active-but-waiting-on-I/O situations.
But I also doubt whether Azure PostgreSQL offers this kind of control.
On Default Parameters
PostgreSQL’s default parameters are quite conservative. For example, it defaults to using 128 MB of memory (the minimum can be set to 128 KB!). On the bright side, this allows its default configuration to run in almost any environment. On the downside, I’ve actually seen a case of a production system with 1TB of physical memory running with the 128 MB default… (thanks to double buffering, it actually ran for a long time).
But overall, I think conservative defaults aren’t a bad thing. This issue can be solved in a more flexible, dynamic configuration process.
RDS and Pigsty both provide pretty good initial parameter heuristic config rules,
which fully address this problem. But this feature could indeed be added to the PG command-line tools,
for example, having initdb automatically detect CPU/memory count, disk size, and storage type and set optimized parameter values accordingly.
Self-hosted PostgreSQL?
The challenges OpenAI raised are not really from PostgreSQL itself, but from the additional limitations of managed cloud services. One solution is to use the IaaS layer and self-host a PostgreSQL cluster on instances with local NVMe SSD storage to bypass these restrictions.
In fact, my project Pigsty built for ourselves to solve PostgreSQL challenges at a similar scale. It scales well, having supported Tantan’s 25K vCPU PostgreSQL cluster and 2.5M QPS. It includes solutions for all the problems mentioned above, and even for many that OpenAI hasn’t encountered yet. And in a self-hosting manner, open-source, free, and ready to use out of the box.
If OpenAI is interested, I’d certainly be happy to provide some help. But I think when you’re in a phase of hyper-growth, fiddling with database infra is probably not a high-priority item. Fortunately, they still have excellent PostgreSQL DBAs who can continue to forge these paths.
References
[1] HackerNews OpenAI: Scaling Postgres to the Next Level: https://news.ycombinator.com/item?id=44071418#44072781
[2] PostgreSQL is eating the database world: https://pigsty.io/blog/pg/pg-eat-db-world
[3] Chinese: Scaling Postgres to the Next Level at OpenAI https://pigsty.cc/blog/db/openai-pg/
[4] The part of PostgreSQL we hate the most: https://www.cs.cmu.edu/~pavlo/blog/2023/04/the-part-of-postgresql-we-hate-the-most.html
[5] PGConf.Dev 2025: https://2025.pgconf.dev/schedule.html
[6] Schedule: Scaling Postgres to the next level at OpenAI: https://www.pgevents.ca/events/pgconfdev2025/schedule/session/433-scaling-postgres-to-the-next-level-at-openai/
[7] Bohan Zhang: https://www.linkedin.com/in/bohan-zhang-52b17714b
[8] Ruohang Feng / Vonng: https://github.com/Vonng/
[9] Pigsty: https://pigsty.io
[10] Instagram’s Sharding IDs: https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c
[11] Reclaim hardware bouns: https://pigsty.io/blog/cloud/bonus/
[12] Distributed Databases Are a False Need: https://pigsty.io/blog/db/distributive-bullshit/
Database Planet Collision: When PG Falls for DuckDB
When I published “PostgreSQL Is Eating the Database World” last year, I tossed out this wild idea: Could Postgres really unify OLTP and OLAP? I had no clue we’d see fireworks so quickly.
The PG community’s now in an all-out frenzy to stitch DuckDB into the Postgres bloodstream — big enough for Andy Pavlo to give it prime-time coverage in his 2024 database retrospective. If you ask me, we’re on the brink of a cosmic collision in database-land, and Postgres + DuckDB is the meteor we should all be watching.

DuckDB as an OLAP Challenger
DuckDB came to life at CWI, the Netherlands’ National Research Institute for Mathematics and Computer Science, founded by Mark Raasveldt and Hannes Mühleisen. CWI might look like a quiet research outfit, but it’s actually the secret sauce behind numerous analytic databases—pioneering columnar storage and vectorized queries that power systems like ClickHouse, Snowflake, and Databricks.
After helping guide these heavy hitters, the same minds built DuckDB—an embedded OLAP database for a new generation. Their timing and niche were spot on.
Why DuckDB? The creators noticed data scientists often prefer Python and Pandas, and they’d rather avoid wrestling with heavyweight RDBMS overhead, user authentication, data import/export tangles, etc. DuckDB’s solution? An embedded, SQLite-like analyzer that’s as simple as it gets.
It compiles down to a single binary from just a C++ file and a header. The database itself is just a file on disk. Its SQL syntax and parser come straight from Postgres, creating practically zero friction. Despite its minimalist packaging, DuckDB is a performance beast—besting ClickHouse in some ClickBench tests on ClickHouse’s own turf.
And since DuckDB lands under the MIT license, you get blazing-fast analytics, super-simple onboarding, open source freedom, and any-wrap-you-want packaging. Hard to imagine it not going viral.
The Golden Combo: Strengths and Weaknesses
For all its top-notch OLAP chops, DuckDB’s Achilles’ heel is data management—users, permissions, concurrency, backups, HA…basically all the stuff data scientists love to skip. Ironically, that’s the sweet spot of traditional databases, and it’s also the most painful piece for enterprises.
Hence, DuckDB feels more like an “OLAP operator” or a storage engine, akin to RocksDB, and less like a fully operational “big data platform.”
Meanwhile, PostgreSQL has spent decades polishing data management—rock-solid transactions, access control, backups, HA, a healthy extension ecosystem, and so on. As an OLTP juggernaut, Postgres is a performence beast.. The only lingering complaint is that while Postgres handles standard analytics adequately, it still lags behind specialized OLAP systems when data volumes balloon.

But what if we combine PostgreSQL for data management with DuckDB for high-speed analytics? If these two join forces deeply, we could see a brand-new hybrid in the DB universe.
DuckDB patches Postgres’s bulk-analytics limitations—plus, it can read and write external columnar formats like Parquet in object stores, unleashing a near-infinite data lake. Conversely, DuckDB’s weaker management features get covered by the veteran Postgres ecosystem. Instead of rolling out a brand-new “big data platform” or forging a separate “analytic engine” for Postgres, hooking them together is arguably the simplest and most valuable route.
And guess what—it’s already happening. Multiple teams and vendors are weaving DuckDB into Postgres, racing to open up a massive untapped market.
The Race to Stitch Them Together
Take a quick peek and you’ll see competition is fierce
- A lone-wolf developer in China, Steven Lee, kicked things off with
duckdb_fdw. It flew under the radar for a while, but definitely laid groundwork. - After the post “PostgreSQL Is Eating the Database World” used vector databases as a hint toward future OLAP, the PG crowd got charged up about grafting DuckDB onto Postgres.
- By March 2024, ParadeDB retooled
pg_analyticsto stitch in DuckDB. - Hydra, in the PG ecosystem, and DuckDB’s parent MotherDuck launched
pg_duckdb. DuckDB officially jumped into Postgres integration — ironically pausing their own direct approachhydrafor a long time. - Neon, always quick to ride the wave, sponsored
pg_mooncake, built onpg_duckdb. It aims to embed DuckDB’s compute engine in PG while also fusing Parquet-based lakehouse storage. - Even big clouds like Alibaba Cloud RDS are experimenting with DuckDB add-ons (
rds_duckdb). That’s a sure sign the giants have caught on.
It’s eerily reminiscent of the vector-database frenzy. Once AI and semantic search took off, vendors piled on. In Postgres alone, at least six vector DB extensions sprang up: pgvector, pgvector.rs, pg_embedding, latern, pase, pgvectorscale. It was a good ol’ Wild West. Ultimately, pgvector—fueled by AWS—triumphed, overshadowing latecomers from Oracle/MySQL/MariaDB. Now OLAP might be next in line.
Why DuckDB + Postgres?
Some folks might ask: If we want DuckDB’s power, why not fuse it with MySQL, Oracle, SQL Server, or even MongoDB? Don’t they all crave sharper OLAP?
But Postgres and DuckDB fit like a glove. The synergy boils down to three points:
-
Syntax Compatibility. DuckDB practically clones Postgres syntax and parser, meaning near-zero friction.
-
Extensibility. Both Postgres and DuckDB are known for “extensibility mania.” FDWs, storage engines, custom data types—any piece can snap in as an extension. No need to hack deep into either codebase when you can build a bridging extension.
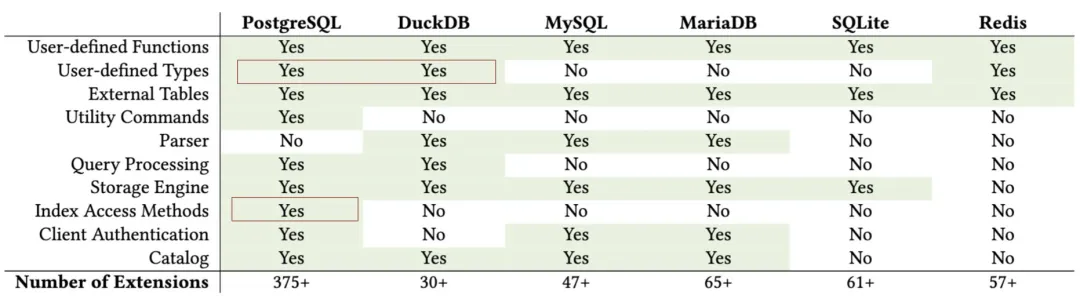
Survey and Evaluation of Database Management System Extensibility
-
Massive Market. Postgres is already the world’s most popular database and the only major RDBMS still growing fast. Integrating with PG brings way more mileage than targeting smaller players.
Hence, hooking Postgres + DuckDB is like a “path of least resistance for maximum impact.” Nature abhors a vacuum, so everyone’s rushing in.
The Dream: One System for OLTP and OLAP
OLTP vs. OLAP has historically been a massive fault line in databases. We’ve spent decades patching it up with data warehouses, separate RDBMS solutions, ETL pipelines, and more. But if Postgres can maintain its OLTP might while leveraging DuckDB for analytics, do we really need an extra analytics DB?
That scenario suggests huge cost savings and simpler engineering. No more data migration migraines or maintaining two different data stacks. Anyone who nails that seamless integration might detonate a deep-sea bomb in the big-data market.
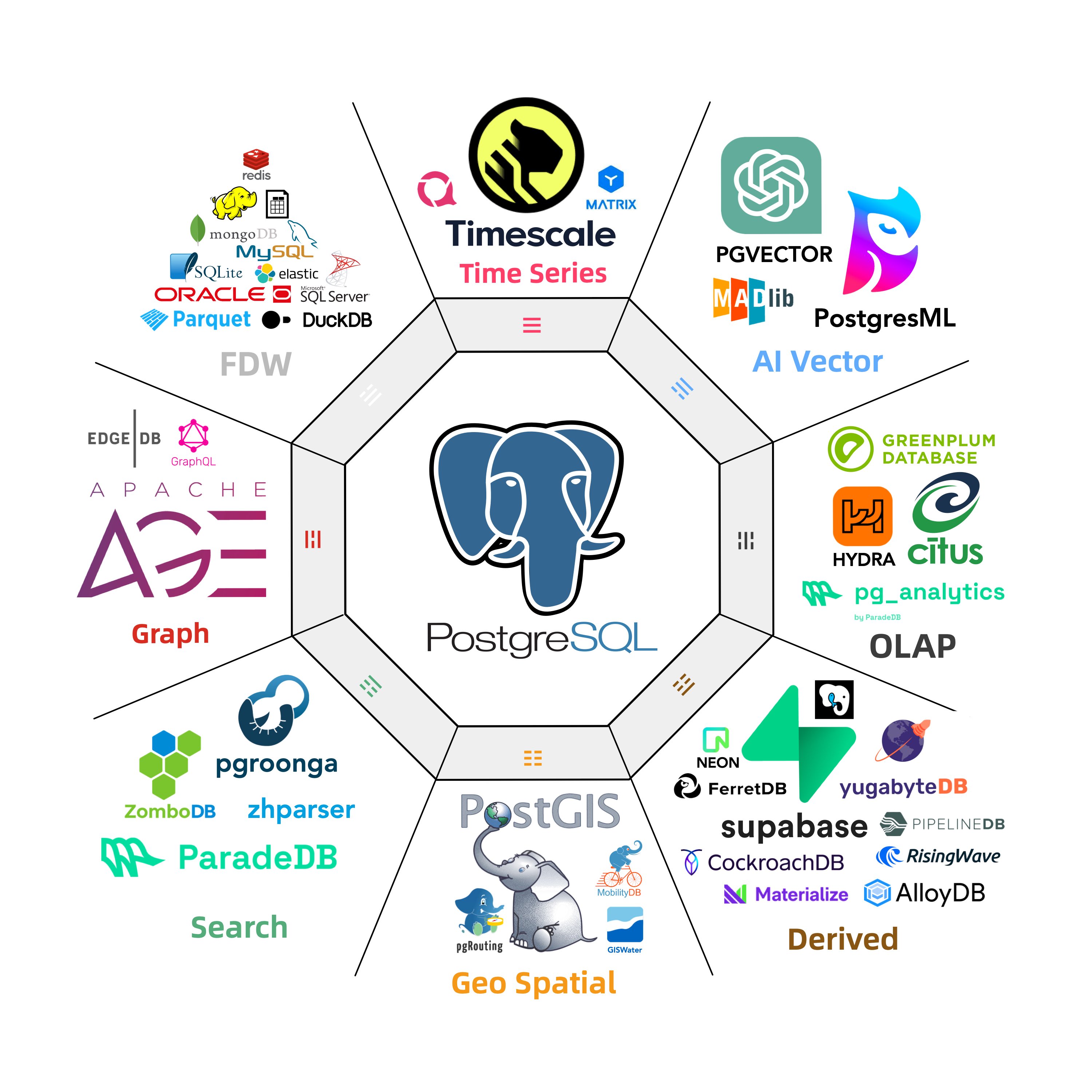
People call Postgres the “Linux kernel of databases” — open source, infinitely extensible, morphable into anything: even mimic MySQL, Oracle, MsSQL and Mongo. We’ve already watched PG conquer geospatial, time series, NoSQL, and vector search through its extension hooks. OLAP might just be its biggest conquest yet.
A polished “plug-and-play” DuckDB integration could flip big data analytics on its head. Will specialized OLAP services withstand a nuclear-level blow? Could they end up like “specialized vector DBs” overshadowed by pgvector? We don’t know, but we’ll definitely have opinions once the dust settles.
Paving the Way for PG + DuckDB
Right now, Postgres OLAP extensions feel like the early vector DB days—small community, big excitement. The beauty of fresh tech is that if you spot the potential, you can jump in early and catch the wave.
When pgvector was just getting started, Pigsty was among the first adopters, right behind Supabase & Neon. I even suggested it be added to PGDG’s yum repos. Now, with the DuckDB stitching craze, you can bet I’ll do better.
As a seasoned data hand, I’m bundling all the PG+DuckDB integration extensions into simple RPMs/DEBs for major Linux distros., fully compatible with official PGDG binaries. Anyone can install them and start playing with “DuckDB+PG” in minutes — call it a battleground where the new contenders can test their mettle on equal footing.
The missing package manager for PostgreSQL:
pig
| Name (Detail) | Repo | Description |
|---|---|---|
| citus | PIGSTY | Distributed PostgreSQL as an extension |
| citus_columnar | PIGSTY | Citus columnar storage engine |
| hydra | PIGSTY | Hydra Columnar extension |
| pg_analytics | PIGSTY | Postgres for analytics, powered by DuckDB |
| pg_duckdb | PIGSTY | DuckDB Embedded in Postgres |
| pg_mooncake | PIGSTY | Columnstore Table in Postgres |
| duckdb_fdw | PIGSTY | DuckDB Foreign Data Wrapper |
| pg_parquet | PIGSTY | copy data between Postgres and Parquet |
| pg_fkpart | MIXED | Table partitioning by foreign key utility |
| pg_partman | PGDG | Extension to manage partitioned tables by time or ID |
| plproxy | PGDG | Database partitioning implemented as procedural language |
| pg_strom | PGDG | PG-Strom - big-data processing acceleration using GPU and NVME |
| tablefunc | CONTRIB | functions that manipulate whole tables, including crosstab |
Sure, a lot of these plugins are alpha/beta: concurrency quirks, partial feature sets, performance oddities. But fortune favors the bold. I’m convinced this “PG + DuckDB” show is about to take center stage.
The Real Explosion Is Coming
In enterprise circles, OLAP dwarfs most hype markets by sheer scale and practicality. Meanwhile, Postgres + DuckDB looks set to disrupt this space further, possibly demolishing the old “RDBMS + big data” two-stack architecture.
In months—or a year or two—we might see a new wave of “chimera” systems spring from these extension projects and claim the database spotlight. Whichever team nails usability, integration, and performance first will seize a formidable edge.
For database vendors, this is an epic collision; for businesses, it’s a chance to do more with less. Let’s see how the dust settles—and how it reshapes the future of data analytics and management.
Further Reading
- PostgreSQL Is Eating the Database World
- Whoever Masters DuckDB Integration Wins the OLAP Database World
- Alibaba Cloud rds_duckdb: Homage or Ripoff?
- Is Distributed Databases a Mythical Need?
- Andy Pavlo’s 2024 Database Recap
Self-Hosting Supabase on PostgreSQL
Supabase is great, own your own Supabase is even better. Here’s a comprehensive tutorial for self-hosting production-grade supabase on local/cloud VM/BMs.
This tutorial is obsolete for the latest pigsty version, Check the latest tutorial here: Self-Hosting Supabase
What is Supabase?
Supabase is an open-source Firebase alternative, a Backend as a Service (BaaS).
Supabase wraps PostgreSQL kernel and vector extensions, alone with authentication, realtime subscriptions, edge functions, object storage, and instant REST and GraphQL APIs from your postgres schema. It let you skip most backend work, requiring only database design and frontend skills to ship quickly.
Currently, Supabase may be the most popular open-source project in the PostgreSQL ecosystem, boasting over 74,000 stars on GitHub. And become quite popular among developers, and startups, since they have a generous free plan, just like cloudflare & neon.
Why Self-Hosting?
Supabase’s slogan is: “Build in a weekend, Scale to millions”. It has great cost-effectiveness in small scales (4c8g) indeed. But there is no doubt that when you really grow to millions of users, some may choose to self-hosting their own Supabase —— for functionality, performance, cost, and other reasons.
That’s where Pigsty comes in. Pigsty provides a complete one-click self-hosting solution for Supabase. Self-hosted Supabase can enjoy full PostgreSQL monitoring, IaC, PITR, and high availability capability,
You can run the latest PostgreSQL 17(,16,15,14) kernels, (supabase is using the 15 currently), alone with 421 PostgreSQL extensions out-of-the-box. Run on mainstream Linus OS distros with production grade HA PostgreSQL, MinIO, Prometheus & Grafana Stack for observability, and Nginx for reverse proxy.
Since most of the supabase maintained extensions are not available in the official PGDG repo, we have compiled all the RPM/DEBs for these extensions and put them in the Pigsty repo: pg_graphql, pg_jsonschema, wrappers, index_advisor, pg_net, vault, pgjwt, supautils, pg_plan_filter,…
Everything is under your control, you have the ability and freedom to scale PGSQL, MinIO, and Supabase itself. And take full advantage of the performance and cost advantages of modern hardware like Gen5 NVMe SSD.
All you need is prepare a VM with several commands and wait for 10 minutes….
Get Started
First, download & install pigsty as usual, with the supa config template:
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./bootstrap # install ansible
./configure -c app/supa # use supabase config (please CHANGE CREDENTIALS in pigsty.yml)
vi pigsty.yml # edit domain name, password, keys,...
./install.yml # install pigsty
Please change the
pigsty.ymlconfig file according to your need before deploying Supabase. (Credentials) For dev/test/demo purposes, we will just skip that, and comes back later.
Then, run the docker.yml to install docker, and app.yml to launch stateless part of supabase.
./docker.yml # install docker compose
./app.yml # launch supabase stateless part with docker
You can access the supabase API / Web UI through the 8000/8443 directly.
with configured DNS, or a local /etc/hosts entry, you can also use the default supa.pigsty domain name via the 80/443 infra portal.
Credentials for Supabase Studio:
supabase:pigsty

Architecture
Pigsty’s supabase is based on the Supabase Docker Compose Template, with some slight modifications to fit-in Pigsty’s default ACL model.
The stateful part of this template is replaced by Pigsty’s managed PostgreSQL cluster and MinIO cluster. The container part are stateless, so you can launch / destroy / run multiple supabase containers on the same stateful PGSQL / MINIO cluster simultaneously to scale out.

The built-in supa.yml config template will create a single-node supabase, with a singleton PostgreSQL and SNSD MinIO server.
You can use Multinode PostgreSQL Clusters and MNMD MinIO Clusters / external S3 service instead in production, we will cover that later.
Config Detail
Here are checklists for self-hosting
- Hardware: necessary VM/BM resources, one node at least, 3-4 are recommended for HA.
- Linux OS: Linux x86_64 server with fresh installed Linux, check compatible distro
- Network: Static IPv4 address which can be used as node identity
- Admin User: nopass ssh & sudo are recommended for admin user
- Conf Template: Use the
supaconfig template, if you don’t know how to manually configure pigsty
The built-in supa.yml config template is shown below.
The supa Config Template
all:
children:
# the supabase stateless (default username & password: supabase/pigsty)
supa:
hosts:
10.10.10.10: {}
vars:
app: supabase # specify app name (supa) to be installed (in the apps)
apps: # define all applications
supabase: # the definition of supabase app
conf: # override /opt/supabase/.env
# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!
# https://supabase.com/docs/guides/self-hosting/docker#securing-your-services
JWT_SECRET: your-super-secret-jwt-token-with-at-least-32-characters-long
ANON_KEY: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GE
SERVICE_ROLE_KEY: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Q
DASHBOARD_USERNAME: supabase
DASHBOARD_PASSWORD: pigsty
# postgres connection string (use the correct ip and port)
POSTGRES_HOST: 10.10.10.10 # point to the local postgres node
POSTGRES_PORT: 5436 # access via the 'default' service, which always route to the primary postgres
POSTGRES_DB: postgres # the supabase underlying database
POSTGRES_PASSWORD: DBUser.Supa # password for supabase_admin and multiple supabase users
# expose supabase via domain name
SITE_URL: https://supa.pigsty # <------- Change This to your external domain name
API_EXTERNAL_URL: https://supa.pigsty # <------- Otherwise the storage api may not work!
SUPABASE_PUBLIC_URL: https://supa.pigsty # <------- DO NOT FORGET TO PUT IT IN infra_portal!
# if using s3/minio as file storage
S3_BUCKET: supa
S3_ENDPOINT: https://sss.pigsty:9000
S3_ACCESS_KEY: supabase
S3_SECRET_KEY: S3User.Supabase
S3_FORCE_PATH_STYLE: true
S3_PROTOCOL: https
S3_REGION: stub
MINIO_DOMAIN_IP: 10.10.10.10 # sss.pigsty domain name will resolve to this ip statically
# if using SMTP (optional)
#SMTP_ADMIN_EMAIL: [email protected]
#SMTP_HOST: supabase-mail
#SMTP_PORT: 2500
#SMTP_USER: fake_mail_user
#SMTP_PASS: fake_mail_password
#SMTP_SENDER_NAME: fake_sender
#ENABLE_ANONYMOUS_USERS: false
# infra cluster for proxy, monitor, alert, etc..
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
# etcd cluster for ha postgres
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
# minio cluster, s3 compatible object storage
minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
# pg-meta, the underlying postgres database for supabase
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users:
# supabase roles: anon, authenticated, dashboard_user
- { name: anon ,login: false }
- { name: authenticated ,login: false }
- { name: dashboard_user ,login: false ,replication: true ,createdb: true ,createrole: true }
- { name: service_role ,login: false ,bypassrls: true }
# supabase users: please use the same password
- { name: supabase_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: true ,roles: [ dbrole_admin ] ,superuser: true ,replication: true ,createdb: true ,createrole: true ,bypassrls: true }
- { name: authenticator ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] }
- { name: supabase_auth_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_storage_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] ,createrole: true }
- { name: supabase_functions_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_replication_admin ,password: 'DBUser.Supa' ,replication: true ,roles: [ dbrole_admin ]}
- { name: supabase_read_only_user ,password: 'DBUser.Supa' ,bypassrls: true ,roles: [ dbrole_readonly, pg_read_all_data ] }
pg_databases:
- name: postgres
baseline: supabase.sql
owner: supabase_admin
comment: supabase postgres database
schemas: [ extensions ,auth ,realtime ,storage ,graphql_public ,supabase_functions ,_analytics ,_realtime ]
extensions:
- { name: pgcrypto ,schema: extensions } # cryptographic functions
- { name: pg_net ,schema: extensions } # async HTTP
- { name: pgjwt ,schema: extensions } # json web token API for postgres
- { name: uuid-ossp ,schema: extensions } # generate universally unique identifiers (UUIDs)
- { name: pgsodium } # pgsodium is a modern cryptography library for Postgres.
- { name: supabase_vault } # Supabase Vault Extension
- { name: pg_graphql } # pg_graphql: GraphQL support
- { name: pg_jsonschema } # pg_jsonschema: Validate json schema
- { name: wrappers } # wrappers: FDW collections
- { name: http } # http: allows web page retrieval inside the database.
- { name: pg_cron } # pg_cron: Job scheduler for PostgreSQL
- { name: timescaledb } # timescaledb: Enables scalable inserts and complex queries for time-series data
- { name: pg_tle } # pg_tle: Trusted Language Extensions for PostgreSQL
- { name: vector } # pgvector: the vector similarity search
- { name: pgmq } # pgmq: A lightweight message queue like AWS SQS and RSMQ
# supabase required extensions
pg_libs: 'timescaledb, plpgsql, plpgsql_check, pg_cron, pg_net, pg_stat_statements, auto_explain, pg_tle, plan_filter'
pg_parameters:
cron.database_name: postgres
pgsodium.enable_event_trigger: off
pg_hba_rules: # supabase hba rules, require access from docker network
- { user: all ,db: postgres ,addr: intra ,auth: pwd ,title: 'allow supabase access from intranet' }
- { user: all ,db: postgres ,addr: 172.17.0.0/16 ,auth: pwd ,title: 'allow access from local docker network' }
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # make a full backup every 1am
#==============================================================#
# Global Parameters
#==============================================================#
vars:
version: v3.5.0 # pigsty version string
admin_ip: 10.10.10.10 # admin node ip address
region: default # upstream mirror region: default|china|europe
node_tune: oltp # node tuning specs: oltp,olap,tiny,crit
pg_conf: oltp.yml # pgsql tuning specs: {oltp,olap,tiny,crit}.yml
docker_enabled: true # enable docker on app group
#docker_registry_mirrors: ["https://docker.1ms.run"] # use mirror in mainland china
proxy_env: # global proxy env when downloading packages & pull docker images
no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.tsinghua.edu.cn"
#http_proxy: 127.0.0.1:12345 # add your proxy env here for downloading packages or pull images
#https_proxy: 127.0.0.1:12345 # usually the proxy is format as http://user:[email protected]
#all_proxy: 127.0.0.1:12345
certbot_email: [email protected] # your email address for applying free let's encrypt ssl certs
infra_portal: # domain names and upstream servers
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus : { domain: p.pigsty ,endpoint: "${admin_ip}:9090" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9093" }
minio : { domain: m.pigsty ,endpoint: "10.10.10.10:9001", https: true, websocket: true }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" } # expose supa studio UI and API via nginx
supa : # nginx server config for supabase
domain: supa.pigsty # REPLACE WITH YOUR OWN DOMAIN!
endpoint: "10.10.10.10:8000" # supabase service endpoint: IP:PORT
websocket: true # add websocket support
certbot: supa.pigsty # certbot cert name, apply with `make cert`
#----------------------------------#
# Credential: CHANGE THESE PASSWORDS
#----------------------------------#
#grafana_admin_username: admin
grafana_admin_password: pigsty
#pg_admin_username: dbuser_dba
pg_admin_password: DBUser.DBA
#pg_monitor_username: dbuser_monitor
pg_monitor_password: DBUser.Monitor
#pg_replication_username: replicator
pg_replication_password: DBUser.Replicator
#patroni_username: postgres
patroni_password: Patroni.API
#haproxy_admin_username: admin
haproxy_admin_password: pigsty
#minio_access_key: minioadmin
minio_secret_key: minioadmin # minio root secret key, `minioadmin` by default, also change pgbackrest_repo.minio.s3_key_secret
# use minio as supabase file storage, single node single driver mode for demonstration purpose
minio_buckets: [ { name: pgsql }, { name: supa } ]
minio_users:
- { access_key: dba , secret_key: S3User.DBA, policy: consoleAdmin }
- { access_key: pgbackrest , secret_key: S3User.Backup, policy: readwrite }
- { access_key: supabase , secret_key: S3User.Supabase, policy: readwrite }
minio_endpoint: https://sss.pigsty:9000 # explicit overwrite minio endpoint with haproxy port
node_etc_hosts: ["10.10.10.10 sss.pigsty"] # domain name to access minio from all nodes (required)
# use minio as default backup repo for PostgreSQL
pgbackrest_method: minio # pgbackrest repo method: local,minio,[user-defined...]
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
s3_endpoint: sss.pigsty # minio endpoint domain name, `sss.pigsty` by default
s3_region: us-east-1 # minio region, us-east-1 by default, useless for minio
s3_bucket: pgsql # minio bucket name, `pgsql` by default
s3_key: pgbackrest # minio user access key for pgbackrest
s3_key_secret: S3User.Backup # minio user secret key for pgbackrest <------------------ HEY, DID YOU CHANGE THIS?
s3_uri_style: path # use path style uri for minio rather than host style
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9000 # minio port, 9000 by default
storage_ca_file: /etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by default
block: y # Enable block incremental backup
bundle: y # bundle small files into a single file
bundle_limit: 20MiB # Limit for file bundles, 20MiB for object storage
bundle_size: 128MiB # Target size for file bundles, 128MiB for object storage
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest' <----- HEY, DID YOU CHANGE THIS?
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
pg_version: 17
repo_extra_packages: [pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-util ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]
pg_extensions: [ pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-feat ,pg17-lang ,pg17-type ,pg17-util ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl, pg_mooncake, pg_analytics, pg_parquet ] #,pg17-olap]
For advanced topics, we may need to modify the configuration file to fit our needs.
- Security Enhancement
- Domain Name and HTTPS
- Sending Mail with SMTP
- MinIO or External S3
- True High Availability
Security Enhancement
For security reasons, you should change the default passwords in the pigsty.yml config file.
grafana_admin_password:pigsty, Grafana admin passwordpg_admin_password:DBUser.DBA, PGSQL superuser passwordpg_monitor_password:DBUser.Monitor, PGSQL monitor user passwordpg_replication_password:DBUser.Replicator, PGSQL replication user passwordpatroni_password:Patroni.API, Patroni HA Agent Passwordhaproxy_admin_password:pigsty, Load balancer admin passwordminio_access_key:minioadmin, MinIO root usernameminio_secret_key:minioadmin, MinIO root password
Supabase will use PostgreSQL & MinIO as its backend, so also change the following passwords for supabase business users:
pg_users: password for supabase business users in postgresminio_users:minioadmin, MinIO business user’s password
The pgbackrest will take backups and WALs to MinIO, so also change the following passwords reference
pgbackrest_repo: refer to the
PLEASE check the Supabase Self-Hosting: Generate API Keys to generate supabase credentials:
jwt_secret: a secret key with at least 40 charactersanon_key: a jwt token generate for anonymous users, based onjwt_secretservice_role_key: a jwt token generate for elevated service roles, based onjwt_secretdashboard_username: supabase studio web portal username,supabaseby defaultdashboard_password: supabase studio web portal password,pigstyby default
If you have chanaged the default password for PostgreSQL and MinIO, you have to update the following parameters as well:
postgres_password, according topg_userss3_access_keyands3_secret_key, according tominio_users
Domain Name and HTTPS
For local or intranet use, you can connect directly to Kong port on http://<IP>:8000 or 8443 for https.
This works but isn’t ideal. Using a domain with HTTPS is strongly recommended when serving Supabase to the public.
Pigsty has a Nginx server installed & configured on the admin node to act as a reverse proxy for all web based service.
which is configured via the infra_portal parameter.
all:
vars:
infra_portal:
supa :
domain: supa.pigsty.cc # replace the default supa.pigsty domain name with your own domain name
endpoint: "10.10.10.10:8000"
websocket: true
certbot: supa.pigsty.cc # certificate name, usually the same as the domain name
On the client side, you can use the domain supa.pigsty to access the Supabase Studio management interface.
You can add this domain to your local /etc/hosts file or use a local DNS server to resolve it to the server’s external IP address.
To use a real domain with HTTPS, you will need to modify the all.vars.infra_portal.supa with updated domain name (such as supa.pigsty.cc here).
You can obtain a free HTTPS certificate with certbot as simple as:
make cert
You also have to update the all.children.supa.apps.supabase.conf to tell supabase to use the new domain name:
all:
children: # clusters
supa:
vars:
apps:
supabase:
conf:
SITE_URL: https://supa.pigsty.cc # <------- Change This to your external domain name
API_EXTERNAL_URL: https://supa.pigsty.cc # <------- Otherwise the storage api may not work!
SUPABASE_PUBLIC_URL: https://supa.pigsty.cc # <------- DO NOT FORGET TO PUT IT IN infra_portal!
And reload the supabase service to apply the new configuration:
./app.yml -t app_config,app_launch # reload supabase config
Sending Mail with SMTP
Some Supabase features require email. For production use, I’d recommend using an external SMTP service. Since self-hosted SMTP servers often result in rejected or spam-flagged emails.
To do this, modify the Supabase configuration and add SMTP credentials:
all:
children: # clusters
supa:
vars:
apps:
supabase:
conf:
SMTP_HOST: smtpdm.aliyun.com:80
SMTP_PORT: 80
SMTP_USER: [email protected]
SMTP_PASS: your_email_user_password
SMTP_SENDER_NAME: MySupabase
SMTP_ADMIN_EMAIL: [email protected]
ENABLE_ANONYMOUS_USERS: false
And don’t forget to reload the supabase service with app.yml -t app_config,app_launch
MinIO or External S3
Pigsty’s self-hosting supabase will use a local SNSD MinIO server, which is used by Supabase itself for object storage, and by PostgreSQL for backups. For production use, you should consider using a HA MNMD MinIO cluster or an external S3 compatible service instead.
We recommend using an external S3 when:
- you just have one single server available, then external s3 gives you a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
- you are operating in the cloud, then using S3 directly is recommended rather than wrap expensively EBS with MinIO
The
terraform/spec/aliyun-meta-s3.tfprovides an example of how to provision a single node alone with an S3 bucket.
To use an external S3 compatible service, you’ll have to update two related references in the pigsty.yml config.
For example, to use Aliyun OSS as the object storage for Supabase, you can modify the all.children.supabase.vars.supa_config to point to the Aliyun OSS bucket:
all:
children:
supabase:
vars:
supa_config:
s3_bucket: pigsty-oss
s3_endpoint: https://oss-cn-beijing-internal.aliyuncs.com
s3_access_key: xxxxxxxxxxxxxxxx
s3_secret_key: xxxxxxxxxxxxxxxx
s3_force_path_style: false
s3_protocol: https
s3_region: oss-cn-beijing
Reload the supabase service with ./supabase.yml -t supa_config,supa_launch again.
The next reference is in the PostgreSQL backup repo:
all:
vars:
# use minio as default backup repo for PostgreSQL
pgbackrest_method: minio # pgbackrest repo method: local,minio,[user-defined...]
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
# update your credentials here
s3_endpoint: oss-cn-beijing-internal.aliyuncs.com
s3_region: oss-cn-beijing
s3_bucket: pigsty-oss
s3_key: xxxxxxxxxxxxxx
s3_key_secret: xxxxxxxx
s3_uri_style: host
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9000 # minio port, 9000 by default
storage_ca_file: /pg/cert/ca.crt # minio ca file path, `/pg/cert/ca.crt` by default
bundle: y # bundle small files into a single file
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
After updating the pgbackrest_repo, you can reset the pgBackrest backup with ./pgsql.yml -t pgbackrest.
True High Availability
The default single-node deployment (with external S3) provide a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
To achieve RTO < 30s and zero data loss, you need a multi-node high availability cluster with at least 3-nodes.
Which involves high availability for these components:
- ETCD: DCS requires at least three nodes to tolerate one node failure.
- PGSQL: PGSQL synchronous commit mode recommends at least three nodes.
- INFRA: It’s good to have two or three copies of observability stack.
- Supabase itself can also have multiple replicas to achieve high availability.
We recommend you to refer to the trio and safe config to upgrade your cluster to three nodes or more.
In this case, you also need to modify the access points for PostgreSQL and MinIO to use the DNS / L2 VIP / HAProxy HA access points.
all:
children:
supabase:
hosts:
10.10.10.10: { supa_seq: 1 }
10.10.10.11: { supa_seq: 2 }
10.10.10.12: { supa_seq: 3 }
vars:
supa_cluster: supa # cluster name
supa_config:
postgres_host: 10.10.10.2 # use the PG L2 VIP
postgres_port: 5433 # use the 5433 port to access the primary instance through pgbouncer
s3_endpoint: https://sss.pigsty:9002 # If you are using MinIO through the haproxy lb port 9002
minio_domain_ip: 10.10.10.3 # use the L2 VIP binds to all proxy nodes
MySQL is dead, Long live PostgreSQL!
This July, MySQL 9.0 was finally released—a full eight years after its last major version, 8.0 (@2016-09). Yet, this hollow “innovation” release feels like a bad joke, signaling that MySQL is on its deathbed.
While PostgreSQL continues to surge ahead, MySQL’s sunset is painfully acknowledged by Percona, a major flag-bearer of the MySQL ecosystem, through a series of poignant posts: “Where is MySQL Heading?”, “Did Oracle Finally Kill MySQL?”, and “Can Oracle Save MySQL?”, openly expressing disappointment and frustration with MySQL.
Peter Zaitsev, CEO of Percona, remarked:
Who needs MySQL when there’s PostgreSQL? But if MySQL dies, PostgreSQL might just monopolize the database world, so at least MySQL can serve as a whetstone for PostgreSQL to reach its zenith.
Some databases are eating the DBMS world, while others are fading into obscurity.
MySQL is dead, Long live PostgreSQL!
- Hollow Innovations
- Sloppy Vector Types
- Belated JavaScript Functions
- Lagging Features
- Degrading Performance
- Irredeemable Isolation Levels
- Shrinking Ecosystem
- Who Really Killed MySQL?
- PostgreSQL Ascends as MySQL Rests in Peace
Hollow Innovations
The official MySQL website’s “What’s New in MySQL 9.0” introduces a few new features of version 9.0, with six features.
And that’s it? That’s all there is?
This is surprisingly underwhelming because PostgreSQL’s major releases every year brim with countless new features. For instance, PostgreSQL 17, slated for release this fall, already boasts an impressive list of new features, even though it’s just in beta1:

The recent slew of PostgreSQL features could even fill a book, as seen in “Quickly Mastering New PostgreSQL Features”, which covers the key enhancements from the last seven years, packing the contents to the brim:

Looking back at MySQL’s update, the last four of the six touted features are mere minor patches, barely worth mentioning. The first two—vector data types and JavaScript stored procedures—are supposed to be the highlights.
BUT —
MySQL 9.0’s vector data types are just an alias of BLOB — with a simple array length function added. This kind of feature was supported by PostgreSQL when it was born 28 years ago.
And MySQL’s support for JavaScript stored procedures? It’s an enterprise-only feature—not available in the open-source version, while PostgreSQL has had this capability since 13 years ago with version 9.1.
After an eight-year wait, the “innovative update” delivers two “old features,” one of which is gated behind an enterprise edition. The term “innovation” here seems bitterly ironic and sarcastic.
Sloppy Vector Types
In the past few years, AI has exploded in popularity, boosting interest in vector databases. Nearly every mainstream DBMS now supports vector data types—except for MySQL.
Users might have hoped that MySQL 9.0, touted as an innovative release, would fill some gaps in this area. Instead, they were greeted with a shocking level of complacency—how could they be so sloppy?
According to MySQL 9.0’s official documentation, there are only three functions related to vector types. Ignoring the two that deal with string conversions, the only real functional command is VECTOR_DIM: it returns the dimension of a vector (i.e., the length of an array)!

The bar for entry into vector databases is not high—a simple vector distance function (think dot product, a 10-line C program, a coding task suitable for elementary students) would suffice. This could enable basic vector retrieval through a full table scan with an ORDER BY d LIMIT n query, representing a minimally viable feature. Yet MySQL 9 didn’t even bother to implement this basic vector distance function, which is not a capability issue but a clear sign that Oracle has lost interest in progressing MySQL. Any seasoned tech observer can see that this so-called “vector type” is merely a BLOBunder a different name—it only manages your binary data input without caring how users want to search or utilize it. Of course, it’s possible Oracle has a more robust version on its MySQL Heatwave, but what’s delivered on MySQL itself is a feature you could hack together in ten minutes.
In contrast, let’s look at PostgreSQL, MySQL’s long-standing rival. Over the past year, the PostgreSQL ecosystem has spawned at least six vector database extensions (pgvector, pgvector.rs, pg_embedding, latern, pase, pgvectorscale) and has reached new heights in a competitive race. The frontrunner, pgvector, which emerged in 2021, quickly reached heights that many specialized vector databases couldn’t, thanks to the collective efforts of developers, vendors, and users standing on PostgreSQL’s shoulders. It could even be argued that pgvector single-handedly ended this niche in databases—“Is the Dedicated Vector Database Era Over?”.
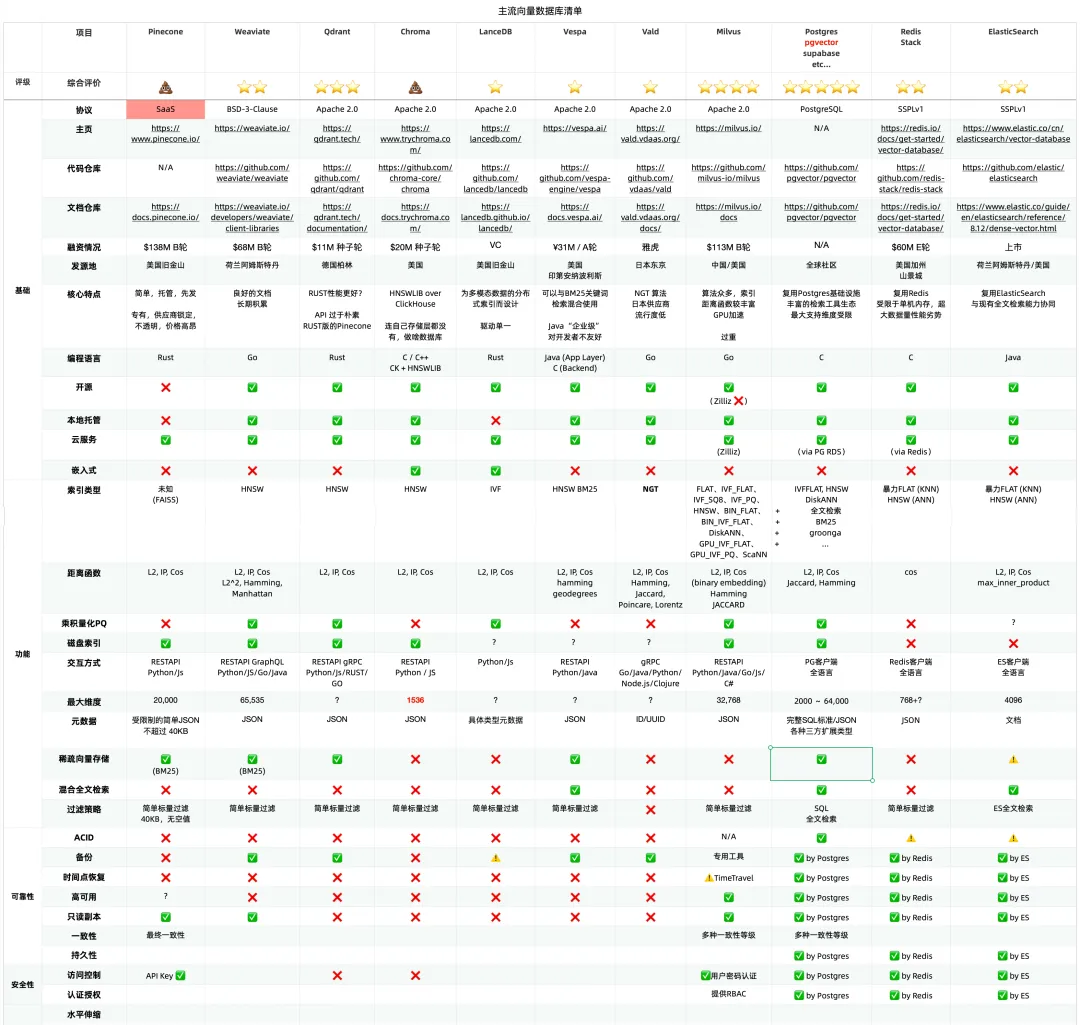
Within this year, pgvector improved its performance by 150 times, and its functionality has dramatically expanded. pgvector offers data types like float vectors, half-precision vectors, bit vectors, and sparse vectors; distance metrics like L1, L2, dot product, Hamming, and Jaccard; various vector and scalar functions and operators; supports IVFFLAT and HNSW vector indexing methods (with the pgvectorscale extension adding DiskANN indexing); supports parallel index building, vector quantization, sparse vector handling, sub-vector indexing, and hybrid retrieval, with potential SIMD instruction acceleration. These rich features, combined with a free open-source license and the collaborative power of the entire PostgreSQL ecosystem, have made pgvector a resounding success. Together with PostgreSQL, it has become the default database for countless AI projects.
Comparing pgvector with MySQL 9’s “vector” support might seem unfair, as MySQL’s offering doesn’t even come close to PostgreSQL’s “multidimensional array type” available since its inception in 1996—at least that had a robust array of functions, not just an array length calculation.
Vectors are the new JSON, but the party at the vector database table has ended, and MySQL hasn’t even managed to serve its dish. It has completely missed the growth engine of the next AI decade, just as it missed the JSON document database wave of the internet era in the previous decade.
Belated JavaScript Functions
Another “blockbuster” feature of MySQL 9.0 is JavaScript Stored Procedures.
However, using JavaScript for stored procedures isn’t a novel concept—back in 2011, PostgreSQL 9.1 could already script JavaScript stored procedures through the plv8 extension, and MongoDB began supporting JavaScript around the same time.
A glance at the past twelve years of the “Database Popularity Trend” on DB-Engine shows that only PostgreSQL and Mongo have truly led the pack. MongoDB (2009) and PostgreSQL 9.2 (2012) were quick to grasp internet developers’ needs, adding JSON feature support (document databases) right as the “Rise of JSON” began, thereby capturing the largest growth share in the database realm over the last decade.
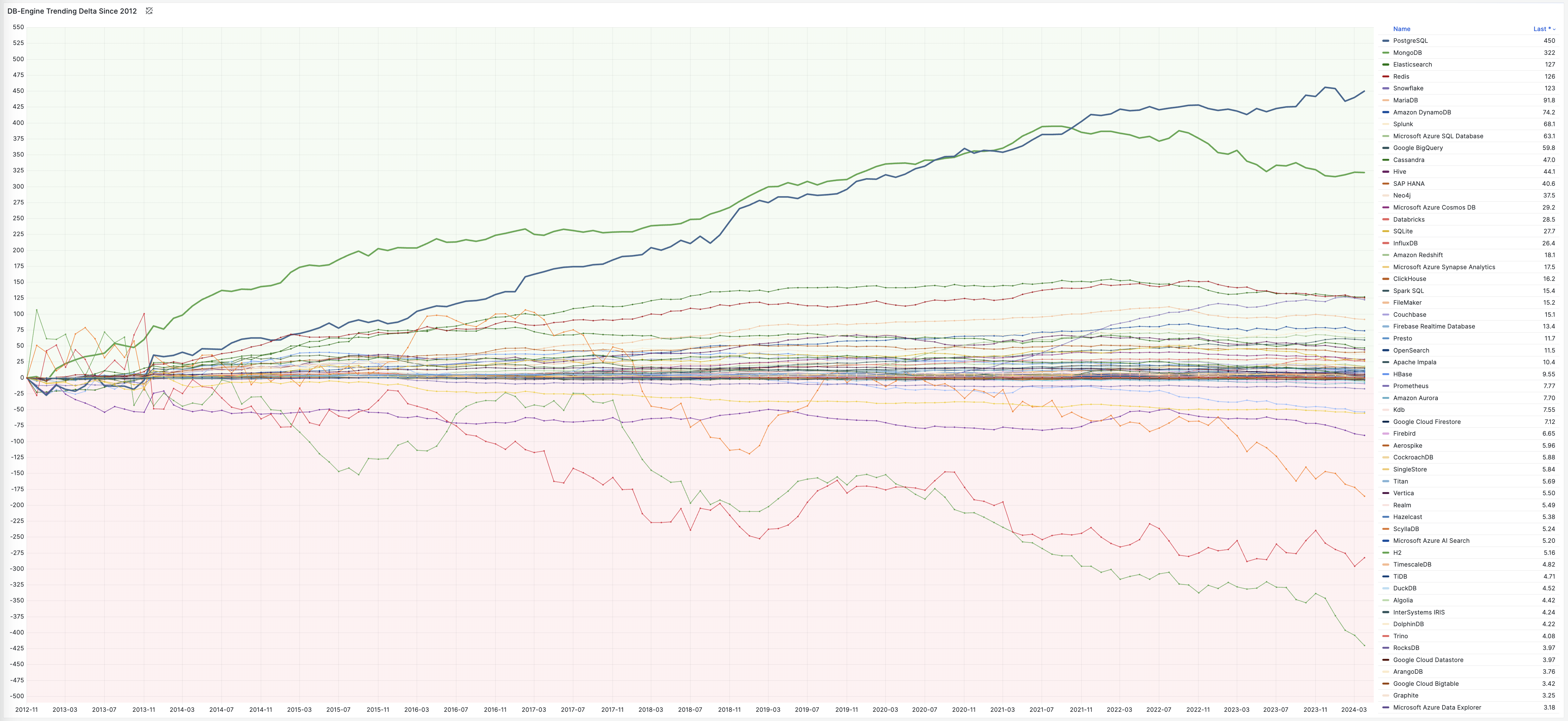
Of course, Oracle, MySQL’s stepfather, added JSON features and JavaScript stored procedure support by the end of 2014 in version 12.1—while MySQL itself unfortunately didn’t catch up until 2024—but it’s too late now!
Oracle allows stored procedures to be written in C, SQL, PL/SQL, Python, Java, and JavaScript. But compared to PostgreSQL’s more than twenty supported procedural languages, it’s merely a drop in the bucket:

Unlike PostgreSQL and Oracle’s development philosophy, MySQL’s best practices generally discourage using stored procedures—making JavaScript functions a rather superfluous feature for MySQL. Even so, Oracle made JavaScript stored procedures a MySQL Enterprise Edition exclusive—considering most MySQL users opt for the open-source community version, this feature essentially went unnoticed.
Falling Behind: Features and Flexibility
MySQL’s feature deficiencies go beyond mere programming language and stored procedure support. Across various dimensions, MySQL significantly lags behind its competitor PostgreSQL—not just in core database capabilities but also in its extensibility ecosystem.
Abigale Kim from CMU has conducted research on scalability across mainstream databases, highlighting PostgreSQL’s superior extensibility among all DBMSs, boasting an unmatched number of extension plugins—375+ listed on PGXN alone, with actual ecosystem extensions surpassing a thousand.
These plugins enable PostgreSQL to serve diverse functionalities—geospatial, time-series, vector search, machine learning, OLAP, full-text search, graph databases—effectively turning it into a multi-faceted, full-stack database. A single PostgreSQL instance can replace an array of specialized components: MySQL, MongoDB, Kafka, Redis, ElasticSearch, Neo4j, and even dedicated analytical data warehouses and data lakes.
While MySQL remains confined to its “relational OLTP database” niche, PostgreSQL has transcended its relational roots to become a multi-modal database and a platform for data management abstraction and development.
PostgreSQL is devouring the database world, internalizing the entire database realm through its plugin architecture. “Just use Postgres” has moved from being a fringe exploration by elite teams to a mainstream best practice.
In contrast, MySQL shows a lackluster enthusiasm for new functionalities—a major version update that should be rife with innovative ‘breaking changes’ turns out to be either lackluster features or insubstantial enterprise gimmicks.
Deteriorated Performance
The lack of features might not be an insurmountable issue—if a database excels at its core functionalities, architects can cobble together the required features using various data components.
MySQL’s once-celebrated core attribute was its performance—notably in simple OLTP CRUD operations typical of internet-scale applications. Unfortunately, this strength is now under siege. Percona’s blog post “Sakila: Where Are You Going?” unveils a startling revelation:
Newer MySQL versions are performing worse than their predecessors.
According to Percona’s benchmarks using sysbench and TPC-C, the latest MySQL 8.4 shows a performance degradation of up to 20% compared to MySQL 5.7. MySQL expert Mark Callaghan has further corroborated this trend in his detailed performance regression tests:
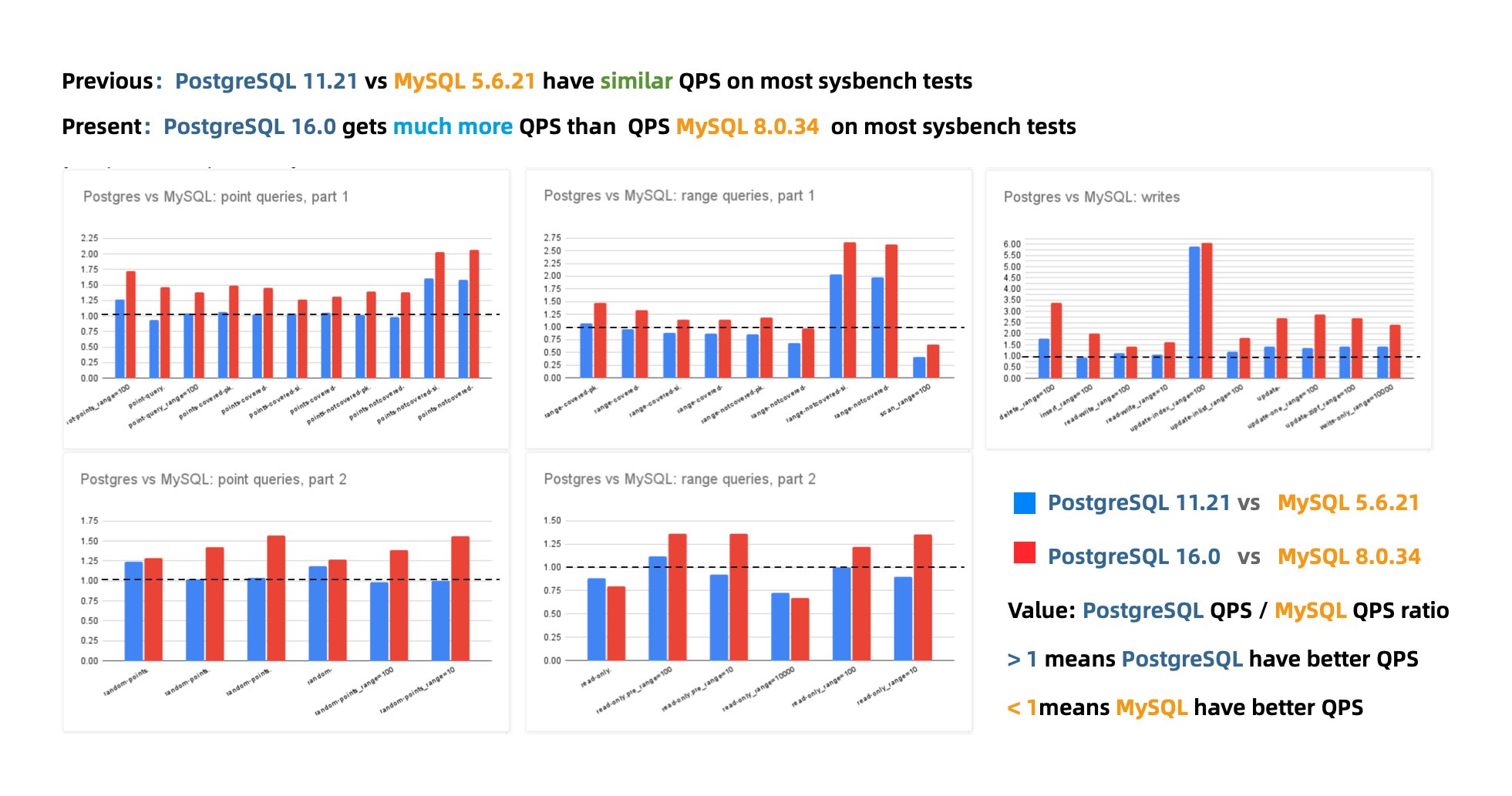
MySQL 8.0.36 shows a 25% – 40% drop in QPS throughput performance compared to MySQL 5.6!
While there have been some optimizer improvements in MySQL 8.x, enhancing performance in complex query scenarios, complex queries were never MySQL’s forte. Conversely, a significant drop in the fundamental OLTP CRUD performance is indefensible.
Peter Zaitsev commented in his post “Oracle Has Finally Killed MySQL”: “Compared to MySQL 5.6, MySQL 8.x has shown a significant performance decline in single-threaded simple workloads. One might argue that adding features inevitably impacts performance, but MariaDB shows much less performance degradation, and PostgreSQL has managed to significantly enhance performance while adding features.”
Years ago, the industry consensus was that PostgreSQL and MySQL performed comparably in simple OLTP CRUD scenarios. However, as PostgreSQL has continued to improve, it has vastly outpaced MySQL in performance. PostgreSQL now significantly exceeds MySQL in various read and write scenarios, with throughput improvements ranging from 200% to even 500% in some cases.
The performance edge that MySQL once prided itself on no longer exists.
The Incurable Isolation Levels
While performance issues can usually be patched up, correctness issues are a different beast altogether.
An article, “The Grave Correctness Problems with MySQL?”, points out that MySQL falls embarrassingly short on correctness—a fundamental attribute expected of any respectable database product.
The renowned distributed transaction testing organization, JEPSEN, discovered that the Repeatable Read (RR) isolation level claimed by MySQL’s documentation actually provides much weaker correctness guarantees. MySQL 8.0.34’s default RR isolation level isn’t truly repeatable read, nor is it atomic or monotonic, failing even the basic threshold of Monotonic Atomic View (MAV).
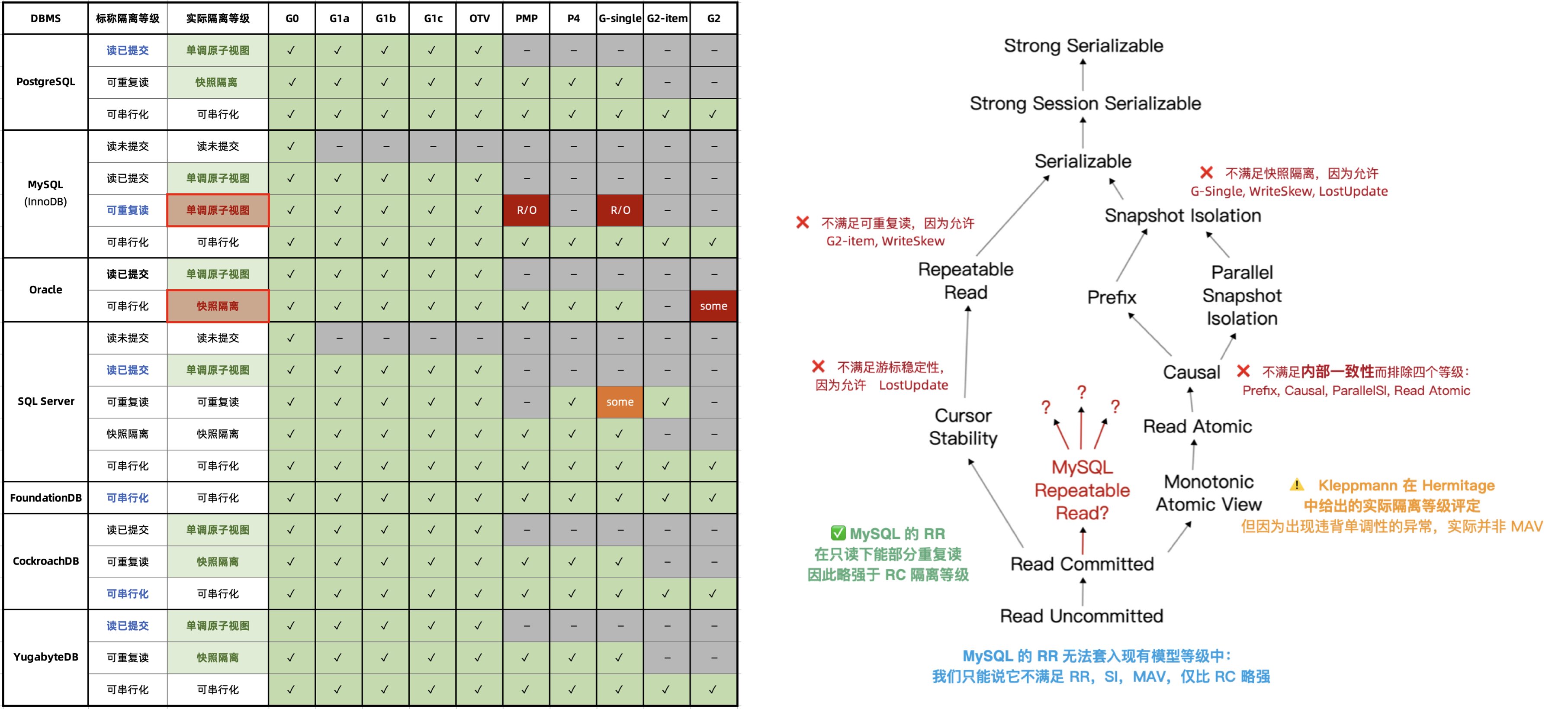
MySQL’s ACID properties are flawed and do not align with their documentation—a blind trust in these false promises can lead to severe correctness issues, such as data discrepancies and reconciliation errors, which are intolerable in scenarios where data integrity is crucial, like finance.
Moreover, the Serializable (SR) isolation level in MySQL, which could “avoid” these anomalies, is hard to use in production and isn’t recognized as best practice by official documentation or the community. While expert developers might circumvent such issues by explicitly locking in queries, this approach severely impacts performance and is prone to deadlocks.
In contrast, PostgreSQL’s introduction of Serializable Snapshot Isolation (SSI) in version 9.1 offers a complete serializable isolation level with minimal performance overhead—achieving a level of correctness even Oracle struggles to match.
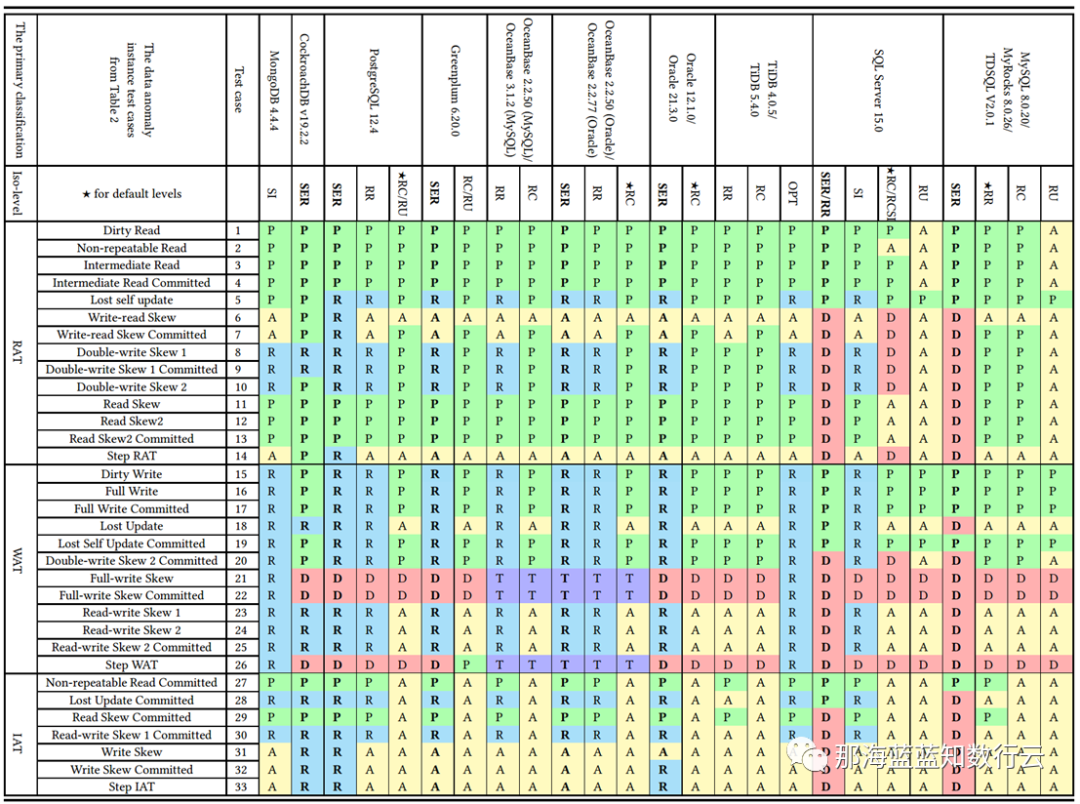
Professor Li Haixiang’s paper, “The Consistency Pantheon”, systematically evaluates the correctness of isolation levels across mainstream DBMSs. The chart uses blue/green to indicate correct handling rules/rollbacks to avoid anomalies; yellow A indicates anomalies, with more implying greater correctness issues; red “D” indicates performance-impacting deadlock detection used to handle anomalies, with more Ds indicating severe performance issues.
It’s clear that the best correctness implementation (no yellow A) is PostgreSQL’s SR, along with CockroachDB’s SR based on PG, followed by Oracle’s slightly flawed SR; mainly, these systems avoid concurrency anomalies through mechanisms and rules. Meanwhile, MySQL shows a broad swath of yellow As and red Ds, with a level of correctness and implementation that is crudely inadequate.
Doing things right is critical, and correctness should not be a trade-off. Early on, the open-source relational database giants MySQL and PostgreSQL chose divergent paths: MySQL sacrificed correctness for performance, while the academically inclined PostgreSQL opted for correctness at the expense of performance.
During the early days of the internet boom, MySQL surged ahead due to its performance advantages. However, as performance becomes less of a core concern, correctness has emerged as MySQL’s fatal flaw. What’s more tragic is that even the performance MySQL sacrificed correctness for is no longer competitive, a fact that’s disheartening.
The Shrinking Ecosystem Scale
For any technology, the scale of its user base directly determines the vibrancy of its ecosystem. Even a dying camel is larger than a horse, and a rotting ship still holds three pounds of nails. MySQL once soared with the winds of the internet, amassing a substantial legacy, aptly captured by its slogan—“The world’s most popular open-source relational database”.
![]()
Unfortunately, at least according to the 2023 results of one of the world’s most authoritative developer surveys, the StackOverflow Annual Developer Survey, MySQL has been overtaken by PostgreSQL—the crown of the most popular database has been claimed by PostgreSQL.
Especially notable, when examining the past seven years of survey data together, one can clearly see the trend of PostgreSQL becoming more popular as MySQL becomes less so (top left chart)—an obvious trend even under the same benchmarking standards.
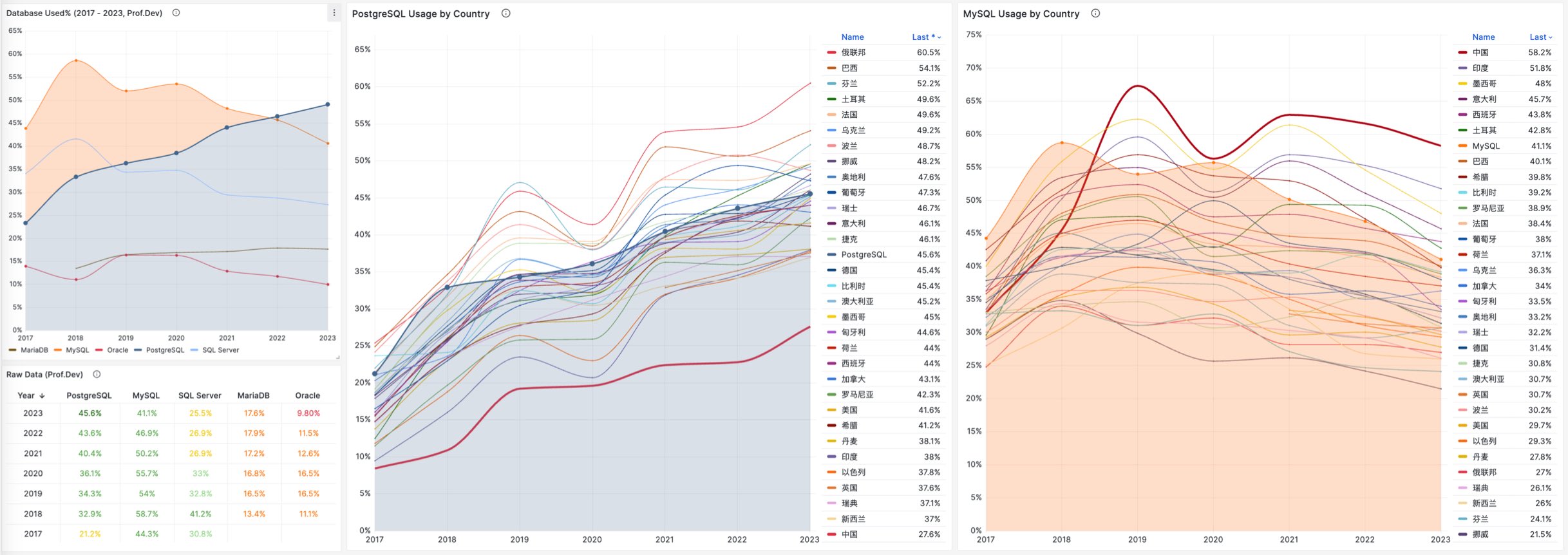
This rise and fall trend is also true in China. However, claiming PostgreSQL is more popular than MySQL in China would indeed go against intuition and fact.
Breaking down StackOverflow’s professional developers by country, it’s evident that in major countries (31 countries with sample sizes > 600), China has the highest usage rate of MySQL—58.2%, while the usage rate of PG is the lowest at only 27.6%, nearly double the PG user base.
In stark contrast, in the Russian Federation, which faces international sanctions, the community-driven and non-corporately controlled PostgreSQL has become a savior—its PG usage rate tops the chart at 60.5%, double its MySQL usage rate of 27%.
In China, due to similar motivations for self-reliance in technology, PostgreSQL’s usage rate has also seen a significant increase—tripling over the last few years. The ratio of PG to MySQL users has rapidly evolved from 5:1 six or seven years ago to 3:1 three years ago, and now to 2:1, with expectations to soon match and surpass the global average.
After all, many national databases are built on PostgreSQL—if you’re in the government or enterprise tech industry, chances are you’re already using PostgreSQL.
Who Really Killed MySQL?
Who killed MySQL, was it PostgreSQL? Peter Zaitsev argues in “Did Oracle Ultimately Kill MySQL?” that Oracle’s inaction and misguided directives ultimately doomed MySQL. He further explains the real root cause in “Can Oracle Save MySQL?”:
MySQL’s intellectual property is owned by Oracle, and unlike PostgreSQL, which is “owned and managed by the community,” it lacks the broad base of independent company contributors that PostgreSQL enjoys. Neither MySQL nor its fork, MariaDB, are truly community-driven pure open-source projects like Linux, PostgreSQL, or Kubernetes, but are dominated by a single commercial entity.
It might be wiser to leverage a competitor’s code without contributing back—AWS and other cloud providers compete in the database arena using the MySQL kernel, yet offer no contributions in return. Consequently, as a competitor, Oracle also loses interest in properly managing MySQL, instead focusing solely on its MySQL HeatWave cloud version, just as AWS focuses solely on its RDS management and Aurora services. Cloud providers share the blame for the decline of the MySQL community.
What’s gone is gone, but the future awaits. PostgreSQL should learn from the demise of MySQL—although the PostgreSQL community is very careful to avoid the dominance of any single entity, the ecosystem is indeed evolving towards a few cloud giants dominating. The cloud is devouring open source—cloud providers write the management software for open-source software, form pools of experts, and capture most of the lifecycle value of maintenance, but the largest costs—R&D—are borne by the entire open-source community. And truly valuable management/monitoring code is never given back to the open-source community—this phenomenon has been observed in MongoDB, ElasticSearch, Redis, and MySQL, and the PostgreSQL community should take heed.
Fortunately, the PG ecosystem always has enough resilient people and companies willing to stand up and maintain the balance of the ecosystem, resisting the hegemony of public cloud providers. For example, my own PostgreSQL distribution, Pigsty, aims to provide an out-of-the-box, local-first open-source cloud database RDS alternative, raising the baseline of community-built PostgreSQL database services to the level of cloud provider RDS PG. And my column series “Mudslide of Cloud Computing” aims to expose the information asymmetry behind cloud services, helping public cloud providers to operate more honorably—achieving notable success.
Although I am a staunch supporter of PostgreSQL, I agree with Peter Zaitsev’s view: “If MySQL completely dies, open-source relational databases would essentially be monopolized by PostgreSQL, and monopoly is not good as it leads to stagnation and reduced innovation. Having MySQL as a competitor is not a bad thing for PostgreSQL to reach its full potential.”
At least, MySQL can serve as a spur to motivate the PostgreSQL community to maintain cohesion and a sense of urgency, continuously improve its technical level, and continue to promote open, transparent, and fair community governance, thus driving the advancement of database technology.
MySQL had its days of glory and was once a benchmark of “open-source software,” but even the best shows must end. MySQL is dying—lagging updates, falling behind in features, degrading performance, quality issues, and a shrinking ecosystem are inevitable, beyond human control. Meanwhile, PostgreSQL, carrying the original spirit and vision of open-source software, will continue to forge ahead—it will continue on the path MySQL could not finish and write the chapters MySQL did not complete.
Reference
PostgreSQL 17 Beta1 发布!牙膏管挤爆了!
MySQL's Terrible ACID
MySQL was once the world’s most popular open-source relational database. But popularity doesn’t equal excellence, and popular things can have major issues. JEPSEN’s isolation level evaluation of MySQL 8.0.34 has blown the lid off this one - when it comes to correctness, a basic requirement for any respectable database product, MySQL’s performance is a spectacular mess.
MySQL’s documentation claims to implement Repeatable Read (RR) isolation, but the actual correctness guarantees are much weaker. Building on Hermitage’s research, JEPSEN further points out that MySQL’s RR isolation level is not actually repeatable read, and is neither atomic nor monotonic - it doesn’t even meet the basic level of Monotonic Atomic View (MAV), which is barely below Read Committed (RC) in most DBMSes
Furthermore, MySQL’s Serializable (SR) isolation level, which could theoretically “avoid” these anomalies, is impractical for production use and isn’t recognized as best practice by either official or the community. Even worse, under AWS RDS default configuration, MySQL SR doesn’t actually meet “serializable” requirements. Professor Li Haixiang’s analysis of MySQL consistency further reveals design flaws and issues with SR.
In summary, MySQL’s ACID properties have flaws and don’t match their documented promises - this can lead to severe correctness issues. While these problems can be worked around through explicit locking and other mechanisms, users should be fully aware of the trade-offs and risks: exercise caution when choosing MySQL for scenarios where correctness/consistency matters.
- Why Does Correctness Matter?
- What Did Hermitage Tell Us?
- What New Issues Did JEPSEN Find?
- Isolation Issues: Non-Repeatable Reads
- Atomicity Issues: Non-Monotonic Views
- Serialization Issues: Useless and Terrible
- The Trade-off Between Correctness and Performance
- References
Why Does Correctness Matter?
Reliable systems need to handle various errors, and in the harsh reality of data systems, many things can go wrong. Ensuring data integrity without loss or corruption is a massive undertaking prone to errors. Transactions solved this problem. They’re one of the greatest abstractions in data processing and the crown jewel of relational databases’ pride and dignity.
The transaction abstraction reduces all possible outcomes to two scenarios: either COMMIT successfully or ROLLBACK completely. Having this “undo button” means programmers no longer need to worry about half-failed operations leaving data consistency in a horrific crash site. Application error handling becomes much simpler because it doesn’t need to deal with partial failures. The guarantees it provides are summarized in four words: ACID.
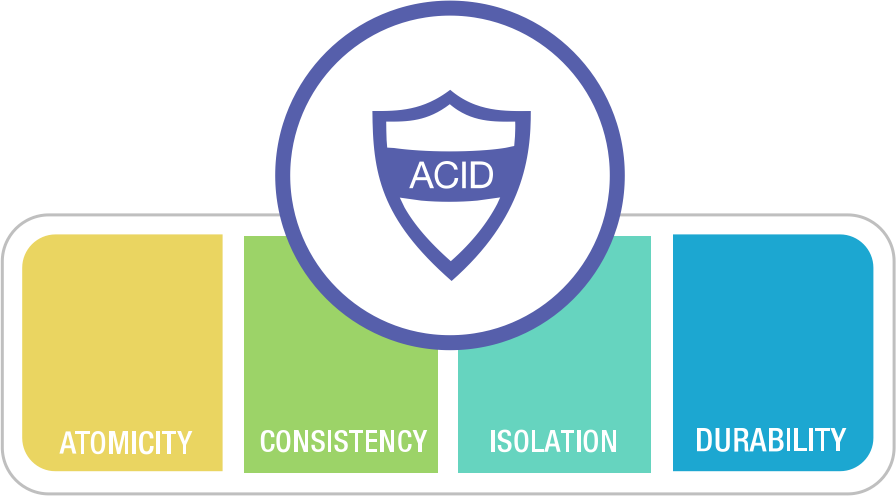
Transaction Atomicity lets you abort and discard all writes before committing, while Durability promises that once a transaction commits successfully, any written data won’t be lost even if hardware fails or the database crashes. Isolation ensures each transaction can pretend it’s the only one running on the entire database - the database guarantees that when multiple transactions commit, the result is the same as if they ran one after another serially, even though they may actually run concurrently. Atomicity and isolation serve Consistency - which is really about application Correctness - the C in ACID is actually an application property rather than a transaction property, thrown in to make a nice acronym.
However, in practice, full Isolation is rare - users rarely use the so-called “Serializable” isolation level because it comes with significant performance overhead. Some popular databases like Oracle don’t even implement it - Oracle has an isolation level called “Serializable”, but it actually implements something called snapshot isolation, which is weaker than true serializability.
| Isolation Level | Dirty Read | Non-Repeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted (RU) | ⚠️ Yes | ⚠️ Yes | ⚠️ Yes |
| Read Committed (RC) | ❌ No | ⚠️ Yes | ⚠️ Yes |
| Repeatable Read (RR) | ❌ No | ❌ No | ⚠️ Yes |
| Serializable (SR) | ❌ No | ❌ No | ❌ No |
RDBMSes allow different isolation levels, letting users trade off between performance and correctness. ANSI SQL92 (poorly) standardized this trade-off by defining four isolation levels based on three types of concurrency anomalies: Weaker isolation levels “theoretically” provide better performance but allow more types of anomalies that can affect application correctness.
To ensure correctness, users can employ additional concurrency control mechanisms like explicit locking or SELECT FOR UPDATE, but this adds complexity and impacts system simplicity. For financial scenarios, correctness is crucial - accounting errors and reconciliation mismatches can have serious real-world consequences. However, for fast-and-loose internet scenarios, missing a few records may be acceptable - correctness often takes a back seat to performance. This laid the groundwork for the correctness issues in MySQL that rode the internet wave to popularity.
What Did Hermitage Tell Us?
Before diving into JEPSEN’s findings, let’s revisit the Hermitage project. Started in 2014 by Martin Kleppmann (author of the internet classic “DDIA”), it aimed to evaluate the correctness of mainstream relational databases. The project designed a series of concurrent transaction scenarios to assess the actual level of database’s claimed isolation levels.
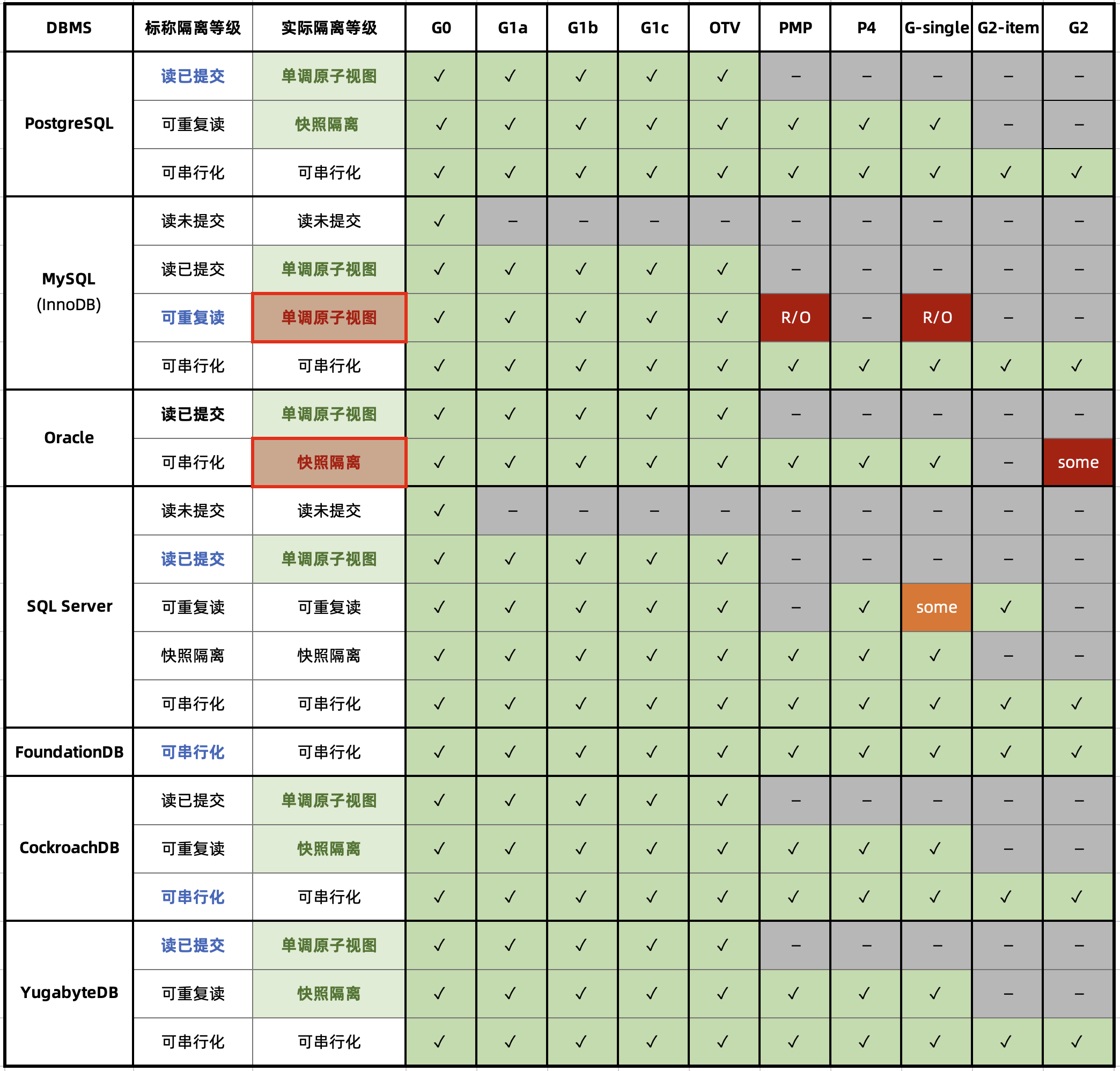
The Hermitage evaluation results table reveals two glaring issues (marked with red circles): Oracle’s Serializable fails to prevent G2 anomalies, making it effectively “Snapshot Isolation”.
MySQL’s issues are even more striking: because its default Repeatable Read can’t prevent PMP / G-Single anomalies, Hermitage downgraded its actual level to Monotonic Atomic View.
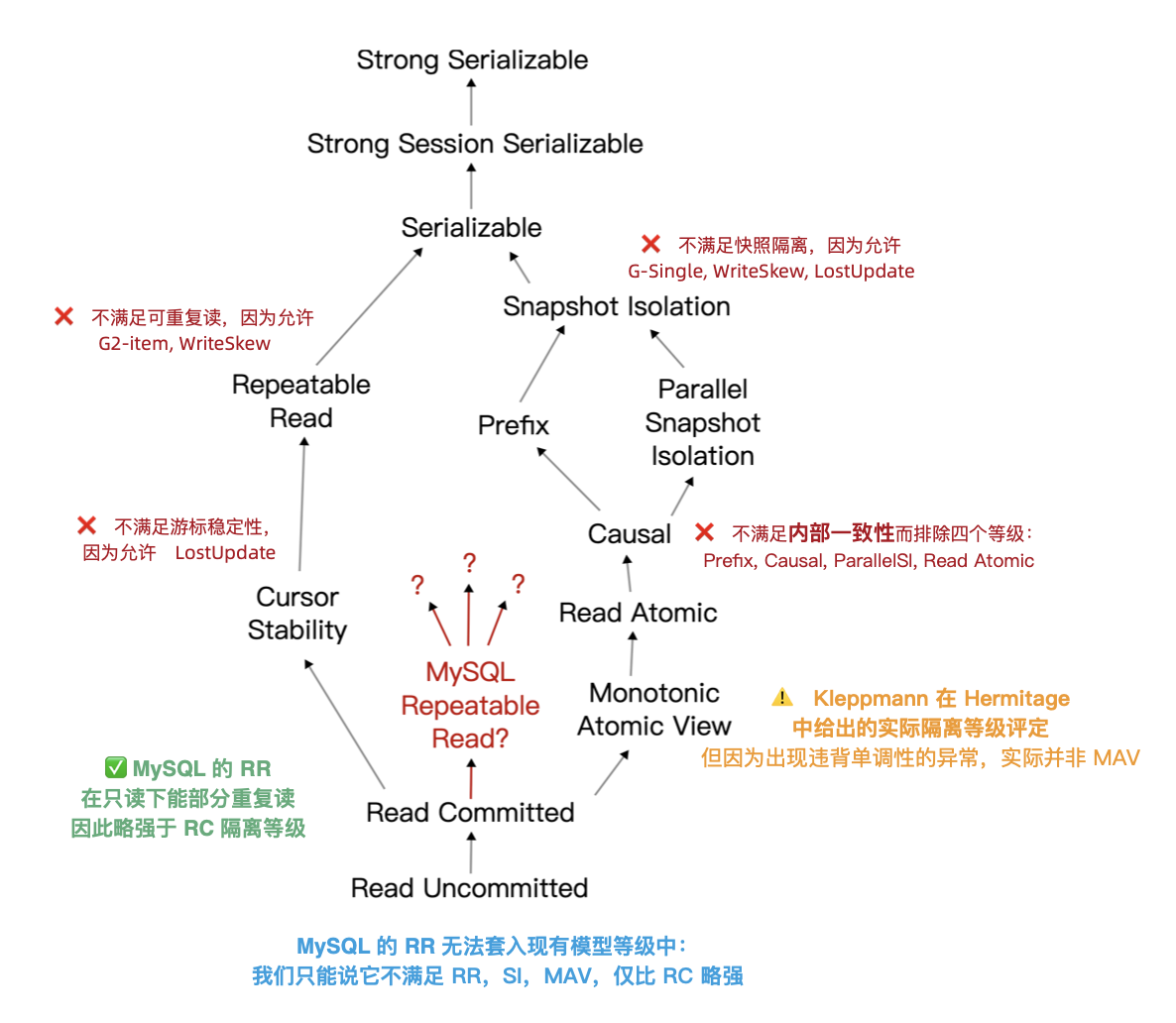
It’s worth noting that ANSI SQL 92 isolation levels are a notoriously poor and widely criticized standard, defining only three anomalies to distinguish four isolation levels - but actual anomalies/isolation levels are far more numerous. The famous paper “A Critique of ANSI SQL Isolation Levels” proposed corrections, introduced several important new isolation levels, and provided their partial order of strength (left figure).
Under the new model, many databases’ “Read Committed” and “Repeatable Read” are actually the more practical “Monotonic Atomic View” and “Snapshot Isolation”. But MySQL is truly unique: in Hermitage’s evaluation, MySQL’s Repeatable Read falls far short of Snapshot Isolation, doesn’t meet ANSI 92 Repeatable Read standards, and actually provides Monotonic Atomic View level. JEPSEN’s research further reveals that MySQL Repeatable Read doesn’t even satisfy Monotonic Atomic View, barely stronger than Read Committed.
What New Issues Did JEPSEN Find?
JEPSEN is the most authoritative testing framework in distributed systems. They recently published their evaluation of MySQL’s latest 8.0.34 version. Readers should read the original paper, but here’s the abstract:
MySQL is a popular relational database. We revisited Kleppmann’s 2014 Hermitage findings and confirmed that MySQL’s Repeatable Read isolation still exhibits G2-item, G-single, and lost update anomalies. Using Elle, our transactional consistency checker, we discovered that MySQL’s repeatable read isolation also violates internal consistency. Worse yet - it violates monotonic atomic view: a transaction can observe another transaction’s effects, then fail to observe those same effects in a subsequent attempt. As a bonus, we found that AWS RDS MySQL clusters frequently violate serializability requirements. This research was conducted independently, without compensation, and follows Jepsen research ethics.
MySQL 8.0.34’s RU, RC, and SR isolation levels match ANSI standard descriptions. And under default configuration (RR with innodb_flush_log_at_trx_commit = on), Durability isn’t an issue. The problems lie in MySQL’s default Repeatable Read isolation:
- Doesn’t satisfy ANSI SQL92 Repeatable Read (G2, WriteSkew)
- Doesn’t satisfy Snapshot Isolation (G-single, ReadSkew, LostUpdate)
- Doesn’t satisfy Cursor Stability (LostUpdate)
- Violates internal consistency (revealed by Hermitage)
- Violates read monotonicity (newly revealed by JEPSEN)
Under MySQL RR, transactions exhibited phenomena violating internal consistency, monotonicity, and atomicity. This pushed its rating down to an undefined isolation level barely above RC.
JEPSEN’s tests revealed six anomalies, skipping the known issues from 2014, let’s focus on JEPSEN’s new findings with some concrete examples.
Isolation Issues: Non-Repeatable Reads
In this test case (JEPSEN 2.3), there’s a simple people table with id as primary key, pre-populated with one row.
CREATE TABLE people (
id int PRIMARY KEY,
name text not null,
gender text not null
);
INSERT INTO people (id, name, gender) VALUES (0, "moss", "enby");
Then concurrent write transactions run - each transaction first reads the name field of this row, updates the gender field, then reads the name field again. Proper repeatable read means that within this transaction, both reads of name should return the same result.
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION; -- Start RR transaction
SELECT name FROM people WHERE id = 0; -- Returns "pebble"
UPDATE people SET gender = "femme" WHERE id = 0; -- Random update
SELECT name FROM people WHERE id = 0; -- Returns "moss"
COMMIT;
But in the test results, 126 out of 9048 transactions showed internal consistency errors - despite running at Repeatable Read isolation, the name actually changed between reads. This behavior contradicts MySQL’s isolation level documentation, which claims: “Consistent reads within the same transaction read the snapshot established by the first read.” It contradicts MySQL’s consistent read documentation, which specifically states that “InnoDB assigns a transaction a timepoint at its first read, and concurrent transaction effects shouldn’t appear in subsequent reads.”
ANSI/Adya repeatable read essentially means: once a transaction observes a value, it can count on that value staying stable for the rest of the transaction. MySQL does the opposite: write requests are invitations for another transaction to sneak in and wreck the state you just read. This isolation design and behavior is incredibly stupid. But wait, there’s more - like monotonicity and atomicity issues.
Atomicity Issues: Non-Monotonic Views
Kleppmann’s Hermitage rated MySQL repeatable read as Monotonic Atomic View (MAV). According to Bailis et al, monotonic atomic view ensures that once transaction T2 observes any results of transaction T1, T2 observes all of T1’s results.
If MySQL’s RR just took a new snapshot each time it executed a write query, it could still provide MAV isolation guarantees if snapshots were monotonic - that’s actually how PostgreSQL’s Read Committed isolation works.
However, in standard MySQL single-node deployments, that’s not the case: MySQL frequently violates monotonic atomic view under RR isolation. This JEPSEN example (2.4) demonstrates: there’s a mav table pre-populated with two records (id=0,1), both with initial value of 0.
CREATE TABLE mav (
id int PRIMARY KEY,
`value` int not null,
noop int not null
);
INSERT INTO mav (id, `value`, noop) VALUES (0, 0, 0);
INSERT INTO mav (id, `value`, noop) VALUES (1, 0, 0);
The workload is mixed read-write transactions: write transactions increment the value field of both records in the same transaction; by transaction atomicity, other transactions observing these records should see value increasing in lock-step.
START TRANSACTION;
SELECT value FROM mav WHERE id = 0; --> 0 reads 0
update mav SET noop = 73 WHERE id = 1; --> "invites" new snapshot
SELECT value FROM mav WHERE id = 1; --> 1 reads new value 1, so other row should be 1 too
SELECT value FROM mav WHERE id = 0; --> 0 but reads old value 0
COMMIT;
However, from this reading transaction’s view, it observed an “intermediate state”. The reading transaction first reads record 0’s value, then sets record 1’s noop to a random value (based on the previous case, this should let it see other transactions’ changes), then reads value from records 0/1. The result: reading record 0 gets the new value, reading record 1 gets the old value, indicating serious flaws in both monotonicity and atomicity.
MySQL’s consistent read documentation extensively discusses snapshots, but this behavior doesn’t look anything like snapshots. Snapshot systems typically provide consistent, point-in-time views of database state. They’re usually atomic: either containing all of a transaction’s results or none. Even if MySQL somehow got a non-atomic snapshot of the write transaction’s intermediate state, it must see row 0’s new value before getting row 1’s new value. But that’s not what happened: this read transaction saw changes to row 1 but missed changes to row 0 - what kind of snapshot is this?
Therefore, MySQL’s Repeatable Read isolation is neither atomic nor monotonic. In this respect, it’s even worse than most databases’ Read Committed, which at least provides actual Monotonic Atomic View.
Another noteworthy issue: MySQL transactions can violate atomicity under default configuration. I raised this issue for industry discussion in an article two years ago. The MySQL community’s stance is that this is a configurable feature via sql_mode rather than a defect.
But this doesn’t change the fact: MySQL violates the principle of least surprise by allowing users to do such atomicity-breaking stupid things under default configuration. Similar issues exist with the replica_preserve_commit_order parameter.
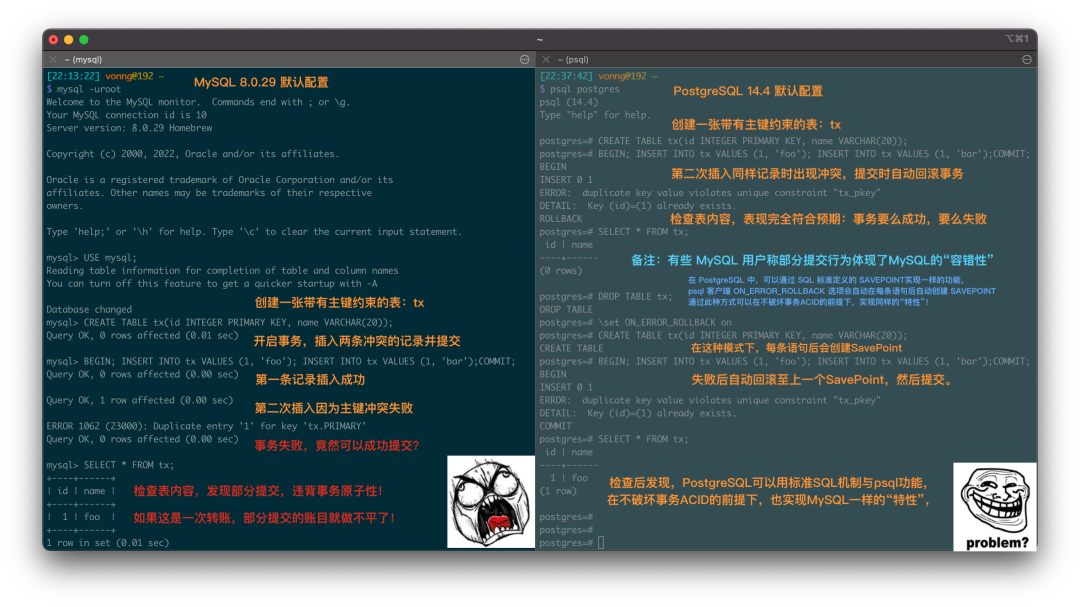
Serialization Issues: Useless and Terrible
Can Serializable prevent these concurrency anomalies? Theoretically yes, that’s what it’s designed for. But disturbingly, JEPSEN observed “Fractured Read-Like” anomalies (an example of G2) in AWS RDS clusters even under Serializable isolation. These anomalies should be prevented by RR and only appear in RC or lower levels.
Deeper investigation revealed this was related to MySQL’s replica_preserve_commit_order parameter: disabling it allows MySQL to achieve higher parallelism when replaying logs at the cost of correctness. With this option disabled, JEPSEN observed similar G-Single and G2-Item anomalies in local cluster SR isolation.
Serializable systems should guarantee transactions appear to execute in total order - not preserving this order on replicas is terrible. That’s why this parameter was disabled by default in the past (8.0.26 and below) but changed to enabled by default in MySQL 8.0.27 (2021-10-19). However, AWS RDS cluster parameter groups still use the old default “OFF” without proper documentation, hence these anomalies.
While this anomalous behavior can be avoided by enabling the parameter, using Serializable itself isn’t encouraged by MySQL official/community. The common view in the MySQL community is: avoid Serializable unless absolutely necessary; MySQL docs state: "SERIALIZABLE enforces stricter rules than REPEATABLE READ and is used mainly in special situations, like XA transactions and solving concurrency and deadlock issues."
Coincidentally, Professor Li Haixiang (former Tencent T14) specializing in database consistency, evaluated actual isolation levels of various databases including MySQL (InnoDB/8.0.20) in his “Third Generation Distributed Database” series, providing this more detailed “《Consistency Ba-Xian Diagram》” from another perspective.
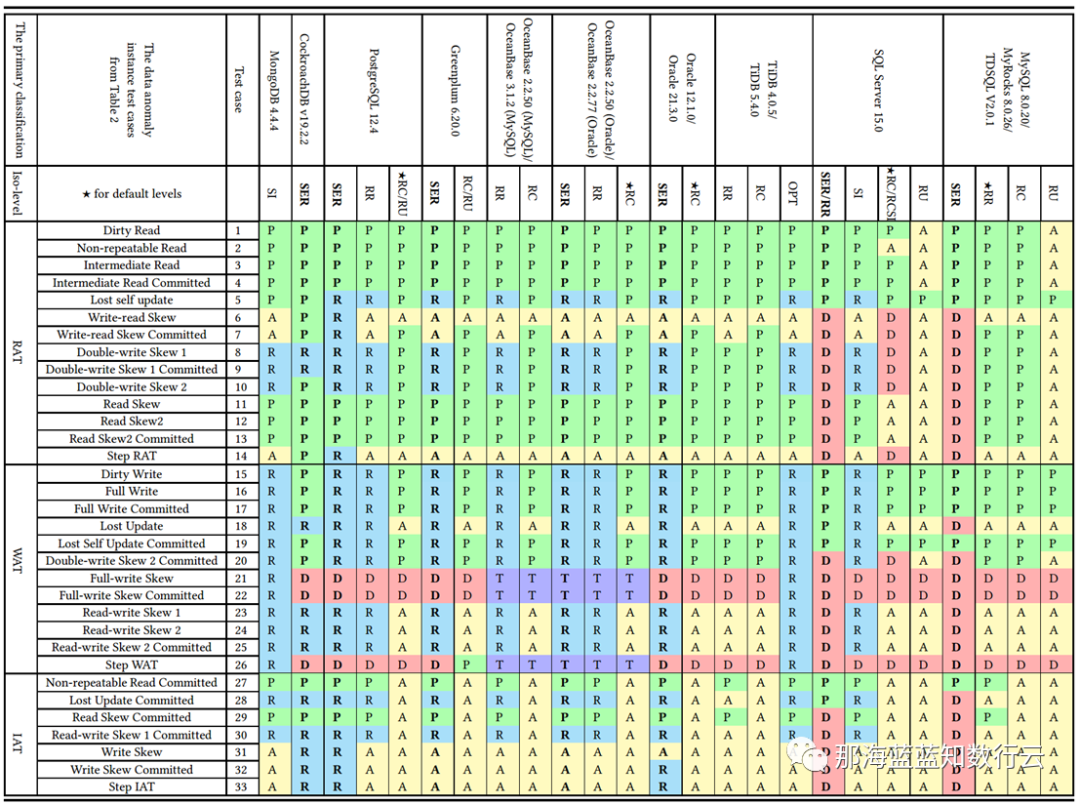
In the diagram, blue/green represents correctly using rules/rollback to avoid anomalies; yellow A represents anomalies, more yellow “A"s mean more correctness issues; red “D” indicates using performance-impacting deadlock detection to handle anomalies, more red D’s mean more performance issues.
Clearly, PostgreSQL SR and CockroachDB SR built on it have the best correctness, followed by Oracle SR; they mainly avoid concurrency anomalies through mechanisms and rules; while MySQL’s correctness level is painfully bad.
Professor Li analyzed this in detail in 《MySQL Is Good For Nothing》: although MySQL’s Serializable can ensure correctness through extensive use of deadlock detection algorithms, handling concurrency anomalies this way severely impacts the database’s performance and practical value.
The Trade-off Between Correctness and Performance
Professor Li raised a question in 《Third Generation Distributed Databases: The Kicking Era》: How to trade off between system correctness and performance?
The database world has some “habits become nature” loops. For example, many databases default to Read Committed, and many people say “RC isolation level is enough”! But why? Why set it to RC? Because they think RC level gives better database performance.
But as shown below, there’s a vicious cycle: users want better database performance, so developers set application isolation level to RC. However, users, especially in finance/insurance/securities/telecom industries, also expect data correctness, so developers have to add SELECT FOR UPDATE locks in SQL statements to ensure data correctness. This leads to severe database system performance degradation. TPC-C and YCSB scenario tests show that user-added locking causes severe performance degradation, while performance overhead under strong isolation levels isn’t actually that bad.
Using weak isolation levels seriously deviates from the original intent of the “transaction” abstraction - writing reliable transactions in lower isolation level databases is extremely complex, and the number and impact of weak isolation-related errors are widely underestimated[13]. Using weak isolation levels essentially kicks the responsibility for correctness & performance that should be guaranteed by the database to application developers.
The root of this weak isolation habit might trace back to Oracle and MySQL. For example, Oracle never provided true serializable isolation (SR is actually Snapshot Isolation), even today. So they had to promote ”using RC isolation" as a good thing. Oracle was one of the most popular databases in the past, so later ones followed suit.
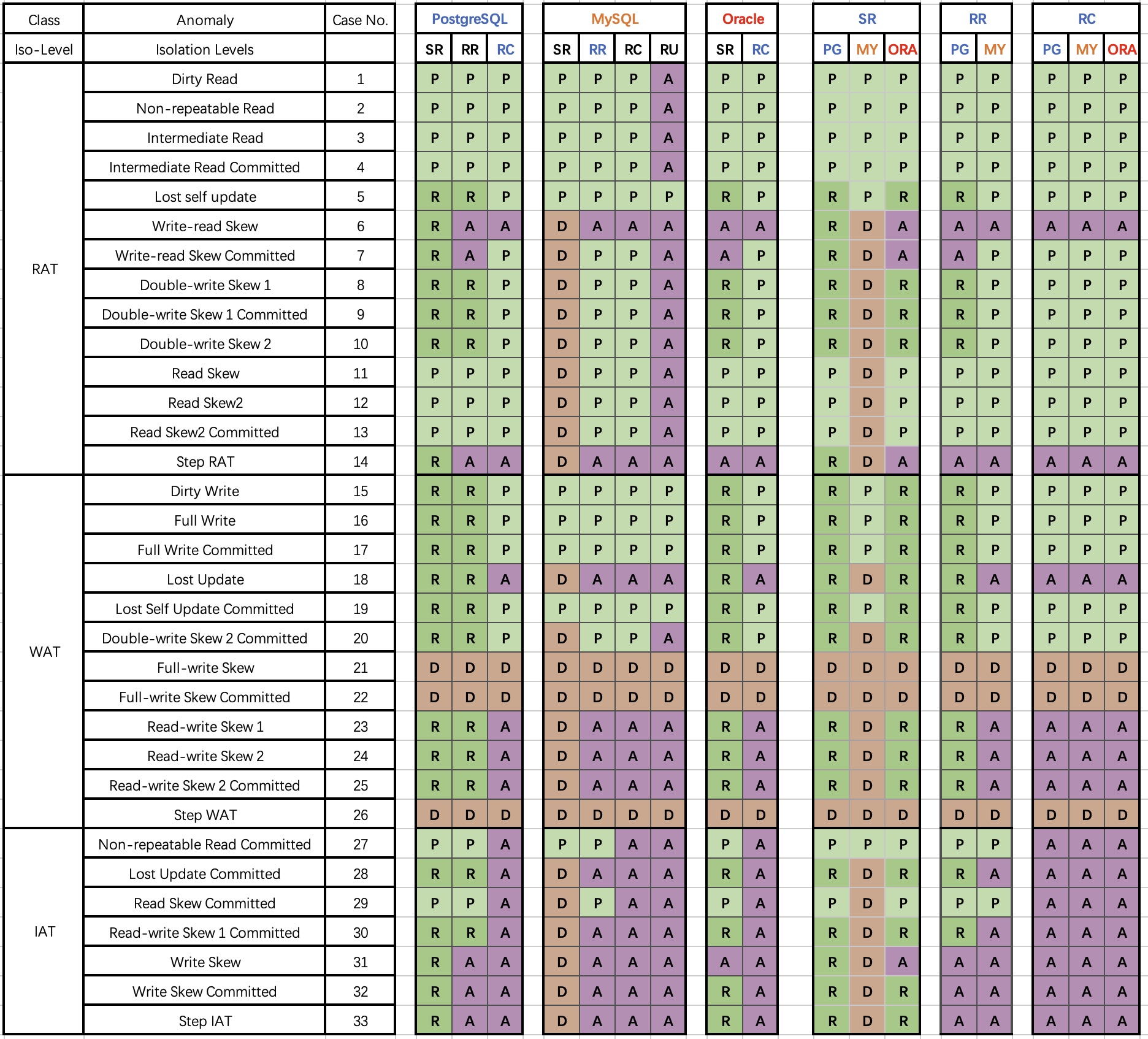
And the stereotype that weak isolation levels perform better might come from MySQL - SR implemented with extensive deadlock detection (marked red) does perform terribly. But this isn’t necessarily true for other DBMSes. For example, PostgreSQL’s Serializable Snapshot Isolation (SSI) algorithm introduced in 9.1 can provide full serializability with minimal performance overhead compared to Snapshot Isolation.
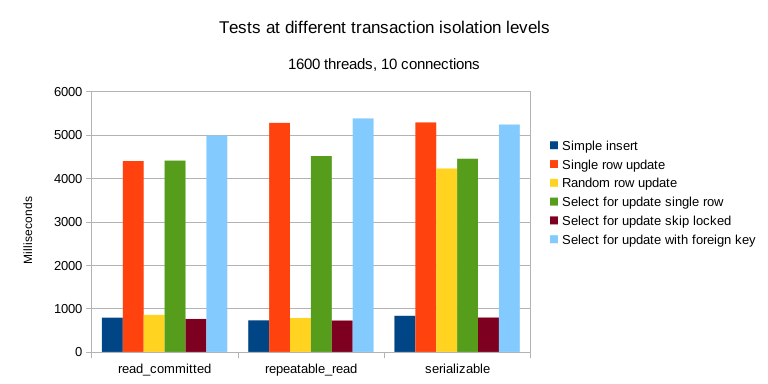
Furthermore, hardware performance improvements and price collapse under Moore’s Law mean OLTP performance is no longer scarce - in today’s world where Twitter can run on a single server, over-provisioned abundant hardware performance costs pocket change. Compared to potential losses and mental overhead from data errors, worrying about performance overhead from serializable isolation is really making mountains out of molehills.
Times have changed, software and hardware progress has made “default serializable isolation, prioritize 100% correctness” truly feasible. Trading correctness for slight performance gains seems outdated even for fast-and-loose internet scenarios. New generation distributed databases like CockroachDB and FoundationDB have chosen to default to Serializable isolation.
Doing the right thing matters, and correctness shouldn’t be a trade-off. On this point, open-source relational database giants MySQL and PostgreSQL chose opposite paths in their early implementations: MySQL pursued performance at the cost of correctness; while academic PostgreSQL pursued correctness at the cost of performance. MySQL took the lead riding the internet wave in the first half due to performance advantages. But when performance is no longer the core consideration, correctness became MySQL’s fatal bleeding point.
There are many ways to solve performance problems, even waiting for hardware performance exponential growth is a viable approach (like Paypal); but correctness issues often involve global architectural restructuring, impossible to fix overnight. Over the past decade, PostgreSQL stayed true while innovating, making great strides while ensuring best correctness, outperforming MySQL in many scenarios; while functionally crushing MySQL with ecosystem extensions introducing vector, JSON, GIS, time series, full-text search and other features.
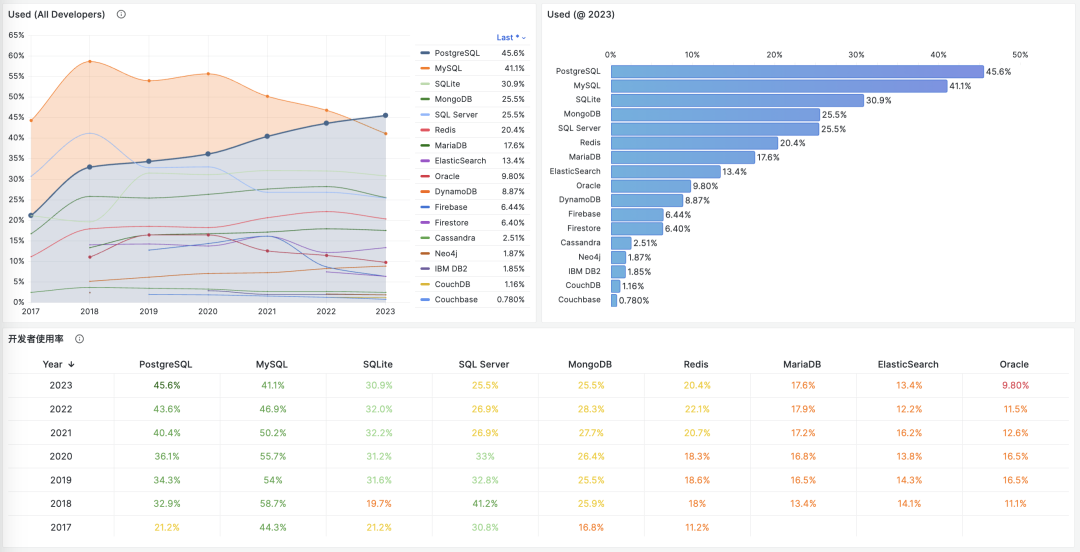
In StackOverflow’s 2023 global developer survey, PostgreSQL’s developer usage officially surpassed MySQL, becoming the world’s most popular database. While MySQL, with its mess of correctness issues and difficulty achieving high performance, should really think about its path forward.
References
[1] JEPSEN: https://jepsen.io/analyses/mysql-8.0.34
[2] Hermitage: https://github.com/ept/hermitage
[4] Jepsen Research Ethics: https://jepsen.io/ethics
[5] innodb_flush_log_at_trx_commit: https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
[6] Isolation Levels Documentation: https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html#isolevel_repeatable-read
[7] Consistent Read Documentation: https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
[9] Monotonic Atomic View/MAV: https://jepsen.io/consistency/models/monotonic-atomic-view
[10] Highly Available Transactions: Virtues and Limitations, Bailis et al: https://amplab.cs.berkeley.edu/wp-content/uploads/2013/10/hat-vldb2014.pdf
[12] replica_preserve_commit_order: https://dev.mysql.com/doc/refman/8.0/en/replication-options-replica.html#sysvar_replica_preserve_commit_order
[13] The number and impact of weak isolation-related errors are widely underestimated: https://dl.acm.org/doi/10.1145/3035918.3064037
[14] Testing PostgreSQL’s Parallel Performance: https://lchsk.com/benchmarking-concurrent-operations-in-postgresql
[15] Running Twitter on a Single Server: https://thume.ca/2023/01/02/one-machine-twitter/
Database in K8S: Pros & Cons
Whether databases should be housed in Kubernetes/Docker remains highly controversial. While Kubernetes (k8s) excels in managing stateless applications, it has fundamental drawbacks with stateful services, especially databases like PostgreSQL and MySQL.
In the previous article, “Databases in Docker: Good or Bad,” we discussed the pros and cons of containerizing databases. Today, let’s delve into the trade-offs in orchestrating databases in K8S and explore why it’s not a wise decision.
Summary
Kubernetes (k8s) is an exceptional container orchestration tool aimed at helping developers better manage a vast array of complex stateless applications. Despite its offerings like StatefulSet, PV, PVC, and LocalhostPV for supporting stateful services (i.e., databases), these features are still insufficient for running production-level databases that demand higher reliability.
Databases are more like “pets” than “cattle” and require careful nurturing. Treating databases as “cattle” in K8S essentially turns external disk/file system/storage services into new “database pets.” Running databases on EBS/network storage presents significant disadvantages in reliability and performance. However, using high-performance local NVMe disks will make the database bound to nodes and non-schedulable, negating the primary purpose of putting them in K8S.
Placing databases in K8S results in a “lose-lose” situation - K8S loses its simplicity in statelessness, lacking the flexibility to quickly relocate, schedule, destroy, and rebuild like purely stateless use. On the other hand, databases suffer several crucial attributes: reliability, security, performance, and complexity costs, in exchange for limited “elasticity” and utilization - something virtual machines can also achieve. For users outside public cloud vendors, the disadvantages far outweigh the benefits.
The “cloud-native frenzy,” exemplified by K8S, has become a distorted phenomenon: adopting k8s for the sake of k8s. Engineers add extra complexity to increase their irreplaceability, while managers fear being left behind by the industry and getting caught up in deployment races. Using tanks for tasks that could be done with bicycles, to gain experience or prove oneself, without considering if the problem needs such “dragon-slaying” techniques - this kind of architectural juggling will eventually lead to adverse outcomes.
Until the reliability and performance of the network storage surpass local storage, placing databases in K8S is an unwise choice. There are other ways to seal the complexity of database management, such as RDS and open-source RDS solutions like Pigsty, which are based on bare Metal or bare OS. Users should make wise decisions based on their situations and needs, carefully weighing the pros and cons.
The Status Quo
K8S excels in orchestrating stateless application services but was initially limited to stateful services. Despite not being the intended purpose of K8S and Docker, the community’s zeal for expansion has been unstoppable. Evangelists depict K8S as the next-generation cloud operating system, asserting that databases will inevitably become regular applications within Kubernetes. Various abstractions have emerged to support stateful services: StatefulSet, PV, PVC, and LocalhostPV.
Countless cloud-native enthusiasts have attempted to migrate existing databases into K8S, resulting in a proliferation of CRDs and Operators for databases. Taking PostgreSQL as an example, there are already more than ten different K8S deployment solutions available: PGO, StackGres, CloudNativePG, PostgresOperator, PerconaOperator, CYBERTEC-pg-operator, TemboOperator, Kubegres, KubeDB, KubeBlocks, and so on. The CNCF landscape rapidly expands, turning into a playground of complexity.
However, complexity is a cost. With “cost reduction” becoming mainstream, voices of reflection have begun to emerge. Could-Exit Pioneers like DHH, who deeply utilized K8S in public clouds, abandoned it due to its excessive complexity during the transition to self-hosted open-source solutions, relying only on Docker and a Ruby tool named Kamal as alternatives. Many began to question whether stateful services like databases suit Kubernetes.
K8S itself, in its effort to support stateful applications, has become increasingly complex, straying from its original intention as a container orchestration platform. Tim Hockin, a co-founder of Kubernetes, also voiced his rare concerns at this year’s KubeCon in “K8s is Cannibalizing Itself!”: “Kubernetes has become too complex; it needs to learn restraint, or it will stop innovating and lose its base.”
Lose-Lose Situation
In the cloud-native realm, the analogy of “pets” versus “cattle” is often used for illustrating stateful services. “Pets,” like databases, need careful and individual care, while “cattle” represent disposable, stateless applications (Disposability).
Cloud Native Applications 12 Factors: Disposability
source: https://user-images.githubusercontent.com/5445356/47986421-a8f62080-e117-11e8-9a39-3fdc6030c324.png
{kind=link}
Cloud Native Applications 12 Factors: Disposability
One of the leading architectural goals of K8S is to treat what can be treated as cattle as cattle. The attempt to “separate storage from computation” in databases follows this strategy: splitting stateful database services into state storage outside K8S and pure computation inside K8S. The state is stored on the EBS/cloud disk/distributed storage service, allowing the “stateless” database part to be freely created, destroyed, and scheduled in K8S.
Unfortunately, databases, especially OLTP databases, heavily depend on disk hardware, and network storage’s reliability and performance still lag behind local disks by orders of magnitude. Thus, K8S offers the LocalhostPV option, allowing containers to use data volumes directly lies on the host operating system, utilizing high-performance/high-reliability local NVMe disk storage.
However, this presents a dilemma: should one use subpar cloud disks and tolerate poor database reliability/performance for K8S’s scheduling and orchestration capabilities? Or use high-performance local disks tied to host nodes, virtually losing all flexible scheduling abilities? The former is like stuffing an anchor into K8S’s small boat, slowing overall speed and agility; the latter is like anchoring and pinning the ship to a specific point.
Running a stateless K8S cluster is simple and reliable, as is running a stateful database on a physical machine’s bare operating system. Mixing the two, however, results in a lose-lose situation: K8S loses its stateless flexibility and casual scheduling abilities, while the database sacrifices core attributes like reliability, security, efficiency, and simplicity in exchange for elasticity, resource utilization, and Day1 delivery speed that are not fundamentally important to databases.
A vivid example of the former is the performance optimization of PostgreSQL@K8S, which KubeBlocks contributed. K8S experts employed various advanced methods to solve performance issues that did not exist on bare metal/bare OS at all. A fresh case of the latter is Didi’s K8S architecture juggling disaster; if it weren’t for putting the stateful MySQL in K8S, would rebuilding a stateless K8S cluster and redeploying applications take 12 hours to recover?
Pros and Cons
For serious technology decisions, the most crucial aspect is weighing the pros and cons. Here, in the order of “quality, security, performance, cost,” let’s discuss the technical trade-offs of placing databases in K8S versus classic bare metal/VM deployments. I don’t want to write a comprehensive paper that covers everything. Instead, I’ll throw some specific questions for consideration and discussion.
Quality
K8S, compared to physical deployments, introduces additional failure points and architectural complexity, increasing the blast radius and significantly prolonging the average recovery time of failures. In “Is it a Good Idea to Put Databases into Docker?”, we provided an argument about reliability, which can also apply to Kubernetes — K8S and Docker introduce additional and unnecessary dependencies and failure points to databases, lacking community failure knowledge accumulation and reliability track record (MTTR/MTBF).
In the cloud vendor classification system, K8S belongs to PaaS, while RDS belongs to a more fundamental layer, IaaS. Database services have higher reliability requirements than K8S; for instance, many companies’ cloud management platforms rely on an additional CMDB database. Where should this database be placed? You shouldn’t let K8S manage things it depends on, nor should you add unnecessary extra dependencies. The Alibaba Cloud global epic failure and Didi’s K8S architecture juggling disaster have taught us this lesson. Moreover, maintaining a separate database system inside K8S when there’s already one outside is even more unjustifiable.
Security
The database in a multi-tenant environment introduces additional attack surfaces, bringing higher risks and more complex audit compliance challenges. Does K8S make your database more secure? Maybe the complexity of K8S architecture juggling will deter script kiddies unfamiliar with K8S, but for real attackers, more components and dependencies often mean a broader attack surface.
In “BrokenSesame Alibaba Cloud PostgreSQL Vulnerability Technical Details”, security personnel escaped to the K8S host node using their own PostgreSQL container and accessed the K8S API and other tenants’ containers and data. This is clearly a K8S-specific issue — the risk is real, such attacks have occurred, and even Alibaba Cloud, a local cloud industry leader, has been compromised.
《The Attacker Perspective - Insights From Hacking Alibaba Cloud》
Performance
As stated in “Is it a Good Idea to Put Databases into Docker?”, whether it’s additional network overhead, Ingress bottlenecks, or underperforming cloud disks, all negatively impact database performance. For example, as revealed in “PostgreSQL@K8s Performance Optimization” — you need a considerable level of technical prowess to make database performance in K8S barely match that on bare metal.
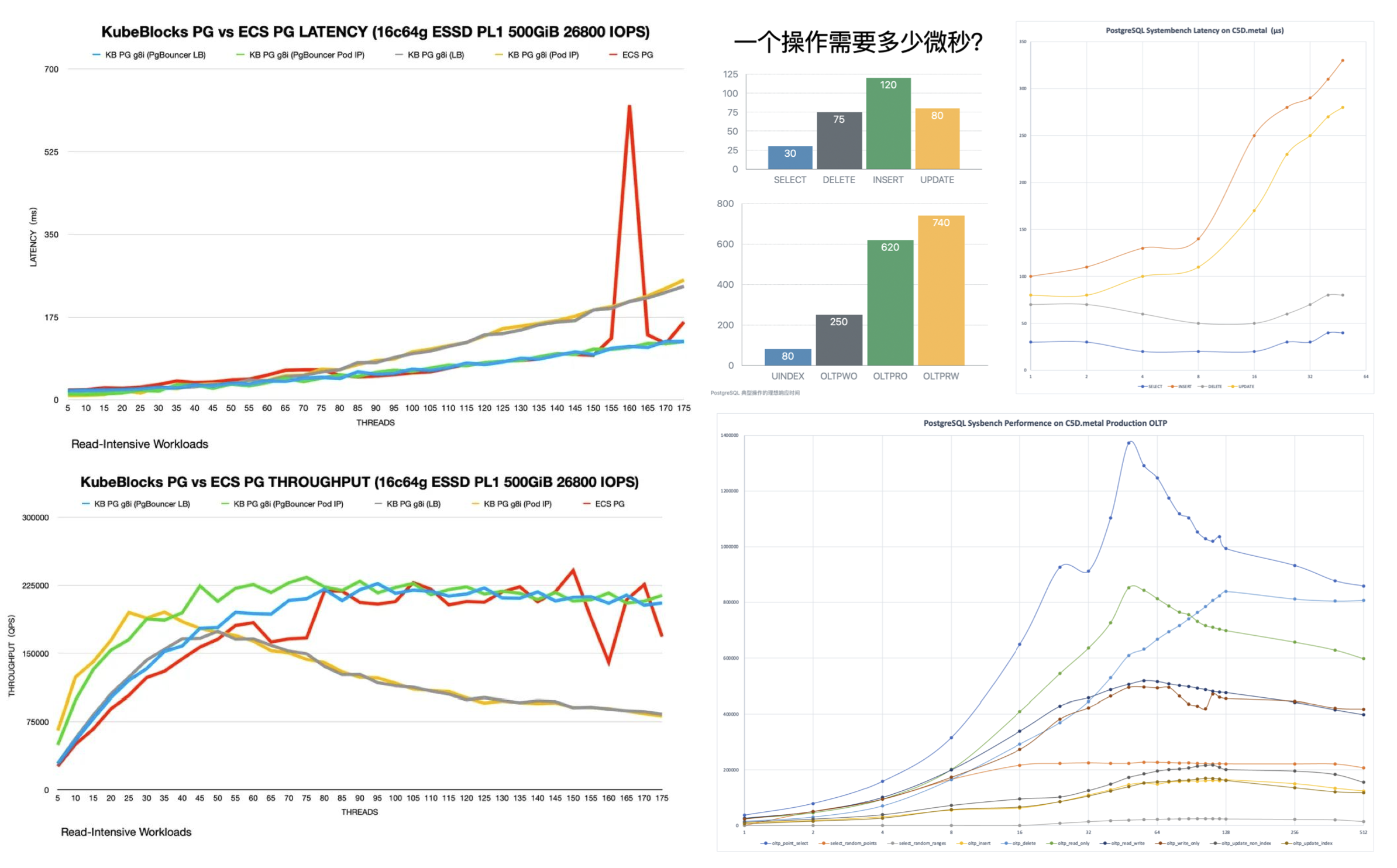
Latency is measured in ms, not µs; I almost thought my eyes were deceiving me.
Another misconception about efficiency is resource utilization. Unlike offline analytical businesses, critical online OLTP databases should not aim to increase resource utilization but rather deliberately lower it to enhance system reliability and user experience. If there are many fragmented businesses, resource utilization can be improved through PDB/shared database clusters. K8S’s advocated elasticity efficiency is not unique to it — KVM/EC2 can also effectively address this issue.
In terms of cost, K8S and various Operators provide a decent abstraction, encapsulating some of the complexity of database management, which is attractive for teams without DBAs. However, the complexity reduced by using it to manage databases pales in comparison to the complexity introduced by using K8S itself. For instance, random IP address drifts and automatic Pod restarts may not be a big issue for stateless applications, but for databases, they are intolerable — many companies have had to attempt to modify kubelet to avoid this behavior, thereby introducing more complexity and maintenance costs.
As stated in “From Reducing Costs and Smiles to Reducing Costs and Efficiency” “Reducing Complexity Costs” section: Intellectual power is hard to accumulate spatially: when a database encounters problems, it needs database experts to solve them; when Kubernetes has problems, it needs K8S experts to look into them; however, when you put a database into Kubernetes, complexities combine, the state space explodes, but the intellectual bandwidth of individual database experts and K8S experts is hard to stack — you need a dual expert to solve the problem, and such experts are undoubtedly much rarer and more expensive than pure database experts. Such architectural juggling is enough to cause major setbacks for most teams, including top public clouds/big companies, in the event of a failure.

The Cloud-Native Frenzy
An interesting question arises: if K8S is unsuitable for stateful databases, why are so many companies, including big players, rushing to do this? The reasons are not technical.
Google open-sourced its K8S battleship, modeled after its internal Borg spaceship, and managers, fearing being left behind, rushed to adopt it, thinking using K8S would put them on par with Google. Ironically, Google doesn’t use K8S; it was more likely to disrupt AWS and mislead the industry. However, most companies don’t have the manpower like Google to operate such a battleship. More importantly, their problems might need a simple vessel. Running MySQL + PHP, PostgreSQL + Go/Python on bare metal has already taken many companies to IPO.
Under modern hardware conditions, the complexity of most applications throughout their lifecycle doesn’t justify using K8S. Yet, the “cloud-native” frenzy, epitomized by K8S, has become a distorted phenomenon: adopting k8s just for the sake of k8s. Some engineers are looking for “advanced” and “cool” technologies used by big companies to fulfill their personal goals like job hopping or promotions or to increase their job security by adding complexity, not considering if these “dragon-slaying” techniques are necessary for solving their problems.
The cloud-native landscape is filled with fancy projects. Every new development team wants to introduce something new: Helm today, Kubevela tomorrow. They talk big about bright futures and peak efficiency, but in reality, they create a mountain of architectural complexities and a playground for “YAML Boys” - tinkering with the latest tech, inventing concepts, earning experience and reputation at the expense of users who bear the complexity and maintenance costs.
CNCF Landscape
The cloud-native movement’s philosophy is compelling - democratizing the elastic scheduling capabilities of public clouds for every user. K8S indeed excels in stateless applications. However, excessive enthusiasm has led K8S astray from its original intent and direction - simply doing well in orchestrating stateless applications, burdened by the ill-conceived support for stateful applications.
Making Wise Decisions
Years ago, when I first encountered K8S, I too was fervent —— It was at TanTan. We had over twenty thousand cores and hundreds of database clusters, and I was eager to try putting databases in Kubernetes and testing all the available Operators. However, after two to three years of extensive research and architectural design, I calmed down and abandoned this madness. Instead, I architected our database service based on bare metal/operating systems. For us, the benefits K8S brought to databases were negligible compared to the problems and hassles it introduced.
Should databases be put into K8S? It depends: for public cloud vendors who thrive on overselling resources, elasticity and utilization are crucial, which are directly linked to revenue and profit, While reliability and performance take a back seat - after all, an availability below three nines means compensating 25% monthly credit. But for most user, including ourselves, these trade-offs hold different: One-time Day1 Setup, elasticity, and resource utilization aren’t their primary concerns; reliability, performance, Day2 Operation costs, these core database attributes are what matter most.
We open-sourced our database service architecture — an out-of-the-box PostgreSQL distribution and a local-first RDS alternative: Pigsty. We didn’t choose the so-called “build once, run anywhere” approach of K8S and Docker. Instead, we adapted to different OS distros & major versions, and used Ansible to achieve a K8S CRD IaC-like API to seal management complexity. This was arduous, but it was the right thing to do - the world does not need another clumsy attempt at putting PostgreSQL into K8S. Still, it does need a production database service architecture that maximizes hardware performance and reliability.
Pigsty vs StackGres
Perhaps one day, when the reliability and performance of distributed network storage surpass local storage and mainstream databases have some native support for storage-computation separation, things might change again — K8S might become suitable for databases. But for now, I believe putting serious production OLTP databases into K8S is immature and inappropriate. I hope readers will make wise choices on this matter.
Reference
Database in Docker: Is that a good idea?
《What can we learn from DiDi’s Epic k8s Failure》
NewSQL: Distributive Nonsens
As hardware technology advances, the capacity and performance of standalone databases have reached unprecedented heights. In this transformative era, distributed (TP) databases appear utterly powerless, much like the “data middle platform,” donning the emperor’s new clothes in a state of self-deception.
- TL; DR
- The Pull of the Internet
- The Trade-Offs of Distributive
- The Impact of New Hardware
- The Predicament of False Needs
- The Struggles in Confusion
- References
TL; DR
The core trade-off of distributed databases is: “quality for quantity,” sacrificing functionality, performance, complexity, and reliability for greater data capacity and throughput. However, “what divides must eventually converge,” and hardware innovations have propelled centralized databases to new heights in capacity and throughput, rendering distributed (TP) databases obsolete.
Hardware, exemplified by NVMe SSDs, follows Moore’s Law, evolving at an exponential pace. Over a decade, performance has increased by tens of times, and prices have dropped significantly, improving the cost-performance ratio by three orders of magnitude. A single card can now hold 32TB+, with 4K random read/write IOPS reaching 1600K/600K, latency at 70µs/10µs, and a cost of less than 200 ¥/TB·year. Running a centralized database on a single machine can achieve one to two million point write/point query QPS.
Scenarios truly requiring distributed databases are few and far between, with typical mid-sized internet companies/banks handling request volumes ranging from tens to hundreds of thousands of QPS, and non-repetitive TP data at the hundred TB level. In the real world, over 99% of scenarios do not need distributed databases, and the remaining 1% can likely be addressed through classic engineering solutions like horizontal/vertical partitioning.
Top-tier internet companies might have a few genuine use cases, yet these companies have no intention to pay. The market simply cannot sustain so many distributed database cores, and the few products that do survive don’t necessarily rely on distribution as their selling point. HATP and the integration of distributed and standalone databases represent the struggles of confused distributed TP database vendors seeking transformation, but they are still far from achieving product-market fit.
The Pull of the Internet
“Distributed database” is not a term with a strict definition. In a narrow sense, it highly overlaps with NewSQL databases such as CockroachDB, YugabyteDB, TiDB, OceanBase, and TDSQL; broadly speaking, classic databases like Oracle, PostgreSQL, MySQL, SQL Server, PolarDB, and Aurora, which span multiple physical nodes and use master-slave replication or shared storage, can also be considered distributed databases. In the context of this article, a distributed database refers to the former, specifically focusing on transactional processing (OLTP) distributed relational databases.
The rise of distributed databases stemmed from the rapid development of internet applications and the explosive growth of data volumes. In that era, traditional relational databases often encountered performance bottlenecks and scalability issues when dealing with massive data and high concurrency. Even using Oracle with Exadata struggled in the face of voluminous CRUD operations, not to mention the prohibitively expensive annual hardware and software costs.
Internet companies embarked on a different path, building their infrastructure with free, open-source databases like MySQL. Veteran developers/DBAs might still recall the MySQL best practice: keep single-table records below 21 million to avoid rapid performance degradation. Correspondingly, database sharding became a widely recognized practice among large companies.
The basic idea here was “three cobblers with their wits combined equal Zhuge Liang,” using a bunch of inexpensive x86 servers + numerous sharded open-source database instances to create a massive CRUD simple data store. Thus, distributed databases often originated from internet company scenarios, evolving along the manual sharding → sharding middleware → distributed database path.
As an industry solution, distributed databases have successfully met the needs of internet companies. However, before abstracting and solidifying it into a product for external output, several questions need to be clarified:
Do the trade-offs from ten years ago still hold up today?
Are the scenarios of internet companies applicable to other industries?
Could distribute OLTP databases be a false necessity?
The Trade-Offs of Distributive
“Distributed,” along with buzzwords like “HTAP,” “compute-storage separation,” “Serverless,” and “lakehouse,” holds no inherent meaning for enterprise users. Practical clients focus on tangible attributes and capabilities: functionality, performance, security, reliability, return on investment, and cost-effectiveness. What truly matters is the trade-off: compared to classic centralized databases, what do distributed databases sacrifice, and what do they gain in return?

数据库需求层次金字塔[1]
The core trade-off of distributed databases can be summarized as “quality for quantity”: sacrificing functionality, performance, complexity, and reliability to gain greater data capacity and request throughput.
NewSQL often markets itself on the concept of “distribution,” solving scalability issues through “distribution.” Architecturally, it typically features multiple peer data nodes and a coordinator, employing distributed consensus protocols like Paxos/Raft for replication, allowing for horizontal scaling by adding data nodes.
Firstly, due to their inherent limitations, distributed databases sacrifice many features, offering only basic and limited CRUD query support. Secondly, because distributed databases require multiple network RPCs to complete requests, their performance typically suffers a 70% or more degradation compared to centralized databases. Furthermore, distributed databases, consisting of DN/CN and TSO components among others, introduce significant complexity in operations and management. Lastly, in terms of high availability and disaster recovery, distributed databases do not offer a qualitative improvement over the classic centralized master-slave setup; instead, they introduce numerous additional failure points due to their complex components.
SYSBENCH吞吐对比[2]
In the past, the trade-offs of distributed databases were justified: the internet required larger data storage capacities and higher access throughputs—a must-solve problem, and these drawbacks were surmountable. But today, hardware advancements have rendered the “quantity” question obsolete, thus erasing the raison d’être of distributed databases along with the very problem they sought to solve.

Times have changed, My lord!
The Impact of New Hardware
Moore’s Law posits that every 18 to 24 months, processor performance doubles while costs halve. This principle largely applies to storage as well. From 2013 to 2023, spanning 5 to 6 cycles, we should see performance and cost differences of dozens of times compared to a decade ago. Is this the case?
Let’s examine the performance metrics of a typical SSD from 2013 and compare them with those of a typical PCI-e Gen4 NVMe SSD from 2022. It’s evident that the SSD’s 4K random read/write IOPS have jumped from 60K/40K to 1600K/600K, with prices plummeting from 2220$/TB to 40$/TB. Performance has improved by 15 to 26 times, while prices have dropped 56-fold[3,4,5], certainly validating the rule of thumb at a magnitude level.
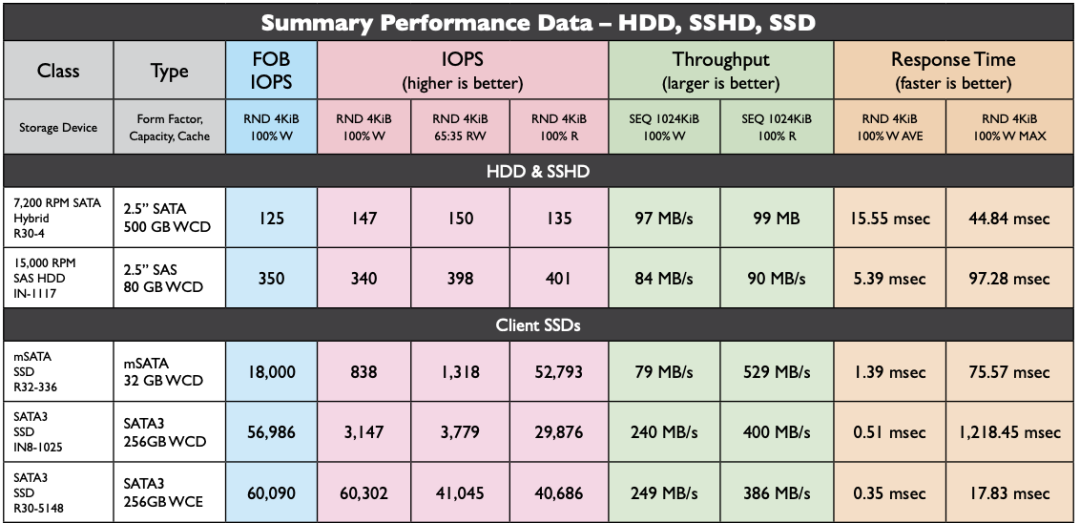
HDD/SSD Performance in 2013
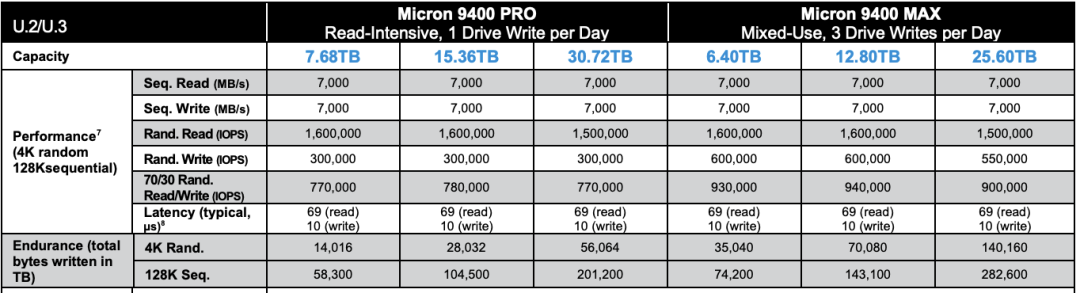
NVMe Gen4 SSD in 2022
A decade ago, mechanical hard drives dominated the market. A 1TB hard drive cost about seven or eight hundred yuan, and a 64GB SSD was even more expensive. Ten years later, a mainstream 3.2TB enterprise-grade NVMe SSD costs just three thousand yuan. Considering a five-year warranty, the monthly cost per TB is only 16 yuan, with an annual cost under 200 yuan. For reference, cloud providers’ reputedly cost-effective S3 object storage costs 1800¥/TB·year.
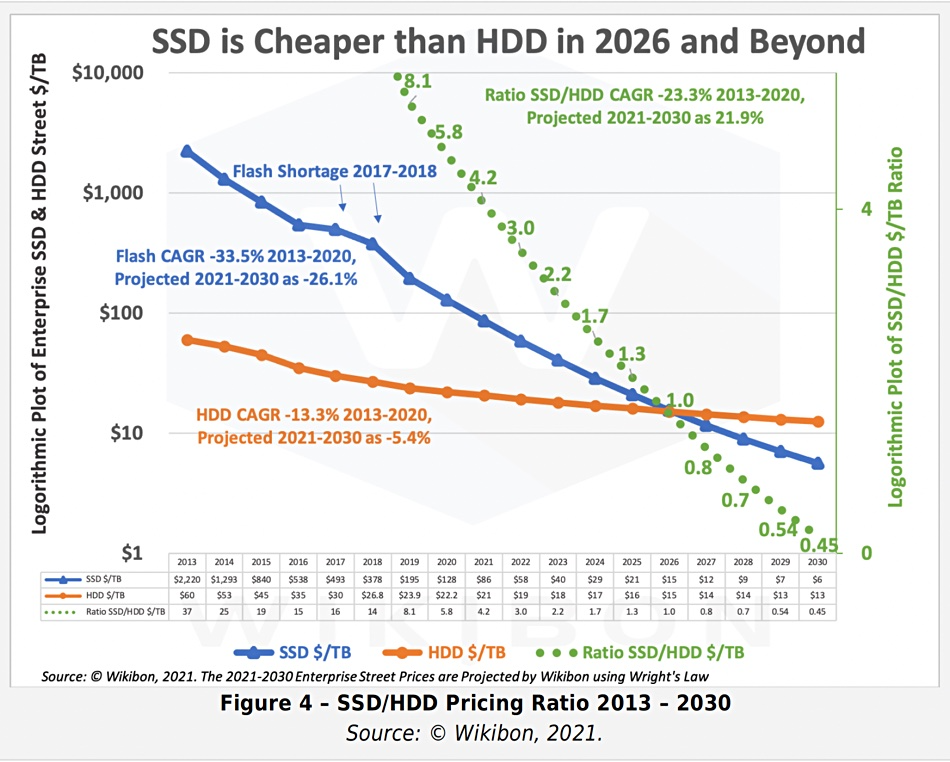
Price per unit of SSD/HDD from 2013 to 2030 with predictions
The typical fourth-generation local NVMe disk can reach a maximum capacity of 32TB to 64TB, offering 70µs/10µs 4K random read/write latencies, and 1600K/600K read/write IOPS, with the fifth generation boasting an astonishing bandwidth of several GB/s per card.
Equipping a classic Dell 64C / 512G server with such a card, factoring in five years of IDC depreciation, the total cost is under one hundred thousand yuan. Such a server running PostgreSQL sysbench can nearly reach one million QPS for single-point writes and two million QPS for point queries without issue.
What does this mean? For a typical mid-sized internet company/bank, the demand for database requests is usually in the tens of thousands to hundreds of thousands of QPS, with non-repeated TP data volumes fluctuating around hundreds of TBs. Considering hardware storage compression cards can achieve several times compression ratio, such scenarios might now be manageable by a centralized database on a single machine and card under modern hardware conditions[6].
Previously, users might have had to invest millions in high-end storage solutions like exadata, then spend a fortune on Oracle commercial database licenses and original factory services. Now, achieving similar outcomes starts with just a few thousand yuan on an enterprise-grade SSD card; open-source Oracle alternatives like PostgreSQL, capable of smoothly running the largest single tables of 32TB, no longer suffer from the limitations that once forced MySQL into partitioning. High-performance database services, once luxury items restricted to intelligence/banking sectors, have become affordable for all industries[7].
Cost-effectiveness is the primary product strength. The cost-effectiveness of high-performance, large-capacity storage has improved by three orders of magnitude over a decade, making the once-highlighted value of distributed databases appear weak in the face of such remarkable hardware evolution.
The Predicament of False Needs
Nowadays, sacrificing functionality, performance, complexity for scalability is most likely to be a fake-demands in most scenarios.
With the support of modern hardware, over 99% of real-world scenarios do not exceed the capabilities of a centralized, single-machine database. The remaining scenarios can likely be addressed through classical engineering methods like horizontal or vertical splitting. This holds true even for internet companies: even among the global top firms, scenarios where a transactional (TP) single table exceeds several tens of TBs are still rare.
Google Spanner, the forefather of NewSQL, was designed to solve the problem of massive data scalability, but how many enterprises actually handle data volumes comparable to Google’s? In terms of data volume, the lifetime TP data volume for the vast majority of enterprises will not exceed the bottleneck of a centralized database, which continues to grow exponentially with Moore’s Law. Regarding request throughput, many enterprises have enough database performance headroom to implement all their business logic in stored procedures and run it smoothly within the database.
“Premature optimization is the root of all evil,” designing for unneeded scale is a waste of effort. If volume is no longer an issue, then sacrificing other attributes for unneeded volume becomes meaningless.

“Premature optimization is the root of all evil”
In many subfields of databases, distributed technology is not a pseudo-requirement: if you need a highly reliable, disaster-resilient, simple, low-frequency KV storage for metadata, then a distributed etcd is a suitable choice; if you require a globally distributed table for arbitrary reads and writes across different locations and are willing to endure significant performance degradation, then YugabyteDB might be a good choice. For ensuring transparency and preventing tampering and denial, blockchain is fundamentally a leaderless distributed ledger database;
For large-scale data analytics (OLAP), distributed technology is indispensable (though this is usually referred to as data warehousing, MPP); however, in the transaction processing (OLTP) domain, distributed technology is largely unnecessary: OLTP databases are like working memory, characterized by being small, fast, and feature-rich. Even in very large business systems, the active working set at any one moment is not particularly large. A basic rule of thumb for OLTP system design is: If your problem can be solved within a single machine, don’t bother with distributed databases.
OLTP databases have a history spanning several decades, with existing cores developing to a mature stage. Standards in the TP domain are gradually converging towards three Wire Protocols: PostgreSQL, MySQL, and Oracle. If the discussion is about tinkering with database auto-sharding and adding global transactions as a form of “distribution,” it’s definitely a dead end. If a “distributed” database manages to break through, it’s likely not because of the “pseudo-requirement” of “distribution,” but rather due to new features, open-source ecosystems, compatibility, ease of use, domestic innovation, and self-reliance.
The Struggles in Confusion
The greatest challenge for distributed databases stems from the market structure: Internet companies, the most likely candidates to utilize distributed TP databases, are paradoxically the least likely to pay for them. Internet companies can serve as high-quality users or even contributors, offering case studies, feedback, and PR, but they inherently resist the notion of financially supporting software, clashing with their meme instincts. Even leading distributed database vendors face the challenge of being applauded but not financially supported.
In a recent casual conversation with an engineer at a distributed database company, it was revealed that during a POC with a client, a query that Oracle completed in 10 seconds, their distributed database could only match with an order of magnitude difference, even when utilizing various resources and Dirty Hacks. Even openGauss, which forked from PostgreSQL 9.2 a decade ago, can outperform many distributed databases in certain scenarios, not to mention the advancements seen in PostgreSQL 15 and Oracle 23c ten years later. This gap is so significant that even the original manufacturers are left puzzled about the future direction of distributed databases.
Thus, some distributed databases have started pivoting towards self-rescue, with HTAP being a prime example: while transaction processing in a distributed setting is suboptimal, analytics can benefit greatly. So, why not combine the two? A single system capable of handling both transactions and analytics! However, engineers in the real world understand that AP systems and TP systems each have their own patterns, and forcibly merging two diametrically opposed systems will only result in both tasks failing to succeed. Whether it’s classic ETL/CDC pushing and pulling to specialized solutions like ClickHouse/Greenplum/Doris, or logical replication to a dedicated in-memory columnar store, any of these approaches is more reliable than using a chimera HTAP database.
Another idea is monolithic-distributed integration: if you can’t beat them, join them by adding a monolithic mode to avoid the high costs of network RPCs, ensuring that in 99% of scenarios where distributed capabilities are unnecessary, they aren’t completely outperformed by centralized databases — even if distributed isn’t needed, it’s essential to stay in the game and prevent others from taking the lead! But the fundamental issue here is the same as with HTAP: forcing heterogeneous data systems together is pointless. If there was value in doing so, why hasn’t anyone created a monolithic binary that integrates all heterogeneous databases into a do-it-all behemoth — the Database Jack-of-all-trades? Because it violates the KISS principle: Keep It Simple, Stupid!

The plight of distributed databases is similar to that of Middle Data Platforms: originating from internal scenarios at major internet companies and solving domain-specific problems. Once riding the wave of the internet industry, the discussion of databases was dominated by distributed technologies, enjoying a moment of pride. However, due to excessive hype and promises of unrealistic capabilities, they failed to meet user expectations, ending in disappointment and becoming akin to the emperor’s new clothes.
There are still many areas within the TP database field worthy of focus: Leveraging new hardware, actively embracing changes in underlying architectures like CXL, RDMA, NVMe; or providing simple and intuitive declarative interfaces to make database usage and management more convenient; offering more intelligent automatic monitoring and control systems to minimize operational tasks; developing compatibility plugins like Babelfish for MySQL/Oracle, aiming for a unified relational database WireProtocol. Even investing in better support services would be more meaningful than chasing the false need for “distributed” features.
Time changes, and a wise man adapts. It is hoped that distributed database vendors will find their Product-Market Fit and focus on what users truly need.
References
[1] 数据库需求层次金字塔 : https://mp.weixin.qq.com/s/1xR92Z67kvvj2_NpUMie1Q
[2] PostgreSQL到底有多强? : https://mp.weixin.qq.com/s/651zXDKGwFy8i0Owrmm-Xg
[3] SSD Performence in 2013 : https://www.snia.org/sites/default/files/SNIASSSI.SSDPerformance-APrimer2013.pdf
[4] 2022 Micron NVMe SSD Spec: https://media-www.micron.com/-/media/client/global/documents/products/product-flyer/9400_nvme_ssd_product_brief.pdf
[5] 2013-2030 SSD Pricing : https://blocksandfiles.com/2021/01/25/wikibon-ssds-vs-hard-drives-wrights-law/
[6] Single Instance with 100TB: https://mp.weixin.qq.com/s/JSQPzep09rDYbM-x5ptsZA
[7] EBS: Scam: https://mp.weixin.qq.com/s/UxjiUBTpb1pRUfGtR9V3ag
[8] 中台:一场彻头彻尾的自欺欺人: https://mp.weixin.qq.com/s/VgTU7NcOwmrX-nbrBBeH_w
Is running postgres in docker a good idea?
For stateless app services, containers are an almost perfect devops solution. However, for stateful services like databases, it’s not so straightforward. Whether production databases should be containerized remains controversial.
From a developer’s perspective, I’m a big fan of Docker & Kubernetes and believe that they might be the future standard for software deployment and operations. But as a database administrator, I think hosting production databases in Docker/K8S is still a bad idea.
What problems does Docker solve?
Docker is described with terms like lightweight, standardized, portable, cost-effective, efficient, automated, integrated, and high-performance in operations. These claims are valid, as Docker indeed simplifies both development and operations. This explains why many companies are eager to containerize their software and services. However, this enthusiasm sometimes goes to the extreme of containerizing everything, including production databases.
Containers were originally designed for stateless apps, where temporary data produced by the app is logically part of the container. A service is created with a container and destroyed after use. These apps are stateless, with the state typically stored outside in a database, reflecting the classic architecture and philosophy of containerization.
But when it comes to containerizing the production database itself, the scenario changes: databases are stateful. To maintain their state without losing it when the container stops, database containers need to “punch a hole” to the underlying OS, which is named data volumes.
Such containers are no longer ephemeral entities that can be freely created, destroyed, moved, or transferred; they become bound to the underlying environment. Thus, the many advantages of using containers for traditional apps are not applicable to database containers.
Reliability
Getting software up & running is one thing; ensuring its reliability is another. Databases, central to information systems, are often critical, with failure leading to catastrophic consequences. This reflects common experience: while office software crashes can be tolerated and resolved with restarts, document loss or corruption is unresolvable and disastrous. Database failure without replica & backups can be terminal, particularly for internet/finance companies.
Reliability is the paramount attribute for databases. It’s the system’s ability to function correctly during adversity (hardware/software faults, human error), i.e. fault tolerance and resilience. Unlike liveness attribute such as performance, reliability, a safety attribute, proves itself over time or falsify by failures, often overlooked until disaster strikes.
Docker’s description notably omits “reliability” —— the crucial attribute for database.
Reliability Proof
As mentioned, reliability lacks a definitive measure. Confidence in a system’s reliability builds over time through consistent, correct operation (MTTF). Deploying databases on bare metal has been a long-standing practice, proven reliable over decades. Docker, despite revolutionizing DevOps, has a mere ten-year track record, which is insufficient for establishing reliability, especially for mission-critical production databases. In essence, there haven’t been enough “guinea pigs” to clear the minefield.
Community Knowledge
Improving reliability hinges on learning from failures. Failures are invaluable, turning unknowns into knowns and forming the bedrock of operational knowledge. Community experience with failures is predominantly based on bare-metal deployments, with a plethora of issues well-trodden over decades. Encountering a problem often means finding a well-documented solution, thanks to previous experiences. However, add “Docker” to the mix, and the pool of useful information shrinks significantly. This implies a lower success rate in data recovery and longer times to resolve complex issues when they arise.
A subtle reality is that, without compelling reasons, businesses and individuals are generally reluctant to share experiences with failures. Failures can tarnish a company’s reputation, potentially exposing sensitive data or reflecting poorly on the organization and team. Moreover, insights from failures are often the result of costly lessons and financial losses, representing core value for operations personnel, thus public documentation on failures is scarce.
Extra Failure Point
Running databases in Docker doesn’t reduce the chances of hardware failures, software bugs, or human errors. Hardware issues persist with or without Docker. Software defects, mainly application bugs, aren’t lessened by containerization, and the same goes for human errors. In fact, Docker introduces extra components, complexity, and failure points, decreasing overall system reliability.
Consider this simple scenario: if the Docker daemon crashes, the database process dies. Such incidents, albeit rare, are non-existent on bare-metal.
Moreover, the failure points from an additional component like Docker aren’t limited to Docker itself. Issues could arise from interactions between Docker and the database, the OS, orchestration systems, VMs, networks, or disks. For evidence, see the issue tracker for the official PostgreSQL Docker image: https://github.com/docker-library/postgres/issues?q=.
Intellectual power doesn’t easily stack — a team’s intellect relies on the few seasoned members and their communication overhead. Database issues require database experts; container issues, container experts. However, when databases are deployed on kubernetes & dockers, merging the expertise of database and K8S specialists is challenging — you need a dual-expert to resolve issues, and such individuals are rarer than specialists in one domain.
Moreover, one man’s meat is another man’s poison. Certain Docker features might turn into bugs under specific conditions.
Unnecessary Isolation
Docker provides process-level isolation, which generally benefits applications by reducing interaction-related issues, thereby enhancing system reliability. However, this isolation isn’t always advantageous for databases.
A subtle real-world case involved starting two PostgreSQL server on the same data directory, either on the host or one in the host and another inside a container. On bare metal, the second instance would fail to start as PostgreSQL recognizes the existing instance and refuses to launch; however, Docker’s isolation allows the second instance to start obliviously, potentially toast the data files if proper fencing mechanisms (like host port or PID file exclusivity) aren’t in place.
Do databases need isolation? Absolutely, but not this kind. Databases often demand dedicated physical machines for performance reasons, with only the database process and essential tools running. Even in containers, they’re typically bound exclusively to physical/virtual machines. Thus, the type of isolation Docker provides is somewhat irrelevant for such deployments, though it is a handy feature for cloud providers to efficiently oversell in a multi-tenant environment.
Maintainability
Docker simplify the day one setup, but bring much more troubles on day two operation.
The bulk of software expenses isn’t in initial development but in ongoing maintenance, which includes fixing vulnerabilities, ensuring operational continuity, handling outages, upgrading versions, repaying technical debt, and adding new features. Maintainability is crucial for the quality of life in operations work. Docker shines in this aspect with its infrastructure-as-code approach, effectively turning operational knowledge into reusable code, accumulating it in a streamlined manner rather than scattered across various installation/setup documents. Docker excels here, especially for stateless applications with frequently changing logic. Docker and Kubernetes facilitate deployment, scaling, publishing, and rolling upgrades, allowing Devs to perform Ops tasks, and Ops to handle DBA duties (somewhat convincingly).
Day 1 Setup
Perhaps Docker’s greatest strength is the standardization of environment configuration. A standardized environment aids in delivering changes, discussing issues, and reproducing bugs. Using binary images (essentially materialized Dockerfile installation scripts) is quicker and easier to manage than running installation scripts. Not having to rebuild complex, dependency-heavy extensions each time is a notable advantage.
Unfortunately, databases don’t behave like typical business applications with frequent updates, and creating new instances or delivering environments is a rare operation. Additionally, DBAs often accumulate various installation and configuration scripts, making environment setup almost as fast as using Docker. Thus, Docker’s advantage in environment configuration isn’t as pronounced, falling into the “nice to have” category. Of course, in the absence of a dedicated DBA, using Docker images might still be preferable as they encapsulate some operational experience.
Typically, it’s not unusual for databases to run continuously for months or years after initialization. The primary aspect of database management isn’t creating new instances or delivering environments, but the day-to-day operations — Day2 Operation. Unfortunately, Docker doesn’t offer much benefit in this area and can introduce additional complications.
Day2 Operation
Docker can significantly streamline the maintenance of stateless apps, enabling easy create/destroy, version upgrades, and scaling. However, does this extend to databases?
Unlike app containers, database containers can’t be freely destroyed or created. Docker doesn’t enhance the operational experience for databases; tools like Ansible are more beneficial. Often, operations require executing scripts inside containers via docker exec, adding unnecessary complexity.
CLI tools often struggle with Docker integration. For instance, docker exec mixes stderr and stdout, breaking pipeline-dependent commands. In bare-metal deployments, certain ETL tasks for PostgreSQL can be easily done with a single Bash line.
psql <src-url> -c 'COPY tbl TO STDOUT' | psql <dst-url> -c 'COPY tdb FROM STDIN'
Yet, without proper client binaries on the host, one must awkwardly use Docker’s binaries like:
docker exec -it srcpg gosu postgres bash -c "psql -c \"COPY tbl TO STDOUT\" 2>/dev/null" |\
docker exec -i dstpg gosu postgres psql -c 'COPY tbl FROM STDIN;'
complicating simple commands like physical backups, which require layers of command wrapping:
docker exec -i postgres_pg_1 gosu postgres bash -c 'pg_basebackup -Xf -Ft -c fast -D - 2>/dev/null' | tar -xC /tmp/backup/basebackup
docker,gosu,bash,pg_basebackup
Client-side applications (psql, pg_basebackup, pg_dump) can bypass these issues with version-matched client tools on the host, but server-side solutions lack such workarounds. Upgrading containerized database software shouldn’t necessitate host server binary upgrades.
Docker advocates for easy software versioning; updating a minor database version is straightforward by tweaking the Dockerfile and restarting the container. However, major version upgrades requiring state modification are more complex in Docker, often leading to convoluted processes like those in https://github.com/tianon/docker-postgres-upgrade.
If database containers can’t be scheduled, scaled, or maintained as easily as AppServers, why use them in production? While stateless apps benefit from Docker and Kubernetes’ scaling ease, stateful applications like databases don’t enjoy such flexibility. Replicating a large production database is time-consuming and manual, questioning the efficiency of using docker run for such operations.
Docker’s awkwardness in hosting production databases stems from the stateful nature of databases, requiring additional setup steps. Setting up a new PostgreSQL replica, for instance, involves a local data directory clone and starting the postmaster process. Container lifecycle tied to a single process complicates database scaling and replication, leading to inelegant and complex solutions. This process isolation in containers, or “abstraction leakage,” fails to neatly cover the multiprocess, multitasking nature of databases, introducing unnecessary complexity and affecting maintainability.
In conclusion, while Docker can improve system maintainability in some aspects, like simplifying new instance creation, the introduced complexities often undermine these benefits.
Tooling
Databases require tools for maintenance, including a variety of operational scripts, deployment, backup, archiving, failover, version upgrades, plugin installation, connection pooling, performance analysis, monitoring, tuning, inspection, and repair. Most of these tools are designed for bare-metal deployments. Like databases, these tools need thorough and careful testing. Getting something to run versus ensuring its stable, long-term, and correct operation are distinct levels of reliability.
A simple example is plugin and package management. PostgreSQL offers many useful plugins, such as PostGIS. On bare metal, installing this plugin is as easy as executing yum install followed by create extension postgis. However, in Docker, following best practices requires making changes at the image level to persist the extension beyond container restarts. This necessitates modifying the Dockerfile, rebuilding the image, pushing it to the server, and restarting the database container, undeniably a more cumbersome process.
Package management is a core aspect of OS distributions. Docker complicates this, as many PostgreSQL binaries are distributed not as RPM/DEB packages but as Docker images with pre-installed extensions. This raises a significant issue: how to consolidate multiple disparate images if one needs to use two, three, or over a hundred extensions from the PostgreSQL ecosystem? Compared to reliable OS package management, building Docker images invariably requires more time and effort to function properly.
Take monitoring as another example. In traditional bare-metal deployment, machine metrics are crucial for database monitoring. Monitoring in containers differs subtly from that on bare metal, and oversight can lead to pitfalls. For instance, the sum of various CPU mode durations always equals 100% on bare metal, but this assumption doesn’t necessarily hold in containers. Moreover, monitoring tools relying on the /proc filesystem may yield metrics in containers that differ significantly from those on bare metal. While such issues are solvable (e.g., mounting the Proc filesystem inside the container), complex and ugly workarounds are generally unwelcome compared to straightforward solutions.
Similar issues arise with some failure detection tools and common system commands. Theoretically, these could be executed directly on the host, but can we guarantee that the results in the container will be identical to those on bare metal? More frustrating is the emergency troubleshooting process, where necessary tools might be missing in the container, and with no external network access, the Dockerfile→Image→Restart path can be exasperating.
Treating Docker like a VM, many tools may still function, but this defeats much of Docker’s purpose, reducing it to just another package manager. Some argue that Docker enhances system reliability through standardized deployment, given the more controlled environment. While this is true, I believe that if the personnel managing the database understand how to configure the database environment, there’s no fundamental difference between scripting environment initialization in a Shell script or in a Dockerfile.
Scalability
Performance is another point that people concerned a lot. From the performance perspective, the basic principle of database deployment is: The close to hardware, The better it is. Additional isolation & abstraction layer is bad for database performance. More isolation means more overhead, even if it is just an additional memcpy in the kernel .
For performance-seeking scenarios, some databases choose to bypass the operating system’s page management mechanism to operate the disk directly, while some databases may even use FPGA or GPU to speed up query processing. Docker as a lightweight container, performance suffers not much, and the impact to performance-insensitive scenarios may not be significant, but the extra abstract layer will definitely make performance worse than make it better.
Summary
Container and orchestration technologies are valuable for operations, bridging the gap between software and services by aiming to codify and modularize operational expertise and capabilities. Container technology is poised to become the future of package management, while orchestration evolves into a “data center distributed cluster operating system,” forming the underlying infrastructure runtime for all software. As more challenges are addressed, confidently running both stateful and stateless applications in containers will become feasible. However, for databases, this remains an ideal rather than a practical option, especially in production.
It’s crucial to reiterate that the above discussion applies specifically to production databases. For development and testing, despite the existence of Vagrant-based virtual machine sandboxes, I advocate for Docker use—many developers are unfamiliar with configuring local test database environments, and Docker provides a clearer, simpler solution. For stateless production applications or those with non-critical derivative state data (like Redis caches), Docker is a good choice. But for core relational databases in production, where data integrity is paramount, one should carefully consider the risks and benefits: What’s the value of using Docker here? Can it handle potential issues? Are you prepared to assume the responsibility if things go wrong?
Every technological decision involves balancing pros and cons, like the core trade-off here of sacrificing reliability for maintainability with Docker. Some scenarios may warrant this, such as cloud providers optimizing for containerization to oversell resources, where container isolation, high resource utilization, and management convenience align well. Here, the benefits might outweigh the drawbacks. However, in many cases, reliability is the top priority, and compromising it for maintainability is not advisable. Moreover, it’s debatable whether using Docker significantly eases database management; sacrificing long-term operational maintainability for short-term deployment ease is unwise.
In conclusion, containerizing production databases is likely not a prudent choice.