Query Optimization: The Macro Approach with pg_stat_statements
In production databases, slow queries not only impact end-user experience but also waste system resources, increase resource saturation, cause deadlocks and transaction conflicts, add pressure to database connections, and lead to replication lag. Therefore, query optimization is one of the core responsibilities of DBAs.
There are two distinct approaches to query optimization:
Macro Optimization: Analyze the overall workload, break it down, and identify and improve the worst-performing components from top to bottom.
Micro Optimization: Analyze and improve specific queries, which requires slow query logging, mastering EXPLAIN, and understanding execution plans.
Today, let’s focus on the former. Macro optimization has three main objectives:
Reduce Resource Consumption: Lower the risk of resource saturation, optimize CPU/memory/IO, typically targeting total query execution time/IO.
Improve User Experience: The most common optimization goal, typically measured by reducing average query response time in OLTP systems.
Balance Workload: Ensure proper resource usage/performance ratios between different query groups.
The key to achieving these goals lies in data support, but where does this data come from?
— pg_stat_statements!
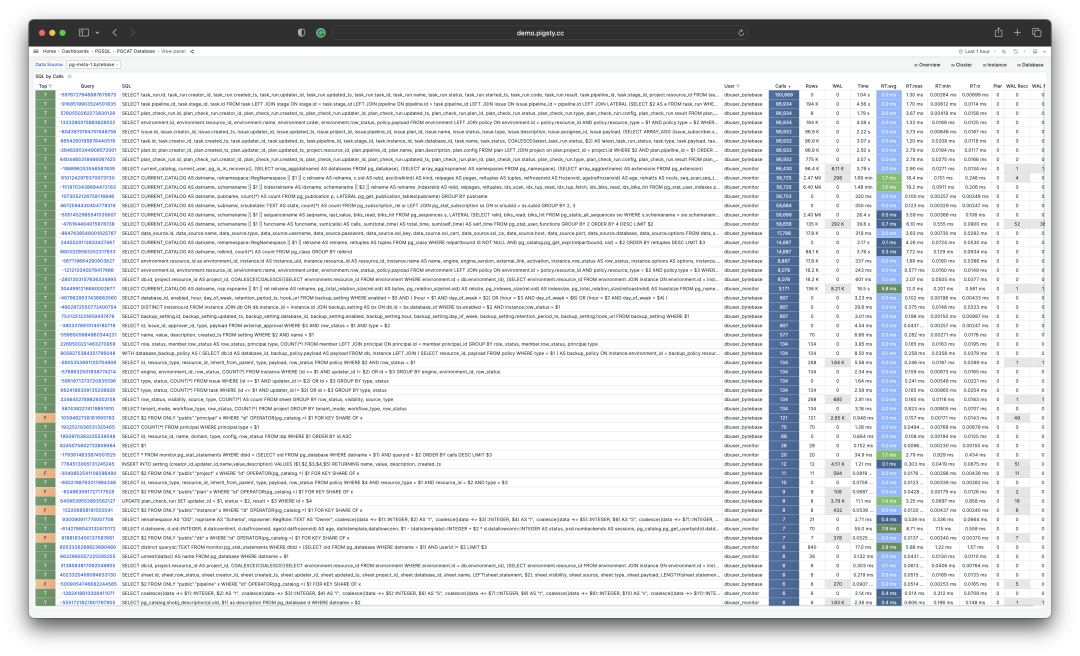
The Extension: PGSS
pg_stat_statements, hereafter referred to as PGSS, is the core tool for implementing the macro approach.
PGSS is developed by the PostgreSQL Global Development Group, distributed as a first-party extension alongside the database kernel. It provides methods for tracking SQL query-level metrics.
Among the many PostgreSQL extensions, if there’s one that’s “essential”, I would unhesitatingly answer: PGSS. This is why in Pigsty, we prefer to “take matters into our own hands” and enable this extension by default, along with auto_explain for micro-optimization.
PGSS needs to be explicitly loaded in shared_preload_library and created in the database via CREATE EXTENSION. After creating the extension, you can access query statistics through the pg_stat_statements view.
In PGSS, each query type (i.e., queries with the same execution plan after variable extraction) is assigned a query ID, followed by call count, total execution time, and various other metrics. The complete schema definition is as follows (PG15+):
CREATE TABLE pg_stat_statements
(
userid OID, -- (Label) OID of user executing this statement
dbid OID, -- (Label) OID of database containing this statement
toplevel BOOL, -- (Label) Whether this is a top-level SQL statement
queryid BIGINT, -- (Label) Query ID: hash of normalized query
query TEXT, -- (Label) Text of normalized query statement
plans BIGINT, -- (Counter) Number of times this statement was planned
total_plan_time FLOAT, -- (Counter) Total time spent planning this statement
min_plan_time FLOAT, -- (Gauge) Minimum planning time
max_plan_time FLOAT, -- (Gauge) Maximum planning time
mean_plan_time FLOAT, -- (Gauge) Average planning time
stddev_plan_time FLOAT, -- (Gauge) Standard deviation of planning time
calls BIGINT, -- (Counter) Number of times this statement was executed
total_exec_time FLOAT, -- (Counter) Total time spent executing this statement
min_exec_time FLOAT, -- (Gauge) Minimum execution time
max_exec_time FLOAT, -- (Gauge) Maximum execution time
mean_exec_time FLOAT, -- (Gauge) Average execution time
stddev_exec_time FLOAT, -- (Gauge) Standard deviation of execution time
rows BIGINT, -- (Counter) Total rows returned by this statement
shared_blks_hit BIGINT, -- (Counter) Total shared buffer blocks hit
shared_blks_read BIGINT, -- (Counter) Total shared buffer blocks read
shared_blks_dirtied BIGINT, -- (Counter) Total shared buffer blocks dirtied
shared_blks_written BIGINT, -- (Counter) Total shared buffer blocks written to disk
local_blks_hit BIGINT, -- (Counter) Total local buffer blocks hit
local_blks_read BIGINT, -- (Counter) Total local buffer blocks read
local_blks_dirtied BIGINT, -- (Counter) Total local buffer blocks dirtied
local_blks_written BIGINT, -- (Counter) Total local buffer blocks written to disk
temp_blks_read BIGINT, -- (Counter) Total temporary buffer blocks read
temp_blks_written BIGINT, -- (Counter) Total temporary buffer blocks written to disk
blk_read_time FLOAT, -- (Counter) Total time spent reading blocks
blk_write_time FLOAT, -- (Counter) Total time spent writing blocks
wal_records BIGINT, -- (Counter) Total number of WAL records generated
wal_fpi BIGINT, -- (Counter) Total number of WAL full page images generated
wal_bytes NUMERIC, -- (Counter) Total number of WAL bytes generated
jit_functions BIGINT, -- (Counter) Number of JIT-compiled functions
jit_generation_time FLOAT, -- (Counter) Total time spent generating JIT code
jit_inlining_count BIGINT, -- (Counter) Number of times functions were inlined
jit_inlining_time FLOAT, -- (Counter) Total time spent inlining functions
jit_optimization_count BIGINT, -- (Counter) Number of times queries were JIT-optimized
jit_optimization_time FLOAT, -- (Counter) Total time spent on JIT optimization
jit_emission_count BIGINT, -- (Counter) Number of times code was JIT-emitted
jit_emission_time FLOAT, -- (Counter) Total time spent on JIT emission
PRIMARY KEY (userid, dbid, queryid, toplevel)
);
PGSS View SQL Definition (PG 15+ version)
PGSS has some limitations: First, currently executing queries are not included in these statistics and need to be viewed from pg_stat_activity. Second, failed queries (e.g., statements canceled due to statement_timeout) are not counted in these statistics — this is a problem for error analysis, not query optimization.
Finally, the stability of the query identifier queryid requires special attention: When the database binary version and system data directory are identical, the same query type will have the same queryid (i.e., on physical replication primary and standby, query types have the same queryid by default), but this is not the case for logical replication. However, users should not rely too heavily on this property.
Raw Data
The columns in the PGSS view can be categorized into three types:
Descriptive Label Columns: Query ID (queryid), database ID (dbid), user (userid), a top-level query flag, and normalized query text (query).
Measured Metrics (Gauge): Eight statistical columns related to minimum, maximum, mean, and standard deviation, prefixed with min, max, mean, stddev, and suffixed with plan_time and exec_time.
Cumulative Metrics (Counter): All other metrics except the above eight columns and label columns, such as calls, rows, etc. The most important and useful metrics are in this category.
First, let’s explain queryid: queryid is the hash value of a normalized query after parsing and constant stripping, so it can be used to identify the same query type. Different query statements may have the same queryid (same structure after normalization), and the same query statement may have different queryids (e.g., due to different search_path, leading to different actual tables being queried).
The same query might be executed by different users in different databases. Therefore, in the PGSS view, the four label columns queryid, dbid, userid, and toplevel together form the “primary key” that uniquely identifies a record.
For metric columns, measured metrics (GAUGE) are mainly the eight statistics related to execution time and planning time. However, users cannot effectively control the statistical range of these metrics, so their practical value is limited.
The truly important metrics are cumulative metrics (Counter), such as:
calls: Number of times this query group was called.
total_exec_time + total_plan_time: Total time spent by the query group.
rows: Total rows returned by the query group.
shared_blks_hit + shared_blks_read: Total number of buffer pool hit and read operations.
wal_bytes: Total WAL bytes generated by queries in this group.
blk_read_time and blk_write_time: Total time spent on block I/O operations.
Here, the most meaningful metrics are calls and total_exec_time, which can be used to calculate the query group’s core metrics QPS (throughput) and RT (latency/response time), but other metrics are also valuable references.
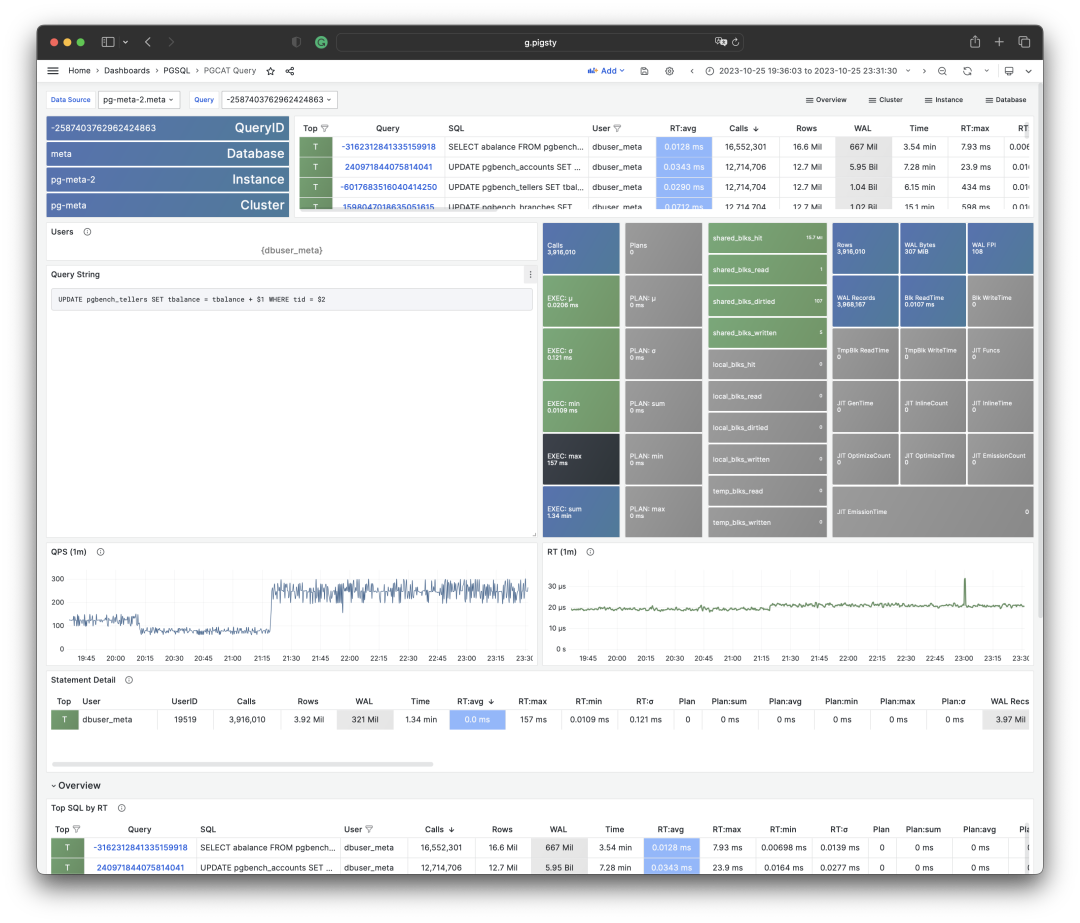
Visualization of a query group snapshot from the PGSS view
To interpret cumulative metrics, data from a single point in time is insufficient. We need to compare at least two snapshots to draw meaningful conclusions.
As a special case, if your area of interest happens to be from the beginning of the statistical period (usually when the extension was enabled) to the present, then you indeed don’t need to compare “two snapshots”. But users’ time granularity of interest is usually not this coarse, often being in minutes, hours, or days.
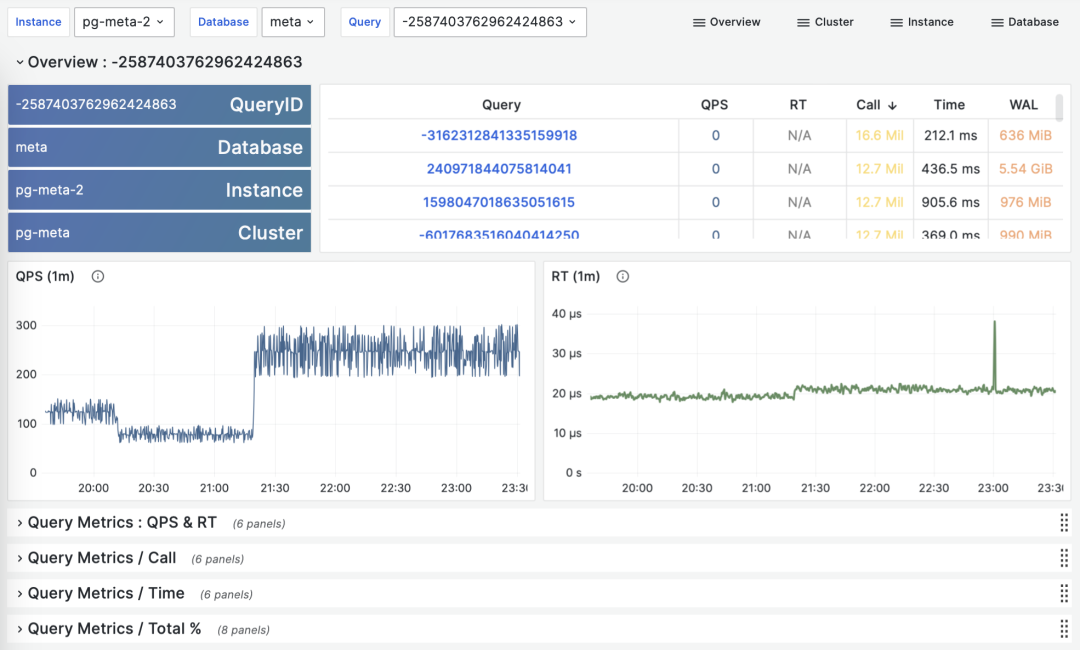
Calculating historical time-series metrics based on multiple PGSS query group snapshots
Fortunately, tools like Pigsty monitoring system regularly (default every 10s) capture snapshots of top queries (Top256 by execution time). With many different types of cumulative metrics (Metrics) at different time points, we can calculate three important derived metrics for any cumulative metric:
dM/dt: The time derivative of metric M, i.e., the increment per second.
dM/dc: The derivative of metric M with respect to call count, i.e., the average increment per call.
%M: The percentage of metric M in the entire workload.
These three types of metrics correspond exactly to the three objectives of macro optimization. The time derivative dM/dt reveals resource usage per second, typically used for the objective of reducing resource consumption. The call derivative dM/dc reveals resource usage per call, typically used for the objective of improving user experience. The percentage metric %M shows the proportion of a query group in the entire workload, typically used for the objective of balancing workload.
Time Derivatives
Let’s first look at the first type of metric: time derivatives. Here, we can use metrics M including: calls, total_exec_time, rows, wal_bytes, shared_blks_hit + shared_blks_read, and blk_read_time + blk_write_time. Other metrics are also valuable references, but let’s start with the most important ones.
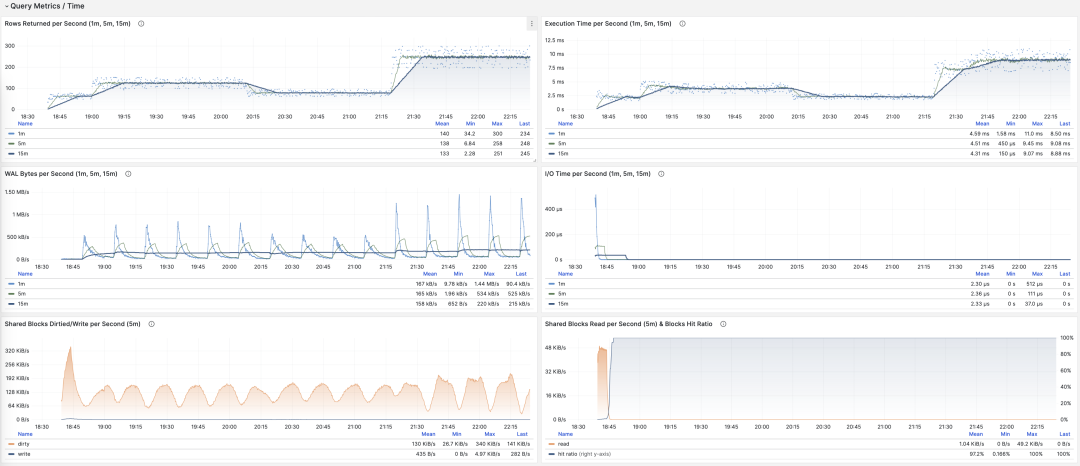
Visualization of time derivative metrics dM/dt
The calculation of these metrics is quite simple:
- First, calculate the difference in metric value M between two snapshots: M2 - M1
- Then, calculate the time difference between two snapshots: t2 - t1
- Finally, calculate (M2 - M1) / (t2 - t1)
Production environments typically use sampling intervals of 5s, 10s, 15s, 30s, 60s. For workload analysis, 1m, 5m, 15m are commonly used as analysis window sizes.
For example, when calculating QPS, we calculate QPS for the last 1 minute, 5 minutes, and 15 minutes respectively. Longer windows result in smoother curves, better reflecting long-term trends; but they hide short-term fluctuation details, making it harder to detect instant anomalies. Therefore, metrics of different granularities need to be considered together.
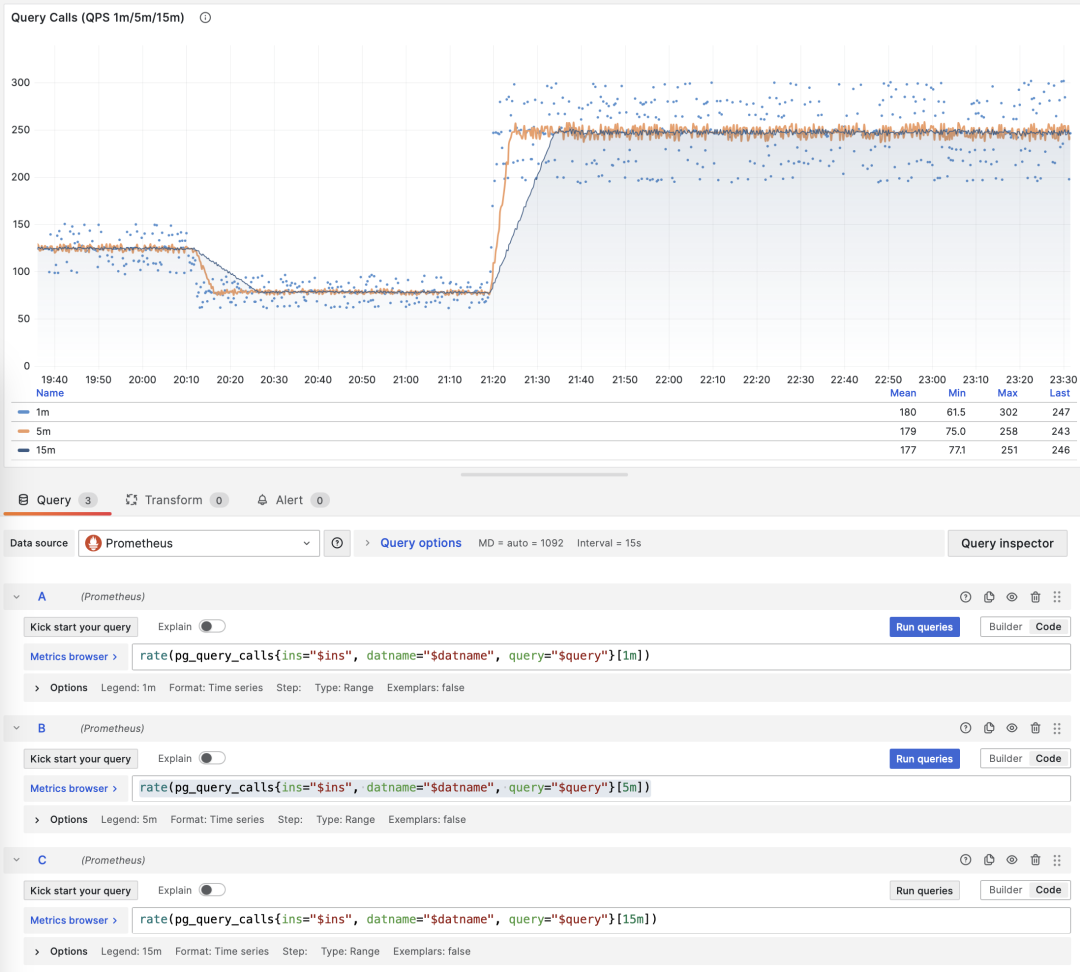
Showing QPS for a specific query group in 1/5/15 minute windows
If you use Pigsty / Prometheus to collect monitoring data, you can easily perform these calculations using PromQL. For example, to calculate the QPS metric for all queries in the last minute, you can use: rate(pg_query_calls{}[1m])
QPS
When M is calls, the time derivative is QPS, with units of queries per second (req/s). This is a very fundamental metric. Query QPS is a throughput metric that directly reflects the load imposed by the business. If a query’s throughput is too high (e.g., 10000+) or too low (e.g., 1-), it might be worth attention.
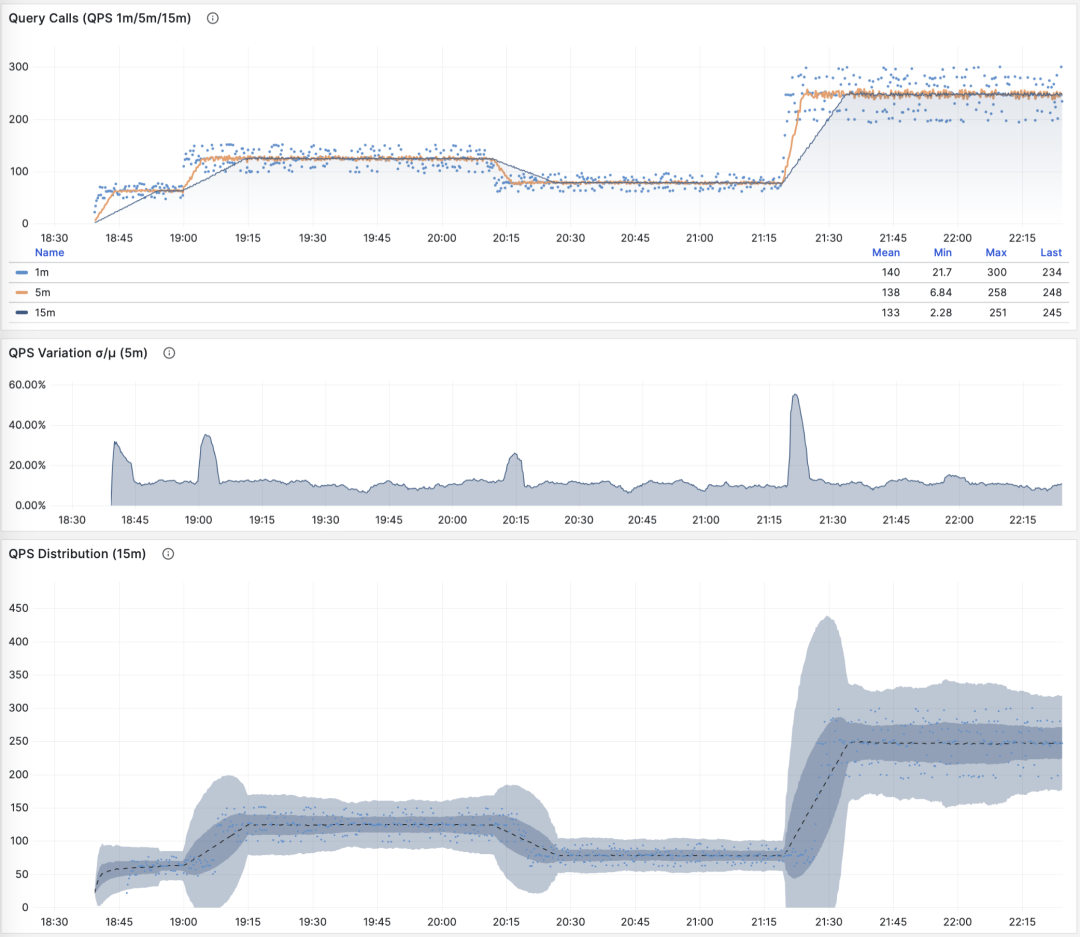
QPS: 1/5/15 minute µ/CV, ±1/3σ distribution
If we sum up the QPS metrics of all query groups (and haven’t exceeded PGSS’s collection range), we get the so-called “global QPS”. Another way to obtain global QPS is through client-side instrumentation, collection at connection pool middleware like Pgbouncer, or using ebpf probes. But none are as convenient as PGSS.
Note that QPS metrics don’t have horizontal comparability in terms of load. Different query groups may have the same QPS, while individual query execution times may vary dramatically. Even the same query group may produce vastly different load levels at different time points due to execution plan changes. Execution time per second is a better metric for measuring load.
Execution Time Per Second
When M is total_exec_time (+ total_plan_time, optional), we get one of the most important metrics in macro optimization: execution time spent on the query group. Interestingly, the units of this derivative are seconds per second, so the numerator and denominator cancel out, making it actually a dimensionless metric.
This metric’s meaning is: how many seconds per second the server spends processing queries in this group. For example, 2 s/s means the server spends two seconds of execution time per second on this group of queries; for multi-core CPUs, this is certainly possible: just use all the time of two CPU cores.
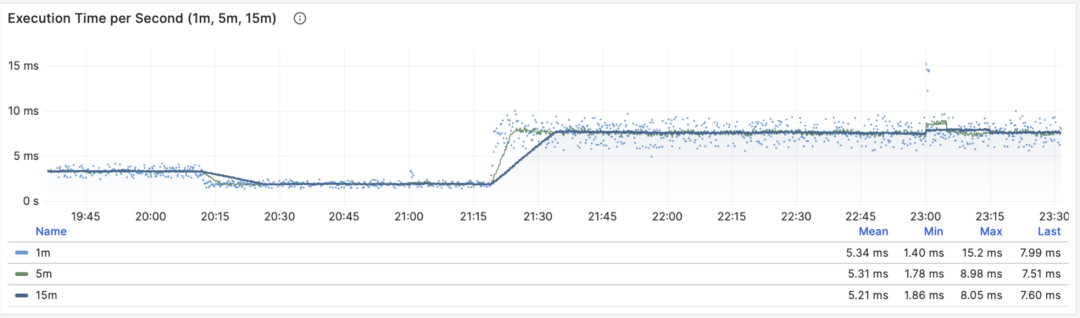
Execution time per second: 1/5/15 minute mean
Therefore, this value can also be understood as a percentage: it can exceed 100%. From this perspective, it’s a metric similar to host load1, load5, load15, revealing the load level produced by this query group. If divided by the number of CPU cores, we can even get a normalized query load contribution metric.
However, we need to note that execution time includes time spent waiting for locks and I/O. So it’s indeed possible that a query has a long execution time but doesn’t impact CPU load. Therefore, for detailed analysis of slow queries, we need to further analyze with reference to wait events.
Rows Per Second
When M is rows, we get the number of rows returned per second by this query group, with units of rows per second (rows/s). For example, 10000 rows/s means this type of query returns 10,000 rows of data to the client per second. Returned rows consume client processing resources, making this a very valuable reference metric when we need to examine application client data processing pressure.
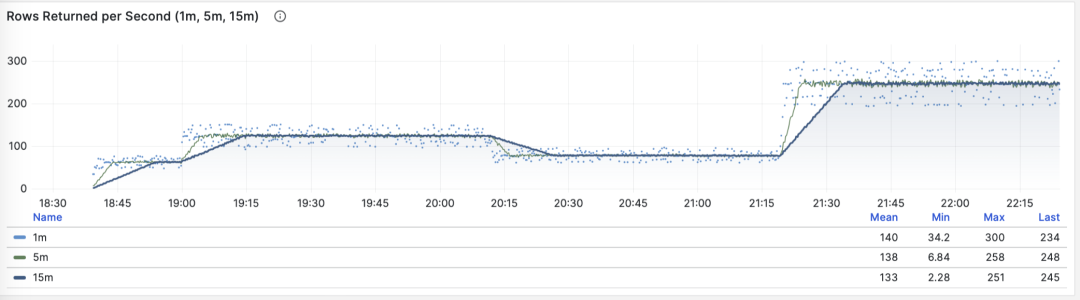
Rows returned per second: 1/5/15 minute mean
Shared Buffer Access Bandwidth
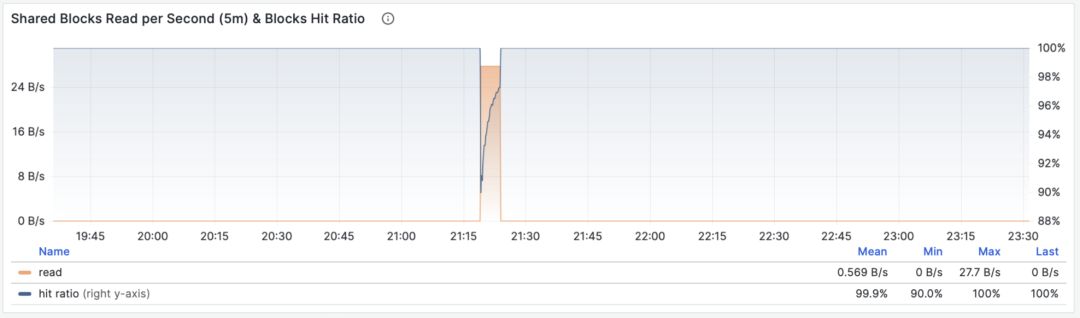
When M is shared_blks_hit + shared_blks_read, we get the number of shared buffer blocks hit/read per second. If we multiply this by the default block size of 8KiB (rarely might be other sizes, e.g., 32KiB), we get the bandwidth of a query type “accessing” memory/disk: units are bytes per second.
For example, if a certain query type accesses 500,000 shared buffer blocks per second, equivalent to 3.8 GiB/s of internal access data flow: then this is a significant load, and might be a good candidate for optimization. You should probably check this query to see if it deserves these “resource consumption”.
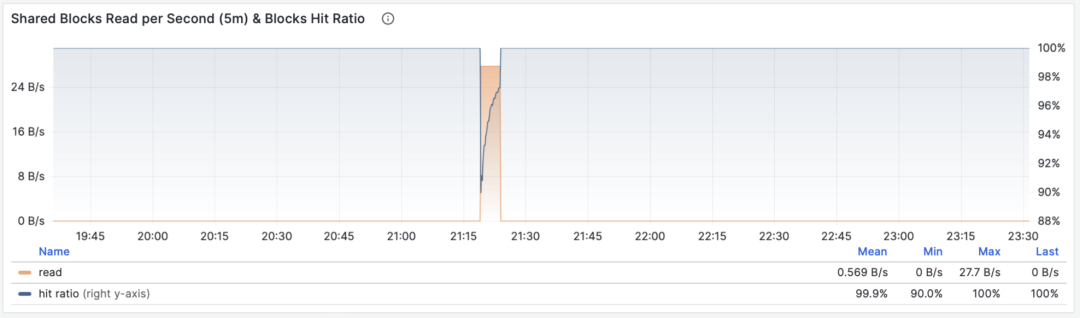
Shared buffer access bandwidth and buffer hit rate
Another valuable derived metric is buffer hit rate: hit / (hit + read), which can be used to analyze possible causes of performance changes — cache misses. Of course, repeated access to the same shared buffer pool block doesn’t actually result in a new read, and even if it does read, it might not be from disk but from memory in FS Cache. So this is just a reference value, but it is indeed a very important macro query optimization reference metric.
WAL Log Volume
When M is wal_bytes, we get the rate at which this query generates WAL, with units of bytes per second (B/s). This metric was newly introduced in PostgreSQL 13 and can be used to quantitatively reveal the WAL size generated by queries: the more and faster WAL is written, the greater the pressure on disk flushing, physical/logical replication, and log archiving.
A typical example is: BEGIN; DELETE FROM xxx; ROLLBACK;. Such a transaction deletes a lot of data, generates a large amount of WAL, but performs no useful work. This metric can help identify such cases.
WAL bytes per second: 1/5/15 minute mean
There are two things to note here: As mentioned above, PGSS cannot track failed statements, but here the transaction was ROLLBACKed, but the statements were successfully executed, so they are tracked by PGSS.
The second thing is: in PostgreSQL, not only INSERT/UPDATE/DELETE operations generate WAL logs, SELECT operations might also generate WAL logs, because SELECT might modify tuple marks (Hint Bit) causing page checksums to change, triggering WAL log writes.
There’s even the possibility that if the read load is very large, it might have a higher probability of causing FPI image generation, producing considerable WAL log volume. You can check this further through the wal_fpi metric.
Shared buffer dirty/write-back bandwidth
For versions below 13, shared buffer dirty/write-back bandwidth metrics can serve as approximate alternatives for analyzing write load characteristics of query groups.
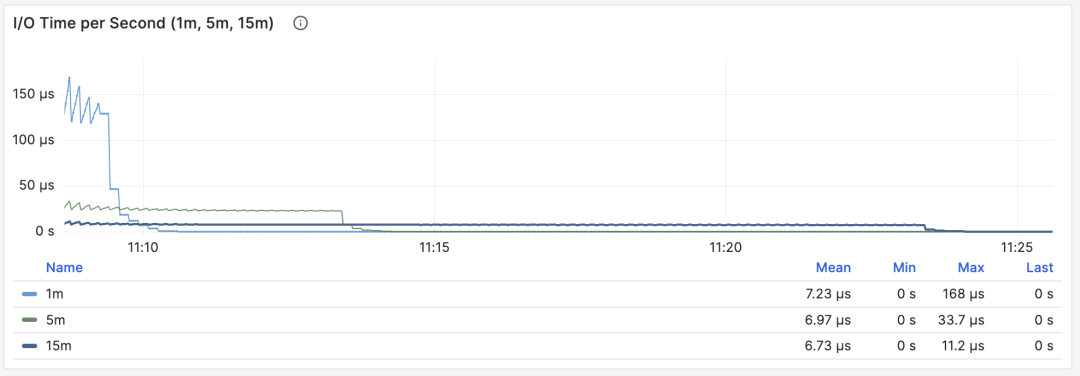
I/O Time
When M is blks_read_time + blks_write_time, we get the proportion of time spent on block I/O by the query group, with units of “seconds per second”, same as the execution time per second metric, it also reflects the proportion of time occupied by such operations.
I/O time is helpful for analyzing query spike causes
Because PostgreSQL uses the operating system’s FS Cache, even if block reads/writes are performed here, they might still be buffer operations at the filesystem level. So this can only be used as a reference metric, requiring careful use and comparison with disk I/O monitoring on the host node.
Time derivative metrics dM/dt can reveal the complete picture of workload within a database instance/cluster, especially useful for scenarios aiming to optimize resource usage. But if your optimization goal is to improve user experience, then another set of metrics — call derivatives dM/dc — might be more relevant.
Call Derivatives
Above we’ve calculated time derivatives for six important metrics. Another type of derived metric calculates derivatives with respect to “call count”, where the denominator changes from time difference to QPS.
This type of metric is even more important than the former, as it provides several core metrics directly related to user experience, such as the most important — Query Response Time (RT), or Latency.
The calculation of these metrics is also simple:
- Calculate the difference in metric value M between two snapshots: M2 - M1
- Then calculate the difference in calls between two snapshots: c2 - c1
- Finally calculate (M2 - M1) / (c2 - c1)
For PromQL implementation, call derivative metrics dM/dc can be calculated from “time derivative metrics dM/dt”. For example, to calculate RT, you can use execution time per second / queries per second, dividing the two metrics:
rate(pg_query_exec_time{}[1m]) / rate(pg_query_calls{}[1m])
dM/dt can be used to calculate dM/dc
Call Count
When M is calls, taking its own derivative is meaningless (result will always be 1).
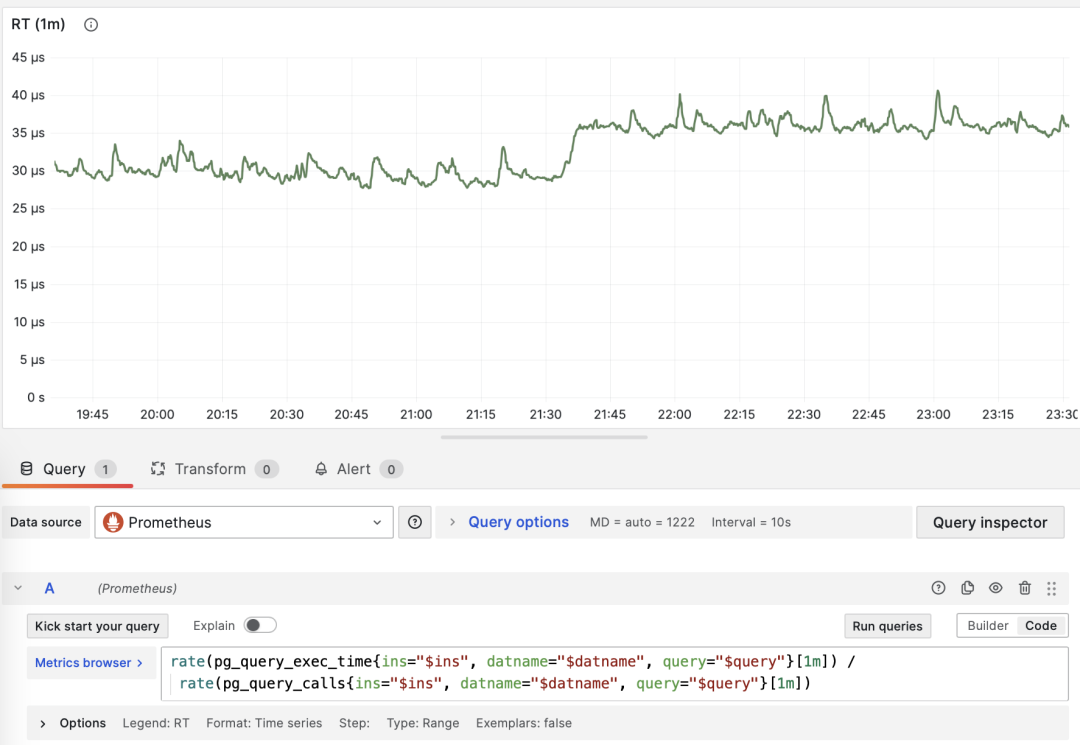
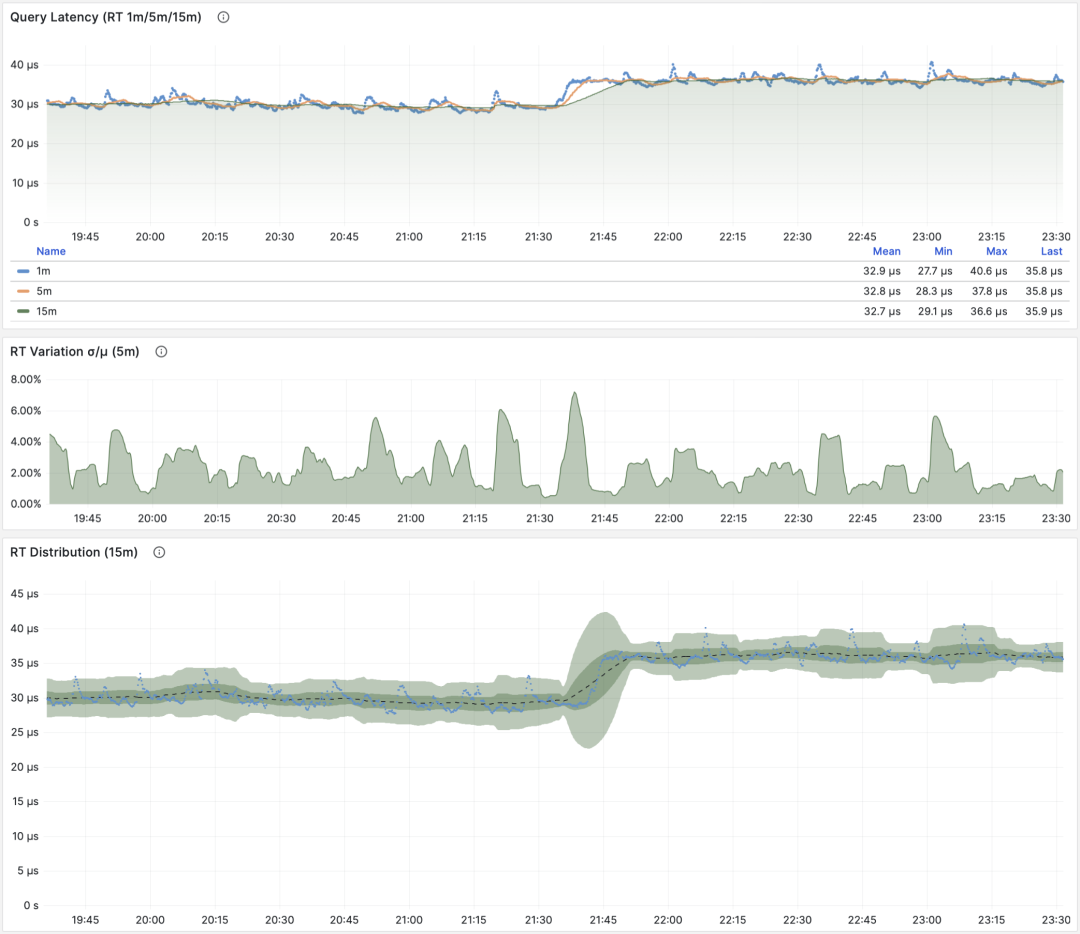
Average Latency/Response Time/RT
When M is total_exec_time, the call derivative is RT, or response time/latency. Its unit is seconds (s). RT directly reflects user experience and is the most important metric in macro performance analysis. This metric’s meaning is: the average query response time of this query group on the server. If conditions allow enabling pg_stat_statements.track_planning, you can also add total_plan_time to the calculation for more precise and representative results.
RT: statement level/connection pool level/database level
Unlike throughput metrics like QPS, RT has horizontal comparability: for example, if a query group’s RT is normally within 1 millisecond, then events exceeding 10ms should be considered serious deviations for analysis.
When failures occur, RT views are also helpful for root cause analysis: if all queries’ overall RT slows down, it’s most likely related to insufficient resources. If only specific query groups’ RT changes, it’s more likely that some slow queries are causing problems and should be further investigated. If RT changes coincide with application deployment, you should consider rolling back these deployments.
Moreover, in performance analysis, stress testing, and benchmarking, RT is the most important metric. You can evaluate system performance by comparing typical queries’ latency performance in different environments (e.g., different PG versions, hardware, configuration parameters) and use this as a basis for continuous system performance adjustment and improvement.
RT is so important that RT itself spawns many downstream metrics: 1-minute/5-minute/15-minute means µ and standard deviations σ are naturally essential; past 15 minutes’ ±σ, ±3σ can be used to measure RT fluctuation range, and past 1 hour’s 95th, 99th percentiles are also valuable references.
RT is the core metric for evaluating OLTP workloads, and its importance cannot be overemphasized.
Average Rows Returned
When M is rows, we get the average rows returned per query, with units of rows per query. For OLTP workloads, typical query patterns are point queries, returning a few rows of data per query.
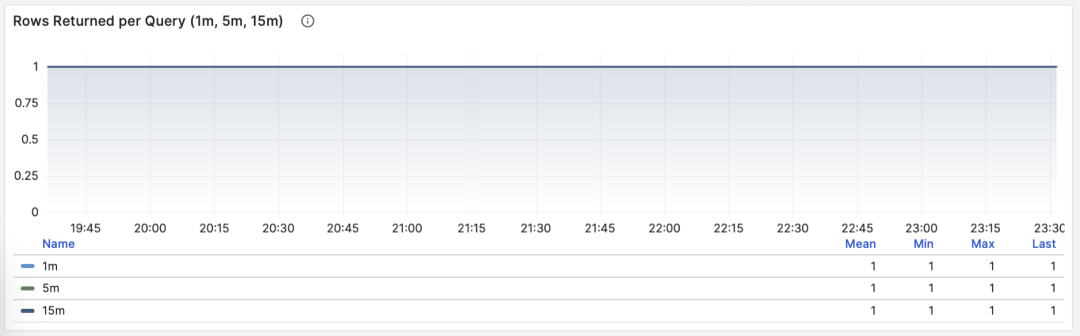
Querying single record by primary key, average rows returned stable at 1
If a query group returns hundreds or even thousands of rows to the client per query, it should be examined. If this is by design, like batch loading tasks/data dumps, then no action is needed. If this is initiated by the application/client, there might be errors, such as statements missing LIMIT restrictions, queries lacking pagination design. Such queries should be adjusted and fixed.
Average Shared Buffer Reads/Hits
When M is shared_blks_hit + shared_blks_read, we get the average number of shared buffer “hits” and “reads” per query. If we multiply this by the default block size of 8KiB, we get this query type’s “bandwidth” per execution, with units of B/s: how many MB of data does each query access/read on average?
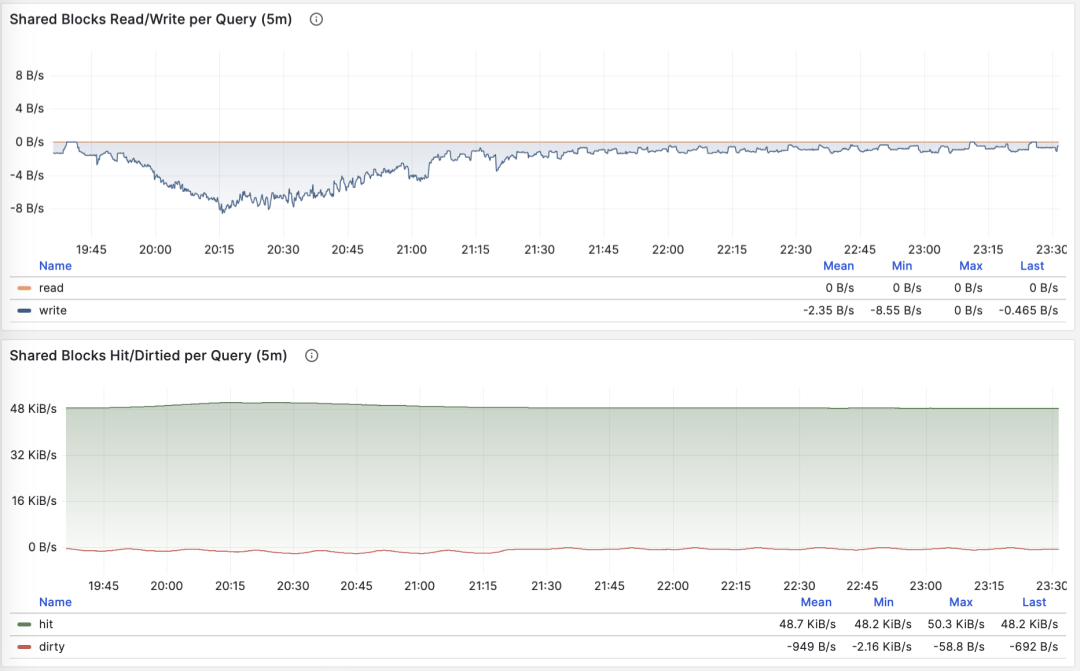
Querying single record by primary key, average rows returned stable at 1
The average data accessed by a query typically matches the average rows returned. If your query returns only a few rows on average but accesses megabytes or gigabytes of data blocks, you need to pay special attention: such queries are very sensitive to data hot/cold state. If all blocks are in the buffer, its performance might be acceptable, but if starting cold from disk, execution time might change dramatically.
Of course, don’t forget PostgreSQL’s double caching issue. The so-called “read” data might have already been cached once at the operating system filesystem level. So you need to cross-reference with operating system monitoring metrics, or system views like pg_stat_kcache, pg_stat_io for analysis.
Another pattern worth attention is sudden changes in this metric, which usually means the query group’s execution plan might have flipped/degraded, very worthy of attention and further research.
Average WAL Log Volume
When M is wal_bytes, we get the average WAL size generated per query, a field newly introduced in PostgreSQL 13. This metric can measure a query’s change footprint size and calculate important evaluation parameters like read/write ratios.
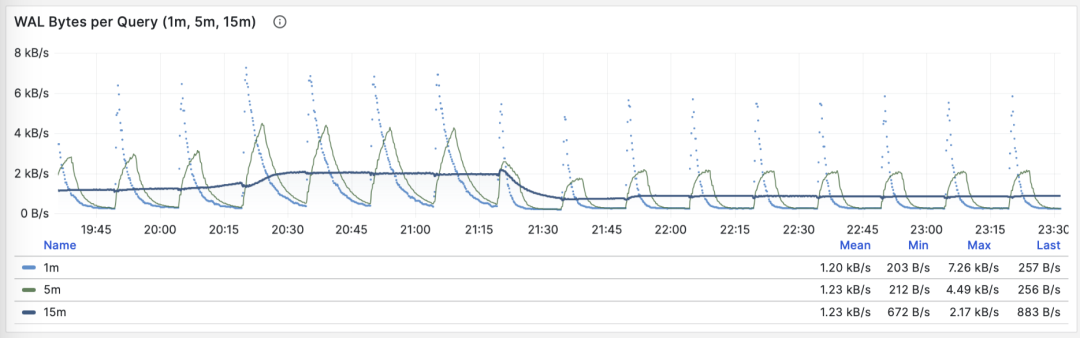
Stable QPS with periodic WAL fluctuations, can infer FPI influence
Another use is optimizing checkpoints/Checkpoint: if you observe periodic fluctuations in this metric (period approximately equal to checkpoint_timeout), you can optimize the amount of WAL generated by queries by adjusting checkpoint spacing.
Call derivative metrics dM/dc can reveal a query type’s workload characteristics, very useful for optimizing user experience. Especially RT is the golden metric for performance optimization, and its importance cannot be overemphasized.
dM/dc metrics provide us with important absolute value metrics, but to find which queries have the greatest potential optimization benefits, we also need %M percentage metrics.
Percentage Metrics
Now let’s examine the third type of metric, percentage metrics. These show the proportion of a query group relative to the overall workload.
Percentage metrics M% provide us with a query group’s proportion relative to the overall workload, helping us identify “major contributors” in terms of frequency, time, I/O time/count, and find query groups with the greatest potential optimization benefits as important criteria for priority assessment.
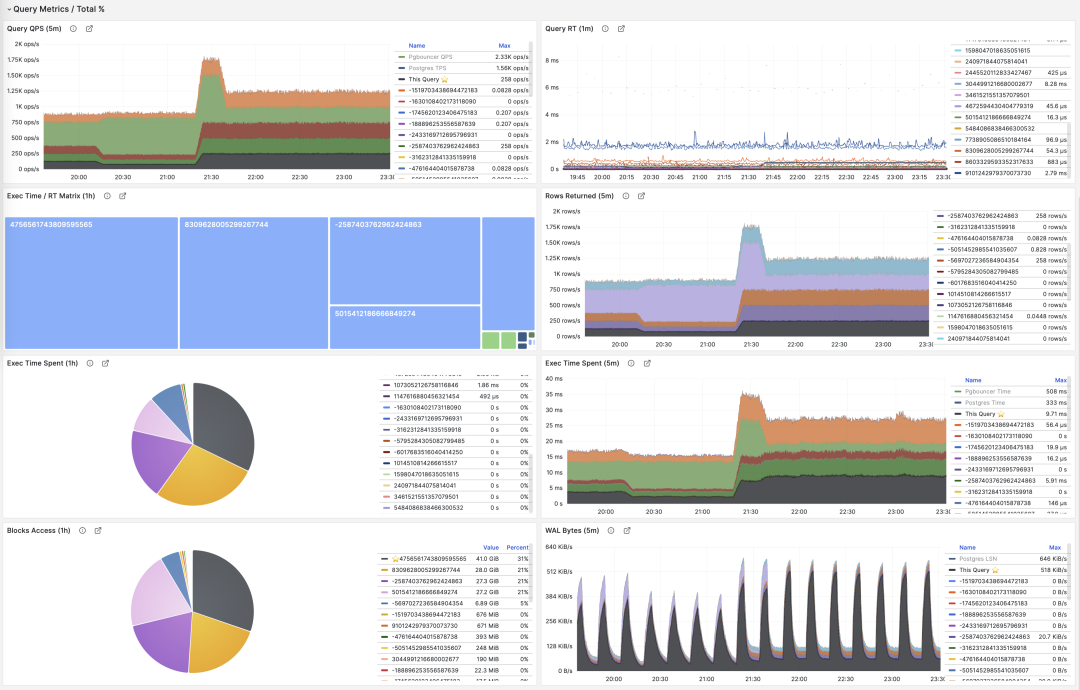
Common percentage metrics %M overview
For example, if a query group has an absolute value of 1000 QPS, it might seem significant; but if it only accounts for 3% of the entire workload, then the benefits and priority of optimizing this query aren’t that high. Conversely, if it accounts for more than 50% of the entire workload — if you can optimize it, you can cut the instance’s throughput in half, making its optimization priority very high.
A common optimization strategy is: first sort all query groups by the important metrics mentioned above: calls, total_exec_time, rows, wal_bytes, shared_blks_hit + shared_blks_read, and blk_read_time + blk_write_time over a period of time’s dM/dt values, take TopN (e.g., N=10 or more), and add them to the optimization candidate list.
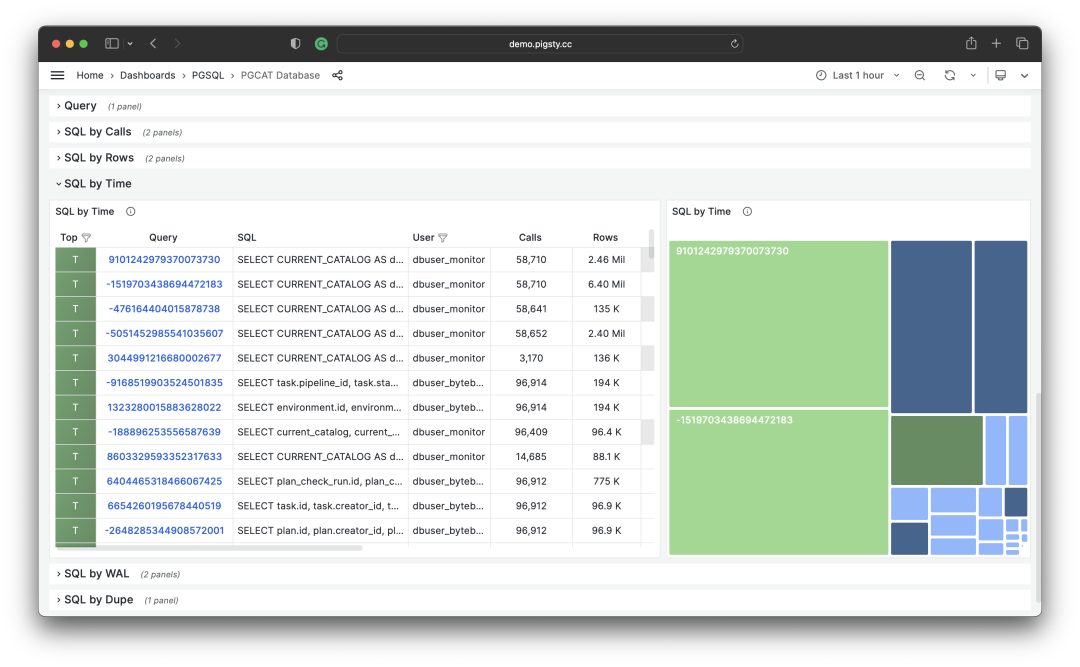
Selecting TopSQL for optimization based on specific criteria
Then, for each query group in the optimization candidate list, analyze its dM/dc metrics, combine with specific query statements and slow query logs/wait events for analysis, and decide if this is a query worth optimizing. For queries decided (Plan) to optimize, you can use the techniques to be introduced in the subsequent “Micro Optimization” article for tuning (Do), and use the monitoring system to evaluate optimization effects (Check). After summarizing and analyzing, enter the next PDCA Deming cycle, continuously managing and optimizing.
Besides taking TopN of metrics, visualization can also be used. Visualization is very helpful for identifying “major contributors” from the workload. Complex judgment algorithms might be far inferior to human DBAs’ intuition about monitoring graph patterns. To form a sense of proportion, we can use pie charts, tree maps, or stacked time series charts.
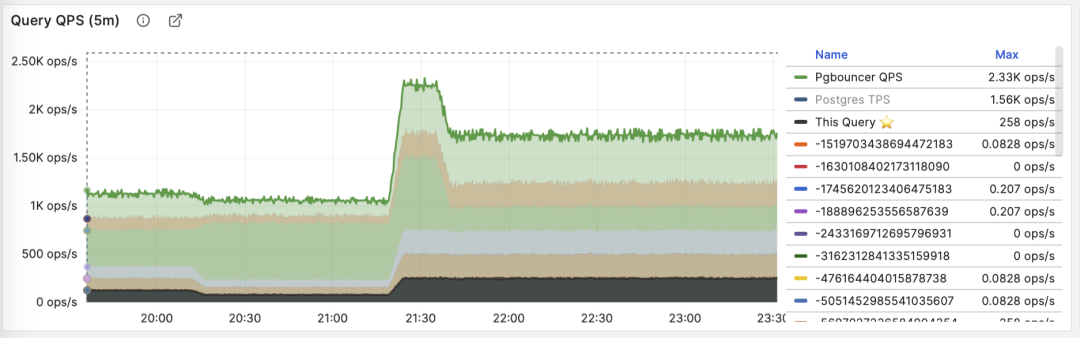
Stacking QPS of all query groups
For example, we can use pie charts to identify queries with the highest time/IO usage in the past hour, use 2D tree maps (size representing total time, color representing average RT) to show an additional dimension, and use stacked time series charts to show proportion changes over time.
We can also directly analyze the current PGSS snapshot, sort by different concerns, and select queries that need optimization according to your own criteria.
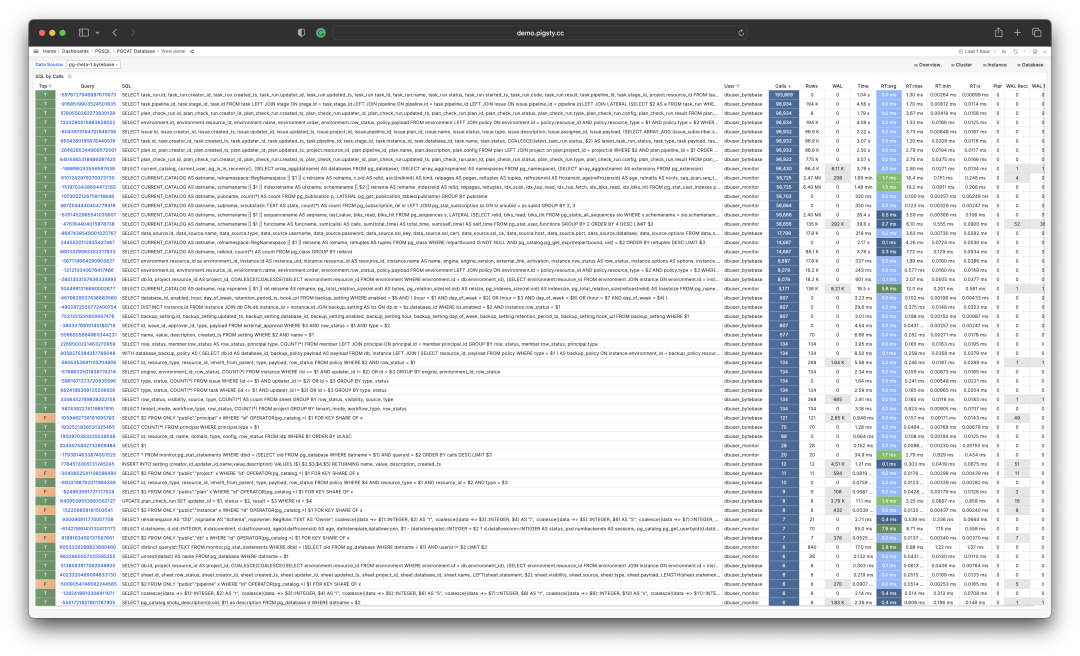
I/O time is helpful for analyzing query spike causes
Summary
Finally, let’s summarize the above content.
PGSS provides rich metrics, among which the most important cumulative metrics can be processed in three ways:
dM/dt: The time derivative of metric M, revealing resource usage per second, typically used for the objective of reducing resource consumption.
dM/dc: The call derivative of metric M, revealing resource usage per call, typically used for the objective of improving user experience.
%M: Percentage metrics showing a query group’s proportion in the entire workload, typically used for the objective of balancing workload.
Typically, we select high-value candidate queries for optimization based on %M: percentage metrics Top queries, and use dM/dt and dM/dc metrics for further evaluation, confirming if there’s optimization space and feasibility, and evaluating optimization effects. Repeat this process continuously.
After understanding the methodology of macro optimization, we can use this approach to locate and optimize slow queries. Here’s a concrete example of Using Monitoring System to Diagnose PG Slow Queries. In the next article, we’ll introduce experience and techniques for PostgreSQL query micro optimization.
References
[1] PostgreSQL HowTO: pg_stat_statements by Nikolay Samokhvalov
[3] Using Monitoring System to Diagnose PG Slow Queries
[4] How to Monitor Existing PostgreSQL (RDS/PolarDB/On-prem) with Pigsty?
[5] Pigsty v2.5 Released: Ubuntu/Debian Support & Monitoring Revamp/New Extensions