This is the multi-page printable view of this section. Click here to print.
Pigsty Blog
- Database
- Scaling Postgres to the next level at OpenAI
- Database Planet Collision: When PG Falls for DuckDB
- Self-Hosting Supabase on PostgreSQL
- MySQL is dead, Long live PostgreSQL!
- MySQL's Terrible ACID
- Database in K8S: Pros & Cons
- NewSQL: Distributive Nonsens
- Is running postgres in docker a good idea?
- Cloud Exit
- S3: Elite to Mediocre
- Reclaim Hardware Bonus from the Cloud
- FinOps: Endgame Cloud-Exit
- SLA: Placebo or Insurance?
- EBS: Pig Slaughter Scam
- RDS: The Idiot Tax
- Postgres
- pg_exporter v1.0.0 Released – Next-Level PostgreSQL Observability
- OrioleDB is Here! 4x Performance, Zero Bloat, Decoupled Storage
- OpenHalo: PostgreSQL Now Speaks MySQL Wire Protocol!
- PGFS: Using PostgreSQL as a File System
- PostgreSQL Frontier
- Pig, The PostgreSQL Extension Wizard
- Don't Update! Rollback Issued on Release Day: PostgreSQL Faces a Major Setback
- PostgreSQL 12 Reaches End-of-Life as PG 17 Takes the Throne
- The idea way to install PostgreSQL Extensions
- PostgreSQL 17 Released: The Database That's Not Just Playing Anymore!
- Can PostgreSQL Replace Microsoft SQL Server?
- Whoever Integrates DuckDB Best Wins the OLAP World
- StackOverflow 2024 Survey: PostgreSQL Is Dominating the Field
- Self-Hosting Dify with PG, PGVector, and Pigsty
- PGCon.Dev 2024, The conf that shutdown PG for a week
- Postgres is eating the database world
- Technical Minimalism: Just Use PostgreSQL for Everything
- ParadeDB: ElasticSearch Alternative in PG Ecosystem
- The Astonishing Scalability of PostgreSQL
- PostgreSQL Crowned Database of the Year 2024!
- PostgreSQL Convention 2024
- FerretDB: When PG Masquerades as MongoDB
- PostgreSQL, The most successful database
- How Powerful Is PostgreSQL?
- Why Is PostgreSQL the Most Successful Database?
- Pigsty: The Production-Ready PostgreSQL Distribution
- Why PostgreSQL Has a Bright Future
- What Makes PostgreSQL So Awesome?
- PG Admin
- PG Logical Replication Explained
- Query Optimization: The Macro Approach with pg_stat_statements
- Rescue Data with pg_filedump?
- Collation in PostgreSQL
- PostgreSQL Replica Identity Explained
- Slow Query Diagnosis
- Releases
- v3.4: MySQL Wire-Compatibility and Improvements
- v3.3:Extension 404,Odoo, Dify, Supabase, Nginx Enhancement
- v3.2: The pig CLI, ARM64 Repo, Self-hosting Supabase
- v3.1: PG 17 as default, Better Supabase & MinIO, ARM & U24 support
- Pigsty v3.0: Extension Exploding & Plugable Kernels
- v2.7: Extension Overwhelming
- v2.6: the OLAP New Challenger
- v2.5: Debian / Ubuntu / PG16
- v2.4: Monitoring Cloud RDS
- v2.3: Ecosystem Applications
- v2.2: Observability Overhaul
- v2.1: Vector Embedding & RAG
- v2.0: Free RDS PG Alternative
- v1.5.0 Release Note
- v1.4.0 Release Note
- v1.3.0 Release Note
- v1.2.0 Release Note
- v1.1.0 Release Note
- v1.0.0 Release Note
- v0.9.0 Release Note
- v0.8.0 Release Note
- v0.7.0 Release Note
- v0.6.0 Release Note
- v0.5.0 Release Note
- v0.4.0 Release Note
- v0.3.0 Release Note
Database
Scaling Postgres to the next level at OpenAI
At PGConf.Dev 2025, Bohan Zhang from OpenAI shared a session titled Scaling Postgres to the next level at OpenAI, giving us a peek into the database usage of a top-tier unicorn.
“At OpenAl, we’ve proven that PostgreSQL can scale to support massive read-heavy workloads - even without sharding - using a single primary writer”
—— Bohan Zhang from OpenAI, PGConf.Dev 2025

Bohan Zhang is a member of the OpenAI Infra team, student of Andy Pavlo, and co-found OtterTune with him.
This article is based on Bohan’s presentation at the conference. with chinese translation/commentary by Ruohang Feng (Vonng): Author of Pigsty. The original chinese version is available on WeChat Column and Pigsty CN Blog.
Hacker News Discussion: OpenAI: Scaling Postgres to the Next Level
Background
Postgres is the backbone of our most critical systems at OpenAl. If Postgres goes down, many of OpenAI’s key features go down with it — and there’s plenty of precedent for this. PostgreSQL-related failures have caused several ChatGPT outages in the past.

OpenAI uses managed PostgreSQL databases on Azure, without sharding. Instead, they employ a classic primary-replica replication architecture with one primary and over dozens of read replicas. For a service with several hundred million active users like OpenAI, scalability is a major concern.
Challenges
In OpenAI’s PostgreSQL architecture, read scalability is excellent, but “write requests” have become the primary bottleneck. OpenAI has already made many optimizations here, such as offloading write workloads wherever possible and avoiding placing new business logic into the main database.

PostgreSQL’s MVCC design has some known issues, such as table and index bloat. Tuning autovacuum is complex, and every write generates a completely new version of a row. Index access might also require additional heap fetches for visibility checks. These design choices create challenges for scaling read replicas: for instance, more WAL typically leads to greater replication lag, and as the number of replicas grows, network bandwidth can become the new bottleneck.
Measures
To tackle these issues, we’ve made efforts on multiple fronts:
Reduce Load on Primary
The first optimization is to smooth out write spikes on the primary and minimize its load as much as possible, for example:
- Offloading all possible writes.
- Avoiding unnecessary writes at the application level.
- Using lazy writes to smooth out write bursts.
- Controlling the rate of data backfilling.
Additionally, OpenAI offloads as many read requests as possible to replicas. The few read requests that cannot be moved from the primary because they are part of read-write transactions are required to be as efficient as possible.

Query Optimization
The second area is query-level optimization. Since long-running transactions can block garbage collection and consume resources, they use timeout settings to prevent long “idle in transaction” states and set session, statement, and client-level timeouts. They also optimized some multi-way JOIN queries (e.g., joining 12 tables at once). The talk specifically mentioned that using ORMs can easily lead to inefficient queries and should be used with caution.

Mitigating Single Points of Failure
The primary is a single point of failure; if it goes down, writes are blocked. In contrast, we have many read-only replicas. If one fails, applications can still read from others. In fact, many critical requests are read-only, so even if the primary goes down, they can continue to serve reads.
Furthermore, we’ve distinguished between low-priority and high-priority requests. For high-priority requests, OpenAI allocates dedicated read-only replicas to prevent them from being impacted by low-priority ones.

Schema Management
The fourth measure is to allow only lightweight schema changes on this cluster. This means:
- Creating new tables or adding new workloads to it is not allowed.
- Adding or removing columns is allowed (with a 5-second timeout), but any operation that requires a full table rewrite is forbidden.
- Creating or removing indexes is allowed, but must be done using
CONCURRENTLY.
Another issue mentioned was that persistent long-running queries (>1s) would continuously block schema changes, eventually causing them to fail. The solution was to have the application optimize or move these slow queries to replicas.

Results
- Scaled PostgreSQL on Azure to millions of QPS, supporting OpenAI’s critical services.
- Added dozens of replicas without increasing replication lag.
- Deployed read-only replicas to different geographical regions while maintaining low latency.
- Only one SEV0 incident related to PostgreSQL in the past nine months.
- Still have plenty of room for future growth.

“At OpenAl, we’ve proven that PostgreSQL can scale to support massive read-heavy workloads - even without sharding - using a single primary writer”
Case Studies
OpenAI also shared a few case studies of failures they’ve faced. The first was a cascading failure caused by a redis outage.

The second incident was more interesting: extremely high CPU usage triggered a bug where the WALSender process kept spin-looping instead of sending WAL to replicas, even after CPU levels returned to normal. This led to increased replication lag.

Feature Suggestions
Finally, Bohan raised some questions and feature suggestions to the PostgreSQL developer community:
First, regarding disabling indexes. Unused indexes cause write amplification and extra maintenance overhead. They want to remove useless indexes, but to minimize risk, they wish for a feature to “disable” an index. This would allow them to monitor performance metrics to ensure everything is fine before actually dropping it.

Second is about RT observability. Currently, pg_stat_statement only provides the average response time for each query type, but doesn’t directly offer latency metrics like p95 or p99. They hope for more histogram-like and percentile latency metrics.

The third point is about schema changes. They want PostgreSQL to record a history of schema change events, such as adding/removing columns and other DDL operations.

The fourth case is about the semantics of monitoring views. They found a session with state = 'active' and wait_event = 'ClientRead' that lasted for over two hours. This means a connection remained active long after query_start, and such connections can’t be killed by the idle_in_transaction_timeout. They wanted to know if this is a bug and how to resolve it.

Finally, a suggestion for optimizing PostgreSQL’s default parameters. The default values are too conservative. Could better defaults be used, or perhaps a heuristic-based configuration rule?
Vonng’s Commentary
Although PGConf.Dev 2025 is primarily focused on development, you often see use case presentations from users, like this one from OpenAI on their PostgreSQL scaling practices. These topics are actually quite interesting for core developers, as many of them don’t have a clear picture of how PostgreSQL is used in extreme scenarios, and these talks are very helpful.

Since late 2017, I managed dozens of PostgreSQL clusters at Tantan, which was one of the largest and most complex PG deployments in the Chinese internet scene: dozens of PG clusters with around 2.5 million QPS. Back then, our largest core primary had a 1-primary-33-replica setup, with a single cluster handling around 400K QPS. The bottleneck was also on single-database writes, which we eventually solved with application-side sharding, similar to Instagram’s approach.
You could say I’ve encountered all the problems and used all the solutions OpenAI mentioned in their talk. Of course, the difference is that today’s top-tier hardware is orders of magnitude better than it was eight years ago. This allows a startup like OpenAI to serve its entire business with a single PostgreSQL cluster without sharding. This is undoubtedly another powerful piece of evidence for the argument that “Distributed Databases Are a False Need”.
During the Q&A, I learned that OpenAI uses managed PostgreSQL on Azure with the highest available server hardware specs. They have dozens of replicas, including some in different geographical regions, and this behemoth cluster handles a total of about millions QPS. They use Datadog for monitoring, and the services access the RDS cluster from Kubernetes through a business-side PgBouncer connection pool.
As a strategic customer, the Azure PostgreSQL team provides them with dedicated support. But it’s clear that even with top-tier cloud database services, the customer needs to have sufficient knowledge and skill on the application and operations side. Even with the brainpower of OpenAI, they still stumble on some of the practical driving lessons of PostgreSQL.
During the social event after the conference, I had a great chat with Bohan and two other database founders until the wee hours. The off-the-record discussions were fascinating, but I can’t disclose more here, haha.

Vonng’s Q&A
Regarding the questions and feature requests Bohan raised, I can offer some answers here.
Most of the features OpenAI wants already exist in the PostgreSQL ecosystem, they just might not be available in the vanilla PG kernel or in a managed cloud database environment.
On Disabling Indexes
PostgreSQL actually has a “feature” to disable indexes. You just need to update the indisvalid field in the pg_index system catalog to false.
The planner will then stop using the index, but it will continue to be maintained during DML operations. In principle, there’s nothing wrong with this, as concurrent index creation uses these two flags (isready, isvalid). It’s not black magic.
However, I can understand why OpenAI can’t use this method: it’s an undocumented “internal detail” rather than a formal feature. But more importantly, cloud databases usually don’t grant superuser privileges, so you just can’t update the system catalog like this.
But back to the original need — fear of accidentally deleting an index.
There’s a simpler solution: just confirm from monitoring view (pg_stat_all_indexes) that the index isn’t being used on either the primary or the replicas.
If you know an index hasn’t been used for a long time, you can safely delete it.
Monitoring index switch with Pigsty PGSQL TABLES Dashboard
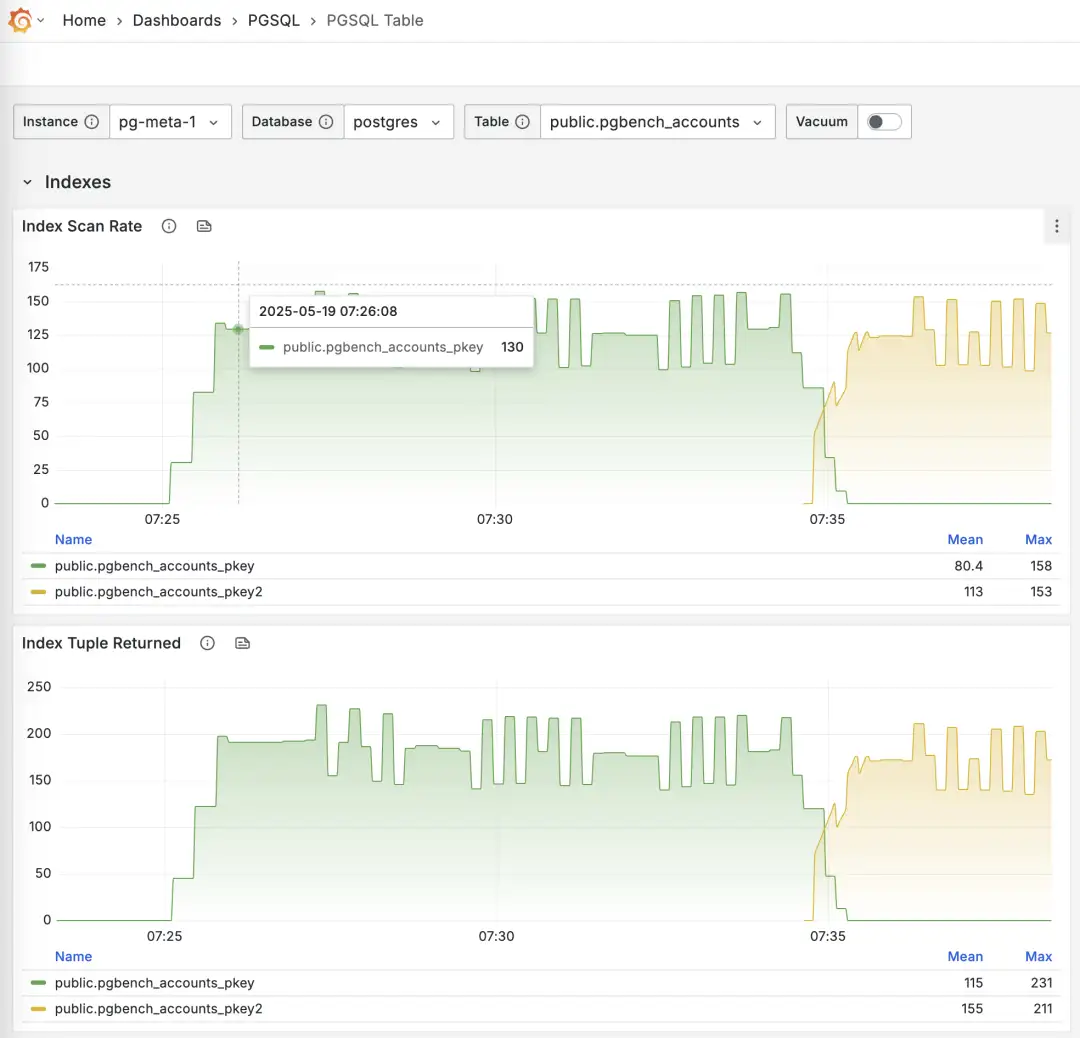
-- Create a new index
CREATE UNIQUE INDEX CONCURRENTLY pgbench_accounts_pkey2 ON pgbench_accounts USING BTREE(aid);
-- Mark the original index as invalid (not used), but still maintained. planner will not use it.
UPDATE pg_index SET indisvalid = false WHERE indexrelid = 'pgbench_accounts_pkey'::regclass;
On Observability
Actually, pg_stat_statements provides the mean and stddev metrics, which you can use with properties of the normal distribution to estimate percentile metrics.
But this is only a rough estimate, and you need to reset the counters periodically, otherwise the effectiveness of the full historical statistics will degrade over time.
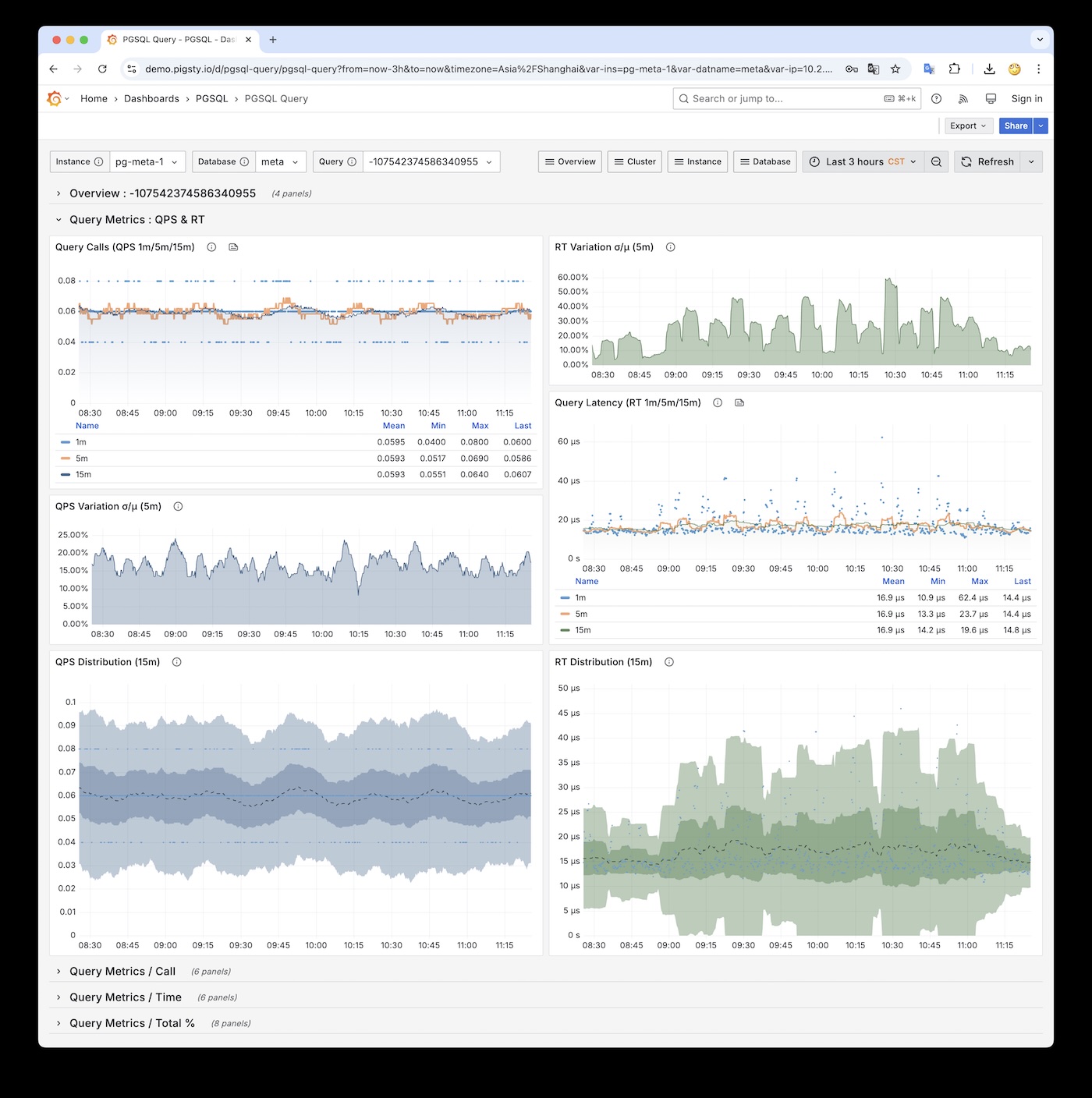
RT Distribution with PGSQL QUERY Dashboard from PGSS
PGSS is unlikely to provide P95, P99 RT percentile metrics anytime soon, because it would increase the extension’s memory footprint by several dozen times. While that’s not a big deal for modern servers, it could be an issue in extremely conservative environments. I asked the maintainer of PGSS about this at the Unconference, and it’s unlikely to happen in the short term. I also asked Jelte, the maintainer of Pgbouncer, if this could be solved at the connection pool level, and a feature like that is not coming soon either.
However, there are other solutions to this problem. First, the pg_stat_monitor extension explicitly provides detailed percentile RT metrics,
but you have to consider the performance impact of collecting these metrics on the cluster.
A universal, non-intrusive method with no database performance overhead is to add query RT monitoring directly at the application’s Data Access Layer (DAL), but this requires cooperation and effort from the application side.
Also, using eBPF for side-channel collection of RT metrics is a great idea, but considering they’re using managed PostgreSQL on Azure, they won’t have server access, so that path is likely blocked.
On Schema Change History
Actually, PostgreSQL’s logging already provides this option. You just need to set log_statement to ddl (or the more advanced mod or all),
and all DDL logs will be preserved. The pgaudit extension also provides similar functionality.
But I suspect what they really want isn’t DDL logs, but something like a system view that can be queried via SQL.
In that case, another option is CREATE EVENT TRIGGER.
You can use an event trigger to log DDL events directly into a data table.
The pg_ddl_historization extension provides a more convenient way to do this, and I’ve compiled and packaged this extension as well.
Creating an event trigger also requires superuser privileges. AWS RDS has some special handling to allow this, but it seems that PostgreSQL on Azure does not support it.
On Monitoring View Semantics
In OpenAI’s example, pg_stat_activity.state = active means the backend process is still within the lifecycle of a single SQL statement.
The WaitEvent = ClientRead means the process is on the CPU waiting for data from the client.
When both appear together, a typical example is an idle COPY FROM STDIN, but it could also be TCP blocking or being stuck between BIND / EXECUTE. So it’s hard to say if it’s a bug without knowing what the connection is actually doing.
Some might argue that waiting for client I/O should be considered “idle” from a CPU perspective. But state tracks the execution state of the statement itself, not whether the CPU is busy.
state = 'active' means the PostgreSQL backend considers “this statement is not yet finished.” Resources like row locks, buffer pins, snapshots, and file handles are considered “in use.”
This doesn’t mean it’s running on the CPU. When the process is running on the CPU in a loop waiting for client data, the wait event is ClientRead. When it yields the CPU and “waits” in the background, the wait event is NULL.
But back to the problem itself, there are other solutions. For example, in Pigsty, when accessing PostgreSQL through HAProxy, we set a connection timeout at the LB level for the primary service,
defaulting to 24 hours. More stringent environments would have a shorter timeout, like 1 hour. This means any connection lasting over an hour would be terminated.
Of course, this also needs to be configured with a corresponding max lifetime in the application-side connection pool, to proactively close connections rather than having them be cut off.
For offline, read-only services, this parameter can be omitted to allow for ultra-long queries that might run for two or three days. This provides a safety net for these active-but-waiting-on-I/O situations.
But I also doubt whether Azure PostgreSQL offers this kind of control.
On Default Parameters
PostgreSQL’s default parameters are quite conservative. For example, it defaults to using 128 MB of memory (the minimum can be set to 128 KB!). On the bright side, this allows its default configuration to run in almost any environment. On the downside, I’ve actually seen a case of a production system with 1TB of physical memory running with the 128 MB default… (thanks to double buffering, it actually ran for a long time).
But overall, I think conservative defaults aren’t a bad thing. This issue can be solved in a more flexible, dynamic configuration process.
RDS and Pigsty both provide pretty good initial parameter heuristic config rules,
which fully address this problem. But this feature could indeed be added to the PG command-line tools,
for example, having initdb automatically detect CPU/memory count, disk size, and storage type and set optimized parameter values accordingly.
Self-hosted PostgreSQL?
The challenges OpenAI raised are not really from PostgreSQL itself, but from the additional limitations of managed cloud services. One solution is to use the IaaS layer and self-host a PostgreSQL cluster on instances with local NVMe SSD storage to bypass these restrictions.
In fact, my project Pigsty built for ourselves to solve PostgreSQL challenges at a similar scale. It scales well, having supported Tantan’s 25K vCPU PostgreSQL cluster and 2.5M QPS. It includes solutions for all the problems mentioned above, and even for many that OpenAI hasn’t encountered yet. And in a self-hosting manner, open-source, free, and ready to use out of the box.
If OpenAI is interested, I’d certainly be happy to provide some help. But I think when you’re in a phase of hyper-growth, fiddling with database infra is probably not a high-priority item. Fortunately, they still have excellent PostgreSQL DBAs who can continue to forge these paths.
References
[1] HackerNews OpenAI: Scaling Postgres to the Next Level: https://news.ycombinator.com/item?id=44071418#44072781
[2] PostgreSQL is eating the database world: https://pigsty.io/blog/pg/pg-eat-db-world
[3] Chinese: Scaling Postgres to the Next Level at OpenAI https://pigsty.cc/blog/db/openai-pg/
[4] The part of PostgreSQL we hate the most: https://www.cs.cmu.edu/~pavlo/blog/2023/04/the-part-of-postgresql-we-hate-the-most.html
[5] PGConf.Dev 2025: https://2025.pgconf.dev/schedule.html
[6] Schedule: Scaling Postgres to the next level at OpenAI: https://www.pgevents.ca/events/pgconfdev2025/schedule/session/433-scaling-postgres-to-the-next-level-at-openai/
[7] Bohan Zhang: https://www.linkedin.com/in/bohan-zhang-52b17714b
[8] Ruohang Feng / Vonng: https://github.com/Vonng/
[9] Pigsty: https://pigsty.io
[10] Instagram’s Sharding IDs: https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c
[11] Reclaim hardware bouns: https://pigsty.io/blog/cloud/bonus/
[12] Distributed Databases Are a False Need: https://pigsty.io/blog/db/distributive-bullshit/
Database Planet Collision: When PG Falls for DuckDB
When I published “PostgreSQL Is Eating the Database World” last year, I tossed out this wild idea: Could Postgres really unify OLTP and OLAP? I had no clue we’d see fireworks so quickly.
The PG community’s now in an all-out frenzy to stitch DuckDB into the Postgres bloodstream — big enough for Andy Pavlo to give it prime-time coverage in his 2024 database retrospective. If you ask me, we’re on the brink of a cosmic collision in database-land, and Postgres + DuckDB is the meteor we should all be watching.

DuckDB as an OLAP Challenger
DuckDB came to life at CWI, the Netherlands’ National Research Institute for Mathematics and Computer Science, founded by Mark Raasveldt and Hannes Mühleisen. CWI might look like a quiet research outfit, but it’s actually the secret sauce behind numerous analytic databases—pioneering columnar storage and vectorized queries that power systems like ClickHouse, Snowflake, and Databricks.
After helping guide these heavy hitters, the same minds built DuckDB—an embedded OLAP database for a new generation. Their timing and niche were spot on.
Why DuckDB? The creators noticed data scientists often prefer Python and Pandas, and they’d rather avoid wrestling with heavyweight RDBMS overhead, user authentication, data import/export tangles, etc. DuckDB’s solution? An embedded, SQLite-like analyzer that’s as simple as it gets.
It compiles down to a single binary from just a C++ file and a header. The database itself is just a file on disk. Its SQL syntax and parser come straight from Postgres, creating practically zero friction. Despite its minimalist packaging, DuckDB is a performance beast—besting ClickHouse in some ClickBench tests on ClickHouse’s own turf.
And since DuckDB lands under the MIT license, you get blazing-fast analytics, super-simple onboarding, open source freedom, and any-wrap-you-want packaging. Hard to imagine it not going viral.
The Golden Combo: Strengths and Weaknesses
For all its top-notch OLAP chops, DuckDB’s Achilles’ heel is data management—users, permissions, concurrency, backups, HA…basically all the stuff data scientists love to skip. Ironically, that’s the sweet spot of traditional databases, and it’s also the most painful piece for enterprises.
Hence, DuckDB feels more like an “OLAP operator” or a storage engine, akin to RocksDB, and less like a fully operational “big data platform.”
Meanwhile, PostgreSQL has spent decades polishing data management—rock-solid transactions, access control, backups, HA, a healthy extension ecosystem, and so on. As an OLTP juggernaut, Postgres is a performence beast.. The only lingering complaint is that while Postgres handles standard analytics adequately, it still lags behind specialized OLAP systems when data volumes balloon.

But what if we combine PostgreSQL for data management with DuckDB for high-speed analytics? If these two join forces deeply, we could see a brand-new hybrid in the DB universe.
DuckDB patches Postgres’s bulk-analytics limitations—plus, it can read and write external columnar formats like Parquet in object stores, unleashing a near-infinite data lake. Conversely, DuckDB’s weaker management features get covered by the veteran Postgres ecosystem. Instead of rolling out a brand-new “big data platform” or forging a separate “analytic engine” for Postgres, hooking them together is arguably the simplest and most valuable route.
And guess what—it’s already happening. Multiple teams and vendors are weaving DuckDB into Postgres, racing to open up a massive untapped market.
The Race to Stitch Them Together
Take a quick peek and you’ll see competition is fierce
- A lone-wolf developer in China, Steven Lee, kicked things off with
duckdb_fdw. It flew under the radar for a while, but definitely laid groundwork. - After the post “PostgreSQL Is Eating the Database World” used vector databases as a hint toward future OLAP, the PG crowd got charged up about grafting DuckDB onto Postgres.
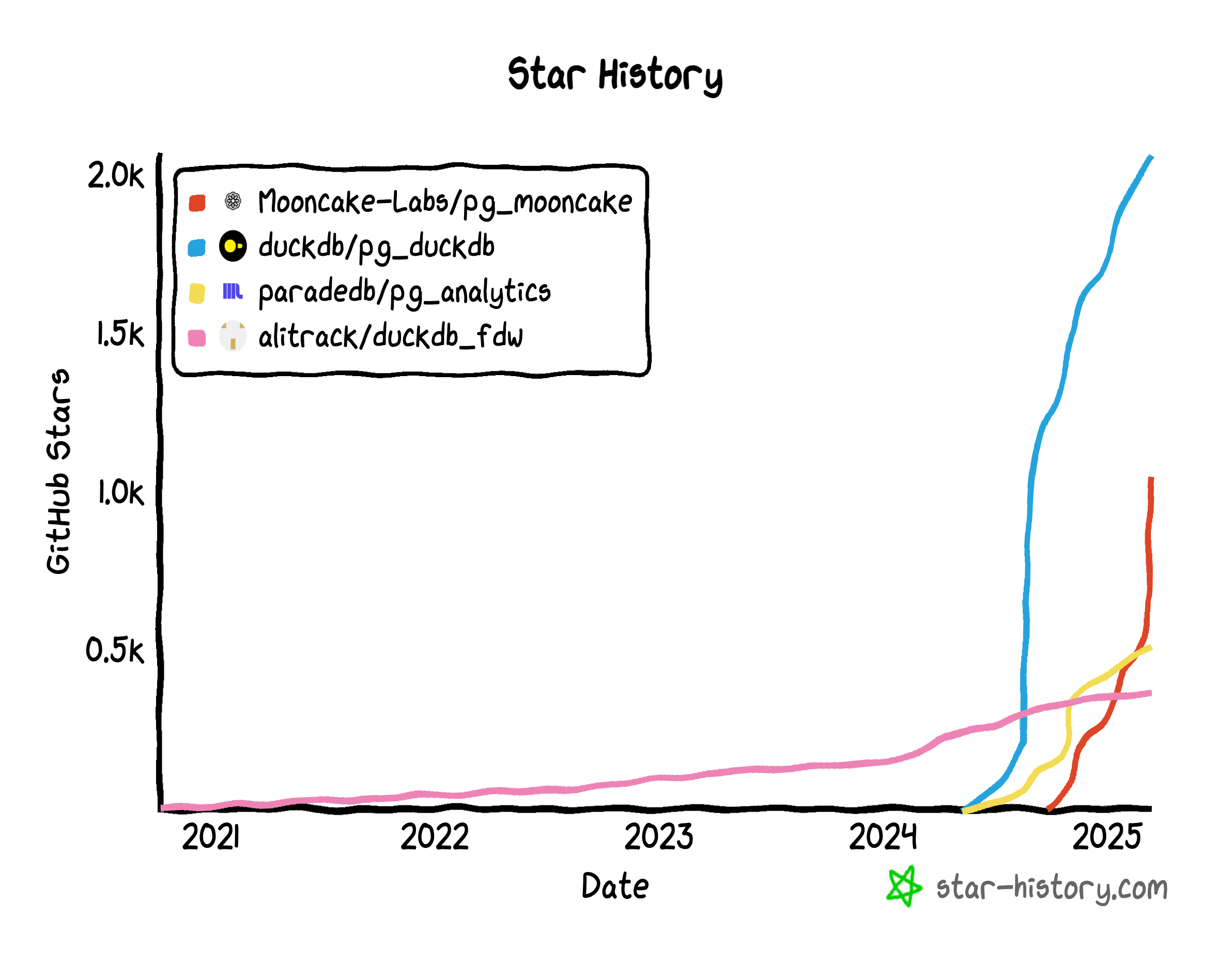
- By March 2024, ParadeDB retooled
pg_analyticsto stitch in DuckDB. - Hydra, in the PG ecosystem, and DuckDB’s parent MotherDuck launched
pg_duckdb. DuckDB officially jumped into Postgres integration — ironically pausing their own direct approachhydrafor a long time. - Neon, always quick to ride the wave, sponsored
pg_mooncake, built onpg_duckdb. It aims to embed DuckDB’s compute engine in PG while also fusing Parquet-based lakehouse storage. - Even big clouds like Alibaba Cloud RDS are experimenting with DuckDB add-ons (
rds_duckdb). That’s a sure sign the giants have caught on.
It’s eerily reminiscent of the vector-database frenzy. Once AI and semantic search took off, vendors piled on. In Postgres alone, at least six vector DB extensions sprang up: pgvector, pgvector.rs, pg_embedding, latern, pase, pgvectorscale. It was a good ol’ Wild West. Ultimately, pgvector—fueled by AWS—triumphed, overshadowing latecomers from Oracle/MySQL/MariaDB. Now OLAP might be next in line.
Why DuckDB + Postgres?
Some folks might ask: If we want DuckDB’s power, why not fuse it with MySQL, Oracle, SQL Server, or even MongoDB? Don’t they all crave sharper OLAP?
But Postgres and DuckDB fit like a glove. The synergy boils down to three points:
-
Syntax Compatibility. DuckDB practically clones Postgres syntax and parser, meaning near-zero friction.
-
Extensibility. Both Postgres and DuckDB are known for “extensibility mania.” FDWs, storage engines, custom data types—any piece can snap in as an extension. No need to hack deep into either codebase when you can build a bridging extension.
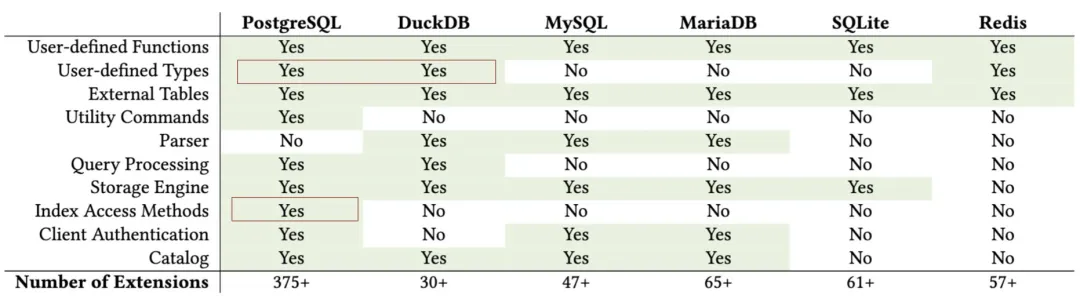
Survey and Evaluation of Database Management System Extensibility
-
Massive Market. Postgres is already the world’s most popular database and the only major RDBMS still growing fast. Integrating with PG brings way more mileage than targeting smaller players.
Hence, hooking Postgres + DuckDB is like a “path of least resistance for maximum impact.” Nature abhors a vacuum, so everyone’s rushing in.
The Dream: One System for OLTP and OLAP
OLTP vs. OLAP has historically been a massive fault line in databases. We’ve spent decades patching it up with data warehouses, separate RDBMS solutions, ETL pipelines, and more. But if Postgres can maintain its OLTP might while leveraging DuckDB for analytics, do we really need an extra analytics DB?
That scenario suggests huge cost savings and simpler engineering. No more data migration migraines or maintaining two different data stacks. Anyone who nails that seamless integration might detonate a deep-sea bomb in the big-data market.
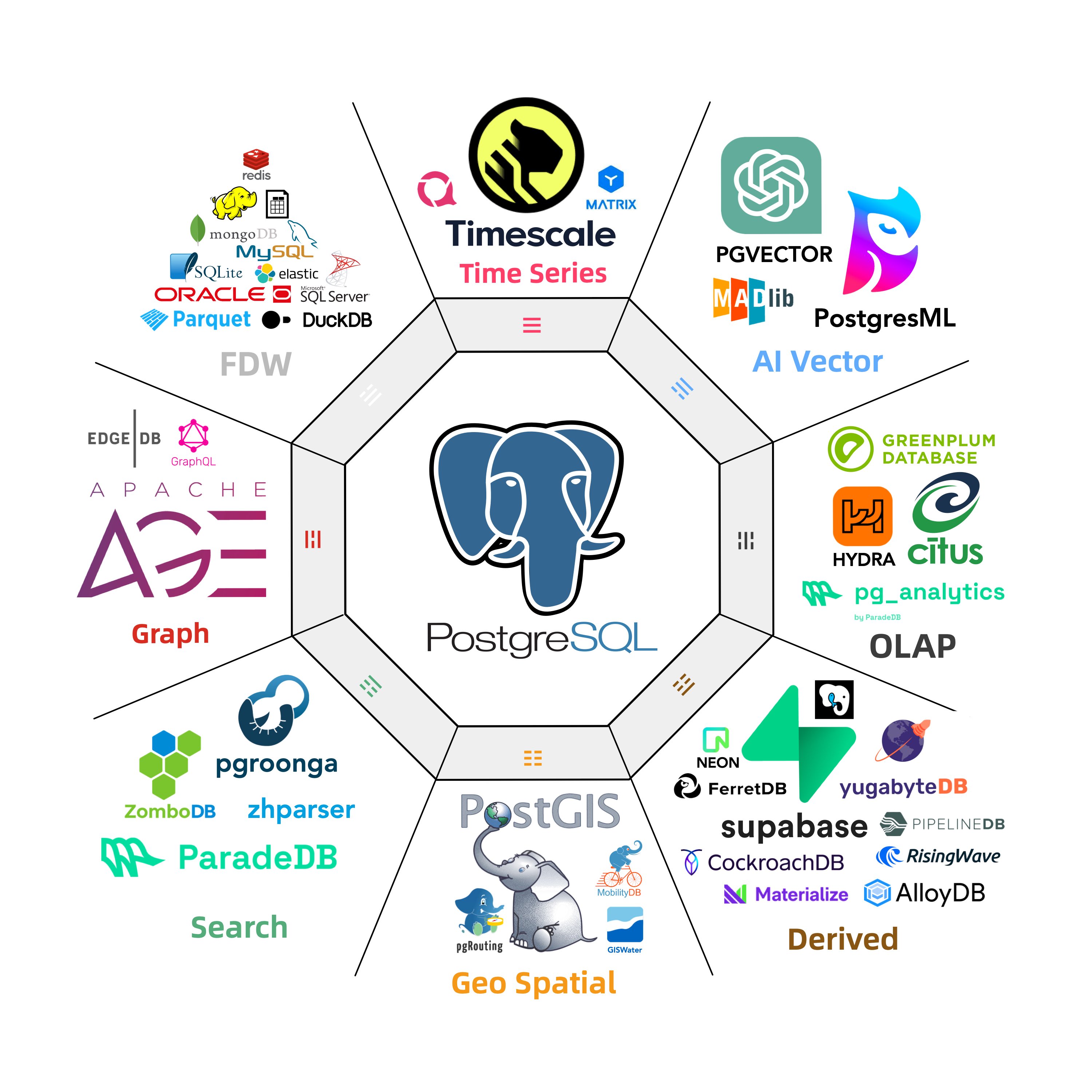
People call Postgres the “Linux kernel of databases” — open source, infinitely extensible, morphable into anything: even mimic MySQL, Oracle, MsSQL and Mongo. We’ve already watched PG conquer geospatial, time series, NoSQL, and vector search through its extension hooks. OLAP might just be its biggest conquest yet.
A polished “plug-and-play” DuckDB integration could flip big data analytics on its head. Will specialized OLAP services withstand a nuclear-level blow? Could they end up like “specialized vector DBs” overshadowed by pgvector? We don’t know, but we’ll definitely have opinions once the dust settles.
Paving the Way for PG + DuckDB
Right now, Postgres OLAP extensions feel like the early vector DB days—small community, big excitement. The beauty of fresh tech is that if you spot the potential, you can jump in early and catch the wave.
When pgvector was just getting started, Pigsty was among the first adopters, right behind Supabase & Neon. I even suggested it be added to PGDG’s yum repos. Now, with the DuckDB stitching craze, you can bet I’ll do better.
As a seasoned data hand, I’m bundling all the PG+DuckDB integration extensions into simple RPMs/DEBs for major Linux distros., fully compatible with official PGDG binaries. Anyone can install them and start playing with “DuckDB+PG” in minutes — call it a battleground where the new contenders can test their mettle on equal footing.
The missing package manager for PostgreSQL:
pig
| Name (Detail) | Repo | Description |
|---|---|---|
| citus | PIGSTY | Distributed PostgreSQL as an extension |
| citus_columnar | PIGSTY | Citus columnar storage engine |
| hydra | PIGSTY | Hydra Columnar extension |
| pg_analytics | PIGSTY | Postgres for analytics, powered by DuckDB |
| pg_duckdb | PIGSTY | DuckDB Embedded in Postgres |
| pg_mooncake | PIGSTY | Columnstore Table in Postgres |
| duckdb_fdw | PIGSTY | DuckDB Foreign Data Wrapper |
| pg_parquet | PIGSTY | copy data between Postgres and Parquet |
| pg_fkpart | MIXED | Table partitioning by foreign key utility |
| pg_partman | PGDG | Extension to manage partitioned tables by time or ID |
| plproxy | PGDG | Database partitioning implemented as procedural language |
| pg_strom | PGDG | PG-Strom - big-data processing acceleration using GPU and NVME |
| tablefunc | CONTRIB | functions that manipulate whole tables, including crosstab |
Sure, a lot of these plugins are alpha/beta: concurrency quirks, partial feature sets, performance oddities. But fortune favors the bold. I’m convinced this “PG + DuckDB” show is about to take center stage.
The Real Explosion Is Coming
In enterprise circles, OLAP dwarfs most hype markets by sheer scale and practicality. Meanwhile, Postgres + DuckDB looks set to disrupt this space further, possibly demolishing the old “RDBMS + big data” two-stack architecture.
In months—or a year or two—we might see a new wave of “chimera” systems spring from these extension projects and claim the database spotlight. Whichever team nails usability, integration, and performance first will seize a formidable edge.
For database vendors, this is an epic collision; for businesses, it’s a chance to do more with less. Let’s see how the dust settles—and how it reshapes the future of data analytics and management.
Further Reading
- PostgreSQL Is Eating the Database World
- Whoever Masters DuckDB Integration Wins the OLAP Database World
- Alibaba Cloud rds_duckdb: Homage or Ripoff?
- Is Distributed Databases a Mythical Need?
- Andy Pavlo’s 2024 Database Recap
Self-Hosting Supabase on PostgreSQL
Supabase is great, own your own Supabase is even better. Here’s a comprehensive tutorial for self-hosting production-grade supabase on local/cloud VM/BMs.
This tutorial is obsolete for the latest pigsty version, Check the latest tutorial here: Self-Hosting Supabase
What is Supabase?
Supabase is an open-source Firebase alternative, a Backend as a Service (BaaS).
Supabase wraps PostgreSQL kernel and vector extensions, alone with authentication, realtime subscriptions, edge functions, object storage, and instant REST and GraphQL APIs from your postgres schema. It let you skip most backend work, requiring only database design and frontend skills to ship quickly.
Currently, Supabase may be the most popular open-source project in the PostgreSQL ecosystem, boasting over 74,000 stars on GitHub. And become quite popular among developers, and startups, since they have a generous free plan, just like cloudflare & neon.
Why Self-Hosting?
Supabase’s slogan is: “Build in a weekend, Scale to millions”. It has great cost-effectiveness in small scales (4c8g) indeed. But there is no doubt that when you really grow to millions of users, some may choose to self-hosting their own Supabase —— for functionality, performance, cost, and other reasons.
That’s where Pigsty comes in. Pigsty provides a complete one-click self-hosting solution for Supabase. Self-hosted Supabase can enjoy full PostgreSQL monitoring, IaC, PITR, and high availability capability,
You can run the latest PostgreSQL 17(,16,15,14) kernels, (supabase is using the 15 currently), alone with 421 PostgreSQL extensions out-of-the-box. Run on mainstream Linus OS distros with production grade HA PostgreSQL, MinIO, Prometheus & Grafana Stack for observability, and Nginx for reverse proxy.
Since most of the supabase maintained extensions are not available in the official PGDG repo, we have compiled all the RPM/DEBs for these extensions and put them in the Pigsty repo: pg_graphql, pg_jsonschema, wrappers, index_advisor, pg_net, vault, pgjwt, supautils, pg_plan_filter,…
Everything is under your control, you have the ability and freedom to scale PGSQL, MinIO, and Supabase itself. And take full advantage of the performance and cost advantages of modern hardware like Gen5 NVMe SSD.
All you need is prepare a VM with several commands and wait for 10 minutes….
Get Started
First, download & install pigsty as usual, with the supa config template:
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./bootstrap # install ansible
./configure -c app/supa # use supabase config (please CHANGE CREDENTIALS in pigsty.yml)
vi pigsty.yml # edit domain name, password, keys,...
./install.yml # install pigsty
Please change the
pigsty.ymlconfig file according to your need before deploying Supabase. (Credentials) For dev/test/demo purposes, we will just skip that, and comes back later.
Then, run the docker.yml to install docker, and app.yml to launch stateless part of supabase.
./docker.yml # install docker compose
./app.yml # launch supabase stateless part with docker
You can access the supabase API / Web UI through the 8000/8443 directly.
with configured DNS, or a local /etc/hosts entry, you can also use the default supa.pigsty domain name via the 80/443 infra portal.
Credentials for Supabase Studio:
supabase:pigsty

Architecture
Pigsty’s supabase is based on the Supabase Docker Compose Template, with some slight modifications to fit-in Pigsty’s default ACL model.
The stateful part of this template is replaced by Pigsty’s managed PostgreSQL cluster and MinIO cluster. The container part are stateless, so you can launch / destroy / run multiple supabase containers on the same stateful PGSQL / MINIO cluster simultaneously to scale out.

The built-in supa.yml config template will create a single-node supabase, with a singleton PostgreSQL and SNSD MinIO server.
You can use Multinode PostgreSQL Clusters and MNMD MinIO Clusters / external S3 service instead in production, we will cover that later.
Config Detail
Here are checklists for self-hosting
- Hardware: necessary VM/BM resources, one node at least, 3-4 are recommended for HA.
- Linux OS: Linux x86_64 server with fresh installed Linux, check compatible distro
- Network: Static IPv4 address which can be used as node identity
- Admin User: nopass ssh & sudo are recommended for admin user
- Conf Template: Use the
supaconfig template, if you don’t know how to manually configure pigsty
The built-in supa.yml config template is shown below.
The supa Config Template
all:
children:
# the supabase stateless (default username & password: supabase/pigsty)
supa:
hosts:
10.10.10.10: {}
vars:
app: supabase # specify app name (supa) to be installed (in the apps)
apps: # define all applications
supabase: # the definition of supabase app
conf: # override /opt/supabase/.env
# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!
# https://supabase.com/docs/guides/self-hosting/docker#securing-your-services
JWT_SECRET: your-super-secret-jwt-token-with-at-least-32-characters-long
ANON_KEY: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GE
SERVICE_ROLE_KEY: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Q
DASHBOARD_USERNAME: supabase
DASHBOARD_PASSWORD: pigsty
# postgres connection string (use the correct ip and port)
POSTGRES_HOST: 10.10.10.10 # point to the local postgres node
POSTGRES_PORT: 5436 # access via the 'default' service, which always route to the primary postgres
POSTGRES_DB: postgres # the supabase underlying database
POSTGRES_PASSWORD: DBUser.Supa # password for supabase_admin and multiple supabase users
# expose supabase via domain name
SITE_URL: https://supa.pigsty # <------- Change This to your external domain name
API_EXTERNAL_URL: https://supa.pigsty # <------- Otherwise the storage api may not work!
SUPABASE_PUBLIC_URL: https://supa.pigsty # <------- DO NOT FORGET TO PUT IT IN infra_portal!
# if using s3/minio as file storage
S3_BUCKET: supa
S3_ENDPOINT: https://sss.pigsty:9000
S3_ACCESS_KEY: supabase
S3_SECRET_KEY: S3User.Supabase
S3_FORCE_PATH_STYLE: true
S3_PROTOCOL: https
S3_REGION: stub
MINIO_DOMAIN_IP: 10.10.10.10 # sss.pigsty domain name will resolve to this ip statically
# if using SMTP (optional)
#SMTP_ADMIN_EMAIL: [email protected]
#SMTP_HOST: supabase-mail
#SMTP_PORT: 2500
#SMTP_USER: fake_mail_user
#SMTP_PASS: fake_mail_password
#SMTP_SENDER_NAME: fake_sender
#ENABLE_ANONYMOUS_USERS: false
# infra cluster for proxy, monitor, alert, etc..
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
# etcd cluster for ha postgres
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
# minio cluster, s3 compatible object storage
minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
# pg-meta, the underlying postgres database for supabase
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users:
# supabase roles: anon, authenticated, dashboard_user
- { name: anon ,login: false }
- { name: authenticated ,login: false }
- { name: dashboard_user ,login: false ,replication: true ,createdb: true ,createrole: true }
- { name: service_role ,login: false ,bypassrls: true }
# supabase users: please use the same password
- { name: supabase_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: true ,roles: [ dbrole_admin ] ,superuser: true ,replication: true ,createdb: true ,createrole: true ,bypassrls: true }
- { name: authenticator ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] }
- { name: supabase_auth_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_storage_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] ,createrole: true }
- { name: supabase_functions_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole: true }
- { name: supabase_replication_admin ,password: 'DBUser.Supa' ,replication: true ,roles: [ dbrole_admin ]}
- { name: supabase_read_only_user ,password: 'DBUser.Supa' ,bypassrls: true ,roles: [ dbrole_readonly, pg_read_all_data ] }
pg_databases:
- name: postgres
baseline: supabase.sql
owner: supabase_admin
comment: supabase postgres database
schemas: [ extensions ,auth ,realtime ,storage ,graphql_public ,supabase_functions ,_analytics ,_realtime ]
extensions:
- { name: pgcrypto ,schema: extensions } # cryptographic functions
- { name: pg_net ,schema: extensions } # async HTTP
- { name: pgjwt ,schema: extensions } # json web token API for postgres
- { name: uuid-ossp ,schema: extensions } # generate universally unique identifiers (UUIDs)
- { name: pgsodium } # pgsodium is a modern cryptography library for Postgres.
- { name: supabase_vault } # Supabase Vault Extension
- { name: pg_graphql } # pg_graphql: GraphQL support
- { name: pg_jsonschema } # pg_jsonschema: Validate json schema
- { name: wrappers } # wrappers: FDW collections
- { name: http } # http: allows web page retrieval inside the database.
- { name: pg_cron } # pg_cron: Job scheduler for PostgreSQL
- { name: timescaledb } # timescaledb: Enables scalable inserts and complex queries for time-series data
- { name: pg_tle } # pg_tle: Trusted Language Extensions for PostgreSQL
- { name: vector } # pgvector: the vector similarity search
- { name: pgmq } # pgmq: A lightweight message queue like AWS SQS and RSMQ
# supabase required extensions
pg_libs: 'timescaledb, plpgsql, plpgsql_check, pg_cron, pg_net, pg_stat_statements, auto_explain, pg_tle, plan_filter'
pg_parameters:
cron.database_name: postgres
pgsodium.enable_event_trigger: off
pg_hba_rules: # supabase hba rules, require access from docker network
- { user: all ,db: postgres ,addr: intra ,auth: pwd ,title: 'allow supabase access from intranet' }
- { user: all ,db: postgres ,addr: 172.17.0.0/16 ,auth: pwd ,title: 'allow access from local docker network' }
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # make a full backup every 1am
#==============================================================#
# Global Parameters
#==============================================================#
vars:
version: v3.5.0 # pigsty version string
admin_ip: 10.10.10.10 # admin node ip address
region: default # upstream mirror region: default|china|europe
node_tune: oltp # node tuning specs: oltp,olap,tiny,crit
pg_conf: oltp.yml # pgsql tuning specs: {oltp,olap,tiny,crit}.yml
docker_enabled: true # enable docker on app group
#docker_registry_mirrors: ["https://docker.1ms.run"] # use mirror in mainland china
proxy_env: # global proxy env when downloading packages & pull docker images
no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.tsinghua.edu.cn"
#http_proxy: 127.0.0.1:12345 # add your proxy env here for downloading packages or pull images
#https_proxy: 127.0.0.1:12345 # usually the proxy is format as http://user:[email protected]
#all_proxy: 127.0.0.1:12345
certbot_email: [email protected] # your email address for applying free let's encrypt ssl certs
infra_portal: # domain names and upstream servers
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus : { domain: p.pigsty ,endpoint: "${admin_ip}:9090" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9093" }
minio : { domain: m.pigsty ,endpoint: "10.10.10.10:9001", https: true, websocket: true }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" } # expose supa studio UI and API via nginx
supa : # nginx server config for supabase
domain: supa.pigsty # REPLACE WITH YOUR OWN DOMAIN!
endpoint: "10.10.10.10:8000" # supabase service endpoint: IP:PORT
websocket: true # add websocket support
certbot: supa.pigsty # certbot cert name, apply with `make cert`
#----------------------------------#
# Credential: CHANGE THESE PASSWORDS
#----------------------------------#
#grafana_admin_username: admin
grafana_admin_password: pigsty
#pg_admin_username: dbuser_dba
pg_admin_password: DBUser.DBA
#pg_monitor_username: dbuser_monitor
pg_monitor_password: DBUser.Monitor
#pg_replication_username: replicator
pg_replication_password: DBUser.Replicator
#patroni_username: postgres
patroni_password: Patroni.API
#haproxy_admin_username: admin
haproxy_admin_password: pigsty
#minio_access_key: minioadmin
minio_secret_key: minioadmin # minio root secret key, `minioadmin` by default, also change pgbackrest_repo.minio.s3_key_secret
# use minio as supabase file storage, single node single driver mode for demonstration purpose
minio_buckets: [ { name: pgsql }, { name: supa } ]
minio_users:
- { access_key: dba , secret_key: S3User.DBA, policy: consoleAdmin }
- { access_key: pgbackrest , secret_key: S3User.Backup, policy: readwrite }
- { access_key: supabase , secret_key: S3User.Supabase, policy: readwrite }
minio_endpoint: https://sss.pigsty:9000 # explicit overwrite minio endpoint with haproxy port
node_etc_hosts: ["10.10.10.10 sss.pigsty"] # domain name to access minio from all nodes (required)
# use minio as default backup repo for PostgreSQL
pgbackrest_method: minio # pgbackrest repo method: local,minio,[user-defined...]
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
s3_endpoint: sss.pigsty # minio endpoint domain name, `sss.pigsty` by default
s3_region: us-east-1 # minio region, us-east-1 by default, useless for minio
s3_bucket: pgsql # minio bucket name, `pgsql` by default
s3_key: pgbackrest # minio user access key for pgbackrest
s3_key_secret: S3User.Backup # minio user secret key for pgbackrest <------------------ HEY, DID YOU CHANGE THIS?
s3_uri_style: path # use path style uri for minio rather than host style
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9000 # minio port, 9000 by default
storage_ca_file: /etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by default
block: y # Enable block incremental backup
bundle: y # bundle small files into a single file
bundle_limit: 20MiB # Limit for file bundles, 20MiB for object storage
bundle_size: 128MiB # Target size for file bundles, 128MiB for object storage
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest' <----- HEY, DID YOU CHANGE THIS?
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
pg_version: 17
repo_extra_packages: [pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-util ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]
pg_extensions: [ pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-feat ,pg17-lang ,pg17-type ,pg17-util ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl, pg_mooncake, pg_analytics, pg_parquet ] #,pg17-olap]
For advanced topics, we may need to modify the configuration file to fit our needs.
- Security Enhancement
- Domain Name and HTTPS
- Sending Mail with SMTP
- MinIO or External S3
- True High Availability
Security Enhancement
For security reasons, you should change the default passwords in the pigsty.yml config file.
grafana_admin_password:pigsty, Grafana admin passwordpg_admin_password:DBUser.DBA, PGSQL superuser passwordpg_monitor_password:DBUser.Monitor, PGSQL monitor user passwordpg_replication_password:DBUser.Replicator, PGSQL replication user passwordpatroni_password:Patroni.API, Patroni HA Agent Passwordhaproxy_admin_password:pigsty, Load balancer admin passwordminio_access_key:minioadmin, MinIO root usernameminio_secret_key:minioadmin, MinIO root password
Supabase will use PostgreSQL & MinIO as its backend, so also change the following passwords for supabase business users:
pg_users: password for supabase business users in postgresminio_users:minioadmin, MinIO business user’s password
The pgbackrest will take backups and WALs to MinIO, so also change the following passwords reference
pgbackrest_repo: refer to the
PLEASE check the Supabase Self-Hosting: Generate API Keys to generate supabase credentials:
jwt_secret: a secret key with at least 40 charactersanon_key: a jwt token generate for anonymous users, based onjwt_secretservice_role_key: a jwt token generate for elevated service roles, based onjwt_secretdashboard_username: supabase studio web portal username,supabaseby defaultdashboard_password: supabase studio web portal password,pigstyby default
If you have chanaged the default password for PostgreSQL and MinIO, you have to update the following parameters as well:
postgres_password, according topg_userss3_access_keyands3_secret_key, according tominio_users
Domain Name and HTTPS
For local or intranet use, you can connect directly to Kong port on http://<IP>:8000 or 8443 for https.
This works but isn’t ideal. Using a domain with HTTPS is strongly recommended when serving Supabase to the public.
Pigsty has a Nginx server installed & configured on the admin node to act as a reverse proxy for all web based service.
which is configured via the infra_portal parameter.
all:
vars:
infra_portal:
supa :
domain: supa.pigsty.cc # replace the default supa.pigsty domain name with your own domain name
endpoint: "10.10.10.10:8000"
websocket: true
certbot: supa.pigsty.cc # certificate name, usually the same as the domain name
On the client side, you can use the domain supa.pigsty to access the Supabase Studio management interface.
You can add this domain to your local /etc/hosts file or use a local DNS server to resolve it to the server’s external IP address.
To use a real domain with HTTPS, you will need to modify the all.vars.infra_portal.supa with updated domain name (such as supa.pigsty.cc here).
You can obtain a free HTTPS certificate with certbot as simple as:
make cert
You also have to update the all.children.supa.apps.supabase.conf to tell supabase to use the new domain name:
all:
children: # clusters
supa:
vars:
apps:
supabase:
conf:
SITE_URL: https://supa.pigsty.cc # <------- Change This to your external domain name
API_EXTERNAL_URL: https://supa.pigsty.cc # <------- Otherwise the storage api may not work!
SUPABASE_PUBLIC_URL: https://supa.pigsty.cc # <------- DO NOT FORGET TO PUT IT IN infra_portal!
And reload the supabase service to apply the new configuration:
./app.yml -t app_config,app_launch # reload supabase config
Sending Mail with SMTP
Some Supabase features require email. For production use, I’d recommend using an external SMTP service. Since self-hosted SMTP servers often result in rejected or spam-flagged emails.
To do this, modify the Supabase configuration and add SMTP credentials:
all:
children: # clusters
supa:
vars:
apps:
supabase:
conf:
SMTP_HOST: smtpdm.aliyun.com:80
SMTP_PORT: 80
SMTP_USER: [email protected]
SMTP_PASS: your_email_user_password
SMTP_SENDER_NAME: MySupabase
SMTP_ADMIN_EMAIL: [email protected]
ENABLE_ANONYMOUS_USERS: false
And don’t forget to reload the supabase service with app.yml -t app_config,app_launch
MinIO or External S3
Pigsty’s self-hosting supabase will use a local SNSD MinIO server, which is used by Supabase itself for object storage, and by PostgreSQL for backups. For production use, you should consider using a HA MNMD MinIO cluster or an external S3 compatible service instead.
We recommend using an external S3 when:
- you just have one single server available, then external s3 gives you a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
- you are operating in the cloud, then using S3 directly is recommended rather than wrap expensively EBS with MinIO
The
terraform/spec/aliyun-meta-s3.tfprovides an example of how to provision a single node alone with an S3 bucket.
To use an external S3 compatible service, you’ll have to update two related references in the pigsty.yml config.
For example, to use Aliyun OSS as the object storage for Supabase, you can modify the all.children.supabase.vars.supa_config to point to the Aliyun OSS bucket:
all:
children:
supabase:
vars:
supa_config:
s3_bucket: pigsty-oss
s3_endpoint: https://oss-cn-beijing-internal.aliyuncs.com
s3_access_key: xxxxxxxxxxxxxxxx
s3_secret_key: xxxxxxxxxxxxxxxx
s3_force_path_style: false
s3_protocol: https
s3_region: oss-cn-beijing
Reload the supabase service with ./supabase.yml -t supa_config,supa_launch again.
The next reference is in the PostgreSQL backup repo:
all:
vars:
# use minio as default backup repo for PostgreSQL
pgbackrest_method: minio # pgbackrest repo method: local,minio,[user-defined...]
pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository
local: # default pgbackrest repo with local posix fs
path: /pg/backup # local backup directory, `/pg/backup` by default
retention_full_type: count # retention full backups by count
retention_full: 2 # keep 2, at most 3 full backup when using local fs repo
minio: # optional minio repo for pgbackrest
type: s3 # minio is s3-compatible, so s3 is used
# update your credentials here
s3_endpoint: oss-cn-beijing-internal.aliyuncs.com
s3_region: oss-cn-beijing
s3_bucket: pigsty-oss
s3_key: xxxxxxxxxxxxxx
s3_key_secret: xxxxxxxx
s3_uri_style: host
path: /pgbackrest # minio backup path, default is `/pgbackrest`
storage_port: 9000 # minio port, 9000 by default
storage_ca_file: /pg/cert/ca.crt # minio ca file path, `/pg/cert/ca.crt` by default
bundle: y # bundle small files into a single file
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for last 14 days
After updating the pgbackrest_repo, you can reset the pgBackrest backup with ./pgsql.yml -t pgbackrest.
True High Availability
The default single-node deployment (with external S3) provide a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
To achieve RTO < 30s and zero data loss, you need a multi-node high availability cluster with at least 3-nodes.
Which involves high availability for these components:
- ETCD: DCS requires at least three nodes to tolerate one node failure.
- PGSQL: PGSQL synchronous commit mode recommends at least three nodes.
- INFRA: It’s good to have two or three copies of observability stack.
- Supabase itself can also have multiple replicas to achieve high availability.
We recommend you to refer to the trio and safe config to upgrade your cluster to three nodes or more.
In this case, you also need to modify the access points for PostgreSQL and MinIO to use the DNS / L2 VIP / HAProxy HA access points.
all:
children:
supabase:
hosts:
10.10.10.10: { supa_seq: 1 }
10.10.10.11: { supa_seq: 2 }
10.10.10.12: { supa_seq: 3 }
vars:
supa_cluster: supa # cluster name
supa_config:
postgres_host: 10.10.10.2 # use the PG L2 VIP
postgres_port: 5433 # use the 5433 port to access the primary instance through pgbouncer
s3_endpoint: https://sss.pigsty:9002 # If you are using MinIO through the haproxy lb port 9002
minio_domain_ip: 10.10.10.3 # use the L2 VIP binds to all proxy nodes
MySQL is dead, Long live PostgreSQL!
This July, MySQL 9.0 was finally released—a full eight years after its last major version, 8.0 (@2016-09). Yet, this hollow “innovation” release feels like a bad joke, signaling that MySQL is on its deathbed.
While PostgreSQL continues to surge ahead, MySQL’s sunset is painfully acknowledged by Percona, a major flag-bearer of the MySQL ecosystem, through a series of poignant posts: “Where is MySQL Heading?”, “Did Oracle Finally Kill MySQL?”, and “Can Oracle Save MySQL?”, openly expressing disappointment and frustration with MySQL.
Peter Zaitsev, CEO of Percona, remarked:
Who needs MySQL when there’s PostgreSQL? But if MySQL dies, PostgreSQL might just monopolize the database world, so at least MySQL can serve as a whetstone for PostgreSQL to reach its zenith.
Some databases are eating the DBMS world, while others are fading into obscurity.
MySQL is dead, Long live PostgreSQL!
- Hollow Innovations
- Sloppy Vector Types
- Belated JavaScript Functions
- Lagging Features
- Degrading Performance
- Irredeemable Isolation Levels
- Shrinking Ecosystem
- Who Really Killed MySQL?
- PostgreSQL Ascends as MySQL Rests in Peace
Hollow Innovations
The official MySQL website’s “What’s New in MySQL 9.0” introduces a few new features of version 9.0, with six features.
And that’s it? That’s all there is?
This is surprisingly underwhelming because PostgreSQL’s major releases every year brim with countless new features. For instance, PostgreSQL 17, slated for release this fall, already boasts an impressive list of new features, even though it’s just in beta1:

The recent slew of PostgreSQL features could even fill a book, as seen in “Quickly Mastering New PostgreSQL Features”, which covers the key enhancements from the last seven years, packing the contents to the brim:

Looking back at MySQL’s update, the last four of the six touted features are mere minor patches, barely worth mentioning. The first two—vector data types and JavaScript stored procedures—are supposed to be the highlights.
BUT —
MySQL 9.0’s vector data types are just an alias of BLOB — with a simple array length function added. This kind of feature was supported by PostgreSQL when it was born 28 years ago.
And MySQL’s support for JavaScript stored procedures? It’s an enterprise-only feature—not available in the open-source version, while PostgreSQL has had this capability since 13 years ago with version 9.1.
After an eight-year wait, the “innovative update” delivers two “old features,” one of which is gated behind an enterprise edition. The term “innovation” here seems bitterly ironic and sarcastic.
Sloppy Vector Types
In the past few years, AI has exploded in popularity, boosting interest in vector databases. Nearly every mainstream DBMS now supports vector data types—except for MySQL.
Users might have hoped that MySQL 9.0, touted as an innovative release, would fill some gaps in this area. Instead, they were greeted with a shocking level of complacency—how could they be so sloppy?
According to MySQL 9.0’s official documentation, there are only three functions related to vector types. Ignoring the two that deal with string conversions, the only real functional command is VECTOR_DIM: it returns the dimension of a vector (i.e., the length of an array)!

The bar for entry into vector databases is not high—a simple vector distance function (think dot product, a 10-line C program, a coding task suitable for elementary students) would suffice. This could enable basic vector retrieval through a full table scan with an ORDER BY d LIMIT n query, representing a minimally viable feature. Yet MySQL 9 didn’t even bother to implement this basic vector distance function, which is not a capability issue but a clear sign that Oracle has lost interest in progressing MySQL. Any seasoned tech observer can see that this so-called “vector type” is merely a BLOBunder a different name—it only manages your binary data input without caring how users want to search or utilize it. Of course, it’s possible Oracle has a more robust version on its MySQL Heatwave, but what’s delivered on MySQL itself is a feature you could hack together in ten minutes.
In contrast, let’s look at PostgreSQL, MySQL’s long-standing rival. Over the past year, the PostgreSQL ecosystem has spawned at least six vector database extensions (pgvector, pgvector.rs, pg_embedding, latern, pase, pgvectorscale) and has reached new heights in a competitive race. The frontrunner, pgvector, which emerged in 2021, quickly reached heights that many specialized vector databases couldn’t, thanks to the collective efforts of developers, vendors, and users standing on PostgreSQL’s shoulders. It could even be argued that pgvector single-handedly ended this niche in databases—“Is the Dedicated Vector Database Era Over?”.
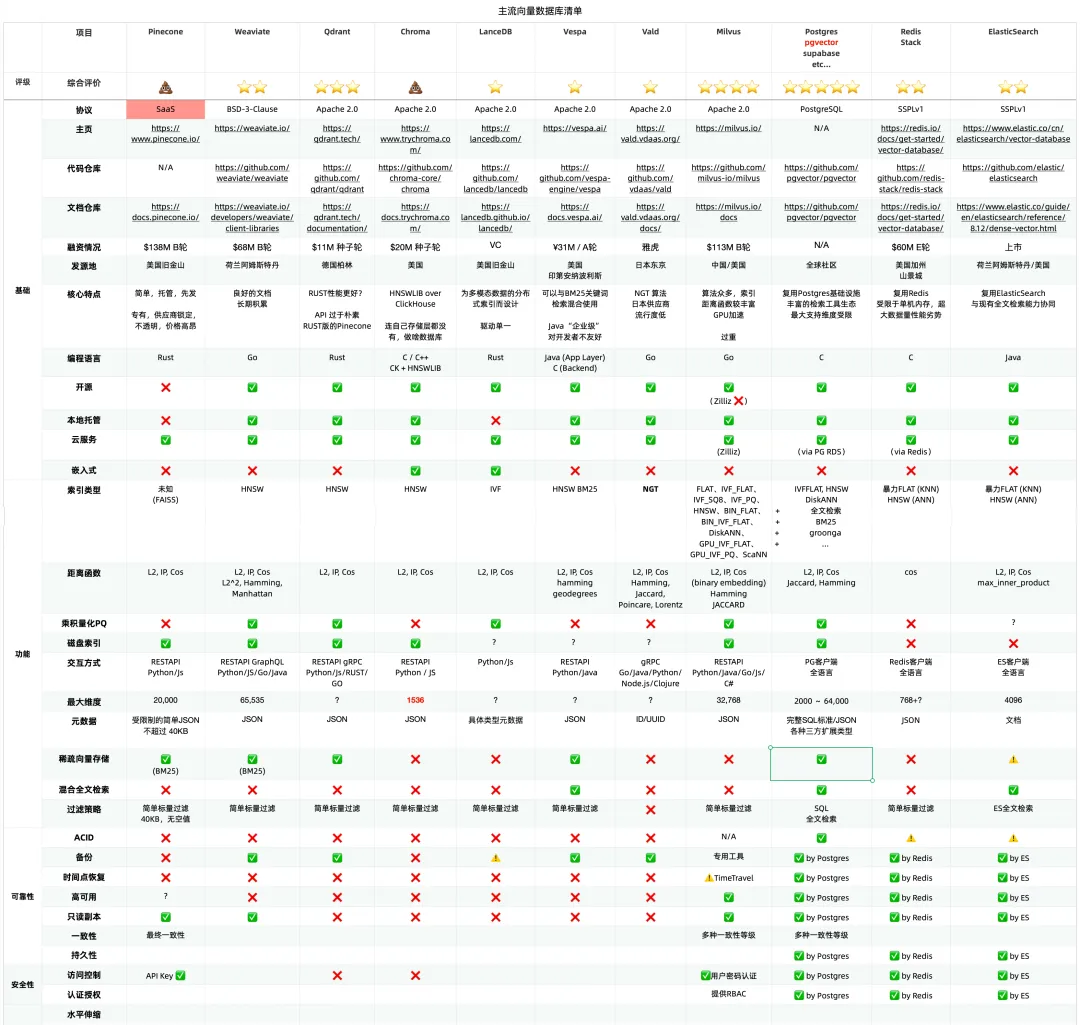
Within this year, pgvector improved its performance by 150 times, and its functionality has dramatically expanded. pgvector offers data types like float vectors, half-precision vectors, bit vectors, and sparse vectors; distance metrics like L1, L2, dot product, Hamming, and Jaccard; various vector and scalar functions and operators; supports IVFFLAT and HNSW vector indexing methods (with the pgvectorscale extension adding DiskANN indexing); supports parallel index building, vector quantization, sparse vector handling, sub-vector indexing, and hybrid retrieval, with potential SIMD instruction acceleration. These rich features, combined with a free open-source license and the collaborative power of the entire PostgreSQL ecosystem, have made pgvector a resounding success. Together with PostgreSQL, it has become the default database for countless AI projects.
Comparing pgvector with MySQL 9’s “vector” support might seem unfair, as MySQL’s offering doesn’t even come close to PostgreSQL’s “multidimensional array type” available since its inception in 1996—at least that had a robust array of functions, not just an array length calculation.
Vectors are the new JSON, but the party at the vector database table has ended, and MySQL hasn’t even managed to serve its dish. It has completely missed the growth engine of the next AI decade, just as it missed the JSON document database wave of the internet era in the previous decade.
Belated JavaScript Functions
Another “blockbuster” feature of MySQL 9.0 is JavaScript Stored Procedures.
However, using JavaScript for stored procedures isn’t a novel concept—back in 2011, PostgreSQL 9.1 could already script JavaScript stored procedures through the plv8 extension, and MongoDB began supporting JavaScript around the same time.
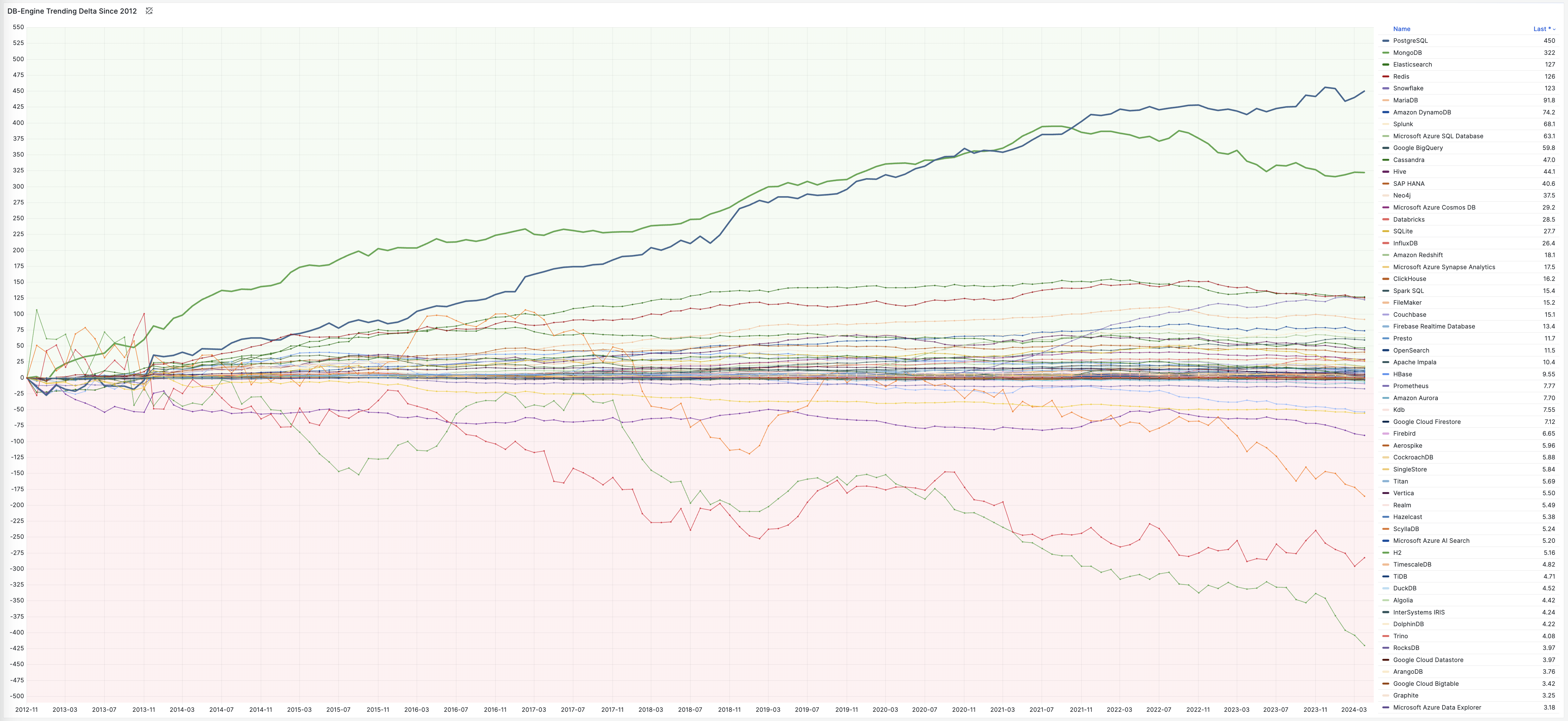
A glance at the past twelve years of the “Database Popularity Trend” on DB-Engine shows that only PostgreSQL and Mongo have truly led the pack. MongoDB (2009) and PostgreSQL 9.2 (2012) were quick to grasp internet developers’ needs, adding JSON feature support (document databases) right as the “Rise of JSON” began, thereby capturing the largest growth share in the database realm over the last decade.
Of course, Oracle, MySQL’s stepfather, added JSON features and JavaScript stored procedure support by the end of 2014 in version 12.1—while MySQL itself unfortunately didn’t catch up until 2024—but it’s too late now!
Oracle allows stored procedures to be written in C, SQL, PL/SQL, Python, Java, and JavaScript. But compared to PostgreSQL’s more than twenty supported procedural languages, it’s merely a drop in the bucket:

Unlike PostgreSQL and Oracle’s development philosophy, MySQL’s best practices generally discourage using stored procedures—making JavaScript functions a rather superfluous feature for MySQL. Even so, Oracle made JavaScript stored procedures a MySQL Enterprise Edition exclusive—considering most MySQL users opt for the open-source community version, this feature essentially went unnoticed.
Falling Behind: Features and Flexibility
MySQL’s feature deficiencies go beyond mere programming language and stored procedure support. Across various dimensions, MySQL significantly lags behind its competitor PostgreSQL—not just in core database capabilities but also in its extensibility ecosystem.
Abigale Kim from CMU has conducted research on scalability across mainstream databases, highlighting PostgreSQL’s superior extensibility among all DBMSs, boasting an unmatched number of extension plugins—375+ listed on PGXN alone, with actual ecosystem extensions surpassing a thousand.
These plugins enable PostgreSQL to serve diverse functionalities—geospatial, time-series, vector search, machine learning, OLAP, full-text search, graph databases—effectively turning it into a multi-faceted, full-stack database. A single PostgreSQL instance can replace an array of specialized components: MySQL, MongoDB, Kafka, Redis, ElasticSearch, Neo4j, and even dedicated analytical data warehouses and data lakes.
While MySQL remains confined to its “relational OLTP database” niche, PostgreSQL has transcended its relational roots to become a multi-modal database and a platform for data management abstraction and development.
PostgreSQL is devouring the database world, internalizing the entire database realm through its plugin architecture. “Just use Postgres” has moved from being a fringe exploration by elite teams to a mainstream best practice.
In contrast, MySQL shows a lackluster enthusiasm for new functionalities—a major version update that should be rife with innovative ‘breaking changes’ turns out to be either lackluster features or insubstantial enterprise gimmicks.
Deteriorated Performance
The lack of features might not be an insurmountable issue—if a database excels at its core functionalities, architects can cobble together the required features using various data components.
MySQL’s once-celebrated core attribute was its performance—notably in simple OLTP CRUD operations typical of internet-scale applications. Unfortunately, this strength is now under siege. Percona’s blog post “Sakila: Where Are You Going?” unveils a startling revelation:
Newer MySQL versions are performing worse than their predecessors.
According to Percona’s benchmarks using sysbench and TPC-C, the latest MySQL 8.4 shows a performance degradation of up to 20% compared to MySQL 5.7. MySQL expert Mark Callaghan has further corroborated this trend in his detailed performance regression tests:
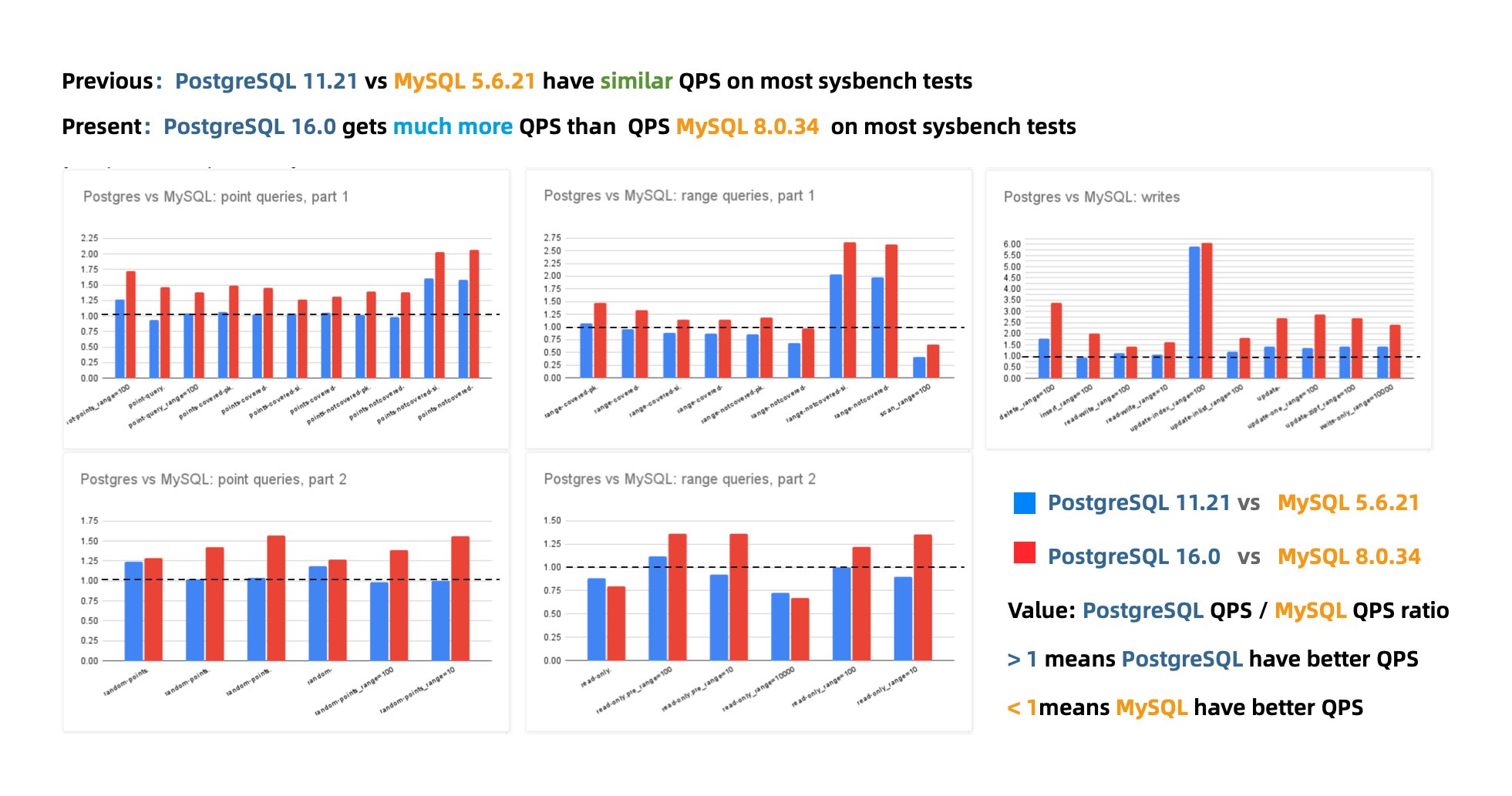
MySQL 8.0.36 shows a 25% – 40% drop in QPS throughput performance compared to MySQL 5.6!
While there have been some optimizer improvements in MySQL 8.x, enhancing performance in complex query scenarios, complex queries were never MySQL’s forte. Conversely, a significant drop in the fundamental OLTP CRUD performance is indefensible.
Peter Zaitsev commented in his post “Oracle Has Finally Killed MySQL”: “Compared to MySQL 5.6, MySQL 8.x has shown a significant performance decline in single-threaded simple workloads. One might argue that adding features inevitably impacts performance, but MariaDB shows much less performance degradation, and PostgreSQL has managed to significantly enhance performance while adding features.”
Years ago, the industry consensus was that PostgreSQL and MySQL performed comparably in simple OLTP CRUD scenarios. However, as PostgreSQL has continued to improve, it has vastly outpaced MySQL in performance. PostgreSQL now significantly exceeds MySQL in various read and write scenarios, with throughput improvements ranging from 200% to even 500% in some cases.
The performance edge that MySQL once prided itself on no longer exists.
The Incurable Isolation Levels
While performance issues can usually be patched up, correctness issues are a different beast altogether.
An article, “The Grave Correctness Problems with MySQL?”, points out that MySQL falls embarrassingly short on correctness—a fundamental attribute expected of any respectable database product.
The renowned distributed transaction testing organization, JEPSEN, discovered that the Repeatable Read (RR) isolation level claimed by MySQL’s documentation actually provides much weaker correctness guarantees. MySQL 8.0.34’s default RR isolation level isn’t truly repeatable read, nor is it atomic or monotonic, failing even the basic threshold of Monotonic Atomic View (MAV).
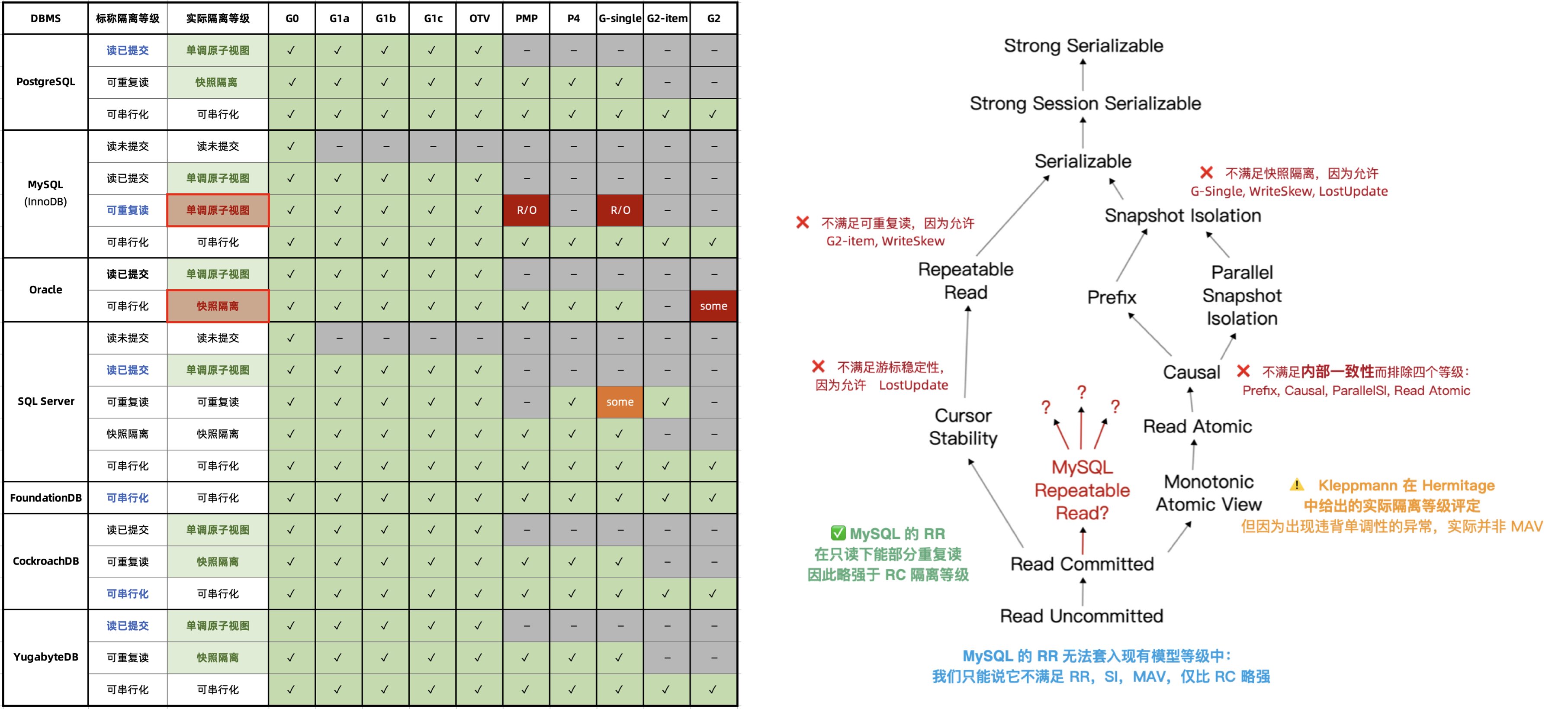
MySQL’s ACID properties are flawed and do not align with their documentation—a blind trust in these false promises can lead to severe correctness issues, such as data discrepancies and reconciliation errors, which are intolerable in scenarios where data integrity is crucial, like finance.
Moreover, the Serializable (SR) isolation level in MySQL, which could “avoid” these anomalies, is hard to use in production and isn’t recognized as best practice by official documentation or the community. While expert developers might circumvent such issues by explicitly locking in queries, this approach severely impacts performance and is prone to deadlocks.
In contrast, PostgreSQL’s introduction of Serializable Snapshot Isolation (SSI) in version 9.1 offers a complete serializable isolation level with minimal performance overhead—achieving a level of correctness even Oracle struggles to match.
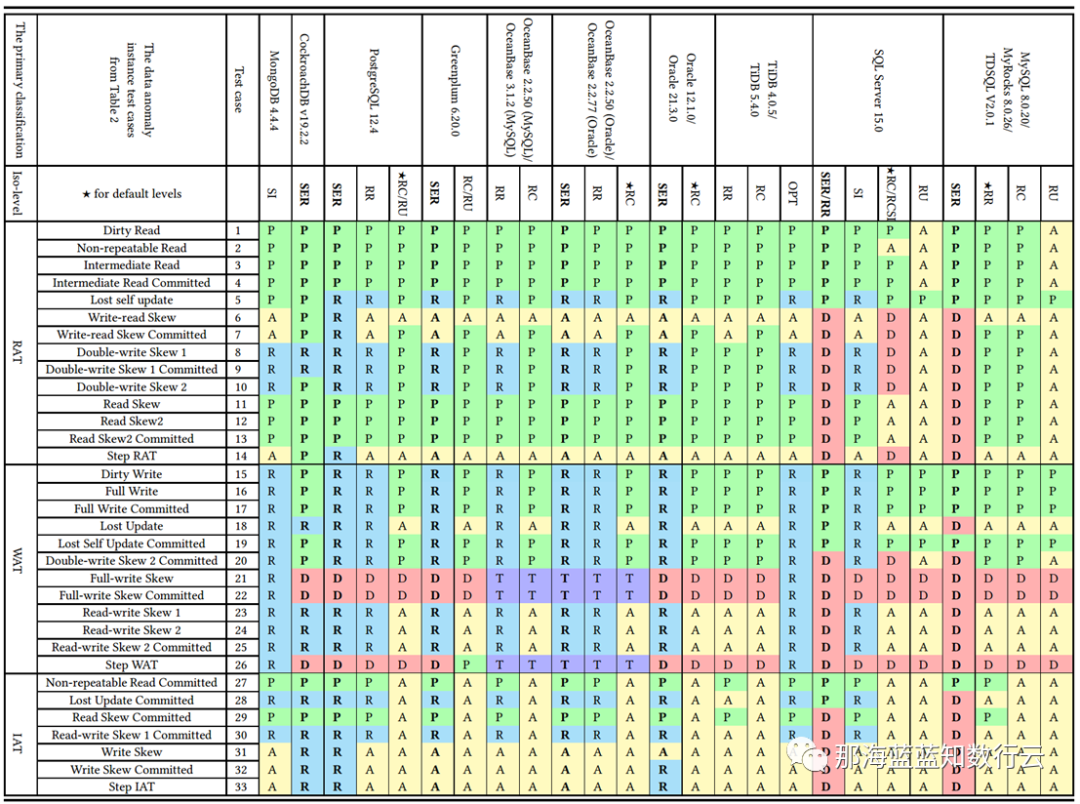
Professor Li Haixiang’s paper, “The Consistency Pantheon”, systematically evaluates the correctness of isolation levels across mainstream DBMSs. The chart uses blue/green to indicate correct handling rules/rollbacks to avoid anomalies; yellow A indicates anomalies, with more implying greater correctness issues; red “D” indicates performance-impacting deadlock detection used to handle anomalies, with more Ds indicating severe performance issues.
It’s clear that the best correctness implementation (no yellow A) is PostgreSQL’s SR, along with CockroachDB’s SR based on PG, followed by Oracle’s slightly flawed SR; mainly, these systems avoid concurrency anomalies through mechanisms and rules. Meanwhile, MySQL shows a broad swath of yellow As and red Ds, with a level of correctness and implementation that is crudely inadequate.
Doing things right is critical, and correctness should not be a trade-off. Early on, the open-source relational database giants MySQL and PostgreSQL chose divergent paths: MySQL sacrificed correctness for performance, while the academically inclined PostgreSQL opted for correctness at the expense of performance.
During the early days of the internet boom, MySQL surged ahead due to its performance advantages. However, as performance becomes less of a core concern, correctness has emerged as MySQL’s fatal flaw. What’s more tragic is that even the performance MySQL sacrificed correctness for is no longer competitive, a fact that’s disheartening.
The Shrinking Ecosystem Scale
For any technology, the scale of its user base directly determines the vibrancy of its ecosystem. Even a dying camel is larger than a horse, and a rotting ship still holds three pounds of nails. MySQL once soared with the winds of the internet, amassing a substantial legacy, aptly captured by its slogan—“The world’s most popular open-source relational database”.
![]()
Unfortunately, at least according to the 2023 results of one of the world’s most authoritative developer surveys, the StackOverflow Annual Developer Survey, MySQL has been overtaken by PostgreSQL—the crown of the most popular database has been claimed by PostgreSQL.
Especially notable, when examining the past seven years of survey data together, one can clearly see the trend of PostgreSQL becoming more popular as MySQL becomes less so (top left chart)—an obvious trend even under the same benchmarking standards.
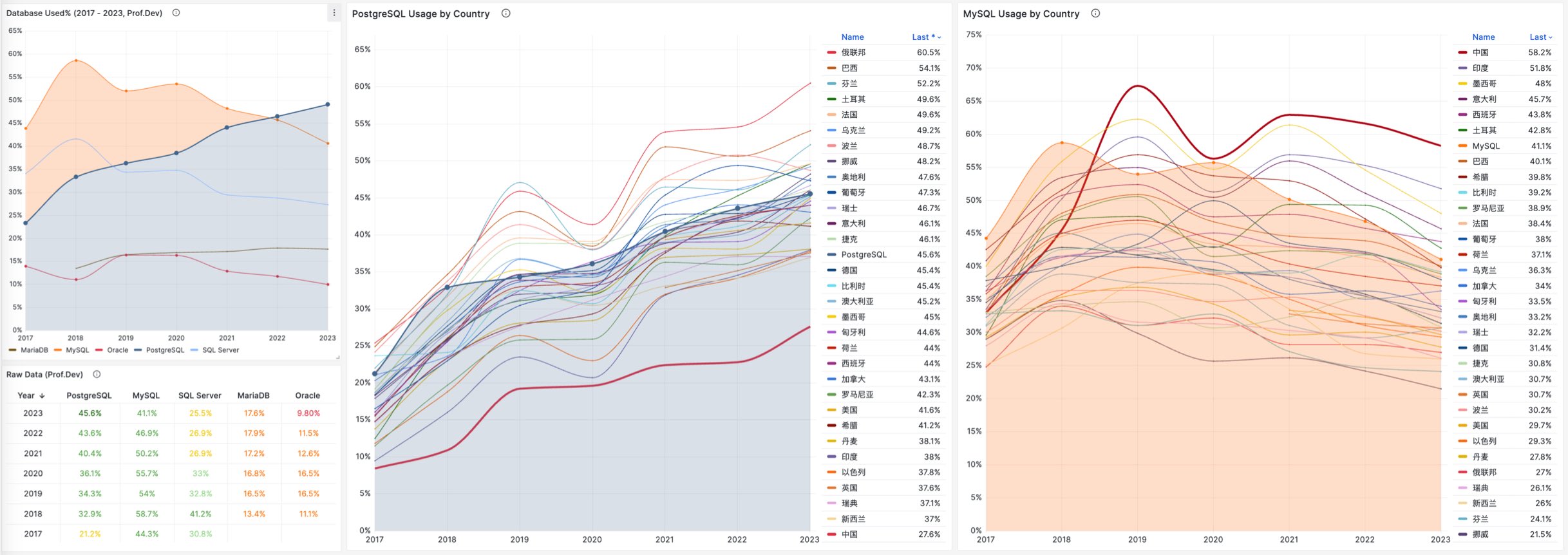
This rise and fall trend is also true in China. However, claiming PostgreSQL is more popular than MySQL in China would indeed go against intuition and fact.
Breaking down StackOverflow’s professional developers by country, it’s evident that in major countries (31 countries with sample sizes > 600), China has the highest usage rate of MySQL—58.2%, while the usage rate of PG is the lowest at only 27.6%, nearly double the PG user base.
In stark contrast, in the Russian Federation, which faces international sanctions, the community-driven and non-corporately controlled PostgreSQL has become a savior—its PG usage rate tops the chart at 60.5%, double its MySQL usage rate of 27%.
In China, due to similar motivations for self-reliance in technology, PostgreSQL’s usage rate has also seen a significant increase—tripling over the last few years. The ratio of PG to MySQL users has rapidly evolved from 5:1 six or seven years ago to 3:1 three years ago, and now to 2:1, with expectations to soon match and surpass the global average.
After all, many national databases are built on PostgreSQL—if you’re in the government or enterprise tech industry, chances are you’re already using PostgreSQL.
Who Really Killed MySQL?
Who killed MySQL, was it PostgreSQL? Peter Zaitsev argues in “Did Oracle Ultimately Kill MySQL?” that Oracle’s inaction and misguided directives ultimately doomed MySQL. He further explains the real root cause in “Can Oracle Save MySQL?”:
MySQL’s intellectual property is owned by Oracle, and unlike PostgreSQL, which is “owned and managed by the community,” it lacks the broad base of independent company contributors that PostgreSQL enjoys. Neither MySQL nor its fork, MariaDB, are truly community-driven pure open-source projects like Linux, PostgreSQL, or Kubernetes, but are dominated by a single commercial entity.
It might be wiser to leverage a competitor’s code without contributing back—AWS and other cloud providers compete in the database arena using the MySQL kernel, yet offer no contributions in return. Consequently, as a competitor, Oracle also loses interest in properly managing MySQL, instead focusing solely on its MySQL HeatWave cloud version, just as AWS focuses solely on its RDS management and Aurora services. Cloud providers share the blame for the decline of the MySQL community.
What’s gone is gone, but the future awaits. PostgreSQL should learn from the demise of MySQL—although the PostgreSQL community is very careful to avoid the dominance of any single entity, the ecosystem is indeed evolving towards a few cloud giants dominating. The cloud is devouring open source—cloud providers write the management software for open-source software, form pools of experts, and capture most of the lifecycle value of maintenance, but the largest costs—R&D—are borne by the entire open-source community. And truly valuable management/monitoring code is never given back to the open-source community—this phenomenon has been observed in MongoDB, ElasticSearch, Redis, and MySQL, and the PostgreSQL community should take heed.
Fortunately, the PG ecosystem always has enough resilient people and companies willing to stand up and maintain the balance of the ecosystem, resisting the hegemony of public cloud providers. For example, my own PostgreSQL distribution, Pigsty, aims to provide an out-of-the-box, local-first open-source cloud database RDS alternative, raising the baseline of community-built PostgreSQL database services to the level of cloud provider RDS PG. And my column series “Mudslide of Cloud Computing” aims to expose the information asymmetry behind cloud services, helping public cloud providers to operate more honorably—achieving notable success.
Although I am a staunch supporter of PostgreSQL, I agree with Peter Zaitsev’s view: “If MySQL completely dies, open-source relational databases would essentially be monopolized by PostgreSQL, and monopoly is not good as it leads to stagnation and reduced innovation. Having MySQL as a competitor is not a bad thing for PostgreSQL to reach its full potential.”
At least, MySQL can serve as a spur to motivate the PostgreSQL community to maintain cohesion and a sense of urgency, continuously improve its technical level, and continue to promote open, transparent, and fair community governance, thus driving the advancement of database technology.
MySQL had its days of glory and was once a benchmark of “open-source software,” but even the best shows must end. MySQL is dying—lagging updates, falling behind in features, degrading performance, quality issues, and a shrinking ecosystem are inevitable, beyond human control. Meanwhile, PostgreSQL, carrying the original spirit and vision of open-source software, will continue to forge ahead—it will continue on the path MySQL could not finish and write the chapters MySQL did not complete.
Reference
PostgreSQL 17 Beta1 发布!牙膏管挤爆了!
MySQL's Terrible ACID
MySQL was once the world’s most popular open-source relational database. But popularity doesn’t equal excellence, and popular things can have major issues. JEPSEN’s isolation level evaluation of MySQL 8.0.34 has blown the lid off this one - when it comes to correctness, a basic requirement for any respectable database product, MySQL’s performance is a spectacular mess.
MySQL’s documentation claims to implement Repeatable Read (RR) isolation, but the actual correctness guarantees are much weaker. Building on Hermitage’s research, JEPSEN further points out that MySQL’s RR isolation level is not actually repeatable read, and is neither atomic nor monotonic - it doesn’t even meet the basic level of Monotonic Atomic View (MAV), which is barely below Read Committed (RC) in most DBMSes
Furthermore, MySQL’s Serializable (SR) isolation level, which could theoretically “avoid” these anomalies, is impractical for production use and isn’t recognized as best practice by either official or the community. Even worse, under AWS RDS default configuration, MySQL SR doesn’t actually meet “serializable” requirements. Professor Li Haixiang’s analysis of MySQL consistency further reveals design flaws and issues with SR.
In summary, MySQL’s ACID properties have flaws and don’t match their documented promises - this can lead to severe correctness issues. While these problems can be worked around through explicit locking and other mechanisms, users should be fully aware of the trade-offs and risks: exercise caution when choosing MySQL for scenarios where correctness/consistency matters.
- Why Does Correctness Matter?
- What Did Hermitage Tell Us?
- What New Issues Did JEPSEN Find?
- Isolation Issues: Non-Repeatable Reads
- Atomicity Issues: Non-Monotonic Views
- Serialization Issues: Useless and Terrible
- The Trade-off Between Correctness and Performance
- References
Why Does Correctness Matter?
Reliable systems need to handle various errors, and in the harsh reality of data systems, many things can go wrong. Ensuring data integrity without loss or corruption is a massive undertaking prone to errors. Transactions solved this problem. They’re one of the greatest abstractions in data processing and the crown jewel of relational databases’ pride and dignity.
The transaction abstraction reduces all possible outcomes to two scenarios: either COMMIT successfully or ROLLBACK completely. Having this “undo button” means programmers no longer need to worry about half-failed operations leaving data consistency in a horrific crash site. Application error handling becomes much simpler because it doesn’t need to deal with partial failures. The guarantees it provides are summarized in four words: ACID.
Transaction Atomicity lets you abort and discard all writes before committing, while Durability promises that once a transaction commits successfully, any written data won’t be lost even if hardware fails or the database crashes. Isolation ensures each transaction can pretend it’s the only one running on the entire database - the database guarantees that when multiple transactions commit, the result is the same as if they ran one after another serially, even though they may actually run concurrently. Atomicity and isolation serve Consistency - which is really about application Correctness - the C in ACID is actually an application property rather than a transaction property, thrown in to make a nice acronym.
However, in practice, full Isolation is rare - users rarely use the so-called “Serializable” isolation level because it comes with significant performance overhead. Some popular databases like Oracle don’t even implement it - Oracle has an isolation level called “Serializable”, but it actually implements something called snapshot isolation, which is weaker than true serializability.
| Isolation Level | Dirty Read | Non-Repeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted (RU) | ⚠️ Yes | ⚠️ Yes | ⚠️ Yes |
| Read Committed (RC) | ❌ No | ⚠️ Yes | ⚠️ Yes |
| Repeatable Read (RR) | ❌ No | ❌ No | ⚠️ Yes |
| Serializable (SR) | ❌ No | ❌ No | ❌ No |
RDBMSes allow different isolation levels, letting users trade off between performance and correctness. ANSI SQL92 (poorly) standardized this trade-off by defining four isolation levels based on three types of concurrency anomalies: Weaker isolation levels “theoretically” provide better performance but allow more types of anomalies that can affect application correctness.
To ensure correctness, users can employ additional concurrency control mechanisms like explicit locking or SELECT FOR UPDATE, but this adds complexity and impacts system simplicity. For financial scenarios, correctness is crucial - accounting errors and reconciliation mismatches can have serious real-world consequences. However, for fast-and-loose internet scenarios, missing a few records may be acceptable - correctness often takes a back seat to performance. This laid the groundwork for the correctness issues in MySQL that rode the internet wave to popularity.
What Did Hermitage Tell Us?
Before diving into JEPSEN’s findings, let’s revisit the Hermitage project. Started in 2014 by Martin Kleppmann (author of the internet classic “DDIA”), it aimed to evaluate the correctness of mainstream relational databases. The project designed a series of concurrent transaction scenarios to assess the actual level of database’s claimed isolation levels.
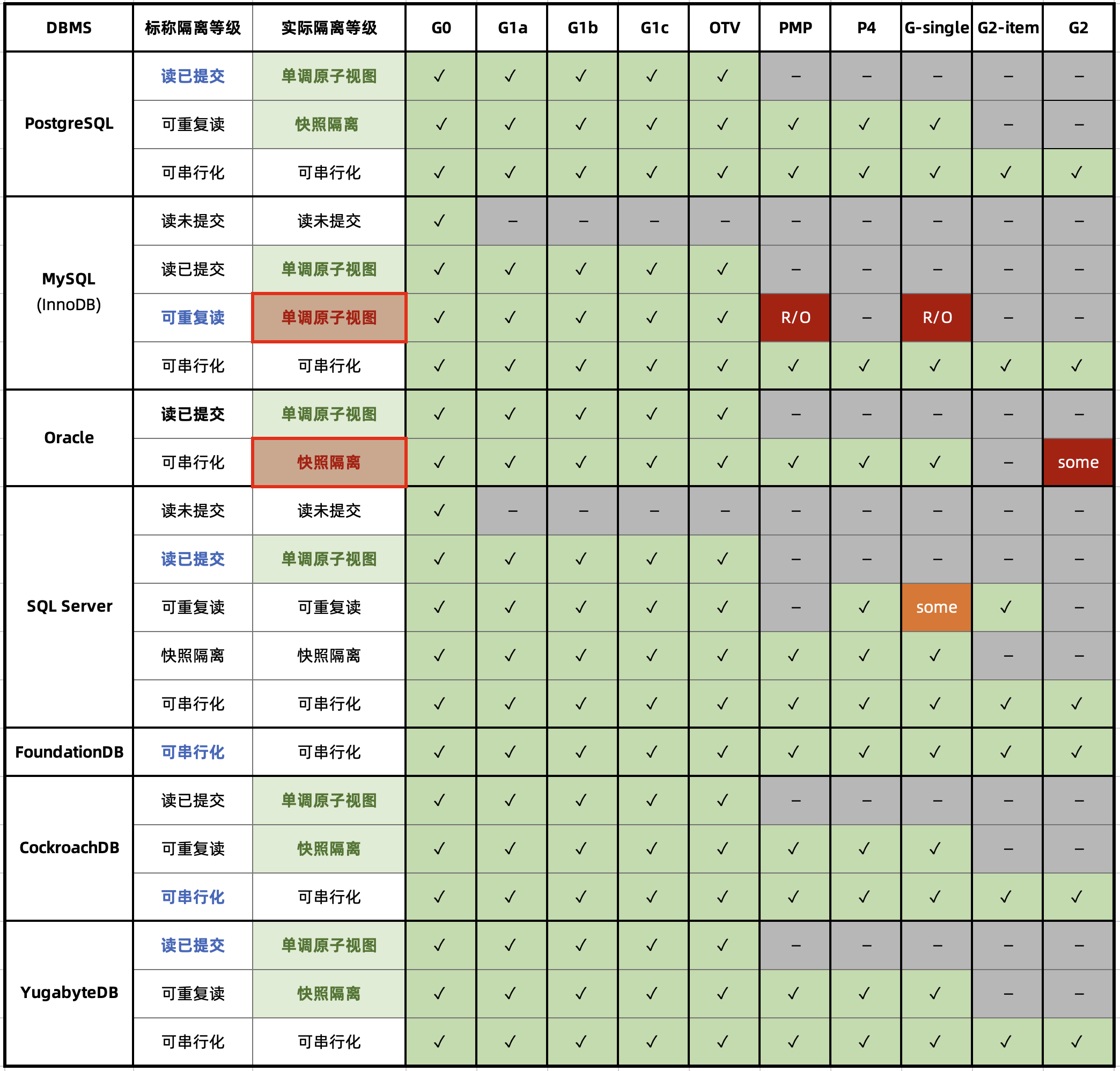
The Hermitage evaluation results table reveals two glaring issues (marked with red circles): Oracle’s Serializable fails to prevent G2 anomalies, making it effectively “Snapshot Isolation”.
MySQL’s issues are even more striking: because its default Repeatable Read can’t prevent PMP / G-Single anomalies, Hermitage downgraded its actual level to Monotonic Atomic View.
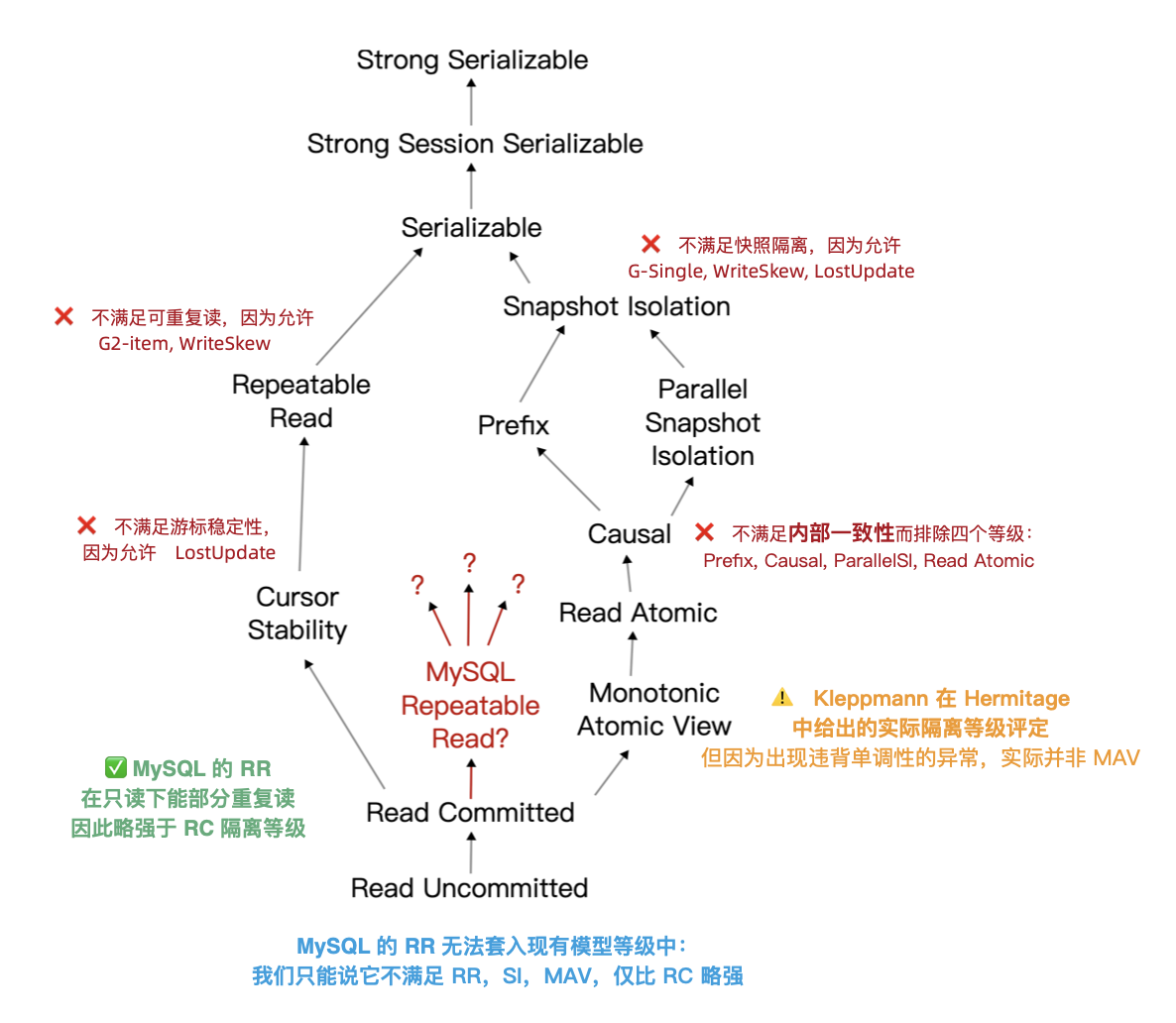
It’s worth noting that ANSI SQL 92 isolation levels are a notoriously poor and widely criticized standard, defining only three anomalies to distinguish four isolation levels - but actual anomalies/isolation levels are far more numerous. The famous paper “A Critique of ANSI SQL Isolation Levels” proposed corrections, introduced several important new isolation levels, and provided their partial order of strength (left figure).
Under the new model, many databases’ “Read Committed” and “Repeatable Read” are actually the more practical “Monotonic Atomic View” and “Snapshot Isolation”. But MySQL is truly unique: in Hermitage’s evaluation, MySQL’s Repeatable Read falls far short of Snapshot Isolation, doesn’t meet ANSI 92 Repeatable Read standards, and actually provides Monotonic Atomic View level. JEPSEN’s research further reveals that MySQL Repeatable Read doesn’t even satisfy Monotonic Atomic View, barely stronger than Read Committed.
What New Issues Did JEPSEN Find?
JEPSEN is the most authoritative testing framework in distributed systems. They recently published their evaluation of MySQL’s latest 8.0.34 version. Readers should read the original paper, but here’s the abstract:
MySQL is a popular relational database. We revisited Kleppmann’s 2014 Hermitage findings and confirmed that MySQL’s Repeatable Read isolation still exhibits G2-item, G-single, and lost update anomalies. Using Elle, our transactional consistency checker, we discovered that MySQL’s repeatable read isolation also violates internal consistency. Worse yet - it violates monotonic atomic view: a transaction can observe another transaction’s effects, then fail to observe those same effects in a subsequent attempt. As a bonus, we found that AWS RDS MySQL clusters frequently violate serializability requirements. This research was conducted independently, without compensation, and follows Jepsen research ethics.
MySQL 8.0.34’s RU, RC, and SR isolation levels match ANSI standard descriptions. And under default configuration (RR with innodb_flush_log_at_trx_commit = on), Durability isn’t an issue. The problems lie in MySQL’s default Repeatable Read isolation:
- Doesn’t satisfy ANSI SQL92 Repeatable Read (G2, WriteSkew)
- Doesn’t satisfy Snapshot Isolation (G-single, ReadSkew, LostUpdate)
- Doesn’t satisfy Cursor Stability (LostUpdate)
- Violates internal consistency (revealed by Hermitage)
- Violates read monotonicity (newly revealed by JEPSEN)
Under MySQL RR, transactions exhibited phenomena violating internal consistency, monotonicity, and atomicity. This pushed its rating down to an undefined isolation level barely above RC.
JEPSEN’s tests revealed six anomalies, skipping the known issues from 2014, let’s focus on JEPSEN’s new findings with some concrete examples.
Isolation Issues: Non-Repeatable Reads
In this test case (JEPSEN 2.3), there’s a simple people table with id as primary key, pre-populated with one row.
CREATE TABLE people (
id int PRIMARY KEY,
name text not null,
gender text not null
);
INSERT INTO people (id, name, gender) VALUES (0, "moss", "enby");
Then concurrent write transactions run - each transaction first reads the name field of this row, updates the gender field, then reads the name field again. Proper repeatable read means that within this transaction, both reads of name should return the same result.
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION; -- Start RR transaction
SELECT name FROM people WHERE id = 0; -- Returns "pebble"
UPDATE people SET gender = "femme" WHERE id = 0; -- Random update
SELECT name FROM people WHERE id = 0; -- Returns "moss"
COMMIT;
But in the test results, 126 out of 9048 transactions showed internal consistency errors - despite running at Repeatable Read isolation, the name actually changed between reads. This behavior contradicts MySQL’s isolation level documentation, which claims: “Consistent reads within the same transaction read the snapshot established by the first read.” It contradicts MySQL’s consistent read documentation, which specifically states that “InnoDB assigns a transaction a timepoint at its first read, and concurrent transaction effects shouldn’t appear in subsequent reads.”
ANSI/Adya repeatable read essentially means: once a transaction observes a value, it can count on that value staying stable for the rest of the transaction. MySQL does the opposite: write requests are invitations for another transaction to sneak in and wreck the state you just read. This isolation design and behavior is incredibly stupid. But wait, there’s more - like monotonicity and atomicity issues.
Atomicity Issues: Non-Monotonic Views
Kleppmann’s Hermitage rated MySQL repeatable read as Monotonic Atomic View (MAV). According to Bailis et al, monotonic atomic view ensures that once transaction T2 observes any results of transaction T1, T2 observes all of T1’s results.
If MySQL’s RR just took a new snapshot each time it executed a write query, it could still provide MAV isolation guarantees if snapshots were monotonic - that’s actually how PostgreSQL’s Read Committed isolation works.
However, in standard MySQL single-node deployments, that’s not the case: MySQL frequently violates monotonic atomic view under RR isolation. This JEPSEN example (2.4) demonstrates: there’s a mav table pre-populated with two records (id=0,1), both with initial value of 0.
CREATE TABLE mav (
id int PRIMARY KEY,
`value` int not null,
noop int not null
);
INSERT INTO mav (id, `value`, noop) VALUES (0, 0, 0);
INSERT INTO mav (id, `value`, noop) VALUES (1, 0, 0);
The workload is mixed read-write transactions: write transactions increment the value field of both records in the same transaction; by transaction atomicity, other transactions observing these records should see value increasing in lock-step.
START TRANSACTION;
SELECT value FROM mav WHERE id = 0; --> 0 reads 0
update mav SET noop = 73 WHERE id = 1; --> "invites" new snapshot
SELECT value FROM mav WHERE id = 1; --> 1 reads new value 1, so other row should be 1 too
SELECT value FROM mav WHERE id = 0; --> 0 but reads old value 0
COMMIT;
However, from this reading transaction’s view, it observed an “intermediate state”. The reading transaction first reads record 0’s value, then sets record 1’s noop to a random value (based on the previous case, this should let it see other transactions’ changes), then reads value from records 0/1. The result: reading record 0 gets the new value, reading record 1 gets the old value, indicating serious flaws in both monotonicity and atomicity.
MySQL’s consistent read documentation extensively discusses snapshots, but this behavior doesn’t look anything like snapshots. Snapshot systems typically provide consistent, point-in-time views of database state. They’re usually atomic: either containing all of a transaction’s results or none. Even if MySQL somehow got a non-atomic snapshot of the write transaction’s intermediate state, it must see row 0’s new value before getting row 1’s new value. But that’s not what happened: this read transaction saw changes to row 1 but missed changes to row 0 - what kind of snapshot is this?
Therefore, MySQL’s Repeatable Read isolation is neither atomic nor monotonic. In this respect, it’s even worse than most databases’ Read Committed, which at least provides actual Monotonic Atomic View.
Another noteworthy issue: MySQL transactions can violate atomicity under default configuration. I raised this issue for industry discussion in an article two years ago. The MySQL community’s stance is that this is a configurable feature via sql_mode rather than a defect.
But this doesn’t change the fact: MySQL violates the principle of least surprise by allowing users to do such atomicity-breaking stupid things under default configuration. Similar issues exist with the replica_preserve_commit_order parameter.
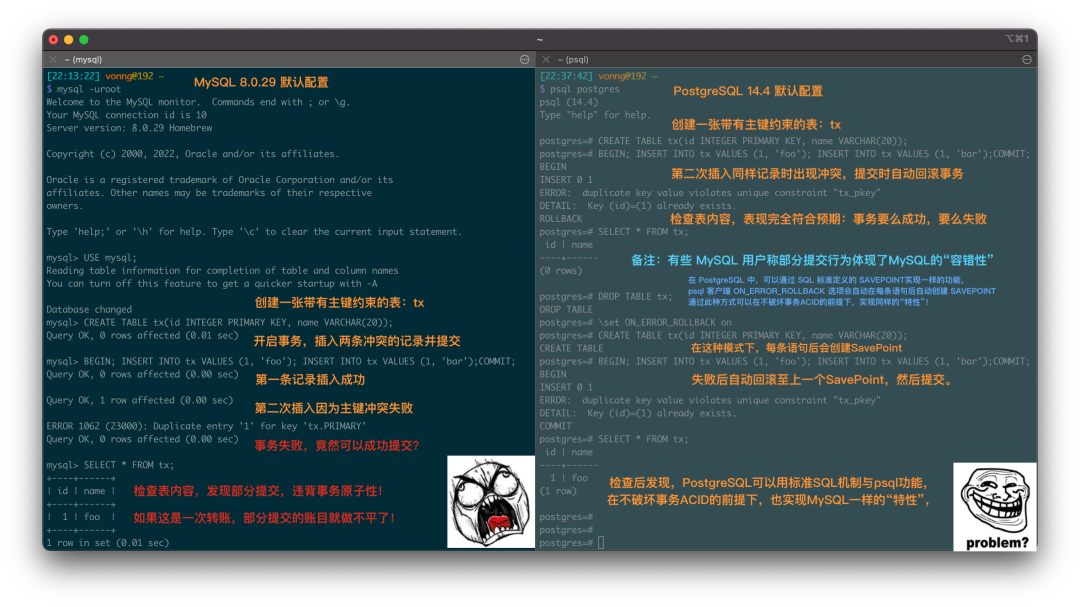
Serialization Issues: Useless and Terrible
Can Serializable prevent these concurrency anomalies? Theoretically yes, that’s what it’s designed for. But disturbingly, JEPSEN observed “Fractured Read-Like” anomalies (an example of G2) in AWS RDS clusters even under Serializable isolation. These anomalies should be prevented by RR and only appear in RC or lower levels.
Deeper investigation revealed this was related to MySQL’s replica_preserve_commit_order parameter: disabling it allows MySQL to achieve higher parallelism when replaying logs at the cost of correctness. With this option disabled, JEPSEN observed similar G-Single and G2-Item anomalies in local cluster SR isolation.
Serializable systems should guarantee transactions appear to execute in total order - not preserving this order on replicas is terrible. That’s why this parameter was disabled by default in the past (8.0.26 and below) but changed to enabled by default in MySQL 8.0.27 (2021-10-19). However, AWS RDS cluster parameter groups still use the old default “OFF” without proper documentation, hence these anomalies.
While this anomalous behavior can be avoided by enabling the parameter, using Serializable itself isn’t encouraged by MySQL official/community. The common view in the MySQL community is: avoid Serializable unless absolutely necessary; MySQL docs state: "SERIALIZABLE enforces stricter rules than REPEATABLE READ and is used mainly in special situations, like XA transactions and solving concurrency and deadlock issues."
Coincidentally, Professor Li Haixiang (former Tencent T14) specializing in database consistency, evaluated actual isolation levels of various databases including MySQL (InnoDB/8.0.20) in his “Third Generation Distributed Database” series, providing this more detailed “《Consistency Ba-Xian Diagram》” from another perspective.
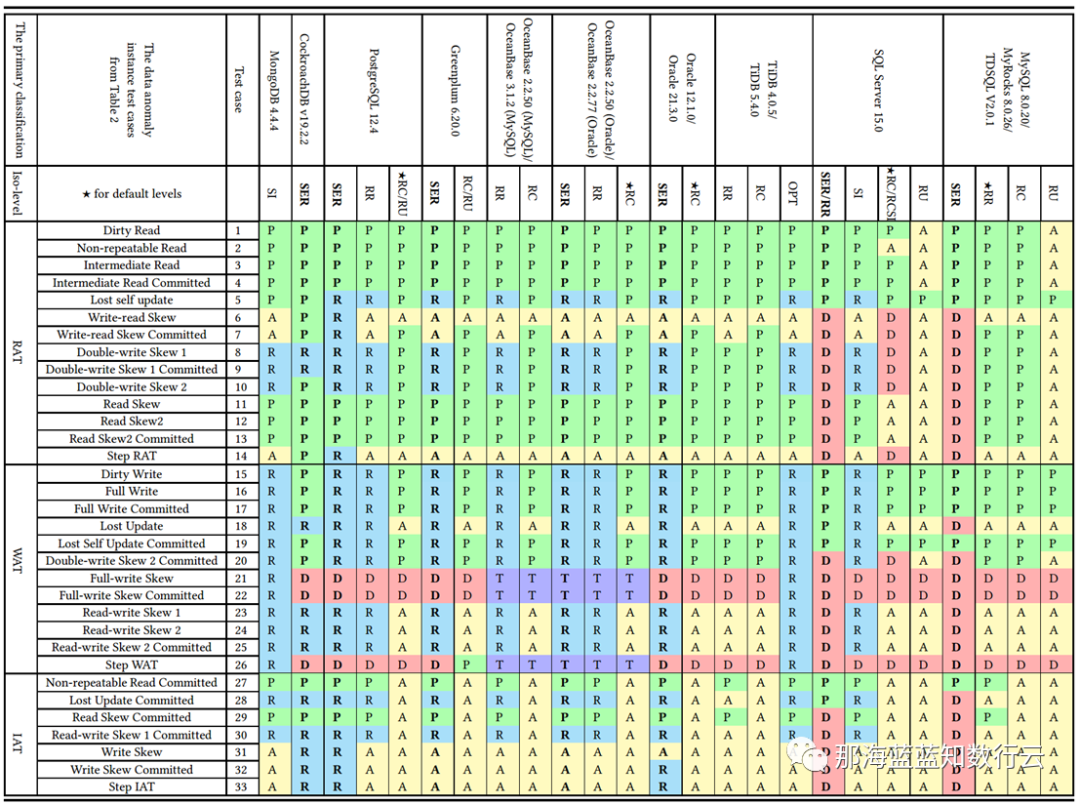
In the diagram, blue/green represents correctly using rules/rollback to avoid anomalies; yellow A represents anomalies, more yellow “A"s mean more correctness issues; red “D” indicates using performance-impacting deadlock detection to handle anomalies, more red D’s mean more performance issues.
Clearly, PostgreSQL SR and CockroachDB SR built on it have the best correctness, followed by Oracle SR; they mainly avoid concurrency anomalies through mechanisms and rules; while MySQL’s correctness level is painfully bad.
Professor Li analyzed this in detail in 《MySQL Is Good For Nothing》: although MySQL’s Serializable can ensure correctness through extensive use of deadlock detection algorithms, handling concurrency anomalies this way severely impacts the database’s performance and practical value.
The Trade-off Between Correctness and Performance
Professor Li raised a question in 《Third Generation Distributed Databases: The Kicking Era》: How to trade off between system correctness and performance?
The database world has some “habits become nature” loops. For example, many databases default to Read Committed, and many people say “RC isolation level is enough”! But why? Why set it to RC? Because they think RC level gives better database performance.
But as shown below, there’s a vicious cycle: users want better database performance, so developers set application isolation level to RC. However, users, especially in finance/insurance/securities/telecom industries, also expect data correctness, so developers have to add SELECT FOR UPDATE locks in SQL statements to ensure data correctness. This leads to severe database system performance degradation. TPC-C and YCSB scenario tests show that user-added locking causes severe performance degradation, while performance overhead under strong isolation levels isn’t actually that bad.
Using weak isolation levels seriously deviates from the original intent of the “transaction” abstraction - writing reliable transactions in lower isolation level databases is extremely complex, and the number and impact of weak isolation-related errors are widely underestimated[13]. Using weak isolation levels essentially kicks the responsibility for correctness & performance that should be guaranteed by the database to application developers.
The root of this weak isolation habit might trace back to Oracle and MySQL. For example, Oracle never provided true serializable isolation (SR is actually Snapshot Isolation), even today. So they had to promote ”using RC isolation" as a good thing. Oracle was one of the most popular databases in the past, so later ones followed suit.
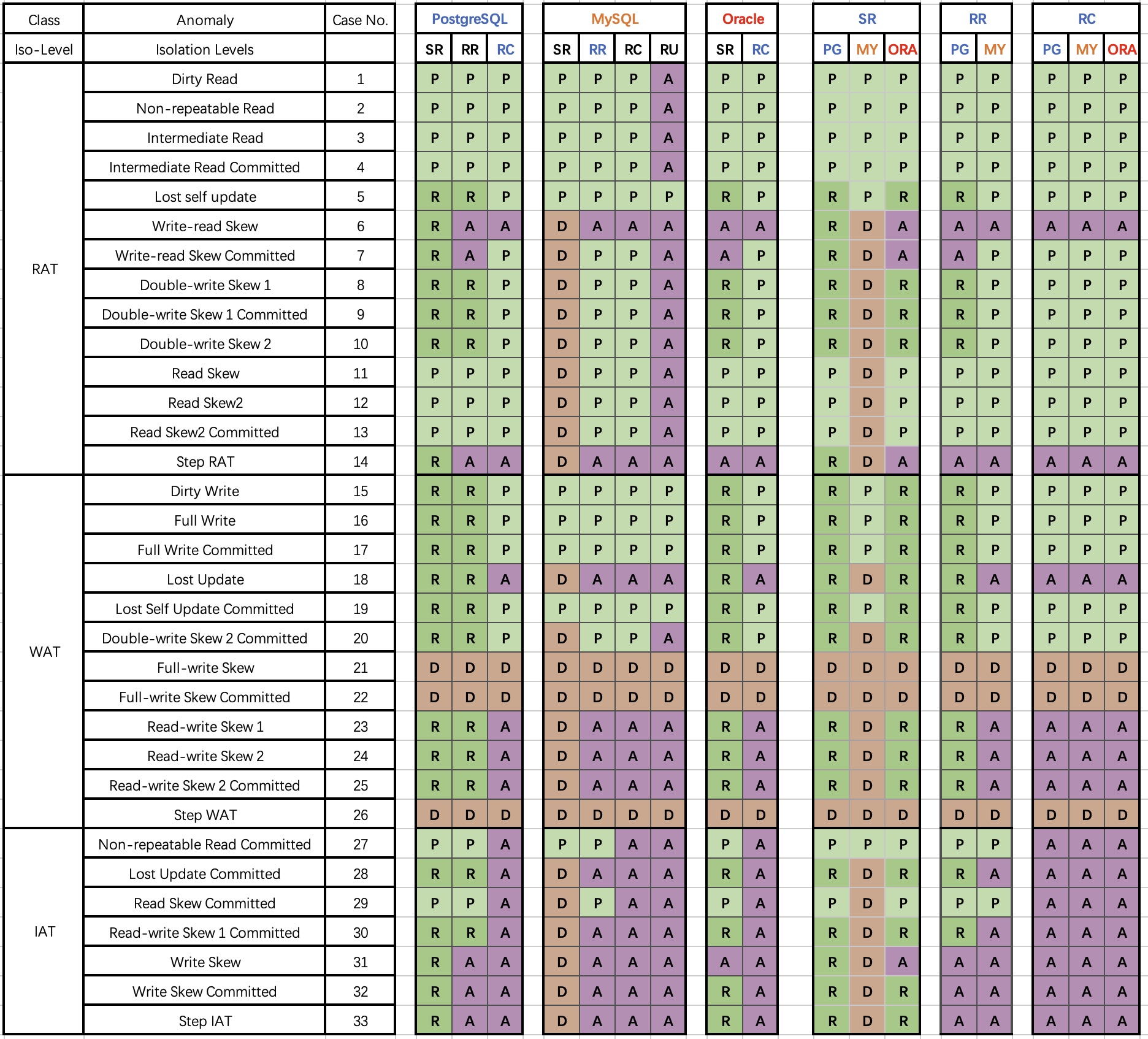
And the stereotype that weak isolation levels perform better might come from MySQL - SR implemented with extensive deadlock detection (marked red) does perform terribly. But this isn’t necessarily true for other DBMSes. For example, PostgreSQL’s Serializable Snapshot Isolation (SSI) algorithm introduced in 9.1 can provide full serializability with minimal performance overhead compared to Snapshot Isolation.
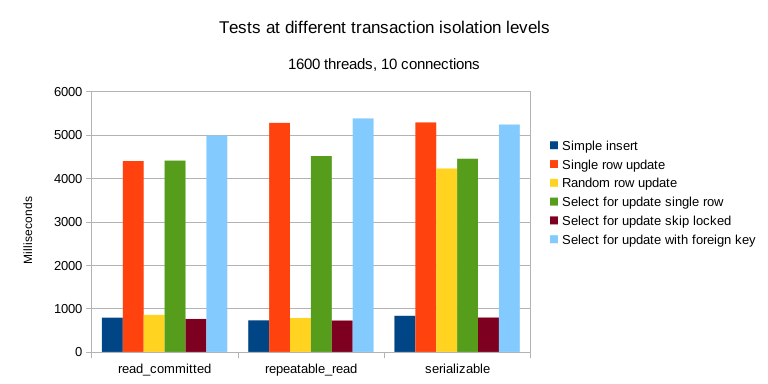
Furthermore, hardware performance improvements and price collapse under Moore’s Law mean OLTP performance is no longer scarce - in today’s world where Twitter can run on a single server, over-provisioned abundant hardware performance costs pocket change. Compared to potential losses and mental overhead from data errors, worrying about performance overhead from serializable isolation is really making mountains out of molehills.
Times have changed, software and hardware progress has made “default serializable isolation, prioritize 100% correctness” truly feasible. Trading correctness for slight performance gains seems outdated even for fast-and-loose internet scenarios. New generation distributed databases like CockroachDB and FoundationDB have chosen to default to Serializable isolation.
Doing the right thing matters, and correctness shouldn’t be a trade-off. On this point, open-source relational database giants MySQL and PostgreSQL chose opposite paths in their early implementations: MySQL pursued performance at the cost of correctness; while academic PostgreSQL pursued correctness at the cost of performance. MySQL took the lead riding the internet wave in the first half due to performance advantages. But when performance is no longer the core consideration, correctness became MySQL’s fatal bleeding point.
There are many ways to solve performance problems, even waiting for hardware performance exponential growth is a viable approach (like Paypal); but correctness issues often involve global architectural restructuring, impossible to fix overnight. Over the past decade, PostgreSQL stayed true while innovating, making great strides while ensuring best correctness, outperforming MySQL in many scenarios; while functionally crushing MySQL with ecosystem extensions introducing vector, JSON, GIS, time series, full-text search and other features.
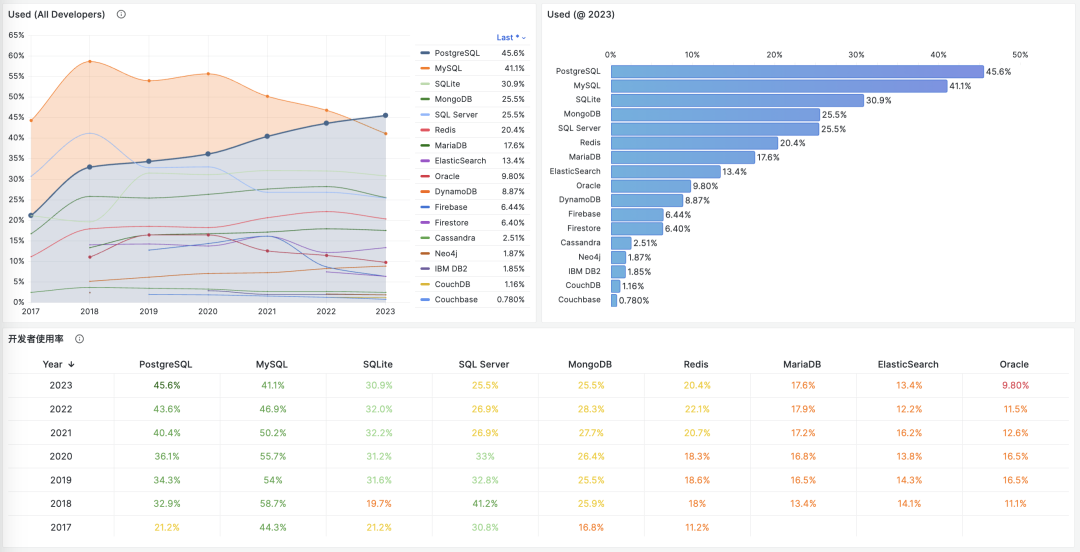
In StackOverflow’s 2023 global developer survey, PostgreSQL’s developer usage officially surpassed MySQL, becoming the world’s most popular database. While MySQL, with its mess of correctness issues and difficulty achieving high performance, should really think about its path forward.
References
[1] JEPSEN: https://jepsen.io/analyses/mysql-8.0.34
[2] Hermitage: https://github.com/ept/hermitage
[4] Jepsen Research Ethics: https://jepsen.io/ethics
[5] innodb_flush_log_at_trx_commit: https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
[6] Isolation Levels Documentation: https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html#isolevel_repeatable-read
[7] Consistent Read Documentation: https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
[9] Monotonic Atomic View/MAV: https://jepsen.io/consistency/models/monotonic-atomic-view
[10] Highly Available Transactions: Virtues and Limitations, Bailis et al: https://amplab.cs.berkeley.edu/wp-content/uploads/2013/10/hat-vldb2014.pdf
[12] replica_preserve_commit_order: https://dev.mysql.com/doc/refman/8.0/en/replication-options-replica.html#sysvar_replica_preserve_commit_order
[13] The number and impact of weak isolation-related errors are widely underestimated: https://dl.acm.org/doi/10.1145/3035918.3064037
[14] Testing PostgreSQL’s Parallel Performance: https://lchsk.com/benchmarking-concurrent-operations-in-postgresql
[15] Running Twitter on a Single Server: https://thume.ca/2023/01/02/one-machine-twitter/
Database in K8S: Pros & Cons
Whether databases should be housed in Kubernetes/Docker remains highly controversial. While Kubernetes (k8s) excels in managing stateless applications, it has fundamental drawbacks with stateful services, especially databases like PostgreSQL and MySQL.
In the previous article, “Databases in Docker: Good or Bad,” we discussed the pros and cons of containerizing databases. Today, let’s delve into the trade-offs in orchestrating databases in K8S and explore why it’s not a wise decision.
Summary
Kubernetes (k8s) is an exceptional container orchestration tool aimed at helping developers better manage a vast array of complex stateless applications. Despite its offerings like StatefulSet, PV, PVC, and LocalhostPV for supporting stateful services (i.e., databases), these features are still insufficient for running production-level databases that demand higher reliability.
Databases are more like “pets” than “cattle” and require careful nurturing. Treating databases as “cattle” in K8S essentially turns external disk/file system/storage services into new “database pets.” Running databases on EBS/network storage presents significant disadvantages in reliability and performance. However, using high-performance local NVMe disks will make the database bound to nodes and non-schedulable, negating the primary purpose of putting them in K8S.
Placing databases in K8S results in a “lose-lose” situation - K8S loses its simplicity in statelessness, lacking the flexibility to quickly relocate, schedule, destroy, and rebuild like purely stateless use. On the other hand, databases suffer several crucial attributes: reliability, security, performance, and complexity costs, in exchange for limited “elasticity” and utilization - something virtual machines can also achieve. For users outside public cloud vendors, the disadvantages far outweigh the benefits.
The “cloud-native frenzy,” exemplified by K8S, has become a distorted phenomenon: adopting k8s for the sake of k8s. Engineers add extra complexity to increase their irreplaceability, while managers fear being left behind by the industry and getting caught up in deployment races. Using tanks for tasks that could be done with bicycles, to gain experience or prove oneself, without considering if the problem needs such “dragon-slaying” techniques - this kind of architectural juggling will eventually lead to adverse outcomes.
Until the reliability and performance of the network storage surpass local storage, placing databases in K8S is an unwise choice. There are other ways to seal the complexity of database management, such as RDS and open-source RDS solutions like Pigsty, which are based on bare Metal or bare OS. Users should make wise decisions based on their situations and needs, carefully weighing the pros and cons.
The Status Quo
K8S excels in orchestrating stateless application services but was initially limited to stateful services. Despite not being the intended purpose of K8S and Docker, the community’s zeal for expansion has been unstoppable. Evangelists depict K8S as the next-generation cloud operating system, asserting that databases will inevitably become regular applications within Kubernetes. Various abstractions have emerged to support stateful services: StatefulSet, PV, PVC, and LocalhostPV.
Countless cloud-native enthusiasts have attempted to migrate existing databases into K8S, resulting in a proliferation of CRDs and Operators for databases. Taking PostgreSQL as an example, there are already more than ten different K8S deployment solutions available: PGO, StackGres, CloudNativePG, PostgresOperator, PerconaOperator, CYBERTEC-pg-operator, TemboOperator, Kubegres, KubeDB, KubeBlocks, and so on. The CNCF landscape rapidly expands, turning into a playground of complexity.
However, complexity is a cost. With “cost reduction” becoming mainstream, voices of reflection have begun to emerge. Could-Exit Pioneers like DHH, who deeply utilized K8S in public clouds, abandoned it due to its excessive complexity during the transition to self-hosted open-source solutions, relying only on Docker and a Ruby tool named Kamal as alternatives. Many began to question whether stateful services like databases suit Kubernetes.
K8S itself, in its effort to support stateful applications, has become increasingly complex, straying from its original intention as a container orchestration platform. Tim Hockin, a co-founder of Kubernetes, also voiced his rare concerns at this year’s KubeCon in “K8s is Cannibalizing Itself!”: “Kubernetes has become too complex; it needs to learn restraint, or it will stop innovating and lose its base.”
Lose-Lose Situation
In the cloud-native realm, the analogy of “pets” versus “cattle” is often used for illustrating stateful services. “Pets,” like databases, need careful and individual care, while “cattle” represent disposable, stateless applications (Disposability).
Cloud Native Applications 12 Factors: Disposability
source: https://user-images.githubusercontent.com/5445356/47986421-a8f62080-e117-11e8-9a39-3fdc6030c324.png
{kind=link}
Cloud Native Applications 12 Factors: Disposability
One of the leading architectural goals of K8S is to treat what can be treated as cattle as cattle. The attempt to “separate storage from computation” in databases follows this strategy: splitting stateful database services into state storage outside K8S and pure computation inside K8S. The state is stored on the EBS/cloud disk/distributed storage service, allowing the “stateless” database part to be freely created, destroyed, and scheduled in K8S.
Unfortunately, databases, especially OLTP databases, heavily depend on disk hardware, and network storage’s reliability and performance still lag behind local disks by orders of magnitude. Thus, K8S offers the LocalhostPV option, allowing containers to use data volumes directly lies on the host operating system, utilizing high-performance/high-reliability local NVMe disk storage.
However, this presents a dilemma: should one use subpar cloud disks and tolerate poor database reliability/performance for K8S’s scheduling and orchestration capabilities? Or use high-performance local disks tied to host nodes, virtually losing all flexible scheduling abilities? The former is like stuffing an anchor into K8S’s small boat, slowing overall speed and agility; the latter is like anchoring and pinning the ship to a specific point.
Running a stateless K8S cluster is simple and reliable, as is running a stateful database on a physical machine’s bare operating system. Mixing the two, however, results in a lose-lose situation: K8S loses its stateless flexibility and casual scheduling abilities, while the database sacrifices core attributes like reliability, security, efficiency, and simplicity in exchange for elasticity, resource utilization, and Day1 delivery speed that are not fundamentally important to databases.
A vivid example of the former is the performance optimization of PostgreSQL@K8S, which KubeBlocks contributed. K8S experts employed various advanced methods to solve performance issues that did not exist on bare metal/bare OS at all. A fresh case of the latter is Didi’s K8S architecture juggling disaster; if it weren’t for putting the stateful MySQL in K8S, would rebuilding a stateless K8S cluster and redeploying applications take 12 hours to recover?
Pros and Cons
For serious technology decisions, the most crucial aspect is weighing the pros and cons. Here, in the order of “quality, security, performance, cost,” let’s discuss the technical trade-offs of placing databases in K8S versus classic bare metal/VM deployments. I don’t want to write a comprehensive paper that covers everything. Instead, I’ll throw some specific questions for consideration and discussion.
Quality
K8S, compared to physical deployments, introduces additional failure points and architectural complexity, increasing the blast radius and significantly prolonging the average recovery time of failures. In “Is it a Good Idea to Put Databases into Docker?”, we provided an argument about reliability, which can also apply to Kubernetes — K8S and Docker introduce additional and unnecessary dependencies and failure points to databases, lacking community failure knowledge accumulation and reliability track record (MTTR/MTBF).
In the cloud vendor classification system, K8S belongs to PaaS, while RDS belongs to a more fundamental layer, IaaS. Database services have higher reliability requirements than K8S; for instance, many companies’ cloud management platforms rely on an additional CMDB database. Where should this database be placed? You shouldn’t let K8S manage things it depends on, nor should you add unnecessary extra dependencies. The Alibaba Cloud global epic failure and Didi’s K8S architecture juggling disaster have taught us this lesson. Moreover, maintaining a separate database system inside K8S when there’s already one outside is even more unjustifiable.
Security
The database in a multi-tenant environment introduces additional attack surfaces, bringing higher risks and more complex audit compliance challenges. Does K8S make your database more secure? Maybe the complexity of K8S architecture juggling will deter script kiddies unfamiliar with K8S, but for real attackers, more components and dependencies often mean a broader attack surface.
In “BrokenSesame Alibaba Cloud PostgreSQL Vulnerability Technical Details”, security personnel escaped to the K8S host node using their own PostgreSQL container and accessed the K8S API and other tenants’ containers and data. This is clearly a K8S-specific issue — the risk is real, such attacks have occurred, and even Alibaba Cloud, a local cloud industry leader, has been compromised.
《The Attacker Perspective - Insights From Hacking Alibaba Cloud》
Performance
As stated in “Is it a Good Idea to Put Databases into Docker?”, whether it’s additional network overhead, Ingress bottlenecks, or underperforming cloud disks, all negatively impact database performance. For example, as revealed in “PostgreSQL@K8s Performance Optimization” — you need a considerable level of technical prowess to make database performance in K8S barely match that on bare metal.
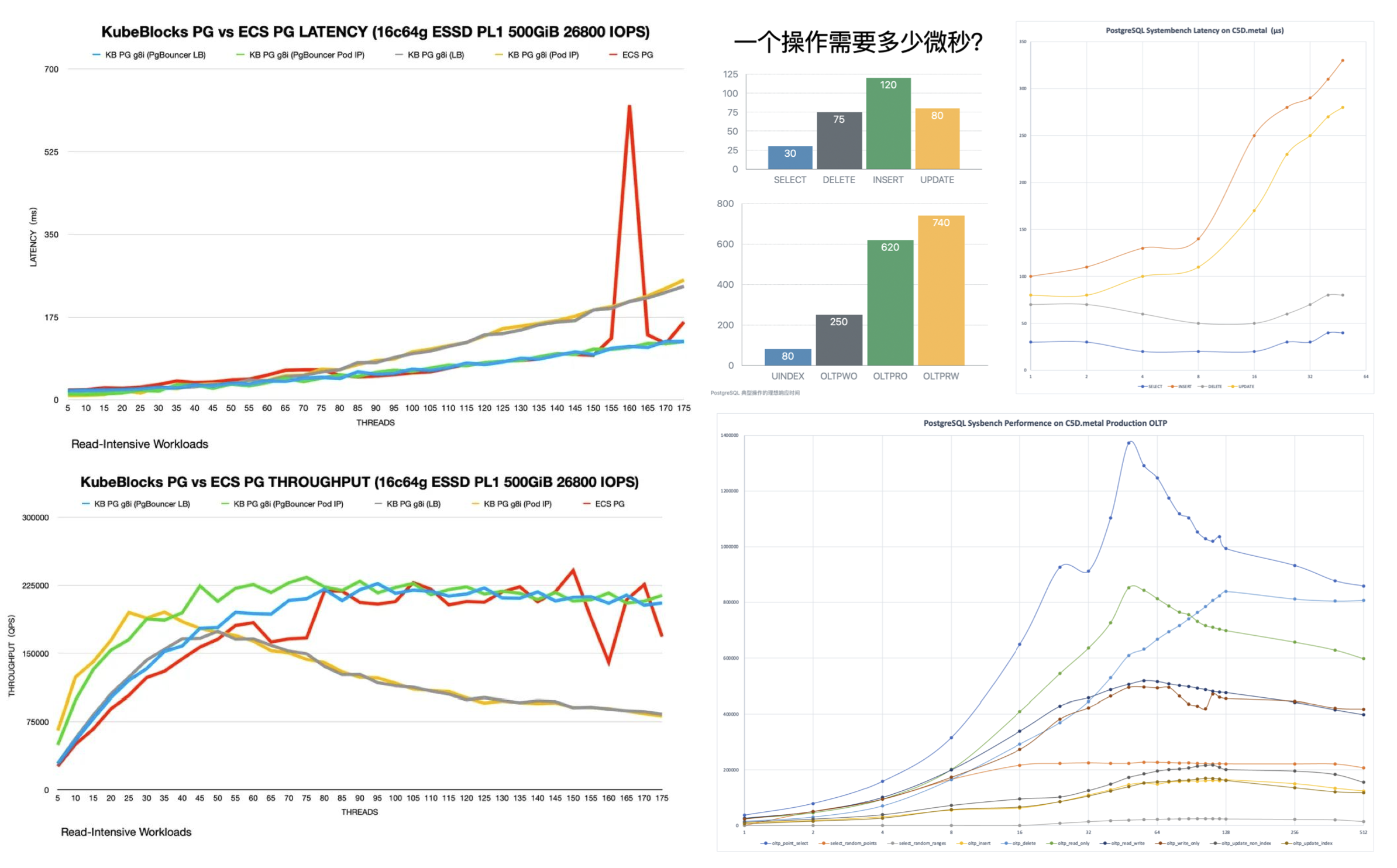
Latency is measured in ms, not µs; I almost thought my eyes were deceiving me.
Another misconception about efficiency is resource utilization. Unlike offline analytical businesses, critical online OLTP databases should not aim to increase resource utilization but rather deliberately lower it to enhance system reliability and user experience. If there are many fragmented businesses, resource utilization can be improved through PDB/shared database clusters. K8S’s advocated elasticity efficiency is not unique to it — KVM/EC2 can also effectively address this issue.
In terms of cost, K8S and various Operators provide a decent abstraction, encapsulating some of the complexity of database management, which is attractive for teams without DBAs. However, the complexity reduced by using it to manage databases pales in comparison to the complexity introduced by using K8S itself. For instance, random IP address drifts and automatic Pod restarts may not be a big issue for stateless applications, but for databases, they are intolerable — many companies have had to attempt to modify kubelet to avoid this behavior, thereby introducing more complexity and maintenance costs.
As stated in “From Reducing Costs and Smiles to Reducing Costs and Efficiency” “Reducing Complexity Costs” section: Intellectual power is hard to accumulate spatially: when a database encounters problems, it needs database experts to solve them; when Kubernetes has problems, it needs K8S experts to look into them; however, when you put a database into Kubernetes, complexities combine, the state space explodes, but the intellectual bandwidth of individual database experts and K8S experts is hard to stack — you need a dual expert to solve the problem, and such experts are undoubtedly much rarer and more expensive than pure database experts. Such architectural juggling is enough to cause major setbacks for most teams, including top public clouds/big companies, in the event of a failure.

The Cloud-Native Frenzy
An interesting question arises: if K8S is unsuitable for stateful databases, why are so many companies, including big players, rushing to do this? The reasons are not technical.
Google open-sourced its K8S battleship, modeled after its internal Borg spaceship, and managers, fearing being left behind, rushed to adopt it, thinking using K8S would put them on par with Google. Ironically, Google doesn’t use K8S; it was more likely to disrupt AWS and mislead the industry. However, most companies don’t have the manpower like Google to operate such a battleship. More importantly, their problems might need a simple vessel. Running MySQL + PHP, PostgreSQL + Go/Python on bare metal has already taken many companies to IPO.
Under modern hardware conditions, the complexity of most applications throughout their lifecycle doesn’t justify using K8S. Yet, the “cloud-native” frenzy, epitomized by K8S, has become a distorted phenomenon: adopting k8s just for the sake of k8s. Some engineers are looking for “advanced” and “cool” technologies used by big companies to fulfill their personal goals like job hopping or promotions or to increase their job security by adding complexity, not considering if these “dragon-slaying” techniques are necessary for solving their problems.
The cloud-native landscape is filled with fancy projects. Every new development team wants to introduce something new: Helm today, Kubevela tomorrow. They talk big about bright futures and peak efficiency, but in reality, they create a mountain of architectural complexities and a playground for “YAML Boys” - tinkering with the latest tech, inventing concepts, earning experience and reputation at the expense of users who bear the complexity and maintenance costs.
CNCF Landscape
The cloud-native movement’s philosophy is compelling - democratizing the elastic scheduling capabilities of public clouds for every user. K8S indeed excels in stateless applications. However, excessive enthusiasm has led K8S astray from its original intent and direction - simply doing well in orchestrating stateless applications, burdened by the ill-conceived support for stateful applications.
Making Wise Decisions
Years ago, when I first encountered K8S, I too was fervent —— It was at TanTan. We had over twenty thousand cores and hundreds of database clusters, and I was eager to try putting databases in Kubernetes and testing all the available Operators. However, after two to three years of extensive research and architectural design, I calmed down and abandoned this madness. Instead, I architected our database service based on bare metal/operating systems. For us, the benefits K8S brought to databases were negligible compared to the problems and hassles it introduced.
Should databases be put into K8S? It depends: for public cloud vendors who thrive on overselling resources, elasticity and utilization are crucial, which are directly linked to revenue and profit, While reliability and performance take a back seat - after all, an availability below three nines means compensating 25% monthly credit. But for most user, including ourselves, these trade-offs hold different: One-time Day1 Setup, elasticity, and resource utilization aren’t their primary concerns; reliability, performance, Day2 Operation costs, these core database attributes are what matter most.
We open-sourced our database service architecture — an out-of-the-box PostgreSQL distribution and a local-first RDS alternative: Pigsty. We didn’t choose the so-called “build once, run anywhere” approach of K8S and Docker. Instead, we adapted to different OS distros & major versions, and used Ansible to achieve a K8S CRD IaC-like API to seal management complexity. This was arduous, but it was the right thing to do - the world does not need another clumsy attempt at putting PostgreSQL into K8S. Still, it does need a production database service architecture that maximizes hardware performance and reliability.
Pigsty vs StackGres
Perhaps one day, when the reliability and performance of distributed network storage surpass local storage and mainstream databases have some native support for storage-computation separation, things might change again — K8S might become suitable for databases. But for now, I believe putting serious production OLTP databases into K8S is immature and inappropriate. I hope readers will make wise choices on this matter.
Reference
Database in Docker: Is that a good idea?
《What can we learn from DiDi’s Epic k8s Failure》
NewSQL: Distributive Nonsens
As hardware technology advances, the capacity and performance of standalone databases have reached unprecedented heights. In this transformative era, distributed (TP) databases appear utterly powerless, much like the “data middle platform,” donning the emperor’s new clothes in a state of self-deception.
- TL; DR
- The Pull of the Internet
- The Trade-Offs of Distributive
- The Impact of New Hardware
- The Predicament of False Needs
- The Struggles in Confusion
- References
TL; DR
The core trade-off of distributed databases is: “quality for quantity,” sacrificing functionality, performance, complexity, and reliability for greater data capacity and throughput. However, “what divides must eventually converge,” and hardware innovations have propelled centralized databases to new heights in capacity and throughput, rendering distributed (TP) databases obsolete.
Hardware, exemplified by NVMe SSDs, follows Moore’s Law, evolving at an exponential pace. Over a decade, performance has increased by tens of times, and prices have dropped significantly, improving the cost-performance ratio by three orders of magnitude. A single card can now hold 32TB+, with 4K random read/write IOPS reaching 1600K/600K, latency at 70µs/10µs, and a cost of less than 200 ¥/TB·year. Running a centralized database on a single machine can achieve one to two million point write/point query QPS.
Scenarios truly requiring distributed databases are few and far between, with typical mid-sized internet companies/banks handling request volumes ranging from tens to hundreds of thousands of QPS, and non-repetitive TP data at the hundred TB level. In the real world, over 99% of scenarios do not need distributed databases, and the remaining 1% can likely be addressed through classic engineering solutions like horizontal/vertical partitioning.
Top-tier internet companies might have a few genuine use cases, yet these companies have no intention to pay. The market simply cannot sustain so many distributed database cores, and the few products that do survive don’t necessarily rely on distribution as their selling point. HATP and the integration of distributed and standalone databases represent the struggles of confused distributed TP database vendors seeking transformation, but they are still far from achieving product-market fit.
The Pull of the Internet
“Distributed database” is not a term with a strict definition. In a narrow sense, it highly overlaps with NewSQL databases such as CockroachDB, YugabyteDB, TiDB, OceanBase, and TDSQL; broadly speaking, classic databases like Oracle, PostgreSQL, MySQL, SQL Server, PolarDB, and Aurora, which span multiple physical nodes and use master-slave replication or shared storage, can also be considered distributed databases. In the context of this article, a distributed database refers to the former, specifically focusing on transactional processing (OLTP) distributed relational databases.
The rise of distributed databases stemmed from the rapid development of internet applications and the explosive growth of data volumes. In that era, traditional relational databases often encountered performance bottlenecks and scalability issues when dealing with massive data and high concurrency. Even using Oracle with Exadata struggled in the face of voluminous CRUD operations, not to mention the prohibitively expensive annual hardware and software costs.
Internet companies embarked on a different path, building their infrastructure with free, open-source databases like MySQL. Veteran developers/DBAs might still recall the MySQL best practice: keep single-table records below 21 million to avoid rapid performance degradation. Correspondingly, database sharding became a widely recognized practice among large companies.
The basic idea here was “three cobblers with their wits combined equal Zhuge Liang,” using a bunch of inexpensive x86 servers + numerous sharded open-source database instances to create a massive CRUD simple data store. Thus, distributed databases often originated from internet company scenarios, evolving along the manual sharding → sharding middleware → distributed database path.
As an industry solution, distributed databases have successfully met the needs of internet companies. However, before abstracting and solidifying it into a product for external output, several questions need to be clarified:
Do the trade-offs from ten years ago still hold up today?
Are the scenarios of internet companies applicable to other industries?
Could distribute OLTP databases be a false necessity?
The Trade-Offs of Distributive
“Distributed,” along with buzzwords like “HTAP,” “compute-storage separation,” “Serverless,” and “lakehouse,” holds no inherent meaning for enterprise users. Practical clients focus on tangible attributes and capabilities: functionality, performance, security, reliability, return on investment, and cost-effectiveness. What truly matters is the trade-off: compared to classic centralized databases, what do distributed databases sacrifice, and what do they gain in return?

数据库需求层次金字塔[1]
The core trade-off of distributed databases can be summarized as “quality for quantity”: sacrificing functionality, performance, complexity, and reliability to gain greater data capacity and request throughput.
NewSQL often markets itself on the concept of “distribution,” solving scalability issues through “distribution.” Architecturally, it typically features multiple peer data nodes and a coordinator, employing distributed consensus protocols like Paxos/Raft for replication, allowing for horizontal scaling by adding data nodes.
Firstly, due to their inherent limitations, distributed databases sacrifice many features, offering only basic and limited CRUD query support. Secondly, because distributed databases require multiple network RPCs to complete requests, their performance typically suffers a 70% or more degradation compared to centralized databases. Furthermore, distributed databases, consisting of DN/CN and TSO components among others, introduce significant complexity in operations and management. Lastly, in terms of high availability and disaster recovery, distributed databases do not offer a qualitative improvement over the classic centralized master-slave setup; instead, they introduce numerous additional failure points due to their complex components.
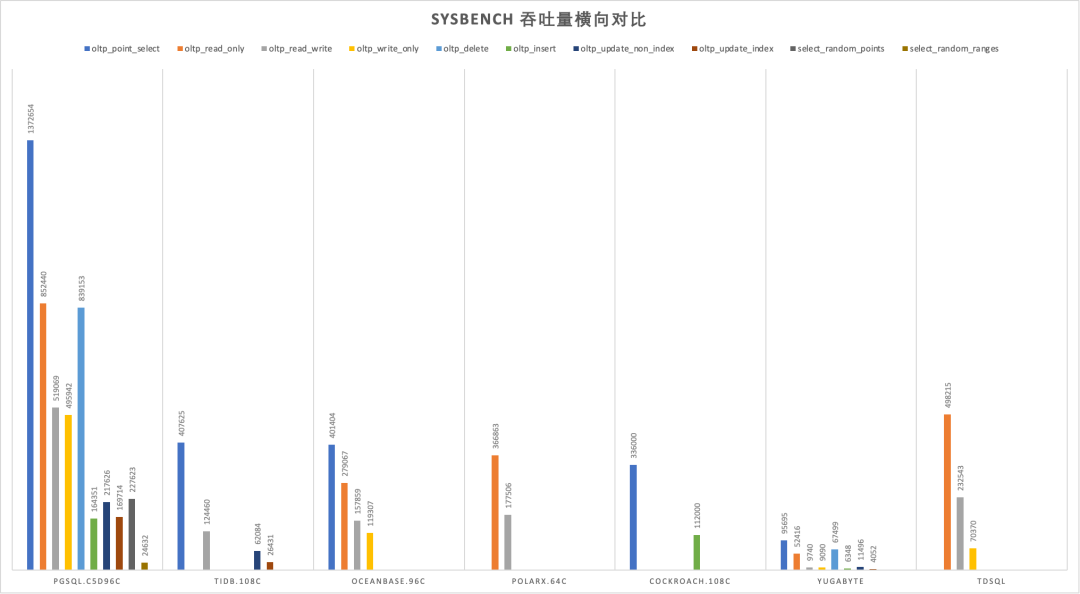
SYSBENCH吞吐对比[2]
In the past, the trade-offs of distributed databases were justified: the internet required larger data storage capacities and higher access throughputs—a must-solve problem, and these drawbacks were surmountable. But today, hardware advancements have rendered the “quantity” question obsolete, thus erasing the raison d’être of distributed databases along with the very problem they sought to solve.

Times have changed, My lord!
The Impact of New Hardware
Moore’s Law posits that every 18 to 24 months, processor performance doubles while costs halve. This principle largely applies to storage as well. From 2013 to 2023, spanning 5 to 6 cycles, we should see performance and cost differences of dozens of times compared to a decade ago. Is this the case?
Let’s examine the performance metrics of a typical SSD from 2013 and compare them with those of a typical PCI-e Gen4 NVMe SSD from 2022. It’s evident that the SSD’s 4K random read/write IOPS have jumped from 60K/40K to 1600K/600K, with prices plummeting from 2220$/TB to 40$/TB. Performance has improved by 15 to 26 times, while prices have dropped 56-fold[3,4,5], certainly validating the rule of thumb at a magnitude level.
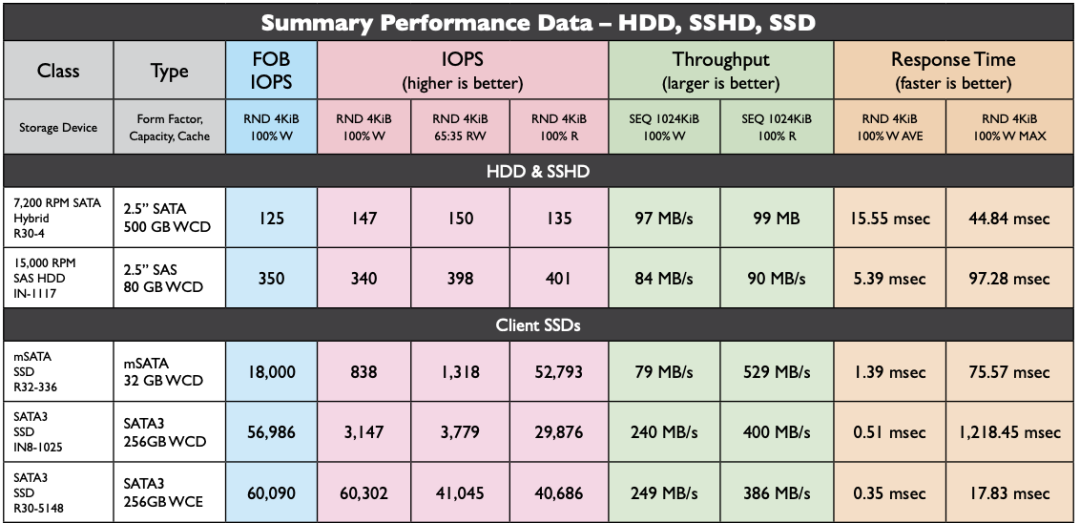
HDD/SSD Performance in 2013
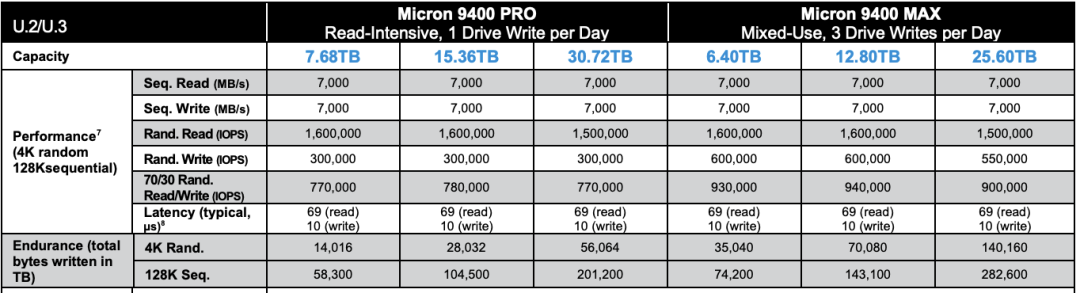
NVMe Gen4 SSD in 2022
A decade ago, mechanical hard drives dominated the market. A 1TB hard drive cost about seven or eight hundred yuan, and a 64GB SSD was even more expensive. Ten years later, a mainstream 3.2TB enterprise-grade NVMe SSD costs just three thousand yuan. Considering a five-year warranty, the monthly cost per TB is only 16 yuan, with an annual cost under 200 yuan. For reference, cloud providers’ reputedly cost-effective S3 object storage costs 1800¥/TB·year.
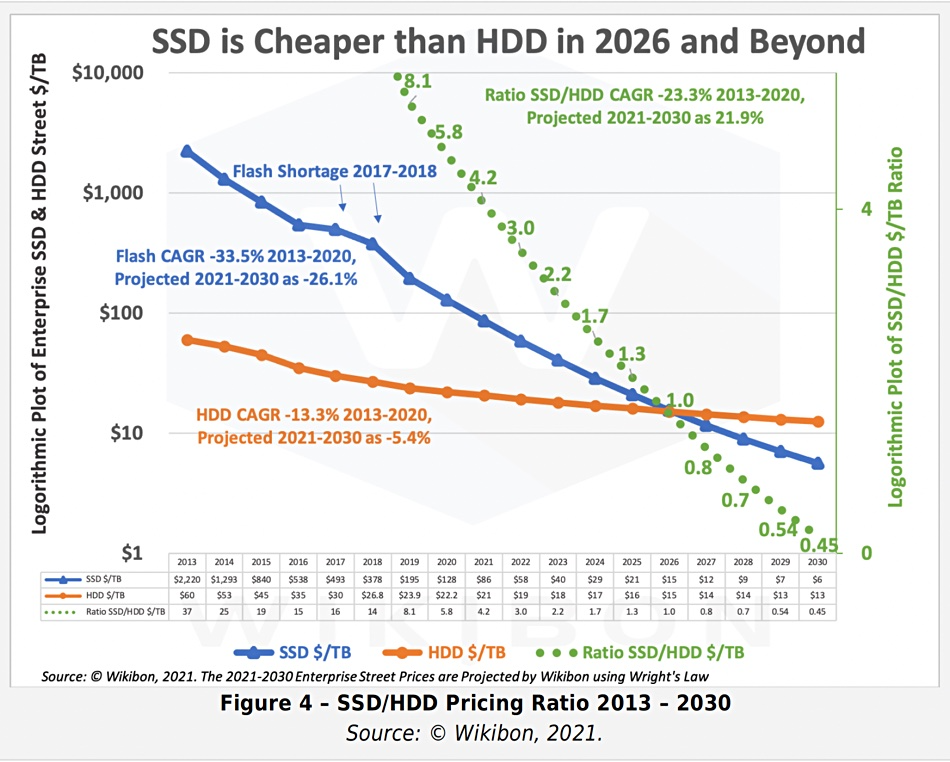
Price per unit of SSD/HDD from 2013 to 2030 with predictions
The typical fourth-generation local NVMe disk can reach a maximum capacity of 32TB to 64TB, offering 70µs/10µs 4K random read/write latencies, and 1600K/600K read/write IOPS, with the fifth generation boasting an astonishing bandwidth of several GB/s per card.
Equipping a classic Dell 64C / 512G server with such a card, factoring in five years of IDC depreciation, the total cost is under one hundred thousand yuan. Such a server running PostgreSQL sysbench can nearly reach one million QPS for single-point writes and two million QPS for point queries without issue.
What does this mean? For a typical mid-sized internet company/bank, the demand for database requests is usually in the tens of thousands to hundreds of thousands of QPS, with non-repeated TP data volumes fluctuating around hundreds of TBs. Considering hardware storage compression cards can achieve several times compression ratio, such scenarios might now be manageable by a centralized database on a single machine and card under modern hardware conditions[6].
Previously, users might have had to invest millions in high-end storage solutions like exadata, then spend a fortune on Oracle commercial database licenses and original factory services. Now, achieving similar outcomes starts with just a few thousand yuan on an enterprise-grade SSD card; open-source Oracle alternatives like PostgreSQL, capable of smoothly running the largest single tables of 32TB, no longer suffer from the limitations that once forced MySQL into partitioning. High-performance database services, once luxury items restricted to intelligence/banking sectors, have become affordable for all industries[7].
Cost-effectiveness is the primary product strength. The cost-effectiveness of high-performance, large-capacity storage has improved by three orders of magnitude over a decade, making the once-highlighted value of distributed databases appear weak in the face of such remarkable hardware evolution.
The Predicament of False Needs
Nowadays, sacrificing functionality, performance, complexity for scalability is most likely to be a fake-demands in most scenarios.
With the support of modern hardware, over 99% of real-world scenarios do not exceed the capabilities of a centralized, single-machine database. The remaining scenarios can likely be addressed through classical engineering methods like horizontal or vertical splitting. This holds true even for internet companies: even among the global top firms, scenarios where a transactional (TP) single table exceeds several tens of TBs are still rare.
Google Spanner, the forefather of NewSQL, was designed to solve the problem of massive data scalability, but how many enterprises actually handle data volumes comparable to Google’s? In terms of data volume, the lifetime TP data volume for the vast majority of enterprises will not exceed the bottleneck of a centralized database, which continues to grow exponentially with Moore’s Law. Regarding request throughput, many enterprises have enough database performance headroom to implement all their business logic in stored procedures and run it smoothly within the database.
“Premature optimization is the root of all evil,” designing for unneeded scale is a waste of effort. If volume is no longer an issue, then sacrificing other attributes for unneeded volume becomes meaningless.

“Premature optimization is the root of all evil”
In many subfields of databases, distributed technology is not a pseudo-requirement: if you need a highly reliable, disaster-resilient, simple, low-frequency KV storage for metadata, then a distributed etcd is a suitable choice; if you require a globally distributed table for arbitrary reads and writes across different locations and are willing to endure significant performance degradation, then YugabyteDB might be a good choice. For ensuring transparency and preventing tampering and denial, blockchain is fundamentally a leaderless distributed ledger database;
For large-scale data analytics (OLAP), distributed technology is indispensable (though this is usually referred to as data warehousing, MPP); however, in the transaction processing (OLTP) domain, distributed technology is largely unnecessary: OLTP databases are like working memory, characterized by being small, fast, and feature-rich. Even in very large business systems, the active working set at any one moment is not particularly large. A basic rule of thumb for OLTP system design is: If your problem can be solved within a single machine, don’t bother with distributed databases.
OLTP databases have a history spanning several decades, with existing cores developing to a mature stage. Standards in the TP domain are gradually converging towards three Wire Protocols: PostgreSQL, MySQL, and Oracle. If the discussion is about tinkering with database auto-sharding and adding global transactions as a form of “distribution,” it’s definitely a dead end. If a “distributed” database manages to break through, it’s likely not because of the “pseudo-requirement” of “distribution,” but rather due to new features, open-source ecosystems, compatibility, ease of use, domestic innovation, and self-reliance.
The Struggles in Confusion
The greatest challenge for distributed databases stems from the market structure: Internet companies, the most likely candidates to utilize distributed TP databases, are paradoxically the least likely to pay for them. Internet companies can serve as high-quality users or even contributors, offering case studies, feedback, and PR, but they inherently resist the notion of financially supporting software, clashing with their meme instincts. Even leading distributed database vendors face the challenge of being applauded but not financially supported.
In a recent casual conversation with an engineer at a distributed database company, it was revealed that during a POC with a client, a query that Oracle completed in 10 seconds, their distributed database could only match with an order of magnitude difference, even when utilizing various resources and Dirty Hacks. Even openGauss, which forked from PostgreSQL 9.2 a decade ago, can outperform many distributed databases in certain scenarios, not to mention the advancements seen in PostgreSQL 15 and Oracle 23c ten years later. This gap is so significant that even the original manufacturers are left puzzled about the future direction of distributed databases.
Thus, some distributed databases have started pivoting towards self-rescue, with HTAP being a prime example: while transaction processing in a distributed setting is suboptimal, analytics can benefit greatly. So, why not combine the two? A single system capable of handling both transactions and analytics! However, engineers in the real world understand that AP systems and TP systems each have their own patterns, and forcibly merging two diametrically opposed systems will only result in both tasks failing to succeed. Whether it’s classic ETL/CDC pushing and pulling to specialized solutions like ClickHouse/Greenplum/Doris, or logical replication to a dedicated in-memory columnar store, any of these approaches is more reliable than using a chimera HTAP database.
Another idea is monolithic-distributed integration: if you can’t beat them, join them by adding a monolithic mode to avoid the high costs of network RPCs, ensuring that in 99% of scenarios where distributed capabilities are unnecessary, they aren’t completely outperformed by centralized databases — even if distributed isn’t needed, it’s essential to stay in the game and prevent others from taking the lead! But the fundamental issue here is the same as with HTAP: forcing heterogeneous data systems together is pointless. If there was value in doing so, why hasn’t anyone created a monolithic binary that integrates all heterogeneous databases into a do-it-all behemoth — the Database Jack-of-all-trades? Because it violates the KISS principle: Keep It Simple, Stupid!

The plight of distributed databases is similar to that of Middle Data Platforms: originating from internal scenarios at major internet companies and solving domain-specific problems. Once riding the wave of the internet industry, the discussion of databases was dominated by distributed technologies, enjoying a moment of pride. However, due to excessive hype and promises of unrealistic capabilities, they failed to meet user expectations, ending in disappointment and becoming akin to the emperor’s new clothes.
There are still many areas within the TP database field worthy of focus: Leveraging new hardware, actively embracing changes in underlying architectures like CXL, RDMA, NVMe; or providing simple and intuitive declarative interfaces to make database usage and management more convenient; offering more intelligent automatic monitoring and control systems to minimize operational tasks; developing compatibility plugins like Babelfish for MySQL/Oracle, aiming for a unified relational database WireProtocol. Even investing in better support services would be more meaningful than chasing the false need for “distributed” features.
Time changes, and a wise man adapts. It is hoped that distributed database vendors will find their Product-Market Fit and focus on what users truly need.
References
[1] 数据库需求层次金字塔 : https://mp.weixin.qq.com/s/1xR92Z67kvvj2_NpUMie1Q
[2] PostgreSQL到底有多强? : https://mp.weixin.qq.com/s/651zXDKGwFy8i0Owrmm-Xg
[3] SSD Performence in 2013 : https://www.snia.org/sites/default/files/SNIASSSI.SSDPerformance-APrimer2013.pdf
[4] 2022 Micron NVMe SSD Spec: https://media-www.micron.com/-/media/client/global/documents/products/product-flyer/9400_nvme_ssd_product_brief.pdf
[5] 2013-2030 SSD Pricing : https://blocksandfiles.com/2021/01/25/wikibon-ssds-vs-hard-drives-wrights-law/
[6] Single Instance with 100TB: https://mp.weixin.qq.com/s/JSQPzep09rDYbM-x5ptsZA
[7] EBS: Scam: https://mp.weixin.qq.com/s/UxjiUBTpb1pRUfGtR9V3ag
[8] 中台:一场彻头彻尾的自欺欺人: https://mp.weixin.qq.com/s/VgTU7NcOwmrX-nbrBBeH_w
Is running postgres in docker a good idea?
For stateless app services, containers are an almost perfect devops solution. However, for stateful services like databases, it’s not so straightforward. Whether production databases should be containerized remains controversial.
From a developer’s perspective, I’m a big fan of Docker & Kubernetes and believe that they might be the future standard for software deployment and operations. But as a database administrator, I think hosting production databases in Docker/K8S is still a bad idea.
What problems does Docker solve?
Docker is described with terms like lightweight, standardized, portable, cost-effective, efficient, automated, integrated, and high-performance in operations. These claims are valid, as Docker indeed simplifies both development and operations. This explains why many companies are eager to containerize their software and services. However, this enthusiasm sometimes goes to the extreme of containerizing everything, including production databases.
Containers were originally designed for stateless apps, where temporary data produced by the app is logically part of the container. A service is created with a container and destroyed after use. These apps are stateless, with the state typically stored outside in a database, reflecting the classic architecture and philosophy of containerization.
But when it comes to containerizing the production database itself, the scenario changes: databases are stateful. To maintain their state without losing it when the container stops, database containers need to “punch a hole” to the underlying OS, which is named data volumes.
Such containers are no longer ephemeral entities that can be freely created, destroyed, moved, or transferred; they become bound to the underlying environment. Thus, the many advantages of using containers for traditional apps are not applicable to database containers.
Reliability
Getting software up & running is one thing; ensuring its reliability is another. Databases, central to information systems, are often critical, with failure leading to catastrophic consequences. This reflects common experience: while office software crashes can be tolerated and resolved with restarts, document loss or corruption is unresolvable and disastrous. Database failure without replica & backups can be terminal, particularly for internet/finance companies.
Reliability is the paramount attribute for databases. It’s the system’s ability to function correctly during adversity (hardware/software faults, human error), i.e. fault tolerance and resilience. Unlike liveness attribute such as performance, reliability, a safety attribute, proves itself over time or falsify by failures, often overlooked until disaster strikes.
Docker’s description notably omits “reliability” —— the crucial attribute for database.
Reliability Proof
As mentioned, reliability lacks a definitive measure. Confidence in a system’s reliability builds over time through consistent, correct operation (MTTF). Deploying databases on bare metal has been a long-standing practice, proven reliable over decades. Docker, despite revolutionizing DevOps, has a mere ten-year track record, which is insufficient for establishing reliability, especially for mission-critical production databases. In essence, there haven’t been enough “guinea pigs” to clear the minefield.
Community Knowledge
Improving reliability hinges on learning from failures. Failures are invaluable, turning unknowns into knowns and forming the bedrock of operational knowledge. Community experience with failures is predominantly based on bare-metal deployments, with a plethora of issues well-trodden over decades. Encountering a problem often means finding a well-documented solution, thanks to previous experiences. However, add “Docker” to the mix, and the pool of useful information shrinks significantly. This implies a lower success rate in data recovery and longer times to resolve complex issues when they arise.
A subtle reality is that, without compelling reasons, businesses and individuals are generally reluctant to share experiences with failures. Failures can tarnish a company’s reputation, potentially exposing sensitive data or reflecting poorly on the organization and team. Moreover, insights from failures are often the result of costly lessons and financial losses, representing core value for operations personnel, thus public documentation on failures is scarce.
Extra Failure Point
Running databases in Docker doesn’t reduce the chances of hardware failures, software bugs, or human errors. Hardware issues persist with or without Docker. Software defects, mainly application bugs, aren’t lessened by containerization, and the same goes for human errors. In fact, Docker introduces extra components, complexity, and failure points, decreasing overall system reliability.
Consider this simple scenario: if the Docker daemon crashes, the database process dies. Such incidents, albeit rare, are non-existent on bare-metal.
Moreover, the failure points from an additional component like Docker aren’t limited to Docker itself. Issues could arise from interactions between Docker and the database, the OS, orchestration systems, VMs, networks, or disks. For evidence, see the issue tracker for the official PostgreSQL Docker image: https://github.com/docker-library/postgres/issues?q=.
Intellectual power doesn’t easily stack — a team’s intellect relies on the few seasoned members and their communication overhead. Database issues require database experts; container issues, container experts. However, when databases are deployed on kubernetes & dockers, merging the expertise of database and K8S specialists is challenging — you need a dual-expert to resolve issues, and such individuals are rarer than specialists in one domain.
Moreover, one man’s meat is another man’s poison. Certain Docker features might turn into bugs under specific conditions.
Unnecessary Isolation
Docker provides process-level isolation, which generally benefits applications by reducing interaction-related issues, thereby enhancing system reliability. However, this isolation isn’t always advantageous for databases.
A subtle real-world case involved starting two PostgreSQL server on the same data directory, either on the host or one in the host and another inside a container. On bare metal, the second instance would fail to start as PostgreSQL recognizes the existing instance and refuses to launch; however, Docker’s isolation allows the second instance to start obliviously, potentially toast the data files if proper fencing mechanisms (like host port or PID file exclusivity) aren’t in place.
Do databases need isolation? Absolutely, but not this kind. Databases often demand dedicated physical machines for performance reasons, with only the database process and essential tools running. Even in containers, they’re typically bound exclusively to physical/virtual machines. Thus, the type of isolation Docker provides is somewhat irrelevant for such deployments, though it is a handy feature for cloud providers to efficiently oversell in a multi-tenant environment.
Maintainability
Docker simplify the day one setup, but bring much more troubles on day two operation.
The bulk of software expenses isn’t in initial development but in ongoing maintenance, which includes fixing vulnerabilities, ensuring operational continuity, handling outages, upgrading versions, repaying technical debt, and adding new features. Maintainability is crucial for the quality of life in operations work. Docker shines in this aspect with its infrastructure-as-code approach, effectively turning operational knowledge into reusable code, accumulating it in a streamlined manner rather than scattered across various installation/setup documents. Docker excels here, especially for stateless applications with frequently changing logic. Docker and Kubernetes facilitate deployment, scaling, publishing, and rolling upgrades, allowing Devs to perform Ops tasks, and Ops to handle DBA duties (somewhat convincingly).
Day 1 Setup
Perhaps Docker’s greatest strength is the standardization of environment configuration. A standardized environment aids in delivering changes, discussing issues, and reproducing bugs. Using binary images (essentially materialized Dockerfile installation scripts) is quicker and easier to manage than running installation scripts. Not having to rebuild complex, dependency-heavy extensions each time is a notable advantage.
Unfortunately, databases don’t behave like typical business applications with frequent updates, and creating new instances or delivering environments is a rare operation. Additionally, DBAs often accumulate various installation and configuration scripts, making environment setup almost as fast as using Docker. Thus, Docker’s advantage in environment configuration isn’t as pronounced, falling into the “nice to have” category. Of course, in the absence of a dedicated DBA, using Docker images might still be preferable as they encapsulate some operational experience.
Typically, it’s not unusual for databases to run continuously for months or years after initialization. The primary aspect of database management isn’t creating new instances or delivering environments, but the day-to-day operations — Day2 Operation. Unfortunately, Docker doesn’t offer much benefit in this area and can introduce additional complications.
Day2 Operation
Docker can significantly streamline the maintenance of stateless apps, enabling easy create/destroy, version upgrades, and scaling. However, does this extend to databases?
Unlike app containers, database containers can’t be freely destroyed or created. Docker doesn’t enhance the operational experience for databases; tools like Ansible are more beneficial. Often, operations require executing scripts inside containers via docker exec, adding unnecessary complexity.
CLI tools often struggle with Docker integration. For instance, docker exec mixes stderr and stdout, breaking pipeline-dependent commands. In bare-metal deployments, certain ETL tasks for PostgreSQL can be easily done with a single Bash line.
psql <src-url> -c 'COPY tbl TO STDOUT' | psql <dst-url> -c 'COPY tdb FROM STDIN'
Yet, without proper client binaries on the host, one must awkwardly use Docker’s binaries like:
docker exec -it srcpg gosu postgres bash -c "psql -c \"COPY tbl TO STDOUT\" 2>/dev/null" |\
docker exec -i dstpg gosu postgres psql -c 'COPY tbl FROM STDIN;'
complicating simple commands like physical backups, which require layers of command wrapping:
docker exec -i postgres_pg_1 gosu postgres bash -c 'pg_basebackup -Xf -Ft -c fast -D - 2>/dev/null' | tar -xC /tmp/backup/basebackup
docker,gosu,bash,pg_basebackup
Client-side applications (psql, pg_basebackup, pg_dump) can bypass these issues with version-matched client tools on the host, but server-side solutions lack such workarounds. Upgrading containerized database software shouldn’t necessitate host server binary upgrades.
Docker advocates for easy software versioning; updating a minor database version is straightforward by tweaking the Dockerfile and restarting the container. However, major version upgrades requiring state modification are more complex in Docker, often leading to convoluted processes like those in https://github.com/tianon/docker-postgres-upgrade.
If database containers can’t be scheduled, scaled, or maintained as easily as AppServers, why use them in production? While stateless apps benefit from Docker and Kubernetes’ scaling ease, stateful applications like databases don’t enjoy such flexibility. Replicating a large production database is time-consuming and manual, questioning the efficiency of using docker run for such operations.
Docker’s awkwardness in hosting production databases stems from the stateful nature of databases, requiring additional setup steps. Setting up a new PostgreSQL replica, for instance, involves a local data directory clone and starting the postmaster process. Container lifecycle tied to a single process complicates database scaling and replication, leading to inelegant and complex solutions. This process isolation in containers, or “abstraction leakage,” fails to neatly cover the multiprocess, multitasking nature of databases, introducing unnecessary complexity and affecting maintainability.
In conclusion, while Docker can improve system maintainability in some aspects, like simplifying new instance creation, the introduced complexities often undermine these benefits.
Tooling
Databases require tools for maintenance, including a variety of operational scripts, deployment, backup, archiving, failover, version upgrades, plugin installation, connection pooling, performance analysis, monitoring, tuning, inspection, and repair. Most of these tools are designed for bare-metal deployments. Like databases, these tools need thorough and careful testing. Getting something to run versus ensuring its stable, long-term, and correct operation are distinct levels of reliability.
A simple example is plugin and package management. PostgreSQL offers many useful plugins, such as PostGIS. On bare metal, installing this plugin is as easy as executing yum install followed by create extension postgis. However, in Docker, following best practices requires making changes at the image level to persist the extension beyond container restarts. This necessitates modifying the Dockerfile, rebuilding the image, pushing it to the server, and restarting the database container, undeniably a more cumbersome process.
Package management is a core aspect of OS distributions. Docker complicates this, as many PostgreSQL binaries are distributed not as RPM/DEB packages but as Docker images with pre-installed extensions. This raises a significant issue: how to consolidate multiple disparate images if one needs to use two, three, or over a hundred extensions from the PostgreSQL ecosystem? Compared to reliable OS package management, building Docker images invariably requires more time and effort to function properly.
Take monitoring as another example. In traditional bare-metal deployment, machine metrics are crucial for database monitoring. Monitoring in containers differs subtly from that on bare metal, and oversight can lead to pitfalls. For instance, the sum of various CPU mode durations always equals 100% on bare metal, but this assumption doesn’t necessarily hold in containers. Moreover, monitoring tools relying on the /proc filesystem may yield metrics in containers that differ significantly from those on bare metal. While such issues are solvable (e.g., mounting the Proc filesystem inside the container), complex and ugly workarounds are generally unwelcome compared to straightforward solutions.
Similar issues arise with some failure detection tools and common system commands. Theoretically, these could be executed directly on the host, but can we guarantee that the results in the container will be identical to those on bare metal? More frustrating is the emergency troubleshooting process, where necessary tools might be missing in the container, and with no external network access, the Dockerfile→Image→Restart path can be exasperating.
Treating Docker like a VM, many tools may still function, but this defeats much of Docker’s purpose, reducing it to just another package manager. Some argue that Docker enhances system reliability through standardized deployment, given the more controlled environment. While this is true, I believe that if the personnel managing the database understand how to configure the database environment, there’s no fundamental difference between scripting environment initialization in a Shell script or in a Dockerfile.
Scalability
Performance is another point that people concerned a lot. From the performance perspective, the basic principle of database deployment is: The close to hardware, The better it is. Additional isolation & abstraction layer is bad for database performance. More isolation means more overhead, even if it is just an additional memcpy in the kernel .
For performance-seeking scenarios, some databases choose to bypass the operating system’s page management mechanism to operate the disk directly, while some databases may even use FPGA or GPU to speed up query processing. Docker as a lightweight container, performance suffers not much, and the impact to performance-insensitive scenarios may not be significant, but the extra abstract layer will definitely make performance worse than make it better.
Summary
Container and orchestration technologies are valuable for operations, bridging the gap between software and services by aiming to codify and modularize operational expertise and capabilities. Container technology is poised to become the future of package management, while orchestration evolves into a “data center distributed cluster operating system,” forming the underlying infrastructure runtime for all software. As more challenges are addressed, confidently running both stateful and stateless applications in containers will become feasible. However, for databases, this remains an ideal rather than a practical option, especially in production.
It’s crucial to reiterate that the above discussion applies specifically to production databases. For development and testing, despite the existence of Vagrant-based virtual machine sandboxes, I advocate for Docker use—many developers are unfamiliar with configuring local test database environments, and Docker provides a clearer, simpler solution. For stateless production applications or those with non-critical derivative state data (like Redis caches), Docker is a good choice. But for core relational databases in production, where data integrity is paramount, one should carefully consider the risks and benefits: What’s the value of using Docker here? Can it handle potential issues? Are you prepared to assume the responsibility if things go wrong?
Every technological decision involves balancing pros and cons, like the core trade-off here of sacrificing reliability for maintainability with Docker. Some scenarios may warrant this, such as cloud providers optimizing for containerization to oversell resources, where container isolation, high resource utilization, and management convenience align well. Here, the benefits might outweigh the drawbacks. However, in many cases, reliability is the top priority, and compromising it for maintainability is not advisable. Moreover, it’s debatable whether using Docker significantly eases database management; sacrificing long-term operational maintainability for short-term deployment ease is unwise.
In conclusion, containerizing production databases is likely not a prudent choice.
Cloud Exit
S3: Elite to Mediocre
Object storage (S3) has been a defining service of cloud computing, once hailed as a paragon of cost reduction in the cloud era. Unfortunately, with the evolution of hardware and the emergence of resources cloud (Cloudflare R2) and open-source alternatives (MinIO), the once “cost-effective” object storage services have lost their value for money, becoming as much a “cash cow” as EBS. In our “Mudslide of Cloud Computing” series, we’ve already delved into the cost structure of cloud-based EC2 compute power, EBS disks, and RDS databases. Today, let’s examine the anchor of cloud services—object storage.

From Cost Reduction to Cash Cow
Object Storage, also known as Simple Storage Service (abbreviated as S3, hereafter referred to as S3), was once the flagship product for its cost-effectiveness in the cloud.
A decade ago, hardware was expensive; managing to use a bunch of several hundred GB mechanical hard drives to build a reliable storage service and design an elegant HTTP API was a significant barrier. Therefore, compared to those “enterprise IT” storage solutions, the cost-effective S3 seemed very attractive.
However, the field of computer hardware is quite unique—with a Moore’s Law that sees prices halve every two years. AWS S3 has indeed seen several price reductions in its history. The table below organizes the main post-reduction prices for S3 standard tier storage, along with the reference unit prices for enterprise-grade HDD/SSD in the corresponding years.
| Date | $/GB·Month | ¥/TB·5年 | HDD ¥/TB | SSD ¥/TB |
|---|---|---|---|---|
| 2006.03 | 0.150 | 63000 | 2800 | |
| 2010.11 | 0.140 | 58800 | 1680 | |
| 2012.12 | 0.095 | 39900 | 420 | 15400 |
| 2014.04 | 0.030 | 12600 | 371 | 9051 |
| 2016.12 | 0.023 | 9660 | 245 | 3766 |
| 2023.12 | 0.023 | 9660 | 105 | 280 |
| Price Ref | EBS | All Upfront | Buy NVMe SSD | Price Ref |
|---|---|---|---|---|
| S3 Express | 0.160 | 67200 | DHH 12T | 1400 |
| EBS io2 | 0.125 + IOPS | 114000 | Shannon 3.2T | 900 |
It’s not hard to see that the unit price of S3’s standard tier dropped from $0.15/GB·month in 2006 to $0.023/GB·month in 2023, a reduction to 15% of the original or a 6-fold decrease, which sounds good. However, when you consider that the price of the underlying HDDs for S3 dropped to 3.7% of their original, a whopping 26-fold decrease, the trickery becomes apparent.
The resource premium multiple of S3 increased from 7 times in 2006 to 30 times today!
In 2023, when we re-calculate the costs, it’s clear that the value for money of storage services like S3/EBS has changed dramatically—cloud computing power EC2 compared to building one’s own servers has a 5 – 10 times premium, while cloud block storage EBS has a several dozen to a hundred times premium compared to local SSDs. Cloud-based S3 compared to ordinary HDDs also has about a thirty times resource premium. And as the anchor of cloud services, the prices of S3/EBS/EC2 are passed on to almost all cloud services—completely stripping cloud services of their cost-effectiveness.
The core issue here is: The price of hardware resources drops exponentially according to Moore’s Law, but the savings are not passed through the cloud providers’ intermediary layer to the end-user service prices. To not advance is to go back; failing to reduce prices at the pace of Moore’s Law is effectively a price increase. Taking S3 as an example, over the past decade, cloud providers’ S3 has nominally reduced prices by 6-fold, but hardware resources have become 26 times cheaper, so how should we view this pricing now?
Cost, Performance, Throughput
Despite the high premiums of cloud services, if it represents an irreplaceable best choice, the use by high-value, price-insensitive top-tier customers is not affected even with a high premium and low cost-effectiveness. However, it’s not just about cost; the performance of storage hardware also follows Moore’s Law. Over time, building one’s own S3 has started to show a significant advantage in performance.
The performance of S3 is mainly reflected in its throughput. AWS S3’s 100 Gb/s network provides up to 12.5 GB/s of access bandwidth, which is indeed commendable. Such throughput was undoubtedly impressive a decade ago. However, today, an enterprise-level 12 TB NVMe SSD, costing less than $20,000, can achieve 14 GB/s of read/write bandwidth. 100Gb switches and network cards have also become very common, making such performance readily achievable.
In another key performance indicator, “latency,” S3 is significantly outperformed by local disks. The first-byte latency of the S3 standard tier is quite poor, ranging between 100-200ms according to the documentation. Of course, AWS has just launched “High-Performance S3” — S3 Express One Zone at 2023 Re:Invent, which can achieve millisecond-level latency, addressing this shortcoming. However, it still falls far short of the NVMe’s 4K random read/write latency of 55µs/9µs.
S3 Express’s millisecond-level latency sounds good, but when we compare it to a self-built NVMe SSD + MinIO setup, this “millisecond-level” performance is embarrassingly inadequate. Modern NVMe SSDs achieve 4K random read/write latencies of 55µs/9µs. With a thin layer of MinIO forwarding, the first-byte output latency is at least an order of magnitude better than S3 Express. If standard tier S3 is used for comparison, the performance gap widens to three orders of magnitude.
The gap in performance is just one aspect; the cost is even more crucial. The price of standard tier S3 has remained unchanged since 2016 at $0.023/GB·month, equating to 161 RMB/TB·month. The higher-tier S3 Express One Zone is an order of magnitude more expensive, at $0.16/GB·month, equating to 1120 RMB/TB·month. For reference, we can compare the data from “Reclaiming the Dividends of Computer Hardware” and “Is Cloud Storage a Cash Cow?”:
| Factor | Local PCI-E NVME SSD | Aliyun ESSD PL3 | AWS io2 Block Express |
|---|---|---|---|
| Cost | 14.5 RMB/TB·month (5-year amortization / 3.2T MLC) 5-year warranty, ¥3000 retail | 3200 RMB/TB·month (Original price 6400 RMB, monthly package 4000 RMB) 50% discount for 3-year upfront payment | 1900 RMB/TB·month Best discount for the largest specification 65536GB 256K IOPS |
| Capacity | 32TB | 32 TB | 64 TB |
| IOPS | 4K random read: 600K ~ 1.1M 4K random write 200K ~ 350K | Max 4K random read: 1M | 16K random IOPS: 256K |
| Latency | 4K random read: 75µs 4K random write: 15µs | 4K random read: 200µs | Random IO: 500µs (assumed 16K) |
| Reliability | UBER < 1e-18, equivalent to 18 nines MTBF: 2 million hours 5DWPD, over three years | Data reliability: 9 nines Storage and Data Reliability | Durability: 99.999%, 5 nines (0.001% annual failure rate) io2 details |
| SLA | 5-year warranty, direct replacement for issues | Aliyun RDS SLA Availability 99.99%: 15% monthly fee 99%: 30% monthly fee 95%: 100% monthly fee | Amazon RDS SLA Availability 99.95%: 15% monthly fee 99%: 25% monthly fee 95%: 100% monthly fee |
e local NVMe SSD example used here is the Shannon DirectIO G5i 3.2TB MLC particle enterprise-level SSD, extensively used by us. Brand new, disassembled retail pieces are priced at ¥2788 (available on Xianyu!), translating to a monthly cost per TB of 14.5 RMB over 60 months (5 years). Even if we calculate using the Inspur list price of ¥4388, the cost per TB·month is only 22.8. If this example is not convincing enough, we can refer to the 12 TB Gen4 NVMe enterprise-level SSDs purchased by DHH in “Is It Time to Give Up on Cloud Computing?”, priced at $2390 each, with a cost per TB·month of exactly 23 RMB.
So, why are NVMe SSDs, which outperform by several orders of magnitude, priced an order of magnitude cheaper than standard tier S3 (161 vs 23) and two orders of magnitude cheaper than S3 Express (1120 vs 23 x3)? If I were to use such hardware (even accounting for triple replication) + open-source software to build an object storage service, could I achieve a three orders of magnitude improvement in cost-effectiveness? (This doesn’t even account for the reliability advantages of SSDs over HDDs.)
It’s worth noting that the comparison above focuses solely on the cost of storage space. The cost of data transfer in and out of object storage is also a significant expense, with some tiers charging not for storage but for retrieval traffic. Additionally, there are issues of SSD reliability compared to HDD, data sovereignty in the cloud, etc., which will not be elaborated further here.
Of course, cloud providers might argue that their S3 service is not just about storage hardware resources but an out-of-the-box service. This includes software intellectual property and maintenance labor costs. They may claim that self-hosting has a higher failure rate, is riskier, and incurs significant operational labor costs. Unfortunately, these arguments might have been valid in 2006 or 2013, but they seem rather ludicrous today.
Self-Hosted OSS S3
A decade and a half ago, the vast majority of users lacked the IT capabilities to self-host, and there were no mature open-source alternatives to S3. Users could tolerate the premium for this high technology. However, as various cloud providers and IDCs began offering object storage, and even open-source free object storage solutions like MinIO emerged, the market shifted from a seller’s to a buyer’s market. The logic of value pricing turned into cost pricing, and the unyielding premium on resources naturally faced scrutiny — what extra value does it actually provide to justify such significant costs?
Proponents of cloud storage claim that moving to the cloud is cheaper, simpler, and faster than self-hosting. For individual webmasters and small to medium-sized internet companies within the cloud’s suitable spectrum, this claim certainly holds. If your data scale is only a few dozen GBs, or you have some medium-scale overseas business and CDN needs, I would not recommend jumping on the bandwagon to self-host object storage. You should instead turn to Cloudflare and use R2 — perhaps the best solution.
However, for the truly high-value, medium-to-large scale customers who contribute the majority of revenue, these value propositions do not necessarily hold. If you are primarily using local storage for TB/PB scale data, then you should seriously consider the cost and benefits of self-hosting object storage services — which has become very simple, stable, and mature with open-source software. Storage service reliability mainly depends on disk redundancy: apart from occasional hard drive failures (HDD AFR 1%, SSD 0.2-0.3%), requiring you (or a maintenance service provider) to replace parts, there isn’t much additional burden.
If the open-source Ceph, which mixes EBS/S3 capabilities, is considered somewhat operationally complex and not fully feature-complete; then the fully S3-compatible object storage service MinIO can be considered truly plug-and-play — a standalone binary without external dependencies, requiring only a few configuration parameters to quickly set up, transforming server disk arrays into a standard local S3-compatible service, even integrating AWS’s AK/SK/IAM compatible implementations!
From an operational management perspective, the operational complexity of Redis is an order of magnitude lower than PostgreSQL, and MinIO’s operational complexity is another order of magnitude lower than Redis. It’s so simple that I could spend less than a week to integrate MinIO deployment/monitoring as an add-on into our open-source PostgreSQL RDS solution, serving as an optional central backup storage repository.
At Tantan, several MinIO clusters were built and maintained this way: holding 25PB of data, possibly the largest scale of MinIO deployment in China at the time. How many people were needed for maintenance? Just a fraction of one operations engineer’s working time was enough, and the overall self-hosting cost was about half of the cloud list price. Practice proves the point, if anyone tells you that self-hosting object storage is difficult and expensive, you can try it yourself — in just a few hours, these sales FUD tactics will fall apart.
For object storage services, the cloud’s three core value propositions: “cheaper, simpler, faster”, the “simpler” part may not hold up, “cheaper” has turned the other way, probably only leaving “faster” — indeed, no one can beat the cloud on this point. You can apply for PB-level storage services across all regions of the world in less than a minute on the cloud, which is amazing! However, you also have to pay a high premium, several times to dozens of times over for this privilege.
Therefore, for object storage services, among the cloud’s three core value propositions: “cheaper, simpler, faster”, the “simpler” part may not hold, and “cheaper” has gone in the opposite direction, probably only leaving “faster” — indeed, no one can beat the cloud on this point. You can indeed apply for PB-level storage services across all regions of the world in less than a minute on the cloud, which is amazing! However, you also have to pay a high premium for this privilege, several to dozens of times over. For enterprises of a certain scale, compared to the cost of operations increasing several times, waiting a couple of weeks or making a one-time capital investment is not a big deal.
Summary
The exponential decline in hardware costs has not been fully reflected in the service prices of cloud providers, turning public clouds from universally beneficial infrastructure into monopolistic profit centers.
However, the tide is turning. Hardware is becoming interesting again, and cloud providers can no longer indefinitely hide this advantage. The savvy are starting to crunch the numbers, and the bold have already taken action. Pioneers like Elon Musk and DHH have fully realized this, moving away from the cloud to reap millions in financial benefits, enjoy performance gains, and gain more operational independence. More and more people are beginning to notice this, following in the footsteps of these pioneers to make the wise choice and reclaim their hardware dividends.
References
[1] 2006: https://aws.amazon.com/cn/blogs/aws/amazon_s3/
[2] 2010: http://aws.typepad.com/aws/2010/11/what-can-i-say-another-amazon-s3-price-reduction.html
[3] 2012: http://aws.typepad.com/aws/2012/11/amazon-s3-price-reduction-december-1-2012.html
[5] 2016: https://aws.amazon.com/ru/blogs/aws/aws-storage-update-s3-glacier-price-reductions/
[6] 2023: https://aws.amazon.com/cn/s3/pricing
[7] First-byte Latency: https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance.html
[8] Storage & Reliability: https://help.aliyun.com/document_detail/476273.html
[9] EBS io2 Spec: https://aws.amazon.com/cn/blogs/storage/achieve-higher-database-performance-using-amazon-ebs-io2-block-express-volumes/
[10] Aliyun RDS SLA: https://terms.aliyun.com/legal-agreement/terms/suit_bu1_ali_cloud/suit_bu1_ali_cloud201910310944_35008.html?spm=a2c4g.11186623.0.0.270e6e37n8Exh5
[11] Amazon RDS SLA: https://d1.awsstatic.com/legal/amazonrdsservice/Amazon-RDS-Service-Level-Agreement-Chinese.pdf
Reclaim Hardware Bonus from the Cloud
Hardware is interesting again, with the AI wave fueling a GPU frenzy. However, the intrigue isn’t limited to GPUs —— developments in CPUs and SSDs remain largely unnoticed by the majority of devs. A whole generation of developers is obscured by cloud hype and marketing noise.
Hardware performance is skyrocketing, and costs are plummeting, turning the public cloud from a decent service into a cash cow. These shifts necessitate a reevaluation of technology and software. It’s time to get back to basics and reclaim the hardware dividend that belongs to users.

Revolutionary New Hardware
If you’ve been unaware of computer hardware for a while, the specs of the latest gear might shock you.
Once, Intel’s CPUs saw marginal gains each generation, allowing old PCs to remain viable year after year. However, CPU evolution has recently accelerated, with significant leaps in core counts and regular 20-30% improvements in single-core performance.
For instance, AMD’s recently released desktop CPU, the Threadripper 7995WX, is a performance beast with 96 cores and 192 threads at speeds ranging from 2.5 to 5.1 GHz, retailing on Amazon for $5600. The server CPU series, EPYC, includes the previous generation EPYC Genoa 9654, with 96 cores and 192 threads at speeds ranging from 2.4 to 3.55 GHz, priced at $3940 on Amazon. This year’s new EPYC 9754 goes even further, offering a single CPU with 128 cores and 256 threads. This means a standard dual-socket server could have an astonishing 512 threads! If we consider cloud computing/container platforms’ 500% overselling rate, this could virtualize more than two thousand five hundred 1-core virtual machines.
Take AMD’s new Threadripper 7995WX, a 96-core, 192-thread behemoth clocked at 2.5 to 5.1 GHz, retailing at $5600 on Amazon. On the server side, the previous-gen EPYC Genoa 9654 offered 96 cores and 192 threads at 2.4 to 3.55 GHz, priced at $3940. The latest EPYC 9754 pushes boundaries further with 128 cores and 256 threads, enabling a dual-socket server to boast a staggering 512 vCPUs — enough to oversubscribe and virtualize over 2500+ 1c VMs at 500% oversell rates.
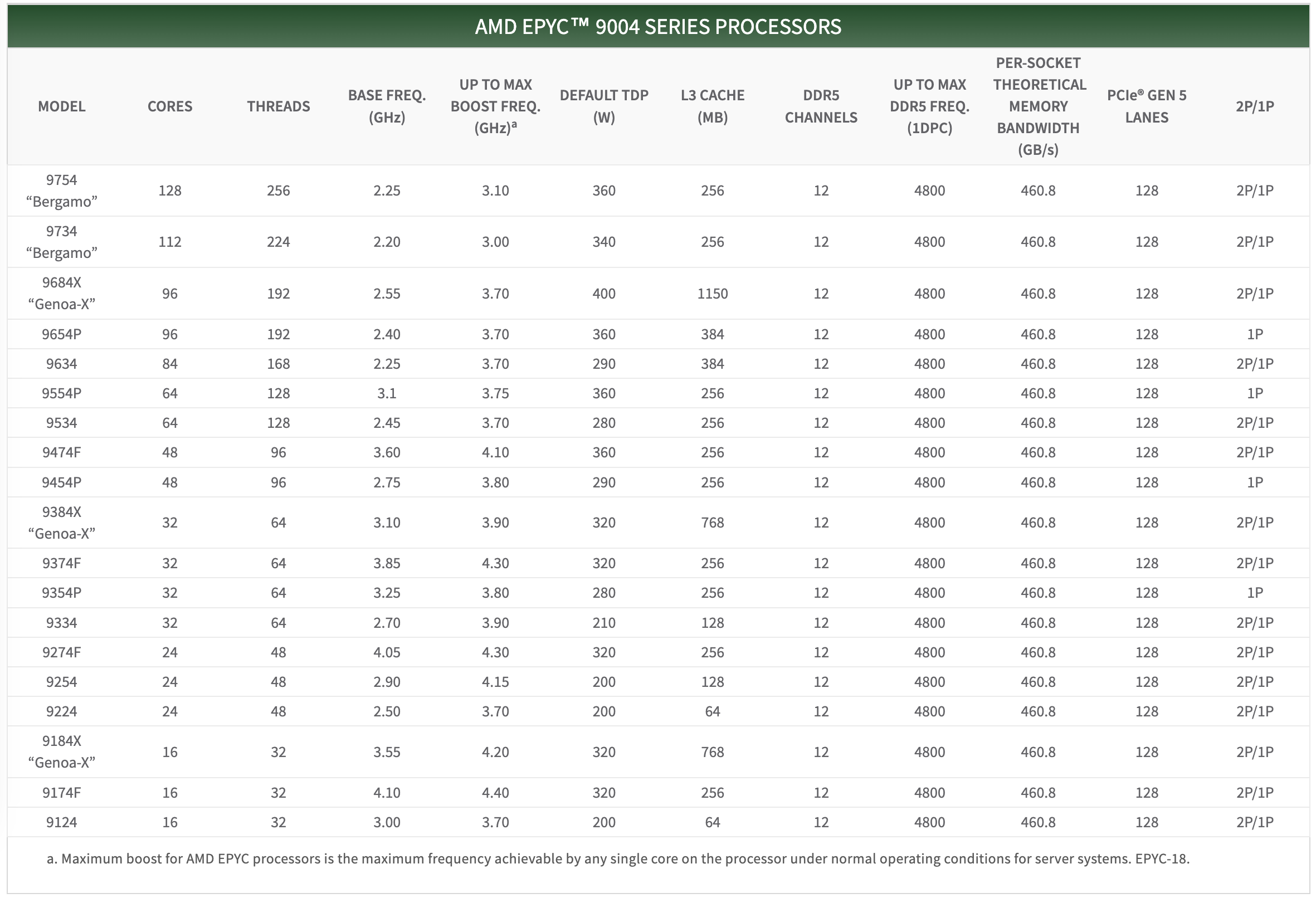
SSD/NVMe storage has seen even more dramatic generational jumps. Speeds have escalated from Gen2’s 500MB/s to Gen3’s 2.5GB/s, and now Gen4’s mainstream 7GB/s, with Gen5 at 14GB/s emerging. Gen6 is released, with Gen7 on the horizon, as I/O bandwidth doubles exponentially.
Consider the Gen5 NVMe SSD: KIOXIA CM7, which offers 128K sequential read bandwidth of 14GB/s and write bandwidth of 7GB/s, with 4K random IOPS of 2.7M for reads and 600K for writes. It’s doubtful that many database software packages can fully utilize this insane read/write bandwidth and IOPS. For context, HDD generally fluctuates around a read/write bandwidth of a few hundred MB/s, with 7200 RPM drives achieving IOPS in the tens and 15000 RPM drives in the low hundreds. NVMe SSDs’ I/O bandwidth rates are already four orders of magnitude better than HDD — 10,000x better.
In terms of 4K RankRW response times, which are of utmost concern for databases, NVMe SSDs have achieved 55/9 µs for reads & writes since several generations ago. Meanwhile, HDD seek time usually measures around 10ms, with an average rotational latency depending on speed between 2ms and 4ms, meaning a single I/O operation typically takes over a dozen milliseconds. Comparing dozens of milliseconds to 55/9µs, NVMe SSDs are three orders of magnitude faster than mechanical disks — 1000x faster!
Besides computing and storage, network hardware has also improved significantly. 40GbE and 100GbE are now commonplace — a 100GbE optical module network card costs just about several hundred dollars, offering a network transfer speed of 12 GB/s, a hundred times faster than the gigabit network cards familiar to older programmers.
1.6T Ethernet is already on the radar.
As computing, storage, and networking hardware evolve exponentially following Moore’s Law, hardware becomes fascinating again. But the real intrigue lies in how these technological leaps will impact the world.
Distributed Losing Favor
The landscape of hardware has undergone monumental changes over the past decade, rendering many assumptions in the software realm obsolete, such as those concerning distributed databases.
Today, the capabilities of a standard x86 server have reached astonishing levels. An intriguing draft calculation roughly demonstrates the feasibility of running the entirety of Twitter on a modern server (Dell PowerEdge R740xd, with 32 cores, 768GB RAM, 6TB NVMe, 360TB HDD, GPU slots, and 4x40Gbe networking). While you wouldn’t do this for production redundancy (using two or three servers might be safer), this calculation indeed raises an interesting question — Is scalability still a real issue?
At the turn of the century, an Apache server could barely handle a few hundred concurrent requests. The best software struggled with tens of thousands of concurrent connections — the industry’s notorious C10K problem, where handling several thousand connections was seen as a feat. However, with the advent of Epoll and Nginx in 2003/2004, “high concurrency” ceased to be a challenge — any novice who learned to configure Nginx could achieve what masters only dreamed of a few years earlier. “Customers in the Eyes of Cloud Providers: Poor, Idle, and Lacking Love” details this evolution.
As of 2023, the impact of hardware has once again revolutionized distributed databases: Scalability, much like the C10K problem two decades ago, has become a solved issue of the past. If a service like Twitter can run on a single server, then 99.xxxx+% of services will not exceed the scalability needs that such a server can provide throughout their entire lifecycle. This means the once-prized “distributed” technology boasted by big tech companies has become redundant with the advent of new hardware — Anyone still discussing partitioning, distributed databases, and high concurrency on a massive scale is living in the past, having ceased to learn and grow over the past decade.
The foundational assumption of distributed databases — that a single machine’s processing power is insufficient to support the load — has been shattered by contemporary hardware. Centralized databases don’t even need to lift a finger; their capacity automatically scales to meet demands that most services will never reach in their lifetime. Some might argue that services like WeChat or Alipay require distributed databases, but setting aside whether distributed databases are the only solution, assuming these rare extreme cases can sustain a couple of distributed TP kernels, distributed OLTP databases will no longer be the main direction for database development as network hardware becomes more cost-effective than disk storage. Alibaba’s choice of a distributed path for its database progeny, OceanBase, versus its current preference for centralized architectures with PolarDB, serves as a telling example.
In the realm of big data analytics (OLAP), distributed systems might have been essential, but now even this is questionable — for the majority of companies, their entire database volume could potentially be processed on a single server. Scenarios that previously demanded “distributed data warehouses” might now be addressed by running PostgreSQL or DuckDB on a modern server. True, large internet companies may have PB/ZB-level data scenarios, but even for core internet services, it’s rare for a single service’s data volume to exceed a single machine’s processing limits. For instance, BreachForums’ recent leak of 5 years of Taobao shopping records (2015-2020, 8.2 billion records) compressed to 600GB, and similarly, the data sizes for JD.com’s billions and Pinduoduo’s 14.5 billion records are on par. Moreover, companies like Dell or Inspur offer PB-level NVMe all-flash storage cabinets, capable of housing the entire U.S. insurance industry’s historical data and analysis tasks in a single box for less than $200,000.
The core trade-off of distributed databases is “quality for quantity,” sacrificing functionality, performance, complexity, and reliability in exchange for greater data capacity and throughput. However, “premature optimization is the root of all evil,” and designing for unnecessary scale is futile. If scale is no longer an issue, then sacrificing other attributes for unneeded capacity, incurring extra complexity and costs, becomes utterly pointless.
Cost of Owning Servers
With new hardware boasting such powerful performance, what about the cost? Moore’s Law states that every 18 to 24 months, processor performance doubles while the cost halves. Compared to a decade ago, new hardware is not only more powerful but also cheaper.
In “DHH: The Cloud-Exit Odyssey”, we have a fresh example of a public procurement. DHH and 37 Signals purchased a batch of physical machines for their move away from the cloud in 2023: they bought 20 servers from Dell, totaling 4,000-core vCPUs, 7,680GB of memory, and 384TB of NVMe storage, among other things, for a total expenditure of $500,000.
The specific configuration of each server was as follows: Dell R7625 server, 192 vCPU / 384 GB memory: two AMD EPYC 9454 processors (48 cores/96 threads, 2.75 GHz), equipped with 2x vCPU memory (16 x 32GB memory), a 12 TB NVMe Gen4 SSD, plus other components, at a cost of $20,000 per server ($\19,980), amortized over five years is $333 per month.
To verify the validity of this quote, we can directly refer to the retail market prices of the core components: the CPU is the EPYC 9654, with a current retail price of $3,725 each, totaling $7,450 for two. 32GB DDR5 ECC server memory, retailing at $128 per stick, 16 sticks total $2,048. Enterprise-grade NVMe SSD 12TB, priced at $2,390. 100G optical module 100GbE QSFP28 priced at $1,804, adding up to around $13,692, plus the server barebone, power supply, system disk, RAID card, fans, etc., the total price of $20,000 is reasonable.
Of course, a server is not just made up of CPUs, memory, hard drives, and network cards; we also need to consider the total cost of ownership. Data centers need to provide these machines with electricity, rack space, and networking, maintenance fees, and reserve redundancy (prices in the US). After accounting for these costs, they are basically on par with the monthly hardware amortization cost, so the comprehensive monthly cost of a server with 192C / 384G / 12T NVMe storage is $666, which is about $3.5 / vCPU·month.
I believe DHH’s figures are accurate, as at Tantan, from day one, we chose to build our IDC / resource cloud, and after several rounds of cost optimization, we achieved a similar price — our database server model (Dell R730, 64 vCPU / 512GB / 3.2 TB NVMe SSD) plus the cost of manpower, maintenance, electricity, and internet, the TCO was about $10,400 , with a core-month cost of $2.71 / vCPU·month. Here is a table for reference on the price per unit of computing power:
| BM / EC2 / ECS Specs | $ / vCPU·Month |
|---|---|
| DHH’s self-hosted vCPU·Month Price (192C 384G) | 3.5 |
| TanTan IDC self-hosted DC (64C 384G) | 2.7 |
| TanTan container platform (container, oversold 500%) | 1.0 |
| Aliyun ECS family c 2x (us-east-1), hourly | 23.8 |
| Aliyun ECS family c 2x (us-east-1), monthly | 18.2 |
| Aliyun ECS family c 2x (us-east-1), yearly | 15.6 |
| Aliyun ECS family c 2x (us-east-1), 3-year upfront | 10.0 |
| Aliyun ECS family c 2x (us-east-1), 5-year upfront | 6.9 |
| AWS C5N.METAL 96C (On Demand) | 35.0 |
| AWS C5N.METAL 96C (1y Reserve, All Upfront) | 20.6 |
| AWS C5N.METAL 96C (3y Reserve, All Upfront) | 12.8 |
Cloud Rental Price
For reference, we can compare the cost to leasing compute power from AWS EC2. A monthly expense of $666 can get you the best specification without storage, the c6in.4xlarge on-demand instance (16 cores, 32G x 3.5GHz); while the on-demand cost for a c7a.metal instance, which has similar compute and memory specification (192C/384G) but excludes EBS storage, is $7,200 per month, which is 10.8 times the comprehensive local build cost; the lowest monthly cost for a 3-year reserved instance can go down to $2,756, which is still 4.1 times the cost of building your own server. If we calculate the cost per core-month, the price for the majority of AWS EC2 instances ranges between $10 ~ $30, which is roughly a hundred to a few hundred dollars, leading us to a rough conclusion: the unit price of cloud compute is 5 to 10 times that of self-built solutions.
Note that these prices do not include the hundredfold premium for EBS cloud storage. In “Is Cloud Disk a Rip-off?”, we’ve already detailed the cost comparison between enterprise SSDs and equivalent cloud disks. Here, we can provide two updated reference values: the cost per TB-month for the 12TB enterprise NVMe SSD purchased by DHH (with a five-year warranty) is 24 CNY, while the cost per TB-month for a retail Samsung consumer SSD 990Pro on GameStop can reach an astonishing 6.6 CNY… Meanwhile, the corresponding block storage TB-month cost on AWS and Alibaba Cloud, even after full discounts, is respectively 1,900 and 3,200 CNY. In the most outrageous scenarios (6400 vs 6.6), the premium can even reach a thousandfold. However, a more apples-to-apples comparison results in: the unit price of cloud block storage is 100 to 200 times that of self-built solutions (and the performance is not as good as local disks).
EC2 and EBS prices can be considered the anchor of cloud service pricing, for example, the premium rate of cloud databases RDS that mainly use EC2 and EBS compared to local self-built solutions fluctuates between the two, depending on your storage usage: the unit price of cloud databases is dozens of times that of self-built solutions. For more details, refer to “Is Cloud Database a Dumb Tax?”.
Of course, we can’t deny the cost advantages of public clouds for micro instances and startups — for example, the nano instances on public clouds used to patch together 12C, 0.52G configurations really can be offered to users at a core-month cost of a few dollars. In “Exploiting Alibaba Cloud ECS for a Digital Homestead,” I recommended exploiting Alibaba Cloud’s Double 11 virtual machine deals for this reason. For instance, a 2C 2G server’s compute cost, calculated with a 500% overselling, is 84 CNY per year, and the cost for 40G cloud disk storage, calculated with triple replication, is about 20 CNY per year, making the annual cost for these two parts over a hundred CNY. This doesn’t include the cost of a public IP or the more valuable 3M bandwidth (for example, if you could fully utilize 3M bandwidth 24 hours a day, that would mean 32G of data per day, costing about 25 CNY). The list price for such cloud servers is ¥1500 per year, so the 99¥ price allowing for a low-cost renewal for four years indeed can be considered a loss-leading benefit.
However, when your business can no longer be covered by a bunch of micro instances, you really should do the math again carefully: in several key examples, the cost of cloud services is extremely high — whether for large physical machine databases, large NVMe storage, or just the latest and fastest compute. The rental price for such production-grade resources is so high — that a few months’ rent could equal the cost of buying it outright. In such cases, you really should just buy the donkey!
Reclaim Hardware Bonus from Cloud
I still remember on April 1, 2019, when the domestic value-added tax in China was officially reduced from 16% to 13%, Apple’s official website immediately implemented a price reduction across the board, with the maximum discount reaching 8% — several iconic iPhone models were reduced by 500 yuan, effectively passing the tax cut benefits to the users. However, many manufacturers chose to turn a deaf ear and maintain their original prices, pocketing the benefits for themselves — why would they want to distribute this newfound wealth to the less fortunate? A similar situation has occurred in the cloud computing domain — the exponential decrease in hardware costs has not been fully reflected in the service prices of cloud providers, gradually turning public cloud from a universally accessible infrastructure into a monopolistic cash cow.
In the old days, developers had to deeply understand hardware to write code. However, the older generation of engineers and programmers, who had a keen sense of hardware, have mostly retired, changed positions, moved into management, or stopped learning. Subsequently, as operating systems and compiler technologies advanced and various VM programming languages emerged, software no longer needed to concern itself with how hardware executed instructions. Then came services like EC2, which encapsulated computing power, and S3/EBS, which encapsulated storage, leading applications to interact with HTTP APIs rather than system calls. Software and hardware diverged into two separate realms, each going its own way. An entire new generation of engineers grew up in the cloud environment, shielded from an understanding of computer hardware.
However, things are beginning to change, with hardware becoming interesting again, and cloud providers are unable to perpetually hide this dividend — the wise are starting to crunch the numbers, and the brave have already taken action. Pioneers like Musk and DHH have fully recognized this, moving off the cloud and onto solid ground — directly generating tens of millions of dollars in financial benefits, with returns in performance, and gaining more independence in operations. More and more people will come to the same realization, following in the footsteps of these trailblazers to make the wise choice of reclaiming their hardware bonus from the cloud.
FinOps: Endgame Cloud-Exit
At the SACC 2023 FinOps session, I fiercely criticized cloud vendors. This is a transcript of my speech, introducing the ultimate FinOps concept — cloud-exit and its best practice.
TL; DR
Misaligned FinOps Focus: Total Cost = Unit Price x Quantity. FinOps efforts are centered around reducing the quantity of wasted resources, deliberately ignoring the elephant in the room — cloud resource unit price.
Public Cloud as a Slaughterhouse: Attract customers with cheap EC2/S3, then slaughter them with EBS/RDS. The cost of cloud compute is five times that of in-house, while block storage costs can be over a hundred times more, making it the ultimate cost assassin.
The Endgame of FinOps is Going Off-Cloud: For enterprises of a certain scale, the cost of in-house IDC is around 10% of the list price of cloud services. Going off-cloud is both the endgame of orthodox FinOps and the starting point of true FinOps.
In-house Capabilities Determine Bargaining Power: Users with in-house capabilities can negotiate extremely low discounts even without going off-cloud, while companies without in-house capabilities can only pay a high “no-expert tax” to public cloud vendors.
Databases are Key to In-House Transition: Migrating stateless applications on K8S and data warehouses is relatively easy. The real challenge is building databases in-house without compromising quality and security.
Misaligned FinOps Focus
Compared to the amount of waste, the unit price of resources is the key point.
The FinOps Foundation states that FinOps focuses on “cloud cost optimization”. However, we believe that emphasizing only public clouds deliberately narrows this concept — the focus should be on the cost control and optimization of all resources, not just those on public clouds — including “hybrid clouds” and “private clouds”. Even without using public clouds, some FinOps methodologies can still be applied to the entire K8S cloud-native ecosystem. Because of this, many involved in FinOps are led astray — their focus is limited to reducing the quantity of cloud resource waste, neglecting a very important issue: unit price.
Total cost depends on two factors: Quantity ✖️ Unit Price. Compared to quantity, unit price might be the key to cost reduction and efficiency improvement. Previous speakers mentioned that about 1/3 of cloud resources are wasted on average, which is the optimization space for FinOps. However, if you use non-elastic services on public clouds, the unit price of the resources you use is already several to dozens of times higher, making the wasted portion negligible in comparison.
In the first stop of my career, I experienced a FinOps movement firsthand. Our BU was among the first internal users of Alibaba Cloud and also where the “data middle platform” concept originated. Alibaba Cloud sent over a dozen engineers to help us migrate to the cloud. After migrating to ODPS, our annual storage and computing costs were 70 million, and through FinOps methods like health scoring, we did optimize and save tens of millions. However, running the same services with an in-house Hadoop suite in our data center cost less than 10 million annually — savings are good, but they’re nothing compared to the multiplied resource costs.
As cost reduction and efficiency become the main theme, cloud repatriation is becoming a trend. Alibaba, the inventor of the middle platform concept, has already started dismantling its own middle platform. Yet, many companies are still falling into the trap of the slaughterhouse, repeating the old path of cloud migration - cloud repatriation.
Public Clouds: A Slaughterhouse in Disguise
Attract customers with cheap EC2/S3, then slaughter them with EBS/RDS pricing.
The elasticity touted by public clouds is designed for their business model: low startup costs, exorbitant maintenance costs. Low initial costs lure users onto the cloud, and its good elasticity can adapt to business growth at any time. However, once the business stabilizes, vendor lock-in occurs, making it difficult to switch providers without incurring high costs, turning maintenance into a financial nightmare for users. This model is colloquially known as a pig slaughterhouse.
To slaughter pigs, one must first raise them. You can’t catch a wolf without putting your child at risk. Hence, for new users, startups, and small businesses, public clouds offer sweet deals, even at a loss, to make noise and attract business. New users get first-time discounts, startups receive free or half-price credits, and there’s a sophisticated pricing strategy. Taking AWS RDS pricing as an example, the mini models with 1 or 2 cores are priced at just a few dollars per core per month, translating to a few hundred yuan per year (excluding storage). This is an affordable option for those needing a low-usage database for small data storage.
However, even a slight increase in configuration leads to a magnitude increase in the price per core month, skyrocketing to twenty or thirty to a hundred dollars, sometimes even more — not to mention the shocking EBS prices. Users may only realize what has happened when they see the exorbitant bill suddenly appearing.
Compared to in-house solutions, the price of cloud resources is generally several to more than ten times higher, with a rent-to-buy ratio ranging from a few days to several months. For example, the cost of a physical server core month in an IDC, including all costs for network, electricity, maintenance, and IT staff, is about 19 yuan. Using a K8S container private cloud, the cost of a virtual core month is only 7 yuan.
In contrast, the price per core month for Alibaba Cloud’s ECS is a couple of hundred yuan, and for AWS EC2, it’s two to three hundred yuan. If you “don’t care about elasticity” and prepay for three years, you can usually get a discount of about 50-60%. But no matter how you calculate it, the price difference between cloud computing power and local in-house computing power is there and significant.
The pricing of cloud storage resources is even more outrageous. A common 3.2 TB enterprise-grade NVMe SSD, with its formidable performance, reliability, and cost-effectiveness, has a wholesale price of just over ¥3000, significantly outperforming older storage solutions. However, for the same storage on the cloud, providers dare to charge 100 times the price. Compared to direct hardware procurement, the cost of AWS EBS io2 is 120 times higher, while Alibaba Cloud’s ESSD PL3 is 200 times higher.
Using a 3.2TB enterprise-grade PCI-E SSD card as a benchmark, the rent-to-buy ratio on AWS is 15 days, while on Alibaba Cloud it’s less than 5 days, meaning renting for this period allows you to purchase the entire disk outright. If you opt for a three-year prepaid purchase on Alibaba Cloud with the maximum discount of 50%, the three-year rental fee could buy over 120 similar disks.
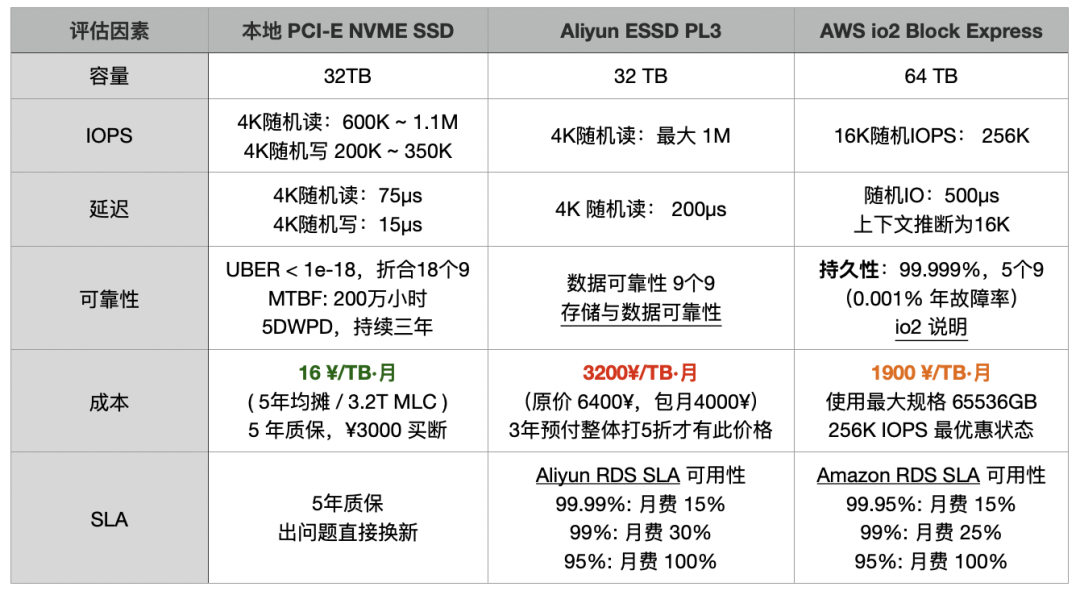
The price markup ratio of cloud databases (RDS) falls between that of cloud disks and cloud servers. For example, using RDS for PostgreSQL on AWS, a 64C / 256GB RDS costs $25,817 per month, equivalent to 180,000 yuan per month. One month’s rent is enough to purchase two servers with much better performance for in-house use. The rent-to-buy ratio is not even a month; renting for just over ten days would be enough to purchase an entire server.
Any rational enterprise user can see the folly in this: If the procurement of such services is not for short-term, temporary needs, then it definitely qualifies as a significant financial misjudgment.
| Payment Model | Price | Cost Per Year (¥10k) |
|---|---|---|
| Self-hosted IDC (Single Physical Server) | ¥75k / 5 years | 1.5 |
| Self-hosted IDC (2-3 Server HA Cluster) | ¥150k / 5 years | 3.0 ~ 4.5 |
| Alibaba Cloud RDS (On-demand) | ¥87.36/hour | 76.5 |
| Alibaba Cloud RDS (Monthly) | ¥42k / month | 50 |
| Alibaba Cloud RDS (Yearly, 15% off) | ¥425,095 / year | 42.5 |
| Alibaba Cloud RDS (3-year, 50% off) | ¥750,168 / 3 years | 25 |
| AWS (On-demand) | $25,817 / month | 217 |
| AWS (1-year, no upfront) | $22,827 / month | 191.7 |
| AWS (3-year, full upfront) | $120k + $17.5k/month | 175 |
| AWS China/Ningxia (On-demand) | ¥197,489 / month | 237 |
| AWS China/Ningxia (1-year, no upfront) | ¥143,176 / month | 171 |
| AWS China/Ningxia (3-year, full upfront) | ¥647k + ¥116k/month | 160.6 |
Comparing the costs of self-hosting versus using a cloud database:
| Method | Cost Per Year (¥10k) |
|---|---|
| Self-hosted Servers 64C / 384G / 3.2TB NVME SSD 660K IOPS (2-3 servers) | 3.0 ~ 4.5 |
| Alibaba Cloud RDS PG High-Availability pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG High-Availability db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
RDS pricing compared to self-hosting, see “Is Cloud Database an idiot Tax?”
Any meaningful cost reduction and efficiency increase initiative cannot ignore this issue: if there’s potential to slash resource prices by 50% to 200%, then focusing on a 30% reduction in waste is not a priority. As long as your main business is on the cloud, traditional FinOps is like scratching an itch through a boot — migrating off the cloud is the focal point of FinOps.
The Endgame of FinOps is Exiting from the Cloud
The well-fed do not understand the pangs of hunger, human joys and sorrows are not universally shared.
I spent five years at Tantan — a Nordic-style internet startup founded by a Swede. Nordic engineers have a characteristic pragmatism. When it comes to choosing between cloud and on-premise solutions, they are not swayed by hype or marketing but rather make decisions based on quantitative analysis of pros and cons. We meticulously calculated the costs of building our own infrastructure versus using the cloud — the straightforward conclusion was that the total cost of on-premise solutions (including labor) generally fluctuates between 10% to 100% of the list price for cloud services.
Thus, from its inception, Tantan chose to build its own infrastructure. Apart from overseas compliance businesses, CDN, and a very small amount of elastic services using public clouds, the main part of our operations was entirely hosted in IDC-managed data centers. Our database was not small, with 13K cores for PostgreSQL and 12K cores for Redis, 4.5 million QPS, and 300TB of unique transactional data. The annual cost for these two parts was less than 10 million yuan: including salaries for two DBAs, one network engineer, network and electricity, managed hosting fees, and hardware amortized over five years. However, for such a scale, if we were to use cloud databases, even with significant discounts, the starting cost would be between 50 to 60 million yuan, not to mention the even more expensive big data sector.
However, digitalization in enterprises is phased, and different companies are at different stages. For many internet companies, they have reached the stage where they are fully engaged with building cloud-native K8S ecosystems. At this stage, focusing on resource utilization, mixed online and offline deployments, and reducing waste are reasonable demands and directions where FinOps should concentrate its efforts. Yet, for the vast majority of enterprises outside the digital realm, the urgent need is not reducing waste but lowering the unit cost of resources — Dell servers can be discounted by 50%, IDC virtual machines by 50%, and even cloud services can be heavily discounted. Are these companies still paying the list price, or even facing several times the markup in rebates? A great many companies are still being severely exploited due to information asymmetry and lack of capability.
Enterprises should evaluate their scale and stage, assess their business, and weigh the pros and cons accordingly. For small-scale startups, the cloud can indeed save a lot of manpower costs, which is very attractive — but please be cautious not to be locked in by vendors due to the convenience offered. If your annual cloud expenditure has already exceeded 1 million yuan, it’s time to seriously consider the benefits of descending from the cloud — many businesses do not require the elasticity for massive concurrent spikes or training AI models. Paying a premium for temporary/sudden needs or overseas compliance is reasonable, but paying several times to tens of times more for unnecessary elasticity is wasteful. You can keep the truly elastic parts of your operations on the public cloud and transfer those parts that do not require elasticity to IDCs. Just by doing this, the cost savings could be astonishing.
Descending from the cloud is the ultimate goal of traditional FinOps and the starting point of true FinOps.
Self-Hosting Matters
“To seek peace through struggle is to preserve peace; to seek peace through compromise is to lose peace.”
When the times are favorable, the world joins forces; when fortune fades, even heroes lose their freedom: During the bubble phase, it was easy to disregard spending heavily in the cloud. However, in an economic downturn, cost reduction and efficiency become central themes. An increasing number of companies are realizing that using cloud services is essentially paying a “no-expert tax” and “protection money”. Consequently, a trend of “cloud repatriation” has emerged, with 37Signals’ DHH being one of the most notable proponents. Correspondingly, the revenue growth rate of major cloud providers worldwide has been experiencing a continuous decline, with Alibaba Cloud’s revenue even starting to shrink in the first quarter of 2023.
《“Why Cloud Computing Hasn’t Yet Hit Its Stride in Earning Profits”》
The underlying trend is the emergence of open-source alternatives, breaking down the technical barriers of public clouds; the advent of resource clouds/IDC2.0, offering a cost-effective alternative to public cloud resources; and the release of technical talents from large layoffs, along with the future of AI models, giving every industry the opportunity to possess the expert knowledge and capability required for self-hosting. Combining these trends, the combination of IDC2.0 + open-source self-hosting is becoming increasingly competitive: Bypassing the public cloud intermediaries and working directly with IDCs is clearly a more economical choice.
Public cloud providers are not incapable of engaging in the business of selling IDC resources profitably. Given their higher level of expertise compared to IDCs, they should, in theory, leverage their technological advantages and economies of scale to offer cheaper resources than IDC self-hosting. However, the harsh reality is that resource clouds can offer users virtual machines at a 80% discount, while public clouds cannot. Even considering the exponential growth law of Moore’s Law in the storage and computing industry, public clouds are actually increasing their prices every year!
Well-informed major clients, especially those capable of migrating at will, can indeed negotiate for 80% off the list prices with public clouds, a feat unlikely for smaller clients — in this sense, clouds are essentially subsidizing large clients by bleeding small and medium-sized clients dry. Cloud vendors offer massive discounts to large clients while fleecing small and medium-sized clients and developers, completely contradicting the original intention and vision of cloud computing.
Clouds lure in users with low initial prices, but once users are deeply locked in, the slaughter begins — the previously discussed discounts and benefits disappear at each renewal. Escaping the cloud entails a significant cost, leaving users in a dilemma between a rock and a hard place, forced to continue paying protection money.
However, for users with the capability to self-host, capable of flexibly moving between multi-cloud and on-premises hybrid clouds, this is not an issue: The trump card in negotiations is the ability to go off-cloud or migrate to another cloud at any time. This is more effective than any argument — as the saying goes, “To seek peace through struggle is to preserve peace; to seek peace through compromise is to lose peace.” The extent of cost reduction depends on your bargaining power, which in turn depends on your ability to self-host.
Self-hosting might seem daunting, but it is not difficult for those who know how. The key is addressing the core issues of resources and capabilities. In 2023, due to the emergence of resource clouds and open-source alternatives, these issues have become much simpler than before.
In terms of resources, IDC and resource clouds have solved the problem adequately. The aforementioned IDC self-hosting doesn’t mean buying land and building data centers from scratch but directly using the hosting services of resource clouds/IDCs — you might only need a network engineer to plan the network, with other maintenance tasks managed by the provider.
If you prefer not to hassle, IDCs can directly sell you virtual machines at 20% of the list price, or you can rent a physical server with 64C/256G for a couple thousand a month; whether renting an entire data center or just a single colocation space, it’s all feasible. A retail colocation space with comprehensive services can be settled for about five thousand a year, running a K8S or virtualization on a couple of hundred-core physical servers, why bother with flexible ECS?
FinOps Leads to CLoud-Exit
Building your own infrastructure comes with the added perk of extreme FinOps—utilizing out-of-warranty or even second-hand servers. Servers are typically depreciated over three to five years, yet it’s not rare to see them operational for eight to ten years. This contrasts with cloud services, where you’re just consuming resources; owning your server translates to tangible assets, making any extended use essentially a gain.
For instance, a new 64-core, 256GB server could cost around $7,000, but after a year or two, the price for such “electronic waste” drops to merely $400. By replacing the most failure-prone components with brand new enterprise-grade 3.2TB NVMe SSDs (costing $390), you could secure the entire setup for just $800.
In such scenarios, your vCPU·Month price could plummet to less than $0.15, a figure legendary in the gaming industry, where server costs can dip to mere cents. With Kubernetes (K8S) orchestration and database high-availability switching, reliability can be assured through parallel operation of multiple such servers, achieving an astonishing cost-efficiency ratio.
In terms of capability, with the emergence of sufficiently robust open-source alternatives, the difficulty of self-hosting has dramatically decreased compared to a few years ago.
For example, Kubernetes/OpenStack/SealOS are open-source alternatives to cloud providers’ EC2/ECS/VPS management software; MinIO/Ceph aim to replace S3/OSS; while Pigsty and various database operators serve as open-source substitutes for RDS cloud database management. There’s a plethora of open-source software available for effectively utilizing these resources, along with numerous commercial entities offering transparently priced support services.
Your operations should ideally converge to using just virtual machines and object storage, the lowest common denominator across all cloud providers. Ideally, all applications should run on Kubernetes, which can operate in any environment—be it a cloud-hosted K8S, ECS, dedicated servers, or your own data center. External states like database backups and big data warehouses should be managed with compute-storage separation, using MinIO/S3 storage.
Such a CloudNative tech stack theoretically enables operation and flexible migration across any resource environment, thus avoiding vendor lock-in and maintaining control. This allows you to either significantly cut costs by moving off the cloud or leverage it to negotiate discounts with public cloud providers.
However, self-hosting isn’t without risks, with RDS representing a major potential vulnerability.
Database: The Biggest Risk Factor
Cloud databases may not be the most expensive line item, but they are definitely the most deeply locked-in and challenging to migrate.
Quality, security, efficiency, and cost represent different levels of a hierarchical pyramid of needs. The goal of FinOps is to reduce costs and increase efficiency without compromising quality and security.
Stateless apps on K8S or offline big data platforms pose little fatal risk when migrating. Especially if you have already achieved big data compute-storage separation and stateless app cloud-native transformation, moving these components is generally not too troublesome. The former can afford a few hours of downtime, while the latter can be updated through blue-green deployments and canary releases. The database, serving as the working memory, is prone to major issues when migrated.
Most IT system architectures are centered around the database, making it the key risk point in cloud migration, particularly with OLTP databases/RDS. Many users hesitate to move off the cloud and self-host due to the lack of reliable database services — traditional Kubernetes Operators don’t fully replicate the cloud database experience: hosting OLTP databases on K8S/containers with EBS is not yet a mature practice.
There’s a growing demand for a viable open-source alternative to RDS, and that’s precisely what we aim to address: enabling users to establish a local RDS service in any environment that matches or exceeds cloud databases — Pigsty, a free open-source alternative to RDS PG. It empowers users to effectively utilize PostgreSQL, the world’s most advanced and successful database.
Pigsty is a non-profit, open-source software powered by community love. It offers a ready-to-use, feature-rich PostgreSQL distribution with automatic high availability, PITR, top-tier monitoring systems, Infrastructure as Code, cloud-based Terraform templates, local Vagrant sandbox for one-click installation, and SOP manuals for various operations, enabling quick RDS self-setup without needing a professional DBA.
Although Pigsty is a database distribution, it enables users to practice ultimate FinOps—running production-level PostgreSQL RDS services anywhere (ECS, resource clouds, data center servers, or even local laptop VMs) at almost pure resource cost. It turns the cost of cloud database capabilities from being proportional to marginal resource costs to nearly zero in fixed learning costs.
Perhaps it’s the socialist ethos of Nordic companies that nurtures such pure free software. Our goal isn’t profit but to promote a philosophy: to democratize the expertise of using the advanced open-source database PostgreSQL for everyone, not just cloud monopolies. Cloud providers monopolize open-source expertise and roles, exploiting free open-source software, and we aim to break this monopoly—Freedom is not free. You shouldn’t concede the world to those you despise but rather overturn their table.
This is the essence of FinOps—empowering users with viable alternatives and the ability to self-host, thus negotiating with cloud providers from a position of strength.
References
[1] 云计算为啥还没挖沙子赚钱?
[2] 云数据库是不是智商税?
[3] 云SLA是不是安慰剂?
[4] 云盘是不是杀猪盘?
[5] 范式转移:从云到本地优先
[6] 杀猪盘真的降价了吗?
[8] 垃圾腾讯云CDN:从入门到放弃
[9] 云RDS:从删库到跑路
[10] 分布式数据库是伪需求吗?
[11] 微服务是不是个蠢主意?
[12] 更好的开源RDS替代:Pigsty
SLA: Placebo or Insurance?
In the world of cloud computing, Service Level Agreements (SLAs) are seen as a cloud provider’s commitment to the quality of its services. However, a closer examination of these SLAs reveals that they might not offer the safety net one might expect: you might think you’ve insured your database for peace of mind, but in reality, you’ve bought a placebo that provides emotional comfort rather than actual coverage.
Insurance Policy or Placebo?
One of the reasons many users opt for cloud services is for the “safety net” they supposedly provide, often referring to the SLA when asked what this “safety net” entails. Cloud experts liken purchasing cloud services to buying insurance: certain failures might never occur throughout many companies’ lifespans, but should they happen, the consequences could be catastrophic. In such cases, a cloud service provider’s SLA is supposed to act as this safety net. Yet, when we actually review these SLAs, we find that this “policy” isn’t as useful as one might think.
Data is the lifeline of many businesses, and cloud storage serves as the foundation for nearly all data storage on the public cloud. Let’s take cloud storage services as an example. Many cloud service providers boast of their cloud storage services having nine nines of data reliability [1]. However, upon examining their SLAs, we find that these crucial promises are conspicuously absent from the SLAs [2].
What is typically included in the SLAs is the service’s availability. Even this promised availability is superficial, paling in comparison to the core business reliability metrics in the real world, with compensation schemes that are practically negligible in the face of common downtime losses. Compared to an insurance policy, SLAs more closely resemble placebos that offer emotional value.
Subpar Availability
The key metric used in cloud SLAs is availability. Cloud service availability is typically represented as the proportion of time a resource can be accessed from the outside, usually over a one-month period. If a user cannot access the resource over the Internet due to a problem on the cloud provider’s end, the resource is considered unavailable/down.
Taking the industry benchmark AWS as an example, most of its services use a similar SLA template [3]. The SLA for a single virtual machine on AWS is as follows [4]. This means that in the best-case scenario, if an EC2 instance on AWS is unavailable for less than 21 minutes in a month (99.9% availability), AWS compensates nothing. In the worst-case scenario, only when the unavailability exceeds 36 hours (95% availability) can you receive a 100% credit return.
Instance-Level SLA
For each individual Amazon EC2 instance (“Single EC2 Instance”), AWS will use commercially reasonable efforts to make the Single EC2 Instance available with an Instance-Level Uptime Percentage of at least 99.5%, in each case during any monthly billing cycle (the “Instance-Level SLA”). In the event any Single EC2 Instance does not meet the Instance-Level SLA, you will be eligible to receive a Service Credit as described below.
Instance-Level Uptime Percentage Service Credit Percentage Less than 99.5% but equal to or greater than 99.0% 10% Less than 99.0% but equal to or greater than 95.0% 30% Less than 95.0% 100% Note: In addition to the Instance-Level SLA, AWS will not charge you for any Single EC2 Instance that is Unavailable for more than six minutes of a clockhour. This applies automatically and you do not need to request credit for any such hour with more than six minutes of Unavailability.
For some internet companies, a 15-minute service outage is enough to jeopardize bonuses, and a 30-minute outage is sufficient for leadership changes. The actual availability of core systems running most of the time might have five nines, six nines, or even infinite nines. Cloud providers, incubated from major internet companies, using such inferior availability metrics is indeed disappointing.
What’s more outrageous is that these compensations are not automatically provided to you after a failure occurs. Users are required to measure downtime themselves, submit evidence for claims within a specific timeframe (usually two months), and request compensation to receive any. This requires users to collect monitoring metrics and log evidence to negotiate with cloud providers, and the compensation returned is not in cash but in vouchers/duration compensations — meaning virtually no real loss for the cloud providers and no actual value for the users, with almost no chance of compensating for the actual losses incurred during service interruptions.
Is the “Safety Net” Meaningful?
For businesses, a “safety net” means minimizing losses as much as possible when failures occur. Unfortunately, SLAs are of little help in this regard.
The impact of service unavailability on business varies by industry, time, and duration. A brief outage of a few seconds to minutes might not significantly affect general industries, however, long-term outages (several hours to several days) can severely affect revenue and reputation.
In the Uptime Institute’s 2021 data center survey [5], several of the most severe outages cost respondents an average of nearly $1 million, not including the worst 2% of cases, which suffered losses exceeding $40 million.

However, SLA compensations are a drop in the ocean compared to these business losses. Taking the t4g.nano virtual machine instance in the us-east-1 region as an example, priced at about $3 per month. If the unavailability is less than 7 hours and 18 minutes (99% monthly availability), AWS will pay 10% of the monthly cost of that virtual machine, a total compensation of 30 cents. If the virtual machine is unavailable for less than 36 hours (95% availability within a month), the compensation is only 30% — less than $1. Only if the unavailability exceeds a day and a half, can users receive a full refund for the month — $3. Even if compensating for thousands of instances, this is virtually negligible compared to the losses.
In contrast, the traditional insurance industry genuinely provides coverage for its customers. For instance, SF Express charges 1% of the item’s value for insurance, but if the item is lost, they compensate the full amount. Similarly, commercial health insurance costing tens of thousands yearly can cover millions in medical expenses. “Insurance” in this industry truly means you get what you pay for.
Cloud service providers charge far more than the BOM for their expensive services (see: “Are Public Clouds a Pig Butchering Scam?” [7]), but when service issues arise, their so-called “safety net” compensation is merely vouchers, which is clearly unfair.
Vanished Reliability
Some people use cloud services to “pass the buck,” absolving themselves of responsibility. However, some critical responsibilities cannot be shifted to external IT suppliers, such as data security. Users might tolerate temporary service unavailability, but the damage caused by lost or corrupted data is often unacceptable. Blindly trusting exaggerated promises can have severe consequences, potentially a matter of life and death for a startup.
In storage products offered by various cloud providers, it’s common to see promises of nine nines of reliability [1], implying a one in a billion chance of data loss when using cloud disks. Examining actual reports on cloud provider disk failure rates [6] casts doubt on these figures. However, as long as providers are bold enough to make, stand by, and honor such claims, there shouldn’t be an issue.
Yet, upon examining the SLAs of various cloud providers, this promise disappears! [2]
In the 2018 sensational case “The Disaster Tencent Cloud Brought to a Startup Company!” [8], the startup believed the cloud provider’s promises and stored data on server hard drives, only to encounter what was termed “silent disk errors”: “Years of accumulated data were lost, causing nearly ten million yuan in losses.” Tencent Cloud expressed apologies to the company, willing to compensate the actual expenses incurred on Tencent Cloud totaling 3,569 yuan and, with the aim of helping the business quickly recover, promised an additional compensation of 132,900 yuan
What Exactly is an SLA
Having discussed this far, proponents of cloud services might play their last card: although the post-failure “safety net” is a facade, what users need is to avoid failures as much as possible. According to the SLA promises, there is a 99.99% probability of avoiding failures, which is of the most value to users.
However, SLAs are deliberately confused with the actual reliability of the service: Users should not consider SLAs as reliable indicators of service availability — not even as accurate records of past availability levels. For providers, an SLA is not a real commitment to reliability or a track record but a marketing tool designed to convince buyers that the cloud provider can host critical business applications.
The UPTIME INSTITUTE’s annual data center failure analysis report shows that many cloud services perform below their published SLAs. The analysis of failures in 2022 found that efforts to contain the frequency of failures have failed, and the cost and consequences of failures are worsening [9].
Key Findings Include:
- High outage rates haven’t changed significantly. One in five organizations report experiencing a “serious” or “severe” outage (involving significant financial losses, reputational damage, compliance breaches and in some severe cases, loss of life) in the past three years, marking a slight upward trend in the prevalence of major outages. According to Uptime’s 2022 Data Center Resiliency Survey, 80% of data center managers and operators have experienced some type of outage in the past three years – a marginal increase over the norm, which has fluctuated between 70% and 80%.
- The proportion of outages costing over $100,000 has soared in recent years. Over 60% of failures result in at least $100,000 in total losses, up substantially from 39% in 2019. The share of outages that cost upwards of $1 million increased from 11% to 15% over that same period.
- Power-related problems continue to dog data center operators. Power-related outages account for 43% of outages that are classified as significant (causing downtime and financial loss). The single biggest cause of power incidents is uninterruptible power supply (UPS) failures.
- Networking issues are causing a large portion of IT outages. According to Uptime’s 2022 Data Center Resiliency Survey, networking-related problems have been the single biggest cause of all IT service downtime incidents – regardless of severity – over the past three years. Outages attributed to software, network and systems issues are on the rise due to complexities from the increasing use of cloud technologies, software-defined architectures and hybrid, distributed architectures.
- The overwhelming majority of human error-related outages involve ignored or inadequate procedures. Nearly 40% of organizations have suffered a major outage caused by human error over the past three years. Of these incidents, 85% stem from staff failing to follow procedures or from flaws in the processes and procedures themselves.
- External IT providers cause most major public outages. The more workloads that are outsourced to external providers, the more these operators account for high-profile, public outages. Third-party, commercial IT operators (including cloud, hosting, colocation, telecommunication providers, etc.) account for 63% of all publicly reported outages that Uptime has tracked since 2016. In 2021, commercial operators caused 70% of all outages.
- Prolonged downtime is becoming more common in publicly reported outages. The gap between the beginning of a major public outage and full recovery has stretched significantly over the last five years. Nearly 30% of these outages in 2021 lasted more than 24 hours, a disturbing increase from just 8% in 2017.
- Public outage trends suggest there will be at least 20 serious, high-profile IT outages worldwide each year. Of the 108 publicly reported outages in 2021, 27 were serious or severe. This ratio has been fairly consistent since the Uptime Intelligence team began cataloging major outages in 2016, indicating that roughly one-fourth of publicly recorded outages each year are likely to be serious or severe.
Rather than compensating users, SLAs are more of a “punishment” for cloud providers when their service quality fails to meet standards. The deterrent effect of the punishment depends on the certainty and severity of the punishment. Monthly duration/voucher compensations impose virtually no real cost on cloud providers, making the severity of the punishment nearly zero; compensation also requires users to submit evidence and get approval from the cloud provider, meaning the certainty is not high either.
Compared to experts and engineers who might lose bonuses and jobs due to failures, the punishment of SLAs for cloud providers is akin to a slap on the wrist. If the punishment is meaningless, then cloud providers have no incentive to improve service quality. When users encounter problems, they can only wait and die, and the service attitude towards small customers, in particular, is arrogantly dismissive compared to self-built/third-party service companies.
More subtly, cloud providers have absolute power over the SLA agreement: they reserve the right to unilaterally adjust and revise SLAs and inform users of their effectiveness, leaving users with only the right to choose not to use the service, without any participation or choice. As a default “take-it-or-leave-it” clause, it blocks any possibility for users to seek meaningful compensation.
Thus, SLAs are not an insurance policy against losses for users. In the worst-case scenario, it’s an unavoidable loss; at best, it provides emotional comfort. Therefore, when choosing cloud services, we need to be vigilant and fully understand the contents of their SLAs to make informed decisions.
Reference
【1】阿里云 ESSD云盘
【2】阿里云 SLA 汇总页
【3】AWS SLA 汇总页
【7】公有云是不是杀猪盘
EBS: Pig Slaughter Scam
We already answer the question: Is RDS an Idiot Tax?. But when compared to the hundredfold markup of public cloud block storage, cloud databases seem almost reasonable. This article uses real data to reveal the true business model of public cloud: “Cheap” EC2/S3 to attract customers, and fleece with “Expensive” EBS/RDS. Such practices have led public clouds to diverge from their original mission and vision.

TL; DR
EC2/S3/EBS pricing serves as the anchor for all cloud services pricing. While the pricing for EC2/S3 might still be considered reasonable, EBS pricing is outright extortionate. The best block storage services offered by public cloud providers are essentially on par with off-the-shelf PCI-E NVMe SSDs in terms of performance specifications. Yet, compared to direct hardware purchases, the cost of AWS EBS can be up to 60 times higher, and Alibaba Cloud’s ESSD can reach up to 100 times higher.
Why is there such a staggering markup for plug-and-play disk hardware? Cloud providers fail to justify the exorbitant prices. When considering the design and pricing models of other cloud storage services, there’s only one plausible explanation: The high markup on EBS is a deliberately set barrier, intended to fleece cloud database customers.
With EC2 and EBS serving as the pricing anchors for cloud databases, their markups are several and several dozen times higher, respectively, thus supporting the exorbitant profit margins of cloud databases. However, such monopolistic profits are unsustainable: the impact of IDC 2.0/telecom/national cloud on IaaS; private cloud/cloud-native/open source as alternatives to PaaS; and the tech industry’s massive layoffs, AI disruption, and the impact of China’s low labor costs on cloud services (through IT outsourcing/shared expertise). If public clouds continue to adhere to their current fleecing model, diverging from their original mission of providing fundamental compute and storage infrastructure, they will inevitably face increasingly severe competition and challenges from the aforementioned forces.
WHAT a Scam!
When you use a microwave at home to heat up a ready-to-eat braised chicken rice meal costing 10 yuan, you wouldn’t mind if a restaurant charges you 30 yuan for microwaving the same meal and serving it to you, considering the costs of rent, utilities, labor, and service. But what if the restaurant charges you 1000 yuan for the same dish, claiming: “What we offer is not just braised chicken rice, but a reliable and flexible dining service”, with the chef controlling the quality and cooking time, pay-per-portion so you get exactly as much as you want, pay-per-need so you get as much as you eat, with options to switch to hot and spicy soup or skewers if you don’t feel like chicken, claiming it’s all worth the price. Wouldn’t you feel the urge to give the owner a piece of your mind? This is exactly what’s happening with block storage!
With hardware technology evolving rapidly, PCI-E NVMe SSDs have reached a new level of performance across various metrics. A common 3.2 TB enterprise-grade MLC SSD offers incredible performance, reliability, and value for money, costing less than ¥3000, significantly outperforming older storage solutions.
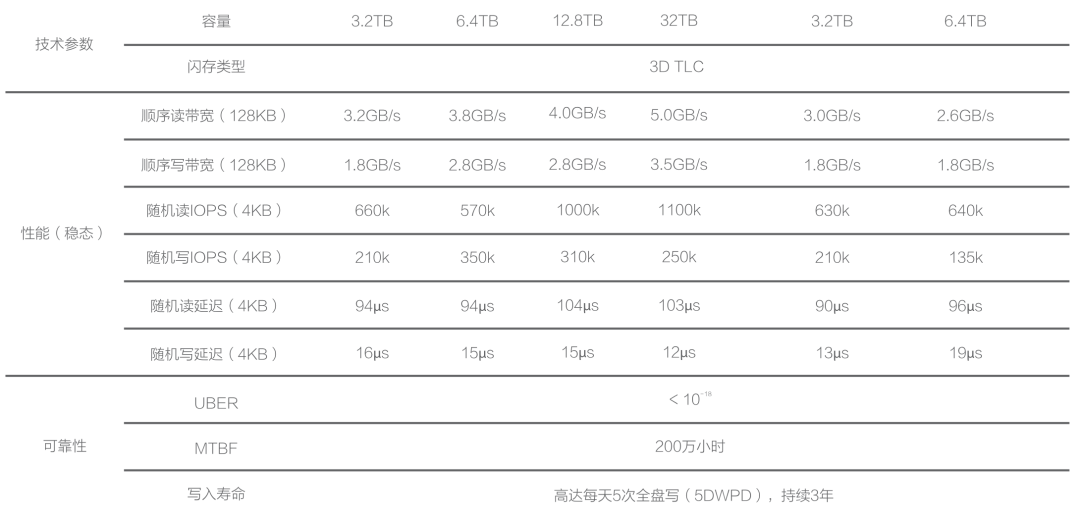
Aliyun ESSD PL3 and our own IDC’s procured PCI-E NVMe SSDs come from the same supplier. Hence, their maximum capacity and IOPS limitations are identical. AWS’s top-tier block storage solution, io2 Block Express, also shares similar specifications and metrics. Cloud providers’ highest-end storage solutions utilize these 32TB single cards, leading to a maximum capacity limit of 32TB (64TB for AWS), which suggests a high degree of hardware consistency underneath.
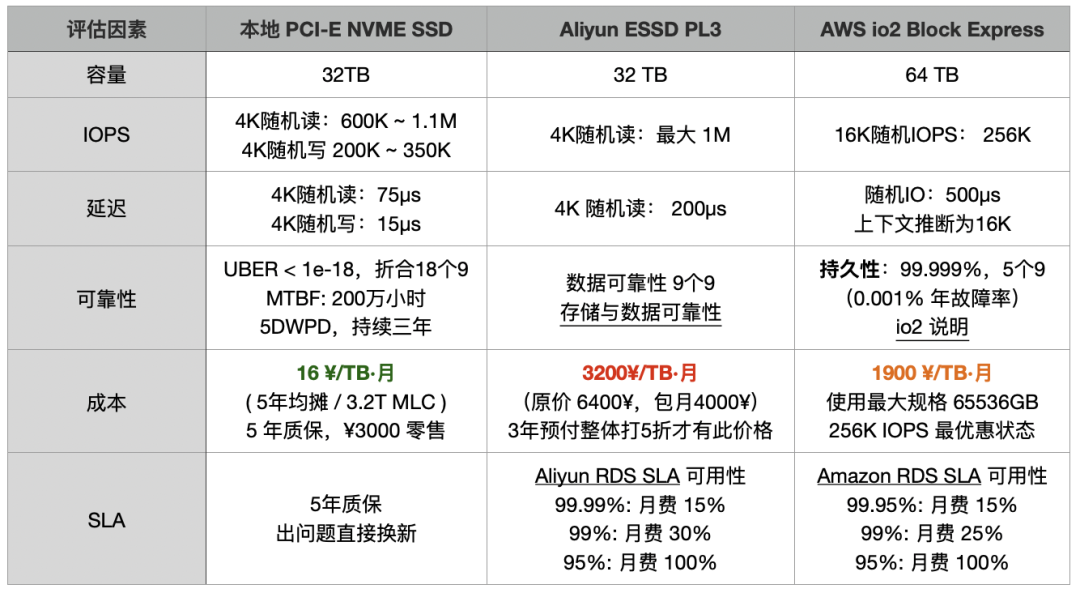
However, compared to direct hardware procurement, the cost of AWS EBS io2 is up to 120 times higher, while Aliyun’s ESSD PL3 is up to 200 times higher. Taking a 3.2TB enterprise-grade PCI-E SSD card as a reference, the ratio of on-demand rental to purchase price is 15 days on AWS and less than 5 days on Aliyun, meaning you could own the entire disk after renting it for this duration. If you opt for a three-year prepaid purchase on Aliyun, taking advantage of the maximum 50% discount, the rental fees over three years could buy over 120 disks of the same model.

Is that SSD made of gold ?
Cloud providers argue that block storage should be compared to SAN rather than local DAS, which should be compared to instance storage (Host Storage) on the cloud. However, public cloud instance storage is generally ephemeral (Ephemeral Storage), with data being wiped once the instance is paused/stopped【7,11】, making it unsuitable for serious production databases. Cloud providers themselves advise against storing critical data on it. Therefore, the only viable option for database storage is EBS block storage. Products like DBFS, which have similar performance and cost metrics to EBS, are also included in this category.
Ultimately, users care not about whether the underlying hardware is SAN, SSD, or HDD; the real priorities are tangible metrics: latency, IOPS, reliability, and cost. Comparing local options with the best cloud solutions poses no issue, especially when the top-tier cloud storage uses the same local disks.
Some “experts” claim that cloud block storage is stable and reliable, offering multi-replica redundancy and error correction. In the past, Share Everything databases required SAN storage, but many databases now operate on a Share Nothing architecture. Redundancy is managed at the database instance level, eliminating the need for triple-replica storage redundancy, especially since enterprise-grade disks already possess strong self-correction capabilities and safety redundancy (UBER < 1e-18). With redundancy already in place at the database level, multi-replica block storage becomes an unnecessary waste for databases. Even if cloud providers did use two additional replicas for redundancy, it would only reduce the markup from 200x to 66x, without fundamentally changing the situation.
“Experts” also liken purchasing “cloud services” to buying insurance: “An annual failure rate of 0.02% may seem negligible to most, but a single incident can be devastating, with the cloud provider offering a safety net.” This sounds appealing, but a closer look at cloud providers’ EBS SLAs reveals no guarantees for reliability. ESSD cloud disk promotions mention 9 nines of data reliability, but such claims are conspicuously absent from the SLAs. Cloud providers only guarantee availability, and even then, the guarantees are modest, as illustrated by the AWS EBS SLA:

In plain language: if the service is down for a day and a half in a month (95% availability), you get a 100% coupon for that month’s service fee; seven hours of downtime (99%) yields a 30% coupon; and a few minutes of downtime (99.9% for a single disk, 99.99% for a region) earns a 10% coupon. Cloud providers charge a hundredfold more, yet offer mere coupons as compensation for significant outages. Applications that can’t tolerate even a few minutes of downtime wouldn’t benefit from these meager coupons, reminiscent of the past incident, “The Disaster Tencent Cloud Brought to a Startup Company.”
SF Express offers 1% insurance for parcels, compensating for losses with real money. Annual commercial health insurance plans costing tens of thousands can cover millions in expenses when issues arise. The insurance industry should not be insulted; it operates on a principle of value for money. Thus, an SLA is not an insurance policy against losses for users. At worst, it’s a bitter pill to swallow without recourse; at best, it provides emotional comfort.
The premium charged for cloud database services might be justified by “expert manpower,” but this rationale falls flat for plug-and-play disks, with cloud providers unable to explain the exorbitant price markup. When pressed, their engineers might only say:
“We’re just following AWS; that’s how they designed it.”
WHY so Pricing?
Even engineers within public cloud services may not fully grasp the rationale behind their pricing strategies, and those who do are unlikely to share. However, this does not prevent us from deducing the reasoning behind such decisions from the design of the product itself.
Storage follows a de facto standard: POSIX file system + block storage. Whether it’s database files, images, audio, or video, they all use the same file system interface to store data on disks. But AWS’s “divine intervention” splits this into two distinct services: S3 (Simple Storage Service) and EBS (Elastic Block Store). Many “followers” have imitated AWS’s product design and pricing model, yet the logic and principles behind such actions remain elusive.
Aliyun EBS OSS Compare
S3, standing for Simple Storage Service, is a simplified alternative to file system/storage: sacrificing strong consistency, directory management, and access latency for the sake of low cost and massive scalability. It offers a simple, high-latency, high-throughput flat KV storage service, detached from standard storage services. This aspect, being cost-effective, serves as a major allure for users to migrate to the cloud, thus becoming possibly the only de facto cloud computing standard across all public cloud providers.
Databases, on the other hand, require low latency, strong consistency, high quality, high performance, and random read/write block storage, which is encapsulated in the EBS service: Elastic Block Store. This segment becomes the forbidden fruit for cloud providers: reluctant to let users dabble. Because EBS serves as the pricing anchor for RDS — the barrier and moat for cloud databases.
For IaaS providers, who make their living by selling resources, there’s not much room for price inflation, as costs can be precisely calculated against the BOM. However, for PaaS services like cloud databases, which include “services,” labor/development costs are significantly marked up, allowing for astronomical pricing and high profits. Despite storage, computing, and networking making up half of the revenue for domestic public cloud IaaS, their gross margin stands only at 15% to 20%. In contrast, public cloud PaaS, represented by cloud databases, can achieve gross margins of 50% or higher, vastly outperforming the IaaS model.
If users opt to use IaaS resources (EC2/EBS) to build their own databases, it represents a significant loss of profit for cloud providers. Thus, cloud providers go to great lengths to prevent this scenario. But how is such a product designed to meet this need?
Firstly, instance storage, which is best suited for self-hosted databases, must come with various restrictions: instances that are hibernated/stopped are reclaimed and wiped, preventing serious production database services from running on EC2’s built-in disks. Although EBS’s performance and reliability might slightly lag behind local NVMe SSD storage, it’s still viable for database operations, hence the restrictions: but not without giving users an option, hence the exorbitant pricing! As compensation, the secondary, cheaper, and massive storage option, S3, can be priced more affordably to lure customers.
Of course, to make customers bite, some cloud computing KOLs promote the accompanying “public cloud-native” philosophy: “EC2 is not suitable for stateful applications. Please store state in S3 or RDS and other managed services, as these are the ‘best practices’ for using our cloud.”

These four points are well summarized, but what public clouds will not disclose is the cost of these “best practices.” To put these four points in layman’s terms, they form a carefully designed trap for customers:
Dump ordinary files in S3! (With such cost-effective S3, who needs EBS?)
Don’t build your own database! (Forget about tinkering with open-source alternatives using instance storage)
Please deeply use the vendor’s proprietary identity system (vendor lock-in)
Faithfully contribute to the cloud database! (Once users are locked in, the time to “slaughter” arrives)
HOW to Do that
The business model of public clouds can be summarized as: Attract customers with cheap EC2/S3, make a killing with EBS/RDS.
To slaughter the pig, you first need to raise it. No pains, no gains. Thus, for new users, startups, and small-to-medium enterprises, public clouds spare no effort in offering sweeteners, even at a loss, to drum up business. New users enjoy a significant discount on their first order, startups receive free or half-price credits, and the pricing strategy is subtly crafted.
Taking AWS RDS pricing as an example, the unit price for mini models with 1 to 2 cores is only a few dollars per core per month, which translates to three to four hundred yuan per year (excluding storage): If you need a low-usage database for minor storage, this might be the most straightforward and affordable choice.
However, as soon as you slightly increase the configuration, even by just a little, the price per core per month jumps by orders of magnitude, reaching twenty to a hundred dollars, with the potential to skyrocket by dozens of times — and that’s before the doubling effect of the astonishing EBS prices. Users only realize what has happened when they are faced with a suddenly astronomical bill.
For instance, using RDS for PostgreSQL on AWS, the price for a 64C / 256GB db.m5.16xlarge RDS for one month is $25,817, which is equivalent to about 180,000 yuan per month. The monthly rent is enough for you to buy two servers with even better performance and set them up on your own. The rent-to-buy ratio doesn’t even last a month; renting for just over ten days is enough to buy the whole server for yourself.
| Payment Model | Price | Cost Per Year (¥10k) |
|---|---|---|
| Self-hosted IDC (Single Physical Server) | ¥75k / 5 years | 1.5 |
| Self-hosted IDC (2-3 Server HA Cluster) | ¥150k / 5 years | 3.0 ~ 4.5 |
| Alibaba Cloud RDS (On-demand) | ¥87.36/hour | 76.5 |
| Alibaba Cloud RDS (Monthly) | ¥42k / month | 50 |
| Alibaba Cloud RDS (Yearly, 15% off) | ¥425,095 / year | 42.5 |
| Alibaba Cloud RDS (3-year, 50% off) | ¥750,168 / 3 years | 25 |
| AWS (On-demand) | $25,817 / month | 217 |
| AWS (1-year, no upfront) | $22,827 / month | 191.7 |
| AWS (3-year, full upfront) | $120k + $17.5k/month | 175 |
| AWS China/Ningxia (On-demand) | ¥197,489 / month | 237 |
| AWS China/Ningxia (1-year, no upfront) | ¥143,176 / month | 171 |
| AWS China/Ningxia (3-year, full upfront) | ¥647k + ¥116k/month | 160.6 |
Comparing the costs of self-hosting versus using a cloud database:
| Method | Cost Per Year (¥10k) |
|---|---|
| Self-hosted Servers 64C / 384G / 3.2TB NVME SSD 660K IOPS (2-3 servers) | 3.0 ~ 4.5 |
| Alibaba Cloud RDS PG High-Availability pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG High-Availability db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
RDS pricing compared to self-hosting, see “Is Cloud Database an idiot Tax?”
Any rational business user can see the logic here: **If the purchase of such a service is not for short-term, temporary needs, then it is definitely considered a major financial misstep.
This is not just the case with Relational Database Services / RDS, but with all sorts of cloud databases. MongoDB, ClickHouse, Cassandra, if it uses EC2 / EBS, they are all doing the same. Take the popular NoSQL document database MongoDB as an example:
This kind of pricing could only come from a product manager without a decade-long cerebral thrombosis
Five years is the typical depreciation period for servers, and with the maximum discount, a 12-node (64C 512G) configuration is priced at twenty-three million. The minor part of this quote alone could easily cover the five-year hardware maintenance, plus you could afford a team of MongoDB experts to customize and set up as you wish.
Fine dining restaurants charge a 15% service fee on dishes, and users can understand and support this reasonable profit margin. If cloud databases charge a few tens of percent on top of hardware resources for service fees and elasticity premiums (let’s not even start on software costs for cloud services that piggyback on open-source), it can be justified as pricing for productive elements, with the problems solved and services provided being worth the money.
However, charging several hundred or even thousands of percent as a premium falls into the category of destructive element distribution: cloud providers bank on the fact that once users are onboard, they have no alternatives, and migration would incur significant costs, so they can confidently proceed with the slaughter! In this sense, the money users pay is not for the service, but rather a compulsory levy of a “no-expert tax” and “protection money”.
The Forgotten Vision
Facing accusations of “slaughtering the pig,” cloud vendors often defend themselves by saying: “Oh, what you’re seeing is the list price. Sure, it’s said to be a minimum of 50% off, but for major customers, there are no limits to the discounts.” As a rule of thumb: the cost of self-hosting fluctuates around 5% to 10% of the current cloud service list prices. If such discounts can be maintained long-term, cloud services become more competitive than self-hosting.
Professional and knowledgeable large customers, especially those capable of migrating at any time, can indeed negotiate steep discounts of up to 80% with public clouds, while smaller customers naturally lack bargaining power and are unlikely to secure such deals.
However, cloud computing should not turn into ‘calculating clouds’: if cloud providers can only offer massive discounts to large enterprises while “shearing the sheep” and “slaughtering the pig” when dealing with small and medium-sized customers and developers, they are essentially robbing the poor to subsidize the rich. This practice completely contradicts the original intent and vision of cloud computing and is unsustainable in the long run.
When cloud computing first emerged, the focus was on the cloud hardware / IaaS layer: computing power, storage, bandwidth. Cloud hardware represents the founding story of cloud vendors: to make computing and storage resources as accessible as utilities, with themselves playing the role of infrastructure providers. This is a compelling vision: public cloud vendors can reduce hardware costs and spread labor costs through economies of scale; ideally, while keeping a profit for themselves, they can offer storage and computing power that is more cost-effective and flexible than IDC prices.
On the other hand, cloud software (PaaS / SaaS) follows a fundamentally different business logic: cloud hardware relies on economies of scale to optimize overall efficiency and earn money through resource pooling and overselling, which represents a progress in efficiency. Cloud software, however, relies on sharing expertise and charging service fees for outsourced operations and maintenance. Many services on the public cloud are essentially wrappers around free open-source software, relying on monopolizing expertise and exploiting information asymmetry to charge exorbitant insurance fees, which constitutes a transfer of value.
Unfortunately, for the sake of obfuscation, both cloud software and cloud hardware are branded under the “cloud” title. Thus, the narrative of cloud computing mixes breaking resource monopolies with establishing expertise monopolies: it combines the idealistic glow of democratizing computing power across millions of households with the greed of monopolizing and unethically profiting from it.
Public cloud providers that abandon platform neutrality and their original intent of being infrastructure providers, indulging in PaaS / SaaS / and even application layer profiteering, will sink in a bottomless competition.
Where to Go
Monopolistic profits vanish as competition emerges, plunging public cloud providers into a grueling battle.
At the infrastructure level, telecom operators, state-owned clouds, and IDC 1.5/2.0 have entered the fray, offering highly competitive IaaS services. These services include turnkey network and electricity hosting and maintenance, with high-end servers available for either purchase and hosting or direct rental at actual prices, showing no fear in terms of flexibility.
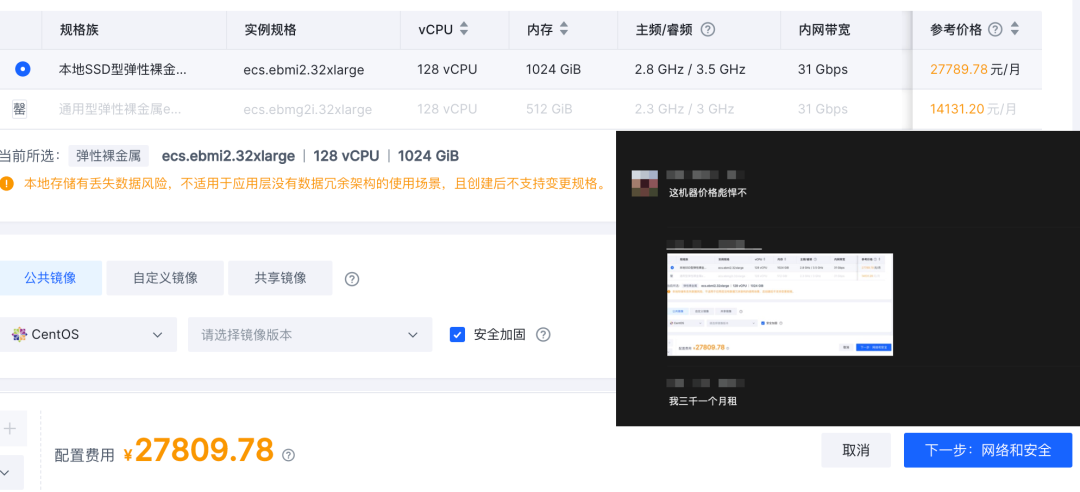
IDC 2.0’s new server rental model: Actual price rental, ownership transfers to the user after a full term
On the software front, what once were the technical barriers of public clouds, various management software / PaaS solutions, have seen excellent open-source alternatives emerge. OpenStack / Kubernetes have replaced EC2, MinIO / Ceph have taken the place of S3, and on RDS, open-source alternatives like Pigsty and various K8S Operators have appeared.
The whole “cloud-native” movement, in essence, is the open-source ecosystem’s response to the challenge of public cloud “freeloading”: users and developers have created a complete set of local-priority public cloud open-source alternatives to avoid being exploited by public cloud providers.
The term “CloudNative” is aptly named, reflecting different perspectives: public clouds see it as being “born on the public cloud,” while private clouds think of it as “running cloud-like services locally.” Ironically, the biggest proponents of Kubernetes are the public clouds themselves, akin to a salesman crafting his own noose.
In the context of economic downturn, cost reduction and efficiency gains have become the main theme. Massive layoffs in the tech sector, coupled with the future large-scale impact of AI on intellectual industries, will release a large amount of related talent. Additionally, the low-wage advantage in our era will significantly alleviate the scarcity and high cost of building one’s own talent pool. Labor costs, in comparison to cloud service costs, offer much more advantage.
Considering these trends, the combination of IDC2.0 and open-source self-building is becoming increasingly competitive: for organizations with a bit of scale and talent reserves, bypassing public clouds as middlemen and directly collaborating with IDCs is clearly a more economical choice.
Staying true to the original mission is essential. Public clouds do an admirable job at the cloud hardware / IaaS level, except for being outrageously expensive, there aren’t many issues, and the offerings are indeed solid. If they could return to their original vision and truly excel as providers of basic infrastructure, akin to utilities, selling resources might not offer high margins, but it would allow them to earn money standing up. Continuing down the path of exploitation, however, will ultimately lead customers to vote with their feet.
References
【2】云数据库是不是智商税
【3】范式转移:从云到本地优先
【7】AWS实例存储
【9】AWS EBS SLA
【12】阿里云:云盘概述
【13】图说块存储与云盘
【15】云计算为啥还没挖沙子赚钱?
RDS: The Idiot Tax
As the season of layoffs hits big tech companies, cost-cutting and efficiency are top of mind. Public cloud databases, often referred to as the “slaughterhouse knives” of the cloud, are under increasing scrutiny. The question now is: Can their dominance continue?
Recently, DHH (David Heinemeier Hansson), co-founder of Basecamp and HEY, published a thought-provoking piece that has sparked a lot of debate. His core message is succinct:
“We spend $500,000 a year on cloud databases (RDS/ES). Do you know how many powerful servers that kind of money could buy?
We’re off the cloud. Goodbye!”
So, How Many Powerful Servers Could $500,000 Buy?

Absurd Pricing
Sharpening the knives for the sheep and pigs
Let’s rephrase the question: how much do servers and RDS (Relational Database Service) cost?
Taking the physical server model we heavily use as an example: Dell R730, 64 cores, 384GB of memory, equipped with a 3.2 TB MLC NVME SSD. A server like this, running a standard production-level PostgreSQL, can handle up to hundreds of thousands of TPS (Transactions Per Second), and read-only queries can reach four to five hundred thousand. How much does it cost? Including electricity, internet, IDC (Internet Data Center) hosting, and maintenance fees, and amortizing the cost over a 5-year depreciation period, the total lifecycle cost is around seventy-five thousand, or fifteen thousand per year. Of course, for production use, high availability is a must, so a typical database cluster would need two to three physical servers, amounting to an annual cost of thirty to forty-five thousand dollars.
This calculation does not include the cost of DBA (Database Administrator) salaries: managing tens of thousands of cores with just two or three people is not that expensive.
If you directly purchase a cloud database of this specification, what would the cost be? Let’s look at the pricing from Alibaba Cloud in China. Since the basic version is practically unusable for production (for reference, see: “Cloud Database: From Deletion to Desertion”), we’ll choose the high-availability version, which usually involves two to three instances. Opting for a yearly or monthly subscription, for an exclusive use of a 64-core, 256GB instance with PostgreSQL 15 on x86 in East China 1 availability zone, and adding a 3.2TB ESSD PL3 cloud disk, the annual cost ranges from 250,000 (for a 3-year contract) to 750,000 (on-demand), with storage costs accounting for about a third.
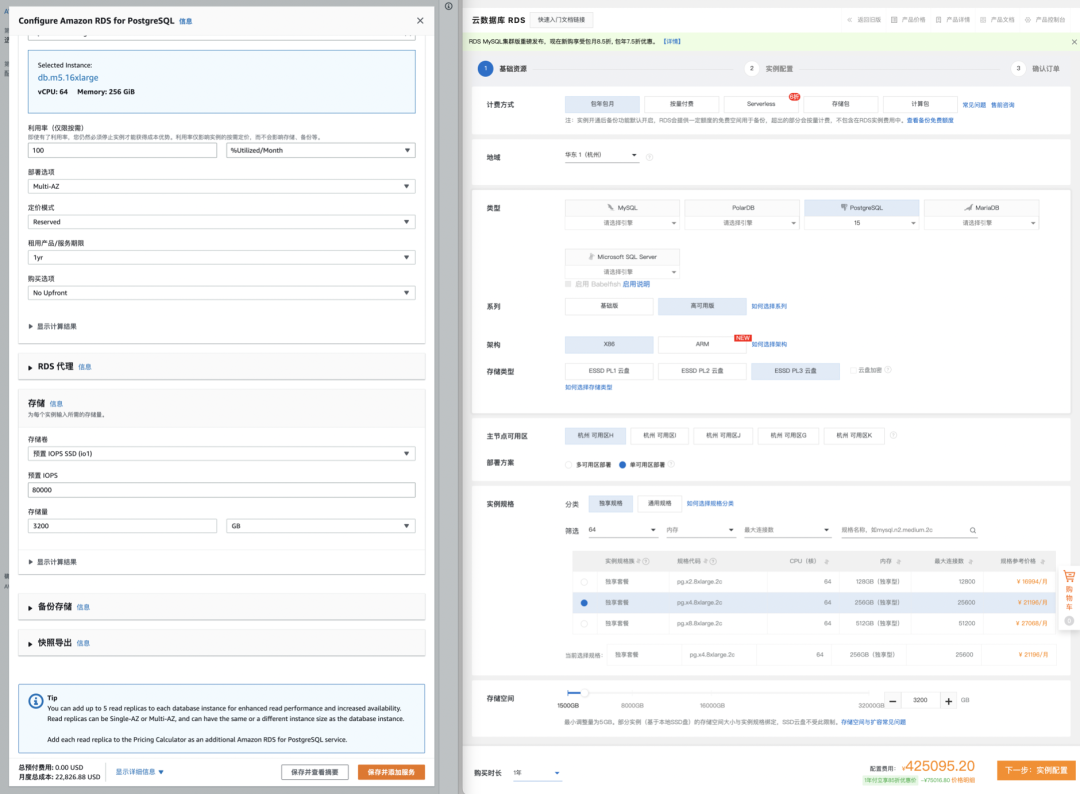
Let’s also consider AWS, the leading public cloud provider. The closest equivalent on AWS is the db.m5.16xlarge, also with 64 cores and 256GB across multiple availability zones. Similarly, we add a 3.2TB io1 SSD disk with up to 80,000 IOPS, and review the global and China-specific pricing from AWS. The overall cost ranges from 1.6 million to 2.17 million yuan per year, with storage costs accounting for about half. The table below summarizes the costs:
| Payment Model | Price | Cost Per Year (¥10k) |
|---|---|---|
| Self-hosted IDC (Single Physical Server) | ¥75k / 5 years | 1.5 |
| Self-hosted IDC (2-3 Server HA Cluster) | ¥150k / 5 years | 3.0 ~ 4.5 |
| AWS (On-demand) | $25,817 / month | 217 |
| AWS (1-year, no upfront) | $22,827 / month | 191.7 |
| AWS (3-year, full upfront) | $120k + $17.5k/month | 175 |
| AWS China/Ningxia (On-demand) | ¥197,489 / month | 237 |
| AWS China/Ningxia (1-year, no upfront) | ¥143,176 / month | 171 |
| AWS China/Ningxia (3-year, full upfront) | ¥647k + ¥116k/month | 160.6 |
Comparing the costs of self-hosting versus using a cloud database:
| Method | Cost Per Year (¥10k) |
|---|---|
| Self-hosted Servers 64C / 384G / 3.2TB NVME SSD 660K IOPS (2-3 servers) | 3.0 ~ 4.5 |
| Alibaba Cloud RDS PG High-Availability pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG High-Availability db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
So, the question arises, if the cost of using a cloud database for one year is enough to buy several or even more than a dozen better-performing servers, what then is the real benefit of using a cloud database? Of course, large public cloud customers can usually receive business discounts, but even with discounts, the magnitude of the cost difference is hard to ignore.
Is using a cloud database essentially paying a “tax” for lack of better judgment?
Comfort Zone
No Silver Bullet
Databases are the heart of data-intensive applications, and since applications follow the lead of databases, choosing the right database requires great care. Evaluating a database involves many dimensions: reliability, security, simplicity, scalability, extensibility, observability, maintainability, cost-effectiveness, and more. What clients truly care about are these attributes, not the fluffy tech hype: decoupling of compute and storage, Serverless, HTAP, cloud-native, hyper-converged… These must be translated into the language of engineering: what is sacrificed for what is gained to be meaningful.
Public cloud proponents like to gild it: cost-saving, flexible elasticity, reliable security, a panacea for enterprise digital transformation, a revolution from horse-drawn carriage to automobile, good, fast, and cheap, and so on. Unfortunately, few of these claims are realistic. Cutting through the fluff, the only real advantage of cloud databases over professional database services is elasticity, specifically in two aspects: low startup costs and strong scalability.
Low startup costs mean that users don’t need to build data centers, hire and train personnel, or purchase servers to get started; strong scalability refers to the ease of upgrading or downgrading configurations and scaling capacity. Thus, the core scenarios where public cloud truly fits are these two:
- Initial stages, simple applications with minimal traffic
- Workloads with no predictable pattern, experiencing drastic fluctuations
The former mainly includes simple websites, personal blogs, small apps and tools, demos/PoC, and the latter includes low-frequency data analysis/model training, sudden spike sales or ticket grabs, celebrity concurrent affairs, and other special scenarios.
The business model of the public cloud is essentially renting: renting servers, bandwidth, storage, experts. It’s fundamentally no different from renting houses, cars, or power banks. Of course, renting servers and outsourcing operations doesn’t sound very appealing, hence the term “cloud” sounds more like a cyber landlord. The characteristic of the renting model is its elasticity.
The renting model has its benefits, for example, shared power banks can meet the temporary, small-scale charging needs when out and about. However, for many people who travel daily between home and work, using shared power banks to charge phones and computers every day is undoubtedly absurd, especially when renting a power bank for an hour costs about the same as buying one outright after just a few hours. Renting a car can perfectly meet temporary, emergency, or one-off transportation needs: traveling or hauling goods on short notice. But if your travel needs are frequent and local, purchasing an autonomous car might be the most convenient and cost-effective choice.
The key issue is the rent-to-own ratio, with houses taking decades, cars a few years, but public cloud servers usually only a few months. If your business can sustain for more than a few months, why rent instead of buying outright?
Thus, the money cloud vendors make comes either from VC-funded tech startups seeking explosive growth, from entities in gray areas where the rent-seeking space exceeds the cloud premium, from the foolishly wealthy, or from a mishmash of webmasters, students, VPN individual users. Smart, high-net-worth enterprise customers, who could enjoy a comfortable, affordable big house, why would they choose to squeeze into rental cube apartments?
If your business fits within the suitable spectrum for the public cloud, that’s fantastic; but paying several times or even more than a tenfold premium for unnecessary flexibility and elasticity is purely a tax on lack of intelligence.
The Cost Assassin
Profit margins lie in information asymmetry, but you can’t fool everyone forever.
The elasticity of public clouds is designed for their business model: low startup costs, high maintenance costs. Low startup costs lure users to the cloud, and the excellent elasticity adapts to business growth at any time. However, once the business stabilizes, vendor lock-in occurs, making it difficult to switch providers, and the high maintenance costs become unbearable for users. This model is colloquially known as the pig slaughtering scam.

In the first stop of my career, I had such a pig slaughtering experience that remains vivid in my memory. As one of the first internal BUs forced onto A Cloud, A Cloud directly sent engineers to handhold us through the cloud migration process. We replaced our self-built big data/database suite with ODPS. The service was indeed decent, but the annual cost of storage and computing soared from tens of millions to nearly a hundred million, almost transferring all profits to A Cloud, making it the ultimate cost assassin.

At my next stop, the situation was entirely different. We managed a PostgreSQL and Redis database cluster with 25,000 cores and 4.5 million QPS. For databases of this size, if charged by AWS RCU/WCU, the cost would be billions annually; even with a long-term, yearly subscription and a substantial business discount, it would still cost at least fifty to sixty million. Yet, we had only two or three DBAs and a few hundred servers, with a total annual cost of manpower and assets of less than ten million.
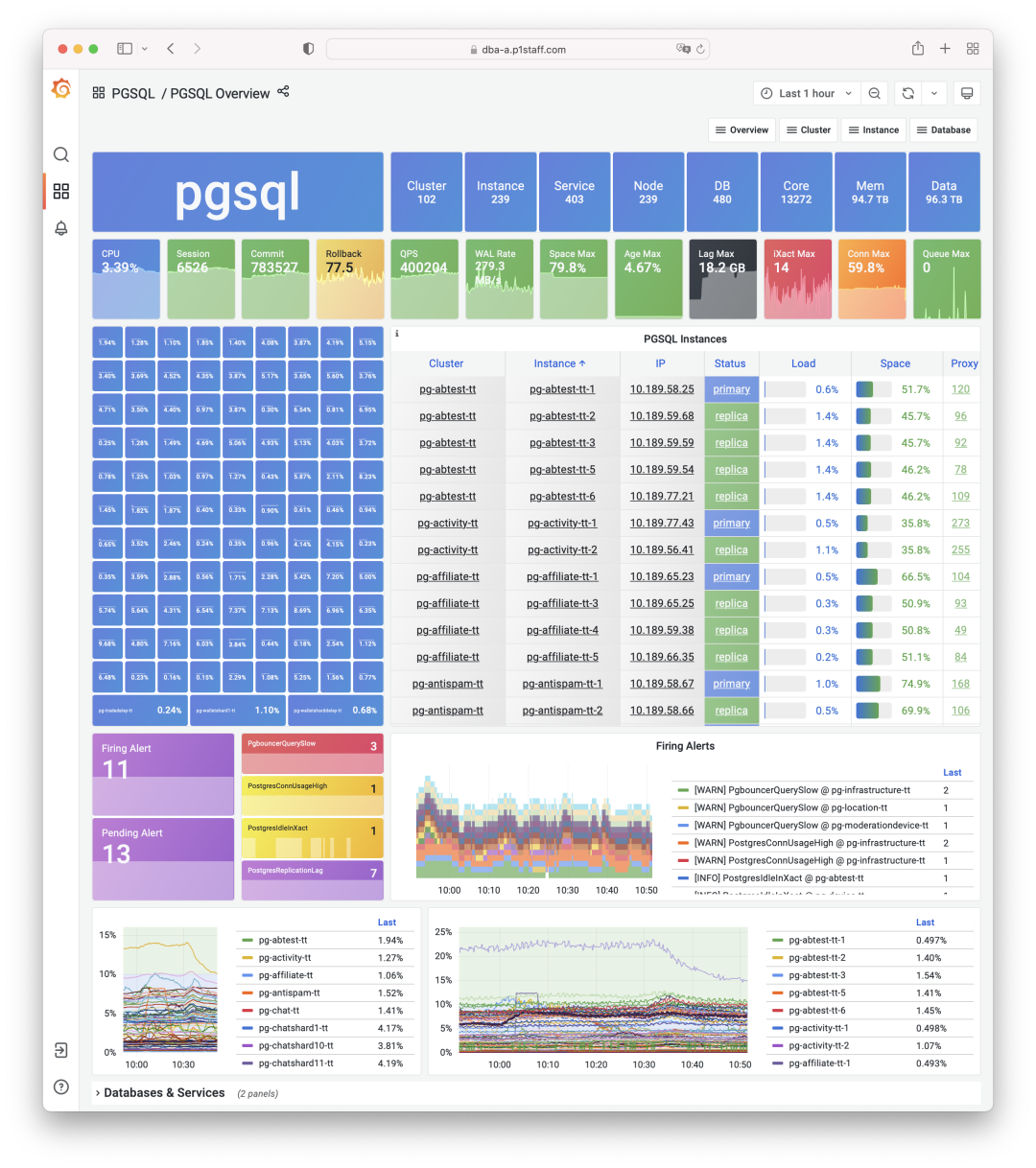
Here, we can calculate the unit cost in a simple way: the comprehensive cost of using one core (including memory/disk) for a month, termed as core·month. We have calculated the costs of self-built server types and compared them with the quotes from cloud providers, with the following rough results:
| 硬件算力 | 单价 |
|---|---|
| IDC自建机房(独占物理机 A1: 64C384G) | 19 |
| IDC自建机房(独占物理机 B1: 40C64G) | 26 |
| IDC自建机房(独占物理机 C2: 8C16G) | 38 |
| IDC自建机房(容器,超卖200%) | 17 |
| IDC自建机房(容器,超卖500%) | 7 |
| UCloud 弹性虚拟机(8C16G,有超卖) | 25 |
| 阿里云 弹性服务器 2x内存(独占无超卖) | 107 |
| 阿里云 弹性服务器 4x内存(独占无超卖) | 138 |
| 阿里云 弹性服务器 8x内存(独占无超卖) | 180 |
| AWS C5D.METAL 96C 200G (按月无预付) | 100 |
| AWS C5D.METAL 96C 200G(预付3年) | 80 |
| 数据库 | |
| AWS RDS PostgreSQL db.T2 (4x) | 440 |
| AWS RDS PostgreSQL db.M5 (4x) | 611 |
| AWS RDS PostgreSQL db.R6G (8x) | 786 |
| AWS RDS PostgreSQL db.M5 24xlarge | 1328 |
| 阿里云 RDS PG 2x内存(独占) | 260 |
| 阿里云 RDS PG 4x内存(独占) | 320 |
| 阿里云 RDS PG 8x内存(独占) | 410 |
| ORACLE数据库授权 | 10000 |
So, the question arises, why can server hardware priced at twenty units be sold for hundreds, and why does installing cloud database software on it multiply the price? Is it because the operations are made of gold, or is the server made of gold?
A common response is: Databases are the crown jewels of foundational software, embodying countless intangible intellectual properties BlahBlah. Thus, it’s reasonable for the software to be priced much higher than the hardware. This reasoning might be acceptable for top-tier commercial databases like Oracle, or console games from Sony and Nintendo.
But for cloud databases (RDS for PostgreSQL/MySQL/…) on public clouds, which are essentially rebranded and modified open-source database kernels with added control software and shared DBA services, this markup is absurd: the database kernel is free. Is your control software made of gold, or are your DBAs made of gold?
The secret of public clouds lies here: they acquire customers with ‘cheap’ S3 and EC2, then “slaughter the pig” with RDS.
Although nearly half of the revenue of domestic public cloud IaaS (storage, computing, network) comes with only a 15% to 20% gross margin, the revenue from public cloud PaaS may be lower, but its gross margin can reach 50%, utterly outperforming the resource-selling IaaS. And the most representative of PaaS services is the cloud database.
Normally, if you’re not using public cloud as just an IDC 2.0 or CDN provider, the most expensive service would be the database. Are the storage, computing, and networking resources on the public cloud expensive? Strictly speaking, not outrageously so. The cost of hosting and maintaining a physical machine in an IDC is about twenty to thirty units per core·month, while the price of using one CPU core for a month on the public cloud ranges from seventy to two hundred units, considering various discounts and activities, as well as the premium for elasticity, it’s barely within an acceptable range.
However, cloud databases are outrageously expensive, with the price for the same computing power per month being several times to over ten times higher than the corresponding hardware. For the cheaper Alibaba Cloud, the price per core·month ranges from two hundred to four hundred units, and for the more expensive AWS, it can reach seven to eight hundred or even more than a thousand.
If you’re only using one or two cores of RDS, then it might not be worth the hassle to switch, just consider it a tax. But if your business scales up and you’re still not moving away from the cloud, then you’re really paying a tax on intelligence.
Good Enough?
Make no mistake, RDS are just mediocre solutions.
When it comes to the cost of cloud databases/cloud servers, if you manage to bring this up with a sales representative, their pitch usually shifts to: Yes, we are expensive, but we are good!
But, is RDS really that good?
It could be argued that for toy applications, small websites, personal hosting, and self-built databases by those without technical knowledge, RDS might be good enough. However, from the perspective of high-value clients and database experts, RDS is seen as nothing more than a barely passable, communal pot meal.
At its core, the public cloud stems from the operational capabilities that overflowed from major tech companies. People within these companies are well aware of their own technological capabilities, so there’s no need for any undue idolization. (Google might be an exception).
Take performance as an example, where the core metric is latency/response time, especially tail latency, which directly impacts user experience: nobody wants to wait several seconds for a screen swipe to register. Here, disks play a crucial role.
In our production environment, we use local NVME SSDs, with a typical 4K write latency of 15µs and read latency of 94µs. Consequently, the response time for a simple query on PostgreSQL is usually between 100 ~ 300µs, and the response time on the application side typically ranges from 200 ~ 600µs; for simple queries, our SLO is to achieve within 1ms for hits, and within 10ms for misses, with anything over 10ms considered a slow query that needs optimization.
AWS’s EBS service, when tested with fio, shows disastrously poor performance【6】, with default gp3 read/write latencies at 40ms and io1 at 10ms, a difference of nearly three orders of magnitude. Moreover, the maximum IOPS is only eighty thousand. RDS uses EBS for storage, and if even a single disk access takes 10ms, it’s just not workable. io2 does use the same kind of NVMe SSDs as we do, but remote block storage has double the latency compared to local disks.

Indeed, sometimes cloud providers do offer sufficiently good local NVMe SSDs, but they cunningly impose various restrictions to prevent users from using EC2 to build their own databases. AWS restricts this by offering NVMe SSD Ephemeral Storage, which is wiped clean upon EC2 restart, rendering it unusable. Alibaba Cloud, on the other hand, sells at exorbitant prices, with Alibaba Cloud’s ESSD PL3 being 200 times more expensive compared to direct hardware purchases. For a reference, a 3.2TB enterprise-grade PCI-E SSD card, AWS’s rental ratio is one month, while Alibaba Cloud’s is nine days, meaning the cost of renting for this period is equivalent to purchasing the entire disk. If purchasing on Alibaba Cloud with a three-year maximum discount at 50% off, the cost of three years of rent could buy 123 of the same disks, nearly 400TB in total ownership.
Observability is another example where no RDS monitoring can be considered “good”. Just looking at the number of monitoring metrics, while knowing whether a service is dead or alive may require only a few metrics, fault root cause analysis benefits from as many monitoring metrics as possible to build a good context. Most RDS services only provide basic monitoring metrics and rudimentary dashboards. For example, Alibaba Cloud RDS PG【7】’s so-called “enhanced monitoring” includes only a few pitiful metrics. AWS and PG database-related metrics are also less than 100, while our own monitoring system includes over 800 types of host metrics, 610 types for PGSQL database, 257 types for REDIS, totaling around three thousand metrics, dwarfing those of RDS.

Public Demo: https://demo.pigsty.io
As for reliability, I used to have basic trust in the reliability of RDS, until the scandal in A Cloud’s Hong Kong data center a month ago. The rented data center had a fire suppression incident with water spraying, OSS malfunction, and numerous RDS services became unusable and could not be switched over; then, A Cloud’s entire Region’s control services crashed due to a single AZ failure, making a mockery of the idea of remote disaster recovery for cloud databases.
Of course, this is not to say that self-hosting would not have these issues, but a somewhat reliable IDC hosting would not commit such egregious errors. Security needs no further discussion; recent high-profile incidents, such as the infamous SHGA; hardcoding AK/SK in a bunch of sample codes, is cloud RDS more secure? Don’t make me laugh. At least traditional architecture has a VPN bastion as a layer of protection, while databases exposed on the public network with weak passwords are all too common, undeniably increasing the attack surface.
Another widespread criticism of cloud databases is their extensibility. RDS does not grant users dbsu permissions, meaning users cannot install extension plugins in the database. PostgreSQL’s charm lies in its extensions; without extensions, PostgreSQL is like cola without ice, yogurt without sugar. A more severe issue is that in some failure scenarios, users even lose the ability to help themselves, as seen in the real case of “Cloud Database: From Deleting Databases to Running Away”: WAL archiving and PITR, basic functionalities, are charged features in RDS. Regarding maintainability, some say cloud databases are convenient as they can be created and destroyed with just a few clicks, but those people have likely never experienced the ordeal of receiving SMS verification codes for restarting each database. With Database as Code style management tools, true engineers would never resort to such “ClickOps”.
However, everything has its rationale for existence, and cloud databases are not entirely without merit. In terms of scalability, cloud databases have indeed reached new heights, such as various Serverless offerings, but this is more about saving money and overselling for cloud providers, offering little real benefit to users.
The Obsolescence of DBAs?
Dominated by cloud vendors, hard to hire, and now obsolete?
Another pitch from cloud databases is that with RDS, you don’t need a DBA anymore!
For instance, this infamous article, “Why Are You Still Hiring DBAs?”, argues: We have autonomous database services! RDS and DAS can solve these database-related issues for you, making DBAs redundant, haha. I believe anyone who seriously reviews these so-called “autonomous services” or “AI4DB” official documents will not buy into this nonsense: Can a module, hardly a decent monitoring system, truly autonomize database management? This is simply a pipe dream.
DBA, Database Administrator, historically also known as database coordinators or database programmers, is a role that spans across development and operations teams, covering responsibilities related to DA, SA, Dev, Ops, and SRE. They manage everything related to data and databases: setting management policies and operational standards, planning hardware and software architecture, coordinating database management, verifying table schema designs, optimizing SQL queries, analyzing execution plans, and even handling emergencies and data recovery.
The first value of a DBA is in security fallback: They are the guardians of a company’s core data assets and can potentially inflict fatal damage on the company. There’s a joke at Ant Financial that besides regulatory bodies, DBAs could bring Alipay down. Executives often fail to recognize the importance of DBAs until a database incident occurs, and a group of CXOs anxiously watches the DBA firefighting and fixing… Compared to the cost of avoiding a database failure, such as a nationwide flight halt, Youtube downtime, or a factory’s day-long shutdown, hiring a DBA seems trivial.
The second value of a DBA is in model design and optimization. Many companies do not care if their queries perform poorly, thinking “hardware is cheap,” and solve problems by throwing money at hardware. However, improperly tuned queries/SQL or poorly designed data models and table structures can degrade performance by orders of magnitude. At some scale, the cost of stacking hardware becomes prohibitively expensive compared to hiring a competent DBA. Frankly, I believe the largest IT expenditure in most companies is due to developers not using databases correctly.
A DBA’s basic skill is managing DBs, but their essence lies in Administration: managing the entropy created by developers requires more than just technical skills. “Autonomous databases” might help analyze loads and create indexes, but they cannot understand business needs or push for table structure optimization, and this is something unlikely to be replaced by cloud services in the next two to three decades.
Whether it’s public cloud vendors, cloud-native/private clouds represented by Kubernetes, or local open-source RDS alternatives like Pigsty, their core value is to use software as much as possible, not manpower, to deal with system complexity. So, will cloud software revolutionize operations and DBA roles?
Cloud is not a maintenance-free outsourcing magic. According to the law of complexity conservation, the only way for the roles of system administrators or database administrators to disappear is for them to be rebranded as “DevOps Engineers” or SREs. Good cloud software can shield you from mundane operational tasks and solve 70% of routine issues, but there will always be complex problems that only humans can handle. You might need fewer people to manage these cloud services, but you still need people【12】. After all, you need knowledgeable individuals to coordinate and manage, so you don’t get exploited by cloud vendors.
In large organizations, a good DBA is crucial. However, excellent DBAs are quite rare and in high demand, leading to this role being outsourced in most organizations: either to professional database service companies or to cloud database RDS service teams. Organizations unable to find DBA providers must internally assign this responsibility to their development/operations staff, until the company grows large enough or suffers enough setbacks for some Dev/Ops to develop the necessary skills.
DBAs won’t become obsolete; they will just be monopolized by cloud vendors to provide services.
The Shadow of Monopoly
In 2020, the adversary of computing freedom was cloud computing software.
Beyond the “obsolescence of DBAs,” the emergence of the cloud harbors a larger threat. We should be concerned about a scenario where public clouds (or “Fruit Clouds”) grow dominant, controlling both hardware and operators up and down the stream, monopolizing computation, storage, networking, and top-tier expert resources to become the de facto standards. If all top-tier DBAs are poached by cloud vendors to provide centralized shared expert services, ordinary business organizations will completely lose the capability to utilize databases effectively, eventually left with no choice but to be “taxed” by public clouds. Ultimately, all IT resources would be concentrated in the hands of cloud vendors, who, by controlling a critical few, could control the entire internet. This is undeniably contrary to the original intent behind the creation of the internet.
Let me reference Martin Kelppmann:
In the 2020s, the enemy of freedom in computing is cloud software
i.e. software that runs primarily on the vendor’s servers, with all your data also stored on those servers. This cloud software may have a client-side component (a mobile app, or the JavaScript running in your web browser), but it only works in conjunction with the vendor’s server. And there are lots of problems with cloud software:
- If the company providing the cloud software goes out of business or decides to discontinue a product, the software stops working, and you are locked out of the documents and data you created with that software. This is an especially common problem with software made by a startup, which may get acquired by a bigger company that has no interest in continuing to maintain the startup’s product.
- Google and other cloud services may suddenly suspend your account with no warning and no recourse, for example if an automated system thinks you have violated its terms of service. Even if your own behaviour has been faultless, someone else may have hacked into your account and used it to send malware or phishing emails without your knowledge, triggering a terms of service violation. Thus, you could suddenly find yourself permanently locked out of every document you ever created on Google Docs or another app.
- With software that runs on your own computer, even if the software vendor goes bust, you can continue running it forever (in a VM/emulator if it’s no longer compatible with your OS, and assuming it doesn’t need to contact a server to check for a license check). For example, the Internet Archive has a collection of over 100,000 historical software titles that you can run in an emulator inside your web browser! In contrast, if cloud software gets shut down, there is no way for you to preserve it, because you never had a copy of the server-side software, neither as source code nor in compiled form.
- The 1990s problem of not being able to customise or extend software you use is aggravated further in cloud software. With closed-source software that runs on your own computer, at least someone could reverse-engineer the file format it uses to store its data, so that you could load it into alternative software (think pre-OOXML Microsoft Office file formats, or Photoshop files before the spec was published). With cloud software, not even that is possible, since the data is only stored in the cloud, not in files on your own computer.
If all software was free and open source, these problems would all be solved. However, making the source code available is not actually necessary to solve the problems with cloud software; even closed-source software avoids the aforementioned problems, as long as it is running on your own computer rather than the vendor’s cloud server. Note that the Internet Archive is able to keep historical software working without ever having its source code: for purposes of preservation, running the compiled machine code in an emulator is just fine. Maybe having the source code would make it a little easier, but it’s not crucial. The important thing is having a copy of the software at all.
My collaborators and I have previously argued for local-first software, which is a response to these problems with cloud software. Local-first software runs on your own computer, and stores its data on your local hard drive, while also retaining the convenience of cloud software, such as real-time collaboration and syncing your data across all of your devices. It is nice for local-first software to also be open source, but this is not necessary: 90% of its benefits apply equally to closed-source local-first software.
Cloud software, not closed-source software, is the real threat to software freedom, because the harm from being suddenly locked out of all of your data at the whim of a cloud provider is much greater than the harm from not being able to view and modify the source code of your software. For that reason, it is much more important and pressing that we make local-first software ubiquitous. If, in that process, we can also make more software open-source, then that would be nice, but that is less critical. Focus on the biggest and most urgent challenges first.
However, where there is action, there is reaction; local-first software began to emerge as a countermeasure to cloud software. For instance, the Cloud Native movement, represented by Kubernetes, is a prime example. “Cloud Native,” as interpreted by cloud vendors, means “software that is natively developed in a public cloud environment”; but its real significance should be “local,” as in the opposite of “Cloud” — “Local” cloud / private cloud / proprietary cloud / native cloud, the name doesn’t matter. What matters is that it can run anywhere the user desires (including on cloud servers), not just exclusively in public clouds!
Open-source projects, like Kubernetes, have democratized resource scheduling/smart operations capabilities previously unique to public clouds, enabling enterprises to run ‘cloud’-like capabilities locally. For stateless applications, it already serves as a sufficiently robust “cloud operating system” kernel. Open-source alternatives like Ceph/Minio offer S3 object storage solutions, leaving only one question unanswered: how to manage and deploy stateful, production-grade database services?
The era is calling for an open-source alternative to RDS.
Answer & Solution
Pigsty —— Battery-Included, Local-First PostgreSQL Distribution as an Open-Source RDS Alternative
I envision a future where everyone has the factual right to freely use superior services, not confined within the pens (Pigsty) provided by a few public cloud vendors, feeding on subpar offerings. This is why I created Pigsty — a better, open-source, free alternative to PostgreSQL RDS. It enables users to launch a database service better than cloud RDS with just one click, anywhere (including on cloud servers).
Pigsty is a comprehensive complement to PostgreSQL, and a spicy critique of cloud databases. Its name signifies “pigpen,” but it also stands for Postgres In Great STYle, symbolizing PostgreSQL at its peak. It is a solution distilled from best practices in managing and using PostgreSQL, entirely based on open source software and capable of running anywhere. Born from real-world, high-standard PostgreSQL clusters, it was developed to fulfill the database management needs of Tantan, performing valuable work across eight dimensions:
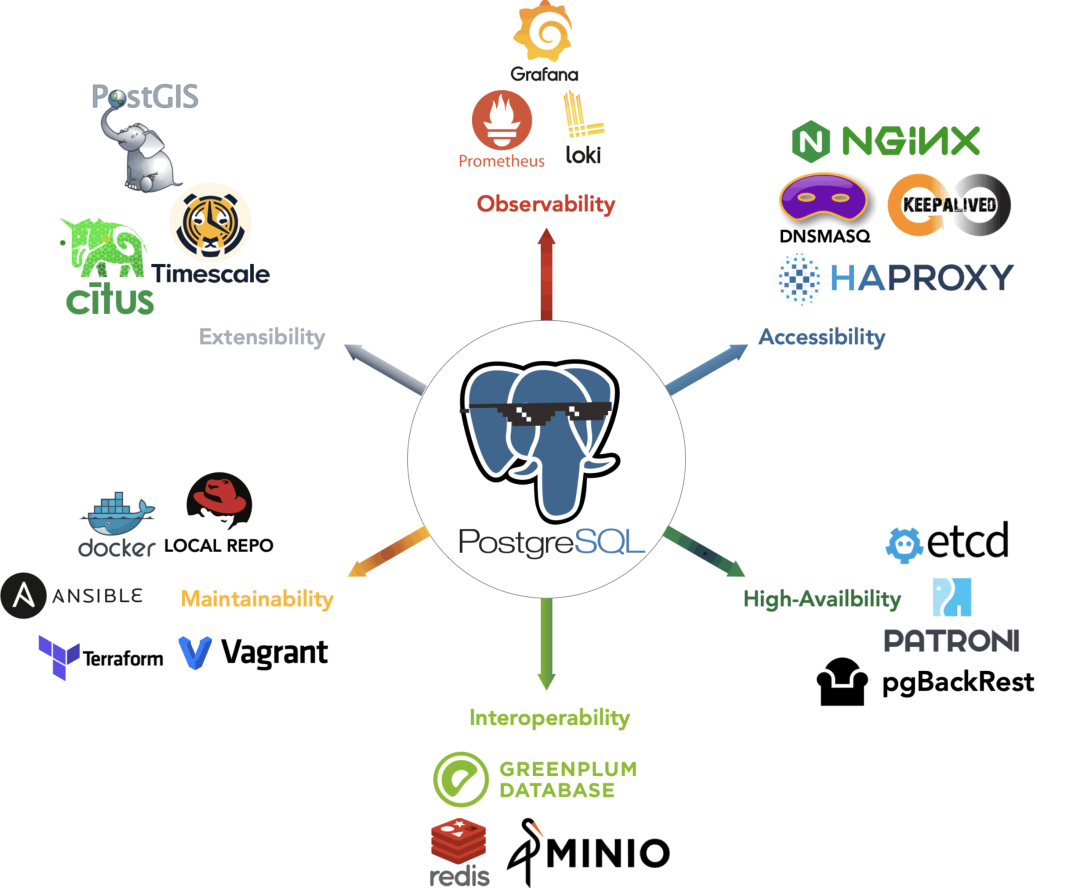
Observability is akin to heaven; as heaven maintains vigor through movement, a gentleman should constantly strive for self-improvement; Pigsty utilizes a modern observability tech stack to create an unparalleled monitoring system for PostgreSQL, offering a comprehensive overview from global dashboards to granular historical metrics for individual tables/indexes/functions, enabling users to see through the system and control everything. Additionally, Pigsty’s monitoring system can operate independently to monitor third-party database instances.
Controllability is akin to earth; as earth’s nature is broad and bearing, a gentleman should carry the world with broad virtue; Pigsty provides Database as Code capabilities: describing the state of database clusters through expressive declarative interfaces and employing idempotent scripts for deployment and adjustments. This allows users to customize finely without worrying about implementation details, freeing their mental capacity and lowering the barrier from expert to novice level in database operations and management.
Scalability is like water; as water flows and encompasses all, a gentleman should maintain virtue consistently; Pigsty offers pre-configured tuning templates (OLTP / OLAP / CRIT / TINY), automatically optimizes system parameters, and can infinitely scale read capabilities through cascading replication. It also utilizes Pgbouncer for connection pool optimization to handle massive concurrent connections; Pigsty ensures PostgreSQL’s performance is maximized under modern hardware conditions: achieving tens of thousands of concurrent connections, million-level single-point query QPS, and hundred thousand-level single transaction TPS.
Maintainability is like fire; as fire illuminates, a great person should illuminate the surroundings; Pigsty allows for online instance addition or removal for scaling, Switchover/rolling upgrades for scaling up or down, and offers a downtime-free migration solution based on logical replication, minimizing maintenance windows to sub-second levels, thus enhancing the system’s evolvability, availability, and maintainability to a new standard.
Security is like thunder; as thunder signifies awe, a gentleman should reflect and be cautious; Pigsty offers an access control model following the principle of least privilege, along with various security features: synchronous commit for replication to prevent data loss, data directory checksums to prevent corruption, SSL encryption for network traffic to prevent eavesdropping, and AES-256 for remote backups to prevent data leaks. As long as physical hardware and passwords are secure, users need not worry about database security.
Simplicity is like wind; as wind follows its path, a gentleman should decree and act accordingly; Using Pigsty is no more difficult than any cloud database. It aims to deliver complete RDS functionality with the least complexity, allowing users to choose and combine modules as needed. Pigsty offers a Vagrant-based local development testing sandbox and Terraform cloud IaC for one-click deployment templates, enabling offline installation on any new EL node and complete environment replication.
Reliability is like a mountain; as a mountain stands firm, a gentleman should be steadfast in thought; Pigsty provides a high-availability architecture with self-healing capabilities to address hardware issues and offers out-of-the-box PITR for recovery from accidental data deletion and software flaws, verified through long-term, large-scale production environment operation and high-availability drills.
Extensibility is like a lake; as a lake reflects beauty, a gentleman should discuss and practice with friends; Pigsty deeply integrates core PostgreSQL ecosystem extensions like PostGIS, TimescaleDB, Citus, PGVector, and numerous extension plugins. It offers a modular design of the Prometheus/Grafana observability tech stack, and high-availability deployment of MINIO, ETCD, Redis, Greenplum, etc., in combination with PostgreSQL.

More importantly, Pigsty is entirely open-source and free software, licensed under AGPL v3.0. Powered by passion, you can run a fully functional, even superior RDS service at the cost of mere hardware expenses per month. Whether you are a beginner or a seasoned DBA, managing a massive cluster or a small setup, whether you’re already using RDS or have set up databases locally, if you are a PostgreSQL user, Pigsty will be beneficial to you, completely free. You can focus on the most interesting or valuable parts of your business and leave the routine tasks to the software.
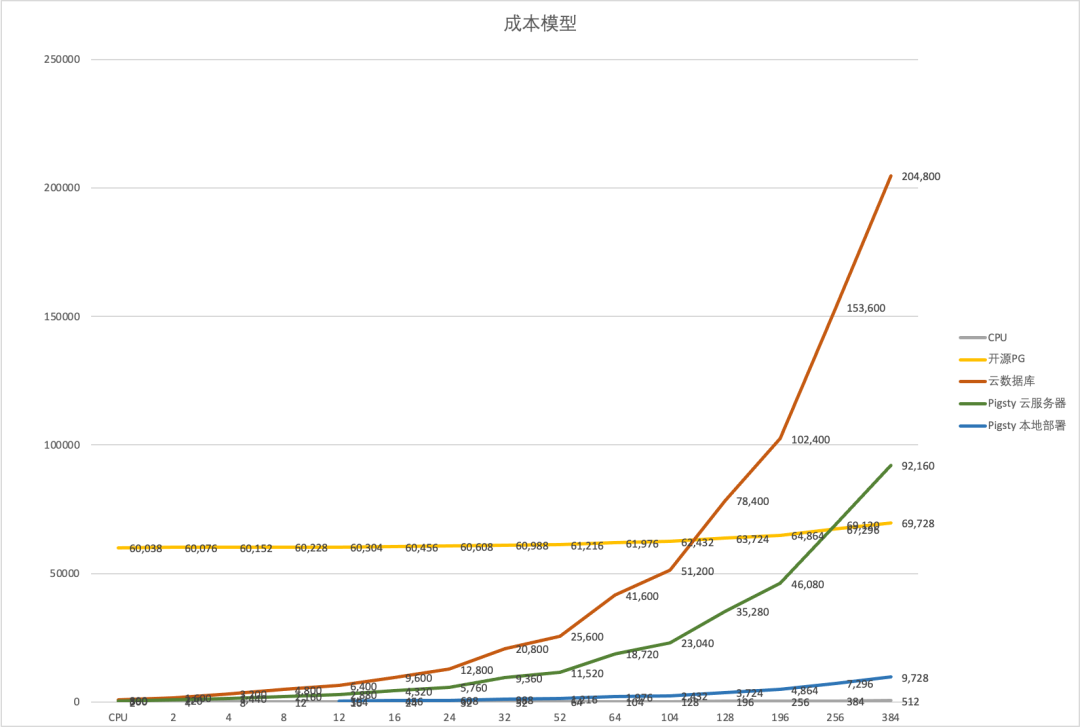
RDS Cost and Scale Cost Curve
Pigsty allows you to practice the ultimate FinOps principle — running production-level PostgreSQL RDS database services anywhere (ECS, resource cloud, data center servers, even local notebook virtual machines) at prices close to pure resource costs. Turning the cost capability of cloud databases from being proportional to marginal resource costs to virtually zero fixed learning costs.
If you can use a better RDS service at a fraction of the cost, then continuing to use cloud databases is truly just a tax on your intellect.
Reference
【1】Why we’re leaving the cloud
【2】上云“被坑”十年终放弃,寒冬里第一轮“下云潮”要来了?
【3】Aliyun RDS for PostgreSQL Pricing
【5】 AWS Pricing Calculator (China NingXia)
Postgres
pg_exporter v1.0.0 Released – Next-Level PostgreSQL Observability
We’re delighted to announce pg_exporter v1.0.0, an advanced open-source Prometheus exporter that takes PostgreSQL observability to the next level.
Built for DBAs and developers who need deep insight, pg_exporter exposes 600 + metrics—roughly 3 K – 20 K time series per instance — covering core PostgreSQL internals, popular extensions such as TimescaleDB, Citus, pg_stat_statements, pg_wait_sampling, and even pgBouncer, all through a single, fully customizable exporter.
Unlike other exporters, pg_exporter values customizability: every metric lives in a YAML definition, so you can add, modify, or extend metrics without recompiling. The configuration allows fine-grained control over collection logic — PostgreSQL version branching, caching, timeouts, pre-condition queries, a health-check API, and live reload & replanning are all built in.
Battle-tested for more than six years in production clusters exceeding 25K+ CPU cores, pg_exporter also powers the Pigsty observability stack — see it in action in the live demo.
Version 1.0.0 brings a host of new features, including early support for PostgreSQL 18 — ready even before PG 18 beta release. Explore 50 + pre-defined collectors, or create your own (including app-specific metrics via SQL) simply by adding new configs.
Enjoy next-level insight into your PostgreSQL ecosystem with pg_exporter v1.0.0!
Features
- Highly Customizable: Define almost all metrics through declarative YAML configs
- Full Coverage: Monitor both PostgreSQL (10-18+) and pgBouncer (1.8-1.24+) in single exporter
- Fine-grained Control: Configure timeout, caching, skip conditions, and fatality per collector
- Dynamic Planning: Define multiple query branches based on different conditions
- Self-monitoring: Rich metrics about pg_exporter itself for complete observability
- Production-Ready: Battle-tested in real-world environments across 12K+ cores for 6+ years
- Auto-discovery: Automatically discover and monitor multiple databases within an instance
- Health Check APIs: Comprehensive HTTP endpoints for service health and traffic routing
- Extension Support:
timescaledb,citus,pg_stat_statements,pg_wait_sampling,…
OrioleDB is Here! 4x Performance, Zero Bloat, Decoupled Storage
OrioleDB - while the name might make you think of cookies, it’s actually named after the songbird. But whether you call it Cookie DB or Bird DB doesn’t matter - what matters is that this PG storage engine extension + kernel fork is genuinely fascinating, and it’s about to hit prime time.
As Zheap’s successor, I’ve been watching OrioleDB for quite a while. It has three major selling points: performance, operability, and cloud-native capabilities. Let me give you a quick tour of this PG kernel newcomer, along with some recent work I’ve done to help you get it up and running.
Extreme Performance: 4x Throughput
While hardware performance is overkill for most OLTP databases these days, hitting the single-node write throughput ceiling isn’t exactly rare - it’s usually what drives people to shard their databases.
OrioleDB aims to solve this. According to their homepage, they achieve 4x PostgreSQL’s read/write throughput - a pretty wild number. A 40% performance boost wouldn’t justify adopting a new storage engine, but 400%? Now that’s an interesting proposition.
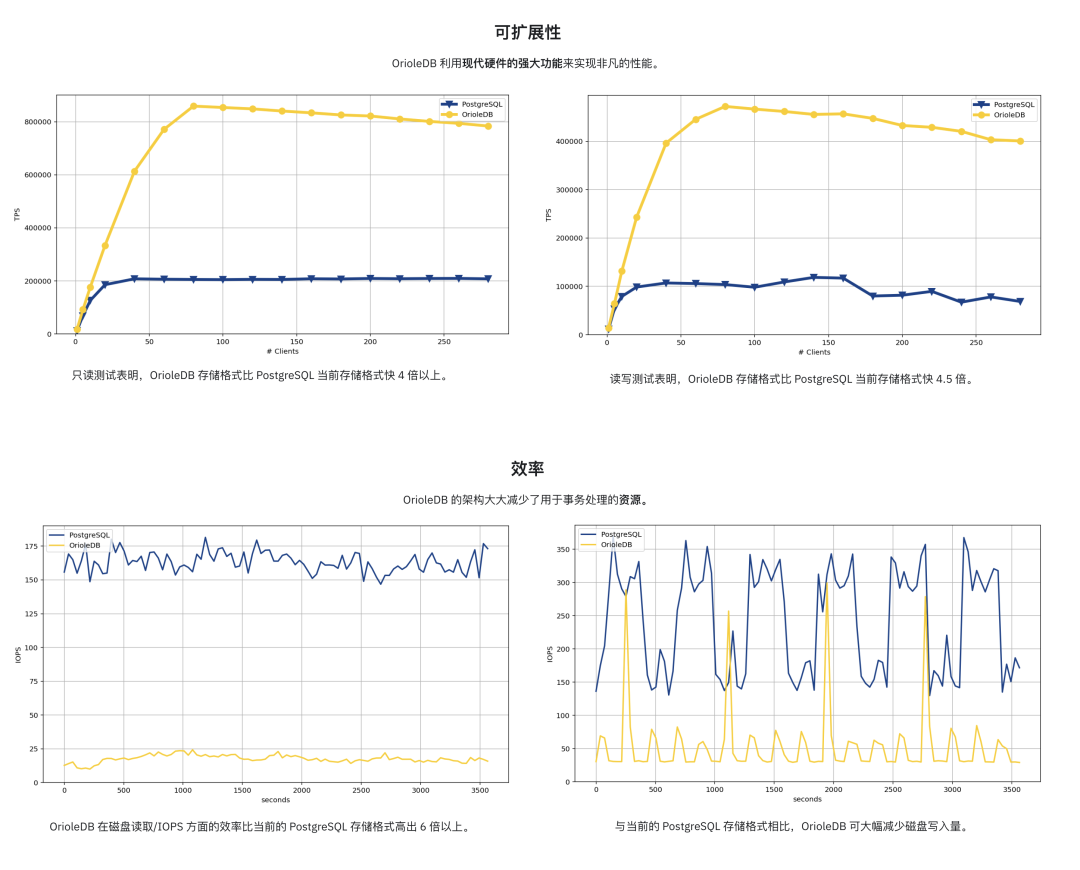
Plus, OrioleDB claims to significantly reduce resource consumption in OLTP scenarios, notably lowering disk IOPS usage.
The secret sauce includes several optimizations over PG heap tables: ditching FS Cache, direct memory-to-storage page linking, lock-free memory page access, MVCC via UNDO logs/rollback segments instead of PG’s REDO, and row-level WAL that’s easier to parallelize.
Haven’t benchmarked it myself yet, but it’s tempting. Might grab a server and give it a spin soon.
Zero Headaches: Simplified Ops
PostgreSQL’s most notorious pain points are XID Wraparound and table bloat - both stemming from its MVCC design.
PostgreSQL’s default storage engine was designed with “infinite time travel” in mind, using an append-only MVCC approach - DELETEs are marked-for-deletion, and UPDATEs are delete-mark-plus-new-version.
While this design has perks - non-blocking reads/writes, instant rollbacks regardless of transaction size, and minimal replication lag - it’s given PostgreSQL users their fair share of headaches. Even with modern hardware and automatic vacuum, a high-standard PostgreSQL setup still needs to keep an eye on bloat and garbage collection.
OrioleDB tackles this with a new storage engine - think Oracle/MySQL-style approach, inheriting both their pros and cons. Using new MVCC practices, OrioleDB tables say goodbye to bloat and XID wraparound concerns.
Of course, there’s no free lunch - you inherit the downsides too: large transaction issues, slower rollbacks, and analytical performance trade-offs. But it excels at what it aims for: maximum OLTP CRUD performance.
Most importantly, it’s a PG extension - an optional storage engine that plays nice with PG’s native heap tables. You can mix and match based on your needs, letting your extreme OLTP tables shine where it counts.
-- Enable OrioleDB extension (Pigsty has it ready)
CREATE EXTENSION orioledb;
CREATE TABLE blog_post
(
id int8 NOT NULL,
title text NOT NULL,
body text NOT NULL,
PRIMARY KEY(id)
) USING orioledb; -- Use OrioleDB storage engine
Using OrioleDB is dead simple - just add the
USINGkeyword when creating tables.
Currently, OrioleDB is a storage engine extension requiring a patched PG kernel, as some necessary storage engine APIs haven’t landed in PG core yet. If all goes well, PostgreSQL 18 will include these patches, eliminating the need for kernel modifications.
| Name | Link | Version | |
|---|---|---|---|
| ✅ | Add missing inequality searches to rbtree | Link | PostgreSQL 16 |
| ✅ | Document the ability to specify TableAM for pgbench | Link | PostgreSQL 16 |
| ✅ | Remove Tuplesortstate.copytup function | Link | PostgreSQL 16 |
| ✅ | Add new Tuplesortstate.removeabbrev function | Link | PostgreSQL 16 |
| ✅ | Put abbreviation logic into puttuple_common() | Link | PostgreSQL 16 |
| ✅ | Move memory management away from writetup() and tuplesort_put*() | Link | PostgreSQL 16 |
| ✅ | Split TuplesortPublic from Tuplesortstate | Link | PostgreSQL 16 |
| ✅ | Split tuplesortvariants.c from tuplesort.c | Link | PostgreSQL 16 |
| ✅ | Fix typo in comment for writetuple() function | Link | PostgreSQL 16 |
| ✅ | Support for custom slots in the custom executor nodes | Link | PostgreSQL 16 |
| ✉️ | Allow table AM to store complex data structures in rd_amcache | Link | PostgreSQL 18 |
| ✉️ | Allow table AM tuple_insert() method to return the different slot | Link | PostgreSQL 18 |
| ✉️ | Add TupleTableSlotOps.is_current_xact_tuple() method | Link | PostgreSQL 18 |
| ✉️ | Allow locking updated tuples in tuple_update() and tuple_delete() | Link | PostgreSQL 18 |
| ✉️ | Add EvalPlanQual delete returning isolation test | Link | PostgreSQL 18 |
| ✉️ | Generalize relation analyze in table AM interface | Link | PostgreSQL 18 |
| ✉️ | Custom reloptions for table AM | Link | PostgreSQL 18 |
| ✉️ | Let table AM insertion methods control index insertion | Link | PostgreSQL 18 |
I’ve prepared oriolepg_17 (patched PG) and orioledb_17 (extension) on EL, plus a ready-to-use config template for instant OrioleDB deployment.
Cloud-Native Storage
“Cloud-native” is an overused term that nobody quite understands. But for databases, it usually means one thing: storing data in object storage.
OrioleDB recently pivoted their slogan from “High-performance OLTP storage engine” to “Cloud-native storage engine”. I get why - Supabase acquired OrioleDB, and the sugar daddy’s needs come first.

As a “cloud database provider”, offloading cold data to “cheap” object storage instead of “premium” EBS block storage is quite profitable. Plus, it makes databases stateless “cattle” that can be freely scaled in K8s. Their motivation is crystal clear.
So I’m pretty excited that OrioleDB not only offers a new storage engine but also supports object storage. While PG-over-S3 projects exist, this is the first mature, mainline-compatible, open-source solution.
So, How Do I Try It?
OrioleDB sounds great - solving key PG issues, (future) mainline compatibility, open-source, well-funded, and led by Alexander Korotkov who has serious PG community cred.
Obviously, OrioleDB isn’t “production-ready” yet. I’ve watched it from Alpha1 three years ago to Beta10 now, each release making me more antsy. But I noticed it’s now in Supabase’s postgres mainline - release can’t be far off.
So when OrioleDB dropped beta10 on April 1st, I decided to package it. Fresh off building OpenHalo RPMs and a MySQL-compatible PG kernel, what’s one more? I created RPM packages for the patched PG kernel (oriolepg_17) and extension (orioledb_17), available for EL8/EL9 on x86/ARM64.
Better yet, I added native OrioleDB support to Pigsty, meaning OrioleDB gets the full PG ecosystem - Patroni for HA, pgBackRest for backups, pg_exporter for monitoring, pgbouncer for connection pooling, all wrapped up in a one-click production-grade RDS service:
This Qingming Festival, I released Pigsty v3.4.1 with built-in OrioleDB and OpenHalo kernel support. Spinning up an OrioleDB cluster is as simple as a regular PostgreSQL cluster:
all:
children:
pg-orio:
vars:
pg_databases:
- {name: meta ,extensions: [orioledb]}
vars:
pg_mode: oriole
pg_version: 17
pg_packages: [ orioledb, pgsql-common ]
pg_libs: 'orioledb.so, pg_stat_statements, auto_explain'
repo_extra_packages: [ orioledb ]
More Kernel Tricks
Of course, OrioleDB isn’t the only PG fork we support. You can also use:
- Microsoft SQL Server-compatible Babelfish (by AWS)
- Oracle-compatible IvorySQL (by HighGo)
- MySQL-compatible openHalo (by EsgynDB)
- Aurora RAC-flavored PolarDB (by Alibaba Cloud)
- Officially certified Oracle-compatible PolarDB O 2.0
- FerretDB + Microsoft’s DocumentDB to emulate MongoDB
- One-click local Supabase (OrioleDB’s parent!) deployment using Pigsty templates
Plus, my friend Yurii, Omnigres founder, is adding ETCD protocol support to PostgreSQL. Soon, you might be able to use PG as a better-performing, more reliable etcd for Kubernetes/Patroni.
Best of all, everything’s open-source and ready to roll in Pigsty, free of charge. So if you’re curious about OrioleDB, grab a server and give it a shot - 10-minute setup, one command. Let’s see if it lives up to the hype.
OpenHalo: PostgreSQL Now Speaks MySQL Wire Protocol!
PostgreSQL speaking MySQL? Yes, you read that right. OpenHalo, freshly open-sourced on April Fools’ Day, brings this capability to life - allowing users to read, write, and manage the same database using both MySQL and PostgreSQL clients. Built on PG 14.10, it provides MySQL 5.7 wire protocol compatibility.
OpenHalo just open-sourced their MySQL-compatible PG kernel. I’ve packaged it into RPMs and integrated it into Pigsty. The deployment is butter-smooth, and after a few code tweaks, it plays nicely with HA, monitoring, and backup components.

On the DB-Engines ranking, five databases stand head and shoulders above the rest: Oracle, SQL Server, MySQL, PostgreSQL, and MongoDB.
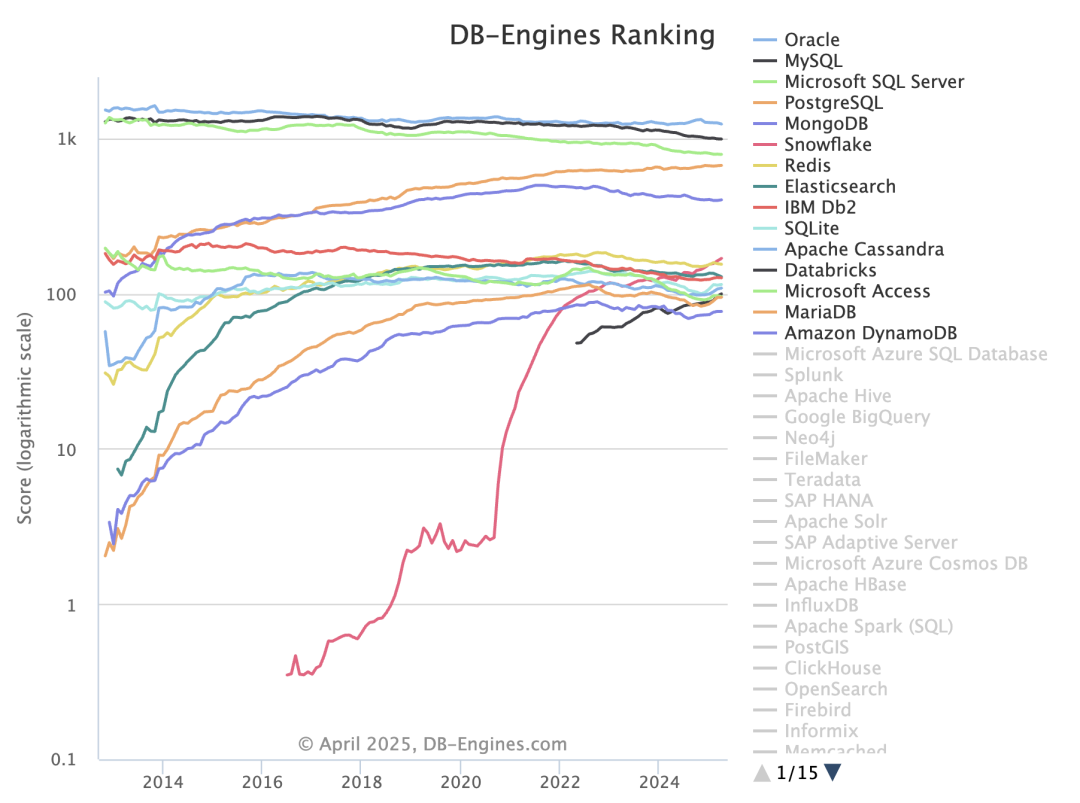
Here’s the kicker - PostgreSQL can now emulate all four of its top competitors:
- OpenHalo speaks MySQL
- AWS Babelfish speaks SQL Server
- IvorySQL and Alibaba PolarDB O speak Oracle
- FerretDB/Microsoft DocumentDB speaks MongoDB
Fun fact: All these capabilities are available out-of-the-box in Pigsty.
Want to Try It Out?
Pigsty now supports OpenHalo on EL systems. Here’s how to get started:
Follow the Pigsty standard installation process with the mysql config template:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # Prepare dependencies
./configure -c mysql # Use MySQL (OpenHalo) template
./install.yml # Install (modify passwords in pigsty.yml for prod)
Pro tip: For production deployments, modify the passwords in pigsty.yml before running the installation playbook.
OpenHalo’s configuration mirrors PostgreSQL’s. You can use psql to connect to the postgres database and mysql CLI to connect to the mysql database.
all:
children:
pg-orio:
vars:
pg_databases:
- {name: postgres ,extensions: [aux_mysql]}
vars:
pg_mode: mysql # MySQL Compatible Mode by HaloDB
pg_version: 14 # The current HaloDB is compatible with PG Major Version 14
pg_packages: [ openhalodb, pgsql-common, mysql ] # also install mysql client shell
repo_modules: node,pgsql,infra,mysql
repo_extra_packages: [ openhalodb, mysql ] # replace default postgresql kernel with openhalo packages
MySQL’s default port is 3306, and when accessing MySQL, you’re actually connecting to the postgres database. Note that MySQL’s “database” concept maps to PostgreSQL’s “schema”. So use mysql actually uses the mysql schema in the postgres database.
MySQL credentials mirror PostgreSQL’s - manage users and permissions the PostgreSQL way. Currently, OpenHalo officially supports Navicat, though IntelliJ IDEA’s DataGrip might throw some tantrums.
mysql -h 127.0.0.1 -u dbuser_dba
Pigsty’s OpenHalo fork includes some QoL improvements over HaloTech-Co-Ltd/openHalo:
- Default database renamed from
halo0roottopostgres - Version number simplified from
1.0.14.10to14.10 - MySQL compatibility and port 3306 enabled by default
Disclaimer: Pigsty provides no warranty for OpenHalo - direct support queries to the original vendor.
More Kernel Tricks Up Our Sleeve
OpenHalo isn’t the only PG fork Pigsty supports. Check out:
- Babelfish by AWS (SQL Server compatibility)
- IvorySQL by Highgo (Oracle compatibility)
- OrioleDB by Supabase (OLTP performance beast)
- PolarDB by Alibaba Cloud (Aurora RAC flavor)
- PolarDB O 2.0 (Oracle-compatible with Chinese certification)
- FerretDB + Microsoft’s DocumentDB (MongoDB emulation)
- One-click Supabase local deployment (OrioleDB’s parent!)
BTW, my friend Yurii, Omnigres founder, is working on ETCD protocol support for PostgreSQL. Soon you might be able to use PG as a beefed-up etcd for Kubernetes/Patroni.

Best part? All this goodness is open-source and ready to roll in Pigsty. Want to take OpenHaloDB for a spin? Grab a server, and you’re 10 minutes away from finding out if it lives up to the hype.
PGFS: Using PostgreSQL as a File System
Recently, I received an interesting request from the Odoo community. They were grappling with a fascinating challenge: “If databases can do PITR (Point-in-Time Recovery), is there a way to roll back the file system as well?”
The Birth of “PGFS”
From a database veteran’s perspective, this is both challenging and exciting. We all know that in systems like Odoo, the most valuable asset is the core business data stored in PostgreSQL.
However, many “enterprise applications” also deal with file operations — attachments, images, documents, and the like. While these files might not be as “mission-critical” as the database, having the ability to roll back both the database and files to a specific point in time would be incredibly valuable from security, data integrity, and operational perspectives.
This led me to an intriguing thought: Could we give file systems PITR capabilities similar to databases? Traditional approaches often point to expensive and complex CDP (Continuous Data Protection) solutions, requiring specialized hardware or block-level storage logging. But I wondered: Could we solve this elegantly with open-source technology for the “rest of us”?
After much contemplation, a brilliant combination emerged: JuiceFS + PostgreSQL. By transforming PostgreSQL into a file system, all file writes would be stored in the database, sharing the same WAL logs and enabling rollback to any historical point. This might sound like science fiction, but hold on — it actually works. Let’s see how JuiceFS makes this possible.
Meet JuiceFS: When Database Becomes a File System
JuiceFS is a high-performance, cloud-native distributed file system that can mount object storage (like S3/MinIO) as a local POSIX file system. It’s incredibly lightweight to install and use, requiring just a few commands to format, mount, and start reading/writing.
For example, these commands will use SQLite as JuiceFS’s metadata store and a local path as object storage for testing:
juicefs format sqlite3:///tmp/jfs.db myjfs # Use SQLite3 for metadata, local FS for data
juicefs mount sqlite3:///tmp/jfs.db ~/jfs -d # Mount the filesystem to ~/jfs
The magic happens when you realize that JuiceFS also supports PostgreSQL as both metadata and object data storage backend! This means you can transform any PostgreSQL instance into a “file system” by simply changing JuiceFS’s backend.
So, if you have a PostgreSQL database (like one installed via Pigsty), you can spin up a “PGFS” with just a few commands:
METAURL=postgres://dbuser_meta:DBUser.Meta@:5432/meta
OPTIONS=(
--storage postgres
--bucket :5432/meta
--access-key dbuser_meta
--secret-key DBUser.Meta
${METAURL}
jfs
)
juicefs format "${OPTIONS[@]}" # Create a PG filesystem
juicefs mount ${METAURL} /data2 -d # Mount in background to /data2
juicefs bench /data2 # Test performance
juicefs umount /data2 # Unmount
Now, any data written to /data2 is actually stored in the jfs_blob table in PostgreSQL. In other words, this file system and PG database have become one!
PGFS in Action: File System PITR
Imagine we have an Odoo instance that needs to store file data in /var/lib/odoo or similar.
Traditionally, if you needed to roll back Odoo’s database, while the database could use WAL logs for point-in-time recovery, the file system would still rely on external snapshots or CDP.
But now, if we mount /var/lib/odoo to PGFS, all file system writes become database writes.
The database is no longer just storing SQL data; it’s also hosting the file system information.
This means: When performing PITR, not only does the database roll back to a specific point, but files instantly “roll back” with the database to the same moment.
Some might ask, “Can’t ZFS do snapshots too?” Yes, ZFS can create and roll back snapshots, but that’s still based on specific snapshot points. For precise rollback to a specific second or minute, you need true log-based solutions or CDP capabilities. The JuiceFS+PG combination effectively writes file operation logs into the database’s WAL, which is something PostgreSQL is naturally great at.
Let’s demonstrate this with a simple experiment. First, we’ll write timestamps to the file system while continuously inserting heartbeat records into the database:
while true; do date "+%H-%M-%S" >> /data2/ts.log; sleep 1; done
/pg/bin/pg-heartbeat # Generate database heartbeat records
tail -f /data2/ts.log
Then, let’s verify the JuiceFS table in PostgreSQL:
postgres@meta:5432/meta=# SELECT min(modified),max(modified) FROM jfs_blob;
min | max
----------------------------+----------------------------
2025-03-21 02:26:00.322397 | 2025-03-21 02:40:45.688779
When we decide to roll back to, say, one minute ago (2025-03-21 02:39:00), we just execute:
pg-pitr --time="2025-03-21 02:39:00" # Using pgbackrest to roll back to specific time, actual command:
pgbackrest --stanza=pg-meta --type=time --target='2025-03-21 02:39:00+00' restore
What? You’re asking where PITR and pgBackRest came from? Pigsty has already configured monitoring, backup, high availability, and more out of the box! You can set it up manually too, but it’s a bit more work.
Then when we check the file system logs and database heartbeat table, both have stopped at 02:39:00:
$ tail -n1 /data2/ts.log
02-38-59
$ psql -c 'select * from monitor.heartbeat'
id | ts | lsn | txid
---------+-------------------------------+-----------+------
pg-meta | 2025-03-21 02:38:59.129603+00 | 251871544 | 2546
This proves our approach works! We’ve successfully achieved FS/DB consistent PITR through PGFS!
How’s the Performance?
So we’ve got the functionality, but how does it perform?
I ran some tests on a development server with SSD using the built-in juicefs bench, and the results look promising — more than enough for applications like Odoo:
$ juicefs bench ~/jfs # Simple single-threaded performance test
BlockSize: 1.0 MiB, BigFileSize: 1.0 GiB,
SmallFileSize: 128 KiB, SmallFileCount: 100, NumThreads: 1
Time used: 42.2 s, CPU: 687.2%, Memory: 179.4 MiB
+------------------+------------------+---------------+
| ITEM | VALUE | COST |
+------------------+------------------+---------------+
| Write big file | 178.51 MiB/s | 5.74 s/file |
| Read big file | 31.69 MiB/s | 32.31 s/file |
| Write small file | 149.4 files/s | 6.70 ms/file |
| Read small file | 545.2 files/s | 1.83 ms/file |
| Stat file | 1749.7 files/s | 0.57 ms/file |
| FUSE operation | 17869 operations | 3.82 ms/op |
| Update meta | 1164 operations | 1.09 ms/op |
| Put object | 356 operations | 303.01 ms/op |
| Get object | 256 operations | 1072.82 ms/op |
| Delete object | 0 operations | 0.00 ms/op |
| Write into cache | 356 operations | 2.18 ms/op |
| Read from cache | 100 operations | 0.11 ms/op |
+------------------+------------------+---------------+
Another sample: Alibaba Cloud ESSD PL1 basic disk test results
+------------------+------------------+---------------+
| ITEM | VALUE | COST |
+------------------+------------------+---------------+
| Write big file | 18.08 MiB/s | 56.64 s/file |
| Read big file | 98.07 MiB/s | 10.44 s/file |
| Write small file | 268.1 files/s | 3.73 ms/file |
| Read small file | 1654.3 files/s | 0.60 ms/file |
| Stat file | 7465.7 files/s | 0.13 ms/file |
| FUSE operation | 17855 operations | 4.28 ms/op |
| Update meta | 1192 operations | 16.28 ms/op |
| Put object | 357 operations | 2845.34 ms/op |
| Get object | 255 operations | 327.37 ms/op |
| Delete object | 0 operations | 0.00 ms/op |
| Write into cache | 357 operations | 2.05 ms/op |
| Read from cache | 102 operations | 0.18 ms/op |
+------------------+------------------+---------------+
While the throughput might not match native file systems, it’s more than sufficient for applications with moderate file volumes and lower access frequencies. After all, using a “database as a file system” isn’t about running large-scale storage or high-concurrency writes — it’s about keeping your database and file system “in sync through time.” If it works, it works.
Completing the Vision: One-Click “Enterprise” Deployment
Now, let’s put this all together in a practical scenario — like one-click deploying an “enterprise-grade” Odoo with “automatic” CDP capabilities for files.
Pigsty provides PostgreSQL with external high availability, automatic backup, monitoring, PITR, and more. Installing it is a breeze:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # Install Pigsty dependencies
./configure -c app/odoo # Use Odoo configuration template
./install.yml # Install Pigsty
That’s the standard Pigsty installation process. Next, we’ll use playbooks to install Docker, create the PGFS mount, and launch stateless Odoo with Docker Compose:
./docker.yml -l odoo # Install Docker module, launch Odoo stateless components
./juice.yml -l odoo # Install JuiceFS module, mount PGFS to /data2
./app.yml -l odoo # Launch Odoo stateless components, using external PG/PGFS
Yes, it’s that simple. Everything is ready, though the key lies in the configuration file.
The pigsty.yml configuration file would look something like this, with the only modification being the addition of JuiceFS configuration to mount PGFS to /data/odoo:
odoo:
hosts: { 10.10.10.10: {} }
vars:
# ./juice.yml -l odoo
juice_fsname: jfs
juice_mountpoint: /data/odoo
juice_options:
- --storage postgres
- --bucket :5432/meta
- --access-key dbuser_meta
- --secret-key DBUser.Meta
- postgres://dbuser_meta:DBUser.Meta@:5432/meta
- ${juice_fsname}
# ./app.yml -l odoo
app: odoo # specify app name to be installed (in the apps)
apps: # define all applications
odoo: # app name, should have corresponding ~/app/odoo folder
file: # optional directory to be created
- { path: /data/odoo ,state: directory, owner: 100, group: 101 }
- { path: /data/odoo/webdata ,state: directory, owner: 100, group: 101 }
- { path: /data/odoo/addons ,state: directory, owner: 100, group: 101 }
conf: # override /opt/<app>/.env config file
PG_HOST: 10.10.10.10 # postgres host
PG_PORT: 5432 # postgres port
PG_USERNAME: odoo # postgres user
PG_PASSWORD: DBUser.Odoo # postgres password
ODOO_PORT: 8069 # odoo app port
ODOO_DATA: /data/odoo/webdata # odoo webdata
ODOO_ADDONS: /data/odoo/addons # odoo plugins
ODOO_DBNAME: odoo # odoo database name
ODOO_VERSION: 18.0 # odoo image version
After this, you have an “enterprise-grade” Odoo running on the same server: backend database managed by Pigsty, file system mounted via JuiceFS, with JuiceFS’s backend connected to PostgreSQL. When a “rollback need” arises, simply perform PITR on PostgreSQL, and both files and database will “roll back to the specified moment.” This approach works equally well for similar applications like Dify, Gitlab, Gitea, MatterMost, and others.
Looking back at all this, you’ll realize: What once required expensive hardware and high-end storage solutions to achieve CDP can now be accomplished with a lightweight open-source combination. While it might have a “DIY for the rest of us” feel, it’s simple, stable, and practical enough to be worth exploring in more scenarios.
PostgreSQL Frontier
Dear readers, I’m off on vacation starting today—likely no new posts for about two weeks. Let me wish everyone a Happy New Year in advance.
Of course, before heading out, I wanted to share some recent interesting developments in the Postgres (PG) ecosystem. Just yesterday, I hurried to release Pigsty 3.2.2 and Pig v0.1.3 before my break. In this new version, the number of available PG extensions has shot up from 350 to 400, bundling many fascinating toys. Below is a quick rundown:
Omnigres: Full-stack web development inside PostgreSQL
PG Mooncake: Bringing ClickHouse-level analytical performance into PG
Citus: Distributed extension for PG17—Citus 13 is out!
FerretDB: MongoDB “compatibility” layer on PG with 20x performance boost in 2.0
ParadeDB: ES-like full-text search in PG with PG block storage
Pigsty 3.2.2: Packs all of the above into one box for immediate use
Omnigres
I introduced Omnigres in a previous article, “Database as Architecture”. In short, it allows you to cram all your business logic—including a web server and the entire backend—into PostgreSQL.
For example, the following SQL will launch a web server and expose /www as the root directory. This means you can package what’s normally a classic three-tier architecture (frontend–backend–database) entirely into a single database!
If you’re familiar with Oracle, you might notice it’s somewhat reminiscent of Oracle Apex. But in PostgreSQL, you have over twenty different languages to develop your stored procedures in—not just PL/SQL! Plus, Omnigres gives you far more than just an HTTPD server; it actually ships 33 extension plugins that function almost like a “standard library” for web development within PG.
They say, “what’s split apart will eventually recombine, what’s recombined will eventually split apart.” In ancient times, many C/S or B/S applications were basically a few clients directly reading/writing to the database. Later, as business logic grew more complex and hardware (relative to business needs) got stretched, we peeled away a lot of functionality from the database, forming the traditional three-tier model.
Now, with significant improvements in hardware performance—giving us surplus capacity on database servers—and with easier ways to write stored procedures, this “split” trend may well reverse. Business logic once stripped out of the database might come back in. I see Omnigres (and Supabase, too) as a renewed attempt at “recombination.”
If you’re running tens of thousands of TPS, dealing with tens of terabytes of data, or handling a life-critical mega-sized core system, this might not be your best approach. But if you’re developing personal projects, small websites, or an early-stage startup with an innovative, smaller-scale system, this architecture can dramatically speed up your iteration cycle, simplifying both development and operations.
Pigsty v3.2.2 comes with the Omnigres extension included—this took quite some effort. With hands-on help from the original author, Yurii, we managed to build and package it for 10 major Linux distributions. Note that these extensions come from an independent repo you can use on its own—you’re not required to run Pigsty just to get them. (Omnigres and AutoBase PG both rely on this repo for extension distribution, a terrific example of open-source ecosystems thriving on mutual benefit.)
pg_mooncake
Ever since the “DuckDB Mash-up Contest” kicked off, pg_mooncake was the last entrant. At one point, I almost thought they had gone dormant. But last week, they dropped a bombshell with their new 0.1.0 release, catapulting themselves directly into the top 10 on the ClickBench leaderboard, right alongside ClickHouse.
This is the first time a PostgreSQL setup—plus an extension—has broken into that Tier 0 bracket on an analytical leaderboard. It’s a milestone worth noting. Looks like pg_duckdb just met a fierce contender—and that’s good news for everyone, since we now have multiple ways to do high-performance analytics in PG. Internal competition keeps the ecosystem thriving, and it also widens the gap between the entire Postgres ecosystem and other DBMSs.
Most people still see PostgreSQL as a rock-solid OLTP database, rarely associating it with “real-time analytics.” Yet PostgreSQL’s extensibility allows it to transcend that image and carve out new territory in real-time analytics. The pg_mooncake team leveraged PG’s extensibility to write a native extension that embeds DuckDB’s query engine for columnar queries. This means queries can process data in batches (instead of row-by-row) and utilize SIMD instructions, yielding significant speedups in scanning, grouping, and aggregation.
pg_mooncake also employs a more efficient metadata mechanism: instead of fetching metadata and statistics externally from Parquet or some other storage, it stores them directly in PostgreSQL. This speeds up query optimization and execution, and enables higher-level features such as file-level skipping to accelerate scans.
All these optimizations have yielded impressive performance results—reportedly up to 1000x faster. That means PostgreSQL is no longer just a “heavy-duty workhorse” for OLTP. With the right engineering and optimization, it can go head-to-head with specialized analytical databases while retaining PG’s hallmark flexibility and vast ecosystem. This could simplify the entire data stack—no more complicated big-data toolkits or ETL pipelines. Top-tier analytics can happen directly inside Postgres.
Pigsty v3.2.2 now officially includes the mooncake 0.1 binary. Note that this extension conflicts with pg_duckdb since both bundle their own libduckdb. You can only choose one of them on a given system. That’s a bit of a pity—I filed an issue suggesting they share a single libduckdb. It’s exhausting that each extension builds DuckDB from scratch, especially when you’re compiling them both.
Finally, you can tell from the name “mooncake” that it’s led by a Chinese-speaking team. It’s awesome to see more people from China contributing and standing out in the Postgres ecosystem.
Blog: ClickBench says “Postgres is a great analytics database” https://www.mooncake.dev/blog/clickbench-v0.1
ParadeDB
ParadeDB is an old friend of Pigsty. We’ve supported ParadeDB from its very early days and watched it grow into the leading solution in the PostgreSQL ecosystem to provide an ElasticSearch-like capability.
pg_search is ParadeDB’s extension for Postgres, implementing a custom index that supports full-text search and analytics. It’s powered underneath by a Rust-based search library Tantivy, inspired by Lucene.
pg_search just released version 0.14 in the past two weeks, switching to PG’s native block storage instead of relying on Tantivy’s own file format. This is a huge architectural shift that dramatically boosts reliability and yields multiple times the performance. It’s no longer just some “stitch-it-together hack”—it’s now deeply embedded into PG.
Prior to v0.14.0, pg_search did not use Postgres’s block storage or buffer cache. The extension managed its own files outside Postgres control, reading them directly from disk. While it’s not unusual for an extension to access the file system directly (see note 1), migrating to block storage delivers:
- Deep integration with Postgres WAL (write-ahead logging), enabling physical replication of indexes.
- Support for crash recovery and point-in-time recovery (PITR).
- Full support for Postgres MVCC (multi-version concurrency control).
- Integration with Postgres’s buffer cache, significantly boosting index build speed and write throughput.


The latest version of pg_search is now included in Pigsty. Of course, we also bundle other full-text search / tokenizing extensions like pgroonga, pg_bestmatch, hunspell, and Chinese tokenizer zhparser, so you can pick the best fit.
Blog: Full-text search with Postgres block storage layout https://www.paradedb.com/blog/block_storage_part_one
citus
While pg_duckdb and pg_mooncake represent the new wave of OLAP in the PG ecosystem, Citus (and Hydra) are more old-school OLAP— or perhaps HTAP—extensions. Just the day before yesterday, Citus 13.0.0 was released, officially supporting the latest PostgreSQL version 17. That means all the major extensions now have PG17-compatible releases. Full speed ahead for PG17!
Citus is a distributed extension for PG, letting you seamlessly turn a single Postgres primary–replica deployment into a horizontally scaled cluster. Microsoft acquired Citus and fully open-sourced it; the cloud version is called Hyperscale PG or CosmosDB PG.
In reality, most users nowadays don’t push the hardware to the point that they absolutely need a distributed database—but such scenarios do exist. For instance, in “Escaping from cloud fraude” (an article about someone trying to escape steep cloud costs), the user ended up considering Citus to offset expensive cloud disk usage. So, Pigsty has also updated and included full Citus support.
Typically, a distributed database is more of a headache to administer than a simple primary–replica setup. But we devised an elegant abstraction so deploying and managing Citus is pretty straightforward—just treat them as multiple horizontal PG clusters. A single configuration file can spin up a 10-node Citus cluster with one command.
I recently wrote a tutorial on how to deploy a highly available Citus cluster. Feel free to check it out: https://pigsty.cc/docs/tasks/citus/
Blog: Release notes for Citus v13.0.0: https://github.com/citusdata/citus/blob/v13.0.0/CHANGELOG.md
FerretDB
Finally, we have FerretDB 2.0. FerretDB is another old friend of Pigsty. Marcin reached out to me right away to share the excitement of the new release. Unfortunately, 2.0 is still in RC, so I couldn’t package it into the Pigsty repo in time for the v3.2.2 release. No worries—it’ll be included next time!
FerretDB turns PostgreSQL into a “wire-protocol compatible” MongoDB. It’s licensed under Apache 2.0—truly open source. FerretDB 2.0 leverages Microsoft’s newly open-sourced DocumentDB PostgreSQL extension, delivering major improvements in performance, compatibility, support, and flexibility. Highlights include:
- Over 20x performance boost
- Greater feature parity
- Vector search support
- Replication support
- Broad community backing and services
FerretDB offers a low-friction path for MongoDB users to migrate to PostgreSQL. You don’t need to touch your application code—just swap out the back end and voilà. You get the MongoDB API compatibility plus the superpowers of the entire PG ecosystem, which offers hundreds of extensions.
Blog: https://blog.ferretdb.io/ferretdb-releases-v2-faster-more-compatible-mongodb-alternative/
Pigsty 3.2.2
And that brings us to Pigsty v3.2.2. This release adds 40 brand-new extensions (33 of which come from Omnigres) and updates many existing ones (Citus, ParadeDB, PGML, etc.). We also contributed to and followed up on PolarDB PG’s ARM64 support, as well as support for Debian systems, and tracked IvorySQL’s latest 4.2 release compatible with PostgreSQL 17.2.
Sure, it may sound like a bunch of version sync chores, but if it weren’t for those chores, I wouldn’t have dropped this release a day before my vacation! Anyway, I hope you’ll give these new extensions a try. If you run into any issues, feel free to let me know—just understand I can’t guarantee a quick response while I’m off.
One more thing: some users told me the old Pigsty website was “ugly”—basically overflowing with “tech-bro aesthetic,” cramming all the info into a single dense page. They have a point, so I recently used a front-end template to give the homepage a fresh coat of paint. Now it looks a bit more “international.”
To be honest, I haven’t touched front-end in seven or eight years. Last time, it was a jQuery-fest. This time around, Next.js / Vercel / all the new stuff had me dazzled. But once I got my bearings (and thanks to GPT o1 pro plus Cursor), it all came together in a day. The productivity gains with AI these days are truly astounding.
Alright, that’s the latest news from the PostgreSQL world. I’m about to pack my bags—my flight to Thailand departs this afternoon, fingers crossed I don’t run into any phone-scam rings. Let me wish everyone a Happy New Year in advance!
Pig, The PostgreSQL Extension Wizard
Ever wished installing or upgrading PostgreSQL extensions didn’t feel like digging through outdated readmes, cryptic configure scripts, or random GitHub forks & patches? The painful truth is that Postgres’s richness of extension often comes at the cost of complicated setups—especially if you’re juggling multiple distros or CPU architectures.
Enter Pig, a Go-based package manager built to tame Postgres and its ecosystem of 420+ extensions in one fell swoop. TimescaleDB, Citus, PGVector, 30+ Rust extensions, plus every must-have piece to self-host Supabase — Pig’s unified CLI makes them all effortlessly accessible. It cuts out messy source builds and half-baked repos, offering version-aligned RPM/DEB packages that work seamlessly across Debian, Ubuntu, and RedHat flavors. No guesswork, no drama.
Instead of reinventing the wheel, Pig piggyback your system’s native package manager (APT, YUM, DNF) and follow official PGDG packaging conventions to ensure a glitch-free fit. That means you don’t have to choose between “the right way” and “the quick way”; Pig respects your existing repos, aligns with standard OS best practices, and fits neatly alongside other packages you already use.
Ready to give your Postgres superpowers without the usual hassle? Check out GitHub for documentation, installation steps, and a peek at its massive extension list. Then, watch your local Postgres instance transform into a powerhouse of specialized modules—no black magic is required. If the future of Postgres is unstoppable extensibility, Pig is the genie that helps you unlock it. Honestly, nobody ever complained that they had too many extensions.
PIG v0.1 Release | GitHub Repo | Blog: The Idea Way to deliver PG Extensions
Get Started
Install the pig package itself with scripts or the traditional yum/apt way.
curl -fsSL https://repo.pigsty.io/pig | bash
Then it’s ready to use; assume you want to install the pg_duckdb extension:
$ pig repo add pigsty pgdg -u # add pgdg & pigsty repo, update cache
$ pig repo set -u # overwrite all existing repos, brute but effective
$ pig ext install pg17 # install native PGDG PostgreSQL 17 kernels packages
$ pig ext install pg_duckdb # install the pg_duckdb extension (for current pg17)
Extension Management
pig ext list [query] # list & search extension
pig ext info [ext...] # get information of a specific extension
pig ext status [-v] # show installed extension and pg status
pig ext add [ext...] # install extension for current pg version
pig ext rm [ext...] # remove extension for current pg version
pig ext update [ext...] # update extension to the latest version
pig ext import [ext...] # download extension to local repo
pig ext link [ext...] # link postgres installation to path
pig ext build [ext...] # setup building env for extension
Repo Management
pig repo list # available repo list (info)
pig repo info [repo|module...] # show repo info (info)
pig repo status # show current repo status (info)
pig repo add [repo|module...] # add repo and modules (root)
pig repo rm [repo|module...] # remove repo & modules (root)
pig repo update # update repo pkg cache (root)
pig repo create # create repo on current system (root)
pig repo boot # boot repo from offline package (root)
pig repo cache # cache repo as offline package (root)
Don't Update! Rollback Issued on Release Day: PostgreSQL Faces a Major Setback
As the old saying goes, never release code on Friday. Although PostgreSQL’s recent minor release carefully avoided a Friday launch, it still gave the community a full week of extra work — PostgreSQL will release an unscheduled emergency update next Thursday: PostgreSQL 17.2, 16.6, 15.10, 14.15, 13.20, and even 12.22 for the just-EOLed PG 12.
This is the first time in a decade that such a situation has occurred: on the very day of PostgreSQL’s release, the new version was pulled due to issues discovered by the community. There are two reasons for this emergency release. First, to fix the CVE-2024-10978 security vulnerability, which isn’t a major concern. The real problem is that the new PostgreSQL minor version modified its ABI, causing extensions that depend on ABI stability — like TimescaleDB — to crash.
The issue of PostgreSQL minor version ABI compatibility was actually raised by Yuri back in June at PGConf 2024. During the extensions summit and his talk “Pushing boundaries with extensions, for extension”, he brought up this concern, but it didn’t receive much attention. Now it has exploded spectacularly, and I imagine Yuri is probably shrugging his shoulders saying: “Told you so.”
In short, the PostgreSQL community strongly recommends that users do not upgrade PostgreSQL in the coming week. Tom Lane has proposed releasing an unscheduled emergency minor version next Thursday to roll back these changes, overwriting the older 17.1, 16.5, and so on — essentially treating the problematic versions as if they “never existed.” Consequently, Pigsty 3.1, which was scheduled for release in the next couple of days and set to use the latest PostgreSQL 17.1 by default, will also be delayed by a week.
Overall, I believe this incident will have a positive impact. First, it’s not a quality issue with the core kernel itself. Second, because it was discovered early enough — on the very day of release — and promptly halted, there was no substantial impact on users. Unlike vulnerabilities in other databases/chips/operating systems that cause widespread damage upon discovery, this was caught early. Apart from a few overzealous update enthusiasts or unfortunate new installations, there shouldn’t be much impact. This is similar to the recent xz backdoor incident, which was also discovered by PG core developer Peter during PostgreSQL testing, further highlighting the vitality and insight of the PostgreSQL ecosystem.
What Happened
On the morning of November 14th, an email appeared on the PostgreSQL Hackers mailing list mentioning that the new minor version had actually broken the ABI. This isn’t a problem for the PostgreSQL database kernel itself, but the ABI change broke the convention between the PG kernel and extension plugins, causing extensions like TimescaleDB to fail on the new PG minor version.
PostgreSQL extension plugins are provided for specific major versions on specific operating system distributions. For example, PostGIS, TimescaleDB, and Citus are built for major versions like PG 12, 13, 14, 15, 16, and 17 released each year. Extensions built for PG 16.0 are generally expected to continue working on PG 16.1, 16.2, … 16.x. This means you can perform rolling upgrades of the PG kernel’s minor versions without worrying about extension plugin issues.
However, this isn’t an explicit promise but rather an implicit community understanding — ABI belongs to internal implementation details and shouldn’t have such promises or expectations. PostgreSQL has simply performed too well in the past, and everyone has grown accustomed to this behavior, making it a default working assumption reflected in various aspects including PGDG repository package naming and installation scripts.
This time, though, PG 17.1 and the backported versions to 16-12 modified the size of an internal structure, which can cause — extensions compiled for PG 17.0 when used on 17.1 — potential conflicts resulting in illegal writes or program crashes. Note that this issue doesn’t affect users of the PostgreSQL kernel itself; PostgreSQL has internal assertions to check for such situations.
However, for users of extensions like TimescaleDB, this means if you don’t use extensions recompiled for the current minor version, you’ll face such security risks. Given the current maintenance logic of PGDG repositories, extension plugins are only compiled against the latest PG minor version when a new extension version is released.
Regarding the PostgreSQL ABI issue, Marco Slot from CrunchyData wrote a detailed thread explaining it. Available for professional readers to reference.
https://x.com/marcoslot/status/1857403646134153438
How to Avoid Such Problems
As I mentioned previously in “PG’s Ultimate Achievement: The Most Complete PG Extension Repository”, I maintain a repository of many PG extension plugins for EL and Debian/Ubuntu, covering nearly half of the extensions in the entire PG ecosystem.
The PostgreSQL ABI issue was actually mentioned by Yuri before. As long as your extension plugins are compiled for the PostgreSQL minor version you’re currently using, there won’t be any problems. That’s why I recompile and package these extension plugins whenever a new minor version is released.
Last month, I had just finished compiling all the extension plugins for 17.0, and was about to start updates for compiling the 17.1 version. It looks like that won’t be necessary now, as 17.2 will roll back the ABI changes. While this means extensions compiled on 17.0 can continue to be used, I’ll still recompile and package against PG 17.2 and other main versions after 17.2 is released.
If you’re in the habit of installing PostgreSQL and extension plugins from the internet and don’t promptly upgrade minor versions, you’ll indeed face this security risk — where your newly installed extensions aren’t compiled for your older kernel version and crash due to ABI conflicts.
To be honest, I’ve encountered this problem in the real world quite early on, which is why when developing Pigsty, an out-of-the-box PostgreSQL distribution, I chose from Day 1 to first download all necessary packages and their dependencies locally, build a local software repository, and then provide Yum/Apt repositories to all nodes that need them. This approach ensures that all nodes in the environment install the same versions, and that it’s a consistent snapshot — the extension versions match the kernel version.
Moreover, this approach achieves the requirement of “independent control,” meaning that after your deployment goes live, you won’t encounter absurd situations like — the original software source shutting down or moving, or simply the upstream repository releasing an incompatible new version or new dependency, leading to major failures when setting up new machines/instances. This means you have a complete software copy for replication/expansion, with the ability to keep your services running indefinitely without worrying about someone “truly cutting off your lifeline.”
For example, when 17.1 was recently released, RedHat updated the default version of LLVM from 17 to 18 just two days prior, and unfortunately only updated EL8 without updating EL9. If users chose to install from the internet upstream at this time, it would fail directly. After I raised this issue to Devrim, he spent two hours fixing it by adding LLVM-18 to the EL9-specific patch Fix repository.
PS: If you didn’t know about this independent repository, you’d probably continue to encounter issues even after the fix, until RedHat fixed the problem themselves. But Pigsty would handle all these dirty details for you.
Some might say they could solve such version problems using Docker, which is certainly true. However, running databases in Docker comes with other issues, and these Docker images essentially use the operating system’s package manager in their Dockerfiles to download RPM/DEB packages from official repositories. Ultimately, someone has to do this work…
Of course, adapting to different operating systems means a significant maintenance workload. For example, I maintain 143 PG extension plugins for EL and 144 for Debian, each needing to be compiled for 10 major operating system versions (EL 8/9, Ubuntu 22/24, Debian 12, five major systems, amd64 and arm64) and 6 database major versions (PG 17-12). The combination of these elements means there are nearly 10,000 packages to build/test/distribute, including twenty Rust extensions that take half an hour to compile… But honestly, since it’s all semi-automated pipeline work, changing from running once a year to once every 3 months is acceptable.
Appendix: Explanation of the ABI Issue
About the PostgreSQL extension ABI issue in the latest patch versions (17.1, 16.5, etc.)
C code in PostgreSQL extensions includes headers from PostgreSQL itself. When an extension is compiled, functions from the headers are represented as abstract symbols in the binary. These symbols are linked to actual function implementations when the extension is loaded, based on function names. This way, an extension compiled for PostgreSQL 17.0 can typically still load into PostgreSQL 17.1, as long as function names and signatures in the headers haven’t changed (i.e., the Application Binary Interface or “ABI” is stable).
Headers also declare structures (passed as pointers) to functions. Strictly speaking, structure definitions are also part of the ABI, but there are more subtleties here. After compilation, structures are primarily defined by their size and field offsets, so name changes don’t affect the ABI (though they affect the API). Size changes slightly affect the ABI. In most cases, PostgreSQL uses a macro (“makeNode”) to allocate structures on the heap, which looks at the compile-time size of the structure and initializes the bytes to 0.
The difference in 17.1 is that a new boolean was added to the ResultRelInfo structure, increasing its size. What happens next depends on who calls makeNode. If it’s code from PostgreSQL 17.1, it uses the new size. If it’s an extension compiled for 17.0, it uses the old size. When it calls PostgreSQL functions with a pointer allocated using the old size, PostgreSQL functions still assume the new size and may write beyond the allocated block. Generally, this is quite problematic. It can lead to bytes being written to unrelated memory areas or program crashes.
When running tests, PostgreSQL has internal checks (assertions) to detect this situation and throw warnings. However, PostgreSQL uses its own allocator, which always rounds up allocated bytes to powers of 2. The ResultRelInfo structure is 376 bytes (on my laptop), so it rounds up to 512 bytes, and similarly after the change (384 bytes on my laptop). Therefore, this particular structure change typically doesn’t affect allocation size. There might be uninitialized bytes, but this is usually resolved by calling InitResultRelInfo.
This issue mainly raises warnings in tests or assertion-enabled builds where extensions allocate ResultRelInfo, especially when running those tests with extension binaries compiled against older PostgreSQL versions. Unfortunately, the story doesn’t end there. TimescaleDB is a heavy user of ResultRelInfo and indeed encountered problems with the size change. For example, in one of its code paths, it needs to find an index in an array of ResultRelInfo pointers, for which it performs pointer arithmetic. This array is allocated by PostgreSQL (384 bytes), but the Timescale binary assumes 376 bytes, resulting in a meaningless number that triggers assertion failures or segfaults. https://github.com/timescale/timescaledb/blob/2.17.2/src/nodes/hypertable_modify.c#L1245…
The code here isn’t actually wrong, but the contract with PostgreSQL isn’t as expected. This is an interesting lesson for all of us. Similar issues might exist in other extensions, though not many extensions are as advanced as Timescale. Another advanced extension is Citus, but I’ve verified that Citus is safe. It does show assertion warnings. Everyone is advised to be cautious. The safest approach is to ensure extensions are compiled with headers from the PostgreSQL version you’re running.
PostgreSQL 12 Reaches End-of-Life as PG 17 Takes the Throne
According to PostgreSQL’s versioning policy, PostgreSQL 12, released in 2019, officially exits its support lifecycle today (November 14, 2024).
PostgreSQL 12’s final minor version, 12.21, released today (November 14, 2024), marks the end of the road for PG 12. Meanwhile, the newly released PostgreSQL 17.1 emerges as the ideal choice for new projects.
| Version | Current minor | Supported | First Release | Final Release |
|---|---|---|---|---|
| 17 | 17.1 | Yes | September 26, 2024 | November 8, 2029 |
| 16 | 16.5 | Yes | September 14, 2023 | November 9, 2028 |
| 15 | 15.9 | Yes | October 13, 2022 | November 11, 2027 |
| 14 | 14.14 | Yes | September 30, 2021 | November 12, 2026 |
| 13 | 13.17 | Yes | September 24, 2020 | November 13, 2025 |
| 12 | 12.21 | No | October 3, 2019 | November 14, 2024 |
Farewell to PG 12
Over the past five years, PostgreSQL 12.20 (the previous minor version) addressed 34 security issues and fixed 936 bugs compared to PostgreSQL 12.0 released five years ago.

This final release (12.21) patches four CVE security vulnerabilities and includes 17 bug fixes. From this point forward, PostgreSQL 12 enters retirement, with no further security or error fixes.
- CVE-2024-10976: PostgreSQL row security ignores user ID changes in certain contexts (e.g., subqueries)
- CVE-2024-10977: PostgreSQL libpq preserves error messages from man-in-the-middle attacks
- CVE-2024-10978: PostgreSQL SET ROLE, SET SESSION AUTHORIZATION resets to incorrect user ID
- CVE-2024-10979: PostgreSQL PL/Perl environment variable changes execute arbitrary code
The risks of running outdated versions will continue to increase over time. Users still running PG 12 or earlier versions in production should develop an upgrade plan to a supported major version (13-17).
PostgreSQL 12, released five years ago, was a milestone release in my view - the most significant since PG 10. Notably, PG 12 introduced pluggable storage engine interfaces, allowing third parties to develop new storage engines. It also delivered major observability and usability improvements, such as real-time progress reporting for various tasks and csvlog format for easier log processing and analysis. Additionally, partitioned tables saw significant performance improvements and matured considerably.

My personal connection to PG 12 runs deep - when I created Pigsty, an out-of-the-box PostgreSQL database distribution, PG 12 was the first major version we publicly supported. It’s remarkable how five years have flown by; I still vividly remember adapting features from PG 11 to PG 12.
During these five years, Pigsty evolved from a personal PG monitoring system/testing sandbox into a widely-used open source project with global community recognition. Looking back, I can’t help but feel a sense of accomplishment.
PG 17 Takes the Throne
As one version departs, another ascends. Following PostgreSQL’s versioning policy, today’s routine quarterly release brings us PostgreSQL 17.1.

My friend Longxi Shuai from Qunar likes to upgrade immediately when a new PG version drops, while I prefer to wait for the first minor release after a major version launch.
Typically, many small fixes and refinements appear in the x.1 release following a major version. Additionally, the three-month buffer provides enough time for the PostgreSQL ecosystem of extensions to catch up and support the new major version - a crucial consideration for users of the PG ecosystem.
From PG 12 to the current PG 17, the PostgreSQL community has added 48 new feature enhancements and introduced 130 performance improvements. PostgreSQL 17’s write throughput, according to official statements, shows up to a 2x improvement in some scenarios compared to previous versions - making it well worth the upgrade.

https://smalldatum.blogspot.com/2024/09/postgres-17rc1-vs-sysbench-on-small.html
I conducted a comprehensive performance evaluation of PostgreSQL 14 three years ago, and I’m planning to run a fresh benchmark on PostgreSQL 17.1.
I recently acquired a beast of a physical machine: 128 cores, 256GB RAM, with four 3.2TB Gen4 NVMe SSDs plus a hardware NVMe RAID acceleration card. I’m eager to see what performance PostgreSQL, pgvector, and various OLAP extensions can achieve on this hardware monster - stay tuned for the results.
Overall, I believe 17.1’s release represents an opportune time to upgrade. I plan to release Pigsty v3.1 in the coming days, which will promote PG 17 as Pigsty’s default major version, replacing PG 16.
Considering that PostgreSQL has offered logical replication since 10.0, and Pigsty provides a complete solution for blue-green deployment upgrades using logical replication without downtime, major version upgrades are far less challenging than they once were. I’ll soon publish a tutorial on zero-downtime major version upgrades to help users seamlessly upgrade from PostgreSQL 16 or earlier versions to PG 17.
PG 17 Extensions
One particularly encouraging development is how quickly the PostgreSQL extension ecosystem has adapted to PG 17 compared to the transition from PG 15 to PG 16.
Last year, PG 16 was released in mid-September, but it took nearly six months for major extensions to catch up. For instance, TimescaleDB, a core extension in the PG ecosystem, only completed PG 16 support in early February with version 2.13. Other extensions followed similar timelines.
Only after PG 16 had been out for six months did it reach a satisfactory state. That’s when Pigsty promoted PG 16 to its default major version, replacing PG 15.
| Version | Date | Summary | Link |
|---|---|---|---|
| v3.1.0 | 2024-11-20 | PG 17 as default, config simplification, Ubuntu 24 & ARM support | WIP |
| v3.0.4 | 2024-10-30 | PG 17 extensions, OLAP suite, pg_duckdb | v3.0.4 |
| v3.0.3 | 2024-09-27 | PostgreSQL 17, Etcd maintenance optimizations, IvorySQL 3.4, PostGIS 3.5 | v3.0.3 |
| v3.0.2 | 2024-09-07 | Streamlined installation, PolarDB 15 support, monitor view updates | v3.0.2 |
| v3.0.1 | 2024-08-31 | Routine fixes, Patroni 4 support, Oracle compatibility improvements | v3.0.1 |
| v3.0.0 | 2024-08-25 | 333 extensions, pluggable kernels, MSSQL, Oracle, PolarDB compatibility | v3.0.0 |
| v2.7.0 | 2024-05-20 | Extension explosion with 20+ powerful new extensions and Docker applications | v2.7.0 |
| v2.6.0 | 2024-02-28 | PG 16 as default, introduced ParadeDB and DuckDB extensions | v2.6.0 |
| v2.5.1 | 2023-12-01 | Routine minor update, key PG16 extension support | v2.5.1 |
| v2.5.0 | 2023-09-24 | Ubuntu/Debian support: bullseye, bookworm, jammy, focal | v2.5.0 |
| v2.4.1 | 2023-09-24 | Supabase/PostgresML support & new extensions: graphql, jwt, pg_net, vault | v2.4.1 |
| v2.4.0 | 2023-09-14 | PG16, RDS monitoring, service consulting, new extensions: Chinese FTS/graph/HTTP/embeddings | v2.4.0 |
| v2.3.1 | 2023-09-01 | PGVector with HNSW, PG 16 RC1, docs overhaul, Chinese docs, routine fixes | v2.3.1 |
| v2.3.0 | 2023-08-20 | Host VIP, ferretdb, nocodb, MySQL stub, CVE fixes | v2.3.0 |
| v2.2.0 | 2023-08-04 | Dashboard & provisioning overhaul, UOS compatibility | v2.2.0 |
| v2.1.0 | 2023-06-10 | Support for PostgreSQL 12 ~ 16beta | v2.1.0 |
| v2.0.2 | 2023-03-31 | Added pgvector support, fixed MinIO CVE | v2.0.2 |
| v2.0.1 | 2023-03-21 | v2 bug fixes, security enhancements, Grafana version upgrade | v2.0.1 |
| v2.0.0 | 2023-02-28 | Major architectural upgrade, significantly improved compatibility, security, maintainability | v2.0.0 |
This time, the ecosystem adaptation from PG 16 to PG 17 has accelerated significantly - completing in less than three months what previously took six. I’m proud to say I’ve contributed substantially to this effort.
As I described in “PostgreSQL’s Ultimate Power: The Most Complete Extension Repository”, I maintain a repository that covers over half of the extensions in the PG ecosystem.
I recently completed the massive task of building over 140 extensions for PG 17 (also adding Ubuntu 24.04 and partial ARM support), while personally fixing or coordinating fixes for dozens of extensions with compatibility issues. The result: on EL systems, 301 out of 334 available extensions now work on PG 17, while on Debian systems, 302 out of 326 extensions are PG 17-compatible.
| Entry / Filter | All | PGDG | PIGSTY | CONTRIB | MISC | MISS | PG17 | PG16 | PG15 | PG14 | PG13 | PG12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPM Extension | 334 | 115 | 143 | 70 | 4 | 6 | 301 | 330 | 333 | 319 | 307 | 294 |
| DEB Extension | 326 | 104 | 144 | 70 | 4 | 14 | 302 | 322 | 325 | 316 | 303 | 293 |
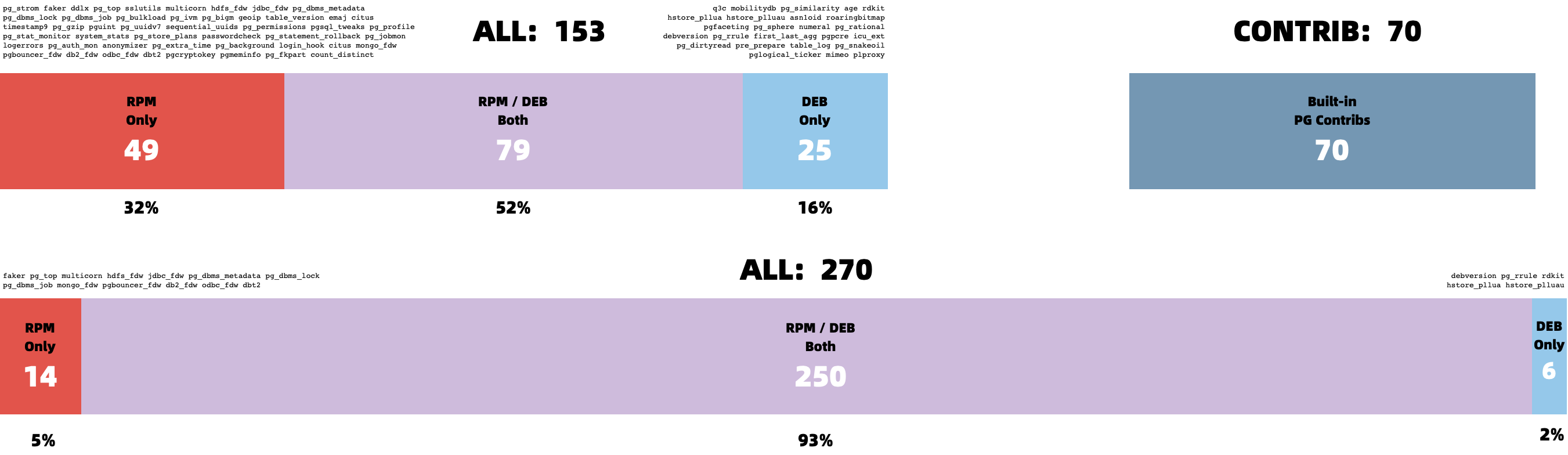
Pigsty has achieved grand unification of the PostgreSQL extension ecosystem
Among major extensions, only a few remain without PG 17 support: the distributed extension Citus, the columnar storage extension Hydra, graph database extension AGE, and PGML. However, all other powerful extensions are now PG 17-ready.
Particularly noteworthy is the recent OLAP DuckDB integration competition in the PG ecosystem. ParadeDB’s pg_analytics, personal developer Hongyan Li’s duckdb_fdw, CrunchyData’s pg_parquet, MooncakeLab’s pg_mooncake, and even pg_duckdb from Hydra and DuckDB’s parent company MotherDuck - all now support PG 17 and are available in the Pigsty extension repository.
Considering that Citus has a relatively small user base, and the columnar Hydra already has numerous DuckDB extensions as alternatives, I believe PG 17 has reached a satisfactory state for extension support and is ready for production use as the primary major version. Achieving this milestone took about half the time it required for PG 16.
About Pigsty v3.1
Pigsty is a free and open-source, out-of-the-box PostgreSQL database distribution that allows users to deploy enterprise-grade RDS cloud database services locally with a single command, helping users leverage PostgreSQL - the world’s most advanced open-source database.
PostgreSQL is undoubtedly becoming the Linux kernel of the database world, and Pigsty aims to be its Debian distribution. Our PostgreSQL database distribution offers six key value propositions:
- Provides the most comprehensive extension support in the PostgreSQL ecosystem
- Delivers the most powerful and complete monitoring system in the PostgreSQL ecosystem
- Offers out-of-the-box, user-friendly tools and best practices
- Provides self-healing, low-maintenance high availability and PITR experience
- Delivers reliable deployment directly on bare OS without containers
- No vendor lock-in, a democratized RDS experience with full control
Worth mentioning, we’ve added PG-derived kernel replacement capabilities in Pigsty v3, allowing you to use derivative PG kernels for unique features and capabilities:
- Microsoft SQL Server-compatible Babelfish kernel support
- Oracle-compatible IvorySQL 3.4 kernel support
- Alibaba Cloud PolarDB for PostgreSQL/Oracle kernel support
- Easier self-hosting of Supabase - the open-source Firebase alternative and all-in-one backend platform
If you’re looking for an authentic PostgreSQL experience, we welcome you to try our distribution - it’s open-source, free, and comes with no vendor lock-in. We also offer commercial consulting support to solve challenging issues and provide peace of mind.
The idea way to install PostgreSQL Extensions
PostgreSQL Is Eating the Database World through the power of extensibility. With 400 extensions powering PostgreSQL, we may not say it’s invincible, but it’s definitely getting much closer.
I believe the PostgreSQL community has reached a consensus on the importance of extensions. So the real question now becomes: “What should we do about it?”
What’s the primary problem with PostgreSQL extensions? In my opinion, it’s their accessibility. Extensions are useless if most users can’t easily install and enable them. But it’s not that easy.
Even the largest cloud postgres vendors are struggling with this. They have some inherent limitations (multi-tenancy, security, licensing) that make it hard for them to fully address this issue.
So here’s my plan, I’ve created a repository that hosts 400 of the most capable extensions in the PostgreSQL ecosystem, available as RPM / DEB packages on mainstream Linux OS distros. And the goal is to take PostgreSQL one solid step closer to becoming the all-powerful database and achieve the great alignment between the Debian and EL OS ecosystems.
The status quo
The PostgreSQL ecosystem is rich with extensions, but how do you actually install and use them? This initial hurdle becomes a roadblock for many. There are some existing solutions:
PGXN says, “You can download and compile extensions on the fly with pgxnclient.”
Tembo says, “We have prepared pre-configured extension stack as Docker images.”
StackGres & Omnigres says, “We download .so files on the fly.” All solid ideas.
While based on my experience, the vast majority of users still rely on their operating system’s package manager to install PG extensions. On-the-fly compilation and downloading shared libraries might not be a viable option for production env. Since many DB setups don’t have internet access or a proper toolchain ready.
In the meantime, Existing OS package managers like yum/dnf/apt already solve issues like dependency resolution, upgrades, and version management well.
There’s no need to reinvent the wheel or disrupt existing standards. So the real question is: Who’s going to package these extensions into ready-to-use software?
PGDG has already made a fantastic effort with official YUM and APT repositories. In addition to the 70 built-in Contrib extensions bundled with PostgreSQL,the PGDG YUM repo offers 128 RPM extensions, while the APT repo offers 104 DEB extensions. These extensions are compiled and packaged in the same environment as the PostgreSQL kernel, making them easy to install alongside the PostgreSQL binary packages. In fact, even most PostgreSQL Docker images rely on the PGDG repo to install extensions.
I’m deeply grateful for Devrim’s maintenance of the PGDG YUM repo and Christoph’s work with the APT repo. Their efforts to make PostgreSQL installation and extension management seamless are incredibly valuable. But as a distribution creator myself, I’ve encountered some challenges with PostgreSQL extension distribution.
What’s the challenge?
The first major issue facing extension users is Alignment.
In the two primary Linux distro camps — Debian and EL — there’s a significant number of PostgreSQL extensions. Excluding the 70 built-in Contrib extensions bundled with PostgreSQL, the YUM repo offers 128 extensions, and the APT repo provides 104.
However, when we dig deeper, we see that alignment between the two repos is not ideal. The combined total of extensions across both repos is 153, but the overlap is just 79. That means only half of the extensions are available in both ecosystems!

Only half of the extensions are available in both EL and Debian ecosystems!
Next, we run into further alignment issues within each ecosystem itself. The availability of extensions can vary between different major OS versions.
For instance, pljava, sequential_uuids, and firebird_fdw are only available in EL9, but not in EL8. Similarly, rdkit is available in Ubuntu 22+ / Debian 12+, but not in Ubuntu 20 / Debian 11.
There’s also the issue of architecture support. For example, citus does not provide arm64 packages in the Debian repo.
And then we have alignment issues across different PostgreSQL major versions. Some extensions won’t compile on older PostgreSQL versions, while others won’t work on newer ones. Some extensions are only available for specific PostgreSQL versions in certain distributions, and so on.
These alignment issues lead to a significant number of permutations. For example, if we consider five mainstream OS distributions (el8, el9, debian12, ubuntu22, ubuntu24),
two CPU architectures (x86_64 and arm64), and six PostgreSQL major versions (12–17), that’s 60-70 RPM/DEB packages per extension—just for one extension!
On top of alignment, there’s the problem of completeness. PGXN lists over 375 extensions, but the PostgreSQL ecosystem could have as many as 1,000+. The PGDG repos, however, contain only about one-tenth of them.
There are also several powerful new Rust-based extensions that PGDG doesn’t include, such as pg_graphql, pg_jsonschema, and wrappers for self-hosting Supabase;
pg_search as an Elasticsearch alternative; and pg_analytics, pg_parquet, pg_mooncake for OLAP processing. The reason? They are too slow to compile…
What’s the solution?
Over the past six months, I’ve focused on consolidating the PostgreSQL extension ecosystem. Recently, I reached a milestone I’m quite happy with. I’ve created a PG YUM/APT repository with a catalog of 400available PostgreSQL extensions.
Here are some key stats for the repo: It hosts 400 extensions in total. Excluding the 70 built-in extensions that come with PostgreSQL, this leaves 270 third-party extensions. Of these, about half are maintained by the official PGDG repos (126 RPM, 102 DEB). The other half (131 RPM, 143DEB) are maintained, fixed, compiled, packaged, and distributed by myself.
| OS \ Entry | All | PGDG | PIGSTY | CONTRIB | MISC | MISS | PG17 | PG16 | PG15 | PG14 | PG13 | PG12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPM | 334 | 115 | 143 | 70 | 4 | 6 | 301 | 330 | 333 | 319 | 307 | 294 |
| DEB | 326 | 104 | 144 | 70 | 4 | 14 | 302 | 322 | 325 | 316 | 303 | 293 |
For each extension, I’ve built versions for the 6 major PostgreSQL versions (12–17) across five popular Linux distributions: EL8, EL9, Ubuntu 22.04, Ubuntu 24.04, and Debian 12. I’ve also provided some limited support for older OS versions like EL7, Debian 11, and Ubuntu 20.04.
This repository also addresses most of the alignment issue. Initially, there were extensions in the APT and YUM repos that were unique to each, but I’ve worked to port as many of these unique extensions to the other ecosystem. Now, only 7 APT extensions are missing from the YUM repo, and 16 extensions are missing in APT—just 6% of the total. Many missing PGDG extensions have also been resolved.

I’ve created a comprehensive directory listing all supported extensions, with detailed info, dependency installation instructions, and other important notes.

I hope this repository can serve as the ultimate solution to the frustration users face when extensions are difficult to find, compile, or install.
How to use this repo?
Now, for a quick plug — what’s the easiest way to install and use these extensions?
The simplest option is to use the OSS PostgreSQL distribution: Pigsty. The repo is autoconfigured by default, so all you need to do is declare them in the config inventory.
For example, the self-hosting supabase template requires extensions that aren’t available in the PGDG repo. You can simply download, install, preload, config and create extensions by referring to their names.
all:
children:
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
# INSTALL EXTENSIONS
pg_extensions:
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
# LOAD EXTENSIONS
pg_libs: 'pg_stat_statements, plpgsql, plpgsql_check, pg_cron, pg_net, timescaledb, auto_explain, pg_tle, plan_filter'
# CONFIG EXTENSIONS
pg_parameters:
cron.database_name: postgres
pgsodium.enable_event_trigger: off
# CREATE EXTENSIONS
pg_databases:
- name: postgres
baseline: supabase.sql
schemas: [ extensions ,auth ,realtime ,storage ,graphql_public ,supabase_functions ,_analytics ,_realtime ]
extensions:
- { name: pgcrypto ,schema: extensions }
- { name: pg_net ,schema: extensions }
- { name: pgjwt ,schema: extensions }
- { name: uuid-ossp ,schema: extensions }
- { name: pgsodium }
- { name: supabase_vault }
- { name: pg_graphql }
- { name: pg_jsonschema }
- { name: wrappers }
- { name: http }
- { name: pg_cron }
- { name: timescaledb }
- { name: pg_tle }
- { name: vector }
vars:
pg_version: 17
# DOWNLOAD EXTENSIONS
repo_extra_packages:
- pgsql-main
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
To simply add extensions to existing clusters:
./infra.yml -t repo_build -e '{"repo_packages":[citus]}' # download
./pgsql.yml -t pg_extension -e '{"pg_extensions": ["citus"]}' # install
Through this repo was meant to be used with Pigsty, But it is not mandatory. You can still enable this repository on any EL/Debian/Ubuntu system with a simple one-liner in the shell:
APT Repo
For Ubuntu 22.04 & Debian 12 or any compatible platforms, use the following commands to add the APT repo:
curl -fsSL https://repo.pigsty.io/key | sudo gpg --dearmor -o /etc/apt/keyrings/pigsty.gpg
sudo tee /etc/apt/sources.list.d/pigsty-io.list > /dev/null <<EOF
deb [signed-by=/etc/apt/keyrings/pigsty.gpg] https://repo.pigsty.io/apt/infra generic main
deb [signed-by=/etc/apt/keyrings/pigsty.gpg] https://repo.pigsty.io/apt/pgsql/$(lsb_release -cs) $(lsb_release -cs) main
EOF
sudo apt update
YUM Repo
For EL 8/9 and compatible platforms, use the following commands to add the YUM repo:
curl -fsSL https://repo.pigsty.io/key | sudo tee /etc/pki/rpm-gpg/RPM-GPG-KEY-pigsty >/dev/null # add gpg key
curl -fsSL https://repo.pigsty.io/yum/repo | sudo tee /etc/yum.repos.d/pigsty.repo >/dev/null # add repo file
sudo yum makecache
What’s in this repo?
In this repo, all the extensions are categorized into one of the 15 categories: TIME, GIS, RAG, FTS, OLAP, FEAT, LANG, TYPE, FUNC, ADMIN, STAT, SEC, FDW, SIM, ETL, as shown below.
Check pigsty.io/ext for all the details.
Some Thoughts
Each major PostgreSQL version introduces changes, making the maintenance of 140+ extension packages a bit of a beast.
Especially when some extension authors haven’t updated their work in years. In these cases, you often have no choice but to take matters into your own hands. I’ve personally fixed several extensions and ensured they support the latest PostgreSQL major versions. For those authors I could reach, I’ve submitted numerous PRs and issues to keep things moving forward.

Back to the point: my goal with this repo is to establish a standard for PostgreSQL extension installation and distribution, solving the distribution challenges that have long troubles the users.
A recent milestone is that, the popular open-source PostgreSQL HA cluster project postgresql_cluster, has made this extension repository the default upstream for PG extension installation.
Currently, this repository (repo.pigsty.io) is hosted on Cloudflare. In the past month, the repo and its mirrors have served about 300GB of downloads. Given that most extensions are just a few KB to a few MB, that amounts to nearly a million downloads per month. Since Cloudflare doesn’t charge for traffic, I can confidently commit to keeping this repository completely free & under active maintenance for the foreseeable future, as long as cloudflare doesn’t charge me too much.
I believe my work can help PostgreSQL users worldwide and contribute to the thriving PostgreSQL ecosystem. I hope it proves useful to you as well. Enjoy PostgreSQL!
PostgreSQL 17 Released: The Database That's Not Just Playing Anymore!
The annual PostgreSQL major release is here! What surprises does PostgreSQL 17 have in store for us?
In this release announcement, the PostgreSQL global community has finally dropped the act — sorry, we’re not playing anymore — “PostgreSQL is now the world’s most advanced open-source database, becoming the preferred choice for organizations of all sizes”. While not explicitly naming names, the official announcement comes incredibly close to shouting “we’re taking down the top commercial databases” (Oracle).

In my article “PostgreSQL is Eating the Database World” published earlier this year, I argued that scalability is PostgreSQL’s unique core advantage. I’m thrilled to see this become the focus and consensus of the PostgreSQL community in just six months, as demonstrated at PGCon.Dev 2024 and this PostgreSQL 17 release.
Regarding new features, I’ve already covered them in my article “PostgreSQL 17 Beta1 Released! The Performance Tube is Bursting!”, so I won’t repeat them here. This major version brings many new features, but what impressed me most is that PG managed to double its write throughput on top of its already impressive performance — unpretentiously powerful.
However, beyond specific features, I believe the biggest transformation in the PG community is in its mindset and spirit — in this release announcement, PostgreSQL has dropped the “relational” qualifier from its slogan “the world’s most advanced open-source relational database”, becoming simply “the world’s most advanced open-source database”. And in the “About PostgreSQL” section, it states: “PG’s feature set, advanced capabilities, scalability, security, and stability now rival and even surpass top-tier commercial databases”. So I think it won’t be long before the “open-source” qualifier can be dropped too, becoming simply “the world’s most advanced database”.
The PostgreSQL beast has awakened — it’s no longer the peaceful, non-confrontational entity of the past, but has transformed into an aggressive, forward-looking force — ready to take over and conquer the entire database world. And countless capital has already flooded into the PostgreSQL ecosystem, with PG-based startups taking almost all the new money in database funding. PostgreSQL is destined to become the “Linux kernel” of the database world, and DBMS disputes might evolve into internal PostgreSQL distribution battles in the future. Let’s wait and see.

Original: PostgreSQL 17 Release Notes
Can PostgreSQL Replace Microsoft SQL Server?
Many people don’t have a clear picture of how far the PostgreSQL ecosystem has evolved. Beyond devouring the database world with its all-encompassing extension ecosystem, PostgreSQL can now directly replace Oracle, SQL Server, and MongoDB at the kernel level – and MySQL is even less of a challenge.
When it comes to mainstream databases at highest risk of displacement, Microsoft SQL Server undeniably tops the list. MSSQL faces the most comprehensive replacement – right down to the wire protocol level. And who’s leading this charge? None other than AWS, Amazon’s cloud service division.
Babelfish
While I’ve often criticized cloud vendors for free-riding on open source, I must admit this strategy is extremely effective. AWS has leveraged the open-source PostgreSQL and MySQL kernels to dominate the database market, punching Oracle and kicking Microsoft, becoming the undisputed market leader. In recent years, AWS has pulled off an even more brilliant move by developing the BabelfishPG extension, providing compatibility at the “wire protocol” level.

“Wire protocol compatibility” means clients don’t need to change anything – they can still access the SQL Server port 1433 using MSSQL drivers and command-line tools (sqlcmd) to connect to clusters equipped with BabelfishPG. Even more remarkably, you can still use PostgreSQL’s protocol language syntax to access the original 5432 port, coexisting with SQL Server clients – this creates tremendous convenience for migration.
WiltonDB
Of course, Babelfish isn’t merely a simple PG extension plugin. It makes minor modifications and adaptations to the PostgreSQL kernel and provides four extension plugins that offer TSQL syntax support, TDS wire protocol support, data types, and other function support.

Compiling and packaging such kernels and extensions on different platforms isn’t a simple task. That’s where WiltonDB – a Babelfish distribution – comes in. It compiles and packages BabelfishPG as RPM/DEB/MSI packages for EL 7/8/9, Ubuntu systems, and even Windows.
Pigsty v3
Having RPM/DEB packages alone is still far from offering production-grade services. In the recently released Pigsty v3, we provide the ability to replace the native PostgreSQL kernel with BabelfishPG.
Creating such an MSSQL cluster requires only modifying a few parameters in the cluster definition. The setup process remains fool-proof – similar to primary-replica setup, extension installation, parameter optimization, user configuration, HBA rule settings, and even service traffic distribution will automatically be established based on the configuration file.
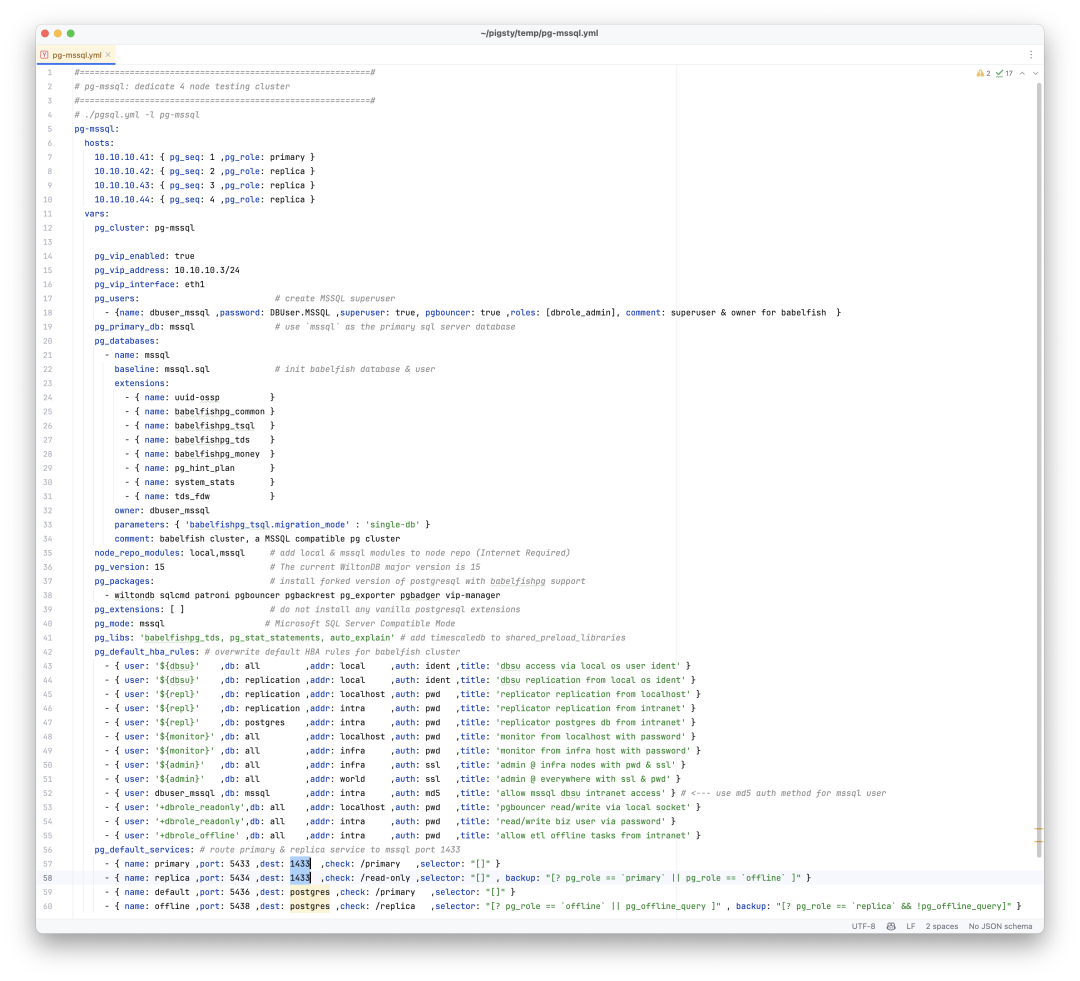
In practice, you can treat a Babelfish cluster exactly like a regular PostgreSQL cluster for use and management. The only difference is that clients can choose whether to use TSQL protocol support on port 1433 in addition to the PGSQL protocol on port 5432.

For example, you can easily redirect the Primary service (which originally points to the primary database connection pool on port 6432) to port 1433 through configuration, achieving seamless TDS/TSQL traffic switching during failovers.

This means that capabilities originally belonging to PostgreSQL RDS – high availability, point-in-time recovery, monitoring systems, IaC control, SOP plans, and countless extension plugins – can all be grafted onto the SQL Server version kernel.
How to Migrate?
Beyond powerful kernels and extensions like Babelfish, the PostgreSQL ecosystem boasts a flourishing toolkit ecosystem. For migrations from SQL Server or MySQL to PostgreSQL, I strongly recommend a killer migration tool: PGLOADER.
This migration tool is ridiculously straightforward – under ideal conditions, you only need connection strings for both databases to complete the migration. Yes, really, without a single line of unnecessary code.
pgloader mssql://user@mshost/dbname pgsql://pguser@pghost/dbname
With MSSQL-compatible kernel extensions and migration tools, moving existing SQL Server installations becomes remarkably easy.
Beyond MSSQL…
Besides MSSQL, the PostgreSQL ecosystem offers Oracle replacements like PolarDB O and IvorySQL, MongoDB replacements like FerretDB and PongoDB, as well as over three hundred extensions providing various functionalities.
In fact, nearly the entire database world is feeling PostgreSQL’s impact – except for those that occupy different ecological niches (SQLite, DuckDB, MinIO) or are essentially PostgreSQL in disguise (Supabase, RDS, Aurora/Polar).

Our recently released open-source PostgreSQL RDS solution, Pigsty, now supports these PG replacement kernels, allowing users to provide MSSQL, Oracle, MongoDB, Firebase, and MongoDB compatibility within a single PostgreSQL deployment.
But due to space limitations, those will be topics for upcoming articles.
Whoever Integrates DuckDB Best Wins the OLAP World
In the post “PostgreSQL is Eating the World”, I posed a question: Who will ultimately unify the database world? My take is that it’ll be the PostgreSQL ecosystem coupled with a rich variety of extension plugins. And I believe that to conquer OLAP—arguably the biggest and most distinct kingdom in the database domain—this “analysis extension” absolutely has something to do with DuckDB.
I’ve long been a huge fan of PostgreSQL. But interestingly, my second favorite database over the past two years has shifted from Redis to DuckDB. DuckDB is a very compact yet powerful embedded OLAP database, achieving top-tier performance and usability in analytics. It also ranks just behind PostgreSQL in terms of extensibility.
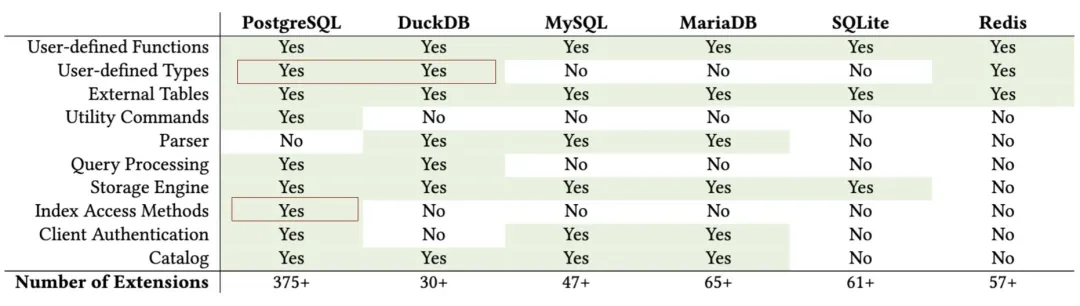
Much like the vector database extension race two years back, the new frontier in the PG ecosystem is a competition centered around DuckDB—“Whoever integrates DuckDB into PG more elegantly will be the future champion of the OLAP world.” Although many participants are sharpening their swords for this battle, DuckDB’s official entry into the race leaves no doubt that the competition is about to ignite.
DuckDB: A Rising Challenger in the OLAP Space
DuckDB was created by database researchers Mark Raasveldt and Hannes Mühleisen at the Centrum Wiskunde & Informatica (CWI) in Amsterdam. CWI is not just a research institute—it’s arguably the hidden powerhouse behind the development of analytical databases, pioneering columnar storage engines and vectorized query execution. Products like ClickHouse, Snowflake, and Databricks all carry CWI’s influence. Fun fact: Guido van Rossum (a.k.a. the father of Python) also created the Python language while at CWI.
Now these pioneers in analytical research are directly bringing their expertise to an OLAP database, choosing a smart timing and niche by introducing DuckDB.
DuckDB was born from observing database users’ pain points: data scientists mostly rely on tools like Python and Pandas and are less familiar with traditional databases. They’re often bogged down by hassles like connectivity, authentication, data import/export, and so on. So why not build a simple, embedded analytical database for them—kinda like SQLite for analytics?
The entire DuckDB project is essentially one header file and one C++ file, which compiles into a standalone binary. The database itself is just a single file. It uses a PostgreSQL-compatible parser and syntax, making it almost frictionless for newcomers. Though DuckDB seems refreshingly simple, its most impressive feature is “simplicity without compromise”—it boasts world-class analytical performance. For instance, on ClickHouse’s own benchmark site (ClickBench), DuckDB can beat the local champion on its home turf.
Another highlight: because DuckDB’s creators are government-funded researchers, they consider offering their work to everyone for free a social responsibility. Thus, DuckDB is released under the very permissive MIT License.
I believe DuckDB’s rise is inevitable: a database that’s blazing fast, requires virtually zero setup, and is also open-source and free—it’s hard not to become popular. In StackOverflow’s 2023 Developer Survey, DuckDB made the “Most Popular Databases” list for the first time at a 0.61% usage rate (29th place, fourth from the bottom). Just one year later, in the 2024 survey, DuckDB saw a 2.3x growth in popularity (1.4%), nearly catching up to ClickHouse (1.7%).
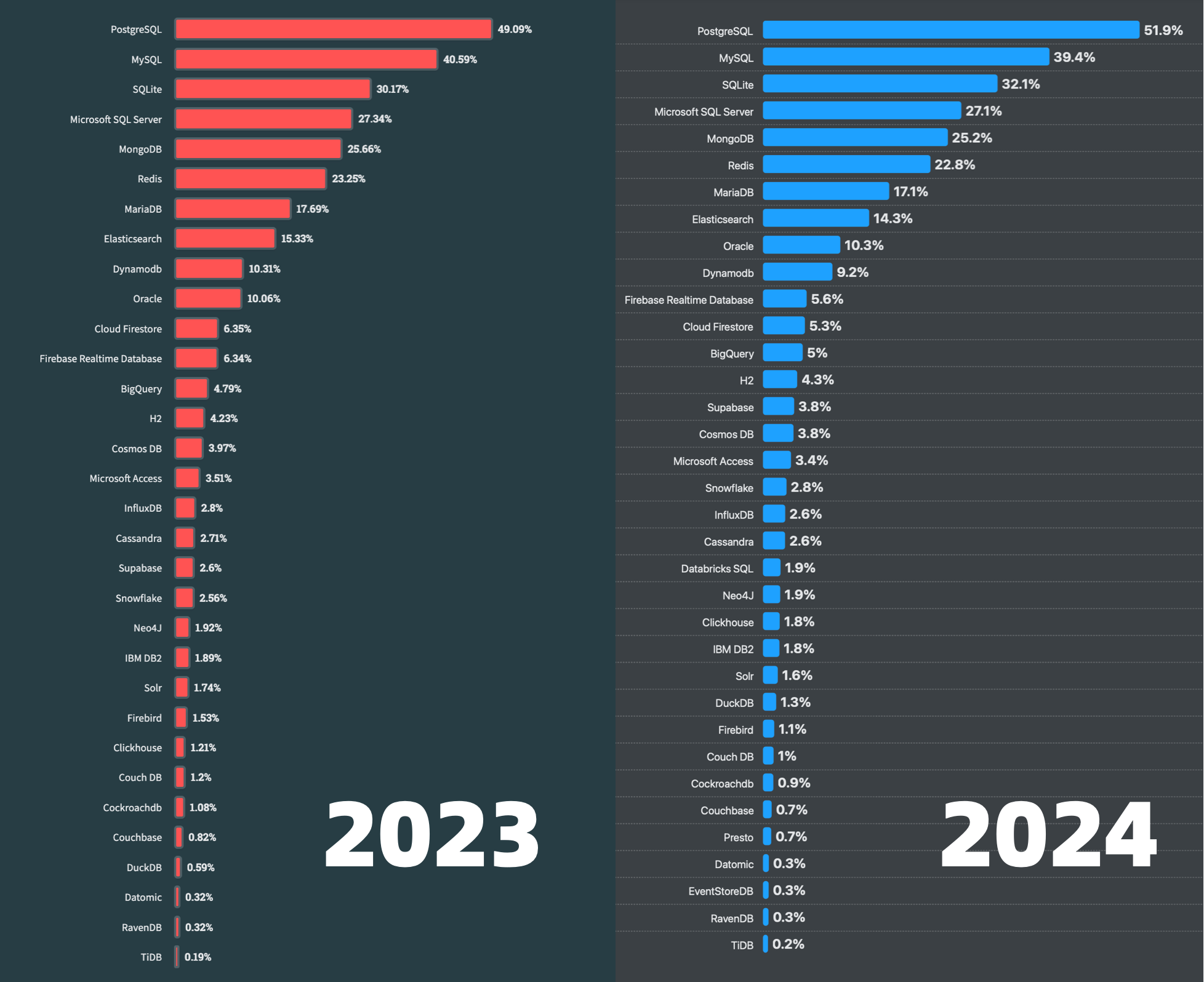
At the same time, DuckDB has garnered an excellent reputation among its users. In terms of developer appreciation and satisfaction (69.2%), it’s second only to PostgreSQL (74.5%) among major databases. If we look at DB-Engine’s popularity trend, it’s clear that since 2022, DuckDB has been on a meteoric rise—though it’s still nowhere near PostgreSQL levels, it has already surpassed every other NewSQL product in popularity scores.
DuckDB’s Weaknesses—and the Opportunity They Present
DuckDB can be used as a standalone database, but it truly shines as an embedded analytical engine. Being “embedded” is both a strength and a weakness. While DuckDB boasts top-notch analytics performance, its biggest shortcoming is its rather minimal data-management capabilities—the stuff data scientists hate dealing with: ACID, concurrent access, access control, data persistence, HA, database import/export… Ironically, these are precisely the strong suits of classic databases and the core pain points for enterprise analytics systems.
We can expect a wave of DuckDB “sidecar” products to address these gaps. It’s reminiscent of what happened when Facebook open-sourced RocksDB (a KV store): countless “new database” projects merely slapped a thin SQL layer on top of RocksDB and sold themselves as the next big thing—Yet another SQL sidecar for RocksDB. The same phenomenon happened with the vector search library hnswlib—numerous “specialized vector databases” sprang up, all just wrapping hnswlib. And with Lucene or its next-gen replacement Tantivy, we’ve seen a flurry of “full-text search databases” that are basically wrapped versions of those engines.
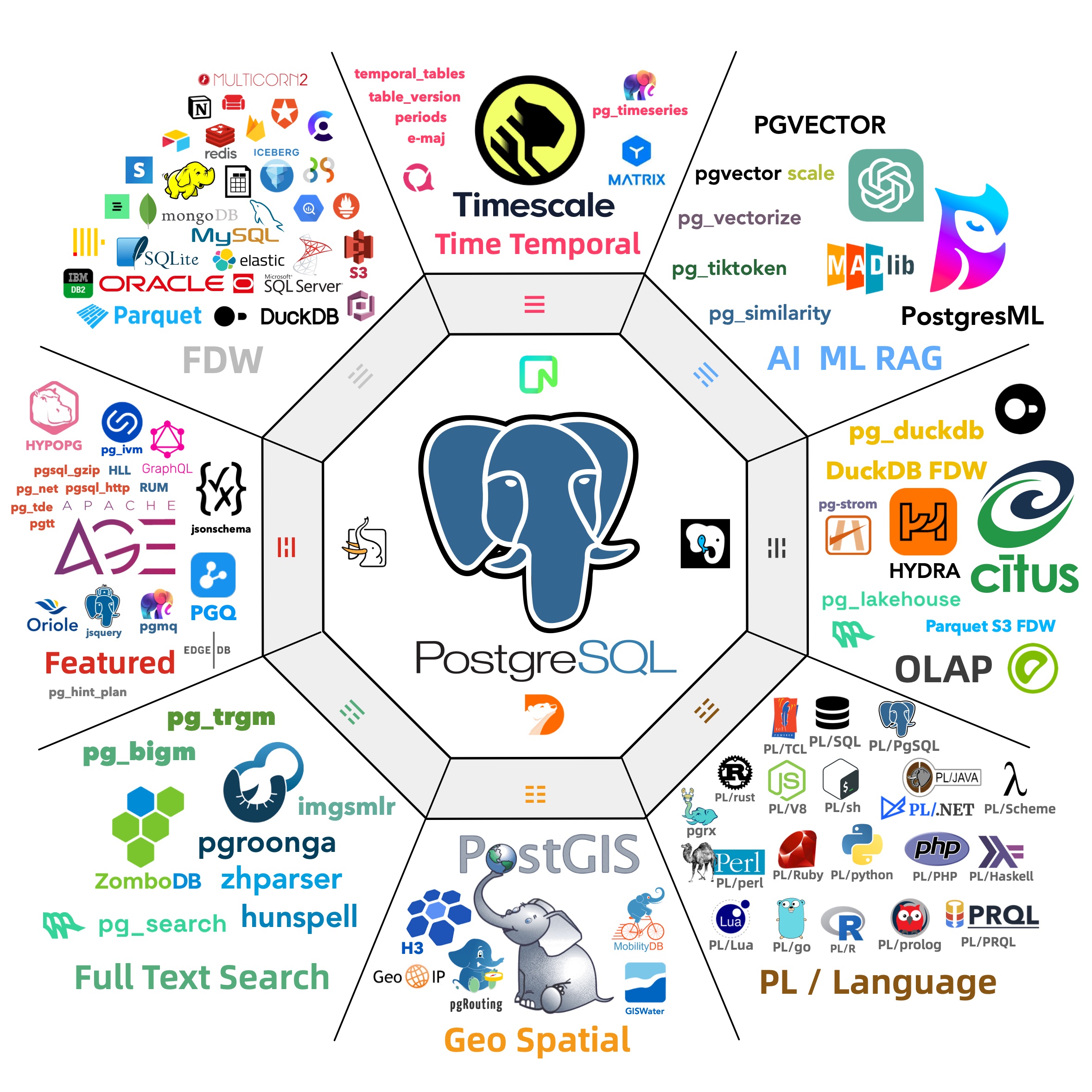
In fact, this is already happening within the PostgreSQL ecosystem. Before other database companies realized what was happening, five PG players jumped into the race, including ParadeDB’s pg_lakehouse, duckdb_fdw by independent developer Li Hongyan, CrunchyData’s crunchy_bridge, Hydra’s pg_quack, and now the official DuckDB team has arrived with a PG extension—pg_duckdb.
The Second PG Extension Grand Prix
It reminds me of the vector database extension frenzy in the PG community over the past year. As AI went mainstream, the PG world saw at least six vector extensions (pgvector, pgvector.rs, pg_embedding, latern, pase, pgvectorscale) racing to outdo each other. Eventually, pgvector, boosted heavily by AWS and others, steamrolled the specialized vector-database market before Oracle/MySQL/MariaDB even rolled out their half-baked offerings.
So, who will become the “pgvector” of the PG OLAP ecosystem? Personally, I’d bet on the official extension overshadowing community ones. Although pg_duckdb has only just arrived—it hasn’t even hit version v0.0.1 yet—its architectural design suggests it’s likely the future winner. Indeed, this extension arms race has only just started, but it’s already converging fast:
Hydra (YC W22), which originally forked Citus’ column store extension to create pg_quack, was so impressed by DuckDB that they abandoned their own engine and teamed up with MotherDuck to build pg_duckdb. This extension, blending Hydra’s PG know-how with DuckDB’s native expertise, can seamlessly read PG tables inside your database, use DuckDB for computation, and directly read Parquet/IceBerg formats from the filesystem/S3—thus creating a “data lakehouse” setup.

Similarly, ParadeDB (YC S23)—another YC-backed startup—originally built pg_analytics in Rust for OLAP capabilities, achieving decent traction. They, too, switched gears to build a DuckDB-based pg_lakehouse. Right after the pg_duckdb announcement, ParadeDB founder Phillipe essentially waved the white flag and said they’d develop on top of pg_duckdb rather than compete against it.

Meanwhile, Chinese independent developer Li Hongyan created duckdb_fdw as a different approach altogether—using PostgreSQL’s foreign-data-wrapper infrastructure to connect PG and DuckDB. The official DuckDB folks publicly critiqued this, highlighting it as a “bad example,” possibly motivating the birth of “pg_duckdb”: “We have grand visions for uniting PG and Duck, but you moved too fast—here’s the official shock and awe.”
As for CrunchyData’s crunchy_bridge or any other closed-source wrappers, I suspect they’ll struggle to gain broader adoption.
Of course, as the author of the PostgreSQL distribution Pigsty, my position is simply—let them race. I’ll bundle all these extensions and distribute them to end users, so they can pick whatever suits them best. Just like when vector databases were on the rise, I bundled pgvector, pg_embedding, pase, pg_sparse, etc.—the most promising candidates. It doesn’t matter who ultimately wins; PG and Pigsty will always be the ones reaping the spoils.
Speed trumps all, so in Pigsty v3 I’ve already integrated the three most promising extensions: pg_duckdb, pg_lakehouse, and duckdb_fdw, plus the main duckdb binary—all ready to go out of the box. Users can experience a one-stop PostgreSQL solution that handles both OLTP and OLAP—truly an all-conquering HTAP dream come true.
StackOverflow 2024 Survey: PostgreSQL Is Dominating the Field
2024 StackOverflow Global Developer Survey Results have just been released, featuring high-quality responses from 60,000 developers in 185 countries and regions. Naturally, as a seasoned database aficionado, the part I’m most interested in is the “Database” section of the survey:
Popularity
First up is database popularity: Database usage among professional developers
A technology’s popularity is measured by the proportion of overall respondents who used it in the past year. This figure reflects accumulated usage over that period—think of it as the market “stock” metric, the most fundamental indicator of current status.
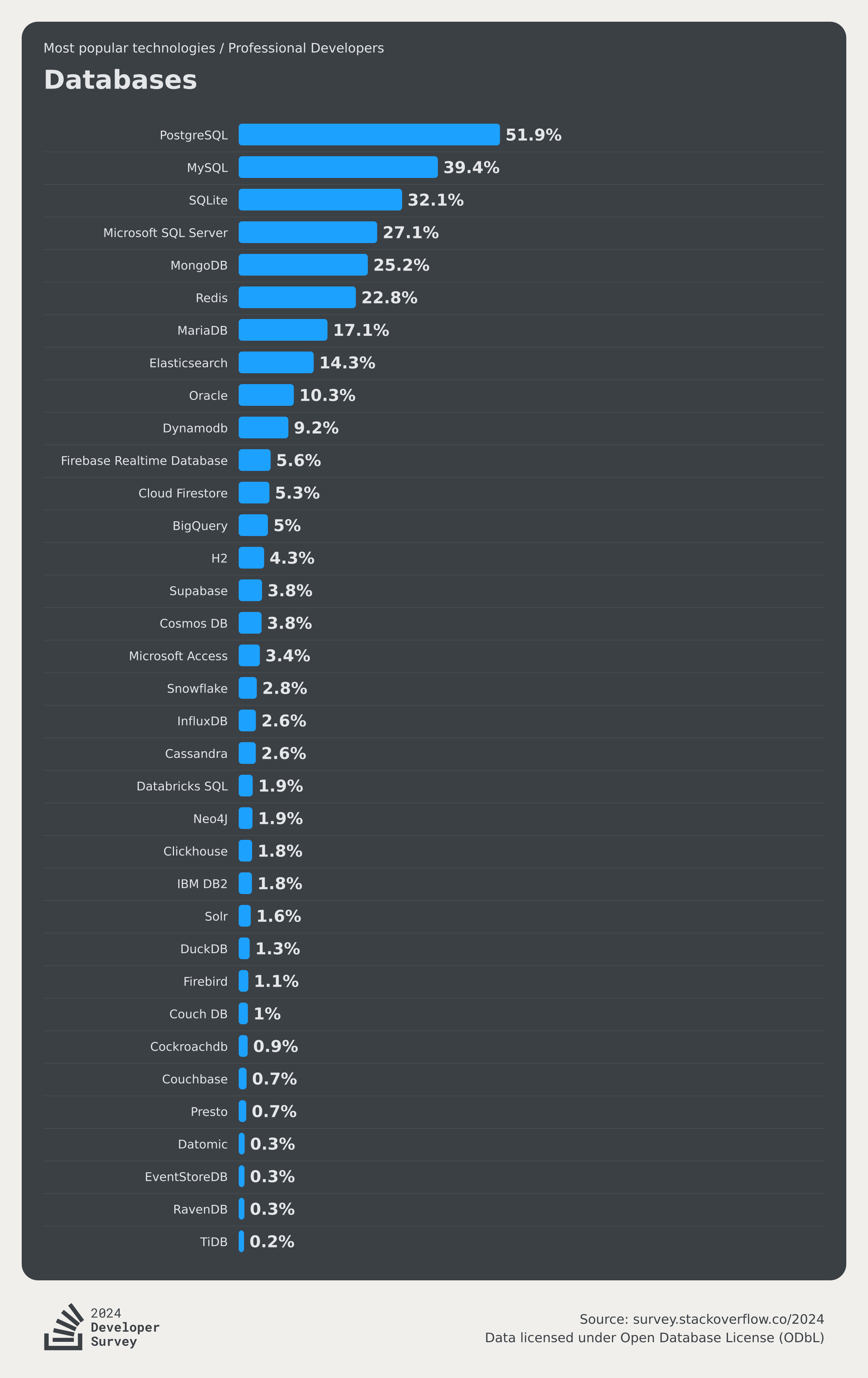
In terms of usage, PostgreSQL leads the pack among professional developers at 51.9%, clinching the top spot for the third consecutive year—and surpassing the 50% mark for the first time ever! The gap between PostgreSQL and the second-place MySQL (39.4%) has widened to 12.5 percentage points (it was 8.5 points last year).
Looking at the entire developer community (including non-professionals), PostgreSQL has become the world’s most popular database for the second year in a row, at 48.7% usage—pulling 8.4 points ahead of MySQL (40.3%), compared to a 4.5-point lead in the previous year.
Plotting the past eight years of survey data on a scatter chart shows PostgreSQL enjoying a near-linear, high-speed growth trend.
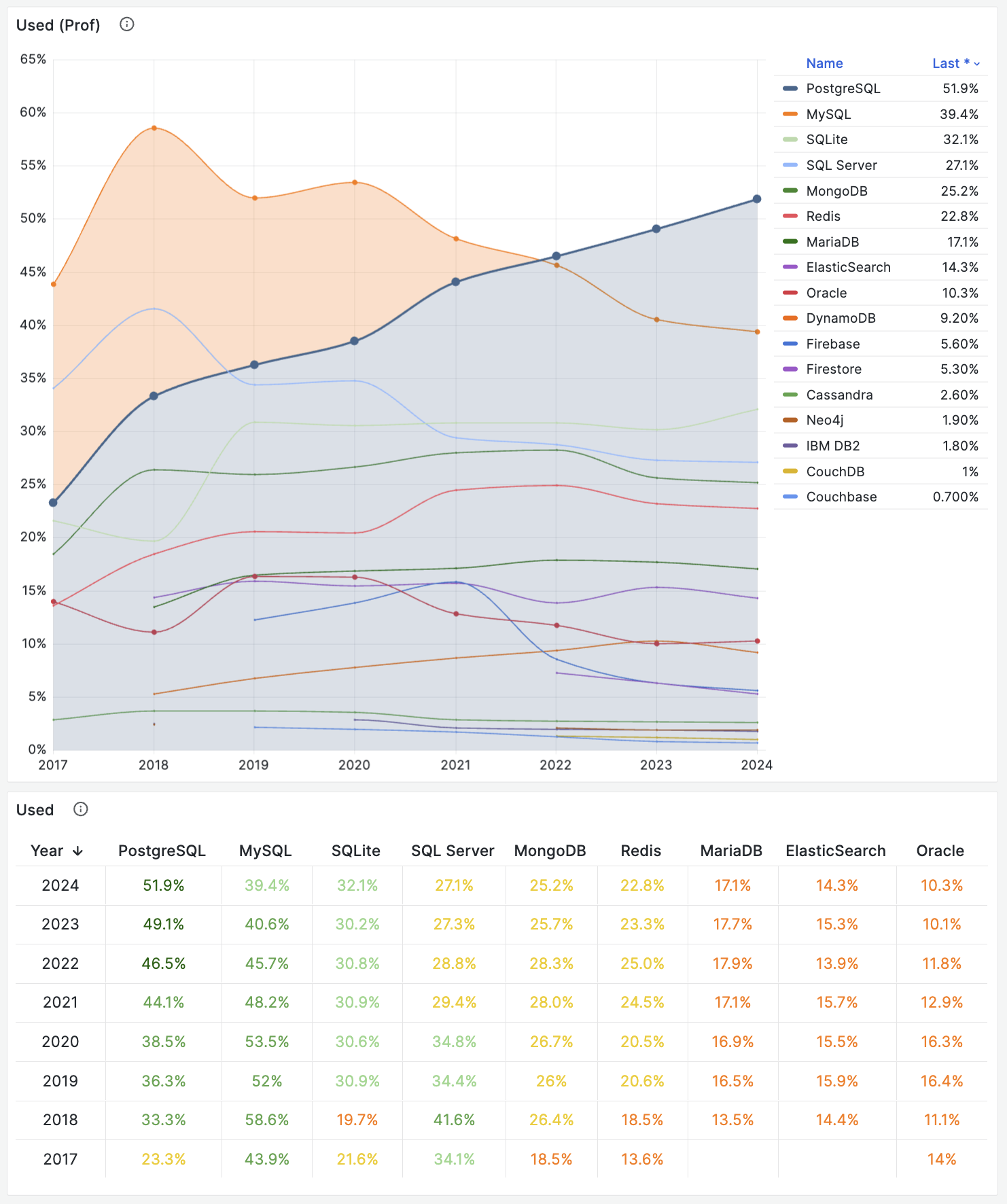
Besides PostgreSQL, other databases seeing notable growth include SQLite, DuckDB, Supabase, BigQuery, Snowflake, and Databricks SQL. BigQuery, Snowflake, and Databricks are the darlings of the big data analytics realm, while SQLite and DuckDB occupy a unique embedded database niche that doesn’t really clash with traditional relational databases. Supabase, on the other hand, encapsulates PostgreSQL under the hood as its backend development platform.
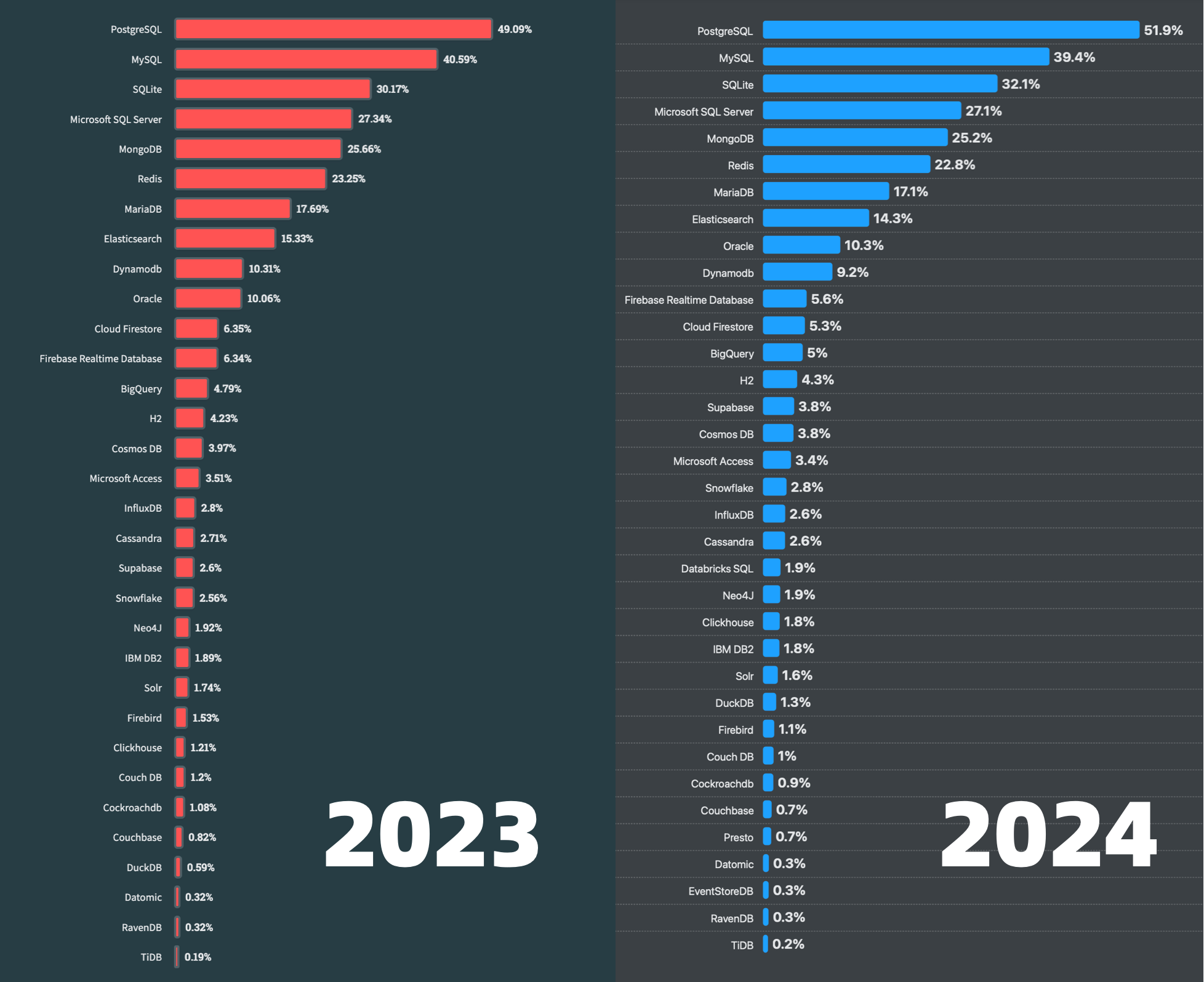
All other databases have, to varying degrees, felt the impact of PostgreSQL’s rise.
Admiration & Demand
Next, let’s look at a database’s admiration (in red) and demand (in blue): Which databases are most loved and most wanted by all developers over the past year, sorted by demand.
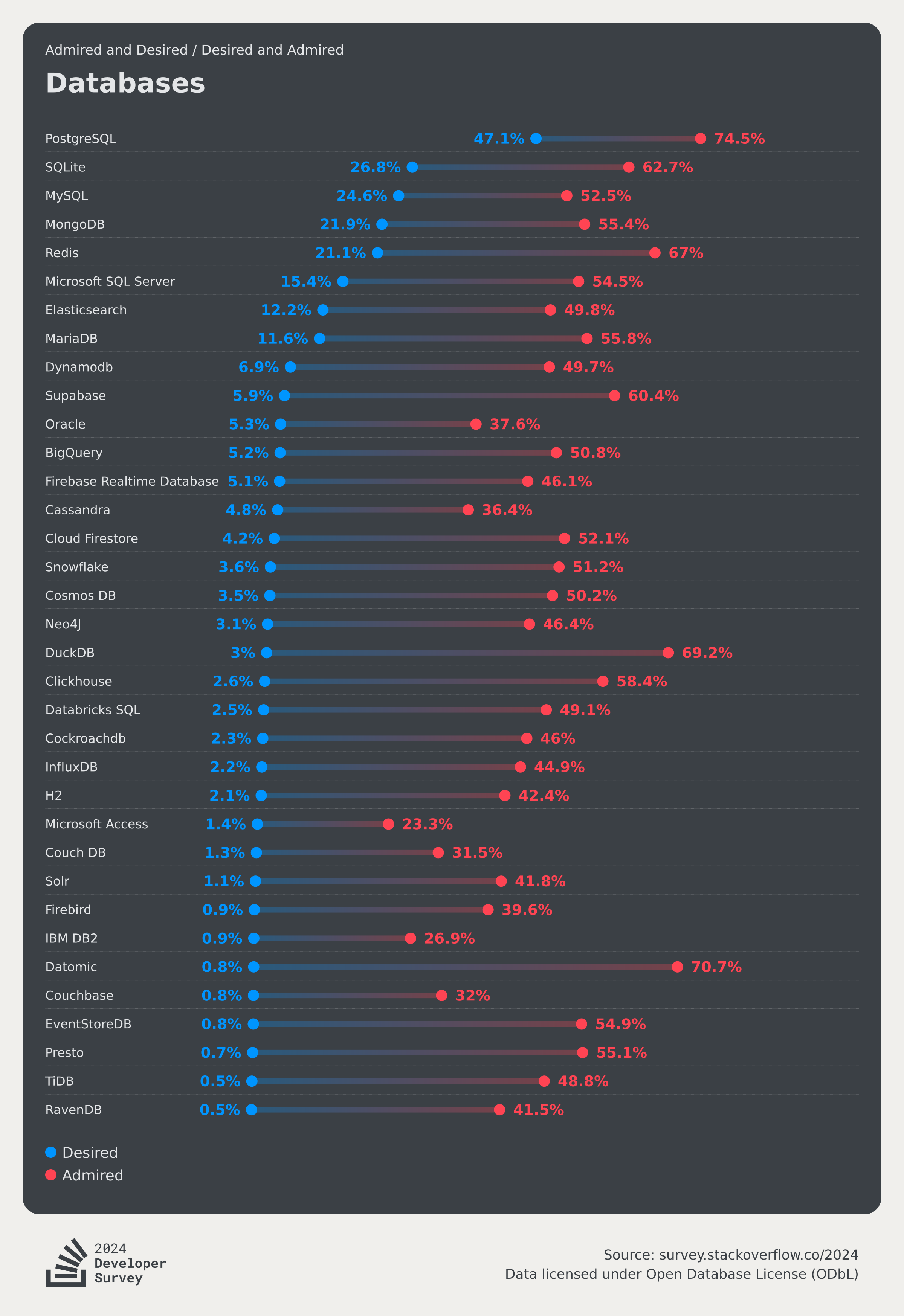
So-called “reputation” (the red dot)—Loved/Admired—tells us what percentage of current users would be happy to keep using the technology. It’s like an annual “retention rate” that captures the perception and valuation of a database, reflecting its future growth potential.
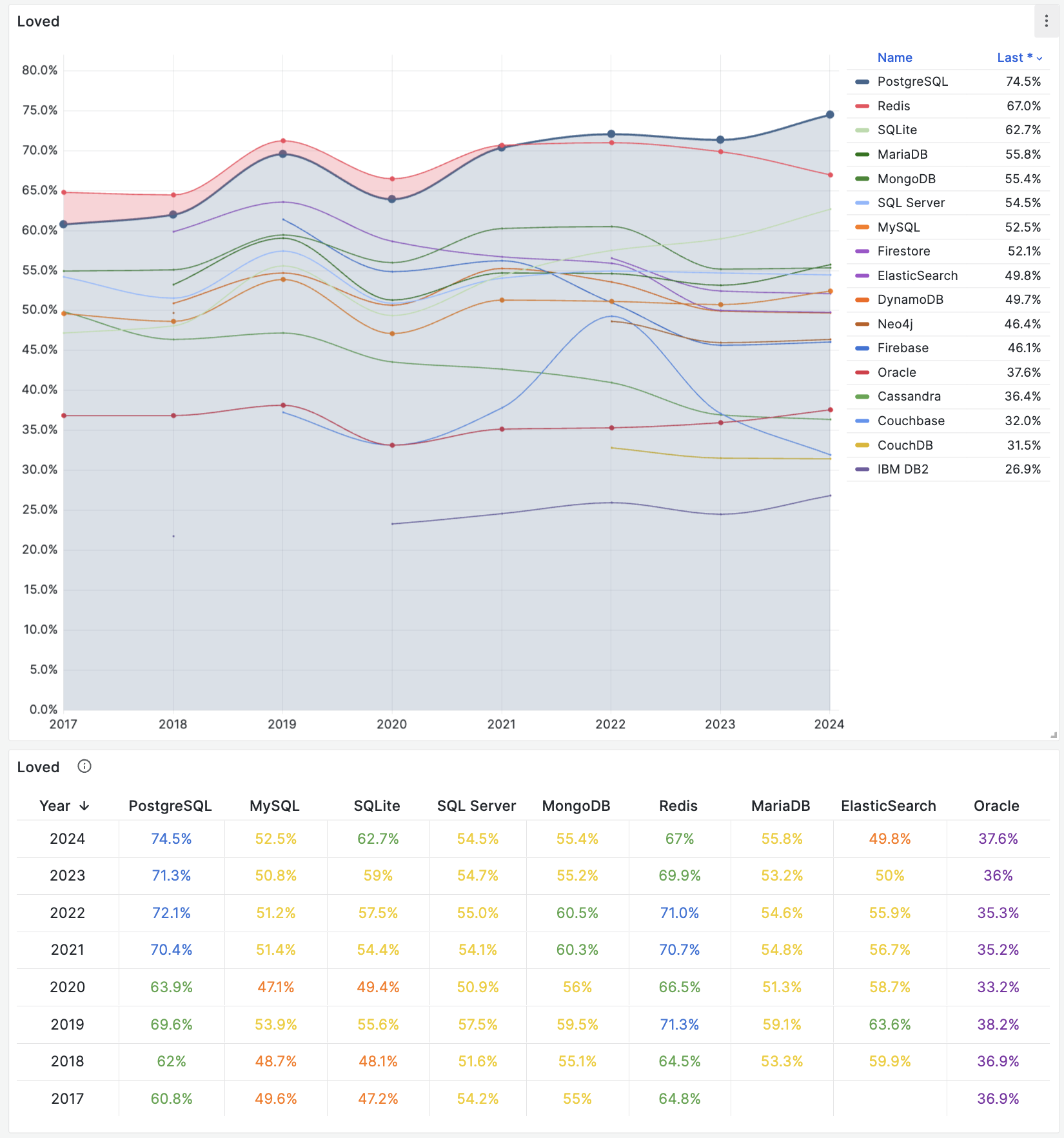
In terms of reputation, PostgreSQL remains at the top for the second consecutive year, with a 74.5% admiration rate. Two other databases worth noting are SQLite and DuckDB, both of which have seen a significant uptick in user admiration in the past year, while TiDB experienced a dramatic drop (from 64.33 down to 48.8).
The proportion of all respondents who say they want to use a given technology next year is the “Wanted” or “Desired” rate (the blue dot). This metric indicates how many plan to adopt that technology in the coming year, making it a solid predictor of near-future growth. Hence the survey ranks databases by this demand figure.
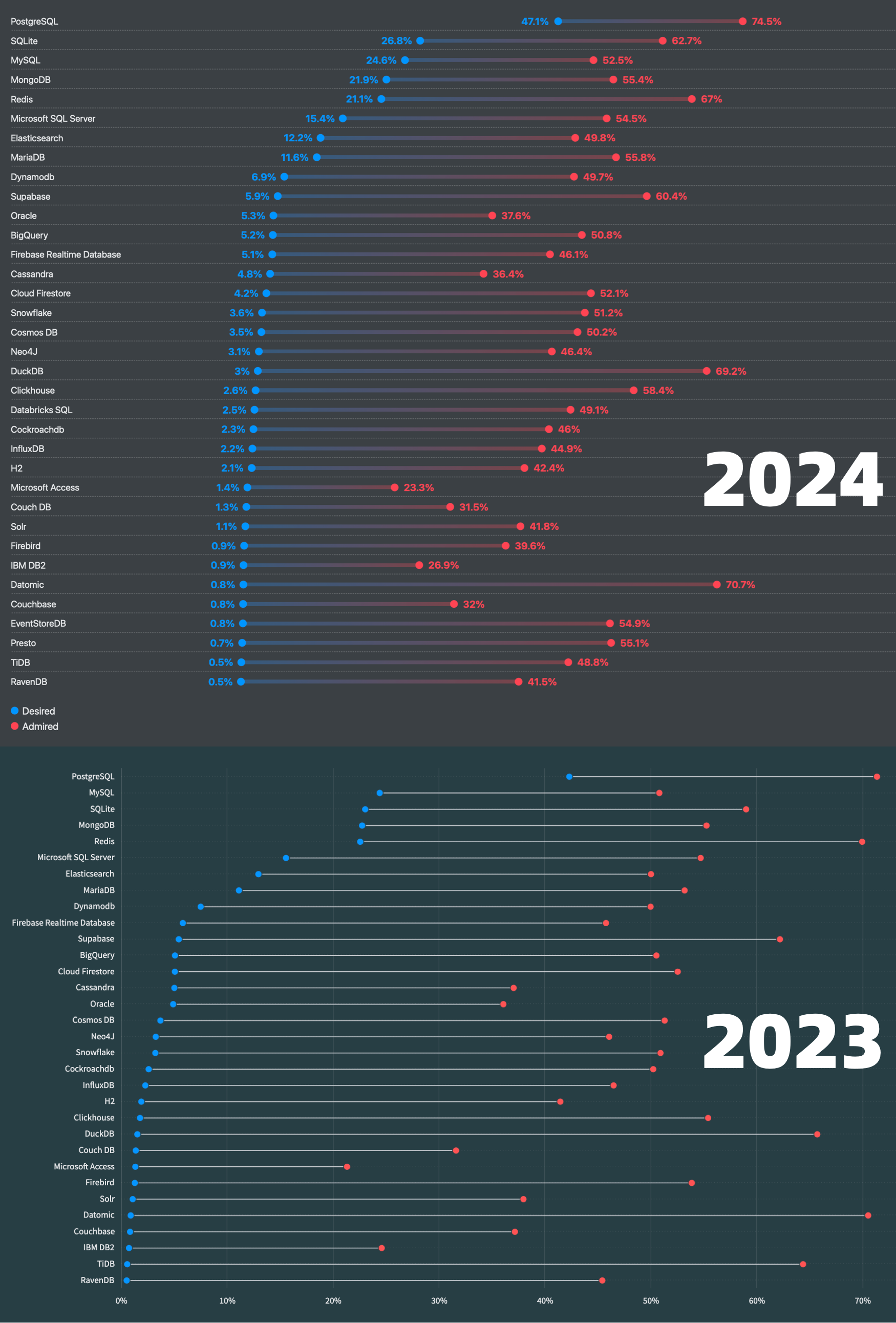
This is PostgreSQL’s third consecutive year at the top, now boasting a commanding lead over the runners-up. Perhaps driven by recent interest in vector databases, PostgreSQL’s demand has skyrocketed—from 19% in 2022 to 47% in 2024. By contrast, MySQL’s demand fell behind even SQLite, slipping from second place in 2023 to third this year.
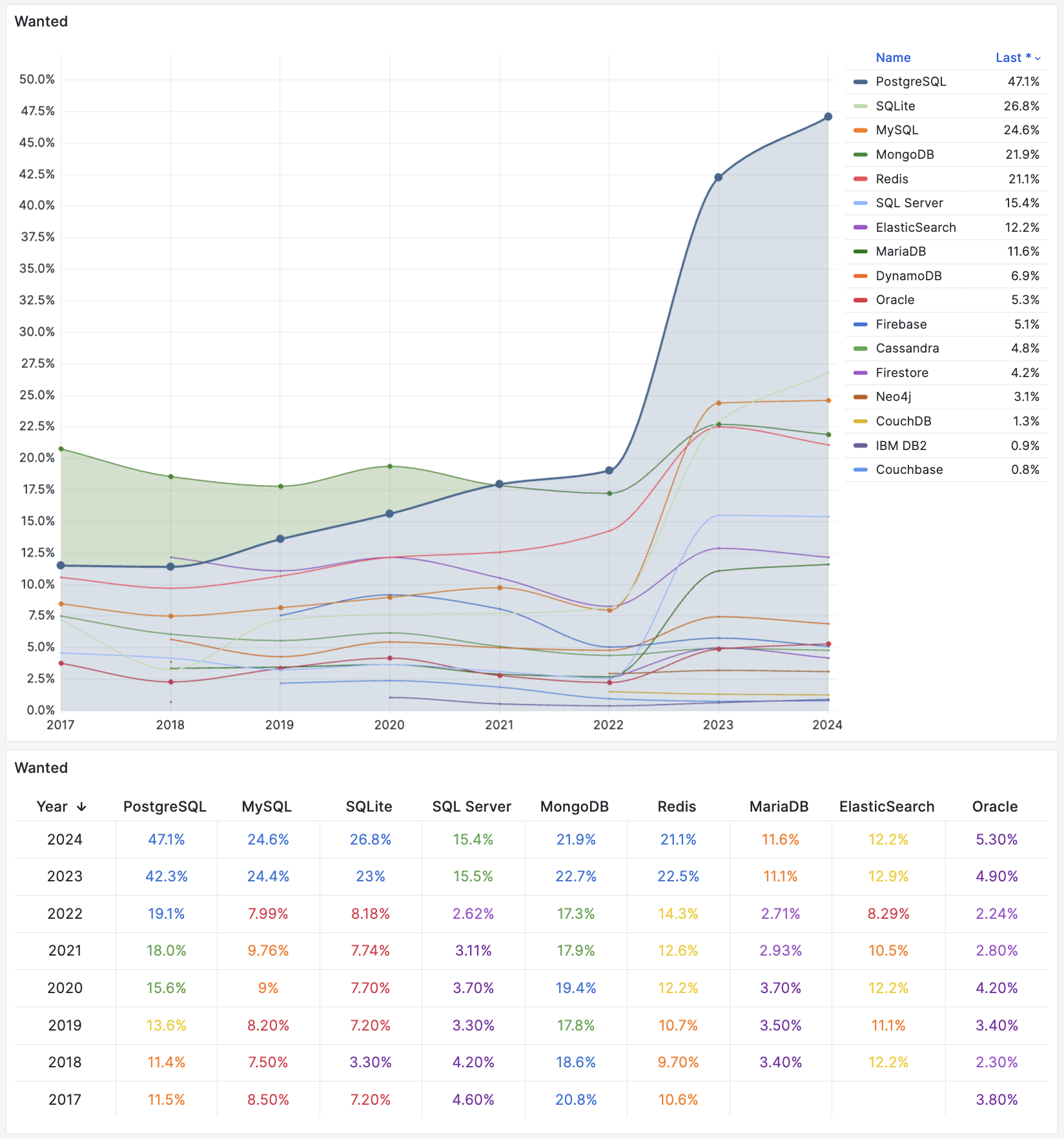
This demand metric—representing explicit statements like, “I plan to use this database next year”—accurately forecasts next year’s new adoption. That means this spike in demand for PostgreSQL will likely be reflected in higher popularity numbers next year.
Conclusion
For the second consecutive year, PostgreSQL has unequivocally staked its claim as the world’s most popular, most loved, and most in-demand database.
Looking at the eight-year trend and next year’s demand projections, it seems unlikely any rival will be able to topple PostgreSQL’s ascendancy.
MySQL, once PostgreSQL’s main competitor, clearly shows signs of decline, and other databases are feeling the pressure too. Those that continue to grow either avoid going head-to-head with PostgreSQL by occupying a different niche, or they’ve rebranded themselves into PostgreSQL-compatible or PostgreSQL-based solutions.
PostgreSQL is on track to become the Linux kernel of the database world, with the “PostgreSQL distribution wars” set to begin in earnest.
Self-Hosting Dify with PG, PGVector, and Pigsty
Dify – The Innovation Engine for GenAI Applications
Dify is an open-source LLM app development platform. Orchestrate LLM apps from agents to complex AI workflows, with an RAG engine. Which claims to be more production-ready than LangChain.
Of course, a workflow orchestration software like this needs a database underneath — Dify uses PostgreSQL for meta data storage, as well as Redis for caching and a dedicated vector database. You can pull the Docker images and play locally, but for production deployment, this setup won’t suffice — there’s no HA, backup, PITR, monitoring, and many other things.
Fortunately, Pigsty provides a battery-include production-grade highly available PostgreSQL cluster, along with the Redis and S3 (MinIO) capabilities that Dify needs, as well as Nginx to expose the Web service, making it the perfect companion for Dify.
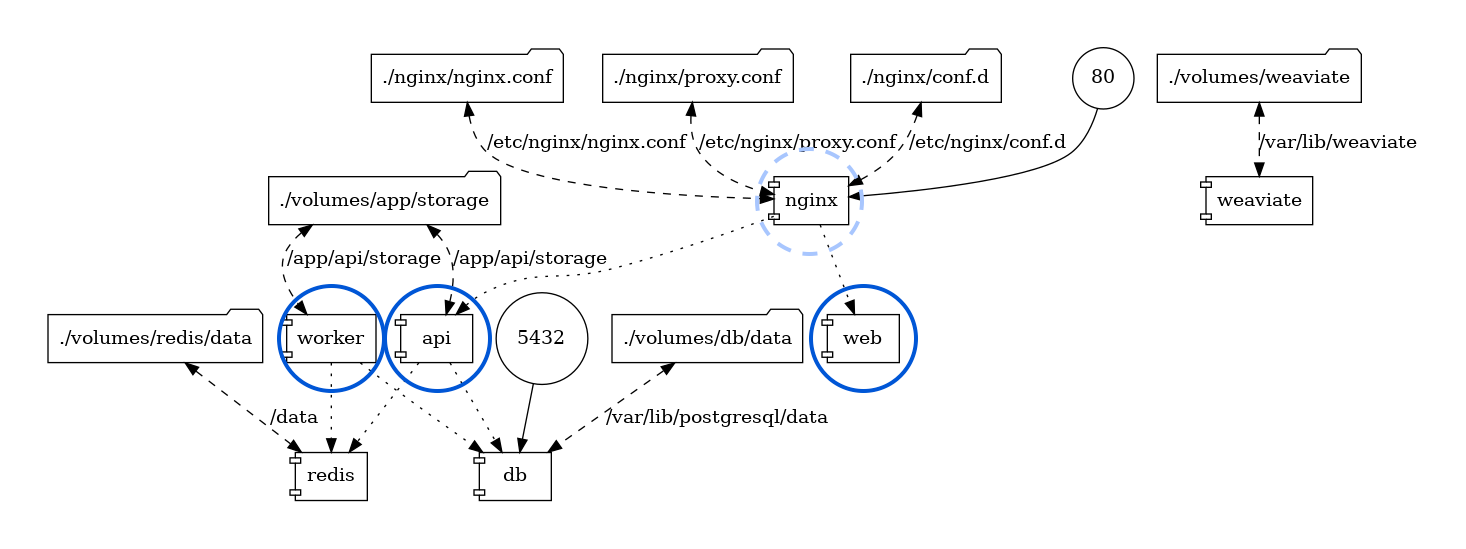
Off-load the stateful part to Pigsty, you only need to pull up the stateless blue circle part with a simple
docker compose up.
BTW, I have to criticize the design of the Dify template. Since the metadata is already stored in PostgreSQL, why not add pgvector to use it as a vector database? What’s even more baffling is that pgvector is a separate image and container. Why not just use a PG image with pgvector included?
Dify “supports” a bunch of flashy vector databases, but since PostgreSQL is already chosen, using pgvector as the default vector database is the natural choice. Similarly, I think the Dify team should consider removing Redis. Celery task queues can use PostgreSQL as backend storage, so having multiple databases is unnecessary. Entities should not be multiplied without necessity.
Therefore, the Pigsty-provided Dify Docker Compose template has made some adjustments to the official example. It removes the db and redis database images, using instances managed by Pigsty. The vector database is fixed to use pgvector, reusing the same PostgreSQL instance.
In the end, the architecture is simplified to three stateless containers: dify-api, dify-web, and dify-worker, which can be created and destroyed at will. There are also two optional containers, ssrf_proxy and nginx, for providing proxy and some security features.
There’s a bit of state management left with file system volumes, storing things like private keys. Regular backups are sufficient.
Reference:
Pigsty Preparation
Let’s take the single-node installation of Pigsty as an example. Suppose you have a machine with the IP address 10.10.10.10 and already pigsty installed.
We need to define the database clusters required in the Pigsty configuration file pigsty.yml.
Here, we define a cluster named pg-meta, which includes a superuser named dbuser_dify (the implementation is a bit rough as the Migration script executes CREATE EXTENSION which require dbsu privilege for now),
And there’s a database named dify with the pgvector extension installed, and a specific firewall rule allowing users to access the database from anywhere using a password (you can also restrict it to a more precise range, such as the Docker subnet 172.0.0.0/8).
Additionally, a standard single-instance Redis cluster redis-dify with the password redis.dify is defined.
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users: [ { name: dbuser_dify ,password: DBUser.Dify ,superuser: true ,pgbouncer: true ,roles: [ dbrole_admin ] } ]
pg_databases: [ { name: dify, owner: dbuser_dify, extensions: [ { name: pgvector } ] } ]
pg_hba_rules: [ { user: dbuser_dify , db: all ,addr: world ,auth: pwd ,title: 'allow dify user world pwd access' } ]
redis-dify:
hosts: { 10.10.10.10: { redis_node: 1 , redis_instances: { 6379: { } } } }
vars: { redis_cluster: redis-dify ,redis_password: 'redis.dify' ,redis_max_memory: 64MB }
For demonstration purposes, we use single-instance configurations. You can refer to the Pigsty documentation to deploy high availability PG and Redis clusters. After defining the clusters, use the following commands to create the PG and Redis clusters:
bin/pgsql-add pg-meta # create the dify database cluster
bin/redis-add redis-dify # create redis cluster
Alternatively, you can define a new business user and business database on an existing PostgreSQL cluster, such as pg-meta, and create them with the following commands:
bin/pgsql-user pg-meta dbuser_dify # create dify biz user
bin/pgsql-db pg-meta dify # create dify biz database
You should be able to access PostgreSQL and Redis with the following connection strings, adjusting the connection information as needed:
psql postgres://dbuser_dify:[email protected]:5432/dify -c 'SELECT 1'
redis-cli -u redis://[email protected]:6379/0 ping
Once you confirm these connection strings are working, you’re all set to start deploying Dify.
For demonstration purposes, we’re using direct IP connections. For a multi-node high availability PG cluster, please refer to the service access section.
The above assumes you are already a Pigsty user familiar with deploying PostgreSQL and Redis clusters. You can skip the next section and proceed to see how to configure Dify.
Starting from Scratch
If you’re already familiar with setting up Pigsty, feel free to skip this section.
Prepare a fresh Linux x86_64 node that runs compatible OS, then run as a sudo-able user:
curl -fsSL https://repo.pigsty.io/get | bash
It will download Pigsty source to your home, then perform configure and install to finish the installation.
cd ~/pigsty # get pigsty source and entering dir
./bootstrap # download bootstrap pkgs & ansible [optional]
./configure # pre-check and config templating [optional]
# change pigsty.yml, adding those cluster definitions above into all.children
./install.yml # install pigsty according to pigsty.yml
You should insert the above PostgreSQL cluster and Redis cluster definitions into the pigsty.yml file, then run install.yml to complete the installation.
Redis Deploy
Pigsty will not deploy redis in install.yml, so you have to run redis.yml playbook to install Redis explicitly:
./redis.yml
Docker Deploy
Pigsty will not deploy Docker by default, so you need to install Docker with the docker.yml playbook.
./docker.yml
Dify Confiugration
You can configure dify in the .env file:
All parameters are self-explanatory and filled in with default values that work directly in the Pigsty sandbox env. Fill in the database connection information according to your actual conf, consistent with the PG/Redis cluster configuration above.
Changing the SECRET_KEY field is recommended. You can generate a strong key with openssl rand -base64 42:
# meta parameter
DIFY_PORT=8001 # expose dify nginx service with port 8001 by default
LOG_LEVEL=INFO # The log level for the application. Supported values are `DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL`
SECRET_KEY=sk-9f73s3ljTXVcMT3Blb3ljTqtsKiGHXVcMT3BlbkFJLK7U # A secret key for signing and encryption, gen with `openssl rand -base64 42`
# postgres credential
PG_USERNAME=dbuser_dify
PG_PASSWORD=DBUser.Dify
PG_HOST=10.10.10.10
PG_PORT=5432
PG_DATABASE=dify
# redis credential
REDIS_HOST=10.10.10.10
REDIS_PORT=6379
REDIS_USERNAME=''
REDIS_PASSWORD=redis.dify
# minio/s3 [OPTIONAL] when STORAGE_TYPE=s3
STORAGE_TYPE=local
S3_ENDPOINT='https://sss.pigsty'
S3_BUCKET_NAME='infra'
S3_ACCESS_KEY='dba'
S3_SECRET_KEY='S3User.DBA'
S3_REGION='us-east-1'
Now we can pull up dify with docker compose:
cd pigsty/app/dify && make up
Expose Dify Service via Nginx
Dify expose web/api via its own nginx through port 80 by default, while pigsty uses port 80 for its own Nginx. T
herefore, we expose Dify via port 8001 by default, and use Pigsty’s Nginx to forward to this port.
Change infra_portal in pigsty.yml, with the new dify line:
infra_portal: # domain names and upstream servers
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus : { domain: p.pigsty ,endpoint: "${admin_ip}:9090" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9093" }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" }
dify : { domain: dify.pigsty ,endpoint: "10.10.10.10:8001", websocket: true }
Then expose dify web service via Pigsty’s Nginx server:
./infra.yml -t nginx
Don’t forget to add dify.pigsty to your DNS or local /etc/hosts / C:\Windows\System32\drivers\etc\hosts to access via domain name.
PGCon.Dev 2024, The conf that shutdown PG for a week
PGCon.Dev, once known as PGCon—the annual must-attend gathering for PostgreSQL hackers and key forum for its future direction, has been held in Ottawa since its inception in 2007.
This year marks a new chapter as the original organizer, Dan, hands over the reins to a new team, and the event moves to SFU’s Harbour Centre in Vancouver, kicking off a new era with grandeur.
How engaging was this event? Peter Eisentraut, member of the PostgreSQL core team, noted that during PGCon.Dev, there were no code commits to PostgreSQL – resulting in the longest pause in twenty years, a whopping week! a historic coding ceasefire! Why? Because all the developers were at the conference!
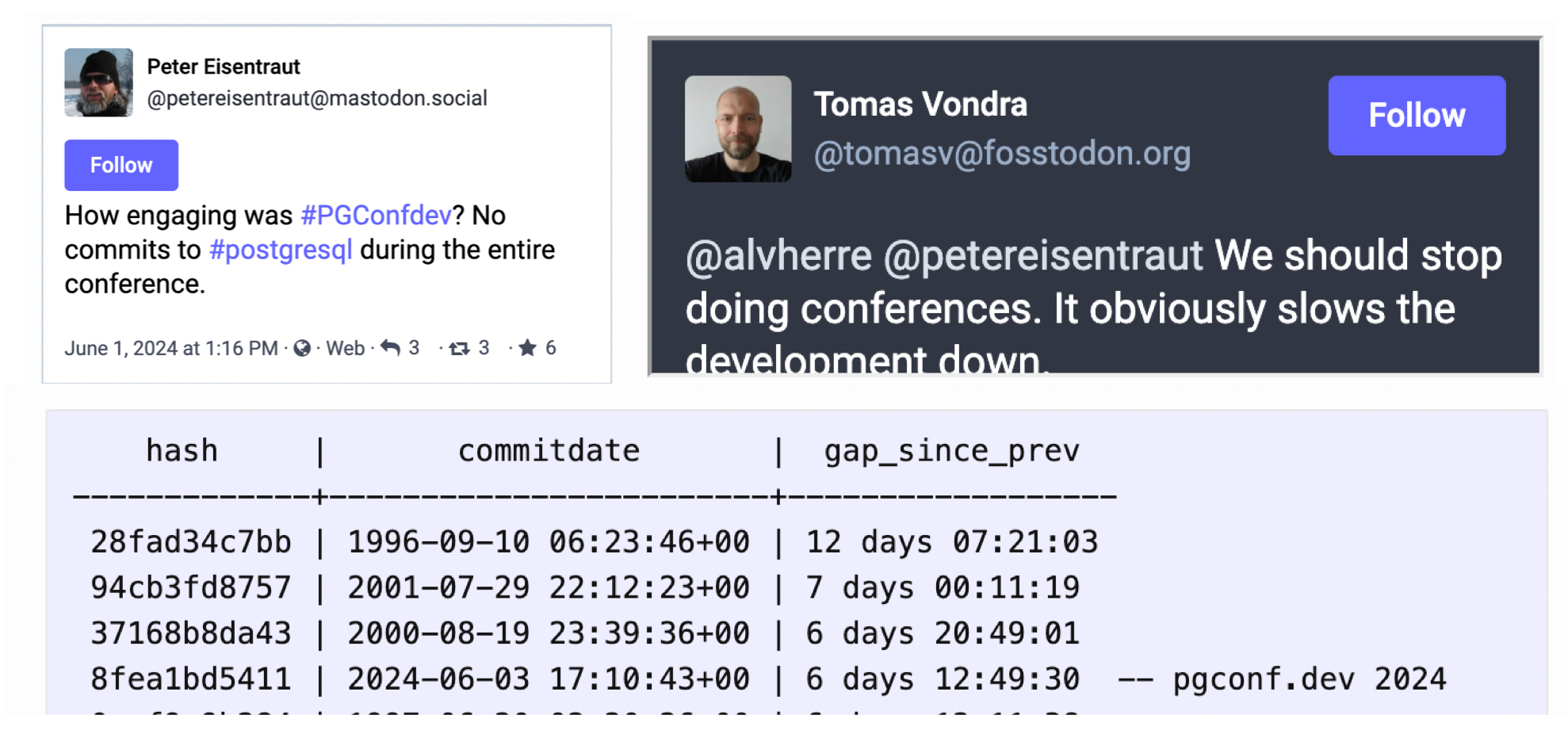
Considering the last few interruptions that occurred in the early days of the project twenty years ago,
I’ve been embracing PostgreSQL for a decade, but attending a global PG Hacker conference in person was a first for me, and I’m immensely grateful for the organizer’s efforts. PGCon.Dev 2024 wrapped up on May 31st, though this post comes a bit delayed as I’ve been exploring Vancouver and Banff National Park ;)
Day Zero: Extension Summit
Day zero is for leadership meetings, and I’ve signed up for the afternoon’s Extension Ecosystem Summit.
Maybe this summit is somewhat subtly related to my recent post, “Postgres is eating the database world,” highlighting PostgreSQL’s thriving extension ecosystem as a unique and critical success factor and drawing the community’s attention.
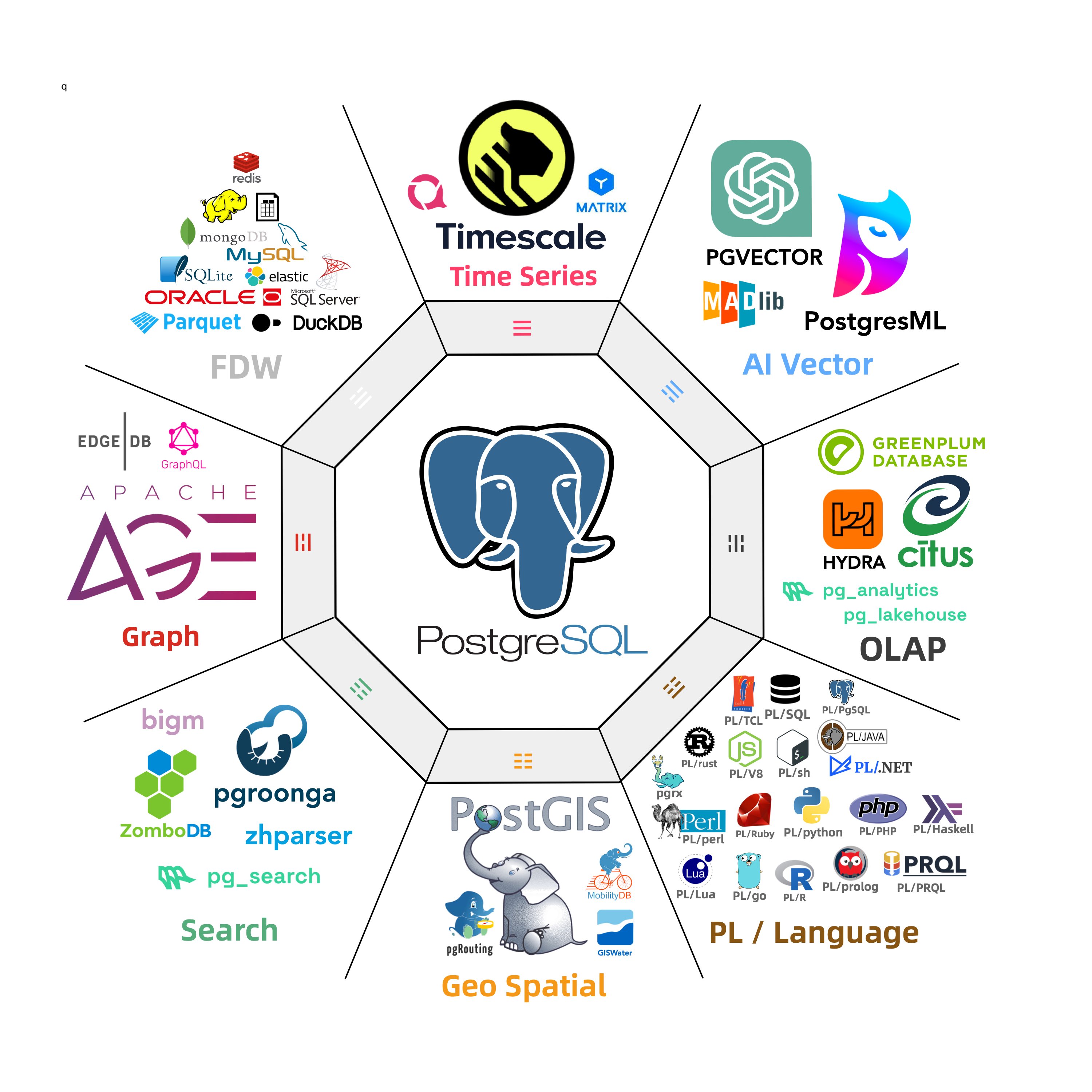
I participated in David Wheeler’s Binary Packing session along with other PostgreSQL community leaders. Despite some hesitation to new standards like PGXN v2 from current RPM/APT maintainers. In the latter half of the summit, I attended a session led by Yurii Rashkovskii, discussing extension directory structures, metadata, naming conflicts, version control, and binary distribution ideas.
Prior to this summit, the PostgreSQL community had held six mini-summits discussing these topics intensely, with visions for the extension ecosystem’s future development shared by various speakers. Recordings of these sessions are available on YouTube.
And after the summit, I had a chance to chat with Devrim, the RPM maintainer, about extension packing, which was quite enlightening.

“Keith Fan Group” – from Devrim on Extension Summit
Day One: Brilliant Talks and Bar Social
The core of PGCon.Dev lies in its sessions. Unlike some China domestic conferences with mundane product pitches or irrelevant tech details, PGCon.Dev presentations are genuinely engaging and substantive. The official program kicked off on May 29th, after a day of closed-door leadership meetings and the Ecosystem Summit on the 28th.
The opening was co-hosted by Jonathan Katz, 1 of the 7 core PostgreSQL team members and a chief product manager at AWS RDS, and Melanie Plageman, a recent PG committer from Microsoft. A highlight was when Andres Freund, the developer who uncovered the famous xz backdoor, was celebrated as a superhero on stage.

Following the opening, the regular session tracks began. Although conference videos aren’t out yet, I’m confident they’ll “soon” be available on YouTube. Most sessions had three tracks running simultaneously; here are some highlights I chose to attend.
Pushing the Boundaries of PG Extensions
Yurii’s talk, “Pushing the Boundaries of PG Extensions,” tackled what kind of extension APIs PostgreSQL should offer. PostgreSQL boasts robust extensibility, but the current extension API set is decades old, from the 9.x era. Yurii’s proposal aims to address issues with the existing extension mechanisms. Challenges such as installing multiple versions of an extension simultaneously, avoiding database restarts post-extension installations, managing extensions as seamlessly as data, and handling dependencies among extensions were discussed.
Yurii and Viggy, founders of Omnigres, aim to transform PostgreSQL into a full-fledged application development platform, including hosting HTTP servers directly within the database. They designed a new extension API and management system for PostgreSQL to achieve this. Their innovative improvements represent the forefront of exploration into PostgreSQL’s core extension mechanisms.
I had a great conversation with Viggy and Yurii. Yurii walked me through compiling and installing Omni. I plan to support the Omni extension series in the next version of Pigsty, making this powerful application development framework plug-and-play.
Anarchy in DBMS
Abigale Kim from CMU, under the mentorship of celebrity professor Andy Pavlo, delivered the talk “Anarchy in the Database—A Survey and Evaluation of DBMS Extensibility.” This topic intrigued me since Pigsty’s primary value proposition is about PostgreSQL’s extensibility.
Kim’s research revealed interesting insights: PostgreSQL is the most extensible DBMS, supporting 9 out of 10 extensibility points, closely followed by DuckDB. With over 375+ available extensions, PostgreSQL significantly outpaces other databases.

Kim’s quantitative analysis of compatibility levels among these extensions resulted in a compatibility matrix, unveiling conflicts—most notably, powerful extensions like TimescaleDB and Citus are prone to clashes. This information is very valuable for users and distribution maintainers. Read the detailed study.
I joked with Kim that — now I could brag about PostgreSQL’s extensibility with her research data.
How PostgreSQL is Misused and Abused
The first-afternoon session featured Karen Jex from CrunchyData, an unusual perspective from a user — and a female DBA. Karen shared common blunders by PostgreSQL beginners. While I knew all of what was discussed, it reaffirmed that beginners worldwide make similar mistakes — an enlightening perspective for PG Hackers, who found the session quite engaging.
PostgreSQL and the AI Ecosystem
The second-afternoon session by Bruce Momjian, co-founder of the PGDG and a core committee member from the start, was unexpectedly about using PostgreSQL’s multi-dimensional arrays and queries to implement neural network inference and training.

Haha, some ArgParser code. I see it
During the lunch, Bruce explained that Jonathan Katz needed a topic to introduce the vector database extension PGVector in the PostgreSQL ecosystem, so Bruce was roped in to “fill the gap.” Check out Bruce’s presentation.
PB-Level PostgreSQL Deployments
The third afternoon session by Chris Travers discussed their transition from using ElasticSearch for data storage—with a poor experience and high maintenance for 1PB over 30 days retention, to a horizontally scaled PostgreSQL cluster perfectly handling 10PB of data. Normally, PostgreSQL comfort levels on a single machine range from several dozen to a few hundred TB. Deployments at the PB scale, especially at 10PB, even within a horizontally scaled cluster, are exceptionally rare. While the practice itself is standard—partitioning and sharding—the scale of data managed is truly impressive.
Highlight: When Hardware and Database Collide
Undoubtedly, the standout presentation of the event, Margo Seltzer’s talk “When Hardware and Database Collide” was not only the most passionate and compelling talk I’ve attended live but also a highlight across all conferences.
Professor Margo Seltzer, formerly of Harvard and now at UBC, a member of the National Academy of Engineering and the creator of BerkeleyDB, delivered a powerful discourse on the core challenges facing databases today. She pinpointed that the bottleneck for databases has shifted from disk I/O to main memory speed. Emerging hardware technologies like HBM and CXL could be the solution, posing new challenges for PostgreSQL hackers to tackle.

This was a refreshing divergence from China’s typically monotonous academic talks, leaving a profound impact and inspiration. Once the conference video is released, I highly recommend checking out her energizing presentation.
WetBar Social
Following Margo’s session, the official Social Event took place at Rogue Kitchen & Wetbar, just a street away from the venue at Waterfront Station, boasting views of the Pacific and iconic Vancouver landmarks.
The informal setting was perfect for engaging with new and old peers. Conversations with notable figures like Devrim, Tomasz, Yurii, and Keith were particularly enriching. As an RPM maintainer, I had an extensive and fruitful discussion with Devrim, resolving many longstanding queries.

The atmosphere was warm and familiar, with many reconnecting after long periods. A couple of beers in, conversations flowed even more freely among fellow PostgreSQL enthusiasts. The event concluded with an invitation from Melanie for a board game session, which I regretfully declined due to my limited English in such interactive settings.
Day 2: Debate, Lunch, and Lighting Talks
Multi-Threading Postgres
The warmth from the previous night’s socializing carried over into the next day, marked by the eagerly anticipated session on “Multi-threaded PostgreSQL,” which was packed to capacity. The discussion, initiated by Heikki, centered on the pros and cons of PostgreSQL’s process and threading models, along with detailed implementation plans and current progress.
The threading model promises numerous benefits: cheaper connections (akin to a built-in connection pool), shared relation and plan caches, dynamic adjustment of shared memory, config changes without restarts, more aggressive Vacuum operations, runtime Explain Analyze, and easier memory usage limits per connection. However, there’s significant opposition, maybe led by Tom Lane, concerned about potential bugs, loss of isolation benefits from the multi-process model, and extensive incompatibilities requiring many extensions to be rewritten.

Heikki laid out a detailed plan to transition to the threading model over five to seven years, aiming for a seamless shift without intermediate states. Intriguingly, he cited Tom Lane’s critical comment in his presentation:
For the record, I think this will be a disaster. There is far too much code that will get broken, largely silently, and much of it is not under our control. – regards, tom lane
Although Tom Lane smiled benignly without voicing any objections, the strongest dissent at the conference came not from him but from an extension maintainer. The elder developer, who maintained several extensions, raised concerns about compatibility, specifically regarding memory allocation and usage. Heikki suggested that extension authors should adapt their work to a new model during a transition grace period of about five years. This suggestion visibly upset the maintainer, who left the meeting in anger.
Given the proposed threading model’s significant impact on the existing extension ecosystem, I’m skeptical about this change. At the conference, I consulted on the threading model with Heikki, Tom Lane, and other hackers. The community’s overall stance is one of curious & cautious observation. So far, the only progress is in PG 17, where the fork-exec-related code has been refactored and global variables marked for future modifications. Any real implementation would likely not occur until at least PG 20+.
Hallway Track
The sessions on the second day were slightly less intense than the first, so many attendees chose the “Hallway Track”—engaging in conversations in the corridors and lobby. I’m usually not great at networking as an introvert, but the vibrant atmosphere quickly drew me in. Eye contact alone was enough to spark conversations, like triggering NPC dialogue in an RPG. I also managed to subtly promote Pigsty to every corner of the PG community.

Despite being a first-timer at PGCon.Dev, I was surprised by the recognition and attention I received, largely thanks to the widely read article, “PostgreSQL is eating the Database world.” Many recognized me by my badge Vonng / Pigsty.
A simple yet effective networking trick is never to underestimate small gifts’ effect. I handed out gold-plated Slonik pins, PostgreSQL’s mascot, which became a coveted item at the conference. Everyone who talked with me received one, and those who didn’t have one were left asking where to get one. LOL

Anyway, I’m glad to have made many new friends and connections.
Multinational Community Lunch
As for lunch, HighGo hosted key participants from the American, European, Japanese, and Chinese PostgreSQL communities at a Cantonese restaurant in Vancouver. The conversation ranged from serious technical discussions to lighter topics. I’ve made acquaintance with Tatsuro Yamada, who gives a talk, “Advice is seldom welcome but efficacious”, and Kyotaro Horiguchi, a core contributor to PostgreSQL known for his work on WAL replication and multibyte string processing and the author of pg_hint_plan.

Another major contributor to the PostgreSQL community, Mark Wong organizes PGUS and has developed a series of PostgreSQL monitoring extensions. He also manages community merchandise like contributor coins, shirts, and stickers. He even handcrafted a charming yarn elephant mascot, which was so beloved that one was sneakily “borrowed” at the last PG Conf US.

Bruce, already a familiar face in the PG Chinese community, Andreas Scherbaum from Germany, organizer of the European PG conferences, and Miao Jian, founder of Han Gao, representing the only Chinese database company at PGCon.Dev, all shared insightful stories and discussions about the challenges and nuances of developing databases in their respective regions.
On returning to the conference venue, I had a conversation with Jan Wieck, a PostgreSQL Hackers Emeritus. He shared his story of participating in the PostgreSQL project from the early days and encouraged me to get more involved in the PostgreSQL community, reminding me its future depends on the younger generation.
Making PG Hacking More Inclusive
At PGCon.Dev, a special session on community building chaired by Robert Hass, featured three new PostgreSQL contributors sharing their journey and challenges, notably the barriers for non-native English speakers, timezone differences, and emotionally charged email communications.
Robert emphasized in a post-conference blog his desire to see more developers from India and Japan rise to senior positions within PostgreSQL’s ranks, noting the underrepresentation from these countries despite their significant developer communities.
While we’re at it, I’d really like to see more people from India and Japan in senior positions within the project. We have very large developer communities from both countries, but there is no one from either of those countries on the core team, and they’re also underrepresented in other senior positions. At the risk of picking specific examples to illustrate a general point, there is no one from either country on the infrastructure team or the code of conduct committee. We do have a few committers from those countries, which is very good, and I was pleased to see Amit Kapila on the 2024.pgconf.dev organizing commitee, but, overall, I think we are still not where we should be. Part of getting people involved is making them feel like they are not alone, and part of it is also making them feel like progression is possible. Let’s try harder to do that.
Frankly, the lack of mention of China in discussions about inclusivity at PGCon.Dev, in favor of India and Japan, left a bittersweet taste. But I think China deserves the snub, given its poor international community engagement.
China has hundreds of “domestic/national” databases, many mere forks of PostgreSQL, yet there’s only a single notable Chinese contributor to PostgreSQL is Richard Guo from PieCloudDB, recently promoted to PG Committer. At the conference, the Chinese presence was minimal, summing up to five attendees, including myself. It’s regrettable that China’s understanding and adoption of PostgreSQL lag behind the global standard by about 10-15 years.
I hope my involvement can bootstrap and enhance Chinese participation in the global PostgreSQL ecosystem, making their users, developers, products, and open-source projects more recognized and accepted worldwide.
Lightning Talks
Yesterday’s event closed with a series of lightning talks—5 minutes max per speaker, or you’re out. Concise and punchy, the session wrapped up 11 topics in just 45 minutes. Keith shared improvements to PG Monitor, and Peter Eisentraut discussed SQL standard updates. But from my perspective, the highlight was Devrim Gündüz’s talk on PG RPMs, which lived up to his promise of a “big reveal” made at the bar the previous night, packing a 75-slide presentation into 5 lively minutes.

Speaking of PostgreSQL, despite being open-source, most users rely on official pre-compiled binaries packages rather than building from source. I maintain 34 RPM extensions for Pigsty, my Postgres distribution, but much of the ecosystem, including over a hundred other extensions, is managed by Devrim from the official PGDG repo. His efforts ensure quality for the world’s most advanced and popular database.
Devrim is a fascinating character — a Turkish native living in London, a part-time DJ, and the maintainer of the PGDG RPM repository, sporting a PostgreSQL logo tattoo. After an engaging chat about the PGDG repository, he shared insights on how extensions are added, highlighting the community-driven nature of PGXN and recent popular additions like pgvector, (which I made the suggestion haha).
Interestingly, with the latest Pigsty v2.7 release, four of my maintained (packaging) extensions (pgsql-http, pgsql-gzip, pg_net, pg_bigm) were adopted into the PGDG official repository. Devrim admitted to scouring Pigsty’s extension list for good picks, though he humorously dismissed any hopes for my Rust pgrx extensions making the cut, reaffirming his commitment to not blending Go and Rust plugins into the official repository. Our conversation was so enriching that I’ve committed myself to becoming a “PG Extension Hunter,” scouting and recommending new plugins for official inclusion.
Day 3: Unconference
One of the highlights of PGCon.Dev is the Unconference, a self-organized meeting with no predefined agenda, driven by attendee-proposed topics. On day three, Joseph Conway facilitated the session where anyone could pitch topics for discussion, which were then voted on by participants. My proposal for a Built-in Prometheus Metrics Exporter was merged into a broader Observability topic spearheaded by Jeremy.

The top-voted topics were Multithreading (42 votes), Observability (35 votes), and Enhanced Community Engagement (35 votes). Observability features were a major focus, reflecting the community’s priority. I proposed integrating a contrib monitoring extension in PostgreSQL to directly expose metrics via HTTP endpoint, using pg_exporter as a blueprint but embedded to overcome the limitations of external components, especially during crash recovery scenarios.

There’s a clear focus on observability among the community. As the author of pg_exporter, I proposed developing a first-party monitoring extension. This extension would integrate Prometheus monitoring endpoints directly into PostgreSQL, exposing metrics via HTTP without needing external components.
The rationale for this proposal is straightforward. While pg_exporter works well, it’s an external component that adds management complexity. Additionally, in scenarios where PostgreSQL is recovering from a crash and cannot accept new connections, external tools struggle to access internal states. An in-kernel extension could seamlessly capture this information.
The suggested implementation involves a background worker process similar to the bgw_replstatus extension. This process would listen on an additional port to expose monitoring metrics through HTTP, using pg_exporter as a blueprint. Metrics would primarily be defined via a Collector configuration table, except for a few critical system indicators.
This idea garnered attention from several PostgreSQL hackers at the event. Developers from EDB and CloudNativePG are evaluating whether pg_exporter could be directly integrated into their distributions as part of their monitoring solutions. And finally, an Observability Special Interest Group (SIG) was formed by attendees interested in observability, planning to continue discussions through a mailing list.
Issue: Support for LoongArch Architecture
During the last two days, I have had some discussions with PG Hackers about some Chinese-specific issues.
A notable suggestion was supporting the LoongArch architecture in the PGDG global repository, which was backed by some enthusiastically local chip and OS manufacturers. Despite the interest, Devrim indicated a “No” due to the lack of support for LoongArch in OS Distro used in the PG community, like CentOS 7, Rocky 8/9, and Debian 10/11/12. Tomasz Rybak was more receptive, noting potential future support if LoongArch runs on Debian 13.
In summary, official PG RPMs might not yet support LoongArch, but APT has a chance, contingent on broader OS support for mainstream open-source Linux distributions.
Issue: Server-side Chinese Character Encoding
At the recent conference, Jeremy Schneider presented an insightful talk on collation rules that resonated with me. He highlighted the pitfalls of not using C.UTF8 for collation, a practice I’ve advocated for based on my own research, and which is detailed in his presentation here.
Post-talk, I discussed further with Jeremy and Peter Eisentraut the nuances of character sets in China, especially the challenges posed by the mandatory GB18030 standard, which PostgreSQL can handle on the client side but not the server side. Also, there are some issues about 20 Chinese characters not working on the convert_to + gb18030 encoding mapping.
Closing
The event closed with Jonathan Katz and Melanie Plageman wrapping up an exceptional conference that leaves us looking forward to next year’s PGCon.Dev 2025 in Canada, possibly in Vancouver, Toronto, Ottawa, or Montreal.

Inspired by the engagement at this conference, I’m considering presenting on Pigsty or PostgreSQL observability next year.
Notably, following the conference, Pigsty’s international CDN traffic spiked significantly, highlighting the growing global reach of our PostgreSQL distribution, which really made my day.
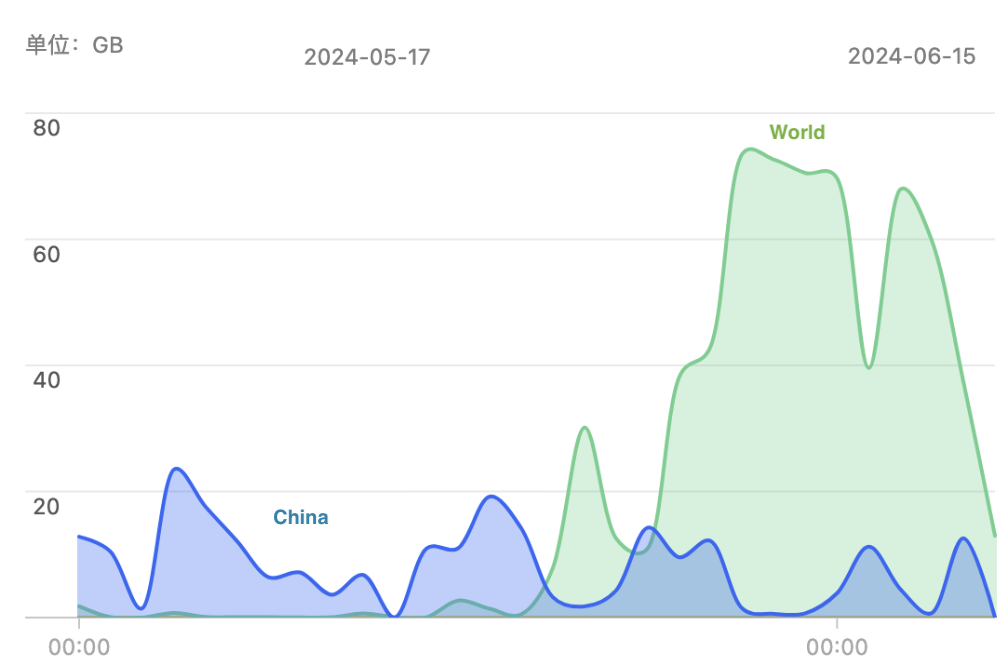
Pigsty CDN Traffic Growth after PGCon.Dev 2024
Some slides are available on the official site, and some blog posts about PGCon are here.Dev 2024:
Postgres is eating the database world
PostgreSQL isn’t just a simple relational database; it’s a data management framework with the potential to engulf the entire database realm. The trend of “Using Postgres for Everything” is no longer limited to a few elite teams but is becoming a mainstream best practice.
OLAP’s New Challenger
In a 2016 database meetup, I argued that a significant gap in the PostgreSQL ecosystem was the lack of a sufficiently good columnar storage engine for OLAP workloads. While PostgreSQL itself offers lots of analysis features, its performance in full-scale analysis on larger datasets doesn’t quite measure up to dedicated real-time data warehouses.
Consider ClickBench, an analytics performance benchmark, where we’ve documented the performance of PostgreSQL, its ecosystem extensions, and derivative databases. The untuned PostgreSQL performs poorly (x1050), but it can reach (x47) with optimization. Additionally, there are three analysis-related extensions: columnar store Hydra (x42), time-series TimescaleDB (x103), and distributed Citus (x262).
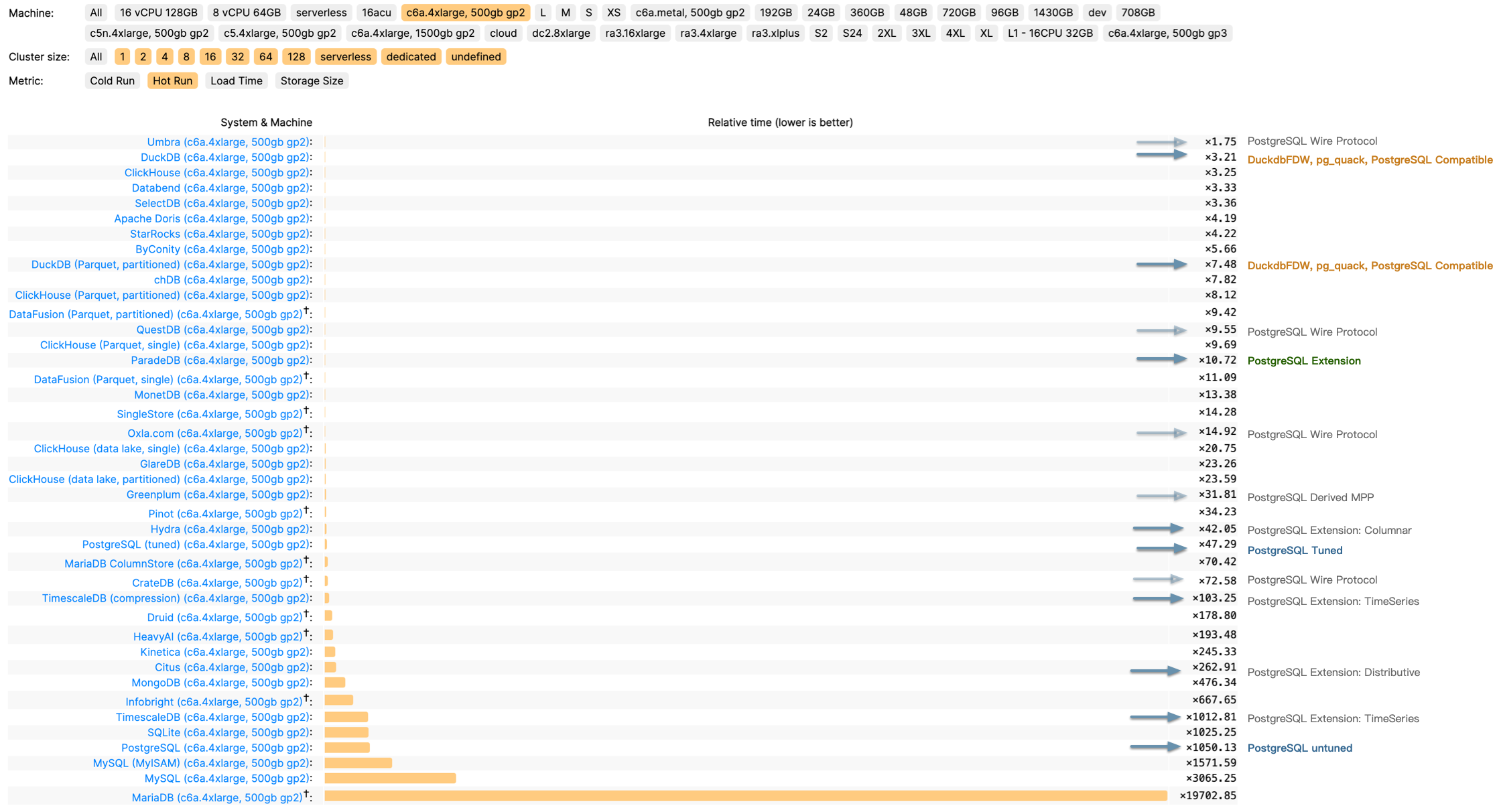
ClickBench c6a.4xlarge, 500gb gp2 results in relative time
This performance can’t be considered bad, especially compared to pure OLTP databases like MySQL and MariaDB (x3065, x19700); however, its third-tier performance is not “good enough,” lagging behind the first-tier OLAP components like Umbra, ClickHouse, Databend, SelectDB (x3~x4) by an order of magnitude. It’s a tough spot - not satisfying enough to use, but too good to discard.
However, the arrival of ParadeDB and DuckDB changed the game!
ParadeDB’s native PG extension pg_analytics achieves second-tier performance (x10), narrowing the gap to the top tier to just 3–4x. Given the additional benefits, this level of performance discrepancy is often acceptable - ACID, freshness and real-time data without ETL, no additional learning curve, no maintenance of separate services, not to mention its ElasticSearch grade full-text search capabilities.
DuckDB focuses on pure OLAP, pushing analysis performance to the extreme (x3.2) — excluding the academically focused, closed-source database Umbra, DuckDB is arguably the fastest for practical OLAP performance. It’s not a PG extension, but PostgreSQL can fully leverage DuckDB’s analysis performance boost as an embedded file database through projects like DuckDB FDW and pg_quack.
The emergence of ParadeDB and DuckDB propels PostgreSQL’s analysis capabilities to the top tier of OLAP, filling the last crucial gap in its analytic performance.
The Pendulum of Database Realm
The distinction between OLTP and OLAP didn’t exist at the inception of databases. The separation of OLAP data warehouses from databases emerged in the 1990s due to traditional OLTP databases struggling to support analytics scenarios’ query patterns and performance demands.
For a long time, best practice in data processing involved using MySQL/PostgreSQL for OLTP workloads and syncing data to specialized OLAP systems like Greenplum, ClickHouse, Doris, Snowflake, etc., through ETL processes.
DDIA, Martin Kleppmann, ch3, The republic of OLTP & Kingdom of OLAP
Like many “specialized databases,” the strength of dedicated OLAP systems often lies in performance — achieving 1-3 orders of magnitude improvement over native PG or MySQL. The cost, however, is redundant data, excessive data movement, lack of agreement on data values among distributed components, extra labor expense for specialized skills, extra licensing costs, limited query language power, programmability and extensibility, limited tool integration, poor data integrity and availability compared with a complete DMBS.
However, as the saying goes, “What goes around comes around”. With hardware improving over thirty years following Moore’s Law, performance has increased exponentially while costs have plummeted. In 2024, a single x86 machine can have hundreds of cores (512 vCPU EPYC 9754x2), several TBs of RAM, a single NVMe SSD can hold up to 64TB, and a single all-flash rack can reach 2PB; object storage like S3 offers virtually unlimited storage.
Hardware advancements have solved the data volume and performance issue, while database software developments (PostgreSQL, ParadeDB, DuckDB) have addressed access method challenges. This puts the fundamental assumptions of the analytics sector — the so-called “big data” industry — under scrutiny.
As DuckDB’s manifesto "Big Data is Dead" suggests, the era of big data is over. Most people don’t have that much data, and most data is seldom queried. The frontier of big data recedes as hardware and software evolve, rendering “big data” unnecessary for 99% of scenarios.
If 99% of use cases can now be handled on a single machine with standalone DuckDB or PostgreSQL (and its replicas), what’s the point of using dedicated analytics components? If every smartphone can send and receive texts freely, what’s the point of pagers? (With the caveat that North American hospitals still use pagers, indicating that maybe less than 1% of scenarios might genuinely need “big data.”)
The shift in fundamental assumptions is steering the database world from a phase of diversification back to convergence, from a big bang to a mass extinction. In this process, a new era of unified, multi-modeled, super-converged databases will emerge, reuniting OLTP and OLAP. But who will lead this monumental task of reconsolidating the database field?
PostgreSQL: The Database World Eater
There are a plethora of niches in the database realm: time-series, geospatial, document, search, graph, vector databases, message queues, and object databases. PostgreSQL makes its presence felt across all these domains.
A case in point is the PostGIS extension, which sets the de facto standard in geospatial databases; the TimescaleDB extension awkwardly positions “generic” time-series databases; and the vector extension, PGVector, turns the dedicated vector database niche into a punchline.
This isn’t the first time; we’re witnessing it again in the oldest and largest subdomain: OLAP analytics. But PostgreSQL’s ambition doesn’t stop at OLAP; it’s eyeing the entire database world!
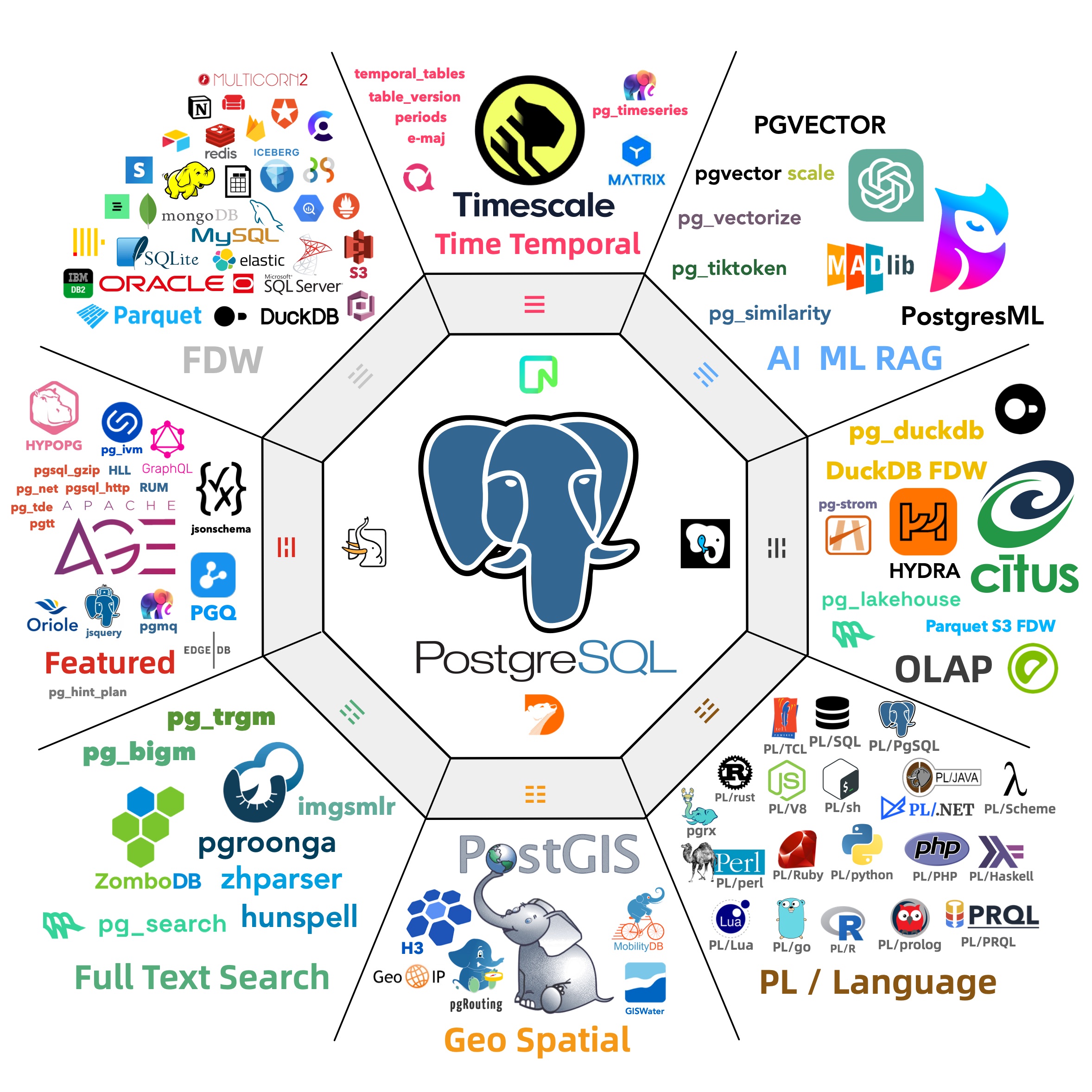
What makes PostgreSQL so capable? Sure, it’s advanced, but so is Oracle; it’s open-source, as is MySQL. PostgreSQL’s edge comes from being both advanced and open-source, allowing it to compete with Oracle/MySQL. But its true uniqueness lies in its extreme extensibility and thriving extension ecosystem.
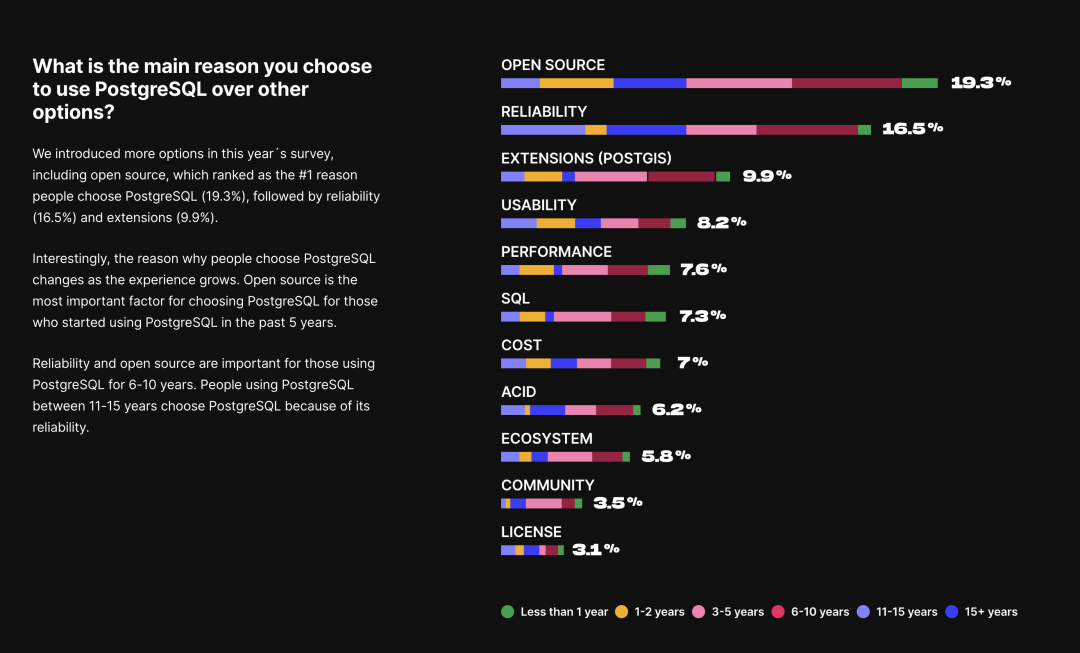
TimescaleDB survey: what is the main reason you choose to use PostgreSQL
PostgreSQL isn’t just a relational database; it’s a data management framework capable of engulfing the entire database galaxy. Besides being open-source and advanced, its core competitiveness stems from extensibility, i.e., its infra’s reusability and extension’s composability.
The Magic of Extreme Extensibility
PostgreSQL allows users to develop extensions, leveraging the database’s common infra to deliver features at minimal cost. For instance, the vector database extension pgvector, with just several thousand lines of code, is negligible in complexity compared to PostgreSQL’s millions of lines. Yet, this “insignificant” extension achieves complete vector data types and indexing capabilities, outperforming lots of specialized vector databases.
Why? Because pgvector’s creators didn’t need to worry about the database’s general additional complexities: ACID, recovery, backup & PITR, high availability, access control, monitoring, deployment, 3rd-party ecosystem tools, client drivers, etc., which require millions of lines of code to solve well. They only focused on the essential complexity of their problem.
For example, ElasticSearch was developed on the Lucene search library, while the Rust ecosystem has an improved next-gen full-text search library, Tantivy, as a Lucene alternative. ParadeDB only needs to wrap and connect it to PostgreSQL’s interface to offer search services comparable to ElasticSearch. More importantly, it can stand on the shoulders of PostgreSQL, leveraging the entire PG ecosystem’s united strength (e.g., mixed searches with PG Vector) to “unfairly” compete with another dedicated database.
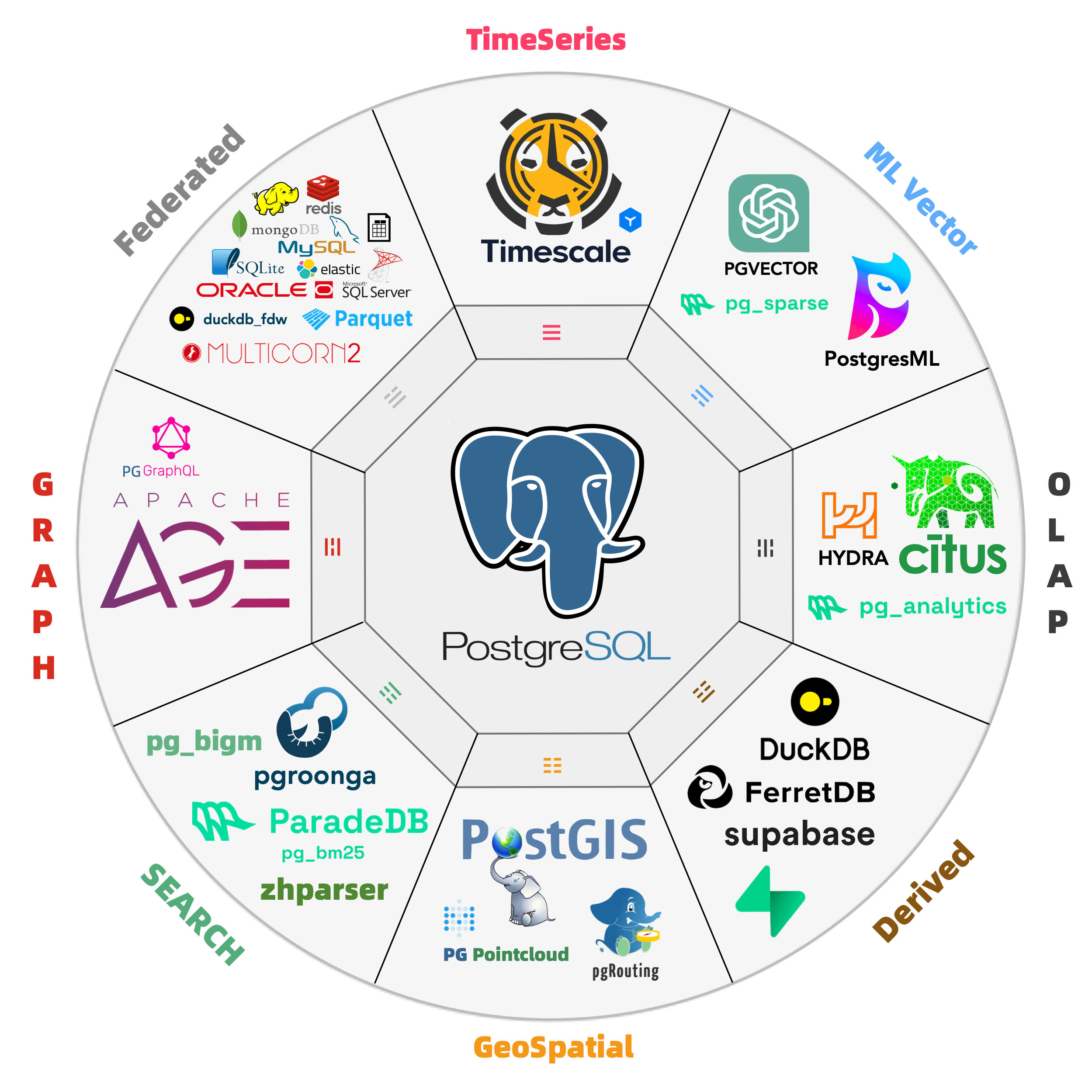
Pigsty has 255 extensions available. And there are 1000+ more in the ecosystem
The extensibility brings another huge advantage: the composability of extensions, allowing different extensions to work together, creating a synergistic effect where 1+1 » 2. For instance, TimescaleDB can be combined with PostGIS for spatio-temporal data support; the BM25 extension for full-text search can be combined with the PGVector extension, providing hybrid search capabilities.
Furthermore, the distributive extension Citus can transparently transform a standalone cluster into a horizontally partitioned distributed database cluster. This capability can be orthogonally combined with other features, making PostGIS a distributed geospatial database, PGVector a distributed vector database, ParadeDB a distributed full-text search database, and so on.
What’s more powerful is that extensions evolve independently, without the cumbersome need for main branch merges and coordination. This allows for scaling — PG’s extensibility lets numerous teams explore database possibilities in parallel, with all extensions being optional, not affecting the core functionality’s reliability. Those features that are mature and robust have the chance to be stably integrated into the main branch.
PostgreSQL achieves both foundational reliability and agile functionality through the magic of extreme extensibility, making it an outlier in the database world and changing the game rules of the database landscape.
Game Changer in the DB Arena
The emergence of PostgreSQL has shifted the paradigms in the database domain: Teams endeavoring to craft a “new database kernel” now face a formidable trial — how to stand out against the open-source, feature-rich Postgres. What’s their unique value proposition?
Until a revolutionary hardware breakthrough occurs, the advent of practical, new, general-purpose database kernels seems unlikely. No singular database can match the overall prowess of PG, bolstered by all its extensions — not even Oracle, given PG’s ace of being open-source and free.
A niche database product might carve out a space for itself if it can outperform PostgreSQL by an order of magnitude in specific aspects (typically performance). However, it usually doesn’t take long before the PostgreSQL ecosystem spawns open-source extension alternatives. Opting to develop a PG extension rather than a whole new database gives teams a crushing speed advantage in playing catch-up!
Following this logic, the PostgreSQL ecosystem is poised to snowball, accruing advantages and inevitably moving towards a monopoly, mirroring the Linux kernel’s status in server OS within a few years. Developer surveys and database trend reports confirm this trajectory.
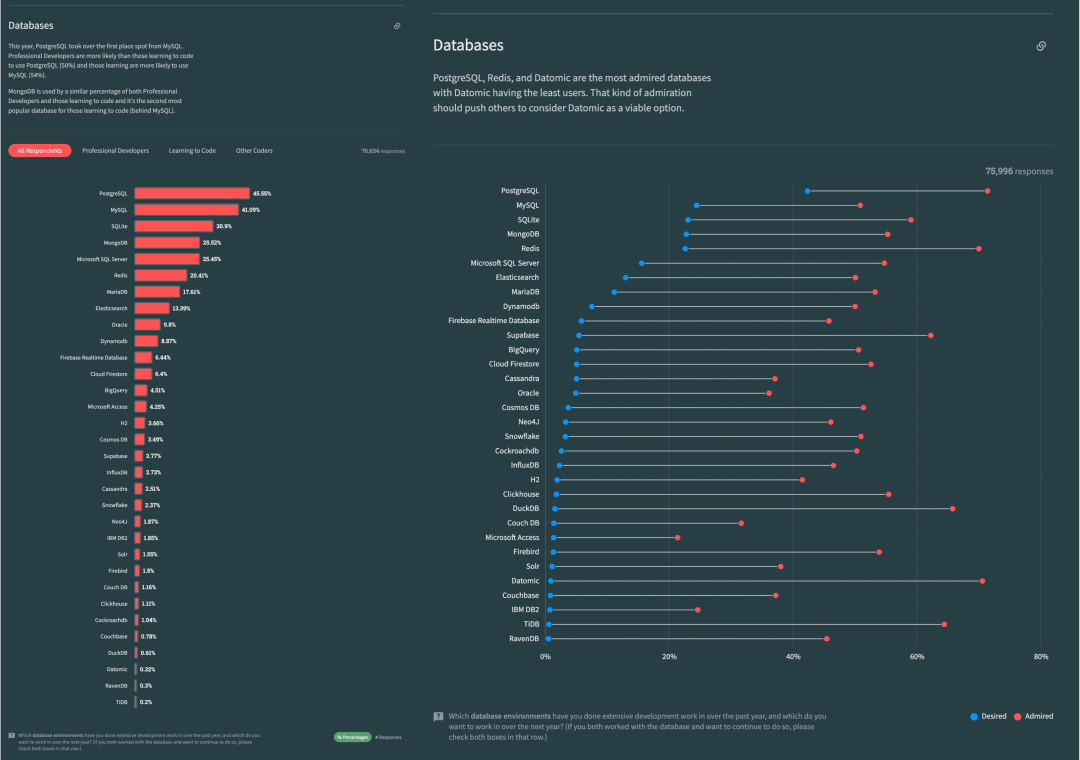
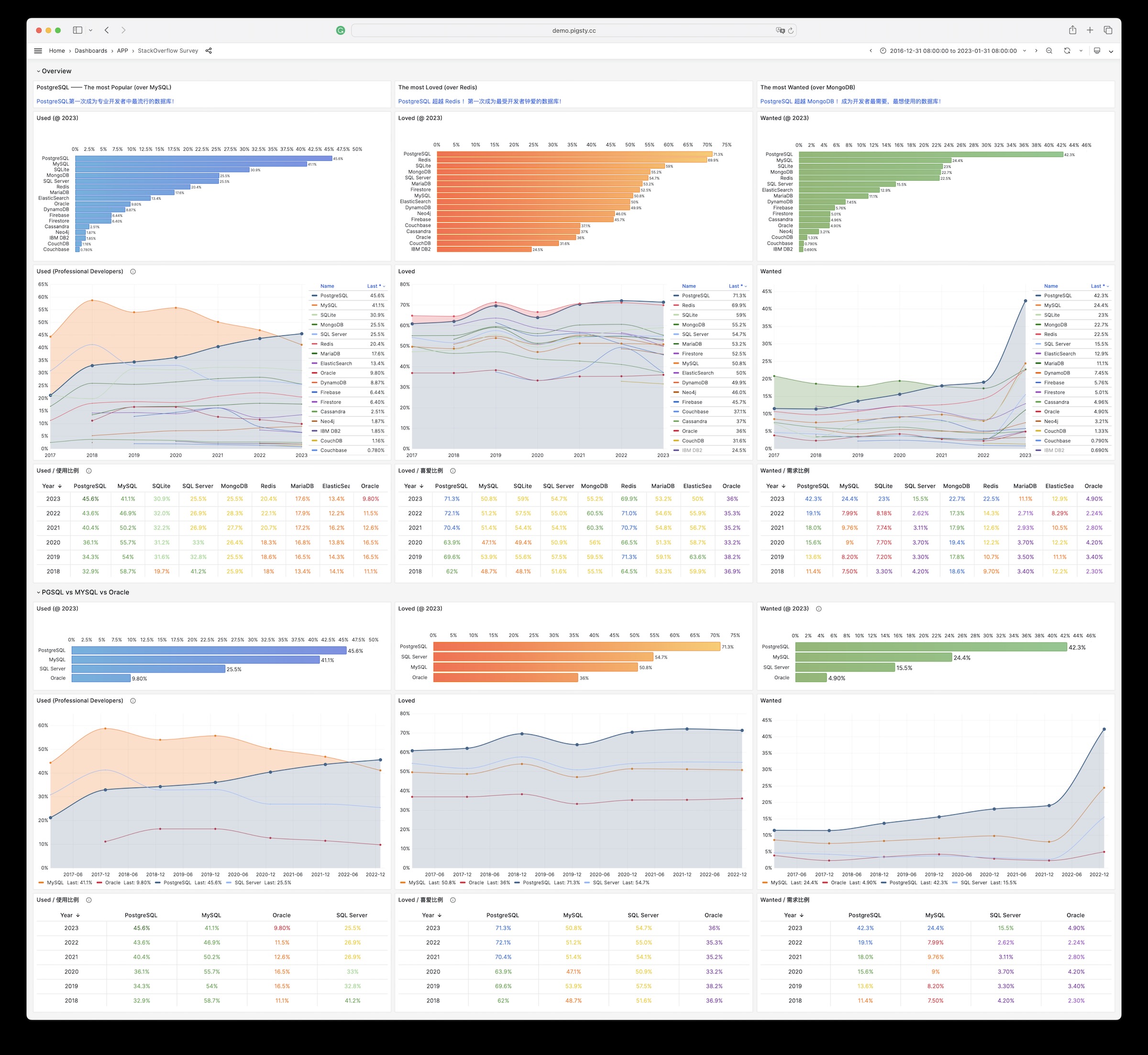
PostgreSQL has long been the favorite database in HackerNews & StackOverflow. Many new open-source projects default to PostgreSQL as their primary, if not only, database choice. And many new-gen companies are going All in PostgreSQL.
As “Radical Simplicity: Just Use Postgres” says, Simplifying tech stacks, reducing components, accelerating development, lowering risks, and adding more features can be achieved by “Just Use Postgres.” Postgres can replace many backend technologies, including MySQL, Kafka, RabbitMQ, ElasticSearch, Mongo, and Redis, effortlessly serving millions of users. Just Use Postgres is no longer limited to a few elite teams but becoming a mainstream best practice.
What Else Can Be Done?
The endgame for the database domain seems predictable. But what can we do, and what should we do?
PostgreSQL is already a near-perfect database kernel for the vast majority of scenarios, making the idea of a kernel “bottleneck” absurd. Forks of PostgreSQL and MySQL that tout kernel modifications as selling points are essentially going nowhere.
This is similar to the situation with the Linux OS kernel today; despite the plethora of Linux distros, everyone opts for the same kernel. Forking the Linux kernel is seen as creating unnecessary difficulties, and the industry frowns upon it.
Accordingly, the main conflict is no longer the database kernel itself but two directions— database extensions and services! The former pertains to internal extensibility, while the latter relates to external composability. Much like the OS ecosystem, the competitive landscape will concentrate on database distributions. In the database domain, only those distributions centered around extensions and services stand a chance for ultimate success.
Kernel remains lukewarm, with MariaDB, the fork of MySQL’s parent, nearing delisting, while AWS, profiting from offering services and extensions on top of the free kernel, thrives. Investment has flowed into numerous PG ecosystem extensions and service distributions: Citus, TimescaleDB, Hydra, PostgresML, ParadeDB, FerretDB, StackGres, Aiven, Neon, Supabase, Tembo, PostgresAI, and our own PG distro — — Pigsty.

A dilemma within the PostgreSQL ecosystem is the independent evolution of many extensions and tools, lacking a unifier to synergize them. For instance, Hydra releases its own package and Docker image, and so does PostgresML, each distributing PostgreSQL images with their own extensions and only their own. These images and packages are far from comprehensive database services like AWS RDS.
Even service providers and ecosystem integrators like AWS fall short in front of numerous extensions, unable to include many due to various reasons (AGPLv3 license, security challenges with multi-tenancy), thus failing to leverage the synergistic amplification potential of PostgreSQL ecosystem extensions.
Extesion Category Pigsty RDS & PGDG AWS RDS PG Aliyun RDS PG Add Extension Free to Install Not Allowed Not Allowed Geo Spatial PostGIS 3.4.2 PostGIS 3.4.1 PostGIS 3.3.4 Time Series TimescaleDB 2.14.2 Distributive Citus 12.1 AI / ML PostgresML 2.8.1 Columnar Hydra 1.1.1 Vector PGVector 0.6 PGVector 0.6 pase 0.0.1 Sparse Vector PG Sparse 0.5.6 Full-Text Search pg_bm25 0.5.6 Graph Apache AGE 1.5.0 GraphQL PG GraphQL 1.5.0 Message Queue pgq 3.5.0 OLAP pg_analytics 0.5.6 DuckDB duckdb_fdw 1.1 CDC wal2json 2.5.3 wal2json 2.5 Bloat Control pg_repack 1.5.0 pg_repack 1.5.0 pg_repack 1.4.8 Point Cloud PG PointCloud 1.2.5 Ganos PointCloud 6.1 Many important extensions are not available on Cloud RDS (PG 16, 2024-02-29)
Extensions are the soul of PostgreSQL. A Postgres without the freedom to use extensions is like cooking without salt, a giant constrained.
Addressing this issue is one of our primary goals.
Our Resolution: Pigsty
Despite earlier exposure to MySQL Oracle, and MSSQL, when I first used PostgreSQL in 2015, I was convinced of its future dominance in the database realm. Nearly a decade later, I’ve transitioned from a user and administrator to a contributor and developer, witnessing PG’s march toward that goal.
Interactions with diverse users revealed that the database field’s shortcoming isn’t the kernel anymore — PostgreSQL is already sufficient. The real issue is leveraging the kernel’s capabilities, which is the reason behind RDS’s booming success.
However, I believe this capability should be as accessible as free software, like the PostgreSQL kernel itself — available to every user, not just renting from cyber feudal lords.
Thus, I created Pigsty, a battery-included, local-first PostgreSQL distribution as an open-source RDS Alternative, which aims to harness the collective power of PostgreSQL ecosystem extensions and democratize access to production-grade database services.
Pigsty stands for PostgreSQL in Great STYle, representing the zenith of PostgreSQL.
We’ve defined six core propositions addressing the central issues in PostgreSQL database services:
Extensible Postgres, Reliable Infras, Observable Graphics, Available Services, Maintainable Toolbox, and Composable Modules.
The initials of these value propositions offer another acronym for Pigsty:
Postgres, Infras, Graphics, Service, Toolbox, Yours.
Your graphical Postgres infrastructure service toolbox.
Extensible PostgreSQL is the linchpin of this distribution. In the recently launched Pigsty v2.6, we integrated DuckDB FDW and ParadeDB extensions, massively boosting PostgreSQL’s analytical capabilities and ensuring every user can easily harness this power.
Our aim is to integrate the strengths within the PostgreSQL ecosystem, creating a synergistic force akin to the Ubuntu of the database world. I believe the kernel debate is settled, and the real competitive frontier lies here.
- PostGIS: Provides geospatial data types and indexes, the de facto standard for GIS (& pgPointCloud, pgRouting).
- TimescaleDB: Adds time-series, continuous aggregates, distributed, columnar storage, and automatic compression capabilities.
- PGVector: Support AI vectors/embeddings and ivfflat, hnsw vector indexes (& pg_sparse for sparse vectors).
- Citus: Transforms classic master-slave PG clusters into horizontally partitioned distributed database clusters.
- Hydra: Adds columnar storage and analytics, rivaling ClickHouse’s analytic capabilities.
- ParadeDB: Elevates full-text search and mixed retrieval to ElasticSearch levels (& zhparser for Chinese tokenization).
- Apache AGE: Graph database extension, adding Neo4J-like OpenCypher query support to PostgreSQL.
- PG GraphQL: Adds native built-in GraphQL query language support to PostgreSQL.
- DuckDB FDW: Enables direct access to DuckDB’s powerful embedded analytic database files through PostgreSQL (& DuckDB CLI).
- Supabase: An open-source Firebase alternative based on PostgreSQL, providing a complete app development storage solution.
- FerretDB: An open-source MongoDB alternative based on PostgreSQL, compatible with MongoDB APIs/drivers.
- PostgresML: Facilitates classic machine learning algorithms, calling, deploying, and training AI models with SQL.
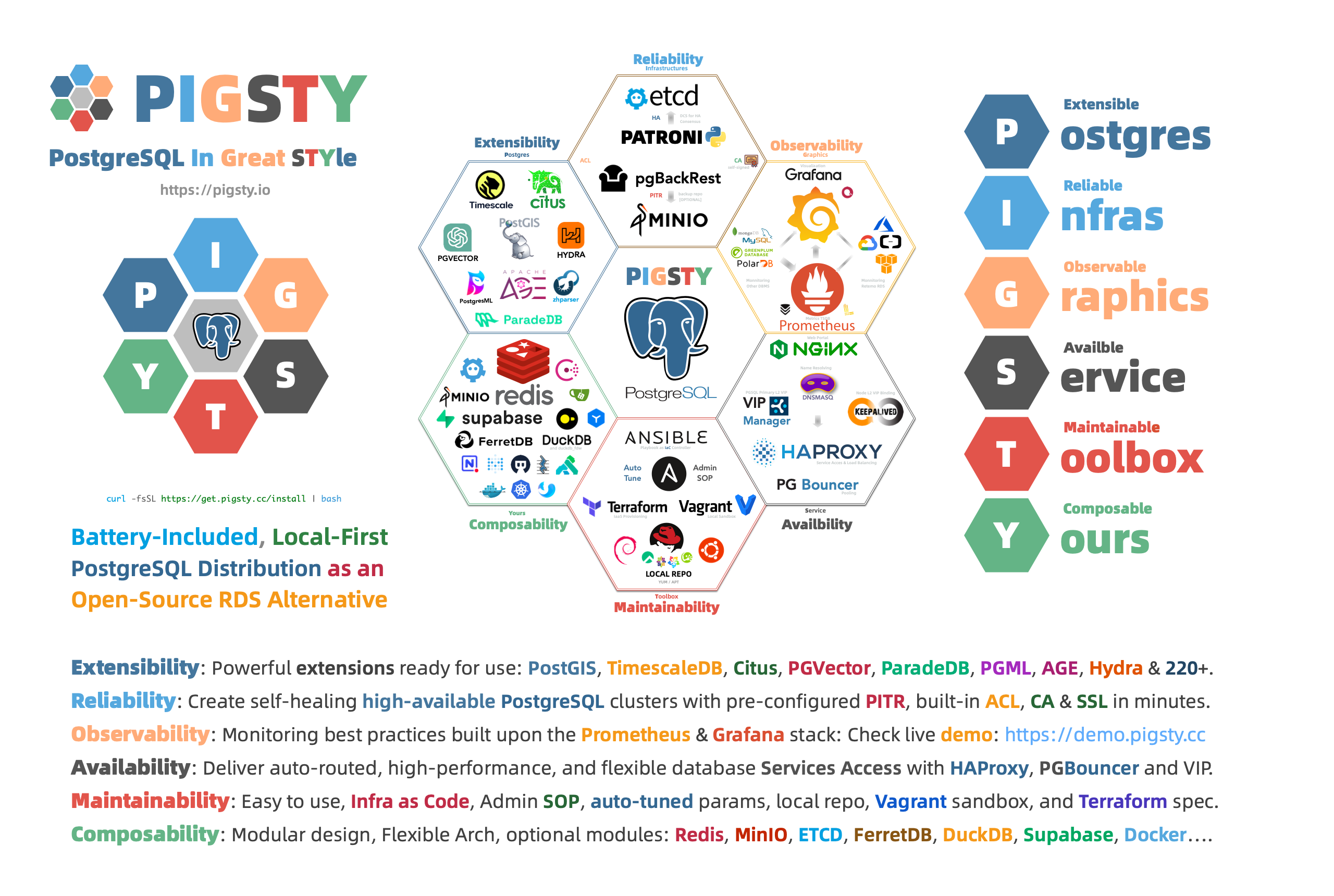
Developers, your choices will shape the future of the database world. I hope my work helps you better utilize the world’s most advanced open-source database kernel: PostgreSQL.
Read in Pigsty’s Blog | GitHub Repo: Pigsty | Official Website
Technical Minimalism: Just Use PostgreSQL for Everything
This article was originally published by Stephan Schmidt @ KingOfCoders and sparked heated discussions on Hacker News[1]: Using PostgreSQL as a replacement for Kafka, RabbitMQ, ElasticSearch, MongoDB, and Redis is a practical approach that can significantly reduce system complexity and maximize agility.
How to Simplify Complexity and Move Fast: Do Everything with PostgreSQL
Welcome, HN readers. Technology is the art of trade-offs. Using PostgreSQL for everything is also a strategy and compromise. Obviously, we should choose appropriate tools based on needs. In many cases, that tool is Postgres.
In assisting many startups, I’ve observed that far more companies overcomplicate their systems than those who choose overly simple tools. If you have over a million users, more than fifty developers, and you genuinely need Kafka, Spark, and Kubernetes, then go ahead. If you have more systems than developers, using only Postgres is a wise choice.
P.S. Using Postgres for everything doesn’t mean using a single instance for everything ;-)
Simply Put, Everything Can Be Solved with Postgres
It’s easy to invite complexity in, but much harder to show it the door.
However, We Have an Ultimate Simplification Solution
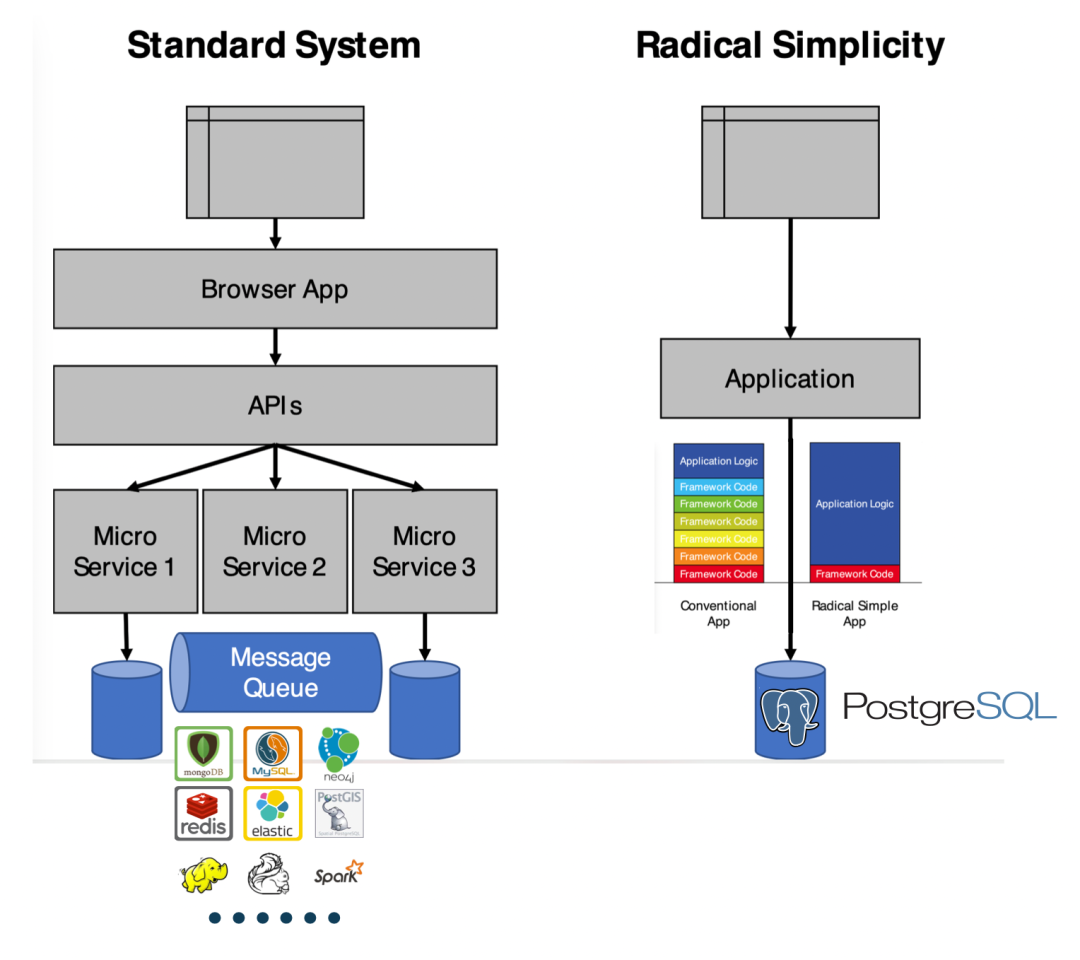
One way to simplify the tech stack, reduce components, speed up development, lower risks, and deliver more features in startups is to “Just Use Postgres for Everything”. Postgres can replace many backend technologies, including Kafka, RabbitMQ, ElasticSearch, MongoDB, and Redis, at least until you reach millions of users.
Use Postgres instead of Redis for caching, using UNLOGGED Tables[3] and storing JSON data in TEXT columns, with stored procedures to add and enforce expiration times, just like Redis does.
Use Postgres as a message queue, employing SKIP LOCKED[4] instead of Kafka (if you only need message queue capabilities).
Use Postgres with the TimescaleDB[5] extension as your data warehouse.
Use PostgreSQL’s JSONB[6] type to store, index, and search JSON documents, replacing MongoDB.
Use Postgres with the pg_cron[7] extension as your scheduled task daemon, executing specific tasks at certain times, such as sending emails or adding events to message queues.
Use Postgres + PostGIS for geospatial queries[8].
Use Postgres for full-text search[9], with ParadeDB replacing ElasticSearch.
Use Postgres to generate JSON in the database[10], eliminating the need for server-side code, directly serving your API.
Use a GraphQL adapter[11] to let PostgreSQL provide GraphQL services.
As I’ve said, Everything Can Be Postgres.
About the Author Stephan
As a CTO, interim CTO, CTO coach, and developer, Stephan has left his mark in the technical departments of many fast-growing startups. He learned programming in a department store around 1981 because he wanted to write video games. Stephan studied computer science at the University of Ulm, specializing in distributed systems and artificial intelligence, and also studied philosophy. When the internet came to Germany in the 90s, he was the first programming employee at several startups. He founded a venture capital-backed startup, handled architecture, processes, and growth challenges in other VC-backed fast-growing startups, held management positions at ImmoScout, and was CTO at an eBay Inc. company. After his wife successfully sold her startup, they moved to the seaside, where Stephan began CTO coaching. You can find him on LinkedIn or follow @KingOfCoders on Twitter.
Translator’s Note
Translator: Feng Ruohang, entrepreneur and PostgreSQL expert, cloud-native advocate, author of Pigsty, an open-source PostgreSQL RDS alternative that’s ready to use out of the box.
Using Postgres for everything is not a pipe dream but a best practice that’s gaining popularity. I’m very pleased about this: I saw this potential back in 2016[12] and chose to dive in, and things have developed exactly as hoped.
Tantan, where I previously worked, was a pioneer on this path - PostgreSQL for Everything. This Chinese internet app, founded by a Swedish team, used PostgreSQL at a scale and complexity that was second to none in China. Tantan’s technical architecture choices were inspired by Instagram - or even more radical, with almost all business logic implemented in PostgreSQL stored procedures (including recommendation algorithms with 100ms latency!).
Tantan’s entire system architecture was designed and built around PostgreSQL. With millions of daily active users, millions of global DB-TPS, and hundreds of TB of data, the data component only used PostgreSQL. It wasn’t until approaching ten million daily active users that they began architectural adjustments to introduce independent data warehouses, message queues, and caching. In 2017, we didn’t even use Redis for caching; 2.5 million TPS was handled directly by PostgreSQL across over a hundred servers. Message queues were also implemented in PostgreSQL, and early/mid-stage data analysis was handled by a dedicated PG cluster of several dozen TB. We had long practiced the philosophy of “using PostgreSQL for everything” and reaped many benefits.
There’s a second part to this story - the subsequent “microservices transformation” brought massive complexity, eventually bogging down the system. This made me even more certain from another angle - I deeply miss that simple, reliable, efficient, and agile state when we used PostgreSQL for everything.
PostgreSQL is not just a simple relational database but an abstract framework for data management with the potential to encompass everything and devour the entire database world. Ten years ago, this was merely potential and possibility; ten years later, it has materialized into real influence. I’m glad to have witnessed this process and helped push it forward.
Further Reading
PGSQL x Pigsty: The Database Swiss Army Knife is Here
ParadeDB: A New Player in the PG Ecosystem
FerretDB: PostgreSQL Dressed as MongoDB
AI Large Models and Vector Databases with PGVECTOR
How Powerful is PostgreSQL Really?
PostgreSQL: The World’s Most Successful Database
Why is PostgreSQL the Most Successful Database?
Why Does PostgreSQL Have a Bright Future?
Better Open Source RDS Alternative: Pigsty
References
[1]Just use Postgres for everything: https://news.ycombinator.com/item?id=33934139[2]Technical Minimalism Manifesto: https://www.radicalsimpli.city/[3]UNLOGGED Table: https://www.compose.com/articles/faster-performance-with-unlogged-tables-in-postgresql/[4]SKIP LOCKED: https://www.enterprisedb.com/blog/what-skip-locked-postgresql-95[5]Timescale: https://www.timescale.com/[6]JSONB: https://scalegrid.io/blog/using-jsonb-in-postgresql-how-to-effectively-store-index-json-data-in-postgresql/[7]pg_cron: https://github.com/citusdata/pg_cron[8]Geospatial Queries: https://postgis.net/[9]Full-Text Search: https://supabase.com/blog/postgres-full-text-search-vs-the-rest[10]Generate JSON in Database: https://www.amazingcto.com/graphql-for-server-development/[11]GraphQL Adapter: https://graphjin.com/[12]What are PostgreSQL’s Advantages over MySQL?: https://www.zhihu.com/question/20010554/answer/94999834
ParadeDB: ElasticSearch Alternative in PG Ecosystem
ParadeDB: A New Player in the PostgreSQL Ecosystem
YC S23 invested in an exciting new project called ParadeDB. Their slogan? “Postgres for Search & Analytics — Modern Elasticsearch Alternative built on Postgres.” In essence, it’s PostgreSQL optimized for search and analytics, aiming to be a drop-in replacement for Elasticsearch.
The PostgreSQL ecosystem continues to flourish with innovative extensions and derivatives. We’ve already seen FerretDB as an open-source MongoDB alternative, Babelfish for SQL Server, Supabase for Firebase, and NocoDB for AirTable. Now, we can add ParadeDB to the list as an open-source Elasticsearch alternative.
ParadeDB consists of three PostgreSQL extensions: pg_bm25, pg_analytics, and pg_sparse. Each extension can be used independently. I’ve packaged these extensions (v0.5.6) and will include them by default in the next Pigsty release, making them available out of the box for users.
I’ve translated ParadeDB’s official website introduction and four blog posts to introduce this rising star in the PostgreSQL ecosystem. Today’s post is the first one — an overview.
![]()
ParadeDB
We’re thrilled to introduce ParadeDB: a PostgreSQL database optimized for search scenarios. ParadeDB is the first PostgreSQL build designed to be an Elasticsearch alternative, offering lightning-fast full-text search, semantic search, and hybrid search capabilities on PostgreSQL tables.
![]()
What Problem Does ParadeDB Solve?
For many organizations, search remains an unsolved problem — despite giants like Elasticsearch in the market. Most developers who’ve worked with Elasticsearch know the pain of running, tuning, and managing it. While other search engine services exist, integrating external services with existing databases introduces complex challenges and costs associated with rebuilding indexes and data replication.
Developers seeking a unified source of truth and search capabilities have turned to PostgreSQL. While PG offers basic full-text search through tsvector and semantic search through pgvector, these tools fall short when dealing with large tables or complex queries:
- Sorting and keyword searches on large tables are painfully slow
- No BM25 scoring support
- No hybrid search capabilities combining vector and full-text search
- No real-time search — data must be manually reindexed or re-embedded
- Limited support for complex queries like faceting or relevance tuning
We’ve seen many engineering teams reluctantly layer Elasticsearch on top of PostgreSQL, only to abandon it due to its bloated nature, high costs, or complexity. We wondered: what if PostgreSQL had Elasticsearch-level search capabilities built-in? This would eliminate the dilemma of choosing between using PostgreSQL with limited search capabilities or maintaining separate services for source of truth and search.
Who Is ParadeDB For?
While Elasticsearch serves a wide range of use cases, we’re not trying to cover everything — at least not yet. We’re focusing on core scenarios, specifically serving users who want to perform search within PostgreSQL. ParadeDB is ideal for you if:
- You want to use PostgreSQL as your single source of truth and hate data replication between multiple services
- You need to perform full-text search on massive documents stored in PostgreSQL without compromising performance and scalability
- You want to combine ANN/similarity search with full-text search for more precise semantic matching
ParadeDB Product Overview
ParadeDB is a fully managed Postgres database with indexing and search capabilities for PostgreSQL tables that you won’t find in any other PostgreSQL provider:
| Feature | Description |
|---|---|
| BM25 Full-Text Search | Full-text search supporting boolean, fuzzy, boosting, and keyword queries. Search results are scored using the BM25 algorithm. |
| Faceted Search | PostgreSQL columns can be defined as facets for easy bucketing and metric collection. |
| Hybrid Search | Search results can be scored considering both semantic relevance (vector search) and text relevance (BM25). |
| Distributed Search | Tables can be sharded for parallel query acceleration. |
| Generative Search | PostgreSQL columns can be fed into large language models (LLMs) for automatic summarization, classification, or text generation. |
| Real-time Search | Text indexes and vector columns automatically stay in sync with underlying data. |
Unlike managed services like AWS RDS, ParadeDB is a PostgreSQL extension plugin that requires no setup, integrates with the entire PG ecosystem, and is fully customizable. ParadeDB is open-source (AGPLv3) and provides a simple Docker Compose template for developers who need to self-host or customize.
How ParadeDB Is Built
At its core, ParadeDB is a standard Postgres database with custom extensions written in Rust that introduce enhanced search capabilities.
ParadeDB’s search engine is built on top of Tantivy, an open-source Rust search library inspired by Apache Lucene. Its indexes are stored natively in PostgreSQL as PG indexes, eliminating the need for cumbersome data replication/ETL work while maintaining transaction ACID guarantees.
ParadeDB introduces a new extension to the Postgres ecosystem: pg_bm25. This extension implements Rust-based full-text search in PostgreSQL using the BM25 scoring algorithm. ParadeDB comes pre-installed with this extension.
What’s Next?
ParadeDB’s managed cloud version is currently in PrivateBeta. We aim to launch a self-service cloud platform in early 2024. If you’d like to access the PrivateBeta version during this period, join our waitlist.
Our core team is focused on developing the open-source version of ParadeDB, which will be released in Winter 2023.
We’re building in public and are excited to share ParadeDB with the community. Stay tuned for future blog posts where we’ll dive deeper into the fascinating technical challenges behind ParadeDB.
The Astonishing Scalability of PostgreSQL
This article outlines how Cloudflare uses 15 PostgreSQL clusters to scale up to 55 million requests per second.
In July 2009, in California, USA, a startup team created a Content Delivery Network (CDN) called Cloudflare to accelerate internet requests, making web access more stable and faster. While facing various challenges in their early development, their growth rate was astounding.
Global overview of internet traffic
Today, they handle 20% of all internet traffic, processing 55 million HTTP requests per second. And they accomplish this with just 15 PostgreSQL clusters.
Cloudflare uses PostgreSQL to store service metadata and handle OLTP workloads. However, supporting tenants with different types of workloads on the same cluster presents a challenge. A cluster is a group of database servers, while a tenant is an isolated data space dedicated to a specific user or group of users.
PostgreSQL Scalability
Here’s how they pushed PostgreSQL’s scalability to its limits.
1. Contention
Most clients compete for Postgres connections. But Postgres connections are expensive because each connection is a separate OS-level process. And since each tenant has a unique workload type, it’s difficult to create a global threshold for rate limiting.
Moreover, manually restricting misbehaving tenants is a massive undertaking. A tenant might initiate an extremely expensive query, blocking queries from neighboring tenants and starving them. Once a query reaches the database server, isolating it becomes challenging.
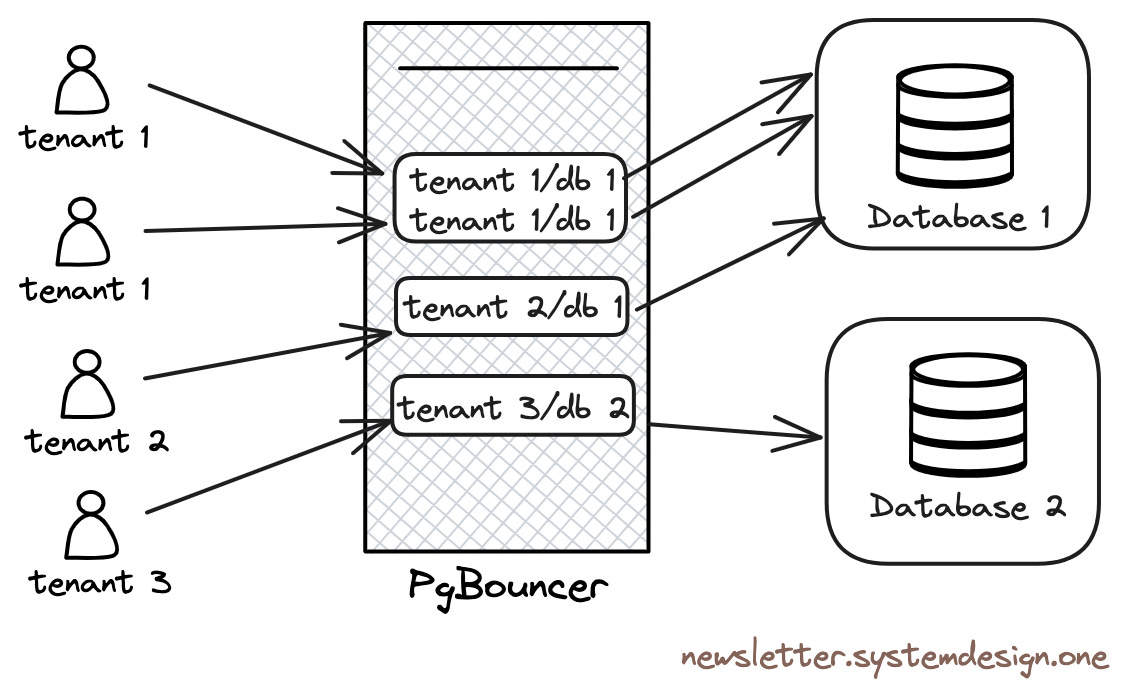
Connection pooling with PgBouncer
Therefore, they use PgBouncer as a connection pool in front of Postgres. PgBouncer acts as a TCP proxy, pooling Postgres connections. Tenants connect to PgBouncer rather than directly to Postgres. This limits the number of Postgres connections and prevents connection starvation.
Additionally, PgBouncer avoids the high overhead of creating and destroying database connections by using persistent connections and is used to throttle tenants that initiate high-cost queries at runtime.
2. Thundering Herd
The Thundering Herd problem occurs when many clients query the server simultaneously, leading to database performance degradation.

When applications are redeployed, their state initializes, and the applications create many database connections at once. Thus, when tenants compete for Postgres connections, it triggers the thundering herd phenomenon. Cloudflare uses PgBouncer to limit the number of Postgres connections created by specific tenants.
3. Performance
Cloudflare doesn’t run PostgreSQL in the cloud but uses bare-metal physical machines without any virtualization overhead to achieve the best performance.
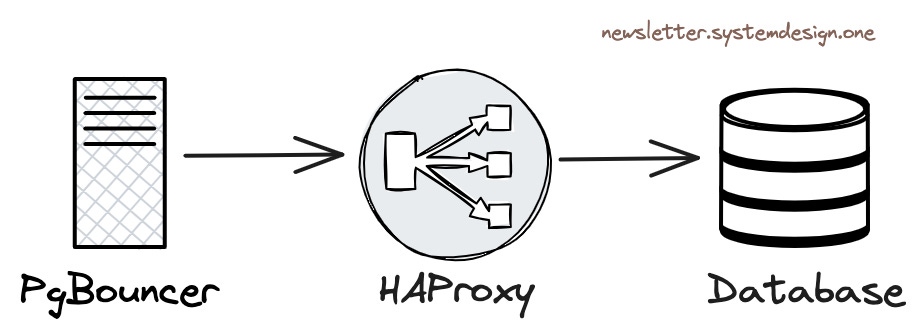
Load balancing traffic between database instances
Cloudflare uses HAProxy as a layer-four load balancer. PgBouncer forwards queries to HAProxy, and the HAProxy load balancer balances traffic between the cluster’s primary instance and read-only replicas.
4. Concurrency
Performance decreases when many tenants make concurrent queries.
Congestion control throttling algorithm
Therefore, Cloudflare uses the TCP Vegas congestion control algorithm to throttle tenants. This algorithm works by first sampling each tenant’s transaction round-trip time (RTT) to Postgres, then continuously adjusting the connection pool size as long as the RTT doesn’t degrade, enabling throttling before resources are exhausted.
5. Queuing
Cloudflare queues queries at the PgBouncer level. The order of queries in the queue depends on their historical resource usage—in other words, queries requiring more resources are placed at the end of the queue.
Using priority queues to order queries
Cloudflare only enables priority queuing during peak traffic to prevent resource starvation. In other words, during normal traffic, queries won’t always end up at the back of the queue.
This approach improves latency for the vast majority of queries, though tenants initiating high-cost queries during peak traffic will observe higher latency.
6. High Availability
Cloudflare uses Stolon cluster management for Postgres high availability.
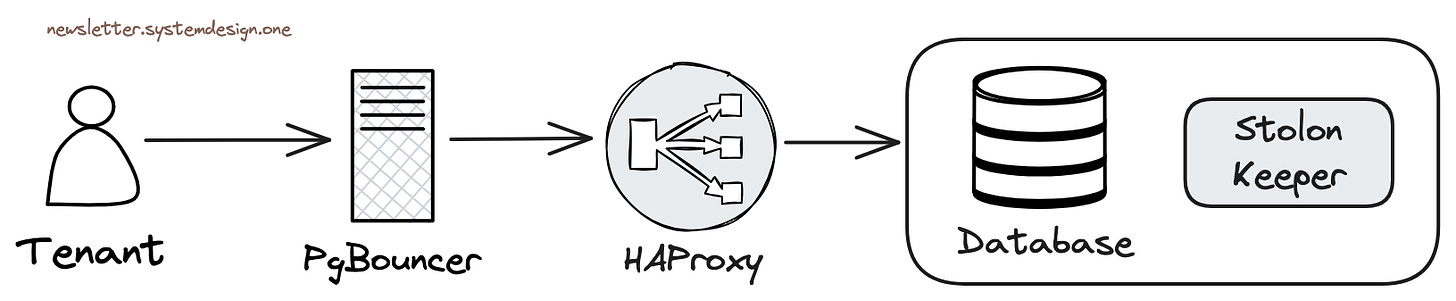
Using Stolon for database high availability
Stolon can be used to set up Postgres master-slave replication and is responsible for electing a Postgres cluster leader (primary) and handling failover when problems arise.
Each database cluster here replicates to two regions, with three instances in each region.
Write requests are routed to the primary in the main region, then asynchronously replicated to the secondary region, while read requests are routed to the secondary region for processing.
Cloudflare conducts component interconnectivity tests to actively detect network partition issues, performs chaos testing to optimize system resilience, and configures redundant network switches and routers to avoid network partitioning.
When failover completes and the primary instance comes back online, they use the pg_rewind tool to replay missed write changes to resynchronize the old primary with the cluster.
Cloudflare has over 100 Postgres primary and replica instances combined. They use a combination of OS resource management, queuing theory, congestion control algorithms, and even PostgreSQL metrics to achieve PostgreSQL scalability.
Evaluation and Discussion
This is a valuable experience-sharing article, mainly introducing how to use PgBouncer to solve PostgreSQL’s scalability issues. Fifty million QPS + 20% of internet traffic sounds like a significant scale. Although from a PostgreSQL expert’s perspective, the practices described here might seem somewhat basic and rudimentary, the article raises a meaningful question—PostgreSQL’s scalability.
Current State of PostgreSQL Scalability
PostgreSQL has a reputation for vertical and horizontal scaling capabilities. For read requests, PostgreSQL has no scalability issues—since reads and writes don’t block each other, the throughput limit for read-only queries grows almost linearly with invested resources (CPU), whether by vertically increasing CPU/memory or horizontally expanding with replica instances.
PostgreSQL’s write scalability isn’t as strong as its read capabilities. Single-machine WAL write/replay speed reaches a software bottleneck at 100 MB/s to 300 MB/s—but for regular production OLTP loads, this is already a substantial value. As a reference, an application like Tantan, with 200 million users and 10 million daily active users, has a structured data rate for all database writes of around 120 MB/s. The PostgreSQL community is also discussing ways to expand this bottleneck through DIO/AIO and parallel WAL replay. Users can also consider using Citus or other sharding middleware to achieve write scalability.
In terms of capacity, PostgreSQL’s scalability primarily depends on disk space and doesn’t have inherent bottlenecks. With today’s NVMe SSDs offering 64TB per card, supporting hundreds of terabytes of data capacity is no problem when combined with compression cards. Even larger capacities can be supported using RAID or multiple tablespaces. The community has reported numerous OLTP instances in the hundreds of terabytes range, with occasional instances at the petabyte level. The challenges with large instances are mainly in backup management and space maintenance, not performance.
In the past, a notable criticism of PostgreSQL’s scalability was its support for massive connections (significantly improved after PostgreSQL 14). PostgreSQL uses a multi-process architecture like Oracle by default. This design provides better reliability but can be a bottleneck when facing massive high-concurrency scenarios.
In internet scenarios, database access patterns primarily involve massive short connections: creating a connection for a query and destroying it after execution—PHP used to do this, making it compatible with MySQL, which uses a thread model. But for PostgreSQL, massive backend processes and frequent process creation/destruction waste considerable hardware and software resources, making its performance somewhat inadequate in these scenarios.
Connection Pooling — Solving High Concurrency Issues
PostgreSQL recommends a default connection count of about twice the number of CPU cores, typically appropriate in the range of a few dozen to a few hundred. In internet scenarios with thousands or tens of thousands of client connections directly connecting to PostgreSQL, there would be significant additional overhead. Connection pooling emerged to solve this problem—it can be said that connection pooling is a must-have for using PostgreSQL in internet scenarios, capable of transforming the ordinary into the extraordinary.
Note that PostgreSQL is not incapable of high throughput; the key issue is the number of concurrent connections. In “How Strong is PG Performance,” we achieved a sysbench point query throughput peak of 2.33 million on a 92 vCPU server using about 96 connections. Once resources are exceeded, this maximum throughput begins to slowly decline as concurrency further increases.
Using connection pooling has several significant benefits: First, tens of thousands of client connections can be pooled and buffered down to a few active server connections (using transaction-level connection pooling), greatly reducing the number of processes and overhead on the operating system, and avoiding the overhead of process creation and destruction. Second, concurrent contention is greatly reduced due to the reduction in active connections, further optimizing performance. Third, sudden load peaks will queue at the connection pool instead of overwhelming the database, reducing the probability of cascading failures and improving system stability.
Performance and Bottlenecks
I had many best practices with PgBouncer at Tantan. We had a core database cluster with 500,000 QPS, 20,000 client connections on the primary, and a write TPS of about 50,000. Such a load would immediately overwhelm Postgres if directed straight to it. Therefore, between the application and the database, there was a PgBouncer connection pooling middleware. All twenty thousand client connections, after transaction pooling, only required 5-8 active server connections to support all requests, with a CPU utilization of about 20%—a tremendous performance improvement.
PgBouncer is a lightweight connection pool that can be deployed on either the user side or the database side. PgBouncer itself, due to its single-process mode, has a QPS/TPS bottleneck of about 30,000-50,000. Therefore, to avoid PgBouncer’s single point of failure and bottleneck, we used 4 idempotent PgBouncer instances on the core primary and evenly distributed traffic through HAProxy to these four PgBouncer instances before reaching the database primary. But for most scenarios, a single PgBouncer process’s capability to handle 30,000 QPS is more than sufficient.
Management Flexibility
A huge advantage of PgBouncer is that it can provide query response time metrics (RT) at the User/Database/Instance level. This is a core metric for performance measurement, and for older versions of PostgreSQL, statistics in PgBouncer were the only way to obtain such data. Although users can obtain query group RT through the pg_stat_statements extension, and PostgreSQL 14 and later can obtain database-level session active time to calculate transaction RT, and the newly emerged eBPF can also accomplish this, the performance monitoring data provided by PgBouncer remains a very important reference for database management.
The PgBouncer connection pool not only provides performance improvements but also offers handles for fine-grained management. For example, in online database migration without downtime, if online traffic completely accesses through the connection pool, you can simply redirect read/write traffic from the old cluster to the new one by modifying the PgBouncer configuration file, without even requiring immediate participation from the business side to change configurations and restart services. You can also, like in Cloudflare’s example above, modify Database/User parameters in the connection pool to implement throttling capabilities. If a database tenant behaves poorly, affecting the entire shared cluster, administrators can easily implement throttling and blocking capabilities in PgBouncer.
Other Alternatives
There are other connection pool products in the PostgreSQL ecosystem. PGPool-II, which emerged around the same time as PgBouncer, was once a strong competitor: it provided more powerful load balancing/read-write splitting capabilities and could fully utilize multi-core capabilities, but it had invasiveness to the PostgreSQL database itself—requiring extension installation to use, and once had significant performance penalties (30%). So in the connection pool battle, the simple and lightweight PgBouncer became the winner, occupying the mainstream ecological niche of PG connection pools.
Besides PgBouncer, new PostgreSQL connection pool projects continue to emerge, such as Odyssey, pgcat, pgagroal, ZQPool, etc. I very much look forward to a high-performance/more user-friendly in-place replacement fully compatible with PgBouncer.
Additionally, many programming language standard library database drivers now have built-in connection pools, plus PostgreSQL 14’s improvements have reduced the overhead of multiple processes. And with the exponential growth of hardware performance (there are now servers with 512 vCPUs, and memory is no longer a scarce resource), sometimes not using a connection pool and directly handling a few thousand connections is also a viable option.
Can I Use Cloudflare’s Practices?
With the continuous improvement of hardware performance, the ongoing optimization of software architecture, and the gradual popularization of management best practices—high availability, high concurrency, and high performance (scalability) are old topics for internet companies and basically not new technologies anymore.
For example, nowadays, even a junior DBA/ops person, as long as they use Pigsty to deploy a PostgreSQL cluster, can easily achieve this, including the PgBouncer connection pool mentioned by Cloudflare, and Patroni, which has replaced the high availability component Stolon, are all ready to use out of the box. As long as the hardware meets requirements, handling massive concurrent requests in the millions is not a dream.
At the beginning of this century, an Apache server could only handle a miserable one or two hundred concurrent requests. Even the most excellent software could hardly handle tens of thousands of concurrent requests—there was a famous C10K high concurrency problem in the industry; anyone who could achieve thousands of concurrent connections was an industry expert. But with the successive emergence of Epoll and Nginx in 2003/2004, “high concurrency” was no longer a difficult problem—any novice who learned to configure Nginx could achieve what masters could not even dream of a few years ago—as Swedish Marcus says in “Cloud Providers’ View of Customers: Poor, Idle, and Lacking Love”
This is just like now any novice can use Nginx to achieve the massive web requests and high concurrency that masters using httpd could not even dream of before. PostgreSQL’s scalability has also entered thousands of households with the popularization of PgBouncer.
For example, in Pigsty, PgBouncer instances are deployed 1:1 for all PostgreSQL by default, using transaction pooling mode and incorporated into monitoring. And the default Primary and Replica services also access the Postgres database through PgBouncer. Users don’t need to worry too much about details related to PgBouncer—for instance, PgBouncer’s databases and users are automatically maintained when creating Postgres databases/users through scripts. Some common configuration considerations and pitfalls are also avoided in the preset configuration templates, striving to achieve out-of-the-box usability.
Of course, for non-internet scenario applications, PgBouncer is not a must-have. And the default Transaction Pooling, although excellent in performance, comes at the cost of sacrificing some session-level functionality. So you can also configure Primary/Replica services to connect directly to Postgres, bypassing PgBouncer; or use the Session Pooling mode with the best compatibility.
Overall, PgBouncer is indeed a very practical tool in the PostgreSQL ecosystem. If your system has high requirements for PostgreSQL client concurrent connections, be sure to try this middleware when testing performance.
Original article: How Cloudflare Used 15 PG Clusters to Support 55M QPS |
PostgreSQL Crowned Database of the Year 2024!
Today, the renowned database popularity ranking site DB-Engines announced its Database of the Year for 2024. PostgreSQL has claimed this honor for the fifth time. Of course, PostgreSQL was also crowned Database of the Year in 2023, 2019, 2018, and 2017. If Snowflake hadn’t stolen the spotlight in 2020 and 2021, pushing PostgreSQL to second place, we’d be looking at a seven-year winning streak.
PostgreSQL Claims the Crown as “Database Management System of the Year” for 2024
DB-Engines has officially announced that PostgreSQL has once again been crowned “DBMS of the Year” - marking its second consecutive win and fifth overall triumph following its dominance in 2017, 2018, 2019, and 2023. Snowflake secured the runner-up position with its impressive momentum, while Microsoft claimed third place. Over the past year, PostgreSQL has emerged as the most popular database management system, surpassing all other 423 databases monitored by DB-Engines.
Rewind nearly 35 years to when “Postgres” first burst onto the scene. Since then, PostgreSQL has continuously evolved to keep pace with database technology trends, growing more powerful while maintaining rock-solid stability. PostgreSQL 17, released in September 2024, pushed this “evergreen tree” to new heights with enhanced performance and expanded replication capabilities. In today’s open-source landscape, PostgreSQL stands as a shining example of how to maintain both popularity and technical excellence.
Here’s where it gets interesting: Looking at DB-Engines’ popularity score increments this year, Snowflake gained 28 points while PostgreSQL increased by 14.5 points. Following their usual calculation rules for Database of the Year (based on popularity scores from January 2024 to January 2025), Snowflake should have technically claimed the title. Yet, the editors still chose PostgreSQL as Database of the Year.
Of course, I don’t believe DB-Engines’ editors would make such an elementary mathematical error. To be frank, given PostgreSQL’s remarkable growth and impressive metrics in 2024, if they hadn’t named PG as Database of the Year, it would have only damaged the credibility of their rankings (much like how a gaming publication would lose face if they didn’t recognize Breath of the Wild or The Witcher 3 as Game of the Year). I suspect the editors had no choice but to crown PostgreSQL as No. 1, even if it meant going against their own metrics.
To be honest, compared to first-hand, large-sample surveys like the StackOverflow Annual Global Developer Survey, popularity rankings like DB-Engines should only be taken as rough references. While their standardized methodology makes them valuable for tracking a database’s historical popularity trends (vertical comparability), they’re less reliable for comparing different databases head-to-head (horizontal comparability).
Original DB-Engines Blog Post
PostgreSQL Named Database Management System of the Year 2024
By Tom Russell, January 13, 2025
https://db-engines.com/en/blog_post/109
DB-Engines has officially announced that PostgreSQL has been crowned “DBMS of the Year” - marking its second consecutive win and fifth overall triumph following its dominance in 2017, 2018, 2019, and 2023. Snowflake secured the runner-up position with its impressive momentum, while Microsoft claimed third place. Over the past year, PostgreSQL has emerged as the most popular database management system, surpassing all other 423 databases monitored by DB-Engines.
Rewind nearly 35 years to when “Postgres” first burst onto the scene. Since then, PostgreSQL has continuously evolved to keep pace with database technology trends, growing more powerful while maintaining rock-solid stability. PostgreSQL 17, released in September 2024, pushed this “evergreen tree” to new heights with enhanced performance and expanded replication capabilities. In today’s open-source landscape, PostgreSQL stands as a shining example of how to maintain both popularity and technical excellence.
Snowflake, this year’s runner-up, is much more than just a “snowflake” - it’s a cloud-based data warehouse service that has attracted a massive following with its unique architecture separating storage and compute. Combined with multi-cloud support and data sharing capabilities, it has become an industry hot spot. Snowflake’s rising rankings clearly demonstrate its growing influence in the field.
Microsoft, securing third place, remains a “veteran” in the database arena: Azure SQL Database offers fully managed relational database services with AI-driven performance optimization and elastic scaling, while SQL Server bridges the gap between on-premises and cloud with hybrid cloud capabilities. Microsoft’s continuous database innovations, coupled with its comprehensive data service ecosystem, make it a force to be reckoned with.
PostgreSQL Convention 2024

- Background
- 0x01 Naming Convention
- 0x01 Design Convention
- 0x01 Query Convention
- 0x01 Admin Convention
Roughly translated from PostgreSQL Convention 2024 with Google.
0x00 Background
No Rules, No Lines
The functions of PostgreSQL are very powerful, but to use PostgreSQL well requires the cooperation of backend, operation and maintenance, and DBA.
This article has compiled a development/operation and maintenance protocol based on the principles and characteristics of the PostgreSQL database, hoping to reduce the confusion you encounter when using the PostgreSQL database: hello, me, everyone.
The first version of this article is mainly for PostgreSQL 9.4 - PostgreSQL 10. The latest version has been updated and adjusted for PostgreSQL 15/16.
0x01 naming convention
There are only two hard problems in computer science: cache invalidation and naming .
Generic naming rules (Generic)
- This rule applies to all objects in the database , including: library names, table names, index names, column names, function names, view names, serial number names, aliases, etc.
- The object name must use only lowercase letters, underscores, and numbers, and the first letter must be a lowercase letter.
- The length of the object name must not exceed 63 characters, and the naming
snake_casestyle must be uniform. - The use of SQL reserved words is prohibited, use
select pg_get_keywords();to obtain a list of reserved keywords. - Dollar signs are prohibited
$, Chinese characters are prohibited, and do notpgbegin with . - Improve your wording taste and be honest and elegant; do not use pinyin, do not use uncommon words, and do not use niche abbreviations.
Cluster naming rules (Cluster)
- The name of the PostgreSQL cluster will be used as the namespace of the cluster resource and must be a valid DNS domain name without any dots or underscores.
- The cluster name should start with a lowercase letter, contain only lowercase letters, numbers, and minus signs, and conform to the regular expression:
[a-z][a-z0-9-]*. - PostgreSQL database cluster naming usually follows a three-part structure:
pg-<biz>-<tld>. Database type/business name/business line or environment bizThe English words that best represent the characteristics of the business should only consist of lowercase letters and numbers, and should not contain hyphens-.- When using a backup cluster to build a delayed slave database of an existing cluster,
bizthe name should be<biz>delay, for examplepg-testdelay. - When branching an existing cluster, you can
bizadd a number at the end of : for example,pg-user1you can branch frompg-user2,pg-user3etc. - For horizontally sharded clusters,
bizthe name should includeshardand be preceded by the shard number, for examplepg-testshard1,pg-testshard2,… <tld>It is the top-level business line and can also be used to distinguish different environments: for example-tt,-dev,-uat,-prodetc. It can be omitted if not required.
Service naming rules (Service)
- Each PostgreSQL cluster will provide 2 to 6 types of external services, which use fixed naming rules by default.
- The service name is prefixed with the cluster name and the service type is suffixed, for example
pg-test-primary,pg-test-replica. - Read-write services are uniformly
primarynamed with the suffix, and read-only services are uniformlyreplicanamed with the suffix. These two services are required. - ETL pull/individual user query is
offlinenamed with the suffix, and direct connection to the main database/ETL write isdefaultnamed with the suffix, which is an optional service. - The synchronous read service is
standbynamed with the suffix, and the delayed slave library service isdelayednamed with the suffix. A small number of core libraries can provide this service.
Instance naming rules (Instance)
- A PostgreSQL cluster consists of at least one instance, and each instance has a unique instance number assigned from zero or one within the cluster.
- The instance name
-is composed of the cluster name + instance number with hyphens , for example:pg-test-1,pg-test-2. - Once assigned, the instance number cannot be modified until the instance is offline and destroyed, and cannot be reassigned for use.
- The instance name will be used as a label for monitoring system data
insand will be attached to all data of this instance. - If you are using a host/database 1:1 exclusive deployment, the node Hostname can use the database instance name.
Database naming rules (Database)
- The database name should be consistent with the cluster and application, and must be a highly distinguishable English word.
- The naming is
<tld>_<biz>constructed in the form of ,<tld>which is the top-level business line. It can also be used to distinguish different environments and can be omitted if not used. <biz>For a specific business name, for example,pg-test-ttthe cluster can use the library namett_testortest. This is not mandatory, i.e. it is allowed to create<biz>other databases with different cluster names.- For sharded libraries,
<biz>the section mustshardend with but should not contain the shard number, for examplepg-testshard1,pg-testshard2bothtestshardshould be used. - Multiple parts use
-joins. For example:<biz>-chat-shard,<biz>-paymentetc., no more than three paragraphs in total.
Role naming convention (Role/User)
dbsuThere is only one database super user :postgres, the user used for streaming replication is namedreplicator.- The users used for monitoring are uniformly named
dbuser_monitor, and the super users used for daily management are:dbuser_dba. - The business user used by the program/service defaults to using
dbuser_<biz>as the username, for exampledbuser_test. Access from different services should be differentiated using separate business users. - The database user applied for by the individual user agrees to use
dbp_<name>, where isnamethe standard user name in LDAP. - The default permission group naming is fixed as:
dbrole_readonly,dbrole_readwrite,dbrole_admin,dbrole_offline.
Schema naming rules (Schema)
- The business uniformly uses a global
<prefix>as the schema name, as short as possible, and is set tosearch_paththe first element by default. <prefix>You must not usepublic,monitor, and must not conflict with any schema name used by PostgreSQL extensions, such as:timescaledb,citus,repack,graphql,net,cron,… It is not appropriate to use special names:dba,trash.- Sharding mode naming rules adopt:
rel_<partition_total_num>_<partition_index>. The middle is the total number of shards, which is currently fixed at 8192. The suffix is the shard number, counting from 0. Such asrel_8192_0,…,,,rel_8192_11etc. - Creating additional schemas, or using
<prefix>schema names other than , will require R&D to explain their necessity.
Relationship naming rules (Relation)
- The first priority for relationship naming is to have clear meaning. Do not use ambiguous abbreviations or be too lengthy. Follow general naming rules.
- Table names should use plural nouns and be consistent with historical conventions. Words with irregular plural forms should be avoided as much as possible.
- Views use
v_as the naming prefix, materialized views usemv_as the naming prefix, temporary tables usetmp_as the naming prefix. - Inherited or partitioned tables should be prefixed by the parent table name and suffixed by the child table attributes (rules, shard ranges, etc.).
- The time range partition uses the starting interval as the naming suffix. If the first partition has no upper bound, the R&D will specify a far enough time point: grade partition:
tbl_2023, month-level partitiontbl_202304, day-level partitiontbl_20230405, hour-level partitiontbl_2023040518. The default partition_defaultends with . - The hash partition is named with the remainder as the suffix of the partition table name, and the list partition is manually specified by the R&D team with a reasonable partition table name corresponding to the list item.
Index naming rules (Index)
- When creating an index, the index name should be specified explicitly and consistent with the PostgreSQL default naming rules.
- Index names are prefixed with the table name, primary key indexes
_pkeyend with , unique indexes_keyend with , ordinary indexes end_idxwith , and indexes used forEXCLUDEDconstraints_exclend with . - When using conditional index/function index, the function and condition content used should be reflected in the index name. For example
tbl_md5_title_idx,tbl_ts_ge_2023_idx, but the length limit cannot be exceeded.
Field naming rules (Attribute)
- It is prohibited to use system column reserved field names:
oid,xmin,xmax,cmin,cmax,ctid. - Primary key columns are usually named with
idor asida suffix. - The conventional name is the creation time field
created_time, and the conventional name is the last modification time field.updated_time is_It is recommended to use , etc. as the prefix for Boolean fieldshas_.- Additional flexible JSONB fields are fixed using
extraas column names. - The remaining field names must be consistent with existing table naming conventions, and any field naming that breaks conventions should be accompanied by written design instructions and explanations.
Enumeration item naming (Enum)
- Enumeration items should be used by default
camelCase, but other styles are allowed.
Function naming rules (Function)
- Function names start with verbs:
select,insert,delete,update,upsert,create,…. - Important parameters can be reflected in the function name through
_by_idsthe_by_user_idssuffix of. - Avoid function overloading and try to keep only one function with the same name.
BIGINT/INTEGER/SMALLINTIt is forbidden to overload function signatures through integer types such as , which may cause ambiguity when calling.- Use named parameters for variables in stored procedures and functions, and avoid positional parameters (
$1,$2,…). - If the parameter name conflicts with the object name, add before the parameter
_, for example_user_id.
Comment specifications (Comment)
- Try your best to provide comments (
COMMENT) for various objects. Comments should be in English, concise and concise, and one line should be used. - When the object’s schema or content semantics change, be sure to update the annotations to keep them in sync with the actual situation.
0x02 Design Convention
To each his own
Things to note when creating a table
- The DDL statement for creating a table needs to use the standard format, with SQL keywords in uppercase letters and other words in lowercase letters.
- Use lowercase letters uniformly in field names/table names/aliases, and try not to be case-sensitive. If you encounter a mixed case, or a name that conflicts with SQL keywords, you need to use double quotation marks for quoting.
- Use specialized type (NUMERIC, ENUM, INET, MONEY, JSON, UUID, …) if applicable, and avoid using
TEXTtype as much as possible. TheTEXTtype is not conducive to the database’s understanding of the data. Use these types to improve data storage, query, indexing, and calculation efficiency, and improve maintainability. - Optimizing column layout and alignment types can have additional performance/storage gains.
- Unique constraints must be guaranteed by the database, and any unique column must have a corresponding unique constraint.
EXCLUDEConstraints are generalized unique constraints that can be used to ensure data integrity in low-frequency update scenarios.
Partition table considerations
- If a single table exceeds hundreds of TB, or the monthly incremental data exceeds more than ten GB, you can consider table partitioning.
- A guideline for partitioning is to keep the size of each partition within the comfortable range of 1GB to 64GB.
- Tables that are conditionally partitioned by time range are first partitioned by time range. Commonly used granularities include: decade, year, month, day, and hour. The partitions required in the future should be created at least three months in advance.
- For extremely skewed data distributions, different time granularities can be combined, for example: 1900 - 2000 as one large partition, 2000 - 2020 as year partitions, and after 2020 as month partitions. When using time partitioning, the table name uses the value of the lower limit of the partition (if infinity, use a value that is far enough back).
Notes on wide tables
- Wide tables (for example, tables with dozens of fields) can be considered for vertical splitting, with mutual references to the main table through the same primary key.
- Because of the PostgreSQL MVCC mechanism, the write amplification phenomenon of wide tables is more obvious, reducing frequent updates to wide tables.
- In Internet scenarios, it is allowed to appropriately lower the normalization level and reduce multi-table connections to improve performance.
Primary key considerations
- Every table must have an identity column , and in principle it must have a primary key. The minimum requirement is to have a non-null unique constraint .
- The identity column is used to uniquely identify any tuple in the table, and logical replication and many third-party tools depend on it.
- If the primary key contains multiple columns, it should be specified using a single column after creating the field list of the table DDL
PRIMARY KEY(a,b,...). - In principle, it is recommended to use integer
UUIDtypes for primary keys, which can be used with caution and text types with limited length. Using other types requires explicit explanation and evaluation. - The primary key usually uses a single integer column. In principle, it is recommended to use it
BIGINT. Use it with cautionINTEGERand it is not allowedSMALLINT. - The primary key should be used to
GENERATED ALWAYS AS IDENTITYgenerate a unique primary key;SERIAL,BIGSERIALwhich is only allowed when compatibility with PG versions below 10 is required. - The primary key can use
UUIDthe type as the primary key, and it is recommended to use UUID v1/v7; use UUIDv4 as the primary key with caution, as random UUID has poor locality and has a collision probability. - When using a string column as a primary key, you should add a length limit. Generally used
VARCHAR(64), use of longer strings should be explained and evaluated. INSERT/UPDATEIn principle, it is forbidden to modify the value of the primary key column, andINSERT RETURNINGit can be used to return the automatically generated primary key value.
Foreign key considerations
- When defining a foreign key, the reference must explicitly set the corresponding action:
SET NULL,SET DEFAULT,CASCADE, and use cascading operations with caution. - The columns referenced by foreign keys need to be primary key columns in other tables/this table.
- Internet businesses, especially partition tables and horizontal shard libraries, use foreign keys with caution and can be solved at the application layer.
Null/Default Value Considerations
- If there is no distinction between zero and null values in the field semantics, null values are not allowed and
NOT NULLconstraints must be configured for the column. - If a field has a default value semantically,
DEFAULTthe default value should be configured.
Numeric type considerations
- Used for regular numeric fields
INTEGER. Used for numeric columns whose capacity is uncertainBIGINT. - Don’t use it without special reasons
SMALLINT. The performance and storage improvements are very small, but there will be many additional problems. - Note that the SQL standard does not provide unsigned integers, and values exceeding
INTMAXbut not exceedingUINTMAXneed to be upgraded and stored. Do not store moreINT64MAXvalues inBIGINTthe column as it will overflow into negative numbers. REALRepresents a 4-byte floating point number,FLOATrepresents an 8-byte floating point number. Floating point numbers can only be used in scenarios where the final precision doesn’t matter, such as geographic coordinates. Remember not to use equality judgment on floating point numbers, except for zero values .- Use exact numeric types
NUMERIC. If possible, useNUMERIC(p)andNUMERIC(p,s)to set the number of significant digits and the number of significant digits in the decimal part. For example, the temperature in Celsius (37.0) canNUMERIC(3,1)be stored with 3 significant digits and 1 decimal place using type. - Currency value type is used
MONEY.
Text type considerations
- PostgreSQL text types include
char(n),varchar(n),text. By default,textthe type can be used, which does not limit the string length, but is limited by the maximum field length of 1GB. - If conditions permit, it is preferable to use
varchar(n)the type to set a maximum string length. This will introduce minimal additional checking overhead, but can avoid some dirty data and corner cases. - Avoid use
char(n), this type has unintuitive behavior (padding spaces and truncation) and has no storage or performance advantages in order to be compatible with the SQL standard.
Time type considerations
- There are only two ways to store time: with time zone
TIMESTAMPTZand without time zoneTIMESTAMP. - It is recommended to use one with time zone
TIMESTAMPTZ. If you useTIMESTAMPstorage, you must use 0 time zone standard time. - Please use it to generate 0 time zone time
now() AT TIME ZONE 'UTC'. You cannot truncate the time zone directlynow()::TIMESTAMP. - Uniformly use ISO-8601 format input and output time type:
2006-01-02 15:04:05to avoid DMY and MDY problems. - Users in China can use
Asia/Hong_Kongthe +8 time zone uniformly because the Shanghai time zone abbreviationCSTis ambiguous.
Notes on enumeration types
- Fields that are more stable and have a small value space (within tens to hundreds) should use enumeration types instead of integers and strings.
- Enumerations are internally implemented using dynamic integers, which have readability advantages over integers and performance, storage, and maintainability advantages over strings.
- Enumeration items can only be added, not deleted, but existing enumeration values can be renamed.
ALTER TYPE <enum_name>Used to modify enumerations.
UUID type considerations
- Please note that the fully random UUIDv4 has poor locality when used as a primary key. Consider using UUIDv1/v7 instead if possible.
- Some UUID generation/processing functions require additional extension plug-ins, such as
uuid-ossp,pg_uuidv7etc. If you have this requirement, please specify it during configuration.
JSON type considerations
- Unless there is a special reason, always use the binary storage
JSONBtype and related functions instead of the text versionJSON. - Note the subtle differences between atomic types in JSON and their PostgreSQL counterparts: the zero character
textis not allowed in the type corresponding to a JSON string\u0000, and the andnumericis not allowed in the type corresponding to a JSON numeric type . Boolean values only accept lowercase and literal values.NaN``infinity``true``false - Please note that objects in the JSON standard
nulland null values in the SQL standardNULLare not the same concept.
Array type considerations
- When storing a small number of elements, array fields can be used instead of individually.
- Suitable for storing data with a relatively small number of elements and infrequent changes. If the number of elements in the array is very large or changes frequently, consider using a separate table to store the data and using foreign key associations.
- For high-dimensional floating-point arrays, consider using
pgvectorthe dedicated data types provided by the extension.
GIS type considerations
- The GIS type uses the srid=4326 reference coordinate system by default.
- Longitude and latitude coordinate points should use the Geography type without explicitly specifying the reference system coordinates 4326
Trigger considerations
- Triggers will increase the complexity and maintenance cost of the database system, and their use is discouraged in principle. The use of rule systems is prohibited and such requirements should be replaced by triggers.
- Typical scenarios for triggers are to automatically modify a row to the current timestamp after modifying it
updated_time, or to record additions, deletions, and modifications of a table to another log table, or to maintain business consistency between the two tables. - Operations in triggers are transactional, meaning if the trigger or operations in the trigger fail, the entire transaction is rolled back, so test and prove the correctness of your triggers thoroughly. Special attention needs to be paid to recursive calls, deadlocks in complex query execution, and the execution sequence of multiple triggers.
Stored procedure/function considerations
-
Functions/stored procedures are suitable for encapsulating transactions, reducing concurrency conflicts, reducing network round-trips, reducing the amount of returned data, and executing a small amount of custom logic.
-
Stored procedures are not suitable for complex calculations, and are not suitable for trivial/frequent type conversion and packaging. In critical high-load systems, unnecessary computationally intensive logic in the database should be removed, such as using SQL in the database to convert WGS84 to other coordinate systems. Calculation logic closely related to data acquisition and filtering can use functions/stored procedures: for example, geometric relationship judgment in PostGIS.
-
Replaced functions and stored procedures that are no longer in use should be taken offline in a timely manner to avoid conflicts with future functions.
-
Use a unified syntax format for function creation. The signature occupies a separate line (function name and parameters), the return value starts on a separate line, and the language is the first label. Be sure to mark the function volatility level:
IMMUTABLE,STABLE,VOLATILE. Add attribute tags, such as:RETURNS NULL ON NULL INPUT,PARALLEL SAFE,ROWS 1etc.CREATE OR REPLACE FUNCTION nspname.myfunc(arg1_ TEXT, arg2_ INTEGER) RETURNS VOID LANGUAGE SQL STABLE PARALLEL SAFE ROWS 1 RETURNS NULL ON NULL INPUT AS $function$ SELECT 1; $function$;
Use sensible Locale options
- Used by default
en_US.UTF8and cannot be changed without special reasons. - The default
collaterule must beC, to avoid string indexing problems. - https://mp.weixin.qq.com/s/SEXcyRFmdXNI7rpPUB3Zew
Use reasonable character encoding and localization configuration
- Character encoding must be used
UTF8, any other character encoding is strictly prohibited. - Must be used
CasLC_COLLATEthe default collation, any special requirements must be explicitly specified in the DDL/query clause to implement. - Character set
LC_CTYPEis used by defaulten_US.UTF8, some extensions rely on character set information to work properly, such aspg_trgm.
Notes on indexing
- All online queries must design corresponding indexes according to their access patterns, and full table scans are not allowed except for very small tables.
- Indexes have a price, and it is not allowed to create unused indexes. Indexes that are no longer used should be cleaned up in time.
- When building a joint index, columns with high differentiation and selectivity should be placed first, such as ID, timestamp, etc.
- GiST index can be used to solve the nearest neighbor query problem, and traditional B-tree index cannot provide good support for KNN problem.
- For data whose values are linearly related to the storage order of the heap table, if the usual query is a range query, it is recommended to use the BRIN index. The most typical scenario is to only append written time series data. BRIN index is more efficient than Btree.
- When retrieving against JSONB/array fields, you can use GIN indexes to speed up queries.
Clarify the order of null values in B-tree indexes
NULLS FIRSTIf there is a sorting requirement on a nullable column, it needs to be explicitly specified in the query and indexNULLS LAST.- Note that
DESCthe default rule for sorting isNULLS FIRSTthat null values appear first in the sort, which is generally not desired behavior. - The sorting conditions of the index must match the query, such as:
CREATE INDEX ON tbl (id DESC NULLS LAST);
Disable indexing on large fields
- The size of the indexed field cannot exceed 2KB (1/3 of the page capacity). You need to be careful when creating indexes on text types. The text to be indexed should use
varchar(n)types with length constraints. - When a text type is used as a primary key, a maximum length must be set. In principle, the length should not exceed 64 characters. In special cases, the evaluation needs to be explicitly stated.
- If there is a need for large field indexing, you can consider hashing the large field and establishing a function index. Or use another type of index (GIN).
Make the most of functional indexes
- Any redundant fields that can be inferred from other fields in the same row can be replaced using functional indexes.
- For statements that often use expressions as query conditions, you can use expression or function indexes to speed up queries.
- Typical scenario: Establish a hash function index on a large field, and establish a
reversefunction index for text columns that require left fuzzy query.
Take advantage of partial indexes
- For the part of the query where the query conditions are fixed, partial indexes can be used to reduce the index size and improve query efficiency.
- If a field to be indexed in a query has only a limited number of values, several corresponding partial indexes can also be established.
- If the columns in some indexes are frequently updated, please pay attention to the expansion of these indexes.
0x03 Query Convention
The limits of my language mean the limits of my world.
—Ludwig Wittgenstein
Use service access
- Access to the production database must be through domain name access services , and direct connection using IP addresses is strictly prohibited.
- VIP is used for services and access, LVS/HAProxy shields the role changes of cluster instance members, and master-slave switching does not require application restart.
Read and write separation
- Internet business scenario: Write requests must go through the main library and be accessed through the Primary service.
- In principle, read requests go from the slave library and are accessed through the Replica service.
- Exceptions: If you need “Read Your Write” consistency guarantees, and significant replication delays are detected, read requests can access the main library; or apply to the DBA to provide Standby services.
Separation of speed and slowness
- Queries within 1 millisecond in production are called fast queries, and queries that exceed 1 second in production are called slow queries.
- Slow queries must go to the offline slave database - Offline service/instance, and a timeout should be set during execution.
- In principle, the execution time of online general queries in production should be controlled within 1ms.
- If the execution time of an online general query in production exceeds 10ms, the technical solution needs to be modified and optimized before going online.
- Online queries should be configured with a Timeout of the order of 10ms or faster to avoid avalanches caused by accumulation.
- ETL data from the primary is prohibited, and the offline service should be used to retrieve data from a dedicated instance.
Use connection pool
- Production applications must access the database through a connection pool and the PostgreSQL database through a 1:1 deployed Pgbouncer proxy. Offline service, individual users are strictly prohibited from using the connection pool directly.
- Pgbouncer connection pool uses Transaction Pooling mode by default. Some session-level functions may not be available (such as Notify/Listen), so special attention is required. Pre-1.21 Pgbouncer does not support the use of Prepared Statements in this mode. In special scenarios, you can use Session Pooling or bypass the connection pool to directly access the database, which requires special DBA review and approval.
- When using a connection pool, it is prohibited to modify the connection status, including modifying connection parameters, modifying search paths, changing roles, and changing databases. The connection must be completely destroyed after modification as a last resort. Putting the changed connection back into the connection pool will lead to the spread of contamination. Use of pg_dump to dump data via Pgbouncer is strictly prohibited.
Configure active timeout for query statements
- Applications should configure active timeouts for all statements and proactively cancel requests after timeout to avoid avalanches. (Go context)
- Statements that are executed periodically must be configured with a timeout smaller than the execution period to avoid avalanches.
- HAProxy is configured with a default connection timeout of 24 hours for rolling expired long connections. Please do not run SQL that takes more than 1 day to execute on offline instances. This requirement will be specially adjusted by the DBA.
Pay attention to replication latency
- Applications must be aware of synchronization delays between masters and slaves and properly handle situations where replication delays exceed reasonable limits.
- Under normal circumstances, replication delays are on the order of 100µs/tens of KB, but in extreme cases, slave libraries may experience replication delays of minutes/hours. Applications should be aware of this phenomenon and have corresponding degradation plans - Select Read from the main library and try again later, or report an error directly.
Retry failed transactions
- Queries may be killed due to concurrency contention, administrator commands, etc. Applications need to be aware of this and retry if necessary.
- When the application reports a large number of errors in the database, it can trigger the circuit breaker to avoid an avalanche. But be careful to distinguish the type and nature of errors.
Disconnected and reconnected
- The database connection may be terminated for various reasons, and the application must have a disconnection reconnection mechanism.
- It can be used
SELECT 1as a heartbeat packet query to detect the presence of messages on the connection and keep it alive periodically.
Online service application code prohibits execution of DDL
- It is strictly forbidden to execute DDL in production applications and do not make big news in the application code.
- Exception scenario: Creating new time partitions for partitioned tables can be carefully managed by the application.
- Special exception: Databases used by office systems, such as Gitlab/Jira/Confluence, etc., can grant application DDL permissions.
SELECT statement explicitly specifies column names
- Avoid using it
SELECT *, orRETURNINGuse it in a clause*. Please use a specific field list and do not return unused fields. When the table structure changes (for example, a new value column), queries that use column wildcards are likely to encounter column mismatch errors. - After the fields of some tables are maintained, the order will change. For example: after
idupgrading the INTEGER primary key toBIGINT,idthe column order will be the last column. This problem can only be fixed during maintenance and migration. R&D developers should resist the compulsion to adjust the column order and explicitly specify the column order in the SELECT statement. - Exception: Wildcards are allowed when a stored procedure returns a specific table row type.
Disable online query full table scan
- Exceptions: constant minimal table, extremely low-frequency operations, table/return result set is very small (within 100 records/100 KB).
- Using negative operators such as on the first-level filter condition will result in a full table scan and must be
!=avoided .<>
Disallow long waits in transactions
- Transactions must be committed or rolled back as soon as possible after being started. Transactions that exceed 10 minutes
IDEL IN Transactionwill be forcibly killed. - Applications should enable AutoCommit to avoid
BEGINunpairedROLLBACKor unpaired applications laterCOMMIT. - Try to use the transaction infrastructure provided by the standard library, and do not control transactions manually unless absolutely necessary.
Things to note when using count
count(*)It is the standard syntax for counting rows and has nothing to do with null values.count(col)The count is the number of non-null recordscolin the column . NULL values in this column will not be counted.count(distinct col)Whencoldeduplicating columns and counting them, null values are also ignored, that is, only the number of non-null distinct values is counted.count((col1, col2))When counting multiple columns, even if the columns to be counted are all empty, they will still be counted.(NULL,NULL)This is valid.a(distinct (col1, col2))For multi-column deduplication counting, even if the columns to be counted are all empty, they will be counted,(NULL,NULL)which is effective.
Things to note when using aggregate functions
- All
countaggregate functions exceptNULLButcount(col)in this case it will be returned0as an exception. - If returning null from an aggregate function is not expected, use
coalesceto set a default value.
Handle null values with caution
-
Clearly distinguish between zero values and null values. Use null values
IS NULLfor equivalence judgment, and use regular=operators for zero values for equivalence judgment. -
When a null value is used as a function input parameter, it should have a type modifier, otherwise the overloaded function will not be able to identify which one to use.
-
Pay attention to the null value comparison logic: the result of any comparison operation involving null values is
unknownyou need to pay attention tonullthe logic involved in Boolean operations:and:TRUE or NULLWill return due to logical short circuitTRUE.or:FALSE and NULLWill return due to logical short circuitFALSE- In other cases, as long as the operand appears
NULL, the result isNULL
-
The result of logical judgment between null value and any value is null value, for example,
NULL=NULLthe return result isNULLnotTRUE/FALSE. -
For equality comparisons involving null values and non-null values, please use ``IS DISTINCT FROM
-
NULL values and aggregate functions: When all input values are NULL, the aggregate function returns NULL.
Note that the serial number is empty
- When using
Serialtypes,INSERT,UPSERTand other operations will consume sequence numbers, and this consumption will not be rolled back when the transaction fails. - When using an integer
INTEGERas the primary key and the table has frequent insertion conflicts, you need to pay attention to the problem of integer overflow.
The cursor must be closed promptly after use
Repeated queries using prepared statements
- Prepared Statements should be used for repeated queries to eliminate the CPU overhead of database hard parsing. Pgbouncer versions earlier than 1.21 cannot support this feature in transaction pooling mode, please pay special attention.
- Prepared statements will modify the connection status. Please pay attention to the impact of the connection pool on prepared statements.
Choose the appropriate transaction isolation level
- The default isolation level is read committed , which is suitable for most simple read and write transactions. For ordinary transactions, choose the lowest isolation level that meets the requirements.
- For write transactions that require transaction-level consistent snapshots, use the Repeatable Read isolation level.
- For write transactions that have strict requirements on correctness (such as money-related), use the serializable isolation level.
- When a concurrency conflict occurs between the RR and SR isolation levels, the application should actively retry depending on the error type.
rh 09 Do not use count when judging the existence of a result.
- It is faster than Count to
SELECT 1 FROM tbl WHERE xxx LIMIT 1judge whether there are columns that meet the conditions. SELECT exists(SELECT * FROM tbl WHERE xxx LIMIT 1)The existence result can be converted to a Boolean value using .
Use the RETURNING clause to retrieve the modified results in one go
RETURNINGThe clause can be used after theINSERT,UPDATE,DELETEstatement to effectively reduce the number of database interactions.
Use UPSERT to simplify logic
- When the business has an insert-failure-update sequence of operations, consider using
UPSERTsubstitution.
Use advisory locks to deal with hotspot concurrency .
- For extremely high-frequency concurrent writes (spike) of single-row records, advisory locks should be used to lock the record ID.
- If high concurrency contention can be resolved at the application level, don’t do it at the database level.
Optimize IN operator
- Use
EXISTSclause instead ofINoperator for better performance. - Use
=ANY(ARRAY[1,2,3,4])insteadIN (1,2,3,4)for better results. - Control the size of the parameter list. In principle, it should not exceed 10,000. If it exceeds, you can consider batch processing.
It is not recommended to use left fuzzy search
- Left fuzzy search
WHERE col LIKE '%xxx'cannot make full use of B-tree index. If necessary,reverseexpression function index can be used.
Use arrays instead of temporary tables
- Consider using an array instead of a temporary table, for example when obtaining corresponding records for a series of IDs.
=ANY(ARRAY[1,2,3])Better than temporary table JOIN.
0x04 Administration Convention
Use Pigsty to build PostgreSQL cluster and infrastructure
- The production environment uses the Pigsty trunk version uniformly, and deploys the database on x86_64 machines and CentOS 7.9 / RockyLinux 8.8 operating systems.
pigsty.ymlConfiguration files usually contain highly sensitive and important confidential information. Git should be used for version management and access permissions should be strictly controlled.files/pkiThe CA private key and other certificates generated within the system should be properly kept, regularly backed up to a secure area for storage and archiving, and access permissions should be strictly controlled.- All passwords are not allowed to use default values, and make sure they have been changed to new passwords with sufficient strength.
- Strictly control access rights to management nodes and configuration code warehouses, and only allow DBA login and access.
Monitoring system is a must
- Any deployment must have a monitoring system, and the production environment uses at least two sets of Infra nodes to provide redundancy.
Properly plan the cluster architecture according to needs
- Any production database cluster managed by a DBA must have at least one online slave database for online failover.
- The template is used by default
oltp, the analytical database usesolapthe template, the financial database usescritthe template, and the micro virtual machine (within four cores) usestinythe template. - For businesses whose annual data volume exceeds 1TB, or for clusters whose write TPS exceeds 30,000 to 50,000, you can consider building a horizontal sharding cluster.
Configure cluster high availability using Patroni and Etcd
- The production database cluster uses Patroni as the high-availability component and etcd as the DCS.
etcdUse a dedicated virtual machine cluster, with 3 to 5 nodes, strictly scattered and distributed on different cabinets.- Patroni Failsafe mode must be turned on to ensure that the cluster main library can continue to work when etcd fails.
Configure cluster PITR using pgBackRest and MinIO
- The production database cluster uses pgBackRest as the backup recovery/PITR solution and MinIO as the backup storage warehouse.
- MinIO uses a multi-node multi-disk cluster, and can also use S3/OSS/COS services instead. Password encryption must be set for cold backup.
- All database clusters perform a local full backup every day, retain the backup and WAL of the last week, and save a full backup every other month.
- When a WAL archiving error occurs, you should check the backup warehouse and troubleshoot the problem in time.
Core business database configuration considerations
- The core business cluster needs to configure at least two online slave libraries, one of which is a dedicated offline query instance.
- The core business cluster needs to build a delayed slave cluster with a 24-hour delay for emergency data recovery.
- Core business clusters usually use asynchronous submission, while those related to money use synchronous submission.
Financial database configuration considerations
- The financial database cluster requires at least two online slave databases, one of which is a dedicated synchronization Standby instance, and Standby service access is enabled.
- Money-related libraries must use
crittemplates with RPO = 0, enable synchronous submission to ensure zero data loss, and enable Watchdog as appropriate. - Money-related libraries must be forced to turn on data checksums and, if appropriate, turn on full DML logs.
Use reasonable character encoding and localization configuration
- Character encoding must be used
UTF8, any other character encoding is strictly prohibited. - Must be used
CasLC_COLLATEthe default collation, any special requirements must be explicitly specified in the DDL/query clause to implement. - Character set
LC_CTYPEis used by defaulten_US.UTF8, some extensions rely on character set information to work properly, such aspg_trgm.
Business database management considerations
- Multiple different databases are allowed to be created in the same cluster, and Ansible scripts must be used to create new business databases.
- All business databases must exist synchronously in the Pgbouncer connection pool.
Business user management considerations
- Different businesses/services must use different database users, and Ansible scripts must be used to create new business users.
- All production business users must be synchronized in the user list file of the Pgbouncer connection pool.
- Individual users should set a password with a default validity period of 90 days and change it regularly.
- Individual users are only allowed to access authorized cluster offline instances or slave
pg_offline_querylibraries with from the springboard machine.
Notes on extension management
yum/aptWhen installing a new extension, you must first install the corresponding major version of the extension binary package in all instances of the cluster .- Before enabling the extension, you need to confirm whether the extension needs to be added
shared_preload_libraries. If necessary, a rolling restart should be arranged. - Note that
shared_preload_librariesin order of priority,citus,timescaledb,pgmlare usually placed first. pg_stat_statementsandauto_explainare required plugins and must be enabled in all clusters.- Install extensions uniformly using , and create them
dbsuin the business database .CREATE EXTENSION
Database XID and age considerations
- Pay attention to the age of the database and tables to avoid running out of XID transaction numbers. If the usage exceeds 20%, you should pay attention; if it exceeds 50%, you should intervene immediately.
- When processing XID, execute the table one by one in order of age from largest to smallest
VACUUM FREEZE.
Database table and index expansion considerations
- Pay attention to the expansion rate of tables and indexes to avoid index performance degradation, and use
pg_repackonline processing to handle table/index expansion problems. - Generally speaking, indexes and tables whose expansion rate exceeds 50% can be considered for reorganization.
- When dealing with table expansion exceeding 100GB, you should pay special attention and choose business low times.
Database restart considerations
- Before restarting the database, execute it
CHECKPOINTtwice to force dirty pages to be flushed, which can speed up the restart process. - Before restarting the database, perform
pg_ctl reloadreload configuration to confirm that the configuration file is available normally. - To restart the database, use
pg_ctl restartpatronictl or patronictl to restart the entire cluster at the same time. - Use
kill -9to shut down any database process is strictly prohibited.
Replication latency considerations
- Monitor replication latency, especially when using replication slots.
New slave database data warm-up
- When adding a new slave database instance to a high-load business cluster, the new database instance should be warmed up, and the HAProxy instance weight should be gradually adjusted and applied in gradients: 4, 8, 16, 32, 64, and 100.
pg_prewarmHot data can be loaded into memory using .
Database publishing process
- Online database release requires several evaluation stages: R&D self-test, supervisor review, QA review (optional), and DBA review.
- During the R&D self-test phase, R&D should ensure that changes are executed correctly in the development and pre-release environments.
- If a new table is created, the record order magnitude, daily data increment estimate, and read and write throughput magnitude estimate should be given.
- If it is a new function, the average execution time and extreme case descriptions should be given.
- If it is a mode change, all upstream and downstream dependencies must be sorted out.
- If it is a data change and record revision, a rollback SQL must be given.
- The R&D Team Leader needs to evaluate and review changes and be responsible for the content of the changes.
- The DBA evaluates and reviews the form and impact of the release, puts forward review opinions, and calls back or implements them uniformly.
Data work order format
- Database changes are made through the platform, with one work order for each change.
- The title is clear: A certain business needs
xxto perform an action in the databaseyy. - The goal is clear: what operations need to be performed on which instances in each step, and how to verify the results.
- Rollback plan: Any changes need to provide a rollback plan, and new ones also need to provide a cleanup script.
- Any changes need to be recorded and archived, and have complete approval records. They are first approved by the R&D superior TL Review and then approved by the DBA.
Database change release considerations
- Using a unified release window, changes of the day will be collected uniformly at 16:00 every day and executed sequentially; requirements confirmed by TL after 16:00 will be postponed to the next day. Database release is not allowed after 19:00. For emergency releases, please ask TL to make special instructions and send a copy to the CTO for approval before execution.
- Database DDL changes and DML changes are uniformly
dbuser_dbaexecuted remotely using the administrator user to ensure that the default permissions work properly. - When the business administrator executes DDL by himself, he must
SET ROLE dbrole_adminfirst execute the release to ensure the default permissions. - Any changes require a rollback plan before they can be executed, and very few operations that cannot be rolled back need to be handled with special caution (such as enumeration of value additions)
- Database changes use
psqlcommand line tools, connect to the cluster main database to execute, use\iexecution scripts or\emanual execution in batches.
Things to note when deleting tables
- The production data table
DROPshould be renamed first and allowed to cool for 1 to 3 days to ensure that it is not accessed before being removed. - When cleaning the table, you must sort out all dependencies, including directly and indirectly dependent objects: triggers, foreign key references, etc.
- The temporary table to be deleted is usually placed in
trashSchema andALTER TABLE SET SCHEMAthe schema name is modified. - In high-load business clusters, when removing particularly large tables (> 100G), select business valleys to avoid preempting I/O.
Things to note when creating and deleting indexes
- You must use
CREATE INDEX CONCURRENTLYconcurrent index creation andDROP INDEX CONCURRENTLYconcurrent index removal. - When rebuilding an index, always create a new index first, then remove the old index, and modify the new index name to be consistent with the old index.
- After index creation fails, you should remove
INVALIDthe index in time. After modifying the index, useanalyzeto re-collect statistical data on the table. - When the business is idle, you can enable parallel index creation and set it
maintenance_work_memto a larger value to speed up index creation.
Make schema changes carefully
- Try to avoid full table rewrite changes as much as possible. Full table rewrite is allowed for tables within 1GB. The DBA should notify all relevant business parties when the changes are made.
- When adding new columns to an existing table, you should avoid using functions in default values
VOLATILEto avoid a full table rewrite. - When changing a column type, all functions and views that depend on that type should be rebuilt if necessary, and
ANALYZEstatistics should be refreshed.
Control the batch size of data writing
- Large batch write operations should be divided into small batches to avoid generating a large amount of WAL or occupying I/O at one time.
- After a large batch
UPDATEis executed,VACUUMthe space occupied by dead tuples is reclaimed. - The essence of executing DDL statements is to modify the system directory, and it is also necessary to control the number of DDL statements in a batch.
Data loading considerations
- Use
COPYload data, which can be executed in parallel if necessary. - You can temporarily shut down before loading data
autovacuum, disable triggers as needed, and create constraints and indexes after loading. - Turn it up
maintenance_work_mem, increase itmax_wal_size. - Executed after loading is complete
vacuum verbose analyze table.
Notes on database migration and major version upgrades
- The production environment uniformly uses standard migration to build script logic, and realizes requirements such as non-stop cluster migration and major version upgrades through blue-green deployment.
- For clusters that do not require downtime, you can use
pg_dump | psqllogical export and import to stop and upgrade.
Data Accidental Deletion/Accidental Update Process
- After an accident occurs, immediately assess whether it is necessary to stop the operation to stop bleeding, assess the scale of the impact, and decide on treatment methods.
- If there is a way to recover on the R&D side, priority will be given to the R&D team to make corrections through SQL publishing; otherwise, use
pageinspectandpg_dirtyreadto rescue data from the bad table. - If there is a delayed slave library, extract data from the delayed slave library for repair. First, confirm the time point of accidental deletion, and advance the delay to extract data from the database to the XID.
- A large area was accidentally deleted and written. After communicating with the business and agreeing, perform an in-place PITR rollback to a specific time.
Data corruption processing process
- Confirm whether the slave database data can be used for recovery. If the slave database data is intact, you can switchover to the slave database first.
- Temporarily shut down
auto_vacuum, locate the root cause of the error, replace the failed disk and add a new slave database. - If the system directory is damaged, or use to
pg_filedumprecover data from table binaries. - If the CLOG is damaged, use
ddto generate a fake submission record.
Things to note when the database connection is full
- When the connection is full (avalanche), immediately use the kill connection query to cure the symptoms and stop the loss:
pg_cancel_backendorpg_terminate_backend. - Use to
pg_terminate_backendabort all normal backend processes,psql\watch 1starting with once per second ( ). And confirm the connection status from the monitoring system. If the accumulation continues, continue to increase the execution frequency of the connection killing query, for example, once every 0.1 seconds until there is no more accumulation. - After confirming that the bleeding has stopped from the monitoring system, try to stop the killing connection. If the accumulation reappears, immediately resume the killing connection. Immediately analyze the root cause and perform corresponding processing (upgrade, limit current, add index, etc.)
FerretDB: When PG Masquerades as MongoDB
MongoDB was once a revolutionary technology that liberated developers from the “schema shackles” of relational databases, enabling rapid application development. However, as time passed, MongoDB gradually drifted away from its open-source roots, leaving many open-source projects and early-stage businesses in a bind.
Here’s the thing: most MongoDB users don’t actually need MongoDB’s advanced features. What they really need is a user-friendly, open-source document database solution. PostgreSQL has already evolved into a fully-featured, high-performance document database with its mature JSON capabilities: binary JSONB storage, GIN indexing for arbitrary fields, rich JSON processing functions, JSON PATH, and JSON Schema support. But having alternative functionality is one thing - providing a direct emulation is another beast entirely.
Enter FerretDB, born to fill this gap with a mission to provide a truly open-source MongoDB alternative. It’s an fascinating project with an interesting history - it was originally named “MangoDB” but changed to FerretDB for its 1.0 release to avoid any confusion with “MongoDB” (Mango DB vs Mongo DB). FerretDB offers applications using MongoDB drivers a smooth migration path to PostgreSQL.
Its magic trick? Making PostgreSQL impersonate MongoDB. It acts as a protocol translation middleware/proxy that enables PG to speak the MongoDB Wire Protocol. The last time we saw something similar was AWS’s Babelfish, which made PostgreSQL pretend to be Microsoft SQL Server by supporting the SQL Server wire protocol.
As an optional component, FerretDB significantly enriches the PostgreSQL ecosystem. Pigsty has supported FerretDB deployment via Docker templates since version 1.x and now offers native deployment support in v2.3. The Pigsty community has formed a partnership with the FerretDB community, paving the way for deeper integration and support.
This article will walk you through the installation, deployment, and usage of FerretDB.
Configuration
Before deploying a Mongo (FerretDB) cluster, you’ll need to define it in your configuration manifest. Here’s an example that uses the default single-node pg-meta cluster’s meta database as FerretDB’s underlying storage:
ferret:
hosts: { 10.10.10.10: { mongo_seq: 1 } }
vars:
mongo_cluster: ferret
mongo_pgurl: 'postgres://dbuser_meta:[email protected]:5432/meta'
Here mongo_cluster and mongo_seq are essential identity parameters, and for FerretDB, another required parameter is mongo_pgurl, specifying the underlying PG location.
You can use the pg-meta cluster as the underlying storage for FerretDB, and deploy multiple FerretDB instance replicas with L2 VIP binding to achieve high availability at the FerretDB layer itself.
ferret-ha:
hosts:
10.10.10.45: { mongo_seq: 1 }
10.10.10.46: { mongo_seq: 2 }
10.10.10.47: { mongo_seq: 3 }
vars:
mongo_cluster: ferret
mongo_pgurl: 'postgres://test:[email protected]:5436/test'
vip_enabled: true
vip_vrid: 128
vip_address: 10.10.10.99
vip_interface: eth1
Management
Create Mongo Cluster
After defining the MONGO cluster in the configuration manifest, you can use the following command to complete the installation.
./mongo.yml -l ferret # Install "MongoDB/FerretDB" on the ferret group
Because FerretDB uses PostgreSQL as its underlying storage, repeating this playbook usually won’t cause any harm.
Remove Mongo Cluster
To remove the Mongo/FerretDB cluster, run the mongo.yml playbook’s task: mongo_purge, and use the mongo_purge command line parameter:
./mongo.yml -e mongo_purge=true -t mongo_purge
Install MongoSH
You can use MongoSH as a client tool to access the FerretDB cluster
cat > /etc/yum.repos.d/mongo.repo <<EOF
[mongodb-org-6.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/6.0/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-6.0.asc
EOF
yum install -y mongodb-mongosh
Of course, you can also directly install the RPM package of mongosh:
rpm -ivh https://mirrors.tuna.tsinghua.edu.cn/mongodb/yum/el7/RPMS/mongodb-mongosh-1.9.1.x86_64.rpm
Connect to FerretDB
You can use the MongoDB connection string to access FerretDB using any language’s MongoDB driver. Here’s an example using the mongosh command line tool we installed:
mongosh 'mongodb://dbuser_meta:[email protected]:27017?authMechanism=PLAIN'mongosh 'mongodb://test:[email protected]:27017/test?authMechanism=PLAIN'
Pigsty’s managed PostgreSQL cluster uses scram-sha-256 as the default authentication method, so you must use the PLAIN authentication method to connect to FerretDB. See FerretDB: Authentication[17] for more details.
You can also use other PostgreSQL users to access FerretDB by specifying them in the connection string:
mongosh 'mongodb://dbuser_dba:[email protected]:27017?authMechanism=PLAIN'
Quick Start
You can connect to FerretDB and pretend it’s a MongoDB cluster.
$ mongosh 'mongodb://dbuser_meta:[email protected]:27017?authMechanism=PLAIN'
MongoDB commands will be translated to SQL commands and executed in the underlying PostgreSQL:
use test # CREATE SCHEMA test;
db.dropDatabase() # DROP SCHEMA test;
db.createCollection('posts') # CREATE TABLE posts(_data JSONB,...)
db.posts.insert({ # INSERT INTO posts VALUES(...);
title: 'Post One',body: 'Body of post one',category: 'News',tags: ['news', 'events'],
user: {name: 'John Doe',status: 'author'},date: Date()}
)
db.posts.find().limit(2).pretty() # SELECT * FROM posts LIMIT 2;
db.posts.createIndex({ title: 1 }) # CREATE INDEX ON posts(_data->>'title');
If you’re not familiar with MongoDB, here’s a quick start tutorial that’s also applicable to FerretDB: Perform CRUD Operations with MongoDB Shell[18]
If you want to generate some sample load, you can use mongosh to execute the following simple test playbook:
cat > benchmark.js <<'EOF'
const coll = "testColl";
const numDocs = 10000;
for (let i = 0; i < numDocs; i++) { // insert
db.getCollection(coll).insert({ num: i, name: "MongoDB Benchmark Test" });
}
for (let i = 0; i < numDocs; i++) { // select
db.getCollection(coll).find({ num: i });
}
for (let i = 0; i < numDocs; i++) { // update
db.getCollection(coll).update({ num: i }, { $set: { name: "Updated" } });
}
for (let i = 0; i < numDocs; i++) { // delete
db.getCollection(coll).deleteOne({ num: i });
}
EOF
mongosh 'mongodb://dbuser_meta:[email protected]:27017?authMechanism=PLAIN' benchmark.js
You can check out the MongoDB commands supported by FerretDB, as well as some known differences for basic usage, which usually isn’t a big deal.
- FerretDB uses the same protocol error names and codes, but the exact error messages may be different in some cases.
- FerretDB does not support NUL (
\0) characters in strings. - FerretDB does not support nested arrays.
- FerretDB converts
-0(negative zero) to0(positive zero). - Document restrictions:
- document keys must not contain
.sign; - document keys must not start with
$sign; - document fields of double type must not contain
Infinity,-Infinity, orNaNvalues.
- document keys must not contain
- When insert command is called, insert documents must not have duplicate keys.
- Update command restrictions:
- update operations producing
Infinity,-Infinity, orNaNare not supported.
- update operations producing
- Database and collection names restrictions:
- name cannot start with the reserved prefix
_ferretdb_; - database name must not include non-latin letters;
- collection name must be valid UTF-8 characters;
- name cannot start with the reserved prefix
- FerretDB offers the same validation rules for the
scaleparameter in both thecollStatsanddbStatscommands. If an invalidscalevalue is provided in thedbStatscommand, the same error codes will be triggered as with thecollStatscommand.
Playbook
Pigsty provides a built-in playbook: mongo.yml, for installing a FerretDB cluster on a node.
mongo.yml
This playbook consists of the following tasks:
mongo_check: Check mongo identity parameters•mongo_dbsu: Create the mongod operating system user•mongo_install: Install mongo/ferretdb RPM package•mongo_purge: Clean up existing mongo/ferretdb cluster (default not executed)•mongo_config: Configure mongo/ferretdbmongo_cert: Issue mongo/ferretdb SSL certificatemongo_launch: Start mongo/ferretdb service•mongo_register:Register mongo/ferretdb to Prometheus monitoring
Monitoring
MONGO module provides a simple monitoring panel: Mongo Overview
Mongo Overview
Mongo Overview: Mongo/FerretDB cluster overview
This monitoring panel provides basic monitoring metrics about FerretDB, as FerretDB uses PostgreSQL as its underlying storage, so more monitoring metrics, please refer to PostgreSQL itself monitoring.
Parameters
MONGO[24] module provides 9 related configuration parameters, as shown in the table below:
| Parameter | Type | Level | Comment |
|---|---|---|---|
mongo_seq |
int | I | mongo instance number, required identity parameter |
mongo_cluster |
string | C | mongo cluster name, required identity parameter |
mongo_pgurl |
pgurl | C/I | mongo/ferretdb underlying PGURL connection string, required |
mongo_ssl_enabled |
bool | C | Whether mongo/ferretdb enable SSL? Default is false |
mongo_listen |
ip | C | mongo listening address, default to listen to all addresses |
mongo_port |
port | C | mongo service port, default to use 27017 |
mongo_ssl_port |
port | C | mongo TLS listening port, default to use 27018 |
mongo_exporter_port |
port | C | mongo exporter port, default to use 9216 |
mongo_extra_vars |
string | C | MONGO server additional environment variables, default blank string |
PostgreSQL, The most successful database
The StackOverflow 2023 Survey, featuring feedback from 90K developers across 185 countries, is out. PostgreSQL topped all three survey categories (used, loved, and wanted), earning its title as the undisputed “Decathlete Database” – it’s hailed as the “Linux of Database”!
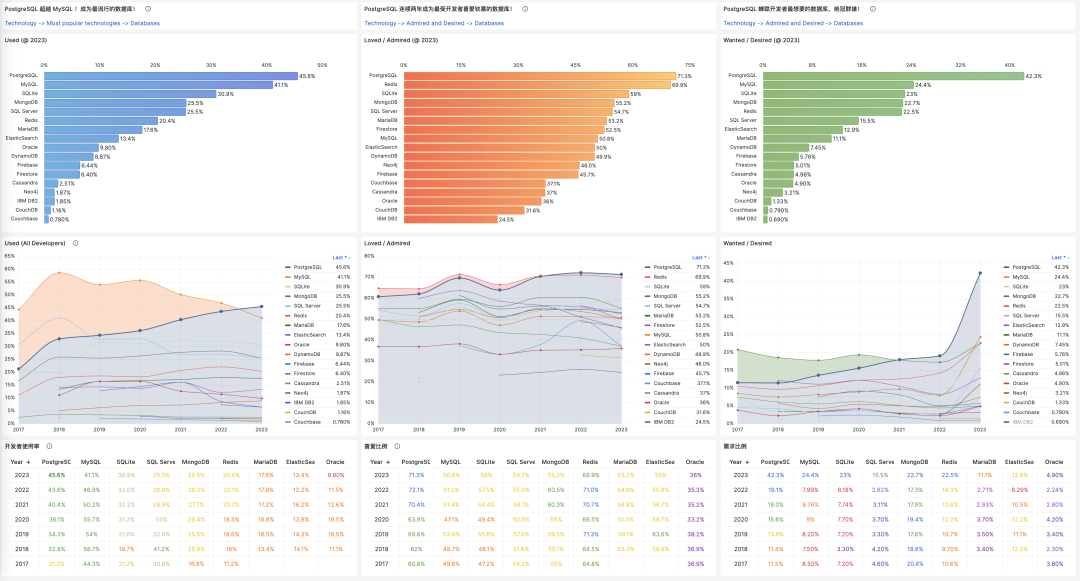
What makes a database “successful”? It’s a mix of features, quality, security, performance, and cost, but success is mainly about adoption and legacy. The size, preference, and needs of its user base are what truly shape its ecosystem’s prosperity. StackOverflow’s annual surveys for seven years have provided a window into tech trends.
PostgreSQL is now the world’s most popular database.
PostgreSQL is developers’ favorite database!
PostgreSQL sees the highest demand among users!
Popularity, the used reflects the past, the loved indicates the present, and the wanted suggests the future. These metrics vividly showcase the vitality of a technology. PostgreSQL stands strong in both stock and potential, unlikely to be rivaled soon.
As a dedicated user, community member, expert, evangelist, and contributor to PostgreSQL, witnessing this moment is profoundly moving. Let’s delve into the “Why” and “What” behind this phenomenon.
Source: Community Survey
Developers define the success of databases, and StackOverflow’s survey, with popularity, love, and demand metrics, captures this directly.
“Which database environments have you done extensive development work in over the past year, and which do you want to work in over the next year? If you both worked with the database and want to continue to do so, please check both boxes in that row.”
Each database in the survey had two checkboxes: one for current use, marking the user as “Used,” and one for future interest, marking them as “Wanted.” Those who checked both were labeled as “Loved/Admired.”
The percentage of “Used” respondents represents popularity or usage rate, shown as a bar chart, while “Wanted” indicates demand or desire, marked with blue dots. “Loved/Admired” shows as red dots, indicating love or reputation. In 2023, PostgreSQL outstripped MySQL in popularity, becoming the world’s most popular database, and led by a wide margin in demand and reputation.
Reviewing seven years of data and plotting the top 10 databases on a scatter chart of popularity vs. net love percentage (2*love% - 100), we gain insights into the database field’s evolution and sense of scale.
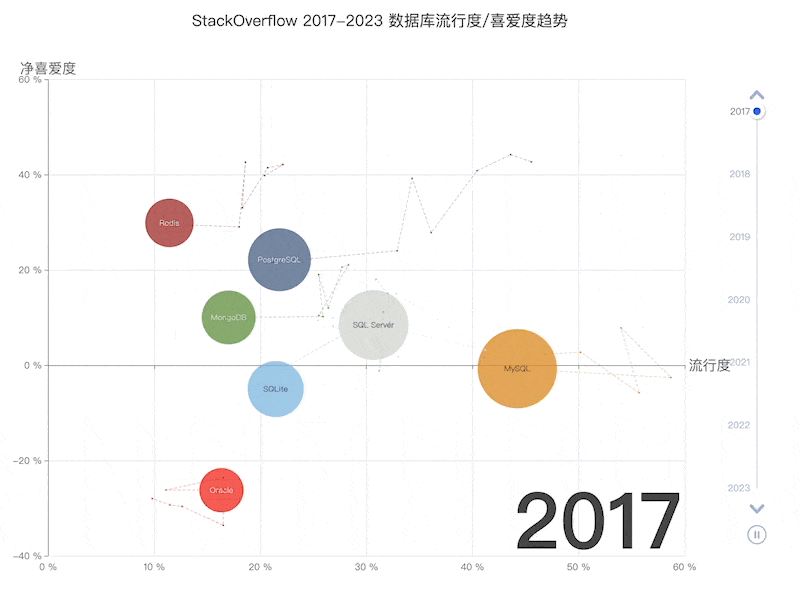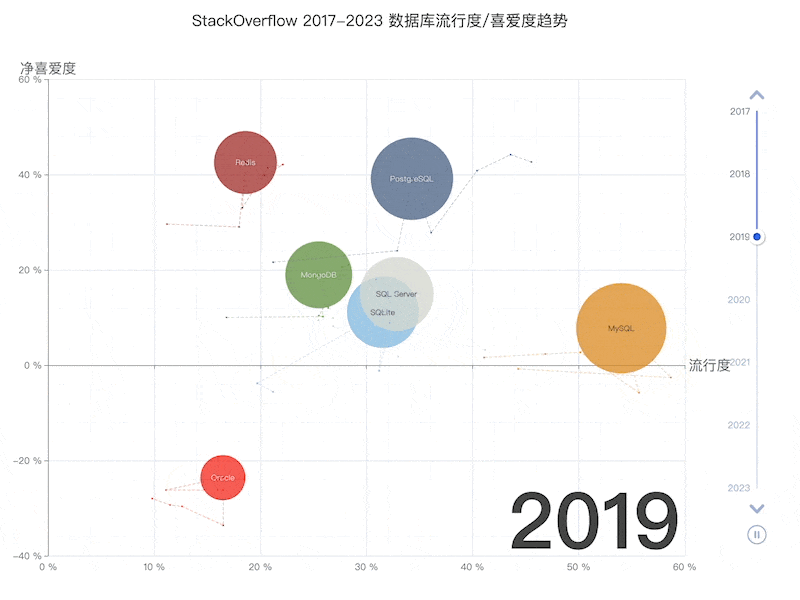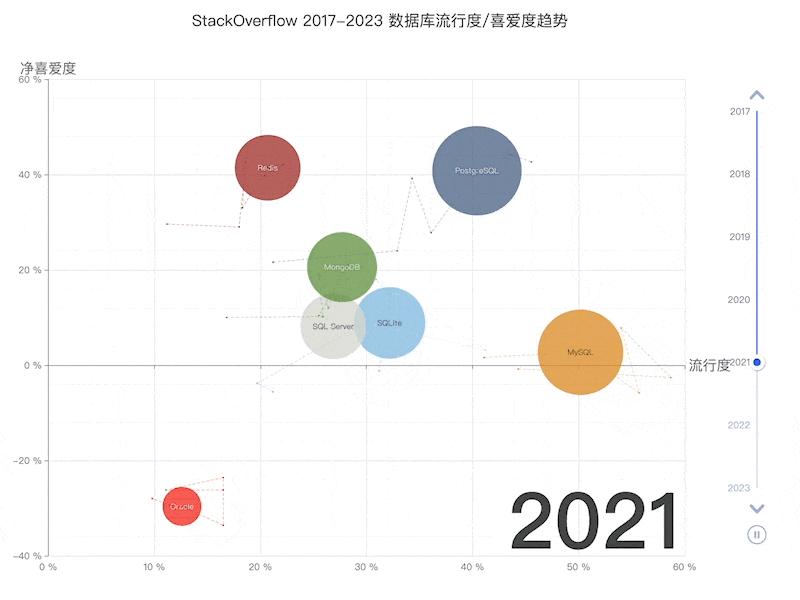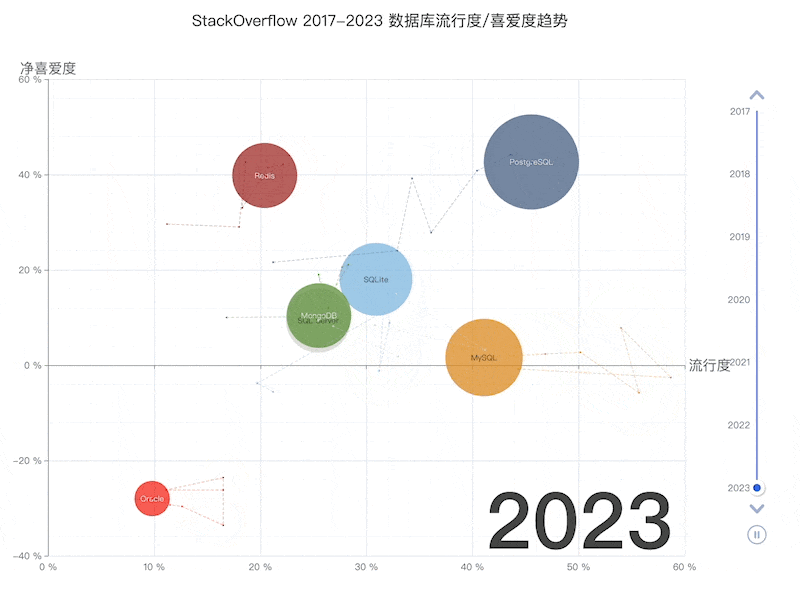
X: Popularity, Y: Net Love Index (2 * loved - 100)
The 2023 snapshot shows PostgreSQL in the top right, popular and loved, while MySQL, popular yet less favored, sits in the bottom right. Redis, moderately popular but much loved, is in the top left, and Oracle, neither popular nor loved, is in the bottom left. In the middle lie SQLite, MongoDB, and SQL Server.
Trends indicate PostgreSQL’s growing popularity and love; MySQL’s love remains flat with falling popularity. Redis and SQLite are progressing, MongoDB is peaking and declining, and the commercial RDBMSs SQL Server and Oracle are on a downward trend.
The takeaway: PostgreSQL’s standing in the database realm, akin to Linux in server OS, seems unshakeable for the foreseeable future.
Historical Accumulation: Popularity
PostgreSQL — The world’s most popular database
Popularity is the percentage of total users who have used a technology in the past year. It reflects the accumulated usage over the past year and is a core metric of factual significance.
In 2023, PostgreSQL, branded as the “most advanced,” surpassed the “most popular” database MySQL with a usage rate of 45.6%, leading by 4.5% and reaching 1.1 times the usage rate of MySQL at 41.1%. Among professional developers (about three-quarters of the sample), PostgreSQL had already overtaken MySQL in 2022, with a 0.8 percentage point lead (46.5% vs 45.7%); this gap widened in 2023 to 49.1% vs 40.6%, or 1.2 times the usage rate among professional developers.
Over the past years, MySQL enjoyed the top spot in database popularity, proudly claiming the title of the “world’s most popular open-source relational database.” However, PostgreSQL has now claimed the crown. Compared to PostgreSQL and MySQL, other databases are not in the same league in terms of popularity.
The key trend to note is that among the top-ranked databases, only PostgreSQL has shown a consistent increase in popularity, demonstrating strong growth momentum, while all other databases have seen a decline in usage. As time progresses, the gap in popularity between PostgreSQL and other databases will likely widen, making it hard for any challenger to displace PostgreSQL in the near future.
Notably, the “domestic database” TiDB has entered the StackOverflow rankings for the first time, securing the 32nd spot with a 0.2% usage rate.
Popularity reflects the current scale and potential of a database, while love indicates its future growth potential.
Current Momentum: Love
PostgreSQL — The database developers love the most
Love or admiration is a measure of the percentage of users who are willing to continue using a technology, acting as an annual “retention rate” metric that reflects the user’s opinion and evaluation of the technology.
In 2023, PostgreSQL retained its title as the most loved database by developers. While Redis had been the favorite in previous years, PostgreSQL overtook Redis in 2022, becoming the top choice. PostgreSQL and Redis have maintained close reputation scores (around 70%), significantly outpacing other contenders.
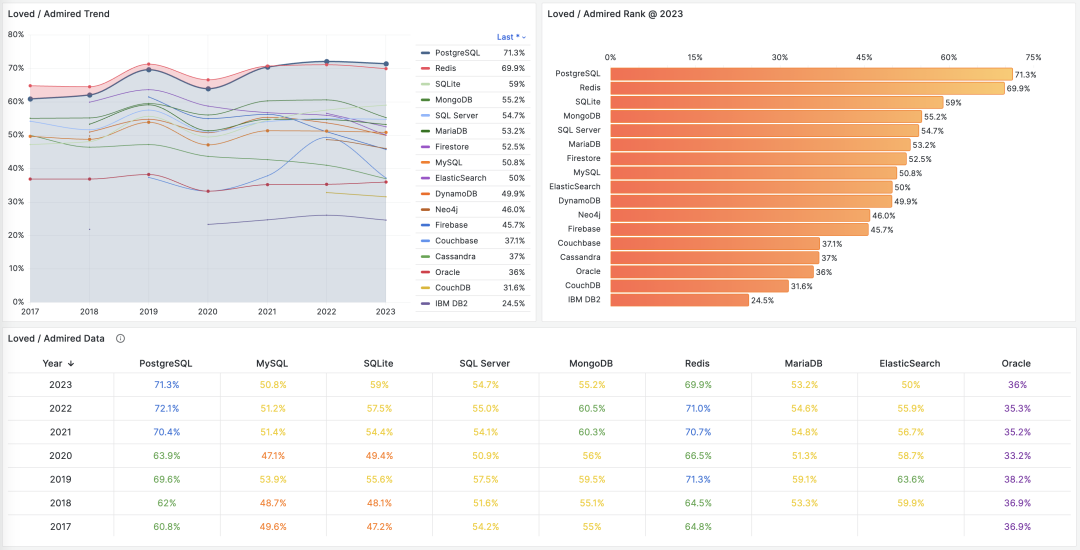
In the 2022 PostgreSQL community survey, the majority of existing PostgreSQL users reported increased usage and deeper engagement, highlighting the stability of its core user base.
Redis, known for its simplicity and ease of use as a data structure cache server, is often paired with the relational database PostgreSQL, enjoying considerable popularity (20%, ranking sixth) among developers. Cross-analysis shows a strong connection between the two: 86% of Redis users are interested in using PostgreSQL, and 30% of PostgreSQL users want to use Redis. Other databases with positive reviews include SQLite, MongoDB, and SQL Server. MySQL and ElasticSearch receive mixed feedback, hovering around the 50% mark. The least favored databases include Access, IBM DB2, CouchDB, Couchbase, and Oracle.
Not all potential can be converted into kinetic energy. While user affection is significant, it doesn’t always translate into action, leading to the third metric of interest – demand.
Future Trends: Demand
PostgreSQL - The Most Wanted Database
The demand rate, or the level of desire, represents the percentage of users who will actually opt for a technology in the coming year. PostgreSQL stands out in demand/desire, significantly outpacing other databases with a 42.3% rate for the second consecutive year, showing relentless growth and widening the gap with its competitors.
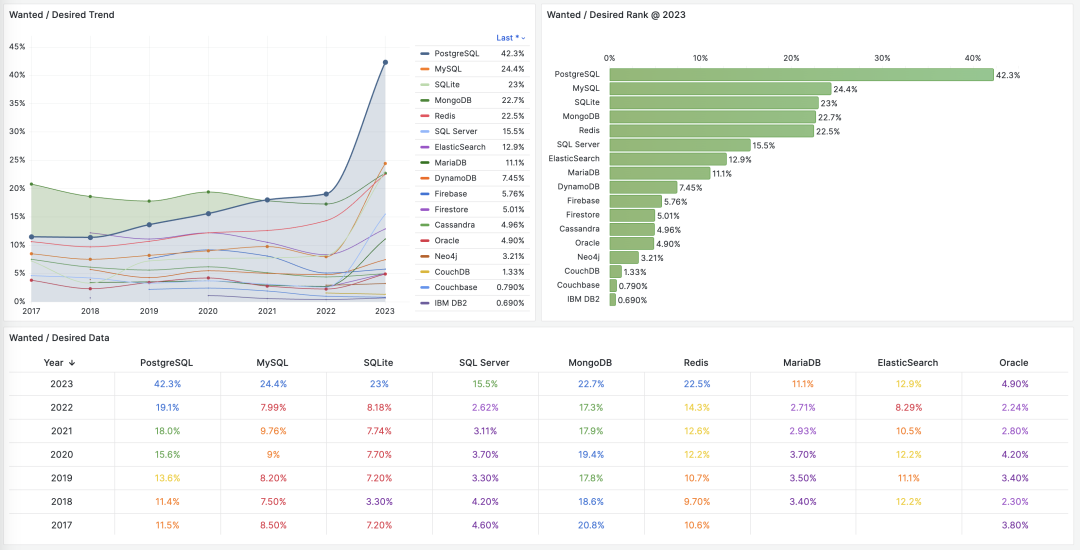
In 2023, some databases saw notable demand increases, likely driven by the surge in large language model AI, spearheaded by OpenAI’s ChatGPT. This demand for intelligence has, in turn, fueled the need for robust data infrastructure. A decade ago, support for NoSQL features like JSONB/GIN laid the groundwork for PostgreSQL’s explosive growth during the internet boom. Today, the introduction of pgvector, the first vector extension built on a mature database, grants PostgreSQL a ticket into the AI era, setting the stage for growth in the next decade.
But Why?
PostgreSQL leads in demand, usage, and popularity, with the right mix of timing, location, and human support, making it arguably the most successful database with no visible challengers in the near future. The secret to its success lies in its slogan: “The World’s Most Advanced Open Source Relational Database.”
Relational databases are so prevalent and crucial that they might dwarf the combined significance of other types like key-value, document, search engine, time-series, graph, and vector databases. Typically, “database” implicitly refers to “relational database,” where no other category dares claim mainstream status. Last year’s “Why PostgreSQL Will Be the Most Successful Database?” delves into the competitive landscape of relational databases—a tripartite dominance. Excluding Microsoft’s relatively isolated SQL Server, the database scene, currently in a phase of consolidation, has three key players rooted in WireProtocol: Oracle, MySQL, and PostgreSQL, mirroring a “Three Kingdoms” saga in the relational database realm.
Oracle/MySQL are waning, while PostgreSQL is thriving. Oracle is an established commercial DB with deep tech history, rich features, and strong support, favored by well-funded, risk-averse enterprises, especially in finance. Yet, it’s pricey and infamous for litigious practices. MS SQL Server shares similar traits with Oracle. Commercial databases are facing a slow decline due to the open-source wave.
MySQL, popular yet beleaguered, lags in stringent transaction processing and data analysis compared to PostgreSQL. Its agile development approach is also outperformed by NoSQL alternatives. Oracle’s dominance, sibling rivalry with MariaDB, and competition from NewSQL players like TiDB/OB contribute to its decline.
Oracle, no doubt skilled, lacks integrity, hence “talented but unprincipled.” MySQL, despite its open-source merit, is limited in capability and sophistication, hence “limited talent, weak ethics.” PostgreSQL, embodying both capability and integrity, aligns with the open-source rise, popular demand, and advanced stability, epitomizing “talented and principled.”
Open Source & Advanced
The primary reasons for choosing PostgreSQL, as reflected in the TimescaleDB community survey, are its open-source nature and stability. Open-source implies free use, potential for modification, no vendor lock-in, and no “chokepoint” issues. Stability means reliable, consistent performance with a proven track record in large-scale production environments. Experienced developers value these attributes highly.
Broadly, aspects like extensibility, ecosystem, community, and protocols fall under “open-source.” Stability, ACID compliance, SQL support, scalability, and availability define “advanced.” These resonate with PostgreSQL’s slogan: “The world’s most advanced open source relational database.”
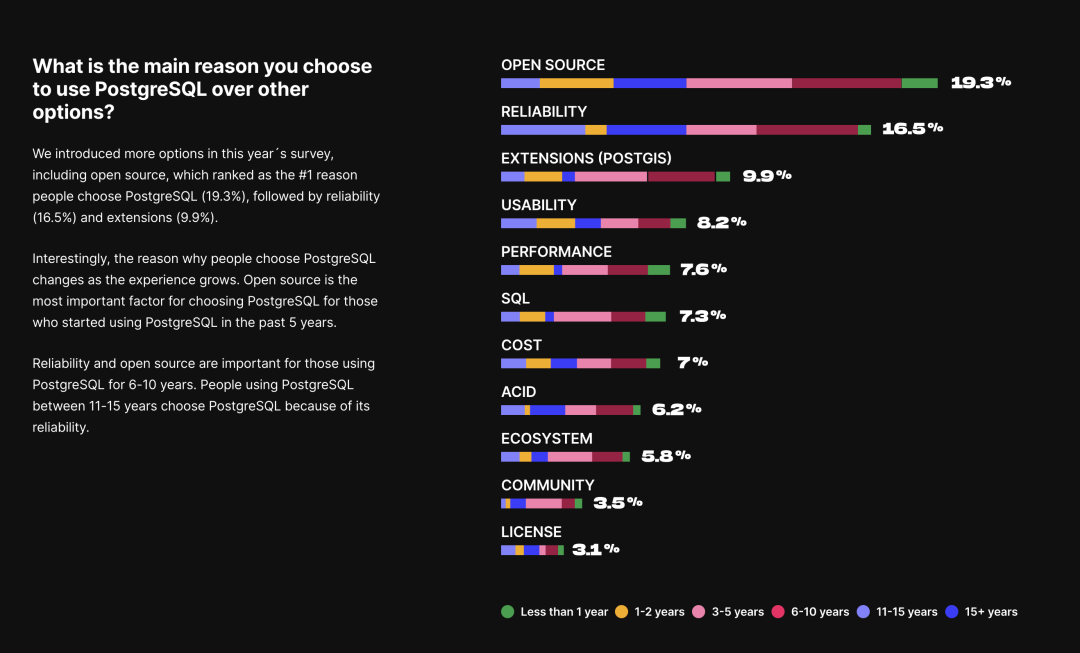
The Virtue of Open Source
powered by developers worldwide. Friendly BSD license, thriving ecosystem, extensive expansion. A robust Oracle alternative, leading the charge.
What is “virtue”? It’s the manifestation of “the way,” and this way is open source. PostgreSQL stands as a venerable giant among open-source projects, epitomizing global collaborative success.
Back in the day, developing software/information services required exorbitantly priced commercial databases. Just the software licensing fees could hit six or seven figures, not to mention similar costs for hardware and service subscriptions. Oracle’s licensing fee per CPU core could reach hundreds of thousands annually, prompting even giants like Alibaba to seek IOE alternatives. The rise of open-source databases like PostgreSQL and MySQL offered a fresh choice.
Open-source databases, free of charge, spurred an industry revolution: from tens of thousands per core per month for commercial licenses to a mere 20 bucks per core per month for hardware. Databases became accessible to regular businesses, enabling the provision of free information services.

Open source has been monumental: the history of the internet is a history of open-source software. The prosperity of the IT industry and the plethora of free information services owe much to open-source initiatives. Open source represents a form of successful Communism in software, with the industry’s core means of production becoming communal property, available to developers worldwide as needed. Developers contribute according to their abilities, embracing the ethos of mutual benefit.
An open-source programmer’s work encapsulates the intellect of countless top-tier developers. Programmers command high salaries because they are not mere laborers but contractors orchestrating software and hardware. They own the core means of production: software from the public domain and readily available server hardware. Thus, a few skilled engineers can swiftly tackle domain-specific problems leveraging the open-source ecosystem.
Open source synergizes community efforts, drastically reducing redundancy and propelling technical advancements at an astonishing pace. Its momentum, now unstoppable, continues to grow like a snowball. Open source dominates foundational software, and the industry now views insular development or so-called “self-reliance” in software, especially in foundational aspects, as a colossal joke.

For PostgreSQL, open source is its strongest asset against Oracle.
Oracle is advanced, but PostgreSQL holds its own. It’s the most Oracle-compatible open-source database, natively supporting 85% of Oracle’s features, with specialized distributions reaching 96% compatibility. However, the real game-changer is cost: PG’s open-source nature and significant cost advantage provide a substantial ecological niche. It doesn’t need to surpass Oracle in features; being “90% right at a fraction of the cost” is enough to outcompete Oracle.
PostgreSQL is like an open-source “Oracle,” the only real threat to Oracle’s dominance. As a leader in the “de-Oracle” movement, PG has spawned numerous “domestically controllable” database companies. According to CITIC, 36% of “domestic databases” are based on PG modifications or rebranding, with Huawei’s openGauss and GaussDB as prime examples. Crucially, PostgreSQL uses a BSD-Like license, permitting such adaptations — you can rebrand and sell without deceit. This open attitude is something Oracle-acquired, GPL-licensed MySQL can’t match.
The advanced in Talent
The talent of PG lies in its advancement. Specializing in multiple areas, PostgreSQL offers a full-stack, multi-model approach: “Self-managed, autonomous driving temporal-geospatial AI vector distributed document graph with full-text search, programmable hyper-converged, federated stream-batch processing in a single HTAP Serverless full-stack platform database”, covering almost all database needs with a single component.
PostgreSQL is not just a traditional OLTP “relational database” but a multi-modal database. For SMEs, a single PostgreSQL component can cover the vast majority of their data needs: OLTP, OLAP, time-series, GIS, tokenization and full-text search, JSON/XML documents, NoSQL features, graphs, vectors, and more.

Emperor of Databases — Self-managed, autonomous driving temporal-geospatial AI vector distributed document graph with full-text search, programmable hyper-converged, federated stream-batch processing in a single HTAP Serverless full-stack platform database.
The superiority of PostgreSQL is not only in its acclaimed kernel stability but also in its powerful extensibility. The plugin system transforms PostgreSQL from a single-threaded evolving database kernel to a platform with countless parallel-evolving extensions, exploring all possibilities simultaneously like quantum computing. PostgreSQL is omnipresent in every niche of data processing.
For instance, PostGIS for geospatial databases, TimescaleDB for time-series, Citus for distributed/columnar/HTAP databases, PGVector for AI vector databases, AGE for graph databases, PipelineDB for stream processing, and the ultimate trick — using Foreign Data Wrappers (FDW) for unified SQL access to all heterogeneous external databases. Thus, PG is a true full-stack database platform, far more advanced than a simple OLTP system like MySQL.
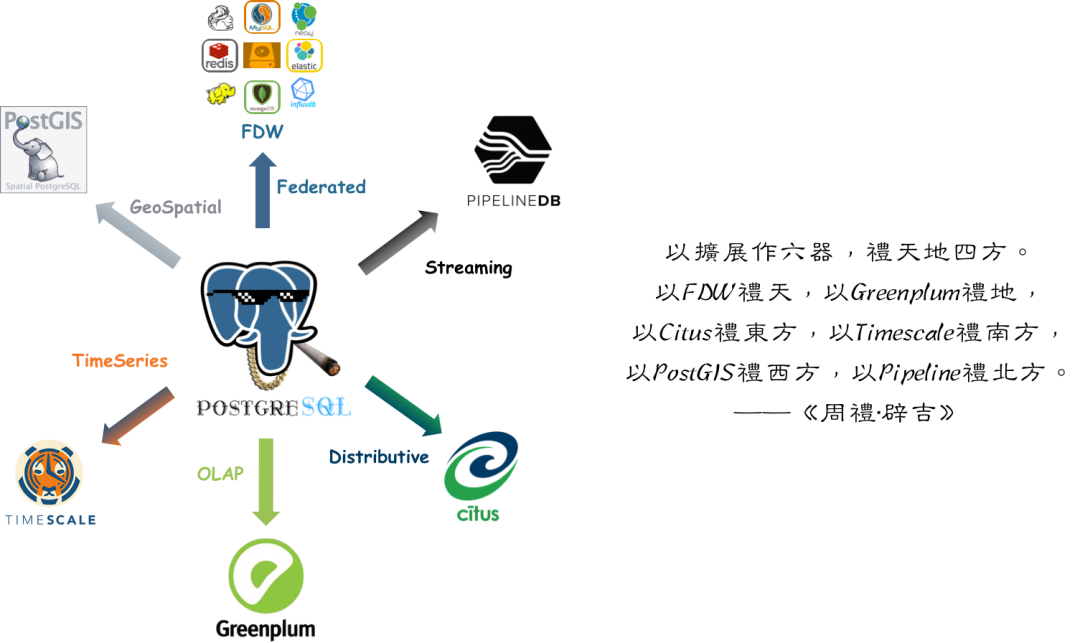
Within a significant scale, PostgreSQL can play multiple roles with a single component, greatly reducing project complexity and cost. Remember, designing for unneeded scale is futile and an example of premature optimization. If one technology can meet all needs, it’s the best choice rather than reimplementing it with multiple components.
Taking Tantan as an example, with 250 million TPS and 200 TB of unique TP data, a single PostgreSQL selection remains stable and reliable, covering a wide range of functions beyond its primary OLTP role, including caching, OLAP, batch processing, and even message queuing. However, as the user base approaches tens of millions daily active users, these additional functions will eventually need to be handled by dedicated components.
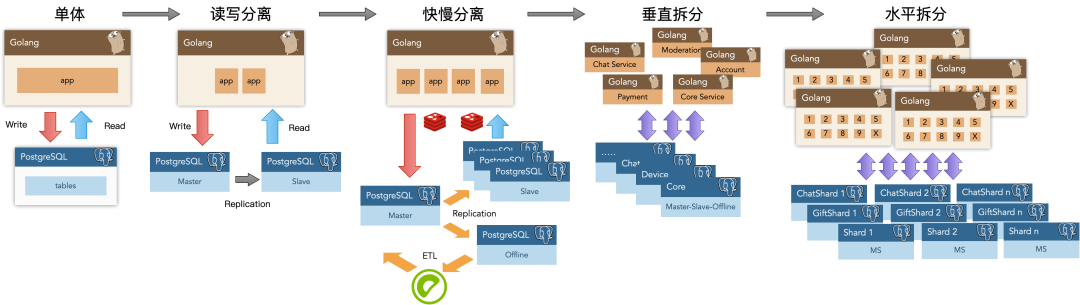
PostgreSQL’s advancement is also evident in its thriving ecosystem. Centered around the database kernel, there are specialized variants and “higher-level databases” built on it, like Greenplum, Supabase (an open-source alternative to Firebase), and the specialized graph database edgedb, among others. There are various open-source/commercial/cloud distributions integrating tools, like different RDS versions and the plug-and-play Pigsty; horizontally, there are even powerful mimetic components/versions emulating other databases without changing client drivers, like babelfish for SQL Server, FerretDB for MongoDB, and EnterpriseDB/IvorySQL for Oracle compatibility.
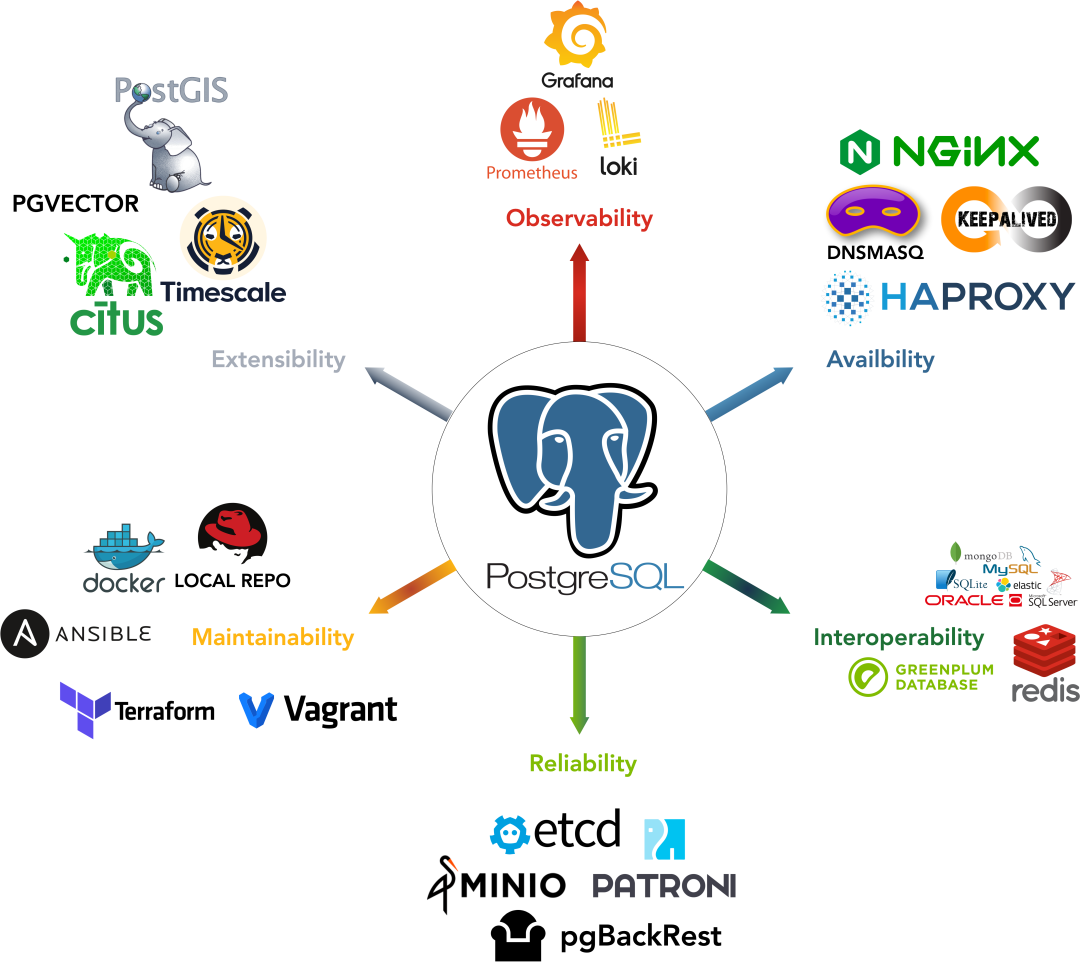
PostgreSQL’s advanced features are its core competitive strength against MySQL, another open-source relational database.
Advancement is PostgreSQL’s core competitive edge over MySQL.
MySQL’s slogan is “the world’s most popular open-source relational database,” characterized by being rough, fierce, and fast, catering to internet companies. These companies prioritize simplicity (mainly CRUD), data consistency and accuracy less than traditional sectors like banking, and can tolerate data inaccuracies over service downtime, unlike industries that cannot afford financial discrepancies.
However, times change, and PostgreSQL has rapidly advanced, surpassing MySQL in speed and robustness, leaving only “roughness” as MySQL’s remaining trait.
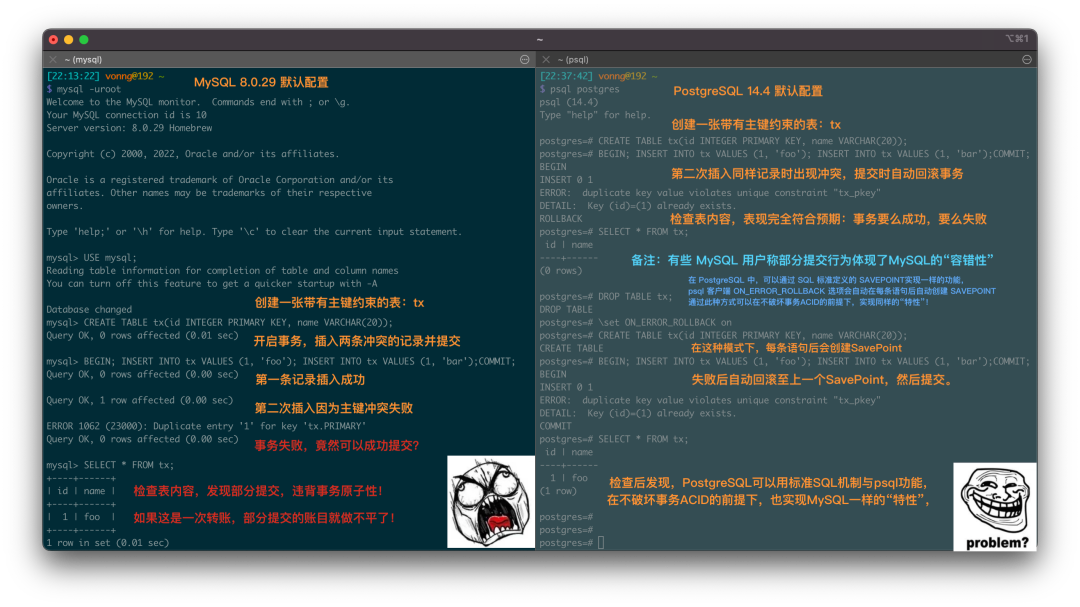
MySQL allows partial transaction commits by default, shocked
MySQL allows partial transaction commits by default, revealing a gap between “popular” and “advanced.” Popularity fades with obsolescence, while advancement gains popularity through innovation. In times of change, without advanced features, popularity is fleeting. Research shows MySQL’s pride in “popularity” cannot stand against PostgreSQL’s “advanced” superiority.
Advancement and open-source are PostgreSQL’s success secrets. While Oracle is advanced and MySQL is open-source, PostgreSQL boasts both. With the right conditions, success is inevitable.
Looking Ahead
The PostgreSQL database kernel’s role in the database ecosystem mirrors the Linux kernel’s in the operating system domain. For databases, particularly OLTP, the battle of kernels has settled—PostgreSQL is now a perfect engine.
However, users need more than an engine; they need the complete car, driving capabilities, and traffic services. The database competition has shifted from software to Software enabled Service—complete database distributions and services. The race for PostgreSQL-based distributions is just beginning. Who will be the PostgreSQL equivalent of Debian, RedHat, or Ubuntu?
This is why we created Pigsty — to develop an battery-included, open-source, local-first PostgreSQL distribution, making it easy for everyone to access and utilize a quality database service. Due to space limits, the detailed story is for another time.

参考阅读
2022-08 《PostgreSQL 到底有多强?》
2022-07 《为什么PostgreSQL是最成功的数据库?》
2022-06 《StackOverflow 2022数据库年度调查》
2021-05 《Why PostgreSQL Rocks!》
2021-05 《为什么说PostgreSQL前途无量?》
2018 《PostgreSQL 好处都有啥?》
2023 《更好的开源RDS替代:Pigsty》
2023 《StackOverflow 7年调研数据跟踪》
2022 《PostgreSQL 社区状态调查报告 2022》
How Powerful Is PostgreSQL?
Last time, we analyzed StackOverflow survey data to explain why PostgreSQL is the most successful database.
This time, let’s rely on performance metrics to see just how powerful “the most successful” PostgreSQL really is. We want everyone to walk away feeling, in the words of a certain meme, “I know the numbers.”

TL;DR
If you’re curious about any of the following questions, this post should be helpful:
- How fast is PostgreSQL, exactly?
Point-read queries (QPS) can exceed 600k, and in extreme conditions can even hit 2 million. For mixed read-write TPS (4 writes + 1 read in each transaction), you can reach 70k+ or even as high as 140k. - How does PostgreSQL compare with MySQL at the performance limit?
Under extreme tuning, PostgreSQL’s point-read throughput beats MySQL by a noticeable margin. In other metrics, they’re roughly on par. - How does PostgreSQL compare with other databases?
Under the same hardware specs, “distributed/NewSQL” databases often lag far behind classic databases in performance. - What about PostgreSQL versus other analytical databases in TPC-H?
As a native hybrid transaction/analysis (HTAP) database, PostgreSQL’s analytical performance is quite impressive. - Are cloud databases or cloud servers actually cost-effective?
It turns out you could purchase a c5d.metal server outright (and host it yourself for 5 years) for about the cost of renting it on the cloud for 1 year. Meanwhile, a similarly provisioned cloud database of the same spec could cost about 20 times as much as a raw EC2 box in 1 year.
All detailed test steps and raw data are on: github.com/Vonng/pgtpc
PGBENCH
Technology evolves at breakneck speed. Although benchmark articles are everywhere, it’s tough to find reliable performance data that reflect today’s newest hardware and software. Here, we used pgbench to test the latest PostgreSQL 14.5 on two types of cutting-edge hardware specs:
We ran four different hardware setups: two Apple laptops and three AWS EC2 instances, specifically:
- A 2018 15-inch top-spec MacBook Pro using an Intel 6-core i9
- A 2021 16-inch MacBook Pro powered by an M1 Max chip (10-core)
- AWS z1d.2xlarge (8C / 64G)
- AWS c5d.metal (96C / 192G)
All are readily available commercial hardware configurations.
pgbench is a built-in benchmarking tool for PostgreSQL, based on a TPC-B–like workload, widely used to evaluate PostgreSQL (and its derivatives/compatibles). We focused on two test modes:
- Read-Only (RO)
A single SQL statement that randomly selects and returns one row from a table of 100 million rows. - Read-Write (RW)
Five SQL statements per transaction: 1 read, 1 insert, and 3 updates.
We used s=1000 for the dataset scale, then gradually increased client connections. At peak throughput, we tested for 3-5 minutes and recorded stable averages. Results are as follows:
| No | Spec | Config | CPU | Freq | S | RO | RW |
|---|---|---|---|---|---|---|---|
| 1 | Apple MBP Intel 2018 | Normal | 6 | 2.9GHz - 4.8GHz | 1000 | 113,870 | 15,141 |
| 2 | AWS z1d.2xlarge | Normal | 8 | 4GHz | 1000 | 162,315 | 24,808 |
| 3 | Apple MBP M1 Max 2021 | Normal | 10 | 600MHz - 3.22GHz | 1000 | 240,841 | 31,903 |
| 4 | AWS c5d.metal | Normal | 96 | 3.6GHz | 1000 | 625,849 | 71,624 |
| 5 | AWS c5d.metal | Extreme | 96 | 3.6GHz | 5000 | 1,998,580 | 137,127 |
Read-Write
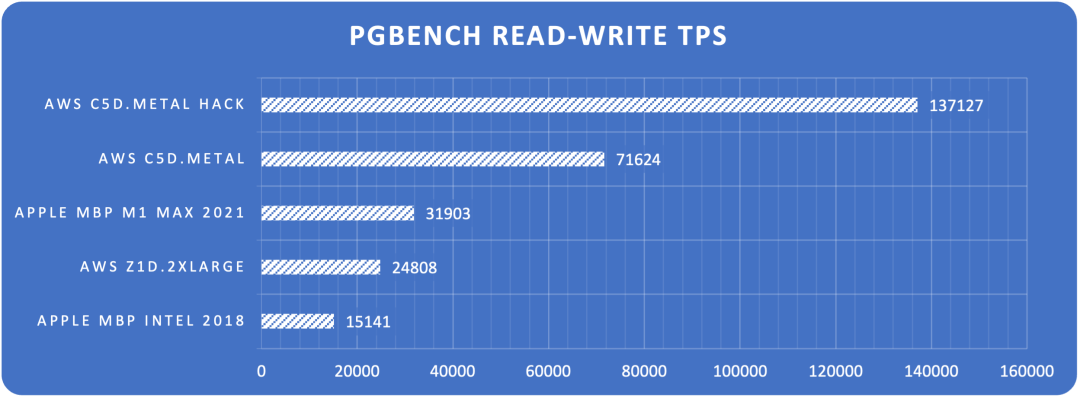
Chart: Max read-write TPS on each hardware
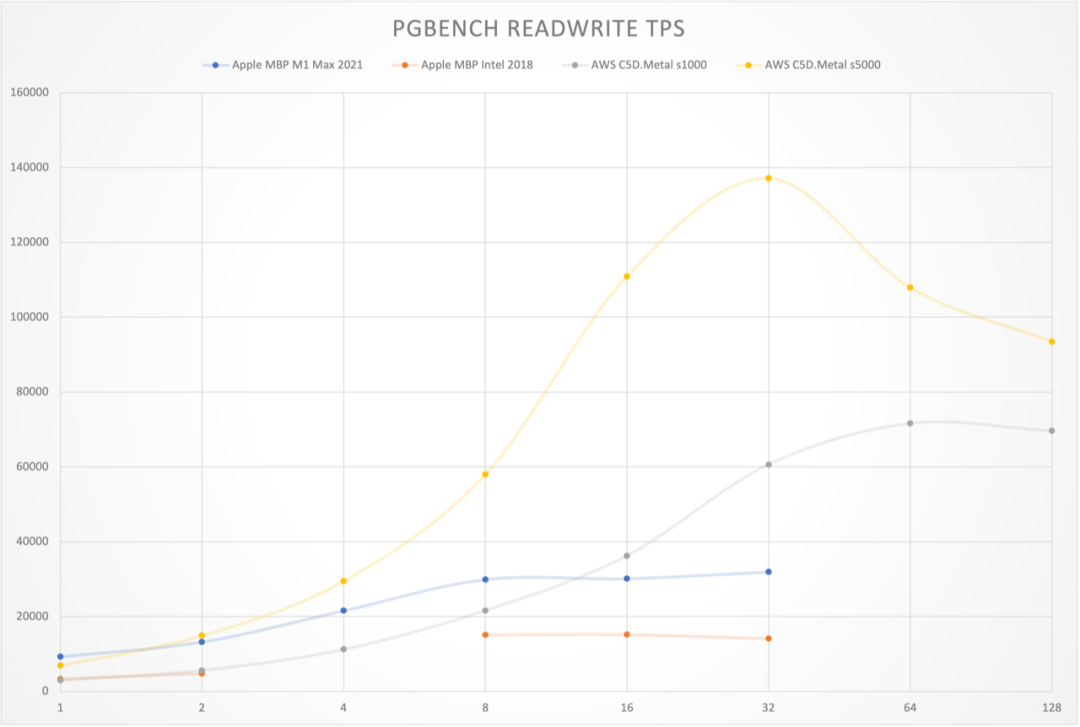
Chart: TPS curves for read-write transactions
Read-Only
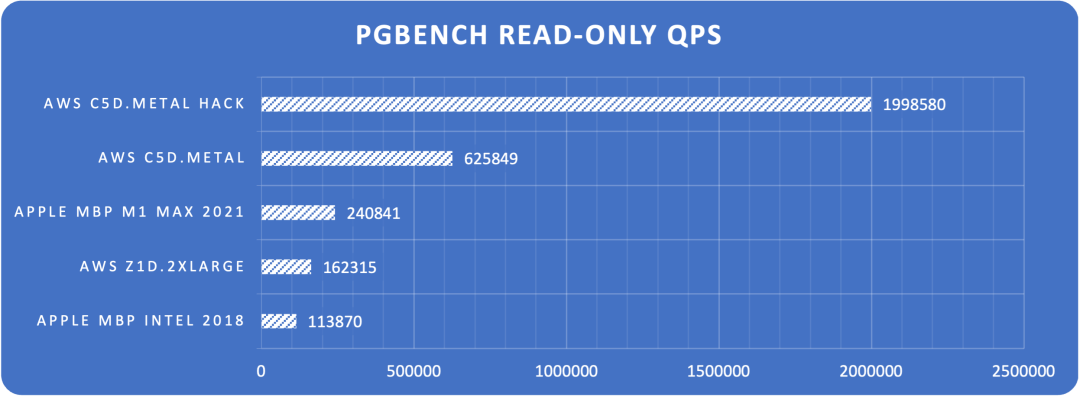
Chart: Max point-read QPS on each hardware
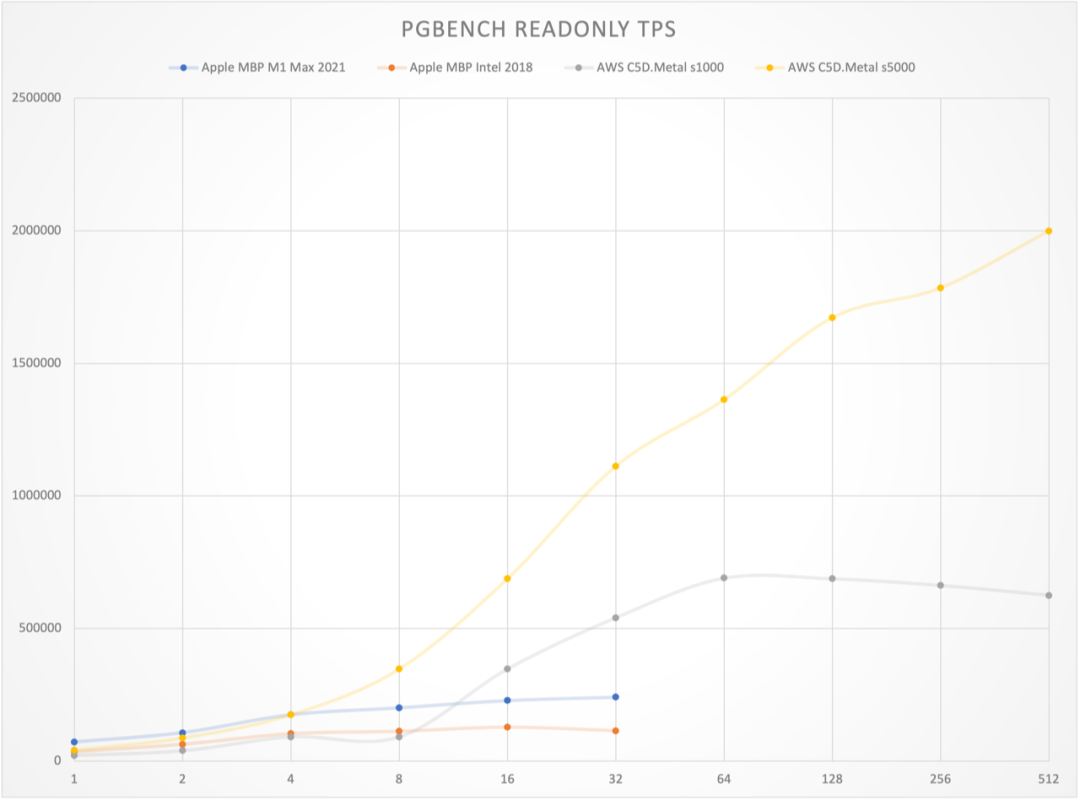
Chart: Point-read QPS vs. concurrency
These results are jaw-dropping. On a 10-core Apple M1 Max laptop, PostgreSQL hits ~32k TPS (read-write) and ~240k QPS (point lookups). On an AWS c5d.metal production-grade physical server, it goes up to ~72k TPS and ~630k QPS. With extreme config tuning, we were able to push it to 137k TPS and 2 million QPS on a single machine. Yes, a single server can do that.
By way of rough scale reference: Tantan (a major dating/social networking app in China) has a global TPS of ~400k across its entire PostgreSQL fleet. These new laptops or a few top-spec servers (costing around 100k RMB) could potentially support a large-scale app’s DB load. That’s insane compared to just a few years ago.
A Note on Costs
Take AWS c5d.metal in Ningxia region as an example. It’s one of the best overall compute options, coming with local 3.6TB NVMe SSD storage. There are seven different payment models (prices below in RMB/month or RMB/year):
| Payment Model | Monthly | Up-Front | Yearly |
|---|---|---|---|
| On-Demand | 31,927 | 0 | 383,124 |
| Standard 1-yr, no upfront | 12,607 | 0 | 151,284 |
| Standard 1-yr, partial | 5,401 | 64,540 | 129,352 |
| Standard 1-yr, all upfront | 0 | 126,497 | 126,497 |
| Convertible 3-yr, no upfront | 11,349 | 0 | 136,188 |
| Convertible 3-yr, partial | 4,863 | 174,257 | 116,442 |
| Convertible 3-yr, all upfront | 0 | 341,543 | 113,847 |
Effectively, annual costs range from about 110k to 150k RMB, or 380k at on-demand retail. Meanwhile, buying a similar server outright and hosting it in a data center for 5 years might cost under 100k total. So yes, the cloud is easily ~5x more expensive if you only compare raw hardware costs. Still, if you consider the elasticity, discount programs, and coupon offsets, an EC2 instance can be “worth it,” especially if you self-manage PostgreSQL on it.
But if you want an RDS for PostgreSQL with roughly the same specs (the closest is db.m5.24xlarge, 96C/384G + 3.6T io1 @80k IOPS), the monthly cost is ~240k RMB, or 2.87 million RMB per year, nearly 20 times more than simply running PostgreSQL on the same c5d.metal instance yourself.
AWS cost calculator: https://calculator.amazonaws.cn/
SYSBENCH
So PostgreSQL alone is impressive—but how does it compare to other databases? pgbench is built for PostgreSQL-based systems. For a broader look, we can turn to sysbench, an open-source, multi-threaded benchmarking tool that can assess transaction performance in any SQL database (commonly used for both MySQL and PostgreSQL). It includes 10 typical scenarios like:
oltp_point_selectfor point-read performanceoltp_update_indexfor index update performanceoltp_read_onlyfor transaction mixes of 16 queriesoltp_read_writefor a mix of 20 queries in a transaction (read + write)oltp_write_onlyfor a set of 6 insert/update statements
Because sysbench can test both MySQL and PostgreSQL, it provides a fair basis for comparing their performance. Let’s start with the most popular face-off: the world’s “most popular” open-source RDBMS—MySQL—vs. the world’s “most advanced” open-source RDBMS—PostgreSQL.
Dirty Hack
MySQL doesn’t provide official sysbench results, but there is a third-party benchmark on MySQL.com claiming 1 million QPS for point-reads, 240k for index updates, and about 39k TPS for mixed read-write.
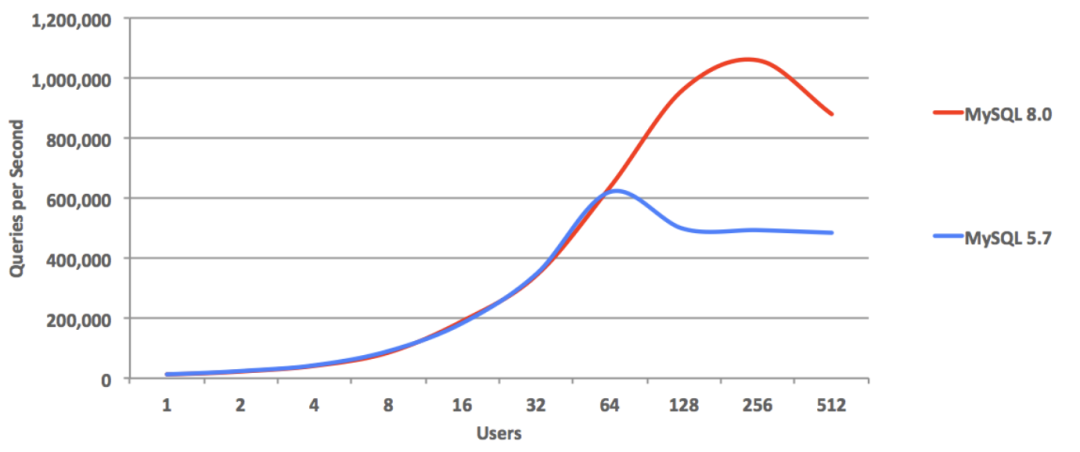
That approach is somewhat “unethical” if you will—because reading the linked article reveals that they turned off all major safety features to get these numbers: no binlog, no fsync on commit, no double-write buffer, no checksums, forcing LATIN-1, no monitoring, etc. Great for scoreboard inflation, not so great for real production usage.
But if we’re going down that path, we can similarly do a “Dirty Hack” for PostgreSQL—shut off everything that ensures data safety—and see how high we can push the scoreboard. The result? PostgreSQL point-reads soared past 2.33 million QPS, beating MySQL’s 1M QPS by more than double.
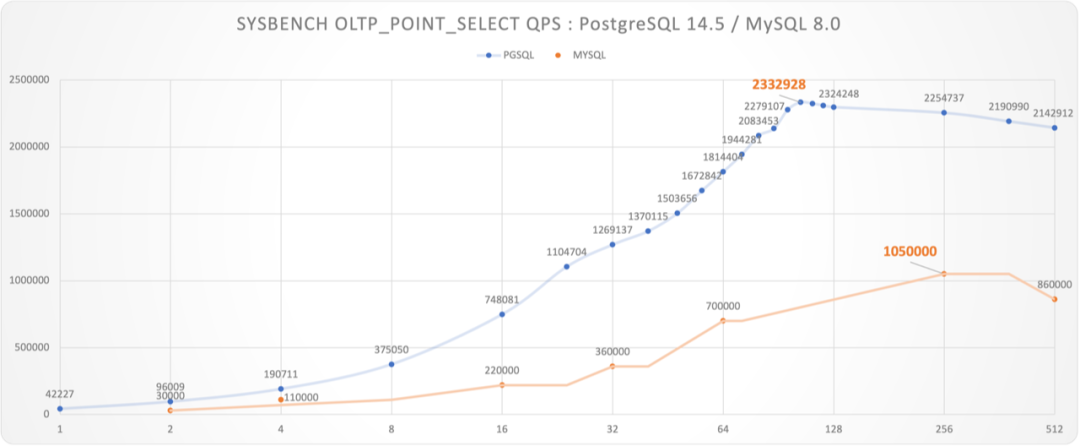
Chart: “Unfair” Benchmark—PG vs. MySQL, everything turned off
PostgreSQL’s “extreme config” point-read test in progress
To be fair, MySQL’s test used a 48C/2.7GHz machine, whereas our PostgreSQL run was on a 96C/3.6GHz box. But because PostgreSQL uses a multi-process model (rather than MySQL’s multi-thread model), we can sample performance at c=48 to approximate performance if we only had 48 cores. That still gives ~1.5M QPS for PG on 48 cores, 43% higher than MySQL’s best number.
We’d love to see MySQL experts produce a benchmark on identical hardware for a more direct comparison.
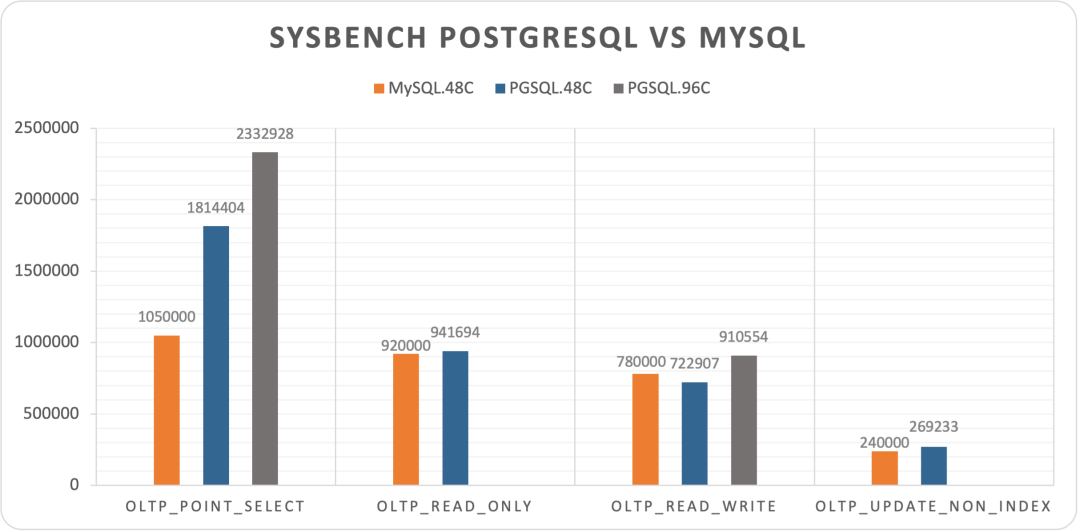
Chart: Four sysbench metrics from MySQL’s “Dirty Hack,” with c=48 concurrency
In other tests, MySQL also reaches impressive extremes. oltp_read_only and oltp_update_non_index are roughly on par with PG’s c=48 scenario, and MySQL even beats PostgreSQL by a bit in oltp_read_write. Overall, aside from a resounding win for PostgreSQL in point-reads, the two are basically neck and neck in these “unfair” scenarios.
Fair Play
In terms of features, MySQL and PostgreSQL are worlds apart. But at the performance limit, the two are close, with PostgreSQL taking the lead in point-lookups. Now, how about next-generation, distributed, or “NewSQL” databases?
Most “Fair Play” database vendors who show sysbench benchmarks do so in realistic, production-like configurations (unlike MySQL’s “dirty hack”). So let’s compare them with a fully production-configured PostgreSQL on the same c5d.metal machine. Production config obviously reduces PG’s peak throughput by about half, but it’s more appropriate for apples-to-apples comparisons.
We collected official sysbench numbers from a few representative NewSQL database websites (or at least from detailed 3rd-party tests). Not every system published results for all 10 sysbench scenarios, and the hardware/table sizes vary. However, each test environment is around 100 cores with ~160M rows (except OB, YB, or where stated). That should give us enough to see who’s who:
| Database | PGSQL.C5D96C | TiDB.108C | OceanBase.96C | PolarX.64C | Cockroach | Yugabyte |
|---|---|---|---|---|---|---|
| oltp_point_select | 1,372,654 | 407,625 | 401,404 | 336,000 | 95,695 | |
| oltp_read_only | 852,440 | 279,067 | 366,863 | 52,416 | ||
| oltp_read_write | 519,069 | 124,460 | 157,859 | 177,506 | 9,740 | |
| oltp_write_only | 495,942 | 119,307 | 9,090 | |||
| oltp_delete | 839,153 | 67,499 | ||||
| oltp_insert | 164,351 | 112,000 | 6,348 | |||
| oltp_update_non_index | 217,626 | 62,084 | 11,496 | |||
| oltp_update_index | 169,714 | 26,431 | 4,052 | |||
| select_random_points | 227,623 | |||||
| select_random_ranges | 24,632 | |||||
| Machine | c5d.metal | m5.xlarge x3 i3.4xlarge x3 c5.4xlarge x3 |
ecs.hfg7.8xlarge x3 ecs.hfg7.8xlarge x1 |
Enterprise | c5d.9xlarge x3 | c5.4xlarge x3 |
| Spec | 96C / 192G | 108C / 510G | 96C / 384G | 64C / 256G | 108C / 216G | 48C / 96G |
| Table | 16 x 10M | 16 x 10M | 30 x 10M | 1 x 160M | N/A | 10 x 0.1M |
| CPU | 96 | 108 | 96 | 64 | 108 | 48 |
| Source | Vonng | TiDB 6.1 | OceanBase | PolarDB | Cockroach | YugaByte |
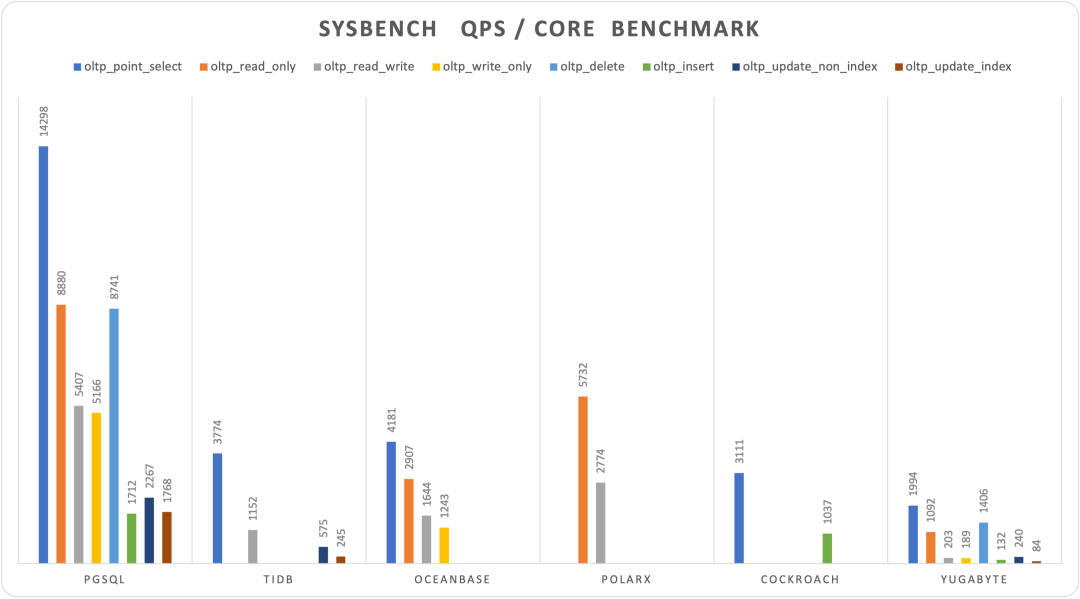
Chart: sysbench results (QPS, higher is better) for up to 10 tests
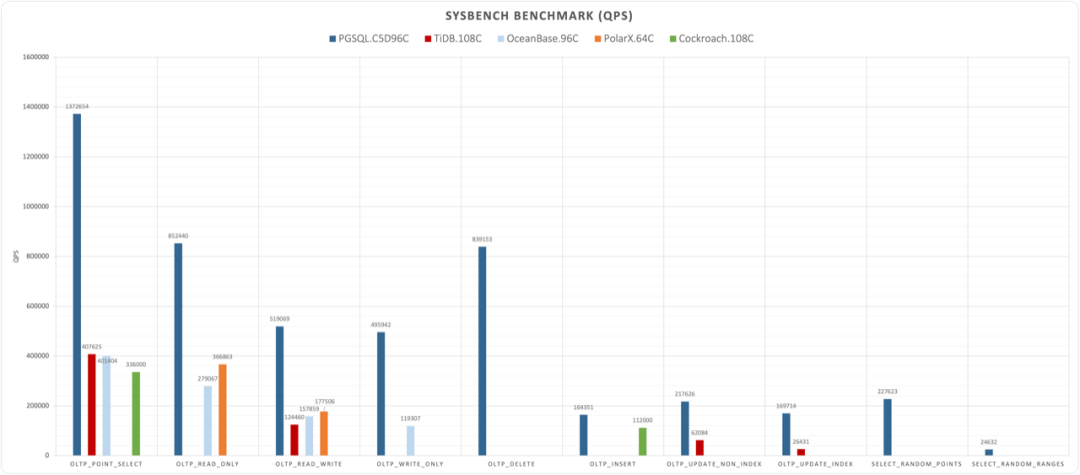
Chart: Normalized performance per core across different databases
Shockingly, the new wave of distributed NewSQL databases lags across the board. On similar hardware, performance can be one order of magnitude behind classic relational databases. The best among them is actually still PolarDB, which uses a classic primary-standby design. This begs the question: Should we re-examine the distributed DB / NewSQL hype?
In theory, distributed databases always trade off complexity (and sometimes stability or functionality) for unlimited scale. But we’re seeing that they often give up a lot of raw performance too. As Donald Knuth famously said: “Premature optimization is the root of all evil.” Opting for a distributed solution for data volumes you don’t actually need (like Google-scale, multi-trillion-row problems) could also be a form of premature optimization. Many real-world workloads never come close to that scale.
TPC-H Analytical Performance
Perhaps the distributed DB argument is: Sure, we’re behind in TP, but we’ll shine in AP. Indeed, many distributed databases pitch an “HTAP” story for big data. So, let’s look at the TPC-H benchmark, used to measure analytical database performance.
TPC-H simulates a data warehouse with 8 tables and 22 complex analytical queries. The performance metric is typically the time to run all 22 queries at a given data scale (often SF=100, ~100GB). We tested TPC-H with scale factors 1, 10, 50, and 100 on a local laptop and a small AWS instance. Below is the total runtime of the 22 queries:
| Scale Factor | Time (s) | CPU | Environment | Comment |
|---|---|---|---|---|
| 1 | 8 | 10 | 10C / 64G | Apple M1 Max |
| 10 | 56 | 10 | 10C / 64G | Apple M1 Max |
| 50 | 1,327 | 10 | 10C / 64G | Apple M1 Max |
| 100 | 4,835 | 10 | 10C / 64G | Apple M1 Max |
| 1 | 13.5 | 8 | 8C / 64G | z1d.2xlarge |
| 10 | 133 | 8 | 8C / 64G | z1d.2xlarge |
For a broader view, we compared these results to other databases’ TPC-H data found on official or semi-official tests. Note:
- Some use a different
SF(not always 100). - Hardware specs differ.
- We’re not always quoting from official sources.
So, it’s only a rough guide:
| Database | Time | S | CPU | QPH | Environment | Source |
|---|---|---|---|---|---|---|
| PostgreSQL | 8 | 1 | 10 | 45.0 | 10C / 64G M1 Max | Vonng |
| PostgreSQL | 56 | 10 | 10 | 64.3 | 10C / 64G M1 Max | Vonng |
| PostgreSQL | 1,327 | 50 | 10 | 13.6 | 10C / 64G M1 Max | Vonng |
| PostgreSQL | 4,835 | 100 | 10 | 7.4 | 10C / 64G M1 Max | Vonng |
| PostgreSQL | 13.51 | 1 | 8 | 33.3 | 8C / 64G z1d.2xlarge | Vonng |
| PostgreSQL | 133.35 | 10 | 8 | 33.7 | 8C / 64G z1d.2xlarge | Vonng |
| TiDB | 190 | 100 | 120 | 15.8 | 120C / 570G | TiDB |
| Spark | 388 | 100 | 120 | 7.7 | 120C / 570G | TiDB |
| Greenplum | 436 | 100 | 288 | 2.9 | 120C / 570G | TiDB |
| DeepGreen | 148 | 200 | 256 | 19.0 | 288C / 1152G | Digoal |
| MatrixDB | 2,306 | 1000 | 256 | 6.1 | 256C / 1024G | MXDB |
| Hive | 59,599 | 1000 | 256 | 0.2 | 256C / 1024G | MXDB |
| StoneDB | 3,388 | 100 | 64 | 1.7 | 64C / 128G | StoneDB |
| ClickHouse | 11,537 | 100 | 64 | 0.5 | 64C / 128G | StoneDB |
| OceanBase | 189 | 100 | 96 | 19.8 | 96C / 384G | OceanBase |
| PolarDB | 387 | 50 | 32 | 14.5 | 32C / 128G | Aliyun |
| PolarDB | 755 | 50 | 16 | 14.9 | 16C / 64G | Aliyun |
We introduce the metric QPH = (warehouses per core per hour). That is:
QPH = (1 / Time) * (Warehouses / CPU) * 3600
References
[1] Vonng: PGTPC
[2] WHY MYSQL
[3] MySQL Performance : 1M IO-bound QPS with 8.0 GA on Intel Optane SSD !
[4] MySQL Performance : 8.0 and Sysbench OLTP_RW / Update-NoKEY
[5] MySQL Performance : The New InnoDB Double Write Buffer in Action
[6] TiDB Sysbench Performance Test Report – v6.1.0 vs. v6.0.0
[7] OceanBase 3.1 Sysbench 性能测试报告
[8] Cockroach 22.15 Benchmarking Overview
[9] Benchmark YSQL performance using sysbench (v2.15)
[10] PolarDB-X 1.0 Sysbench 测试说明
[12] Elena Milkai: “How Good is My HTAP System?",SIGMOD ’22 Session 25
[13] AWS Calculator
Why Is PostgreSQL the Most Successful Database?

When we say a database is “successful,” what exactly do we mean? Are we referring to features, performance, or ease of use? Or perhaps total cost, ecosystem, or complexity? There are many evaluation criteria, but in the end, it’s the users—developers—who make the final call.
So, what do developers prefer? Over the past six years, StackOverflow has repeatedly asked over seventy thousand developers across 180 countries three simple questions.
Looking at these survey results over that six-year period, it’s evident that, by 2022, PostgreSQL has claimed the crown in all three categories, becoming the literal “most successful database”:
- PostgreSQL became the most commonly used database among professional developers! (Used)
- PostgreSQL became the most loved database among developers! (Loved)
- PostgreSQL became the most wanted database among developers! (Wanted)
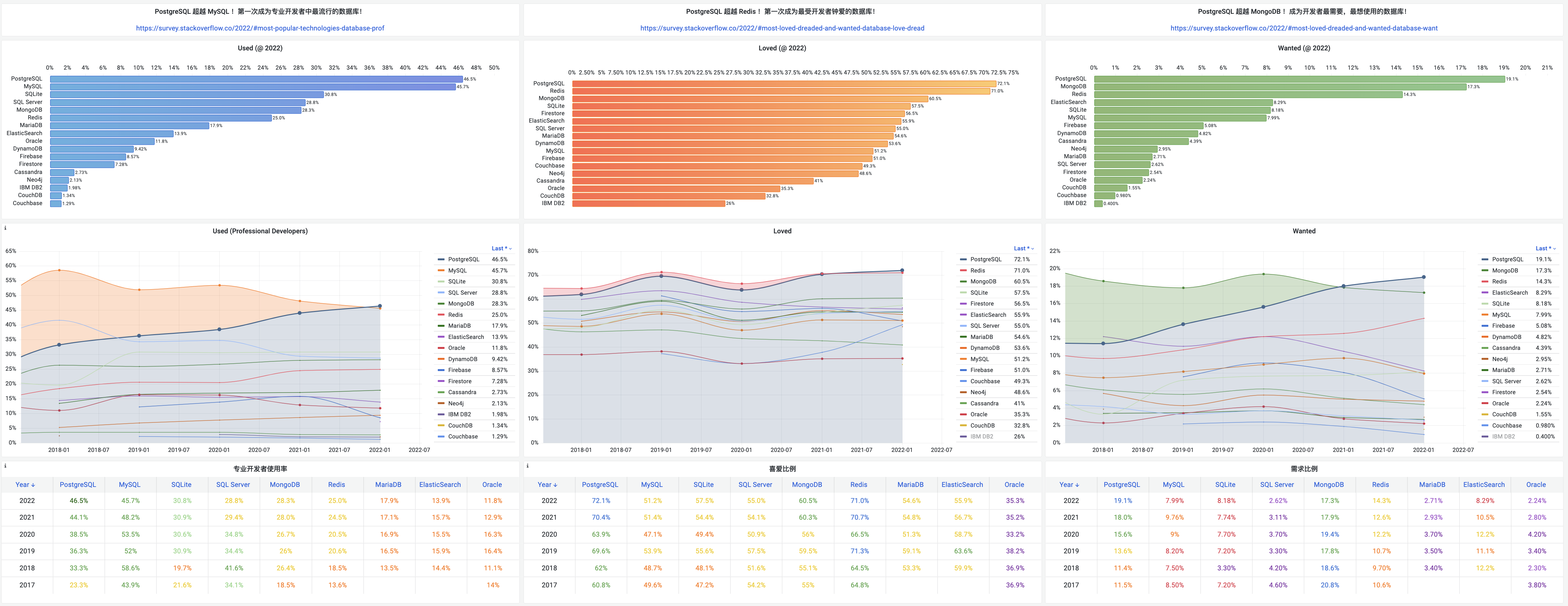
Popularity reflects the current “momentum,” demand points toward “potential energy,” and developer love signals long-term promise. Time and tide now favor PostgreSQL. Let’s take a look at the concrete data behind these results.
Most Popular
PostgreSQL—The Most Popular Database Among Professional Developers! (Used)
The first survey question examines which databases developers are actively using right now—i.e., popularity.
In previous years, MySQL consistently held the top spot as the most popular database, living up to its tagline of being “the world’s most popular open-source relational database.” However, this year, it seems that MySQL has to surrender the crown of “most popular” to PostgreSQL.
Among professional developers, PostgreSQL claimed first place for the first time with a 46.5% usage rate, surpassing MySQL’s 45.7%. These two open-source, general-purpose relational databases dominate the top two spots, significantly outpacing all other databases.
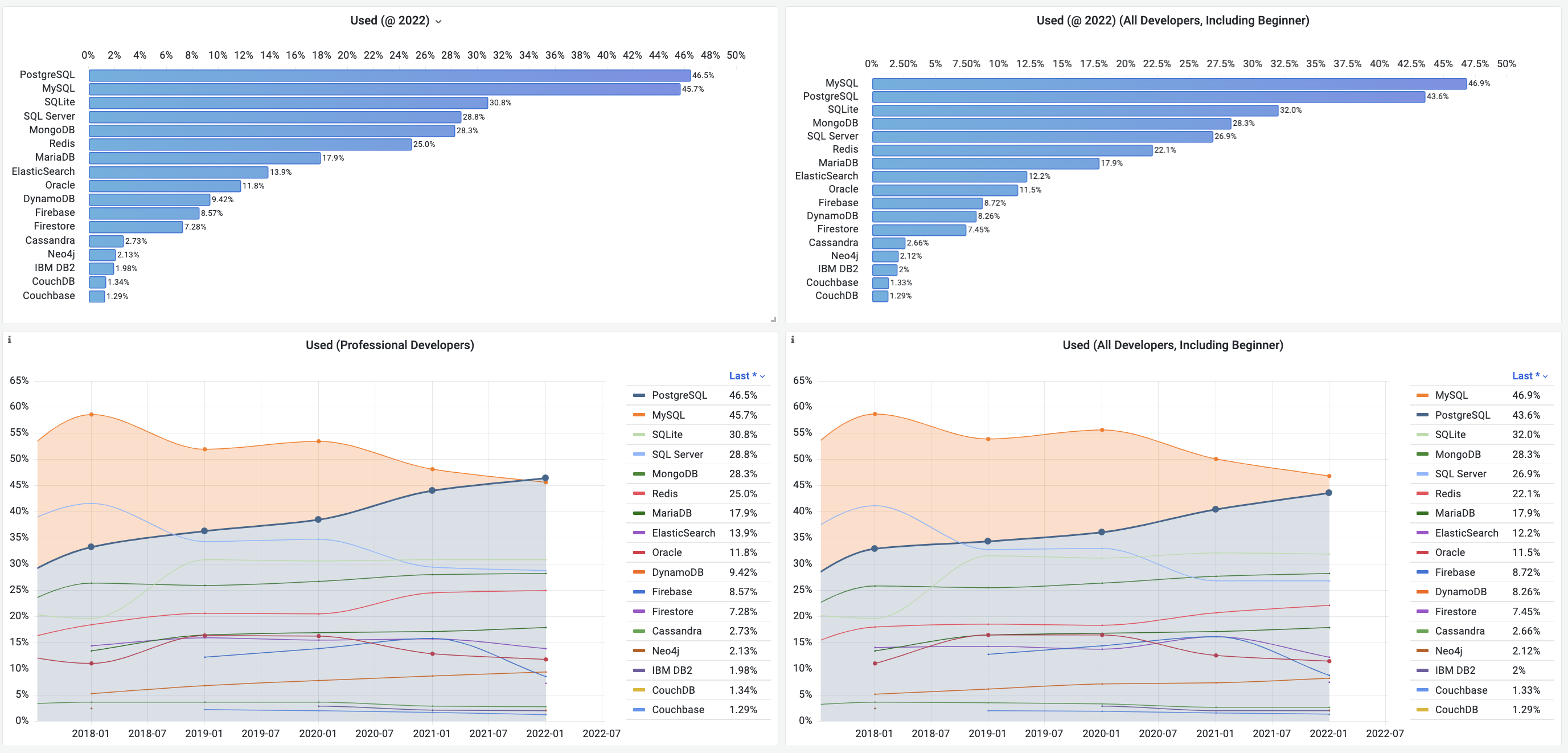
TOP 9 Database Popularity Trends (2017–2022)
PGSQL and MySQL aren’t that far apart. It’s worth noting that among junior developers, MySQL still enjoys a noticeable lead (58.4%). In fact, if we factor in all developer cohorts including juniors, MySQL retains a slim overall lead of 3.3%.
But if you look at the chart below, it’s clear that PostgreSQL is growing at a remarkable pace, whereas other databases—especially MySQL, SQL Server, and Oracle—have been on a steady decline in recent years. As time goes on, PostgreSQL’s advantage will likely become even more pronounced.
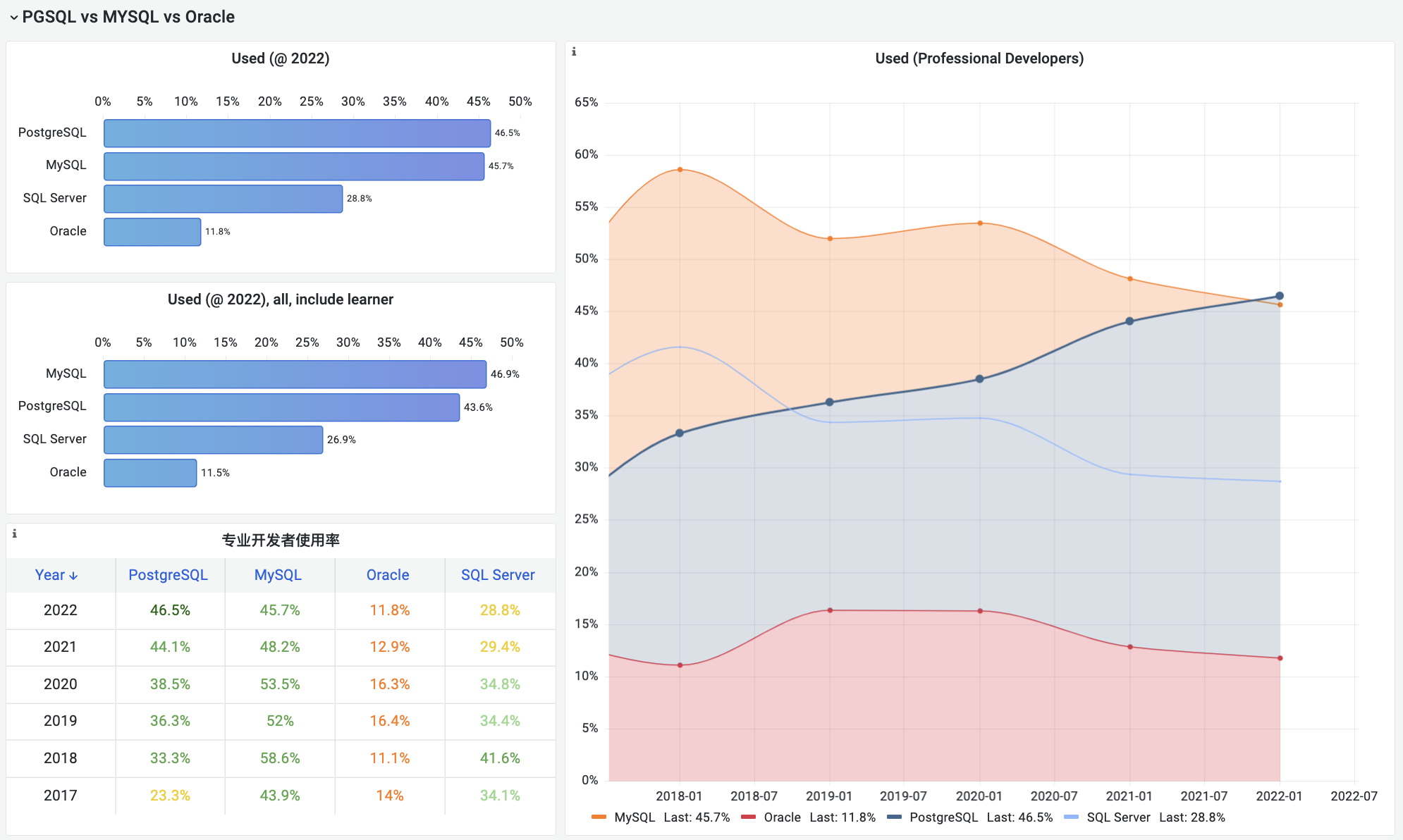
Popularity of Four Major Relational Databases Compared
Popularity represents a database’s current market presence (or “momentum”). Affection (“loved” status) signals the potential for future growth.
Most Loved
PostgreSQL—The Most Loved Database Among Developers! (Loved)
The second question StackOverflow asks is about which databases developers love and which they dread. In this survey, PostgreSQL and Redis stand head and shoulders above the rest with over 70% developer affection, significantly outpacing all other databases.
For years, Redis held the title of the most loved database. But in 2022, things changed: PostgreSQL edged out Redis for the first time and became the most loved database among developers. Redis, a super-simple, data-structure-based cache server that pairs well with relational databases, has always been a developer favorite. But apparently, developers love the much more powerful PostgreSQL just a little bit more.
In contrast, MySQL and Oracle lag behind. MySQL is basically split down the middle in terms of those who love or dread it, while only about 35% of users love Oracle—meaning nearly two-thirds of developers dislike it.
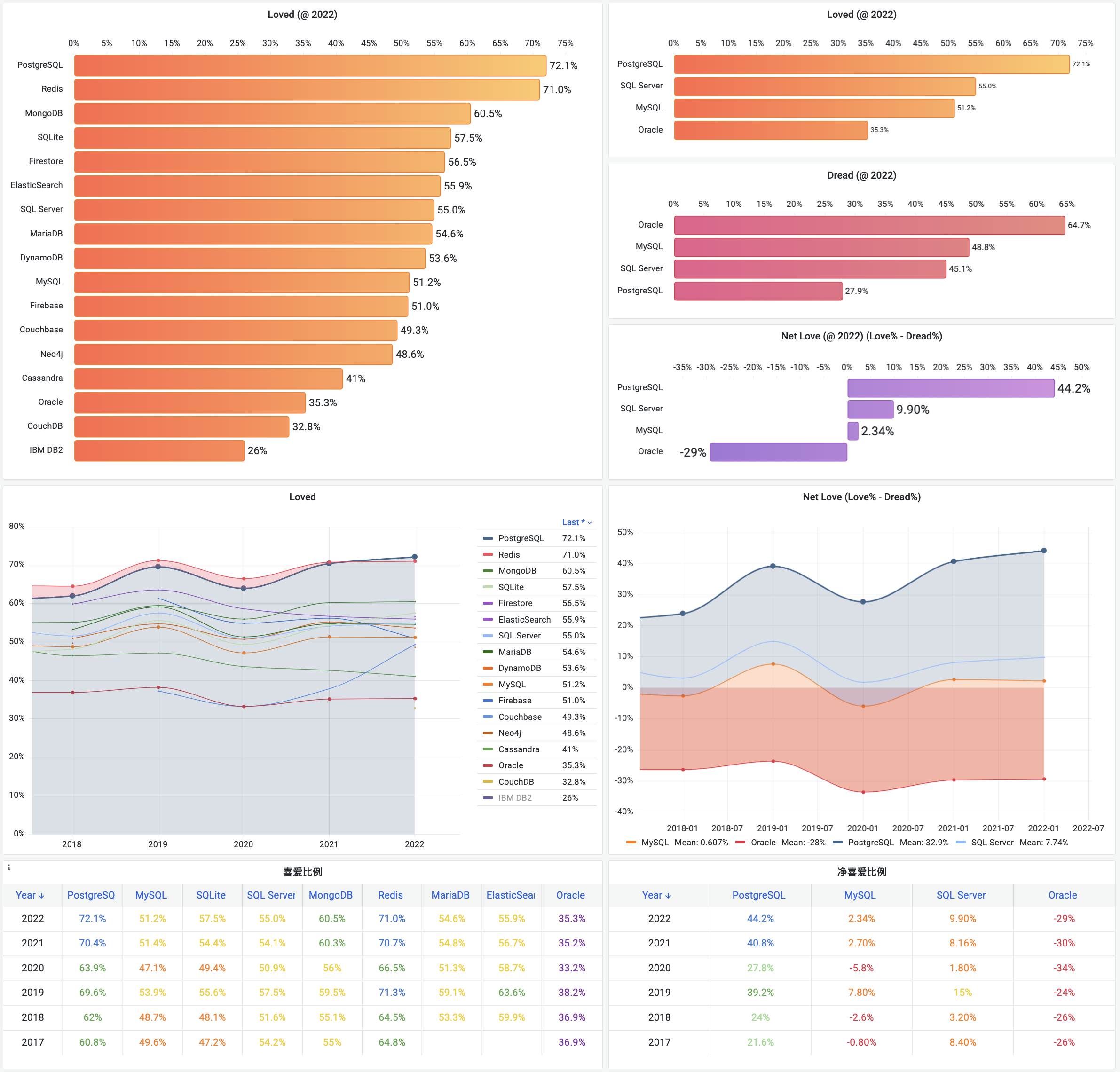
TOP 9 Database Affection Trends (2017–2022)
Logically, what people love tends to become what people use; what people dread tends to fade away. If we borrow from the Net Promoter Score (NPS) concept—(Promoters% – Detractors%)—we could define a similar “Net Love Score” (NLS): (Loved% – Dreaded%). We’d expect a positive correlation between a database’s usage growth rate and its NLS.
The data backs this up nicely: PostgreSQL boasts the highest NLS in the chart: 44%, corresponding to a whopping 460 basis-point growth every year. MySQL hovers just above breakeven with an NLS of 2.3%, translating to a modest 36 basis-point annual increase in usage. Oracle, on the other hand, scores a negative 29% NLS, tracking about 44 basis points of annual decline in usage. But it’s not even the most disliked on the list: IBM DB2 sits at an even more dismal -48%, accompanied by an average 46 basis-point annual decline.
Of course, not all potential (love) translates into actual usage growth. People might love it but never actually adopt it. That’s precisely where the third survey question comes in.
Most Wanted
PostgreSQL—The Most Wanted Database Among Developers! (Wanted)
“In the past year, which database environments did you do a lot of development work in? In the coming year, which databases do you want to work with?”
Answers to the first part led us to the “most popular” results. The second part answers the question of “most wanted.” If developer love points to a database’s growth potential, then developers’ actual desire (“want”) is a more tangible measure of next year’s growth momentum.
In this year’s survey, PostgreSQL didn’t hesitate to bump MongoDB from the top spot, becoming developers’ most desired database. A striking 19% of respondents said they want to work in a PostgreSQL environment next year. Following close behind are MongoDB (17%) and Redis (14%). These three lead the pack by a wide margin.
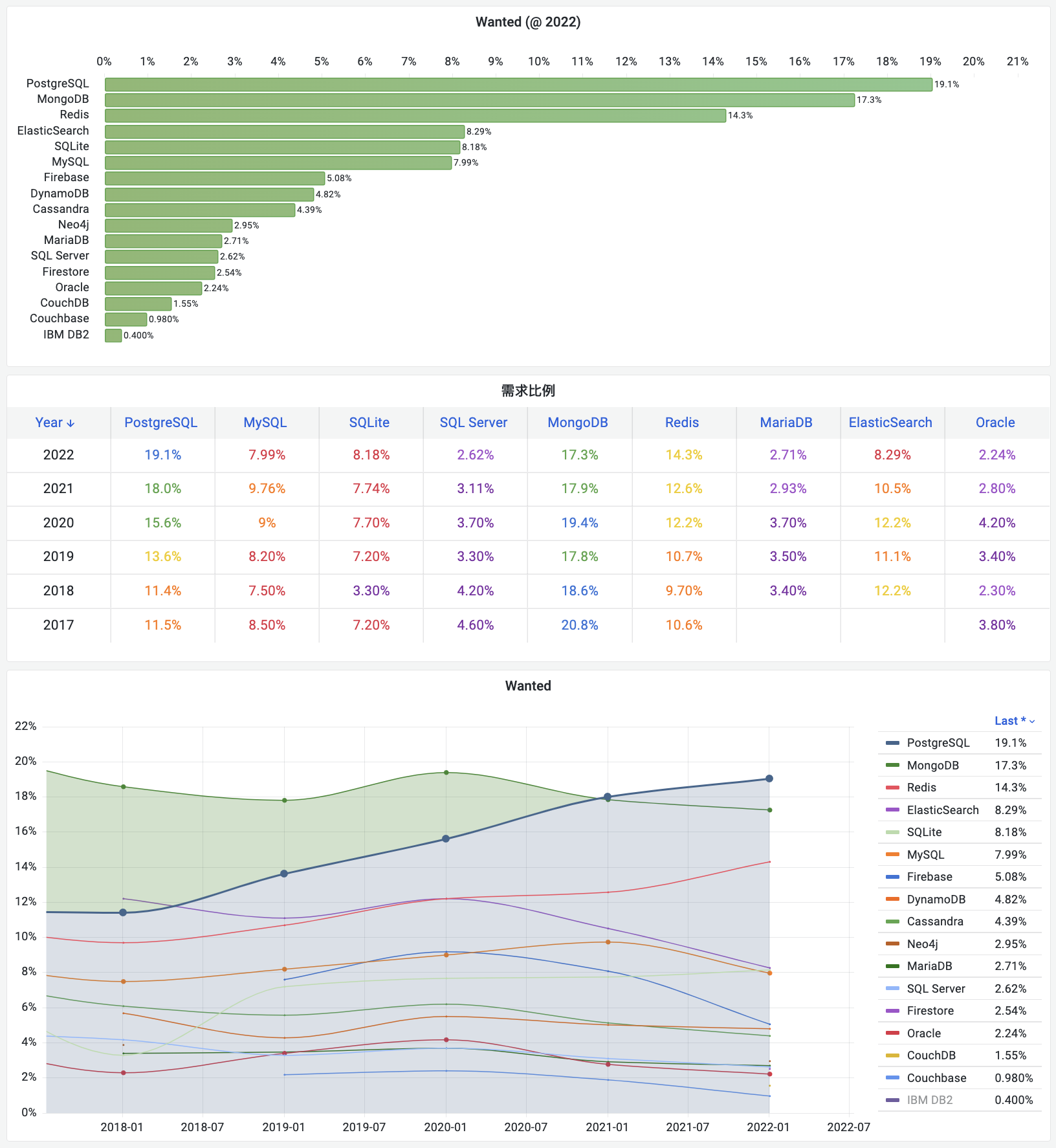
Previously, MongoDB consistently topped the “most wanted” ranking. Lately, though, it seems to be losing steam, for a variety of reasons—PostgreSQL itself being one of them. PostgreSQL has robust JSON support that covers most of the use cases of a document database. And there are projects like FerretDB (formerly MangoDB) that provide MongoDB’s API on top of PG, allowing you to use the same interface with a PostgreSQL engine underneath.
MongoDB and Redis were key players in the NoSQL movement. But unlike MongoDB, Redis continues to see growing demand. PostgreSQL and Redis, leaders in the SQL and NoSQL worlds respectively, are riding strong developer interest and high growth potential. The future looks bright.
Why?
PostgreSQL has come out on top in usage, demand, and developer love. It has the wind at its back on all fronts—past momentum, present energy, future potential. It’s fair to call it the most successful database.
But how did PostgreSQL achieve this level of success?
The secret is hidden in its own slogan: “The world’s most advanced open source relational database.”
A Relational Database
Relational databases are so prevalent and critical that they overshadow all other categories—key-value, document, search, time series, graph, and vector combined likely don’t add up to a fraction of the footprint of relational databases. By default, when people talk about a “database,” they usually mean a relational database. None of the other categories would dare to call themselves “mainstream” by comparison.
Take DB-Engines as an example. DB-Engines ranks databases by combining various signals—search engine results for the database name, Google Trends, Stack Overflow discussions, job postings on Indeed, user profiles on LinkedIn, mentions on Twitter, etc.—to form what you might consider a “composite popularity” metric.
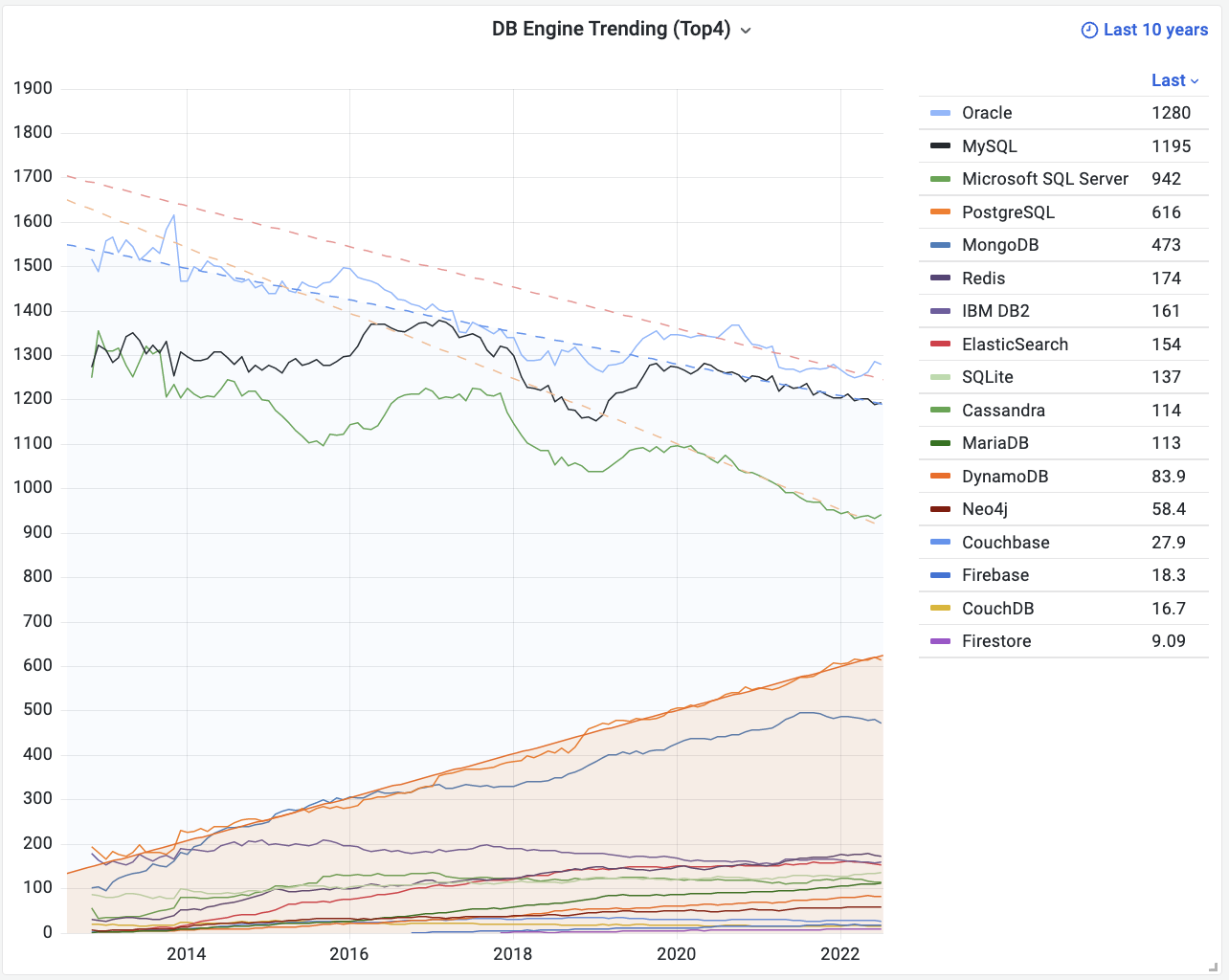
DB-Engines Popularity Trend: https://db-engines.com/en/ranking_trend
From the DB-Engines trend chart, you’ll notice a deep divide. The top four databases are all relational. Including MongoDB in fifth, these five are orders of magnitude ahead of all the rest in terms of popularity. So we really need to focus on those four major relational databases: Oracle, MySQL, SQL Server, and PostgreSQL.
Because they occupy essentially the same ecological niche, relational databases compete in what is almost a zero-sum game. Let’s set aside Microsoft’s SQL Server, which largely lives in its own closed-off commercial ecosystem. Among relational databases, it’s a three-way saga.
Oracle: “talented but unethical,” MySQL: “less capable, less principled,” PostgreSQL: “noble and skillful.”
Oracle is a long-established commercial database with an extensive feature set and historical pedigree, widely chosen by enterprises that “have cash to burn and need someone to take the blame.” It has always been at the top of the database market but is also notorious for expensive licensing and aggressive litigation—earning it a reputation as the corporate world’s “toxic troll.” Microsoft’s SQL Server is basically the same style: a commercial database living within a closed ecosystem. All commercial databases have been feeling the squeeze from open-source alternatives and are slowly losing ground.
MySQL claims second place in overall popularity but finds itself hemmed in on all sides: it’s got an “adoptive father” who doesn’t exactly have its best interests at heart, and “forked offspring” plus new distributed SQL contenders biting at its heels. In rigorous transaction processing and analytics, MySQL is outclassed by PostgreSQL. When it comes to quick-and-dirty solutions, many find NoSQL simpler and more flexible. Meanwhile, Oracle (MySQL’s “foster father”) imposes constraints at the top, MariaDB and others fork from within, and “prodigal children” like TiDB replicate the MySQL interface with new distributed architectures—meaning MySQL is also slipping.
Oracle has impressive talent yet shows questionable “ethics.” MySQL might get partial credit for open source but remains limited in capability—“less capable, less principled.” Only PostgreSQL manages to combine both capability and open ethics, reaping the benefits of advanced technology plus open source licensing. Like they say, “Sometimes the quiet turtle wins the race.” PostgreSQL stayed quietly brilliant for many years, then shot to the top in one fell swoop.
Where does PostgreSQL get its “ethics”? From being open source. And where does it get its “talent”? From being advanced.
The “Open Source” Ethos
PostgreSQL’s “virtue” lies in its open source nature: a founding-father-level open-source project, born of the combined efforts of developers worldwide.
It has a friendly BSD license and a thriving ecosystem that’s branching out in all directions, making it the main flag-bearer in the quest to replace Oracle.
What do we mean by “virtue” or “ethics”? Following the “Way” (道) in software is adhering to open source.
PostgreSQL is an old-guard, foundational project in the open-source world, a shining example of global developer collaboration.
A thriving ecosystem with extensive extensions and distributions—“branching out with many descendants.”
Way back when, developing software or providing any significant IT service usually required outrageously expensive commercial database software, like Oracle or SQL Server. Licensing alone could cost six or seven figures, not to mention hardware and support fees that matched or exceeded those numbers. For example, one CPU core’s worth of Oracle licensing can easily run into tens of thousands of dollars per year. Even giants like Alibaba balked at these costs and started the infamous “IOE phase-out.” The rise of open-source databases such as PostgreSQL and MySQL offered a new choice: free-as-in-beer software.
“Free” open-source software meant you could use the database without paying a licensing fee—a seismic shift that shaped the entire industry. It ushered in an era in which a business might only pay for hardware resources—maybe 20 bucks per CPU core per month—and that was it. Relational databases became accessible even to smaller companies, paving the way for free consumer-facing online services.
Open source has done an immense service to the world. The history of the internet is the history of open source: the reason we have an explosion of free online services is in large part because these services can be built on open-source components. Open source is a real success story—“community-ism,” if you will—where developers own the means of software production, share it freely, and cooperate globally. Everyone benefits from each other’s work.
An open-source programmer can stand on the shoulders of tens of thousands of top developers. Instead of paying a fortune in software licensing, they can simply use and extend what the community provides. This synergy is why developer salaries are relatively high. Essentially, each programmer is orchestrating entire armies of code and hardware. Open source means that fundamental building blocks are public domain, drastically cutting down on repeated “reinventing the wheel” across the industry. The entire tech world gets to move faster.

The deeper and more essential the software layer, the stronger the advantage open source tends to have—an advantage PostgreSQL leverages fully against Oracle.
Oracle may be advanced, but PostgreSQL isn’t far behind. In fact, PostgreSQL is the open-source database that’s most compatible with Oracle, covering about 85% of its features out of the box. Special enterprise distributions of PostgreSQL can reach 96% feature compatibility. Meanwhile, Oracle’s massive licensing costs give PG a huge advantage in cost-effectiveness: you don’t necessarily need to exceed Oracle’s capabilities to win; being 90% as good but an order of magnitude cheaper is enough to topple Oracle.
As an “open-source Oracle,” PostgreSQL is the only database truly capable of challenging Oracle’s dominance. It’s the standard-bearer for “de-Oracle-fication” (去O). Many of the so-called “domestic proprietary databases” (especially in China) are actually based on PostgreSQL under the hood—36% of them, by one estimate. This has created a whole family of “PG descendants” and fueled a wave of “independent controllable” database vendors. PostgreSQL’s BSD licensing does not forbid such derivative works, and the community does not oppose it. This open-minded stance stands in contrast to MySQL, which was purchased by Oracle and remains under the GPL, limiting what you can do with it.
The “Advanced” Edge
PostgreSQL’s “talent” lies in being advanced. A one-stop, all-in-one, multi-purpose database—essentially an HTAP solution by design.
Spatial, GIS, distributed, time-series, documents, it’s all in there. One component can cover nearly every use case.
PostgreSQL’s “talent” is that it’s a multi-specialist. It’s a comprehensive, full-stack database that can handle both OLTP and OLAP (making it naturally HTAP). It can also handle time-series data, geospatial queries (PostGIS), JSON documents, full-text search, and more. Essentially, one PostgreSQL instance can replace up to ten different specialized tools for small to medium enterprises, covering almost all their database needs.
Among relational databases, PostgreSQL is arguably the best value for money: it can handle traditional transactional workloads (OLTP) while also excelling at analytics, which are often an afterthought in other systems. And the specialized features provide entry points into all kinds of industries: geospatial data analytics with PostGIS, time-series financial or IoT solutions with Timescale, streaming pipelines with triggers and stored procedures, full-text search, or the FDW (foreign data wrapper) architecture to unify external data sources. PostgreSQL really is a multi-specialist, going far beyond the typical single-use relational engine.
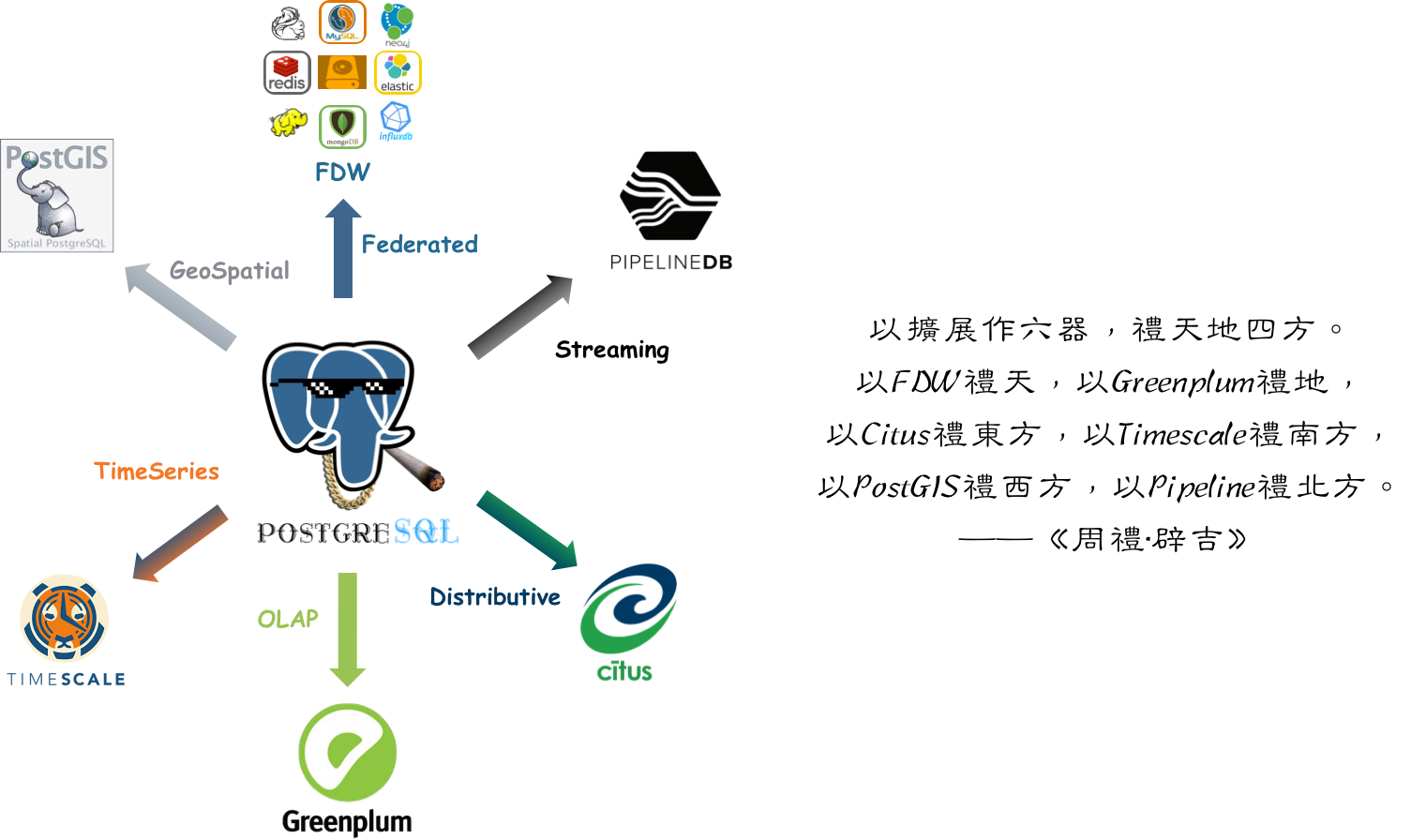
In many cases, one PostgreSQL node can do the job of multiple specialized systems, significantly reducing complexity and cutting costs. This might mean the difference between needing ten people on your team vs. just one. Of course, this doesn’t mean PG is going to destroy all specialized databases: for large-scale specialized workloads, dedicated components still shine. But for many scenarios—and especially for those not at hyperscale—it’s overkill to maintain extra systems. If a single tool does everything you need, why complicate things?
For example, at Tantan (a major dating/social app in China), a single PostgreSQL setup handled 2.5 million TPS and 200 TB of data reliably. It wore multiple hats—OLTP for transactions, caching, analytics, batch processing, and even a bit of message queue functionality. Eventually, as they scaled to tens of millions of daily active users, these specialized roles did break out into their own dedicated systems—but that was only after the user base had grown enormously.

vs. MySQL
PostgreSQL’s advanced feature set is widely recognized, and this forms its real edge against its long-standing open-source rival—MySQL.
MySQL’s tagline is “the world’s most popular open-source relational database.” Historically, it’s attracted the “quick and dirty” side of the internet developer community. The typical web startup often only needs simple CRUD operations, can tolerate some data inconsistency or loss, and prioritizes time-to-market. They want to spin up solutions quickly—think LAMP stacks—without needing highly specialized DBAs.
But the times have changed. PostgreSQL has improved at a blistering pace, with performance that rivals or surpasses MySQL. What remains of MySQL’s core advantage is its “leniency.” MySQL is known for “better to run than to fail,” or “I don’t care if your data’s messed up as long as I’m not crashing.” For instance, it even allows certain broken SQL commands to run, leading to bizarre results. One of the strangest behaviors is that MySQL may allow partial commits by default, violating the atomicity of transactions that relational databases are supposed to guarantee.

Screenshot: MySQL can silently allow partial transaction commits by default.
The advanced inevitably overtakes the old, and the once-popular eventually fades if it doesn’t evolve. Thanks to its broad, sophisticated features, PostgreSQL has left MySQL behind and is now even surpassing it in popularity. As the saying goes, “When your time comes, the world helps you move forward; when your luck runs out, not even a hero can save you.”
Between Oracle’s advanced but closed nature and MySQL’s open but limited functionality, PostgreSQL is both advanced and open-source, enjoying the best of both worlds—technical edge plus community-driven development. With the stars aligned in its favor, how could it not succeed?
The Road Ahead
“Software is eating the world. Open source is eating software. And the cloud is eating open source.”
So from this vantage point, it seems the database wars are largely settled. No other database engine is likely to seriously challenge PostgreSQL anytime soon. The real threat to the PostgreSQL open-source community no longer comes from another open-source or commercial database engine—it comes from the changing paradigm of software usage itself: the arrival of the cloud.
Initially, you needed expensive commercial software (like Oracle, SQL Server, or Unix) to build or run anything big. Then, open-source took the stage (Linux, PostgreSQL, etc.), offering a choice that was essentially free. Of course, truly getting the most out of open source requires in-house expertise, so companies ended up paying people, rather than licensing fees.
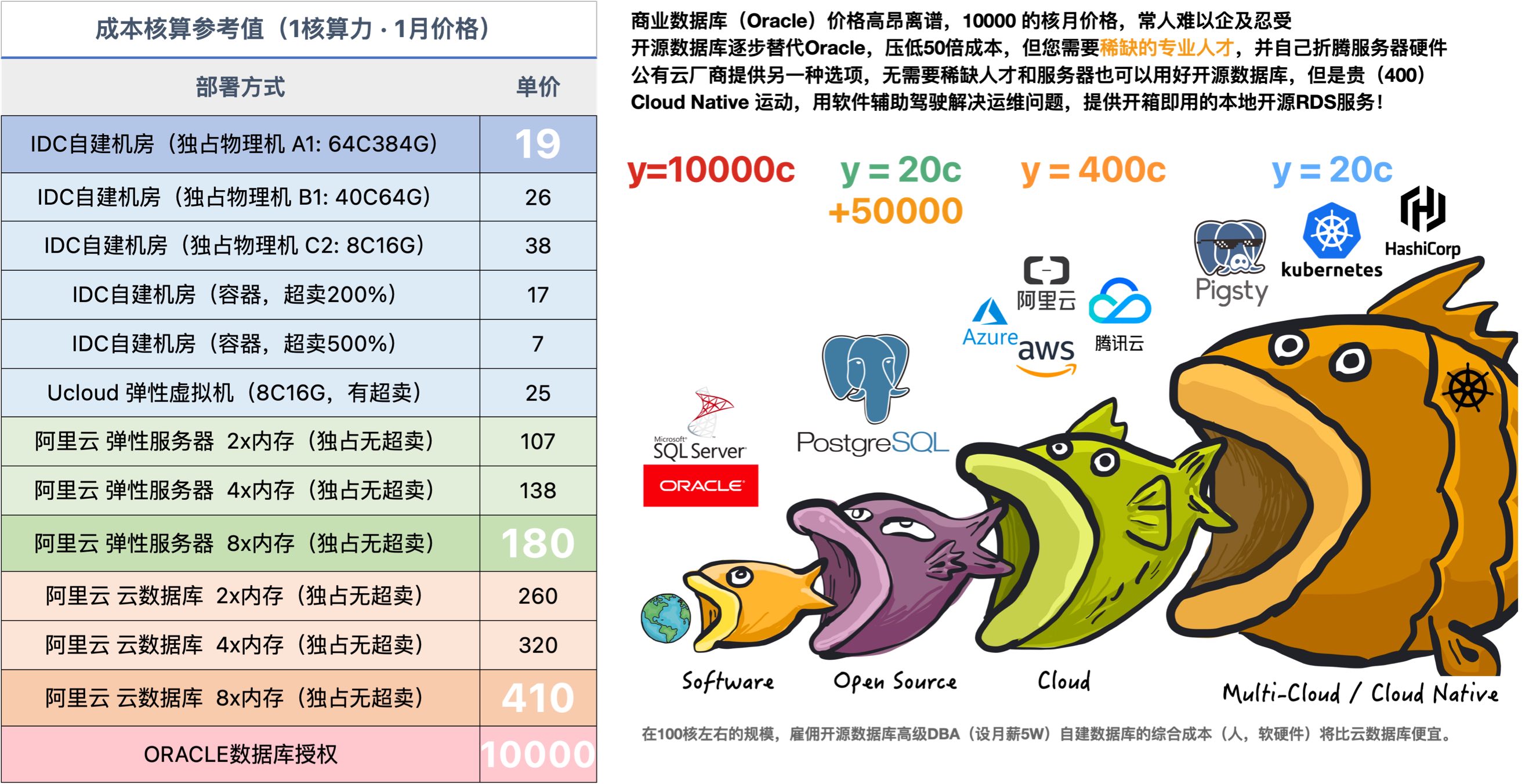
Once your DB scale grows large enough, hiring open-source DBA talent becomes more cost-effective. The challenge is that good DBAs are scarce.
That’s the open-source model: open-source contributors enhance the software for free; the software is free for all to use; users then hire open-source experts to implement and operate it, creating more open-source contributors. It’s a virtuous cycle.
Public cloud vendors, however, have disrupted this cycle by taking open-source software, wrapping it with their cloud hardware and admin tools, and selling it as a cloud service—often returning very little to the upstream open-source project. They’re effectively free-riding on open source, turning it into a service they profit from, which can undermine the community’s sustainability by consolidating the jobs and expertise within a handful of cloud giants, thus eroding software freedom for everyone.
By 2020, the primary enemy of software freedom was no longer proprietary software but cloud-hosted software.
That’s a paraphrase of Martin Kleppmann (author of Designing Data-Intensive Applications), who proposed in his “Local-First Software” movement that cloud-based solutions—like Google Docs, Trello, Slack, Figma, Notion, and crucially, cloud databases—are the new walled gardens.
How should the open-source community respond to the rise of cloud services? The Cloud Native movement offers one possible way forward. It’s a movement to reclaim software freedom from public clouds, and databases are right at the heart of it.
A grand view of the Cloud Native ecosystem—still missing the last piece of the puzzle: robust support for stateful databases!
That’s also our motivation for building Pigsty: an open-source PostgreSQL “distribution” that’s as easy to deploy as RDS or any managed cloud service, but fully under your control!
Pigsty comes with out-of-the-box RDS/PaaS/SaaS integration, featuring an unrivaled PostgreSQL monitoring system and an “auto-driving” high-availability cluster solution. It can be installed with a single command, giving you “Database as Code.” You get an experience on par with, or even better than, managed cloud databases, but you own the data, and the cost can be 50–90% lower. We hope it drastically lowers the barriers to using a good database and helps you get the most out of that database.
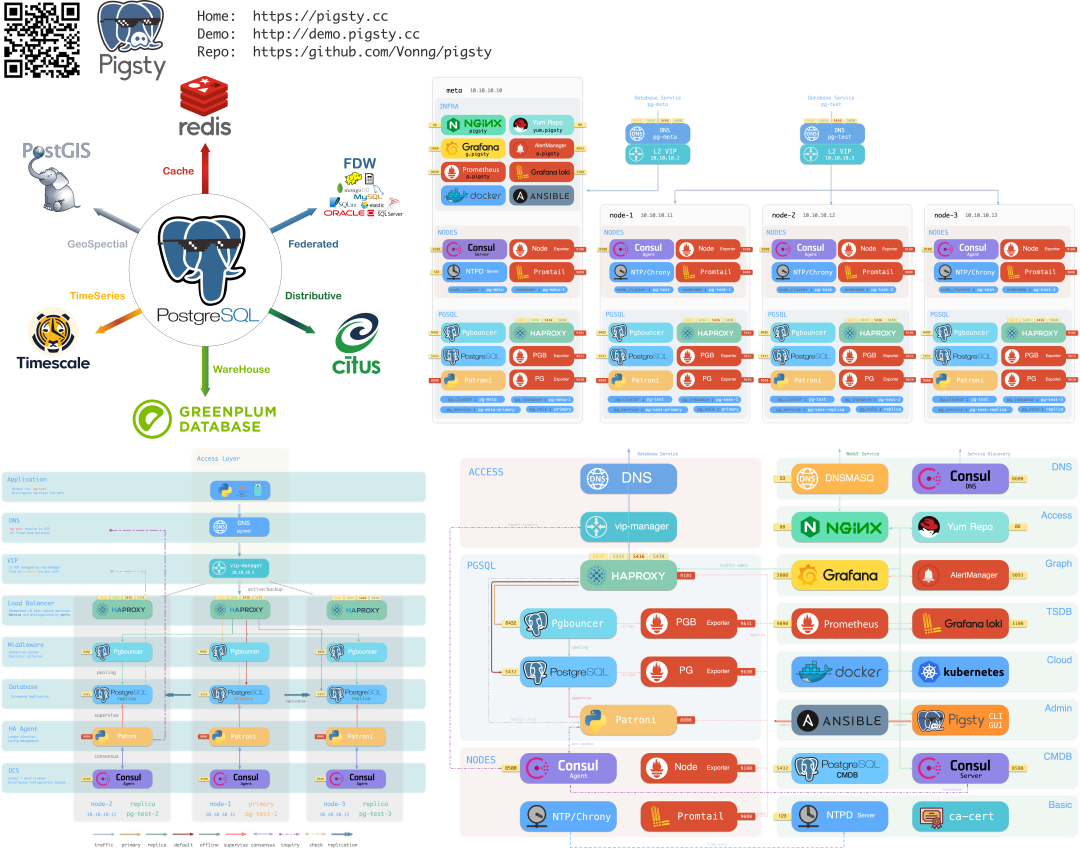
Of course, we’re out of space here, so the future of databases in a post-cloud era will have to wait for the next installment.
Pigsty: The Production-Ready PostgreSQL Distribution
What is Pigsty?
Pigsty is a production-ready, batteries-included PostgreSQL distribution.

A distribution, in this context, refers to a complete database solution comprised of the database kernel and a curated set of software packages. Just as Linux is an operating system kernel while RedHat, Debian, and SUSE are operating system distributions built upon it, PostgreSQL is a database kernel, and Pigsty, along with BigSQL, Percona, various cloud RDS offerings, and other database variants are database distributions built on top of it.
Pigsty distinguishes itself from other database distributions through five core features:
- A comprehensive and professional monitoring system
- A stable and reliable deployment solution
- A simple and hassle-free user interface
- A flexible and open extension mechanism
- A free and friendly open-source license
These five features make Pigsty a truly batteries-included PostgreSQL distribution.
Who Should Be Interested?
Pigsty caters to a diverse audience including DBAs, architects, ops engineers, software vendors, cloud providers, application developers, kernel developers, data engineers; those interested in data analysis and visualization; students, junior programmers, and anyone curious about databases.
For DBAs, architects, and other professional users, Pigsty offers a unique professional-grade PostgreSQL monitoring system that provides irreplaceable value for database management. Additionally, Pigsty comes with a stable and reliable, battle-tested production-grade PostgreSQL deployment solution that can automatically deploy database clusters with monitoring, alerting, log collection, service discovery, connection pooling, load balancing, VIP, and high availability in production environments.
For developers (application, kernel, or data), students, junior programmers, and database enthusiasts, Pigsty provides a low-barrier, one-click launch, one-click install local sandbox. This sandbox environment, identical to production except for machine specifications, includes a complete feature set: ready-to-use database instances and monitoring systems. It’s perfect for learning, development, testing, and data analysis scenarios.
Furthermore, Pigsty introduces a flexible extension mechanism called “Datalet”. Those interested in data analysis and visualization might be surprised to find that Pigsty can serve as an integrated development environment for data analysis and visualization. Pigsty integrates PostgreSQL with common data analysis plugins and comes with Grafana and embedded Echarts support, allowing users to write, test, and distribute data mini-applications (Datelets). Examples include “Additional monitoring dashboard packs for Pigsty”, “Redis monitoring system”, “PG log analysis system”, “Application monitoring”, “Data directory browser”, and more.
Finally, Pigsty adopts the free and friendly Apache License 2.0, making it free for commercial use. Cloud providers and software vendors are welcome to integrate and customize it for commercial use, as long as they comply with the Apache 2 License’s attribution requirements.
Comprehensive Professional Monitoring System

You can’t manage what you don’t measure.
— Peter F.Drucker
Pigsty provides a professional-grade monitoring system that delivers irreplaceable value to professional users.
To draw a medical analogy, basic monitoring systems are like heart rate monitors or pulse oximeters - tools that anyone can use without training. They show core vital signs: at least users know if the patient is about to die, but they’re not much help for diagnosis and treatment. Most monitoring systems provided by cloud vendors and software companies fall into this category: a dozen core metrics that tell you if the database is alive, giving you a rough idea and nothing more.
A professional-grade monitoring system, on the other hand, is more like a CT or MRI machine, capable of examining every detail inside the subject. Professional physicians can quickly identify diseases and potential issues from CT/MRI reports: treating what’s broken and maintaining what’s healthy. Pigsty can scrutinize every table, every index, every query in each database, providing comprehensive metrics (1,155 types) and transforming them into insights through thousands of dashboards: killing problems in their infancy and providing real-time feedback for performance optimization.
Pigsty’s monitoring system is built on industry best practices, using Prometheus and Grafana as monitoring infrastructure. It’s open-source, customizable, reusable, portable, and free from vendor lock-in. It can integrate with various existing database instances.

Stable and Reliable Deployment Solution

A complex system that works is invariably found to have evolved from a simple system that works.
—John Gall, Systemantics (1975)
If databases are software for managing data, then control systems are software for managing databases.
Pigsty includes a database control solution centered around Ansible, wrapped with command-line tools and a graphical interface. It integrates core database management functions: creating, destroying, and scaling database clusters; creating users, databases, and services. Pigsty adopts an “Infrastructure as Code” design philosophy using declarative configuration, describing and customizing databases and runtime environments through numerous optional configuration parameters, and automatically creating required database clusters through idempotent preset playbooks, providing a private cloud-like experience.
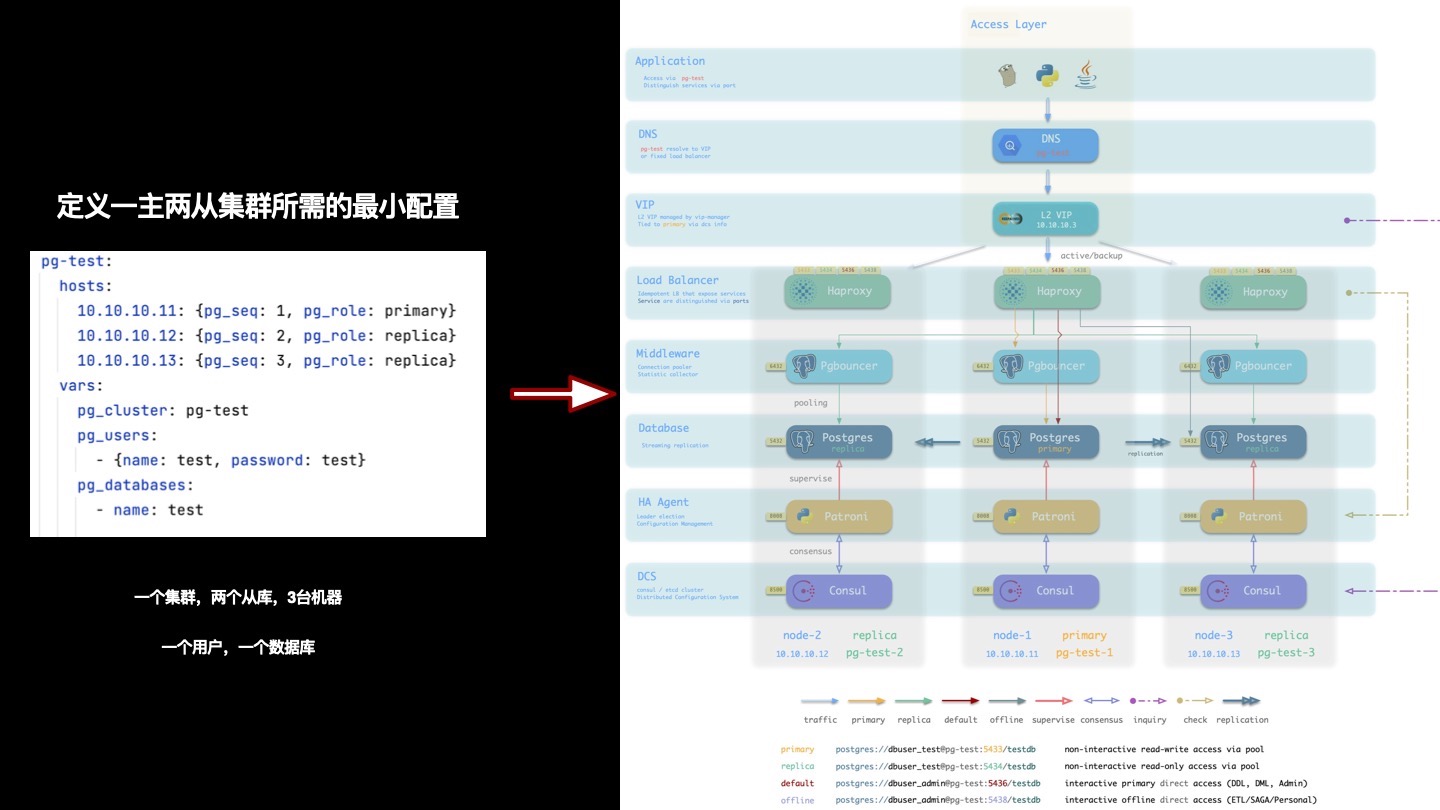
Pigsty creates distributed, highly available database clusters. Built on DCS, Patroni, and HAProxy, Pigsty’s database clusters achieve high availability. Each database instance in the cluster is idempotent in usage - any instance can provide complete read-write services through built-in load balancing components, delivering a distributed database experience. Database clusters can automatically detect failures and perform primary-replica failover, with common failures self-healing within seconds to tens of seconds, during which read-only traffic remains unaffected. During failures, as long as any instance survives, the cluster can provide complete service.
Pigsty’s architecture has been carefully designed and evaluated, focusing on achieving required functionality with minimal complexity. This solution has been validated through long-term, large-scale production environment use across internet/B/G/M/F industries.
Simple and Hassle-Free User Interface

Pigsty aims to lower PostgreSQL’s barrier to entry and has invested heavily in usability.
Installation and Deployment
Someone told me that each equation I included in the book would halve the sales.
— Stephen Hawking
Pigsty’s deployment consists of three steps: download source code, configure environment, and execute installation - all achievable through single commands. Following classic software installation patterns and providing a configuration wizard, all you need is a CentOS 7.8 machine with root access. For managing new nodes, Pigsty uses Ansible over SSH, requiring no agent installation, making deployment easy even for beginners.
Pigsty can manage hundreds or thousands of high-spec production nodes in production environments, or run independently on a local 1-core 1GB virtual machine as an out-of-the-box database instance. For local computer use, Pigsty provides a sandbox based on Vagrant and VirtualBox. It can spin up a database environment identical to production with one click, perfect for learning, development, testing, data analysis, and data visualization scenarios.
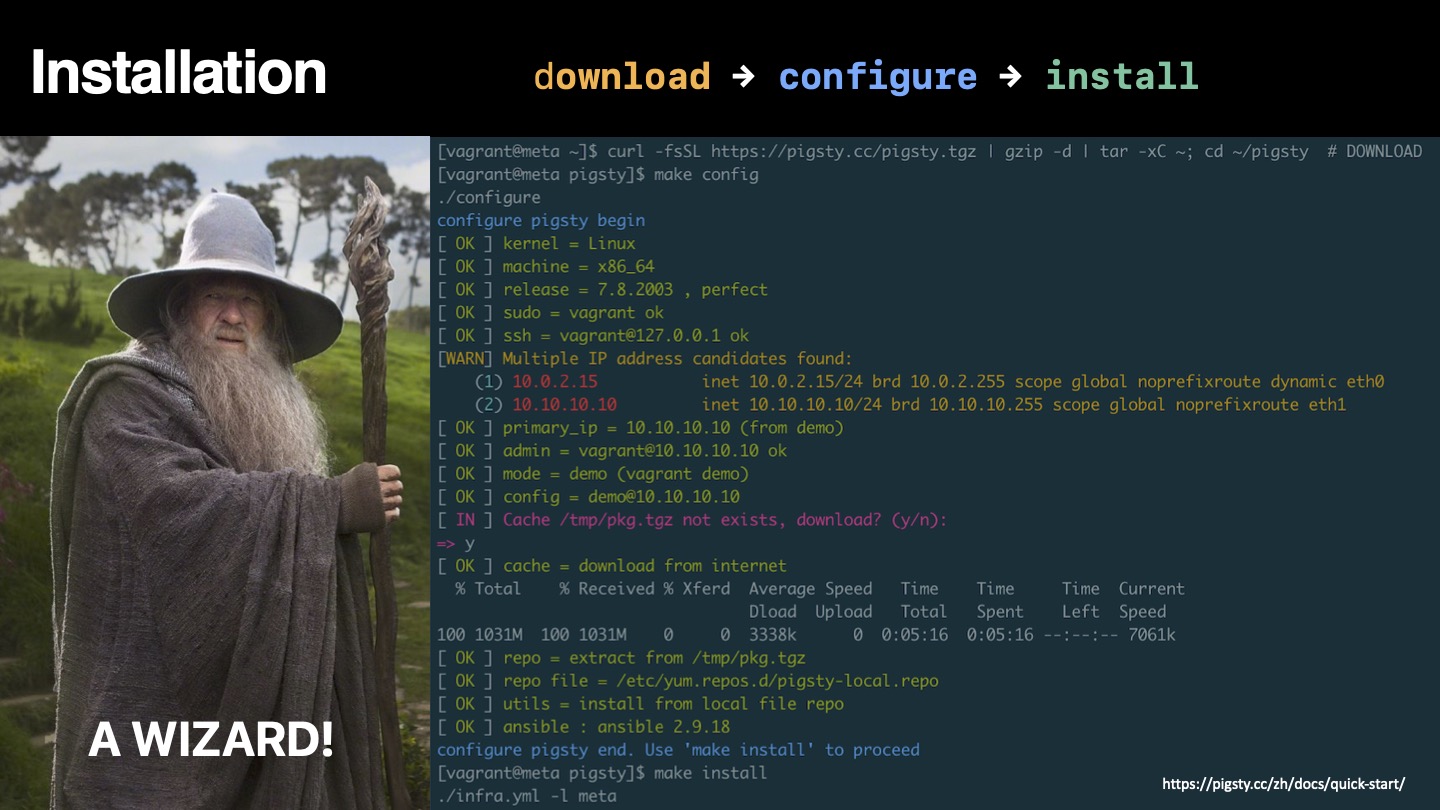
User Interface
Clearly, we must break away from the sequential and not limit the computers. We must state definitions and provide for priorities and descriptions of data. We must state relationships, not procedures.
—Grace Murray Hopper, Management and the Computer of the Future (1962)
Pigsty incorporates the essence of Kubernetes architecture design, using declarative configuration and idempotent operation playbooks. Users only need to describe “what kind of database they want” without worrying about how Pigsty creates or modifies it. Based on the user’s configuration manifest, Pigsty will create the required database cluster from bare metal nodes in minutes.
For management and usage, Pigsty provides different levels of user interfaces to meet various user needs. Novice users can use the one-click local sandbox and graphical user interface, while developers might prefer the pigsty-cli command-line tool and configuration files for management. Experienced DBAs, ops engineers, and architects can directly control task execution through Ansible primitives for fine-grained control.
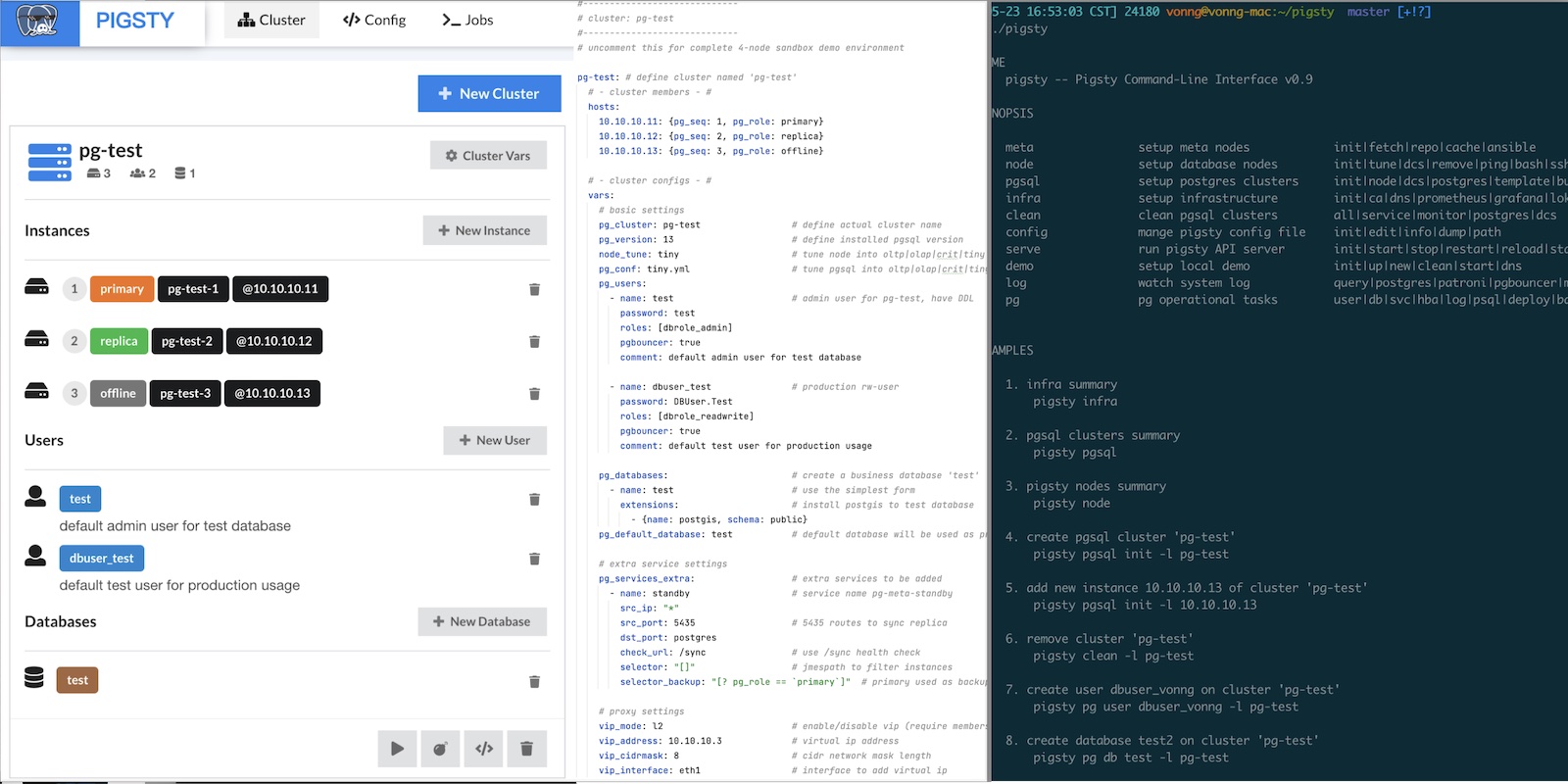
Flexible and Open Extension Mechanism
PostgreSQL’s extensibility has always been praised, with various extension plugins making it the most advanced open-source relational database. Pigsty respects this value and provides an extension mechanism called “Datalet”, allowing users and developers to further customize Pigsty and use it in “unexpected” ways, such as data analysis and visualization.

When we have a monitoring system and control solution, we also have an out-of-the-box visualization platform Grafana and a powerful database PostgreSQL. This combination packs a punch - especially for data-intensive applications. Users can perform data analysis and visualization, create data application prototypes with rich interactions, or even full applications without writing frontend or backend code.
Pigsty integrates Echarts and common map tiles, making it convenient to implement advanced visualization requirements. Compared to traditional scientific computing languages/plotting libraries like Julia, Matlab, and R, the PG + Grafana + Echarts combination allows you to create shareable, deliverable, standardized data applications or visualization works at minimal cost.
Pigsty’s monitoring system itself is a prime example of Datalet: all Pigsty advanced monitoring dashboards are published as Datelets. Pigsty also comes with some interesting Datalet examples: Redis monitoring system, COVID-19 data analysis, China’s seventh census population data analysis, PG log mining, etc. More out-of-the-box Datelets will be added in the future, continuously expanding Pigsty’s functionality and application scenarios.
Free and Friendly Open Source License

Once open source gets good enough, competing with it would be insane.
Larry Ellison —— Oracle CEO
In the software industry, open source is a major trend. The history of the internet is the history of open source software. One key reason why the IT industry is so prosperous today and people can enjoy so many free information services is open source software. Open source is a truly successful form of communism (better translated as communitarianism) composed of developers: software, the core means of production in the IT industry, becomes collectively owned by developers worldwide - all for one and one for all.
When an open source programmer works, their labor potentially embodies the wisdom of tens of thousands of top developers. Through open source, all community developers form a joint force, greatly reducing the waste of reinventing wheels. This has pushed the industry’s technical level forward at an incredible pace. The momentum of open source is like a snowball, unstoppable today. Except for some special scenarios and path dependencies, developing software behind closed doors and striving for self-reliance has become a joke.
Relying on open source and giving back to open source, Pigsty adopts the friendly Apache License 2.0, free for commercial use. Cloud providers and software vendors are welcome to integrate and customize it for commercial use, as long as they comply with the Apache 2 License’s attribution requirements.
About Pigsty
A system cannot be successful if it is too strongly influenced by a single person. Once the initial design is complete and fairly robust, the real test begins as people with many different viewpoints undertake their own experiments. — Donald Knuth
Pigsty is built around the open-source database PostgreSQL, the most advanced open-source relational database in the world, and Pigsty’s goal is to be the most user-friendly open-source PostgreSQL distribution.
Initially, Pigsty didn’t have such grand ambitions. Unable to find any monitoring system that met my needs in the market, I had to roll up my sleeves and build one myself. Surprisingly, it turned out better than expected, and many external PostgreSQL users wanted to use it. Then, deploying and delivering the monitoring system became an issue, so the database deployment and control parts were added; after production deployment, developers wanted local sandbox environments for testing, so the local sandbox was created; users found Ansible difficult to use, so the pigsty-cli command-line tool was developed; users wanted to edit configuration files through UI, so Pigsty GUI was born. This way, as demands grew, features became richer, and Pigsty became more refined through long-term polishing, far exceeding initial expectations.
This project itself is a challenge - creating a distribution is somewhat like creating a RedHat, a SUSE, or an “RDS product”. Usually, only professional companies and teams of certain scale would attempt this. But I wanted to try: could one person do it? Actually, except for being slower, there’s nothing impossible about it. It’s an interesting experience switching between product manager, developer, and end-user roles, and the biggest advantage of “eating your own dog food” is that you’re both developer and user - you understand what you need and won’t cut corners on your own requirements.
However, as Donald Knuth said, “A system cannot be successful if it is too strongly influenced by a single person.” To make Pigsty a project with vigorous vitality, it must be open source, letting more people use it. “Once the initial design is complete and fairly robust, the real test begins as people with many different viewpoints undertake their own experiments.”
Pigsty has well solved my own problems and needs, and now I hope it can help more people and make the PostgreSQL ecosystem more prosperous and colorful.
Why PostgreSQL Has a Bright Future
Recently, everything I’ve been working on revolves around the PostgreSQL ecosystem, because I’ve always believed it’s a direction with limitless potential.
Why do I say this? Because databases are the core components of information systems, relational databases are the absolute workhorses among databases, and PostgreSQL is the most advanced open-source relational database in the world. With timing and positioning in its favor, how could greatness not be achieved?
The most important thing when doing anything is to understand the situation clearly. When the time is right, everything aligns in your favor; when it’s not, even heroes are powerless.
The Big Picture
Today’s database world is divided in three parts, with Oracle | MySQL | SQL Server in decline, their sun setting in the west. PostgreSQL follows closely behind, rising like the midday sun. Among the top four databases, the first three are heading downhill, while only PG continues to grow unabated. As one falls and another rises, the future looks boundless.
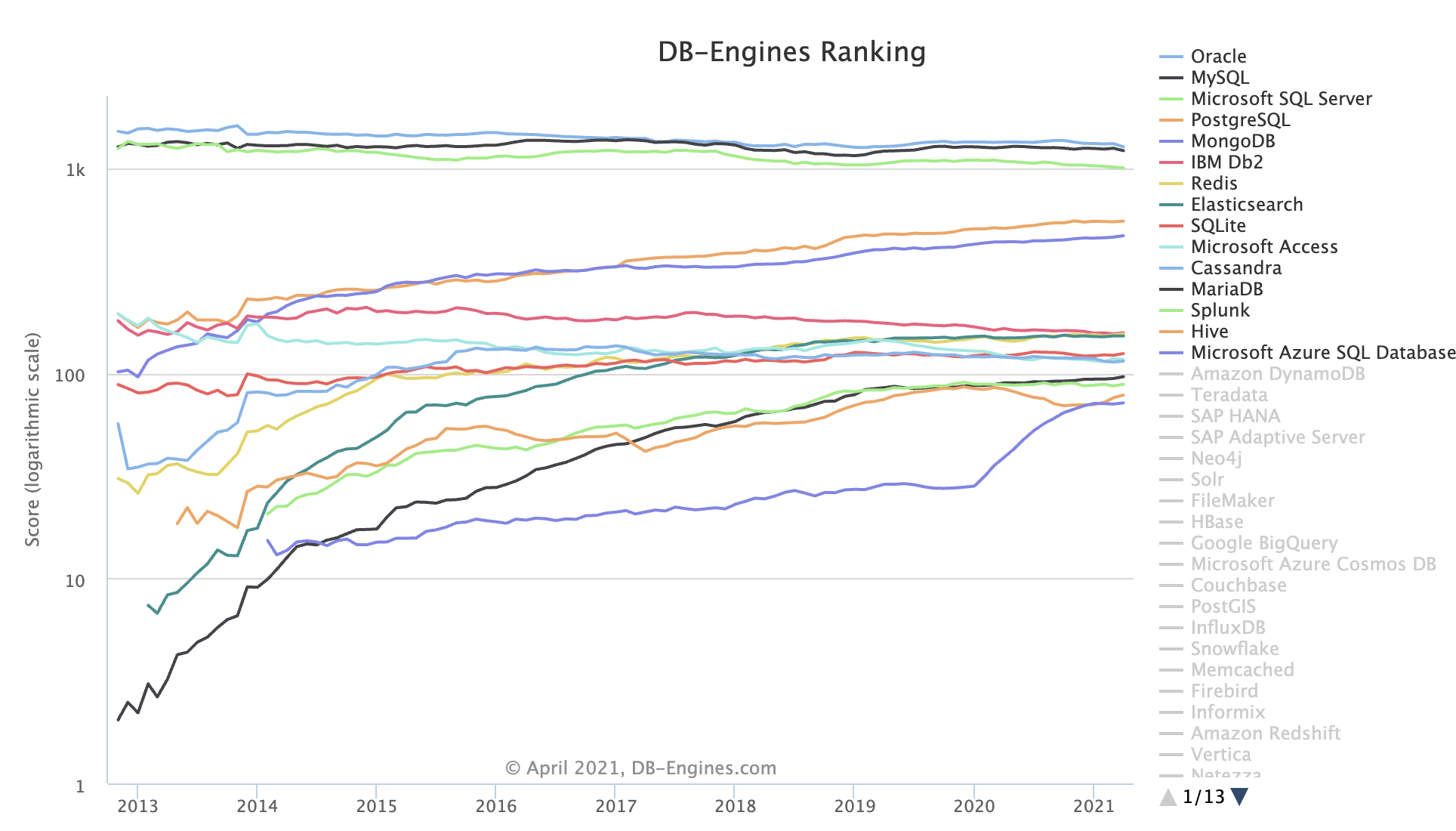
DB-Engine Database Popularity Trend (Note that this is a logarithmic scale)
Between the only two leading open-source relational databases, MySQL (2nd) holds the upper hand, but its ecological niche is gradually being encroached upon by both PostgreSQL (4th) and the non-relational document database MongoDB (5th). At the current pace, PostgreSQL’s popularity will soon break into the top three, standing shoulder to shoulder with Oracle and MySQL.
Competitive Landscape
Relational databases occupy highly overlapping ecological niches, and their relationship can be viewed as a zero-sum game. The direct competitors to PostgreSQL are Oracle and MySQL.
Oracle ranks first in popularity, an established commercial database with deep historical and technical foundations, rich features, and comprehensive support. It sits firmly in the top database chair, beloved by organizations with deep pockets. But Oracle is expensive, and its litigious behavior has made it a notorious industry parasite. SQL Server, ranking third, belongs to the relatively independent Microsoft ecosystem and is similar to Oracle in nature—both are commercial databases. Overall, commercial databases are experiencing slow decline due to pressure from open-source alternatives.
MySQL ranks second in popularity but finds itself in an unfavorable position, caught between wolves ahead and tigers behind, with a domineering parent above and rebellious offspring below. For rigorous transaction processing and data analysis, MySQL lags several streets behind fellow open-source relational database PostgreSQL. For quick and dirty agile methods, MySQL can’t compete with emerging NoSQL solutions. Meanwhile, MySQL faces suppression from its Oracle parent, competition from its MariaDB fork, and market share erosion from MySQL-compatible newcomers like TiDB and OceanBase. As a result, it has stagnated.
Only PostgreSQL is surging forward, maintaining nearly exponential growth. If a few years ago PG’s momentum was merely “potential,” that potential is now being realized as “impact,” posing a serious challenge to competitors.
In this life-or-death struggle, PostgreSQL holds three key advantages:
-
The spread of open-source software, eating away at the commercial software market
Against the backdrop of “de-IOE” (eliminating IBM, Oracle, EMC) and the open-source wave, the open-source ecosystem has effectively suppressed commercial software (Oracle).
-
Meeting users’ growing data processing requirements
With PostGIS, the de facto standard for geospatial data, PostgreSQL has established an unbeatable position, while its Oracle-comparable rich feature set gives it a technical edge over MySQL.
-
Market share regression to the mean
PG’s market share in China is far below the global average for historical reasons, which harbors enormous potential energy.
Oracle, as an established commercial software, unquestionably has talent, while as an industry parasite, its virtue needs no further comment—hence, “talented but lacking virtue.” MySQL has the virtue of being open-source, but it adopted the GPL license, which is less generous than PostgreSQL’s permissive BSD license, plus it was acquired by Oracle (accepting a thief as father), and it’s technically shallow and functionally crude—hence, “shallow talent, thin virtue.”
When virtue doesn’t match position, disaster inevitably follows. Only PostgreSQL occupies the right time with the rise of open source, the right place with powerful features, and the right people with its permissive BSD license. As the saying goes: “Store up your capabilities, act when the time is right. Silent until ready, then make a thunderous entrance.” With both virtue and talent, the advantage in both offense and defense is clear!
Virtue and Talent Combined
PostgreSQL’s Virtue
PG’s “virtue” lies in being open source. What is “virtue”? It’s behavior that conforms to the “Way.” And this “Way” is open source.
PG itself is a founding-level open-source software, a jewel in the open-source world, a successful example of global developer collaboration. More importantly, it uses the selfless BSD license: aside from fraudulently using the PG name, basically everything is permitted—including rebranding it as a domestic database for sale. PG can truly be called the bread and butter of countless database vendors. With countless descendants and beneficiaries, its merit is immeasurable.
Database genealogy chart. If all PostgreSQL derivatives were listed, this chart would likely explode.
PostgreSQL’s Talent
PG’s “talent” lies in being versatile while specialized. PostgreSQL is a full-stack database that excels in many areas, born as an HTAP, hyper-converged database that can do the work of ten. A single component can cover most database needs for small and medium enterprises: OLTP, OLAP, time-series, spatial GIS, full-text search, JSON/XML, graph databases, caching, and more.
PostgreSQL can play the role of a jack-of-all-trades within a considerable scale, using a single component where multiple would normally be needed. And a single data component selection can greatly reduce project complexity, which means significant cost savings. It turns what would require ten talented people into something one person can handle. If there’s truly a technology that can meet all your needs, using that technology is the best choice, rather than trying to re-implement it with multiple components.
Recommended reading: What’s Good About PG
The Virtue of Open Source
Open source has great virtue. The history of the internet is the history of open-source software. One of the core reasons the IT industry has today’s prosperity, allowing people to enjoy so many free information services, is open-source software. Open source is a truly successful form of communism (better translated as communitarianism) made up of developers: software, the core means of production in the IT industry, becomes the common property of developers worldwide—everyone for me, me for everyone.
When an open-source programmer works, their labor potentially embodies the crystallized wisdom of tens of thousands of top developers. Internet programmers are valuable because, in effect, they aren’t workers but foremen commanding software and machines. Programmers themselves are the core means of production, servers are easy to obtain (compared to research equipment and experimental environments in other industries), software comes from the public community, and one or a few senior software engineers can easily use the open-source ecosystem to quickly solve domain problems.
Through open source, all community developers join forces, greatly reducing the waste of reinventing wheels. This has propelled the entire industry’s technical level forward at an unimaginable speed. The momentum of open source is like a snowball, becoming unstoppable today. Basically, except for some special scenarios and path dependencies, developing software behind closed doors has become almost a joke.
So, whether in databases or software in general, if you want to work with technology, work with open-source technology. Closed-source things have too weak a vitality to be interesting. The virtue of open source is also PostgreSQL and MySQL’s greatest advantage over Oracle.
The Ecosystem Battle
The core of open source lies in the ecosystem (ECO). Every open-source technology has its own small ecosystem. An ecosystem is a system formed by various entities and their environment through intensive interactions. The open-source software ecosystem model can be described as a positive feedback loop consisting of three steps:
- Open-source software developers contribute to open-source software
- Open-source software itself is free, attracting more users
- Users use open-source software, generating demand and creating more open-source software-related jobs
The prosperity of an open-source ecosystem depends on this closed loop, and the scale (number of users/developers) and complexity (quality of users/developers) of the ecosystem directly determine the vitality of the software. Therefore, every piece of open-source software has a mandate to expand its scale. The scale of software usually depends on the ecological niche it occupies, and if different software occupy overlapping niches, competition occurs. In the ecological niche of open-source relational databases, PostgreSQL and MySQL are the most direct competitors.
Popular vs. Advanced
MySQL’s slogan is “The world’s most popular open-source relational database,” while PostgreSQL’s is “The world’s most advanced open-source relational database"—clearly a pair of old rivals. These two slogans nicely reflect the qualities of the two products: PostgreSQL is feature-rich, consistency-first, high-end, and academically rigorous; MySQL is feature-sparse, availability-first, quick and dirty, with an “engineering” approach.
MySQL’s primary user base is concentrated in internet companies. What are the typical characteristics of internet companies? They pursue trends with a “quick and dirty” approach. Quick because internet companies have simple business scenarios (mostly CRUD); data importance is low, unlike traditional industries (e.g., banks) that care deeply about data consistency (correctness); and availability is prioritized (they can tolerate data loss or errors more than service outages, while some traditional industries would rather stop service than have accounting errors). Dirty refers to the large volumes of data at internet companies—they need cement mixer trucks, not high-speed trains or manned spacecraft. Fast means internet companies have rapidly changing requirements, short delivery cycles, and demand quick response times, requiring out-of-the-box software suites (like LAMP) and CRUD developers who can get to work after minimal training. So the quick-and-dirty internet companies and quick-and-dirty MySQL are a perfect match.
PG users, meanwhile, tend toward traditional industries. Traditional industries are called “traditional” because they’ve already gone through the wild growth phase and have mature business models with deep foundations. They need correct results, stable performance, rich features, and the ability to analyze, process, and refine data. So in traditional industries, Oracle, SQL Server, and PostgreSQL dominate, with PostgreSQL having an irreplaceable position especially in geography-related scenarios. At the same time, many internet companies’ businesses are beginning to mature and settle, with one foot already in the “traditional industry” door. More and more internet companies are escaping the quick-and-dirty low-level loop, turning their attention to PostgreSQL.
Which is More Correct?
Those who understand a person best are often their competitors. PostgreSQL and MySQL’s slogans precisely target each other’s pain points. PG’s “most advanced” implies MySQL is too backward, while MySQL’s “most popular” says PG isn’t popular. Few users but advanced, many users but backward. Which is “better”? Such value judgments are difficult to answer.
But I believe time stands on the side of advanced technology: because advanced versus backward is the core measure of technology—it’s the cause, while popularity is the effect. Popularity is the result of internal factors (how advanced the technology is) and external factors (historical path dependencies) integrated over time. Today’s causes will be reflected in tomorrow’s effects: popular things become outdated because they’re backward, while advanced things become popular because they’re advanced.
While many popular things are garbage, popularity doesn’t necessarily mean backwardness. If MySQL merely lacked some features, it wouldn’t be labeled “backward.” The problem is that MySQL is so crude it has flaws in transactions, a basic feature of relational databases, which isn’t a question of backwardness but of qualification.
ACID
Some authors argue that supporting generalized two-phase commit is too expensive and causes performance and availability problems. It’s much better to have programmers deal with performance problems due to overuse of transactions than to have them program without transactions. — James Corbett et al., Spanner: Google’s Globally-Distributed Database (2012)
In my view, MySQL’s philosophy can be described as: “Better a bad life than a good death” and “After me, the flood.” Its “availability” is reflected in various “fault tolerances,” such as allowing erroneous SQL queries written by amateur programmers to run anyway. The most outrageous example is that MySQL actually allows partially successful transactions to commit, which violates the basic constraints of relational databases: atomicity and data consistency.
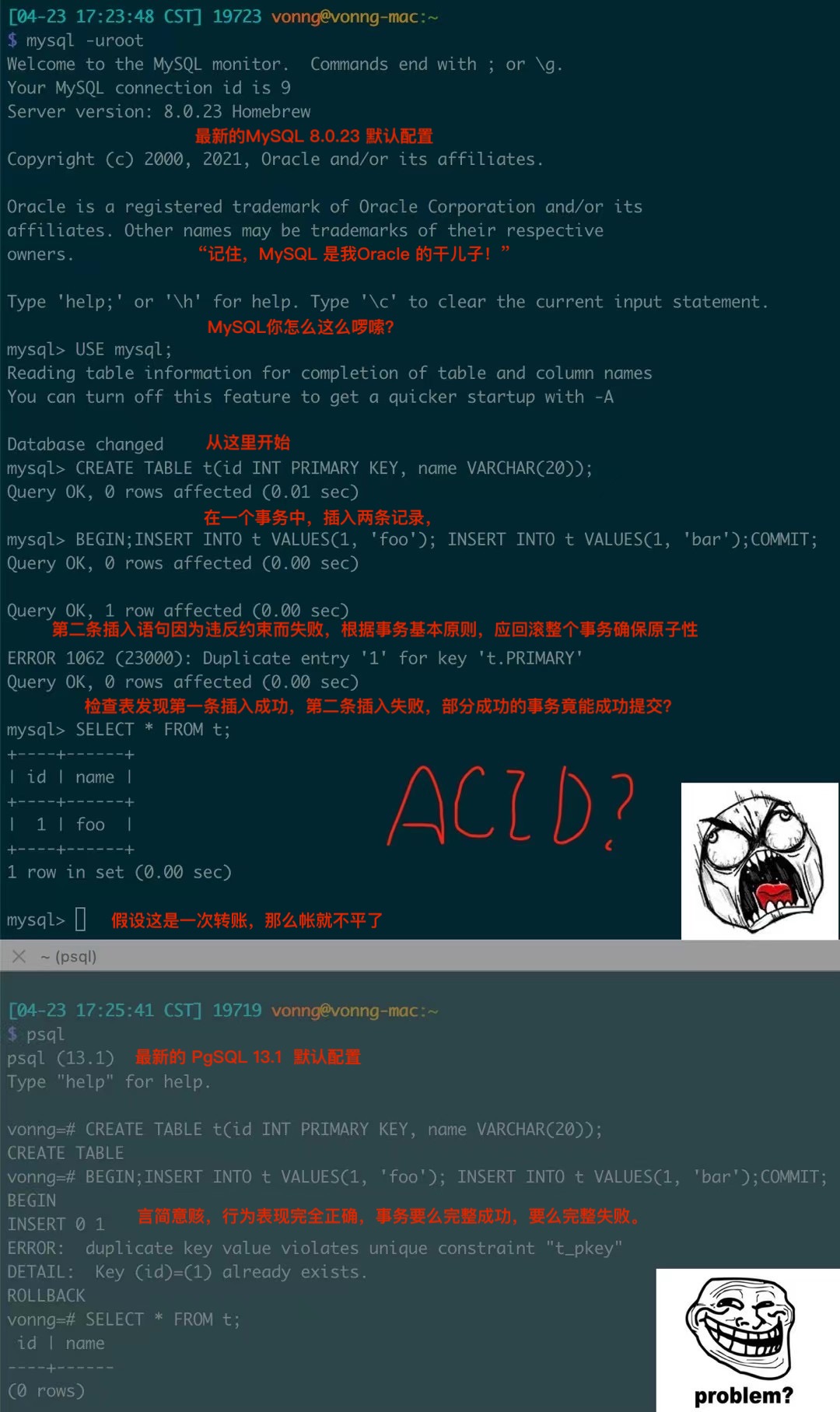
Image: MySQL actually allows partially successful transaction commits
Here, two records are inserted in a transaction, the first succeeding and the second failing due to a constraint violation. According to transaction atomicity, the entire transaction should either succeed or fail (with no records inserted in the end). But MySQL’s default behavior actually allows partially successful transactions to commit, meaning the transaction has no atomicity, and without atomicity, there is no consistency. If this transaction were a transfer (debit first, then credit) that failed for some reason, the accounts would be unbalanced. Using such a database for accounting would probably result in a mess, so the notion of “financial-grade MySQL” is likely a joke.
Of course, hilariously, some MySQL users call this a “feature,” saying it demonstrates MySQL’s fault tolerance. In reality, such “special fault tolerance” requirements can be perfectly implemented through the SAVEPOINT mechanism in the SQL standard. PG’s implementation is exemplary—the psql client allows the ON_ERROR_ROLLBACK option to implicitly create a SAVEPOINT after each statement and automatically ROLLBACK TO SAVEPOINT when a statement fails, achieving the same seemingly convenient but actually compromising functionality using standard SQL, as a client-side option, without sacrificing ACID. In comparison, MySQL’s so-called “feature” comes at the cost of directly sacrificing transaction ACID properties by default at the server level (meaning users using JDBC, psycopg, and other application drivers are equally affected).
For internet businesses, losing a user’s avatar or comment during registration might not be a big deal. With so much data, what’s a few lost or incorrect records? Not only data, but the business itself might be in precarious condition, so why care about being crude? If it succeeds, someone else will clean up the mess later anyway. So many internet companies typically don’t care about these issues.
PostgreSQL’s so-called “strict constraints and syntax” might seem “unfriendly” to newcomers. For example, if a batch of data contains a few dirty records, MySQL might accept them all, while PG would strictly reject them. Although compromise might seem easier, it plants landmines elsewhere: engineers working overtime to troubleshoot logical bombs and data analysts forced to clean dirty data daily will certainly have complaints. In the long run, to be successful, doing the right thing is most important.
For a technology to succeed, reality must take precedence over public relations. You can fool others, but you can’t fool natural laws.
— Rogers Commission Report (1986)
MySQL’s popularity isn’t that far ahead of PG, yet its functionality lags significantly behind PostgreSQL and Oracle. Oracle and PostgreSQL were born around the same time and, despite their battles from different positions and camps, have a mutual respect as old rivals: both solid practitioners who have honed their internal skills for half a century, accumulating strength steadily. MySQL, on the other hand, is like an impetuous twenty-something youngster playing with knives and guns, relying on brute force and riding the golden two decades of wild internet growth to seize a kingdom.
The benefits bestowed by an era also recede with the era’s passing. In this time of transformation, without advanced features as a foundation, “popularity” may not last long.
Development Prospects
From a personal career development perspective, many programmers learn a technology to enhance their technical competitiveness (and thereby earn more money). PostgreSQL is the most cost-effective choice among relational databases: it can not only handle traditional CRUD OLTP business, but data analysis is its specialty. Its various special features provide opportunities to enter multiple industries: geographic spatiotemporal data processing and analysis based on PostGIS, time-series financial and IoT data processing based on Timescale, stream processing based on Pipeline stored procedures and triggers, search engines based on inverted index full-text search, and FDW for connecting various external data sources. It’s truly a versatile full-stack database, capable of implementing much richer functionality than a pure OLTP database, providing CRUD coders with paths for transformation and advancement.
From the enterprise user perspective, PostgreSQL can independently play multiple roles within a considerable scale, using one component where multiple would normally be needed. And a single data component selection can greatly reduce project complexity, which means significant cost savings. It turns what would require ten talented people into something one person can handle. Of course, this doesn’t mean PG will be one-against-ten and overturn all other databases’ bowls—professional components’ strengths in their domains are undeniable. But never forget, designing for scale you don’t need is wasted effort, actually a form of premature optimization. If there’s truly a technology that can meet all your needs, using that technology is the best choice, rather than trying to re-implement it with multiple components.
Taking Tantan as an example, at a scale of 2.5 million TPS and 200TB of data, a single PostgreSQL deployment still supports the business rock-solid. Being versatile for a considerable scale, PG served not only its primary OLTP role but also, for quite some time, as cache, OLAP, batch processing, and even message queue. Of course, even the divine turtle has a lifespan. Eventually, these secondary functions were gradually split off to be handled by specialized components, but that was only after approaching ten million daily active users.
From the business ecosystem perspective, PostgreSQL also has huge advantages. First, PG is technologically advanced, earning the nickname “open-source Oracle.” Native PG can achieve 80-90% compatibility with Oracle’s functionality, while EDB has a professional PG distribution with 96% Oracle compatibility. Therefore, in capturing market share from the Oracle exodus, PostgreSQL and its derivatives have overwhelming technical advantages. Second, PG’s protocol is friendly, using the permissive BSD license. As a result, various database vendors and cloud providers’ “self-developed databases” and many “cloud databases” are largely based on modified PostgreSQL. For example, Huawei’s recent move to create openGaussDB based on PostgreSQL is a very wise choice. Don’t misunderstand—PG’s license explicitly allows this, and such actions actually make the PostgreSQL ecosystem more prosperous and robust. Selling PostgreSQL derivatives is a mature market: traditional enterprises don’t lack money and are willing to pay for it. The genius fire of open source, fueled by commercial interests, continuously releases vigorous vitality.
vs MySQL
As an old rival, MySQL’s situation is somewhat awkward.
From a personal career development perspective, learning MySQL is primarily for CRUD work. Learning to handle create, read, update, and delete operations to become a qualified coder is fine, but who wants to keep doing “data mining” work forever? Data analysis is where the lucrative positions are in the data industry chain. With MySQL’s weak analytical capabilities, it’s difficult for CRUD programmers to upgrade and transform. Additionally, PostgreSQL market demand is there but currently faces supply shortage (leading to numerous PG training institutions of varying quality springing up like mushrooms after rain). It’s true that MySQL professionals are easier to recruit than PG professionals, but conversely, the degree of competition in the MySQL world is much greater—supply shortage reflects scarcity, and when there are too many people, skills devalue.
From the enterprise user perspective, MySQL is a single-function component specialized for OLTP, often requiring ES, Redis, MongoDB, and others to satisfy complete data storage needs, while PG basically doesn’t have this problem. Furthermore, both MySQL and PostgreSQL are open-source databases, both “free.” Between a free Oracle and a free MySQL, which would users choose?
From a business ecosystem perspective, MySQL’s biggest problem is that it gets praise but not purchases. It gets praise because the more popular it is, the louder the voice, especially since its main users—internet companies—occupy the high ground of discourse. Not getting purchases is also because internet companies themselves have extremely weak willingness to pay for such software: any way you calculate it, hiring a few MySQL DBAs and using the open-source version is more cost-effective. Additionally, because MySQL’s GPL license requires derivative software to be open source, software vendors have weak motivation to develop based on MySQL. Most adopt a “MySQL-compatible” protocol approach to share MySQL’s market cake, rather than developing based on MySQL’s code and contributing back, raising doubts about its ecosystem’s health.
Of course, MySQL’s biggest problem is that its ecological niche is increasingly narrow. For rigorous transaction processing and data analysis, PostgreSQL leaves it streets behind; for quick and dirty prototyping, NoSQL solutions are far more convenient than MySQL. For commercial profit, it has Oracle daddy suppressing it from above; for open-source ecosystem, it constantly faces new MySQL-compatible products trying to replace it. MySQL can be said to be in a position of living off past success, maintaining its current status only through historical accumulated points. Whether time will stand on MySQL’s side remains to be seen.
vs NewSQL
Recently, there have been some eye-catching NewSQL products on the market, such as TiDB, Cockroachdb, Yugabytedb, etc. How about them? I think they’re all good products with some nice technical highlights, all contributing to open-source technology. But they may also face the same praised but not purchased dilemma.
The general characteristics of NewSQL are: emphasizing the concept of “distributed,” using “distributed” to solve horizontal scalability and disaster recovery and high availability issues, and sacrificing many features due to the inherent limitations of distribution, providing only relatively simple and limited query support. Distributed databases don’t have a qualitative difference from traditional master-slave replication in terms of high availability and disaster recovery, so their features can mainly be summarized as “quantity over quality.”
However, for many enterprises, sacrificing functionality for scalability is likely a false requirement or weak requirement. Among the not-few users I’ve encountered, the data volume and load level in the vast majority of scenarios fall completely within single-machine Postgres’s processing range (the current record being 15TB in a single database, 400,000 TPS in a single cluster). In terms of data volume, the vast majority of enterprises won’t exceed this bottleneck throughout their lifecycle; as for performance, it’s even less important—premature optimization is the root of all evil, and many enterprises have enough DB performance margin to happily run all their business logic as stored procedures in the database.
NewSQL’s founding father, Google Spanner, was created to solve massive data scalability problems, but how many enterprises have Google’s business data volume? Probably only typical internet companies or certain parts of some large enterprises would have such scale of data storage needs. So like MySQL, NewSQL’s problem comes back to the fundamental question of who will pay. In the end, it’s probably only investors and state-owned asset commissions who will pay.
But at the very least, NewSQL’s attempts are always praiseworthy.
vs Cloud Databases
“I want to say bluntly: For years, we’ve been like idiots, and they’ve made a fortune off what we developed”.
— Ofer Bengal, Redis Labs CEO
Another noteworthy “competitor” is the so-called cloud database, including two types: one is open-source databases hosted in the cloud, such as RDS for PostgreSQL, and the other is self-developed new-generation cloud databases.
For the former, the main issue is “cloud vendor bloodsucking.” If cloud vendors sell open-source software, it will cause open-source software-related positions and profits to concentrate toward cloud vendors, and whether cloud vendors allow their programmers to contribute to open-source projects, and how much they contribute, is actually hard to say. Responsible major vendors usually give back to the community and ecosystem, but this depends on their conscience. Open-source software should keep its destiny in its own hands, preventing cloud vendors from growing too large and forming monopolies. Compared to a few monopolistic giants, multiple scattered small groups can provide greater ecosystem diversity, more conducive to healthy ecosystem development.
Gartner claims 75% of databases will be deployed to cloud platforms by 2022—this boast is too big. (But there are ways to rationalize it, after all, one machine can easily create hundreds of millions of sqlite file databases, would that count?). Because cloud computing can’t solve a fundamental problem—trust. In commercial activities, how technically impressive something is is a very secondary factor; trust is key. Data is the lifeline of many enterprises, and cloud vendors aren’t truly neutral third parties. Who can guarantee data won’t be peeked at, stolen, leaked, or even directly shut down by having their necks squeezed (like various cloud vendors hammered Parler)? Transparent encryption solutions like TDE are chicken ribs, thoroughly annoying yourself but unable to stop those with real intent. Perhaps we’ll have to wait for truly practical efficient fully homomorphic encryption technology to mature before solving the trust and security problem.
Another fundamental issue is cost: Given current cloud vendor pricing strategies, cloud databases only have advantages at micro-scale. For example, a high-end D740 machine with 64 cores, 400GB memory, 3TB PCI-E SSD has a four-year comprehensive cost of at most 150,000 yuan. However, the largest RDS specification I could find (much worse, 32 cores, 128GB) costs that much for just one year. As soon as data volume and node count rise even slightly, hiring a DBA and building your own becomes far more cost-effective.
The main advantage of cloud databases is management—essentially convenience, point-and-click. Daily operational functions are fairly comprehensively covered, with some basic monitoring support. In short, there’s a minimum standard—if you can’t find reliable database talent, using a cloud database at least won’t cause too many bizarre issues. However, while these management software are good, they’re basically closed-source and deeply bound to their vendors.
If you’re looking for an open-source one-stop PostgreSQL monitoring and management solution, why not try Pigsty.
The latter type of cloud database, represented by AWS Aurora, includes a series of similar products like Alibaba Cloud PolarDB and Tencent Cloud CynosDB. Basically, they all use PostgreSQL and MySQL as the base and protocol layer, customized based on cloud infrastructure (shared storage, S3, RDMA), optimizing scaling speed and performance. These products certainly have novelty and creativity in technology. But the soul-searching question is, what are the benefits of these products compared to using native PostgreSQL? The immediate visible benefit is that cluster expansion is much faster (from hours to 5 minutes), but compared to the high fees and vendor lock-in issues, it really doesn’t scratch where it itches.
Overall, cloud databases pose a limited threat to native PostgreSQL. There’s no need to worry too much about cloud vendors—they’re generally part of the open-source software ecosystem and contribute to the community and ecosystem. Making money isn’t shameful—when everyone makes money, there’s more spare capacity for public good, right?
Abandoning Darkness for Light?
Typically, Oracle programmers transitioning to PostgreSQL don’t have much baggage, as the two are functionally similar and most experience is transferable. In fact, many members of the PostgreSQL ecosystem are former Oracle camp members who switched to PG. For example, EnmoTech, a renowned Oracle service provider in China (founded by Gai Guoqiang, China’s first Oracle ACE Director), publicly announced last year that they were “entering the arena with humility” to embrace PostgreSQL.
There are also quite a few who’ve switched from the MySQL camp to PostgreSQL. These users have the deepest sense of the differences between the two: basically all with an attitude of “wish I’d found you sooner” and “abandoning darkness for light.” Actually, I myself started with MySQL 😆, but embraced PostgreSQL once I could choose my own stack. However, some veteran programmers have formed deep interest bindings with MySQL, shouting about how great MySQL is while not forgetting to come over and bash PostgreSQL (referring to someone specific). This is actually understandable—touching interests is harder than touching souls, and it’s certainly frustrating to see one’s skilled technology setting in the west 😠. After all, having invested so many years in MySQL, no matter how good PostgreSQL 🐘 is, asking me to abandon my beloved little dolphin 🐬 is impossible.

However, newcomers to the industry still have the opportunity to choose a brighter path. Time is the fairest judge, and the choices of the new generation are the most representative benchmarks. According to my personal observation, among the emerging and very vibrant Golang developer community, PostgreSQL’s popularity is significantly higher than MySQL’s. Many startup and innovative companies now choose Go+Pg as their technology stack, such as Instagram, TanTan, and Apple all using Go+PG.
I believe the main reason for this phenomenon is the rise of new-generation developers. Go is to Java as PostgreSQL is to MySQL. The new wave pushes the old wave forward—this is actually the core mechanism of evolution—metabolism. Go and PostgreSQL are slowly flattening Java and MySQL, but of course Go and PostgreSQL may also be flattened in the future by the likes of Rust and some truly revolutionary NewSQL databases. But fundamentally, in technology, we should pursue those with bright prospects, not those setting in the west. (Of course, diving in too early and becoming a martyr isn’t appropriate either). Look at what new-generation developers are using, what vibrant startups, new projects, and new teams are using—these can’t be wrong.
PG’s Problems
Of course, does PostgreSQL have its own problems? Certainly—popularity.
Popularity relates to user scale, trust level, number of mature cases, amount of effective demand feedback, number of developers, and so on. Although given the current popularity development trend, PG will surpass MySQL in a few years, so from a long-term perspective, I don’t think this is a problem. But as a member of the PostgreSQL community, I believe it’s very necessary to do some things to further secure this success and accelerate this progress. And the most effective way to make a technology more popular is to: lower the threshold.
So, I created an open-source software called Pigsty, aiming to smash the deployment, monitoring, management, and usage threshold of PostgreSQL from the ceiling to the floor. It has three core goals:
- Create the most top-notch, professional open-source PostgreSQL monitoring system (like tidashboard)
- Create the lowest-threshold, most user-friendly open-source PostgreSQL management solution (like tiup)
- Create an out-of-the-box integrated development environment for data analysis & visualization (like minikube)
Of course, details are limited by length and won’t be expanded here. Details will be left for the next article.
What Makes PostgreSQL So Awesome?
PostgreSQL’s slogan is “The World’s Most Advanced Open Source Relational Database”, but I find this tagline lacks punch. It also feels like a direct jab at MySQL’s “The World’s Most Popular Open Source Relational Database” - a bit too much like riding on their coattails. If you ask me, the description that truly captures PG’s essence would be: The Full-Stack Database That Does It All - one tool to rule them all.

The Full-Stack Database
Mature applications typically rely on numerous data components and functions: caching, OLTP, OLAP/batch processing/data warehousing, stream processing/message queuing, search indexing, NoSQL/document databases, geographic databases, spatial databases, time-series databases, and graph databases. Traditional architecture selection usually combines multiple components - typically something like Redis + MySQL + Greenplum/Hadoop + Kafka/Flink + ElasticSearch. This combo can handle most requirements, but the real headache comes from integrating these heterogeneous systems: endless boilerplate code just shuffling data from Component A to Component B.

In this ecosystem, MySQL can only play the role of an OLTP relational database. PostgreSQL, however, can wear multiple hats and handle them all:
-
OLTP: Transaction processing is PostgreSQL’s bread and butter
-
OLAP: Citus distributed plugin, ANSI SQL compatibility, window functions, CTEs, CUBE and other advanced analytics features, UDFs in any language
-
Stream Processing: PipelineDB extension, Notify-Listen, materialized views, rules system, and flexible stored procedures and functions
-
Time-Series Data: TimescaleDB plugin, partitioned tables, BRIN indices
-
Spatial Data: PostGIS extension (the silver bullet), built-in geometric type support, GiST indexes
-
Search Indexing: Full-text search indexing sufficient for simple scenarios; rich index types, support for functional indices, conditional indices
-
NoSQL: Native support for JSON, JSONB, XML, HStore, and Foreign Data Wrappers to NoSQL databases
-
Data Warehousing: Smooth migration to GreenPlum, DeepGreen, HAWK, and others in the PG ecosystem, using FDW for ETL
-
Graph Data: Recursive queries
-
Caching: Materialized views
With Extensions as the Six Instruments, to honor Heaven, Earth, and the Four Directions.
With Greenplum to honor Heaven,
With Postgres-XL to honor Earth,
With Citus to honor the East,
With TimescaleDB to honor the South,
With PipelineDB to honor the West,
With PostGIS to honor the North.
— “The Rites of PG”
In Tantan’s (a popular dating app) legacy architecture, the entire system was designed around PostgreSQL. With millions of daily active users, millions of global DB-TPS, and hundreds of terabytes of data, they used PostgreSQL as their only data component. Independent data warehouses, message queues, and caches were only introduced later. And this is just the validated scale - further squeezing PostgreSQL’s potential is entirely feasible.
So, within a considerable scale, PostgreSQL can play the role of a jack-of-all-trades, one component serving as many. While it may not match specialized components in certain domains, it still performs admirably in all of them. And choosing a single data component can dramatically reduce project complexity, which means massive cost savings. It turns what would require ten people into something one person can handle.
Designing for scale you don’t need is wasted effort - a form of premature optimization. Only when no single software can meet all your requirements does the trade-off between splitting and integration become relevant. Integrating heterogeneous technologies is incredibly tricky work. If there’s one technology that can satisfy all your needs, using it is the best choice rather than trying to reinvent it with multiple components.
When business scale grows to a certain threshold, you may have no choice but to use a microservice/bus-based architecture and split database functionality into multiple components. But PostgreSQL’s existence significantly pushes back the threshold for this trade-off, and even after splitting, it continues to play a crucial role.
Operations-Friendly
Beyond its powerful features, another significant advantage of Pg is that it’s operations-friendly. It offers many practical capabilities:
-
DDL can be placed in transactions: dropping tables, TRUNCATE, creating functions, and indices can all be placed in transactions for atomic effect or rollback.
This enables some clever maneuvers, like swapping two tables via RENAME in a single transaction (the database equivalent of a chess castling move).
-
Concurrent creation and deletion of indices, adding non-null fields, and reorganizing indices and tables (without table locks).
This means you can make significant schema changes to production systems without downtime, optimizing indices as needed.
-
Various replication methods: segment replication, streaming replication, trigger-based replication, logical replication, plugin replication, and more.
This makes zero-downtime data migration remarkably easy: replicate, redirect reads, redirect writes - three steps, and your production migration is rock solid.
-
Diverse commit methods: asynchronous commits, synchronous commits, quorum-based synchronous commits.
This means Pg allows trade-offs between consistency and availability - for example, using synchronous commits for transaction databases and asynchronous commits for regular databases.
-
Comprehensive system views make building monitoring systems straightforward.
-
FDW (Foreign Data Wrappers) makes ETL incredibly simple - often just a single SQL statement.
FDW conveniently allows one instance to access data or metadata from other instances. It’s incredibly useful for cross-partition operations, database monitoring metric collection, data migration, and connecting to heterogeneous data systems.
Healthy Ecosystem
PostgreSQL’s ecosystem is thriving with an active community.
Compared to MySQL, PostgreSQL has a huge advantage in its friendly license. PG uses a PostgreSQL license similar to BSD/MIT, which essentially means as long as you’re not falsely claiming to be PostgreSQL, you can do whatever you want - even rebrand and sell it. No wonder so many “domestic databases” or “self-developed databases” are actually just rebranded or extended PG products.
Of course, many derivative products contribute back to the trunk. For instance, timescaledb, pipelinedb, and citus - originally “databases” based on PG - all eventually became native PG plugins. Often when you need some functionality, a quick search reveals existing plugins or implementations. That’s the beauty of open source - a certain idealism prevails.
PG’s code quality is exceptionally high, with crystal-clear comments. Reading the C code feels almost like reading Go - the code practically serves as documentation. You can learn a lot from it. In contrast, with other databases like MongoDB, one glance and I lost all interest in reading further.
As for MySQL, the community edition uses the GPL license, which is quite painful. Without GPL’s viral nature, would there be so many open-source MySQL derivatives? Plus, MySQL is in Oracle’s hands - letting someone else hold your future isn’t wise, especially when that someone is an industry toxin. Facebook’s React license controversy serves as a cautionary tale.
Challenges
Of course, there are some drawbacks or regrets:
- Due to MVCC, the database needs periodic VACUUM maintenance to prevent performance degradation.
- No good open-source cluster monitoring solution (or they’re ugly!), so you need to build your own.
- Slow query logs are mixed with regular logs, requiring custom parsing.
- Official Pg lacks good columnar storage, a minor disappointment for data analysis.
These are just minor issues. The real challenge might not be technical at all…
At the end of the day, MySQL truly is the most popular open-source relational database. Java developers, PHP developers - many people start with MySQL, making it harder to recruit PostgreSQL talent. Often you need to train people yourself. Looking at DB Engines popularity trends, though, the future looks bright.
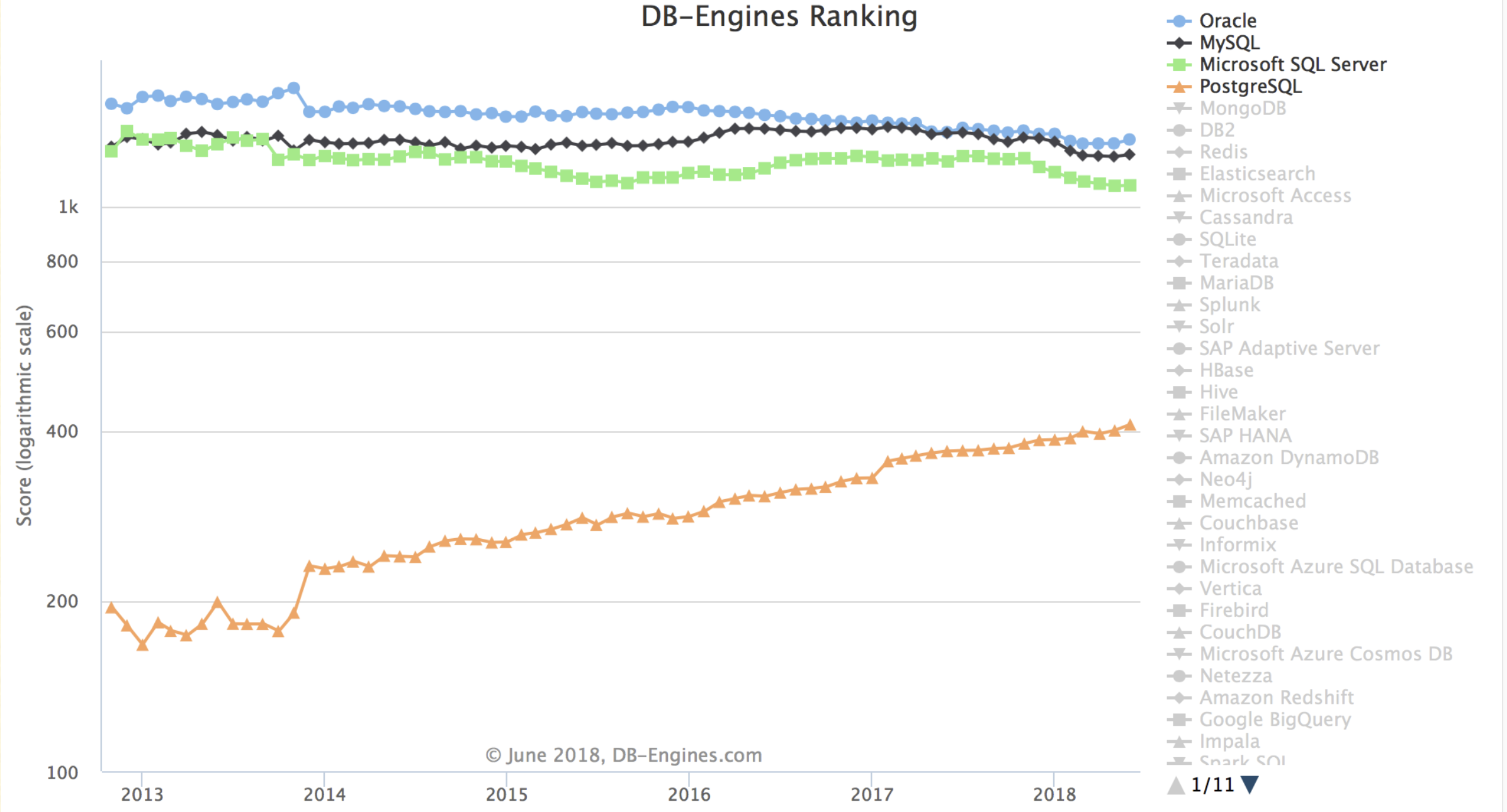
Final Thoughts
Learning PostgreSQL has been fascinating - it showed me that databases can do far more than just CRUD operations. While SQL Server and MySQL were my gateway to databases, it was PostgreSQL that truly revealed the magical world of database possibilities.
I’m writing this because an old post of mine on Zhihu was dug up, reminding me of my early days discovering PostgreSQL (https://www.zhihu.com/question/20010554/answer/94999834). Now that I’ve become a full-time PG DBA, I couldn’t resist adding more to that old grave. “The melon seller praising her own melons” - it’s only right that I praise PG. Hehe…
Full-stack engineers deserve full-stack databases.
I’ve compared MySQL and PostgreSQL myself and had the rare freedom to choose at Alibaba, a MySQL-dominated world. From a purely technical perspective, I believe PG absolutely crushes MySQL. Despite significant resistance, I eventually implemented and promoted PostgreSQL. I’ve used it for numerous projects, solving countless requirements (from small statistical reports to major revenue-generating initiatives). Most requirements were handled by PG alone, with occasional use of MQ and NoSQL (Redis, MongoDB, Cassandra/HBase). PG is truly addictive.
Eventually, my love for PostgreSQL led me to specialize in it full-time.
In my first job, I experienced the sweetness firsthand - with PostgreSQL, one person’s development efficiency rivals that of a small team:
-
Don’t want to write backends? PostGraphQL generates GraphQL APIs directly from database schema definitions, automatically listening for DDL changes and generating corresponding CRUD methods and stored procedure wrappers. Similar tools include PostgREST and pgrest. They’re perfectly usable for small to medium-sized applications, eliminating half the backend development work.
-
Need Redis functionality? Just use Pg - it can simulate standard features effortlessly, and you can skip the cache layer entirely. Implement Pub/Sub using Notify/Listen/Trigger to broadcast configuration changes and implement controls conveniently.
-
Need analytics? Window functions, complex JOINs, CUBE, GROUPING, custom aggregates, custom languages - it’s exhilarating. If you need to scale out, use the citus extension (or switch to Greenplum). It might lack columnar storage compared to data warehouses, but it has everything else.
-
Need geographic functionality? PostGIS is magical - solving complex geographic requirements in a single SQL line that would otherwise require thousands of lines of code.
-
Storing time-series data? The timescaledb extension may not match specialized time-series databases, but it still handles millions of records per second. I’ve used it to solve hardware sensor log storage and monitoring system metrics storage requirements.
-
For stream computing functionality, PipelineDB can define streaming views directly: UV, PV, real-time user profiles.
-
PostgreSQL’s FDW (Foreign Data Wrappers) is a powerful mechanism allowing access to various data sources through a unified SQL interface. Its applications are endless:
-
- The built-in
file_fdwextension can connect any program’s output to a data table. The simplest application is system information monitoring. - When managing multiple PostgreSQL instances, you can use the built-in
postgres_fdwto import data dictionaries from all remote databases into a metadata database. You can access metadata from all database instances uniformly, pull real-time metrics from all databases with a single SQL statement - building monitoring systems becomes a breeze. - I once used hbase_fdw and MongoFDW to wrap historical batch data from HBase and real-time data from MongoDB into PostgreSQL tables. A single view elegantly implemented a Lambda architecture combining batch and stream processing.
- Use
redis_fdwfor cache update pushing;mongo_fdwfor data migration from MongoDB to PG;mysql_fdwto read MySQL data into data warehouses; implement cross-database or even cross-component JOINs; complete complex ETL operations with a single SQL line that would otherwise require hundreds of lines of code - how marvelous is that?
- The built-in
-
Rich types and method support: JSON for generating frontend JSON responses directly from the database - effortless and comfortable. Range types elegantly solve edge cases that would otherwise require programmatic handling. Other examples include arrays, multidimensional arrays, custom types, enumerations, network addresses, UUIDs, and ISBNs. These out-of-the-box data structures save programmers tremendous wheel-reinventing effort.
-
Rich index types: general-purpose Btree indices; Brin indices that significantly optimize sequential access; Hash indices for equality queries; GIN inverted indices; GIST generalized search trees efficiently supporting geographic and KNN queries; Bitmap simultaneously leveraging multiple independent indices; Bloom efficient filtering indices; conditional indices that can dramatically reduce index size; function indices that elegantly replace redundant fields. MySQL offers pathetically few index types by comparison.
-
Stable, reliable, correct, and efficient. MVCC easily implements snapshot isolation, while MySQL’s RR isolation level is deficient, unable to avoid PMP and G-single anomalies. Plus, implementations based on locks and rollback segments have various pitfalls; PostgreSQL can implement high-performance serializability through SSI.
-
Powerful replication: WAL segment replication, streaming replication (appearing in v9: synchronous, semi-synchronous, asynchronous), logical replication (appearing in v10: subscription/publication), trigger replication, third-party replication - every type of replication you could want.
-
Operations-friendly: DDL can be executed in transactions (rollback-capable), index creation without table locks, adding new columns (without default values) without table locks, cleaning/backup without table locks. System views and monitoring capabilities are comprehensive.
-
Numerous extensions, rich features, and extreme customizability. In PostgreSQL, you can write functions in any language: Python, Go, JavaScript, Java, Shell, etc. Rather than calling Pg a database, it’s more accurate to call it a development platform. I’ve experimented with many useless but fun things: in-database crawlers, recommendation systems, neural networks, web servers, and more. There are various third-party plugins with powerful functions or creative ideas: https://pgxn.org/.
-
PostgreSQL’s license is friendly - BSD lets you do whatever you want. No wonder so many databases are rebranded PG products. MySQL has GPL viral infection and remains under Oracle’s thumb.
PG Admin
PG Logical Replication Explained
Logical Replication
Logical Replication is a method of replicating data objects and their changes based on the Replica Identity (typically primary keys) of data objects.
The term Logical Replication contrasts with Physical Replication, where physical replication uses exact block addresses and byte-by-byte copying, while logical replication allows fine-grained control over the replication process.
Logical replication is based on a Publication and Subscription model:
- A Publisher can have multiple publications, and a Subscriber can have multiple subscriptions.
- A publication can be subscribed to by multiple subscribers, while a subscription can only subscribe to one publisher, but can subscribe to multiple different publications from the same publisher.
Logical replication for a table typically works like this: The subscriber takes a snapshot of the publisher’s database and copies the existing data in the table. Once the data copy is complete, changes (inserts, updates, deletes, truncates) on the publisher are sent to the subscriber in real-time. The subscriber applies these changes in the same order, ensuring transactional consistency in logical replication. This approach is sometimes called transactional replication.
Typical use cases for logical replication include:
- Migration: Replication across different PostgreSQL versions and operating system platforms.
- CDC (Change Data Capture): Collecting incremental changes in a database (or a subset of it) and triggering custom logic on subscribers for these changes.
- Data Integration: Combining multiple databases into one, or splitting one database into multiple, for fine-grained integration and access control.
A logical subscriber behaves like a normal PostgreSQL instance (primary), and can also create its own publications and have its own subscribers.
If the logical subscriber is read-only, there will be no conflicts. However, if writes are performed on the subscriber’s subscription set, conflicts may occur.
Publication
A Publication can be defined on a physical replication primary. The node that creates the publication is called the Publisher.
A Publication is a collection of changes from a set of tables. It can also be viewed as a change set or replication set. Each publication can only exist in one Database.
Publications are different from Schemas and don’t affect how tables are accessed. (Whether a table is included in a publication or not doesn’t affect its access)
Currently, publications can only contain tables (i.e., indexes, sequences, materialized views are not published), and each table can be added to multiple publications.
Unless creating a publication for ALL TABLES, objects (tables) in a publication can only be explicitly added (via ALTER PUBLICATION ADD TABLE).
Publications can filter the types of changes required: any combination of INSERT, UPDATE, DELETE, and TRUNCATE, similar to trigger events. By default, all changes are published.
Replica Identity
A table included in a publication must have a Replica Identity, which is necessary to locate the rows that need to be updated on the subscriber side for UPDATE and DELETE operations.
By default, the Primary Key is the table’s replica identity. A UNIQUE NOT NULL index can also be used as a replica identity.
If there is no replica identity, it can be set to FULL, meaning the entire row is used as the replica identity. (An interesting case: multiple identical records can be handled correctly, as shown in later examples) Using FULL mode for replica identity is inefficient (because each row modification requires a full table scan on the subscriber, which can easily overwhelm the subscriber), so this configuration should only be used as a last resort. Using FULL mode for replica identity also has a limitation: the columns included in the replica identity on the subscriber’s table must either match the publisher or be fewer than on the publisher.
INSERT operations can always proceed regardless of the replica identity (because inserting a new record doesn’t require locating any existing records on the subscriber; while deletes and updates need to locate records through the replica identity). If a table without a replica identity is added to a publication with UPDATE and DELETE, subsequent UPDATE and DELETE operations will cause errors on the publisher.
The replica identity mode of a table can be checked in pg_class.relreplident and modified via ALTER TABLE.
ALTER TABLE tbl REPLICA IDENTITY
{ DEFAULT | USING INDEX index_name | FULL | NOTHING };
Although various combinations are possible, in practice, only three scenarios are viable:
- Table has a primary key, using the default
defaultreplica identity - Table has no primary key but has a non-null unique index, explicitly configured with
indexreplica identity - Table has neither primary key nor non-null unique index, explicitly configured with
fullreplica identity (very inefficient, only as a last resort) - All other cases cannot properly complete logical replication functionality. Insufficient information output may result in errors or may not.
- Special attention: If a table with
nothingreplica identity is included in logical replication, performing updates or deletes on it will cause errors on the publisher!
| Replica Identity Mode\Table Constraints | Primary Key(p) | Unique NOT NULL Index(u) | Neither(n) |
|---|---|---|---|
| default | Valid | x | x |
| index | x | Valid | x |
| full | Inefficient | Inefficient | Inefficient |
| nothing | xxxx | xxxx | xxxx |
Managing Publications
CREATE PUBLICATION is used to create a publication, DROP PUBLICATION to remove it, and ALTER PUBLICATION to modify it.
After a publication is created, tables can be dynamically added to or removed from it using ALTER PUBLICATION, and these operations are transactional.
CREATE PUBLICATION name
[ FOR TABLE [ ONLY ] table_name [ * ] [, ...]
| FOR ALL TABLES ]
[ WITH ( publication_parameter [= value] [, ... ] ) ]
ALTER PUBLICATION name ADD TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name SET TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name DROP TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name SET ( publication_parameter [= value] [, ... ] )
ALTER PUBLICATION name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
ALTER PUBLICATION name RENAME TO new_name
DROP PUBLICATION [ IF EXISTS ] name [, ...];
publication_parameter mainly includes two options:
publish: Defines the types of change operations to publish, a comma-separated string, defaulting toinsert, update, delete, truncate.publish_via_partition_root: New option in PostgreSQL 13, if true, partitioned tables will use the root partition’s replica identity for logical replication.
Querying Publications
Publications can be queried using the psql meta-command \dRp.
# \dRp
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
----------+------------+---------+---------+---------+-----------+----------
postgres | t | t | t | t | t | f
pg_publication Publication Definition Table
pg_publication contains the original publication definitions, with each record corresponding to a publication.
# table pg_publication;
oid | 20453
pubname | pg_meta_pub
pubowner | 10
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | t
pubtruncate | t
pubviaroot | f
puballtables: Whether it includes all tablespubinsert|update|delete|truncate: Whether these operations are publishedpubviaroot: If this option is set, any partitioned table (leaf table) will use the top-level partitioned table’s replica identity. This allows treating the entire partitioned table as one table rather than a series of tables for publication.
pg_publication_tables Publication Content Table
pg_publication_tables is a view composed of pg_publication, pg_class, and pg_namespace, recording the table information included in publications.
postgres@meta:5432/meta=# table pg_publication_tables;
pubname | schemaname | tablename
-------------+------------+-----------------
pg_meta_pub | public | spatial_ref_sys
pg_meta_pub | public | t_normal
pg_meta_pub | public | t_unique
pg_meta_pub | public | t_tricky
Use pg_get_publication_tables to get the OIDs of subscribed tables based on the subscription name:
SELECT * FROM pg_get_publication_tables('pg_meta_pub');
SELECT p.pubname,
n.nspname AS schemaname,
c.relname AS tablename
FROM pg_publication p,
LATERAL pg_get_publication_tables(p.pubname::text) gpt(relid),
pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.oid = gpt.relid;
Similarly, pg_publication_rel provides similar information but from a many-to-many OID correspondence perspective, containing raw data.
oid | prpubid | prrelid
-------+---------+---------
20414 | 20413 | 20397
20415 | 20413 | 20400
20416 | 20413 | 20391
20417 | 20413 | 20394
It’s important to note the difference between these two: When publishing for ALL TABLES, pg_publication_rel won’t have specific table OIDs, but pg_publication_tables can query the actual list of tables included in logical replication. Therefore, pg_publication_tables should typically be used as the reference.
When creating a subscription, the database first modifies the pg_publication catalog, then fills in the publication table information into pg_publication_rel.
Subscription
A Subscription is the downstream of logical replication. The node that defines the subscription is called the Subscriber.
A subscription defines: how to connect to another database, and which publications from the target publisher to subscribe to.
A logical subscriber behaves like a normal PostgreSQL instance (primary), and can also create its own publications and have its own subscribers.
Each subscriber receives changes through a Replication Slot, and during the initial data replication phase, additional temporary replication slots may be required.
A logical replication subscription can serve as a synchronous replication standby, with the standby’s name defaulting to the subscription name, or a different name can be used by setting application_name in the connection information.
Only superusers can dump subscription definitions using pg_dump, as only superusers can access the pg_subscription view. Regular users attempting to dump will skip and print a warning message.
Logical replication doesn’t replicate DDL changes, so tables in the publication set must already exist on the subscriber side. Only changes to regular tables are replicated; views, materialized views, sequences, and indexes are not replicated.
Tables on the publisher and subscriber are matched by their fully qualified names (e.g., public.table), and replicating changes to a table with a different name is not supported.
Columns on the publisher and subscriber are matched by name. Column order doesn’t matter, and data types don’t have to be identical, as long as the text representation of the two columns is compatible, meaning the text representation of the data can be converted to the target column’s type. The subscriber’s table can contain columns not present on the publisher, and these new columns will be filled with default values.
Managing Subscriptions
CREATE SUBSCRIPTION is used to create a subscription, DROP SUBSCRIPTION to remove it, and ALTER SUBSCRIPTION to modify it.
After a subscription is created, it can be paused and resumed at any time using ALTER SUBSCRIPTION.
Removing and recreating a subscription will result in loss of synchronization information, meaning the relevant data needs to be resynchronized.
CREATE SUBSCRIPTION subscription_name
CONNECTION 'conninfo'
PUBLICATION publication_name [, ...]
[ WITH ( subscription_parameter [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name CONNECTION 'conninfo'
ALTER SUBSCRIPTION name SET PUBLICATION publication_name [, ...] [ WITH ( set_publication_option [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name REFRESH PUBLICATION [ WITH ( refresh_option [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name ENABLE
ALTER SUBSCRIPTION name DISABLE
ALTER SUBSCRIPTION name SET ( subscription_parameter [= value] [, ... ] )
ALTER SUBSCRIPTION name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
ALTER SUBSCRIPTION name RENAME TO new_name
DROP SUBSCRIPTION [ IF EXISTS ] name;
subscription_parameter defines some options for the subscription, including:
copy_data(bool): Whether to copy data after replication starts, defaults to truecreate_slot(bool): Whether to create a replication slot on the publisher, defaults to trueenabled(bool): Whether to enable the subscription, defaults to trueconnect(bool): Whether to attempt to connect to the publisher, defaults to true. Setting to false will force the above options to false.synchronous_commit(bool): Whether to enable synchronous commit, reporting progress information to the primary.slot_name: The name of the replication slot associated with the subscription. Setting to empty will disassociate the subscription from the replication slot.
Managing Replication Slots
Each active subscription receives changes from the remote publisher through a replication slot.
Typically, this remote replication slot is automatically managed, created automatically during CREATE SUBSCRIPTION and deleted during DROP SUBSCRIPTION.
In specific scenarios, it may be necessary to operate on the subscription and the underlying replication slot separately:
-
When creating a subscription, if the required replication slot already exists. In this case, you can associate with the existing replication slot using
create_slot = false. -
When creating a subscription, if the remote host is unreachable or its state is unclear, you can avoid accessing the remote host using
connect = false. This is whatpg_dumpdoes. In this case, you must manually create the replication slot on the remote side before enabling the subscription locally. -
When removing a subscription, if you need to retain the replication slot. This typically happens when the subscriber is being moved to another machine where you want to restart the subscription. In this case, you need to first disassociate the subscription from the replication slot using
ALTER SUBSCRIPTION. -
When removing a subscription, if the remote host is unreachable. In this case, you need to disassociate the replication slot from the subscription before deleting the subscription.
If the remote instance is no longer in use, it’s fine. However, if the remote instance is only temporarily unreachable, you should manually delete its replication slot; otherwise, it will continue to retain WAL and may cause the disk to fill up.
Querying Subscriptions
Subscriptions can be queried using the psql meta-command \dRs.
# \dRs
Name | Owner | Enabled | Publication
--------------+----------+---------+----------------
pg_bench_sub | postgres | t | {pg_bench_pub}
pg_subscription Subscription Definition Table
Each logical subscription has one record. Note that this view is cluster-wide, and each database can see the subscription information for the entire cluster.
Only superusers can access this view because it contains plaintext passwords (connection information).
oid | 20421
subdbid | 19356
subname | pg_test_sub
subowner | 10
subenabled | t
subconninfo | host=10.10.10.10 user=replicator password=DBUser.Replicator dbname=meta
subslotname | pg_test_sub
subsynccommit | off
subpublications | {pg_meta_pub}
subenabled: Whether the subscription is enabledsubconninfo: Hidden from regular users because it contains sensitive information.subslotname: The name of the replication slot used by the subscription, also used as the logical replication origin name for deduplication.subpublications: List of publication names subscribed to.- Other status information: Whether synchronous commit is enabled, etc.
pg_subscription_rel Subscription Content Table
pg_subscription_rel records information about each table in the subscription, including status and progress.
srrelid: OID of the relation in the subscriptionsrsubstate: State of the relation in the subscription:iinitializing,dcopying data,ssynchronization completed,rnormal replication.srsublsn: When ini|dstate, it’s empty. When ins|rstate, it’s the LSN position on the remote side.
When Creating a Subscription
When a new subscription is created, the following operations are performed in sequence:
- Store the publication information in the
pg_subscriptioncatalog, including connection information, replication slot, publication names, and some configuration options. - Connect to the publisher, check replication permissions (note that it does not check if the corresponding publication exists),
- Create a logical replication slot:
pg_create_logical_replication_slot(name, 'pgoutput') - Register the tables in the replication set to the subscriber’s
pg_subscription_relcatalog. - Execute the initial snapshot synchronization. Note that existing data in the subscriber’s tables is not deleted.
Replication Conflicts
Logical replication behaves like normal DML operations, updating data even if it has been locally changed on the user node. If the replicated data violates any constraints, replication stops, a phenomenon known as conflicts.
When replicating UPDATE or DELETE operations, missing data (i.e., data to be updated/deleted no longer exists) doesn’t cause conflicts, and such operations are simply skipped.
Conflicts cause errors and abort logical replication. The logical replication management process will retry at 5-second intervals. Conflicts don’t block SQL operations on tables in the subscription set on the subscriber side. Details about conflicts can be found in the user’s server logs, and conflicts must be manually resolved by the user.
Possible Conflicts in Logs
| Conflict Mode | Replication Process | Output Log |
|---|---|---|
| Missing UPDATE/DELETE Object | Continue | No Output |
| Table/Row Lock Wait | Wait | No Output |
| Violation of Primary Key/Unique/Check Constraints | Abort | Output |
| Target Table/Column Missing | Abort | Output |
| Cannot Convert Data to Target Column Type | Abort | Output |
To resolve conflicts, you can either modify the data on the subscriber side to avoid conflicts with incoming changes, or skip transactions that conflict with existing data.
Use the subscription’s node_name and LSN position to call the pg_replication_origin_advance() function to skip transactions. The current ORIGIN position can be seen in the pg_replication_origin_status system view.
Limitations
Logical replication currently has the following limitations or missing features. These issues may be resolved in future versions.
Database schemas and DDL commands are not replicated. Existing schemas can be manually replicated using pg_dump --schema-only, and incremental schema changes need to be manually kept in sync (the schemas on both publisher and subscriber don’t need to be absolutely identical). Logical replication remains reliable for online DDL changes: after executing DDL changes in the publisher database, replicated data reaches the subscriber but replication stops due to table schema mismatch. After updating the subscriber’s schema, replication continues. In many cases, executing changes on the subscriber first can avoid intermediate errors.
Sequence data is not replicated. The data in identity columns served by sequences and SERIAL types is replicated as part of the table, but the sequences themselves remain at their initial values on the subscriber. If the subscriber is used as a read-only database, this is usually fine. However, if you plan to perform some form of switchover or failover to the subscriber database, you need to update the sequences to their latest values, either by copying the current data from the publisher (perhaps using pg_dump -t *seq*), or by determining a sufficiently high value from the table’s data content (e.g., max(id)+1000000). Otherwise, if you perform operations that obtain sequence values as identities on the new database, conflicts are likely to occur.
Logical replication supports replicating TRUNCATE commands, but special care is needed when TRUNCATE involves a group of tables linked by foreign keys. When executing a TRUNCATE operation, the group of associated tables on the publisher (through explicit listing or cascade association) will all be TRUNCATEd, but on the subscriber, tables not in the subscription set won’t be TRUNCATEd. This is logically reasonable because logical replication shouldn’t affect tables outside the replication set. But if there are tables not in the subscription set that reference tables in the subscription set through foreign keys, the TRUNCATE operation will fail.
Large objects are not replicated
Only tables can be replicated (including partitioned tables). Attempting to replicate other types of tables will result in errors (views, materialized views, foreign tables, unlogged tables). Specifically, only tables with pg_class.relkind = 'r' can participate in logical replication.
When replicating partitioned tables, replication is done by default at the child table level. By default, changes are triggered according to the leaf partitions of the partitioned table, meaning that every partition child table on the publisher needs to exist on the subscriber (of course, this partition child table on the subscriber doesn’t have to be a partition child table, it could be a partition parent table itself, or a regular table). The publication can declare whether to use the replica identity from the partition root table instead of the replica identity from the partition leaf table. This is a new feature in PostgreSQL 13 and can be specified through the publish_via_partition_root option when creating the publication.
Trigger behavior is different. Row-level triggers fire, but UPDATE OF cols type triggers don’t. Statement-level triggers only fire during initial data copying.
Logging behavior is different. Even with log_statement = 'all', SQL statements generated by replication won’t be logged.
Bidirectional replication requires extreme caution: It’s possible to have mutual publication and subscription as long as the table sets on both sides don’t overlap. But once there’s an intersection of tables, WAL infinite loops will occur.
Replication within the same instance: Logical replication within the same instance requires special caution. You must manually create logical replication slots and use existing logical replication slots when creating subscriptions, otherwise it will hang.
Only possible on primary: Currently, logical decoding from physical replication standbys is not supported, and replication slots cannot be created on standbys, so standbys cannot be publishers. But this issue may be resolved in the future.
Architecture
Logical replication begins by taking a snapshot of the publisher’s database and copying the existing data in tables based on this snapshot. Once the copy is complete, changes (inserts, updates, deletes, etc.) on the publisher are sent to the subscriber in real-time.
Logical replication uses an architecture similar to physical replication, implemented through a walsender and apply process. The publisher’s walsender process loads the logical decoding plugin (pgoutput) and begins logical decoding of WAL logs. The Logical Decoding Plugin reads changes from WAL, filters changes according to the publication definition, transforms changes into a specific format, and transmits them using the logical replication protocol. Data is transmitted to the subscriber’s apply process using the streaming replication protocol. This process maps changes to local tables when received and reapplies these changes in transaction order.
Initial Snapshot
During initialization and data copying, tables on the subscriber side are handled by a special apply process. This process creates its own temporary replication slot and copies the existing data in tables.
Once data copying is complete, the table enters synchronization mode (pg_subscription_rel.srsubstate = 's'), which ensures that the main apply process can apply changes that occurred during the data copying period using standard logical replication methods. Once synchronization is complete, control of table replication is transferred back to the main apply process, returning to normal replication mode.
Process Structure
The publisher creates a corresponding walsender process for each connection from the subscriber, sending decoded WAL logs. On the subscriber side, it creates an apply process to receive and apply changes.
Replication Slots
When creating a subscription, a logical replication slot is created on the publisher. This slot ensures that WAL logs are retained until they are successfully applied on the subscriber.
Logical Decoding
Logical decoding is the process of converting WAL records into a format that can be understood by logical replication. The pgoutput plugin is the default logical decoding plugin in PostgreSQL.
Synchronous Commit
Synchronous commit in logical replication is completed through SIGUSR1 communication between Backend and Walsender.
Temporary Data
Temporary data from logical decoding is written to disk as local log snapshots. When the walsender receives a SIGUSR1 signal from the walwriter, it reads WAL logs and generates corresponding logical decoding snapshots. These snapshots are deleted when transmission ends.
The file location is: $PGDATA/pg_logical/snapshots/{LSN Upper}-{LSN Lower}.snap
Monitoring
Logical replication uses an architecture similar to physical stream replication, so monitoring a logical replication publisher node is not much different from monitoring a physical replication primary.
Subscriber monitoring information can be obtained through the pg_stat_subscription view.
pg_stat_subscription Subscription Statistics Table
Each active subscription will have at least one record in this view, representing the Main Worker (responsible for applying logical logs).
The Main Worker has relid = NULL. If there are processes responsible for initial data copying, they will also have a record here, with relid being the table being copied.
subid | 20421
subname | pg_test_sub
pid | 5261
relid | NULL
received_lsn | 0/2A4F6B8
last_msg_send_time | 2021-02-22 17:05:06.578574+08
last_msg_receipt_time | 2021-02-22 17:05:06.583326+08
latest_end_lsn | 0/2A4F6B8
latest_end_time | 2021-02-22 17:05:06.578574+08
received_lsn: The most recently received log position.latest_end_lsn: The last LSN position reported to the walsender, i.e., theconfirmed_flush_lsnon the primary. However, this value is not updated very frequently.
Typically, an active subscription will have an apply process running, while disabled or crashed subscriptions won’t have records in this view. During initial synchronization, synchronized tables will have additional worker process records.
pg_replication_slot Replication Slots
postgres@meta:5432/meta=# table pg_replication_slots ;
-[ RECORD 1 ]-------+------------
slot_name | pg_test_sub
plugin | pgoutput
slot_type | logical
datoid | 19355
database | meta
temporary | f
active | t
active_pid | 89367
xmin | NULL
catalog_xmin | 1524
restart_lsn | 0/2A08D40
confirmed_flush_lsn | 0/2A097F8
wal_status | reserved
safe_wal_size | NULL
The replication slots view contains both logical and physical replication slots. The main characteristics of logical replication slots are:
pluginfield is not empty, identifying the logical decoding plugin used. Logical replication defaults to using thepgoutputplugin.slot_type = logical, while physical replication slots are of typephysical.datoidanddatabasefields are not empty because physical replication is associated with the cluster, while logical replication is associated with the database.
Logical subscribers also appear as standard replication standbys in the pg_stat_replication view.
pg_replication_origin Replication Origin
Replication origin
table pg_replication_origin_status;
-[ RECORD 1 ]-----------
local_id | 1
external_id | pg_19378
remote_lsn | 0/0
local_lsn | 0/6BB53640
local_id: The local ID of the replication origin, represented efficiently in 2 bytes.external_id: The ID of the replication origin, which can be referenced across nodes.remote_lsn: The most recent commit position on the source.local_lsn: The LSN of locally persisted commit records.
Detecting Replication Conflicts
The most reliable method of detection is always from the logs on both publisher and subscriber sides. When replication conflicts occur, you can see replication connection interruptions on the publisher:
LOG: terminating walsender process due to replication timeout
LOG: starting logical decoding for slot "pg_test_sub"
DETAIL: streaming transactions committing after 0/xxxxx, reading WAL from 0/xxxx
While on the subscriber side, you can see the specific cause of the replication conflict, for example:
logical replication worker PID 4585 exited with exit code 1
ERROR: duplicate key value violates unique constraint "pgbench_tellers_pkey","Key (tid)=(9) already exists.",,,,"COPY pgbench_tellers, line 31",,,,"","logical replication worker"
Additionally, some monitoring metrics can reflect the state of logical replication:
For example: pg_replication_slots.confirmed_flush_lsn consistently lagging behind pg_cureent_wal_lsn. Or significant growth in pg_stat_replication.flush_ag/write_lag.
Security
Tables participating in subscriptions must have their Ownership and Trigger permissions controlled by roles trusted by the superuser (otherwise, modifying these tables could cause logical replication to stop).
On the publisher node, if untrusted users have table creation permissions, publications should explicitly specify table names rather than using the wildcard ALL TABLES. That is, FOR ALL TABLES should only be used when the superuser trusts all users who have permission to create tables (non-temporary) on either the publisher or subscriber side.
The user used for replication connections must have the REPLICATION permission (or be a SUPERUSER). If this role lacks SUPERUSER and BYPASSRLS, row security policies on the publisher may be executed. If the table owner sets row-level security policies after replication starts, this configuration may cause replication to stop directly rather than the policy taking effect. The user must have LOGIN permission, and HBA rules must allow access.
To be able to replicate initial table data, the role used for replication connections must have SELECT permission on the published tables (or be a superuser).
Creating a publication requires CREATE permission in the database, and creating a FOR ALL TABLES publication requires superuser permission.
Adding tables to a publication requires owner permission on the tables.
Creating a subscription requires superuser permission because the subscription’s apply process runs with superuser privileges in the local database.
Permissions are only checked when establishing the replication connection, not when reading each change record on the publisher side, nor when applying each record on the subscriber side.
Configuration Options
Logical replication requires some configuration options to work properly.
On the publisher side, wal_level must be set to logical, max_replication_slots needs to be at least the number of subscriptions + the number used for table data synchronization. max_wal_senders needs to be at least max_replication_slots + the number reserved for physical replication.
On the subscriber side, max_replication_slots also needs to be set, with max_replication_slots needing to be at least the number of subscriptions.
max_logical_replication_workers needs to be configured to at least the number of subscriptions, plus some for data synchronization worker processes.
Additionally, max_worker_processes needs to be adjusted accordingly, at least to max_logical_replication_worker + 1. Note that some extensions and parallel queries will also use connections from the worker process pool.
Configuration Parameter Example
For a 64-core machine with 1-2 publications and subscriptions, up to 6 synchronization worker processes, and up to 8 physical standbys, a sample configuration might look like this:
First, determine the number of slots: 2 subscriptions, 6 synchronization worker processes, 8 physical standbys, so configure for 16. Sender = Slot + Physical Replica = 24.
Limit synchronization worker processes to 6, 2 subscriptions, so set the total logical replication worker processes to 8.
wal_level: logical # logical
max_worker_processes: 64 # default 8 -> 64, set to CPU CORE 64
max_parallel_workers: 32 # default 8 -> 32, limit by max_worker_processes
max_parallel_maintenance_workers: 16 # default 2 -> 16, limit by parallel worker
max_parallel_workers_per_gather: 0 # default 2 -> 0, disable parallel query on OLTP instance
# max_parallel_workers_per_gather: 16 # default 2 -> 16, enable parallel query on OLAP instance
max_wal_senders: 24 # 10 -> 24
max_replication_slots: 16 # 10 -> 16
max_logical_replication_workers: 8 # 4 -> 8, 6 sync worker + 1~2 apply worker
max_sync_workers_per_subscription: 6 # 2 -> 6, 6 sync worker
Quick Setup
First, set the configuration option wal_level = logical on the publisher side. This parameter requires a restart to take effect. Other parameters’ default values don’t affect usage.
Then create a replication user and add pg_hba.conf configuration items to allow external access. A typical configuration is:
CREATE USER replicator REPLICATION BYPASSRLS PASSWORD 'DBUser.Replicator';
Note that logical replication users need SELECT permission. In Pigsty, replicator has already been granted the dbrole_readonly role.
host all replicator 0.0.0.0/0 md5
host replicator replicator 0.0.0.0/0 md5
Then execute in the publisher’s database:
CREATE PUBLICATION mypub FOR TABLE <tablename>;
Then execute in the subscriber’s database:
CREATE SUBSCRIPTION mysub CONNECTION 'dbname=<pub_db> host=<pub_host> user=replicator' PUBLICATION mypub;
The above configuration will start replication, first copying the initial data of the tables, then beginning to synchronize incremental changes.
Sandbox Example
Using the Pigsty standard 4-node two-cluster sandbox as an example, there are two database clusters pg-meta and pg-test. Now we’ll use pg-meta-1 as the publisher and pg-test-1 as the subscriber.
PGSRC='postgres://dbuser_admin@meta-1/meta' # Publisher
PGDST='postgres://dbuser_admin@node-1/test' # Subscriber
pgbench -is100 ${PGSRC} # Initialize Pgbench on publisher
pg_dump -Oscx -t pgbench* -s ${PGSRC} | psql ${PGDST} # Sync table structure on subscriber
# Create a **publication** on the publisher, adding default `pgbench` related tables to the publication set.
psql ${PGSRC} -AXwt <<-'EOF'
CREATE PUBLICATION "pg_meta_pub" FOR TABLE
pgbench_accounts,pgbench_branches,pgbench_history,pgbench_tellers;
EOF
# Create a **subscription** on the subscriber, subscribing to the publisher's publication.
psql ${PGDST} <<-'EOF'
CREATE SUBSCRIPTION pg_test_sub
CONNECTION 'host=10.10.10.10 dbname=meta user=replicator'
PUBLICATION pg_meta_pub;
EOF
Replication Process
After the subscription creation, if everything is normal, logical replication will automatically start, executing the replication state machine logic for each table in the subscription.
As shown in the following figure.
When all tables are completed and enter r (ready) state, the logical replication’s existing data synchronization stage is completed, and the publisher and subscriber sides enter synchronization state as a whole.
Therefore, logically speaking, there are two state machines: Table Level Replication Small State Machine and Global Replication Large State Machine. Each Sync Worker is responsible for a small state machine on one table, while an Apply Worker is responsible for a logical replication large state machine.
Logical Replication State Machine
Logical replication has two Workers: Sync and Apply. Sync
Therefore, logical replication is logically divided into two parts: Each Table Independently Replicating,When the replication progress catches up to the latest position, by
When creating or refreshing a subscription, the table will be added to the subscription set, and each table in the subscription set will have a corresponding record in the pg_subscription_rel view, showing the current replication status of this table. The newly added table is initially in i,即initialize,Initial State.
If the subscription’s copy_data option is true (default),And there is an idle Worker in the worker pool, PostgreSQL will allocate a synchronization worker for this table, synchronize the existing data on this table, and the table state enters d,即Copying Data. Synchronizing table data is similar to basebackup for database cluster, Sync Worker will create a temporary replication slot on the publisher, get the snapshot of the table through COPY, and complete basic data synchronization.
When the basic data copy of the table is completed, the table will enter sync mode, that is, Data Synchronization, the synchronization process will catch up with incremental changes during synchronization. When the catch-up is complete, the synchronization process will mark this table as r (ready) state, turn over the management of changes to the logical replication main Apply process, indicating that this table is in normal replication.
2.4 Waiting for Logical Replication Synchronization
After creating a subscription, first must monitor Ensure no errors are generated on both publisher and subscriber sides’ database logs.
2.4.1 Logical Replication State Machine
2.4.2 Synchronization Progress Tracking
Data synchronization (d) stage may take some time, depending on network card, network, disk, table size and distribution, logical replication synchronization worker quantity factors.
As a reference, 1TB database, 20 tables, containing 250GB large table, dual 10G network card, under the responsibility of 6 data synchronization workers, it takes about 6~8 hours to complete replication.
During data synchronization, each table synchronization task will create a temporary replication slot on the source end. Please ensure that logical replication initial synchronization period does not put unnecessary write pressure on the source primary, so as not to cause WAL to burst disk.
pg_stat_replication,pg_replication_slots,subscriber’s pg_stat_subscription,pg_subscription_rel provide logical replication status related information, need to pay attention.
Query Optimization: The Macro Approach with pg_stat_statements
In production databases, slow queries not only impact end-user experience but also waste system resources, increase resource saturation, cause deadlocks and transaction conflicts, add pressure to database connections, and lead to replication lag. Therefore, query optimization is one of the core responsibilities of DBAs.
There are two distinct approaches to query optimization:
Macro Optimization: Analyze the overall workload, break it down, and identify and improve the worst-performing components from top to bottom.
Micro Optimization: Analyze and improve specific queries, which requires slow query logging, mastering EXPLAIN, and understanding execution plans.
Today, let’s focus on the former. Macro optimization has three main objectives:
Reduce Resource Consumption: Lower the risk of resource saturation, optimize CPU/memory/IO, typically targeting total query execution time/IO.
Improve User Experience: The most common optimization goal, typically measured by reducing average query response time in OLTP systems.
Balance Workload: Ensure proper resource usage/performance ratios between different query groups.
The key to achieving these goals lies in data support, but where does this data come from?
— pg_stat_statements!
The Extension: PGSS
pg_stat_statements, hereafter referred to as PGSS, is the core tool for implementing the macro approach.
PGSS is developed by the PostgreSQL Global Development Group, distributed as a first-party extension alongside the database kernel. It provides methods for tracking SQL query-level metrics.
Among the many PostgreSQL extensions, if there’s one that’s “essential”, I would unhesitatingly answer: PGSS. This is why in Pigsty, we prefer to “take matters into our own hands” and enable this extension by default, along with auto_explain for micro-optimization.
PGSS needs to be explicitly loaded in shared_preload_library and created in the database via CREATE EXTENSION. After creating the extension, you can access query statistics through the pg_stat_statements view.
In PGSS, each query type (i.e., queries with the same execution plan after variable extraction) is assigned a query ID, followed by call count, total execution time, and various other metrics. The complete schema definition is as follows (PG15+):
CREATE TABLE pg_stat_statements
(
userid OID, -- (Label) OID of user executing this statement
dbid OID, -- (Label) OID of database containing this statement
toplevel BOOL, -- (Label) Whether this is a top-level SQL statement
queryid BIGINT, -- (Label) Query ID: hash of normalized query
query TEXT, -- (Label) Text of normalized query statement
plans BIGINT, -- (Counter) Number of times this statement was planned
total_plan_time FLOAT, -- (Counter) Total time spent planning this statement
min_plan_time FLOAT, -- (Gauge) Minimum planning time
max_plan_time FLOAT, -- (Gauge) Maximum planning time
mean_plan_time FLOAT, -- (Gauge) Average planning time
stddev_plan_time FLOAT, -- (Gauge) Standard deviation of planning time
calls BIGINT, -- (Counter) Number of times this statement was executed
total_exec_time FLOAT, -- (Counter) Total time spent executing this statement
min_exec_time FLOAT, -- (Gauge) Minimum execution time
max_exec_time FLOAT, -- (Gauge) Maximum execution time
mean_exec_time FLOAT, -- (Gauge) Average execution time
stddev_exec_time FLOAT, -- (Gauge) Standard deviation of execution time
rows BIGINT, -- (Counter) Total rows returned by this statement
shared_blks_hit BIGINT, -- (Counter) Total shared buffer blocks hit
shared_blks_read BIGINT, -- (Counter) Total shared buffer blocks read
shared_blks_dirtied BIGINT, -- (Counter) Total shared buffer blocks dirtied
shared_blks_written BIGINT, -- (Counter) Total shared buffer blocks written to disk
local_blks_hit BIGINT, -- (Counter) Total local buffer blocks hit
local_blks_read BIGINT, -- (Counter) Total local buffer blocks read
local_blks_dirtied BIGINT, -- (Counter) Total local buffer blocks dirtied
local_blks_written BIGINT, -- (Counter) Total local buffer blocks written to disk
temp_blks_read BIGINT, -- (Counter) Total temporary buffer blocks read
temp_blks_written BIGINT, -- (Counter) Total temporary buffer blocks written to disk
blk_read_time FLOAT, -- (Counter) Total time spent reading blocks
blk_write_time FLOAT, -- (Counter) Total time spent writing blocks
wal_records BIGINT, -- (Counter) Total number of WAL records generated
wal_fpi BIGINT, -- (Counter) Total number of WAL full page images generated
wal_bytes NUMERIC, -- (Counter) Total number of WAL bytes generated
jit_functions BIGINT, -- (Counter) Number of JIT-compiled functions
jit_generation_time FLOAT, -- (Counter) Total time spent generating JIT code
jit_inlining_count BIGINT, -- (Counter) Number of times functions were inlined
jit_inlining_time FLOAT, -- (Counter) Total time spent inlining functions
jit_optimization_count BIGINT, -- (Counter) Number of times queries were JIT-optimized
jit_optimization_time FLOAT, -- (Counter) Total time spent on JIT optimization
jit_emission_count BIGINT, -- (Counter) Number of times code was JIT-emitted
jit_emission_time FLOAT, -- (Counter) Total time spent on JIT emission
PRIMARY KEY (userid, dbid, queryid, toplevel)
);
PGSS View SQL Definition (PG 15+ version)
PGSS has some limitations: First, currently executing queries are not included in these statistics and need to be viewed from pg_stat_activity. Second, failed queries (e.g., statements canceled due to statement_timeout) are not counted in these statistics — this is a problem for error analysis, not query optimization.
Finally, the stability of the query identifier queryid requires special attention: When the database binary version and system data directory are identical, the same query type will have the same queryid (i.e., on physical replication primary and standby, query types have the same queryid by default), but this is not the case for logical replication. However, users should not rely too heavily on this property.
Raw Data
The columns in the PGSS view can be categorized into three types:
Descriptive Label Columns: Query ID (queryid), database ID (dbid), user (userid), a top-level query flag, and normalized query text (query).
Measured Metrics (Gauge): Eight statistical columns related to minimum, maximum, mean, and standard deviation, prefixed with min, max, mean, stddev, and suffixed with plan_time and exec_time.
Cumulative Metrics (Counter): All other metrics except the above eight columns and label columns, such as calls, rows, etc. The most important and useful metrics are in this category.
First, let’s explain queryid: queryid is the hash value of a normalized query after parsing and constant stripping, so it can be used to identify the same query type. Different query statements may have the same queryid (same structure after normalization), and the same query statement may have different queryids (e.g., due to different search_path, leading to different actual tables being queried).
The same query might be executed by different users in different databases. Therefore, in the PGSS view, the four label columns queryid, dbid, userid, and toplevel together form the “primary key” that uniquely identifies a record.
For metric columns, measured metrics (GAUGE) are mainly the eight statistics related to execution time and planning time. However, users cannot effectively control the statistical range of these metrics, so their practical value is limited.
The truly important metrics are cumulative metrics (Counter), such as:
calls: Number of times this query group was called.
total_exec_time + total_plan_time: Total time spent by the query group.
rows: Total rows returned by the query group.
shared_blks_hit + shared_blks_read: Total number of buffer pool hit and read operations.
wal_bytes: Total WAL bytes generated by queries in this group.
blk_read_time and blk_write_time: Total time spent on block I/O operations.
Here, the most meaningful metrics are calls and total_exec_time, which can be used to calculate the query group’s core metrics QPS (throughput) and RT (latency/response time), but other metrics are also valuable references.
Visualization of a query group snapshot from the PGSS view
To interpret cumulative metrics, data from a single point in time is insufficient. We need to compare at least two snapshots to draw meaningful conclusions.
As a special case, if your area of interest happens to be from the beginning of the statistical period (usually when the extension was enabled) to the present, then you indeed don’t need to compare “two snapshots”. But users’ time granularity of interest is usually not this coarse, often being in minutes, hours, or days.
Calculating historical time-series metrics based on multiple PGSS query group snapshots
Fortunately, tools like Pigsty monitoring system regularly (default every 10s) capture snapshots of top queries (Top256 by execution time). With many different types of cumulative metrics (Metrics) at different time points, we can calculate three important derived metrics for any cumulative metric:
dM/dt: The time derivative of metric M, i.e., the increment per second.
dM/dc: The derivative of metric M with respect to call count, i.e., the average increment per call.
%M: The percentage of metric M in the entire workload.
These three types of metrics correspond exactly to the three objectives of macro optimization. The time derivative dM/dt reveals resource usage per second, typically used for the objective of reducing resource consumption. The call derivative dM/dc reveals resource usage per call, typically used for the objective of improving user experience. The percentage metric %M shows the proportion of a query group in the entire workload, typically used for the objective of balancing workload.
Time Derivatives
Let’s first look at the first type of metric: time derivatives. Here, we can use metrics M including: calls, total_exec_time, rows, wal_bytes, shared_blks_hit + shared_blks_read, and blk_read_time + blk_write_time. Other metrics are also valuable references, but let’s start with the most important ones.
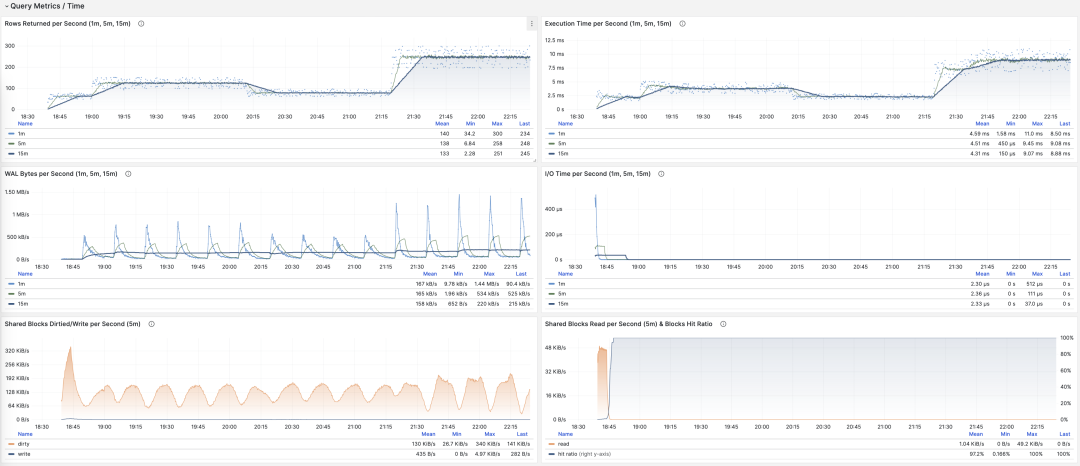
Visualization of time derivative metrics dM/dt
The calculation of these metrics is quite simple:
- First, calculate the difference in metric value M between two snapshots: M2 - M1
- Then, calculate the time difference between two snapshots: t2 - t1
- Finally, calculate (M2 - M1) / (t2 - t1)
Production environments typically use sampling intervals of 5s, 10s, 15s, 30s, 60s. For workload analysis, 1m, 5m, 15m are commonly used as analysis window sizes.
For example, when calculating QPS, we calculate QPS for the last 1 minute, 5 minutes, and 15 minutes respectively. Longer windows result in smoother curves, better reflecting long-term trends; but they hide short-term fluctuation details, making it harder to detect instant anomalies. Therefore, metrics of different granularities need to be considered together.
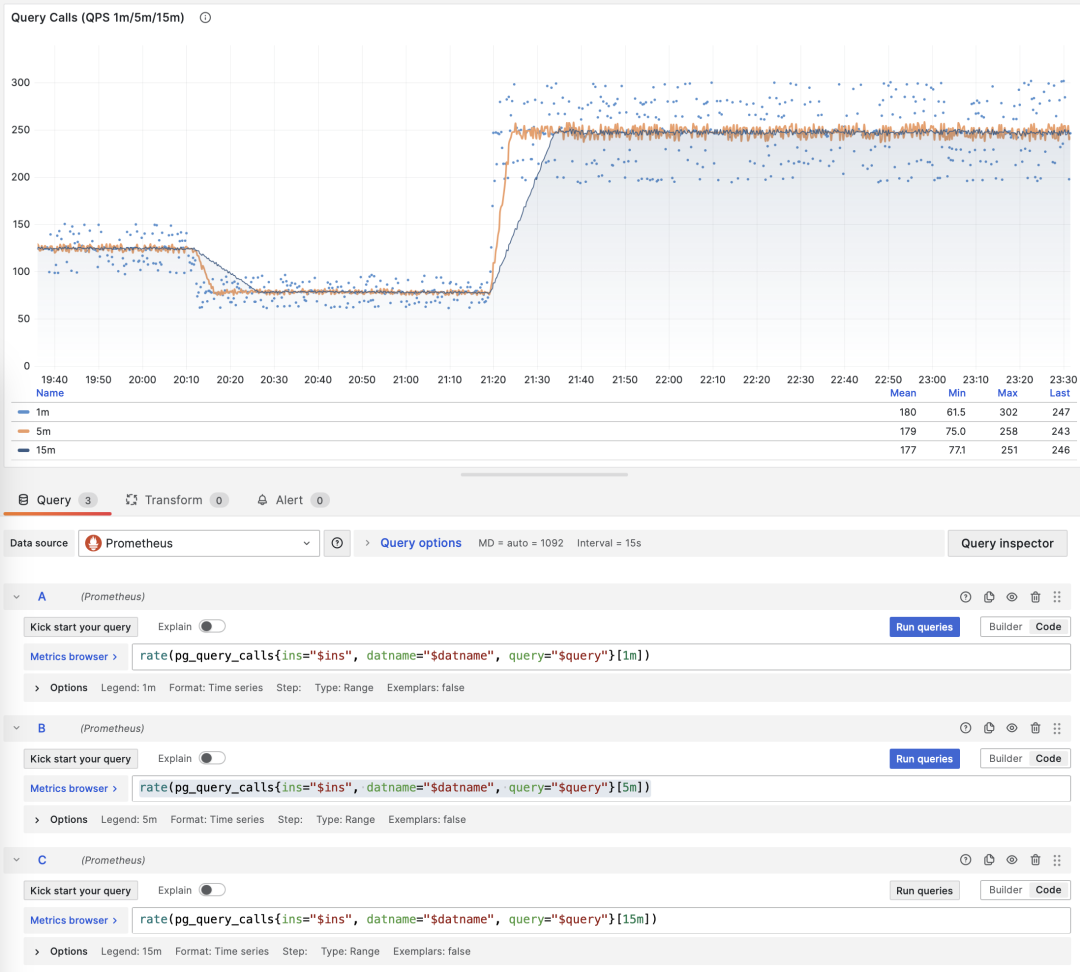
Showing QPS for a specific query group in 1/5/15 minute windows
If you use Pigsty / Prometheus to collect monitoring data, you can easily perform these calculations using PromQL. For example, to calculate the QPS metric for all queries in the last minute, you can use: rate(pg_query_calls{}[1m])
QPS
When M is calls, the time derivative is QPS, with units of queries per second (req/s). This is a very fundamental metric. Query QPS is a throughput metric that directly reflects the load imposed by the business. If a query’s throughput is too high (e.g., 10000+) or too low (e.g., 1-), it might be worth attention.
QPS: 1/5/15 minute µ/CV, ±1/3σ distribution
If we sum up the QPS metrics of all query groups (and haven’t exceeded PGSS’s collection range), we get the so-called “global QPS”. Another way to obtain global QPS is through client-side instrumentation, collection at connection pool middleware like Pgbouncer, or using ebpf probes. But none are as convenient as PGSS.
Note that QPS metrics don’t have horizontal comparability in terms of load. Different query groups may have the same QPS, while individual query execution times may vary dramatically. Even the same query group may produce vastly different load levels at different time points due to execution plan changes. Execution time per second is a better metric for measuring load.
Execution Time Per Second
When M is total_exec_time (+ total_plan_time, optional), we get one of the most important metrics in macro optimization: execution time spent on the query group. Interestingly, the units of this derivative are seconds per second, so the numerator and denominator cancel out, making it actually a dimensionless metric.
This metric’s meaning is: how many seconds per second the server spends processing queries in this group. For example, 2 s/s means the server spends two seconds of execution time per second on this group of queries; for multi-core CPUs, this is certainly possible: just use all the time of two CPU cores.
Execution time per second: 1/5/15 minute mean
Therefore, this value can also be understood as a percentage: it can exceed 100%. From this perspective, it’s a metric similar to host load1, load5, load15, revealing the load level produced by this query group. If divided by the number of CPU cores, we can even get a normalized query load contribution metric.
However, we need to note that execution time includes time spent waiting for locks and I/O. So it’s indeed possible that a query has a long execution time but doesn’t impact CPU load. Therefore, for detailed analysis of slow queries, we need to further analyze with reference to wait events.
Rows Per Second
When M is rows, we get the number of rows returned per second by this query group, with units of rows per second (rows/s). For example, 10000 rows/s means this type of query returns 10,000 rows of data to the client per second. Returned rows consume client processing resources, making this a very valuable reference metric when we need to examine application client data processing pressure.
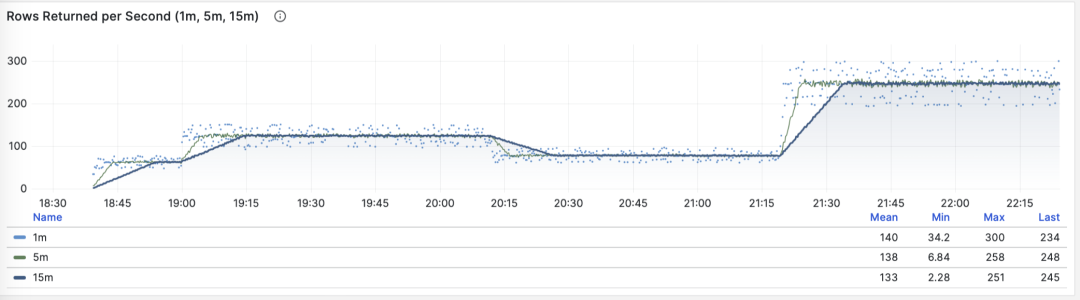
Rows returned per second: 1/5/15 minute mean
Shared Buffer Access Bandwidth
When M is shared_blks_hit + shared_blks_read, we get the number of shared buffer blocks hit/read per second. If we multiply this by the default block size of 8KiB (rarely might be other sizes, e.g., 32KiB), we get the bandwidth of a query type “accessing” memory/disk: units are bytes per second.
For example, if a certain query type accesses 500,000 shared buffer blocks per second, equivalent to 3.8 GiB/s of internal access data flow: then this is a significant load, and might be a good candidate for optimization. You should probably check this query to see if it deserves these “resource consumption”.
Shared buffer access bandwidth and buffer hit rate
Another valuable derived metric is buffer hit rate: hit / (hit + read), which can be used to analyze possible causes of performance changes — cache misses. Of course, repeated access to the same shared buffer pool block doesn’t actually result in a new read, and even if it does read, it might not be from disk but from memory in FS Cache. So this is just a reference value, but it is indeed a very important macro query optimization reference metric.
WAL Log Volume
When M is wal_bytes, we get the rate at which this query generates WAL, with units of bytes per second (B/s). This metric was newly introduced in PostgreSQL 13 and can be used to quantitatively reveal the WAL size generated by queries: the more and faster WAL is written, the greater the pressure on disk flushing, physical/logical replication, and log archiving.
A typical example is: BEGIN; DELETE FROM xxx; ROLLBACK;. Such a transaction deletes a lot of data, generates a large amount of WAL, but performs no useful work. This metric can help identify such cases.
WAL bytes per second: 1/5/15 minute mean
There are two things to note here: As mentioned above, PGSS cannot track failed statements, but here the transaction was ROLLBACKed, but the statements were successfully executed, so they are tracked by PGSS.
The second thing is: in PostgreSQL, not only INSERT/UPDATE/DELETE operations generate WAL logs, SELECT operations might also generate WAL logs, because SELECT might modify tuple marks (Hint Bit) causing page checksums to change, triggering WAL log writes.
There’s even the possibility that if the read load is very large, it might have a higher probability of causing FPI image generation, producing considerable WAL log volume. You can check this further through the wal_fpi metric.
Shared buffer dirty/write-back bandwidth
For versions below 13, shared buffer dirty/write-back bandwidth metrics can serve as approximate alternatives for analyzing write load characteristics of query groups.
I/O Time
When M is blks_read_time + blks_write_time, we get the proportion of time spent on block I/O by the query group, with units of “seconds per second”, same as the execution time per second metric, it also reflects the proportion of time occupied by such operations.
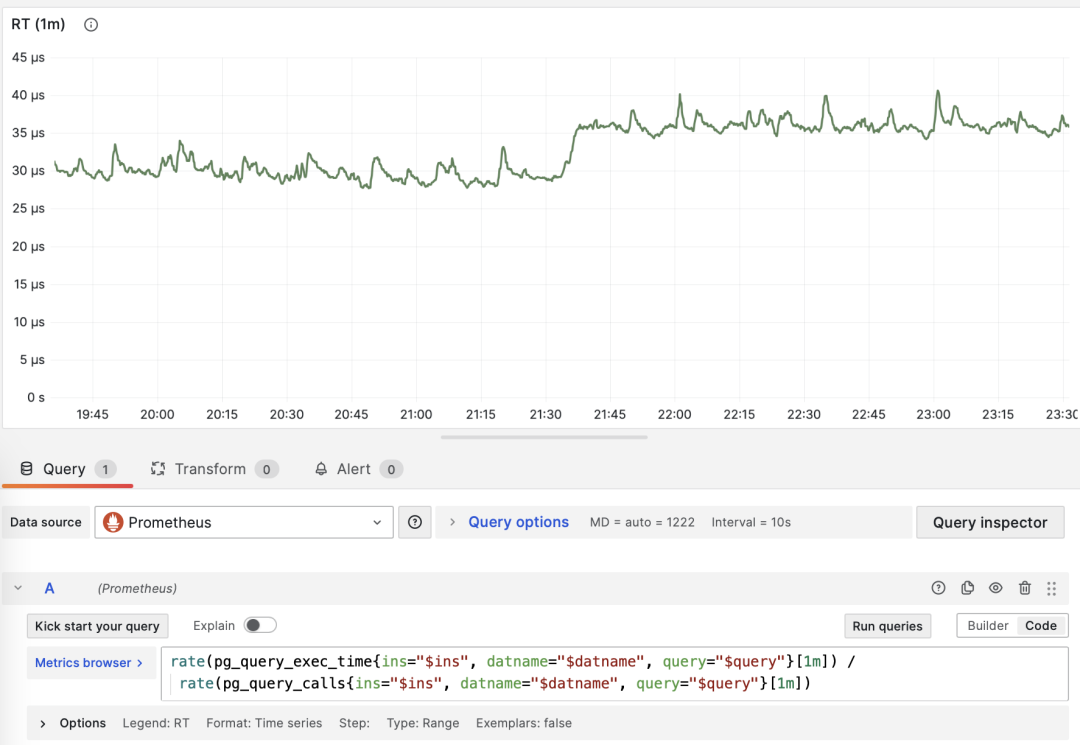
I/O time is helpful for analyzing query spike causes
Because PostgreSQL uses the operating system’s FS Cache, even if block reads/writes are performed here, they might still be buffer operations at the filesystem level. So this can only be used as a reference metric, requiring careful use and comparison with disk I/O monitoring on the host node.
Time derivative metrics dM/dt can reveal the complete picture of workload within a database instance/cluster, especially useful for scenarios aiming to optimize resource usage. But if your optimization goal is to improve user experience, then another set of metrics — call derivatives dM/dc — might be more relevant.
Call Derivatives
Above we’ve calculated time derivatives for six important metrics. Another type of derived metric calculates derivatives with respect to “call count”, where the denominator changes from time difference to QPS.
This type of metric is even more important than the former, as it provides several core metrics directly related to user experience, such as the most important — Query Response Time (RT), or Latency.
The calculation of these metrics is also simple:
- Calculate the difference in metric value M between two snapshots: M2 - M1
- Then calculate the difference in calls between two snapshots: c2 - c1
- Finally calculate (M2 - M1) / (c2 - c1)
For PromQL implementation, call derivative metrics dM/dc can be calculated from “time derivative metrics dM/dt”. For example, to calculate RT, you can use execution time per second / queries per second, dividing the two metrics:
rate(pg_query_exec_time{}[1m]) / rate(pg_query_calls{}[1m])
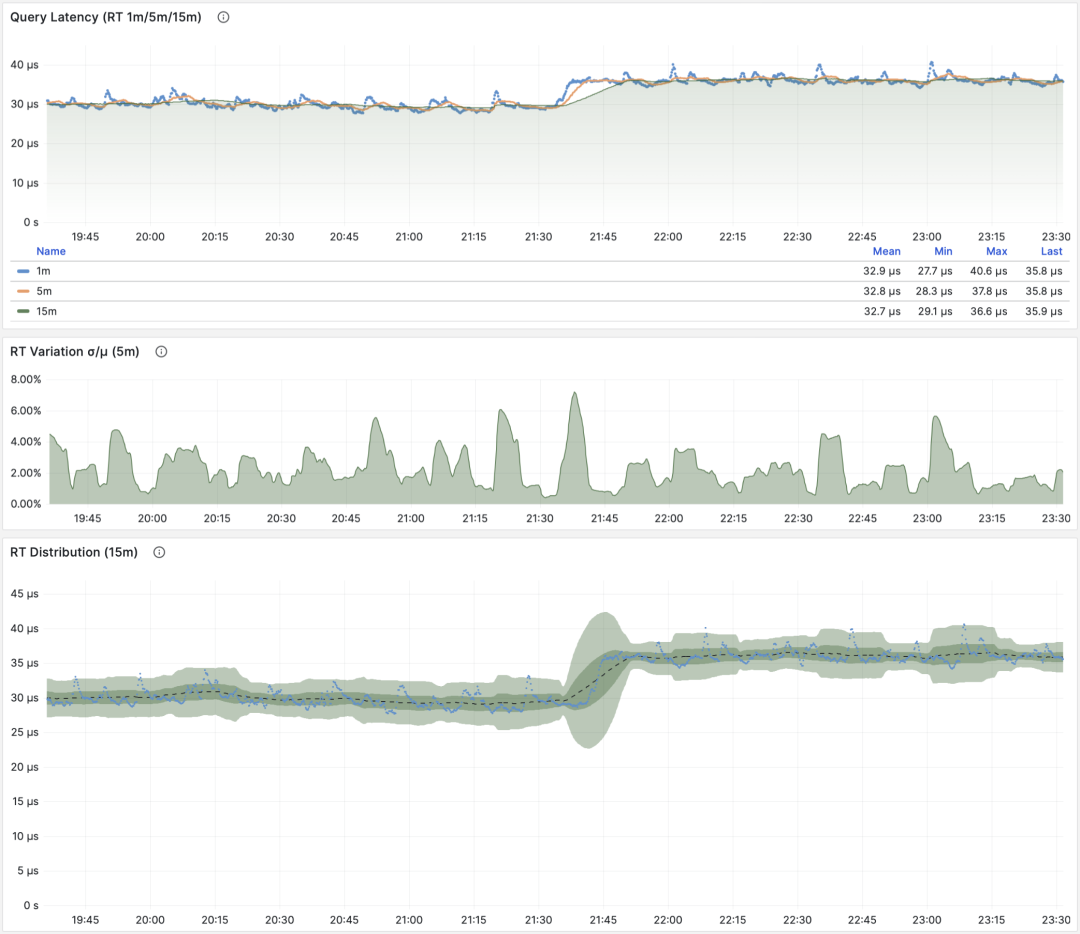
dM/dt can be used to calculate dM/dc
Call Count
When M is calls, taking its own derivative is meaningless (result will always be 1).
Average Latency/Response Time/RT
When M is total_exec_time, the call derivative is RT, or response time/latency. Its unit is seconds (s). RT directly reflects user experience and is the most important metric in macro performance analysis. This metric’s meaning is: the average query response time of this query group on the server. If conditions allow enabling pg_stat_statements.track_planning, you can also add total_plan_time to the calculation for more precise and representative results.
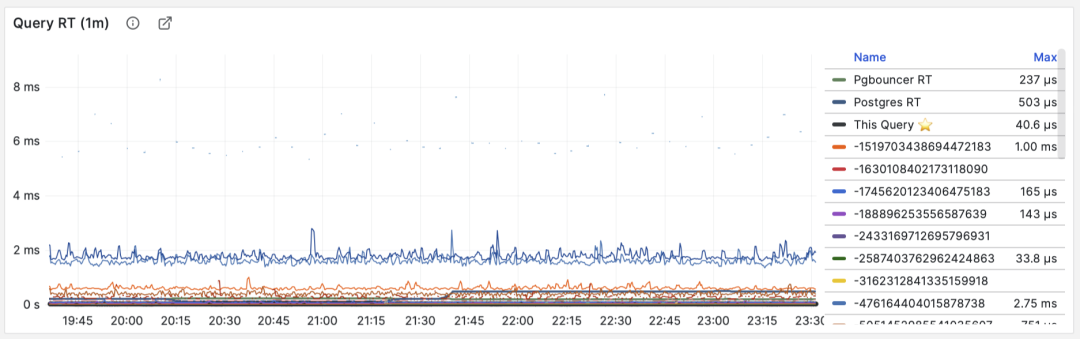
RT: statement level/connection pool level/database level
Unlike throughput metrics like QPS, RT has horizontal comparability: for example, if a query group’s RT is normally within 1 millisecond, then events exceeding 10ms should be considered serious deviations for analysis.
When failures occur, RT views are also helpful for root cause analysis: if all queries’ overall RT slows down, it’s most likely related to insufficient resources. If only specific query groups’ RT changes, it’s more likely that some slow queries are causing problems and should be further investigated. If RT changes coincide with application deployment, you should consider rolling back these deployments.
Moreover, in performance analysis, stress testing, and benchmarking, RT is the most important metric. You can evaluate system performance by comparing typical queries’ latency performance in different environments (e.g., different PG versions, hardware, configuration parameters) and use this as a basis for continuous system performance adjustment and improvement.
RT is so important that RT itself spawns many downstream metrics: 1-minute/5-minute/15-minute means µ and standard deviations σ are naturally essential; past 15 minutes’ ±σ, ±3σ can be used to measure RT fluctuation range, and past 1 hour’s 95th, 99th percentiles are also valuable references.
RT is the core metric for evaluating OLTP workloads, and its importance cannot be overemphasized.
Average Rows Returned
When M is rows, we get the average rows returned per query, with units of rows per query. For OLTP workloads, typical query patterns are point queries, returning a few rows of data per query.
Querying single record by primary key, average rows returned stable at 1
If a query group returns hundreds or even thousands of rows to the client per query, it should be examined. If this is by design, like batch loading tasks/data dumps, then no action is needed. If this is initiated by the application/client, there might be errors, such as statements missing LIMIT restrictions, queries lacking pagination design. Such queries should be adjusted and fixed.
Average Shared Buffer Reads/Hits
When M is shared_blks_hit + shared_blks_read, we get the average number of shared buffer “hits” and “reads” per query. If we multiply this by the default block size of 8KiB, we get this query type’s “bandwidth” per execution, with units of B/s: how many MB of data does each query access/read on average?
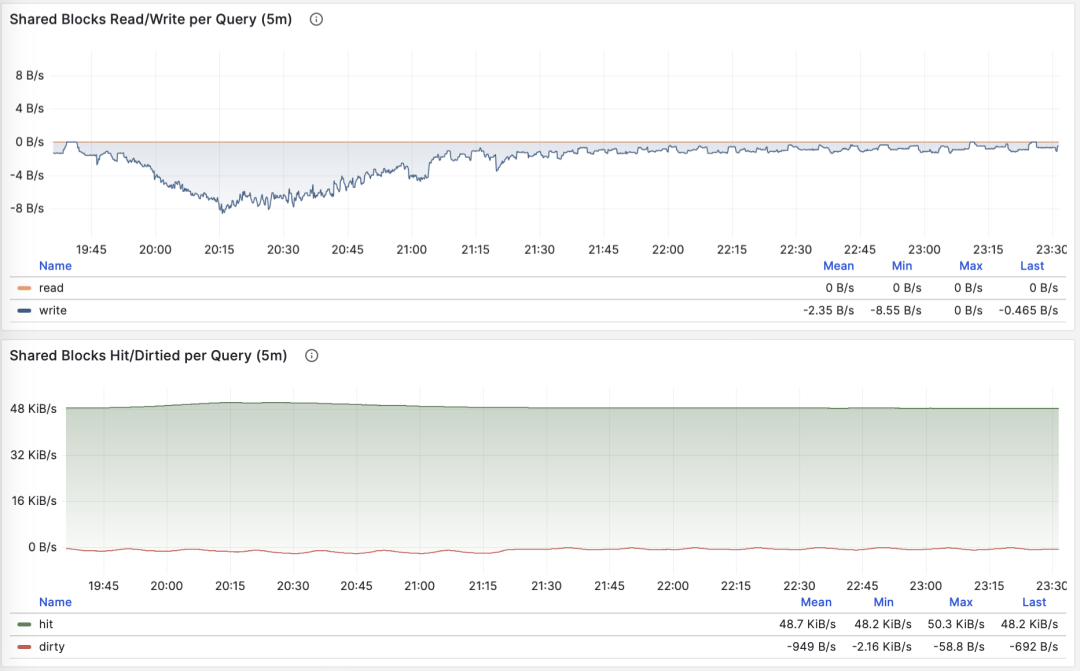
Querying single record by primary key, average rows returned stable at 1
The average data accessed by a query typically matches the average rows returned. If your query returns only a few rows on average but accesses megabytes or gigabytes of data blocks, you need to pay special attention: such queries are very sensitive to data hot/cold state. If all blocks are in the buffer, its performance might be acceptable, but if starting cold from disk, execution time might change dramatically.
Of course, don’t forget PostgreSQL’s double caching issue. The so-called “read” data might have already been cached once at the operating system filesystem level. So you need to cross-reference with operating system monitoring metrics, or system views like pg_stat_kcache, pg_stat_io for analysis.
Another pattern worth attention is sudden changes in this metric, which usually means the query group’s execution plan might have flipped/degraded, very worthy of attention and further research.
Average WAL Log Volume
When M is wal_bytes, we get the average WAL size generated per query, a field newly introduced in PostgreSQL 13. This metric can measure a query’s change footprint size and calculate important evaluation parameters like read/write ratios.
Stable QPS with periodic WAL fluctuations, can infer FPI influence
Another use is optimizing checkpoints/Checkpoint: if you observe periodic fluctuations in this metric (period approximately equal to checkpoint_timeout), you can optimize the amount of WAL generated by queries by adjusting checkpoint spacing.
Call derivative metrics dM/dc can reveal a query type’s workload characteristics, very useful for optimizing user experience. Especially RT is the golden metric for performance optimization, and its importance cannot be overemphasized.
dM/dc metrics provide us with important absolute value metrics, but to find which queries have the greatest potential optimization benefits, we also need %M percentage metrics.
Percentage Metrics
Now let’s examine the third type of metric, percentage metrics. These show the proportion of a query group relative to the overall workload.
Percentage metrics M% provide us with a query group’s proportion relative to the overall workload, helping us identify “major contributors” in terms of frequency, time, I/O time/count, and find query groups with the greatest potential optimization benefits as important criteria for priority assessment.
Common percentage metrics %M overview
For example, if a query group has an absolute value of 1000 QPS, it might seem significant; but if it only accounts for 3% of the entire workload, then the benefits and priority of optimizing this query aren’t that high. Conversely, if it accounts for more than 50% of the entire workload — if you can optimize it, you can cut the instance’s throughput in half, making its optimization priority very high.
A common optimization strategy is: first sort all query groups by the important metrics mentioned above: calls, total_exec_time, rows, wal_bytes, shared_blks_hit + shared_blks_read, and blk_read_time + blk_write_time over a period of time’s dM/dt values, take TopN (e.g., N=10 or more), and add them to the optimization candidate list.
Selecting TopSQL for optimization based on specific criteria
Then, for each query group in the optimization candidate list, analyze its dM/dc metrics, combine with specific query statements and slow query logs/wait events for analysis, and decide if this is a query worth optimizing. For queries decided (Plan) to optimize, you can use the techniques to be introduced in the subsequent “Micro Optimization” article for tuning (Do), and use the monitoring system to evaluate optimization effects (Check). After summarizing and analyzing, enter the next PDCA Deming cycle, continuously managing and optimizing.
Besides taking TopN of metrics, visualization can also be used. Visualization is very helpful for identifying “major contributors” from the workload. Complex judgment algorithms might be far inferior to human DBAs’ intuition about monitoring graph patterns. To form a sense of proportion, we can use pie charts, tree maps, or stacked time series charts.
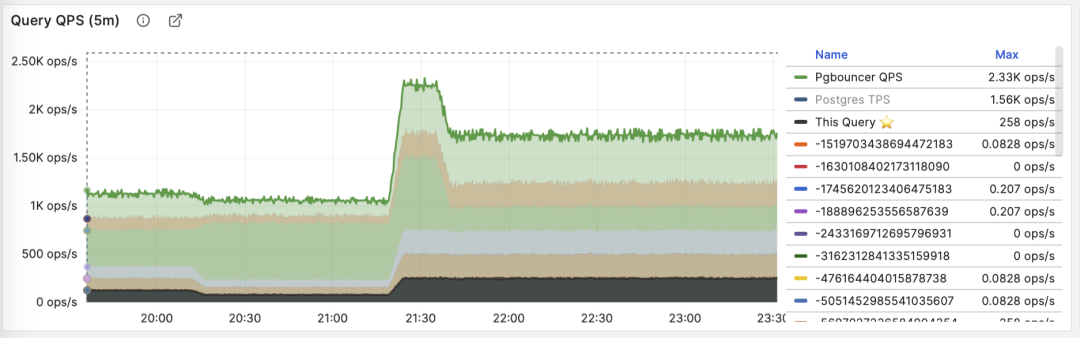
Stacking QPS of all query groups
For example, we can use pie charts to identify queries with the highest time/IO usage in the past hour, use 2D tree maps (size representing total time, color representing average RT) to show an additional dimension, and use stacked time series charts to show proportion changes over time.
We can also directly analyze the current PGSS snapshot, sort by different concerns, and select queries that need optimization according to your own criteria.
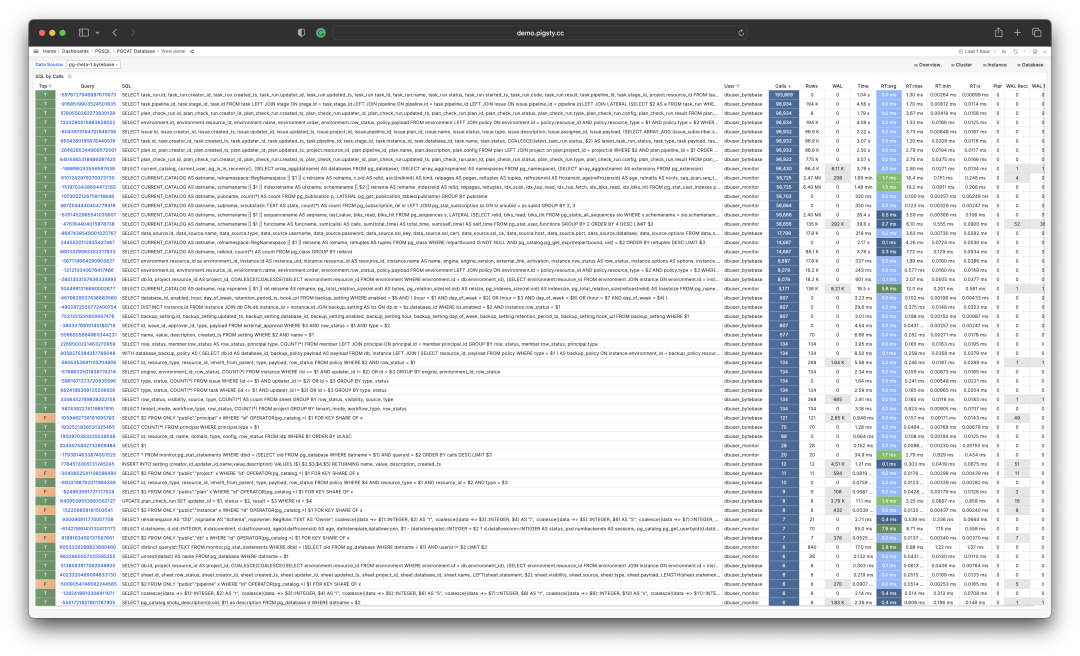
I/O time is helpful for analyzing query spike causes
Summary
Finally, let’s summarize the above content.
PGSS provides rich metrics, among which the most important cumulative metrics can be processed in three ways:
dM/dt: The time derivative of metric M, revealing resource usage per second, typically used for the objective of reducing resource consumption.
dM/dc: The call derivative of metric M, revealing resource usage per call, typically used for the objective of improving user experience.
%M: Percentage metrics showing a query group’s proportion in the entire workload, typically used for the objective of balancing workload.
Typically, we select high-value candidate queries for optimization based on %M: percentage metrics Top queries, and use dM/dt and dM/dc metrics for further evaluation, confirming if there’s optimization space and feasibility, and evaluating optimization effects. Repeat this process continuously.
After understanding the methodology of macro optimization, we can use this approach to locate and optimize slow queries. Here’s a concrete example of Using Monitoring System to Diagnose PG Slow Queries. In the next article, we’ll introduce experience and techniques for PostgreSQL query micro optimization.
References
[1] PostgreSQL HowTO: pg_stat_statements by Nikolay Samokhvalov
[3] Using Monitoring System to Diagnose PG Slow Queries
[4] How to Monitor Existing PostgreSQL (RDS/PolarDB/On-prem) with Pigsty?
[5] Pigsty v2.5 Released: Ubuntu/Debian Support & Monitoring Revamp/New Extensions
Rescue Data with pg_filedump?

Backups are a DBA’s lifeline — but what if your PostgreSQL database has crashed without any backups? Maybe pg_filedump can help!
Recently, I encountered a rather challenging case. Here’s the situation: A user’s PostgreSQL database was corrupted. It was a Gitlab-managed PostgreSQL instance with no replicas, no backups, and no dumps. It was running on BCACHE (using SSD as transparent cache), and after a power outage, it wouldn’t start.
But that wasn’t the end of it. After several rounds of mishandling, it was completely wrecked: First, someone forgot to mount the BCACHE disk, causing Gitlab to reinitialize a new database cluster; then, due to various reasons, isolation failed, and two database processes ran on the same cluster directory, frying the data directory; next, someone ran pg_resetwal without parameters, pushing the database back to its origin point; finally, they let the empty database run for a while and then removed the temporary backup made before the corruption.
When I saw this case, I was speechless: How do you recover from this mess? It seemed like the only option was to extract data directly from the binary files. I suggested they try a data recovery company, and I asked around, but among the many data recovery companies, almost none offered PostgreSQL data recovery services. Those that did only handled basic issues, and for this situation, they all said it was a long shot.
Data recovery quotes are typically based on the number of files, ranging from ¥1000 to ¥5000 per file. With thousands of files in the Gitlab database, roughly 1000 tables, the total recovery cost could easily reach hundreds of thousands. But after a day, no one took the job, which made me think: If no one can handle this, doesn’t that make the PG community look bad?
I thought about it and decided: This job looks painful but also quite challenging and interesting. Let’s treat it as a dead horse and try to revive it — no cure, no pay. You never know until you try, right? So I took it on myself.
The Tool
To do a good job, one must first sharpen one’s tools. For data recovery, the first step is to find the right tool: pg_filedump is a great weapon. It can extract raw binary data from PostgreSQL data pages, handling many low-level tasks.
The tool can be compiled and installed with the classic make three-step process, but you need to have the corresponding major version of PostgreSQL installed first. Gitlab defaults to using PG 13, so ensure the corresponding version’s pg_config is in your path before compiling:
git clone https://github.com/df7cb/pg_filedump
cd pg_filedump && make && sudo make install
Using pg_filedump isn’t complicated. You feed it a data file and tell it the type of each column in the table, and it’ll interpret the data for you. For example, the first step is to find out which databases exist in the cluster. This information is stored in the system view pg_database. This is a system-level table located in the global directory, assigned a fixed OID 1262 during cluster initialization, so the corresponding physical file is typically: global/1262.
vonng=# select 'pg_database'::RegClass::OID;
oid
------
1262
This system view has many fields, but we mainly care about the first two: oid and datname. datname is the database name, and oid can be used to locate the database directory. We can use pg_filedump to extract this table and examine it. The -D parameter tells pg_filedump how to interpret the binary data for each row in the table. You can specify the type of each field, separated by commas, and use ~ to ignore the rest.
As you can see, each row of data starts with COPY. Here we found our target database gitlabhq_production with OID 16386. Therefore, all files for this database should be located in the base/16386 subdirectory.
Recovering the Data Dictionary
Knowing the directory of files to recover, the next step is to extract the data dictionary. There are four important tables to focus on:
•pg_class: Contains important metadata for all tables
•pg_namespace: Contains schema metadata
•pg_attribute: Contains all column definitions
•pg_type: Contains type names
Among these, pg_class is the most crucial and indispensable table. The other system views are nice to have: they make our work easier. So, we first attempt to recover this table.
pg_class is a database-level system view with a default OID = 1259, so the corresponding file for pg_class should be: base/16386/1259, in the gitlabhq_production database directory.

A side note: Those familiar with PostgreSQL internals know that while the actual underlying storage filename (RelFileNode) defaults to matching the table’s OID, some operations might change this. In such cases, you can use pg_filedump -m pg_filenode.map to parse the mapping file in the database directory and find the Filenode corresponding to OID 1259. Of course, here they match, so we’ll move on.
We parse its binary file based on the pg_class table structure definition (note: use the table structure for the corresponding PG major version):
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,text,text,text' -i base/16386/1259
Then you can see the parsed data. The data here is single-line records separated by \t, in the same format as PostgreSQL COPY command’s default output. So you can use scripts to grep and filter, remove the COPY at the beginning of each line, and re-import it into a real database table for detailed examination.
When recovering data, there are many details to pay attention to, and the first one is: You need to handle deleted rows. How to identify them? Use the -i parameter to print each row’s metadata. The metadata includes an XMAX field. If a row was deleted by a transaction, this record’s XMAX will be set to that transaction’s XID. So if a row’s XMAX isn’t zero, it means this is a deleted record and shouldn’t be included in the final output.
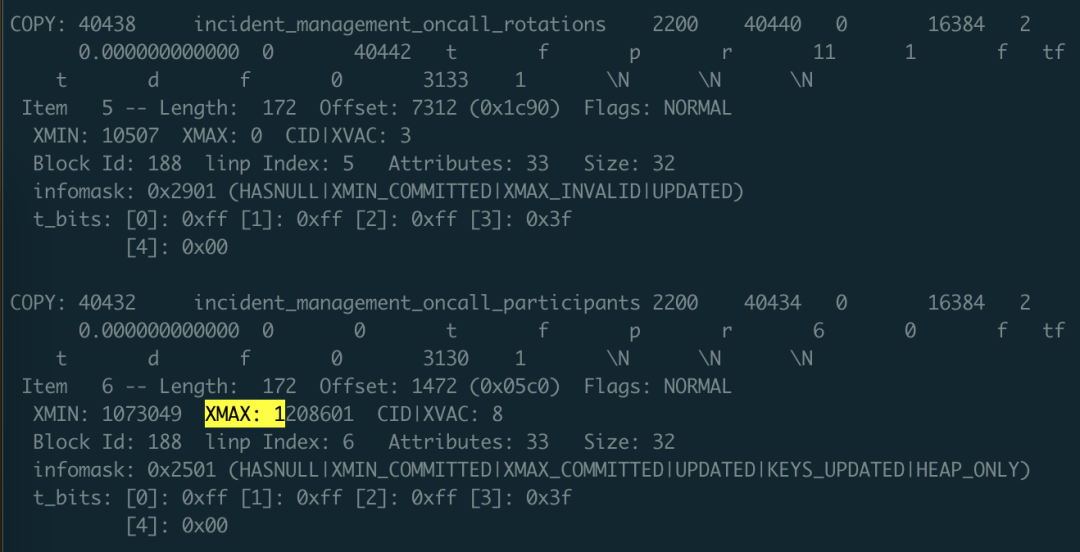
Here XMAX indicates this is a deleted record
With the pg_class data dictionary, you can clearly find the OID correspondences for other tables, including system views. You can recover pg_namespace, pg_attribute, and pg_type using the same method. What can you do with these four tables?

You can use SQL to generate the input path for each table, automatically construct the type of each column as the -D parameter, and generate the schema for temporary result tables. In short, you can automate all the necessary tasks programmatically.
SELECT id, name, nspname, relname, nspid, attrs, fields, has_tough_type,
CASE WHEN toast_page > 0 THEN toast_name ELSE NULL END AS toast_name, relpages, reltuples, path
FROM
(
SELECT n.nspname || '.' || c.relname AS "name", n.nspname, c.relname, c.relnamespace AS nspid, c.oid AS id, c.reltoastrelid AS tid,
toast.relname AS toast_name, toast.relpages AS toast_page,
c.relpages, c.reltuples, 'data/base/16386/' || c.relfilenode::TEXT AS path
FROM meta.pg_class c
LEFT JOIN meta.pg_namespace n ON c.relnamespace = n.oid
, LATERAL (SELECT * FROM meta.pg_class t WHERE t.oid = c.reltoastrelid) toast
WHERE c.relkind = 'r' AND c.relpages > 0
AND c.relnamespace IN (2200, 35507, 35508)
ORDER BY c.relnamespace, c.relpages DESC
) z,
LATERAL ( SELECT string_agg(name,',') AS attrs,
string_agg(std_type,',') AS fields,
max(has_tough_type::INTEGER)::BOOLEAN AS has_tough_type
FROM meta.pg_columns WHERE relid = z.id ) AS columns;
Note that the data type names supported by pg_filedump -D parameter are strictly limited to standard names, so you must convert boolean to bool, INTEGER to int. If the data type you want to parse isn’t in the list below, you can first try using the TEXT type. For example, the INET type for IP addresses can be parsed using TEXT.
bigint bigserial bool char charN date float float4 float8 int json macaddr name numeric oid real serial smallint smallserial text time timestamp timestamptz timetz uuid varchar varcharN xid xml
But there are indeed other special cases that require additional processing, such as PostgreSQL’s ARRAY type, which we’ll cover in detail later.
Recovering a Regular Table
Recovering a regular data table isn’t fundamentally different from recovering a system catalog table: it’s just that catalog schemas and information are publicly standardized, while the schema of the database to be recovered might not be.
Gitlab is also a well-known open-source software, so finding its database schema definition isn’t difficult. If it’s a regular business system, you can spend more effort to reconstruct the original DDL from pg_catalog.
Once you know the DDL definition, you can use the data type of each column in the DDL to interpret the data in the binary file. Let’s use public.approval_merge_request_rules, a regular table in Gitlab, as an example to demonstrate how to recover such a regular data table.
create table approval_project_rules
(
id bigint,
created_at timestamp with time zone,
updated_at timestamp with time zone,
project_id integer,
approvals_required smallint,
name varchar,
rule_type smallint,
scanners text[],
vulnerabilities_allowed smallint,
severity_levels text[],
report_type smallint,
vulnerability_states text[],
orchestration_policy_idx smallint,
applies_to_all_protected_branches boolean,
security_orchestration_policy_configuration_id bigint,
scan_result_policy_id bigint
);
First, we need to convert these types into types that pg_filedump can recognize. This involves type mapping: if you have uncertain types, like the text[] string array fields above, you can first use text type as a placeholder, or simply use ~ to ignore them:
bigint,timestamptz,timestamptz,int,smallint,varchar,smallint,text,smallint,text,smallint,text,smallint,bool,bigint,bigint
Of course, the first thing to know is that PostgreSQL’s tuple column layout is ordered, and this order is stored in the attrnum field of the system view pg_attribute. The type ID for each column in the table is stored in the atttypid field, and to get the English name of the type, you need to reference the pg_type system view through the type ID (of course, system default types have fixed IDs, so you can also use ID mapping directly). In summary, to get the interpretation method for physical records in a table, you need at least the four system dictionary tables mentioned above.
With the order and types of columns in this table, and knowing the location of this table’s binary file, you can use this information to translate the binary data.
pg_filedump -i -f -D 'bigint,...,bigint' 38304
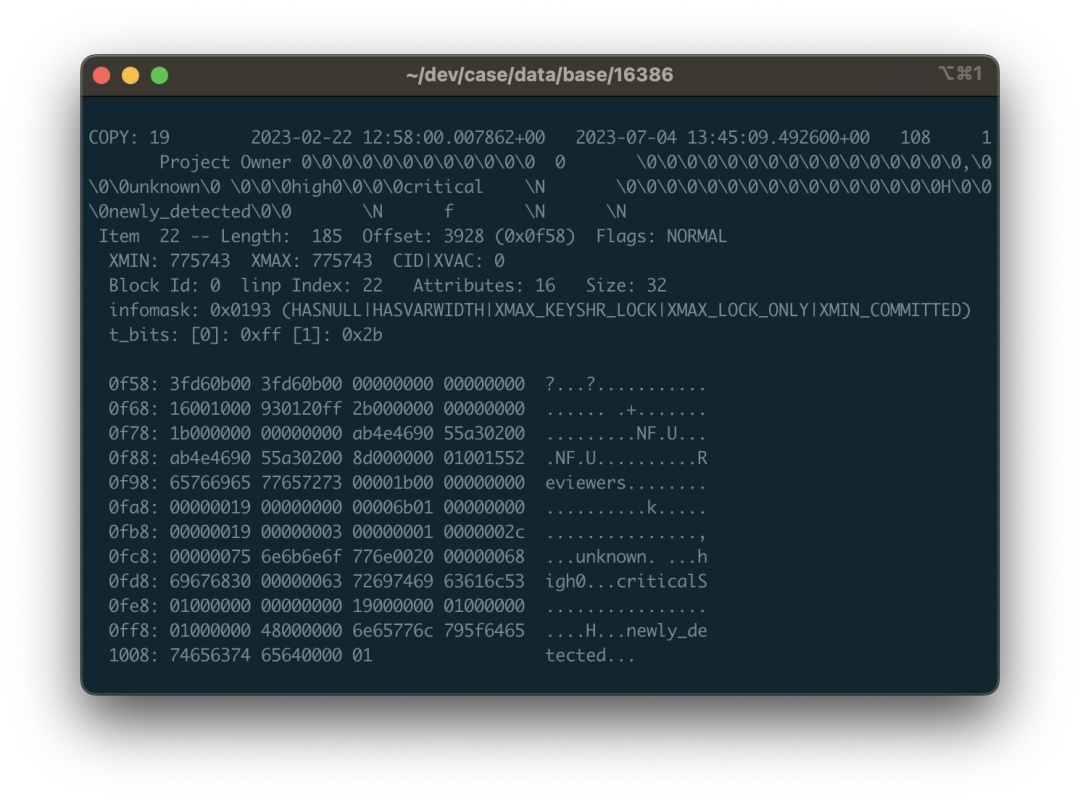
For output, it’s recommended to add the -i and -f options. The former prints metadata for each row (needed to determine if a row has been deleted based on XMAX); the latter prints the original binary data context (necessary for handling complex data that pg_filedump can’t handle).
Normally, each record will start with either COPY: or Error:. The former represents successful extraction, while the latter represents partial success or failure. If it fails, there can be various reasons that need to be handled separately. For successful data, you can take it directly - each line is a piece of data, separated by \t, replace \N with NULL, process it, and save it in a temporary table for later use.
Of course, the devil is in the details. If data recovery were this easy, it wouldn’t be so challenging.
The Devil is in the Details
When handling data recovery, there are many small details to pay attention to. Here are a few important points.
First is TOAST field handling. TOAST stands for “The Oversized-Attribute Storage Technique”. If you find that a parsed field’s content is (TOASTED), it means this field was too long and was sliced and transferred to a dedicated table - the TOAST table.
If a table has fields that might be TOASTed, it will have a corresponding TOAST table, identified by reltoastrelid in pg_class. TOAST can be treated as a regular table, so you can use the same method to parse TOAST data, stitch it back together, and fill it into the original table. We won’t expand on this here.
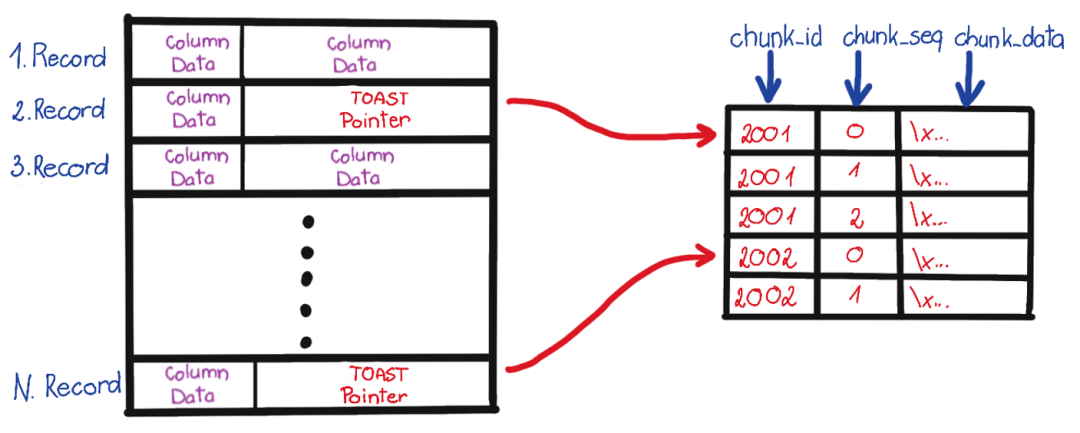
The second issue is complex types. As mentioned in the previous section, pg_filedump’s README lists supported types, but types like arrays require additional binary parsing.
For example, when you dump array binary data, you might see a string of \0\0. This is because pg_filedump directly spits out complex types it can’t handle. This brings additional problems - null values in strings will cause your inserts to fail, so your parsing script needs to handle this. When encountering a complex column that can’t be parsed, you should first mark it and keep the binary value for later processing.
Let’s look at a concrete example: using the public.approval_merge_request_rules table from above. From the dumped data, binary view, and ASCII view, we can see some scattered strings: critical, unknown, etc., mixed in with a string of \0 and binary control characters. Yes, this is the binary representation of a string array. PostgreSQL arrays allow arbitrary type nesting at arbitrary depths, so the data structure here is a bit complex.
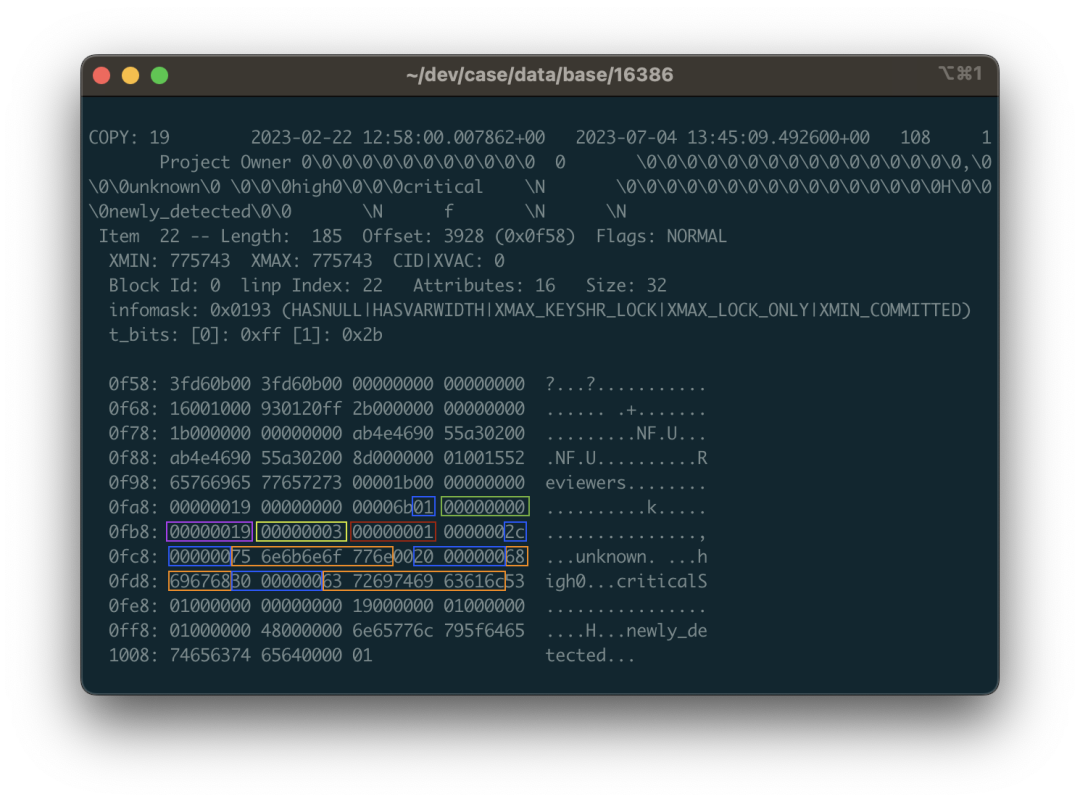
For example, the highlighted area in the image corresponds to data that is an array containing three strings: {unknown,high,critical}::TEXT[]. 01 represents that this is a one-dimensional array, followed by the null bitmap, and the type OID 0x00000019 representing array elements. 0x19 in decimal is 25, corresponding to the text type in pg_type, indicating this is a string array (if it were 0x17, it would be an integer array). Next is the dimension 0x03 for the first dimension of this array, since this array only has one dimension with three elements; the following 1 tells us where the starting offset of the first dimension is. After that are the three string structures: each starts with a 4-byte length (needs to be right-shifted to handle the marker), followed by the string content, with layout alignment and padding to consider.
In summary, you need to dig through the source code implementation, and there are endless details here: variable length, null bitmaps, field compression, out-of-line storage, and endianness. Make one wrong move, and what you extract is just a useless mess.
You can choose to directly parse the original binary from the recorded context using Python scripts, or register new types and callback handler functions in the pg_filedump source code to reuse PG’s provided C parsing functions. Neither approach is particularly easy.
Fortunately, PostgreSQL itself provides some C language helper functions & macros to help you complete most of the work, and luckily, the arrays in Gitlab are all one-dimensional, with types limited to integer arrays and string arrays. Other data pages with complex types can also be reconstructed from other tables, so the overall workload is still manageable.
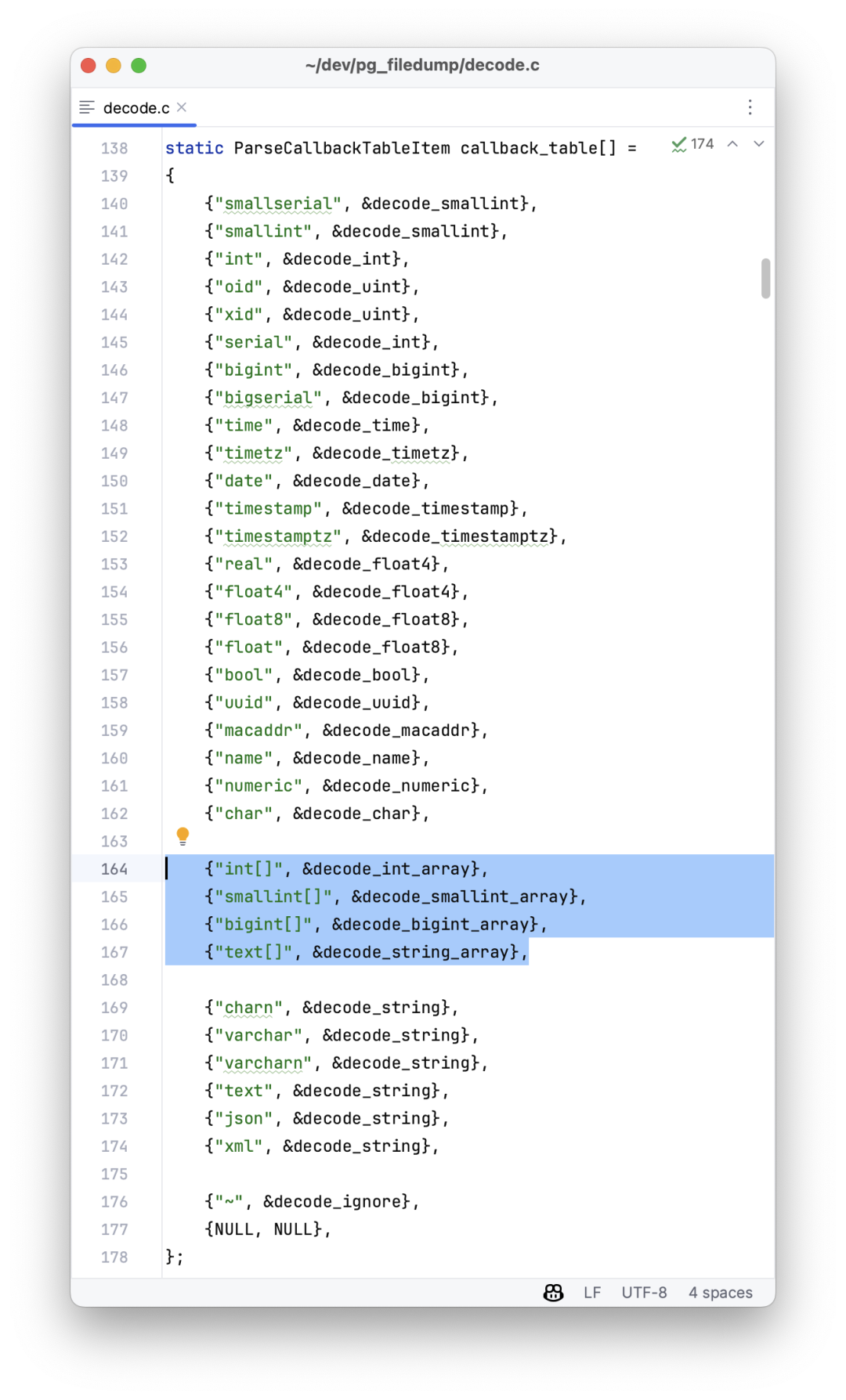
Epilogue
This job took me two days to complete. I won’t go into the dirty details of the process - I doubt readers would be interested. After a series of processing, correction, and verification, the data recovery work was finally completed! Except for a few corrupted records in a few tables, all other data was successfully extracted. Wow, a full thousand tables!
I’ve done some data recovery work before, and most cases were relatively simple: data block corruption, control file/CLOG damage, or ransomware infection (writing a few garbage files to the Tablespace). But this is the first time I’ve encountered a case that was so thoroughly wrecked. The reason I dared to take this job was that I have some understanding of the PG kernel and know these tedious implementation details. As long as you know it’s an engineering problem that can be solved, you won’t worry about not being able to complete it, no matter how dirty or tiring the process is.
Despite some shortcomings, pg_filedump is still a good tool. I might consider improving it later to provide complete support for various data types, so we don’t have to write a bunch of Python scripts to handle various tedious details. After completing this case, I’ve already packaged pg_filedump for PG 12-16 x EL 7-9 and placed it in Pigsty’s Yum repository, included by default in Pigsty’s offline software package. It’s now implemented in Pigsty v2.4.1. I sincerely hope you never need to use this extension, but if you ever find yourself in a situation where you do, I hope it’s right there at your fingertips, ready to use out of the box.
Finally, I want to say one thing: Many software applications need databases, but database installation, deployment, and maintenance are high-threshold tasks. The PostgreSQL instance that Gitlab spins up is already quite good quality, but it’s still helpless in this situation, let alone those crude single-instance Docker images made by hand. One major failure can wipe out a company’s accumulated code, data, CI/CD processes, and Issue/PR/MR records. I really suggest you carefully review your database system and at least make regular backups!
The core difference between Gitlab’s Enterprise and Community editions lies in whether the underlying PG has high availability and monitoring. And Pigsty - the out-of-the-box PostgreSQL distribution can better solve these problems for you, completely open source and free, charging nothing: whether it’s high availability, PITR, or monitoring systems, everything is included. Next time you encounter such a problem, you can automatically switch/roll back with one click, handling it much more gracefully. We previously ran our own Gitlab, Jira, Confluence, and other software on it. If you have similar needs, why not give it a try?
Collation in PostgreSQL
Why does Pigsty default to locale=C and encoding=UTF8 when initializing PostgreSQL databases?
The answer is simple: Unless you explicitly need LOCALE-specific features, you should never configure anything other than C.UTF8 for character encoding and collation settings.
I’ve previously written about character encoding, so let’s focus on LOCALE configuration today.
While there might be some justification for using non-UTF8 character encoding on the server side, using any LOCALE other than C is unforgivable. In PostgreSQL, LOCALE isn’t just about trivial things like date and currency display formats - it affects critical functionality.
Incorrect LOCALE configuration can lead to performance degradation of several to dozens of times, and prevents LIKE queries from using regular indexes. Meanwhile, setting LOCALE=C doesn’t affect scenarios that genuinely need localization rules. As the official documentation states: “Use LOCALE only if you really need it.”
Unfortunately, PostgreSQL’s default locale and encoding settings depend on the operating system configuration, so C.UTF8 might not be the default. This leads many users to unknowingly misuse LOCALE, suffering significant performance penalties and missing out on certain database features.

TL;DR
- Always use
UTF8character encoding andCcollation rules. - Using non-C collation rules can increase string comparison operation overhead by several to dozens of times, significantly impacting performance.
- Using non-C collation rules prevents
LIKEqueries from using regular indexes, creating potential pitfalls. - For instances using non-C collation rules, you can create indexes using
text_ops COLLATE "C"ortext_pattern_opsto supportLIKEqueries.
What is LOCALE?
We often see LOCALE (locale) settings in operating systems and various software, but what exactly is it?
LOCALE support refers to applications adhering to cultural preferences, including alphabets, sorting, number formats, etc. A LOCALE consists of many rules and definitions:
LC_COLLATE |
String sorting order |
|---|---|
LC_CTYPE |
Character classification (What is a character? Is its uppercase form equivalent?) |
LC_MESSAGES |
Language of messages |
LC_MONETARY |
Currency format |
LC_NUMERIC |
Number format |
LC_TIME |
Date and time format |
| …… | Others…… |
A LOCALE is a set of rules, typically named using a language code + country code. For example, the LOCALE zh_CN used in mainland China has two parts: zh is the language code, and CN is the country code. In the real world, one language might be used in multiple countries, and one country might have multiple languages. Taking Chinese and China as an example:
China (COUNTRY=CN) related language LOCALEs:
zh: Chinese:zh_CNbo: Tibetan:bo_CNug: Uyghur:ug_CN
Chinese-speaking (LANG=zh) countries or regions:
CNChina:zh_CNHKHong Kong:zh_HKMOMacau:zh_MOTWTaiwan:zh_TWSGSingapore:zh_SG
A LOCALE Example
Let’s look at a typical Locale definition file: Glibc’s zh_CN
Here’s a small excerpt that shows various format definitions - how months and weeks are named, how currency and decimal points are displayed, etc.
But there’s one crucial element here: LC_COLLATE, the sorting method (Collation), which significantly impacts database behavior.
LC_CTYPE
copy "i18n"
translit_start
include "translit_combining";""
translit_end
class "hanzi"; /
<U4E00>..<U9FA5>;/
<UF92C>;<UF979>;<UF995>;<UF9E7>;<UF9F1>;<UFA0C>;<UFA0D>;<UFA0E>;/
<UFA0F>;<UFA11>;<UFA13>;<UFA14>;<UFA18>;<UFA1F>;<UFA20>;<UFA21>;/
<UFA23>;<UFA24>;<UFA27>;<UFA28>;<UFA29>
END LC_CTYPE
LC_COLLATE
copy "iso14651_t1_pinyin"
END LC_COLLATE
LC_TIME
% January, February, March, April, May, June, July, August, September, October, November, December
mon "<U4E00><U6708>";/
"<U4E8C><U6708>";/
"<U4E09><U6708>";/
"<U56DB><U6708>";/
...
% Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday
day "<U661F><U671F><U65E5>";/
"<U661F><U671F><U4E00>";/
"<U661F><U671F><U4E8C>";/
...
week 7;19971130;1
first_weekday 2
% %Y年%m月%d日 %A %H时%M分%S秒
d_t_fmt "%Y<U5E74>%m<U6708>%d<U65E5> %A %H<U65F6>%M<U5206>%S<U79D2>"
% %Y年%m月%d日
d_fmt "%Y<U5E74>%m<U6708>%d<U65E5>"
% %H时%M分%S秒
t_fmt "%H<U65F6>%M<U5206>%S<U79D2>"
% AM, PM
am_pm "<U4E0A><U5348>";"<U4E0B><U5348>"
% %p %I时%M分%S秒
t_fmt_ampm "%p %I<U65F6>%M<U5206>%S<U79D2>"
% %Y年 %m月 %d日 %A %H:%M:%S %Z
date_fmt "%Y<U5E74> %m<U6708> %d<U65E5> %A %H:%M:%S %Z"
END LC_TIME
LC_NUMERIC
decimal_point "."
thousands_sep ","
grouping 3
END LC_NUMERIC
LC_MONETARY
% ¥
currency_symbol "<UFFE5>"
int_curr_symbol "CNY "
For example, zh_CN provides LC_COLLATE using the iso14651_t1_pinyin collation rule, which is a pinyin-based sorting rule.
Let’s demonstrate how LOCALE’s COLLATION affects PostgreSQL behavior with an example.
Collation Example
Create a table containing 7 Chinese characters and perform sorting operations.
CREATE TABLE some_chinese(
name TEXT PRIMARY KEY
);
INSERT INTO some_chinese VALUES
('阿'),('波'),('磁'),('得'),('饿'),('佛'),('割');
SELECT * FROM some_chinese ORDER BY name;
Execute the following SQL to sort the records using the default C collation rule. Here, we can see that it’s actually sorting based on the ascii|unicode code points.
vonng=# SELECT name, ascii(name) FROM some_chinese ORDER BY name COLLATE "C";
name | ascii
------+-------
佛 | 20315
割 | 21106
得 | 24471
波 | 27874
磁 | 30913
阿 | 38463
饿 | 39295
But this code-point-based sorting might be meaningless for Chinese users. For example, a Chinese dictionary wouldn’t use this sorting method. Instead, it would use the pinyin sorting rule used by zh_CN, sorting by pinyin. Like this:
SELECT * FROM some_chinese ORDER BY name COLLATE "zh_CN";
name
------
阿
波
磁
得
饿
佛
割
We can see that sorting with the zh_CN collation rule produces results in pinyin order abcdefg, rather than the meaningless Unicode code point order.
Of course, this query result depends on the specific definition of the zh_CN collation rule. Such collation rules aren’t defined by the database itself - the database only provides the C collation (or its alias POSIX). COLLATIONs typically come from either the operating system, glibc, or third-party localization libraries (like icu), so different actual definitions might produce different effects.
But at what cost?
The biggest negative impact of using non-C or non-POSIX LOCALE in PostgreSQL is:
Specific collation rules have a huge performance impact on operations involving string comparisons, and they also prevent LIKE queries from using regular indexes.
Additionally, the C LOCALE is guaranteed by the database itself to work on any operating system and platform, while other LOCALEs aren’t, making non-C Locale less portable.
Performance Impact
Let’s consider an example using LOCALE collation rules. We have 1.5 million Apple Store app names and want to sort them according to different regional rules.
-- Create a table of app names, containing both Chinese and English
CREATE TABLE app(
name TEXT PRIMARY KEY
);
COPY app FROM '/tmp/app.csv';
-- View table statistics
SELECT
correlation, -- correlation coefficient 0.03542578, basically random distribution
avg_width, -- average length 25 bytes
n_distinct -- -1, meaning 1,508,076 records with no duplicates
FROM pg_stats WHERE tablename = 'app';
-- Run a series of experiments with different collation rules
SELECT * FROM app;
SELECT * FROM app order by name;
SELECT * FROM app order by name COLLATE "C";
SELECT * FROM app order by name COLLATE "en_US";
SELECT * FROM app order by name COLLATE "zh_CN";
The results are quite shocking - using C and zh_CN can differ by ten times:
| # | Scenario | Time(ms) | Notes |
|---|---|---|---|
| 1 | No sort | 180 | Uses index |
| 2 | order by name |
969 | Uses index |
| 3 | order by name COLLATE "C" |
1430 | Sequential scan, external sort |
| 4 | order by name COLLATE "en_US" |
10463 | Sequential scan, external sort |
| 5 | order by name COLLATE "zh_CN" |
14852 | Sequential scan, external sort |
Here’s the detailed execution plan for experiment 5. Even with sufficient memory configured, it still spills to disk for external sorting. However, all experiments with explicit LOCALE specification showed this behavior, allowing us to compare the performance difference between C and zh_CN.
Another more comparative example is comparison operations.
Here, all strings in the table are compared with 'World', equivalent to performing 1.5 million specific rule comparisons on the table, without even involving disk I/O.
SELECT count(*) FROM app WHERE name > 'World';
SELECT count(*) FROM app WHERE name > 'World' COLLATE "C";
SELECT count(*) FROM app WHERE name > 'World' COLLATE "en_US";
SELECT count(*) FROM app WHERE name > 'World' COLLATE "zh_CN";
Even so, compared to C LOCALE, zh_CN still takes nearly 3 times longer.
| # | Scenario | Time(ms) |
|---|---|---|
| 1 | Default | 120 |
| 2 | C | 145 |
| 3 | en_US | 351 |
| 4 | zh_CN | 441 |
If sorting might be O(n²) comparisons with 10x overhead, then the 3x overhead for O(n) comparisons here roughly matches. We can draw a preliminary conclusion:
Compared to C Locale, using zh_CN or other Locales can cause several times additional performance overhead.
Besides performance issues, incorrect Locale can also lead to functional limitations.
Functional Limitations
Besides poor performance, another unacceptable issue is that using non-C LOCALE prevents LIKE queries from using regular indexes.
Let’s use our previous experiment as an example. We’ll execute the following query on database instances using C and en_US as default LOCALE:
SELECT * FROM app WHERE name LIKE '中国%';
Find all apps starting with “中国” (China).
On a C-based database
This query can normally use the app_pkey index, leveraging the ordered nature of the primary key B-tree to speed up the query, completing in about 2 milliseconds.
postgres@meta:5432/meta=# show lc_collate;
C
postgres@meta:5432/meta=# EXPLAIN SELECT * FROM app WHERE name LIKE '中国%';
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using app_pkey on app (cost=0.43..2.65 rows=1510 width=25)
Index Cond: ((name >= '中国'::text) AND (name < '中图'::text))
Filter: (name ~~ '中国%'::text)
(3 rows)
On an en_US-based database
We find that this query cannot use the index, performing a full table scan. The query degrades to 70 milliseconds, 30-40 times worse performance.
vonng=# show lc_collate;
en_US.UTF-8
vonng=# EXPLAIN SELECT * FROM app WHERE name LIKE '中国%';
QUERY PLAN
----------------------------------------------------------
Seq Scan on app (cost=0.00..29454.95 rows=151 width=25)
Filter: (name ~~ '中国%'::text)
Why?
Because index (B-tree index) construction is also based on ordering, which means equality and comparison operations.
However, LOCALE has its own set of rules for string equivalence. For example, the Unicode standard defines many counterintuitive equivalence rules (after all, it’s a universal language standard - like multiple characters combining to form a string equivalent to another single character, details in the Modern Character Encoding article).
Therefore, only the simplest C LOCALE can perform pattern matching normally. The C LOCALE’s comparison rules are very simple - just compare character code points one by one, without any fancy tricks. So, if your database unfortunately uses a non-C LOCALE, then LIKE queries cannot use default indexes.
Solution
For non-C LOCALE instances, only special types of indexes can support such queries:
CREATE INDEX ON app(name COLLATE "C");
CREATE INDEX ON app(name text_pattern_ops);
Here, using the text_pattern_ops operator family to create an index can also support LIKE queries. This is a special operator family for pattern matching that ignores LOCALE and directly performs pattern matching based on character-by-character comparison, which is the C LOCALE way.
Therefore, in this case, only indexes built on the text_pattern_ops operator family, or indexes using COLLATE "C"' on the default text_ops, can support LIKE queries.
vonng=# EXPLAIN ANALYZE SELECT * FROM app WHERE name LIKE '中国%';
Index Only Scan using app_name_idx on app (cost=0.43..1.45 rows=151 width=25) (actual time=0.053..0.731 rows=2360 loops=1)
Index Cond: ((name ~>=~ '中国'::text) AND (name ~<~ '中图'::text))
Filter: (name ~~ '中国%'::text COLLATE "en_US.UTF-8")
After creating the index, we can see that the original LIKE query can use the index.
The issue of LIKE not being able to use regular indexes might seem solvable by creating an additional text_pattern_ops index. But this means that what could have been solved directly using the existing PRIMARY KEY or UNIQUE constraint’s built-in index now requires additional maintenance costs and storage space.
For developers unfamiliar with this issue, they might encounter performance issues in production because queries aren’t using indexes (e.g., if development uses C but production uses non-C LOCALE).
Compatibility
Suppose you’ve inherited a database already using non-C LOCALE (this is quite common), and now that you know the dangers of using non-C LOCALE, you decide to change it back.
What should you watch out for? Specifically, Locale configuration affects the following PostgreSQL features:
- Queries using
LIKEclauses. - Any queries relying on specific LOCALE collation rules, e.g., using pinyin sorting as result ordering.
- Queries using case conversion related functions:
upper,lower, andinitcap. - The
to_charfunction family, when formatting to local time. - Case-insensitive matching in regular expressions (
SIMILAR TO,~).
So, for any queries involving case conversion, always “explicitly specify Collation!”
If unsure, you can list all queries involving the following keywords using pg_stat_statements for manual review:
LIKE|ILIKE -- Using pattern matching?
SIMILAR TO | ~ | regexp_xxx -- Using i option?
upper, lower, initcap -- Using for languages with case (Western characters)?
ORDER BY col -- When sorting by text columns, relying on specific collation? (e.g., pinyin)
Compatibility Modifications
Generally, C LOCALE is a superset of other LOCALE configurations in terms of functionality, and you can always switch from other LOCALEs to C. If your business doesn’t use these features, you usually don’t need to do anything. If you use localization features, you can always achieve the same effect in C LOCALE by explicitly specifying COLLATE.
SELECT upper('a' COLLATE "zh_CN"); -- Perform case conversion based on zh_CN rules
SELECT '阿' < '波'; -- false, under default collation 阿(38463) > 波(27874)
SELECT '阿' < '波' COLLATE "zh_CN"; -- true, explicitly using Chinese pinyin collation: 阿(a) < 波(bo)
However, please note that collations provided by glibc - like “zh_CN” - aren’t necessarily stable. The PostgreSQL community’s recommended best practice is to use C or POSIX as the default collation.
Then use ICU as the collation provider, for example:
SELECT '阿' < '波' COLLATE "zh-x-icu"; -- true, explicitly using Chinese pinyin collation: 阿(a) < 波(bo)
- zh-x-icu: Roughly represents “Generic Chinese (unspecified simplified/traditional)”, using ICU rules.
- zh-Hans-x-icu: Represents Simplified Chinese (Hans = Han Simplified), ICU rules.
- zh-Hans-CN-x-icu: Simplified Chinese (Mainland China)
- zh-Hans-HK-x-icu: Simplified Chinese (Hong Kong)
- zh-Hant-x-icu: Represents Traditional Chinese (Hant = Han Traditional)
Overriding CTYPE
You can override CTYPE when performing case conversions:
SELECT
'é' AS original,
UPPER('é') AS upper_default, -- Using default Locale
UPPER('é' COLLATE "C") AS upper_en_c, -- C Locale doesn't handle these characters 'é'
UPPER('é' COLLATE PG_C_UTF8) AS upper_en_cutf8, -- C.UTF8 handles some case issues É
UPPER('é' COLLATE "en_US.UTF-8") AS upper_en_us; -- en_US.UTF8 converts to uppercase É
oid | collname | collnamespace | collowner | collprovider | collisdeterministic | collencoding | collcollate | collctype | colllocale | collicurules | collversion
-------+------------------+---------------+-----------+--------------+---------------------+--------------+--------------+--------------+------------+--------------+-------------
12888 | lzh_TW | 11 | 10 | c | t | 6 | lzh_TW | lzh_TW | NULL | NULL | 2.28
12889 | lzh_TW.utf8 | 11 | 10 | c | t | 6 | lzh_TW.utf8 | lzh_TW.utf8 | NULL | NULL | 2.28
13187 | zh_CN | 11 | 10 | c | t | 2 | zh_CN | zh_CN | NULL | NULL | 2.28
13188 | zh_CN.gb2312 | 11 | 10 | c | t | 2 | zh_CN.gb2312 | zh_CN.gb2312 | NULL | NULL | 2.28
13189 | zh_CN.utf8 | 11 | 10 | c | t | 6 | zh_CN.utf8 | zh_CN.utf8 | NULL | NULL | 2.28
13190 | zh_HK.utf8 | 11 | 10 | c | t | 6 | zh_HK.utf8 | zh_HK.utf8 | NULL | NULL | 2.28
13191 | zh_SG | 11 | 10 | c | t | 2 | zh_SG | zh_SG | NULL | NULL | 2.28
13192 | zh_SG.gb2312 | 11 | 10 | c | t | 2 | zh_SG.gb2312 | zh_SG.gb2312 | NULL | NULL | 2.28
13193 | zh_SG.utf8 | 11 | 10 | c | t | 6 | zh_SG.utf8 | zh_SG.utf8 | NULL | NULL | 2.28
13194 | zh_TW.euctw | 11 | 10 | c | t | 4 | zh_TW.euctw | zh_TW.euctw | NULL | NULL | 2.28
13195 | zh_TW.utf8 | 11 | 10 | c | t | 6 | zh_TW.utf8 | zh_TW.utf8 | NULL | NULL | 2.28
13349 | zh_CN | 11 | 10 | c | t | 6 | zh_CN.utf8 | zh_CN.utf8 | NULL | NULL | 2.28
13350 | zh_HK | 11 | 10 | c | t | 6 | zh_HK.utf8 | zh_HK.utf8 | NULL | NULL | 2.28
13351 | zh_SG | 11 | 10 | c | t | 6 | zh_SG.utf8 | zh_SG.utf8 | NULL | NULL | 2.28
13352 | zh_TW | 11 | 10 | c | t | 4 | zh_TW.euctw | zh_TW.euctw | NULL | NULL | 2.28
13353 | zh_TW | 11 | 10 | c | t | 6 | zh_TW.utf8 | zh_TW.utf8 | NULL | NULL | 2.28
14066 | zh-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh | NULL | 153.80.32.1
14067 | zh-Hans-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans | NULL | 153.80.32.1
14068 | zh-Hans-CN-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-CN | NULL | 153.80.32.1
14069 | zh-Hans-HK-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-HK | NULL | 153.80.32.1
14070 | zh-Hans-MO-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-MO | NULL | 153.80.32.1
14071 | zh-Hans-SG-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-SG | NULL | 153.80.32.1
14072 | zh-Hant-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant | NULL | 153.80.32.1
14073 | zh-Hant-HK-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant-HK | NULL | 153.80.32.1
14074 | zh-Hant-MO-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant-MO | NULL | 153.80.32.1
14075 | zh-Hant-TW-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant-TW | NULL | 153.80.32.1
The only known issue currently appears in the pg_trgm extension.
https://www.pgevents.ca/events/pgconfdev2024/sessions/session/95/slides/26/pgcon24_collation.pdf
PostgreSQL Replica Identity Explained
Introduction: DIY Logical Replication
The concept of Replica Identity serves logical replication.
Logical replication fundamentally works by decoding row-level changes (INSERT/UPDATE/DELETE) on published tables and applying them to subscribers.
The mechanism somewhat resembles row-level triggers, where changes are processed row by row after transaction completion.
Suppose you need to implement logical replication manually using triggers, copying changes from table A to table B. The trigger function would typically look like this:
-- Notification trigger
CREATE OR REPLACE FUNCTION replicate_change() RETURNS TRIGGER AS $$
BEGIN
IF (TG_OP = 'INSERT') THEN
-- INSERT INTO tbl_b VALUES (NEW.col);
ELSIF (TG_OP = 'DELETE') THEN
-- DELETE tbl_b WHERE id = OLD.id;
ELSIF (TG_OP = 'UPDATE') THEN
-- UPDATE tbl_b SET col = NEW.col,... WHERE id = OLD.id;
END IF;
END; $$ LANGUAGE plpgsql;
The trigger provides two variables: OLD and NEW, containing the record’s previous and new values respectively.
INSERToperations only have theNEWvariable - we simply insert it into the target table.DELETEoperations only have theOLDvariable - we delete the record by ID from the target table.UPDATEoperations have bothOLDandNEWvariables - we locate the record in table B usingOLD.idand update it withNEWvalues.
This trigger-based “logical replication” achieves our goal. Similarly, in logical replication, when table A has a primary key column id, deleting a record (e.g., id = 1) only requires sending id = 1 to the subscriber, not the entire deleted tuple. Here, the primary key column id serves as the replica identity.
However, this example assumes that tables A and B have identical schemas with a primary key named id.
For a production-grade logical replication solution (PostgreSQL 10.0+), this assumption is unreasonable. The system cannot require users to always have primary keys or to name them id.
Thus, the concept of Replica Identity was introduced. Replica Identity generalizes and abstracts the OLD.id assumption, telling the logical replication system which information can uniquely identify a record.
Replica Identity
For logical replication, INSERT events don’t require special handling, but DELETE|UPDATE operations must provide a way to identify rows - the Replica Identity. A replica identity is a set of columns that can uniquely identify a record. Conceptually, this is similar to a primary key column set, though columns from non-null unique indexes (candidate keys) can serve the same purpose.
A table included in a logical replication publication must have a Replica Identity configured. This allows the subscriber to locate and update the correct rows for UPDATE and DELETE operations. By default, primary keys and non-null unique indexes can serve as replica identities.
Note that Replica Identity is distinct from a table’s primary key or non-null unique indexes. Replica Identity is a table property that specifies which information is used as an identifier in logical replication records for subscriber-side record location and change application.
As described in the PostgreSQL 13 official documentation, there are four configuration modes for table Replica Identity:
- Default mode: The standard mode for non-system tables. Uses primary key columns if available, otherwise falls back to full mode.
- Index mode: Uses columns from a specific qualified index as the identity
- Full mode: Uses all columns in the record as the replica identity (similar to all columns collectively forming a primary key)
- Nothing mode: Records no replica identity, meaning
UPDATE|DELETEoperations cannot be replicated to subscribers.
Querying Replica Identity
A table’s Replica Identity can be checked via pg_class.relreplident.
This is a character-type “enum” indicating which columns are used to assemble the “replica identity”: d = default, f = all columns, i = specific index, n = no replica identity.
To check if a table has usable replica identity index constraints:
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name, con.ri AS keys,
CASE relreplident WHEN 'd' THEN 'default' WHEN 'n' THEN 'nothing' WHEN 'f' THEN 'full' WHEN 'i' THEN 'index' END AS replica_identity
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid, LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
ORDER BY 2,3;
Configuring Replica Identity
Table replica identity can be modified using ALTER TABLE:
ALTER TABLE tbl REPLICA IDENTITY { DEFAULT | USING INDEX index_name | FULL | NOTHING };
-- Four specific forms
ALTER TABLE t_normal REPLICA IDENTITY DEFAULT; -- Use primary key, or FULL if none exists
ALTER TABLE t_normal REPLICA IDENTITY FULL; -- Use entire row as identity
ALTER TABLE t_normal REPLICA IDENTITY USING INDEX t_normal_v_key; -- Use unique index
ALTER TABLE t_normal REPLICA IDENTITY NOTHING; -- No replica identity
Replica Identity Examples
Let’s demonstrate replica identity effects with a concrete example:
CREATE TABLE test(k text primary key, v int not null unique);
We have a table test with two columns k and v.
INSERT INTO test VALUES('Alice', '1'), ('Bob', '2');
UPDATE test SET v = '3' WHERE k = 'Alice'; -- update Alice value to 3
UPDATE test SET k = 'Oscar' WHERE k = 'Bob'; -- rename Bob to Oscar
DELETE FROM test WHERE k = 'Alice'; -- delete Alice
The corresponding logical decoding results:
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: old-key: k[text]:'Bob' new-tuple: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: k[text]:'Alice'
By default, PostgreSQL uses the table’s primary key as the replica identity, so UPDATE|DELETE operations locate records using the k column.
We can manually change the replica identity to use the non-null unique column v:
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key; -- Replica identity based on UNIQUE index
The same changes now produce these logical decoding results, with v appearing as the identity in all UPDATE|DELETE events:
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: old-key: v[integer]:1 new-tuple: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: v[integer]:3
Using full identity mode:
ALTER TABLE test REPLICA IDENTITY FULL; -- Table test now uses all columns as replica identity
Here, both k and v serve as identity identifiers in UPDATE|DELETE logs. This is a fallback option for tables without primary keys.
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: old-key: k[text]:'Alice' v[integer]:1 new-tuple: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: old-key: k[text]:'Bob' v[integer]:2 new-tuple: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: k[text]:'Alice' v[integer]:3
Using nothing mode:
ALTER TABLE test REPLICA IDENTITY NOTHING; -- Table test now has no replica identity
The logical decoding records show UPDATE operations with only new records (no unique identity from old records), and DELETE operations with no information at all:
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: (no-tuple-data)
Such logical change logs are useless for subscribers. In practice, DELETE|UPDATE operations on tables without replica identity in logical replication will fail immediately.
Replica Identity Details
Table replica identity configuration and table indexes are relatively orthogonal factors.
While various combinations are possible, only three scenarios are practical in real-world usage:
- Table has a primary key, using default
defaultreplica identity - Table has no primary key but has non-null unique indexes, explicitly configured with
indexreplica identity - Table has neither primary key nor non-null unique indexes, explicitly configured with
fullreplica identity (very inefficient, only as a fallback) - All other scenarios cannot properly support logical replication functionality
| Replica Identity Mode\Table Constraints | Primary Key(p) | Non-null Unique Index(u) | Neither(n) |
|---|---|---|---|
| default | valid | x | x |
| index | x | valid | x |
| full | ineff | ineff | ineff |
| nothing | x | x | x |
Let’s examine some edge cases.
Rebuilding Primary Keys
Suppose we want to rebuild a table’s primary key index to reclaim space due to index bloat:
CREATE TABLE test(k text primary key, v int);
CREATE UNIQUE INDEX test_pkey2 ON test(k);
BEGIN;
ALTER TABLE test DROP CONSTRAINT test_pkey;
ALTER TABLE test ADD PRIMARY KEY USING INDEX test_pkey2;
COMMIT;
In default mode, rebuilding and replacing the primary key constraint and index does not affect the replica identity.
Rebuilding Unique Indexes
Suppose we want to rebuild a non-null unique index to reclaim space:
CREATE TABLE test(k text, v int not null unique);
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key;
CREATE UNIQUE INDEX test_v_key2 ON test(v);
-- Replace old Unique index with new test_v_key2 index
BEGIN;
ALTER TABLE test ADD UNIQUE USING INDEX test_v_key2;
ALTER TABLE test DROP CONSTRAINT test_v_key;
COMMIT;
Unlike default mode, in index mode, replica identity is bound to the specific index:
Table "public.test"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
k | text | | | | extended | |
v | integer | | not null | | plain | |
Indexes:
"test_v_key" UNIQUE CONSTRAINT, btree (v) REPLICA IDENTITY
"test_v_key2" UNIQUE CONSTRAINT, btree (v)
This means that replacing a UNIQUE index through substitution will cause replica identity loss.
There are two solutions:
- Use
REINDEX INDEX (CONCURRENTLY)to rebuild the index without losing replica identity information. - Refresh the table’s default replica identity when replacing the index:
BEGIN;
ALTER TABLE test ADD UNIQUE USING INDEX test_v_key2;
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key2;
ALTER TABLE test DROP CONSTRAINT test_v_key;
COMMIT;
Note: Removing an index used as an identity. Even though the table configuration still shows index mode, the effect is the same as nothing. So don’t casually modify identity indexes.
Using Unqualified Indexes as Replica Identity
A replica identity requires a unique, non-deferrable, table-wide index on non-nullable columns.
The classic examples are primary key indexes and single-column non-null indexes declared via col type NOT NULL UNIQUE.
The NOT NULL requirement exists because NULL values cannot be compared for equality. A table can have multiple records with NULL values in a UNIQUE column, so nullable columns cannot uniquely identify records. Attempting to use a regular UNIQUE index (without non-null constraints) as a replica identity will fail:
[42809] ERROR: index "t_normal_v_key" cannot be used as replica identity because column "v" is nullable
Using FULL Replica Identity
If no replica identity exists, you can set it to FULL, using the entire row as the replica identity.
Using FULL mode replica identity is inefficient, so this configuration should only be used as a fallback or for very small tables. Each row modification requires a full table scan on the subscriber, which can easily overwhelm the subscriber.
FULL Mode Limitations
Using FULL mode replica identity has another limitation: the subscriber’s table replica identity columns must either match the publisher’s or be fewer in number. Otherwise, correctness cannot be guaranteed. Consider this example:
If both publisher and subscriber tables use FULL replica identity, but the subscriber’s table has an extra column (yes, logical replication allows subscriber tables to have columns not present in the publisher), then the subscriber’s table replica identity includes more columns than the publisher’s. If the publisher deletes a record (f1=a, f2=a), this could delete two records on the subscriber that match the identity equality condition.
(Publication) ------> (Subscription)
|--- f1 ---|--- f2 ---| |--- f1 ---|--- f2 ---|--- f3 ---|
| a | a | | a | a | b |
| a | a | c |
How FULL Mode Handles Duplicate Rows
PostgreSQL’s logical replication can “correctly” handle scenarios with identical rows in FULL mode. Consider this poorly designed table with multiple identical records:
CREATE TABLE shitty_table(
f1 TEXT,
f2 TEXT,
f3 TEXT
);
INSERT INTO shitty_table VALUES ('a', 'a', 'a'), ('a', 'a', 'a'), ('a', 'a', 'a');
In FULL mode, the entire row serves as the replica identity. Suppose we cheat using ctid scanning to delete one of the three identical records:
# SELECT ctid,* FROM shitty_table;
ctid | a | b | c
-------+---+---+---
(0,1) | a | a | a
(0,2) | a | a | a
(0,3) | a | a | a
# DELETE FROM shitty_table WHERE ctid = '(0,1)';
DELETE 1
# SELECT ctid,* FROM shitty_table;
ctid | a | b | c
-------+---+---+---
(0,2) | a | a | a
(0,3) | a | a | a
Logically, using the entire row as an identity, the subscriber would execute:
DELETE FROM shitty_table WHERE f1 = 'a' AND f2 = 'a' AND f3 = 'a'
This would appear to delete all three records. However, because PostgreSQL’s change records operate at the row level, this change only affects the first matching record. Thus, the subscriber’s behavior is to delete one of the three rows, maintaining logical equivalence with the publisher.
Slow Query Diagnosis
You can’t optimize what you can’t measure
Slow queries are the arch-enemy of online business databases. Knowing how to diagnose and locate slow queries is an essential skill for DBAs.
This article introduces a general methodology for diagnosing slow queries using Pigsty, a monitoring system.
The Impact of Slow Queries
For PostgreSQL databases serving online business transactions, slow queries can cause several problems:
- Slow queries consume database connections, leaving no connections available for normal queries, leading to query pileup and potential database meltdown.
- Slow queries can lock old tuple versions that have been cleaned up on the primary, causing replication replay processes to stall and leading to replication lag.
- The slower the query, the higher the chance of deadlocks, lock waits, and transaction conflicts.
- Slow queries waste system resources and increase system load.
Therefore, a competent DBA must know how to quickly identify and address slow queries.
Figure: After optimizing a slow query, system saturation dropped from 40% to 4%
Traditional Methods for Slow Query Diagnosis
Traditionally, there are two ways to obtain information about slow queries in PostgreSQL: the official extension pg_stat_statements and slow query logs.
Slow query logs, as the name suggests, record all queries that take longer than the log_min_duration_statement parameter. They are indispensable for analyzing specific cases and one-off slow queries. However, slow query logs have limitations. In production environments, for performance reasons, we typically only log queries exceeding a certain threshold, which means we miss out on a lot of information. That said, despite the overhead, full query logging remains the ultimate weapon for slow query analysis.
The more commonly used tool for slow query diagnosis is pg_stat_statements. This is an extremely useful extension that collects statistical information about queries running in the database. It’s strongly recommended to enable this extension in all scenarios.
pg_stat_statements provides raw metrics in the form of a system view. Each query type (queries with the same execution plan after variable extraction) is assigned a query ID, followed by metrics like call count, total time, max/min/average execution time, standard deviation of response time, average rows returned per call, and time spent on block I/O.
A simple approach is to look at metrics like mean_time/max_time. From the system catalog, you can indeed see the historical average response time for a query type. For identifying slow queries, this might be sufficient. However, these metrics are just a static snapshot of the system at the current moment, so they can only answer limited questions. For example, if you want to see whether a query’s performance has improved after adding a new index, this approach would be cumbersome.
pg_stat_statements needs to be specified in shared_preload_library and explicitly created in the database using CREATE EXTENSION pg_stat_statements. After creating the extension, you can access query statistics through the pg_stat_statements view.
Defining Slow Queries
How slow is too slow?
This depends on the business and the actual query type - there’s no universal standard.
As a rule of thumb:
- For frequent CRUD point queries, anything over 1ms can be considered slow.
- For occasional one-off queries, typically anything over 100ms or 1s can be considered slow.
Slow Query Diagnosis with Pigsty
A monitoring system can provide more comprehensive answers about slow queries. The data in a monitoring system consists of countless historical snapshots (e.g., sampled every 5 seconds). This allows users to look back at any point in time and examine changes in average query response times across different periods.

The above image shows the interface provided by Pigsty’s PG Query Detail, displaying detailed information about a single query.
This is a typical slow query with an average response time of several seconds. After adding an index, as shown in the Query RT dashboard on the right, the query’s average response time dropped from seconds to milliseconds.
Users can leverage the insights provided by the monitoring system to quickly locate slow queries in the database, identify problems, and formulate hypotheses. More importantly, users can immediately examine detailed metrics at different levels for tables and queries, apply solutions, and get real-time feedback, which is extremely helpful for emergency troubleshooting.
Sometimes, the monitoring system serves not just to provide data and feedback, but also as a calming influence: imagine a slow query causing a production database meltdown. If management or clients don’t have a transparent way to see the current status, they might anxiously push for updates, further affecting problem resolution speed. The monitoring system can also serve as a basis for precise management. You can confidently use monitoring metrics to demonstrate improvements to management and clients.
A Simulated Slow Query Case Study
Talk is cheap, show me the code
Assuming you have a Pigsty Sandbox Demo Environment, we’ll use it to demonstrate the process of locating and handling slow queries.
Simulating Slow Queries
Since we don’t have an actual business system, we’ll simulate slow queries in a simple and quick way using pgbench’s TPC-B-like scenario.
Using make ri / make ro / make rw, initialize pgbench test cases on the pg-test cluster and apply read-write load:
# 50TPS write load
while true; do pgbench -nv -P1 -c20 --rate=50 -T10 postgres://test:test@pg-test:5433/test; done
# 1000TPS read-only load
while true; do pgbench -nv -P1 -c40 --select-only --rate=1000 -T10 postgres://test:test@pg-test:5434/test; done
Now that we have a simulated business system running, let’s simulate a slow query scenario in a straightforward way. On the primary node of the pg-test cluster, execute the following command to drop the primary key from the pgbench_accounts table:
ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey;
This command removes the primary key from the pgbench_accounts table, causing related queries to switch from index scans to sequential full table scans, turning them all into slow queries. Visit PG Instance ➡️ Query ➡️ QPS to see the results:
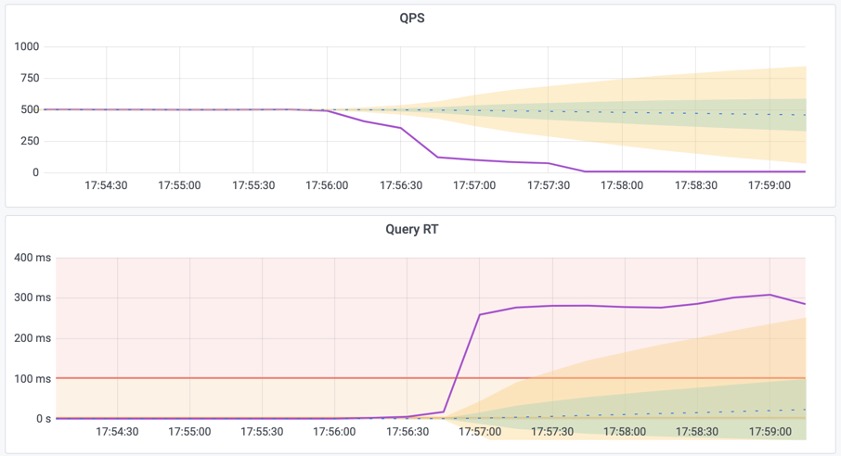
Figure 1: Average query response time spikes from 1ms to 300ms, and QPS on a single replica instance drops from 500 to 7.
Meanwhile, the instance becomes overloaded due to slow query pileup. Visit the PG Cluster homepage to see the cluster load spike:
Figure 2: System load reaches 200%, triggering alerts for high machine load and excessive query response time.
Locating Slow Queries
First, use the PG Cluster panel to locate the specific instance with slow queries, in this case pg-test-2.
Then, use the PG Query panel to locate the specific slow query: ID -6041100154778468427
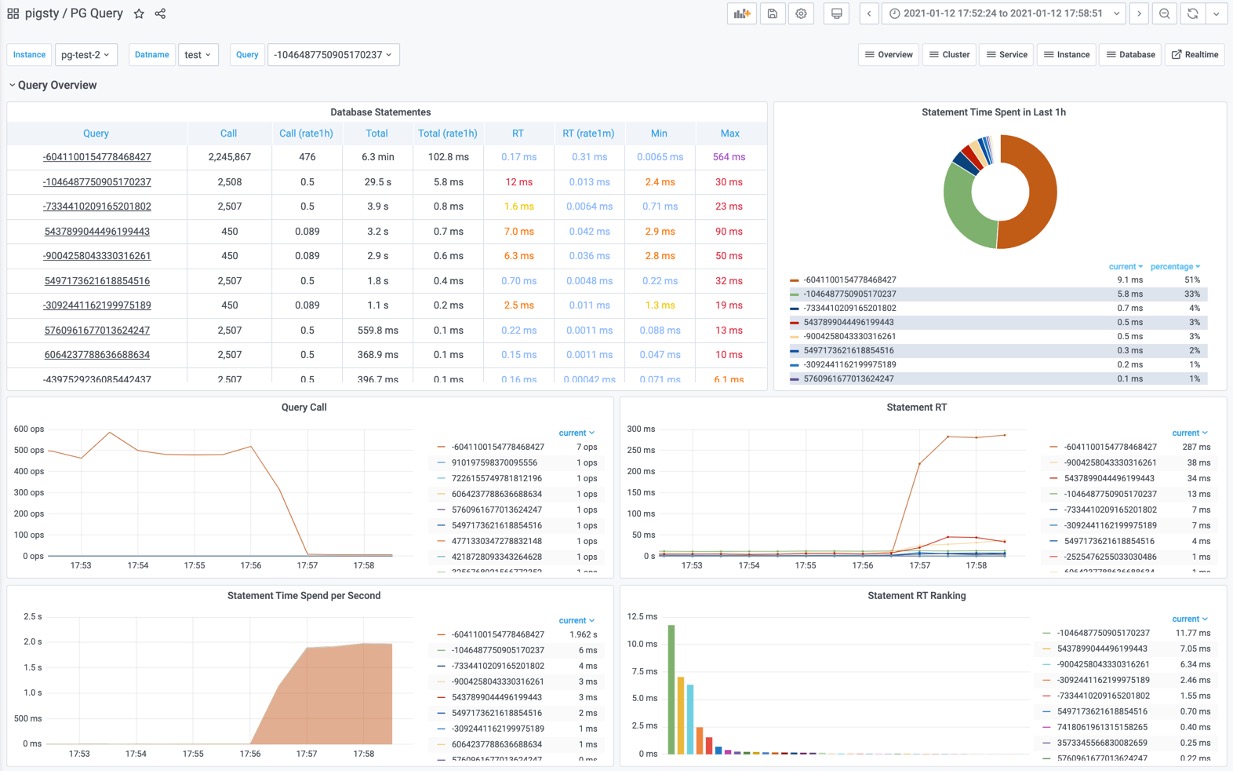
Figure 3: Identifying an abnormal slow query from the query overview
This query shows:
- Significant increase in response time: from 17us to 280ms
- Significant drop in QPS: from 500 to 7
- Significant increase in time spent on this query
We can confirm this is the slow query!
Next, use the PG Stat Statements panel or PG Query Detail to locate the specific statement of the slow query using the query ID.

Figure 4: Identifying the query statement as
SELECT abalance FROM pgbench_accounts WHERE aid = $1
Formulating Hypotheses
After identifying the slow query statement, we need to infer the cause of the slowness.
SELECT abalance FROM pgbench_accounts WHERE aid = $1
This query filters the pgbench_accounts table using aid as the condition. For such a simple query to slow down, it’s likely an issue with the table’s indexes. It’s obvious that we’re missing an index - after all, we just deleted it!
After analyzing the query, we can formulate a hypothesis: The query is slow because the aid column in the pgbench_accounts table is missing an index.
Next, we need to verify our hypothesis.
First, use the PG Table Catalog to examine table details, such as indexes on the table.
Second, check the PG Table Detail panel to examine access patterns on the pgbench_accounts table to verify our hypothesis:
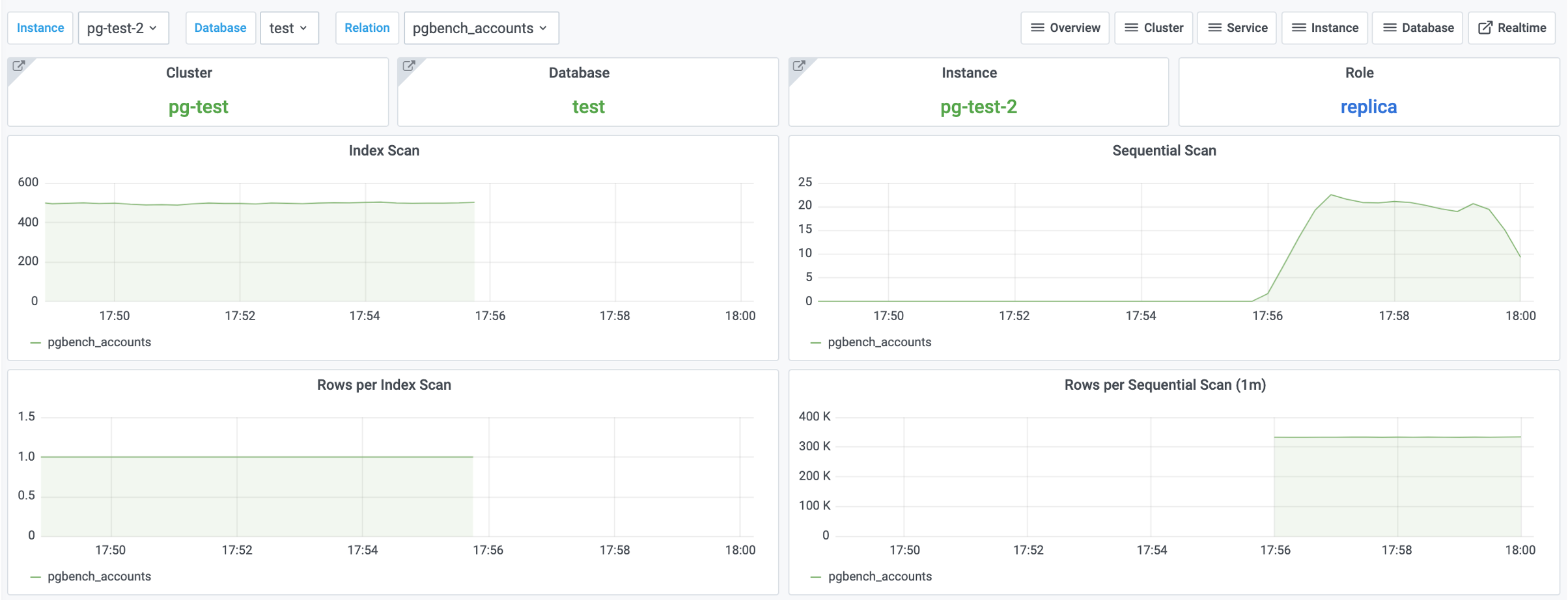
Figure 5: Access patterns on the
pgbench_accountstable
We observe that index scans have dropped to zero, while sequential scans have increased accordingly. This confirms our hypothesis!
Implementing Solutions
Once our hypothesis is confirmed, we can proceed with implementing a solution.
There are typically three ways to solve slow queries: modify table structure, modify queries, or modify indexes.
Modifying table structure and queries usually requires specific business and domain knowledge, requiring case-by-case analysis. However, modifying indexes typically doesn’t require much specific business knowledge.
In this case, we can solve the problem by adding an index. The pgbench_accounts table is missing an index on the aid column, so let’s try adding an index to see if it resolves the issue:
CREATE UNIQUE INDEX ON pgbench_accounts (aid);
After adding the index, something magical happens:
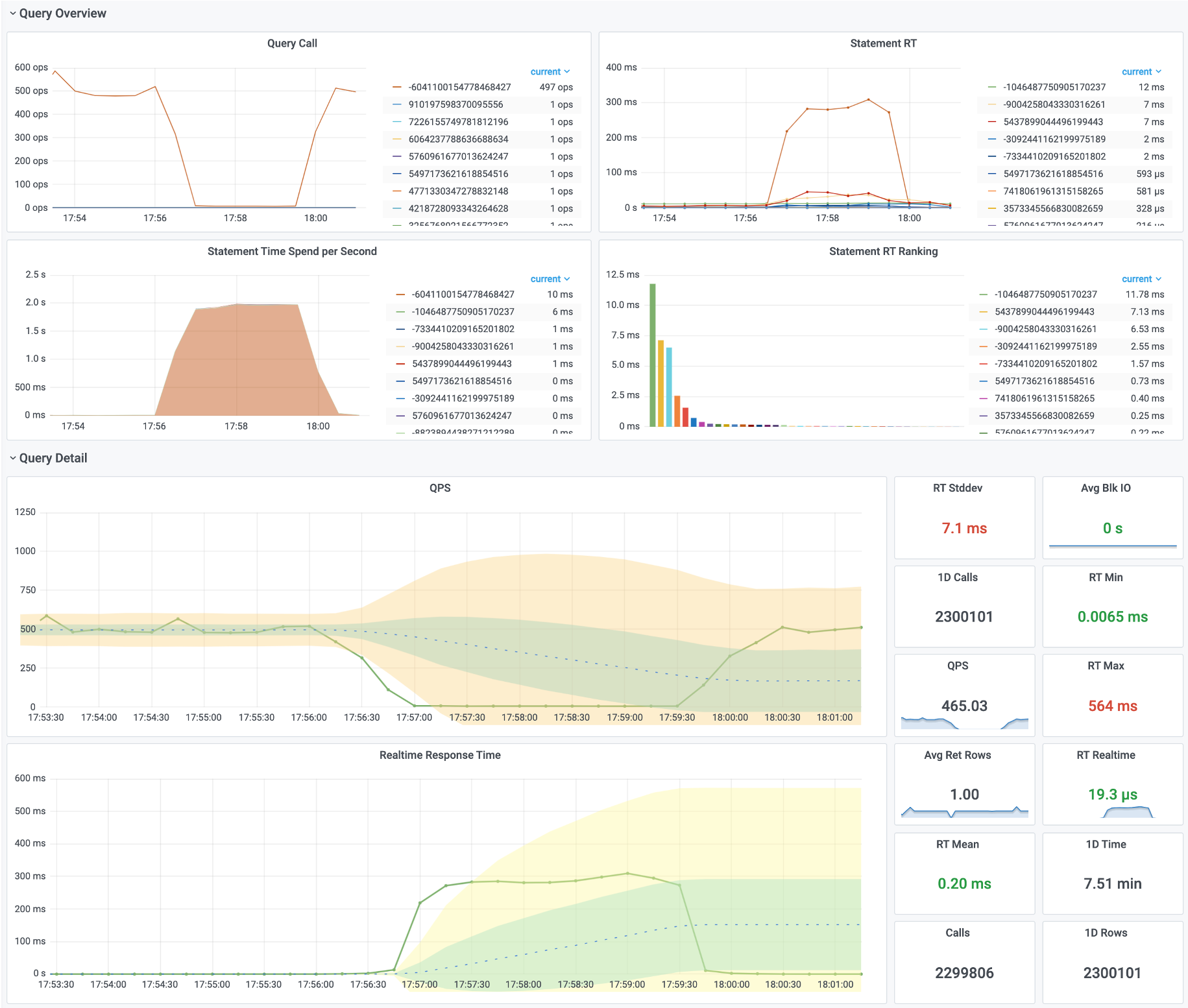
Figure 6: Query response time and QPS have returned to normal.
Figure 7: System load has also returned to normal.
Evaluating Results
As the final step in handling slow queries, we typically need to document the process and evaluate the results.
Sometimes a simple optimization can have dramatic effects. What might have required spending hundreds of thousands on additional machines can be solved by creating a single index.
These kinds of stories can be vividly demonstrated through monitoring systems, helping you earn KPI and credit.
Figure: Before and after optimizing a slow query, overall system saturation dropped from 40% to 4%
(Equivalent to saving X machines and XX dollars - your boss will be thrilled, and you’ll be the next CTO!)
Summary
Through this tutorial, you’ve learned the general methodology for slow query optimization:
- Locate the problem
- Formulate hypotheses
- Verify assumptions
- Implement solutions
- Evaluate results
The monitoring system plays a crucial role throughout the entire slow query handling lifecycle. It also helps express the “experience” and “results” of operations and DBAs in a visual, quantifiable, and reproducible way.
Releases
v3.4: MySQL Wire-Compatibility and Improvements
After a month of intensive development, Pigsty v3.4 is officially released! This release brings support for a new PostgreSQL kernel and significant architectural optimizations, addressing several key concerns from customers and users:
- Support for MySQL-compatible openHalo kernel
- Physical backup and PITR recovery between different clusters
- Monitoring metrics and dashboards for pgBackRest backup component
- Simplified Certbot certificate application process
- Best practices for localization sorting rules and character sets
- Oracle-compatible IvorySQL now available across all platforms
- Graph database extension AGE now available across all platforms
Let’s dive into the key changes introduced in Pigsty v3.4.
MySQL Compatibility
In Pigsty v3.4.1, we introduced support for openHalo, which provides MySQL wire protocol compatibility based on PostgreSQL 14.10.
This means MySQL users can seamlessly migrate to PostgreSQL without code changes, allowing both PG and MySQL clients to connect to the same database.
Currently, Pigsty provides RPM packages for openHalo and allows users to choose openHalo as the PostgreSQL kernel during installation, creating a complete RDS service.
./configure -c mysql # Use MySQL-compatible openHalo configuration template
Besides, we also introduce another new beta kernel OrioleDB.
Automated Cert Management
Recently, many users have adopted Pigsty for self-hosting applications like Dify, Odoo, and Supabase. Some feedback indicated that the certificate application process seemed cumbersome, requiring manual certbot calls. Could this be automated?
In this version, Pigsty has enhanced Nginx configuration. Now, if users define the certbot field for an Nginx Server,
they can use the make cert command to automatically complete certificate application and deployment with a single click, requiring no additional configuration or commands.
Therefore, in application templates like Dify, Odoo, and Supabase, this new feature is utilized.
After installation, make cert will automatically update or apply for required certificates. If you don’t even want to type this command,
simply configure certbot_sign = true to automatically request certificates during installation.
Additionally, v3.4 offers more Nginx configuration options. For example, you can use config to inject configuration into nginx, and enforce to force HTTPS redirection.
When self-hosting a website, you can achieve flexible customization in most scenarios without touching traditional Nginx configurations.
Here’s a configuration example used by the Pigsty Chinese website. With this configuration, I can self-host a Pigsty documentation/software repository site anywhere in the world within minutes.
infra_portal: # domain names and upstream servers
home : { domain: home.pigsty.cc ,certbot: pigsty.demo }
grafana : { domain: demo.pigsty.cc ,endpoint: "${admin_ip}:3000", websocket: true ,certbot: pigsty.demo }
prometheus : { domain: p.pigsty.cc ,endpoint: "${admin_ip}:9090" ,certbot: pigsty.demo }
alertmanager : { domain: a.pigsty.cc ,endpoint: "${admin_ip}:9093" ,certbot: pigsty.demo }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" }
postgrest : { domain: api.pigsty.cc ,endpoint: "127.0.0.1:8884" }
pgadmin : { domain: adm.pigsty.cc ,endpoint: "127.0.0.1:8885" }
pgweb : { domain: cli.pigsty.cc ,endpoint: "127.0.0.1:8886" }
bytebase : { domain: ddl.pigsty.cc ,endpoint: "127.0.0.1:8887" }
jupyter : { domain: lab.pigsty.cc ,endpoint: "127.0.0.1:8888" ,websocket: true }
gitea : { domain: git.pigsty.cc ,endpoint: "127.0.0.1:8889" ,certbot: pigsty.cc }
wiki : { domain: wiki.pigsty.cc ,endpoint: "127.0.0.1:9002" ,certbot: pigsty.cc }
noco : { domain: noco.pigsty.cc ,endpoint: "127.0.0.1:9003" ,certbot: pigsty.cc }
supa : { domain: supa.pigsty.cc ,endpoint: "10.2.82.163:8000" ,websocket: true ,certbot: pigsty.cc }
dify : { domain: dify.pigsty.cc ,endpoint: "10.2.82.163:8001" ,websocket: true ,certbot: pigsty.cc }
odoo : { domain: odoo.pigsty.cc ,endpoint: "127.0.0.1:8069" ,websocket: true ,certbot: pigsty.cc }
mm : { domain: mm.pigsty.cc ,endpoint: "10.2.82.163:8065" ,websocket: true }
web.io:
domain: en.pigsty.cc
path: "/www/web.io"
certbot: pigsty.doc
enforce_https: true
config: |
# rewrite /zh/ to /
location /zh/ {
rewrite ^/zh/(.*)$ /$1 permanent;
}
web.cc:
domain: pigsty.cc
path: "/www/web.cc"
domains: [ zh.pigsty.cc ]
certbot: pigsty.doc
config: |
# rewrite /zh/ to /
location /zh/ {
rewrite ^/zh/(.*)$ /$1 permanent;
}
repo:
domain: pro.pigsty.cc
path: "/www/repo"
index: true
certbot: pigsty.doc
Locale & Collation
Many programmers are not very familiar with Locale/Collation rules, but they are actually quite important. Improper Collation configuration can not only cause several times performance degradation but also lead to data inconsistency or even data loss. Yes, that’s right - indexes are closely related to sorting rules, and Collation is not an insignificant configuration.
Regarding this topic, I strongly recommend interested readers to check out the article Localization Sorting Rules in PostgreSQL, as well as Jeremy Schneider’s presentation at PGCon.Dev 2024: Collations from A to Z, Putting words in order without losing your mind or your data
As a summary, the best practice is to always use C or C.UTF-8 as the Locale sorting rule.
C has the best compatibility - it works on all systems, but it lacks Unicode knowledge for character sets - features like case conversion don’t work for characters beyond ASCII!
C.UTF-8 implements Unicode semantics on top of C, which is more intuitive for users, but not all systems support it by default.
Fortunately, PostgreSQL 17 introduces a new feature with built-in support for both Collations, no longer relying on the operating system’s libc.
Therefore, Pigsty v3.4 has promptly followed and reflected this best practice.
First, all Locale-related parameters now default to C (mainly pg_lc_ctypes changed from en_US.UTF-8 to C), ensuring it works on any system!
Then, during automatic configuration, if PG version >= 17 or the OS explicitly supports C.utf8 (counterexamples: default Debian, EL7, MacOS), the Locale will be configured as C.UTF-8 for better Unicode semantics.
pg_locale: C.UTF-8 # overwrite default C local
pg_lc_collate: C.UTF-8 # overwrite default C lc_collate
pg_lc_ctype: C.UTF-8 # overwrite default C lc_ctype
Unless your database works intensively with specific language sorting scenarios, these defaults represent the best practice. You can use PostgreSQL’s COLLATION syntax to easily specify and configure specific sorting rules for queries/indexes/columns. PG + ICU supports a total of 841 sorting rules, satisfying even the most peculiar sorting preferences.
Point-in-Time Recovery Improvements
Point-in-Time Recovery (PITR) is a core feature of relational databases. Previously, Pigsty used pg-pitr to assist users with semi-automatic PITR.
In Pigsty v3.4, PITR support has been significantly improved. For example, you can now easily select any backup from a centralized backup repository for recovery.
You can achieve this in a more Ansible-native way.
When you define the pg_pitr parameter on a PG cluster,
Pigsty automatically generates the /pg/bin/pg-restore command and /pg/conf/pitr.conf configuration file for recovery.
pg_pitr:
cluster: pg-test # Specify the cluster name to recover
type: 'default' # default, immediate, time, lsn, xid, name, backup
path: '/pg/data' # restore to which path? /pg/data by default
time: '2022-01-01T00:00:00' # if type = time
lsn: '0/1000000' # if type = lsn
xid: '123456' # if type = xid
name: 'restore_point' # if type = name
backup: '20221108-105325F' # if type = set
action: 'promote' # promote, pause, shutdown
exclusive: false # Stop just BEFORE the recovery target (xid,time,lsn) is reached?
db_exclude: [] # Restore excluding the specified databases
db_include: [] # Restore only specified databases
link_map: {} # Restore with tablespace link map
process: max # Number of parallel processes to use for restore (default to CPU count)
When executing the pg-restore command, Pigsty automatically pauses the Patroni cluster, shuts down PG, performs incremental PITR in place, and starts PG after reaching the specified point.
A notable improvement is that if you use a centralized backup repository, you can use backups from other clusters to overwrite the current cluster.
Additionally, for backup monitoring, v3.4 introduces a new component: pgbackrest_exporter, for collecting backup monitoring metrics. The PGSQL PITR monitoring dashboard will also display the current backup status.
While users could previously query PGBackRest backup status directly through PGCAT Instance, it only showed the current state without historical records. This improvement is undoubtedly very helpful for analyzing backup status.
Extension Updates
In the past few versions, Pigsty has mainly focused on the PostgreSQL extension ecosystem. During a year of continuous expansion, we have collected almost all significant extensions in the PG ecosystem - totaling 404.
However, the phase of rapid extension expansion has basically ended. Therefore, in recent versions, I have refocused on Pigsty’s architecture and infrastructure, with extensions being consolidated.
So v3.4 only adds one new extension pgspider_ext, which implements multi-data source queries using various FDWs. However, 28 of the extensions maintained by Pigsty have been updated to their latest versions.
Additionally, we carefully reviewed existing extensions and fixed version and bug issues for several extensions.
Most notably, the graph database extension Apache AGE seems to have lost its maintainer, leaving it in an unmaintained state. As a distribution author, I can only do my best to “keep it alive.” So this time, I recompiled AGE 1.5.0 extensions for versions 13-17 based on Debian patches, finally filling the gap of missing EL RPM packages.
Exotic Kernels
In Pigsty v3.4, we’ve updated support for the latest versions of PolarDB, IvorySQL, and Babelfish.
It’s worth celebrating that after PolarDB, IvorySQL has become the second PostgreSQL kernel available across all ten Linux distributions supported by Pigsty. The only remaining issue is that WiltonDB doesn’t support Debian.
In this update, we collaborated with the IvorySQL team to improve Pigsty’s integration with IvorySQL. Apart from extension plugins, IvorySQL 4.4’s experience is basically consistent with PostgreSQL 17.4.
Using IvorySQL (Oracle compatibility mode) only requires modifying these four parameters:
pg_mode: ivory # Use IvorySQL compatibility mode
pg_packages: [ ivorysql, pgsql-common ] # Install IvorySQL packages
pg_libs: 'liboracle_parser, pg_stat_statements, auto_explain' # Load Oracle compatibility extensions
repo_extra_packages: [ ivorysql ] # Download IvorySQL packages
I should also mention PolarDB here - their DEB packaging wasn’t done carefully, with the Debian package having an incorrect libicu version dependency that made it impossible to install, suggesting it wasn’t tested at all.
Fortunately, their response speed was quite fast. I had already modified the DEB package to fix it, but they quickly released a new fixed version after I reported the issue.
Meanwhile, we’ve also updated the Supabase template to the latest version and updated the distributed extension Citus to 13.0.2. In upcoming versions, I’ll focus on OrioleDB, which specializes in OLTP performance, and the OpenHalo kernel, which provides MySQL protocol compatibility.
Infra Enhancements
In v3.4, we’ve updated many Infra software package versions and added several new components:
- JuiceFS: Mount S3/MinIO as local file system
- Restic: Similar to pgBackRest, but for file system backups
- TimescaleDB EventStreamer: For extracting change data streams from TimescaleDB hypertables
I originally planned to release the JuiceFS Beta module in this version, but time was tight, so this feature will be moved to the next version.
However, in Pigsty v3.4, these components are now downloaded by default, so if you want to use them, just install them directly.
Another change is that the following software packages are now added to Pigsty’s default download list:
extra-modules: "docker-ce docker-compose-plugin ferretdb2 duckdb restic juicefs vray grafana-infinity-ds"
Mainly because I found that Docker is still used by many people, not just for running software but especially for running pgAdmin. Since this is the case, I decided to make Docker part of the default download, not worrying about the extra 100MB.
v3.5 Feature Preview
The v3.5 feature planning has begun, currently including the following features:
The pig command line has been saying it would incorporate fine-grained management of Pigsty Playbook, and now is the perfect time. I hope in the next version, users can say goodbye to directly executing Ansible Playbook and manage everything with a Go command line.
Then there’s the configuration wizard and MCP Server. Many users have feedback that Pigsty’s configuration files are somewhat complex, asking if we could create something like a Vibe Config Wizard.
I thought about it and technically it’s not too difficult - feed the documentation as context, ask a few questions, and modify the configuration on the fly like Cursor.
Of course, I still hope to automatically make some environment-based judgments like the original configure script, so perhaps we need an MCP server to collect environment information and modify configurations.
The third feature, which has been delayed for a while, is Docker images. I plan to create a Debian 12 x86/ARM version of Pigsty Docker in the next version. With the ARM version, Mac laptops can quickly try it out locally.
Finally, there are two new PG kernels: OrioleDB and openHalo. The former just released Beta10 yesterday, and the latter just went open source yesterday. Both just threw out their code without providing DEB/RPM packages, which I’ll need to create myself. But I think these kernels’ features should appeal to many: the former offers PG + extreme OLTP performance + no bloat, while the latter provides PG + MySQL wire protocol compatibility. Barring any surprises, we should see these two new PG kernels in Pigsty in the next version.
That’s all for the new features in Pigsty v3.4. Enjoy using it!
v3.4.1
- MySQL wire-compatible PostgreSQL kernel: openHalo support
- pgAdmin application template optimization, auto-filling pgpass passwords
- Increased PG default max connections to 250, 500, 1000
- Updated pg_search to 0.5.13
- Updated pig to 0.3.4
- Updated pg_exporter to 0.8.1
- Removed mysql_fdw extension with dependency errors from EL8
v3.4.0
New Features
- Added new pgBackRest backup monitoring metrics and dashboards
- Enhanced Nginx server configuration options, with support for automated Certbot issuance
- Now prioritizing PostgreSQL’s built-in
C/C.UTF-8locale settings - IvorySQL 4.4 is now fully supported across all platforms (RPM/DEB on x86/ARM)
- Added new software packages: Juicefs, Restic, TimescaleDB EventStreamer
- The Apache AGE graph database extension now fully supports PostgreSQL 13–17 on EL
- Improved the
app.ymlplaybook: launch standard Docker app without extra config - Bump Supabase, Dify, and Odoo app templates, bump to their latest versions
- Add electric app template, local-first PostgreSQL Sync Engine
Infra Packages
- +restic 0.17.3
- +juicefs 1.2.3
- +timescaledb-event-streamer 0.12.0
- Prometheus 3.2.1
- AlertManager 0.28.1
- blackbox_exporter 0.26.0
- node_exporter 1.9.0
- mysqld_exporter 0.17.2
- kafka_exporter 1.9.0
- redis_exporter 1.69.0
- pgbackrest_exporter 0.19.0-2
- DuckDB 1.2.1
- etcd 3.5.20
- FerretDB 2.0.0
- tigerbeetle 0.16.31
- vector 0.45.0
- VictoriaMetrics 1.113.0
- VictoriaLogs 1.17.0
- rclone 1.69.1
- pev2 1.14.0
- grafana-victorialogs-ds 0.16.0
- grafana-victoriametrics-ds 0.14.0
- grafana-infinity-ds 3.0.0
PostgreSQL Related
- Patroni 4.0.5
- PolarDB 15.12.3.0-e1e6d85b
- IvorySQL 4.4
- pgbackrest 2.54.2
- pev2 1.14
- WiltonDB 13.17
PostgreSQL Extensions
- pgspider_ext 1.3.0 (new extension)
- apache age 13–17 el rpm (1.5.0)
- timescaledb 2.18.2 → 2.19.0
- citus 13.0.1 → 13.0.2
- documentdb 1.101-0 → 1.102-0
- pg_analytics 0.3.4 → 0.3.7
- pg_search 0.15.2 → 0.15.8
- pg_ivm 1.9 → 1.10
- emaj 4.4.0 → 4.6.0
- pgsql_tweaks 0.10.0 → 0.11.0
- pgvectorscale 0.4.0 → 0.6.0 (pgrx 0.12.5)
- pg_session_jwt 0.1.2 → 0.2.0 (pgrx 0.12.6)
- wrappers 0.4.4 → 0.4.5 (pgrx 0.12.9)
- pg_parquet 0.2.0 → 0.3.1 (pgrx 0.13.1)
- vchord 0.2.1 → 0.2.2 (pgrx 0.13.1)
- pg_tle 1.2.0 → 1.5.0
- supautils 2.5.0 → 2.6.0
- sslutils 1.3 → 1.4
- pg_profile 4.7 → 4.8
- pg_snakeoil 1.3 → 1.4
- pg_jsonschema 0.3.2 → 0.3.3
- pg_incremental 1.1.1 → 1.2.0
- pg_stat_monitor 2.1.0 → 2.1.1
- ddl_historization 0.7 → 0.0.7 (bug fix)
- pg_sqlog 3.1.7 → 1.6 (bug fix)
- pg_random removed development suffix (bug fix)
- asn1oid 1.5 → 1.6
- table_log 0.6.1 → 0.6.4
Interface Changes
- Added new Docker parameters:
docker_dataanddocker_storage_driver(#521 by @waitingsong) - Added new Infra parameter:
alertmanager_port, which lets you specify the AlertManager port - Added new Infra parameter:
certbot_sign, apply for cert during nginx init? (false by default) - Added new Infra parameter:
certbot_email, specifying the email used when requesting certificates via Certbot - Added new Infra parameter:
certbot_options, specifying additional parameters for Certbot - Updated IvorySQL to place its default binary under
/usr/ivory-4starting in IvorySQL 4.4 - Changed the default for
pg_lc_ctypeand other locale-related parameters fromen_US.UTF-8toC - For PostgreSQL 17, if using
UTF8encoding withCorC.UTF-8locales, PostgreSQL’s built-in localization rules now take priority configureautomatically detects whetherC.utf8is supported by both the PG version and the environment, and adjusts locale-related options accordingly- Set the default IvorySQL binary path to
/usr/ivory-4 - Updated the default value of
pg_packagestopgsql-main patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager - Updated the default value of
repo_packagesto[node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility, extra-modules] - Removed
LANGandLC_ALLenvironment variable settings from/etc/profile.d/node.sh - Now using
bento/rockylinux-8andbento/rockylinux-9as the Vagrant box images for EL - Added a new alias,
extra_modules, which includes additional optional modules - Updated PostgreSQL aliases:
postgresql,pgsql-main,pgsql-core,pgsql-full - GitLab repositories are now included among available modules
- The Docker module has been merged into the Infra module
- The
node.ymlplaybook now includes anode_piptask to configure a pip mirror on each node - The
pgsql.ymlplaybook now includes apgbackrest_exportertask for collecting backup metrics - The
Makefilenow allows the use ofMETA/PKGenvironment variables - Added
/pg/spooldirectory as temporary storage for pgBackRest - Disabled pgBackRest’s
link-alloption by default - Enabled block-level incremental backups for MinIO repositories by default
Bug Fixes
- Fixed the exit status code in
pg-backup(#532 by @waitingsong) - In
pg-tune-hugepage, restricted PostgreSQL to use only large pages (#527 by @waitingsong) - Fixed logic errors in the
pg-roletask - Corrected type conversion for hugepage configuration parameters
- Fixed default value issues for
node_repo_modulesin theslimtemplate
Checksums
768bea3bfc5d492f4c033cb019a81d3a pigsty-v3.4.0.tgz
7c3d47ef488a9c7961ca6579dc9543d6 pigsty-pkg-v3.4.0.d12.aarch64.tgz
b5d76aefb1e1caa7890b3a37f6a14ea5 pigsty-pkg-v3.4.0.d12.x86_64.tgz
42dacf2f544ca9a02148aeea91f3153a pigsty-pkg-v3.4.0.el8.aarch64.tgz
d0a694f6cd6a7f2111b0971a60c49ad0 pigsty-pkg-v3.4.0.el8.x86_64.tgz
7caa82254c1b0750e89f78a54bf065f8 pigsty-pkg-v3.4.0.el9.aarch64.tgz
8f817e5fad708b20ee217eb2e12b99cb pigsty-pkg-v3.4.0.el9.x86_64.tgz
8b2fcaa6ef6fd8d2726f6eafbb488aaf pigsty-pkg-v3.4.0.u22.aarch64.tgz
83291db7871557566ab6524beb792636 pigsty-pkg-v3.4.0.u22.x86_64.tgz
c927238f0343cde82a4a9ab230ecd2ac pigsty-pkg-v3.4.0.u24.aarch64.tgz
14cbcb90693ed5de8116648a1f2c3e34 pigsty-pkg-v3.4.0.u24.x86_64.tgz
v3.4.1
GitHub Release Page: v3.4.1
- Added support for MySQL wire-compatible PostgreSQL kernel on EL systems: openHalo
- Added support for OLTP-enhanced PostgreSQL kernel on EL systems: orioledb
- Optimized pgAdmin 9.2 application template with automatic server list updates and pgpass password population
- Increased PG default max connections to 250, 500, 1000
- Removed the
mysql_fdwextension with dependency errors from EL8
Infra Updates
- pig 0.3.4
- etcd 3.5.21
- restic 0.18.0
- ferretdb 2.1.0
- tigerbeetle 0.16.34
- pg_exporter 0.8.1
- node_exporter 1.9.1
- grafana 11.6.0
- zfs_exporter 3.8.1
- mongodb_exporter 0.44.0
- victoriametrics 1.114.0
- minio 20250403145628
- mcli 20250403170756
Extension Update
- Bump pg_search to 0.15.13
- Bump citus to 13.0.3
- Bump timescaledb to 2.19.1
- Bump pgcollection RPM to 1.0.0
- Bump pg_vectorize RPM to 0.22.1
- Bump pglite_fusion RPM to 0.0.4
- Bump aggs_for_vecs RPM to 1.4.0
- Bump pg_tracing RPM to 0.1.3
- Bump pgmq RPM to 1.5.1
v3.3:Extension 404,Odoo, Dify, Supabase, Nginx Enhancement
After two months of careful polishing, Pigsty v3.3 is officially released! As an open-source, “battery-included” PostgreSQL distribution, Pigsty aims to optimize the PostgreSQL ecosystem and provide smooth self-hosting experience just like cloud RDS, with minimal maintenance and ease of use.
The newly released v3.3 focuses on three key areas: Postgres Extension, Self-Hosting Experience, and Application Templates,
400+ Available Extensions: Building a Strong Ecosystem
PostgreSQL has always been known for its rich extension mechanism, giving rise to a massive database ecosystem. Pigsty aligns with this trend by maximizing the plugin and extension capabilities of PostgreSQL.
About one year ago, I wrote an article titled “PostgreSQL is eating the Database World,” where I described PG’s trend and vision to dominate the database market through extensions. At that time, the number of available extensions in Pigsty was just 150, mainly consisting of PG’s built-in extensions (70) and those from the official PGDG repository.
Now, with Pigsty v3.3, the number of available extensions has skyrocketed to an astonishing 404 extensions! This means the users can instantly plug in almost any PostgreSQL extension, unlocking a wealth of powerful features for their databases.
Among the newly added extensions, there are some notable “rookie” plugins:
- pg_documentdb, open-sourced by Microsoft, gives PostgreSQL document database capabilities, making it easier to store and query JSON documents.
- pg_collection, a high-performance memory-optimized collection data type extension from AWS, adds advanced collection support to PG.
- pg_tracing, open-sourced by DataDog, provides distributed tracing capabilities for PostgreSQL, useful for performance analysis and debugging.
- pg_curl allows PostgreSQL to make requests using dozens of network protocols, expanding beyond just HTTP to call external APIs.
- pgpdf enables users to read and perform full-text searches on PDF documents directly within SQL queries.
Additionally, over thirty Omni-series extensions developed by Omnigres open new doors for web application development within PG. Pigsty has forged a partnership with Omnigres, integrating and distributing their extensions. And omnigres can deliver these extensions from the Pigsty repository to their users, creating a mutually beneficial ecosystem.
We have also partnered with the FerretDB team to deliver a PostgreSQL-based MongoDB solution.
Yes, you can now easily use the newly released FerretDB 2.0 to turn PG into a fully-functional MongoDB 5.0 alternative,
and with FerretDB 2.0, backed by Microsoft’s open-source DocumentDB, provides better performance and a more complete feature set.
Meanwhile, the DuckDB stitching competition is still ongoing, and Pigsty v3.3 quickly integrated the latest versions of pg_duckdb 0.3.1, pg_mooncake 0.1.2, and pg_analytics 0.5.4. These extensions add analytical capabilities to PostgreSQL, rivaling ClickHouse in certain dimensions.
Yes, on ClickHouse’s ClickBench leaderboard, PG extensions have now joined the top 10 tier.
I believe that in this fierce competition, PostgreSQL will soon see an OLAP player akin to pgvector in the vector database ecosystem, shaking up the OLAP and big data markets.
With so many extensions available, installation and management have become a challenge. Our solution, pig, allows users to effortlessly manage and install extensions with a single command, unlocking the power of 400 extensions—without even needing Pigsty.
While having a unique and extensive extension library is a core competitive advantage for Pigsty, we also aim to contribute more to the PostgreSQL ecosystem, allowing more users to enjoy PostgreSQL’s powerful features. Thus, the pig package manager and the extension repository are open-source under the permissive Apache 2.0 license, and they are open to the public and industry peers. We’ve already seen two PostgreSQL vendors using the Pigsty extension repository to install extensions, and we’ve established a NextGen Package Manager interest group, inviting participants interested in PostgreSQL extension ecosystems to join.
Sefl-Hosting Experience: Nginx IaC and Free HTTPS Certs
Pigsty is not just a PostgreSQL distribution; it’s a complete monitoring infrastructure solution, including Etcd, MinIO, Redis, Docker deployment management, and even a toolbox for self-hosting websites.
Why? Because Pigsty offers a fully-featured Nginx configuration and a certbot Request SOP (Standard Operating Procedure). In fact, Pigsty’s own websites and software repositories are hosted using Pigsty itself. This solution was developed purely to meet my personal needs—how to quickly set up a proper website in minutes?
For instance, the Pigsty Chinese and English websites and beta repositories are defined on a single server with the following configuration. After installing Pigsty and adding a few lines to the configuration file, Nginx automatically creates the necessary configuration and generates the HTTPS certificate. Then, I simply use rsync/scp to upload the site content and repository files, and voilà—the website is live!
infra_portal: # domain names and upstream servers
home : { domain: home.pigsty.cc ,certbot: home.pigsty.cc }
grafana : { domain: demo.pigsty.io ,endpoint: "${admin_ip}:3000" ,certbot: home.pigsty.cc}
prometheus : { domain: p.pigsty.cc ,endpoint: "${admin_ip}:9090" ,certbot: home.pigsty.cc}
alertmanager : { domain: a.pigsty.cc ,endpoint: "${admin_ip}:9093" ,certbot: home.pigsty.cc}
minio : { domain: m.pigsty.cc ,endpoint: "${admin_ip}:9001" ,scheme: https ,websocket: true }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" }
web.cc : { domain: pigsty.cc ,path: "/www/web.cc" , domains: [zh.pigsty.cc] ,certbot: home.pigsty.cc , conf: cc.conf }
web.io : { domain: en.pigsty.cc ,path: "/www/web.io" ,certbot: home.pigsty.cc}
repo : { domain: beta.pigsty.cc ,path: "/www/repo" , index: true ,certbot: home.pigsty.cc}
Starting with Pigsty v3.2, we’ve integrated certbot and made it the default on infrastructure nodes, allowing users to easily apply and renew HTTPS certificates with just one command, without worrying about the details. You no longer need to pay for expensive certificates or click through tedious processes.
Pigsty’s Nginx can proxy various services, use different domain names, and unify everything through ports 80/443, making firewall management and security best practices straightforward. Simply open ports 80/443 (and maybe 22/SSH), and you’re set.
Of course, all details and SOPs are updated in the doc, so you can quickly deploy a secure, reliable, high-performance website!
Application Templates: Simplified Deployment
Many software applications rely on PostgreSQL, and Pigsty has previously provided Docker Compose templates for such software. But before, users still had to manually copy application directories, modify .env configuration files, and use docker-compose to deploy.
Pigsty v3.3 introduces a new app.yml script that automates this process, turning the last mile of PostgreSQL-based Docker software delivery into a single command.
Let’s look at a few examples:
To deploy a full-featured Odoo ERP system, simply run the following commands:
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./bootstrap # install ansible
./configure -c app/odoo # use odoo config (please CHANGE CREDENTIALS in pigsty.yml)
./install.yml # install pigsty
./docker.yml # install docker compose
./app.yml # launch odoo stateless part with docker
For a complex AI workflow orchestration software like Dify, utilizing the high-availability, high-performance PostgreSQL cluster with PITR and IaC management, just a few lines of code are enough:
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./bootstrap # install ansible
./configure -c app/dify # use dify config (please CHANGE CREDENTIALS in pigsty.yml)
./install.yml # install pigsty
./docker.yml # install docker compose
./app.yml # launch dify stateless part with docker
Even for the popular Supabase self-hosting solution, we’ve simplified it into a one-click app that offers a beginner-friendly delivery experience:
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./bootstrap # install ansible
./configure -c app/supa # use supabase config (please CHANGE CREDENTIALS in pigsty.yml)
./install.yml # install pigsty
./docker.yml # install docker compose
./app.yml # launch supabase stateless part with docker
With just a few commands, you can move from bare metal to a fully operational production service in minutes. We plan to add more Docker-based applications and provide this simplified template and delivery model in the future.
pig Command Line Tool: Growing Build Capabilities
The command-line tool pig provided by Pigsty has also received significant upgrades. Pig v0.3 introduces a new subcommand, pig build,
which lets you quickly set up a complete environment for building PG extensions on your server.
With over 400 extension plugins maintained in Pigsty, I personally handle over 200 of them, which is near double the number in the PGDG repository.
Previously, building extensions required manually written scripts for basic automation, but with the increase in extensions,
this approach became impractical. So, I spent two days integrating all the extension-building tools into the new pig build command.
For example, the workflow for building PG extensions on a specific OS distribution is as follows:
curl https://repo.pigsty.cc/pig | bash # Install pig
pig build repo # Add upstream repositories
pig build tool # Install build tools
pig build rust # Configure Rust/PGRX toolchain (optional)
pig build spec # Download build specifications
pig build proxy # Configure proxy
pig build get citus # Download source package for an extension like citus
pig build ext citus # Build the citus extension from source
This is how 200+ extensions are built! With this tool, even if your operating system is not one of the top 10 supported by Pigsty, you can still easily DIY RPM/DEB packages for extensions.
A hidden feature is the automatic download of proxy configurations to simplify downloading dependencies from GitHub. Of course, I wouldn’t add that to the documentation! 😄
New Website: First Contact with Next.js
Another major improvement in Pigsty v3.3 is the infrastructure behind the websites. Starting with v3.3, the Pigsty global site (pigsty.io) and Pigsty China site (pigsty.cc) have been fully separated, each with its own domain, documentation, demos, and repositories.
I found a Next.js template and spent two days building a new Pigsty homepage. It actually turned out pretty well. The last time I worked on frontend stuff was in the era of jQuery, but surprisingly, React and Next.js weren’t that complicated, especially with the help of GPT-1 pro and Cursor. Even as a “newbie,” I was able to quickly create a landing page.
I experimented with hosting on native Vercel, exporting statically to Cloudflare Pages, as well as Alibaba Cloud’s ClawCloud in Singapore/Hong Kong and other cloud providers. Thanks to Pigsty’s self-hosting enhancement, the whole process was much smoother. The best options in terms of experience and cost-effectiveness turned out to be:
- Cloudflare for global hosting, and 2. Domestic on-demand cloud servers in Beijing. I might write a dedicated post about this in the future.
During this process, I automated the website-building flow to such an extent that now, in just ten minutes, I can deploy a Pigsty doc and repository site in any region.
In addition to a beautiful homepage, the content of the documentation is more important. In Pigsty v3.3, I’ve integrated the ext.pigsty.io PG extension directory into the documentation site at pigsty.io/ext, which is available in both Chinese and English for easy access. I also developed a small tool to automatically scan extensions from both Pigsty and PGDG repositories, generating database records and information pages so that users can easily see which extensions are missing or have inconsistent versions. Users can directly browse and download RPM/DEB packages from the website.
Other Improvements
Pigsty v3.0 already supports multiple PG forks, such as IvorySQL (Oracle compatibility), PolarDB O, Babelfish (SQL Server compatibility), and PolarDB for PostgreSQL.
In version 3.3, we’ve followed up with IvorySQL 4.2, compatible with PG 17, and resolved the issue with pgBackRest backups not working on IvorySQL. Now, IvorySQL runs smoothly and as fully functional as the standard PG kernel.
I’ve also pushed the PolarDB team to provide DEB packages for Debian and ARM64 platforms. Yes, PolarDB now runs smoothly on all ten major operating systems supported by Pigsty!
As for why I use the PolarDB kernel instead of PostgreSQL—if your boss insists on a “domestic” solution, PolarDB may be the easiest, most cost-effective choice!
By the way, the PolarDB Developer Conference is happening tomorrow in Beijing, and I plan to attend to see what new features they’ve come up with.
Looking Ahead to Pigsty 3.4
As we celebrate the success of version 3.3, the Pigsty project is already looking ahead to version 3.4.
Honestly, I feel like Pigsty has already achieved a grand slam with PostgreSQL. Virtually every major extension plugin in the ecosystem has been integrated. To continue expanding, we may need to focus on some forks, like Neon, OrioleDB, and PolarDB, and support extensions for these branches.
But another direction I see as meaningful is further developing the pig command-line tool: integrating more operations into this compact Go-based tool and eventually creating a complete PostgreSQL management toolchain (ideally replacing Ansible). I think when this tool is mature, it will coincide with Pigsty v4.
Another long-term direction is converting more software that uses PostgreSQL into one-click solutions like Odoo, Dify, Supabase, and more. Many SMEs need such solutions—GitLab (code hosting), Odoo (ERP), Dify (AI workflow orchestration), Supabase (backend), MatterMost (chat), Discourse (forum), all powered by PostgreSQL.
v3.3.0 Release Note
New Features
- Total available postgres extensions: 404!
- New Website Design: Global website:
pigsty.ioand zh-cn Site:pigsty.cc - PostgreSQL February Minor Updates: 17.4, 16.8, 15.12, 14.17, 13.20
- New Feature:
app.ymlfor installing apps like Odoo, Supabase, Dify. - New Feature: Fine-grained Nginx config customization in
infra_portal. - New Feature: Added Certbot support for quick free HTTPS certificate requests.
- Improvement: Added Aliyun mirror for Debian Security repository.
- Improvement: pgBackRest backup support for IvorySQL kernel.
- Improvement: ARM64 and Debian/Ubuntu support for PolarDB.
- pg_exporter 0.8.0 now supports new metrics in pgbouncer 1.24.
- New Feature: Auto-completion for common commands like
git,docker,systemctl#506 #507 by @waitingsong. - Improvement: Refined
ignore_startup_parametersinpgbouncerconfig template #488 by @waitingsong. - Extension Catalog: Detailed information and download links for RPM/DEB binary packages.
- Extension Build:
pigCLI now auto-sets PostgreSQL extension build environment.
New Extensions
12 new PostgreSQL extensions added, bringing the total to 404 available extensions.
- documentdb 0.101-0
- VectorChord-bm25 (vchord_bm25) 0.1.0
- pg_tracing 0.1.2
- pg_curl 2.4
- pgxicor 0.1.0
- pgsparql 1.0
- pgjq 0.1.0
- hashtypes 0.1.5
- db_migrator 1.0.0
- pg_cooldown 0.1
- pgcollection 0.9.1
- pg_bzip 1.0.0
API Change
- New Parameter:
node_aliasesto add command aliases for Nodes. - New Option: using plain extension name in
pg_default_extensions - New Option: using
conf,index,log,certbotoptions ininfra_portalentries. - New Defaults: add
mongo,redis,pgroongarepos torepo_upstreamdefault values - New Defaults: Remove
hydrafrom default olap list, replaceferretdbwithferretdb2
Bug Fix
- Fix: Resolved default EPEL repo address issue in Bootstrap script.
- Fix: Fix Debian Security China Mirror URL
Postgres Update
- PostgreSQL 17.4, 16.8, 15.12, 14.17, 13.20
- Pgbouncer 1.24
- Patroni 4.0.5
- pgBackRest 2.54.2
- pg_exporter 0.8.0
- pig 0.3.0
Extension Update
- citus 13.0.0 -> 13.0.1
- pg_duckdb 0.2.0 -> 0.3.1
- pg_mooncake 0.1.0 -> 0.1.2
- timescaledb 2.17.2 -> 2.18.2
- supautils 2.5.0 -> 2.6.0
- supabase_vault 0.3.1 (become C)
- VectorChord 0.1.0 -> 0.2.1
- pg_bulkload 3.1.22 (+pg17)
- pg_store_plan 1.8 (+pg17)
- pg_search 0.14 -> 0.15.2
- pg_analytics 0.3.0 -> 0.3.4
- pgroonga 3.2.5 -> 4.0.0
- zhparser 2.2 -> 2.3
- pg_vectorize 0.20.0 -> 0.21.1
- pg_net 0.14.0
- pg_curl 2.4.2
- table_version 1.10.3 -> 1.11.0
- pg_duration 1.0.2
- pg_graphql 1.5.9 -> 1.5.11
- vchord 0.1.1 -> 0.2.1 ((+13))
- vchord_bm25 0.1.0 -> 0.1.1
- pg_mooncake 0.1.1 -> 0.1.2
- pgddl 0.29
- pgsql_tweaks 0.11.0
Infra Updates
- pig 0.1.3 -> 0.3.0
- pushgateway 1.10.0 -> 1.11.0
- alertmanager 0.27.0 -> 0.28.0
- nginx_exporter 1.4.0 -> 1.4.1
- pgbackrest_exporter 0.18.0 -> 0.19.0
- redis_exporter 1.66.0 -> 1.67.0
- mongodb_exporter 0.43.0 -> 0.43.1
- VictoriaMetrics 1.107.0 -> 1.111.0
- VictoriaLogs v1.3.2 -> 1.9.1
- DuckDB 1.1.3 -> 1.2.0
- Etcd 3.5.17 -> 3.5.18
- pg_timetable 5.10.0 -> 5.11.0
- FerretDB 1.24.0 -> 2.0.0-rc
- tigerbeetle 0.16.13 -> 0.16.27
- grafana 11.4.0 -> 11.5.2
- vector 0.43.1 -> 0.44.0
- minio 20241218131544 -> 20250218162555
- mcli 20241121172154 -> 20250215103616
- rclone 1.68.2 -> 1.69.0
- vray 5.23 -> 5.28
Checksums
5b5dbb91c42068e25efc5b420f540909 pigsty-v3.3.0.tgz
048c7d5b3fbf1727e156e7d4885ac2eb pigsty-pkg-v3.3.0.d12.aarch64.tgz
bbb5c225e2a429f49a653695678676b6 pigsty-pkg-v3.3.0.d12.x86_64.tgz
756ec04632fb42c6f75a7b4dd29ffb09 pigsty-pkg-v3.3.0.el9.aarch64.tgz
602e1596219c1e33fdf1cd49e5b17c21 pigsty-pkg-v3.3.0.el9.x86_64.tgz
ca0fd50a99cfc5b342717594e0ca1353 pigsty-pkg-v3.3.0.u22.aarch64.tgz
4c694893c6c42e401516f0070d373b69 pigsty-pkg-v3.3.0.u22.x86_64.tgz
v3.2: The pig CLI, ARM64 Repo, Self-hosting Supabase
The New Year is just around the corner, and Pigsty is celebrating the last release of 2024 with v3.2. This release introduces a new command-line tool, pig, and enhanced ARM extension support. Together, these features deliver a smooth PostgreSQL experience across the top 10 major Linux distributions. This release also includes routine bug fixes, follows up on the changes during Supabase release week, and provides RPM/DEB packages for Grafana extension plugins and data sources.
Pig Command-Line Tool
Pigsty v3.2 comes with a command-line tool, pig, designed to further simplify the installation and deployment process of Pigsty. But pig is more than just a command-line tool for Pigsty; it’s a fully functional PostgreSQL package manager that can be used independently.
Have you ever struggled with installing PostgreSQL extensions, navigating through various distributions, and dealing with different chip architectures? Wasting time on outdated READMEs, obscure configuration scripts, and random GitHub branches? Or perhaps frustrated by the challenges of the domestic network environment, with missing repositories and blocked mirrors? Downloads feel like a traffic jam?
Now, “Pig rides the elephant” is here to solve all your problems: Introducing Pig, a new Go-based package manager designed to handle PostgreSQL and its ever-expanding extension library, without turning your day into a debugging marathon.
Pig is a lightweight binary written in Go, with no dependencies and easy installation: a single command is all it takes to install and start your “pig charge.” It respects the traditional package management systems of operating systems and avoids reinventing the wheel, using yum/dnf/apt to manage packages.
Pig focuses on cross-distribution harmony — whether you’re on Debian, Ubuntu, or Red Hat derivatives, you can have a consistent and smooth method to install and update PostgreSQL and any extensions. No more compiling from source or dealing with incomplete repositories.
If PostgreSQL’s future is unstoppable scalability, Pig is the genie that helps you unlock it. Honestly, no one will ever complain that their PostgreSQL instance has too many extensions — they don’t affect anything when not in use, and when needed, they’re right there, and who doesn’t love a free lunch?
ARM Extension Repository
The magic behind Pig is a supplementary extension repository filled with hard-to-find or newly released extensions, so you always have easy access to high-quality extensions that are tested, well-curated, and ready to use.
Over the past month, Pigsty has fully supported ARM64 architecture. We’ve provided complete ARM support for five major Linux distributions (EL8, EL9, Debian 12, Ubuntu 22/24). “Complete” means that the configuration files you use on AMD64 can be used identically on ARM64 systems. Of course, there are a few exceptions: some extensions currently lack ARM support, and we will address these cases one by one in the future.
Still struggling to find niche Git repositories, incomplete Docker builds, or outdated wiki documentation just to install a required PostgreSQL plugin? We understand your pain. While PostgreSQL’s scalability is superpower-level, the biggest challenge in the ecosystem has always been distribution — how to install various FDWs, vector extensions, GIS libraries, Rust modules, and other “superweapons” without getting stuck in compilation hell?
Now, with the Pigsty Extension Repo, we’ve gathered over 340 carefully selected PostgreSQL extensions, compiled into convenient .rpm and .deb packages supporting multiple versions and architectures. Timescale? Check. Supabase-related? Fully covered. Various DuckDB patches? Ready to go. We’ve built a cross-distribution pipeline that integrates community-developed new extensions, long-standing old modules, and official PGDG packages, allowing them to be installed seamlessly on Debian, Ubuntu, Red Hat, and other major systems with just one click. What’s the secret? We don’t reinvent the wheel; we use each distribution’s native package manager (YUM, APT, DNF, etc.) and align with the official PGDG repositories.
At the core, this repository is part of the larger Pigsty PostgreSQL distribution, but you can also use it independently in your environment without fully adopting Pigsty. We’ve invested a lot of time and effort into patching, testing, and polishing each extension, so you can benefit from it. Everything is free and open-source, and integration is incredibly easy. Several partners are already using it as an additional upstream source for installing extensions!
Want to solve all your PostgreSQL extension headaches? Visit ext.pigsty.io for more details, and check out the full extension index and usage instructions. We’ve packaged and tested every plugin we could find, just to make PostgreSQL the “ultimate form” it was meant to be — after all, who wouldn’t want more superpowers? Come and experience it!
The ARM64 platform support has given me a lot of confidence, and now I’m looking at supporting more chip architectures. For example, IBM LinuxOne Cloud recently sponsored an open-source project with a permanent virtual machine (2c/8g/100g), and most importantly, it’s an s390x mainframe. So I’m planning to try running Pigsty on an IBM mainframe soon, haha.
Supabase Routine Follow-Up
Pigsty previously released a Supabase self-hosting guide to help users quickly set up their own Supabase services on a single machine. This has sparked some attention among startups that heavily use Supabase, so we’ve followed up on the latest version of Supabase.
In the last month of 2024, Supabase rolled out a series of significant updates, and Pigsty v3.2 has incorporated these changes, providing users with the latest version of Supabase. To be honest, aside from AI buzz, most of the updates are: Supabase now offers XXX feature (such as queues), but essentially they’ve just added XXX PG extension (such as PGMQ).
The major move recently from Supabase is OrieloDB (acquired by Supabase mid-year!), an interesting PostgreSQL fork focused on enhancing PG’s OLTP performance. Currently, this feature is marked as Beta in Supabase and available as an optional choice, but I need to ensure that even if Supabase adopts it as the main branch in the future, Pigsty will continue to support it.
We’re currently preparing RPM/DEB packages for OrieloDB and its extensions. With this opportunity, we also plan to expand these superpowers to more PG forks, such as Oracle-compatible IvorySQL 3/4, SQL Server-compatible WiltonDB, and PolarDB PG.
Grafana’s Extensibility
Grafana is a very popular open-source monitoring and visualization tool. Of course, it also has many extension plugins, such as various data visualization panels and data sources. However, installing and managing these extensions has always been an issue. Grafana’s own CLI tool can be used to install plugins, but users in China must use a VPN, which is highly inconvenient.
In v3.2, we’ve packaged common Grafana panel and data source extensions as RPM/DEB packages, making them ready to use out of the box. For example, the following architecture-independent extensions are now packaged as a single grafana-plugins package:
- volkovlabs-echarts-panel
- volkovlabs-image-panel
- volkovlabs-form-panel
- volkovlabs-table-panel
- volkovlabs-variable-panel
- knightss27-weathermap-panel
- marcusolsson-dynamictext-panel
- marcusolsson-treemap-panel
- marcusolsson-calendar-panel
- marcusolsson-hourly-heatmap-panel
- marcusolsson-static-datasource
- marcusolsson-json-datasource
- volkovlabs-rss-datasource
- volkovlabs-grapi-datasource
Additionally, we’ve created independent RPM/DEB packages for architecture-dependent (including x86, ARM binaries) data source extensions, such as the recently released Infinity data source plugin from Grafana: You can use any REST/GRAPHQL API and CSV/TSV/XML/HTML as data sources, greatly extending Grafana’s data access capabilities.
Meanwhile, we’ve also made RPM/DEB packages for VictoriaMetrics and VictoriaLogs’ Grafana data source plugins, so users can easily use these two open-source time-series and log databases in Grafana.
Next Steps
Currently, Pigsty has reached a state that I’m very satisfied with. In the upcoming period, my focus will be on maintaining the pig tool and the extension repository.
This is a rare opportunity window, as both users and developers are starting to realize the importance of extensions, but PostgreSQL still lacks a factual standard for extension distribution. At this crucial moment, I hope that Pigsty/pig can become an influential de facto standard for PG extension plugins and claim the high ground in the ecosystem.
Of course, Pigsty itself has also lacked a sufficiently powerful CLI tool, so I’ll integrate the scattered functions from various Ansible playbooks into pig, making it easier for users to manage Pigsty and PostgreSQL.
v3.2.0 Release Note
Highlights
- New CLI: Introducing the
pigcommand-line tool for managing extension plugins. - ARM64 Support: 390 extensions are now available for ARM64 across five major distributions.
- Supabase Update: Latest Supabase Release Week updates are now supported for self-hosting on all distributions.
- Grafana v11.4: Upgraded Grafana to version 11.4, featuring a new Infinity datasource.
Package Changes
- New Extensions
- Added
timescaledb,timescaledb-loader,timescaledb-toolkit, andtimescaledb-toolto the PIGSTY repository. - Added a custom-compiled pg_timescaledb for EL.
- Added pgroonga, custom-compiled for all EL variants.
- Added vchord 0.1.0.
- Added pg_bestmatch.rs 0.0.1.
- Added pglite_fusion 0.0.3.
- Added pgpdf 0.1.0.
- Added
- Updated Extensions
- pgvectorscale: 0.4.0 → 0.5.1
- pg_parquet: 0.1.0 → 0.1.1
- pg_polyline: 0.0.1
- pg_cardano: 1.0.2 → 1.0.3
- pg_vectorize: 0.20.0
- pg_duckdb: 0.1.0 → 0.2.0
- pg_search: 0.13.0 → 0.13.1
- aggs_for_vecs: 1.3.1 → 1.3.2
- Infrastructure
- Added promscale 0.17.0
- Added grafana-plugins 11.4
- Added grafana-infinity-plugins
- Added grafana-victoriametrics-ds
- Added grafana-victorialogs-ds
- vip-manager: 2.8.0 → 3.0.0
- vector: 0.42.0 → 0.43.0
- grafana: 11.3 → 11.4
- prometheus: 3.0.0 → 3.0.1 (package name changed from
prometheus2toprometheus) - nginx_exporter: 1.3.0 → 1.4.0
- mongodb_exporter: 0.41.2 → 0.43.0
- VictoriaMetrics: 1.106.1 → 1.107.0
- VictoriaLogs: 1.0.0 → 1.3.2
- pg_timetable: 5.9.0 → 5.10.0
- tigerbeetle: 0.16.13 → 0.16.17
- pg_export: 0.7.0 → 0.7.1
- New Docker App
- Add mattermost the open-source Slack alternative self-hosting template
- Bug Fixes
- Added
python3-cdiffforel8.aarch64to fix missing Patroni dependency. - Added
timescaledb-toolsforel9.aarch64to fix missing package in official repo. - Added
pg_filedumpforel9.aarch64to fix missing package in official repo.
- Added
- Removed Extensions
- pg_mooncake: Removed due to conflicts with
pg_duckdb. - pg_top: Removed because of repeated version issues and quality concerns.
- hunspell_pt_pt: Removed because of conflict with official PG dictionary files.
- pgml: Disabled by default (no longer downloaded or installed).
- pg_mooncake: Removed due to conflicts with
API Changes
repo_url_packagesnow defaults to an empty array; packages are installed via OS package managers.grafana_plugin_cacheis deprecated; Grafana plugins are now installed via OS package managers.grafana_plugin_listis deprecated for the same reason.- The 36-node “production” template has been renamed to
simu. - Auto-generated code under
node_id/varsnow includesaarch64support. infra_packagesnow includes thepigCLI tool.- The
configurecommand now updates the version numbers ofpgsql-xxxaliases in auto-generated config files. - Update terraform templates with Makefile shortcuts and better provision experience
Bug Fix
- Fix pgbouncer dashboard selector issue #474
- Add
--arg valuesupport forpg-pitrby @waitingsong - Fix redis log message typo by @waitingsong
Checksums
c42da231067f25104b71a065b4a50e68 pigsty-pkg-v3.2.0.d12.aarch64.tgz
ebb818f98f058f932b57d093d310f5c2 pigsty-pkg-v3.2.0.d12.x86_64.tgz
d2b85676235c9b9f2f8a0ad96c5b15fd pigsty-pkg-v3.2.0.el9.aarch64.tgz
649f79e1d94ec1845931c73f663ae545 pigsty-pkg-v3.2.0.el9.x86_64.tgz
24c0be1d8436f3c64627c12f82665a17 pigsty-pkg-v3.2.0.u22.aarch64.tgz
0b9be0e137661e440cd4f171226d321d pigsty-pkg-v3.2.0.u22.x86_64.tgz
8fdc6a60820909b0a2464b0e2b90a3a6 pigsty-v3.2.0.tgz
v3.2.1 Release Note
Highlights
- 351 PostgreSQL Extensions, including the powerful postgresql-anonymizer 2.0
- IvorySQL 4.0 support for EL 8/9
- Now use the Pigsty compiled Citus, TimescaleDB and pgroonga on all distros
- Add self-hosting Odoo template and support
Bump software versions
- pig CLI 0.1.2 self-updating capability
- prometheus 3.1.0
Add New Extension
- add pg_anon 2.0.0
- add omnisketch 1.0.2
- add ddsketch 1.0.1
- add pg_duration 1.0.1
- add ddl_historization 0.0.7
- add data_historization 1.1.0
- add schedoc 0.0.1
- add floatfile 1.3.1
- add pg_upless 0.0.3
- add pg_task 1.0.0
- add pg_readme 0.7.0
- add vasco 0.1.0
- add pg_xxhash 0.0.1
Update Extension
- lower_quantile 1.0.3
- quantile 1.1.8
- sequential_uuids 1.0.3
- pgmq 1.5.0 (subdir)
- floatvec 1.1.1
- pg_parquet 0.2.0
- wrappers 0.4.4
- pg_later 0.3.0
- topn fix for deb.arm64
- add age 17 on debian
- powa + pg17, 5.0.1
- h3 + pg17
- ogr_fdw + pg17
- age + pg17 1.5 on debian
- pgtap + pg17 1.3.3
- repmgr
- topn + pg17
- pg_partman 5.2.4
- credcheck 3.0
- ogr_fdw 1.1.5
- ddlx 0.29
- postgis 3.5.1
- tdigest 1.4.3
- pg_repack 1.5.2
v3.2.2 Release Note
- New Extension(s):
Omnigres33 extensions, postgres as platform - New Extension:
pg_mooncake: duckdb in postgres - New Extensions:
pg_xxhash - New Extension:
timescaledb_toolkit - New Extension:
pg_xenophile - New Extension:
pg_drop_events - New Extension:
pg_incremental - Bump
citusto 13.0.0 with PostgreSQL 17 support. - Bump
pgmlto 2.10.0 - Bump
pg_extra_timeto 2.0.0 - Bump
pg_vectorizeto 0.20.0
What’s Changed
- Bump IvorySQL to 4.2 (PostgreSQL 17.2)
- Add Arm64 and Debian support for PolarDB kernel
- Add certbot and certbot-nginx to default
infra_packages - Increase pgbouncer max_prepared_statements to 256
- remove
pgxxx-cituspackage alias - hide
pgxxx-olapcategory inpg_extensionsby default
v3.1: PG 17 as default, Better Supabase & MinIO, ARM & U24 support
With the release of PostgreSQL 17.2 earlier this week, Pigsty promptly followed up with its v3.1 release.
In this version, PostgreSQL 17 has been promoted as the default major version, and nearly 400 PostgreSQL extensions are now available out of the box.
Additionally, Pigsty 3.1 introduces the ability to self-hosting Supabase with a simple command, improves best practices for using MinIO the object storage.
It also supports the ARM64 arch, and the newly released Ubuntu 24.04 LTS. And provide a way to simplify configuration management across different OS distro and PG major versions.
Finally, pigsty also provides a range of ready-to-use scenario-based templates in this release.
Self-Hosting Supabase
The complete tutorial for self-hosting supabase
Supabase is an open-source Firebase alternative, a Backend as a Service (BaaS).
Supabase wraps PostgreSQL kernel and vector extensions, alone with authentication, realtime subscriptions, edge functions, object storage, and instant REST and GraphQL APIs from your postgres schema. It let you skip most backend work, requiring only database design and frontend skills to ship quickly.
Currently, Supabase may be the most popular open-source project in the PostgreSQL ecosystem, boasting over 74,000 stars on GitHub. And become quite popular among developers, and startups, since they have a generous free plan, just like cloudflare & neon.
Supabase’s slogan is: “Build in a weekend, Scale to millions”. It has great cost-effectiveness in small scales (4c8g) indeed. But there is no doubt that when you really grow to millions of users, some may choose to self-hosting their own Supabase —— for functionality, performance, cost, and other reasons.
That’s where Pigsty comes in. Pigsty provides a complete one-click self-hosting solution for Supabase. Self-hosted Supabase can enjoy full PostgreSQL monitoring, IaC, PITR, and high availability capability,
You can run the latest PostgreSQL 17(,16,15,14) kernels, (supabase is using the 15 currently), alone with 400 PostgreSQL extensions out-of-the-box. Run on mainstream Linus OS distros with production grade HA PostgreSQL, MinIO, Prometheus & Grafana Stack for observability, and Nginx for reverse proxy.
Since most of the supabase maintained extensions are not available in the official PGDG repo, we have compiled all the RPM/DEBs for these extensions and put them in the Pigsty repo: pg_graphql, pg_jsonschema, wrappers, index_advisor, pg_net, vault, pgjwt, supautils, pg_plan_filter,
Everything is under your control, you have the ability and freedom to scale PGSQL, MinIO, and Supabase itself. And take full advantage of the performance and cost advantages of modern hardware like Gen5 NVMe SSD.
All you need is prepare a VM with several commands and wait for 10 minutes….
curl -fsSL https://repo.pigsty.io/get | bash
./bootstrap # install deps (ansible)
./configure -c supa # use supa config template (IMPORTANT: CHANGE PASSWORDS!)
./install.yml # install pigsty, create ha postgres & minio clusters
./supabase.yml # launch stateless supabase containers with docker compose
PostgreSQL 17
PostgreSQL 17 has some exciting new features, but the most notable improvement is its write performance. I tested it on a 128c physical machine and found that it performed well as expected under pigsty’s default OLTP configuration without any tuning.

pgbench & sysbench results on a 128c BM with PG 17.2
For example, the max LSN Rate (WAL throughput) is around 110 MiB/s @ PostgreSQL 14, while it can reach 180 MiB/s @ PostgreSQL 17. Of course, this is the software bottleneck, not the hardware. We can see a significant improvement in write performance, which is crucial for many OLTP workloads.
The detailed performance comparison will be published in the upcoming blog post, so stay tuned!
400 Extensions
One of the standout features of Pigsty 3.1 is its support for 400 PostgreSQL extensions. This impressive number comes even after carefully pruning over a dozen “obsolete extensions”.
To achieve this milestone, I’ve built a YUM/APT repository that offers pre-packaged RPM/DEB files for the following combinations of operating systems and PostgreSQL versions:
- Operating Systems: EL 8/9, Ubuntu 22.04/24.04, Debian 12
- PostgreSQL Versions: PG 12–17
| Code | OS Distro | x86_64 |
PG17 | PG16 | PG15 | PG14 | PG13 | PG12 |
|---|---|---|---|---|---|---|---|---|
| EL9 | RHEL 9 / Rocky9 / Alma9 | el9.x86_64 |
||||||
| EL8 | RHEL 8 / Rocky8 / Alma8 / Anolis8 | el8.x86_64 |
||||||
| U24 | Ubuntu 24.04 (noble) |
u24.x86_64 |
||||||
| U22 | Ubuntu 22.04 (jammy) |
u22.x86_64 |
||||||
| D12 | Debian 12 (bookworm) |
d12.x86_64 |
Currently, the repository provides packages for the x86_64 architecture. ARM64 and other architectures are under development, and are currently only offered to advanced users upon request.
More importantly, I maintain an Extension Directory that meticulously documents metadata, compatibility across OS/DB versions, and usage guidelines for every extension, helping users quickly locate the extensions they need.

Using the Repository
Pigsty’s extension repository integrates seamlessly with native OS package managers and is openly shared.
You’re not required to use Pigsty to access these extensions. Simply add the repository to your existing system or Dockerfile, then install extensions with standard commands like yum or apt install.
Notably, the popular open-source project postgresql-cluster has already adopted this repository. It integrates with the repository as part of its installation workflow to distribute extensions to its users.

Rust Extensions
The PostgreSQL ecosystem is seeing a growing number of Rust-based extensions developed using the pgrx framework. Pigsty’s repository currently includes 23 Rust extensions.
If you know of a promising extension, feel free to recommend it! I’ll do my best to include them in the repository. If you’re a PostgreSQL extension developer, I’m happy to provide assistance with packaging and distribution to ensure a smooth final delivery process to all end users.
Ubuntu 24.04 Support
Ubuntu 24.04 “Noble” has been out for six months now, and some users have started using it in production. Pigsty 3.1 formally adds support for Ubuntu 24.04 as a primary platform.
That said, being a relatively new system, Ubuntu 24.04 still has a few gaps compared to 22.04. For instance:
- Extensions like
citusandtopnare unavailable system-wide. timescaledb_toolkitlacks pre-built binaries for Ubuntu 24.04 on x86_64.
Despite these minor exceptions, most extensions are fully compatible with Ubuntu 24.04, making it a strong candidate for Pigsty’s supported platforms.
Sunsetting Ubuntu 20.04
As part of this update, Ubuntu 20.04 “Focal” is being retired from Pigsty’s list of primary supported systems, even though its official EOL is in May 2025. This decision stems from challenges like outdated software (e.g., PostGIS) and dependency issues, which made supporting it increasingly impractical. I’m more than happy to see it phased out.
However, you can still technically use Pigsty on Ubuntu 20.04, and subscription customers will continue to receive support for this version.
Current Supported Platforms
Pigsty now supports the following major operating systems:
- EL 8/9
- Ubuntu 22.04 and Ubuntu 24.04
- Debian 12
For these platforms, Pigsty provides the latest packages and the full set of PostgreSQL extensions.
| Code | OS Distro | x86_64 |
PG17 | PG16 | PG15 | PG14 | PG13 | PG12 | Arm64 |
PG17 | PG16 | PG15 | PG14 | PG13 | PG12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EL9 | RHEL 9 / Rocky9 / Alma9 | el9.x86_64 |
el9.arm64 |
||||||||||||
| EL8 | RHEL 8 / Rocky8 / Alma8 / Anolis8 | el8.x86_64 |
el8.arm64 |
||||||||||||
| U24 | Ubuntu 24.04 (noble) |
u24.x86_64 |
u24.arm64 |
||||||||||||
| U22 | Ubuntu 22.04 (jammy) |
u22.x86_64 |
u22.arm64 |
||||||||||||
| D12 | Debian 12 (bookworm) |
d12.x86_64 |
d12.arm64 |
||||||||||||
| D11 | Debian 11 (bullseye) |
d12.x86_64 |
d11.arm64 |
||||||||||||
| U20 | Ubuntu 20.04 (focal) |
d12.x86_64 |
u20.arm64 |
||||||||||||
| EL7 | RHEL7 / CentOS7 / UOS … | d12.x86_64 |
el7.arm64 |
= Primary Support; = Optional; = EOL, Extended Commercial Support
ARM64 Support
The ARM architecture has been steadily gaining ground, particularly in the cloud computing sector, where ARM servers are capturing an increasing market share. Users have been requesting ARM support for Pigsty for over two years. In fact, Pigsty previously supported ARM when adapting for “domestic systems,” but version 3.1 marks the first time ARM64 support is included in the open-source release.
Currently, ARM64 support is in Beta. All the core features are functional, and everything works end-to-end, but the actual performance and reliability need more real-world testing and user feedback.
Supported Features
Most of Pigsty’s key functionalities have been adapted, including the Grafana/Prometheus stack, which now has ARM-compatible packages. The remaining gap lies in PostgreSQL extensions, particularly the 140 extensions maintained by Pigsty. These are still in progress for ARM64 support. However, if you rely on extensions already provided by PGDG(e.g., postgis, pgvector), you should encounter no issues.
Currently, the ARM version runs smoothly on EL9, Debian 12, and Ubuntu 22.04.
- EL8: Missing some official PGDG packages.
- Ubuntu 24.04: A few missing extensions.
Due to these limitations, ARM64 support is not yet recommended for these two platforms.
Future Plans
I plan to run ARM in a pilot phase over the next one or two minor releases. Once the extension ecosystem is complete, ARM64 support will be marked as GA. In the meantime, I welcome feedback from anyone testing Pigsty’s ARM version. Your input will help refine and stabilize the implementation.
Simplified Config
Another significant improvement in Pigsty v3.1 is the simplification of config management. Handling package variations across different OS distros and PG major versions has always been a headache.
The Problem
Different OS distributions often have subtle differences in package names and available software, requiring Pigsty to generate separate configuration files for each distribution. This approach quickly leads to combinatorial explosion. For instance, Pigsty offers config templates for over a dozen scenarios. If each template must support 5–7 operating systems, the total number of configurations becomes unmanageable.
The Solution: Indirection
As the adage in computer science goes: “Any problem can be solved by adding a layer of indirection.”
Version 3.1 addresses this issue by introducing a new configuration file, package_map, which defines package aliases.
For each OS distribution, a node_id/vars file translates these aliases into the specific package names required by the OS.

How It Works
Take the Supabase self-hosting template as an example. It uses dozens of PostgreSQL extensions. Users only need to specify the extension names; details like CPU architecture, OS version, PostgreSQL version, or package names are handled internally.
pg_extensions: # extensions to be installed on this cluster
- supabase # essential extensions for supabase
- timescaledb postgis pg_graphql pg_jsonschema wrappers pg_search pg_analytics pg_parquet plv8 duckdb_fdw pg_cron pg_timetable pgqr
- supautils pg_plan_filter passwordcheck plpgsql_check pgaudit pgsodium pg_vault pgjwt pg_ecdsa pg_session_jwt index_advisor
- pgvector pgvectorscale pg_summarize pg_tiktoken pg_tle pg_stat_monitor hypopg pg_hint_plan pg_http pg_net pg_smtp_client pg_idkit
Here’s an example: If you want to install PostgreSQL 16 and its extensions, you no longer need to manually specify the real package name in
repo_packages and pg_extension (you can still do that!)
the download or installation lists with PG16-specific packages. Instead, you just modify a single parameter: pg_version: 16, all settled!
Infra Improvement
Beyond functional improvements, Pigsty continues to enhance its underlying infrastructure. For instance, in version 3.0, we introduced support for alternative PostgreSQL kernels such as Babelfish (MSSQL compatibility), IvorySQL (Oracle compatibility), and PolarDB (a domestic PG-compatible kernel).
Previously, users needed to install these kernels from external repositories online. With Pigsty v3.1, the official repository now directly includes mirrors of Babelfish/WiltonDB, IvorySQL, PolarDB, and similar “exotic” PostgreSQL kernels. This means installation is now much simpler—just use the pre-configured templates, and you can set up these alternative kernels with a single command, no extra configuration required.
Additionally, Pigsty maintains Prometheus and Grafana repositories for both YUM and APT package managers, supporting AMD and ARM architectures. These repositories are updated in real-time to track the latest versions of these observability tools. In this release:
- Prometheus was upgraded to its major v3 version.
- VictoriaLogs officially released its v1.0 version.
If you rely on these monitoring tools, Pigsty’s repositories can be a valuable resource.
Improvements to MinIO
Let’s talk about MinIO, an open-source object storage solution. Pigsty leverages MinIO for PostgreSQL backups and as the underlying storage service for Supabase. Our goal with MinIO has always been to reduce deployment complexity to the bare minimum —— “Deploy in minutes, Scale to millions.”
When we first adopted MinIO internally, it was still in its 0.x days. At the time, we used it to store 25 PB of data, but since MinIO didn’t support online scaling, we had to break this into 7–8 independent clusters. Today, MinIO has come a long way. While it still doesn’t support directly modifying disk/node counts online, it now offers storage pool expansion. This allows smooth scaling by adding new storage pools, migrating data, and retiring old ones without downtime.
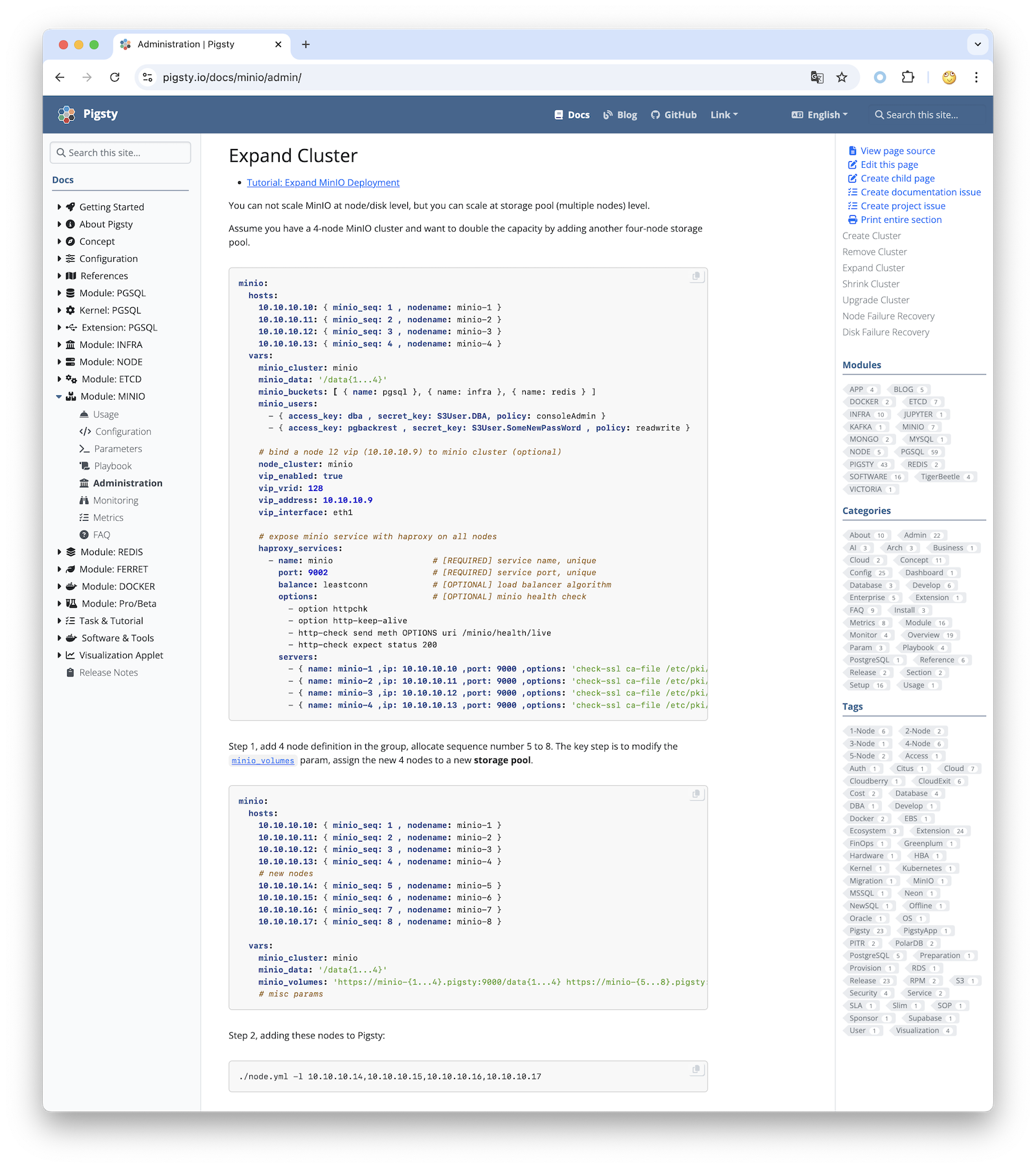
For v3.1, I re-read MinIO’s latest documentation and updated the best-practice templates and SOPs to reflect its new features. These include:
- Single node, single disk
- Single node, multi-disk
- Multi-node, multi-disk
- Multi-storage-pool deployments
- Handling disk failures and node failures
- Expand/Shrink cluster
- Using VIP and HAProxy for high-availability access
All procedures are documented and can be executed with just a few commands.
The Case for MinIO
Object storage is foundational for modern cloud infrastructure. MinIO, as a leading open-source object storage solution, delivers excellent performance and features. Most importantly, it is cloud-neutral, giving you independence from cloud vendor lock-in.
MinIO is also a compelling alternative to cloud object storage. Consider the scenario outlined in “DHH: Our cloud-exit savings will now top ten million over five years”:
- Their cloud infrastructure included 10 PB of object storage.
- The standard cost: $3M/year, reduced to $1.3M/year with saving plans
- By contrast, a dedicated storage server with 1.2 PB of capacity costs just $20,000.
- With OSS MinIO, 3-copies, DC, power, operations, the 5year TCO is still less than the one-year S3 cost.
If your business heavily relies on object storage, a self-hosted MinIO deployment combined with Cloudflare for external access could unlock significant cost savings and efficiency improvements. For many use cases, it’s an optimization worth serious consideration.
v3.1.0
Features
- PostgreSQL 17 as the default major version (17.2)
- Ubuntu 24.04 noble support
- ARM64 support (el9, debian12, ubuntu 22.04)
- New playbook
supabase.ymlfor quick self-hosting supabase - MinIO Enhancement, best, practice, conf template, dashboards,…
- Allow using
-vto specify PG major version duringconfigure - A series of out-of-the-box configuration templates and documentation.
- Now install the
pgvectorextension by default - Simplify the repo packages configuration with package map alias
- Setup WiltonDB, IvorySQL, PolarDB repo mirror
- Enable postgres checksum by default
Software Upgrades
- PostgreSQL 17.2, 16.6, 15.10, 14.15, 13.18, 12.22
- PostgreSQL Extension Upgrades: https://ext.pigsty.io
- Patroni 4.0.4
- MinIO 20241107 / MCLI 20241117
- Rclone 1.68.2
- Prometheus: 2.54.0 -> 3.0.0
- VictoriaMetrics 1.102.1 -> 1.106.1
- VictoriaLogs v0.28.0 -> 1.0.0
- vslogcli 1.0.0
- MySQL Exporter 0.15.1 -> 0.16.0
- Redis Exporter 1.62.0 -> 1.66.0
- MongoDB Exporter 0.41.2 -> 0.42.0
- Keepalived Exporter 1.3.3 -> 1.4.0
- DuckDB 1.1.2 -> 1.1.3
- etcd 3.5.16 -> 3.5.17
- tigerbeetle 16.8 -> 0.16.13
API Change
repo_upstream: Now has defaults per distro:roles/node_id/vars.repo_packages: Now support usingpackage_mapalias.repo_extra_packages: Now support missing default values, and usingpackage_mapalias.pg_checksum: Now the default value istrue.pg_packages: Change topostgresql, wal2json pg_repack pgvector, patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager.pg_extensions: Change to empty array[].infra_portal: Now allow usingpathin thehomeserver.
News: Pigsty v3.1 Released
Pigsty v3.1 is now live, closely following the release of PostgreSQL 17.2. This version marks PostgreSQL 17 as the default, featuring compatibility with the latest Ubuntu 24.04 LTS and initial ARM64 arch support. It also introduces nearly 400 ready-to-use PostgreSQL extensions right from the start.
A notable feature is the one-click setup for a self-hosted Supabase, which is built upon PostgreSQL. Pigsty v3.1 enables you to run Supabase on local-first HA PostgreSQL (ver14-17) alone with 300+ extensions on mainstream Linux distros without virtualization or containers, utilizing modern hardware to its full potential.
The update enhances its repository with new PostgreSQL-compatible kernels like Babelfish, IvorySQL, and PolarDB,
and the OLAP / DuckDB race players such as pg_analytics, pg_duckdb, pg_mooncake, pg_parquet, and duckdb_fdw,
now directly accessible for the pigsty repo.
Additionally, MinIO best practices have been refined to lower deployment barriers and allow expanding existing clusters, which are detailed in the new admin SOP.
Pigsty 3.1 simplifies configuration across various OS distros by standardizing scenario-based config templates.
You can download and install kernels and extensions by specifying their name. and changing the significant versions with just one pg_version parameter.
With comprehensive support for new operating systems and architectural improvements, Pigsty 3.1 aims to deliver a more feature-rich and cost-effective OSS RDS PG solution. I hope this could help you easily enjoy the latest PostgreSQL features and extensions.
Pigsty v3.0: Extension Exploding & Plugable Kernels
Get started with:
curl -fsSL https://repo.pigsty.io/get | bash
cd ~/pigsty; ./bootstrap; ./configure; ./install.yml
Highlight Features
Extension Exploding:
Pigsty now has an unprecedented 400 available extensions for PostgreSQL. This includes 121 extension RPM packages and 133 DEB packages, surpassing the total number of extensions provided by the PGDG official repository (135 RPM/109 DEB). Pigsty has ported unique PG extensions from the EL/DEB system to each other, achieving a great alignment of extension ecosystems between the two major distributions.
A crude list of the extension ecosystem is as follows:
- timescaledb periods temporal_tables emaj table_version pg_cron pg_later pg_background pg_timetable
- postgis pgrouting pointcloud pg_h3 q3c ogr_fdw geoip #pg_geohash #mobilitydb
- pgvector pgvectorscale pg_vectorize pg_similarity pg_tiktoken pgml #smlar
- pg_search pg_bigm zhparser hunspell
- hydra pg_lakehouse pg_duckdb duckdb_fdw pg_fkpart pg_partman plproxy #pg_strom citus
- pg_hint_plan age hll rum pg_graphql pg_jsonschema jsquery index_advisor hypopg imgsmlr pg_ivm pgmq pgq #rdkit
- pg_tle plv8 pllua plprql pldebugger plpgsql_check plprofiler plsh #pljava plr pgtap faker dbt2
- prefix semver pgunit md5hash asn1oid roaringbitmap pgfaceting pgsphere pg_country pg_currency pgmp numeral pg_rational pguint ip4r timestamp9 chkpass #pg_uri #pgemailaddr #acl #debversion #pg_rrule
- topn pg_gzip pg_http pg_net pg_html5_email_address pgsql_tweaks pg_extra_time pg_timeit count_distinct extra_window_functions first_last_agg tdigest aggs_for_arrays pg_arraymath pg_idkit pg_uuidv7 permuteseq pg_hashids
- sequential_uuids pg_math pg_random pg_base36 pg_base62 floatvec pg_financial pgjwt pg_hashlib shacrypt cryptint pg_ecdsa pgpcre icu_ext envvar url_encode #pg_zstd #aggs_for_vecs #quantile #lower_quantile #pgqr #pg_protobuf
- pg_repack pg_squeeze pg_dirtyread pgfincore pgdd ddlx pg_prioritize pg_checksums pg_readonly safeupdate pg_permissions pgautofailover pg_catcheck preprepare pgcozy pg_orphaned pg_crash pg_cheat_funcs pg_savior table_log pg_fio #pgpool pgagent
- pg_profile pg_show_plans pg_stat_kcache pg_stat_monitor pg_qualstats pg_store_plans pg_track_settings pg_wait_sampling system_stats pg_meta pgnodemx pg_sqlog bgw_replstatus pgmeminfo toastinfo pagevis powa pg_top #pg_statviz #pgexporter_ext #pg_mon
- passwordcheck supautils pgsodium pg_vault anonymizer pg_tde pgsmcrypto pgaudit pgauditlogtofile pg_auth_mon credcheck pgcryptokey pg_jobmon logerrors login_hook set_user pg_snakeoil pgextwlist pg_auditor noset #sslutils
- wrappers multicorn mysql_fdw tds_fdw sqlite_fdw pgbouncer_fdw mongo_fdw redis_fdw pg_redis_pubsub kafka_fdw hdfs_fdw firebird_fdw aws_s3 log_fdw #oracle_fdw #db2_fdw
- orafce pgtt session_variable pg_statement_rollback pg_dbms_metadata pg_dbms_lock pgmemcache #pg_dbms_job #wiltondb
- pglogical pgl_ddl_deploy pg_failover_slots wal2json wal2mongo decoderbufs decoder_raw mimeo pgcopydb pgloader pg_fact_loader pg_bulkload pg_comparator pgimportdoc pgexportdoc #repmgr #slony
- gis-stack rag-stack fdw-stack fts-stack etl-stack feat-stack olap-stack supa-stack stat-stack json-stack
Plugable Kernels:
Pigsty v3 allows you to replace the PostgreSQL kernel, currently supporting Babelfish (SQL Server compatible, with wire protocol emulation), IvorySQL (Oracle compatible), and RAC PolarDB for PostgreSQL. Additionally, self-hosted Supabase is now available on Debian systems. You can emulate MSSQL (via WiltonDB), Oracle (via IvorySQL), Oracle RAC (via PolarDB), MongoDB (via FerretDB), and Firebase (via Supabase) in Pigsty with production-grade PostgreSQL clusters featuring HA, IaC, PITR, and monitoring.
Pro Edition:
We now offer PGSTY Pro, a professional edition that provides value-added services on top of the open-source features. The professional edition includes additional modules: MSSQL, Oracle, Mongo, K8S, Victoria, Kafka, etc., and offers broader support for PG major versions, operating systems, and chip architectures. It provides offline installation packages customized for precise minor versions of all operating systems, and support for legacy systems like EL7, Debian 11, Ubuntu 20.04.
Major Changes
This Pigsty release updates the major version number from 2.x to 3.0, with several significant changes:
- Primary supported operating systems updated to: EL 8 / EL 9 / Debian 12 / Ubuntu 22.04
- EL7 / Debian 11 / Ubuntu 20.04 systems are now deprecated and no longer supported.
- Users needing to run on these systems should consider our subscription service.
- Default to online installation, offline packages are no longer provided to resolve minor OS version compatibility issues.
- The
bootstrapprocess will no longer prompt for downloading offline packages, but if/tmp/pkg.tgzexists, it will still use the offline package automatically. - For offline installation needs, please create offline packages yourself or consider our pro version.
- The
- Unified adjustment of upstream software repositories used by Pigsty, address changes, and GPG signing and verification for all packages.
- Standard repository:
https://repo.pigsty.io/{apt/yum} - Domestic mirror:
https://repo.pigsty.cc/{apt/yum}
- Standard repository:
- API parameter changes and configuration template changes
- Configuration templates for EL and Debian systems are now consolidated, with differing parameters managed in the
roles/node_id/vars/directory. - Configuration directory changes, all configuration file templates are now placed in the
confdirectory and categorized intodefault,dbms,demo,build.
- Configuration templates for EL and Debian systems are now consolidated, with differing parameters managed in the
Dockeris now completely treated as a separate module, and will not be downloaded by default- New beta module:
KAFKA - New beta module:
KUBE
Other New Features
- Epic enhancement of PG OLAP analysis capabilities: DuckDB 1.0.0, DuckDB FDW, and PG Lakehouse, Hydra have been ported to the Debian system.
- Strengthened PG vector search and full-text search capabilities: Vectorscale provides DiskANN vector indexing, Hunspell dictionary support, pg_search 0.8.6.
- Resolved package build issues for ParadeDB, now available on Debian/Ubuntu.
- All required extensions for Supabase are now available on Debian/Ubuntu, making Supabase self-hostable across all OSes.
- Provided capability for scenario-based pre-configured extension stacks. If you’re unsure which extensions to install, we offer extension recommendation packages (Stacks) tailored for specific application scenarios.
- Created metadata tables, documentation, indexes, and name mappings for all PostgreSQL ecosystem extensions, ensuring alignment and usability for both EL and Debian systems.
- Enhanced
proxy_envparameter functionality to mitigate DockerHub ban issues, simplifying configuration. - Established a new dedicated software repository offering all extension plugins for versions 12-17, with the PG16 extension repository implemented by default in Pigsty.
- Upgraded existing software repositories, employing standard signing and verification mechanisms to ensure package integrity and security. The APT repository adopts a new standard layout built through
reprepro. - Provided sandbox environments for 1, 2, 3, 4, 43 nodes:
meta,dual,trio,full,prod, and quick configuration templates for 7 major OS Distros. - Add PostgreSQL 17 and pgBouncer 1.23 metrics support in pg_exporter config, adding related dashboard panels.
- Add logs panel for PGSQL Pgbouncer / PGSQL Patroni Dashboard
- Add new playbook
cache.ymlto make offline packages, instead of bashbin/cacheandbin/release-pkg
API Changes
-
New parameter option:
pg_modenow have several new options:pgsql: Standard PostgreSQL high availability cluster.citus: Citus horizontally distributed PostgreSQL native high availability cluster.gpsql: Monitoring for Greenplum and GP compatible databases (Pro edition).mssql: Install WiltonDB / Babelfish to provide Microsoft SQL Server compatibility mode for standard PostgreSQL high availability clusters, with wire protocol level support, extensions unavailable.ivory: Install IvorySQL to provide Oracle compatibility for PostgreSQL high availability clusters, supporting Oracle syntax/data types/functions/stored procedures, extensions unavailable (Pro edition).polar: Install PolarDB for PostgreSQL (PG RAC) open-source version to support localization database capabilities, extensions unavailable (Pro edition).
-
New parameter option:
pg_modenow have several new options:pgsql: Standard PostgreSQL high availability cluster.citus: Citus horizontally distributed PostgreSQL native high availability cluster.gpsql: Monitoring for Greenplum and GP compatible databases (Pro edition).mssql: Install WiltonDB / Babelfish to provide Microsoft SQL Server compatibility mode for standard PostgreSQL high availability clusters, with wire protocol level support, extensions unavailable.ivory: Install IvorySQL to provide Oracle compatibility for PostgreSQL high availability clusters, supporting Oracle syntax/data types/functions/stored procedures, extensions unavailable (Pro edition).polar: Install PolarDB for PostgreSQL (PG RAC) open-source version to support localization database capabilities, extensions unavailable (Pro edition).
-
New parameter:
pg_parameters, used to specify parameters inpostgresql.auto.confat the instance level, overriding cluster configurations for personalized settings on different instance members. -
New parameter:
pg_files, used to specify additional files to be written to the PostgreSQL data directory, to support license feature required by some kernel forks. -
New parameter:
repo_extra_packages, used to specify additional packages to download, to be used in conjunction withrepo_packages, facilitating the specification of extension lists unique to OS versions. -
Parameter renaming:
patroni_citus_dbrenamed topg_primary_db, used to specify the primary database in the cluster (used in Citus mode). -
Parameter enhancement: Proxy server configurations in
proxy_envwill be written to the Docker Daemon to address internet access issues, and theconfigure -xoption will automatically write the proxy server configuration of the current environment. -
Parameter enhancement: Allow using
pathitem ininfra_portalentries, to expose local dir as web service rather than proxy to another upstream. -
Parameter enhancement: The
repo_url_packagesinrepo.pigsty.iowill automatically switch torepo.pigsty.ccwhen the region is China, addressing internet access issues. Additionally, the downloaded file name can now be specified. -
Parameter enhancement: The
extensionfield inpg_databases.extensionsnow supports both dictionary and extension name string modes. The dictionary mode offersversionsupport, allowing the installation of specific extension versions. -
Parameter enhancement: If the
repo_upstreamparameter is not explicitly overridden, it will extract the default value for the corresponding system fromrpm.ymlordeb.yml. -
Parameter enhancement: If the
repo_packagesparameter is not explicitly overridden, it will extract the default value for the corresponding system fromrpm.ymlordeb.yml. -
Parameter enhancement: If the
infra_packagesparameter is not explicitly overridden, it will extract the default value for the corresponding system fromrpm.ymlordeb.yml. -
Parameter enhancement: If the
node_default_packagesparameter is not explicitly overridden, it will extract the default value for the corresponding system fromrpm.ymlordeb.yml. -
Parameter enhancement: The extensions specified in
pg_packagesandpg_extensionswill now perform a lookup and translation from thepg_package_mapdefined inrpm.ymlordeb.yml. -
Parameter enhancement: Packages specified in
node_packagesandpg_extensionswill be upgraded to the latest version upon installation. The default value innode_packagesis now[openssh-server], helping to fix the OpenSSH CVE. -
Parameter enhancement:
pg_dbsu_uidwill automatically adjust to26(EL) or543(Debian) based on the operating system type, avoiding manual adjustments. -
pgBouncer Parameter update,
max_prepared_statements = 128enabled prepared statement support in transaction pooling mode, and setserver_lifetimeto 600. -
Patroni template parameter update, uniformly increase
max_worker_processes+8 available backend processes, increasemax_wal_sendersandmax_replication_slotsto 50, and increase the OLAP template temporary file size limit to 1/5 of the main disk.
Software Upgrade
The main components of Pigsty are upgraded to the following versions (as of the release time):
- PostgreSQL 16.4, 15.8, 14.13, 13.16, 12.20
- pg_exporter : 0.7.0
- Patroni: 3.3.2
- pgBouncer: 1.23.1
- pgBackRest: 2.53.1
- duckdb : 1.0.0
- etcd : 3.5.15
- pg_timetable: 5.9.0
- ferretdb: 1.23.1
- vip-manager: 2.6.0
- minio: 20240817012454
- mcli: 20240817113350
- grafana : 11.1.4
- loki : 3.1.1
- promtail : 3.0.0
- prometheus : 2.54.0
- pushgateway : 1.9.0
- alertmanager : 0.27.0
- blackbox_exporter : 0.25.0
- nginx_exporter : 1.3.0
- node_exporter : 1.8.2
- keepalived_exporter : 0.7.0
- pgbackrest_exporter 0.18.0
- mysqld_exporter : 0.15.1
- redis_exporter : v1.62.0
- kafka_exporter : 1.8.0
- mongodb_exporter : 0.40.0
- VictoriaMetrics : 1.102.1
- VictoriaLogs : v0.28.0
- sealos: 5.0.0
- vector : 0.40.0
The complete list of PostgreSQL extensions can be found here.
| Extension (URL) | Alias | Repo | Version | Category | License | LOAD |
DDL |
TRUST |
RELOC |
Description |
|---|---|---|---|---|---|---|---|---|---|---|
| timescaledb | timescaledb |
PGDG | 2.15.3 | TIME |
Timescale | Enables scalable inserts and complex queries for time-series data (Apache 2 Edition) | ||||
| periods | periods |
PGDG | 1.2 | TIME |
PostgreSQL | Provide Standard SQL functionality for PERIODs and SYSTEM VERSIONING | ||||
| temporal_tables | temporal_tables |
PGDG | 1.2.2 | TIME |
BSD 2 | temporal tables | ||||
| emaj | emaj |
PGDG | 4.4.0 | TIME |
GPLv3 | E-Maj extension enables fine-grained write logging and time travel on subsets of the database. | ||||
| table_version | table_version |
PGDG | 1.10.3 | TIME |
BSD 3 | PostgreSQL table versioning extension | ||||
| pg_cron | pg_cron |
PGDG | 1.6 | TIME |
PostgreSQL | Job scheduler for PostgreSQL | ||||
| pg_later | pg_later |
PIGSTY | 0.1.1 | TIME |
PostgreSQL | pg_later: Run queries now and get results later | ||||
| pg_background | pg_background |
PGDG | 1.0 | TIME |
GPLv3 | Run SQL queries in the background | ||||
| pg_timetable | pg_timetable |
PGDG | 5.9.0 | TIME |
PostgreSQL | Advanced scheduling for PostgreSQL | ||||
| postgis | postgis |
PGDG | 3.4.2 | GIS |
GPLv2 | PostGIS geometry and geography spatial types and functions | ||||
| postgis_topology | postgis |
PGDG | 3.4.2 | GIS |
GPLv2 | PostGIS topology spatial types and functions | ||||
| postgis_raster | postgis |
PGDG | 3.4.2 | GIS |
GPLv2 | PostGIS raster types and functions | ||||
| postgis_sfcgal | postgis |
PGDG | 3.4.2 | GIS |
GPLv2 | PostGIS SFCGAL functions | ||||
| postgis_tiger_geocoder | postgis |
PGDG | 3.4.2 | GIS |
GPLv2 | PostGIS tiger geocoder and reverse geocoder | ||||
| address_standardizer | postgis |
PGDG | 3.4.2 | GIS |
GPLv2 | Used to parse an address into constituent elements. Generally used to support geocoding address normalization step. | ||||
| address_standardizer_data_us | postgis |
PGDG | 3.4.2 | GIS |
GPLv2 | Address Standardizer US dataset example | ||||
| pgrouting | pgrouting |
PGDG | 3.6.0 | GIS |
GPLv2 | pgRouting Extension | ||||
| pointcloud | pointcloud |
PIGSTY | 1.2.5 | GIS |
BSD 3 | data type for lidar point clouds | ||||
| pointcloud_postgis | pointcloud |
PGDG | 1.2.5 | GIS |
BSD 3 | integration for pointcloud LIDAR data and PostGIS geometry data | ||||
| h3 | pg_h3 |
PGDG | 4.1.3 | GIS |
Apache-2.0 | H3 bindings for PostgreSQL | ||||
| h3_postgis | pg_h3 |
PGDG | 4.1.3 | GIS |
Apache-2.0 | H3 PostGIS integration | ||||
| q3c | q3c |
PIGSTY | 2.0.1 | GIS |
GPLv2 | q3c sky indexing plugin | ||||
| ogr_fdw | ogr_fdw |
PGDG | 1.1 | GIS |
MIT | foreign-data wrapper for GIS data access | ||||
| geoip | geoip |
PGDG | 0.3.0 | GIS |
BSD 2 | IP-based geolocation query | ||||
| pg_geohash | pg_geohash |
PIGSTY | 1.0 | GIS |
MIT | Handle geohash based functionality for spatial coordinates | ||||
| mobilitydb | mobilitydb |
PGDG | 1.1.1 | GIS |
GPLv3 | MobilityDB geospatial trajectory data management & analysis platform | ||||
| earthdistance | earthdistance |
CONTRIB | 1.1 | GIS |
PostgreSQL | calculate great-circle distances on the surface of the Earth | ||||
| vector | pgvector |
PGDG | 0.7.3 | RAG |
PostgreSQL | vector data type and ivfflat and hnsw access methods | ||||
| vectorscale | pgvectorscale |
PIGSTY | 0.2.0 | RAG |
PostgreSQL | pgvectorscale: Advanced indexing for vector data | ||||
| vectorize | pg_vectorize |
PIGSTY | 0.17.0 | RAG |
PostgreSQL | The simplest way to do vector search on Postgres | ||||
| pg_similarity | pg_similarity |
PIGSTY | 1.0 | RAG |
BSD 3 | support similarity queries | ||||
| smlar | smlar |
PIGSTY | 1.0 | RAG |
PostgreSQL | Effective similarity search | ||||
| pg_tiktoken | pg_tiktoken |
PIGSTY | 0.0.1 | RAG |
Apache-2.0 | pg_tictoken: tiktoken tokenizer for use with OpenAI models in postgres | ||||
| pgml | pgml |
PIGSTY | 2.9.3 | RAG |
MIT | PostgresML: Run AL/ML workloads with SQL interface | ||||
| pg_search | pg_search |
PIGSTY | 0.9.1 | FTS |
AGPLv3 | pg_search: Full text search for PostgreSQL using BM25 | ||||
| pg_bigm | pg_bigm |
PGDG | 1.2 | FTS |
PostgreSQL | create 2-gram (bigram) index for faster full text search. | ||||
| zhparser | zhparser |
PIGSTY | 2.2 | FTS |
PostgreSQL | a parser for full-text search of Chinese | ||||
| hunspell_cs_cz | hunspell_cs_cz |
PIGSTY | 1.0 | FTS |
PostgreSQL | Czech Hunspell Dictionary | ||||
| hunspell_de_de | hunspell_de_de |
PIGSTY | 1.0 | FTS |
PostgreSQL | German Hunspell Dictionary | ||||
| hunspell_en_us | hunspell_en_us |
PIGSTY | 1.0 | FTS |
PostgreSQL | en_US Hunspell Dictionary | ||||
| hunspell_fr | hunspell_fr |
PIGSTY | 1.0 | FTS |
PostgreSQL | French Hunspell Dictionary | ||||
| hunspell_ne_np | hunspell_ne_np |
PIGSTY | 1.0 | FTS |
PostgreSQL | Nepali Hunspell Dictionary | ||||
| hunspell_nl_nl | hunspell_nl_nl |
PIGSTY | 1.0 | FTS |
PostgreSQL | Dutch Hunspell Dictionary | ||||
| hunspell_nn_no | hunspell_nn_no |
PIGSTY | 1.0 | FTS |
PostgreSQL | Norwegian (norsk) Hunspell Dictionary | ||||
| hunspell_pt_pt | hunspell_pt_pt |
PIGSTY | 1.0 | FTS |
PostgreSQL | Portuguese Hunspell Dictionary | ||||
| hunspell_ru_ru | hunspell_ru_ru |
PIGSTY | 1.0 | FTS |
PostgreSQL | Russian Hunspell Dictionary | ||||
| hunspell_ru_ru_aot | hunspell_ru_ru_aot |
PIGSTY | 1.0 | FTS |
PostgreSQL | Russian Hunspell Dictionary (from AOT.ru group) | ||||
| fuzzystrmatch | fuzzystrmatch |
CONTRIB | 1.2 | FTS |
PostgreSQL | determine similarities and distance between strings | ||||
| pg_trgm | pg_trgm |
CONTRIB | 1.6 | FTS |
PostgreSQL | text similarity measurement and index searching based on trigrams | ||||
| citus | citus |
PGDG | 12.1-1 | OLAP |
AGPLv3 | Distributed PostgreSQL as an extension | ||||
| citus_columnar | citus |
PGDG | 11.3-1 | OLAP |
AGPLv3 | Citus columnar storage engine | ||||
| columnar | hydra |
PIGSTY | 11.1-11 | OLAP |
AGPLv3 | Hydra Columnar extension | ||||
| pg_lakehouse | pg_lakehouse |
PIGSTY | 0.9.0 | OLAP |
AGPLv3 | pg_lakehouse: An analytical query engine for Postgres | ||||
| pg_duckdb | pg_duckdb |
PIGSTY | 0.0.1 | OLAP |
MIT | DuckDB Embedded in Postgres | ||||
| duckdb_fdw | duckdb_fdw |
PIGSTY | 1.0.0 | OLAP |
MIT | DuckDB Foreign Data Wrapper | ||||
| parquet_s3_fdw | parquet_s3_fdw |
PIGSTY | 0.3.1 | OLAP |
MIT | foreign-data wrapper for parquet on S3 | ||||
| pg_fkpart | pg_fkpart |
PGDG | 1.7 | OLAP |
GPLv2 | Table partitioning by foreign key utility | ||||
| pg_partman | pg_partman |
PGDG | 5.1.0 | OLAP |
PostgreSQL | Extension to manage partitioned tables by time or ID | ||||
| plproxy | plproxy |
PGDG | 2.11.0 | OLAP |
BSD 0 | Database partitioning implemented as procedural language | ||||
| pg_strom | pg_strom |
PGDG | 5.1 | OLAP |
PostgreSQL | PG-Strom - big-data processing acceleration using GPU and NVME | ||||
| tablefunc | tablefunc |
CONTRIB | 1.0 | OLAP |
PostgreSQL | functions that manipulate whole tables, including crosstab | ||||
| age | age |
PIGSTY | 1.5.0 | FEAT |
Apache-2.0 | AGE graph database extension | ||||
| hll | hll |
PGDG | 2.18 | FEAT |
Apache-2.0 | type for storing hyperloglog data | ||||
| rum | rum |
PGDG | 1.3 | FEAT |
PostgreSQL | RUM index access method | ||||
| pg_graphql | pg_graphql |
PIGSTY | 1.5.7 | FEAT |
Apache-2.0 | pg_graphql: GraphQL support | ||||
| pg_jsonschema | pg_jsonschema |
PIGSTY | 0.3.1 | FEAT |
Apache-2.0 | PostgreSQL extension providing JSON Schema validation | ||||
| jsquery | jsquery |
PGDG | 1.1 | FEAT |
PostgreSQL | data type for jsonb inspection | ||||
| pg_hint_plan | pg_hint_plan |
PGDG | 1.6.0 | FEAT |
BSD 3 | Give PostgreSQL ability to manually force some decisions in execution plans. | ||||
| hypopg | hypopg |
PGDG | 1.4.1 | FEAT |
PostgreSQL | Hypothetical indexes for PostgreSQL | ||||
| index_advisor | index_advisor |
PIGSTY | 0.2.0 | FEAT |
PostgreSQL | Query index advisor | ||||
| imgsmlr | imgsmlr |
PIGSTY | 1.0 | FEAT |
PostgreSQL | Image similarity with haar | ||||
| pg_ivm | pg_ivm |
PGDG | 1.8 | FEAT |
PostgreSQL | incremental view maintenance on PostgreSQL | ||||
| pgmq | pgmq |
PIGSTY | 1.2.1 | FEAT |
PostgreSQL | A lightweight message queue. Like AWS SQS and RSMQ but on Postgres. | ||||
| pgq | pgq |
PGDG | 3.5.1 | FEAT |
ISC | Generic queue for PostgreSQL | ||||
| rdkit | rdkit |
PGDG | 4.3.0 | FEAT |
BSD 3 | Cheminformatics functionality for PostgreSQL. | ||||
| bloom | bloom |
CONTRIB | 1.0 | FEAT |
PostgreSQL | bloom access method - signature file based index | ||||
| pg_tle | pg_tle |
PIGSTY | 1.2.0 | LANG |
Apache-2.0 | Trusted Language Extensions for PostgreSQL | ||||
| plv8 | plv8 |
PIGSTY | 3.2.2 | LANG |
PostgreSQL | PL/JavaScript (v8) trusted procedural language | ||||
| plluau | pllua |
PGDG | 2.0 | LANG |
MIT | Lua as an untrusted procedural language | ||||
| hstore_plluau | pllua |
PGDG | 1.0 | LANG |
MIT | Hstore transform for untrusted Lua | ||||
| pllua | pllua |
PGDG | 2.0 | LANG |
MIT | Lua as a procedural language | ||||
| hstore_pllua | pllua |
PGDG | 1.0 | LANG |
MIT | Hstore transform for Lua | ||||
| plprql | plprql |
PIGSTY | 0.1.0 | LANG |
Apache-2.0 | Use PRQL in PostgreSQL - Pipelined Relational Query Language | ||||
| pldbgapi | pldebugger |
PGDG | 1.1 | LANG |
Artistic | server-side support for debugging PL/pgSQL functions | ||||
| plpgsql_check | plpgsql_check |
PGDG | 2.7 | LANG |
MIT | extended check for plpgsql functions | ||||
| plprofiler | plprofiler |
PGDG | 4.2 | LANG |
Artistic | server-side support for profiling PL/pgSQL functions | ||||
| plsh | plsh |
PGDG | 2 | LANG |
MIT | PL/sh procedural language | ||||
| pljava | pljava |
PGDG | 1.6.6 | LANG |
BSD 3 | PL/Java procedural language (https://tada.github.io/pljava/) | ||||
| plr | plr |
PGDG | 8.4.6 | LANG |
GPLv2 | load R interpreter and execute R script from within a database | ||||
| pgtap | pgtap |
PGDG | 1.3.1 | LANG |
PostgreSQL | Unit testing for PostgreSQL | ||||
| faker | faker |
PGDG | 0.5.3 | LANG |
PostgreSQL | Wrapper for the Faker Python library | ||||
| dbt2 | dbt2 |
PGDG | 0.45.0 | LANG |
Artistic | OSDL-DBT-2 test kit | ||||
| pltcl | pltcl |
CONTRIB | 1.0 | LANG |
PostgreSQL | PL/Tcl procedural language | ||||
| pltclu | pltcl |
CONTRIB | 1.0 | LANG |
PostgreSQL | PL/TclU untrusted procedural language | ||||
| plperl | plperl |
CONTRIB | 1.0 | LANG |
PostgreSQL | PL/Perl procedural language | ||||
| bool_plperl | plperl |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between bool and plperl | ||||
| hstore_plperl | plperl |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between hstore and plperl | ||||
| jsonb_plperl | plperl |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between jsonb and plperl | ||||
| plperlu | plperlu |
CONTRIB | 1.0 | LANG |
PostgreSQL | PL/PerlU untrusted procedural language | ||||
| bool_plperlu | plperlu |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between bool and plperlu | ||||
| jsonb_plperlu | plperlu |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between jsonb and plperlu | ||||
| hstore_plperlu | plperlu |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between hstore and plperlu | ||||
| plpgsql | plpgsql |
CONTRIB | 1.0 | LANG |
PostgreSQL | PL/pgSQL procedural language | ||||
| plpython3u | plpython3u |
CONTRIB | 1.0 | LANG |
PostgreSQL | PL/Python3U untrusted procedural language | ||||
| jsonb_plpython3u | plpython3u |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between jsonb and plpython3u | ||||
| ltree_plpython3u | plpython3u |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between ltree and plpython3u | ||||
| hstore_plpython3u | plpython3u |
CONTRIB | 1.0 | LANG |
PostgreSQL | transform between hstore and plpython3u | ||||
| prefix | prefix |
PGDG | 1.2.0 | TYPE |
PostgreSQL | Prefix Range module for PostgreSQL | ||||
| semver | semver |
PGDG | 0.32.1 | TYPE |
PostgreSQL | Semantic version data type | ||||
| unit | pgunit |
PGDG | 7 | TYPE |
GPLv3 | SI units extension | ||||
| md5hash | md5hash |
PIGSTY | 1.0.1 | TYPE |
BSD 2 | type for storing 128-bit binary data inline | ||||
| asn1oid | asn1oid |
PIGSTY | 1 | TYPE |
GPLv3 | asn1oid extension | ||||
| roaringbitmap | roaringbitmap |
PIGSTY | 0.5 | TYPE |
Apache-2.0 | support for Roaring Bitmaps | ||||
| pgfaceting | pgfaceting |
PIGSTY | 0.2.0 | TYPE |
BSD 3 | fast faceting queries using an inverted index | ||||
| pg_sphere | pgsphere |
PIGSTY | 1.5.1 | TYPE |
BSD 3 | spherical objects with useful functions, operators and index support | ||||
| country | pg_country |
PIGSTY | 0.0.3 | TYPE |
PostgreSQL | Country data type, ISO 3166-1 | ||||
| currency | pg_currency |
PIGSTY | 0.0.3 | TYPE |
MIT | Custom PostgreSQL currency type in 1Byte | ||||
| pgmp | pgmp |
PGDG | 1.1 | TYPE |
LGPLv3 | Multiple Precision Arithmetic extension | ||||
| numeral | numeral |
PIGSTY | 1 | TYPE |
GPLv2 | numeral datatypes extension | ||||
| pg_rational | pg_rational |
PIGSTY | 0.0.2 | TYPE |
MIT | bigint fractions | ||||
| uint | pguint |
PGDG | 0 | TYPE |
PostgreSQL | unsigned integer types | ||||
| ip4r | ip4r |
PGDG | 2.4 | TYPE |
PostgreSQL | IPv4/v6 and IPv4/v6 range index type for PostgreSQL | ||||
| uri | pg_uri |
PIGSTY | 1.20151224 | TYPE |
PostgreSQL | URI Data type for PostgreSQL | ||||
| pgemailaddr | pgemailaddr |
PIGSTY | 0 | TYPE |
PostgreSQL | Email address type for PostgreSQL | ||||
| acl | acl |
PIGSTY | 1.0.4 | TYPE |
BSD-2 | ACL Data type | ||||
| debversion | debversion |
PGDG | 1.1 | TYPE |
PostgreSQL | Debian version number data type | ||||
| pg_rrule | pg_rrule |
PGDG | 0.2.0 | TYPE |
MIT | RRULE field type for PostgreSQL | ||||
| timestamp9 | timestamp9 |
PGDG | 1.4.0 | TYPE |
MIT | timestamp nanosecond resolution | ||||
| chkpass | chkpass |
PIGSTY | 1.0 | TYPE |
PostgreSQL | data type for auto-encrypted passwords | ||||
| isn | isn |
CONTRIB | 1.2 | TYPE |
PostgreSQL | data types for international product numbering standards | ||||
| seg | seg |
CONTRIB | 1.4 | TYPE |
PostgreSQL | data type for representing line segments or floating-point intervals | ||||
| cube | cube |
CONTRIB | 1.5 | TYPE |
PostgreSQL | data type for multidimensional cubes | ||||
| ltree | ltree |
CONTRIB | 1.2 | TYPE |
PostgreSQL | data type for hierarchical tree-like structures | ||||
| hstore | hstore |
CONTRIB | 1.8 | TYPE |
PostgreSQL | data type for storing sets of (key, value) pairs | ||||
| citext | citext |
CONTRIB | 1.6 | TYPE |
PostgreSQL | data type for case-insensitive character strings | ||||
| xml2 | xml2 |
CONTRIB | 1.1 | TYPE |
PostgreSQL | XPath querying and XSLT | ||||
| topn | topn |
PGDG | 2.6.0 | FUNC |
AGPLv3 | type for top-n JSONB | ||||
| gzip | pg_gzip |
PGDG | 1.0 | FUNC |
MIT | gzip and gunzip functions. | ||||
| zstd | pg_zstd |
PIGSTY | 1.1.0 | FUNC |
ISC | Zstandard compression algorithm implementation in PostgreSQL | ||||
| http | pg_http |
PGDG | 1.6 | FUNC |
MIT | HTTP client for PostgreSQL, allows web page retrieval inside the database. | ||||
| pg_net | pg_net |
PGDG | 0.8.0 | FUNC |
Apache-2.0 | Async HTTP Requests | ||||
| pg_html5_email_address | pg_html5_email_address |
PIGSTY | 1.2.3 | FUNC |
PostgreSQL | PostgreSQL email validation that is consistent with the HTML5 spec | ||||
| pgsql_tweaks | pgsql_tweaks |
PGDG | 0.10.3 | FUNC |
PostgreSQL | Some functions and views for daily usage | ||||
| pg_extra_time | pg_extra_time |
PGDG | 1.1.3 | FUNC |
PostgreSQL | Some date time functions and operators that, | ||||
| timeit | pg_timeit |
PIGSTY | 1.0 | FUNC |
PostgreSQL | High-accuracy timing of SQL expressions | ||||
| count_distinct | count_distinct |
PGDG | 3.0.1 | FUNC |
BSD 2 | An alternative to COUNT(DISTINCT …) aggregate, usable with HashAggregate | ||||
| extra_window_functions | extra_window_functions |
PGDG | 1.0 | FUNC |
PostgreSQL | Extra Window Functions for PostgreSQL | ||||
| first_last_agg | first_last_agg |
PIGSTY | 0.1.4 | FUNC |
PostgreSQL | first() and last() aggregate functions | ||||
| tdigest | tdigest |
PGDG | 1.4.1 | FUNC |
Apache-2.0 | Provides tdigest aggregate function. | ||||
| aggs_for_vecs | aggs_for_vecs |
PIGSTY | 1.3.0 | FUNC |
MIT | Aggregate functions for array inputs | ||||
| aggs_for_arrays | aggs_for_arrays |
PIGSTY | 1.3.2 | FUNC |
MIT | Various functions for computing statistics on arrays of numbers | ||||
| arraymath | pg_arraymath |
PIGSTY | 1.1 | FUNC |
MIT | Array math and operators that work element by element on the contents of arrays | ||||
| quantile | quantile |
PIGSTY | 1.1.7 | FUNC |
BSD | Quantile aggregation function | ||||
| lower_quantile | lower_quantile |
PIGSTY | 1.0.0 | FUNC |
BSD-2 | Lower quantile aggregate function | ||||
| pg_idkit | pg_idkit |
PIGSTY | 0.2.3 | FUNC |
Apache-2.0 | multi-tool for generating new/niche universally unique identifiers (ex. UUIDv6, ULID, KSUID) | ||||
| pg_uuidv7 | pg_uuidv7 |
PGDG | 1.5 | FUNC |
MPLv2 | pg_uuidv7: create UUIDv7 values in postgres | ||||
| permuteseq | permuteseq |
PIGSTY | 1.2 | FUNC |
PostgreSQL | Pseudo-randomly permute sequences with a format-preserving encryption on elements | ||||
| pg_hashids | pg_hashids |
PIGSTY | 1.3 | FUNC |
MIT | Short unique id generator for PostgreSQL, using hashids | ||||
| sequential_uuids | sequential_uuids |
PGDG | 1.0.2 | FUNC |
MIT | generator of sequential UUIDs | ||||
| pg_math | pg_math |
PIGSTY | 1.0 | FUNC |
GPLv3 | GSL statistical functions for postgresql | ||||
| random | pg_random |
PIGSTY | 2.0.0-dev | FUNC |
PostgreSQL | random data generator | ||||
| base36 | pg_base36 |
PIGSTY | 1.0.0 | FUNC |
MIT | Integer Base36 types | ||||
| base62 | pg_base62 |
PIGSTY | 0.0.1 | FUNC |
MIT | Base62 extension for PostgreSQL | ||||
| floatvec | floatvec |
PIGSTY | 1.0.1 | FUNC |
MIT | Math for vectors (arrays) of numbers | ||||
| financial | pg_financial |
PIGSTY | 1.0.1 | FUNC |
PostgreSQL | Financial aggregate functions | ||||
| pgjwt | pgjwt |
PIGSTY | 0.2.0 | FUNC |
MIT | JSON Web Token API for Postgresql | ||||
| pg_hashlib | pg_hashlib |
PIGSTY | 1.1 | FUNC |
PostgreSQL | Stable hash functions for Postgres | ||||
| shacrypt | shacrypt |
PIGSTY | 1.1 | FUNC |
PostgreSQL | Implements SHA256-CRYPT and SHA512-CRYPT password encryption schemes | ||||
| cryptint | cryptint |
PIGSTY | 1.0.0 | FUNC |
PostgreSQL | Encryption functions for int and bigint values | ||||
| pguecc | pg_ecdsa |
PIGSTY | 1.0 | FUNC |
BSD-2 | uECC bindings for Postgres | ||||
| pgpcre | pgpcre |
PIGSTY | 1 | FUNC |
PostgreSQL | Perl Compatible Regular Expression functions | ||||
| icu_ext | icu_ext |
PIGSTY | 1.8 | FUNC |
PostgreSQL | Access ICU functions | ||||
| pgqr | pgqr |
PIGSTY | 1.0 | FUNC |
BSD-3 | QR Code generator from PostgreSQL | ||||
| envvar | envvar |
PIGSTY | 1.0.0 | FUNC |
PostgreSQL | Fetch the value of an environment variable | ||||
| pg_protobuf | pg_protobuf |
PIGSTY | 1.0 | FUNC |
MIT | Protobuf support for PostgreSQL | ||||
| url_encode | url_encode |
PIGSTY | 1.2.5 | FUNC |
PostgreSQL | url_encode, url_decode functions | ||||
| refint | refint |
CONTRIB | 1.0 | FUNC |
PostgreSQL | functions for implementing referential integrity (obsolete) | ||||
| autoinc | autoinc |
CONTRIB | 1.0 | FUNC |
PostgreSQL | functions for autoincrementing fields | ||||
| insert_username | insert_username |
CONTRIB | 1.0 | FUNC |
PostgreSQL | functions for tracking who changed a table | ||||
| moddatetime | moddatetime |
CONTRIB | 1.0 | FUNC |
PostgreSQL | functions for tracking last modification time | ||||
| tsm_system_time | tsm_system_time |
CONTRIB | 1.0 | FUNC |
PostgreSQL | TABLESAMPLE method which accepts time in milliseconds as a limit | ||||
| dict_xsyn | dict_xsyn |
CONTRIB | 1.0 | FUNC |
PostgreSQL | text search dictionary template for extended synonym processing | ||||
| tsm_system_rows | tsm_system_rows |
CONTRIB | 1.0 | FUNC |
PostgreSQL | TABLESAMPLE method which accepts number of rows as a limit | ||||
| tcn | tcn |
CONTRIB | 1.0 | FUNC |
PostgreSQL | Triggered change notifications | ||||
| uuid-ossp | uuid-ossp |
CONTRIB | 1.1 | FUNC |
PostgreSQL | generate universally unique identifiers (UUIDs) | ||||
| btree_gist | btree_gist |
CONTRIB | 1.7 | FUNC |
PostgreSQL | support for indexing common datatypes in GiST | ||||
| btree_gin | btree_gin |
CONTRIB | 1.3 | FUNC |
PostgreSQL | support for indexing common datatypes in GIN | ||||
| intarray | intarray |
CONTRIB | 1.5 | FUNC |
PostgreSQL | functions, operators, and index support for 1-D arrays of integers | ||||
| intagg | intagg |
CONTRIB | 1.1 | FUNC |
PostgreSQL | integer aggregator and enumerator (obsolete) | ||||
| dict_int | dict_int |
CONTRIB | 1.0 | FUNC |
PostgreSQL | text search dictionary template for integers | ||||
| unaccent | unaccent |
CONTRIB | 1.1 | FUNC |
PostgreSQL | text search dictionary that removes accents | ||||
| pg_repack | pg_repack |
PGDG | 1.5.0 | ADMIN |
BSD 3 | Reorganize tables in PostgreSQL databases with minimal locks | ||||
| pg_squeeze | pg_squeeze |
PGDG | 1.6 | ADMIN |
BSD 2 | A tool to remove unused space from a relation. | ||||
| pg_dirtyread | pg_dirtyread |
PIGSTY | 2 | ADMIN |
BSD 3 | Read dead but unvacuumed rows from table | ||||
| pgfincore | pgfincore |
PGDG | 1.3.1 | ADMIN |
BSD 3 | examine and manage the os buffer cache | ||||
| pgdd | pgdd |
PIGSTY | 0.5.2 | ADMIN |
MIT | An in-database data dictionary providing database introspection via standard SQL query syntax. Developed using pgx (https://github.com/zombodb/pgx). | ||||
| ddlx | ddlx |
PGDG | 0.27 | ADMIN |
PostgreSQL | DDL eXtractor functions | ||||
| prioritize | pg_prioritize |
PGDG | 1.0 | ADMIN |
PostgreSQL | get and set the priority of PostgreSQL backends | ||||
| pg_checksums | pg_checksums |
PGDG | 1.1 | ADMIN |
BSD 2 | Activate/deactivate/verify checksums in offline Postgres clusters | ||||
| pg_readonly | pg_readonly |
PGDG | 1.0.0 | ADMIN |
PostgreSQL | cluster database read only | ||||
| safeupdate | safeupdate |
PGDG | 1.4 | ADMIN |
ISC | Require criteria for UPDATE and DELETE | ||||
| pg_permissions | pg_permissions |
PGDG | 1.3 | ADMIN |
BSD 2 | view object permissions and compare them with the desired state | ||||
| pgautofailover | pgautofailover |
PGDG | 2.1 | ADMIN |
PostgreSQL | pg_auto_failover | ||||
| pg_catcheck | pg_catcheck |
PGDG | 1.4.0 | ADMIN |
BSD 3 | Diagnosing system catalog corruption | ||||
| pre_prepare | preprepare |
PIGSTY | 0.4 | ADMIN |
PostgreSQL | Pre Prepare your Statement server side | ||||
| pgcozy | pgcozy |
PIGSTY | 1.0 | ADMIN |
PostgreSQL | Pre-warming shared buffers according to previous pg_buffercache snapshots for PostgreSQL. | ||||
| pg_orphaned | pg_orphaned |
PIGSTY | 1.0 | ADMIN |
PostgreSQL | Deal with orphaned files | ||||
| pg_crash | pg_crash |
PIGSTY | 1.0 | ADMIN |
BSD-3 | Send random signals to random processes | ||||
| pg_cheat_funcs | pg_cheat_funcs |
PIGSTY | 1.0 | ADMIN |
PostgreSQL | Provides cheat (but useful) functions | ||||
| pg_savior | pg_savior |
PIGSTY | 0.0.1 | ADMIN |
Apache-2.0 | Postgres extension to save OOPS mistakes | ||||
| table_log | table_log |
PIGSTY | 0.6.1 | ADMIN |
PostgreSQL | record table modification logs and PITR for table/row | ||||
| pg_fio | pg_fio |
PIGSTY | 1.0 | ADMIN |
BSD-3 | PostgreSQL File I/O Functions | ||||
| pgpool_adm | pgpool |
PGDG | 1.5 | ADMIN |
PostgreSQL | Administrative functions for pgPool | ||||
| pgpool_recovery | pgpool |
PGDG | 1.4 | ADMIN |
PostgreSQL | recovery functions for pgpool-II for V4.3 | ||||
| pgpool_regclass | pgpool |
PGDG | 1.0 | ADMIN |
PostgreSQL | replacement for regclass | ||||
| pgagent | pgagent |
PGDG | 4.2 | ADMIN |
PostgreSQL | A PostgreSQL job scheduler | ||||
| vacuumlo | vacuumlo |
CONTRIB | 16.3 | ADMIN |
PostgreSQL | utility program that will remove any orphaned large objects from a PostgreSQL database | ||||
| pg_prewarm | pg_prewarm |
CONTRIB | 1.2 | ADMIN |
PostgreSQL | prewarm relation data | ||||
| oid2name | oid2name |
CONTRIB | 16.3 | ADMIN |
PostgreSQL | utility program that helps administrators to examine the file structure used by PostgreSQL | ||||
| lo | lo |
CONTRIB | 1.1 | ADMIN |
PostgreSQL | Large Object maintenance | ||||
| basic_archive | basic_archive |
CONTRIB | 16.3 | ADMIN |
PostgreSQL | an example of an archive module | ||||
| basebackup_to_shell | basebackup_to_shell |
CONTRIB | 16.3 | ADMIN |
PostgreSQL | adds a custom basebackup target called shell | ||||
| old_snapshot | old_snapshot |
CONTRIB | 1.0 | ADMIN |
PostgreSQL | utilities in support of old_snapshot_threshold | ||||
| adminpack | adminpack |
CONTRIB | 2.1 | ADMIN |
PostgreSQL | administrative functions for PostgreSQL | ||||
| amcheck | amcheck |
CONTRIB | 1.3 | ADMIN |
PostgreSQL | functions for verifying relation integrity | ||||
| pg_surgery | pg_surgery |
CONTRIB | 1.0 | ADMIN |
PostgreSQL | extension to perform surgery on a damaged relation | ||||
| pg_profile | pg_profile |
PGDG | 4.6 | STAT |
BSD 2 | PostgreSQL load profile repository and report builder | ||||
| pg_show_plans | pg_show_plans |
PGDG | 2.1 | STAT |
PostgreSQL | show query plans of all currently running SQL statements | ||||
| pg_stat_kcache | pg_stat_kcache |
PGDG | 2.2.3 | STAT |
BSD 3 | Kernel statistics gathering | ||||
| pg_stat_monitor | pg_stat_monitor |
PGDG | 2.0 | STAT |
BSD 3 | The pg_stat_monitor is a PostgreSQL Query Performance Monitoring tool, based on PostgreSQL contrib module pg_stat_statements. pg_stat_monitor provides aggregated statistics, client information, plan details including plan, and histogram information. | ||||
| pg_qualstats | pg_qualstats |
PGDG | 2.1.0 | STAT |
BSD 3 | An extension collecting statistics about quals | ||||
| pg_store_plans | pg_store_plans |
PGDG | 1.8 | STAT |
BSD 3 | track plan statistics of all SQL statements executed | ||||
| pg_track_settings | pg_track_settings |
PGDG | 2.1.2 | STAT |
PostgreSQL | Track settings changes | ||||
| pg_wait_sampling | pg_wait_sampling |
PGDG | 1.1 | STAT |
PostgreSQL | sampling based statistics of wait events | ||||
| system_stats | system_stats |
PGDG | 2.0 | STAT |
PostgreSQL | EnterpriseDB system statistics for PostgreSQL | ||||
| meta | pg_meta |
PIGSTY | 0.4.0 | STAT |
BSD-2 | Normalized, friendlier system catalog for PostgreSQL | ||||
| pgnodemx | pgnodemx |
PIGSTY | 1.6 | STAT |
Apache-2.0 | Capture node OS metrics via SQL queries | ||||
| pg_proctab | pgnodemx |
PIGSTY | 0.0.10-compat | STAT |
BSD 3 | PostgreSQL extension to access the OS process table | ||||
| pg_sqlog | pg_sqlog |
PIGSTY | 1.6 | STAT |
BSD 3 | Provide SQL interface to logs | ||||
| bgw_replstatus | bgw_replstatus |
PGDG | 1.0.6 | STAT |
PostgreSQL | Small PostgreSQL background worker to report whether a node is a replication master or standby | ||||
| pgmeminfo | pgmeminfo |
PGDG | 1.0 | STAT |
MIT | show memory usage | ||||
| toastinfo | toastinfo |
PIGSTY | 1 | STAT |
PostgreSQL | show details on toasted datums | ||||
| pg_mon | pg_mon |
PIGSTY | 1.0 | STAT |
MIT | PostgreSQL extension to enhance query monitoring | ||||
| pg_statviz | pg_statviz |
PGDG | 0.6 | STAT |
BSD 3 | stats visualization and time series analysis | ||||
| pgexporter_ext | pgexporter_ext |
PGDG | 0.2.3 | STAT |
BSD 3 | pgexporter extension for extra metrics | ||||
| pg_top | pg_top |
PGDG | 3.7.0 | STAT |
BSD 3 | Monitor PostgreSQL processes similar to unix top | ||||
| pagevis | pagevis |
PIGSTY | 0.1 | STAT |
MIT | Visualise database pages in ascii code | ||||
| powa | powa |
PGDG | 4.2.2 | STAT |
PostgreSQL | PostgreSQL Workload Analyser-core | ||||
| pageinspect | pageinspect |
CONTRIB | 1.12 | STAT |
PostgreSQL | inspect the contents of database pages at a low level | ||||
| pgrowlocks | pgrowlocks |
CONTRIB | 1.2 | STAT |
PostgreSQL | show row-level locking information | ||||
| sslinfo | sslinfo |
CONTRIB | 1.2 | STAT |
PostgreSQL | information about SSL certificates | ||||
| pg_buffercache | pg_buffercache |
CONTRIB | 1.4 | STAT |
PostgreSQL | examine the shared buffer cache | ||||
| pg_walinspect | pg_walinspect |
CONTRIB | 1.1 | STAT |
PostgreSQL | functions to inspect contents of PostgreSQL Write-Ahead Log | ||||
| pg_freespacemap | pg_freespacemap |
CONTRIB | 1.2 | STAT |
PostgreSQL | examine the free space map (FSM) | ||||
| pg_visibility | pg_visibility |
CONTRIB | 1.2 | STAT |
PostgreSQL | examine the visibility map (VM) and page-level visibility info | ||||
| pgstattuple | pgstattuple |
CONTRIB | 1.5 | STAT |
PostgreSQL | show tuple-level statistics | ||||
| auto_explain | auto_explain |
CONTRIB | 16.3 | STAT |
PostgreSQL | Provides a means for logging execution plans of slow statements automatically | ||||
| pg_stat_statements | pg_stat_statements |
CONTRIB | 1.10 | STAT |
PostgreSQL | track planning and execution statistics of all SQL statements executed | ||||
| passwordcheck_cracklib | passwordcheck |
PGDG | 3.0.0 | SEC |
LGPLv2 | Strengthen PostgreSQL user password checks with cracklib | ||||
| supautils | supautils |
PIGSTY | 3.1.9 | SEC |
Apache-2.0 | Extension that secures a cluster on a cloud environment | ||||
| pgsodium | pgsodium |
PGDG | 3.1.9 | SEC |
BSD 3 | Postgres extension for libsodium functions | ||||
| supabase_vault | pg_vault |
PIGSTY | 0.2.8 | SEC |
Apache-2.0 | Supabase Vault Extension | ||||
| anon | anonymizer |
PGDG | 1.3.2 | SEC |
PostgreSQL | Data anonymization tools | ||||
| pg_tde | pg_tde |
PIGSTY | 1.0 | SEC |
MIT | pg_tde access method | ||||
| pgsmcrypto | pgsmcrypto |
PIGSTY | 0.1.0 | SEC |
MIT | PostgreSQL SM Algorithm Extension | ||||
| pgaudit | pgaudit |
PGDG | 16.0 | SEC |
PostgreSQL | provides auditing functionality | ||||
| pgauditlogtofile | pgauditlogtofile |
PGDG | 1.6 | SEC |
PostgreSQL | pgAudit addon to redirect audit log to an independent file | ||||
| pg_auth_mon | pg_auth_mon |
PGDG | 1.1 | SEC |
MIT | monitor connection attempts per user | ||||
| credcheck | credcheck |
PGDG | 2.7.0 | SEC |
MIT | credcheck - postgresql plain text credential checker | ||||
| pgcryptokey | pgcryptokey |
PGDG | 1.0 | SEC |
PostgreSQL | cryptographic key management | ||||
| pg_jobmon | pg_jobmon |
PGDG | 1.4.1 | SEC |
PostgreSQL | Extension for logging and monitoring functions in PostgreSQL | ||||
| logerrors | logerrors |
PGDG | 2.1 | SEC |
BSD 3 | Function for collecting statistics about messages in logfile | ||||
| login_hook | login_hook |
PGDG | 1.5 | SEC |
GPLv3 | login_hook - hook to execute login_hook.login() at login time | ||||
| set_user | set_user |
PGDG | 4.0.1 | SEC |
PostgreSQL | similar to SET ROLE but with added logging | ||||
| pg_snakeoil | pg_snakeoil |
PIGSTY | 1 | SEC |
PostgreSQL | The PostgreSQL Antivirus | ||||
| pgextwlist | pgextwlist |
PIGSTY | 1.17 | SEC |
PostgreSQL | PostgreSQL Extension Whitelisting | ||||
| pg_auditor | pg_auditor |
PIGSTY | 0.2 | SEC |
BSD-3 | Audit data changes and provide flashback ability | ||||
| sslutils | sslutils |
PIGSTY | 1.3 | SEC |
PostgreSQL | A Postgres extension for managing SSL certificates through SQL | ||||
| noset | noset |
PIGSTY | 0.3.0 | SEC |
AGPLv3 | Module for blocking SET variables for non-super users. | ||||
| sepgsql | sepgsql |
CONTRIB | 16.3 | SEC |
PostgreSQL | label-based mandatory access control (MAC) based on SELinux security policy. | ||||
| auth_delay | auth_delay |
CONTRIB | 16.3 | SEC |
PostgreSQL | pause briefly before reporting authentication failure | ||||
| pgcrypto | pgcrypto |
CONTRIB | 1.3 | SEC |
PostgreSQL | cryptographic functions | ||||
| passwordcheck | passwordcheck |
CONTRIB | 16.3 | SEC |
PostgreSQL | checks user passwords and reject weak password | ||||
| wrappers | wrappers |
PIGSTY | 0.4.1 | FDW |
Apache-2.0 | Foreign data wrappers developed by Supabase | ||||
| multicorn | multicorn |
PGDG | 3.0 | FDW |
PostgreSQL | Fetch foreign data in Python in your PostgreSQL server. | ||||
| mysql_fdw | mysql_fdw |
PGDG | 1.2 | FDW |
BSD 3 | Foreign data wrapper for querying a MySQL server | ||||
| oracle_fdw | oracle_fdw |
PGDG | 1.2 | FDW |
PostgreSQL | foreign data wrapper for Oracle access | ||||
| tds_fdw | tds_fdw |
PGDG | 2.0.3 | FDW |
PostgreSQL | Foreign data wrapper for querying a TDS database (Sybase or Microsoft SQL Server) | ||||
| db2_fdw | db2_fdw |
PGDG | 6.0.1 | FDW |
PostgreSQL | foreign data wrapper for DB2 access | ||||
| sqlite_fdw | sqlite_fdw |
PGDG | 1.1 | FDW |
PostgreSQL | SQLite Foreign Data Wrapper | ||||
| pgbouncer_fdw | pgbouncer_fdw |
PGDG | 1.1.0 | FDW |
PostgreSQL | Extension for querying PgBouncer stats from normal SQL views & running pgbouncer commands from normal SQL functions | ||||
| mongo_fdw | mongo_fdw |
PGDG | 1.1 | FDW |
LGPLv3 | foreign data wrapper for MongoDB access | ||||
| redis_fdw | redis_fdw |
PIGSTY | 1.0 | FDW |
PostgreSQL | Foreign data wrapper for querying a Redis server | ||||
| redis | pg_redis_pubsub |
PIGSTY | 0.0.1 | FDW |
MIT | Send redis pub/sub messages to Redis from PostgreSQL Directly | ||||
| kafka_fdw | kafka_fdw |
PIGSTY | 0.0.3 | FDW |
PostgreSQL | kafka Foreign Data Wrapper for CSV formated messages | ||||
| hdfs_fdw | hdfs_fdw |
PGDG | 2.0.5 | FDW |
BSD 3 | foreign-data wrapper for remote hdfs servers | ||||
| firebird_fdw | firebird_fdw |
PIGSTY | 1.4.0 | FDW |
PostgreSQL | Foreign data wrapper for Firebird | ||||
| aws_s3 | aws_s3 |
PIGSTY | 0.0.1 | FDW |
Apache-2.0 | aws_s3 postgres extension to import/export data from/to s3 | ||||
| log_fdw | log_fdw |
PIGSTY | 1.4 | FDW |
Apache-2.0 | foreign-data wrapper for Postgres log file access | ||||
| dblink | dblink |
CONTRIB | 1.2 | FDW |
PostgreSQL | connect to other PostgreSQL databases from within a database | ||||
| file_fdw | file_fdw |
CONTRIB | 1.0 | FDW |
PostgreSQL | foreign-data wrapper for flat file access | ||||
| postgres_fdw | postgres_fdw |
CONTRIB | 1.1 | FDW |
PostgreSQL | foreign-data wrapper for remote PostgreSQL servers | ||||
| orafce | orafce |
PGDG | 4.10 | SIM |
BSD 0 | Functions and operators that emulate a subset of functions and packages from the Oracle RDBMS | ||||
| pgtt | pgtt |
PGDG | 4.0.0 | SIM |
ISC | Extension to add Global Temporary Tables feature to PostgreSQL | ||||
| session_variable | session_variable |
PIGSTY | 3.3 | SIM |
GPLv3 | Registration and manipulation of session variables and constants | ||||
| pg_statement_rollback | pg_statement_rollback |
PGDG | 1.4 | SIM |
ISC | Server side rollback at statement level for PostgreSQL like Oracle or DB2 | ||||
| pg_dbms_metadata | pg_dbms_metadata |
PGDG | 1.0.0 | SIM |
PostgreSQL | Extension to add Oracle DBMS_METADATA compatibility to PostgreSQL | ||||
| pg_dbms_lock | pg_dbms_lock |
PGDG | 1.0.0 | SIM |
PostgreSQL | Extension to add Oracle DBMS_LOCK full compatibility to PostgreSQL | ||||
| pg_dbms_job | pg_dbms_job |
PGDG | 1.5.0 | SIM |
PostgreSQL | Extension to add Oracle DBMS_JOB full compatibility to PostgreSQL | ||||
| babelfishpg_common | babelfishpg_common |
WILTON | 3.3.3 | SIM |
Apache-2.0 | SQL Server Transact SQL Datatype Support | ||||
| babelfishpg_tsql | babelfishpg_tsql |
WILTON | 3.3.1 | SIM |
Apache-2.0 | SQL Server Transact SQL compatibility | ||||
| babelfishpg_tds | babelfishpg_tds |
WILTON | 1.0.0 | SIM |
Apache-2.0 | SQL Server TDS protocol extension | ||||
| babelfishpg_money | babelfishpg_money |
WILTON | 1.1.0 | SIM |
Apache-2.0 | SQL Server Money Data Type | ||||
| pgmemcache | pgmemcache |
PGDG | 2.3.0 | SIM |
MIT | memcached interface | ||||
| pglogical | pglogical |
PGDG | 2.4.4 | ETL |
PostgreSQL | PostgreSQL Logical Replication | ||||
| pglogical_origin | pglogical |
PGDG | 1.0.0 | ETL |
PostgreSQL | Dummy extension for compatibility when upgrading from Postgres 9.4 | ||||
| pglogical_ticker | pglogical |
PGDG | 1.4 | ETL |
PostgreSQL | Have an accurate view on pglogical replication delay | ||||
| pgl_ddl_deploy | pgl_ddl_deploy |
PGDG | 2.2 | ETL |
MIT | automated ddl deployment using pglogical | ||||
| pg_failover_slots | pg_failover_slots |
PIGSTY | 1.0.1 | ETL |
PostgreSQL | PG Failover Slots extension | ||||
| wal2json | wal2json |
PGDG | 2.5.3 | ETL |
BSD 3 | Changing data capture in JSON format | ||||
| wal2mongo | wal2mongo |
PIGSTY | 1.0.7 | ETL |
Apache-2.0 | PostgreSQL logical decoding output plugin for MongoDB | ||||
| decoderbufs | decoderbufs |
PGDG | 0.1.0 | ETL |
MIT | Logical decoding plugin that delivers WAL stream changes using a Protocol Buffer format | ||||
| decoder_raw | decoder_raw |
PIGSTY | 1.0 | ETL |
PostgreSQL | Output plugin for logical replication in Raw SQL format | ||||
| test_decoding | test_decoding |
CONTRIB | 16.3 | ETL |
PostgreSQL | SQL-based test/example module for WAL logical decoding | ||||
| mimeo | mimeo |
PIGSTY | 1.5.1 | ETL |
PostgreSQL | Extension for specialized, per-table replication between PostgreSQL instances | ||||
| repmgr | repmgr |
PGDG | 5.4 | ETL |
GPLv3 | Replication manager for PostgreSQL | ||||
| pgcopydb | pgcopydb |
PGDG | 0.15 | ETL |
PostgreSQL | Copy a Postgres database to a target Postgres server | ||||
| pgloader | pgloader |
PGDG | 3.6.10 | ETL |
PostgreSQL | Migrate to PostgreSQL in a single command! | ||||
| pg_fact_loader | pg_fact_loader |
PGDG | 2.0 | ETL |
MIT | build fact tables with Postgres | ||||
| pg_bulkload | pg_bulkload |
PGDG | 3.1.21 | ETL |
BSD 3 | pg_bulkload is a high speed data loading utility for PostgreSQL | ||||
| pg_comparator | pg_comparator |
PGDG | 2.2.5 | ETL |
BSD 3 | Comparation of testing and production services PostgreSQL databases. | ||||
| pgimportdoc | pgimportdoc |
PGDG | 0.1.4 | ETL |
BSD 2 | command line utility for importing XML, JSON, BYTEA document to PostgreSQL | ||||
| pgexportdoc | pgexportdoc |
PGDG | 0.1.4 | ETL |
BSD 2 | export XML, JSON and BYTEA documents from PostgreSQL |
Docker Application
Pigsty now offers out-of-the-box Dify and Odoo Docker Compose templates:
There two new beta modules available in Pigsty Pro version:
KAFKA: Deploy a high-availability Kafka cluster supported by the Kraft protocol.KUBE: Deploy a Kubernetes cluster managed by Pigsty using cri-dockerd or containerd.
Bug Fix
- Fixed CVE-2024-6387 by automatically repairing during the Pigsty installation process using the default value
[openssh-server]innode_packages. - Fixed memory consumption issues caused by Loki parsing Nginx log tag cardinality being too large.
- Fixed bootstrap failure caused by upstream Ansible dependency changes in EL8 systems (python3.11-jmespath upgraded to python3.12-jmespath).
v2.7: Extension Overwhelming
The Pigsty community is thrilled to announce Pigsty v2.7.0, which has 255 unique extensions available, to the free PostgreSQL distribution and RDS alternative. We also have introduced some new docker-compose templates for Odoo, Jupyter, PolarDB, and GA Supabase.
About Pigsty
Pigsty is a Battery-included, local-first PostgreSQL Distribution as a Free RDS alternative.
Links: Website | GitHub | Demo | Blog | Install | Feature
Images: Introduction | Extensions | Architecture | Dashboards
{kind=link}
{kind=link}
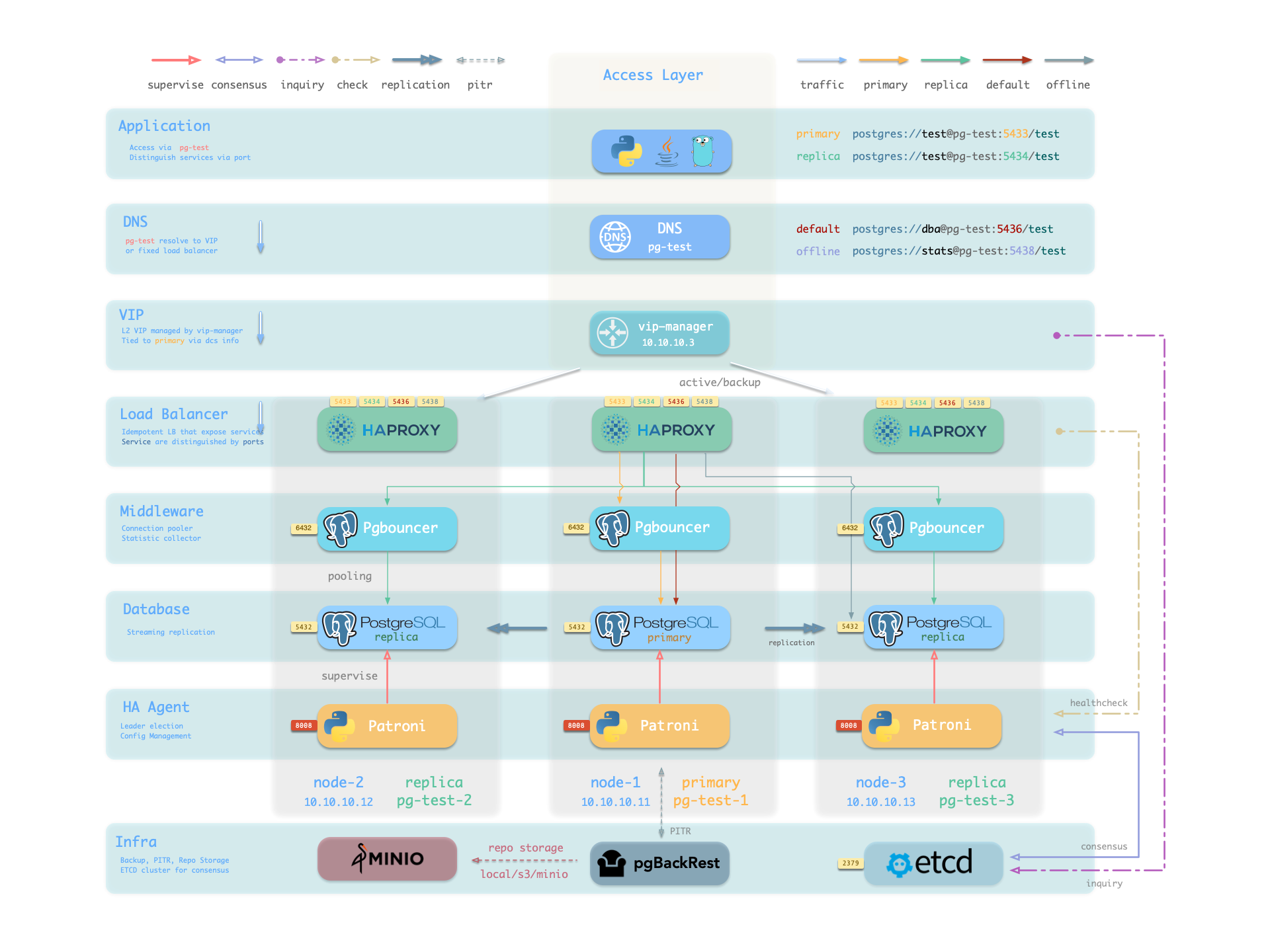{kind=link}
{kind=link}
Getting Started with the latest v2.7.0 release with: curl -L https://get.pigsty.cc/install | bash
Pigsty v2.7: Extension Overwhelming
I wrote a popular article last month - Postgres is eating the database world, explaining why extensions matter to the PostgreSQL ecosystem.
Based on this idea, we’ve packaged 20 brand-new extensions in v2.7. With these extensions added, Pigsty offers 157 non-contrib extensions for EL Distros and 116 for Debian/Ubuntu Distros. Combined with 73 built-in Contrib extensions, Pigsty now has a total of 255 unique extensions available, which takes PostgreSQL’s versatility to a whole new level!
Complete list of available extensions: https://pigsty.io/docs/reference/extension/
v2.7.0 Release Note
Highlight
Adding numerous new extensions written in rust & pgrx:
- pg_search v0.7.0 : Full text search over SQL tables using the BM25 algorithm
- pg_lakehouse v0.7.0 : Query engine over object stores like S3 and table formats like Delta Lake
- pg_analytics v0.6.1 : Accelerates analytical query processing inside Postgres
- pg_graphql v1.5.4 : GraphQL support to your PostgreSQL database.
- pg_jsonschema v0.3.1 : PostgreSQL extension providing JSON Schema validation
- wrappers v0.3.1 : Postgres Foreign Data Wrappers Collections by Supabase
- pgmq v1.5.2 : A lightweight message queue. Like AWS SQS and RSMQ but on Postgres.
- pg_tier v0.0.3 : Postgres Extension written in Rust, to enable data tiering to AWS S3
- pg_vectorize v0.15.0 : The simplest way to orchestrate vector search on Postgres
- pg_later v0.1.0 : Execute SQL now and get the results later.
- pg_idkit v0.2.3 : Generating many popular types of identifiers
- plprql v0.1.0 : Use PRQL in PostgreSQL
- pgsmcrypto v0.1.0 : PostgreSQL SM Algorithm Extension
- pg_tiktoken v0.0.1 : OpenAI tiktoken tokenizer for PostgreSQL
- pgdd v0.5.2 : Access Data Dictionary metadata with pure SQL
And some new extensions in plain C & C++:
- parquet_s3_fdw 1.1.0 : ParquetS3 Foreign Data Wrapper for PostgreSQL
- plv8 3.2.2 : V8 Engine Javascript Procedural Language add-on for PostgreSQL
- md5hash 1.0.1 : Custom data type for storing MD5 hashes rather than text
- pg_tde 1.0 alpha: Experimental encrypted access method for PostgreSQL
- pg_dirtyread 2.6 : Read dead but unvacuumed tuples from a PostgreSQL relation
- New deb PGDG extensions:
pg_roaringbitmap,pgfaceting,mobilitydb,pgsql-http,pg_hint_plan,pg_statviz,pg_rrule - New rpm PGDG extensions:
pg_profile,pg_show_plans, use PGDG’spgsql_http,pgsql_gzip,pg_net,pg_bigminstead of Pigsty RPM.
New Features
- Prepare arm64 packages for infra & pgsql packages for el & deb distros.
- New installation script to download from Cloudflare, and more hints.
- New monitoring dashboard PGSQL PITR to assist the PITR procedure.
- Make preparations for running pigsty inside docker VM containers
- Add a fool-proof design for running pgsql.yml on a node that is not managed by Pigsty
- Add separated template for each OS distro: el7, el8, el9, debian11, debian12, ubuntu20, ubuntu22
New Docker Application
- Odoo: launch open-source ERP over PostgreSQL.
- Jupyter: Run Jupyter notebook containers and expose the HTTP service.
- PolarDB: run the demo playground for the shared-storage version of OSS PG.
- supabase: bump to the latest GA version.
- bytebase: use the
latesttag instead of the ad hoc version. - pg_exporter: update docker image example
Software Upgrade
- PostgreSQL 16.3, 15.7, 14.12, 13.15, 12.19
- Patroni 3.3.0
- pgBackRest 2.51
- vip-manager v2.5.0
- Haproxy 2.9.7
- Grafana 10.4.2
- Prometheus 2.51
- Loki & Promtail: 3.0.0 (breaking changes!)
- Alertmanager 0.27.0
- BlackBox Exporter 0.25.0
- Node Exporter 1.8.0
- pgBackrest Exporter 0.17.0
- duckdb 0.10.2
- etcd 3.5.13
- minio-20240510014138 / mcli-20240509170424
- pev2 v1.8.0 → v1.11.0
- pgvector 0.6.1 → 0.7.0
- pg_tle: v1.3.4 → v1.4.0
- hydra: v1.1.1 → v1.1.2
- duckdb_fdw: v1.1.0 recompile with libduckdb 0.10.2
- pg_bm25 0.5.6 → pg_search 0.7.0
- pg_analytics: 0.5.6 → 0.6.1
- pg_graphql: 1.5.0 → 1.5.4
- pg_net 0.8.0 → 0.9.1
- pg_sparse (deprecated due to pgvector 0.7)
Fixed Issues
- Fix role pg_exporters white space in variable templates
- Fix
minio_clusternot commented in global variables - Fix the non-existent
postgis34package name in theel7config template - Fix EL8
python3.11-cryptographydeps topython3-cryptographyaccording to upstream - Fix
/pg/bin/pg-rolecan not get OS user name from environ in non-interact mode - Fix
/pg/bin/pg-pitrcan not hint-X-Pflag properly
API Change
- New parameter
node_write_etc_hoststo control whether to write/etc/hostsfile on target nodes. - Relocatable prometheus target directory with new parameter
prometheus_sd_dir. - Add
-x|--proxyflag to enable and use the value of global proxy env by @waitingsong in https://github.com/pgsty/pigsty/pull/405 - No longer parse infra nginx log details since it brings too many labels to the log.
- Use alertmanager API Version
v2instead ofv1in prometheus config. - Use
/pg/cert/ca.crtinstead of/etc/pki/ca.crtin rolepgsql.
Acknowledgment
A huge thank you to all our users who contributed patches reported bugs and proposed new features.
Pigsty thrives on community contributions. We warmly welcome your ideas, feature requests, or patches. Please share your contributions on our GitHub page. We look forward to your feedback on Pigsty 2.7 and your continued support in making Pigsty even better.
Best regards,
Ruohang Feng (@vonng), [email protected] , The Pigsty Community
Battery-Included PostgreSQL Distro as a Free RDS Alternative, with:
- Extensible Postgres with 255 extensions available: PostGIS, Timescale, Citus, PGVector, AGE, PGML, ParadeDB, Hydra, DuckFDW, GraphQL, ……
- Reliable Infras: Create self-healing HA PostgreSQL clusters with pre-configured PITR, built-in ACL, & SSL, and secure your infra with local CA & best practices.
- Observable Graphics: Unparalleled monitoring best practices build upon the modern Prometheus & Grafana stack. Reuse them to monitor existing DBs & cloud RDS. Check our Gallery & Demo
- High-Available Service: Deliver auto-routed, high-performance, pooled, reliable, flexible database Services Access via Pgbouncer DNSMasq, Keepalived, vip-manager, and HAProxy.
- Maintainable Toolbox: Infra as Code, Declarative API & Idempotent Playbooks, Vagrant sandbox & Terraform IaaS provisioning specs. Local repo, offline package, delivered without Internet access.
- Composable Modules: Modular design, flexible arch with many bonus features. Redis, MinIO, ETCD, FerretDB, DuckDB, Supabase, and Docker compose templates for software that uses Postgres.
- Painless Experience: Easy to use: Download, Install, and Configure in one command. Built-in configuration templates for different scenarios, auto-tuned params, admin SOP, and zero-downtime blue-green migration plans.
- Compatible Distros: Run on base OS without containerization support: EL 7, 8, 9 and Rocky, Alma, CentOS, OracleLinux,… and Ubuntu 20.04 / 22.04 and Debian 11 / 12 Support.
- Open-Source RDS: Free software open-sourced under the AGPLv3 license, a free RDS for PostgreSQL alternative.
v2.7.0
Highlight
Extension Overwhelming, adding numerous new extensions written in rust & pgrx:
- pg_search v0.7.0 : Full text search over SQL tables using the BM25 algorithm
- pg_lakehouse v0.7.0 : Query engine over object stores like S3 and table formats like Delta Lake
- pg_analytics v0.6.1 : Accelerates analytical query processing inside Postgres
- pg_graphql v1.5.4 : GraphQL support to your PostgreSQL database.
- pg_jsonschema v0.3.1 : PostgreSQL extension providing JSON Schema validation
- wrappers v0.3.1 : Postgres Foreign Data Wrappers Collections by Supabase
- pgmq v1.5.2 : A lightweight message queue. Like AWS SQS and RSMQ but on Postgres.
- pg_tier v0.0.3 : Postgres Extension written in Rust, to enable data tiering to AWS S3
- pg_vectorize v0.15.0 : The simplest way to orchestrate vector search on Postgres
- pg_later v0.1.0 : Execute SQL now and get the results later.
- pg_idkit v0.2.3 : Generating many popular types of identifiers
- plprql v0.1.0 : Use PRQL in PostgreSQL
- pgsmcrypto v0.1.0 : PostgreSQL SM Algorithm Extension
- pg_tiktoken v0.0.1 : OpenAI tiktoken tokenizer for postgres
- pgdd v0.5.2 : Access Data Dictionary metadata with pure SQL
And some new extensions in plain C & C++
- parquet_s3_fdw 1.1.0 : ParquetS3 Foreign Data Wrapper for PostgresSQL
- plv8 3.2.2 : V8 Engine Javascript Procedural Language add-on for PostgreSQL
- md5hash 1.0.1 : Custom data type for storing MD5 hashes rather than text
- pg_tde 1.0 alpha: Experimental encrypted access method for PostgreSQL
- pg_dirtyread 2.6 : Read dead but unvacuumed tuples from a PostgreSQL relation
- New deb PGDG extensions:
pg_roaringbitmap,pgfaceting,mobilitydb,pgsql-http,pg_hint_plan,pg_statviz,pg_rrule - New rpm PGDG extensions:
pg_profile,pg_show_plans, use PGDG’spgsql_http,pgsql_gzip,pg_net,pg_bigminstead of Pigsty RPM.
New Features
- running on certain
dockercontainers. - prepare arm64 packages for infra & pgsql packages for el & deb distros.
- new installation script to download from cloudflare, and more hint.
- new monitoring dashboard for PGSQL PITR to assist the PITR procedure.
- make preparation for running pigsty inside docker VM containers
- add a fool-proof design for running pgsql.yml on node that is not managed by pigsty
- add config template for each major version: el7, el8, el9, debian11, debian12, ubuntu20, ubuntu22
Software Upgrade
- PostgreSQL 16.3
- Patroni 3.3.0
- pgBackRest 2.51
- vip-manager v2.5.0
- Haproxy 2.9.7
- Grafana 10.4.2
- Prometheus 2.51
- Loki & Promtail: 3.0.0 (breaking changes!)
- Alertmanager 0.27.0
- BlackBox Exporter 0.25.0
- Node Exporter 1.8.0
- pgBackrest Exporter 0.17.0
- duckdb 0.10.2
- etcd 3.5.13
- minio-20240510014138 / mcli-20240509170424
- pev2 v1.8.0 -> v1.11.0
- pgvector 0.6.1 -> 0.7.0
- pg_tle: v1.3.4 -> v1.4.0
- hydra: v1.1.1 -> v1.1.2
- duckdb_fdw: v1.1.0 recompile with libduckdb 0.10.2
- pg_bm25 0.5.6 -> pg_search 0.7.0
- pg_analytics: 0.5.6 -> 0.6.1
- pg_graphql: 1.5.0 -> 1.5.4
- pg_net 0.8.0 -> 0.9.1
- pg_sparse (deprecated)
Docker Application
- Odoo: launch open source ERP and plugins
- Jupyter: run jupyter notebook container
- PolarDB: run the demo PG RAC playground.
- supabase: bump to the latest GA version.
- bytebase: use the
latesttag instead of ad hoc version. - pg_exporter: update docker image example
Bug Fix
- Fix role pg_exporters white space in variable templates
- Fix
minio_clusternot commented in global variables - Fix the non-exist
postgis34in el7 config template - Fix EL8
python3.11-cryptographydeps topython3-cryptographyaccording to upstream - Fix
/pg/bin/pg-rolecan not get OS user name from environ in non-interact mode - Fix
/pg/bin/pg-pitrcan not hint -X -P flag properly
API Change
- New parameter
node_write_etc_hoststo control whether to write/etc/hostsfile on target nodes. - Relocatable prometheus target directory with new parameter
prometheus_sd_dir. - Add
-x|--proxyflag to enable and use value of global proxy env by @waitingsong in https://github.com/pgsty/pigsty/pull/405 - No longer parse infra nginx log details since it brings too much labels to the log.
- Use alertmanager API Version v2 instead of v1 in prometheus config.
- Use
/pg/cert/ca.crtinstead of/etc/pki/ca.crtin pgsql roles.
New Contributors
- @NeroSong made their first contribution in https://github.com/pgsty/pigsty/pull/373
- @waitingsong made their first contribution in https://github.com/pgsty/pigsty/pull/405
Package Checksums
ec271a1d34b2b1360f78bfa635986c3a pigsty-pkg-v2.7.0.el8.x86_64.tgz
f3304bfd896b7e3234d81d8ff4b83577 pigsty-pkg-v2.7.0.debian12.x86_64.tgz
5b071c2a651e8d1e68fc02e7e922f2b3 pigsty-pkg-v2.7.0.ubuntu22.x86_64.tgz
v2.6: the OLAP New Challenger
v2.6.0
Highlight
- Use PostgreSQL 16 as the default major version (16.2)
- Introduce ParadeDB extensions:
pg_analytics,pg_bm25, andpg_sparse - Introduce DuckDB and corresponding foreign data wrapper:
duckdb_fdw - Cloudflare CDN https://repo.pigsty.io and QCloud CDN https://repo.pigsty.cc
Configuration
- Disable Grafana Unified Alert to work around the “Database Locked” error.
- add
node_repo_modulesto add upstream repos (including local one) to node - remove
node_local_repo_urls, replaced bynode_repo_modules&repo_upstream. - remove
node_repo_method, replaced bynode_repo_modules. - add the new
localrepo intorepo_upstreaminstead ofnode_local_repo_urls - add
chronyintonode_default_packages - remove redis,minio,postgresql client from infra packages
- replace
repo_upstream.baseurl$releasever for pgdg el8/el9 withmajor.minorinstead ofmajorversion
Software Upgrade
- Grafana 10.3.3
- Prometheus 2.47
- node_exporter 1.7.0
- HAProxy 2.9.5
- Loki / Promtail 2.9.4
- minio-20240216110548 / mcli-20240217011557
- etcd 3.5.11
- Redis 7.2.4
- Bytebase 2.13.2
- HAProxy 2.9.5
- DuckDB 0.10.0
- FerretDB 1.19
- Metabase: new docker compose app template added
PostgreSQL x Pigsty Extensions
- PostgreSQL Minor Version Upgrade 16.2, 15.6, 14.11, 13.14, 12.18
- PostgreSQL 16 is now used as the default major version
- pg_exporter 0.6.1, security fix
- Patroni 3.2.2
- pgBadger 12.4
- pgBouncer 1.22
- pgBackRest 2.50
- vip-manager 2.3.0
- PostGIS 3.4.2
- PGVector 0.6.0
- TimescaleDB 2.14.1
- New Extension duckdb_fdw v1.1
- New Extension pgsql-gzip v1.0.0
- New Extension pg_sparse from ParadeDB: v0.5.6
- New Extension pg_bm25 from ParadeDB: v0.5.6
- New Extension pg_analytics from ParadeDB: v0.5.6
- Bump AI/ML Extension pgml to v2.8.1 with pg16 support
- Bump Columnar Extension hydra to v1.1.1 with pg16 support
- Bump Graph Extension age to v1.5.0 with pg16 support
- Bump Packaging Extension pg_tle to v1.3.4 with pg16 support
- Bump GraphQL Extension pg_graphql to v1.5.0 to support supabase
330e9bc16a2f65d57264965bf98174ff pigsty-v2.6.0.tgz
81abcd0ced798e1198740ab13317c29a pigsty-pkg-v2.6.0.debian11.x86_64.tgz
7304f4458c9abd3a14245eaf72f4eeb4 pigsty-pkg-v2.6.0.debian12.x86_64.tgz
f914fbb12f90dffc4e29f183753736bb pigsty-pkg-v2.6.0.el7.x86_64.tgz
fc23d122d0743d1c1cb871ca686449c0 pigsty-pkg-v2.6.0.el8.x86_64.tgz
9d258dbcecefd232f3a18bcce512b75e pigsty-pkg-v2.6.0.el9.x86_64.tgz
901ee668621682f99799de8932fb716c pigsty-pkg-v2.6.0.ubuntu20.x86_64.tgz
39872cf774c1fe22697c428be2fc2c22 pigsty-pkg-v2.6.0.ubuntu22.x86_64.tgz
v2.5: Debian / Ubuntu / PG16
v2.5.0
curl https://get.pigsty.io/latest | bash
Highlights
-
Dedicate yum/apt repo on
repo.pigsty.ccand mirror on packagecloud.io -
Anolis OS Support (EL 8.8 Compatible)
-
PG Major Candidate: Use PostgreSQL 16 instead of PostgreSQL 14.
-
New Dashboard PGSQL Exporter, PGSQL Patroni, rework on PGSQL Query
-
Extensions Update:
- Bump PostGIS version to v3.4 on el8, el9, ubuntu22, keep postgis 33 on EL7
- Remove extension
pg_embeddingbecause it is no longer maintained, usepgvectorinstead. - New extension on EL:
pointcloudwith LIDAR data type support. - New extension on EL:
imgsmlr,pg_similarity,pg_bigm - Include columnar extension
hydraand removecitusfrom default installed extension list. - Recompile
pg_filedumpas PG major version independent package.
-
Software Version Upgrade:
- Grafana to v10.1.5
- Prometheus to v2.47
- Promtail/Loki to v2.9.1
- Node Exporter to v1.6.1
- Bytebase to v2.10.0
- patroni to v3.1.2
- pgbouncer to v1.21.0
- pg_exporter to v0.6.0
- pgbackrest to v2.48.0
- pgbadger to v12.2
- pg_graphql to v1.4.0
- pg_net to v0.7.3
- ferretdb to v0.12.1
- sealos to 4.3.5
- Supabase support to
20231013070755
Ubuntu Support
Pigsty has two ubuntu LTS support: 22.04 (jammy) and 20.04 (focal), and ship corresponding offline packages for them.
Some parameters need to be specified explicitly when deploying on Ubuntu, please refer to ubuntu.yml
repo_upstream: Adjust according to ubuntu / debian repo.repo_packages: Adjust according to ubuntu / debian naming conventionnode_repo_local_urls: use the default value:['deb [trusted=yes] http://${admin_ip}/pigsty ./']node_default_packages:zlib->zlib1g,readline->libreadline-devvim-minimal->vim-tiny,bind-utils->dnsutils,perf->linux-tools-generic,- new packages
aclto ensure ansible tmp file privileges are set correctly
infra_packages: replace all_with-in names, and replacepostgresql16withpostgresql-client-16pg_packages: replace all_with-in names,patroni-etcdnot needed on ubuntupg_extensions: different naming convention, nopasswordcheck_cracklibon ubuntu.pg_dbsu_uid: You have to manually specifypg_dbsu_uidon ubuntu, because PGDG deb package does not specify pg dbsu uid.
API Changes
default values of following parameters have changed:
-
repo_modules:infra,node,pgsql,redis,minio -
repo_upstream: Now add Pigsty Infra/MinIO/Redis/PGSQL modular upstream repo. -
repo_packages: remove unusedkarma,mtail,dellhw_exporterand pg 14 extra extensions, adding pg 16 extra extensions. -
node_default_packagesnow addpython3-pipas default packages. -
pg_libs:timescaledbis remove from shared_preload_libraries by default. -
pg_extensions: citus is nolonger installed by default, andpasswordcheck_cracklibis installed by default- pg_repack_${pg_version}* wal2json_${pg_version}* passwordcheck_cracklib_${pg_version}* - postgis34_${pg_version}* timescaledb-2-postgresql-${pg_version}* pgvector_${pg_version}*
87e0be2edc35b18709d7722976e305b0 pigsty-pkg-v2.5.0.el7.x86_64.tgz
e71304d6f53ea6c0f8e2231f238e8204 pigsty-pkg-v2.5.0.el8.x86_64.tgz
39728496c134e4352436d69b02226ee8 pigsty-pkg-v2.5.0.el9.x86_64.tgz
e3f548a6c7961af6107ffeee3eabc9a7 pigsty-pkg-v2.5.0.debian11.x86_64.tgz
1e469cc86a19702e48d7c1a37e2f14f9 pigsty-pkg-v2.5.0.debian12.x86_64.tgz
cc3af3b7c12f98969d3c6962f7c4bd8f pigsty-pkg-v2.5.0.ubuntu20.x86_64.tgz
c5b2b1a4867eee624e57aed58ac65a80 pigsty-pkg-v2.5.0.ubuntu22.x86_64.tgz
v2.5.1
Routine update with v16.1, v15.5, 14.10, 13.13, 12.17, 11.22
Now PostgreSQL 16 has all the core extensions available (pg_repack & timescaledb added)
- Software Version Upgrade:
- PostgreSQL to v16.1, v15.5, 14.10, 13.13, 12.17, 11.22
- Patroni v3.2.0
- PgBackrest v2.49
- Citus 12.1
- TimescaleDB 2.13.0 (with PG 16 support)
- Grafana v10.2.2
- FerretDB 1.15
- SealOS 4.3.7
- Bytebase 2.11.1
- Remove
monitorschema prefix from PGCAT dashboard queries - New template
wool.ymlfor Aliyun free ECS singleton - Add
python3-jmespathin addition topython3.11-jmespathfor el9
31ee48df1007151009c060e0edbd74de pigsty-pkg-v2.5.1.el7.x86_64.tgz
a40f1b864ae8a19d9431bcd8e74fa116 pigsty-pkg-v2.5.1.el8.x86_64.tgz
c976cd4431fc70367124fda4e2eac0a7 pigsty-pkg-v2.5.1.el9.x86_64.tgz
7fc1b5bdd3afa267a5fc1d7cb1f3c9a7 pigsty-pkg-v2.5.1.debian11.x86_64.tgz
add0731dc7ed37f134d3cb5b6646624e pigsty-pkg-v2.5.1.debian12.x86_64.tgz
99048d09fa75ccb8db8e22e2a3b41f28 pigsty-pkg-v2.5.1.ubuntu20.x86_64.tgz
431668425f8ce19388d38e5bfa3a948c pigsty-pkg-v2.5.1.ubuntu22.x86_64.tgz
v2.4: Monitoring Cloud RDS
v2.4.0
Get started with bash -c "$(curl -fsSL https://get.pigsty.cc/latest)".
Highlights
- PostgreSQL 16 support
- The first LTS version with business support and consulting service
- Monitoring existing PostgreSQL, RDS for PostgreSQL / PolarDB with PGRDS Dashboards
- New extension: Apache AGE, openCypher graph query engine on PostgreSQL
- New extension: zhparser, full text search for Chinese language
- New extension: pg_roaringbitmap, roaring bitmap for PostgreSQL
- New extension: pg_embedding, hnsw alternative to pgvector
- New extension: pg_tle, admin / manage stored procedure extensions
- New extension: pgsql-http, issue http request with SQL interface
- Add extensions: pg_auth_mon pg_checksums pg_failover_slots pg_readonly postgresql-unit pg_store_plans pg_uuidv7 set_user
- Redis enhancement: add monitoring panels for redis sentinel, and auto HA configuration for redis ms cluster.
API Change
- New Parameter:
REDIS.redis_sentinel_monitor: specify masters monitor by redis sentinel cluster
Bug Fix
- Fix Grafana 10.1 registered datasource will use random uid rather than
ins.datname
MD5 (pigsty-pkg-v2.4.0.el7.x86_64.tgz) = 257443e3c171439914cbfad8e9f72b17
MD5 (pigsty-pkg-v2.4.0.el8.x86_64.tgz) = 41ad8007ffbfe7d5e8ba5c4b51ff2adc
MD5 (pigsty-pkg-v2.4.0.el9.x86_64.tgz) = 9a950aed77a6df90b0265a6fa6029250
v2.3: Ecosystem Applications
v2.3.0
PGSQL/REDIS Update, NODE VIP, Mongo/FerretDB, MYSQL Stub
Get started with bash -c "$(curl -fsSL https://get.pigsty.cc/latest)"
Highlight
- INFRA: NODE/PGSQL VIP monitoring support
- NODE: Allow bind
node_vipto node cluster withkeepalived - REPO: Dedicate yum repo, enable https for
get.pigsty.ccanddemo.pigsty.io - PGSQL: Fix CVE-2023-39417 with PostgreSQL 15.4, 14.9, 13.12, 12.16, bump patroni version to v3.1.0
- APP: Bump
app/bytebaseto v2.6.0,app/ferretdbversion to v1.8, new application nocodb - REDIS: bump to v7.2 and rework on dashboards
- MONGO: basic deploy & monitor support with FerretDB 1.8
- MYSQL: add prometheus/grafana/ca stub for future implementation.
API Change
Add 1 new section NODE.NODE_VIP with 8 new parameter
NODE.VIP.vip_enabled: enable vip on this node cluster?NODE.VIP.vip_address: node vip address in ipv4 format, required if vip is enabledNODE.VIP.vip_vrid: required, integer, 1-255 should be unique among same VLANNODE.VIP.vip_role:master/backup, backup by default, use as init roleNODE.VIP.vip_preempt: optional,true/false, false by default, enable vip preemptionNODE.VIP.vip_interface: node vip network interface to listen,eth0by defaultNODE.VIP.vip_dns_suffix: node vip dns name suffix,.vipby defaultNODE.VIP.vip_exporter_port: keepalived exporter listen port, 9650 by default
MD5 (pigsty-pkg-v2.3.0.el7.x86_64.tgz) = 81db95f1c591008725175d280ad23615
MD5 (pigsty-pkg-v2.3.0.el8.x86_64.tgz) = 6f4d169b36f6ec4aa33bfd5901c9abbe
MD5 (pigsty-pkg-v2.3.0.el9.x86_64.tgz) = 4bc9ae920e7de6dd8988ca7ee681459d
v2.3.1
Get started with bash -c "$(curl -fsSL https://get.pigsty.cc/latest)".
Highlights
- PGVector 0.5 with HNSW index support
- PostgreSQL 16 RC1 for el8/el9 ** Adding SealOS for kubernetes support
Bug Fix
- Fix
infra.repo.repo_pkgtask when downloading rpm with*in their names inrepo_packages.- if
/www/pigstyalready have package name match that pattern, some rpm will be skipped.
- if
- Change default value of
vip_dns_suffixto''empty string rather than.vip - Grant sudo privilege for postgres dbsu when
pg_dbsu_sudo=limitandpatroni_watchdog_mode=required/usr/bin/sudo /sbin/modprobe softdog: enable watchdog module before launching patroni/usr/bin/sudo /bin/chown {{ pg_dbsu }} /dev/watchdog: chown watchdog before launching patroni
Documentation Update
- Add details to English documentation
- Add Chinese/zh-cn documentation
Software Upgrade
- PostgreSQL 16 RC1 on el8/el9
- PGVector 0.5.0 with hnsw index
- TimescaleDB 2.11.2
- grafana 10.1.0
- loki & promtail 2.8.4
- mcli-20230829225506 / minio-20230829230735
- ferretdb 1.9
- sealos 4.3.3
- pgbadger 1.12.2
ce69791eb622fa87c543096cdf11f970 pigsty-pkg-v2.3.1.el7.x86_64.tgz
495aba9d6d18ce1ebed6271e6c96b63a pigsty-pkg-v2.3.1.el8.x86_64.tgz
38b45582cbc337ff363144980d0d7b64 pigsty-pkg-v2.3.1.el9.x86_64.tgz
v2.2: Observability Overhaul
v2.2.0
https://github.com/pgsty/pigsty/releases/tag/v2.2.0
Get started with bash -c "$(curl -fsSL https://get.pigsty.cc/latest)"
Release Note: https://doc.pigsty.cc/#/RELEASENOTE?id=v220
Highlight
- Monitoring Dashboards Overhaul: https://demo.pigsty.io
- Vagrant Sandbox Overhaul: libvirt support and new templates
- Pigsty EL Yum Repo: Building simplified
- OS Compatibility: UOS-v20-1050e support
- New config template: prod simulation with 42 nodes
- Use official pgdg citus distribution for el7
Software Upgrade
- PostgreSQL 16 beta2
- Citus 12 / PostGIS 3.3.3 / TimescaleDB 2.11.1 / PGVector 0.44
- patroni 3.0.4 / pgbackrest 2.47 / pgbouncer 1.20
- grafana 10.0.3 / loki/promtail/logcli 2.8.3
- etcd 3.5.9 / haproxy v2.8.1 / redis v7.0.12
- minio 20230711212934 / mcli 20230711233044
Bug Fix
- Fix docker group ownership issue [29434bd]https://github.com/pgsty/pigsty/commit/29434bdd39548d95d80a236de9099874ed564f9b
- Append infra os group rather than set it as primary group
- Fix redis sentinel systemd enable status 5c96feb
- Loose
bootstrap&configureif/etc/redhat-releasenot exists - Fix grafana 9.x CVE-2023-1410 with 10.0.2
- Add PG 14 - 16 new command tags and error codes for
pglogschema
API Change
Add 1 new parameter
INFRA.NGINX.nginx_exporter_enabled: now you can disable nginx_exporter with this parameter
Default value changes:
repo_modules:node,pgsql,infra: redis is removed from itrepo_upstream:- add
pigsty-el: distribution independent rpms: such as grafana, minio, pg_exporter, etc… - add
pigsty-misc: distribution aware rpms: such as redis, prometheus stack binaries, etc… - remove
citusrepo since pgdg now have full official citus support (on el7) - remove
remi, since redis is now included inpigsty-misc - remove
grafanain build config for acceleration
- add
repo_packages:- ansible python3 python3-pip python3-requests python3.11-jmespath dnf-utils modulemd-tools # el7: python36-requests python36-idna yum-utils
- grafana loki logcli promtail prometheus2 alertmanager karma pushgateway node_exporter blackbox_exporter nginx_exporter redis_exporter
- redis etcd minio mcli haproxy vip-manager pg_exporter nginx createrepo_c sshpass chrony dnsmasq docker-ce docker-compose-plugin flamegraph
- lz4 unzip bzip2 zlib yum pv jq git ncdu make patch bash lsof wget uuid tuned perf nvme-cli numactl grubby sysstat iotop htop rsync tcpdump
- netcat socat ftp lrzsz net-tools ipvsadm bind-utils telnet audit ca-certificates openssl openssh-clients readline vim-minimal
- postgresql13* wal2json_13* pg_repack_13* passwordcheck_cracklib_13* postgresql12* wal2json_12* pg_repack_12* passwordcheck_cracklib_12* postgresql16* timescaledb-tools
- postgresql15 postgresql15* citus_15* pglogical_15* wal2json_15* pg_repack_15* pgvector_15* timescaledb-2-postgresql-15* postgis33_15* passwordcheck_cracklib_15* pg_cron_15*
- postgresql14 postgresql14* citus_14* pglogical_14* wal2json_14* pg_repack_14* pgvector_14* timescaledb-2-postgresql-14* postgis33_14* passwordcheck_cracklib_14* pg_cron_14*
- patroni patroni-etcd pgbouncer pgbadger pgbackrest pgloader pg_activity pg_partman_15 pg_permissions_15 pgaudit17_15 pgexportdoc_15 pgimportdoc_15 pg_statement_rollback_15*
- orafce_15* mysqlcompat_15 mongo_fdw_15* tds_fdw_15* mysql_fdw_15 hdfs_fdw_15 sqlite_fdw_15 pgbouncer_fdw_15 multicorn2_15* powa_15* pg_stat_kcache_15* pg_stat_monitor_15* pg_qualstats_15 pg_track_settings_15 pg_wait_sampling_15 system_stats_15
- plprofiler_15* plproxy_15 plsh_15* pldebugger_15 plpgsql_check_15* pgtt_15 pgq_15* pgsql_tweaks_15 count_distinct_15 hypopg_15 timestamp9_15* semver_15* prefix_15* rum_15 geoip_15 periods_15 ip4r_15 tdigest_15 hll_15 pgmp_15 extra_window_functions_15 topn_15
- pg_background_15 e-maj_15 pg_catcheck_15 pg_prioritize_15 pgcopydb_15 pg_filedump_15 pgcryptokey_15 logerrors_15 pg_top_15 pg_comparator_15 pg_ivm_15* pgsodium_15* pgfincore_15* ddlx_15 credcheck_15 safeupdate_15 pg_squeeze_15* pg_fkpart_15 pg_jobmon_15
repo_url_packages:node_default_packages:- lz4,unzip,bzip2,zlib,yum,pv,jq,git,ncdu,make,patch,bash,lsof,wget,uuid,tuned,nvme-cli,numactl,grubby,sysstat,iotop,htop,rsync,tcpdump
- netcat,socat,ftp,lrzsz,net-tools,ipvsadm,bind-utils,telnet,audit,ca-certificates,openssl,readline,vim-minimal,node_exporter,etcd,haproxy,python3,python3-pip
infra_packages- grafana,loki,logcli,promtail,prometheus2,alertmanager,karma,pushgateway
- node_exporter,blackbox_exporter,nginx_exporter,redis_exporter,pg_exporter
- nginx,dnsmasq,ansible,postgresql15,redis,mcli,python3-requests
PGSERVICEin.pigstyis removed, replaced withPGDATABASE=postgres.
FHS Changes:
bin/dnsandbin/sshnow moved tovagrant/
MD5 (pigsty-pkg-v2.2.0.el7.x86_64.tgz) = 5fb6a449a234e36c0d895a35c76add3c
MD5 (pigsty-pkg-v2.2.0.el8.x86_64.tgz) = c7211730998d3b32671234e91f529fd0
MD5 (pigsty-pkg-v2.2.0.el9.x86_64.tgz) = 385432fe86ee0f8cbccbbc9454472fdd
v2.1: Vector Embedding & RAG
v2.1.0
PostgreSQL 12 ~ 16 support and pgvector for AI embedding.
https://github.com/pgsty/pigsty/releases/tag/v2.1.0
Highlight
- PostgreSQL 16 beta support, and 12 ~ 15 support.
- Add PGVector for AI Embedding for 12 - 15
- Add 6 extra panel & datasource plugins for grafana
- Add
bin/profileto profile remote process and generate flamegraph - Add
bin/validateto validate pigsty.yml configuration file - Add
bin/repo-addto add upstream repo files to /etc/yum.repos.d - PostgreSQL 16 observability:
pg_stat_ioand corresponding dashboards
Software Upgrade
- PostgreSQL 15.3 , 14.8, 13.11, 12.15, 11.20, and 16 beta1
- pgBackRest 2.46
- pgbouncer 1.19
- Redis 7.0.11
- Grafana v9.5.3
- Loki / Promtail / Logcli 2.8.2
- Prometheus 2.44
- TimescaleDB 2.11.0
- minio-20230518000536 / mcli-20230518165900
- Bytebase v2.2.0
Enhancement
- Now use all
id*.pubwhen installing local user’s public key
v2.0: Free RDS PG Alternative
v2.0.0
“PIGSTY” is now the abbr of “PostgreSQL in Great STYle”
or “PostgreSQL & Infrastructure & Governance System allTogether for You”.
Get pigsty v2.0.0 release via the following command:
curl -fsSL http://download.pigsty.cc/get) | bash
Download directly from GitHub Release
bash -c "$(curl -fsSL https://raw.githubusercontent.com/pgsty/pigsty/master/bin/get)"
# or download tarball directly with curl (EL9)
curl -L https://github.com/pgsty/pigsty/releases/download/v2.0.0/pigsty-v2.0.0.tgz -o ~/pigsty.tgz
curl -L https://github.com/pgsty/pigsty/releases/download/v2.0.0/pigsty-pkg-v2.0.0.el9.x86_64.tgz -o /tmp/pkg.tgz
# EL7: https://github.com/pgsty/pigsty/releases/download/v2.0.0/pigsty-pkg-v2.0.0.el7.x86_64.tgz
# EL8: https://github.com/pgsty/pigsty/releases/download/v2.0.0/pigsty-pkg-v2.0.0.el8.x86_64.tgz
Highlights
- PostgreSQL 15.2, PostGIS 3.3, Citus 11.2, TimescaleDB 2.10 now works together and unite as one.
- Now works on EL 7,8,9 for RHEL, CentOS, Rocky, AlmaLinux, and other EL compatible distributions
- Security enhancement with self-signed CA, full SSL support,
scram-sha-256pwd encryption, and more. - Patroni 3.0 with native HA citus cluster support and dcs failsafe mode to prevent global DCS failures.
- Auto-Configured, Battery-Included PITR for PostgreSQL powered by
pgbackrest, local or S3/minio. - Dedicate module
ETCDwhich can be easily deployed and scaled in/out. Used as DCS instead of Consul. - Dedicate module
MINIO, local S3 alternative for the optional central backup repo for PGSQL PITR. - Better config templates with adaptive tuning for Node & PG according to your hardware spec.
- Use AGPL v3.0 license instead of Apache 2.0 license due to Grafana & MinIO reference.
Compatibility
- Pigsty now works on EL7, EL8, EL9, and offers corresponding pre-packed offline packages.
- Pigsty now works on EL compatible distributions: RHEL, CentOS, Rocky, AlmaLinux, OracleLinux,…
- Pigsty now use RockyLinux 9 as default developing & testing environment instead of CentOS 7
- EL version, CPU arch, and pigsty version string are part of source & offline package names.
- PGSQL: PostgreSQL 15.2 / PostGIS 3.3 / TimescaleDB 2.10 / Citus 11.2 now works together.
- PGSQL: Patroni 3.0 is used as default HA solution for PGSQL, and etcd is used as default DCS.
- Patroni 3.0 with DCS failsafe mode to prevent global DCS failures (demoting all primary)
- Patroni 3.0 with native HA citus cluster support, with entirely open sourced v11 citus.
- vip-manager 2.x with ETCDv3 API, ETCDv2 API is deprecated, so does patroni.
- PGSQL: pgBackRest v2.44 is introduced to provide battery-include PITR for PGSQL.
- it will use local backup FS on primary by default for a two-day retention policy
- it will use S3/minio as an alternative central backup repo for a two-week retention policy
- ETCD is used as default DCS instead of Consul, And V3 API is used instead of V2 API.
- NODE module now consist of
nodeitself,haproxy,docker,node_exporter, andpromtailchronydis used as default NTP client instead ofntpd- HAPROXY now attach to
NODEinstead ofPGSQL, which can be used for exposing services - You can register PG Service to dedicate haproxy clusters rather than local cluster nodes.
- You can expose ad hoc service in a NodePort manner with haproxy, not limited to pg services.
- INFRA now consist of
dnsmasq,nginx,prometheus,grafana,loki- DNSMASQ is enabled on all infra nodes, and added to all nodes as the default resolver.
- Add blackbox_exporter for ICMP probe, add pushgateway for batch job metrics.
- Switch to official loki & promtail rpm packages. Use official Grafana Echarts Panel.
- Add infra dashboards for self-monitoring, add patroni & pg15 metrics to monitoring system
- Software Upgrade
- PostgreSQL 15.2 / PostGIS 3.3 / TimescaleDB 2.10 / Citus 11.2
- Patroni 3.0 / Pgbouncer 1.18 / pgBackRest 2.44 / vip-manager 2.1
- HAProxy 2.7 / Etcd 3.5 / MinIO 20230222182345 / mcli 20230216192011
- Prometheus 2.42 / Grafana 9.3 / Loki & Promtail 2.7 / Node Exporter 1.5
Security
- A full-featured self-signed CA enabled by default
- Redact password in postgres logs.
- SSL for Nginx (you have to trust the self-signed CA or use
thisisunsafeto dismiss warning) - SSL for etcd peer/client traffics by @alemacci
- SSL for postgres/pgbouncer/patroni by @alemacci
scram-sha-256auth for postgres password encryption by @alemacci- Pgbouncer Auth Query by @alemacci
- Use
AES-256-CBCforpgbackrestencryption by @alemacci - Adding a security enhancement config template which enforce global SSL
- Now all hba rules are defined in config inventory, no default rules.
Maintainability
- Adaptive tuning template for PostgreSQL & Patroni by @Vonng, @alemacci
- configurable log dir for Patroni & Postgres & Pgbouncer & Pgbackrest by @alemacci
- Replace fixed ip placeholder
10.10.10.10with${admin_ip}that can be referenced - Adaptive upstream repo definition that can be switched according EL ver,
region& arch. - Terraform Templates for AWS CN & Aliyun, which can be used for sandbox IaaS provisioning
- Vagrant Templates:
meta,full,el7el8,el9,build,minio,citus, etc… - New playbook
pgsql-monitor.ymlfor monitoring existing pg instance or RDS PG. - New playbook
pgsql-migration.ymlfor migrating existing pg instance to pigsty manged pg. - New shell utils under
bin/to simplify the daily administration tasks. - Optimize ansible role implementation. which can be used without default parameter values.
- Now you can define pgbouncer parameters on database & user level
API Changes
69 parameters added, 16 parameters removed, rename 14 parameters
INFRA.META.admin_ip: primary meta node ip addressINFRA.META.region: upstream mirror region: default|china|europeINFRA.META.os_version: enterprise linux release version: 7,8,9INFRA.CA.ca_cn: ca common name, pigsty-ca by defaultINFRA.CA.cert_validity: cert validity, 20 years by defaultINFRA.REPO.repo_enabled: build a local yum repo on infra node?INFRA.REPO.repo_upstream: list of upstream yum repo definitionINFRA.REPO.repo_home: home dir of local yum repo, usually same as nginx_home ‘/www’INFRA.NGINX.nginx_ssl_port: https listen portINFRA.NGINX.nginx_ssl_enabled: nginx https enabled?INFRA.PROMTETHEUS.alertmanager_endpoint: altermanager endpoint in (ip|domain):port formatNODE.NODE_TUNE.node_hugepage_count: number of 2MB hugepage, take precedence overnode_hugepage_ratioNODE.NODE_TUNE.node_hugepage_ratio: mem hugepage ratio, 0 disable it by defaultNODE.NODE_TUNE.node_overcommit_ratio: node mem overcommit ratio, 0 disable it by defaultNODE.HAPROXY.haproxy_service: list of haproxy service to be exposedPGSQL.PG_ID.pg_mode: pgsql cluster mode: pgsql,citus,gpsqlPGSQL.PG_BUSINESS.pg_dbsu_password: dbsu password, empty string means no dbsu password by defaultPGSQL.PG_INSTALL.pg_log_dir: postgres log dir,/pg/data/logby defaultPGSQL.PG_BOOTSTRAP.pg_storage_type: SSD|HDD, SSD by defaultPGSQL.PG_BOOTSTRAP.patroni_log_dir: patroni log dir,/pg/logby defaultPGSQL.PG_BOOTSTRAP.patroni_ssl_enabled: secure patroni RestAPI communications with SSL?PGSQL.PG_BOOTSTRAP.patroni_username: patroni rest api usernamePGSQL.PG_BOOTSTRAP.patroni_password: patroni rest api password (IMPORTANT: CHANGE THIS)PGSQL.PG_BOOTSTRAP.patroni_citus_db: citus database managed by patroni, postgres by defaultPGSQL.PG_BOOTSTRAP.pg_max_conn: postgres max connections,autowill use recommended valuePGSQL.PG_BOOTSTRAP.pg_shared_buffer_ratio: postgres shared buffer memory ratio, 0.25 by default, 0.1~0.4PGSQL.PG_BOOTSTRAP.pg_rto: recovery time objective, ttl to failover, 30s by defaultPGSQL.PG_BOOTSTRAP.pg_rpo: recovery point objective, 1MB data loss at most by defaultPGSQL.PG_BOOTSTRAP.pg_pwd_enc: algorithm for encrypting passwords: md5|scram-sha-256PGSQL.PG_BOOTSTRAP.pgbouncer_log_dir: pgbouncer log dir,/var/log/pgbouncerby defaultPGSQL.PG_BOOTSTRAP.pgbouncer_auth_query: if enabled, query pg_authid table to retrieve biz users instead of populating userlistPGSQL.PG_BOOTSTRAP.pgbouncer_sslmode: SSL for pgbouncer client: disable|allow|prefer|require|verify-ca|verify-fullPGSQL.PG_BACKUP.pgbackrest_enabled: pgbackrest enabled?PGSQL.PG_BACKUP.pgbackrest_clean: remove pgbackrest data during init ?PGSQL.PG_BACKUP.pgbackrest_log_dir: pgbackrest log dir,/pg/logby defaultPGSQL.PG_BACKUP.pgbackrest_method: pgbackrest backup repo method, local or minioPGSQL.PG_BACKUP.pgbackrest_repo: pgbackrest backup repo configPGSQL.PG_SERVICE.pg_service_provider: dedicate haproxy node group name, or empty string for local nodes by defaultPGSQL.PG_SERVICE.pg_default_service_dest: default service destination if svc.dest=‘default’PGSQL.PG_SERVICE.pg_vip_enabled: enable a l2 vip for pgsql primary? false by defaultPGSQL.PG_SERVICE.pg_vip_address: vip address in<ipv4>/<mask>format, require if vip is enabledPGSQL.PG_SERVICE.pg_vip_interface: vip network interface to listen, eth0 by defaultPGSQL.PG_SERVICE.pg_dns_suffix: pgsql cluster dns name suffix, ’’ by defaultPGSQL.PG_SERVICE.pg_dns_target: auto, primary, vip, none, or ad hoc ipETCD.etcd_seq: etcd instance identifier, REQUIREDETCD.etcd_cluster: etcd cluster & group name, etcd by defaultETCD.etcd_safeguard: prevent purging running etcd instance?ETCD.etcd_clean: purging existing etcd during initialization?ETCD.etcd_data: etcd data directory, /data/etcd by defaultETCD.etcd_port: etcd client port, 2379 by defaultETCD.etcd_peer_port: etcd peer port, 2380 by defaultETCD.etcd_init: etcd initial cluster state, new or existingETCD.etcd_election_timeout: etcd election timeout, 1000ms by defaultETCD.etcd_heartbeat_interval: etcd heartbeat interval, 100ms by defaultMINIO.minio_seq: minio instance identifier, REQUIREDMINIO.minio_cluster: minio cluster name, minio by defaultMINIO.minio_clean: cleanup minio during init?, false by defaultMINIO.minio_user: minio os user,minioby defaultMINIO.minio_node: minio node name patternMINIO.minio_data: minio data dir(s), use {x…y} to specify multi driversMINIO.minio_domain: minio external domain name,sss.pigstyby defaultMINIO.minio_port: minio service port, 9000 by defaultMINIO.minio_admin_port: minio console port, 9001 by defaultMINIO.minio_access_key: root access key,minioadminby defaultMINIO.minio_secret_key: root secret key,minioadminby defaultMINIO.minio_extra_vars: extra environment variables for minio serverMINIO.minio_alias: alias name for local minio deploymentMINIO.minio_buckets: list of minio bucket to be createdMINIO.minio_users: list of minio user to be created
Removed Parameters
INFRA.CA.ca_homedir: ca home dir, now fixed as/etc/pki/INFRA.CA.ca_cert: ca cert filename, now fixed asca.keyINFRA.CA.ca_key: ca key filename, now fixed asca.keyINFRA.REPO.repo_upstreams: replaced byrepo_upstreamPGSQL.PG_INSTALL.pgdg_repo: now taken care by node playbooksPGSQL.PG_INSTALL.pg_add_repo: now taken care by node playbooksPGSQL.PG_IDENTITY.pg_backup: not used and conflict with section namePGSQL.PG_IDENTITY.pg_preflight_skip: not used anymore, replace bypg_idDCS.dcs_name: removed due to using etcdDCS.dcs_servers: replaced by using ad hoc groupetcdDCS.dcs_registry: removed due to using etcdDCS.dcs_safeguard: replaced byetcd_safeguardDCS.dcs_clean: replaced byetcd_cleanPGSQL.PG_VIP.vip_mode: replaced bypg_vip_enabledPGSQL.PG_VIP.vip_address: replaced bypg_vip_addressPGSQL.PG_VIP.vip_interface: replaced bypg_vip_interface
Renamed Parameters
nginx_upstream->infra_portalrepo_address->repo_endpointpg_hostname->node_id_from_pgpg_sindex->pg_grouppg_services->pg_default_servicespg_services_extra->pg_servicespg_hba_rules_extra->pg_hba_rulespg_hba_rules->pg_default_hba_rulespgbouncer_hba_rules_extra->pgb_hba_rulespgbouncer_hba_rules->pgb_default_hba_rulesnode_packages_default->node_default_packagesnode_packages_meta->infra_packagesnode_packages_meta_pip->infra_packages_pipnode_data_dir->node_data
Checksums
MD5 (pigsty-pkg-v2.0.0.el7.x86_64.tgz) = 9ff3c973fa5915f65622b91419817c9b
MD5 (pigsty-pkg-v2.0.0.el8.x86_64.tgz) = bd108a6c8f026cb79ee62c3b68b72176
MD5 (pigsty-pkg-v2.0.0.el9.x86_64.tgz) = e24288770f240af0511b0c38fa2f4774
Special thanks to @alemacci for his great contribution!
v2.0.1
Bug fix for v2.0.0 and security improvement.
Enhancement
- Replace the pig shape logo for compliance with the PostgreSQL trademark policy.
- Bump grafana version to v9.4 with better UI and bugfix.
- Bump patroni version to v3.0.1 with some bugfix.
- Change: rollback grafana systemd service file to rpm default.
- Use slow
copyinstead ofrsyncto copy grafana dashboards. - Enhancement: add back default repo files after bootstrap
- Add asciinema video for various administration tasks.
- Security Enhance Mode: restrict monitor user privilege.
- New config template:
dual.ymlfor two-node deployment. - Enable
log_connectionsandlog_disconnectionsincrit.ymltemplate. - Enable
$lib/passwordcheckinpg_libsincrit.ymltemplate. - Explicitly grant monitor view permission to
pg_monitorrole. - Remove default
dbrole_readonlyfromdbuser_monitorto limit monitor user privilege - Now patroni listen on
{{ inventory_hostname }}instead of0.0.0.0 - Now you can control postgres/pgbouncer listen to address with
pg_listen - Now you can use placeholder
${ip},${lo},${vip}inpg_listen - Bump Aliyun terraform image to rocky Linux 9 instead of centos 7.9
- Bump bytebase to v1.14.0
Bug Fixes
- Add missing advertise address for alertmanager
- Fix missing
pg_modeerror when adding postgres user withbin/pgsql-user - Add
-a passwordto redis-join task @redis.yml - Fix missing default value in
infra-rm.yml.remove infra data - Fix prometheus targets file ownership to
prometheus - Use admin user rather than root to delete metadata in DCS
- Fix Meta datasource missing database name due to grafana 9.4 bug.
Caveats
Official EL8 pgdg upstream is broken now, DO use it with caution!
Affected packages: postgis33_15, pgloader, postgresql_anonymizer_15*, postgresql_faker_15
How to Upgrade
cd ~/pigsty; tar -zcf /tmp/files.tgz files; rm -rf ~/pigsty # backup files dir and remove
cd ~; bash -c "$(curl -fsSL https://get.pigsty.cc/latest)" # get latest pigsty source
cd ~/pigsty; rm -rf files; tar -xf /tmp/files.tgz -C ~/pigsty # restore files dir
Checksums
MD5 (pigsty-pkg-v2.0.1.el7.x86_64.tgz) = 5cfbe98fd9706b9e0f15c1065971b3f6
MD5 (pigsty-pkg-v2.0.1.el8.x86_64.tgz) = c34aa460925ae7548866bf51b8b8759c
MD5 (pigsty-pkg-v2.0.1.el9.x86_64.tgz) = 055057cebd93c473a67fb63bcde22d33
Special thanks to @cocoonkid for his feedback.
v2.0.2
Highlight
Store OpenAI embedding and search similar vectors with pgvector
- New extension
pgvector - MinIO CVE-2023-28432 fix, and upgrade to 20230324 with new policy API:
Changes
- New extension
pgvectorfor storing OpenAI embedding and searching similar vectors. - MinIO CVE-2023-28432 fix, and upgrade to 20230324 with new policy API.
- Add reload functionality to DNSMASQ systemd services
- Bump pev to v1.8
- Bump grafana to v9.4.7
- Bump MinIO and MCLI version to 20230324
- Bump bytebase version to v1.15.0
- Upgrade monitoring dashboards and fix dead links
- Upgrade aliyun terraform template image to rockylinux 9
- Adopt grafana provisioning API change since v9.4
- Add asciinema videos for various administration tasks
- Fix broken EL8 pgsql deps: remove anonymizer_15 faker_15 and pgloader
MD5 (pigsty-pkg-v2.0.2.el7.x86_64.tgz) = d46440a115d741386d29d6de646acfe2
MD5 (pigsty-pkg-v2.0.2.el8.x86_64.tgz) = 5fa268b5545ac96b40c444210157e1e1
MD5 (pigsty-pkg-v2.0.2.el9.x86_64.tgz) = c8b113d57c769ee86a22579fc98e8345
v1.5.0 Release Note
v1.5.0
Highlights
- Complete Docker Support, enable on meta nodes by default with lot’s of software templates.
- bytebase pgadmin4 pgweb postgrest kong minio,…
- Infra Self Monitoring: Nginx, ETCD, Consul, Grafana, Prometheus, Loki, etc…
- New CMDB design compatible with redis & greenplum, visualize with CMDB Overview
- Service Discovery : Consul SD now works again for prometheus targets management
- Redis playbook now works on single instance with
redis_portoption. - Better cold backup support: crontab for backup, delayed standby with
pg_delay - Use ETCD as DCS, alternative to Consul
Monitoring
Dashboards
- CMDB Overview: Visualize CMDB Inventory
- DCS Overview: Show consul & etcd metrics
- Nginx Overview: Visualize nginx metrics & access/error logs
- Grafana Overview: Grafana self Monitoring
- Prometheus Overview: Prometheus self Monitoring
- INFRA Dashboard & Home Dashboard Reforge
Architecture
- Infra monitoring targets now have a separated target dir
targets/infra - Consul SD is available for prometheus
- etcd , consul , patroni, docker metrics
- Now infra targets are managed by role
infra_register - Upgrade pg_exporter to v0.5.0 with
scaleanddefaultsupportpg_bgwriter,pg_wal,pg_query,pg_db,pgbouncer_statnow use seconds instead of ms and µspg_tablecounters now have default value 0 instead of NaNpg_classis replaced bypg_tableandpg_indexpg_table_sizeis now enabled with 300s ttl
Provisioning
- New optional package
docker.tgzcontains: Pgadmin, Pgweb, Postgrest, ByteBase, Kong, Minio, etc. - New Role
etcdto deploy & monitor etcd dcs service - Specify which type of DCS to use with
pg_dcs_type(etcdnow available) - Add
pg_checksumoption to enable data checksum - Add
pg_delayoption to setup delayed standby leaders - Add
node_crontabandnode_crontab_overwriteto create routine jobs such as cold backup - Add a series of
*_enableoptions to control components - Loki and Promtail are now installed using the RPM package made by
frpm.
Software Updates
- Upgrade PostgreSQL to 14.3
- Upgrade Redis to 6.2.7
- Upgrade PG Exporter to 0.5.0
- Upgrade Consul to 1.12.0
- Upgrade vip-manager to v1.0.2
- Upgrade Grafana to v8.5.2
- Upgrade HAproxy to 2.5.7 without rsyslog dependency
- Upgrade Loki & Promtail to v2.5.0 with RPM packages
- New packages:
pg_probackup
New software / application based on docker:
- bytebase : DDL Schema Migrator
- pgadmin4 : Web Admin UI for PostgreSQL
- pgweb : Web Console for PostgreSQL
- postgrest : Auto generated REST API for PostgreSQL
- kong : API Gateway which use PostgreSQL as backend storage
- swagger openapi : API Specification Generator
- Minio : S3-compatible object storage
Bug Fix
- Fix loki & promtail
/etc/defaultconfig file name issue - Now
node_data_dir (/data)is created before consul init if not exists - Fix haproxy silence
/var/log/messageswith inappropriate rsyslog dependency
API Change
New Variable
node_data_dir: major data mount path, will be created if not exist.node_crontab_overwrite: overwrite/etc/crontabinstead of appendnode_crontab: node crontab to be appended or overwrittennameserver_enabled: enable nameserver on this meta node?prometheus_enabled: enable prometheus on this meta node?grafana_enabled: enable grafana on this meta node?loki_enabled: enable loki on this meta node?docker_enable: enable docker on this node?consul_enable: enable consul server/agent?etcd_enable: enable etcd server/clients?pg_checksum: enable pg cluster data-checksum?pg_delay: recovery min apply delay for standby leader
Reforge
Now *_clean are boolean flags to clean up existing instance during init.
And *_safeguard are boolean flags to avoid purging running instance when executing any playbook.
pg_exists_action->pg_cleanpg_disable_purge->pg_safeguarddcs_exists_action->dcs_cleandcs_disable_purge->dcs_safeguard
Rename
node_ntp_config->node_ntp_enablednode_admin_setup->node_admin_enablednode_admin_pks->node_admin_pk_listnode_dns_hosts->node_etc_hosts_defaultnode_dns_hosts_extra->node_etc_hostsnode_dns_server->node_dns_methodnode_local_repo_url->node_repo_local_urlsnode_packages->node_packages_defaultnode_extra_packages->node_packagesnode_packages_meta->node_packages_metanode_meta_pip_install->node_packages_meta_pipnode_sysctl_params->node_tune_paramsapp_list->nginx_indexesgrafana_plugin->grafana_plugin_methodgrafana_cache->grafana_plugin_cachegrafana_plugins->grafana_plugin_listgrafana_git_plugin_git->grafana_plugin_githaproxy_admin_auth_enabled->haproxy_auth_enabledpg_shared_libraries->pg_libsdcs_type->pg_dcs_type
v1.5.1
Highlights
WARNING: CREATE INDEX|REINDEX CONCURRENTLY PostgreSQL 14.0 - 14.3 may lead to index data corruption!
Please upgrade postgres to 14.4 ASAP.
Software Upgrade
- upgrade postgres to 14.4
- Upgrade haproxy to 2.6.0
- Upgrade grafana to 9.0.0
- Upgrade prometheus 2.36.0
- Upgrade patroni to 2.1.4
Bug fix:
- Fix typo in
pgsql-migration.yml - remove pid file in haproxy config
- remove i686 packages when using repotrack under el7
- Fix redis service systemctl enabled issue
- Fix patroni systemctl service enabled=no by default issue
API Changes
- Mark
grafana_databaseandgrafana_pgurlas obsolete
New Apps
- wiki.js : Local wiki with Postgres
v1.4.0 Release Note
v1.4.0
Architecture
- Decouple system into 4 major categories:
INFRA,NODES,PGSQL,REDIS, which makes pigsty far more clear and more extensible. - Single Node Deployment =
INFRA+NODES+PGSQL - Deploy pgsql clusters =
NODES+PGSQL - Deploy redis clusters =
NODES+REDIS - Deploy other databases =
NODES+ xxx (e.gMONGO,KAFKA, … TBD)
Accessibility
- CDN for mainland China.
- Get the latest source with
bash -c "$(curl -fsSL http://download.pigsty.cc/get)" - Download & Extract packages with new
downloadscript.
Monitor Enhancement
- Split monitoring system into 5 major categories:
INFRA,NODES,REDIS,PGSQL,APP - Logging enabled by default
- now
lokiandpromtailare enabled by default. with prebuilt loki-rpm
- now
- Models & Labels
- A hidden
dsprometheus datasource variable is added for all dashboards, so you can easily switch different datasource simply by select a new one rather than modifying Grafana Datasources & Dashboards - An
iplabel is added for all metrics, and will be used as join key between database metrics & nodes metrics
- A hidden
- INFRA Monitoring
- Home dashboard for infra: INFRA Overview
- Add logging Dashboards : Logs Instance
- PGLOG Analysis & PGLOG Session now treated as an example Pigsty APP.
- NODES Monitoring Application
- If you don’t care database at all, Pigsty now can be used as host monitoring software alone!
- Consist of 4 core dashboards: Nodes Overview & Nodes Cluster & Nodes Instance & Nodes Alert
- Introduce new identity variables for nodes:
node_clusterandnodename - Variable
pg_hostnamenow means set hostname same as postgres instance name to keep backward-compatible - Variable
nodename_overwritecontrol whether overwrite node’s hostname with nodename - Variable
nodename_exchangewill write nodename to each other’s/etc/hosts - All nodes metrics reference are overhauled, join by
ip - Nodes monitoring targets are managed alone under
/etc/prometheus/targets/nodes
- PGSQL Monitoring Enhancement
- Complete new PGSQL Cluster which simplify and focus on important stuff among cluster.
- New Dashboard PGSQL Databases which is cluster level object monitoring. Such as tables & queries among the entire cluster rather than single instance.
- PGSQL Alert dashboard now only focus on pgsql alerts.
- PGSQL Shard are added to PGSQL
- Redis Monitoring Enhancement
- Add nodes monitoring for all redis dashboards.
MatrixDB Support
- MatrixDB (Greenplum 7) can be deployed via
pigsty-matrix.ymlplaybook - MatrixDB Monitor Dashboards : PGSQL MatrixDB
- Example configuration added:
pigsty-mxdb.yml
Provisioning Enhancement
Now pigsty work flow works as this:
infra.yml ---> install pigsty on single meta node
| then add more nodes under pigsty's management
|
nodes.yml ---> prepare nodes for pigsty (node setup, dcs, node_exporter, promtail)
| then choose one playbook to deploy database clusters on those nodes
|
^--> pgsql.yml install postgres on prepared nodes
^--> redis.yml install redis on prepared nodes
infra-demo.yml =
infra.yml -l meta +
nodes.yml -l pg-test +
pgsql.yml -l pg-test +
infra-loki.yml + infra-jupyter.yml + infra-pgweb.yml
nodes.ymlto setup & prepare nodes for pigsty- setup node, node_exporter, consul agent on nodes
node-remove.ymlare used for node de-register
pgsql.ymlnow only works on prepared nodespgsql-removenow only responsible for postgres itself. (dcs and node monitor are taken bynode.yml)- Add a series of new options to reuse
postgresrole in greenplum/matrixdb
redis.ymlnow works on prepared nodes- and
redis-remove.ymlnow remove redis from nodes.
- and
pgsql-matrix.ymlnow install matrixdb (Greenplum 7) on prepared nodes.
Software Upgrade
- PostgreSQL 14.2
- PostGIS 3.2
- TimescaleDB 2.6
- Patroni 2.1.3 (Prometheus Metrics + Failover Slots)
- HAProxy 2.5.5 (Fix stats error, more metrics)
- PG Exporter 0.4.1 (Timeout Parameters, and)
- Grafana 8.4.4
- Prometheus 2.33.4
- Greenplum 6.19.4 / MatrixDB 4.4.0
- Loki are now shipped as rpm packages instead of zip archives
Bug Fix
- Remove consul dependency for patroni , which makes it much more easier to migrate to a new consul cluster
- Fix prometheus bin/new scripts default data dir path :
/export/prometheusto/data/prometheus - Fix typos and tasks
- Add restart seconds to vip-manager systemd service
API Changes
New Variable
node_cluster: Identity variable for node clusternodename_overwrite: If set, nodename will be set to node’s hostnamenodename_exchange: exchange node hostname (in/etc/hosts) among play hostsnode_dns_hosts_extra: extra static dns records which can be easily overwritten by single instance/clusterpatroni_enabled: if disabled, postgres & patroni bootstrap will not be performed during rolepostgrespgbouncer_enabled: if disabled, pgbouncer will not be launched during rolepostgrespg_exporter_params: extra url parameters for pg_exporter when generating monitor target url.pg_provision: bool var to indicate whether perform provision part of rolepostgres(template, db,user)no_cmdb: cli args forinfra.ymlandinfra-demo.ymlplaybook which will not create cmdb on meta node.
MD5 (app.tgz) = f887313767982b31a2b094e5589a75ea
MD5 (matrix.tgz) = 3d063437c482d94bd7e35df1a08bbc84
MD5 (pigsty.tgz) = e143b88ebea1474f9ebaffddc6072c49
MD5 (pkg.tgz) = 73e8f5ce995b1f1760cb63c1904fb91b
v1.4.1
Routine bug fix / Docker Support / English Docs
Now docker is enabled on meta node by default. You can launch ton’s of SaaS with it
English document is available now.
- add docker to default packages
- add docker-compose to default pacakge list
- disable nameserver by default & enable docker role by default
Bug Fix
- fix promtail & loki config var issue
- Fix grafana legacy alerts.
- Disable nameserver by default
- Rename pg-alias.sh for patroni shortcuts
- disable exemplars queries for all dashboards
- fix loki data dir issue https://github.com/pgsty/pigsty/issues/100
- change autovacuum_freeze_max_age from 100000000 to 1000000000
v1.3.0 Release Note
1.3.0
-
[ENHANCEMENT] Redis Deployment (cluster,sentinel,standalone)
-
[ENHANCEMENT] Redis Monitor
- Redis Overview Dashboard
- Redis Cluster Dashboard
- Redis Instance Dashboard
-
[ENHANCEMENT] monitor: PGCAT Overhaul
- New Dashboard: PGCAT Instance
- New Dashboard: PGCAT Database Dashboard
- Remake Dashboard: PGCAT Table
-
[ENHANCEMENT] monitor: PGSQL Enhancement
- New Panels: PGSQL Cluster, add 10 key metrics panel (toggled by default)
- New Panels: PGSQL Instance, add 10 key metrics panel (toggled by default)
- Simplify & Redesign: PGSQL Service
- Add cross-references between PGCAT & PGSL dashboards
-
[ENHANCEMENT] monitor deploy
- Now grafana datasource is automatically registered during monly deployment
-
[ENHANCEMENT] software upgrade
- add PostgreSQL 13 to default package list
- upgrade to PostgreSQL 14.1 by default
- add greenplum rpm and dependencies
- add redis rpm & source packages
- add perf as default packages
v1.3.1
[Monitor]
- PGSQL & PGCAT Dashboard polish
- optimize layout for pgcat instance & pgcat database
- add key metrics panels to pgsql instance dashboard, keep consist with pgsql cluster
- add table/index bloat panels to pgcat database, remove pgcat bloat dashboard.
- add index information in pgcat database dashboard
- fix broken panels in grafana 8.3
- add redis index in nginx homepage
[Deploy]
- New
infra-demo.ymlplaybook for one-pass bootstrap - Use
infra-jupyter.ymlplaybook to deploy optional jupyter lab server - Use
infra-pgweb.ymlplaybook to deploy optional pgweb server - New
pgalias on meta node, can initiate postgres cluster from admin user (in addition to postgres) - Adjust all patroni conf templates’s
max_locks_per_transactionsaccording totimescaledb-tune’s advise - Add
citus.node_conninfo: 'sslmode=prefer'to conf templates in order to use citus without SSL - Add all extensions (except for pgrouting) in pgdg14 in package list
- Upgrade node_exporter to v1.3.1
- Add PostgREST v9.0.0 to package list. Generate API from postgres schema.
[BugFix]
- Grafana’s security breach (upgrade to v8.3.1 issue)
- fix
pg_instance&pg_serviceinregisterrole when start from middle of playbook - Fix nginx homepage render issue when host without
pg_clustervariable exists - Fix style issue when upgrading to grafana 8.3.1
v1.2.0 Release Note
v1.2.0
- [ENHANCEMENT] Use PostgreSQL 14 as default version
- [ENHANCEMENT] Use TimescaleDB 2.5 as default extension
- now timescaledb & postgis are enabled in cmdb by default
- [ENHANCEMENT] new monitor-only mode:
- you can use pigsty to monitor existing pg instances with a connectable url only
- pg_exporter will be deployed on meta node locally
- new dashboard PGSQL Cluster Monly for remote clusters
- [ENHANCEMENT] Software upgrade
- grafana to 8.2.2
- pev2 to v0.11.9
- promscale to 0.6.2
- pgweb to 0.11.9
- Add new extensions: pglogical pg_stat_monitor orafce
- [ENHANCEMENT] Automatic detect machine spec and use proper
node_tuneandpg_conftemplates - [ENHANCEMENT] Rework on bloat related views, now more information are exposed
- [ENHANCEMENT] Remove timescale & citus internal monitoring
- [ENHANCEMENT] New playbook
pgsql-audit.ymlto create audit report. - [BUG FIX] now pgbouncer_exporter resource owner are {{ pg_dbsu }} instead of postgres
- [BUG FIX] fix pg_exporter duplicate metrics on pg_table pg_index while executing
REINDEX TABLE CONCURRENTLY - [CHANGE] now all config templates are minimize into two: auto & demo. (removed:
pub4, pg14, demo4, tiny, oltp)pigsty-demois configured ifvagrantis the default user, otherwisepigsty-autois used.
How to upgrade from v1.1.1
There’s no API change in 1.2.0 You can still use old pigsty.yml configuration files (PG13).
For the infrastructure part. Re-execution of repo will do most of the parts
As for the database. You can still use the existing PG13 instances. In-place upgrade is quite tricky especially when involving extensions such as PostGIS & Timescale. I would highly recommend performing a database migration with logical replication.
The new playbook pgsql-migration.yml will make this a lot easier. It will create a series of
scripts which will help you to migrate your cluster with near-zero downtime.
v1.1.0 Release Note
v1.1.0
- [ENHANCEMENT] add
pg_dummy_filesizeto create fs space placeholder - [ENHANCEMENT] home page overhaul
- [ENHANCEMENT] add jupyter lab integration
- [ENHANCEMENT] add pgweb console integration
- [ENHANCEMENT] add pgbadger support
- [ENHANCEMENT] add pev2 support, explain visualizer
- [ENHANCEMENT] add pglog utils
- [ENHANCEMENT] update default pkg.tgz software version:
- upgrade postgres to v13.4 (with official pg14 support)
- upgrade pgbouncer to v1.16 (metrics definition updates)
- upgrade grafana to v8.1.4
- upgrade prometheus to v2.2.29
- upgrade node_exporter to v1.2.2
- upgrade haproxy to v2.1.1
- upgrade consul to v1.10.2
- upgrade vip-manager to v1.0.1
API Changes
-
nginx_upstreamnow holds different structures. (incompatible) -
new config entries:
app_list, render into home page’s nav entries -
new config entries:
docs_enabled, setup local docs on default server. -
new config entries:
pev2_enabled, setup local pev2 utils. -
new config entries:
pgbadger_enabled, create log summary/report dir -
new config entries:
jupyter_enabled, enable jupyter lab server on meta node -
new config entries:
jupyter_username, specify which user to run jupyter lab -
new config entries:
jupyter_password, specify jupyter lab default password -
new config entries:
pgweb_enabled, enable pgweb server on meta node -
new config entries:
pgweb_username, specify which user to run pgweb -
rename internal flag
repo_existintorepo_exists -
now default value for
repo_addressispigstyinstead ofyum.pigsty -
now haproxy access point is
http://pigstyinstead ofhttp://h.pigsty
v1.1.1
- [ENHANCEMENT] replace timescaledb
apacheversion withtimescaleversion - [ENHANCEMENT] upgrade prometheus to 2.30
- [BUG FIX] now pg_exporter config dir’s owner are {{ pg_dbsu }} instead of prometheus
How to upgrade from v1.1.0
The major change in this release is timescaledb. Which replace old apache license version with timescale license version
stop/pause postgres instance with timescaledb
yum remove -y timescaledb_13
[timescale_timescaledb]
name=timescale_timescaledb
baseurl=https://packagecloud.io/timescale/timescaledb/el/7/$basearch
repo_gpgcheck=0
gpgcheck=0
enabled=1
yum install timescaledb-2-postgresql13
v1.0.0 Release Note
v1.0.0
Highlights
-
Monitoring System Overhaul
- New Dashboards on Grafana 8.0
- New metrics definition, with extra PG14 support
- Simplified labeling system: static label set: (job, cls, ins)
- New Alerting Rules & Derived Metrics
- Monitoring multiple database at one time
- Realtime log search & csvlog analysis
- Link-Rich Dashboards, click graphic elements to drill-down|roll-up
-
Architecture Changes
- Add citus & timescaledb as part of default installation
- Add PostgreSQL 14beta2 support
- Simply haproxy admin page index
- Decouple infra & pgsql by adding a new role
register - Add new role
lokiandpromtailfor logging - Add new role
environfor setting up environment for admin user on admin node - Using
staticservice-discovery for prometheus by default (instead ofconsul) - Add new role
removeto gracefully remove cluster & instance - Upgrade prometheus & grafana provisioning logics.
- Upgrade to vip-manager 1.0 , node_exporter 1.2 , pg_exporter 0.4, grafana 8.0
- Now every database on every instance can be auto-registered as grafana datasource
- Move consul register tasks to role
register, change consul service tags - Add cmdb.sql as pg-meta baseline definition (CMDB & PGLOG)
-
Application Framework
- Extensible framework for new functionalities
- core app: PostgreSQL Monitor System:
pgsql - core app: PostgreSQL Catalog explorer:
pgcat - core app: PostgreSQL Csvlog Analyzer:
pglog - add example app
covidfor visualizing covid-19 data. - add example app
isdfor visualizing isd data.
-
Misc
- Add jupyterlab which brings entire python environment for data science
- Add
vonng-echarts-panelto bring Echarts support back. - Add wrap script
createpg,createdb,createuser - Add cmdb dynamic inventory scripts:
load_conf.py,inventory_cmdb,inventory_conf - Remove obsolete playbooks:
pgsql-monitor,pgsql-service,node-remove, etc….
API Change
- new var :
node_meta_pip_install - rename var:
grafana_urltografana_endpoint - new var:
grafana_admin_username - new var:
grafana_database - new var:
grafana_pgurl - new var:
pg_shared_libraries - new var:
pg_exporter_auto_discovery - new var:
pg_exporter_exclude_database - new var:
pg_exporter_include_database
Bug Fix
- Fix default timezone Asia/Shanghai (CST) issue
- Fix nofile limit for pgbouncer & patroni
- Pgbouncer userlist & database list will be generated when executing tag
pgbouncer
v1.0.1
2021-09-14
- Documentation Update
- Chinese document now viable
- Machine-Translated English document now viable
- Bug Fix:
pgsql-removedoes not remove primary instance. - Bug Fix: replace pg_instance with pg_cluster + pg_seq
- Start-At-Task may fail due to pg_instance undefined
- Bug Fix: remove citus from default shared preload library
- citus will force max_prepared_transaction to non-zero value
- Bug Fix: ssh sudo checking in
configure:- now
ssh -t sudo -n lsis used for privilege checking
- now
- Typo Fix:
pg-backupscript typo - Alert Adjust: Remove ntp sanity check alert (dupe with ClockSkew)
- Exporter Adjust: remove collector.systemd to reduce overhead
v0.9.0 Release Note
Pigsty v0.9.0
Features
-
One-Line Installation
Run this on meta node
/bin/bash -c "$(curl -fsSL https://pigsty.cc/install)" -
MetaDB provisioning
Now you can use pgsql database on meta node as inventory instead of static yaml file affter bootstrap.
-
Add Loki & Prometail as optinal logging collector
Now you can view, query, search postgres|pgbouncer|patroni logs with Grafana UI (PG Instance Log)
-
Pigsty CLI/GUI (beta)
Mange you pigsty deployment with much more human-friendly command line interface.
Bug Fix
- Log related issues
- fix
connection reset by peerentries in postgres log caused by Haproxy health check. - fix
Connect Reset Exceptionin patroni logs caused by haproxy health check - fix patroni log time format (remove mill seconds, add timezone)
- set
log_min_duration_statement=1sfordbuser_monitorto get ride of monitor logs.
- fix
- Fix
pgbouncer-create-userdoes not handle md5 password properly - Fix obsolete
Makefileentries - Fix node dns nameserver lost when abort during resolv.conf rewrite
- Fix db/user template and entry not null check
API Change
- Set default value of
node_disable_swaptofalse - Remove example enties of
node_sysctl_params. grafana_plugindefaultinstallwill now download from CDN if plugins not existsrepo_url_packagesnow download rpm via pigsty CDN to accelerate.proxy_env.no_proxynow add pigsty CDN tonoproxysites.grafana_customizeset tofalseby default, enable it means install pigsty pro UI.node_admin_pk_currentadd current user’s~/.ssh/id_rsa.pubto admin pksloki_cleanwhether to cleanup existing loki data during initloki_data_dirset default data dir for loki logging servicepromtail_enabledenabling promtail logging agent service?promtail_cleanremove existing promtail status during init?promtail_portdefault port used by promtail, 9080 by defaultpromtail_status_filelocation of promtail status filepromtail_send_urlendpoint of loki service which receives log data
v0.8.0 Release Note
Pigsty v0.8.0
Pigsty now is in RC status with guaranteed API stability.
New Features
- Service provision.
- full locale support.
API Changes
Role vip and haproxy are merged into service.
#------------------------------------------------------------------------------
# SERVICE PROVISION
#------------------------------------------------------------------------------
pg_weight: 100 # default load balance weight (instance level)
# - service - #
pg_services: # how to expose postgres service in cluster?
# primary service will route {ip|name}:5433 to primary pgbouncer (5433->6432 rw)
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
pg_services_extra: [] # extra services to be added
# - haproxy - #
haproxy_enabled: true # enable haproxy among every cluster members
haproxy_reload: true # reload haproxy after config
haproxy_policy: roundrobin # roundrobin, leastconn
haproxy_admin_auth_enabled: false # enable authentication for haproxy admin?
haproxy_admin_username: admin # default haproxy admin username
haproxy_admin_password: admin # default haproxy admin password
haproxy_exporter_port: 9101 # default admin/exporter port
haproxy_client_timeout: 3h # client side connection timeout
haproxy_server_timeout: 3h # server side connection timeout
# - vip - #
vip_mode: none # none | l2 | l4
vip_reload: true # whether reload service after config
# vip_address: 127.0.0.1 # virtual ip address ip (l2 or l4)
# vip_cidrmask: 24 # virtual ip address cidr mask (l2 only)
# vip_interface: eth0 # virtual ip network interface (l2 only)
New Options
# - localization - #
pg_encoding: UTF8 # default to UTF8
pg_locale: C # default to C
pg_lc_collate: C # default to C
pg_lc_ctype: en_US.UTF8 # default to en_US.UTF8
pg_reload: true # reload postgres after hba changes
vip_mode: none # none | l2 | l4
vip_reload: true # whether reload service after config
Remove Options
haproxy_check_port # covered by service options
haproxy_primary_port
haproxy_replica_port
haproxy_backend_port
haproxy_weight
haproxy_weight_fallback
vip_enabled # replace by vip_mode
Service
pg_services and pg_services_extra Defines the services in cluster:
A service has some mandatory fields:
name: service’s namesrc_port: which port to listen and expose service?selector: which instances belonging to this service?
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
Database
Add additional locale support: lc_ctype and lc_collate.
It’s mainly because of pg_trgm ’s weird behavior on i18n characters.
pg_databases:
- name: meta # name is the only required field for a database
# owner: postgres # optional, database owner
# template: template1 # optional, template1 by default
# encoding: UTF8 # optional, UTF8 by default , must same as template database, leave blank to set to db default
# locale: C # optional, C by default , must same as template database, leave blank to set to db default
# lc_collate: C # optional, C by default , must same as template database, leave blank to set to db default
# lc_ctype: C # optional, C by default , must same as template database, leave blank to set to db default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
# tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
v0.7.0 Release Note
v0.7.0
Overview
-
Monitor Only Deployment
- Now you can monitor existing postgres clusters without Pigsty provisioning solution.
- Intergration with other provisioning solution is available and under further test.
-
Database/User Management
- Update user/database definition schema to cover more usecases.
- Add
pgsql-createdb.ymlandpgsql-createuser.ymlto mange user/db on running clusters.
Features
- Monitor Only Deployment Support #25
- Split monolith static monitor target file into per-cluster conf #36
- Add create user playbook #29
- Add create database playbook #28
- Database provisioning interface enhancement #33
- User provisioning interface enhancement #34
Bug Fix
API Changes
New Options
prometheus_sd_target: batch # batch|single
exporter_install: none # none|yum|binary
exporter_repo_url: '' # add to yum repo if set
node_exporter_options: '--no-collector.softnet --collector.systemd --collector.ntp --collector.tcpstat --collector.processes' # default opts for node_exporter
pg_exporter_url: '' # optional, overwrite default pg_exporter target
pgbouncer_exporter_url: '' # optional, overwrite default pgbouncer_expoter target
Remove Options
exporter_binary_install: false # covered by exporter_install
Structure Changes
pg_default_roles # refer to pg_users
pg_users # refer to pg_users
pg_databases # refer to pg_databases
Rename Options
pg_default_privilegs -> pg_default_privileges # fix typo
Enhancement
Monitoring Provisioning Enhancement
- Decouple consul #13
- Binary install mode for node_exporter and pg_exporter #14
- Prometheus static targets mode support #11
Haproxy Enhancement
- Adjust relative traffic weight with configuration #10
- HAProxy admin page access via nginx #12
- Readonly traffic fallback on primary if all replicas down #8
Security Enhancement
Software Update
-
Prometheus 2.25 / Grafana 7.4 / Consul 1.9.3 / Node Exporter 1.1 / PG Exporter 0.3.2
API Change
New Config Entries
service_registry: consul # none | consul | etcd | both
prometheus_options: '--storage.tsdb.retention=30d' # prometheus cli opts
prometheus_sd_method: consul # Prometheus service discovery method: static|consul
prometheus_sd_interval: 2s # Prometheus service discovery refresh interval
pg_offline_query: false # set to true to allow offline queries on this instance
node_exporter_enabled: true # enabling Node Exporter
pg_exporter_enabled: true # enabling PG Exporter
pgbouncer_exporter_enabled: true # enabling Pgbouncer Exporter
export_binary_install: false # install Node/PG Exporter via copy binary
dcs_disable_purge: false # force dcs_exists_action = abort to avoid dcs purge
pg_disable_purge: false # force pg_exists_action = abort to avoid pg purge
haproxy_weight: 100 # relative lb weight for backend instance
haproxy_weight_fallback: 1 # primary server weight in replica service group
Obsolete Config Entries
prometheus_metrics_path # duplicate with exporter_metrics_path
prometheus_retention # covered by `prometheus_options`
Database Definition
Database provisioning interface enhancement #33
Old Schema
pg_databases: # create a business database 'meta'
- name: meta
schemas: [meta] # create extra schema named 'meta'
extensions: [{name: postgis}] # create extra extension postgis
parameters: # overwrite database meta's default search_path
search_path: public, monitor
New Schema
pg_databases:
- name: meta # name is the only required field for a database
owner: postgres # optional, database owner
template: template1 # optional, template1 by default
encoding: UTF8 # optional, UTF8 by default
locale: C # optional, C by default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
Changes
- Add new options:
template,encoding,locale,allowconn,tablespace,connlimit - Add new option
revokeconn, which revoke connect privileges from public for this database - Add
commentfield for database
Apply Changes
You can create new database on running postgres clusters with pgsql-createdb.yml playbook.
- Define your new database in config files
- Pass new database.name with option
pg_databaseto playbook.
./pgsql-createdb.yml -e pg_database=<your_new_database_name>
User Definition
User provisioning interface enhancement #34
Old Schema
pg_users:
- username: test # example production user have read-write access
password: test # example user's password
options: LOGIN # extra options
groups: [ dbrole_readwrite ] # dborole_admin|dbrole_readwrite|dbrole_readonly
comment: default test user for production usage
pgbouncer: true # add to pgbouncer
New Schema
pg_users:
# complete example of user/role definition for production user
- name: dbuser_meta # example production user have read-write access
password: DBUser.Meta # example user's password, can be encrypted
login: true # can login, true by default (should be false for role)
superuser: false # is superuser? false by default
createdb: false # can create database? false by default
createrole: false # can create role? false by default
inherit: true # can this role use inherited privileges?
replication: false # can this role do replication? false by default
bypassrls: false # can this role bypass row level security? false by default
connlimit: -1 # connection limit, -1 disable limit
expire_at: '2030-12-31' # 'timestamp' when this role is expired
expire_in: 365 # now + n days when this role is expired (OVERWRITE expire_at)
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly
pgbouncer: true # add this user to pgbouncer? false by default (true for production user)
parameters: # user's default search path
search_path: public
comment: test user
Changes
usernamefield rename tonamegroupsfield rename torolesoptionsnow split into separated configration entries:login,superuser,createdb,createrole,inherit,replication,bypassrls,connlimitexpire_atandexpire_inoptionspgbounceroption for user is nowfalseby default
Apply Changes
You can create new users on running postgres clusters with pgsql-createuser.yml playbook.
- Define your new users in config files (
pg_users) - Pass new user.name with option
pg_userto playbook.
./pgsql-createuser.yml -e pg_user=<your_new_user_name>
v0.6.0 Release Note
v0.6.0
Bug Fix
-
Merge Fix name of dashboard #1, Fix PG Overview Dashboard typo
-
Fix default primary instance to
pg-test-1of clusterpg-testin sandbox environment -
Fix obsolete comments
Enhancement
Monitoring Provisioning Enhancement
- Decouple consul #13
- Binary install mode for node_exporter and pg_exporter #14
- Prometheus static targets mode support #11
Haproxy Enhancement
- Adjust relative traffic weight with configuration #10
- HAProxy admin page access via nginx #12
- Readonly traffic fallback on primary if all replicas down #8
Security Enhancement
Software Update
-
Prometheus 2.25 / Grafana 7.4 / Consul 1.9.3 / Node Exporter 1.1 / PG Exporter 0.3.2
API Change
New Config Entries
service_registry: consul # none | consul | etcd | both
prometheus_options: '--storage.tsdb.retention=30d' # prometheus cli opts
prometheus_sd_method: consul # Prometheus service discovery method: static|consul
prometheus_sd_interval: 2s # Prometheus service discovery refresh interval
pg_offline_query: false # set to true to allow offline queries on this instance
node_exporter_enabled: true # enabling Node Exporter
pg_exporter_enabled: true # enabling PG Exporter
pgbouncer_exporter_enabled: true # enabling Pgbouncer Exporter
export_binary_install: false # install Node/PG Exporter via copy binary
dcs_disable_purge: false # force dcs_exists_action = abort to avoid dcs purge
pg_disable_purge: false # force pg_exists_action = abort to avoid pg purge
haproxy_weight: 100 # relative lb weight for backend instance
haproxy_weight_fallback: 1 # primary server weight in replica service group
Obsolete Config Entries
prometheus_metrics_path # duplicate with exporter_metrics_path
prometheus_retention # covered by `prometheus_options`
v0.5.0 Release Note
v0.5.0
Pigsty now have an Official Site 🎉 !
New Features
- Add Database Provision Template
- Add Init Template
- Add Business Init Template
- Refactor HBA Rules variables
- Fix dashboards bugs.
- Move
pg-cluster-replicationto default dashboards - Use ZJU PostgreSQL mirror as default to accelerate repo build phase.
- Move documentation to official site: https://pigsty.cc
- Download newly created offline installation packages: pkg.tgz (v0.5)
Database Provision Template
Now you can customize your database content with pigsty !
pg_users:
- username: test
password: test
comment: default test user
groups: [ dbrole_readwrite ] # dborole_admin|dbrole_readwrite|dbrole_readonly
pg_databases: # create a business database 'test'
- name: test
extensions: [{name: postgis}] # create extra extension postgis
parameters: # overwrite database meta's default search_path
search_path: public,monitor
pg-init-template.sql wil be used as default template1 database init script pg-init-business.sql will be used as default business database init script
you can customize default role system, schemas, extensions, privileges with variables now:
# - system roles - #
pg_replication_username: replicator # system replication user
pg_replication_password: DBUser.Replicator # system replication password
pg_monitor_username: dbuser_monitor # system monitor user
pg_monitor_password: DBUser.Monitor # system monitor password
pg_admin_username: dbuser_admin # system admin user
pg_admin_password: DBUser.Admin # system admin password
# - default roles - #
pg_default_roles:
- username: dbrole_readonly # sample user:
options: NOLOGIN # role can not login
comment: role for readonly access # comment string
- username: dbrole_readwrite # sample user: one object for each user
options: NOLOGIN
comment: role for read-write access
groups: [ dbrole_readonly ] # read-write includes read-only access
- username: dbrole_admin # sample user: one object for each user
options: NOLOGIN BYPASSRLS # admin can bypass row level security
comment: role for object creation
groups: [dbrole_readwrite,pg_monitor,pg_signal_backend]
# NOTE: replicator, monitor, admin password are overwritten by separated config entry
- username: postgres # reset dbsu password to NULL (if dbsu is not postgres)
options: SUPERUSER LOGIN
comment: system superuser
- username: replicator
options: REPLICATION LOGIN
groups: [pg_monitor, dbrole_readonly]
comment: system replicator
- username: dbuser_monitor
options: LOGIN CONNECTION LIMIT 10
comment: system monitor user
groups: [pg_monitor, dbrole_readonly]
- username: dbuser_admin
options: LOGIN BYPASSRLS
comment: system admin user
groups: [dbrole_admin]
- username: dbuser_stats
password: DBUser.Stats
options: LOGIN
comment: business read-only user for statistics
groups: [dbrole_readonly]
# object created by dbsu and admin will have their privileges properly set
pg_default_privilegs:
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
- GRANT SELECT ON TABLES TO dbrole_readonly
- GRANT SELECT ON SEQUENCES TO dbrole_readonly
- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
- GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite
- GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite
- GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin
- GRANT CREATE ON SCHEMAS TO dbrole_admin
- GRANT USAGE ON TYPES TO dbrole_admin
# schemas
pg_default_schemas: [monitor]
# extension
pg_default_extensions:
- { name: 'pg_stat_statements', schema: 'monitor' }
- { name: 'pgstattuple', schema: 'monitor' }
- { name: 'pg_qualstats', schema: 'monitor' }
- { name: 'pg_buffercache', schema: 'monitor' }
- { name: 'pageinspect', schema: 'monitor' }
- { name: 'pg_prewarm', schema: 'monitor' }
- { name: 'pg_visibility', schema: 'monitor' }
- { name: 'pg_freespacemap', schema: 'monitor' }
- { name: 'pg_repack', schema: 'monitor' }
- name: postgres_fdw
- name: file_fdw
- name: btree_gist
- name: btree_gin
- name: pg_trgm
- name: intagg
- name: intarray
# postgres host-based authentication rules
pg_hba_rules:
- title: allow meta node password access
role: common
rules:
- host all all 10.10.10.10/32 md5
- title: allow intranet admin password access
role: common
rules:
- host all +dbrole_admin 10.0.0.0/8 md5
- host all +dbrole_admin 172.16.0.0/12 md5
- host all +dbrole_admin 192.168.0.0/16 md5
- title: allow intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
- title: allow local read-write access (local production user via pgbouncer)
role: common
rules:
- local all +dbrole_readwrite md5
- host all +dbrole_readwrite 127.0.0.1/32 md5
- title: allow read-only user (stats, personal) password directly access
role: replica
rules:
- local all +dbrole_readonly md5
- host all +dbrole_readonly 127.0.0.1/32 md5
pg_hba_rules_extra: []
# pgbouncer host-based authentication rules
pgbouncer_hba_rules:
- title: local password access
role: common
rules:
- local all all md5
- host all all 127.0.0.1/32 md5
- title: intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
pgbouncer_hba_rules_extra: []
v0.4.0 Release Note
v0.4.0
The second public beta (v0.4.0) of pigsty is available now ! 🎉
Monitoring System
Skim version of monitoring system consist of 10 essential dashboards:
- PG Overview
- PG Cluster
- PG Service
- PG Instance
- PG Database
- PG Query
- PG Table
- PG Table Catalog
- PG Table Detail
- Node
Software upgrade
- Upgrade to PostgreSQL 13.1, Patroni 2.0.1-4, add citus to repo.
- Upgrade to
pg_exporter 0.3.1 - Upgrade to Grafana 7.3, Ton’s of compatibility work
- Upgrade to prometheus 2.23, with new UI as default
- Upgrade to consul 1.9
Misc
- Update prometheus alert rules
- Fix alertmanager info links
- Fix bugs and typos.
- add a simple backup script
Offline Installation
- pkg.tgz is the latest offline install package (1GB rpm packages, made under CentOS 7.8)
v0.3.0 Release Note
v0.3.0
The first public beta (v0.3.0) of pigsty is available now ! 🎉
Monitoring System
Skim version of monitoring system consist of 8 essential dashboards:
- PG Overview
- PG Cluster
- PG Service
- PG Instance
- PG Database
- PG Table Overview
- PG Table Catalog
- Node
Database Cluster Provision
- All config files are merged into one file:
conf/all.ymlby default - Use
infra.ymlto provision meta node(s) and infrastructure - Use
initdb.ymlto provision database clusters - Use
ins-add.ymlto add new instance to database cluster - Use
ins-del.ymlto remove instance from database cluster
Offline Installation
- pkg.tgz is the latest offline install package (1GB rpm packages, made under CentOS 7.8)