Nodes
A node is an abstraction of hardware/OS resources—physical machines, bare metal, VMs, or containers/pods.
Pigsty uses a modular architecture with a declarative interface. You can freely combine modules like building blocks as needed.
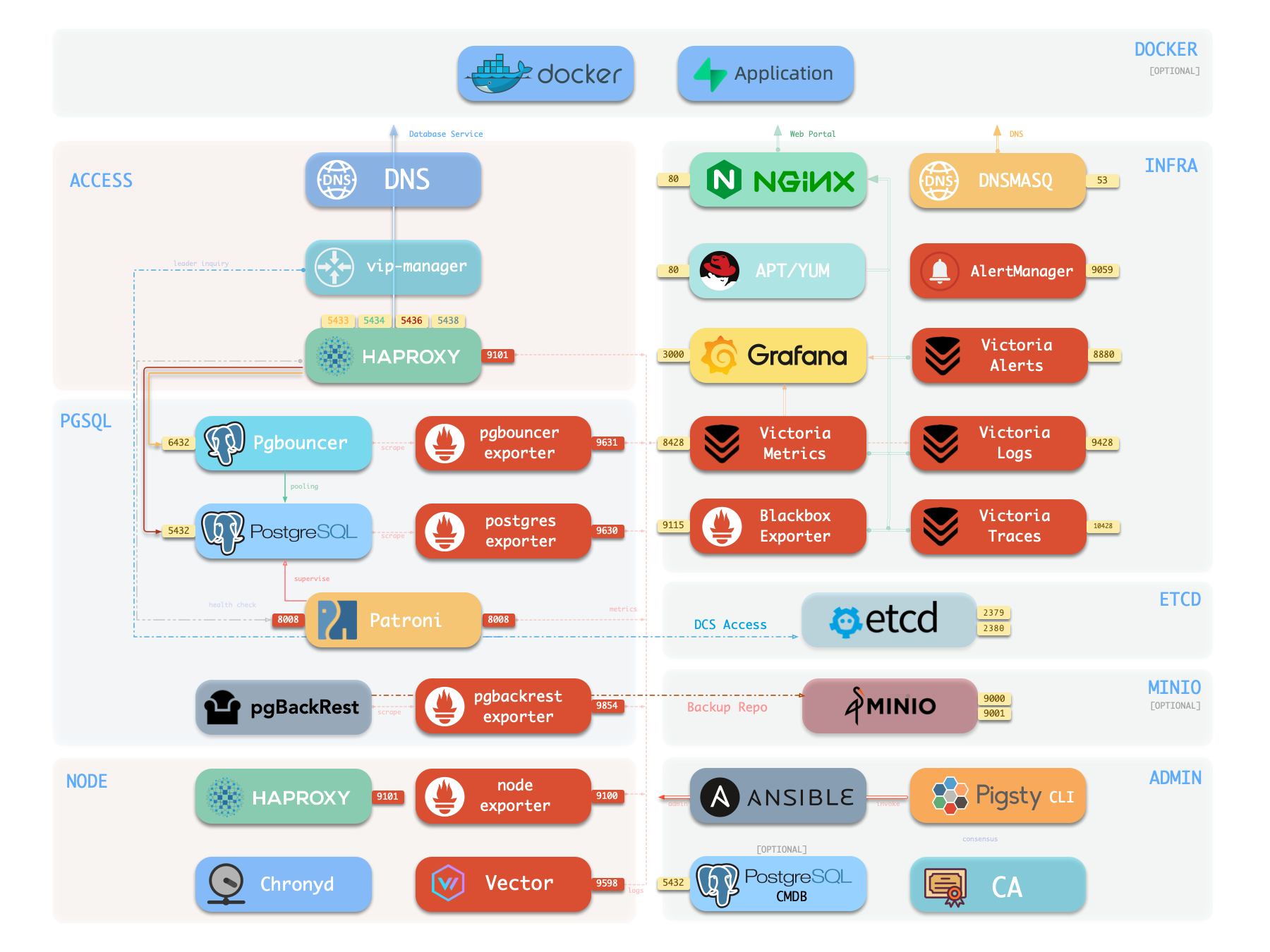
Pigsty uses a modular design with six main default modules: PGSQL, INFRA, NODE, ETCD, REDIS, and MINIO.
PGSQL: Self-healing HA Postgres clusters powered by Patroni, Pgbouncer, HAproxy, PgBackrest, and more.INFRA: Local software repo, Nginx, Grafana, Victoria, AlertManager, Blackbox Exporter—the complete observability stack.NODE: Tune nodes to desired state—hostname, timezone, NTP, ssh, sudo, haproxy, docker, vector, keepalived.ETCD: Distributed key-value store as DCS for HA Postgres clusters: consensus leader election/config management/service discovery.REDIS: Redis servers supporting standalone primary-replica, sentinel, and cluster modes with full monitoring.MINIO: S3-compatible simple object storage that can serve as an optional backup destination for PG databases.You can declaratively compose them freely. If you only want host monitoring, installing the INFRA module on infrastructure nodes and the NODE module on managed nodes is sufficient.
The ETCD and PGSQL modules are used to build HA PG clusters—installing these modules on multiple nodes automatically forms a high-availability database cluster.
You can reuse Pigsty infrastructure and develop your own modules; REDIS and MINIO can serve as examples. More modules will be added—preliminary support for Mongo and MySQL is already on the roadmap.
Note that all modules depend strongly on the NODE module: in Pigsty, nodes must first have the NODE module installed to be managed before deploying other modules.
When nodes (by default) use the local software repo for installation, the NODE module has a weak dependency on the INFRA module. Therefore, the admin/infrastructure nodes with the INFRA module complete the bootstrap process in the deploy.yml playbook, resolving the circular dependency.
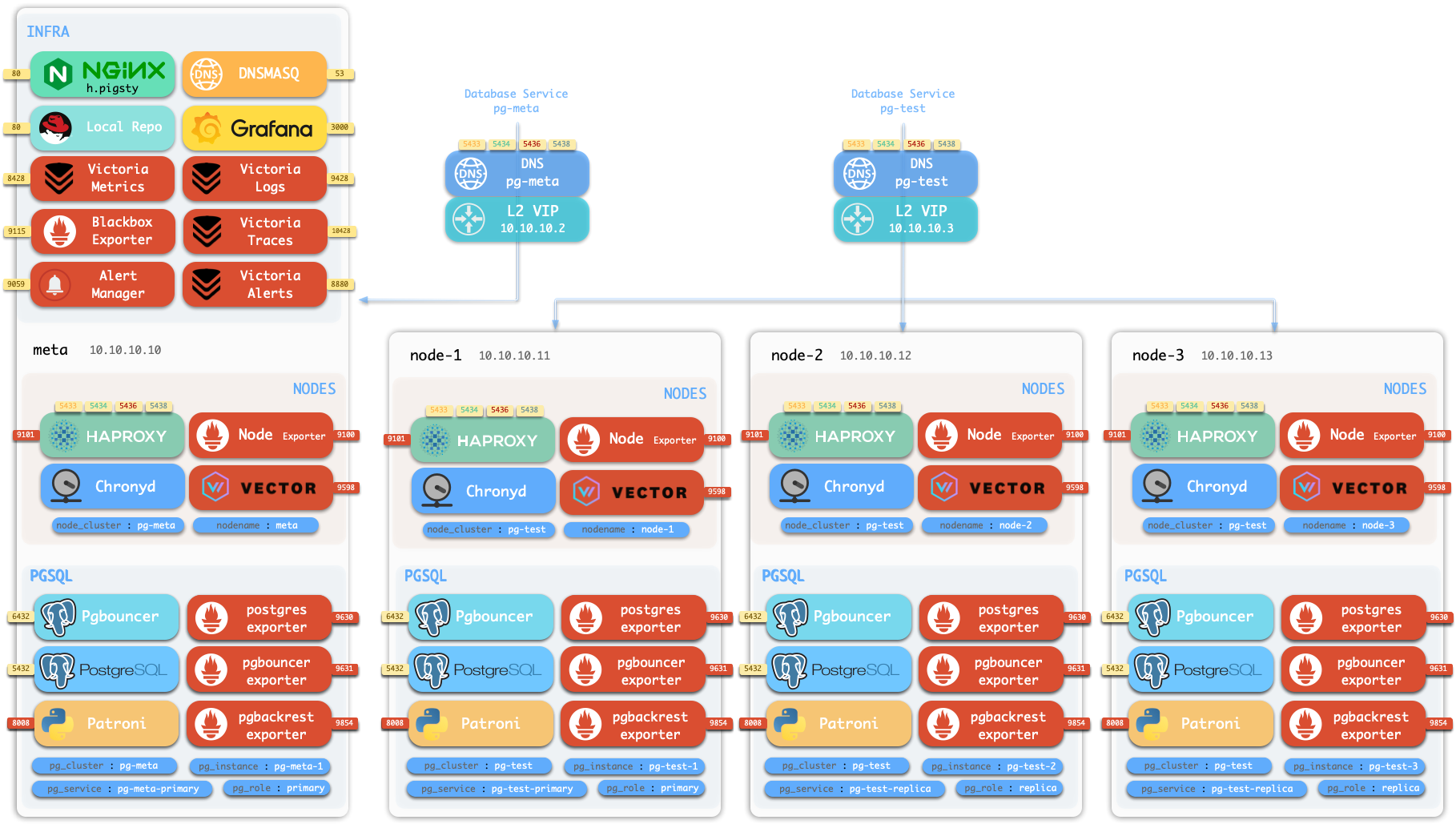
By default, Pigsty installs on a single node (physical/virtual machine). The deploy.yml playbook installs INFRA, ETCD, PGSQL, and optionally MINIO modules on the current node,
giving you a fully-featured observability stack (Prometheus, Grafana, Loki, AlertManager, PushGateway, BlackboxExporter, etc.), plus a built-in PostgreSQL standalone instance as a CMDB, ready to use out of the box (cluster name pg-meta, database name meta).
This node now has a complete self-monitoring system, visualization tools, and a Postgres database with PITR auto-configured (HA unavailable since you only have one node). You can use this node as a devbox, for testing, running demos, and data visualization/analysis. Or, use this node as an admin node to deploy and manage more nodes!
The installed standalone meta node can serve as an admin node and monitoring center to bring more nodes and database servers under its supervision and control.
Pigsty’s monitoring system can be used independently. If you want to install the Prometheus/Grafana observability stack, Pigsty provides best practices! It offers rich dashboards for host nodes and PostgreSQL databases. Whether or not these nodes or PostgreSQL servers are managed by Pigsty, with simple configuration, you immediately have a production-grade monitoring and alerting system, bringing existing hosts and PostgreSQL under management.

Pigsty helps you own your own production-grade HA PostgreSQL RDS service anywhere.
To create such an HA PostgreSQL cluster/RDS service, you simply describe it with a short config and run the playbook to create it:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica }
vars: { pg_cluster: pg-test }
$ bin/pgsql-add pg-test # Initialize cluster 'pg-test'
In less than 10 minutes, you’ll have a PostgreSQL database cluster with service access, monitoring, backup PITR, and HA fully configured.
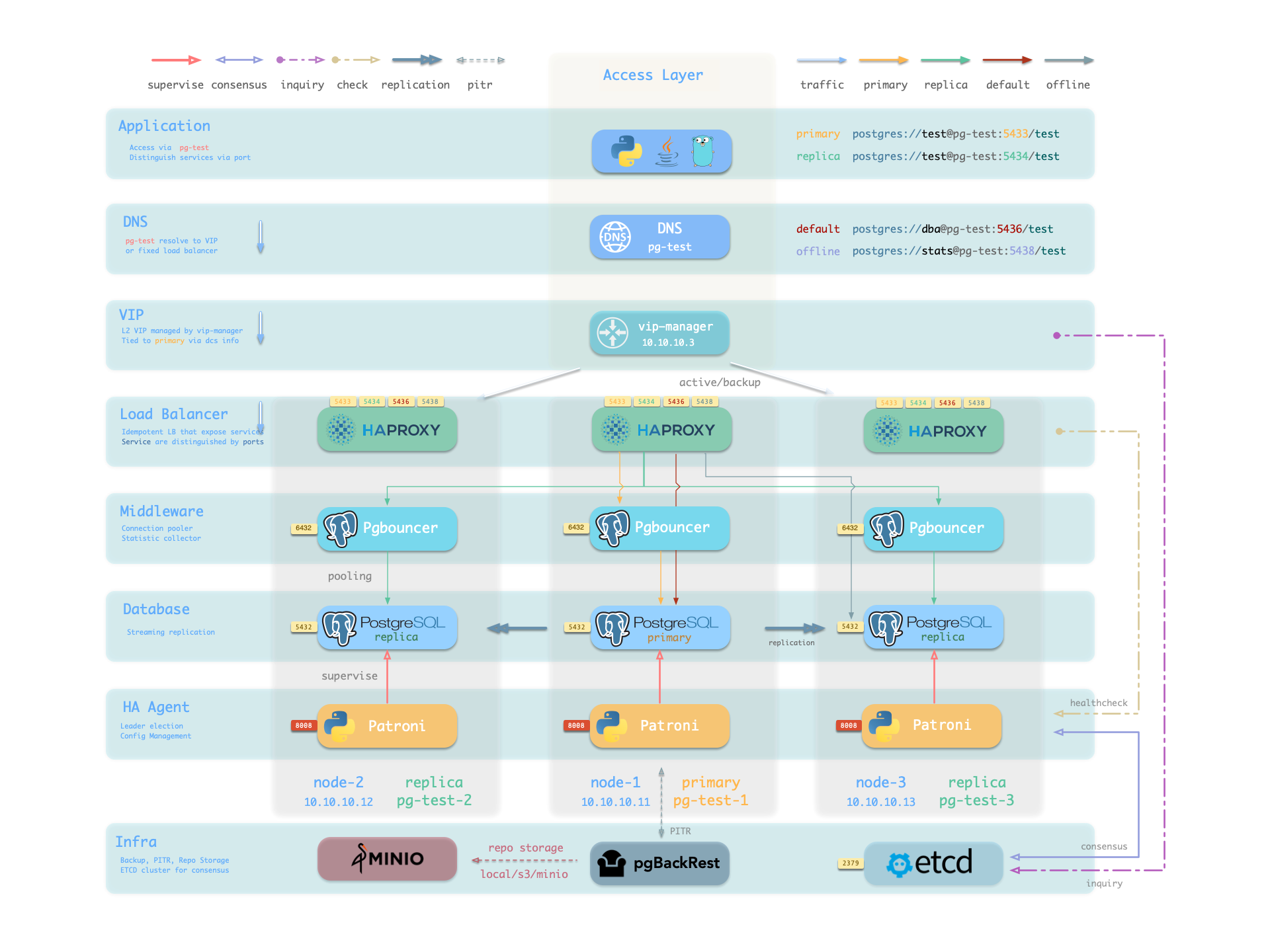
Hardware failures are covered by the self-healing HA architecture provided by patroni, etcd, and haproxy—in case of primary failure, automatic failover executes within 45 seconds by default. Clients don’t need to modify config or restart applications: Haproxy uses patroni health checks for traffic distribution, and read-write requests are automatically routed to the new cluster primary, avoiding split-brain issues. This process is seamless—for example, in case of replica failure or planned switchover, clients experience only a momentary flash of the current query.
Software failures, human errors, and datacenter-level disasters are covered by pgbackrest and the optional MinIO cluster. This provides local/cloud PITR capabilities and, in case of datacenter failure, offers cross-region replication and disaster recovery.
A node is an abstraction of hardware/OS resources—physical machines, bare metal, VMs, or containers/pods.
Infrastructure module architecture, components, and functionality in Pigsty.
PostgreSQL module component interactions and data flow.
Was this page helpful?
Thanks for the feedback! Please let us know how we can improve.
Sorry to hear that. Please let us know how we can improve.