Services & Access
Module:
Categories:
Split read & write, route traffic to the right place, and achieve stable & reliable access to the PostgreSQL cluster.
Service is an abstraction to seal the details of the underlying cluster, especially during cluster failover/switchover.
Personal User
Service is meaningless to personal users. You can access the database with raw IP address or whatever method you like.
psql postgres://dbuser_dba:[email protected]/meta # dbsu direct connect
psql postgres://dbuser_meta:[email protected]/meta # default business admin user
psql postgres://dbuser_view:DBUser.View@pg-meta/meta # default read-only user
Service Overview
We utilize a PostgreSQL database cluster based on replication in real-world production environments. Within the cluster, only one instance is the leader (primary) that can accept writes. Other instances (replicas) continuously fetch WAL from the leader to stay synchronized. Additionally, replicas can handle read-only queries and offload the primary in read-heavy, write-light scenarios. Thus, distinguishing between write and read-only requests is a common practice.
Moreover, we pool requests through a connection pooling middleware (Pgbouncer) for high-frequency, short-lived connections to reduce the overhead of connection and backend process creation. And, for scenarios like ETL and change execution, we need to bypass the connection pool and directly access the database servers. Furthermore, high-availability clusters may undergo failover during failures, causing a change in the cluster leadership. Therefore, the RW requests should be re-routed automatically to the new leader.
These varied requirements (read-write separation, pooling vs. direct connection, and client request failover) have led to the abstraction of the service concept.
Typically, a database cluster must provide this basic service:
- Read-write service (primary): Can read and write to the database.
For production database clusters, at least these two services should be provided:
- Read-write service (primary): Write data: Only carried by the primary.
- Read-only service (replica): Read data: Can be carried by replicas, but fallback to the primary if no replicas are available.
Additionally, there might be other services, such as:
- Direct access service (default): Allows (admin) users to bypass the connection pool and directly access the database.
- Offline replica service (offline): A dedicated replica that doesn’t handle online read traffic, used for ETL and analytical queries.
- Synchronous replica service (standby): A read-only service with no replication delay, handled by synchronous standby/primary for read queries.
- Delayed replica service (delayed): Accesses older data from the same cluster from a certain time ago, handled by delayed replicas.
Default Service
Pigsty will enable four default services for each PostgreSQL cluster:
| service | port | description |
|---|---|---|
| primary | 5433 | pgbouncer read/write, connect to primary 5432 or 6432 |
| replica | 5434 | pgbouncer read-only, connect to replicas 5432/6432 |
| default | 5436 | admin or direct access to primary |
| offline | 5438 | OLAP, ETL, personal user, interactive queries |
Take the default pg-meta cluster as an example, you can access these services in the following ways:
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5433/meta # pg-meta-primary : production read/write via primary pgbouncer(6432)
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5434/meta # pg-meta-replica : production read-only via replica pgbouncer(6432)
psql postgres://dbuser_dba:DBUser.DBA@pg-meta:5436/meta # pg-meta-default : Direct connect primary via primary postgres(5432)
psql postgres://dbuser_stats:DBUser.Stats@pg-meta:5438/meta # pg-meta-offline : Direct connect offline via offline postgres(5432)
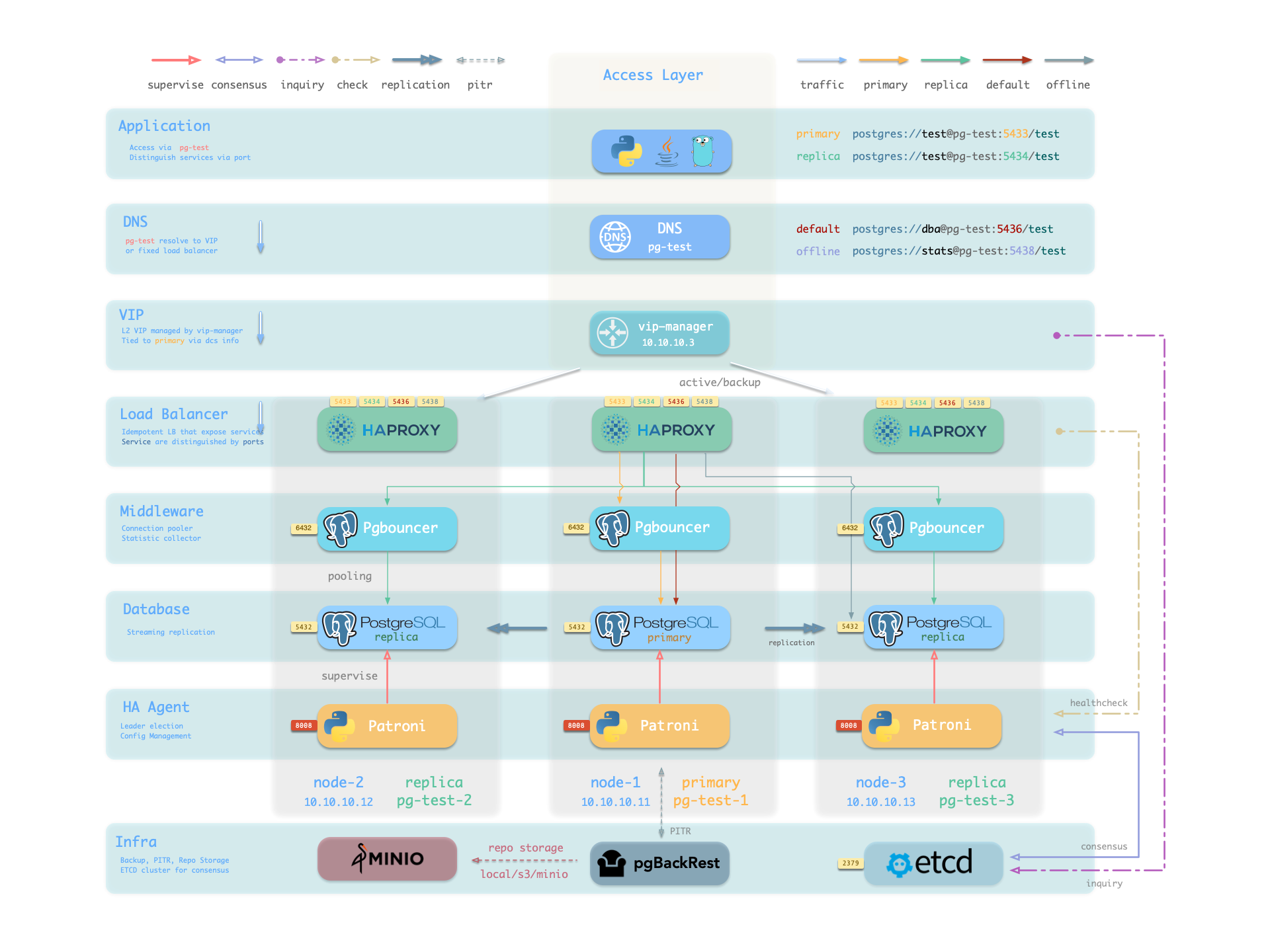
Here the pg-meta domain name point to the cluster’s L2 VIP, which in turn points to the haproxy load balancer on the primary instance. It is responsible for routing traffic to different instances, check Access Services for details.
Primary Service
The primary service may be the most critical service for production usage.
It will route traffic to the primary instance, depending on pg_default_service_dest:
pgbouncer: route traffic to primary pgbouncer port (6432), which is the default behaviorpostgres: route traffic to primary postgres port (5432) directly if you don’t want to use pgbouncer
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
It means all cluster members will be included in the primary service (selector: "[]"), but the one and only one instance that past health check (check: /primary) will be used as the primary instance.
Patroni will guarantee that only one instance is primary at any time, so the primary service will always route traffic to THE primary instance.
Example: pg-test-primary haproxy config
listen pg-test-primary
bind *:5433
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Replica Service
The replica service is used for production read-only traffic.
There may be many more read-only queries than read-write queries in real-world scenarios. You may have many replicas.
The replica service will route traffic to Pgbouncer or postgres depending on pg_default_service_dest, just like the primary service.
- { name: replica ,port: 5434 ,dest: default ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
The replica service traffic will try to use common pg instances with pg_role = replica to alleviate the load on the primary instance as much as possible. It will try NOT to use instances with pg_role = offline to avoid mixing OLAP & OLTP queries as much as possible.
All cluster members will be included in the replica service (selector: "[]") when it passes the read-only health check (check: /read-only).
primary and offline instances are used as backup servers, which will take over in case of all replica instances are down.
Example: pg-test-replica haproxy config
listen pg-test-replica
bind *:5434
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /read-only
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backup
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Default Service
The default service will route to primary postgres (5432) by default.
It is quite like the primary service, except it will always bypass pgbouncer, regardless of pg_default_service_dest.
Which is useful for administration connection, ETL writes, CDC changing data capture, etc…
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
Example: pg-test-default haproxy config
listen pg-test-default
bind *:5436
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:5432 check port 8008 weight 100
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100
Offline Service
The Offline service will route traffic to dedicate postgres instance directly.
Which could be a pg_role = offline instance, or a pg_offline_query flagged instance.
If no such instance is found, it will fall back to any replica instances. the bottom line is: it will never route traffic to the primary instance.
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
listen pg-test-offline
bind *:5438
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /replica
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100 backup
Access Service
Pigsty expose service with haproxy. Which is enabled on all nodes by default.
haproxy load balancers are idempotent among same pg cluster by default, you use ANY / ALL of them by all means.
The typical method is access via cluster domain name, which resolve to cluster L2 VIP, or all instances ip address in a round-robin manner.
Service can be implemented in different ways, You can even implement you own access method such as L4 LVS, F5, etc… instead of haproxy.
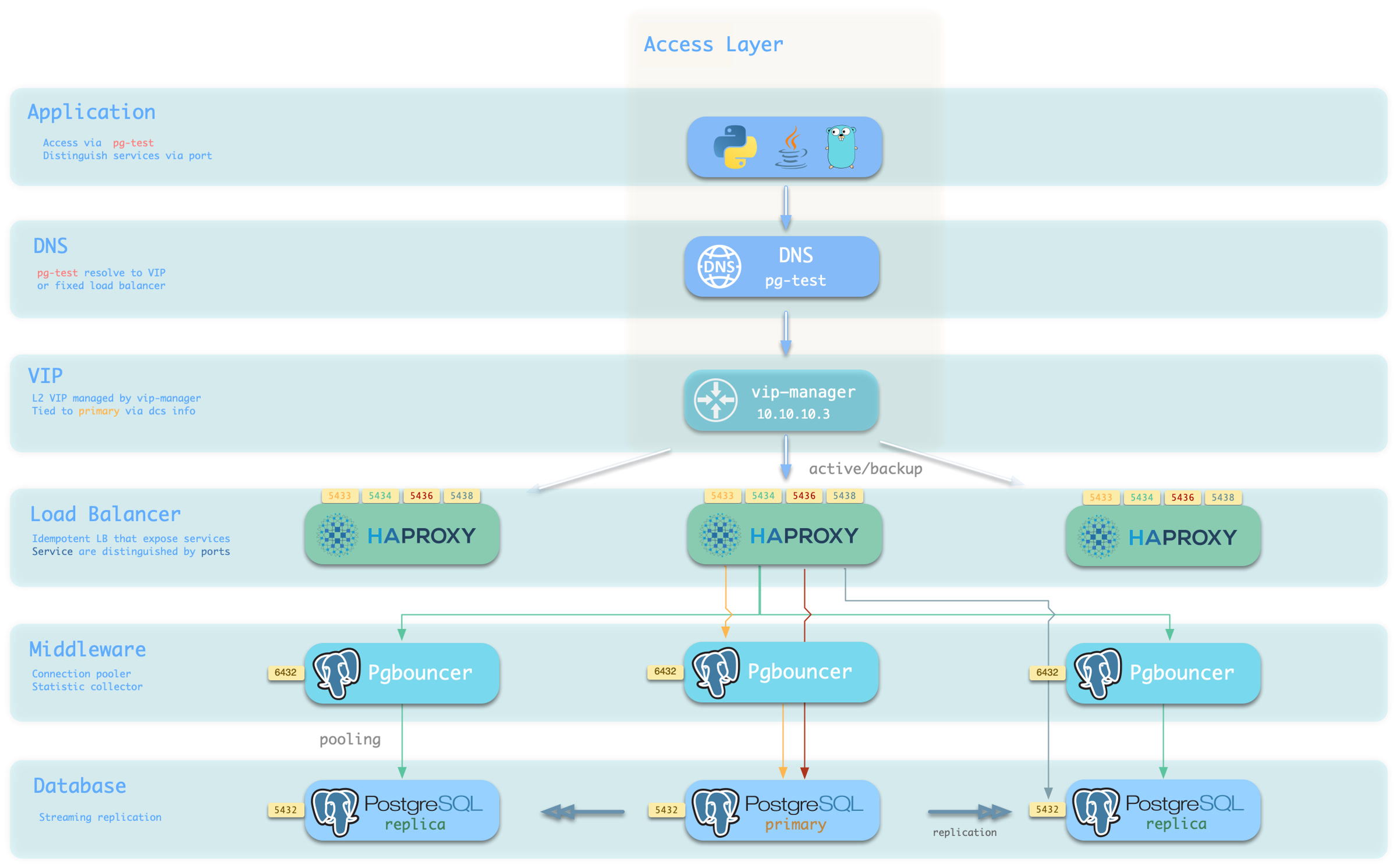
You can use different combination of host & port, they are provide PostgreSQL service in different ways.
Host
| type | sample | description |
|---|---|---|
| Cluster Domain Name | pg-test |
via cluster domain name (resolved by dnsmasq @ infra nodes) |
| Cluster VIP Address | 10.10.10.3 |
via a L2 VIP address managed by vip-manager, bind to primary |
| Instance Hostname | pg-test-1 |
Access via any instance hostname (resolved by dnsmasq @ infra nodes) |
| Instance IP Address | 10.10.10.11 |
Access any instance ip address |
Port
Pigsty uses different ports to distinguish between pg services:
| port | service | type | description |
|---|---|---|---|
| 5432 | postgres | database | Direct access to postgres server |
| 6432 | pgbouncer | middleware | Go through connection pool middleware before postgres |
| 5433 | primary | service | Access primary pgbouncer (or postgres) |
| 5434 | replica | service | Access replica pgbouncer (or postgres) |
| 5436 | default | service | Access primary postgres |
| 5438 | offline | service | Access offline postgres |
Combinations
# Access via cluster domain
postgres://test@pg-test:5432/test # DNS -> L2 VIP -> primary direct connection
postgres://test@pg-test:6432/test # DNS -> L2 VIP -> primary connection pool -> primary
postgres://test@pg-test:5433/test # DNS -> L2 VIP -> HAProxy -> Primary Connection Pool -> Primary
postgres://test@pg-test:5434/test # DNS -> L2 VIP -> HAProxy -> Replica Connection Pool -> Replica
postgres://dbuser_dba@pg-test:5436/test # DNS -> L2 VIP -> HAProxy -> Primary direct connection (for Admin)
postgres://dbuser_stats@pg-test:5438/test # DNS -> L2 VIP -> HAProxy -> offline direct connection (for ETL/personal queries)
# Direct access via cluster VIP
postgres://[email protected]:5432/test # L2 VIP -> Primary direct access
postgres://[email protected]:6432/test # L2 VIP -> Primary Connection Pool -> Primary
postgres://[email protected]:5433/test # L2 VIP -> HAProxy -> Primary Connection Pool -> Primary
postgres://[email protected]:5434/test # L2 VIP -> HAProxy -> Repilca Connection Pool -> Replica
postgres://[email protected]:5436/test # L2 VIP -> HAProxy -> Primary direct connection (for Admin)
postgres://[email protected]::5438/test # L2 VIP -> HAProxy -> offline direct connect (for ETL/personal queries)
# Specify any cluster instance name directly
postgres://test@pg-test-1:5432/test # DNS -> Database Instance Direct Connect (singleton access)
postgres://test@pg-test-1:6432/test # DNS -> connection pool -> database
postgres://test@pg-test-1:5433/test # DNS -> HAProxy -> connection pool -> database read/write
postgres://test@pg-test-1:5434/test # DNS -> HAProxy -> connection pool -> database read-only
postgres://dbuser_dba@pg-test-1:5436/test # DNS -> HAProxy -> database direct connect
postgres://dbuser_stats@pg-test-1:5438/test # DNS -> HAProxy -> database offline read/write
# Directly specify any cluster instance IP access
postgres://[email protected]:5432/test # Database instance direct connection (directly specify instance, no automatic traffic distribution)
postgres://[email protected]:6432/test # Connection Pool -> Database
postgres://[email protected]:5433/test # HAProxy -> connection pool -> database read/write
postgres://[email protected]:5434/test # HAProxy -> connection pool -> database read-only
postgres://[email protected]:5436/test # HAProxy -> Database Direct Connections
postgres://[email protected]:5438/test # HAProxy -> database offline read-write
# Smart client automatic read/write separation (connection pooling)
postgres://[email protected]:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=primary
postgres://[email protected]:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=prefer-standby
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.