bootstrap: OPTIONAL, make sure ansible is installed, and use offline package /tmp/pkg.tgz if applicable
configure: OPTIONAL, recommend & generate pigsty.yml config according to your env.
install.yml: REQUIRED, install Pigsty modules according to your config file.
It may take several minutes to complete the installation according to your network speed and hardware spec.
After that, you will get a pigsty singleton node ready, with Web service on port 80/443 and Postgres on port 5432.
BTW: If you feel Pigsty is too complicated, you can consider the Slim Installation, which only installs the necessary components for HA PostgreSQL clusters.
Example: Singleton Installation on RockyLinux 9:
Use the pig CLI
Pigsty has a built-in CLI tool: pig, which is a package manager for PostgreSQL & extensions, and a cli for Pigsty.
curl https://repo.pigsty.io/pig | bash
It will install the pig cli tool, you can install pigsty with pig sty sub command:
pig sty init # extract the embed src to ~/pigsty pig sty boot # run bootstrap to install ansible & depspig sty conf # run configure to generate pigsty.yml confpig sty install # run install.yml to complete the installation
Prepare
Check Preparation for a complete guide of resource preparation.
Pigsty support the Linux kernel and x86_64/aarch64 arch. It can run on any nodes: physical machine, bare metal, virtual machines, or VM-like containers, but a static IPv4 address is required.
The minimum spec is 1C1G. It is recommended to use bare metals or VMs with at least 2C4G. There’s no upper limit, and node param will be auto-tuned.
We recommend using fresh RockyLinux 8.10 / 9.4 or Ubuntu 22.04 as underlying operating systems.
For a complete list of supported operating systems, please refer to Compatibility.
Public key ssh access to localhost and NOPASSWD sudo privilege is required to perform the installation, Try not using the root user.
If you wish to manage more nodes, these nodes needs to be ssh / sudo accessible via your current admin node & admin user.
DO NOT use the root user
While it is possible to install Pigsty as the root user, It would be much safer using a dedicate admin user (dba, admin, …). due to security consideration
which has to be different from root and dbsu (postgres). Pigsty will create an optional admin user dba according to the config by default.
Pigsty relies on Ansible to execute playbooks. you have to install ansible and jmespath packages fist before install procedure.
This can be done with the following command, or through the bootstrap procedure, especially when you don’t have internet access.
./configure # interactive-wizard, ask for IP address./configure [-i|--ip <ipaddr>]# give primary IP & config mode[-c|--conf <conf>]# specify config template (relative to conf/ dir without .yml suffix)[-v|--version <ver>]# specify PostgreSQL major version (13,14,15,16,17)[-r|--region <default|china|europe>]# choose upstream repo region[-n|--non-interactive]# skip interactive wizard[-x|--proxy]# write proxy env to config
Configure Example Output
$ ./configure
configure pigsty v3.3.0 begin
[ OK ]region= china
[ OK ]kernel= Linux
[ OK ]machine= x86_64
[ OK ]package= rpm,yum
[ OK ]vendor= centos (CentOS Linux)[ OK ]version=7(7)[ OK ]sudo= vagrant ok
[ OK ]ssh=[email protected] ok
[WARN] Multiple IP address candidates found:
(1) 192.168.121.110 inet 192.168.121.110/24 brd 192.168.121.255 scope global noprefixroute dynamic eth0
(2) 10.10.10.10 inet 10.10.10.10/24 brd 10.10.10.255 scope global noprefixroute eth1
[ OK ]primary_ip= 10.10.10.10 (from demo)[ OK ]admin=[email protected] ok
[WARN]mode= el7, CentOS 7.9 EOL @ 2024-06-30, deprecated, consider using el8 or el9 instead
[ OK ] configure pigsty doneproceed with ./install.yml
-i|--ip: Replace IP address placeholder 10.10.10.10 with your primary ipv4 address of current node.
-c|--conf: Generate config from config templates according to this parameter
-v|--version: Specify PostgreSQL major version (13|14|15|16|17)
-r|--region: Set upstream repo mirror according to region (default|china|europe)
-n|--non-interactive: skip interactive wizard and using default/arg values
-x|--proxy: write current proxy env to the config proxy_env (http_proxy/HTTP_PROXY, HTTPS_PROXY, ALL_PROXY, NO_PROXY)
When -n|--non-interactive is specified, you have to specify a primary IP address with -i|--ip <ipaddr> in case of multiple IP address,
since there’s no default value for primary IP address in this case.
If your machine’s network interface have multiple IP addresses, you’ll need to explicitly specify a primary IP address for the current node using -i|--ip <ipaddr>, or provide it during interactive inquiry. The address should be a static IP address, and you should avoid using any public IP addresses.
You can check and modify the generated config file ~/pigsty/pigsty.yml before installation.
Change the default passwords!
PLEASE CHANGE THE DEFAULT PASSWORDs in the config file before installation, check secure password for details.
Install
Run the install.yml playbook to perform a full installation on current node
./install.yml # install everything in one-pass
Installation Output Example
[vagrant@meta pigsty]$ ./install.yml
PLAY [IDENTITY] ********************************************************************************************************************************
TASK [node_id : get node fact] *****************************************************************************************************************
changed: [10.10.10.10]...
...
PLAY RECAP **************************************************************************************************************************************************************************
10.10.10.10 : ok=288changed=215unreachable=0failed=0skipped=64rescued=0ignored=0localhost : ok=3changed=0unreachable=0failed=0skipped=4rescued=0ignored=0
It’s a standard ansible playbook, you can have fine-grained control with ansible options:
-l: limit execution targets
-t: limit execution tasks
-e: passing extra args
-i: use another config
…
DON'T EVER RUN THIS PLAYBOOK AGAIN!
It’s very DANGEROUS to re-run install.yml on existing deployment!
It may nuke your entire deployment!!! Only do this when you know what you are doing.
Otherwise, consider rm install.yml or chmod a-x install.yml to avoid accidental execution.
You can access these web UI directly via IP + port. While the common best practice would be access them through Nginx and distinguish via domain names. You’ll need configure DNS records, or use the local static records (/etc/hosts) for that.
How to access Pigsty Web UI by domain name?
There are several options:
Resolve internet domain names through a DNS service provider, suitable for systems accessible from the public internet.
Configure internal network DNS server resolution records for internal domain name resolution.
Modify the local machine’s /etc/hosts file to add static resolution records. (For Windows, it’s located at:)
We recommend the third method for common users. On the machine (which runs the browser), add the following record into /etc/hosts (sudo required) or C:\Windows\System32\drivers\etc\hosts in Windows:
You have to use the external IP address of the node here.
How to configure server side domain names?
The server-side domain name is configured with Nginx. If you want to replace the default domain name, simply enter the domain you wish to use in the parameter infra_portal. When you access the Grafana monitoring homepage via http://g.pigsty, it is actually accessed through the Nginx proxy to Grafana’s WebUI:
How to install pigsty without Internet access? How to make your own offline packages.
Pigsty’s Installation procedure requires Internet access, but production database servers are often isolated from the Internet.
To address this issue, Pigsty supports offline installation from offline packages,
which can help you install Pigsty in an environment without Internet access, and increase the certainty, reliability, speed and consistency of the installation process.
Pigsty’s install procedure will download all the required rpm/deb packages and all its dependencies from the upstream yum/apt repo, and build a local repo before installing the software.
The repo is served by Nginx and is available to all nodes in the deployment environment, including itself. All the installation will go through this local repo without further internet access.
There are certain benefits to using a local repo:
It can avoid repetitive download requests and traffic consumption, significantly speeding up the installation and improving its reliability.
It will take a snapshot of current software versions, ensuring the consistency of the software versions installed across nodes in the environment.
The snapshot contains all the deps, so it can avoid upstream dependency changes that may cause installation failures. One successful node can ensure all nodes in the same env.
The built local software repo can be packaged as a whole tarball and copied to an isolated environment with the same operating system for offline installation.
The default location for local repo is /www/pigsty (customizable by nginx_home & repo_name).
The repo will be created by createrepo_c or dpkg_dev according to the OS distro, and referenced by all nodes in the environment through repo_upstream entry with module=local.
You can perform install on one node with the exact same OS version, then copy the local repo directory to another node with the same OS version for offline installation.
A more common practice is to package the local software repo directory into an offline package and copy it to the isolated node for installation.
Make Offline Pacakge
Pigsty offers a cache.yml playbook to make offline package.
For example, the following command will take the local software repo on the infra node /www/pigsty and package it into an offline package, and retrieve it to the local dist/${version} directory.
./cache.yml -l infra
You can customize the output directory and name of the offline package with the cache_pkg_dir and cache_pkg_name parameters.
For example, the following command will fetch the made offline package to files/pkg.tgz.
The simpler way is to copy the offline package to /tmp/pkg.tgz on the isolated node to be installed,
and Pigsty will automatically unpack it during the bootstrap process and install from it.
When building the local software repo, Pigsty will generate a marker file repo_complete to mark it as a finished Pigsty local software repo.
When Pigsty install.yml playbook finds that the local software repo already exists, it will enter offline install mode.
In offline install mode, pigsty will no longer download software from the internet, but install from the local software repo directly.
Criteria for Offline Install Mode
The criteria for the existence of a local repo is the presence of a marker file located by default at /www/pigsty/repo_complete.
This marker file is automatically generated after the download is complete during the standard installation procedure, indicating a usable local software repo is done.
Deleting the repo_complete marker file of the local repo will mark the procedure for re-download missing packages from upstream.
Compatibility Notes
The software packages (rpm/deb) can be roughly divided into 3 categories:
INFRA Packages such as Prometheus & Grafana stacks and monitoring agents, which are OS distro/version independent.
PGSQL Packages such as pgsql kernel & extensions, which are optionally bound to the Linux distro major version.
NODE Packages such as so libs, utils, deps, which are bound to the Linux distro major & minor version.
Therefore, the compatibility of offline packages depends on the OS major version and minor version because it contains all three types of packages.
Usually, offline packages can be used in an environment with the exact same OS major/minor version.
If the major version does not match, INFRA packages can usually be installed successfully, while PGSQL and NODE packages may have missing or conflicting dependencies.
If the minor version does not match, INFRA and PGSQL packages can usually be installed successfully, while NODE packages have a chance of success and a chance of failure.
For example, offline packages made on RockLinux 8.9 may have a greater chance of success when offline installed on RockyLinux 8.10 environment.
While offline packages made on Ubuntu 22.04.3 is most likely to fail on Ubuntu 22.04.4.
(Yes the minor version here in Ubuntu is final .3 rather than .04, and the major version is 22.04|jammy)
If the OS minor version is not exactly matched, you can use a hybrid strategy to install, that is, after the bootstrap process,
remove the /www/pigsty/repo_complete marker file, so that Pigsty will re-download the missing NODE packages and related dependencies during the installation process.
Which can effectively solve the dependency conflict problem when using offline packages, and don’t lose the benefits of offline installation.
Download Pre-made Package
Pigsty does not offer pre-made offline packages for download starting from Pigsty v3.0.0.
It will use online installation by default, since it can download the exact NODE packages from the official repo to avoid dependency conflicts.
Besides, there are too much maintenance overhead to keep the offline packages for so many OS distros / major / minor version combinations.
BUT, we do offer pre-made offline packages for the following precise OS versions, which include Docker and pljava/jdbc_fw components, ready to use with a fair price.
RockyLinux 8.10
RockyLinux 9.5
Ubuntu 22.04.5
Debian 12.7
All the integration tests of Pigsty are based on the pre-made offline package snapshot before release,
Using these can effectively reduce the delivery risk caused by upstream dependency changes, save you the trouble and waiting time.
And show your support for the open-source cause, with a fair price of $99, please contact @Vonng ([email protected]) to get the download link.
We use offline package to deliver our pro version, which is precisely matched to your specific OS distro major/minor version and has been tested after integration.
Offline Package
Therefore, Pigsty offers an offline installation feature, allowing you to complete the installation and deployment in an environment without internet access.
If you have internet access, downloading the pre-made Offline Package in advance can help speed up the installation process and enhance the certainty and reliability of the installation.
Pigsty will no longer provide offline software packages for download starting from v3.0.0
You can make your own with the bin/cache script after the standard installation process.
Pigsty Pro offers pre-made offline packages for various OS distros.
Bootstrap
Pigsty needs ansible to run the playbooks, so it is not suitable to install Ansible through playbooks.
The Bootstrap script is used to solve this problem: it will try its best to ensure that Ansible is installed on the node before the real installation.
./bootstrap # make suare ansible installed (if offline package available, setup & use offline install)
If you are using offline package, the Bootstrap script will automatically recognize and process the offline package located at /tmp/pkg.tgz, and install Ansible from it if applicable.
Otherwise, if you have internet access, Bootstrap will automatically add the upstrema yum/apt repo of the corresponding OS/region and install Ansible from it.
If neither internet nor offline package is available, Bootstrap will leave it to the user to handle this issue, and the user needs to ensure that the repo configured on the node contains a usable Ansible.
There are some optional parameters for the Bootstrap script, you can use the -p|--path parameter to specify a different offline package location other than /tmp/pkg.tgz. or designate a region with the -r|--region parameter:
./boostrap
[-r|--region <region][default,china,europe][-p|--path <path>] specify another offline pkg path
[-k|--keep] keep existing upstream repo during bootstrap
And bootstrap will automatically backup and remove the current repo (/etc/yum.repos.d/backup / /etc/apt/source.list.d/backup) of the node during the process to avoid software source conflicts. If this is not the behavior you expected, or you have already configured a local software repo, you can use the -k|--keep parameter to keep the existing software repo.
Example: Use offline package (EL8)
Bootstrap with offline package on a RockyLinux 8 node:
[vagrant@el8 pigsty]$ ls -alh /tmp/pkg.tgz
-rw-r--r--. 1 vagrant vagrant 1.4G Sep 1 10:20 /tmp/pkg.tgz
[vagrant@el8 pigsty]$ ./bootstrap
bootstrap pigsty v3.3.0 begin
[ OK ]region= china
[ OK ]kernel= Linux
[ OK ]machine= x86_64
[ OK ]package= rpm,dnf
[ OK ]vendor= rocky (Rocky Linux)[ OK ]version=8(8.9)[ OK ]sudo= vagrant ok
[ OK ]ssh=[email protected] ok
[ OK ]cache= /tmp/pkg.tgz exists
[ OK ]repo= extract from /tmp/pkg.tgz
[WARN] old repos= moved to /etc/yum.repos.d/backup
[ OK ] repo file= use /etc/yum.repos.d/pigsty-local.repo
[WARN] rpm cache= updating, may take a whilepigsty local8 - x86_64 49 MB/s | 1.3 MB 00:00
Metadata cache created.
[ OK ] repo cache= created
[ OK ] install el8 utils
........ yum install output
Installed:
createrepo_c-0.17.7-6.el8.x86_64 createrepo_c-libs-0.17.7-6.el8.x86_64 drpm-0.4.1-3.el8.x86_64 modulemd-tools-0.7-8.el8.noarch python3-createrepo_c-0.17.7-6.el8.x86_64
python3-libmodulemd-2.13.0-1.el8.x86_64 python3-pyyaml-3.12-12.el8.x86_64 sshpass-1.09-4.el8.x86_64 unzip-6.0-46.el8.x86_64
ansible-9.2.0-1.el8.noarch ansible-core-2.16.3-2.el8.x86_64 git-core-2.43.5-1.el8_10.x86_64 mpdecimal-2.5.1-3.el8.x86_64
python3-cffi-1.11.5-6.el8.x86_64 python3-cryptography-3.2.1-7.el8_9.x86_64 python3-jmespath-0.9.0-11.el8.noarch python3-pycparser-2.14-14.el8.noarch
python3.12-3.12.3-2.el8_10.x86_64 python3.12-cffi-1.16.0-2.el8.x86_64 python3.12-cryptography-41.0.7-1.el8.x86_64 python3.12-jmespath-1.0.1-1.el8.noarch
python3.12-libs-3.12.3-2.el8_10.x86_64 python3.12-pip-wheel-23.2.1-4.el8.noarch python3.12-ply-3.11-2.el8.noarch python3.12-pycparser-2.20-2.el8.noarch
python3.12-pyyaml-6.0.1-2.el8.x86_64
Complete!
[ OK ]ansible= ansible [core 2.16.3][ OK ] boostrap pigsty completeproceed with ./configure
Example: Bootstrap from Internet without offline Package (Debian 12)
On a debian 12 node with internet access, Pigsty add the upstream repo and install ansible and its dependencies using apt:
vagrant@d12:~/pigsty$ ./bootstrap
bootstrap pigsty v3.3.0 begin
[ OK ]region= china
[ OK ]kernel= Linux
[ OK ]machine= x86_64
[ OK ]package= deb,apt
[ OK ]vendor= debian (Debian GNU/Linux)[ OK ]version=12(12)[ OK ]sudo= vagrant ok
[ OK ]ssh=[email protected] ok
[WARN] old repos= moved to /etc/apt/backup
[ OK ] repo file= add debian bookworm china upstream
[WARN] apt cache= updating, may take a while....... apt install output
[ OK ]ansible= ansible [core 2.14.16][ OK ] boostrap pigsty completeproceed with ./configure
Example: Bootstrap from the Default (Ubuntu 20.04)
One an Ubuntu 20.04 node without internet access & offline package, Pigsty will assume you already have resolved this issue with your own way:
Such as a local software repo / mirror / CDROM / intranet repo, etc…
You can explicitly keep the current repo config with the -k parameter, or Pigsty will keep it by default if it detects no internet access and no offline package.
vagrant@ubuntu20:~/pigsty$ ./bootstrap -k
bootstrap pigsty v3.3.0 begin
[ OK ]region= china
[ OK ]kernel= Linux
[ OK ]machine= x86_64
[ OK ]package= deb,apt
[ OK ]vendor= ubuntu (Ubuntu)[ OK ]version=20(20.04)[ OK ]sudo= vagrant ok
[WARN] ubuntu 20 focal does not have corresponding offline package, use online install
[WARN]cache= missing and skip download
[WARN]repo= skip (/tmp/pkg.tgz not exists)[ OK ] repo file= add ubuntu focal china upstream
[WARN] apt cache= updating, make take a while...(apt update/install output)[ OK ]ansible= ansible 2.10.8
[ OK ] boostrap pigsty completeproceed with ./configure
1.3 - Slim Installation
How to perform slim install with HA PostgreSQL related components only
Pigsty has an entire infrastructure stack as an enclosure of HA PostgreSQL clusters, BUT it is viable to install only the PostgreSQL components without the rest of the stack. This is called a slim installation.
Overview
The slim installation focus on Pure HA-PostgreSQL Cluster, and it only installs essential components for this purpose.
There’s NO Infra modules, No monitoring, No local repo Just partial of NODE module, along with ETCD & PGSQL modules
Systemd Service Installed in this mode:
patroni: REQUIRED, bootstrap HA PostgreSQL cluster
etcd: REQUIRED, DCS for patroni
pgbouncer: OPTIONAL, connection pooler for postgres
vip-manager: OPTIONAL, if you want to use a L2 VIP bind to primary
haproxy: OPTIONAL, if you wish to auto-routing service
chronyd: OPTIONAL, if you wish to sync time with NTP server
tuned: OPTIONAL, manage node template and kernel parameters
You can turn off the optional components, the only two essential components are patroni and etcd.
Configure
To perform a slim installation, you need to disable some switches in the pigsty.yml config file: (Example: conf/slim.yml)
all:children:# actually not usedinfra:{hosts:{10.10.10.10:{infra_seq:1}}}#----------------------------------## etcd cluster for HA postgres DCS#----------------------------------#etcd:hosts:10.10.10.10:{etcd_seq:1}vars:etcd_cluster:etcd# postgres cluster 'pg-meta' with 2 instancespg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }10.10.10.11:{pg_seq: 2, pg_role:replica }vars:pg_cluster:pg-metapg_databases:[{name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions:[{name:vector}]}]pg_users:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment:read-only viewer for meta database }node_crontab:['00 01 * * * postgres /pg/bin/pg-backup full']# make a full backup every 1amvars:# global parametersversion:v3.4.1 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default,china,europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.yml# slim installation setupnginx_enabled:false# nginx not existsdns_enabled:false# dnsmasq not existsprometheus_enabled:false# prometheus not existsgrafana_enabled:false# grafana not existspg_exporter_enabled:false# disable pg_exporterpgbouncer_exporter_enabled:falsepg_vip_enabled:false#----------------------------------## Repo, Node, Packages#----------------------------------## if you wish to customize your own repo, change these settings:repo_modules:infra,node,pgsqlrepo_remove:true# remove existing repo on admin node during repo bootstrapnode_repo_modules:local # install the local module in repo_upstream for all nodesnode_repo_remove:true# remove existing node repo for node managed by pigstyrepo_packages:[node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-common ]#,docker]repo_extra_packages:[pg17-main ]#,pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-util ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]pg_version:17# default postgres version#pg_extensions: [pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-feat ,pg17-lang ,pg17-type ,pg17-util ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ] #,pg17-olap]
Describe database and infrastructure as code using declarative Configuration
Pigsty treats Infra & Database as Code. You can describe the infrastructure & database clusters through a declarative interface. All your essential work is to describe your need in the inventory, then materialize it with a simple idempotent playbook.
Inventory
Each pigsty deployment has a corresponding config inventory. It could be stored in a local git-managed file in YAML format
or dynamically generated from CMDB or any ansible compatible format.
Pigsty uses a monolith YAML config file as the default config inventory, which is pigsty.yml, located in the pigsty home directory.
The inventory consists of two parts: global vars & multiple group definitions. You can define new clusters with inventory groups: all.children.
And describe infra and set global default parameters for clusters with global vars: all.vars. Which may look like this:
all: # Top-level object:allvars:{...} # Global Parameterschildren:# Group Definitionsinfra: # Group Definition:'infra'hosts:{...} # Group Membership:'infra'vars:{...} # Group Parameters:'infra'etcd:{...} # Group Definition:'etcd'pg-meta:{...} # Group Definition:'pg-meta'pg-test:{...} # Group Definition:'pg-test'redis-test:{...} # Group Definition:'redis-test'# ...
Each group may represent a cluster, which could be a Node cluster, PostgreSQL cluster, Redis cluster, Etcd cluster, or Minio cluster, etc…
They all use the same format: group vars & hosts. You can define cluster members with all.children.<cls>.hosts and describe cluster with cluster parameters in all.children.<cls>.vars.
Here is an example of 3 nodes PostgreSQL HA cluster named pg-test:
pg-test:# Group Namevars:# Group Vars (Cluster Parameters)pg_cluster:pg-testhosts:# Group Host (Cluster Membership)10.10.10.11:{pg_seq: 1, pg_role:primary }# Host110.10.10.12:{pg_seq: 2, pg_role:replica }# Host210.10.10.13:{pg_seq: 3, pg_role:offline }# Host3
You can also define parameters for a specific host, as known as host vars. It will override group vars and global vars. Which is usually used for assigning identities to nodes & database instances.
Parameter
Global vars, Group vars, and Host vars are dict objects consisting of a series of K-V pairs. Each pair is a named Parameter consisting of a string name as the key and a value of one of five types: boolean, string, number, array, or object. Check parameter reference for detailed syntax & semantics.
Every parameter has a proper default value except for mandatory IDENTITY PARAMETERS; they are used as identifiers and must be set explicitly, such as pg_cluster, pg_role, and pg_seq.
Parameters can be specified & overridden with the following precedence.
Playbook Args > Host Vars > Group Vars > Global Vars > Defaults
For examples:
Force removing existing databases with Playbook CLI Args -e pg_clean=true
Override an instance role with Instance Level Parameter pg_role on Host Vars
Override a cluster name with Cluster Level Parameter pg_cluster on Group Vars.
Specify global NTP servers with Global Parameter node_ntp_servers on Global Vars
If no pg_version is set, it will use the default value from role implementation (16 by default)
Template
There are numerous preset config templates for different scenarios under the conf/ directory.
During configure process, you can specify a template using the -c parameter.
Otherwise, the single-node installation config template will be automatically selected based on your OS distribution.
Details about this built-in configuration files can be found @ Configuration
Switch Config Inventory
To use a different config inventory, you can copy & paste the content into the pigsty.yml file in the home dir as needed.
You can also explicitly specify the config inventory file to use when executing Ansible playbooks by using the -i command-line parameter, for example:
./node.yml -i conf/rich.yml # use another file as config inventory, rather than the default pigsty.yml
If you want to modify the default config inventory filename, you can change the inventory parameter in the ansible.cfg file in the home dir to point to your own inventory file path.
This allows you to run the ansible-playbook command without explicitly specifying the -i parameter.
Pigsty allows you to use a database (CMDB) as a dynamic configuration source instead of a static configuration file. Pigsty provides three convenient scripts:
bin/inventory_load: Loads the content of the pigsty.yml into the local PostgreSQL database (meta.pigsty)
bin/inventory_cmdb: Switches the configuration source to the local PostgreSQL database (meta.pigsty)
bin/inventory_conf: Switches the configuration source to the local static configuration file pigsty.yml
Reference
Pigsty have 280+ parameters, check Parameter for details.
How to prepare the nodes, network, OS distros, admin user, ports, and permissions for Pigsty.
Node
Pigsty supports the Linux kernel and x86_64/aarch64 arch, applicable to any node.
A “node” refers to a resource that is SSH accessible and offers a bare OS environment, such as a physical machine, a virtual machine, or an OS container equipped with systemd and sshd.
Deploying Pigsty requires at least 1 node. The minimum spec requirement is 1C1G, but it is recommended to use at least 2C4G, with no upper limit: parameters will automatically optimize and adapt.
For demos, personal sites, devbox, or standalone monitoring infra, 1-2 nodes are recommended, while at least 3 nodes are suggested for an HA PostgreSQL cluster. For critical scenarios, 4-5 nodes are advisable.
Leverage IaC Tools for chores
Managing a large-scale prod env could be tedious and error-prone. We recommend using Infrastructure as Code (IaC) tools to address these issues.
You can use the Terraform and Vagrant templates provided by Pigsty,
to create the required node environment with just one command through IaC, provisioning network, OS image, admin user, privileges, etc…
Network
Pigsty requires nodes to use static IPv4 addresses, which means you should explicitly assign your nodes a specific fixed IP address rather than using DHCP-assigned addresses.
The IP address used by a node should be the primary IP address for internal network communications and will serve as the node’s unique identifier.
If you wish to use the optional Node VIP and PG VIP features, ensure all nodes are located within an L2 network.
Your firewall policy should ensure the required ports are open between nodes. For a detailed list of ports required by different modules, refer to Node: Ports.
Which Ports Should Be Exposed?
For beginners or those who are just trying it out, you can just open ports 5432 (PostgreSQL database) and 3000 (Grafana visualization interface) to the world.
For a serious prod env, you should only expose the necessary ports to the exterior, such as 80/443 for web services, open to the office network (or the entire Internet).
Exposing database service ports directly to the Internet is not advisable. If you need to do this, consider consulting Security Best Practices and proceed cautiously.
The method for exposing ports depends on your network implementation, such as security group policies, local iptables records, firewall configurations, etc.
Operating System
Pigsty supports various Linux OS. We recommend using RockyLinux 9.4 or Ubuntu 22.04.5 as the default OS for installing Pigsty.
Pigsty supports RHEL (7,8,9), Debian (11,12), Ubuntu (20,22,24), and many other compatible OS distros. Check Compatibility For a complete list of compatible OS distros.
When deploying on multiple nodes, we strongly recommend using the same version of the OS distro and the Linux kernel on all nodes.
We strongly recommend using a clean, minimally installed OS environment with en_US set as the primary language.
How to enable en_US locale?
To ensure the en_US locale is available when using other primary language:
Note: The PostgreSQL cluster deployed by Pigsty defaults to the C.UTF8 locale, but character set definitions use en_US to ensure the pg_trgm extension functions properly.
If you do not need this feature, you can configure the value of pg_lc_ctype to C.UTF8 to avoid this issue when en locale is missing.
Admin User
You’ll need an “admin user” on all nodes where Pigsty is meant to be deployed — an OS user with nopass ssh login and nopass sudo permissions.
On the nodes where Pigsty is installed, you need an “administrative user” who has nopass ssh login and nopass sudo permissions.
No password sudo is required to execute commands during the installation process, such as installing packages, configuring system settings, etc.
How to configure nopass sudo for admin user?
Assuming your admin username is vagrant, you can create a file in /etc/sudoers.d/vagrant and add the following content:
%vagrant ALL=(ALL) NOPASSWD: ALL
This will allow the vagrant user to execute all commands without a sudo password. If your username is not vagrant, replace vagrant in the above steps with your username.
Avoid using the root user
While it is possible to install Pigsty using the root user, we do not recommend it.
We recommend using a dedicated admin user, such as dba, different from the root user (root) and the database superuser (postgres).
There is a dedicated playbook subtask that can use an existing admin user (e.g., root) with ssh/sudo password input to create a dedicated admin user.
SSH Permission
In addition to nopass sudo privilege, Pigsty also requires the admin user to have nopass ssh login privilege (login via ssh key).
For single-host installations setup,
this means the admin user on the local node should be able to log in to the host itself via ssh without a password.
If your Pigsty deployment involves multiple nodes, this means the admin user on the admin node
should be able to log in to all nodes managed by Pigsty (including the local node) via ssh without a password, and execute sudo commands without a password as well.
During the configure procedure, if your current admin user does not have any SSH key,
it will attempt to address this issue by generating a new id_rsa key pair and adding it to the local ~/.ssh/authorized_keys file to ensure local SSH login capability for the local admin user.
By default, Pigsty creates an admin user dba (uid=88) on all managed nodes. If you are already using this user,
we recommend that you change the node_admin_username to a new username with a different uid,
or disable it using the node_admin_enabled parameter.
How to configure nopass SSH login for admin user?
Assuming your admin username is vagrant, execute the following command as the vagrant user will generate a
public/private key pair for login. If a key pair already exists, there is no need to generate a new one.
The generated public key is by default located at: /home/vagrant/.ssh/id_rsa.pub, and the private key at: /home/vagrant/.ssh/id_rsa.
If your OS username is not vagrant, replace vagrant in the above commands with your username.
You should append the public key file (id_rsa.pub) to the authorized_keys file of the user you need to log into: /home/vagrant/.ssh/authorized_keys.
If you already have password access to the remote machine, you can use ssh-copy-id to copy the public key:
ssh-copy-id <ip> # Enter password to complete public key copyingsshpass -p <password> ssh-copy-id <ip> # Or: you can embed the password directly in the command to avoid interactive password entry (cautious!)
Pigsty recommends provisioning the admin user during node provisioning and making it viable by default.
SSH Accessibility
If your environment has some restrictions on SSH access, such as a bastion server or ad hoc firewall rules that prevent simple SSH access via ssh <ip>, consider using SSH aliases.
For example, if there’s a node with IP 10.10.10.10 that can not be accessed directly via ssh but can be accessed via an ssh alias meta defined in ~/.ssh/config,
then you can configure the ansible_host parameter for that node in the inventory to specify the SSH Alias on the host level:
nodes:hosts:# 10.10.10.10 can not be accessed directly via ssh, but can be accessed via ssh alias 'meta'10.10.10.10:{ansible_host:meta }
If the ssh alias does not meet your requirement, there are a plethora of custom ssh connection parameters that can bring fine-grained control over SSH connection behavior.
If the following cmd can be successfully executed on the admin node by the admin user, it means that the target node’s admin user is properly configured.
ssh <ip|alias> 'sudo ls'
Software
On the admin node, Pigsty requires ansible to initiate control.
If you are using the singleton meta installation, Ansible is required on this node. It is not required for common nodes.
The bootstrap procedure will make every effort to do this for you.
But you can always choose to install Ansible manually. The process of manually installing Ansible
varies with different OS distros / major versions (usually involving an additional weak dependency jmespath):
sudo dnf install -y ansible python3.12-jmespath
sudo yum install -y ansible # EL7 does not need to install jmespath explicitly
sudo apt install -y ansible python3-jmespath
brew install ansible
To install Pigsty, you also need to prepare the Pigsty source package. You can directly download a specific version from the
GitHub Release page or use the following command to obtain the latest stable version:
curl -fsSL https://repo.pigsty.io/get | bash
If your env does not have Internet access, consider using the offline packages,
which are pre-packed for different OS distros, and can be downloaded from the GitHub Release page.
1.6 - Playbooks
Pigsty implement module controller with idempotent ansible playbooks, here are available playbooks.
Playbooks are used in Pigsty to install modules on nodes.
To run playbooks, just treat them as executables. e.g. run with ./install.yml.
Note that there’s a circular dependency between NODE and INFRA:
to register a NODE to INFRA, the INFRA should already exist, while the INFRA module relies on NODE to work.
The solution is that INFRA playbook will also install NODE module in addition to INFRA on infra nodes.
Make sure that infra nodes are init first. If you really want to init all nodes including infra in one-pass, install.yml is the way to go.
Ansible
Playbooks require ansible-playbook executable to run, playbooks which is included in ansible rpm / deb package.
Pigsty will try it’s best to install ansible on admin node during bootstrap.
You can install it by yourself with yum|apt|brewinstall ansible, it is included in default OS repo.
Knowledge about ansible is good but not required. Only four parameters needs your attention:
-l|--limit <pattern> : Limit execution target on specific group/host/pattern (Where)
-t|--tags <tags>: Only run tasks with specific tags (What)
-e|--extra-vars <vars>: Extra command line arguments (How)
-i|--inventory <path>: Using another inventory file (Conf)
Designate Inventory
To use a different config inventory, you can copy & paste the content into the pigsty.yml file in the home dir as needed.
The active inventory file can be specified with the -i|--inventory <path> parameter when running Ansible playbooks.
./pgsql.yml -i conf/rich.yml # initialize a single node with all extensions downloaded according to rich config./pgsql.yml -i conf/full.yml # initialize a four-node cluster according to full config./pgsql.yml -i conf/app/supa.yml # initialize a single-node Supabase deployment according to supa.yml config
If you wish to permanently modify the default config inventory filename, you can change the inventory parameter in the ansible.cfg
Limit Host
The target of playbook can be limited with -l|-limit <selector>.
Missing this value could be dangerous since most playbooks will execute on all host, DO USE WITH CAUTION.
Here are some examples of host limit:
./pgsql.yml # run on all hosts (very dangerous!)./pgsql.yml -l pg-test # run on pg-test cluster./pgsql.yml -l 10.10.10.10 # run on single host 10.10.10.10./pgsql.yml -l pg-* # run on host/group matching glob pattern `pg-*`./pgsql.yml -l '10.10.10.11,&pg-test'# run on 10.10.10.10 of group pg-test/pgsql-rm.yml -l 'pg-test,!10.10.10.11'# run on pg-test, except 10.10.10.11./pgsql.yml -l pg-test # Execute the pgsql playbook against the hosts in the pg-test cluster
Limit Tags
You can execute a subset of playbook with -t|--tags <tags>.
You can specify multiple tags in comma separated list, e.g. -t tag1,tag2.
If specified, tasks with given tags will be executed instead of entire playbook.
Here are some examples of task limit:
./pgsql.yml -t pg_clean # cleanup existing postgres if necessary./pgsql.yml -t pg_dbsu # setup os user sudo for postgres dbsu./pgsql.yml -t pg_install # install postgres packages & extensions./pgsql.yml -t pg_dir # create postgres directories and setup fhs./pgsql.yml -t pg_util # copy utils scripts, setup alias and env./pgsql.yml -t patroni # bootstrap postgres with patroni./pgsql.yml -t pg_user # provision postgres business users./pgsql.yml -t pg_db # provision postgres business databases./pgsql.yml -t pg_backup # init pgbackrest repo & basebackup./pgsql.yml -t pgbouncer # deploy a pgbouncer sidecar with postgres./pgsql.yml -t pg_vip # bind vip to pgsql primary with vip-manager./pgsql.yml -t pg_dns # register dns name to infra dnsmasq./pgsql.yml -t pg_service # expose pgsql service with haproxy./pgsql.yml -t pg_exporter # expose pgsql service with haproxy./pgsql.yml -t pg_register # register postgres to pigsty infrastructure# run multiple tasks: reload postgres & pgbouncer hba rules./pgsql.yml -t pg_hba,pg_reload,pgbouncer_hba,pgbouncer_reload
# run multiple tasks: refresh haproxy config & reload it./node.yml -t haproxy_config,haproxy_reload
Extra Vars
Extra command-line args can be passing via -e|-extra-vars KEY=VALUE.
It has the highest precedence over all other definition.
Here are some examples of extra vars
./node.yml -e ansible_user=admin -k -K # run playbook as another user (with admin sudo password)./pgsql.yml -e pg_clean=true# force purging existing postgres when init a pgsql instance./pgsql-rm.yml -e pg_uninstall=true# explicitly uninstall rpm after postgres instance is removed./redis.yml -l 10.10.10.10 -e redis_port=6379 -t redis # init a specific redis instance: 10.10.10.11:6379./redis-rm.yml -l 10.10.10.13 -e redis_port=6379# remove a specific redis instance: 10.10.10.11:6379
You can also pass complex parameters like array and object via JSON:
# install duckdb packages on node with specified upstream repo module./node.yml -t node_repo,node_pkg -e '{"node_repo_modules":"infra","node_default_packages":["duckdb"]}'
Most playbooks are idempotent, meaning that some deployment playbooks may erase existing databases and create new ones without the protection option turned on.
Please read the documentation carefully, proofread the commands several times, and operate with caution. The author is not responsible for any loss of databases due to misuse.
1.7 - Provisioning
Introduce the 4 node sandbox environment. and provision VMs with vagrant & terraform
Pigsty runs on nodes, which are Bare Metals or Virtual Machines. You can prepare them manually, or using terraform & vagrant for provisioning.
Sandbox
Pigsty has a sandbox, which is a 4-node deployment with fixed IP addresses and other identifiers.
Check conf/full.yml for details.
The sandbox consists of 4 nodes with fixed IP addresses: 10.10.10.10, 10.10.10.11, 10.10.10.12, 10.10.10.13.
There’s a primary singleton PostgreSQL cluster: pg-meta on the meta node, which can be used alone if you don’t care about PostgreSQL high availability.
meta 10.10.10.10 pg-meta pg-meta-1
There are 3 additional nodes in the sandbox, form a 3-instance PostgreSQL HA cluster pg-test.
node-1 10.10.10.11 pg-test.pg-test-1
node-2 10.10.10.12 pg-test.pg-test-2
node-3 10.10.10.13 pg-test.pg-test-3
Two optional L2 VIP are bind on primary instances of cluster pg-meta and pg-test:
10.10.10.2 pg-meta
10.10.10.3 pg-test
There’s also a 1-instance etcd cluster, and 1-instance minio cluster on the meta node, too.
You can run sandbox on local VMs or cloud VMs. Pigsty offers a local sandbox based on Vagrant (pulling up local VMs using Virtualbox or libvirt), and a cloud sandbox based on Terraform (creating VMs using the cloud vendor API).
Local sandbox can be run on your Mac/PC for free. Your Mac/PC should have at least 4C/8G to run the full 4-node sandbox.
Cloud sandbox can be easily created and shared. You will have to create a cloud account for that. VMs are created on-demand and can be destroyed with one command, which is also very cheap for a quick glance.
Vagrant use VirtualBox as the default VM provider.
however libvirt, docker, parallel desktop and vmware can also be used.
We will use VirtualBox in this guide.
Installation
Make sure Vagrant and Virtualbox are installed and available on your OS.
If you are using macOS, You can use homebrew to install both of them with one command (reboot required). You can also use vagrant-libvirt on Linux.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"brew install vagrant virtualbox ansible # Run on MacOS with one command, but only works on x86_64 Intel chips
Configuration
Vagranfile is a ruby script file describing VM nodes. Here are some default specs of Pigsty.
Templates
Nodes
Spec
Comment
Alias
meta.rb
1 node
2c4g x 1
Single Node Meta
Devbox
dual.rb
2 node
1c2g x 2
Dual Nodes
trio.rb
3 node
1c2G x 3
Three Nodes
full.rb
4 node
2c4g + 1c2g x 3
Full-Featured 4 Node
Sandbox
prod.rb
36 node
misc
Prod Env Simulation
Simubox
build.r
5 node
1c2g x 4
4-Node Building Env
Buildbox
rpm.rb
3 node
1c2G x 3
3-Node EL Building Env
deb.rb
5 node
1c2G x 5
5-Node Deb Building Env
all.rb
7 node
1c2G x 7
7-Node All Building Env
Each spec file contains a Specs variable describe VM nodes. For example, the full.rb contains:
You can use specs with the config script, it will render the final Vagrantfile according to the spec and other options
cd ~/pigsty
vagrant/config [spec][image][scale][provider]vagrant/config meta # use the 1-node spec, default el8 imagevagrant/config dual el9 # use the 2-node spec, use el9 image instead vagrant/config trio d12 2# use the 3-node spec, use debian12 image, double the cpu/mem resourcevagrant/config full u22 4# use the 4-node spec, use ubuntu22 image instead, use 4x cpu/mem resource vagrant/config prod u20 1 libvirt # use the 43-node spec, use ubuntu20 image instead, use libvirt as provider instead of virtualbox
You can scale the resource unit with environment variable VM_SCALE, the default value is 1.
For example, if you use VM_SCALE=2 with vagrant/config meta, it will double the cpu / mem resources of the meta node.
Create pre-configured environment with make shortcuts:
make meta # 1-node devbox for quick start, dev, test & playgroundmake full # 4-node sandbox for HA-testing & feature demonstrationmake prod # 43-node simubox for production environment simulation# seldom used templates:make dual # 2-node envmake trio # 3-node env
You can use variant alias to create environment with different base image:
make meta9 # create singleton-meta node with generic/rocky9 imagemake full22 # create 4-node sandbox with generic/ubuntu22 imagemake prod12 # create 43-node production env simubox with generic/debian12 image... # available suffix: 7,8,9,11,12,20,22,24
You can also launch pigsty building env with these alias, base image will not be substituted:
make build # 4-node building environment make rpm # 3-node el7/8/9 building envmake deb # 5-node debian11/12 ubuntu20/22/24make all # 7-node building env with all base images
Management
After describing the VM nodes with specs and generate the vagrant/Vagrantfile. you can create the VMs with vagrant up command.
Pigsty templates will use your ~/.ssh/id_rsa[.pub] as the default ssh key for vagrant provisioning.
Make sure you have a valid ssh key pair before you start, you can generate one by: ssh-keygen -t rsa -b 2048
There are some makefile shortcuts that wrap the vagrant commands, you can use them to manage the VMs.
make # = make startmake new # destroy existing vm and create new onesmake ssh # write VM ssh config to ~/.ssh/ (required)make dns # write VM DNS records to /etc/hosts (optional)make start # launch VMs and write ssh config (up + ssh) make up # launch VMs with vagrant upmake halt # shutdown VMs (down,dw)make clean # destroy VMs (clean/del/destroy)make status # show VM status (st)make pause # pause VMs (suspend,pause)make resume # pause VMs (resume)make nuke # destroy all vm & volumes with virsh (if using libvirt)
Caveat
If you are using virtualbox, you have to add 10.0.0.0/8 to /etc/vbox/networks.conf first to use 10.x.x.x in host-only networks.
Terraform is an open-source tool to practice ‘Infra as Code’. Describe the cloud resource you want and create them with one command.
Pigsty has Terraform templates for AWS, Aliyun, and Tencent Cloud, you can use them to create VMs on the cloud for Pigsty Demo.
Terraform can be easily installed with homebrew, too: brew install terraform. You will have to create a cloud account to obtain AccessKey and AccessSecret credentials to proceed.
Quick Start
brew install terraform # install via homebrewterraform init # install terraform provider: aliyun , aws, only required for the first timeterraform apply # plan and apply: create VMs, etc...
Frequently asked questions about download, setup, configuration, and installation in Pigsty.
If you have any unlisted questions or suggestions, please create an Issue or ask the community for help.
How to Get the Pigsty Source Package?
Use the following command to install Pigsty with one click: curl -fsSL https://repo.pigsty.io/get | bash
This command will automatically download the latest stable version pigsty.tgz and extract it to the ~/pigsty directory. You can also manually download a specific version of the Pigsty source code from the following locations.
If you need to install it in an environment without internet access, you can download it in advance in a networked environment and transfer it to the production server via scp/sftp or CDROM/USB.
How to Speed Up RPM Downloads from Upstream Repositories?
Consider using a local repository mirror, which can be configured with the repo_upstream parameter. You can choose region to use different mirror sites.
For example, you can set region = china, which will use the URL with the key china in the baseurl instead of default.
If some repositories are blocked by a firewall or the GFW, consider using proxy_env to bypass it.
How to resolve node package conflict?
Beware that Pigsty’s pre-built offline packages are tailored for specific minor versions OS Distors.
Therefore, if the major.minor version of your OS distro does not precisely align, we advise against using the offline installation packages.
Instead, following the default installation procedure and download the package directly from upstream repo through the Internet, which will acquire the versions that exactly match your OS version.
If online installation doesn’t work for you, you can first try modifying the upstream software sources used by Pigsty.
For example, in EL family operating systems, Pigsty’s default upstream sources use a major version placeholder $releasever, which resolves to specific major versions like 7, 8, 9.
However, many operating system distributions offer a Vault, allowing you to use a package mirror for a specific version.
Therefore, you could replace the front part of the repo_upstream parameter’s BaseURL with a specific Vault minor version repository, such as:
https://dl.rockylinux.org/pub/rocky/$releasever (Original BaseURL prefix, without vault)
https://vault.centos.org/7.6.1810/ (Using 7.6 instead of the default 7.9)
https://dl.rockylinux.org/vault/rocky/8.6/ (Using 8.6 instead of the default 8.10)
https://dl.rockylinux.org/vault/rocky/9.2/ (Using 9.2 instead of the default 9.5)
Make sure the vault URL path exists & valid before replacing the old values. Beware that some repo like epel do not offer specific minor version subdirs.
Upstream repo that support this approach include: base, updates, extras, centos-sclo, centos-sclo-rh, baseos, appstream, extras, crb, powertools, pgdg-common, pgdg1*
After explicitly defining and overriding the repo_upstream in the Pigsty configuration file, (you may clear the /www/pigsty/repo_complete flag) try the installation again.
If the upstream software source and the mirror source software do not solve the problem, you might consider replacing them with the operating system’s built-in software sources and attempt a direct installation from upstream once more.
Finally, if the above methods do not resolve the issue, consider removing conflicting packages from node_packages, infra_packages, pg_packages, pg_extensions, or remove or upgrade the conflicting packages on the existing system.
What does bootstrap do?
Check the environment, ask for downloading offline packages, and make sure the essential tool ansible is installed.
It will make sure the essential tool ansible is installed by various means.
When you download the Pigsty source code, you can enter the directory and execute the bootstrap script.
It will check if your node environment is ready, and if it does not find offline packages, it will ask if you want to download them from the internet if applicable.
You can choose y to use offline packages, which will make the installation procedure faster.
You can also choose n to skip and download directly from the internet during the installation process,
which will download the latest software versions and reduce the chance of RPM conflicts.
What does configure do?
Detect the environment, generate the configuration, enable the offline package (optional), and install the essential tool Ansible.
After downloading the Pigsty source package and unpacking it, you may have to execute ./configure to complete the environment configuration. This is optional if you already know how to configure Pigsty properly.
The configure procedure will detect your node environment and generate a pigsty config file: pigsty.yml for you.
What is the Pigsty config file?
pigsty.yml under the pigsty home dir is the default config file.
Pigsty uses a single config file pigsty.yml, to describe the entire environment, and you can define everything there. There are many config examples in files/pigsty for your reference.
You can pass the -i <path> to playbooks to use other configuration files. For example, you want to install redis according to another config: redis.yml:
./redis.yml -i conf/demo/redis.yml
How to use the CMDB as config inventory
The default config file path is specified in ansible.cfg: inventory = pigsty.yml
You can switch to a dynamic CMDB inventory with bin/inventory_cmdb, and switch back to the local config file with bin/inventory_conf. You must also load the current config file inventory to CMDB with bin/inventory_load.
If CMDB is used, you must edit the inventory config from the database rather than the config file.
What is the IP address placeholder in the config file?
Pigsty uses 10.10.10.10 as a placeholder for the current node IP, which will be replaced with the primary IP of the current node during the configuration.
When the configure detects multiple NICs with multiple IPs on the current node, the config wizard will prompt for the primary IP to be used, i.e., the IP used by the user to access the node from the internal network. Note that please do not use the public IP.
This IP will be used to replace 10.10.10.10 in the config file template.
Which parameters need your attention?
Usually, in a singleton installation, there is no need to make any adjustments to the config files.
Pigsty provides 265 config parameters to customize the entire infra/node/etcd/minio/pgsql. However, there are a few parameters that can be adjusted in advance if needed:
When accessing web service components, the domain name is infra_portal (some services can only be accessed using the domain name through the Nginx proxy).
Pigsty assumes that a /data dir exists to hold all data; you can adjust these paths if the data disk mount point differs from this.
Don’t forget to change those passwords in the config file for your production deployment.
Installation
What was executed during installation?
When running make install, the ansible-playbook install.yml will be invoked to install everything on all nodes
Which will:
Install INFRA module on the current node.
Install NODE module on the current node.
Install ETCD module on the current node.
The MinIO module is optional, and will not be installed by default.
Install PGSQL module on the current node.
How to resolve RPM conflict?
There may have a slight chance that rpm conflict occurs during node/infra/pgsql packages installation.
The simplest way to resolve this is to install without offline packages, which will download directly from the upstream repo.
If there are only a few problematic RPM/DEB pakages, you can use a trick to fix the yum/apt repo quickly:
rm -rf /www/pigsty/repo_complete # delete the repo_complete flag file to mark this repo incompleterm -rf SomeBrokenPackages # delete problematic RPM/DEB packages./infra.yml -t repo_upstream # write upstream repos. you can also use /etc/yum.repos.d/backup/*./infra.yml -t repo_pkg # download rpms according to your current OS
How to create local VMs with vagrant
The first time you use Vagrant to pull up a particular OS repo, it will download the corresponding BOX.
Pigsty sandbox uses generic/rocky9 image box by default, and Vagrant will download the rocky/9 box for the first time the VM is started.
Using a proxy may increase the download speed. Box only needs to be downloaded once, and will be reused when recreating the sandbox.
RPMs error on Aliyun CentOS 7.9
Aliyun CentOS 7.9 server has DNS caching service nscd installed by default. Just remove it.
Aliyun’s CentOS 7.9 repo has nscd installed by default, locking out the glibc version, which can cause RPM dependency errors during installation.
Run various business software & apps with docker-compose templates.
Run demos & data apps, analyze data, and visualize them with ECharts panels.
Battery-Included RDS
Run production-grade RDS for PostgreSQL on your own machine in 10 minutes!
While PostgreSQL shines as a database kernel, it excels as a Relational Database Service (RDS) with Pigsty’s touch.
Pigsty is compatible with PostgreSQL 12-16 and runs seamlessly on EL 7, 8, 9, Debian 11/12, Ubuntu 20/22/24 and similar OS distributions.
It integrates the kernel with a rich set of extensions, provides all the essentials for a production-ready RDS, an entire set of infrastructure runtime coupled with fully automated deployment playbooks.
With everything bundled for offline installation without internet connectivity.
You can transit from a fresh node to a production-ready state effortlessly, deploy a top-tier PostgreSQL RDS service in a mere 10 minutes.
Pigsty will tune parameters to your hardware, handling everything from kernel, extensions, pooling, load balancing, high-availability, monitoring & logging, backups & PITR, security and more!
All you need to do is run the command and connect with the given URL.
Plentiful Extensions
Harness the might of the most advanced Open-Source RDBMS or the world!
PostgreSQL’s has an unique extension ecosystem. Pigsty seamlessly integrates these powerful extensions, delivering turnkey distributed solutions for time-series, geospatial, and vector capabilities.
Pigsty boasts over 400 PostgreSQL extensions, and maintaining some not found in official PGDG repositories. Rigorous testing ensures flawless integration for core extensions:
Leverage PostGIS for geospatial data, TimescaleDB for time-series analysis, Citus for horizontal scale out,
PGVector for AI embeddings, Apache AGE for graph data, ParadeDB for Full-Text Search,
and pg_duckdb, pg_mooncake for OLAP workloads!
You can also run self-hosted Supabase & PostgresML with Pigsty managed HA PostgreSQL.
If you want to add your own extension, feel free to suggest or compile it by yourself.
All functionality is abstracted as Modules that can be freely composed for different scenarios.
INFRA gives you a modern observability stack, while NODE can be used for host monitoring.
Installing the PGSQL module on multiple nodes will automatically form a HA cluster.
And you can also have dedicated ETCD clusters for distributed consensus & MinIO clusters for backup storage.
REDIS are also supported since they work well with PostgreSQL.
You can reuse Pigsty infra and extend it with your Modules (e.g. GPSQL, KAFKA, MONGO, MYSQL…).
Moreover, Pigsty’s INFRA module can be used alone — ideal for monitoring hosts, databases, or cloud RDS.
Stunning Observability
Unparalleled monitoring system based on modern observability stack and open-source best-practice!
Pigsty will automatically monitor any newly deployed components such as Node, Docker, HAProxy, Postgres, Patroni, Pgbouncer, Redis, Minio, and itself. There are 30+ default dashboards and pre-configured alerting rules, which will upgrade your system’s observability to a whole new level. Of course, it can be used as your application monitoring infrastructure too.
There are over 3K+ metrics that describe every aspect of your environment, from the topmost overview dashboard to a detailed table/index/func/seq. As a result, you can have complete insight into the past, present, and future.
Pigsty has pre-configured HA & PITR for PostgreSQL to ensure your database service is always reliable.
Hardware failures are covered by self-healing HA architecture powered by patroni, etcd, and haproxy, which will perform auto failover in case of leader failure (RTO < 30s), and there will be no data loss (RPO = 0) in sync mode. Moreover, with the self-healing traffic control proxy, the client may not even notice a switchover/replica failure.
Software Failures, human errors, and Data Center Failures are covered with Cold backups & PITR, which are implemented with pgBackRest. It allows you to travel time to any point in your database’s history as long as your storage is capable. You can store them in the local backup disk, built-in MinIO cluster, or S3 service.
Large organizations have used Pigsty for several years. One of the largest deployments has 25K CPU cores and 333 massive PostgreSQL instances. In the past three years, there have been dozens of hardware failures & incidents, but the overall availability remains several nines (99.999% +).
Great Maintainability
Infra as Code, Database as Code, Declarative API & Idempotent Playbooks, GitOPS works like a charm.
Pigsty provides a declarative interface: Describe everything in a config file, and Pigsty operates it to the desired state. It works like Kubernetes CRDs & Operators but for databases and infrastructures on any nodes: bare metal or virtual machines.
To create cluster/database/user/extension, expose services, or add replicas. All you need to do is to modify the cluster definition and run the idempotent playbook. Databases & Nodes are tuned automatically according to their hardware specs, and monitoring & alerting is pre-configured. As a result, database administration becomes much more manageable.
Pigsty has a full-featured sandbox powered by Vagrant, a pre-configured one or 4-node environment for testing & demonstration purposes. You can also provision required IaaS resources from cloud vendors with Terraform templates.
Sound Security
Nothing needs to be worried about database security, as long as your hardware & credentials are safe.
Pigsty use SSL for API & network traffic, Encryption for password & backups, HBA rules for host & clients, and access control for users & objects.
Pigsty has an easy-to-use, fine-grained, and fully customizable access control framework based on roles, privileges, and HBA rules. It has four default roles: read-only, read-write, admin (DDL), offline (ETL), and four default users: dbsu, replicator, monitor, and admin. Newly created database objects will have proper default privileges for those roles. And client access is restricted by a set of HBA rules that follows the least privilege principle.
Your entire network communication can be secured with SSL. Pigsty will automatically create a self-signed CA and issue certs for that. Database credentials are encrypted with the scram-sha-256 algorithm, and cold backups are encrypted with the AES-256 algorithm when using MinIO/S3. Admin Pages and dangerous APIs are protected with HTTPS, and access is restricted from specific admin/infra nodes.
Versatile Application
Lots of applications work well with PostgreSQL. Run them in one command with docker.
The database is usually the most tricky part of most software. Since Pigsty already provides the RDS. It could be nice to have a series of docker templates to run software in stateless mode and persist their data with Pigsty-managed HA PostgreSQL (or Redis, MinIO), including Gitlab, Gitea, Wiki.js, NocoDB, Odoo, Jira, Confluence, Harbour, Mastodon, Discourse, and KeyCloak.
Pigsty also provides a toolset to help you manage your database and build data applications in a low-code fashion: PGAdmin4, PGWeb, ByteBase, PostgREST, Kong, and higher “Database” that use Postgres as underlying storage, such as EdgeDB, FerretDB, and Supabase. And since you already have Grafana & Postgres, You can quickly make an interactive data application demo with them. In addition, advanced visualization can be achieved with the built-in ECharts panel.
Open Source & Free
Pigsty is a free & open source software under AGPLv3. It was built for PostgreSQL with love.
Pigsty allows you to run production-grade RDS on your hardware without suffering from human resources. As a result, you can achieve the same or even better reliability & performance & maintainability with only 5% ~ 40% cost compared to Cloud RDS PG. As a result, you may have an RDS with a lower price even than ECS.
There will be no vendor lock-in, annoying license fee, and node/CPU/core limit. You can have as many RDS as possible and run them as long as possible. All your data belongs to you and is under your control.
Pigsty is free software under AGPLv3. It’s free of charge, but beware that freedom is not free, so use it at your own risk! It’s not very difficult, and we are glad to help. For those enterprise users who seek professional consulting services, we do have a subscription for that.
2.2 - Modules
This section lists the available feature modules within Pigsty, and future planning modules
Core Modules
Pigsty offers four PRIMARY modules, which are essential for providing PostgreSQL service:
PGSQL : Autonomous PostgreSQL cluster with HA, PITR, IaC, SOP, monitoring, and 335 extensions!.
INFRA : Local software repository, Prometheus, Grafana, Loki, AlertManager, PushGateway, Blackbox Exporter, etc.
NODE : Adjusts the node to the desired state, name, time zone, NTP, ssh, sudo, haproxy, docker, promtail, keepalived.
ETCD : Distributed key-value store, serving as the DCS (Distributed Consensus System) for the highly available Postgres cluster: consensus leadership election, configuration management, service discovery.
Kernel Modules
Pigsty allow using four different PostgreSQL KERNEL modules, as an optional in-place replacement:
MSSQL: Microsoft SQL Server Wire Protocol Compatible kernel powered by AWS, WiltonDB & Babelfish.
IVORY: Oracle Compatible kernel powered by the IvorySQL project supported by HiGo
POLAR: Oracle RAC / CloudNative kernel powered by Alibaba PolarDB for PostgreSQL
CITUS: Distributive PostgreSQL (also known as Azure Hyperscale) as an extension, with native Patroni HA support.
We also have an ORACLE module powered by PolarDB-O, a commercial kernel from Aliyun, Pro version only.
Extended Modules
Pigsty offers four OPTIONAL modules,which are not necessary for the core functionality but can enhance the capabilities of PostgreSQL:
MINIO: S3-compatible simple object storage server, serving as an optional PostgreSQL database backup repository with production deployment support and monitoring.
REDIS: High-performance data structure server supporting standalone m/s, sentinel, and cluster mode deployments, with comprehensive HA & monitoring support.
FERRET: Native FerertDB deployment — adding MongoDB wire protocol level API compatibility to existing HA PostgreSQL cluster.
DOCKER: Docker Daemon allowing users to easily deploy containerized stateless software tool templates, adding various functionalities.
DBMS Modules
Pigsty allow using other PERIPHERAL modules around the PostgreSQL ecosystem:
DUCKDB: Pigsty has duckdb cli, fdw, and PostgreSQL integration extensions such as pg_duckdb, pg_lakehouse, and duckdb_fdw.
SUPABASE: Run firebase alternative on top of existing HA PostgreSQL Cluster!
GREENPLUM: MPP for of PostgreSQL (PG 12 kernel), WIP
CLOUDBERRY: Greenplum OSS fork with PG 14 kernel, WIP
Pigsty is actively developing some new PILOT modules, which are not yet fully mature yet:
MYSQL: Pigsty is researching adding high-availability deployment support for MySQL as an optional extension feature (Beta).
KAFKA: Pigsty plans to offer message queue support (Beta).
KUBE: Pigsty plans to use SealOS to provide out-of-the-box production-grade Kubernetes deployment and monitoring support (Alpha).
VICTORIA: Prometheus & Loki replacement with VictoriaMetrics & VictoriaLogs with better performance(Alpha)
JUPYTER: Battery-included Jupyter Notebook environment for data analysis and machine learning scenarios(Alpha)
Monitoring Other Databases
Pigsty’s INFRA module can be used independently as a plug-and-play monitoring infrastructure for other nodes or existing PostgreSQL databases:
Existing PostgreSQL services: Pigsty can monitor external, non-Pigsty managed PostgreSQL services, still providing relatively complete monitoring support.
RDS PG: Cloud vendor-provided PostgreSQL RDS services, treated as standard external Postgres instances for monitoring.
PolarDB: Alibaba Cloud’s cloud-native database, treated as an external PostgreSQL 11 / 14 instance for monitoring.
KingBase: A trusted domestic database provided by People’s University of China, treated as an external PostgreSQL 12 instance for monitoring.
Greenplum / YMatrixDB monitoring, currently treated as horizontally partitioned PostgreSQL clusters for monitoring.
2.3 - Roadmap
The Pigsty project roadmap, including new features, development plans, and versioning & release policy.
Release Schedule
Pigsty employs semantic versioning, denoted as <major version>.<minor version>.<patch>. Alpha/Beta/RC versions are indicated with a suffix, such as -a1, -b1, -c1.
Major updates signify foundational changes and a plethora of new features; minor updates typically introduce new features, software package version updates, and minor API changes, while patch updates are meant for bug fixes and documentation improvements.
Pigsty plans to release a major update annually, with minor updates usually following the rhythm of PostgreSQL minor releases, aiming to catch up within a month after a new PostgreSQL version is released, typically resulting in 4 - 6 minor updates annually. For a complete release history, refer to Release Notes.
Do not use the main branch
Please always use a version-specificrelease, do not use the GitHub main branch unless you know what you are doing.
New Features on the Radar
A command-line tool that’s actually good
ARM architecture support for infrastructure components
Adding more extensions to PostgreSQL
More pre-configured scenario-based templates
Migrating package repositories and download sources entirely to Cloudflare
Support for PostgreSQL 17
Offering a richer variety of Docker application templates
Loki and Promtail seem a bit off; could VictoriaLogs and Vector step up?
Swapping Prometheus storage for VictoriaMetrics to handle time-series data
Monitoring deployments of MySQL databases
Monitoring databases within Kubernetes
Deploying and monitoring high-availability Kubernetes clusters with SealOS!
The Origin and Motivation Behind the Pigsty Project, Its Historical Development, and Future Goals and Visions.
Origin Story
The Pigsty project kicked off between 2018 and 2019, originating from Tantan, a dating app akin to China’s Tinder, now acquired by Momo. Tantan, a startup with a Nordic vibe, was founded by a team of Swedish engineers. Renowned for their tech sophistication, they chose PostgreSQL and Go as their core tech stack. Tantan’s architecture, inspired by Instagram, revolves around PostgreSQL. They managed to scale to millions of daily active users, millions of TPS, and hundreds of TBs of data using PostgreSQL exclusively. Almost all business logic was implemented using PG stored procedures, including recommendation algorithms with 100ms latency!
This unconventional development approach, deeply leveraging PostgreSQL features, demanded exceptional engineering and DBA skills. Pigsty emerged from these real-world, high-standard database cluster scenarios as an open-source project encapsulating our top-tier PostgreSQL expertise and best practices.
Dev Journey
Initially, Pigsty didn’t have the vision, objectives, or scope it has today. It was meant to be a PostgreSQL monitoring system for our use. After evaluating every available option—open-source, commercial, cloud-based, datadog, pgwatch,…… none met our observability bar. So, we took matters into our own hands, creating a system based on Grafana and Prometheus, which became the precursor to Pigsty. As a monitoring system, it was remarkably effective, solving countless management issues.
Eventually, developers wanted the same monitoring capabilities on their local dev machines. We used Ansible to write provisioning scripts, transitioning from a one-off setup to a reusable software. New features allowed users to quickly set up local DevBoxes or production servers with Vagrant and Terraform, automating PostgreSQL and monitoring system deployment through Infra as Code.
We then redesigned the production PostgreSQL architecture, introducing Patroni and pgBackRest for high availability and point-in-time recovery. We developed a zero-downtime migration strategy based on logical replication, performing rolling updates across 200 database clusters to the latest major version using blue-green deployments. These capabilities were integrated into Pigsty.
Pigsty, built for our use, reflects our understanding of our needs, avoiding shortcuts. The greatest benefit of “eating our own dog food” is being both developers and users, deeply understanding and not compromising on our requirements.
We tackled one problem after another, incorporating solutions into Pigsty. Its role evolved from a monitoring system to a ready-to-use PostgreSQL distribution. At this stage, we decided to open-source Pigsty, initiating a series of technical talks and promotions, attracting feedback from users across various industries.
Full-time Startup
In 2022, Pigsty secured seed funding from Dr. Qi’s MiraclePlus S22 (Former YC China), enabling me to work on it full-time. As an open-source project, Pigsty has thrived. In the two years since going full-time, its GitHub stars skyrocketed from a few hundred to 2400, On OSSRank, Pigsty ranks 37th among PostgreSQL ecosystem projects.
Originally only compatible with CentOS7, Pigsty now supports all major Linux Distors and PostgreSQL versions 12 - 16, integrating over 400 extensions from the ecosystem. I’ve personally compiled, packaged, and maintained some extensions not found in official PGDG repositories.
Pigsty’s identity has evolved from a PostgreSQL distribution to an open-source cloud database alternative, directly competing with entire cloud database services offered by cloud providers.
Cloud Rebel
Public cloud vendors like AWS, Azure, GCP, and Aliyun offer many conveniences to startups but are proprietary and lock users into high-cost infra rentals.
We believe that top-notch database services should be as accessible same as top-notch database kernel (PostgreSQL), not confined to costly rentals from cyber lords.
Cloud agility and elasticity are great, but it should be open-source, local-first and cheap enough.
We envision a cloud computing universe with an open-source solution, returning the control to users without sacrificing the benefits of the cloud.
Thus, we’re leading the “cloud-exit” movement in China, rebelling against public cloud norms to reshape industry values.
Our Vision
We’d like to see a world where everyone has the factual right to use top services freely, not just view the world from the pens provided by a few public cloud providers.
This is what Pigsty aims to achieve —— a superior, open-source, free RDS alternative. Enabling users to deploy a database service better than cloud RDS with just one click, anywhere (including on cloud servers).
Pigsty is a comprehensive enhancement for PostgreSQL and a spicy satire on cloud RDS. We offer “the Simple Data Stack”, which consists of PostgreSQL, Redis, MinIO, and more optional modules.
Pigsty is entirely open-source and free, sustained through consulting and sponsorship. A well-built system might run for years without issues, but when database problems arise, they’re serious. Often, expert advice can turn a dire situation around, and we offer such services to clients in need—a fairer and more rational model.
About Me
I’m Feng Ruohang, the creator of Pigsty. I’ve developed most of Pigsty’s code solo, with the community contributing specific features.
Unique individuals create unique works —— I hope Pigsty can be one of those creations.
If you are interested in the author, here’s my personal website: https://vonng.com/en/
2.5 - Event & News
Latest activity, event, and news about Pigsty and PostgreSQL.
Latest News
Pigsty 3.4.1 Released
Pigsty v3.4.1 Released! OpenHalo & OrioleDB, MySQL compatibility, pgAdmin improvements
The name of this project always makes me grin: PIGSTY is actually an acronym, standing for Postgres In Great STYle! It’s a Postgres distribution that includes lots of components and tools out of the box in areas like availability, deployment, and observability. The latest release pushes everything up to Postgres 16.2 standards and introduces new ParadeDB and DuckDB FDW extensions.
Pigsty is Build in Public. We have active community in GitHub
The Pigsty community already offers free WeChat/Discord/Telegram Q&A Office Hours, and we are also happy to provide more free value-added services to our supporters.
When having troubles with pigsty. You can ask the community for help, with enough info & context, here’s a template:
What happened? (REQUIRED)
Pigsty Version & OS Version (REQUIRED)
$ grep version pigsty.yml
$ cat /etc/os-release
If you are using a cloud provider, please tell us which cloud provider and what operating system image you are using.
If you have customized and modified the environment after installing the bare OS, or have specific security rules and firewall configurations in your WAN, please also tell us when troubleshooting.
Pigsty Config File (REQUIRED)
Don’t forget to remove sensitive information like passwords, etc…
cat ~/pigsty/pigsty.yml
What did you expect to happen?
Please describe what you expected to happen.
How to reproduce it?
Please tell us as much detail as possible about how to reproduce the problem.
Monitoring Screenshots
If you are using pigsty monitoring system, you can paste RELEVANT screenshots here.
Error Log
Please copy and paste any RELEVANT log output. Do not paste something like “Failed to start xxx service”
Syslog: /var/log/messages (rhel) or /var/log/syslog (debian)
The more information and context you provide, the more likely we are to be able to help you solve the problem.
2.7 - License
Pigsty is open sourced under AGPLv3, here’s the details about permissions, limitations, conditions and exemptions.
Pigsty is open sourced under the AGPLv3 license, which is a copyleft license.
Summary
Pigsty use the AGPLv3 license,
which is a strong copyleft license that requires you to also distribute the source code of your derivative works under the same license.
If you distribute Pigsty, you must make the source code available under the same license, and you must make it clear that the source code is available.
Permissions:
Commercial use
Modification
Distribution
Patent use
Private use
Limitations:
Liability
Warranty
Conditions:
License and copyright notice
State changes
Disclose source
Network use is distribution
Same license
Beware that the Pigsty website itself (this website) is not open sourced yet.
Exemptions
While employing the AGPLv3 license for Pigsty, we extend exemptions to common end users under terms akin to the Apache 2.0 license.
Common end users are defined as all entities except public cloud and database service vendors.
These end users may utilize Pigsty for commercial activities and service provision without AGPL licensing concerns
Our subscription include written guarantees of these terms for additional assurance.
We encourage cloud & databases vendors adhering to AGPLv3 to use Pigsty for derivative works and to contribute back to the community.
Why AGPLv3
We don’t like the idea that public cloud vendors take open-source code, provide as-a-service,
and not give back equally (there controller) to the community. This is a vulnerability in the GPL license that AGPLv3 was designed to close.
The AGPLv3 does not affect regular end users: using Pigsty internally is not “distributing” it,
so you don’t have to worry about whether your business code needs to be open-sourced. If you do worry about it, you can always choose the pro version with written guarantees.
Wile you only need to consider AGPLv3 when you “distribute” Pigsty or modifications to it as part of a software/service offering. Such as database/software/cloud vendors who provide Pigsty as a service or part of their software to their customers.
Sponsors and Investors of Pigsty, Thank You for Your Support of This Project!
Investor
Pigsty is funded by MiraclePlus (formal YC China), S22 Batch.
Thanks to MiraclePlus and Dr.Qi’s support.
Sponsorship
Pigsty is a free & open-source software nurtured by the passion of PostgreSQL community members.
If our work has helped you, please consider sponsoring or supporting our project. Every penny counts, and advertisements are also a form of support:
Make Donation & Sponsor us.
Share your experiences and use cases of Pigsty through articles, lectures, and videos.
Allow us to mention your organization in “These users who use Pigsty”
Nominate/Recommend our project and services to your friends, colleagues, and clients in need.
Follow our WeChat Column and share technical articles with your friends.
2.9 - Privacy Policy
How we process your data & protect your privacy in this website and pigsty’s software.
Pigsty Software
When you install the Pigsty software, if you use offline packages in a network-isolated environment, we will not receive any data about you.
If you choose to install online, then when downloading relevant software packages, our server or the servers of our cloud providers will automatically log the visiting machine’s IP address and/or hostname, as well as the name of the software package you downloaded, in the logs.
We will not share this information with other organizations unless legally required to do so.
When you visit our website, our servers automatically log your IP address and/or host name.
We store information such as your email address, name and locality only if you decide to send us such information by completing a survey, or registering as a user on one of our sites
We collect this information to help us improve the content of our sites, customize the layout of our web pages and to contact people for technical and support purposes. We will not share your email address with other organisations unless required by law.
This website uses Google Analytics, a web analytics service provided by Google, Inc. (“Google”). Google Analytics uses “cookies”, which are text files placed on your computer, to help the website analyze how users use the site.
The information generated by the cookie about your use of the website (including your IP address) will be transmitted to and stored by Google on servers in the United States. Google will use this information for the purpose of evaluating your use of the website, compiling reports on website activity for website operators and providing other services relating to website activity and internet usage. Google may also transfer this information to third parties where required to do so by law, or where such third parties process the information on Google’s behalf. Google will not associate your IP address with any other data held by Google. You may refuse the use of cookies by selecting the appropriate settings on your browser, however please note that if you do this you may not be able to use the full functionality of this website. By using this website, you consent to the processing of data about you by Google in the manner and for the purposes set out above.
If you have any questions or comments around this policy, or to request the deletion of personal data, you can contact us at [email protected]
2.10 - Service
Pigsty offers professional support services & consulting to address your PostgreSQL needs!
Pigsty aims to consolidate the strengths of the PostgreSQL ecosystem and replace manual database operations with automated database controller software, helping users maximize the benefits of PostgreSQL.
We understand the importance of professional support services for enterprise customers, so we provide commercial subscription plans to help users leverage PostgreSQL and Pigsty more effectively.
Consider our subscription if you need:
Backup and support for Pigsty and PostgreSQL-related issues
Strict SLA guarantees for critical database environments
Guidance on PostgreSQL/Pigsty best practices for production
Expert analysis of monitoring data and performance bottlenecks
Post-mortem analysis to identify root causes of failures
Database architecture planning that meets security, disaster recovery, and compliance requirements
Migration assistance from other databases to PostgreSQL
Development of observability systems and dashboards based on Prometheus/Grafana
A cloud-neutral, vendor-lock-in-free alternative to RDS
Professional technical support for Redis/ETCD/MinIO/Greenplum/Citus/TimescaleDB
Written AGPLv3 license exemptions for open-source derivative works
Ability to offer Pigsty as SaaS/PaaS/DBaaS or redistribute it as a commercial product
Subscription
In addition to the open-source version, Pigsty offers 3 subscription plans: Standard, Professional and Enterprise.
You can choose the appropriate subscription plan based on your actual situation and needs.
The number of nodes is defined as the total number of independent IP addresses that exist as Hosts in the config inventory of a Pigsty deployment, i.e., the total number of nodes managed by Pigsty.
Pigsty is built on open source and also gives back to the open source community. It is a gift to the PostgreSQL community and all users — you can obtain the complete core functionality of Pigsty without any payment.
Of course, as is typical with open-source software, the Pigsty Open Source Edition does not offer any warranty service and bears no responsibility for any consequences arising from its use. If you require a warranty, please consider our subscription services.
The Pigsty Open Source Edition is released under the AGPLv3 license, which is a copyleft, strict open-source license.
If you are an ordinary end user (i.e., users other than public cloud vendors or database vendors), we will not pursue any action against your secondary development of Pigsty.
In practice, it is effectively licensed under the more permissive Apache 2.0 license for most end users.
If you discover any defects in Pigsty, we highly encourage you to submit an Issue on GitHub to help us improve.
If you have any questions, you can seek help in the Community.
For the open-source version, we provide prebuilt standard offline packages for PostgreSQL 17 on three precisely targeted OS distributions—EL 9.4, Debian 12.7, Ubuntu 22.04.5—
with the latest minor versions (as a form of open-source support, aarch64 offline packages are also provided for Debian 12).
By using the Pigsty Open Source Edition, entry-level developers and DevOps engineers can access 70%+ of the capabilities of a professional DBA.
Even without a dedicated database expert, you can easily set up a high-availability, high-performance, easy-to-maintain, secure, and reliable PostgreSQL database cluster.
If self-hosted in the cloud, you can immediately save on the price difference between EC2/ESSD and RDS services, achieving significant cost reductions up to 90+%.
Code
Distro Maojr
Minor
x86_64
aarch64
PG17
PG16
PG15
PG14
PG13
EL9
RHEL 9 / Rocky9 / Alma9
9.4
el9.x86_64
el9.aarch64
D12
Debian 12 (bookworm)
12.7
d12.x86_64
d12.aarch64
U22
Ubuntu 22.04 (jammy)
22.04.5
u22.x86_64
u22.aarch64
= Primary Support; = Unavailable; = Available, DIY without Support
Pigsty Standard
Economical choice for SMBs, startups, and freelancers
The Pigsty Standard subscription provides an affordable safety net for small and medium businesses—we offer warranty and support coverage for the Pigsty software itself.
The Standard subscription uses a dedicated commercial license, delivering a written contractual commitment that waives the AGPLv3 derived work open-source obligations of Pigsty.
We provide a one-time architectural consultation service to Standard subscription customers. Based on your environment and available resources, we will propose a suitable database architecture design.
Whether you want to use PostgreSQL to build a business system or self-host Odoo, Dify, Supabase, Gitlab, or other applications, we can provide comprehensive support, including offline installation and network solutions.
The Pigsty Standard subscription includes basic expert ticketing and Q&A services. We commit to responding to your questions within working hours.
For more complex issues requiring additional support, our expert support (man-day) service is also available for purchase.
Our PostgreSQL expertise can help you avoid numerous pitfalls, saving you time, effort, and costs.
For mainstream open-source Linux distributions (EL9, Debian 12, Ubuntu 22.04) at their latest stable minor versions, the Pigsty Standard subscription provides offline software installation packages for both x86_64 and aarch64.
These packages include the PostgreSQL 17 kernel and all available extensions, tested to ensure quick, stable, and efficient installation with consistent versions, independent of network environment and upstream repository changes.
The starting price for Pigsty Standard is 8,000 $ / year, roughly equivalent to the annual fee for 4 vCPUs of AWS HA RDS PG or the salary of an intern with a monthly wage of $600.
Code
Distro Maojr
Minor
x86_64
aarch64
PG17
PG16
PG15
PG14
PG13
EL9
RHEL 9 / Rocky9 / Alma9
9.4
el9.x86_64
el9.aarch64
D12
Debian 12 (bookworm)
12.7
d12.x86_64
d12.aarch64
U22
Ubuntu 22.04 (jammy)
22.04.5
u22.x86_64
u22.aarch64
Pigsty Professional
Suitable choice for typical enterprise users
The Pigsty Professional subscription builds upon the Standard offering with more advanced consultation services.
The Professional subscription includes analysis of complex issues and performance bottleneck optimization, ensuring you can access top-level DBA expertise at critical moments.
We provide comprehensive architectural consultation for Professional subscription customers. Based on your business needs and resource availability, we develop the optimal database architecture design and ensure its successful implementation.
We also assist with high availability testing and PITR exercises, and provide training on Pigsty’s monitoring system, configuration methods, and management commands.
The Pigsty Professional subscription offers enhanced support. We provide one expert man-day per year, along with monthly DBA consultation and Q&A not exceeding five hours.
We also offer a faster SLA response time: for routine questions, we guarantee a response within four hours during weekday working hours (5x8).
The Pigsty Professional subscription supports a broader range of operating systems, adding EL 8 and Ubuntu 24.04 to the list of supported distributions, and provides aarch64 support for all of these versions.
If you are not using the latest minor version, we can customize offline software packages for your specified minor version.
Moreover, the offline packages include all Pigsty feature modules, such as PG branch kernels (IvorySQL, PolarDB, Babelfish) and all Pro/Beta modules.
Pigsty Professional provides support for the three most recent major PostgreSQL releases (17, 16, 15), and offers expert guidance for PostgreSQL major version upgrades as well as Pigsty upgrades.
The starting price for Pigsty Professional is 24,000 $ / year, roughly equivalent to the annual fee for 11 vCPUs of AWS HA RDS PG, or the annual salary of a junior DevOps engineer with a monthly wage of $2,000.
Code
Distro Maojr
Minor
x86_64
aarch64
PG17
PG16
PG15
PG14
PG13
EL9
RHEL 9 / Rocky9 / Alma9
9.4
el9.x86_64
el9.aarch64
D12
Debian 12 (bookworm)
12.7
d12.x86_64
d12.aarch64
U22
Ubuntu 22.04 (jammy)
22.04.5
u22.x86_64
u22.aarch64
U24
Ubuntu 24.04 (noble)
24.04.5
u24.x86_64
u24.aarch64
EL8
RHEL 8 / Rocky8 / Alma8
8.10
el8.x86_64
el8.aarch64
Pigsty Enterprise
Designed for mission-critical scenarios
Pigsty Enterprise is designed for medium and large enterprises or mission-critical scenarios requiring strict SLAs.
With the Enterprise subscription, we offer the highest level of support to meet all your database needs.
Under the Enterprise subscription, we help you design and implement the optimal database architecture solution. Beyond database drills, stress tests, and performance evaluations,
we also provide consultancy and training on management systems, helping you build a comprehensive database management framework that meets various security and compliance requirements.
Pigsty Enterprise includes two expert man-days per year, plus monthly DBA consultation and Q&A of up to 10 hours.
For routine issues, we guarantee a response within 30 minutes, 7x24, and always prioritize your requests.
The Pigsty Enterprise subscription offers the widest range of OS support, adding EL7, Debian 11, and Ubuntu 20.04, including EOL releases.
We can also customize support for Euler, Anolis, UOS, Kylin, TencentOS, AliOS, OpenCloudOS, and other Linux distributions.
The Pigsty Enterprise subscription covers all PostgreSQL major releases (13–17) within their active lifecycles, ensuring smooth in-place upgrades across different major versions.
Using the included man-days, you can migrate your PostgreSQL clusters to the latest major version via a zero-downtime, blue-green deployment process.
Pigsty Enterprise permits usage of Pigsty as DBaaS at a specified scale, allowing you to build and sell cloud database services.
It also allows OEM use—you may distribute Pigsty with your own logo, trademarks, and branding within the agreed scope.
The starting price for Pigsty Enterprise is 60,000 $ / year, which is equivalent to 27 vCPUs of AWS RDS for PostgreSQL, or a developer with a monthly salary of $5,000.
Code
Distro Maojr
Minor
x86_64
aarch64
PG17
PG16
PG15
PG14
PG13
EL9
RHEL 9 / Rocky9 / Alma9
9.4
el9.x86_64
el9.aarch64
D12
Debian 12 (bookworm)
12.7
d12.x86_64
d12.aarch64
U22
Ubuntu 22.04 (jammy)
22.04.5
u22.x86_64
u22.aarch64
U24
Ubuntu 24.04 (noble)
24.04.5
u24.x86_64
u24.aarch64
EL8
RHEL 8 … / Anolis8
8.10
el8.x86_64
el8.aarch64
EL7
RHEL 7 … / UOS / Euler
7.9
el7.x86_64
el7.aarch64
D11
Debian 11 (bullseye)
11.11
d11.x86_64
d11.aarch64
U20
Ubuntu 20.04 (focal)
20.04.6
u20.x86_64
u20.aarch64
Pricing
Pigsty subscriptions are annual, beginning on the agreed date. Payment before expiration implies automatic renewal.
Continuous subscriptions receive discounts: 5% off the second year, 10% off subsequent years, and 15% off for three-year commitments.
After subscription expiration, non-renewal results in cessation of updates, technical support, and consulting, though previously installed Pro software remains usable.
Non-renewal gaps do not require back payment upon re-subscription, but loyalty discounts are reset.
Pigsty’s pricing delivers exceptional value—providing immediate access to top-tier DBA expertise and database management practices at a cost that compares favorably to
hiring full-time experts or using cloud database services. For reference, market prices for comparable enterprise database services include:
AWS RDS for PostgreSQL HA: $160 – $220 / (vCPU·month), equivalent to $1,920 - $2,640/year (per vCPU).
ETCD: Distributed key-value store will be used as DCS for high-available Postgres clusters.
REDIS: Redis servers in standalone master-replica, sentinel, cluster mode with Redis exporter.
MINIO: S3 compatible simple object storage server, can be used as an optional backup center for Postgres.
You can compose them freely in a declarative manner. If you want host monitoring, INFRA & NODE will suffice. Add additional ETCD and PGSQL are used for HA PG Clusters. Deploying them on multiple nodes will form a ha cluster. You can reuse pigsty infra and develop your modules, considering optional REDIS and MINIO as examples.
Singleton Meta
Pigsty will install on a single node (BareMetal / VirtualMachine) by default. The install.yml playbook will install INFRA, ETCD, PGSQL, and optional MINIO modules on the current node, which will give you a full-featured observability infrastructure (Prometheus, Grafana, Loki, AlertManager, PushGateway, BlackboxExporter, etc… ) and a battery-included PostgreSQL Singleton Instance (Named meta).
This node now has a self-monitoring system, visualization toolsets, and a Postgres database with autoconfigured PITR. You can use this node for devbox, testing, running demos, and doing data visualization & analysis. Or, furthermore, adding more nodes to it!
Monitoring
The installed Singleton Meta can be use as an admin node and monitoring center, to take more nodes & Database servers under it’s surveillance & control.
If you want to install the Prometheus / Grafana observability stack, Pigsty just deliver the best practice for you! It has fine-grained dashboards for Nodes & PostgreSQL, no matter these nodes or PostgreSQL servers are managed by Pigsty or not, you can have a production-grade monitoring & alerting immediately with simple configuration.
HA PG Cluster
With Pigsty, you can have your own local production-grade HA PostgreSQL RDS as much as you want.
And to create such a HA PostgreSQL cluster, All you have to do is describe it & run the playbook:
Which will gives you a following cluster with monitoring , replica, backup all set.
Hardware failures are covered by self-healing HA architecture powered by patroni, etcd, and haproxy, which will perform auto failover in case of leader failure under 30 seconds. With the self-healing traffic control powered by haproxy, the client may not even notice there’s a failure at all, in case of a switchover or replica failure.
Software Failures, human errors, and DC Failure are covered by pgbackrest, and optional MinIO clusters. Which gives you the ability to perform point-in-time recovery to anytime (as long as your storage is capable)
Database as Code
Pigsty follows IaC & GitOPS philosophy: Pigsty deployment is described by declarative Config Inventory and materialized with idempotent playbooks.
The user describes the desired status with Parameters in a declarative manner, and the playbooks tune target nodes into that status in an idempotent manner. It’s like Kubernetes CRD & Operator but works on Bare Metals & Virtual Machines.
Take the default config snippet as an example, which describes a node 10.10.10.10 with modules INFRA, NODE, ETCD, and PGSQL installed.
# infra cluster for proxy, monitor, alert, etc...infra:{hosts:{10.10.10.10:{infra_seq:1}}}# minio cluster, s3 compatible object storageminio:{hosts:{10.10.10.10:{minio_seq: 1 } }, vars:{minio_cluster:minio } }# etcd cluster for ha postgres DCSetcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }# postgres example cluster: pg-metapg-meta:{hosts:{10.10.10.10:{pg_seq: 1, pg_role: primary }, vars:{pg_cluster:pg-meta } }
To materialize it, use the following playbooks:
./infra.yml -l infra # init infra module on group 'infra'./etcd.yml -l etcd # init etcd module on group 'etcd'./minio.yml -l minio # init minio module on group 'minio'./pgsql.yml -l pg-meta # init pgsql module on group 'pgsql'
It would be straightforward to perform regular administration tasks. For example, if you wish to add a new replica/database/user to an existing HA PostgreSQL cluster, all you need to do is add a host in config & run that playbook on it, such as:
Pigsty abstracts different types of functionalities into modules & clusters.
PGSQL for production environments is organized in clusters, which clusters are logical entities consisting of a set of database instances associated by primary-replica.
Each database cluster is an autonomous serving unit consisting of at least one database instance (primary).
ER Diagram
Let’s get started with ER diagram. There are four types of core entities in Pigsty’s PGSQL module:
PGSQL Cluster: An autonomous PostgreSQL business unit, used as the top-level namespace for other entities.
PGSQL Service: A named abstraction of cluster ability, route traffics, and expose postgres services with node ports.
PGSQL Instance: A single postgres server which is a group of running processes & database files on a single node.
PGSQL Node: An abstraction of hardware resources, which can be bare metal, virtual machine, or even k8s pods.
Naming Convention
The cluster name should be a valid domain name, without any dot: [a-zA-Z0-9-]+
Service name should be prefixed with cluster name, and suffixed with a single word: such as primary, replica, offline, delayed, join by -
Instance name is prefixed with cluster name and suffixed with an integer, join by -, e.g., ${cluster}-${seq}.
Node is identified by its IP address, and its hostname is usually the same as the instance name since they are 1:1 deployed.
Identity Parameter
Pigsty uses identity parameters to identify entities: PG_ID.
In addition to the node IP address, three parameters: pg_cluster, pg_role, and pg_seq are the minimum set of parameters necessary to define a postgres cluster.
Take the sandbox testing cluster pg-test as an example:
The architecture and implementation of Pigsty’s monitoring system, the service discovery details
3.4 - Self-Signed CA
Pigsty comes with a set of self-signed CA PKI for issuing SSL certs to encrypt network traffic.
Pigsty has some security best practices: encrypting network traffic with SSL and encrypting the Web interface with HTTPS.
To achieve this, Pigsty comes with a built-in local self-signed Certificate Authority (CA) for issuing SSL certificates to encrypt network communication.
By default, SSL and HTTPS are enabled but not enforced. For environments with higher security requirements, you can enforce the use of SSL and HTTPS.
Local CA
Pigsty, by default, generates a self-signed CA in the Pigsty source code directory (~/pigsty) on the ADMIN node during initialization. This CA is used when SSL, HTTPS, digital signatures, issuing database client certificates, and advanced security features are needed.
Hence, each Pigsty deployment uses a unique CA, and CAs from different Pigsty deployments do not trust each other.
The local CA consists of two files, typically located in the files/pki/ca directory:
ca.crt: The self-signed root CA certificate, which should be distributed and installed on all managed nodes for certificate verification.
ca.key: The CA private key, used to issue certificates and verify CA identity. It should be securely stored to prevent leaks!
Protect Your CA Private Key File
Please securely store the CA private key file, do not lose it or let it leak. We recommend encrypting and backing up this file after completing the Pigsty installation.
Using an Existing CA
If you already have a CA public and private key infrastructure, Pigsty can also be configured to use an existing CA.
Simply place your CA public and private key files in the files/pki/ca directory.
files/pki/ca/ca.key # The essential CA private key file, must exist; if not, a new one will be randomly generated by defaultfiles/pki/ca/ca.crt # If a certificate file is absent, Pigsty will automatically generate a new root certificate file from the CA private key
When Pigsty executes the install.yml and infra.yml playbooks for installation, if the ca.key private key file is found in the files/pki/ca directory, the existing CA will be used. The ca.crt file can be generated from the ca.key private key, so if there is no certificate file, Pigsty will automatically generate a new root certificate file from the CA private key.
Note When Using an Existing CA
You can configure the ca_method parameter as copy to ensure that Pigsty reports an error and halts if it cannot find the local CA, rather than automatically regenerating a new self-signed CA.
Trust CA
During the Pigsty installation, ca.crt is distributed to all nodes under the /etc/pki/ca.crt path during the node_ca task in the node.yml playbook.
The default paths for trusted CA root certificates differ between EL family and Debian family operating systems, hence the distribution path and update methods also vary.
By default, Pigsty will issue HTTPS certificates for domain names used by web systems on infrastructure nodes, allowing you to access Pigsty’s web systems via HTTPS.
If you do not want your browser on the client computer to display “untrusted CA certificate” messages, you can distribute ca.crt to the trusted certificate directory on the client computer.
You can double-click the ca.crt file to add it to the system keychain, for example, on macOS systems, you need to open “Keychain Access,” search for pigsty-ca, and then “trust” this root certificate.
Check Cert
Use the following command to view the contents of the Pigsty CA certificate
openssl x509 -text -in /etc/pki/ca.crt
Local CA Root Cert Content
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
50:29:e3:60:96:93:f4:85:14:fe:44:81:73:b5:e1:09:2a:a8:5c:0a
Signature Algorithm: sha256WithRSAEncryption
Issuer: O=pigsty, OU=ca, CN=pigsty-ca
Validity
Not Before: Feb 7 00:56:27 2023 GMT
Not After : Jan 14 00:56:27 2123 GMT
Subject: O=pigsty, OU=ca, CN=pigsty-ca
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
Modulus:
00:c1:41:74:4f:28:c3:3c:2b:13:a2:37:05:87:31:
....
e6:bd:69:a5:5b:e3:b4:c0:65:09:6e:84:14:e9:eb:
90:f7:61
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Alternative Name:
DNS:pigsty-ca
X509v3 Key Usage:
Digital Signature, Certificate Sign, CRL Sign
X509v3 Basic Constraints: critical
CA:TRUE, pathlen:1
X509v3 Subject Key Identifier:
C5:F6:23:CE:BA:F3:96:F6:4B:48:A5:B1:CD:D4:FA:2B:BD:6F:A6:9C
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
89:9d:21:35:59:6b:2c:9b:c7:6d:26:5b:a9:49:80:93:81:18:
....
9e:dd:87:88:0d:c4:29:9e
-----BEGIN CERTIFICATE-----
...
cXyWAYcvfPae3YeIDcQpng==
-----END CERTIFICATE-----
Issue Database Client Certs
If you wish to authenticate via client certificates, you can manually issue PostgreSQL client certificates using the local CA and the cert.yml playbook.
Set the certificate’s CN field to the database username:
The issued certificates will default to being generated in the files/pki/misc/<cn>.{key,crt} path.
3.5 - Infra as Code
Pigsty treat infra & database as code. Manage them in a declarative manner
Infra as Code, Database as Code, Declarative API & Idempotent Playbooks, GitOPS works like a charm.
Pigsty provides a declarative interface: Describe everything in a config file,
and Pigsty operates it to the desired state with idempotent playbooks.
It works like Kubernetes CRDs & Operators but for databases and infrastructures on any nodes: bare metal or virtual machines.
Declare Module
Take the default config snippet as an example, which describes a node 10.10.10.10 with modules INFRA, NODE, ETCD, and PGSQL installed.
# infra cluster for proxy, monitor, alert, etc...infra:{hosts:{10.10.10.10:{infra_seq:1}}}# minio cluster, s3 compatible object storageminio:{hosts:{10.10.10.10:{minio_seq: 1 } }, vars:{minio_cluster:minio } }# etcd cluster for ha postgres DCSetcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }# postgres example cluster: pg-metapg-meta:{hosts:{10.10.10.10:{pg_seq: 1, pg_role: primary }, vars:{pg_cluster:pg-meta } }
To materialize it, use the following playbooks:
./infra.yml -l infra # init infra module on node 10.10.10.10./etcd.yml -l etcd # init etcd module on node 10.10.10.10./minio.yml -l minio # init minio module on node 10.10.10.10./pgsql.yml -l pg-meta # init pgsql module on node 10.10.10.10
Declare Cluster
You can declare the PGSQL module on multiple nodes, and form a cluster.
For example, to create a three-node HA cluster based on streaming replication, just adding the following definition to the all.children section of the config file pigsty.yml:
You can deploy different kinds of instance roles such as
primary, replica, offline, delayed, sync standby, and different kinds of clusters, such as standby clusters, Citus clusters, and even Redis / MinIO / Etcd clusters.
Declare Cluster Internal
Not only can you define clusters in a declarative manner, but you can also specify the databases, users, services, and HBA rules within the cluster. For example, the following configuration file deeply customizes the content of the default pg-meta single-node database cluster:
This includes declaring six business databases and seven business users, adding an additional standby service (a synchronous replica providing read capabilities with no replication delay), defining some extra pg_hba rules, an L2 VIP address pointing to the cluster’s primary database, and a customized backup strategy.
pg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role: primary , pg_offline_query:true}}vars:pg_cluster:pg-metapg_databases:# define business databases on this cluster, array of database definition- name:meta # REQUIRED, `name` is the only mandatory field of a database definitionbaseline:cmdb.sql # optional, database sql baseline path, (relative path among ansible search path, e.g files/)pgbouncer:true# optional, add this database to pgbouncer database list? true by defaultschemas:[pigsty] # optional, additional schemas to be created, array of schema namesextensions: # optional, additional extensions to be installed:array of `{name[,schema]}`- {name: postgis , schema:public }- {name:timescaledb }comment:pigsty meta database # optional, comment string for this databaseowner:postgres # optional, database owner, postgres by defaulttemplate:template1 # optional, which template to use, template1 by defaultencoding:UTF8 # optional, database encoding, UTF8 by default. (MUST same as template database)locale:C # optional, database locale, C by default. (MUST same as template database)lc_collate:C # optional, database collate, C by default. (MUST same as template database)lc_ctype:C # optional, database ctype, C by default. (MUST same as template database)tablespace:pg_default # optional, default tablespace, 'pg_default' by default.allowconn:true# optional, allow connection, true by default. false will disable connect at allrevokeconn:false# optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)register_datasource:true# optional, register this database to grafana datasources? true by defaultconnlimit:-1# optional, database connection limit, default -1 disable limitpool_auth_user:dbuser_meta # optional, all connection to this pgbouncer database will be authenticated by this userpool_mode:transaction # optional, pgbouncer pool mode at database level, default transactionpool_size:64# optional, pgbouncer pool size at database level, default 64pool_size_reserve:32# optional, pgbouncer pool size reserve at database level, default 32pool_size_min:0# optional, pgbouncer pool size min at database level, default 0pool_max_db_conn:100# optional, max database connections at database level, default 100- {name: grafana ,owner: dbuser_grafana ,revokeconn: true ,comment:grafana primary database }- {name: bytebase ,owner: dbuser_bytebase ,revokeconn: true ,comment:bytebase primary database }- {name: kong ,owner: dbuser_kong ,revokeconn: true ,comment:kong the api gateway database }- {name: gitea ,owner: dbuser_gitea ,revokeconn: true ,comment:gitea meta database }- {name: wiki ,owner: dbuser_wiki ,revokeconn: true ,comment:wiki meta database }pg_users:# define business users/roles on this cluster, array of user definition- name:dbuser_meta # REQUIRED, `name` is the only mandatory field of a user definitionpassword:DBUser.Meta # optional, password, can be a scram-sha-256 hash string or plain textlogin:true# optional, can log in, true by default (new biz ROLE should be false)superuser:false# optional, is superuser? false by defaultcreatedb:false# optional, can create database? false by defaultcreaterole:false# optional, can create role? false by defaultinherit:true# optional, can this role use inherited privileges? true by defaultreplication:false# optional, can this role do replication? false by defaultbypassrls:false# optional, can this role bypass row level security? false by defaultpgbouncer:true# optional, add this user to pgbouncer user-list? false by default (production user should be true explicitly)connlimit:-1# optional, user connection limit, default -1 disable limitexpire_in:3650# optional, now + n days when this role is expired (OVERWRITE expire_at)expire_at:'2030-12-31'# optional, YYYY-MM-DD 'timestamp' when this role is expired (OVERWRITTEN by expire_in)comment:pigsty admin user # optional, comment string for this user/roleroles: [dbrole_admin] # optional, belonged roles. default roles are:dbrole_{admin,readonly,readwrite,offline}parameters:{}# optional, role level parameters with `ALTER ROLE SET`pool_mode:transaction # optional, pgbouncer pool mode at user level, transaction by defaultpool_connlimit:-1# optional, max database connections at user level, default -1 disable limit- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly], comment:read-only viewer for meta database}- {name: dbuser_grafana ,password: DBUser.Grafana ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for grafana database }- {name: dbuser_bytebase ,password: DBUser.Bytebase ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for bytebase database }- {name: dbuser_kong ,password: DBUser.Kong ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for kong api gateway }- {name: dbuser_gitea ,password: DBUser.Gitea ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for gitea service }- {name: dbuser_wiki ,password: DBUser.Wiki ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for wiki.js service }pg_services:# extra services in addition to pg_default_services, array of service definition# standby service will route {ip|name}:5435 to sync replica's pgbouncer (5435->6432 standby)- name: standby # required, service name, the actual svc name will be prefixed with `pg_cluster`, e.g:pg-meta-standbyport:5435# required, service exposed port (work as kubernetes service node port mode)ip:"*"# optional, service bind ip address, `*` for all ip by defaultselector:"[]"# required, service member selector, use JMESPath to filter inventorydest:default # optional, destination port, default|postgres|pgbouncer|<port_number>, 'default' by defaultcheck:/sync # optional, health check url path, / by defaultbackup:"[? pg_role == `primary`]"# backup server selectormaxconn:3000# optional, max allowed front-end connectionbalance: roundrobin # optional, haproxy load balance algorithm (roundrobin by default, other:leastconn)options:'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'pg_hba_rules:- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}pg_vip_enabled:truepg_vip_address:10.10.10.2/24pg_vip_interface:eth1node_crontab:# make a full backup 1 am everyday- '00 01 * * * postgres /pg/bin/pg-backup full'
Declare Access Control
You can also deeply customize Pigsty’s access control capabilities through declarative configuration. For example, the following configuration file provides deep security customization for the pg-meta cluster:
Utilizes a three-node core cluster template: crit.yml, to ensure data consistency is prioritized, with zero data loss during failover.
Enables L2 VIP, and restricts the database and connection pool listening addresses to three specific addresses: local loopback IP, internal network IP, and VIP.
The template mandatorily enables SSL API for Patroni and SSL for Pgbouncer, and in the HBA rules, it enforces SSL usage for accessing the database cluster.
Additionally, the $libdir/passwordcheck extension is enabled in pg_libs to enforce a password strength security policy.
Lastly, a separate pg-meta-delay cluster is declared as a delayed replica of pg-meta from one hour ago, for use in emergency data deletion recovery.
pg-meta:# 3 instance postgres cluster `pg-meta`hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }10.10.10.11:{pg_seq: 2, pg_role:replica }10.10.10.12:{pg_seq: 3, pg_role: replica , pg_offline_query:true}vars:pg_cluster:pg-metapg_conf:crit.ymlpg_users:- {name: dbuser_meta , password: DBUser.Meta , pgbouncer: true , roles: [ dbrole_admin ] , comment:pigsty admin user }- {name: dbuser_view , password: DBUser.Viewer , pgbouncer: true , roles: [ dbrole_readonly ] , comment:read-only viewer for meta database }pg_databases:- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions:[{name: postgis, schema:public}, {name: timescaledb}]}pg_default_service_dest:postgrespg_services:- {name: standby ,src_ip:"*",port: 5435 , dest: default ,selector:"[]", backup:"[? pg_role == `primary`]"}pg_vip_enabled:truepg_vip_address:10.10.10.2/24pg_vip_interface:eth1pg_listen:'${ip},${vip},${lo}'patroni_ssl_enabled:truepgbouncer_sslmode:requirepgbackrest_method:miniopg_libs:'timescaledb, $libdir/passwordcheck, pg_stat_statements, auto_explain'# add passwordcheck extension to enforce strong passwordpg_default_roles:# default roles and users in postgres cluster- {name: dbrole_readonly ,login: false ,comment:role for global read-only access }- {name: dbrole_offline ,login: false ,comment:role for restricted read-only access }- {name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment:role for global read-write access }- {name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment:role for object creation }- {name: postgres ,superuser: true ,expire_in: 7300 ,comment:system superuser }- {name: replicator ,replication: true ,expire_in: 7300 ,roles: [pg_monitor, dbrole_readonly] ,comment:system replicator }- {name: dbuser_dba ,superuser: true ,expire_in: 7300 ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment:pgsql admin user }- {name: dbuser_monitor ,roles: [pg_monitor] ,expire_in: 7300 ,pgbouncer: true ,parameters:{log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment:pgsql monitor user }pg_default_hba_rules:# postgres host-based auth rules by default- {user:'${dbsu}',db: all ,addr: local ,auth: ident ,title:'dbsu access via local os user ident'}- {user:'${dbsu}',db: replication ,addr: local ,auth: ident ,title:'dbsu replication from local os ident'}- {user:'${repl}',db: replication ,addr: localhost ,auth: ssl ,title:'replicator replication from localhost'}- {user:'${repl}',db: replication ,addr: intra ,auth: ssl ,title:'replicator replication from intranet'}- {user:'${repl}',db: postgres ,addr: intra ,auth: ssl ,title:'replicator postgres db from intranet'}- {user:'${monitor}',db: all ,addr: localhost ,auth: pwd ,title:'monitor from localhost with password'}- {user:'${monitor}',db: all ,addr: infra ,auth: ssl ,title:'monitor from infra host with password'}- {user:'${admin}',db: all ,addr: infra ,auth: ssl ,title:'admin @ infra nodes with pwd & ssl'}- {user:'${admin}',db: all ,addr: world ,auth: cert ,title:'admin @ everywhere with ssl & cert'}- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: ssl ,title:'pgbouncer read/write via local socket'}- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: ssl ,title:'read/write biz user via password'}- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: ssl ,title:'allow etl offline tasks from intranet'}pgb_default_hba_rules:# pgbouncer host-based authentication rules- {user:'${dbsu}',db: pgbouncer ,addr: local ,auth: peer ,title:'dbsu local admin access with os ident'}- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title:'allow all user local access with pwd'}- {user:'${monitor}',db: pgbouncer ,addr: intra ,auth: ssl ,title:'monitor access via intranet with pwd'}- {user:'${monitor}',db: all ,addr: world ,auth: deny ,title:'reject all other monitor access addr'}- {user:'${admin}',db: all ,addr: intra ,auth: ssl ,title:'admin access via intranet with pwd'}- {user:'${admin}',db: all ,addr: world ,auth: deny ,title:'reject all other admin access addr'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'allow all user intra access with pwd'}# OPTIONAL delayed cluster for pg-metapg-meta-delay:# delayed instance for pg-meta (1 hour ago)hosts:{10.10.10.13:{pg_seq: 1, pg_role: primary, pg_upstream: 10.10.10.10, pg_delay:1h } }vars:{pg_cluster:pg-meta-delay }
Citus Distributive Cluster
Example: Citus Distributed Cluster: 5 Nodes
all:children:pg-citus0:# citus coordinator, pg_group = 0hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus0 , pg_group:0}pg-citus1:# citus data node 1hosts:{10.10.10.11:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus1 , pg_group:1}pg-citus2:# citus data node 2hosts:{10.10.10.12:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus2 , pg_group:2}pg-citus3:# citus data node 3, with an extra replicahosts:10.10.10.13:{pg_seq: 1, pg_role:primary }10.10.10.14:{pg_seq: 2, pg_role:replica }vars:{pg_cluster: pg-citus3 , pg_group:3}vars:# global parameters for all citus clusterspg_mode: citus # pgsql cluster mode:cituspg_shard: pg-citus # citus shard name:pg-cituspatroni_citus_db:meta # citus distributed database namepg_dbsu_password:DBUser.Postgres# all dbsu password access for citus clusterpg_libs:'citus, timescaledb, pg_stat_statements, auto_explain'# citus will be added by patroni automaticallypg_extensions:- postgis34_${ pg_version }* timescaledb-2-postgresql-${ pg_version }* pgvector_${ pg_version }* citus_${ pg_version }*pg_users:[{name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles:[dbrole_admin ] } ]pg_databases:[{name: meta ,extensions:[{name:citus }, { name: postgis }, { name: timescaledb } ] } ]pg_hba_rules:- {user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title:'all user ssl access from localhost'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'all user ssl access from intranet'}
etcd:# dcs service for postgres/patroni ha consensushosts:# 1 node for testing, 3 or 5 for production10.10.10.10:{etcd_seq:1}# etcd_seq required10.10.10.11:{etcd_seq:2}# assign from 1 ~ n10.10.10.12:{etcd_seq:3}# odd number pleasevars:# cluster level parameter override roles/etcdetcd_cluster:etcd # mark etcd cluster name etcdetcd_safeguard:false# safeguard against purgingetcd_clean:true# purge etcd during init process
MinIO Cluster
Example: Minio 3 Node Deployment
minio:hosts:10.10.10.10:{minio_seq:1}10.10.10.11:{minio_seq:2}10.10.10.12:{minio_seq:3}vars:minio_cluster:miniominio_data:'/data{1...2}'# use two disk per nodeminio_node:'${minio_cluster}-${minio_seq}.pigsty'# minio node name patternhaproxy_services:- name:minio # [REQUIRED] service name, uniqueport:9002# [REQUIRED] service port, uniqueoptions:- option httpchk- option http-keep-alive- http-check send meth OPTIONS uri /minio/health/live- http-check expect status 200servers:- {name: minio-1 ,ip: 10.10.10.10 , port: 9000 , options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-2 ,ip: 10.10.10.11 , port: 9000 , options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-3 ,ip: 10.10.10.12 , port: 9000 , options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}
3.6 - High Availability
Pigsty uses Patroni to achieve high availability for PostgreSQL, ensuring automatic failover.
Pigsty’s PostgreSQL cluster has battery-included high-availability powered by Patroni, Etcd, and HAProxy
When your have two or more instances in the PostgreSQL cluster, you have the ability to self-healing from hardware failures without any further configuration — as long as any instance within the cluster survives, the cluster can serve its services. Clients simply need to connect to any node in the cluster to obtain full services without worrying about replication topology changes.
By default, the recovery time objective (RTO) for primary failure is approximately 30s ~ 60s, and the data recovery point objective (RPO) is < 1MB; for standby failure, RPO = 0, RTO ≈ 0 (instantaneous). In consistency-first mode, zero data loss during failover is guaranteed: RPO = 0. These metrics can be configured as needed based on your actual hardware conditions and reliability requirements.
Pigsty incorporates an HAProxy load balancer for automatic traffic switching, offering multiple access methods for clients such as DNS/VIP/LVS. Failovers and switchover are almost imperceptible to the business side except for sporadic interruptions, meaning applications do not need connection string modifications or restarts.
What problems does High-Availability solve?
Elevates the availability aspect of data safety C/IA to a new height: RPO ≈ 0, RTO < 30s.
Enables seamless rolling maintenance capabilities, minimizing maintenance window requirements for great convenience.
Hardware failures can self-heal immediately without human intervention, allowing operations DBAs to sleep soundly.
Standbys can carry read-only requests, sharing the load with the primary to make full use of resources.
What are the costs of High Availability?
Infrastructure dependency: High availability relies on DCS (etcd/zk/consul) for consensus.
Increased entry barrier: A meaningful high-availability deployment environment requires at least three nodes.
Additional resource consumption: Each new standby consumes additional resources, which isn’t a major issue.
Since replication is real-time, all changes are immediately applied to the standby. Thus, high-availability solutions based on streaming replication cannot address human errors and software defects that cause data deletions or modifications. (e.g., DROP TABLE, or DELETE data)
Such failures require the use of Delayed Clusters or Point-In-Time Recovery using previous base backups and WAL archives.
Strategy
RTO (Time to Recover)
RPO (Max Data Loss)
Standalone + Do Nothing
Permanent data loss, irrecoverable
Total data loss
Standalone + Basic Backup
Depends on backup size and bandwidth (hours)
Loss of data since last backup (hours to days)
Standalone + Basic Backup + WAL Archiving
Depends on backup size and bandwidth (hours)
Loss of last unarchived data (tens of MB)
Primary-Replica + Manual Failover
Dozens of minutes
Replication Lag (about 100KB)
Primary-Replica + Auto Failover
Within a minute
Replication Lag (about 100KB)
Primary-Replica + Auto Failover + Synchronous Commit
Within a minute
No data loss
Implementation
In Pigsty, the high-availability architecture works as follows:
PostgreSQL uses standard streaming replication to set up physical standby databases. In case of a primary database failure, the standby takes over.
Patroni is responsible for managing PostgreSQL server processes and handles high-availability-related matters.
Etcd provides Distributed Configuration Store (DCS) capabilities and is used for leader election after a failure.
Patroni relies on Etcd to reach a consensus on cluster leadership and offers a health check interface to the outside.
HAProxy exposes cluster services externally and utilizes the Patroni health check interface to automatically route traffic to healthy nodes.
vip-manager offers an optional layer 2 VIP, retrieves leader information from Etcd, and binds the VIP to the node hosting the primary database.
Upon primary database failure, a new round of leader election is triggered. The healthiest standby in the cluster (with the highest LSN and least data loss) wins and is promoted to the new primary. After the promotion of the winning standby, read-write traffic is immediately routed to the new primary.
The impact of a primary failure is temporary unavailability of write services: from the primary’s failure to the promotion of a new primary, write requests will be blocked or directly fail, typically lasting 15 to 30 seconds, usually not exceeding 1 minute.
When a standby fails, read-only traffic is routed to other standbys. If all standbys fail, the primary will eventually carry the read-only traffic.
The impact of a standby failure is partial read-only query interruption: queries currently running on the failed standby will be aborted due to connection reset and immediately taken over by another available standby.
Failure detection is jointly completed by Patroni and Etcd. The cluster leader holds a lease,
if the cluster leader fails to renew the lease in time (10s) due to a failure, the lease will be released, triggering a failover and a new round of cluster elections.
Even without any failures, you can still proactively perform a Switchover to change the primary of the cluster. In this case, write queries on the primary will be interrupted and immediately routed to the new primary for execution. This operation can typically be used for rolling maintenance/upgrades of the database server.
Trade Offs
The ttl can be tuned with pg_rto, which is 30s by default, increasing it will cause longer failover wait time, while decreasing it will increase the false-positive failover rate (e.g. network jitter).
Pigsty will use availability first mode by default, which means when primary fails, it will try to failover ASAP, data not replicated to the replica may be lost (usually 100KB), and the max potential data loss is controlled by pg_rpo, which is 1MB by default.
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are two parameters that need careful consideration when designing a high-availability cluster.
The default values of RTO and RPO used by Pigsty meet the reliability requirements for most scenarios. You can adjust them based on your hardware level, network quality, and business needs.
Smaller RTO and RPO are not always better!
A smaller RTO increases the likelihood of false positives, and a smaller RPO reduces the probability of successful automatic failovers.
The maximum duration of unavailability during a failover is controlled by the pg_rto parameter, with a default value of 30s. Increasing it will lead to a longer duration of unavailability for write operations during primary failover, while decreasing it will increase the rate of false failovers (e.g., due to brief network jitters).
The upper limit of potential data loss is controlled by the pg_rpo parameter, defaulting to 1MB. Lowering this value can reduce the upper limit of data loss during failovers but also increases the likelihood of refusing automatic failovers due to insufficiently healthy standbys (too far behind).
Pigsty defaults to an availability-first mode, meaning that it will proceed with a failover as quickly as possible when the primary fails, and data not yet replicated to the standby might be lost (under regular ten-gigabit networks, replication delay is usually between a few KB to 100KB).
If you need to ensure no data loss during failovers, you can use the crit.yml template to ensure no data loss during failovers, but this will come at the cost of some performance.
recovery time objective in seconds, This will be used as Patroni TTL value, 30s by default.
If a primary instance is missing for such a long time, a new leader election will be triggered.
Decrease the value can reduce the unavailable time (unable to write) of the cluster during failover,
but it will make the cluster more sensitive to network jitter, thus increase the chance of false-positive failover.
Config this according to your network condition and expectation to trade-off between chance and impact,
the default value is 30s, and it will be populated to the following patroni parameters:
# the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30ttl:{{pg_rto }}# the number of seconds the loop will sleep. Default value: 10 , this is patroni check loop intervalloop_wait:{{(pg_rto / 3)|round(0, 'ceil')|int }}# timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10retry_timeout:{{(pg_rto / 3)|round(0, 'ceil')|int }}# the amount of time a primary is allowed to recover from failures before failover is triggered (in seconds), Max RTO: 2 loop wait + primary_start_timeoutprimary_start_timeout:{{(pg_rto / 3)|round(0, 'ceil')|int }}
recovery point objective in bytes, 1MiB at most by default
default values: 1048576, which will tolerate at most 1MiB data loss during failover.
when the primary is down and all replicas are lagged, you have to make a tough choice to trade off between Availability and Consistency:
Promote a replica to be the new primary and bring system back online ASAP, with the price of an acceptable data loss (e.g. less than 1MB).
Wait for the primary to come back (which may never be) or human intervention to avoid any data loss.
You can use crit.ymlcrit.yml template to ensure no data loss during failover, but it will sacrifice some performance.
3.7 - Point-in-Time Recovery
Pigsty utilizes pgBackRest for PostgreSQL point-in-time recovery, allowing users to roll back to any point within the backup policy limits.
Overview
You can roll back your cluster to any point in time, avoiding data loss caused by software defects and human errors.
Pigsty’s PostgreSQL clusters come with an automatically configured Point in Time Recovery (PITR) solution, based on the backup component pgBackRest and the optional object storage repository MinIO.
High Availability solutions can address hardware failures, but they are powerless against data deletions/overwrites/deletions caused by software defects and human errors. For such scenarios, Pigsty offers an out-of-the-box Point in Time Recovery (PITR) capability, enabled by default without any additional configuration.
Pigsty provides you with the default configuration for base backups and WAL archiving, allowing you to use local directories and disks, or dedicated MinIO clusters or S3 object storage services to store backups and achieve off-site disaster recovery. When using local disks, by default, you retain the ability to recover to any point in time within the past day. When using MinIO or S3, by default, you retain the ability to recover to any point in time within the past week. As long as storage space permits, you can keep a recoverable time span as long as desired, based on your budget.
What problems does Point in Time Recovery (PITR) solve?
Enhanced disaster recovery capability: RPO reduces from ∞ to a few MBs, RTO from ∞ to a few hours/minutes.
Ensures data security: Data Integrity among C/I/A: avoids data consistency issues caused by accidental deletions.
Ensures data security: Data Availability among C/I/A: provides a safety net for “permanently unavailable” disasters.
Singleton Strategy
Event
RTO
RPO
Do nothing
Crash
Permanently lost
All lost
Basic backup
Crash
Depends on backup size and bandwidth (a few hours)
Loss of data after the last backup (a few hours to days)
Basic backup + WAL Archiving
Crash
Depends on backup size and bandwidth (a few hours)
Loss of data not yet archived (a few dozen MBs)
What are the costs of Point in Time Recovery?
Reduced C in data security: Confidentiality, creating additional leakage points, requiring extra protection for backups.
Additional resource consumption: local storage or network traffic/bandwidth costs, usually not a problem.
Increased complexity cost: users need to invest in backup management.
Limitations of Point in Time Recovery
If PITR is the only method for fault recovery, the RTO and RPO metrics are inferior compared to High Availability solutions, and it’s usually best to use both in combination.
RTO: With only a single machine + PITR, recovery time depends on backup size and network/disk bandwidth, ranging from tens of minutes to several hours or days.
RPO: With only a single machine + PITR, a crash might result in the loss of a small amount of data, as one or several WAL log segments might not yet be archived, losing between 16 MB to several dozen MBs of data.
Apart from PITR, you can also use Delayed Clusters in Pigsty to address data deletion or alteration issues caused by human errors or software defects.
How does PITR works?
Point in Time Recovery allows you to roll back your cluster to any “specific moment” in the past, avoiding data loss caused by software defects and human errors. To achieve this, two key preparations are necessary: Base Backups and WAL Archiving. Having a Base Backup allows users to restore the database to the state at the time of the backup, while having WAL Archiving from a certain base backup enables users to restore the database to any point in time after the base backup.
Pigsty uses pgBackRest to manage PostgreSQL backups. pgBackRest will initialize an empty repository on all cluster instances, but it will only use the repository on the primary instance.
pgBackRest supports three backup modes: Full Backup, Incremental Backup, and Differential Backup, with the first two being the most commonly used. A Full Backup takes a complete physical snapshot of the database cluster at a current moment, while an Incremental Backup records the differences between the current database cluster and the last full backup.
Pigsty provides a wrapper command for backups: /pg/bin/pg-backup [full|incr]. You can make base backups periodically as needed through Crontab or any other task scheduling system.
WAL Archiving
By default, Pigsty enables WAL archiving on the primary instance of the cluster and continuously pushes WAL segment files to the backup repository using the pgbackrest command-line tool.
pgBackRest automatically manages the required WAL files and promptly cleans up expired backups and their corresponding WAL archive files according to the backup retention policy.
If you do not need PITR functionality, you can disable WAL archiving by configuring the cluster: archive_mode: off, and remove node_crontab to stop periodic backup tasks.
Implementation
By default, Pigsty provides two preset backup strategies: using the local filesystem backup repository by default, where a full backup is taken daily to ensure users can roll back to any point within a day at any time. The alternative strategy uses a dedicated MinIO cluster or S3 storage for backups, with a full backup on Monday and incremental backups daily, keeping two weeks of backups and WAL archives by default.
Pigsty uses pgBackRest to manage backups, receive WAL archives, and perform PITR. The backup repository can be flexibly configured (pgbackrest_repo): by default, it uses the local filesystem (local) of the primary instance, but it can also use other disk paths, or the optional MinIO service (minio) and cloud-based S3 services.
pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorylocal:# default pgbackrest repo with local posix fspath:/pg/backup # local backup directory, `/pg/backup` by defaultretention_full_type:count # retention full backups by countretention_full:2# keep 2, at most 3 full backup when using local fs repominio:# optional minio repo for pgbackresttype:s3 # minio is s3-compatible, so s3 is useds3_endpoint:sss.pigsty # minio endpoint domain name, `sss.pigsty` by defaults3_region:us-east-1 # minio region, us-east-1 by default, useless for minios3_bucket:pgsql # minio bucket name, `pgsql` by defaults3_key:pgbackrest # minio user access key for pgbackrests3_key_secret:S3User.Backup # minio user secret key for pgbackrests3_uri_style:path # use path style uri for minio rather than host stylepath:/pgbackrest # minio backup path, default is `/pgbackrest`storage_port:9000# minio port, 9000 by defaultstorage_ca_file:/etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by defaultbundle:y# bundle small files into a single filecipher_type:aes-256-cbc # enable AES encryption for remote backup repocipher_pass:pgBackRest # AES encryption password, default is 'pgBackRest'retention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days
Pigsty has two built-in backup options: local file system repository with daily full backups or dedicated MinIO/S3 storage with weekly full and daily incremental backups, retaining two weeks’ worth by default.
The target repositories in Pigsty parameter pgbackrest_repo are translated into repository definitions in the /etc/pgbackrest/pgbackrest.conf configuration file.
For example, if you define a West US region S3 repository for cold backups, you could use the following reference configuration.
You can use the following encapsulated commands for Point in Time Recovery of the PostgreSQL database cluster.
By default, Pigsty uses incremental, differential, parallel recovery, allowing you to restore to a specified point in time as quickly as possible.
pg-pitr # restore to wal archive stream end (e.g. used in case of entire DC failure)
pg-pitr -i # restore to the time of latest backup complete (not often used)
pg-pitr --time="2022-12-30 14:44:44+08" # restore to specific time point (in case of drop db, drop table)
pg-pitr --name="my-restore-point" # restore TO a named restore point create by pg_create_restore_point
pg-pitr --lsn="0/7C82CB8" -X # restore right BEFORE a LSN
pg-pitr --xid="1234567" -X -P # restore right BEFORE a specific transaction id, then promote
pg-pitr --backup=latest # restore to latest backup set
pg-pitr --backup=20221108-105325 # restore to a specific backup set, which can be checked with pgbackrest info
pg-pitr # pgbackrest --stanza=pg-meta restore
pg-pitr -i # pgbackrest --stanza=pg-meta --type=immediate restore
pg-pitr -t "2022-12-30 14:44:44+08" # pgbackrest --stanza=pg-meta --type=time --target="2022-12-30 14:44:44+08" restore
pg-pitr -n "my-restore-point" # pgbackrest --stanza=pg-meta --type=name --target=my-restore-point restore
pg-pitr -b 20221108-105325F # pgbackrest --stanza=pg-meta --type=name --set=20221230-120101F restore
pg-pitr -l "0/7C82CB8" -X # pgbackrest --stanza=pg-meta --type=lsn --target="0/7C82CB8" --target-exclusive restore
pg-pitr -x 1234567 -X -P # pgbackrest --stanza=pg-meta --type=xid --target="0/7C82CB8" --target-exclusive --target-action=promote restore
During PITR, you can observe the LSN point status of the cluster using the Pigsty monitoring system to determine if it has successfully restored to the specified time point, transaction point, LSN point, or other points.
3.8 - Services & Access
Pigsty employs HAProxy for service access, offering optional pgBouncer for connection pooling, and optional L2 VIP and DNS access.
Split read & write, route traffic to the right place, and achieve stable & reliable access to the PostgreSQL cluster.
Service is an abstraction to seal the details of the underlying cluster, especially during cluster failover/switchover.
Personal User
Service is meaningless to personal users. You can access the database with raw IP address or whatever method you like.
psql postgres://dbuser_dba:[email protected]/meta # dbsu direct connectpsql postgres://dbuser_meta:[email protected]/meta # default business admin userpsql postgres://dbuser_view:DBUser.View@pg-meta/meta # default read-only user
Service Overview
We utilize a PostgreSQL database cluster based on replication in real-world production environments. Within the cluster, only one instance is the leader (primary) that can accept writes. Other instances (replicas) continuously fetch WAL from the leader to stay synchronized. Additionally, replicas can handle read-only queries and offload the primary in read-heavy, write-light scenarios. Thus, distinguishing between write and read-only requests is a common practice.
Moreover, we pool requests through a connection pooling middleware (Pgbouncer) for high-frequency, short-lived connections to reduce the overhead of connection and backend process creation. And, for scenarios like ETL and change execution, we need to bypass the connection pool and directly access the database servers.
Furthermore, high-availability clusters may undergo failover during failures, causing a change in the cluster leadership. Therefore, the RW requests should be re-routed automatically to the new leader.
These varied requirements (read-write separation, pooling vs. direct connection, and client request failover) have led to the abstraction of the service concept.
Typically, a database cluster must provide this basic service:
Read-write service (primary): Can read and write to the database.
For production database clusters, at least these two services should be provided:
Read-write service (primary): Write data: Only carried by the primary.
Read-only service (replica): Read data: Can be carried by replicas, but fallback to the primary if no replicas are available.
Additionally, there might be other services, such as:
Direct access service (default): Allows (admin) users to bypass the connection pool and directly access the database.
Offline replica service (offline): A dedicated replica that doesn’t handle online read traffic, used for ETL and analytical queries.
Synchronous replica service (standby): A read-only service with no replication delay, handled by synchronous standby/primary for read queries.
Delayed replica service (delayed): Accesses older data from the same cluster from a certain time ago, handled by delayed replicas.
Default Service
Pigsty will enable four default services for each PostgreSQL cluster:
Take the default pg-meta cluster as an example, you can access these services in the following ways:
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5433/meta # pg-meta-primary : production read/write via primary pgbouncer(6432)psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5434/meta # pg-meta-replica : production read-only via replica pgbouncer(6432)psql postgres://dbuser_dba:DBUser.DBA@pg-meta:5436/meta # pg-meta-default : Direct connect primary via primary postgres(5432)psql postgres://dbuser_stats:DBUser.Stats@pg-meta:5438/meta # pg-meta-offline : Direct connect offline via offline postgres(5432)
Here the pg-meta domain name point to the cluster’s L2 VIP, which in turn points to the haproxy load balancer on the primary instance. It is responsible for routing traffic to different instances, check Access Services for details.
Primary Service
The primary service may be the most critical service for production usage.
It means all cluster members will be included in the primary service (selector: "[]"), but the one and only one instance that past health check (check: /primary) will be used as the primary instance.
Patroni will guarantee that only one instance is primary at any time, so the primary service will always route traffic to THE primary instance.
Example: pg-test-primary haproxy config
listen pg-test-primarybind *:5433mode tcpmaxconn 5000balance roundrobinoption httpchkoption http-keep-alivehttp-check send meth OPTIONS uri /primaryhttp-check expect status 200default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100# serversserver pg-test-1 10.10.10.11:6432 check port 8008 weight 100server pg-test-3 10.10.10.13:6432 check port 8008 weight 100server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Replica Service
The replica service is used for production read-only traffic.
There may be many more read-only queries than read-write queries in real-world scenarios. You may have many replicas.
The replica service traffic will try to use common pg instances with pg_role = replica to alleviate the load on the primary instance as much as possible. It will try NOT to use instances with pg_role = offline to avoid mixing OLAP & OLTP queries as much as possible.
All cluster members will be included in the replica service (selector: "[]") when it passes the read-only health check (check: /read-only).
primary and offline instances are used as backup servers, which will take over in case of all replica instances are down.
Example: pg-test-replica haproxy config
listen pg-test-replicabind *:5434mode tcpmaxconn 5000balance roundrobinoption httpchkoption http-keep-alivehttp-check send meth OPTIONS uri /read-onlyhttp-check expect status 200default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100# serversserver pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backupserver pg-test-3 10.10.10.13:6432 check port 8008 weight 100server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Default Service
The default service will route to primary postgres (5432) by default.
It is quite like the primary service, except it will always bypass pgbouncer, regardless of pg_default_service_dest.
Which is useful for administration connection, ETL writes, CDC changing data capture, etc…
!> Remember to change these password in production deployment !
pg_dbsu:postgres # os user for the databasepg_replication_username:replicator # system replication userpg_replication_password:DBUser.Replicator # system replication passwordpg_monitor_username:dbuser_monitor # system monitor userpg_monitor_password:DBUser.Monitor # system monitor passwordpg_admin_username:dbuser_dba # system admin userpg_admin_password:DBUser.DBA # system admin password
- GRANT USAGE ON SCHEMAS TO dbrole_readonly- GRANT SELECT ON TABLES TO dbrole_readonly- GRANT SELECT ON SEQUENCES TO dbrole_readonly- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly- GRANT USAGE ON SCHEMAS TO dbrole_offline- GRANT SELECT ON TABLES TO dbrole_offline- GRANT SELECT ON SEQUENCES TO dbrole_offline- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline- GRANT INSERT ON TABLES TO dbrole_readwrite- GRANT UPDATE ON TABLES TO dbrole_readwrite- GRANT DELETE ON TABLES TO dbrole_readwrite- GRANT USAGE ON SEQUENCES TO dbrole_readwrite- GRANT UPDATE ON SEQUENCES TO dbrole_readwrite- GRANT TRUNCATE ON TABLES TO dbrole_admin- GRANT REFERENCES ON TABLES TO dbrole_admin- GRANT TRIGGER ON TABLES TO dbrole_admin- GRANT CREATE ON SCHEMAS TO dbrole_admin
Newly created objects will have corresponding privileges when it is created by admin users
The \ddp+ may looks like:
Type
Access privileges
function
=X
dbrole_readonly=X
dbrole_offline=X
dbrole_admin=X
schema
dbrole_readonly=U
dbrole_offline=U
dbrole_admin=UC
sequence
dbrole_readonly=r
dbrole_offline=r
dbrole_readwrite=wU
dbrole_admin=rwU
table
dbrole_readonly=r
dbrole_offline=r
dbrole_readwrite=awd
dbrole_admin=arwdDxt
Default Privilege
ALTER DEFAULT PRIVILEGES allows you to set the privileges that will be applied to objects created in the future.
It does not affect privileges assigned to already-existing objects, and objects created by non-admin users.
Pigsty will use the following default privileges:
{%forprivinpg_default_privileges%}ALTERDEFAULTPRIVILEGESFORROLE{{pg_dbsu}}{{priv}};{%endfor%}{%forprivinpg_default_privileges%}ALTERDEFAULTPRIVILEGESFORROLE{{pg_admin_username}}{{priv}};{%endfor%}-- for additional business admin, they can SET ROLE to dbrole_admin
{%forprivinpg_default_privileges%}ALTERDEFAULTPRIVILEGESFORROLE"dbrole_admin"{{priv}};{%endfor%}
Which will be rendered in pg-init-template.sql alone with ALTER DEFAULT PRIVILEGES statement for admin users.
These SQL command will be executed on postgres & template1 during cluster bootstrap, and newly created database will inherit it from tempalte1 by default.
That is to say, to maintain the correct object privilege, you have to run DDL with admin users, which could be:
It’s wise to use postgres as global object owner to perform DDL changes.
If you wish to create objects with business admin user, YOU MUST USE SET ROLE dbrole_admin before running that DDL to maintain the correct privileges.
You can also ALTER DEFAULT PRIVILEGE FOR ROLE <some_biz_admin> XXX to grant default privilege to business admin user, too.
There are 3 database level privileges: CONNECT, CREATE, TEMP, and a special ‘privilege’: OWNERSHIP.
- name:meta # required, `name` is the only mandatory field of a database definitionowner:postgres # optional, specify a database owner, {{ pg_dbsu }} by defaultallowconn:true# optional, allow connection, true by default. false will disable connect at allrevokeconn:false# optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)
If owner exists, it will be used as database owner instead of default {{ pg_dbsu }}
If revokeconn is false, all users have the CONNECT privilege of the database, this is the default behavior.
If revokeconn is set to true explicitly:
CONNECT privilege of the database will be revoked from PUBLIC
CONNECT privilege will be granted to {{ pg_replication_username }}, {{ pg_monitor_username }} and {{ pg_admin_username }}
CONNECT privilege will be granted to database owner with GRANT OPTION
revokeconn flag can be used for database access isolation, you can create different business users as the owners for each database and set the revokeconn option for all of them.
Pigsty revokes the CREATE privilege on database from PUBLIC by default, for security consideration.
And this is the default behavior since PostgreSQL 15.
The database owner have the full capability to adjust these privileges as they see fit.
4 - Configuration
Batteries-included config templates for specific scenarios, and detailed explanations.
4.1 - Overview
Batteries-included config templates for specific scenarios, and detailed explanations.
Single Node
meta: Default single-node installation template with extensive configuration parameter descriptions.
rich: Downloads all available PostgreSQL extensions and Docker, provisioning a series of databases for software backups.
pitr: A single-node configuration sample for continuous backups and Point-in-Time Recovery (PITR) using remote object storage.
demo: Configuration file used by the Pigsty demo site, configured to serve publicly with domain names and certificates.
supa: Uses Docker Compose to start Supabase on a local single node PostgreSQL instance
bare: The minimal single-node config template, with only the essential components required to run a PostgreSQL instance.
Four Node
full: A 4-node standard sandbox demonstration environment, featuring two PostgreSQL clusters, MinIO, Etcd, Redis, and a sample FerretDB cluster.
safe: A 4-node template with hardened security, delayed cluster, following high-standard security best practices.
mssql: Replaces PostgreSQL with a Microsoft SQL Server-compatible kernel using WiltonDB or Babelfish.
polar: Substitutes native PostgreSQL with Alibaba Cloud’s PolarDB for PostgreSQL kernel.
ivory: Replaces native PostgreSQL with IvorySQL, an Oracle-compatible kernel by HighGo.
minio: 4-node HA MinIO MNMD cluster to provide S3-compatible object storage services.
Other Specs
dual 2-node template to set up a basic high-availability PostgreSQL cluster with master-slave replication, tolerating the failure of one node.
slim 2-node template for minimal installation that avoids setting up local software repo and infra module, with the etcd as only deps.
trio: Three-node configuration template providing a standard High Availability (HA) architecture, tolerating failure of one out of three nodes.
oss: 5-node batch building template for 5 major OS distro in one batch
ext: 5-node extension building template for 5 major OS distro
prod: 36-node production-simulation template, testing different scenarios and multiple pg major versions in the same time.
4.2 - 1-node: meta
Default single-node installation template with extensive configuration parameter descriptions.
The meta configuration template is Pigsty’s default template, designed to fulfill Pigsty’s core functionality—deploying PostgreSQL—on a single node.
To maximize compatibility, meta installs only the minimum required software set to ensure it runs across all operating system distributions and architectures.
all:#==============================================================## Clusters, Nodes, and Modules#==============================================================#children:#----------------------------------## infra: monitor, alert, repo, etc..#----------------------------------#infra:hosts:10.10.10.10:{infra_seq:1}#----------------------------------## etcd cluster for HA postgres DCS#----------------------------------#etcd:hosts:10.10.10.10:{etcd_seq:1}vars:etcd_cluster:etcd#----------------------------------## minio (OPTIONAL backup repo)#----------------------------------##minio:# hosts:# 10.10.10.10: { minio_seq: 1 }# vars:# minio_cluster: minio#----------------------------------## pgsql (singleton on current node)#----------------------------------## this is an example single-node postgres cluster with postgis & timescaledb installed, with one biz database & two biz userspg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }# <---- primary instance with read-write capability#x.xx.xx.xx: { pg_seq: 2, pg_role: replica } # <---- read only replica for read-only online traffic#x.xx.xx.xy: { pg_seq: 3, pg_role: offline } # <---- offline instance of ETL & interactive queriesvars:pg_cluster:pg-meta # required identity parameter, usually same as group name# define business databases here: https://pigsty.io/docs/pgsql/db/pg_databases:# define business databases on this cluster, array of database definition- name:meta # REQUIRED, `name` is the only mandatory field of a database definitionbaseline: cmdb.sql # optional, database sql baseline path, (relative path among ansible search path, e.g:files/)schemas:[pigsty ] # optional, additional schemas to be created, array of schema namesextensions: # optional, additional extensions to be installed:array of `{name[,schema]}`- {name:vector } # install pgvector extension on this database by defaultcomment:pigsty meta database # optional, comment string for this database#pgbouncer: true # optional, add this database to pgbouncer database list? true by default#owner: postgres # optional, database owner, postgres by default#template: template1 # optional, which template to use, template1 by default#encoding: UTF8 # optional, database encoding, UTF8 by default. (MUST same as template database)#locale: C # optional, database locale, C by default. (MUST same as template database)#lc_collate: C # optional, database collate, C by default. (MUST same as template database)#lc_ctype: C # optional, database ctype, C by default. (MUST same as template database)#tablespace: pg_default # optional, default tablespace, 'pg_default' by default.#allowconn: true # optional, allow connection, true by default. false will disable connect at all#revokeconn: false # optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)#register_datasource: true # optional, register this database to grafana datasources? true by default#connlimit: -1 # optional, database connection limit, default -1 disable limit#pool_auth_user: dbuser_meta # optional, all connection to this pgbouncer database will be authenticated by this user#pool_mode: transaction # optional, pgbouncer pool mode at database level, default transaction#pool_size: 64 # optional, pgbouncer pool size at database level, default 64#pool_size_reserve: 32 # optional, pgbouncer pool size reserve at database level, default 32#pool_size_min: 0 # optional, pgbouncer pool size min at database level, default 0#pool_max_db_conn: 100 # optional, max database connections at database level, default 100#- { name: grafana ,owner: dbuser_grafana ,revokeconn: true ,comment: grafana primary database } # define another database# define business users here: https://pigsty.io/docs/pgsql/user/pg_users:# define business users/roles on this cluster, array of user definition- name:dbuser_meta # REQUIRED, `name` is the only mandatory field of a user definitionpassword:DBUser.Meta # optional, password, can be a scram-sha-256 hash string or plain textlogin:true# optional, can log in, true by default (new biz ROLE should be false)superuser:false# optional, is superuser? false by defaultcreatedb:false# optional, can create database? false by defaultcreaterole:false# optional, can create role? false by defaultinherit:true# optional, can this role use inherited privileges? true by defaultreplication:false# optional, can this role do replication? false by defaultbypassrls:false# optional, can this role bypass row level security? false by defaultpgbouncer:true# optional, add this user to pgbouncer user-list? false by default (production user should be true explicitly)connlimit:-1# optional, user connection limit, default -1 disable limitexpire_in:3650# optional, now + n days when this role is expired (OVERWRITE expire_at)expire_at:'2030-12-31'# optional, YYYY-MM-DD 'timestamp' when this role is expired (OVERWRITTEN by expire_in)comment:pigsty admin user # optional, comment string for this user/roleroles: [dbrole_admin] # optional, belonged roles. default roles are:dbrole_{admin,readonly,readwrite,offline}parameters:{}# optional, role level parameters with `ALTER ROLE SET`pool_mode:transaction # optional, pgbouncer pool mode at user level, transaction by defaultpool_connlimit:-1# optional, max database connections at user level, default -1 disable limit- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly], comment:read-only viewer for meta database }# define pg extensions: https://pigsty.io/ext/pg_libs:'pg_stat_statements, auto_explain'# add timescaledb to shared_preload_librariespg_extensions: [ pgvector ] # check list for available extension for your pg & os combination:/ext/list# define HBA rules here: https://pigsty.io/docs/pgsql/hba/#define-hbapg_hba_rules:# example hba rules- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}#pg_vip_enabled: true # define a L2 VIP which bind to cluster primary instance#pg_vip_address: 10.10.10.2/24 # L2 VIP Address and netmask#pg_vip_interface: eth1 # L2 VIP Network interface, overwrite on host vars if member have different network interface namesnode_crontab:['00 01 * * * postgres /pg/bin/pg-backup full']# make a full backup every 1am#==============================================================## Global Parameters#==============================================================#vars:#----------------------------------## Meta Data#----------------------------------#version:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlproxy_env:# global proxy env when downloading packagesno_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"# http_proxy: # set your proxy here: e.g http://user:[email protected]# https_proxy: # set your proxy here: e.g http://user:[email protected]# all_proxy: # set your proxy here: e.g http://user:[email protected]infra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}#minio : { domain: m.pigsty ,endpoint: "${admin_ip}:9001" ,scheme: https ,websocket: true }#----------------------------------## MinIO Related Options#----------------------------------##pgbackrest_method: minio # if you want to use minio as backup repo instead of 'local' fs, uncomment this#minio_users: # and configure `pgbackrest_repo` & `minio_users` accordingly# - { access_key: dba , secret_key: S3User.DBA, policy: consoleAdmin }# - { access_key: pgbackrest , secret_key: S3User.Backup, policy: readwrite }#pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository# minio: ... # optional minio repo for pgbackrest ...# s3_key: pgbackrest # minio user access key for pgbackrest# s3_key_secret: S3User.Backup # minio user secret key for pgbackrest# cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'# if you want to use minio as backup repo instead of 'local' fs, uncomment this, and configure `pgbackrest_repo`#pgbackrest_method: minio#node_etc_hosts: [ '10.10.10.10 h.pigsty a.pigsty p.pigsty g.pigsty sss.pigsty' ]#----------------------------------## Credential: CHANGE THESE PASSWORDS#----------------------------------##grafana_admin_username: admingrafana_admin_password:pigsty#pg_admin_username: dbuser_dbapg_admin_password:DBUser.DBA#pg_monitor_username: dbuser_monitorpg_monitor_password:DBUser.Monitor#pg_replication_username: replicatorpg_replication_password:DBUser.Replicator#patroni_username: postgrespatroni_password:Patroni.API#haproxy_admin_username: adminhaproxy_admin_password:pigsty#minio_access_key: minioadminminio_secret_key:minioadmin#----------------------------------## Safe Guard#----------------------------------## you can enable these flags after bootstrap, to prevent purging running etcd / pgsql instancesetcd_safeguard:false# prevent purging running etcd instance?pg_safeguard:false# prevent purging running postgres instance? false by default#----------------------------------## Repo, Node, Packages#----------------------------------## if you wish to customize your own repo, change these settings:repo_modules:infra,node,pgsqlrepo_remove:true# remove existing repo on admin node during repo bootstrapnode_repo_modules:local # install the local module in repo_upstream for all nodesnode_repo_remove:true# remove existing node repo for node managed by pigstyrepo_packages:[# default packages to be downloadednode-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-common#,docker]repo_extra_packages:[# default postgres packages to be downloadedpg17-main # replace with the following line if you want all extensions#pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]pg_version:17# default postgres version#pg_extensions: [ pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]#pg_extensions: # check extension availability for your OS & PG @ /ext/list# - timescaledb periods temporal_tables emaj table_version pg_cron pg_later pg_background #timescaledb_toolkit #pg_timeseries# - postgis pgrouting pointcloud pg_h3 q3c ogr_fdw geoip pg_polyline pg_geohash mobilitydb# - pgvector vchord pgvectorscale pg_vectorize pg_similarity smlar pg_summarize pg_tiktoken pg4ml #pgml# - pg_search pgroonga pg_bigm zhparser pg_bestmatch hunspell# - pg_analytics pg_duckdb duckdb_fdw pg_parquet pg_fkpart pg_partman plproxy #citus #hydra #pg_strom# - hll rum pg_graphql pg_jsonschema jsquery pg_hint_plan hypopg index_advisor pg_plan_filter imgsmlr pg_ivm pgmq pgq pg_cardano #age #rdkit# - pg_tle plv8 pllua pldebugger plpgsql_check plprofiler plsh pljava #plprql #plr #pgtap #faker #dbt2# - pg_prefix pg_semver pgunit pgpdf pglite_fusion md5hash asn1oid roaringbitmap pgfaceting pgsphere pg_country pg_currency pgmp numeral pg_rational pguint pg_uint128 ip4r pg_uri pgemailaddr pg_acl #debversion pg_rrule timestamp9 chkpass# - pg_gzip pg_zstd pg_http pg_net pg_smtp_client pg_html5_email_address pgsql_tweaks pg_extra_time count_distinct extra_window_functions first_last_agg tdigest aggs_for_vecs aggs_for_arrays pg_arraymath quantile lower_quantile# - pg_idkit pg_uuidv7 permuteseq pg_hashids sequential_uuids pg_math pg_random pg_base36 pg_base62 pg_base58 floatvec pg_financial pgjwt pg_hashlib shacrypt cryptint pg_ecdsa pgpcre icu_ext pgqr envvar pg_protobuf url_encode #topn# - pg_repack pg_squeeze pg_dirtyread pgfincore pg_ddlx pg_prioritize pg_checksums pg_readonly safeupdate pg_permissions pgautofailover pg_catcheck preprepare pgcozy pg_orphaned pg_crash pg_cheat_funcs pg_savior table_log pg_fio #pgpool #pgagent# - pg_profile pg_show_plans pg_stat_kcache pg_stat_monitor pg_qualstats pg_track_settings pg_wait_sampling system_stats pg_meta pgnodemx pg_sqlog bgw_replstatus pgmeminfo toastinfo pg_explain_ui pg_relusage pagevis #pg_store_plans #powa# - passwordcheck supautils pgsodium pg_vault pg_session_jwt pg_anon pgsmcrypto pgaudit pgauditlogtofile pg_auth_mon credcheck pgcryptokey pg_jobmon logerrors login_hook set_user pg_snakeoil pgextwlist pg_auditor sslutils pg_noset #pg_tde# - wrappers mysql_fdw tds_fdw redis_fdw pg_redis_pubsub firebird_fdw aws_s3 log_fdw #multicorn #odbc_fdw #jdbc_fdw #oracle_fdw #db2_fdw #sqlite_fdw #pgbouncer_fdw #mongo_fdw #kafka_fdw #hdfs_fdw# - orafce pgtt session_variable pg_statement_rollback pgmemcache #pg_dbms_metadata #pg_dbms_lock #pg_dbms_job #wiltondb# - pglogical pglogical_ticker pgl_ddl_deploy pg_failover_slots wal2json decoderbufs decoder_raw mimeo pg_fact_loader #wal2mongo #repmgr #pg_bulkload
Caveats
To maintain compatibility across operating systems and architectures, the meta template installs only the minimum required software. This is reflected in the choices for repo_packages and repo_extra_packages:
Docker is not downloaded by default.
Only essential PostgreSQL extensions—pg_repack, wal2json, and pgvector—are downloaded by default.
Tools classified under pgsql-utility but not part of pgsql-common—such as pg_activity, pg_timetable, pgFormatter, pg_filedump, pgxnclient, timescaledb-tools, pgcopydb, and pgloader—are not downloaded.
4.3 - 1-node: rich
Downloads all available PostgreSQL extensions and Docker, provisioning a series of databases for software backups.
The rich template is a 1-node conf aims for running various business software that uses PostgreSQL databases.
If you want to run some business software that uses PostgreSQL databases as the underlying database on a single machine through Docker, such as Odoo, Gitea, Wiki.js, etc., you can consider using this template.
The rich configuration template is designed for single-node deployments. Built upon meta, it downloads all available PostgreSQL extensions and Docker and preconfigures a set of databases to provide an out-of-the-box environment for software integrations.
all:children:infra:hosts:10.10.10.10:{infra_seq:1}etcd:hosts:10.10.10.10:{etcd_seq:1}vars:etcd_cluster:etcdminio:hosts:10.10.10.10:{minio_seq:1}vars:minio_cluster:minio# postgres cluster: pg-metapg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-metapg_users:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment:read-only viewer for meta database }- {name: dbuser_grafana ,password: DBUser.Grafana ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for grafana database }- {name: dbuser_bytebase ,password: DBUser.Bytebase ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for bytebase database }- {name: dbuser_kong ,password: DBUser.Kong ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for kong api gateway }- {name: dbuser_gitea ,password: DBUser.Gitea ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for gitea service }- {name: dbuser_wiki ,password: DBUser.Wiki ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for wiki.js service }- {name: dbuser_noco ,password: DBUser.Noco ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for nocodb service }- {name: dbuser_odoo ,password: DBUser.Odoo ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for odoo service ,createdb: true} #,superuser:true}pg_databases:- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions:[{name:vector},{name: postgis},{name: timescaledb}]}- {name: grafana ,owner: dbuser_grafana ,revokeconn: true ,comment:grafana primary database }- {name: bytebase ,owner: dbuser_bytebase ,revokeconn: true ,comment:bytebase primary database }- {name: kong ,owner: dbuser_kong ,revokeconn: true ,comment:kong api gateway database }- {name: gitea ,owner: dbuser_gitea ,revokeconn: true ,comment:gitea meta database }- {name: wiki ,owner: dbuser_wiki ,revokeconn: true ,comment:wiki meta database }- {name: noco ,owner: dbuser_noco ,revokeconn: true ,comment:nocodb database }- {name: odoo ,owner: dbuser_odoo ,revokeconn: true ,comment:odoo main database }pg_hba_rules:- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}pg_libs:'timescaledb,pg_stat_statements, auto_explain'# add timescaledb to shared_preload_librariesnode_crontab:# make one full backup 1 am everyday- '00 01 * * * postgres /pg/bin/pg-backup full'redis-ms:# redis classic primary & replicahosts:{10.10.10.10:{redis_node: 1 , redis_instances:{6379:{}, 6380:{replica_of:'10.10.10.10 6379'}}}}vars:{redis_cluster: redis-ms ,redis_password: 'redis.ms' ,redis_max_memory:64MB }# To install & enable docker: ./docker.yml -l dockerdocker:hosts:{10.10.10.10:{infra_seq:1}}vars:docker_enabled:true#docker_registry_mirrors: ['https://docker.xxxxx.io'] # add your docker mirror/proxy if neededvars:# global variablesversion:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlproxy_env:# global proxy env when downloading packagesno_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"# http_proxy: # set your proxy here: e.g http://user:[email protected]# https_proxy: # set your proxy here: e.g http://user:[email protected]# all_proxy: # set your proxy here: e.g http://user:[email protected]infra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}minio :{domain: m.pigsty ,endpoint:"${admin_ip}:9001",scheme: https ,websocket:true}postgrest :{domain: api.pigsty ,endpoint:"127.0.0.1:8884"}pgadmin :{domain: adm.pigsty ,endpoint:"127.0.0.1:8885"}pgweb :{domain: cli.pigsty ,endpoint:"127.0.0.1:8886"}bytebase :{domain: ddl.pigsty ,endpoint:"127.0.0.1:8887"}jupyter :{domain: lab.pigsty ,endpoint:"127.0.0.1:8888", websocket:true}gitea :{domain: git.pigsty ,endpoint:"127.0.0.1:8889"}wiki :{domain: wiki.pigsty ,endpoint:"127.0.0.1:9002"}noco :{domain: noco.pigsty ,endpoint:"127.0.0.1:9003"}supa :{domain: supa.pigsty ,endpoint:"10.10.10.10:8000", websocket:true}dify :{domain: dify.pigsty ,endpoint:"10.10.10.10:8001", websocket:true}odoo :{domain: odoo.pigsty, endpoint:"127.0.0.1:8069", websocket:true}nginx_navbar:# application nav links on home page- {name: PgAdmin4 , url : 'http://adm.pigsty' , comment:'PgAdmin4 for PostgreSQL'}- {name: PGWeb , url : 'http://cli.pigsty' , comment:'PGWEB Browser Client'}- {name: ByteBase , url : 'http://ddl.pigsty' , comment:'ByteBase Schema Migrator'}- {name: PostgREST , url : 'http://api.pigsty' , comment:'Kong API Gateway'}- {name: Gitea , url : 'http://git.pigsty' , comment:'Gitea Git Service'}- {name: Minio , url : 'https://m.pigsty' , comment:'Minio Object Storage'}- {name: Wiki , url : 'http://wiki.pigsty' , comment:'Local Wikipedia'}- {name: Noco , url : 'http://noco.pigsty' , comment:'Nocodb Example'}- {name: Odoo , url : 'http://odoo.pigsty' , comment:'Odoo - the OpenERP'}- {name: Explain , url : '/pigsty/pev.html' , comment:'pgsql explain visualizer'}- {name: Package , url : '/pigsty' , comment:'local yum repo packages'}- {name: PG Logs , url : '/logs' , comment:'postgres raw csv logs'}- {name: Schemas , url : '/schema' , comment:'schemaspy summary report'}- {name: Reports , url : '/report' , comment:'pgbadger summary report'}#----------------------------------## MinIO Related Options#----------------------------------##pgbackrest_method: minio # if you want to use minio as backup repo instead of 'local' fs, uncomment this#minio_users: # and configure `pgbackrest_repo` & `minio_users` accordingly# - { access_key: dba , secret_key: S3User.DBA, policy: consoleAdmin }# - { access_key: pgbackrest , secret_key: S3User.Backup, policy: readwrite }#pgbackrest_repo: # pgbackrest repo: https://pgbackrest.org/configuration.html#section-repository# minio: ... # optional minio repo for pgbackrest ...# s3_key: pgbackrest # minio user access key for pgbackrest# s3_key_secret: S3User.Backup # minio user secret key for pgbackrest# cipher_pass: pgBackRest # AES encryption password, default is 'pgBackRest'# if you want to use minio as backup repo instead of 'local' fs, uncomment this, and configure `pgbackrest_repo`pgbackrest_method:minio # use minio as backup repo instead of 'local'node_etc_hosts:["${admin_ip} sss.pigsty"]dns_records:["${admin_ip} api.pigsty adm.pigsty cli.pigsty ddl.pigsty lab.pigsty git.pigsty wiki.pigsty noco.pigsty supa.pigsty dify.pigsty odoo.pigsty"]#----------------------------------## Credential: CHANGE THESE PASSWORDS#----------------------------------##grafana_admin_username: admingrafana_admin_password:pigsty#pg_admin_username: dbuser_dbapg_admin_password:DBUser.DBA#pg_monitor_username: dbuser_monitorpg_monitor_password:DBUser.Monitor#pg_replication_username: replicatorpg_replication_password:DBUser.Replicator#patroni_username: postgrespatroni_password:Patroni.API#haproxy_admin_username: adminhaproxy_admin_password:pigsty#minio_access_key: minioadminminio_secret_key:minioadmin#----------------------------------## Safe Guard#----------------------------------## you can enable these flags after bootstrap, to prevent purging running etcd / pgsql instancesetcd_safeguard:false# prevent purging running etcd instance?pg_safeguard:false# prevent purging running postgres instance? false by default#----------------------------------## Repo, Node, Packages#----------------------------------## if you wish to customize your own repo, change these settings:repo_modules:infra,node,pgsql,dockerrepo_packages:[node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility, docker ]pg_version:17# default postgres versionrepo_extra_packages:[pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]pg_extensions:[pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]...
Caveat
Beware that not all extension plugins are available on the aarch64 (arm64) architecture. Therefore, exercise caution when adding the extensions you need when using the ARM architecture.
To replace extensions, refer to the extension alias list: https://ext.pigsty.io and replace a series of wildcard packages such as pg17-core,pg17-time,....
4.4 - 1-node: demo
Configuration file used by the Pigsty demo site, configured to serve publicly with domain names and certificates.
The demo is a configuration template used by the Pigsty demo site.
It is configured to serve publicly with domain names and certificates.
If you wish to host a website on your cloud server, you can refer to this configuration template.
It will illustrate how to expose your website to the public, configure SSL certificates, and install all the necessary extensions.
Beware that not all extension plugins are available on the aarch64 (arm64) architecture,
so be careful when adding the extensions you need when using the ARM architecture.
Check the https://ext.pigsty.io for extension alias list, replace pg17-core,pg17-time,... with a series of wildcard software packages.
4.5 - 1-node: pitr
A single-node configuration sample for continuous backups and PITR using remote S3/object storage.
The pitr template demonstrates
how to use object storage for continuous backups and Point-in-Time Recovery (PITR)in the cloud with a single EC2/ECS server.
# This 1-node template will use an external S3 (OSS) as backup storage# which provide a basic level RTO / PRO in case of single point failure# terraform template: terraform/spec/aliyun-meta-s3.tfall:#==============================================================## Clusters, Nodes, and Modules#==============================================================#children:#----------------------------------## infra: monitor, alert, repo, etc..#----------------------------------#infra:hosts:10.10.10.10:{infra_seq:1}#----------------------------------## etcd cluster for HA postgres DCS#----------------------------------#etcd:hosts:10.10.10.10:{etcd_seq:1}vars:etcd_cluster:etcd#----------------------------------## minio (OPTIONAL backup repo)#----------------------------------##minio:# hosts:# 10.10.10.10: { minio_seq: 1 }# vars:# minio_cluster: minio#----------------------------------## pgsql (singleton on current node)#----------------------------------## this is an example single-node postgres cluster with postgis & timescaledb installed, with one biz database & two biz userspg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }vars:pg_cluster:pg-meta # required identity parameter, usually same as group name# define business databases here: https://pigsty.io/docs/pgsql/db/pg_databases:# define business databases on this cluster, array of database definition- name:meta # REQUIRED, `name` is the only mandatory field of a database definitionbaseline: cmdb.sql # optional, database sql baseline path, (relative path among ansible search path, e.g:files/)schemas:[pigsty ] # optional, additional schemas to be created, array of schema namesextensions: # optional, additional extensions to be installed:array of `{name[,schema]}`- {name:vector } # install pgvector extension on this database by defaultcomment:pigsty meta database # optional, comment string for this database#pgbouncer: true # optional, add this database to pgbouncer database list? true by default#owner: postgres # optional, database owner, postgres by default#template: template1 # optional, which template to use, template1 by default#encoding: UTF8 # optional, database encoding, UTF8 by default. (MUST same as template database)#locale: C # optional, database locale, C by default. (MUST same as template database)#lc_collate: C # optional, database collate, C by default. (MUST same as template database)#lc_ctype: C # optional, database ctype, C by default. (MUST same as template database)#tablespace: pg_default # optional, default tablespace, 'pg_default' by default.#allowconn: true # optional, allow connection, true by default. false will disable connect at all#revokeconn: false # optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)#register_datasource: true # optional, register this database to grafana datasources? true by default#connlimit: -1 # optional, database connection limit, default -1 disable limit#pool_auth_user: dbuser_meta # optional, all connection to this pgbouncer database will be authenticated by this user#pool_mode: transaction # optional, pgbouncer pool mode at database level, default transaction#pool_size: 64 # optional, pgbouncer pool size at database level, default 64#pool_size_reserve: 32 # optional, pgbouncer pool size reserve at database level, default 32#pool_size_min: 0 # optional, pgbouncer pool size min at database level, default 0#pool_max_db_conn: 100 # optional, max database connections at database level, default 100#- { name: grafana ,owner: dbuser_grafana ,revokeconn: true ,comment: grafana primary database } # define another database# define business users here: https://pigsty.io/docs/pgsql/user/pg_users:# define business users/roles on this cluster, array of user definition- name:dbuser_meta # REQUIRED, `name` is the only mandatory field of a user definitionpassword:DBUser.Meta # optional, password, can be a scram-sha-256 hash string or plain textlogin:true# optional, can log in, true by default (new biz ROLE should be false)superuser:false# optional, is superuser? false by defaultcreatedb:false# optional, can create database? false by defaultcreaterole:false# optional, can create role? false by defaultinherit:true# optional, can this role use inherited privileges? true by defaultreplication:false# optional, can this role do replication? false by defaultbypassrls:false# optional, can this role bypass row level security? false by defaultpgbouncer:true# optional, add this user to pgbouncer user-list? false by default (production user should be true explicitly)connlimit:-1# optional, user connection limit, default -1 disable limitexpire_in:3650# optional, now + n days when this role is expired (OVERWRITE expire_at)expire_at:'2030-12-31'# optional, YYYY-MM-DD 'timestamp' when this role is expired (OVERWRITTEN by expire_in)comment:pigsty admin user # optional, comment string for this user/roleroles: [dbrole_admin] # optional, belonged roles. default roles are:dbrole_{admin,readonly,readwrite,offline}parameters:{}# optional, role level parameters with `ALTER ROLE SET`pool_mode:transaction # optional, pgbouncer pool mode at user level, transaction by defaultpool_connlimit:-1# optional, max database connections at user level, default -1 disable limit- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly], comment:read-only viewer for meta database }# define pg extensions: https://pigsty.io/ext/pg_libs:'pg_stat_statements, auto_explain'# add timescaledb to shared_preload_librariespg_extensions: [ pgvector ] # available extensions:/ext/list# define HBA rules here: https://pigsty.io/docs/pgsql/hba/#define-hbapg_hba_rules:# example hba rules- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}node_crontab:# make a full backup on monday 1am, and an incremental backup during weekdays- '00 01 * * 1 postgres /pg/bin/pg-backup full'- '00 01 * * 2,3,4,5,6,7 postgres /pg/bin/pg-backup'#==============================================================## Global Parameters#==============================================================#vars:#----------------------------------## Meta Data#----------------------------------#version:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlproxy_env:# global proxy env when downloading packagesno_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"# http_proxy: # set your proxy here: e.g http://user:[email protected]# https_proxy: # set your proxy here: e.g http://user:[email protected]# all_proxy: # set your proxy here: e.g http://user:[email protected]infra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}#----------------------------------## MinIO Related Options#----------------------------------## ADD YOUR AK/SK/REGION/ENDPOINT HEREpgbackrest_method:s3 # if you want to use minio as backup repo instead of 'local' fs, uncomment thispgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorys3:# aliyun oss (s3 compatible) object storage servicetype:s3 # oss is s3-compatibles3_endpoint:oss-cn-beijing-internal.aliyuncs.coms3_region:oss-cn-beijings3_bucket:<your_bucket_name>s3_key:<your_access_key>s3_key_secret:<your_secret_key>s3_uri_style:hostpath:/pgbackrestbundle:y# bundle small files into a single filecipher_type:aes-256-cbc # enable AES encryption for remote backup repocipher_pass:PG.${pg_cluster}# AES encryption password, default is 'pgBackRest'retention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days#----------------------------------## Credential: CHANGE THESE PASSWORDS#----------------------------------##grafana_admin_username: admingrafana_admin_password:pigsty#pg_admin_username: dbuser_dbapg_admin_password:DBUser.DBA#pg_monitor_username: dbuser_monitorpg_monitor_password:DBUser.Monitor#pg_replication_username: replicatorpg_replication_password:DBUser.Replicator#patroni_username: postgrespatroni_password:Patroni.API#haproxy_admin_username: adminhaproxy_admin_password:pigsty#----------------------------------## Safe Guard#----------------------------------## you can enable these flags after bootstrap, to prevent purging running etcd / pgsql instancesetcd_safeguard:false# prevent purging running etcd instance?pg_safeguard:false# prevent purging running postgres instance? false by default#----------------------------------## Repo, Node, Packages#----------------------------------## if you wish to customize your own repo, change these settings:repo_modules:infra,node,pgsqlrepo_remove:true# remove existing repo on admin node during repo bootstrapnode_repo_modules:local # install the local module in repo_upstream for all nodesnode_repo_remove:true# remove existing node repo for node managed by pigstyrepo_packages:[# default packages to be downloadednode-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-common#,docker]repo_extra_packages:[# default postgres packages to be downloadedpg17-main # replace with the following line if you want all extensions#pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]pg_version:17# default postgres version#pg_extensions: [ pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]...
Caveats
You have to fill the bucket credentials in the pgbackrest_repo.
4.6 - 1-node: supa
Run self-hosting supabase on existing PostgreSQL
The supa template aims to self-hosting a single node supabase instance.
all:#==============================================================## Clusters, Nodes, and Modules#==============================================================#children:# infra cluster for proxy, monitor, alert, etc..infra:{hosts:{10.10.10.10:{infra_seq:1}}}# etcd cluster for ha postgresetcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }# minio cluster, s3 compatible object storageminio:{hosts:{10.10.10.10:{minio_seq: 1 } }, vars:{minio_cluster:minio } }# pg-meta, the underlying postgres database for supabasepg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-metapg_users:# supabase roles: anon, authenticated, dashboard_user- {name: anon ,login:false}- {name: authenticated ,login:false}- {name: dashboard_user ,login: false ,replication: true ,createdb: true ,createrole:true}- {name: service_role ,login: false ,bypassrls:true}# supabase users: please use the same password- {name: supabase_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: true ,roles: [ dbrole_admin ] ,superuser: true ,replication: true ,createdb: true ,createrole: true ,bypassrls:true}- {name: authenticator ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles:[dbrole_admin, authenticated ,anon ,service_role ] }- {name: supabase_auth_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole:true}- {name: supabase_storage_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin, authenticated ,anon ,service_role ] ,createrole:true}- {name: supabase_functions_admin ,password: 'DBUser.Supa' ,pgbouncer: true ,inherit: false ,roles: [ dbrole_admin ] ,createrole:true}- {name: supabase_replication_admin ,password: 'DBUser.Supa' ,replication: true ,roles:[dbrole_admin ]}- {name: supabase_read_only_user ,password: 'DBUser.Supa' ,bypassrls: true ,roles:[dbrole_readonly, pg_read_all_data ] }pg_databases:- name:postgresbaseline:supabase.sqlowner:supabase_admincomment:supabase postgres databaseschemas:[extensions ,auth ,realtime ,storage ,graphql_public ,supabase_functions ,_analytics ,_realtime ]extensions:- {name: pgcrypto ,schema: extensions } # 1.3 :cryptographic functions- {name: pg_net ,schema: extensions } # 0.9.2 :async HTTP- {name: pgjwt ,schema: extensions } # 0.2.0 :json web token API for postgres- {name: uuid-ossp ,schema: extensions } # 1.1 :generate universally unique identifiers (UUIDs)- {name: pgsodium } # 3.1.9 :pgsodium is a modern cryptography library for Postgres.- {name: supabase_vault } # 0.2.8 :Supabase Vault Extension- {name: pg_graphql } # 1.5.9 : pg_graphql:GraphQL support- {name: pg_jsonschema } # 0.3.3 : pg_jsonschema:Validate json schema- {name: wrappers } # 0.4.3 : wrappers:FDW collections- {name: http } # 1.6 : http:allows web page retrieval inside the database.- {name: pg_cron } # 1.6 : pg_cron:Job scheduler for PostgreSQL- {name: timescaledb } # 2.17 : timescaledb:Enables scalable inserts and complex queries for time-series data- {name: pg_tle } # 1.2 : pg_tle:Trusted Language Extensions for PostgreSQL- {name: vector } # 0.8.0 : pgvector:the vector similarity search- {name: pgmq } # 1.4.4 : pgmq:A lightweight message queue like AWS SQS and RSMQ# supabase required extensionspg_libs:'timescaledb, plpgsql, plpgsql_check, pg_cron, pg_net, pg_stat_statements, auto_explain, pg_tle, plan_filter'pg_parameters:cron.database_name:postgrespgsodium.enable_event_trigger:offpg_hba_rules:# supabase hba rules, require access from docker network- {user: all ,db: postgres ,addr: intra ,auth: pwd ,title:'allow supabase access from intranet'}- {user: all ,db: postgres ,addr: 172.17.0.0/16 ,auth: pwd ,title:'allow access from local docker network'}node_crontab:['00 01 * * * postgres /pg/bin/pg-backup full']# make a full backup every 1am# launch supabase stateless part with docker compose: ./supabase.ymlsupabase:hosts:10.10.10.10:{supa_seq:1}# instance idvars:supa_cluster:supa # cluster namedocker_enabled:true# enable docker# use these to pull docker images via proxy and mirror registries#docker_registry_mirrors: ['https://docker.xxxxx.io']#proxy_env: # add [OPTIONAL] proxy env to /etc/docker/daemon.json configuration file# no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"# #all_proxy: http://user:pass@host:port# these configuration entries will OVERWRITE or APPEND to /opt/supabase/.env file (src template: app/supabase/.env)# check https://github.com/pgsty/pigsty/blob/main/app/supabase/.env for default valuessupa_config:# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!# https://supabase.com/docs/guides/self-hosting/docker#securing-your-servicesjwt_secret:your-super-secret-jwt-token-with-at-least-32-characters-longanon_key:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GEservice_role_key:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Qdashboard_username:supabasedashboard_password:pigsty# postgres connection string (use the correct ip and port)postgres_host:10.10.10.10postgres_port:5436# access via the 'default' service, which always route to the primary postgrespostgres_db:postgrespostgres_password:DBUser.Supa # password for supabase_admin and multiple supabase users# expose supabase via domain namesite_url:http://supa.pigstyapi_external_url:http://supa.pigstysupabase_public_url:http://supa.pigsty# if using s3/minio as file storages3_bucket:supas3_endpoint:https://sss.pigsty:9000s3_access_key:supabases3_secret_key:S3User.Supabases3_force_path_style:trues3_protocol:httpss3_region:stubminio_domain_ip:10.10.10.10# sss.pigsty domain name will resolve to this ip statically# if using SMTP (optional)#smtp_admin_email: [email protected]#smtp_host: supabase-mail#smtp_port: 2500#smtp_user: fake_mail_user#smtp_pass: fake_mail_password#smtp_sender_name: fake_sender#enable_anonymous_users: false#==============================================================## Global Parameters#==============================================================#vars:version:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlinfra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}minio :{domain: m.pigsty ,endpoint:"10.10.10.10:9001", https: true, websocket:true}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}# expose supa studio UI and API via nginxsupa :{domain: supa.pigsty ,endpoint:"10.10.10.10:8000", websocket:true}#----------------------------------## Credential: CHANGE THESE PASSWORDS#----------------------------------##grafana_admin_username: admingrafana_admin_password:pigsty#pg_admin_username: dbuser_dbapg_admin_password:DBUser.DBA#pg_monitor_username: dbuser_monitorpg_monitor_password:DBUser.Monitor#pg_replication_username: replicatorpg_replication_password:DBUser.Replicator#patroni_username: postgrespatroni_password:Patroni.API#haproxy_admin_username: adminhaproxy_admin_password:pigsty# use minio as supabase file storage, single node single driver mode for demonstration purposeminio_access_key:minioadmin # root access key, `minioadmin` by defaultminio_secret_key:minioadmin # root secret key, `minioadmin` by defaultminio_buckets:[{name:pgsql }, { name: supa } ]minio_users:- {access_key: dba , secret_key: S3User.DBA, policy:consoleAdmin }- {access_key: pgbackrest , secret_key: S3User.Backup, policy:readwrite }- {access_key: supabase , secret_key: S3User.Supabase, policy:readwrite }minio_endpoint:https://sss.pigsty:9000 # explicit overwrite minio endpoint with haproxy portnode_etc_hosts:["10.10.10.10 sss.pigsty"]# domain name to access minio from all nodes (required)# use minio as default backup repo for PostgreSQLpgbackrest_method: minio # pgbackrest repo method:local,minio,[user-defined...]pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorylocal:# default pgbackrest repo with local posix fspath:/pg/backup # local backup directory, `/pg/backup` by defaultretention_full_type:count # retention full backups by countretention_full:2# keep 2, at most 3 full backup when using local fs repominio:# optional minio repo for pgbackresttype:s3 # minio is s3-compatible, so s3 is useds3_endpoint:sss.pigsty # minio endpoint domain name, `sss.pigsty` by defaults3_region:us-east-1 # minio region, us-east-1 by default, useless for minios3_bucket:pgsql # minio bucket name, `pgsql` by defaults3_key:pgbackrest # minio user access key for pgbackrests3_key_secret:S3User.Backup # minio user secret key for pgbackrests3_uri_style:path # use path style uri for minio rather than host stylepath:/pgbackrest # minio backup path, default is `/pgbackrest`storage_port:9000# minio port, 9000 by defaultstorage_ca_file:/pg/cert/ca.crt # minio ca file path, `/pg/cert/ca.crt` by defaultbundle:y# bundle small files into a single filecipher_type:aes-256-cbc # enable AES encryption for remote backup repocipher_pass:pgBackRest # AES encryption password, default is 'pgBackRest'retention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days# download docker and all available extensionspg_version:17repo_modules:node,pgsql,infra,dockerrepo_packages:[node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility, docker ]repo_extra_packages:[pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]pg_extensions:[pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]
注意事项
4.7 - 1-node: bare
The minimal single-node config template, with only the essential components required to run a PostgreSQL instance.
The bare is an extremely minimal config template that only includes the essential components required to run a PostgreSQL instance.
This configuration is suitable for users who want to deploy a single-node PostgreSQL instance with the least amount of resources and dependencies. Any configuration template with fewer components than this will not work properly.
A four-node standard sandbox demonstration environment, featuring two PostgreSQL clusters, MinIO, Etcd, Redis, and a sample FerretDB cluster.
The full template is the sandbox template, recommended by Pigsty.
It uses 4 nodes, deploys two PostgreSQL clusters, and can be used to test and demonstrate Pigsty’s capabilities.
Most tutorials and examples are based on this template. sandbox environment.
Description: A four-node standard sandbox demonstration environment, featuring two PostgreSQL clusters, MinIO, Etcd, Redis, and a sample FerretDB cluster.
#==============================================================## File : safe.yml# Desc : Pigsty 3-node security enhance template# Ctime : 2020-05-22# Mtime : 2024-11-12# Docs : https://pigsty.io/docs/conf/safe# Author : Ruohang Feng ([email protected])# License : AGPLv3#==============================================================##===== SECURITY ENHANCEMENT CONFIG TEMPLATE WITH 3 NODES ======## * 3 infra nodes, 3 etcd nodes, single minio node# * 3-instance pgsql cluster with an extra delayed instance# * crit.yml templates, no data loss, checksum enforced# * enforce ssl on postgres & pgbouncer, use postgres by default# * enforce an expiration date for all users (20 years by default)# * enforce strong password policy with passwordcheck extension# * enforce changing default password for all users# * log connections and disconnections# * restrict listen ip address for postgres/patroni/pgbouncerall:children:infra:# infra cluster for proxy, monitor, alert, etchosts:# 1 for common usage, 3 nodes for production10.10.10.10:{infra_seq:1}# identity required10.10.10.11:{infra_seq: 2, repo_enabled:false}10.10.10.12:{infra_seq: 3, repo_enabled:false}vars:{patroni_watchdog_mode:off}minio:# minio cluster, s3 compatible object storagehosts:{10.10.10.10:{minio_seq:1}}vars:{minio_cluster:minio }etcd:# dcs service for postgres/patroni ha consensushosts:# 1 node for testing, 3 or 5 for production10.10.10.10:{etcd_seq:1}# etcd_seq required10.10.10.11:{etcd_seq:2}# assign from 1 ~ n10.10.10.12:{etcd_seq:3}# odd number pleasevars:# cluster level parameter override roles/etcdetcd_cluster:etcd # mark etcd cluster name etcdetcd_safeguard:false# safeguard against purgingetcd_clean:true# purge etcd during init processpg-meta:# 3 instance postgres cluster `pg-meta`hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }10.10.10.11:{pg_seq: 2, pg_role:replica }10.10.10.12:{pg_seq: 3, pg_role: replica , pg_offline_query:true}vars:pg_cluster:pg-metapg_conf:crit.ymlpg_users:- {name: dbuser_meta , password: Pleas3-ChangeThisPwd ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment:pigsty admin user }- {name: dbuser_view , password: Make.3ure-Compl1ance ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment:read-only viewer for meta database }pg_databases:- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [ pigsty ] ,extensions:[{name:vector } ] }pg_services:- {name: standby , ip:"*",port: 5435 , dest: default ,selector:"[]", backup:"[? pg_role == `primary`]"}pg_listen:'${ip},${vip},${lo}'pg_vip_enabled:truepg_vip_address:10.10.10.2/24pg_vip_interface:eth1# OPTIONAL delayed cluster for pg-metapg-meta-delay:# delayed instance for pg-meta (1 hour ago)hosts:{10.10.10.13:{pg_seq: 1, pg_role: primary, pg_upstream: 10.10.10.10, pg_delay:1h } }vars:{pg_cluster:pg-meta-delay }##################################################################### Parameters #####################################################################vars:# global variablesversion:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlpatroni_ssl_enabled:true# secure patroni RestAPI communications with SSL?pgbouncer_sslmode: require # pgbouncer client ssl mode:disable|allow|prefer|require|verify-ca|verify-full, disable by defaultpg_default_service_dest:postgres# default service destination to postgres instead of pgbouncerpgbackrest_method: minio # pgbackrest repo method:local,minio,[user-defined...]#----------------------------------## Credentials#----------------------------------##grafana_admin_username: admingrafana_admin_password:You.Have2Use-A_VeryStrongPassword#pg_admin_username: dbuser_dbapg_admin_password:PessWorb.Should8eStrong-eNough#pg_monitor_username: dbuser_monitorpg_monitor_password:MekeSuerYour.PassWordI5secured#pg_replication_username: replicatorpg_replication_password:doNotUseThis-PasswordFor.AnythingElse#patroni_username: postgrespatroni_password:don.t-forget-to-change-thEs3-password#haproxy_admin_username: adminhaproxy_admin_password:GneratePasswordWith-pwgen-s-16-1#----------------------------------## MinIO Related Options#----------------------------------#minio_users:# and configure `pgbackrest_repo` & `minio_users` accordingly- {access_key: dba , secret_key: S3User.DBA.Strong.Password, policy:consoleAdmin }- {access_key: pgbackrest , secret_key: Min10.bAckup ,policy:readwrite }pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorylocal:# default pgbackrest repo with local posix fspath:/pg/backup # local backup directory, `/pg/backup` by defaultretention_full_type:count # retention full backups by countretention_full:2# keep 2, at most 3 full backup when using local fs repominio:# optional minio repo for pgbackrests3_key:pgbackrest # <-------- CHANGE THIS, SAME AS `minio_users` access_keys3_key_secret:Min10.bAckup # <-------- CHANGE THIS, SAME AS `minio_users` secret_keycipher_pass:'pgBR.${pg_cluster}'# <-------- CHANGE THIS, you can use cluster name as part of passwordtype:s3 # minio is s3-compatible, so s3 is useds3_endpoint:sss.pigsty # minio endpoint domain name, `sss.pigsty` by defaults3_region:us-east-1 # minio region, us-east-1 by default, useless for minios3_bucket:pgsql # minio bucket name, `pgsql` by defaults3_uri_style:path # use path style uri for minio rather than host stylepath:/pgbackrest # minio backup path, default is `/pgbackrest`storage_port:9000# minio port, 9000 by defaultstorage_ca_file:/etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by defaultbundle:y# bundle small files into a single filecipher_type:aes-256-cbc # enable AES encryption for remote backup reporetention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days#----------------------------------## Access Control#----------------------------------## add passwordcheck extension to enforce strong password policypg_libs:'$libdir/passwordcheck, pg_stat_statements, auto_explain'pg_extensions:- passwordcheck, supautils, pgsodium, pg_vault, pg_session_jwt, anonymizer, pgsmcrypto, pgauditlogtofile, pgaudit#, pgaudit17, pgaudit16, pgaudit15, pgaudit14- pg_auth_mon, credcheck, pgcryptokey, pg_jobmon, logerrors, login_hook, set_user, pgextwlist, pg_auditor, sslutils, noset #pg_tde#pg_snakeoilpg_default_roles:# default roles and users in postgres cluster- {name: dbrole_readonly ,login: false ,comment:role for global read-only access }- {name: dbrole_offline ,login: false ,comment:role for restricted read-only access }- {name: dbrole_readwrite ,login: false ,roles: [ dbrole_readonly ] ,comment:role for global read-write access }- {name: dbrole_admin ,login: false ,roles: [ pg_monitor, dbrole_readwrite ] ,comment:role for object creation }- {name: postgres ,superuser: true ,expire_in: 7300 ,comment:system superuser }- {name: replicator ,replication: true ,expire_in: 7300 ,roles: [ pg_monitor, dbrole_readonly ] ,comment:system replicator }- {name: dbuser_dba ,superuser: true ,expire_in: 7300 ,roles: [ dbrole_admin ] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment:pgsql admin user }- {name: dbuser_monitor ,roles: [ pg_monitor ] ,expire_in: 7300 ,pgbouncer: true ,parameters:{log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment:pgsql monitor user }pg_default_hba_rules:# postgres host-based auth rules by default- {user:'${dbsu}',db: all ,addr: local ,auth: ident ,title:'dbsu access via local os user ident'}- {user:'${dbsu}',db: replication ,addr: local ,auth: ident ,title:'dbsu replication from local os ident'}- {user:'${repl}',db: replication ,addr: localhost ,auth: ssl ,title:'replicator replication from localhost'}- {user:'${repl}',db: replication ,addr: intra ,auth: ssl ,title:'replicator replication from intranet'}- {user:'${repl}',db: postgres ,addr: intra ,auth: ssl ,title:'replicator postgres db from intranet'}- {user:'${monitor}',db: all ,addr: localhost ,auth: pwd ,title:'monitor from localhost with password'}- {user:'${monitor}',db: all ,addr: infra ,auth: ssl ,title:'monitor from infra host with password'}- {user:'${admin}',db: all ,addr: infra ,auth: ssl ,title:'admin @ infra nodes with pwd & ssl'}- {user:'${admin}',db: all ,addr: world ,auth: cert ,title:'admin @ everywhere with ssl & cert'}- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: ssl ,title:'pgbouncer read/write via local socket'}- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: ssl ,title:'read/write biz user via password'}- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: ssl ,title:'allow etl offline tasks from intranet'}pgb_default_hba_rules:# pgbouncer host-based authentication rules- {user:'${dbsu}',db: pgbouncer ,addr: local ,auth: peer ,title:'dbsu local admin access with os ident'}- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title:'allow all user local access with pwd'}- {user:'${monitor}',db: pgbouncer ,addr: intra ,auth: ssl ,title:'monitor access via intranet with pwd'}- {user:'${monitor}',db: all ,addr: world ,auth: deny ,title:'reject all other monitor access addr'}- {user:'${admin}',db: all ,addr: intra ,auth: ssl ,title:'admin access via intranet with pwd'}- {user:'${admin}',db: all ,addr: world ,auth: deny ,title:'reject all other admin access addr'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'allow all user intra access with pwd'}#----------------------------------## Repo, Node, Packages#----------------------------------## if you wish to customize your own repo, change these settings:repo_modules:infra,node,pgsql # install upstream repo during repo bootstraprepo_remove:true# remove existing repo on admin node during repo bootstrapnode_repo_modules:local # install the local module in repo_upstream for all nodesnode_repo_remove:true# remove existing node repo for node managed by pigstyrepo_packages:[# default packages to be downloadednode-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-common#,docker]repo_extra_packages:[# default postgres packages to be downloadedpg17-main, pg17-sec # replace with the following line if you want all extensions#pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]
Caveat
Beware that not all security-related extensions are available in ARM64 environments, ARM system users should enable extensions at their discretion.
4.10 - 4-node: mssql
Replaces PostgreSQL with a Microsoft SQL Server-compatible kernel using WiltonDB or Babelfish.
The mssql config template is based on full template.
Which use the WiltonDB / Babelfish kernel to replace the vanilla PostgreSQL kernel, providing Microsoft SQL Server wire protocol level compatibility.
all:children:# infra cluster for proxy, monitor, alert, etc..infra:{hosts:{10.10.10.10:{infra_seq:1}}}# etcd cluster for ha postgresetcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }# postgres example cluster: pg-metapg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-metapg_users:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment:read-only viewer for meta database }pg_databases:- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas:[pigsty]}pg_hba_rules:- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}pg_vip_enabled:truepg_vip_address:10.10.10.2/24pg_vip_interface:eth1# pgsql 3 node ha cluster: pg-testpg-test:hosts:10.10.10.11:{pg_seq: 1, pg_role:primary } # primary instance, leader of cluster10.10.10.12:{pg_seq: 2, pg_role:replica } # replica instance, follower of leader10.10.10.13:{pg_seq: 3, pg_role: replica, pg_offline_query:true}# replica with offline accessvars:pg_cluster:pg-test # define pgsql cluster namepg_users:[{name: test , password: test , pgbouncer: true , roles:[dbrole_admin ] }]pg_databases:[{name:test }]pg_vip_enabled:truepg_vip_address:10.10.10.3/24pg_vip_interface:eth1vars:# global variablesversion:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlinfra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}#----------------------------------## NODE, PGSQL, PolarDB#----------------------------------## THIS SPEC REQUIRE AN AVAILABLE POLARDB KERNEL IN THE LOCAL REPO!pg_version:15pg_packages:['polardb patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager']pg_extensions:[]# do not install any vanilla postgresql extensionspg_mode:polar # polardb compatible modepg_exporter_exclude_database:'template0,template1,postgres,polardb_admin'pg_default_roles:# default roles and users in postgres cluster- {name: dbrole_readonly ,login: false ,comment:role for global read-only access }- {name: dbrole_offline ,login: false ,comment:role for restricted read-only access }- {name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment:role for global read-write access }- {name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment:role for object creation }- {name: postgres ,superuser: true ,comment:system superuser }- {name: replicator ,superuser: true ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment:system replicator }# <- superuser is required for replication- {name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 ,comment:pgsql admin user }- {name: dbuser_monitor ,roles: [pg_monitor] ,pgbouncer: true ,parameters:{log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment:pgsql monitor user }repo_packages:[node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility ]repo_extra_packages:[polardb ]# replace vanilla postgres kernel with polardb kernel
Caveat
PolarDB for PostgreSQL does not have ARM architecture packages available at the moment.
It is currently only available on EL 7/8/9 and Ubuntu 20.04/22.04/24.04 systems, and Debian-based operating system support is not currently available.
The latest version of PolarDB is based on the PostgreSQL 15 fork.
4.12 - 4-node: ivory
Replaces native PostgreSQL with IvorySQL, an Oracle-compatible kernel by HighGo.
The ivory template is based on the full 4-node template,
which replaces the native PostgreSQL kernel with IvorySQL, an Oracle-compatible kernel by HighGo.
all:children:# infra singleton for repo, monitoring,...infra:hosts:10.10.10.10:{infra_seq:1}# etcd singleton for HA postgres DCSetcd:hosts:10.10.10.10:{etcd_seq:1}vars:etcd_cluster:etcd# ivorysql singletonpg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }vars:pg_cluster:pg-metapg_users:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment:read-only viewer for meta database }pg_databases:- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas:[pigsty]}pg_hba_rules:- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}pg_vip_enabled:truepg_vip_address:10.10.10.2/24pg_vip_interface:eth1# ivorysql 3-node ha cluster: 10.10.10.3 ---> 10.10.10.1{1,2,3}pg-test:hosts:10.10.10.11:{pg_seq: 1, pg_role:primary } # primary instance, leader of cluster10.10.10.12:{pg_seq: 2, pg_role:replica } # replica instance, follower of leader10.10.10.13:{pg_seq: 3, pg_role: replica, pg_offline_query:true}# replica with offline accessvars:pg_cluster:pg-test # define pgsql cluster namepg_users:[{name: test , password: test , pgbouncer: true , roles:[dbrole_admin ] }]pg_databases:[{name:test }]pg_vip_enabled:truepg_vip_address:10.10.10.3/24pg_vip_interface:eth1vars:# global variablesversion:v3.4.1 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default,china,europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlinfra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}#----------------------------------## Ivory SQL Configuration#----------------------------------#pg_mode:ivory # IvorySQL Oracle Compatible Modepg_version:17# The current IvorySQL compatible major version is 17pg_packages:['ivorysql patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager']pg_libs:'liboracle_parser, pg_stat_statements, auto_explain'repo_modules:node,pgsql,infrarepo_packages:[node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility ]#dockerrepo_extra_packages:[ivorysql ]# replace default postgresql kernel with ivroysql packages
Notes
IvorySQL currently provides generic RPM/DEB packages that are not tied to specific major versions of OS distributions. Instead, they are only distinguished by distribution family (DEB/RPM) and system architecture (x86_64/aarch64).
To install IvorySQL, your system must have glibc > 2.17. Make sure this requirement is met. All system versions supported by Pigsty meet this condition:
CentOS 7: 2.17
Debian 9: 2.19
Ubuntu 14.04: 2.19
On EL-based systems, the package name is ivorysql4, while on Debian/Ubuntu systems, it is ivorysql-4.
4.13 - 4-node: mysql
Replaces native PostgreSQL with openHalo, an Oracle-compatible kernel by HighGo.
The mysql template is based on the full 4-node template,
which replaces the native PostgreSQL kernel with openHalo, an Oracle-compatible kernel by HighGo.
all:children:infra:hosts:10.10.10.10:{infra_seq:1}etcd:hosts:10.10.10.10:{etcd_seq:1}vars:etcd_cluster:etcd# openHaloDB singletonpg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }vars:pg_cluster:pg-metapg_users:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment:read-only viewer for meta database }pg_databases:- {name: postgres, extensions:[aux_mysql]}# the mysql compatible database- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas:[pigsty]}pg_hba_rules:- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}pg_vip_enabled:truepg_vip_address:10.10.10.2/24pg_vip_interface:eth1# halo 3-node ha cluster: 10.10.10.3 ---> 10.10.10.1{1,2,3}pg-test:hosts:10.10.10.11:{pg_seq: 1, pg_role:primary } # primary instance, leader of cluster10.10.10.12:{pg_seq: 2, pg_role:replica } # replica instance, follower of leader10.10.10.13:{pg_seq: 3, pg_role: replica, pg_offline_query:true}# replica with offline accessvars:pg_cluster:pg-test # define pgsql cluster namepg_users:[{name: test , password: test , pgbouncer: true , roles:[dbrole_admin ] }]pg_databases:[{name:test}, { name: postgres, extensions: [aux_mysql] }]pg_vip_enabled:truepg_vip_address:10.10.10.3/24pg_vip_interface:eth1vars:# global variablesversion:v3.4.1 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default,china,europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.yml#docker_registry_mirrors: ["https://docker.1ms.run", "https://docker.m.daocloud.io"]infra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}pg_mode:mysql # MySQL Compatible Mode by HaloDBpg_version:14# The current HaloDB is compatible with PG Major Version 14pg_packages:[openhalodb, pgsql-common, mysql ] # also install mysql client shellrepo_modules:node,pgsql,infra,mysqlrepo_extra_packages:[openhalodb, mysql ]# replace default postgresql kernel with openhalo packages
Notes
openHalo is newly open-sourced, and the RPM package is currently provided by Pigsty.
Pigsty will provide support for Debian / Ubuntu in the future.
4.14 - 4-node: oriole
Replaces native PostgreSQL with OrioleDB, an OLTP enhanced storage engine.
The oriole template is based on the full 4-node template,
which replaces the native PostgreSQL kernel with OrioleDB, an OLTP enhanced storage engine by HighGo.
all:children:# infra cluster for proxy, monitor, alert, etc..infra:{hosts:{10.10.10.10:{infra_seq:1}}}# minio cluster with 4 nodes and 4 drivers per nodeminio:hosts:10.10.10.10:{minio_seq: 1 , nodename:minio-1 }10.10.10.11:{minio_seq: 2 , nodename:minio-2 }10.10.10.12:{minio_seq: 3 , nodename:minio-3 }10.10.10.13:{minio_seq: 4 , nodename:minio-4 }vars:minio_cluster:miniominio_data:'/data{1...4}'minio_buckets:[{name:pgsql }, { name: infra }, { name: redis } ]minio_users:- {access_key: dba , secret_key: S3User.DBA, policy:consoleAdmin }- {access_key: pgbackrest , secret_key: S3User.SomeNewPassWord , policy:readwrite }# bind a node l2 vip (10.10.10.9) to minio cluster (optional)node_cluster:miniovip_enabled:truevip_vrid:128vip_address:10.10.10.9vip_interface:eth1# expose minio service with haproxy on all nodeshaproxy_services:- name:minio # [REQUIRED] service name, uniqueport:9002# [REQUIRED] service port, uniquebalance:leastconn # [OPTIONAL] load balancer algorithmoptions:# [OPTIONAL] minio health check- option httpchk- option http-keep-alive- http-check send meth OPTIONS uri /minio/health/live- http-check expect status 200servers:- {name: minio-1 ,ip: 10.10.10.10 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-2 ,ip: 10.10.10.11 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-3 ,ip: 10.10.10.12 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-4 ,ip: 10.10.10.13 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}vars:version:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europeinfra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}# domain names to access minio web console via nginx web portal (optional)minio :{domain: m.pigsty ,endpoint:"10.10.10.10:9001",scheme: https ,websocket:true}minio10 :{domain: m10.pigsty ,endpoint:"10.10.10.10:9001",scheme: https ,websocket:true}minio11 :{domain: m11.pigsty ,endpoint:"10.10.10.11:9001",scheme: https ,websocket:true}minio12 :{domain: m12.pigsty ,endpoint:"10.10.10.12:9001",scheme: https ,websocket:true}minio13 :{domain: m13.pigsty ,endpoint:"10.10.10.13:9001",scheme: https ,websocket:true}minio_endpoint:https://sss.pigsty:9002 # explicit overwrite minio endpoint with haproxy portnode_etc_hosts:["10.10.10.9 sss.pigsty"]# domain name to access minio from all nodes (required)
Caveat
4.16 - 2-node: dual
Dual-node template to set up a basic high-availability PostgreSQL cluster with master-slave replication, tolerating the failure of one node.
This template illustrates a “half” high-availability PostgreSQL cluster with primary - replica replication,
tolerating the failure of one specific node. It is a good choice if you only have two servers.
Description: Dual-node template to set up a basic high-availability PostgreSQL cluster with master-slave replication, tolerating the failure of one node.
OS Distro: el8, el9, d12, u22, u24
OS Arch: x86_64, aarch64
Related:
Description
To enable: Use the -c dual parameter during the configure process:
./configure -c dual [-i <primary_ip>]
you may have to replace another node ip placeholder 10.10.10.11
# It is recommended to use at least three nodes in production deployment.# But sometimes, there are only two nodes available, that's dual.yml for## In this setup, we have two nodes, .10 (admin_node) and .11 (pgsql_priamry):## If .11 is down, .10 will take over since the dcs:etcd is still alive# If .10 is down, .11 (pgsql primary) will still be functioning as a primary if:# - Only dcs:etcd is down# - Only pgsql is down# if both etcd & pgsql are down (e.g. node down), the primary will still demote itself.all:children:# infra cluster for proxy, monitor, alert, etc..infra:{hosts:{10.10.10.10:{infra_seq:1}}}# etcd cluster for ha postgresetcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }# minio cluster, optional backup repo for pgbackrest#minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }# postgres cluster 'pg-meta' with single primary instancepg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:replica }10.10.10.11:{pg_seq: 2, pg_role:primary } # <----- use this as primary by defaultvars:pg_cluster:pg-metapg_databases:[{name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [ pigsty ] ,extensions:[{name:vector }] } ]pg_users:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment:read-only viewer for meta database }node_crontab:['00 01 * * * postgres /pg/bin/pg-backup full']# make a full backup every 1ampg_vip_enabled:truepg_vip_address:10.10.10.2/24pg_vip_interface:eth1vars:# global parametersversion:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default,china,europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymlinfra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}#minio : { domain: m.pigsty ,endpoint: "${admin_ip}:9001" ,scheme: https ,websocket: true }# consider using local fs or external s3 service for cold backup storage in dual node configuration#pgbackrest_method: minio#----------------------------------## Repo, Node, Packages#----------------------------------## if you wish to customize your own repo, change these settings:repo_modules:infra,node,pgsql # install upstream repo during repo bootstraprepo_remove:true# remove existing repo on admin node during repo bootstrapnode_repo_modules:local # install the local module in repo_upstream for all nodesnode_repo_remove:true# remove existing node repo for node managed by pigstyrepo_packages:[# default packages to be downloadednode-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-common#,docker]repo_extra_packages:[# default postgres packages to be downloadedpg17-main # replace with the following line if you want all extensions#pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]pg_version:17# default postgres version#pg_extensions: [ pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]#pg_extensions: # check extension availability for your OS & PG @ /ext/list# - timescaledb periods temporal_tables emaj table_version pg_cron pg_later pg_background #timescaledb_toolkit #pg_timeseries# - postgis pgrouting pointcloud pg_h3 q3c ogr_fdw geoip pg_polyline pg_geohash mobilitydb# - pgvector vchord pgvectorscale pg_vectorize pg_similarity smlar pg_summarize pg_tiktoken pg4ml #pgml# - pg_search pgroonga pg_bigm zhparser pg_bestmatch hunspell# - pg_analytics pg_duckdb duckdb_fdw pg_parquet pg_fkpart pg_partman plproxy #citus #hydra #pg_strom# - hll rum pg_graphql pg_jsonschema jsquery pg_hint_plan hypopg index_advisor pg_plan_filter imgsmlr pg_ivm pgmq pgq pg_cardano #age #rdkit# - pg_tle plv8 pllua pldebugger plpgsql_check plprofiler plsh pljava #plprql #plr #pgtap #faker #dbt2# - pg_prefix pg_semver pgunit pgpdf pglite_fusion md5hash asn1oid roaringbitmap pgfaceting pgsphere pg_country pg_currency pgmp numeral pg_rational pguint pg_uint128 ip4r pg_uri pgemailaddr pg_acl #debversion pg_rrule timestamp9 chkpass# - pg_gzip pg_zstd pg_http pg_net pg_smtp_client pg_html5_email_address pgsql_tweaks pg_extra_time count_distinct extra_window_functions first_last_agg tdigest aggs_for_vecs aggs_for_arrays pg_arraymath quantile lower_quantile# - pg_idkit pg_uuidv7 permuteseq pg_hashids sequential_uuids pg_math pg_random pg_base36 pg_base62 pg_base58 floatvec pg_financial pgjwt pg_hashlib shacrypt cryptint pg_ecdsa pgpcre icu_ext pgqr envvar pg_protobuf url_encode #topn# - pg_repack pg_squeeze pg_dirtyread pgfincore pg_ddlx pg_prioritize pg_checksums pg_readonly safeupdate pg_permissions pgautofailover pg_catcheck preprepare pgcozy pg_orphaned pg_crash pg_cheat_funcs pg_savior table_log pg_fio #pgpool #pgagent# - pg_profile pg_show_plans pg_stat_kcache pg_stat_monitor pg_qualstats pg_track_settings pg_wait_sampling system_stats pg_meta pgnodemx pg_sqlog bgw_replstatus pgmeminfo toastinfo pg_explain_ui pg_relusage pagevis #pg_store_plans #powa# - passwordcheck supautils pgsodium pg_vault pg_session_jwt pg_anon pgsmcrypto pgaudit pgauditlogtofile pg_auth_mon credcheck pgcryptokey pg_jobmon logerrors login_hook set_user pg_snakeoil pgextwlist pg_auditor sslutils pg_noset #pg_tde# - wrappers mysql_fdw tds_fdw redis_fdw pg_redis_pubsub firebird_fdw aws_s3 log_fdw #multicorn #odbc_fdw #jdbc_fdw #oracle_fdw #db2_fdw #sqlite_fdw #pgbouncer_fdw #mongo_fdw #kafka_fdw #hdfs_fdw# - orafce pgtt session_variable pg_statement_rollback pgmemcache #pg_dbms_metadata #pg_dbms_lock #pg_dbms_job #wiltondb# - pglogical pglogical_ticker pgl_ddl_deploy pg_failover_slots wal2json decoderbufs decoder_raw mimeo pg_fact_loader #wal2mongo #repmgr #pg_bulkload
Caveat
Typically, in production environments, a complete high-availability deployment requires at least three nodes to ensure that the cluster can continue operating normally if any single server fails. This is because high-availability failure detection DCS (etcd)/Patroni requires participation from a majority of nodes, which cannot be met with just two nodes.
However, sometimes only two servers are available. In such cases, the dual template is a feasible option, assuming you have two servers:
Node A, 10.10.10.10: Defaults as the management node, running Infra infrastructure, single-node etcd, and a PostgreSQL standby.
Node B, 10.10.10.11: Serves only as the PostgreSQL primary.
In this scenario, the dual-node template allows node B to fail and will automatically switch over to node A after a failure. However, if node A fails (the entire node crashes), manual intervention is required. Nevertheless, if node A is not completely offline but only etcd or PostgreSQL itself has issues, the whole system can still continue to operate normally.
This template uses an L2 VIP to achieve high-availability access. If your network conditions do not allow the use of an L2 VIP
(for example, in restricted cloud env or across switch broadcast domains), you may consider using DNS resolution or other access methods instead.
4.17 - 2-node: slim
Minimal installation that avoids setting up local software repositories or infrastructure, relying only on etcd for a highly available PostgreSQL cluster.
The slim template is a minimal installation example that avoids setting up local software repo or any infrastructure components,
focusing on pure PostgreSQL HA cluster installation, relying only on etcd for a highly available PostgreSQL cluster.
If you need a simplest available database instance without deploying monitoring and dependencies, consider the slim install mode.
Description: Minimal installation that avoids setting up local software repositories or infrastructure, relying only on etcd for a highly available PostgreSQL cluster.
all:children:# actually not usedinfra:{hosts:{10.10.10.10:{infra_seq:1}}}#----------------------------------## etcd cluster for HA postgres DCS#----------------------------------#etcd:hosts:10.10.10.10:{etcd_seq:1}vars:etcd_cluster:etcd# postgres cluster 'pg-meta' with 2 instancespg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }10.10.10.11:{pg_seq: 2, pg_role:replica }vars:pg_cluster:pg-metapg_databases:[{name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions:[{name:vector}]}]pg_users:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment:read-only viewer for meta database }node_crontab:['00 01 * * * postgres /pg/bin/pg-backup full']# make a full backup every 1amvars:# global parametersversion:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default,china,europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.yml# slim installation setupnginx_enabled:false# nginx not existsdns_enabled:false# dnsmasq not existsprometheus_enabled:false# prometheus not existsgrafana_enabled:false# grafana not existspg_exporter_enabled:false# disable pg_exporterpgbouncer_exporter_enabled:falsepg_vip_enabled:false#----------------------------------## Repo, Node, Packages#----------------------------------## if you wish to customize your own repo, change these settings:repo_modules:infra,node,pgsqlrepo_remove:true# remove existing repo on admin node during repo bootstrapnode_repo_modules:local # install the local module in repo_upstream for all nodesnode_repo_remove:true# remove existing node repo for node managed by pigstyrepo_packages:[# default packages to be downloadednode-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-common#,docker]repo_extra_packages:[# default postgres packages to be downloadedpg17-main # replace with the following line if you want all extensions#pg17-core ,pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl]#pg_extensions: [ pg17-time ,pg17-gis ,pg17-rag ,pg17-fts ,pg17-olap ,pg17-feat ,pg17-lang ,pg17-type ,pg17-func ,pg17-admin ,pg17-stat ,pg17-sec ,pg17-fdw ,pg17-sim ,pg17-etl ]
Caveat
There’s no monitoring or alerting in this mode, since there’s no infra module installed.
4.18 - 3-node: trio
Three-node configuration template providing a standard High Availability (HA) architecture, tolerating failure of one out of three nodes.
The 3-node configuration template is a standard HA architecture, tolerating failure of 1 out of 3 nodes.
This configuration is the minimum spec for achieving true high availability.
In this case, the DCS (etcd) can tolerate the failure of 1 node.
The INFRA, ETCD, and PGSQL core modules are all deployed with 3 nodes, allowing one node to fail.
Pigsty does not use any virtualization or containerization technologies, running directly on the bare OS. Supported operating systems include EL 7/8/9 (RHEL, Rocky, CentOS, Alma, Oracle, Anolis,…),
Ubuntu 24.04 / 20.04 / 22.04 & Debian 11/12. EL is our long-term supported OS, while support for Ubuntu/Debian systems was introduced in the recent v2.5 version.
The main difference between EL and Debian distributions is the significant variation in package names, as well as the default availability of PostgreSQL extensions.
If you have advanced compatibility requirements, such as using specific operating system distributions, major versions, or minor versions, we offer advance compatibility support options.
Kernel & Arch Support
Currently, Pigsty supports the Linux kernel and the x86_64 / amd64 chip architecture.
MacOS and Windows operating systems can install Pigsty via Linux virtual machines/containers. We provide Vagrant local sandbox support, allowing you to use virtualization software like Vagrant and Virtualbox to effortlessly bring up the deployment environment required by Pigsty on other operating systems.
ARM64 Support
We have partial support for arm64 architecture with our pro service, (EL9 & Debian12 & Ubuntu 22.04)
EL Distribution Support
The EL series operating systems are Pigsty’s primary support target, including compatible distributions such as Red Hat Enterprise Linux, RockyLinux, CentOS, AlmaLinux, OracleLinux, Anolis, etc. Pigsty supports the latest three major versions: 7, 8, 9
EOLed OS, PG16/17, Rust and many other extensions unavailable
RockyLinux 9.5 Recommended
Rocky 9.5 achieves a good balance between system reliability/stability and the novelty/comprehensiveness of software versions. It’s recommended for EL series users to default to this system version.
EL7 End of Life!
Red Hat Enterprise Linux 7 is end of maintenance, Pigsty will no longer have official EL7 support in the open-source version. We have EL7 legacy support in our pro service.
Debian Distribution Support
Pigsty supports Ubuntu / Debian series operating systems and their compatible distributions, currently supporting the two most recent LTS major versions, namely:
U22: Ubuntu 22.04 LTS jammy (24.04.1)
U22: Ubuntu 22.04 LTS jammy (22.04.3 Recommended)
U20: Ubuntu 20.04 LTS focal (20.04.6)
D12: Debian 12 bookworm (12.4)
D11: Debian 11 bullseye (11.8)
Code
Debian Distros
Minor
PG17
PG16
PG15
PG14
PG13
PG12
Limitations
U24
Ubuntu 24.04 (noble)
24.04.1
Missing PGML, citus, topn, timescale_toolkit
U22
Ubuntu 22.04 (jammy)
22.04.5
Standard Debian series feature set
U20
Ubuntu 20.04 (focal)
20.04.6
EOL, Some extensions require online installation
D12
Debian 12 (bookworm)
12.4
Missing polardb, wiltondb/babelfish, and official PGML support
D11
Debian 11 (bullseye)
11.8
EOL
Ubuntu 22.04 LTS Recommended
Ubuntu 22.04 comes with the most comp
PostgresML has official support for the AL/ML extension pgml for Ubuntu 22.04, so users with related needs are advised to use Ubuntu 22.04.3.
Ubuntu 20.04 nearing EOL
Ubuntu 20.04 focal is not recommended, it will end of standard support @ Apr 2025, Check Ubuntu Release Cycle for details
Besides, Ubuntu 20.04 has missing dependencies for the postgresql-16-postgis and postgresql-server-dev-16 packages, requiring online installation in a connected environment.
If your environment does not have internet access, and you need to use the PostGIS extension, please use this operating system with caution.
Vagrant Boxes
When deploying Pigsty on cloud servers, you might consider using the following operating system images in Vagrant, which are also the images used for Pigsty’s development, testing, and building.
When deploying Pigsty on cloud servers, you might consider using the following operating system base images in Terraform, using Alibaba Cloud as an example:
How files are organized in Pigsty, and directories structure used by modules
Pigsty FHS
#------------------------------------------------------------------------------# pigsty# ^-----@app # extra demo application resources# ^-----@bin # bin scripts# ^-----@docs # document (can be docsified)# ^-----@files # ansible file resources # ^-----@pigsty # pigsty config template files# ^-----@prometheus # prometheus rules definition# ^-----@grafana # grafana dashboards# ^-----@postgres # /pg/bin/ scripts# ^-----@migration # pgsql migration task definition# ^-----@pki # self-signed CA & certs# ^-----@roles # ansible business logic# ^-----@templates # ansible templates# ^-----@vagrant # vagrant local VM template# ^-----@terraform # terraform cloud VM template# ^-----configure # configure wizard script# ^-----ansible.cfg # default ansible config file# ^-----pigsty.yml # default config file# ^-----*.yml # ansible playbooks#------------------------------------------------------------------------------# /etc/pigsty/# ^-----@targets # file based service discovery targets definition# ^-----@dashboards # static grafana dashboards# ^-----@datasources # static grafana datasource# ^-----@playbooks # extra ansible playbooks# ^-----@pgadmin # pgadmin server list and password#------------------------------------------------------------------------------
CA FHS
Pigsty’s self-signed CA is located on files/pki/ directory under pigsty home.
YOU HAVE TO SECURE THE CA KEY PROPERLY: files/pki/ca/ca.key,
which is generated by the ca role during install.yml or infra.yml.
# pigsty/files/pki# ^-----@ca # self-signed CA key & cert# ^[email protected] # VERY IMPORTANT: keep it secret# ^[email protected] # VERY IMPORTANT: trusted everywhere# ^-----@csr # signing request csr# ^-----@misc # misc certs, issued certs# ^-----@etcd # etcd server certs# ^-----@minio # minio server certs# ^-----@nginx # nginx SSL certs# ^-----@infra # infra client certs# ^-----@pgsql # pgsql server certs# ^-----@mongo # mongodb/ferretdb server certs# ^-----@mysql # mysql server certs
The managed nodes will have the following files installed:
/etc/pki/ca.crt # all nodes/etc/pki/ca-trust/source/anchors/ca.crt # soft link and trusted anchor
All infra nodes will have the following certs:
/etc/pki/infra.crt # infra nodes cert/etc/pki/infra.key # infra nodes key
In case of admin node failure, you have to keep files/pki and pigsty.yml safe.
You can rsync them to another admin node to make a backup admin node.
# run on meta-1, rsync to meta2cd ~/pigsty;rsync -avz ./ meta-2:~/pigsty
NODE FHS
Node main data dir is specified by node_data parameter, which is /data by default.
The data dir is owned by root with mode 0777. All modules’ local data will be stored under this directory by default.
/data
# ^-----@postgres # postgres main data dir# ^-----@backups # postgres backup data dir (if no dedicated backup disk)# ^-----@redis # redis data dir (shared by multiple redis instances)# ^-----@minio # minio data dir (default when in single node single disk mode)# ^-----@etcd # etcd main data dir# ^-----@prometheus # prometheus time series data dir# ^-----@loki # Loki data dir for logs# ^-----@docker # Docker data dir# ^-----@... # other modules
Prometheus FHS
The prometheus bin / rules are located on files/prometheus/ directory under pigsty home.
Both Alibaba Cloud RDS and AWS RDS are proprietary cloud database services, offered only on the public cloud through a leasing model. The following comparison is based on the latest PostgreSQL 16 main branch version, with the comparison cut-off date being February 2024.
Features
Item
Pigsty
Aliyun RDS
AWS RDS
Major Version
12 - 17
12 - 17
12 - 17
Read on Standby
Of course
Not Readable
Not Readable
Separate R & W
By Port
Paid Proxy
Paid Proxy
Offline Instance
Yes
Not Available
Not Available
Standby Cluster
Yes
Multi-AZ
Multi-AZ
Delayed Instance
Yes
Not Available
Not Available
Load Balancer
HAProxy / LVS
Paid ELB
Paid ELB
Connection Pooling
Pgbouncer
Paid Proxy
Paid RDS Proxy
High Availability
Patroni / etcd
HA Version Only
HA Version Only
Point-in-Time Recovery
pgBackRest / MinIO
Yes
Yes
Monitoring Metrics
Prometheus / Exporter
About 9 Metrics
About 99 Metrics
Logging Collector
Loki / Promtail
Yes
Yes
Dashboards
Grafana / Echarts
Basic Support
Basic Support
Alerts
AlterManager
Basic Support
Basic Support
Extensions
Here are some important extensions in the PostgreSQL ecosystem. The comparison is base on PostgreSQL 16 and complete on 2024-02-29:
Experience shows that the per-unit cost of hardware and software resources for RDS is 5 to 15 times that of self-built solutions, with the rent-to-own ratio typically being one month. For more details, please refer to Cost Analysis.
RDS / DBA Cost reference to help you evaluate the costs of self-hosting database
Cost Reference
EC2
vCPU-Month
RDS
vCPU-Month
DHH’s self-hosted core-month price (192C 384G)
25.32
Junior open-source DBA reference salary
15K/person-month
IDC self-hosted data center (exclusive physical machine: 64C384G)
19.53
Intermediate open-source DBA reference salary
30K/person-month
IDC self-hosted data center (container, oversold 500%)
7
Senior open-source DBA reference salary
60K/person-month
UCloud Elastic Virtual Machine (8C16G, oversold)
25
ORACLE database license
10000
Alibaba Cloud Elastic Server 2x memory (exclusive without overselling)
107
Alibaba Cloud RDS PG 2x memory (exclusive)
260
Alibaba Cloud Elastic Server 4x memory (exclusive without overselling)
138
Alibaba Cloud RDS PG 4x memory (exclusive)
320
Alibaba Cloud Elastic Server 8x memory (exclusive without overselling)
180
Alibaba Cloud RDS PG 8x memory (exclusive)
410
AWS C5D.METAL 96C 200G (monthly without upfront)
100
AWS RDS PostgreSQL db.T2 (2x)
440
For instance, using RDS for PostgreSQL on AWS, the price for a 64C / 256GB db.m5.16xlarge RDS for one month is $25,817, which is equivalent to about 180,000 yuan per month. The monthly rent is enough for you to buy two servers with even better performance and set them up on your own. The rent-to-buy ratio doesn’t even last a month; renting for just over ten days is enough to buy the whole server for yourself.
Payment Model
Price
Cost Per Year (¥10k)
Self-hosted IDC (Single Physical Server)
¥75k / 5 years
1.5
Self-hosted IDC (2-3 Server HA Cluster)
¥150k / 5 years
3.0 ~ 4.5
Alibaba Cloud RDS (On-demand)
¥87.36/hour
76.5
Alibaba Cloud RDS (Monthly)
¥42k / month
50
Alibaba Cloud RDS (Yearly, 15% off)
¥425,095 / year
42.5
Alibaba Cloud RDS (3-year, 50% off)
¥750,168 / 3 years
25
AWS (On-demand)
$25,817 / month
217
AWS (1-year, no upfront)
$22,827 / month
191.7
AWS (3-year, full upfront)
$120k + $17.5k/month
175
AWS China/Ningxia (On-demand)
¥197,489 / month
237
AWS China/Ningxia (1-year, no upfront)
¥143,176 / month
171
AWS China/Ningxia (3-year, full upfront)
¥647k + ¥116k/month
160.6
Comparing the costs of self-hosting versus using a cloud database:
Introduction to core conecpt in PostgreSQL clusters
PGSQL for production environments is organized in clusters, which clusters are logical entities consisting of a set of database instances associated by primary-replica.
Each database cluster is an autonomous serving unit consisting of at least one database instance (primary).
ER Diagram
Let’s get started with ER diagram. There are four types of core entities in Pigsty’s PGSQL module:
PGSQL Cluster: An autonomous PostgreSQL business unit, used as the top-level namespace for other entities.
PGSQL Service: A named abstraction of cluster ability, route traffics, and expose postgres services with node ports.
PGSQL Instance: A single postgres server which is a group of running processes & database files on a single node.
PGSQL Node: An abstraction of hardware resources, which can be bare metal, virtual machine, or even k8s pods.
Naming Convention
The cluster name should be a valid domain name, without any dot: [a-zA-Z0-9-]+
Service name should be prefixed with cluster name, and suffixed with a single word: such as primary, replica, offline, delayed, join by -
Instance name is prefixed with cluster name and suffixed with an integer, join by -, e.g., ${cluster}-${seq}.
Node is identified by its IP address, and its hostname is usually the same as the instance name since they are 1:1 deployed.
Identity Parameters
Here are some common parameters used to identify PGSQL entities: instance, service, etc…
# pg_cluster: #CLUSTER # pgsql cluster name, required identity parameter# pg_seq: 0 #INSTANCE # pgsql instance seq number, required identity parameter# pg_role: replica #INSTANCE # pgsql role, required, could be primary,replica,offline# pg_instances: {} #INSTANCE # define multiple pg instances on node in `{port:ins_vars}` format# pg_upstream: #INSTANCE # repl upstream ip addr for standby cluster or cascade replica# pg_shard: #CLUSTER # pgsql shard name, optional identity for sharding clusters# pg_group: 0 #CLUSTER # pgsql shard index number, optional identity for sharding clusters# gp_role: master #CLUSTER # greenplum role of this cluster, could be master or segmentpg_offline_query:false#INSTANCE # set to true to enable offline query on this instance
You have to assign these identity parameters explicitly, there’s no default value for them.
pg_cluster: It identifies the name of the cluster, which is configured at the cluster level.
pg_role: Configured at the instance level, identifies the role of the ins. Only the primary role will be handled specially. If not filled in, the default is the replica role and the special delayed and offline roles.
pg_seq: Used to identify the ins within the cluster, usually with an integer number incremented from 0 or 1, which is not changed once it is assigned.
{{ pg_cluster }}-{{ pg_seq }} is used to uniquely identify the ins, i.e. pg_instance.
{{ pg_cluster }}-{{ pg_role }} is used to identify the services within the cluster, i.e. pg_service.
pg_shard and pg_group are used for horizontally sharding clusters, for citus & greenplum only.
pg_cluster, pg_role, pg_seq are core identity params,
which are required for any Postgres cluster, and must be explicitly specified. Here’s an example:
pg_users : Define business users & roles at cluster level
The former defines roles and users shared across the entire environment, while the latter defines business roles and users specific to a single cluster.
pg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-metapg_databases:- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment:read-only viewer for meta database }- {name: dbuser_grafana ,password: DBUser.Grafana ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for grafana database }- {name: dbuser_bytebase ,password: DBUser.Bytebase ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for bytebase database }- {name: dbuser_kong ,password: DBUser.Kong ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for kong api gateway }- {name: dbuser_gitea ,password: DBUser.Gitea ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for gitea service }- {name: dbuser_wiki ,password: DBUser.Wiki ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for wiki.js service }- {name: dbuser_noco ,password: DBUser.Noco ,pgbouncer: true ,roles: [dbrole_admin] ,comment:admin user for nocodb service }
And each user definition may look like:
- name:dbuser_meta # REQUIRED, `name` is the only mandatory field of a user definitionpassword:DBUser.Meta # optional, password, can be a scram-sha-256 hash string or plain textlogin:true# optional, can log in, true by default (new biz ROLE should be false)superuser:false# optional, is superuser? false by defaultcreatedb:false# optional, can create database? false by defaultcreaterole:false# optional, can create role? false by defaultinherit:true# optional, can this role use inherited privileges? true by defaultreplication:false# optional, can this role do replication? false by defaultbypassrls:false# optional, can this role bypass row level security? false by defaultpgbouncer:true# optional, add this user to pgbouncer user-list? false by default (production user should be true explicitly)connlimit:-1# optional, user connection limit, default -1 disable limitexpire_in:3650# optional, now + n days when this role is expired (OVERWRITE expire_at)expire_at:'2030-12-31'# optional, YYYY-MM-DD 'timestamp' when this role is expired (OVERWRITTEN by expire_in)comment:pigsty admin user # optional, comment string for this user/roleroles: [dbrole_admin] # optional, belonged roles. default roles are:dbrole_{admin,readonly,readwrite,offline}parameters:{}# optional, role level parameters with `ALTER ROLE SET`pool_mode:transaction # optional, pgbouncer pool mode at user level, transaction by defaultpool_connlimit:-1# optional, max database connections at user level, default -1 disable limitsearch_path: public # key value config parameters according to postgresql documentation (e.g:use pigsty as default search_path)
The only required field is name, which should be a valid & unique username in PostgreSQL.
Roles don’t need a password, while it could be necessary for a login-able user.
The password can be plain text or a scram-sha-256 / md5 hash string.
User/Role are created one by one in array order. So make sure role/group definition is ahead of its members
login, superuser, createdb, createrole, inherit, replication, bypassrls are boolean flags
pgbouncer is disabled by default. To add a business user to the pgbouncer user-list, you should set it to true explicitly.
ACL System
Pigsty has a battery-included ACL system, which can be easily used by assigning roles to users:
dbrole_readonly : The role for global read-only access
dbrole_readwrite : The role for global read-write access
dbrole_admin : The role for object creation
dbrole_offline : The role for restricted read-only access (offline instance)
If you wish to re-design your ACL system, check the following parameters & templates.
Users and roles defined in pg_default_roles and pg_users will be automatically created one by one during cluster initialization.
If you want to create users on an existing cluster, you can use the bin/pgsql-user command line or directly use the pgsql-user.yml playbook.
Add new user/role definitions to all.children.<cls>.pg_users, and create the database using one of the following methods:
bin/pgsql-user <cls> <username> # using command line./pgsql-user.yml -l <cls> -e username=<username> # using playbook
Unlike databases, the user creation playbook is always idempotent. When the target user already exists, Pigsty will modify the user’s attributes to match the configuration.
Use Playbook for User Creation
We do not recommend manually creating new business users, especially when the users you want to create use the default pgbouncer connection pool: unless you are willing to manually maintain the user list in Pgbouncer and keep it in sync with PostgreSQL.
When creating new databases using the bin/pgsql-user tool or pgsql-user.yml playbook, the database will also be added to the Pgbouncer Users list.
Modify User
The method to modify PostgreSQL user attributes is the same as creating users.
First, adjust your user definition by modifying the attributes you want to change, then execute the following command to apply:
bin/pgsql-user <cls> <username> # using command line./pgsql-user.yml -l <cls> -e username=<username> # using playbook
Note that modifying a user does not delete the user, but modifies user attributes using the ALTER USER command; it also does not revoke user permissions and group memberships, and uses the GRANT command to grant new roles.
Delete User
For security reasons, Pigsty does not automatically delete users, even if you remove user definitions from the configuration, Pigsty will not delete existing users.
You need to use the SQL command DROP USER to manually delete users:
DROPUSER"<username>";
If the role you want to delete is a group (has other users belonging to it), you need to first remove other users from the group before deleting the group:
REVOKE"<rolename>"FROM"<other_user>";
If the user you want to delete owns database objects, you need to first change the ownership of these objects to another user before deleting the user:
REASSIGNOWNEDBY"<username>"TO"<another_user>";
Pgbouncer Users
Pigsty installs and enables Pgbouncer connection pool by default and manages users in the connection pool.
Pigsty will by default add users with the pgbouncer: true flag in pg_users to the pgbouncer user list.
Configuration Files
Users in the Pgbouncer connection pool are listed in /etc/pgbouncer/userlist.txt:
The connection pool user configuration files userlist.txt and useropts.txt will be automatically refreshed when you create users and take effect through online configuration reload, normally without affecting existing connections.
When you create databases, the Pgbouncer database list definition file will be refreshed and take effect through online configuration reload, without affecting existing connections.
Manage Users
Pgbouncer runs with the same dbsu as PostgreSQL, defaulting to the postgres operating system user. You can use the pgb alias to access pgbouncer management functions using dbsu.
sudo su - postgres
pgb # login to pgbouncer command line interface using admin user
Pigsty also provides a utility function pgb-route that can quickly switch pgbouncer database traffic to other nodes in the cluster, useful for zero-downtime migration:
Delete Users
For security reasons, Pigsty does not provide commands to delete database/connection pool users by default.
To remove a user from the pgbouncer connection pool, simply delete the corresponding line from the configuration file and reload pgbouncer.
The connection pool user list is managed through full refresh coverage.
If you ensure all database users are created by Pigsty playbooks/command line,
you can use the following command to fully refresh and overwrite the user list in the pgbouncer connection pool:
Note that the pgbouncer_auth_query parameter allows you to use dynamic queries to complete connection pool user authentication, which is a compromise when you don’t want to manage users in the connection pool.
6.4 - Databases
Define business databases in PostgreSQL, which is the object create by SQL CREATE DATABASE
In this context, Database refers to the object created by SQL CREATE DATABASE.
A PostgreSQL server can serve multiple databases simultaneously. And you can customize each database with Pigsty API.
Define Database
Business databases are defined by pg_databases, which is a cluster-level parameter.
For example, the default meta database is defined in the pg-meta cluster:
Each database definition is a dict with the following fields:
- name:meta # REQUIRED, `name` is the only mandatory field of a database definitionbaseline:cmdb.sql # optional, database sql baseline path, (relative path among ansible search path, e.g files/)pgbouncer:true# optional, add this database to pgbouncer database list? true by defaultschemas:[pigsty] # optional, additional schemas to be created, array of schema namesextensions: # optional, additional extensions to be installed:array of `{name[,schema]}`- {name: postgis , schema:public }- {name:timescaledb }comment:pigsty meta database # optional, comment string for this databaseowner:postgres # optional, database owner, postgres by defaulttemplate:template1 # optional, which template to use, template1 by defaultencoding:UTF8 # optional, database encoding, UTF8 by default. (MUST same as template database)locale:C # optional, database locale, C by default. (MUST same as template database)lc_collate:C # optional, database collate, C by default. (MUST same as template database)lc_ctype:C # optional, database ctype, C by default. (MUST same as template database)tablespace:pg_default # optional, default tablespace, 'pg_default' by default.allowconn:true# optional, allow connection, true by default. false will disable connect at allrevokeconn:false# optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)register_datasource:true# optional, register this database to grafana datasources? true by defaultconnlimit:-1# optional, database connection limit, default -1 disable limitpool_auth_user:dbuser_meta # optional, all connection to this pgbouncer database will be authenticated by this userpool_mode:transaction # optional, pgbouncer pool mode at database level, default transactionpool_size:64# optional, pgbouncer pool size at database level, default 64pool_size_reserve:32# optional, pgbouncer pool size reserve at database level, default 32pool_size_min:0# optional, pgbouncer pool size min at database level, default 0pool_max_db_conn:100# optional, max database connections at database level, default 100
The only required field is name, which should be a valid and unique database name in PostgreSQL.
Newly created databases are forked from template1 database by default. which is customized by PG_PROVISION during cluster bootstrap.
It’s usually not a good idea to execute this on the existing database again when a baseline script is used.
If you are using the default pgbouncer as the proxy middleware, YOU MUST create the new database with pgsql-db util or pgsql-db.yml playbook. Otherwise, the new database will not be added to the pgbouncer database list.
Remember, if your database definition has a non-trivial owner (dbsu postgres by default ), make sure the owner user exists.
That is to say, always create the user before the database.
Pgbouncer Database
Pgbouncer is enabled by default and serves as a connection pool middleware.
Pigsty will add all databases in pg_databases to the pgbouncer database list by default.
You can disable the pgbouncer proxy for a specific database by setting pgbouncer: false in the database definition.
The database is listed in /etc/pgbouncer/database.txt, with extra database-level parameters such as:
The Pgbouncer database list will be updated when create database with Pigsty util & playbook.
To access pgbouncer administration functionality, you can use the pgb alias as dbsu.
There’s a util function defined in /etc/profile.d/pg-alias.sh, allowing you to reroute pgbouncer database traffic to a new host quickly, which can be used during zero-downtime migration.
# route pgbouncer traffic to another cluster memberfunction pgb-route(){localip=${1-'\/var\/run\/postgresql'} sed -ie "s/host=[^[:space:]]\+/host=${ip}/g" /etc/pgbouncer/pgbouncer.ini
cat /etc/pgbouncer/pgbouncer.ini
}
6.5 - Services
Define and create new services, and expose them via haproxy
Service Implementation
In Pigsty, services are implemented using haproxy on nodes, differentiated by different ports on the host node.
Every node has Haproxy enabled to expose services. From the database perspective, nodes in the cluster may be primary or replicas, but from the service perspective, all nodes are the same. This means even if you access a replica node, as long as you use the correct service port, you can still use the primary’s read-write service. This design seals the complexity: as long as you can access any instance on the PostgreSQL cluster, you can fully access all services.
This design is akin to the NodePort service in Kubernetes. Similarly, in Pigsty, every service includes these two core elements:
Access endpoints exposed via NodePort (port number, from where to access?)
Target instances chosen through Selectors (list of instances, who will handle it?)
The boundary of Pigsty’s service delivery stops at the cluster’s HAProxy. Users can access these load balancers in various ways. Please refer to Access Service.
All services are declared through configuration files. For instance, the default PostgreSQL service is defined by the pg_default_services parameter:
While you can define your extra PostgreSQL services with pg_services @ the global or cluster level.
These two parameters are both arrays of service objects. Each service definition will be rendered as a haproxy config in /etc/haproxy/<svcname>.cfg, check service.j2 for details.
Here is an example of an extra service definition: standby
- name: standby # required, service name, the actual svc name will be prefixed with `pg_cluster`, e.g:pg-meta-standbyport:5435# required, service exposed port (work as kubernetes service node port mode)ip:"*"# optional, service bind ip address, `*` for all ip by defaultselector:"[]"# required, service member selector, use JMESPath to filter inventorydest:default # optional, destination port, default|postgres|pgbouncer|<port_number>, 'default' by defaultcheck:/sync # optional, health check url path, / by defaultbackup:"[? pg_role == `primary`]"# backup server selectormaxconn:3000# optional, max allowed front-end connectionbalance: roundrobin # optional, haproxy load balance algorithm (roundrobin by default, other:leastconn)options:'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
And it will be translated to a haproxy config file /etc/haproxy/pg-test-standby.conf:
#---------------------------------------------------------------------# service: pg-test-standby @ 10.10.10.11:5435#---------------------------------------------------------------------# service instances 10.10.10.11, 10.10.10.13, 10.10.10.12# service backups 10.10.10.11listen pg-test-standbybind *:5435mode tcpmaxconn 5000balance roundrobinoption httpchkoption http-keep-alivehttp-check send meth OPTIONS uri /sync # <--- true for primary & sync standbyhttp-check expect status 200default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100# serversserver pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backup # the primary is used as backup serverserver pg-test-3 10.10.10.13:6432 check port 8008 weight 100server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Reload Service
When cluster membership has changed, such as append / remove replicas, switchover/failover, or adjust relative weight,
You have to reload service to make the changes take effect.
bin/pgsql-svc <cls> [ip...]# reload service for lb cluster or lb instance# ./pgsql.yml -t pg_service # the actual ansible task to reload service
Override Service
You can override default service configuration with several ways:
Bypass Pgbouncer
When defining a service, if svc.dest='default', this parameter pg_default_service_dest will be used as the default value.
pgbouncer is used by default, you can use postgres instead, so the default primary & replica service will bypass pgbouncer and route traffic to postgres directly
If you don’t need connection pooling at all, you can change pg_default_service_dest to postgres, and remove default and offline services.
If you don’t need read-only replicas for online traffic, you can remove replica from pg_default_services too.
For example, this configuration will expose pg cluster primary service on haproxy node group proxy with port 10013.
pg_service_provider:proxy # use load balancer on group `proxy` with port 10013pg_default_services:[{name: primary ,port: 10013 ,dest: postgres ,check: /primary ,selector:"[]"}]
It’s user’s responsibility to make sure each delegate service port is unique among the proxy cluster.
6.6 - Extensions
Define, Create, Install, Enable Extensions in Pigsty
Extensions are the soul of PostgreSQL, and Pigsty deeply integrates the core extension plugins of the PostgreSQL ecosystem,
providing you with battery-included distributed temporal, geospatial text, graph, and vector database capabilities! Check extension list for details.
Pigsty includes over 404 PostgreSQL extension plugins and has compiled, packaged, integrated, and maintained many extensions not included in the official PGDG source.
It also ensures through thorough testing that all these plugins can work together seamlessly. Including some potent extensions:
Host-Based Authentication in Pigsty, how to manage HBA rules in Pigsty?
Host-Based Authentication in Pigsty
PostgreSQL has various authentication methods. You can use all of them, while pigsty’s battery-include ACL system focuses on HBA, password, and SSL authentication.
Client Authentication
To connect to a PostgreSQL database, the user has to be authenticated (with a password by default).
You can provide the password in the connection string (not secure) or use the PGPASSWORD env or .pgpass file. Check psql docs and PostgreSQL connection string for more details.
Typically, global HBA is defined in all.vars. If you want to modify the global default HBA rules, you can copy from the full.yml template to all.vars for modification.
Here are some examples of cluster HBA rule definitions.
pg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-metapg_hba_rules:- {user: dbuser_view ,db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}- {user: all ,db: all ,addr: 100.0.0.0/8 ,auth: pwd ,title:'all user access all db from kubernetes cluster'}- {user:'${admin}',db: world ,addr: 0.0.0.0/0 ,auth: cert ,title:'all admin world access with client cert'}
Reload HBA
To reload postgres/pgbouncer hba rules:
bin/pgsql-hba <cls> # reload hba rules of cluster `<cls>`bin/pgsql-hba <cls> ip1 ip2... # reload hba rules of specific instances
Pigsty has a default set of HBA rules, which is pretty secure for most cases.
The rules are self-explained in alias form.
pg_default_hba_rules:# postgres default host-based authentication rules- {user:'${dbsu}',db: all ,addr: local ,auth: ident ,title:'dbsu access via local os user ident'}- {user:'${dbsu}',db: replication ,addr: local ,auth: ident ,title:'dbsu replication from local os ident'}- {user:'${repl}',db: replication ,addr: localhost ,auth: pwd ,title:'replicator replication from localhost'}- {user:'${repl}',db: replication ,addr: intra ,auth: pwd ,title:'replicator replication from intranet'}- {user:'${repl}',db: postgres ,addr: intra ,auth: pwd ,title:'replicator postgres db from intranet'}- {user:'${monitor}',db: all ,addr: localhost ,auth: pwd ,title:'monitor from localhost with password'}- {user:'${monitor}',db: all ,addr: infra ,auth: pwd ,title:'monitor from infra host with password'}- {user:'${admin}',db: all ,addr: infra ,auth: ssl ,title:'admin @ infra nodes with pwd & ssl'}- {user:'${admin}',db: all ,addr: world ,auth: ssl ,title:'admin @ everywhere with ssl & pwd'}- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: pwd ,title:'pgbouncer read/write via local socket'}- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: pwd ,title:'read/write biz user via password'}- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: pwd ,title:'allow etl offline tasks from intranet'}pgb_default_hba_rules:# pgbouncer default host-based authentication rules- {user:'${dbsu}',db: pgbouncer ,addr: local ,auth: peer ,title:'dbsu local admin access with os ident'}- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title:'allow all user local access with pwd'}- {user:'${monitor}',db: pgbouncer ,addr: intra ,auth: pwd ,title:'monitor access via intranet with pwd'}- {user:'${monitor}',db: all ,addr: world ,auth: deny ,title:'reject all other monitor access addr'}- {user:'${admin}',db: all ,addr: intra ,auth: pwd ,title:'admin access via intranet with pwd'}- {user:'${admin}',db: all ,addr: world ,auth: deny ,title:'reject all other admin access addr'}- {user: 'all' ,db: all ,addr: intra ,auth: pwd ,title:'allow all user intra access with pwd'}
Example: Rendered pg_hba.conf
#==============================================================## File : pg_hba.conf# Desc : Postgres HBA Rules for pg-meta-1 [primary]# Time : 2023-01-11 15:19# Host : pg-meta-1 @ 10.10.10.10:5432# Path : /pg/data/pg_hba.conf# Note : ANSIBLE MANAGED, DO NOT CHANGE!# Author : Ruohang Feng ([email protected])# License : AGPLv3#==============================================================## addr alias# local : /var/run/postgresql# admin : 10.10.10.10# infra : 10.10.10.10# intra : 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16# user alias# dbsu : postgres# repl : replicator# monitor : dbuser_monitor# admin : dbuser_dba# dbsu access via local os user ident [default]local all postgres ident# dbsu replication from local os ident [default]local replication postgres ident# replicator replication from localhost [default]local replication replicator scram-sha-256host replication replicator 127.0.0.1/32 scram-sha-256# replicator replication from intranet [default]host replication replicator 10.0.0.0/8 scram-sha-256host replication replicator 172.16.0.0/12 scram-sha-256host replication replicator 192.168.0.0/16 scram-sha-256# replicator postgres db from intranet [default]host postgres replicator 10.0.0.0/8 scram-sha-256host postgres replicator 172.16.0.0/12 scram-sha-256host postgres replicator 192.168.0.0/16 scram-sha-256# monitor from localhost with password [default]local all dbuser_monitor scram-sha-256host all dbuser_monitor 127.0.0.1/32 scram-sha-256# monitor from infra host with password [default]host all dbuser_monitor 10.10.10.10/32 scram-sha-256# admin @ infra nodes with pwd & ssl [default]hostssl all dbuser_dba 10.10.10.10/32 scram-sha-256# admin @ everywhere with ssl & pwd [default]hostssl all dbuser_dba 0.0.0.0/0 scram-sha-256# pgbouncer read/write via local socket [default]local all +dbrole_readonly scram-sha-256host all +dbrole_readonly 127.0.0.1/32 scram-sha-256# read/write biz user via password [default]host all +dbrole_readonly 10.0.0.0/8 scram-sha-256host all +dbrole_readonly 172.16.0.0/12 scram-sha-256host all +dbrole_readonly 192.168.0.0/16 scram-sha-256# allow etl offline tasks from intranet [default]host all +dbrole_offline 10.0.0.0/8 scram-sha-256host all +dbrole_offline 172.16.0.0/12 scram-sha-256host all +dbrole_offline 192.168.0.0/16 scram-sha-256# allow application database intranet access [common] [DISABLED]#host kong dbuser_kong 10.0.0.0/8 md5#host bytebase dbuser_bytebase 10.0.0.0/8 md5#host grafana dbuser_grafana 10.0.0.0/8 md5
Example: Rendered pgb_hba.conf
#==============================================================## File : pgb_hba.conf# Desc : Pgbouncer HBA Rules for pg-meta-1 [primary]# Time : 2023-01-11 15:28# Host : pg-meta-1 @ 10.10.10.10:5432# Path : /etc/pgbouncer/pgb_hba.conf# Note : ANSIBLE MANAGED, DO NOT CHANGE!# Author : Ruohang Feng ([email protected])# License : AGPLv3#==============================================================## PGBOUNCER HBA RULES FOR pg-meta-1 @ 10.10.10.10:6432# ansible managed: 2023-01-11 14:30:58# addr alias# local : /var/run/postgresql# admin : 10.10.10.10# infra : 10.10.10.10# intra : 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16# user alias# dbsu : postgres# repl : replicator# monitor : dbuser_monitor# admin : dbuser_dba# dbsu local admin access with os ident [default]local pgbouncer postgres peer# allow all user local access with pwd [default]local all all scram-sha-256host all all 127.0.0.1/32 scram-sha-256# monitor access via intranet with pwd [default]host pgbouncer dbuser_monitor 10.0.0.0/8 scram-sha-256host pgbouncer dbuser_monitor 172.16.0.0/12 scram-sha-256host pgbouncer dbuser_monitor 192.168.0.0/16 scram-sha-256# reject all other monitor access addr [default]host all dbuser_monitor 0.0.0.0/0 reject# admin access via intranet with pwd [default]host all dbuser_dba 10.0.0.0/8 scram-sha-256host all dbuser_dba 172.16.0.0/12 scram-sha-256host all dbuser_dba 192.168.0.0/16 scram-sha-256# reject all other admin access addr [default]host all dbuser_dba 0.0.0.0/0 reject# allow all user intra access with pwd [default]host all all 10.0.0.0/8 scram-sha-256host all all 172.16.0.0/12 scram-sha-256host all all 192.168.0.0/16 scram-sha-256
Security Enhancement
For those critical cases, we have a security.yml template with the following hba rule set as a reference:
pg_default_hba_rules:# postgres host-based auth rules by default- {user:'${dbsu}',db: all ,addr: local ,auth: ident ,title:'dbsu access via local os user ident'}- {user:'${dbsu}',db: replication ,addr: local ,auth: ident ,title:'dbsu replication from local os ident'}- {user:'${repl}',db: replication ,addr: localhost ,auth: ssl ,title:'replicator replication from localhost'}- {user:'${repl}',db: replication ,addr: intra ,auth: ssl ,title:'replicator replication from intranet'}- {user:'${repl}',db: postgres ,addr: intra ,auth: ssl ,title:'replicator postgres db from intranet'}- {user:'${monitor}',db: all ,addr: localhost ,auth: pwd ,title:'monitor from localhost with password'}- {user:'${monitor}',db: all ,addr: infra ,auth: ssl ,title:'monitor from infra host with password'}- {user:'${admin}',db: all ,addr: infra ,auth: ssl ,title:'admin @ infra nodes with pwd & ssl'}- {user:'${admin}',db: all ,addr: world ,auth: cert ,title:'admin @ everywhere with ssl & cert'}- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: ssl ,title:'pgbouncer read/write via local socket'}- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: ssl ,title:'read/write biz user via password'}- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: ssl ,title:'allow etl offline tasks from intranet'}pgb_default_hba_rules:# pgbouncer host-based authentication rules- {user:'${dbsu}',db: pgbouncer ,addr: local ,auth: peer ,title:'dbsu local admin access with os ident'}- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title:'allow all user local access with pwd'}- {user:'${monitor}',db: pgbouncer ,addr: intra ,auth: ssl ,title:'monitor access via intranet with pwd'}- {user:'${monitor}',db: all ,addr: world ,auth: deny ,title:'reject all other monitor access addr'}- {user:'${admin}',db: all ,addr: intra ,auth: ssl ,title:'admin access via intranet with pwd'}- {user:'${admin}',db: all ,addr: world ,auth: deny ,title:'reject all other admin access addr'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'allow all user intra access with pwd'}
6.8 - Configuration
Configure your PostgreSQL cluster & instances according to your needs
You can define different types of instances & clusters.
Identity: Parameters used for describing a PostgreSQL cluster
Offline instance works like common replica instances, but it is used as a backup server in pg-test-replica service.
That is to say, offline and primary instance serves only when all replica instances are down.
Pigsty uses asynchronous stream replication by default. Which may have a small replication lag. (10KB / 10ms).
A small window of data loss may occur when the primary fails (can be controlled with pg_rpo.), but it is acceptable for most scenarios.
But in some critical scenarios (e.g. financial transactions), data loss is totally unacceptable or read-your-write consistency is required.
In this case, you can enable synchronous commit to ensure that.
To enable sync standby mode, you can simply use crit.yml template in pg_conf
To enable sync standby on existing clusters, config the cluster and enable synchronous_mode:
$ pg edit-config pg-test # run on admin node with admin user+++
-synchronous_mode: false# <--- old value+synchronous_mode: true# <--- new value synchronous_mode_strict: falseApply these changes? [y/N]: y
If synchronous_mode: true, the synchronous_standby_names parameter will be managed by patroni.
It will choose a sync standby from all available replicas and write its name to the primary’s configuration file.
Quorum Commit
When sync standby is enabled, PostgreSQL will pick one replica as the standby instance, and all other replicas as candidates.
Primary will wait until the standby instance flushes to disk before a commit is confirmed, and the standby instance will always have the latest data without any lags.
However, you can achieve an even higher/lower consistency level with the quorum commit (trade-off with availability).
For example, to have all 2 replicas to confirm a commit:
synchronous_mode:true# make sure synchronous mode is enabledsynchronous_node_count:2# at least 2 nodes to confirm a commit
If you have more replicas and wish to have more sync standby, increase synchronous_node_count accordingly.
Beware of adjust synchronous_node_count accordingly when you append or remove replicas.
The postgres synchronous_standby_names parameter will be managed by patroni:
The classic quorum commit is to use majority of replicas to confirm a commit.
synchronous_mode:quorum # use quorum commitpostgresql:parameters:# change the PostgreSQL parameter `synchronous_standby_names`, use the `ANY n ()` notionsynchronous_standby_names:'ANY 1 (*)'# you can specify a list of standby names, or use `*` to match them all
Example: Enable Quorum Commit
$ pg edit-config pg-test
+ synchronous_standby_names: 'ANY 1 (*)'# You have to configure this manually+ synchronous_mode: quorum # use quorum commit mode, undocumented parameter- synchronous_node_count: 2# this parameter is no longer needed in quorum modeApply these changes? [y/N]: y
After applying the configuration, we can see that all replicas are no longer sync standby, but just normal replicas.
After that, when we can check pg_stat_replication.sync_state, it becomes quorum instead of sync or async.
Standby Cluster
You can clone an existing cluster and create a standby cluster, which can be used for migration, horizontal split, multi-az deployment, or disaster recovery.
A standby cluster’s definition is just the same as any other normal cluster, except there’s a pg_upstream defined on the primary instance.
For example, you have a pg-test cluster, to create a standby cluster pg-test2, the inventory may look like this:
# pg-test is the original clusterpg-test:hosts:10.10.10.11:{pg_seq: 1, pg_role:primary }vars:{pg_cluster:pg-test }# pg-test2 is a standby cluster of pg-test.pg-test2:hosts:10.10.10.12:{pg_seq: 1, pg_role: primary , pg_upstream:10.10.10.11}# <--- pg_upstream is defined here10.10.10.13:{pg_seq: 2, pg_role:replica }vars:{pg_cluster:pg-test2 }
And pg-test2-1, the primary of pg-test2 will be a replica of pg-test and serve as a Standby Leader in pg-test2.
Just make sure that the pg_upstream parameter is configured on the primary of the backup cluster to pull backups from the original upstream automatically.
bin/pgsql-add pg-test # Creating the original clusterbin/pgsql-add pg-test2 # Creating a Backup Cluster
Example: Change Replication Upstream
You can change the replication upstream of the standby cluster when necessary (e.g. upstream failover).
To do so, just change the standby_cluster.host to the new upstream IP address and apply.
$ pg edit-config pg-test2
standby_cluster:
create_replica_methods:
- basebackup
- host: 10.10.10.13 # <--- The old upstream+ host: 10.10.10.12 # <--- The new upstream port: 5432 Apply these changes? [y/N]: y
Example: Promote Standby Cluster
You can promote the standby cluster to a standalone cluster at any time.
To do so, you have to config the cluster and wipe the entire standby_cluster section then apply.
$ pg edit-config pg-test2
-standby_cluster:
- create_replica_methods:
- - basebackup
- host: 10.10.10.11
- port: 5432Apply these changes? [y/N]: y
Example: Cascade Replica
If the pg_upstream is specified for replica rather than primary, the replica will be configured as a cascade replica with the given upstream ip instead of the cluster primary
pg-test:hosts:# pg-test-1 ---> pg-test-2 ---> pg-test-310.10.10.11:{pg_seq: 1, pg_role:primary }10.10.10.12:{pg_seq: 2, pg_role:replica }# <--- bridge instance10.10.10.13:{pg_seq: 2, pg_role: replica, pg_upstream:10.10.10.12}# ^--- replicate from pg-test-2 (the bridge) instead of pg-test-1 (the primary) vars:{pg_cluster:pg-test }
Delayed Cluster
A delayed cluster is a special type of standby cluster, which is used to recover “drop-by-accident” ASAP.
For example, if you wish to have a cluster pg-testdelay which has the same data as 1-day ago pg-test cluster:
# pg-test is the original clusterpg-test:hosts:10.10.10.11:{pg_seq: 1, pg_role:primary }vars:{pg_cluster:pg-test }# pg-testdelay is a delayed cluster of pg-test.pg-testdelay:hosts:10.10.10.12:{pg_seq: 1, pg_role: primary , pg_upstream: 10.10.10.11, pg_delay:1d }10.10.10.13:{pg_seq: 2, pg_role:replica }vars:{pg_cluster:pg-test2 }
patroni_primary_db has to be defined to specify the database to be managed
pg_dbsu_password has to be set to a non-empty string plain password if you want to use the pg_dbsupostgres rather than default pg_admin_username to perform admin commands
Besides, extra hba rules that allow ssl access from local & other data nodes are required. Which may looks like this
all:children:pg-citus0:# citus data node 0hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus0 , pg_group:0}pg-citus1:# citus data node 1hosts:{10.10.10.11:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus1 , pg_group:1}pg-citus2:# citus data node 2hosts:{10.10.10.12:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus2 , pg_group:2}pg-citus3:# citus data node 3, with an extra replicahosts:10.10.10.13:{pg_seq: 1, pg_role:primary }10.10.10.14:{pg_seq: 2, pg_role:replica }vars:{pg_cluster: pg-citus3 , pg_group:3}vars:# global parameters for all citus clusterspg_mode: citus # pgsql cluster mode:cituspg_shard: pg-citus # citus shard name:pg-cituspatroni_citus_db:meta # citus distributed database namepg_dbsu_password:DBUser.Postgres# all dbsu password access for citus clusterpg_users:[{name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles:[dbrole_admin ] } ]pg_databases:[{name: meta ,extensions:[{name:citus }, { name: postgis }, { name: timescaledb } ] } ]pg_hba_rules:- {user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title:'all user ssl access from localhost'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'all user ssl access from intranet'}
And you can create distributed table & reference table on the coordinator node. Any data node can be used as the coordinator node since citus 11.2.
Beware that these extensions are just not included in Pigsty’s default repo. You can have these extensions on older pg version with proper configuration.
6.9 - Parameters
There are 115 parameters about PostgreSQL in Pigsty
If pg_mode is set to citus or gpsql, pg_shard and pg_group will be required for horizontal sharding clusters.
pg_cluster
name: pg_cluster, type: string, level: C
pgsql cluster name, REQUIRED identity parameter
The cluster name will be used as the namespace for PGSQL related resources within that cluster.
The naming needs to follow the specific naming pattern: [a-z][a-z0-9-]* to be compatible with the requirements of different constraints on the identity.
A serial number of this instance, unique within its cluster, starting from 0 or 1.
pg_role
name: pg_role, type: enum, level: I
pgsql role, REQUIRED, could be primary,replica,offline
Roles for PGSQL instance, can be: primary, replica, standby or offline.
primary: Primary, there is one and only one primary in a cluster.
replica: Replica for carrying online read-only traffic, there may be a slight replication delay through (10ms~100ms, 100KB).
standby: Special replica that is always synced with primary, there’s no replication delay & data loss on this replica. (currently same as replica)
offline: Offline replica for taking on offline read-only traffic, such as statistical analysis/ETL/personal queries, etc.
Identity params, required params, and instance-level params.
pg_instances
name: pg_instances, type: dict, level: I
define multiple pg instances on node in {port:ins_vars} format.
This parameter is reserved for multi-instance deployment on a single node which is not implemented in Pigsty yet.
pg_upstream
name: pg_upstream, type: ip, level: I
Upstream ip address for standby cluster or cascade replica
Setting pg_upstream is set on primary instance indicate that this cluster is a Standby Cluster, and will receiving changes from upstream instance, thus the primary is actually a standby leader.
Setting pg_upstream for a non-primary instance will explicitly set a replication upstream instance, if it is different from the primary ip addr, this instance will become a cascade replica. And it’s user’s responsibility to ensure that the upstream IP addr is another instance in the same cluster.
pg_shard
name: pg_shard, type: string, level: C
pgsql shard name, required identity parameter for sharding clusters (e.g. citus cluster), optional for common pgsql clusters.
When multiple pgsql clusters serve the same business together in a horizontally sharding style, Pigsty will mark this group of clusters as a Sharding Group.
pg_shard is the name of the shard group name. It’s usually the prefix of pg_cluster.
For example, if we have a sharding group pg-citus, and 4 clusters in it, there identity params will be:
pgsql shard index number, required identity for sharding clusters, optional for common pgsql clusters.
Sharding cluster index of sharding group, used in pair with pg_shard. You can use any non-negative integer as the index number.
gp_role
name: gp_role, type: enum, level: C
greenplum/matrixdb role of this cluster, could be master or segment
master: mark the postgres cluster as greenplum master, which is the default value
segment mark the postgres cluster as greenplum segment
This parameter is only used for greenplum/matrixdb database, and is ignored for common pgsql cluster.
pg_exporters
name: pg_exporters, type: dict, level: C
additional pg_exporters to monitor remote postgres instances, default values: {}
If you wish to monitoring remote postgres instances, define them in pg_exporters and load them with pgsql-monitor.yml playbook.
pg_exporters:# list all remote instances here, alloc a unique unused local port as k20001:{pg_cluster: pg-foo, pg_seq: 1, pg_host:10.10.10.10}20004:{pg_cluster: pg-foo, pg_seq: 2, pg_host:10.10.10.11}20002:{pg_cluster: pg-bar, pg_seq: 1, pg_host:10.10.10.12}20003:{pg_cluster: pg-bar, pg_seq: 1, pg_host:10.10.10.13}
set to true to enable offline query on this instance
default value is false
When this parameter is enabled for a PostgreSQL instance, users belonging to the dbrole_offline group can directly connect to that PostgreSQL instance to perform offline queries (slow queries, interactive queries, ETL/analytical queries).
Instances with this flag are functionally similar to setting pg_role = offline, with the only difference being that offline instances by default do not handle replica service requests, as they exist specifically as dedicated offline/analytical replica instances.
If you don’t have spare instances that can be dedicated to this purpose, you can select a regular replica and enable this parameter at the instance level to accommodate offline queries when needed.
PG_BUSINESS
Database credentials, In-Database Objects that need to be taken care of by Users.
WARNING: YOU HAVE TO CHANGE THESE DEFAULT PASSWORDs in production environment.
# postgres business object definition, overwrite in group varspg_users:[]# postgres business userspg_databases:[]# postgres business databasespg_services:[]# postgres business servicespg_hba_rules:[]# business hba rules for postgrespgb_hba_rules:[]# business hba rules for pgbouncer# global credentials, overwrite in global varspg_dbsu_password:''# dbsu password, empty string means no dbsu password by defaultpg_replication_username:replicatorpg_replication_password:DBUser.Replicatorpg_admin_username:dbuser_dbapg_admin_password:DBUser.DBApg_monitor_username:dbuser_monitorpg_monitor_password:DBUser.Monitor
pg_users
name: pg_users, type: user[], level: C
postgres business users, has to be defined at cluster level.
default values: [], each object in the array defines a User/Role. Examples:
- name:dbuser_meta # REQUIRED, `name` is the only mandatory field of a user definitionpassword:DBUser.Meta # optional, password, can be a scram-sha-256 hash string or plain textlogin:true# optional, can log in, true by default (new biz ROLE should be false)superuser:false# optional, is superuser? false by defaultcreatedb:false# optional, can create database? false by defaultcreaterole:false# optional, can create role? false by defaultinherit:true# optional, can this role use inherited privileges? true by defaultreplication:false# optional, can this role do replication? false by defaultbypassrls:false# optional, can this role bypass row level security? false by defaultpgbouncer:true# optional, add this user to pgbouncer user-list? false by default (production user should be true explicitly)connlimit:-1# optional, user connection limit, default -1 disable limitexpire_in:3650# optional, now + n days when this role is expired (OVERWRITE expire_at)expire_at:'2030-12-31'# optional, YYYY-MM-DD 'timestamp' when this role is expired (OVERWRITTEN by expire_in)comment:pigsty admin user # optional, comment string for this user/roleroles: [dbrole_admin] # optional, belonged roles. default roles are:dbrole_{admin,readonly,readwrite,offline}parameters:{}# optional, role level parameters with `ALTER ROLE SET`pool_mode:transaction # optional, pgbouncer pool mode at user level, transaction by defaultpool_connlimit:-1# optional, max database connections at user level, default -1 disable limitsearch_path: public # key value config parameters according to postgresql documentation (e.g:use pigsty as default search_path)
The only mandatory field of a user definition is name, and the rest are optional.
pg_databases
name: pg_databases, type: database[], level: C
postgres business databases, has to be defined at cluster level.
default values: [], each object in the array defines a Database. Examples:
- name:meta # REQUIRED, `name` is the only mandatory field of a database definitionbaseline:cmdb.sql # optional, database sql baseline path, (relative path among ansible search path, e.g files/)pgbouncer:true# optional, add this database to pgbouncer database list? true by defaultschemas:[pigsty] # optional, additional schemas to be created, array of schema namesextensions: # optional, additional extensions to be installed:array of `{name[,schema]}`- {name: postgis , schema:public } # You can specify which schema to install the extension in, or leave it unspecified (if unspecified, it will be installed in the first schema of search_path)- {name:timescaledb } # For example, some extensions will create and use fixed schemas, so you don't need to specify a schema.- vector # You can also directly use a string to specify the extension namecomment:pigsty meta database # optional, comment string for this databaseowner:postgres # optional, database owner, postgres by defaulttemplate:template1 # optional, which template to use, template1 by defaultencoding:UTF8 # optional, database encoding, UTF8 by default. (MUST same as template database)locale:C # optional, database locale, C by default. (MUST same as template database)lc_collate:C # optional, database collate, C by default. (MUST same as template database)lc_ctype:C # optional, database ctype, C by default. (MUST same as template database)tablespace:pg_default # optional, default tablespace, 'pg_default' by default.allowconn:true# optional, allow connection, true by default. false will disable connect at allrevokeconn:false# optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)register_datasource:true# optional, register this database to grafana datasources? true by defaultconnlimit:-1# optional, database connection limit, default -1 disable limitpool_auth_user:dbuser_meta # optional, all connection to this pgbouncer database will be authenticated by this userpool_mode:transaction # optional, pgbouncer pool mode at database level, default transactionpool_size:64# optional, pgbouncer pool size at database level, default 64pool_size_reserve:32# optional, pgbouncer pool size reserve at database level, default 32pool_size_min:0# optional, pgbouncer pool size min at database level, default 0pool_max_db_conn:100# optional, max database connections at database level, default 100
In each database definition, the DB name is mandatory and the rest are optional.
pg_services
name: pg_services, type: service[], level: C
postgres business services exposed via haproxy, has to be defined at cluster level.
default values: [], each object in the array defines a Service. Examples:
- name: standby # required, service name, the actual svc name will be prefixed with `pg_cluster`, e.g:pg-meta-standbyport:5435# required, service exposed port (work as kubernetes service node port mode)ip:"*"# optional, service bind ip address, `*` for all ip by defaultselector:"[]"# required, service member selector, use JMESPath to filter inventorydest:default # optional, destination port, default|postgres|pgbouncer|<port_number>, 'default' by defaultcheck:/sync # optional, health check url path, / by defaultbackup:"[? pg_role == `primary`]"# backup server selectormaxconn:3000# optional, max allowed front-end connectionbalance: roundrobin # optional, haproxy load balance algorithm (roundrobin by default, other:leastconn)options:'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
pg_hba_rules
name: pg_hba_rules, type: hba[], level: C
business hba rules for postgres
default values: [], each object in array is an HBA Rule definition:
Which are array of hba object, each hba object may look like
# RAW HBA RULES- title:allow intranet password accessrole:commonrules:- host all all 10.0.0.0/8 md5- host all all 172.16.0.0/12 md5- host all all 192.168.0.0/16 md5
title: Rule Title, transform into comment in hba file
rules: Array of strings, each string is a raw hba rule record
role: Applied roles, where to install these hba rules
common: apply for all instances
primary, replica,standby, offline: apply on corresponding instances with that pg_role.
special case: HBA rule with role == 'offline' will be installed on instance with pg_offline_query flag
or you can use another alias form
- addr:'intra'# world|intra|infra|admin|local|localhost|cluster|<cidr>auth:'pwd'# trust|pwd|ssl|cert|deny|<official auth method>user:'all'# all|${dbsu}|${repl}|${admin}|${monitor}|<user>|<group>db:'all'# all|replication|....rules:[]# raw hba string precedence over above alltitle:allow intranet password access
pg_default_hba_rules is similar to this, but is used for global HBA rule settings
pgb_hba_rules
name: pgb_hba_rules, type: hba[], level: C
business hba rules for pgbouncer, default values: []
Similar to pg_hba_rules, array of hba rule object, except this is for pgbouncer.
pg_replication_username
name: pg_replication_username, type: username, level: G
postgres replication username, replicator by default
This parameter is globally used, it not wise to change it.
pg_replication_password
name: pg_replication_password, type: password, level: G
postgres replication password, DBUser.Replicator by default
WARNING: CHANGE THIS IN PRODUCTION ENVIRONMENT!!!!
pg_admin_username
name: pg_admin_username, type: username, level: G
postgres admin username, dbuser_dba by default, which is a global postgres superuser.
default values: dbuser_dba
pg_admin_password
name: pg_admin_password, type: password, level: G
postgres admin password in plain text, DBUser.DBA by default
WARNING: CHANGE THIS IN PRODUCTION ENVIRONMENT!!!!
pg_monitor_username
name: pg_monitor_username, type: username, level: G
postgres monitor username, dbuser_monitor by default, which is a global monitoring user.
pg_monitor_password
name: pg_monitor_password, type: password, level: G
postgres monitor password, DBUser.Monitor by default.
Try not using the @:/ character in the password to avoid problems with PGURL string.
WARNING: CHANGE THIS IN PRODUCTION ENVIRONMENT!!!!
PostgreSQL dbsu password for pg_dbsu, empty string means no dbsu password, which is the default behavior.
WARNING: It’s not recommend to set a dbsu password for common PGSQL clusters, except for pg_mode = citus.
PG_INSTALL
This section is responsible for installing PostgreSQL & Extensions.
If you wish to install a different major version, just make sure repo packages exists and overwrite pg_version on cluster level.
To install extra extensions, overwrite pg_extensions on cluster level. Beware that not all extensions are available with other major versions.
pg_dbsu:postgres # os dbsu name, postgres by default, better not change itpg_dbsu_uid:26# os dbsu uid and gid, 26 for default postgres users and groupspg_dbsu_sudo:limit # dbsu sudo privilege, none,limit,all,nopass. limit by defaultpg_dbsu_home:/var/lib/pgsql # postgresql home directory, `/var/lib/pgsql` by defaultpg_dbsu_ssh_exchange:true# exchange postgres dbsu ssh key among same pgsql clusterpg_version:16# postgres major version to be installed, 16 by defaultpg_bin_dir:/usr/pgsql/bin # postgres binary dir, `/usr/pgsql/bin` by defaultpg_log_dir:/pg/log/postgres # postgres log dir, `/pg/log/postgres` by defaultpg_packages:# pg packages to be installed, alias can be used- pgsql-main pgsql-commonpg_extensions:[]# pg extensions to be installed, alias can be used
pg_dbsu
name: pg_dbsu, type: username, level: C
os dbsu name, postgres by default, it’s not wise to change it.
When installing Greenplum / MatrixDB, set this parameter to the corresponding default value: gpadmin|mxadmin.
pg_dbsu_uid
name: pg_dbsu_uid, type: int, level: C
os dbsu uid and gid, 26 for default postgres users and groups, which is consistent with the official pgdg RPM.
For Ubuntu/Debian, there’s no default postgres UID/GID, consider using another ad hoc value, such as 543 instead.
pg_dbsu_sudo
name: pg_dbsu_sudo, type: enum, level: C
dbsu sudo privilege, coud be none, limit ,all ,nopass. limit by default
none: No Sudo privilege
limit: Limited sudo privilege to execute systemctl commands for database-related components, default.
all: Full sudo privilege, password required.
nopass: Full sudo privileges without a password (not recommended).
default values: limit, which only allow sudo systemctl <start|stop|reload> <postgres|patroni|pgbouncer|...>
Available sudo services:
patroni
pgbouncer
postgres
pg_exporter
pgbackrest
pgbouncer_exporter
pgbackrest_exporter
vip-manager
haproxy (reload only)
pg_dbsu_home
name: pg_dbsu_home, type: path, level: C
postgresql home directory, /var/lib/pgsql by default, which is consistent with the official pgdg RPM.
pg_dbsu_ssh_exchange
name: pg_dbsu_ssh_exchange, type: bool, level: C
exchange postgres dbsu ssh key among pgsql instances?
default value is true, means the dbsu can ssh to each other among the playbook execution hosts.
For scenarios where ssh access is strictly limited, you can set it to false.
Please note that SSH key exchange occurs between instances that are executing the same playbook. If you run the pgsql role for a single PostgreSQL cluster, the key exchange will occur between all instances in that cluster.
If you run the pgsql role for all PostgreSQL clusters, the key exchange will occur between all instances, which can lead to severe combinatorial explosions for large clusters.
If any instance involved in the key exchange does not have the pg_dbsu user, the key exchange will fail for that instance, but will not affect other instances.
pg_version
name: pg_version, type: enum, level: C
postgres major version to be installed, 17 by default
Note that PostgreSQL physical stream replication cannot cross major versions, so do not configure this on instance level.
You can use the parameters in pg_packages and pg_extensions to install rpms for the specific pg major version.
pg_bin_dir
name: pg_bin_dir, type: path, level: C
postgres binary dir, /usr/pgsql/bin by default
The default value is a soft link created manually during the installation process, pointing to the specific Postgres version dir installed.
For example /usr/pgsql -> /usr/pgsql-17. For more details, check PGSQL File Structure for details.
pg_log_dir
name: pg_log_dir, type: path, level: C
postgres log dir, /pg/log/postgres by default.
caveat: if pg_log_dir is prefixed with pg_data it will not be created explicitly (it will be created by postgres itself then).
pg_packages
name: pg_packages, type: string[], level: C
PostgreSQL packages (rpm/deb) to be installed. This is an array of package names, where each element is a comma or space-separated list of PG package names or aliases.
Default value: [ pgsql-main pgsql-common ]
These default values are two aliases that are translated through alias mapping into the main RPM/DEB package names for the current PG major version, as well as version-independent common components (such as Patroni, PgBackrest, etc.)
Since Pigsty v3, you can use the alias lists specified in the system configuration in roles/node_id/vars for this parameter.
The advantage of using package aliases is that you don’t need to worry about package names, architectures, and major version numbers for PostgreSQL-related packages across different system platforms, thus abstracting away differences between operating systems:
Packages defined here will first be translated through the package_map, then undergo PG major version number substitution, and finally install the actual RPM/DEB packages.
You can also directly specify the final RPM/DEB package names to be installed, where version placeholders like ${pg_version} or $v in the package name will be replaced with the specific major version number pg_version.
pg_extensions
name: pg_extensions, type: string[], level: C
PG extensions to be installed (rpm/deb), this is an array of software package names, each element is a comma or space separated PG extension package name.
This parameter is similar to pg_packages, but is usually used to specify the extension to be installed @ global | cluster level, and the software packages specified here will be upgraded to the latest available version.
The default value of this parameter is the three most important extension plugins in the PG extension ecosystem: postgis, timescaledb, pgvector.
pg_extensions:[]
The complete list of extensions can be found in auto generated config
Bootstrap a postgres cluster with patroni, and setup pgbouncer connection pool along with it.
It also init cluster template databases with default roles, schemas & extensions & default privileges specified in PG_PROVISION
pg_safeguard:false# prevent purging running postgres instance? false by defaultpg_clean:true# purging existing postgres during pgsql init? true by defaultpg_data:/pg/data # postgres data directory, `/pg/data` by defaultpg_fs_main:/data # mountpoint/path for postgres main data, `/data` by defaultpg_fs_bkup:/data/backups # mountpoint/path for pg backup data, `/data/backup` by defaultpg_storage_type:SSD # storage type for pg main data, SSD,HDD, SSD by defaultpg_dummy_filesize:64MiB # size of `/pg/dummy`, hold 64MB disk space for emergency usepg_listen:'0.0.0.0'# postgres/pgbouncer listen addresses, comma separated listpg_port:5432# postgres listen port, 5432 by defaultpg_localhost:/var/run/postgresql# postgres unix socket dir for localhost connectionpatroni_enabled:true# if disabled, no postgres cluster will be created during initpatroni_mode: default # patroni working mode:default,pause,removepg_namespace:/pg # top level key namespace in etcd, used by patroni & vippatroni_port:8008# patroni listen port, 8008 by defaultpatroni_log_dir:/pg/log/patroni # patroni log dir, `/pg/log/patroni` by defaultpatroni_ssl_enabled:false# secure patroni RestAPI communications with SSL?patroni_watchdog_mode: off # patroni watchdog mode:automatic,required,off. off by defaultpatroni_username:postgres # patroni restapi username, `postgres` by defaultpatroni_password:Patroni.API # patroni restapi password, `Patroni.API` by defaultpg_primary_db:postgres # primary database name, used by citus,etc... ,postgres by defaultpg_parameters:{}# extra parameters in postgresql.auto.confpg_files:[]# extra files to be copied to postgres data directory (e.g. license)pg_conf: oltp.yml # config template:oltp,olap,crit,tiny. `oltp.yml` by defaultpg_max_conn:auto # postgres max connections, `auto` will use recommended valuepg_shared_buffer_ratio:0.25# postgres shared buffers ratio, 0.25 by default, 0.1~0.4pg_rto:30# recovery time objective in seconds, `30s` by defaultpg_rpo:1048576# recovery point objective in bytes, `1MiB` at most by defaultpg_libs:'pg_stat_statements, auto_explain'# preloaded libraries, `pg_stat_statements,auto_explain` by defaultpg_delay:0# replication apply delay for standby cluster leaderpg_checksum:true# enable data checksum for postgres cluster?pg_pwd_enc: scram-sha-256 # passwords encryption algorithm:md5,scram-sha-256pg_encoding:UTF8 # database cluster encoding, `UTF8` by defaultpg_locale:C # database cluster local, `C` by defaultpg_lc_collate:C # database cluster collate, `C` by defaultpg_lc_ctype:C # database character type, `C` by defaultpgbouncer_enabled:true# if disabled, pgbouncer will not be launched on pgsql hostpgbouncer_port:6432# pgbouncer listen port, 6432 by defaultpgbouncer_log_dir:/pg/log/pgbouncer # pgbouncer log dir, `/pg/log/pgbouncer` by defaultpgbouncer_auth_query:false# query postgres to retrieve unlisted business users?pgbouncer_poolmode: transaction # pooling mode:transaction,session,statement, transaction by defaultpgbouncer_sslmode:disable # pgbouncer client ssl mode, disable by default
pg_safeguard
name: pg_safeguard, type: bool, level: G/C/A
prevent purging running postgres instance? false by default
If enabled, pgsql.yml & pgsql-rm.yml will abort immediately if any postgres instance is running.
pg_clean
name: pg_clean, type: bool, level: G/C/A
purging existing postgres during pgsql init? true by default
default value is true, it will purge existing postgres instance during pgsql.yml init. which makes the playbook idempotent.
if set to false, pgsql.yml will abort if there’s already a running postgres instance. and pgsql-rm.yml will NOT remove postgres data (only stop the server).
pg_data
name: pg_data, type: path, level: C
postgres data directory, /pg/data by default
default values: /pg/data, DO NOT CHANGE IT.
It’s a soft link that point to underlying data directory.
mountpoint/path for postgres main data, /data by default
default values: /data, which will be used as parent dir of postgres main data directory: /data/postgres.
It’s recommended to use NVME SSD for postgres main data storage, Pigsty is optimized for SSD storage by default.
But HDD is also supported, you can change pg_storage_type to HDD to optimize for HDD storage.
pg_fs_bkup
name: pg_fs_bkup, type: path, level: C
mountpoint/path for pg backup data, /data/backup by default
If you are using the default pgbackrest_method = local, it is recommended to have a separate disk for backup storage.
The backup disk should be large enough to hold all your backups, at least enough for 3 basebackups + 2 days WAL archive.
This is usually not a problem since you can use cheap & large HDD for that.
It’s recommended to use a separate disk for backup storage, otherwise pigsty will fall back to the main data disk.
pg_storage_type
name: pg_storage_type, type: enum, level: C
storage type for pg main data, SSD,HDD, SSD by default
default values: SSD, it will affect some tuning parameters, such as random_page_cost & effective_io_concurrency
pg_dummy_filesize
name: pg_dummy_filesize, type: size, level: C
size of /pg/dummy, default values: 64MiB, which hold 64MB disk space for emergency use
When the disk is full, removing the placeholder file can free up some space for emergency use, it is recommended to use at least 8GiB for production use.
pg_listen
name: pg_listen, type: ip, level: C
postgres/pgbouncer listen address, 0.0.0.0 (all ipv4 addr) by default
You can use placeholder in this variable:
${ip}: translate to inventory_hostname, which is primary private IP address in the inventory
This parameter is used to specify and manage configuration parameters in postgresql.auto.conf.
After all instances in the cluster have completed initialization, the pg_param task will sequentially overwrite the key/value pairs in this dictionary to /pg/data/postgresql.auto.conf.
Note: Please do not manually modify this configuration file, or use ALTER SYSTEM to change cluster configuration parameters. Any changes will be overwritten during the next configuration sync.
This variable has a higher priority than the cluster configuration in Patroni/DCS (i.e., it has a higher priority than the cluster configuration edited by Patroni edit-config). Therefore, it can typically override the cluster default parameters at the instance level.
When your cluster members have different specifications (not recommended!), you can fine-tune the configuration of each instance using this parameter.
Please note that some important cluster parameters (which have requirements for primary and replica parameter values) are managed directly by Patroni through command-line parameters and have the highest priority. These cannot be overridden by this method. For these parameters, you must use Patroni edit-config for management and configuration.
PostgreSQL parameters that must remain consistent across primary and replicas (inconsistency will prevent the replica from starting!):
wal_level
max_connections
max_locks_per_transaction
max_worker_processes
max_prepared_transactions
track_commit_timestamp
Parameters that should ideally remain consistent across primary and replicas (considering the possibility of primary-replica switch):
listen_addresses
port
cluster_name
hot_standby
wal_log_hints
max_wal_senders
max_replication_slots
wal_keep_segments
wal_keep_size
You can set non-existent parameters (such as GUCs from extensions), but changing existing configurations to illegal values may prevent PostgreSQL from starting. Please configure with caution!
pg_files
Parameter Name: pg_files, Type: path[], Level: C
Designates a list of files to be copied to the {{ pg_data }} directory. The default value is an empty array: [].
Files specified in this parameter will be copied to the {{ pg_data }} directory. This is mainly used to distribute license files required by special commercial versions of the PostgreSQL kernel.
Currently, only the PolarDB (Oracle-compatible) kernel requires a license file. For example, you can place the license.lic file in the files/ directory and specify it in pg_files:
pg_files:[license.lic ]
pg_conf
name: pg_conf, type: enum, level: C
config template: {oltp,olap,crit,tiny}.yml, oltp.yml by default
tiny.yml: optimize for tiny nodes, virtual machines, small demo, (1~8Core, 1~16GB)
oltp.yml: optimize for OLTP workloads and latency sensitive applications, (4C8GB+), which is the default template
olap.yml: optimize for OLAP workloads and throughput (4C8G+)
crit.yml: optimize for data consistency and critical applications (4C8G+)
default values: oltp.yml, but configure procedure will set this value to tiny.yml if current node is a tiny node.
You can have your own template, just put it under templates/<mode>.yml and set this value to the template name.
pg_max_conn
name: pg_max_conn, type: int, level: C
postgres max connections, You can specify a value between 50 and 5000, or use auto to use recommended value.
It’s not recommended to set this value greater than 5000, otherwise you have to increase the haproxy service connection limit manually as well.
Pgbouncer’s transaction pooling can alleviate the problem of too many OLTP connections, but it’s not recommended to use it in OLAP scenarios.
pg_shared_buffer_ratio
name: pg_shared_buffer_ratio, type: float, level: C
postgres shared buffer memory ratio, 0.25 by default, 0.1~0.4
default values: 0.25, means 25% of node memory will be used as PostgreSQL shard buffers.
Setting this value greater than 0.4 (40%) is usually not a good idea.
Note that shared buffer is only part of shared memory in PostgreSQL, to calculate the total shared memory, use show shared_memory_size_in_huge_pages;.
pg_rto
name: pg_rto, type: int, level: C
recovery time objective in seconds, This will be used as Patroni TTL value, 30s by default.
If a primary instance is missing for such a long time, a new leader election will be triggered.
Decrease the value can reduce the unavailable time (unable to write) of the cluster during failover,
but it will make the cluster more sensitive to network jitter, thus increase the chance of false-positive failover.
Config this according to your network condition and expectation to trade-off between chance and impact,
the default value is 30s, and it will be populated to the following patroni parameters:
# the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30ttl:{{pg_rto }}# the number of seconds the loop will sleep. Default value: 10 , this is patroni check loop intervalloop_wait:{{(pg_rto / 3)|round(0, 'ceil')|int }}# timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10retry_timeout:{{(pg_rto / 3)|round(0, 'ceil')|int }}# the amount of time a primary is allowed to recover from failures before failover is triggered (in seconds), Max RTO: 2 loop wait + primary_start_timeoutprimary_start_timeout:{{(pg_rto / 3)|round(0, 'ceil')|int }}
pg_rpo
name: pg_rpo, type: int, level: C
recovery point objective in bytes, 1MiB at most by default
default values: 1048576, which will tolerate at most 1MiB data loss during failover.
when the primary is down and all replicas are lagged, you have to make a tough choice to trade off between Availability and Consistency:
Promote a replica to be the new primary and bring system back online ASAP, with the price of an acceptable data loss (e.g. less than 1MB).
Wait for the primary to come back (which may never be) or human intervention to avoid any data loss.
You can use crit.ymlconf template to ensure no data loss during failover, but it will sacrifice some performance.
pg_libs
name: pg_libs, type: string, level: C
shared preloaded libraries, pg_stat_statements,auto_explain by default.
They are two extensions that come with PostgreSQL, and it is strongly recommended to enable them.
For existing clusters, you can configure the shared_preload_libraries parameter of the cluster and apply it.
If you want to use TimescaleDB or Citus extensions, you need to add timescaledb or citus to this list. timescaledb and citus should be placed at the top of this list, for example:
citus,timescaledb,pg_stat_statements,auto_explain
Other extensions that need to be loaded can also be added to this list, such as pg_cron, pgml, etc.
Generally, citus and timescaledb have the highest priority and should be added to the top of the list.
enable data checksum for postgres cluster?, default value is false.
This parameter can only be set before PGSQL deployment. (but you can enable it manually later)
If pg_confcrit.yml template is used, data checksum is always enabled regardless of this parameter to ensure data integrity.
pg_pwd_enc
name: pg_pwd_enc, type: enum, level: C
passwords encryption algorithm: md5,scram-sha-256
default values: scram-sha-256, if you have compatibility issues with old clients, you can set it to md5 instead.
pg_encoding
name: pg_encoding, type: enum, level: C
database cluster encoding, UTF8 by default
pg_locale
name: pg_locale, type: enum, level: C
The locale set for PostgreSQL, default is C.
When configure detects that the current PG version is greater than or equal to 17, or the current system explicitly supports C.utf8, it will automatically configure this parameter to C.UTF-8.
When the PostgreSQL version is greater than or equal to 17, the C and C.UTF-8 configurations will use the PostgreSQL internal Locale Provider.
Unless you are very clear about what you are doing, it is strongly recommended to use the default C or C.UTF-8 configuration.
pg_lc_collate
name: pg_lc_collate, type: enum, level: C
The locale set for PostgreSQL, default is C.
When configure detects that the current PG version is greater than or equal to 17, or the current system explicitly supports C.utf8, it will automatically configure this parameter to C.UTF-8.
Unless you are very clear about what you are doing, it is strongly recommended to use the default C or C.UTF-8 configuration.
The parameter behaves like pg_locale, but for collate.
pg_lc_ctype
参数名称: pg_lc_ctype, 类型: enum, 层次:C
The locale set for PostgreSQL, default is C.
When configure detects that the current PG version is greater than or equal to 17, or the current system explicitly supports C.utf8, it will automatically configure this parameter to C.UTF-8.
When the PostgreSQL version is greater than or equal to 17, the C and C.UTF-8 configurations will use the PostgreSQL internal Locale Provider.
This parameter behaves like pg_locale, but for ctype.
Unless you are very clear about what you are doing, it is strongly recommended to use the default C or C.UTF-8 configuration.
pgbouncer_enabled
name: pgbouncer_enabled, type: bool, level: C
default value is true, if disabled, pgbouncer will not be launched on pgsql host
pgbouncer_port
name: pgbouncer_port, type: port, level: C
pgbouncer listen port, 6432 by default
pgbouncer_log_dir
name: pgbouncer_log_dir, type: path, level: C
pgbouncer log dir, /pg/log/pgbouncer by default, referenced by promtail the logging agent.
pgbouncer_auth_query
name: pgbouncer_auth_query, type: bool, level: C
query postgres to retrieve unlisted business users? default value is false
If enabled, pgbouncer user will be authenticated against postgres database with SELECT username, password FROM monitor.pgbouncer_auth($1), otherwise, only the users with pgbouncer: true will be allowed to connect to pgbouncer.
pgbouncer_poolmode
name: pgbouncer_poolmode, type: enum, level: C
Pgbouncer pooling mode: transaction, session, statement, transaction by default
session: Session-level pooling with the best compatibility.
transaction: Transaction-level pooling with better performance (lots of small conns), could break some session level features such as notify/listen, etc…
statements: Statement-level pooling which is used for simple read-only queries.
If you application has some compatibility issues with pgbouncer, you can try to change this value to session instead.
pgbouncer_sslmode
name: pgbouncer_sslmode, type: enum, level: C
pgbouncer client ssl mode, disable by default
default values: disable, beware that this may have a huge performance impact on your pgbouncer.
disable: Plain TCP. If client requests TLS, it’s ignored. Default.
allow: If client requests TLS, it is used. If not, plain TCP is used. If the client presents a client certificate, it is not validated.
prefer: Same as allow.
require: Client must use TLS. If not, the client connection is rejected. If the client presents a client certificate, it is not validated.
verify-ca: Client must use TLS with valid client certificate.
verify-full: Same as verify-ca.
PG_PROVISION
PG_BOOTSTRAP will bootstrap a new postgres cluster with patroni, while PG_PROVISION will create default objects in the cluster, including:
pg_provision:true# provision postgres cluster after bootstrappg_init:pg-init # provision init script for cluster template, `pg-init` by defaultpg_default_roles:# default roles and users in postgres cluster- {name: dbrole_readonly ,login: false ,comment:role for global read-only access }- {name: dbrole_offline ,login: false ,comment:role for restricted read-only access }- {name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment:role for global read-write access }- {name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment:role for object creation }- {name: postgres ,superuser: true ,comment:system superuser }- {name: replicator ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment:system replicator }- {name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment:pgsql admin user }- {name: dbuser_monitor ,roles: [pg_monitor, dbrole_readonly] ,pgbouncer: true ,parameters:{log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment:pgsql monitor user }pg_default_privileges:# default privileges when created by admin user- GRANT USAGE ON SCHEMAS TO dbrole_readonly- GRANT SELECT ON TABLES TO dbrole_readonly- GRANT SELECT ON SEQUENCES TO dbrole_readonly- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly- GRANT USAGE ON SCHEMAS TO dbrole_offline- GRANT SELECT ON TABLES TO dbrole_offline- GRANT SELECT ON SEQUENCES TO dbrole_offline- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline- GRANT INSERT ON TABLES TO dbrole_readwrite- GRANT UPDATE ON TABLES TO dbrole_readwrite- GRANT DELETE ON TABLES TO dbrole_readwrite- GRANT USAGE ON SEQUENCES TO dbrole_readwrite- GRANT UPDATE ON SEQUENCES TO dbrole_readwrite- GRANT TRUNCATE ON TABLES TO dbrole_admin- GRANT REFERENCES ON TABLES TO dbrole_admin- GRANT TRIGGER ON TABLES TO dbrole_admin- GRANT CREATE ON SCHEMAS TO dbrole_adminpg_default_schemas:[monitor ] # default schemas to be createdpg_default_extensions:# default extensions to be created- {name: pg_stat_statements ,schema:monitor }- {name: pgstattuple ,schema:monitor }- {name: pg_buffercache ,schema:monitor }- {name: pageinspect ,schema:monitor }- {name: pg_prewarm ,schema:monitor }- {name: pg_visibility ,schema:monitor }- {name: pg_freespacemap ,schema:monitor }- {name: postgres_fdw ,schema:public }- {name: file_fdw ,schema:public }- {name: btree_gist ,schema:public }- {name: btree_gin ,schema:public }- {name: pg_trgm ,schema:public }- {name: intagg ,schema:public }- {name: intarray ,schema:public }- {name:pg_repack }pg_reload:true# reload postgres/pgbouncer/vip after conf changespg_default_hba_rules:# postgres default host-based authentication rules- {user:'${dbsu}',db: all ,addr: local ,auth: ident ,title:'dbsu access via local os user ident'}- {user:'${dbsu}',db: replication ,addr: local ,auth: ident ,title:'dbsu replication from local os ident'}- {user:'${repl}',db: replication ,addr: localhost ,auth: pwd ,title:'replicator replication from localhost'}- {user:'${repl}',db: replication ,addr: intra ,auth: pwd ,title:'replicator replication from intranet'}- {user:'${repl}',db: postgres ,addr: intra ,auth: pwd ,title:'replicator postgres db from intranet'}- {user:'${monitor}',db: all ,addr: localhost ,auth: pwd ,title:'monitor from localhost with password'}- {user:'${monitor}',db: all ,addr: infra ,auth: pwd ,title:'monitor from infra host with password'}- {user:'${admin}',db: all ,addr: infra ,auth: ssl ,title:'admin @ infra nodes with pwd & ssl'}- {user:'${admin}',db: all ,addr: world ,auth: ssl ,title:'admin @ everywhere with ssl & pwd'}- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: pwd ,title:'pgbouncer read/write via local socket'}- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: pwd ,title:'read/write biz user via password'}- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: pwd ,title:'allow etl offline tasks from intranet'}pgb_default_hba_rules:# pgbouncer default host-based authentication rules- {user:'${dbsu}',db: pgbouncer ,addr: local ,auth: peer ,title:'dbsu local admin access with os ident'}- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title:'allow all user local access with pwd'}- {user:'${monitor}',db: pgbouncer ,addr: intra ,auth: pwd ,title:'monitor access via intranet with pwd'}- {user:'${monitor}',db: all ,addr: world ,auth: deny ,title:'reject all other monitor access addr'}- {user:'${admin}',db: all ,addr: intra ,auth: pwd ,title:'admin access via intranet with pwd'}- {user:'${admin}',db: all ,addr: world ,auth: deny ,title:'reject all other admin access addr'}- {user: 'all' ,db: all ,addr: intra ,auth: pwd ,title:'allow all user intra access with pwd'}
pg_provision
name: pg_provision, type: bool, level: C
provision postgres cluster after bootstrap, default value is true.
If disabled, postgres cluster will not be provisioned after bootstrap.
pg_default_privileges:# default privileges when created by admin user- GRANT USAGE ON SCHEMAS TO dbrole_readonly- GRANT SELECT ON TABLES TO dbrole_readonly- GRANT SELECT ON SEQUENCES TO dbrole_readonly- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly- GRANT USAGE ON SCHEMAS TO dbrole_offline- GRANT SELECT ON TABLES TO dbrole_offline- GRANT SELECT ON SEQUENCES TO dbrole_offline- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline- GRANT INSERT ON TABLES TO dbrole_readwrite- GRANT UPDATE ON TABLES TO dbrole_readwrite- GRANT DELETE ON TABLES TO dbrole_readwrite- GRANT USAGE ON SEQUENCES TO dbrole_readwrite- GRANT UPDATE ON SEQUENCES TO dbrole_readwrite- GRANT TRUNCATE ON TABLES TO dbrole_admin- GRANT REFERENCES ON TABLES TO dbrole_admin- GRANT TRIGGER ON TABLES TO dbrole_admin- GRANT CREATE ON SCHEMAS TO dbrole_admin
Pigsty has a built-in privileges base on default role system, check PGSQL Privileges for details.
postgres default host-based authentication rules, array of hba rule object.
default value provides a fair enough security level for common scenarios, check PGSQL Authentication for details.
pg_default_hba_rules:# postgres default host-based authentication rules- {user:'${dbsu}',db: all ,addr: local ,auth: ident ,title:'dbsu access via local os user ident'}- {user:'${dbsu}',db: replication ,addr: local ,auth: ident ,title:'dbsu replication from local os ident'}- {user:'${repl}',db: replication ,addr: localhost ,auth: pwd ,title:'replicator replication from localhost'}- {user:'${repl}',db: replication ,addr: intra ,auth: pwd ,title:'replicator replication from intranet'}- {user:'${repl}',db: postgres ,addr: intra ,auth: pwd ,title:'replicator postgres db from intranet'}- {user:'${monitor}',db: all ,addr: localhost ,auth: pwd ,title:'monitor from localhost with password'}- {user:'${monitor}',db: all ,addr: infra ,auth: pwd ,title:'monitor from infra host with password'}- {user:'${admin}',db: all ,addr: infra ,auth: ssl ,title:'admin @ infra nodes with pwd & ssl'}- {user:'${admin}',db: all ,addr: world ,auth: ssl ,title:'admin @ everywhere with ssl & pwd'}- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: pwd ,title:'pgbouncer read/write via local socket'}- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: pwd ,title:'read/write biz user via password'}- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: pwd ,title:'allow etl offline tasks from intranet'}
pgbouncer default host-based authentication rules, array or hba rule object.
default value provides a fair enough security level for common scenarios, check PGSQL Authentication for details.
pgb_default_hba_rules:# pgbouncer default host-based authentication rules- {user:'${dbsu}',db: pgbouncer ,addr: local ,auth: peer ,title:'dbsu local admin access with os ident'}- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title:'allow all user local access with pwd'}- {user:'${monitor}',db: pgbouncer ,addr: intra ,auth: pwd ,title:'monitor access via intranet with pwd'}- {user:'${monitor}',db: all ,addr: world ,auth: deny ,title:'reject all other monitor access addr'}- {user:'${admin}',db: all ,addr: intra ,auth: pwd ,title:'admin access via intranet with pwd'}- {user:'${admin}',db: all ,addr: world ,auth: deny ,title:'reject all other admin access addr'}- {user: 'all' ,db: all ,addr: intra ,auth: pwd ,title:'allow all user intra access with pwd'}
PG_BACKUP
This section defines variables for pgBackRest, which is used for PGSQL PITR (Point-In-Time-Recovery).
pgbackrest_enabled:true# enable pgbackrest on pgsql host?pgbackrest_clean:true# remove pg backup data during init?pgbackrest_log_dir:/pg/log/pgbackrest# pgbackrest log dir, `/pg/log/pgbackrest` by defaultpgbackrest_method: local # pgbackrest repo method:local,minio,[user-defined...]pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorylocal:# default pgbackrest repo with local posix fspath:/pg/backup # local backup directory, `/pg/backup` by defaultretention_full_type:count # retention full backups by countretention_full:2# keep 2, at most 3 full backup when using local fs repominio:# optional minio repo for pgbackresttype:s3 # minio is s3-compatible, so s3 is useds3_endpoint:sss.pigsty # minio endpoint domain name, `sss.pigsty` by defaults3_region:us-east-1 # minio region, us-east-1 by default, useless for minios3_bucket:pgsql # minio bucket name, `pgsql` by defaults3_key:pgbackrest # minio user access key for pgbackrests3_key_secret:S3User.Backup # minio user secret key for pgbackrests3_uri_style:path # use path style uri for minio rather than host stylepath:/pgbackrest # minio backup path, default is `/pgbackrest`storage_port:9000# minio port, 9000 by defaultstorage_ca_file:/etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by defaultblock:y# Enable block incremental backupbundle:y# bundle small files into a single filebundle_limit:20MiB # Limit for file bundles, 20MiB for object storagebundle_size:128MiB # Target size for file bundles, 128MiB for object storagecipher_type:aes-256-cbc # enable AES encryption for remote backup repocipher_pass:pgBackRest # AES encryption password, default is 'pgBackRest'retention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days
pgbackrest_enabled
name: pgbackrest_enabled, type: bool, level: C
enable pgBackRest on pgsql host? default value is true
When using the local file system backup repository (local), only the primary instance of the cluster will actually enable pgbackrest.
Other instances will only initialize an empty repository.
pgbackrest_clean
name: pgbackrest_clean, type: bool, level: C
remove pg backup data during init? default value is true
pgbackrest_log_dir
name: pgbackrest_log_dir, type: path, level: C
pgBackRest log dir, /pg/log/pgbackrest by default, which is referenced by promtail the logging agent.
pgbackrest_method
name: pgbackrest_method, type: enum, level: C
pgBackRest repo method: local, minio, or other user-defined methods, local by default
This parameter is used to determine which repo to use for pgBackRest, all available repo methods are defined in pgbackrest_repo.
Pigsty will use local backup repo by default, which will create a backup repo on primary instance’s /pg/backup directory. The underlying storage is specified by pg_fs_bkup.
default value includes two repo methods: local and minio, which are defined as follows:
pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorylocal:# default pgbackrest repo with local posix fspath:/pg/backup # local backup directory, `/pg/backup` by defaultretention_full_type:count # retention full backups by countretention_full:2# keep 2, at most 3 full backup when using local fs repominio:# optional minio repo for pgbackresttype:s3 # minio is s3-compatible, so s3 is useds3_endpoint:sss.pigsty # minio endpoint domain name, `sss.pigsty` by defaults3_region:us-east-1 # minio region, us-east-1 by default, useless for minios3_bucket:pgsql # minio bucket name, `pgsql` by defaults3_key:pgbackrest # minio user access key for pgbackrests3_key_secret:S3User.Backup # minio user secret key for pgbackrests3_uri_style:path # use path style uri for minio rather than host stylepath:/pgbackrest # minio backup path, default is `/pgbackrest`storage_port:9000# minio port, 9000 by defaultstorage_ca_file:/etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by defaultblock:y# Enable block incremental backupbundle:y# bundle small files into a single filebundle_limit:20MiB # Limit for file bundles, 20MiB for object storagebundle_size:128MiB # Target size for file bundles, 128MiB for object storagecipher_type:aes-256-cbc # enable AES encryption for remote backup repocipher_pass:pgBackRest # AES encryption password, default is 'pgBackRest'retention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days
You can define a new backup repository, for example using AWS S3, GCP or other cloud provider’s S3-compatible storage service.
In the backup repository definition parameters, you can use ${pg_cluster} variable to reference the cluster name, for example as part of the backup path or encryption key.
But if you have cross-cluster PITR requirements, you should keep the backup repository path and encryption key the same.
PG_SERVICE
This section is about exposing PostgreSQL service to outside world: including:
Exposing different PostgreSQL services on different ports with haproxy
Bind an optional L2 VIP to the primary instance with vip-manager
Register cluster/instance DNS records with to dnsmasq on infra nodes
pg_weight:100#INSTANCE # relative load balance weight in service, 100 by default, 0-255pg_default_service_dest:pgbouncer# default service destination if svc.dest='default'pg_default_services:# postgres default service definitions- {name: primary ,port: 5433 ,dest: default ,check: /primary ,selector:"[]"}- {name: replica ,port: 5434 ,dest: default ,check: /read-only ,selector:"[]", backup:"[? pg_role == `primary` || pg_role == `offline` ]"}- {name: default ,port: 5436 ,dest: postgres ,check: /primary ,selector:"[]"}- {name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector:"[? pg_role == `offline` || pg_offline_query ]", backup:"[? pg_role == `replica` && !pg_offline_query]"}pg_vip_enabled:false# enable a l2 vip for pgsql primary? false by defaultpg_vip_address:127.0.0.1/24 # vip address in `<ipv4>/<mask>` format, require if vip is enabledpg_vip_interface:eth0 # vip network interface to listen, eth0 by defaultpg_dns_suffix:''# pgsql dns suffix, '' by defaultpg_dns_target:auto # auto, primary, vip, none, or ad hoc ip
pg_weight
name: pg_weight, type: int, level: G
relative load balance weight in service, 100 by default, 0-255
default values: 100. you have to define it at instance vars, and reload-service to take effect.
default value is false, means no L2 VIP is created for this cluster.
L2 VIP can only be used in same L2 network, which may incurs extra restrictions on your network topology.
pg_vip_address
name: pg_vip_address, type: cidr4, level: C
vip address in <ipv4>/<mask> format, if vip is enabled, this parameter is required.
default values: 127.0.0.1/24. This value is consist of two parts: ipv4 and mask, separated by /.
pg_vip_interface
name: pg_vip_interface, type: string, level: C/I
vip network interface to listen, eth0 by default.
It should be the same primary intranet interface of your node, which is the IP address you used in the inventory file.
If your node have different interface, you can override it on instance vars:
pg-test:hosts:10.10.10.11:{pg_seq: 1, pg_role: replica ,pg_vip_interface:eth0 }10.10.10.12:{pg_seq: 2, pg_role: primary ,pg_vip_interface:eth1 }10.10.10.13:{pg_seq: 3, pg_role: replica ,pg_vip_interface:eth2 }vars:pg_vip_enabled:true# enable L2 VIP for this cluster, bind to primary instance by defaultpg_vip_address: 10.10.10.3/24 # the L2 network CIDR: 10.10.10.0/24, the vip address:10.10.10.3# pg_vip_interface: eth1 # if your node have non-uniform interface, you can define it here
pg_dns_suffix
name: pg_dns_suffix, type: string, level: C
pgsql dns suffix, ’’ by default, cluster DNS name is defined as {{ pg_cluster }}{{ pg_dns_suffix }}
For example, if you set pg_dns_suffix to .db.vip.company.tld for cluster pg-test, then the cluster DNS name will be pg-test.db.vip.company.tld
pg_dns_target
name: pg_dns_target, type: enum, level: C
Could be: auto, primary, vip, none, or an ad hoc ip address, which will be the target IP address of cluster DNS record.
default values: auto , which will bind to pg_vip_address if pg_vip_enabled, or fallback to cluster primary instance ip address.
vip: bind to pg_vip_address
primary: resolve to cluster primary instance ip address
auto: resolve to pg_vip_address if pg_vip_enabled, or fallback to cluster primary instance ip address.
none: do not bind to any ip address
<ipv4>: bind to the given IP address
PG_EXPORTER
pg_exporter_enabled:true# enable pg_exporter on pgsql hosts?pg_exporter_config:pg_exporter.yml # pg_exporter configuration file namepg_exporter_cache_ttls:'1,10,60,300'# pg_exporter collector ttl stage in seconds, '1,10,60,300' by defaultpg_exporter_port:9630# pg_exporter listen port, 9630 by defaultpg_exporter_params:'sslmode=disable'# extra url parameters for pg_exporter dsnpg_exporter_url:''# overwrite auto-generate pg dsn if specifiedpg_exporter_auto_discovery:true# enable auto database discovery? enabled by defaultpg_exporter_exclude_database:'template0,template1,postgres'# csv of database that WILL NOT be monitored during auto-discoverypg_exporter_include_database:''# csv of database that WILL BE monitored during auto-discoverypg_exporter_connect_timeout:200# pg_exporter connect timeout in ms, 200 by defaultpg_exporter_options:''# overwrite extra options for pg_exporterpgbouncer_exporter_enabled:true# enable pgbouncer_exporter on pgsql hosts?pgbouncer_exporter_port:9631# pgbouncer_exporter listen port, 9631 by defaultpgbouncer_exporter_url:''# overwrite auto-generate pgbouncer dsn if specifiedpgbouncer_exporter_options:''# overwrite extra options for pgbouncer_exporterpgbackrest_exporter_enabled:true# enable pgbackrest_exporter on pgsql hosts?pgbackrest_exporter_port:9854# pgbackrest_exporter listen port, 9854 by defaultpgbackrest_exporter_options:''# overwrite extra options for pgbackrest_exporter
pg_exporter_enabled
name: pg_exporter_enabled, type: bool, level: C
enable pg_exporter on pgsql hosts?
default value is true, if you don’t want to install pg_exporter, set it to false.
pg_exporter_config
name: pg_exporter_config, type: string, level: C
pg_exporter configuration file name, used by pg_exporter & pgbouncer_exporter
default values: pg_exporter.yml, if you want to use a custom configuration file, you can specify its relative path here.
Your config file should be placed in files/<filename>.yml. For example, if you want to monitor a remote PolarDB instance, you can use the sample config: files/polar_exporter.yml.
pg_exporter_cache_ttls
name: pg_exporter_cache_ttls, type: string, level: C
pg_exporter collector ttl stage in seconds, ‘1,10,60,300’ by default
default values: 1,10,60,300, which will use 1s, 10s, 60s, 300s for different metric collectors.
This could be useful if you want to monitor a remote pgbouncer instance, or you want to use a different user/password for monitoring.
pgbouncer_exporter_options
name: pgbouncer_exporter_options, type: arg, level: C
overwrite extra options for pgbouncer_exporter, default value is empty string.
--log.level=info
default value is empty string, which will fall back the following default options:
If you want to customize logging options or other pgbouncer_exporter options, you can set it here.
pgbackrest_exporter_enabled
name: pgbackrest_exporter_enabled, type: bool, level: C
enable pgbackrest_exporter on pgsql hosts? default value is true
If pgbackrest_enabled is false, this parameter will be short-circuited and disabled.
pgbackrest_exporter_port
name: pgbackrest_exporter_port, type: port, level: C
pgbackrest_exporter listen port, 9854 by default
pgbackrest_exporter_options
name: pgbackrest_exporter_options, type: arg, level: C
extra cli args for pgbackrest_exporter, default value is empty string "".
6.10 - Playbook
How to manage PostgreSQL cluster with ansible playbooks
Pigsty has a series of playbooks for PostgreSQL:
pgsql.yml : Init HA PostgreSQL clusters or add new replicas.
pgsql-rm.yml : Remove PostgreSQL cluster, or remove replicas
pgsql-user.yml : Add new business user to existing PostgreSQL cluster
pgsql-db.yml : Add new business database to existing PostgreSQL cluster
pgsql-monitor.yml : Monitor remote PostgreSQL instance with local exporters
pgsql-migration.yml : Generate Migration manual & scripts for existing PostgreSQL
Safeguard
Beware, when using the pgsql.yml and pgsql-rm.yml playbooks, it can pose a risk of accidentally deleting databases if misused!
When using pgsql.yml, please check the --tags|-t and --limit|-l parameters.
Adding the -l parameter when executing playbooks is strongly recommended to limit execution hosts.
Think thrice before proceeding.
To prevent accidental deletions, the PGSQL module offers a safeguard option controlled by the following two parameters:
pg_safeguard is set to false by default: do not prevent purging by default.
pg_clean is set to true by default, meaning it will clean existing instances.
Effects on the init playbook
When meeting a running instance with the same config during the execution of the pgsql.yml playbook:
pg_safeguard / pg_clean
pg_clean=true
pg_clean=false
pg_safeguard=false
Purge
Abort
pg_safeguard=true
Abort
Abort
If pg_safeguard is enabled, the playbook will abort to avoid purging the running instance.
If the safeguard is disabled, it will further decide whether to remove the existing instance according to the value of pg_clean.
If pg_clean is true, the playbook will directly clean up the existing instance to make room for the new instance. This is the default behavior.
If pg_clean is false, the playbook will abort, which requires explicit configuration.
Effects on the remove playbook
When meeting a running instance with the same config during the execution of the pgsql-rm.yml playbook:
pg_safeguard / pg_clean
pg_clean=true
pg_clean=false
pg_safeguard=false
Purge & rm data
Purge
pg_safeguard=true
Abort
Abort
If pg_safeguard is enabled, the playbook will abort to avoid purging the running instance.
If the safeguard is disabled, it purges the running instance and will further decide whether to remove the existing data along with the instance according to the value of pg_clean.
If pg_clean is true, the playbook will directly clean up the PostgreSQL data cluster.
If pg_clean is false, the playbook will skip data purging, which requires explicit configuration.
pgsql.yml
The pgsql.yml is used for init HA PostgreSQL clusters or adding new replicas.
This playbook contains following subtasks:
# pg_clean : cleanup existing postgres if necessary# pg_dbsu : setup os user sudo for postgres dbsu# pg_install : install postgres packages & extensions# - pg_pkg : install postgres related packages# - pg_extension : install postgres extensions only# - pg_path : link pgsql version bin to /usr/pgsql# - pg_env : add pgsql bin to system path# pg_dir : create postgres directories and setup fhs# pg_util : copy utils scripts, setup alias and env# - pg_bin : sync postgres util scripts /pg/bin# - pg_alias : write /etc/profile.d/pg-alias.sh# - pg_psql : create psqlrc file for psql# - pg_dummy : create dummy placeholder file# patroni : bootstrap postgres with patroni# - pg_config : generate postgres config# - pg_conf : generate patroni config# - pg_systemd : generate patroni systemd config# - pgbackrest_config : generate pgbackrest config# - pg_cert : issues certificates for postgres# - pg_launch : launch postgres primary & replicas# - pg_watchdog : grant watchdog permission to postgres# - pg_primary : launch patroni/postgres primary# - pg_init : init pg cluster with roles/templates# - pg_pass : write .pgpass file to pg home# - pg_replica : launch patroni/postgres replicas# - pg_hba : generate pg HBA rules# - patroni_reload : reload patroni config# - pg_patroni : pause or remove patroni if necessary# pg_user : provision postgres business users# - pg_user_config : render create user sql# - pg_user_create : create user on postgres# pg_db : provision postgres business databases# - pg_db_config : render create database sql# - pg_db_create : create database on postgres# pg_backup : init pgbackrest repo & basebackup# - pgbackrest_init : init pgbackrest repo# - pgbackrest_backup : make a initial backup after bootstrap# pgbouncer : deploy a pgbouncer sidecar with postgres# - pgbouncer_clean : cleanup existing pgbouncer# - pgbouncer_dir : create pgbouncer directories# - pgbouncer_config : generate pgbouncer config# - pgbouncer_svc : generate pgbouncer systemd config# - pgbouncer_ini : generate pgbouncer main config# - pgbouncer_hba : generate pgbouncer hba config# - pgbouncer_db : generate pgbouncer database config# - pgbouncer_user : generate pgbouncer user config# - pgbouncer_launch : launch pgbouncer pooling service# - pgbouncer_reload : reload pgbouncer config# pg_vip : bind vip to pgsql primary with vip-manager# - pg_vip_config : generate config for vip-manager# - pg_vip_launch : launch vip-manager to bind vip# pg_dns : register dns name to infra dnsmasq# - pg_dns_ins : register pg instance name# - pg_dns_cls : register pg cluster name# pg_service : expose pgsql service with haproxy# - pg_service_config : generate local haproxy config for pg services# - pg_service_reload : expose postgres services with haproxy# pg_exporter : expose pgsql service with haproxy# - pg_exporter_config : config pg_exporter & pgbouncer_exporter# - pg_exporter_launch : launch pg_exporter# - pgbouncer_exporter_launch : launch pgbouncer exporter# pg_register : register postgres to pigsty infrastructure# - register_prometheus : register pg as prometheus monitor targets# - register_grafana : register pg database as grafana datasource
pgBackRest backup & restore command and shortcuts:
pb info # print pgbackrest repo infopg-backup # make a backup, incr, or full backup if necessarypg-backup full # make a full backuppg-backup diff # make a differential backuppg-backup incr # make a incremental backuppg-pitr -i # restore to the time of latest backup complete (not often used)pg-pitr --time="2022-12-30 14:44:44+08"# restore to specific time point (in case of drop db, drop table)pg-pitr --name="my-restore-point"# restore TO a named restore point create by pg_create_restore_pointpg-pitr --lsn="0/7C82CB8" -X # restore right BEFORE a LSNpg-pitr --xid="1234567" -X -P # restore right BEFORE a specific transaction id, then promotepg-pitr --backup=latest # restore to latest backup setpg-pitr --backup=20221108-105325 # restore to a specific backup set, which can be checked with pgbackrest info
To create a new database user on the existing Postgres cluster, add database definition to all.children.<cls>.pg_databases, then create the database as follows:
Note: If the database has specified an owner, the user should already exist, or you’ll have to Create User first.
Example: Create Business Database
Reload Service
Services are exposed access point served by HAProxy.
This task is used when cluster membership has changed, e.g., append/remove replicas, switchover/failover / exposing new service or updating existing service’s config (e.g., LB Weight)
To create new services or reload existing services on entire proxy cluster or specific instances:
Note: patroni unsafe RestAPI access is limit from infra/admin nodes and protected with an HTTP basic auth username/password and an optional HTTPS mode.
Example: Config Cluster with patronictl
Append Replica
To add a new replica to the existing Postgres cluster, you have to add its definition to the inventory: all.children.<cls>.hosts, then:
bin/node-add <ip> # init node <ip> for the new replica bin/pgsql-add <cls> <ip> # init pgsql instances on <ip> for cluster <cls>
It will add node <ip> to pigsty and init it as a replica of the cluster <cls>.
Cluster services will be reloaded to adopt the new member
Example: Add replica to pg-test
For example, if you want to add a pg-test-3 / 10.10.10.13 to the existing cluster pg-test, you’ll have to update the inventory first:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }# existing member 10.10.10.12: { pg_seq: 2, pg_role: replica }# existing member 10.10.10.13: { pg_seq: 3, pg_role: replica }# <--- new member vars: { pg_cluster: pg-test }
then apply the change as follows:
bin/node-add 10.10.10.13 # add node to pigstybin/pgsql-add pg-test 10.10.10.13 # init new replica on 10.10.10.13 for cluster pg-test
which is similar to cluster init but only works on single instance.
[ OK ] init instances 10.10.10.11 to pgsql cluster 'pg-test':
[WARN] reminder: add nodes to pigsty, then install additional module 'pgsql'[HINT] $ bin/node-add 10.10.10.11 # run this ahead, except infra nodes[WARN] init instances from cluster:
[ OK ] $ ./pgsql.yml -l '10.10.10.11,&pg-test'[WARN] reload pg_service on existing instances:
[ OK ] $ ./pgsql.yml -l 'pg-test,!10.10.10.11' -t pg_service
Remove Replica
To remove a replica from the existing PostgreSQL cluster:
It will remove instance <ip> from cluster <cls>.
Cluster services will be reloaded to kick the removed instance from load balancer.
Example: Remove replica from pg-test
For example, if you want to remove pg-test-3 / 10.10.10.13 from the existing cluster pg-test:
bin/pgsql-rm pg-test 10.10.10.13 # remove pgsql instance 10.10.10.13 from pg-testbin/node-rm 10.10.10.13 # remove that node from pigsty (optional)vi pigsty.yml # remove instance definition from inventorybin/pgsql-svc pg-test # refresh pg_service on existing instances to kick removed instance from load balancer
[ OK ] remove pgsql instances from 10.10.10.13 of 'pg-test':
[WARN] remove instances from cluster:
[ OK ] $ ./pgsql-rm.yml -l '10.10.10.13,&pg-test'
And remove instance definition from the inventory:
pg-test:hosts:10.10.10.11:{pg_seq: 1, pg_role:primary }10.10.10.12:{pg_seq: 2, pg_role:replica }10.10.10.13:{pg_seq: 3, pg_role:replica }# <--- remove this after executionvars:{pg_cluster:pg-test }
Finally, you can update pg service and kick the removed instance from load balancer:
bin/pgsql-svc pg-test # reload pg service on pg-test
Remove Cluster
To remove the entire Postgres cluster, just run:
bin/pgsql-rm <cls> # ./pgsql-rm.yml -l <cls>
Example: Remove Cluster
Example: Force removing a cluster
Note: if pg_safeguard is configured for this cluster (or globally configured to true), pgsql-rm.yml will abort to avoid removing a cluster by accident.
You can use playbook command line args to explicitly overwrite it to force the purge:
./pgsql-rm.yml -l pg-meta -e pg_safeguard=false# force removing pg cluster pg-meta
Switchover
You can perform a PostgreSQL cluster switchover with patroni cmd.
pg switchover <cls> # interactive mode, you can skip that with following optionspg switchover --leader pg-test-1 --candidate=pg-test-2 --scheduled=now --force pg-test
Example: Switchover pg-test
$ pg switchover pg-test
Master [pg-test-1]:
Candidate ['pg-test-2', 'pg-test-3'][]: pg-test-2
When should the switchover take place (e.g. 2022-12-26T07:39 )[now]: now
Current cluster topology
+ Cluster: pg-test (7181325041648035869) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Leader | running |1|| clonefrom: true|||||||| conf: tiny.yml |||||||| spec: 1C.2G.50G |||||||| version: '15'|+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-2 | 10.10.10.12 | Replica | running |1|0| clonefrom: true|||||||| conf: tiny.yml |||||||| spec: 1C.2G.50G |||||||| version: '15'|+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-3 | 10.10.10.13 | Replica | running |1|0| clonefrom: true|||||||| conf: tiny.yml |||||||| spec: 1C.2G.50G |||||||| version: '15'|+-----------+-------------+---------+---------+----+-----------+-----------------+
Are you sure you want to switchover cluster pg-test, demoting current master pg-test-1? [y/N]: y
2022-12-26 06:39:58.02468 Successfully switched over to "pg-test-2"+ Cluster: pg-test (7181325041648035869) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Replica | stopped || unknown | clonefrom: true|||||||| conf: tiny.yml |||||||| spec: 1C.2G.50G |||||||| version: '15'|+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-2 | 10.10.10.12 | Leader | running |1|| clonefrom: true|||||||| conf: tiny.yml |||||||| spec: 1C.2G.50G |||||||| version: '15'|+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-3 | 10.10.10.13 | Replica | running |1|0| clonefrom: true|||||||| conf: tiny.yml |||||||| spec: 1C.2G.50G |||||||| version: '15'|+-----------+-------------+---------+---------+----+-----------+-----------------+
To do so with Patroni API (schedule a switchover from 2 to 1 at a specific time):
To create a backup with pgBackRest, run as local dbsu:
pg-backup # make a postgres base backuppg-backup full # make a full backuppg-backup diff # make a differential backuppg-backup incr # make a incremental backuppb info # check backup information
You can add crontab to node_crontab to specify your backup policy.
# make a full backup 1 am everyday- '00 01 * * * postgres /pg/bin/pg-backup full'# rotate backup: make a full backup on monday 1am, and an incremental backup during weekdays- '00 01 * * 1 postgres /pg/bin/pg-backup full'- '00 01 * * 2,3,4,5,6,7 postgres /pg/bin/pg-backup'
Restore Cluster
To restore a cluster to a previous time point (PITR), run as local dbsu:
pg-pitr -i # restore to the time of latest backup complete (not often used)pg-pitr --time="2022-12-30 14:44:44+08"# restore to specific time point (in case of drop db, drop table)pg-pitr --name="my-restore-point"# restore TO a named restore point create by pg_create_restore_pointpg-pitr --lsn="0/7C82CB8" -X # restore right BEFORE a LSNpg-pitr --xid="1234567" -X -P # restore right BEFORE a specific transaction id, then promotepg-pitr --backup=latest # restore to latest backup setpg-pitr --backup=20221108-105325 # restore to a specific backup set, which can be checked with pgbackrest info
And follow the instructions wizard, Check Backup & PITR for details.
Example: PITR with raw pgBackRest Command
# restore to the latest available point (e.g. hardware failure)pgbackrest --stanza=pg-meta restore
# PITR to specific time point (e.g. drop table by accident)pgbackrest --stanza=pg-meta --type=time --target="2022-11-08 10:58:48"\
--target-action=promote restore
# restore specific backup point and then promote (or pause|shutdown)pgbackrest --stanza=pg-meta --type=immediate --target-action=promote \
--set=20221108-105325F_20221108-105938I restore
Then rebuild repo on infra nodes with ./infra.yml -t repo_build subtask, Then you can install these packages with ansible module package:
ansible pg-test -b -m package -a "name=pg_cron_15,topn_15,pg_stat_monitor_15*"# install some packages
Update Packages Manually
# add repo upstream on admin node, then download them manuallycd ~/pigsty; ./infra.yml -t repo_upstream,repo_cache # add upstream repo (internet)cd /www/pigsty; repotrack "some_new_package_name"# download the latest RPMs# re-create local repo on admin node, then refresh yum/apt cache on all nodescd ~/pigsty; ./infra.yml -t repo_create # recreate local repo on admin node./node.yml -t node_repo # refresh yum/apt cache on all nodes# alternatives: clean and remake cache on all nodes with ansible commandansible all -b -a 'yum clean all'# clean node repo cacheansible all -b -a 'yum makecache'# remake cache from the new repoansible all -b -a 'apt clean'# clean node repo cache (Ubuntu/Debian)ansible all -b -a 'apt update'# remake cache from the new repo (Ubuntu/Debian)
For example, you can then install or upgrade packages with:
ansible pg-test -b -m package -a "name=postgresql15* state=latest"
Install Extension
If you want to install extension on pg clusters, Add them to pg_extensions and make sure them installed with:
./pgsql.yml -t pg_extension # install extensions
Some extension needs to be loaded in shared_preload_libraries, You can add them to pg_libs, or Config an existing cluster.
Finally, CREATE EXTENSION <extname>; on the cluster primary instance to install it.
Example: Install pg_cron on pg-test cluster
ansible pg-test -b -m package -a "name=pg_cron_15"# install pg_cron packages on all nodes# add pg_cron to shared_preload_librariespg edit-config --force -p shared_preload_libraries='timescaledb, pg_cron, pg_stat_statements, auto_explain'pg restart --force pg-test # restart clusterpsql -h pg-test -d postgres -c 'CREATE EXTENSION pg_cron;'# install pg_cron on primary
The simplest way to achieve a major version upgrade is to create a new cluster with the new version, then migration with logical replication & green/blue deployment.
You can also perform an in-place major upgrade, which is not recommended especially when certain extensions are installed. But it is possible.
Assume you want to upgrade PostgreSQL 14 to 15, you have to add packages to yum/apt repo, and guarantee the extensions has exact same version too.
!> Remember to change these password in production deployment !
pg_dbsu:postgres # os user for the databasepg_replication_username:replicator # system replication userpg_replication_password:DBUser.Replicator # system replication passwordpg_monitor_username:dbuser_monitor # system monitor userpg_monitor_password:DBUser.Monitor # system monitor passwordpg_admin_username:dbuser_dba # system admin userpg_admin_password:DBUser.DBA # system admin password
- GRANT USAGE ON SCHEMAS TO dbrole_readonly- GRANT SELECT ON TABLES TO dbrole_readonly- GRANT SELECT ON SEQUENCES TO dbrole_readonly- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly- GRANT USAGE ON SCHEMAS TO dbrole_offline- GRANT SELECT ON TABLES TO dbrole_offline- GRANT SELECT ON SEQUENCES TO dbrole_offline- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline- GRANT INSERT ON TABLES TO dbrole_readwrite- GRANT UPDATE ON TABLES TO dbrole_readwrite- GRANT DELETE ON TABLES TO dbrole_readwrite- GRANT USAGE ON SEQUENCES TO dbrole_readwrite- GRANT UPDATE ON SEQUENCES TO dbrole_readwrite- GRANT TRUNCATE ON TABLES TO dbrole_admin- GRANT REFERENCES ON TABLES TO dbrole_admin- GRANT TRIGGER ON TABLES TO dbrole_admin- GRANT CREATE ON SCHEMAS TO dbrole_admin
Newly created objects will have corresponding privileges when it is created by admin users
The \ddp+ may looks like:
Type
Access privileges
function
=X
dbrole_readonly=X
dbrole_offline=X
dbrole_admin=X
schema
dbrole_readonly=U
dbrole_offline=U
dbrole_admin=UC
sequence
dbrole_readonly=r
dbrole_offline=r
dbrole_readwrite=wU
dbrole_admin=rwU
table
dbrole_readonly=r
dbrole_offline=r
dbrole_readwrite=awd
dbrole_admin=arwdDxt
Default Privilege
ALTER DEFAULT PRIVILEGES allows you to set the privileges that will be applied to objects created in the future.
It does not affect privileges assigned to already-existing objects, and objects created by non-admin users.
Pigsty will use the following default privileges:
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_dbsu }} {{ priv }};
{% endfor %}
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_admin_username }} {{ priv }};
{% endfor %}
-- for additional business admin, they can SET ROLE to dbrole_admin
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" {{ priv }};
{% endfor %}
Which will be rendered in pg-init-template.sql alone with ALTER DEFAULT PRIVILEGES statement for admin users.
These SQL command will be executed on postgres & template1 during cluster bootstrap, and newly created database will inherit it from tempalte1 by default.
That is to say, to maintain the correct object privilege, you have to run DDL with admin users, which could be:
It’s wise to use postgres as global object owner to perform DDL changes.
If you wish to create objects with business admin user, YOU MUST USE SET ROLE dbrole_admin before running that DDL to maintain the correct privileges.
You can also ALTER DEFAULT PRIVILEGE FOR ROLE <some_biz_admin> XXX to grant default privilege to business admin user, too.
There are 3 database level privileges: CONNECT, CREATE, TEMP, and a special ‘privilege’: OWNERSHIP.
- name:meta # required, `name` is the only mandatory field of a database definitionowner:postgres # optional, specify a database owner, {{ pg_dbsu }} by defaultallowconn:true# optional, allow connection, true by default. false will disable connect at allrevokeconn:false# optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)
If owner exists, it will be used as database owner instead of default {{ pg_dbsu }}
If revokeconn is false, all users have the CONNECT privilege of the database, this is the default behavior.
If revokeconn is set to true explicitly:
CONNECT privilege of the database will be revoked from PUBLIC
CONNECT privilege will be granted to {{ pg_replication_username }}, {{ pg_monitor_username }} and {{ pg_admin_username }}
CONNECT privilege will be granted to database owner with GRANT OPTION
revokeconn flag can be used for database access isolation, you can create different business users as the owners for each database and set the revokeconn option for all of them.
Pigsty revokes the CREATE privilege on database from PUBLIC by default, for security consideration.
And this is the default behavior since PostgreSQL 15.
The database owner have the full capability to adjust these privileges as they see fit.
6.13 - Backup & PITR
How to perform base backup & PITR with pgBackRest?
In the case of a hardware failure, a physical replica failover could be the best choice. Whereas for data corruption scenarios (whether machine or human errors), Point-in-Time Recovery (PITR) is often more appropriate.
# stanza name = {{ pg_cluster }} by defaultpgbackrest --stanza=${stanza} --type=full|diff|incr backup
# you can also use the following command in pigsty (/pg/bin/pg-backup)pg-backup # make a backup, incr, or full backup if necessarypg-backup full # make a full backuppg-backup diff # make a differential backuppg-backup incr # make a incremental backup
pg-pitr # restore to wal archive stream end (e.g. used in case of entire DC failure)
pg-pitr -i # restore to the time of latest backup complete (not often used)
pg-pitr --time="2022-12-30 14:44:44+08" # restore to specific time point (in case of drop db, drop table)
pg-pitr --name="my-restore-point" # restore TO a named restore point create by pg_create_restore_point
pg-pitr --lsn="0/7C82CB8" -X # restore right BEFORE a LSN
pg-pitr --xid="1234567" -X -P # restore right BEFORE a specific transaction id, then promote
pg-pitr --backup=latest # restore to latest backup set
pg-pitr --backup=20221108-105325 # restore to a specific backup set, which can be checked with pgbackrest info
pg-pitr # pgbackrest --stanza=pg-meta restore
pg-pitr -i # pgbackrest --stanza=pg-meta --type=immediate restore
pg-pitr -t "2022-12-30 14:44:44+08" # pgbackrest --stanza=pg-meta --type=time --target="2022-12-30 14:44:44+08" restore
pg-pitr -n "my-restore-point" # pgbackrest --stanza=pg-meta --type=name --target=my-restore-point restore
pg-pitr -b 20221108-105325F # pgbackrest --stanza=pg-meta --type=name --set=20221230-120101F restore
pg-pitr -l "0/7C82CB8" -X # pgbackrest --stanza=pg-meta --type=lsn --target="0/7C82CB8" --target-exclusive restore
pg-pitr -x 1234567 -X -P # pgbackrest --stanza=pg-meta --type=xid --target="0/7C82CB8" --target-exclusive --target-action=promote restore
The pg-pitr script will generate instructions for you to perform PITR.
For example, if you wish to rollback current cluster status back to "2023-02-07 12:38:00+08":
$ pg-pitr -t "2023-02-07 12:38:00+08"pgbackrest --stanza=pg-meta --type=time --target='2023-02-07 12:38:00+08' restore
Perform time PITR on pg-meta
[1. Stop PostgreSQL]=========================================== 1.1 Pause Patroni (if there are any replicas) $ pg pause <cls> # pause patroni auto failover 1.2 Shutdown Patroni
$ pt-stop # sudo systemctl stop patroni 1.3 Shutdown Postgres
$ pg-stop # pg_ctl -D /pg/data stop -m fast[2. Perform PITR]=========================================== 2.1 Restore Backup
$ pgbackrest --stanza=pg-meta --type=time --target='2023-02-07 12:38:00+08' restore
2.2 Start PG to Replay WAL
$ pg-start # pg_ctl -D /pg/data start 2.3 Validate and Promote
- If database content is ok, promote it to finish recovery, otherwise goto 2.1
$ pg-promote # pg_ctl -D /pg/data promote[3. Restart Patroni]=========================================== 3.1 Start Patroni
$ pt-start;# sudo systemctl start patroni 3.2 Enable Archive Again
$ psql -c 'ALTER SYSTEM SET archive_mode = on; SELECT pg_reload_conf();' 3.3 Restart Patroni
$ pt-restart # sudo systemctl start patroni[4. Restore Cluster]=========================================== 3.1 Re-Init All Replicas (if any replicas) $ pg reinit <cls> <ins>
3.2 Resume Patroni
$ pg resume <cls> # resume patroni auto failover 3.2 Make Full Backup (optional) $ pg-backup full # pgbackrest --stanza=pg-meta backup --type=full
For example, the default pg-meta will take a full backup every day at 1 am.
node_crontab: # make a full backup 1 am everyday
- '00 01 * * * postgres /pg/bin/pg-backup full'
With the default local repo retention policy, it will keep at most two full backups and temporarily allow three during backup.
pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorylocal:# default pgbackrest repo with local posix fspath:/pg/backup # local backup directory, `/pg/backup` by defaultretention_full_type:count # retention full backups by countretention_full:2# keep 2, at most 3 full backup when using local fs repo
Your backup disk storage should be at least three x database file size + WAL archive in 3 days.
MinIO repo
When using MinIO, storage capacity is usually not a problem. You can keep backups as long as you want.
For example, the default pg-test will take a full backup on Monday and incr backup on other weekdays.
node_crontab:# make a full backup 1 am everyday- '00 01 * * 1 postgres /pg/bin/pg-backup full'- '00 01 * * 2,3,4,5,6,7 postgres /pg/bin/pg-backup'
And with a 14-day time retention policy, backup in the last two weeks will be kept. But beware, this guarantees a week’s PITR period only.
pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repository=minio:# optional minio repo for pgbackresttype:s3 # minio is s3-compatible, so s3 is useds3_endpoint:sss.pigsty # minio endpoint domain name, `sss.pigsty` by defaults3_region:us-east-1 # minio region, us-east-1 by default, useless for minios3_bucket:pgsql # minio bucket name, `pgsql` by defaults3_key:pgbackrest # minio user access key for pgbackrests3_key_secret:S3User.Backup # minio user secret key for pgbackrests3_uri_style:path # use path style uri for minio rather than host stylepath:/pgbackrest # minio backup path, default is `/pgbackrest`storage_port:9000# minio port, 9000 by defaultstorage_ca_file:/etc/pki/ca.crt # minio ca file path, `/etc/pki/ca.crt` by defaultbundle:y# bundle small files into a single filecipher_type:aes-256-cbc # enable AES encryption for remote backup repocipher_pass:pgBackRest # AES encryption password, default is 'pgBackRest'retention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days
6.14 - Migration
How to migrate existing postgres into Pigsty-managed cluster with mimial downtime? The blue-green online migration playbook
Pigsty has a built-in playbook pgsql-migration.yml to perform online database migration based on logical replication.
With proper automation, the downtime could be minimized to several seconds. But beware that logical replication requires PostgreSQL 10+ to work. You can still use the facility here and use a pg_dump | psql instead of logical replication.
Define a Migration Task
You have to create a migration task definition file to use this playbook.
You have to tell pigsty where is the source cluster and destination cluster. The database to be migrated, and the primary IP address.
You should have superuser privileges on both sides to proceed
You can overwrite the superuser connection to the source cluster with src_pg, and logical replication connection string with sub_conn, Otherwise, pigsty default admin & replicator credentials will be used.
---#-----------------------------------------------------------------# PG_MIGRATION#-----------------------------------------------------------------context_dir:~/migration # migration manuals & scripts#-----------------------------------------------------------------# SRC Cluster (The OLD Cluster)#-----------------------------------------------------------------src_cls:pg-meta # src cluster name <REQUIRED>src_db:meta # src database name <REQUIRED>src_ip:10.10.10.10# src cluster primary ip <REQUIRED>#src_pg: '' # if defined, use this as src dbsu pgurl instead of:# # postgres://{{ pg_admin_username }}@{{ src_ip }}/{{ src_db }}# # e.g. 'postgres://dbuser_dba:[email protected]:5432/meta'#sub_conn: '' # if defined, use this as subscription connstr instead of:# # host={{ src_ip }} dbname={{ src_db }} user={{ pg_replication_username }}'# # e.g. 'host=10.10.10.10 dbname=meta user=replicator password=DBUser.Replicator'#-----------------------------------------------------------------# DST Cluster (The New Cluster)#-----------------------------------------------------------------dst_cls:pg-test # dst cluster name <REQUIRED>dst_db:test # dst database name <REQUIRED>dst_ip:10.10.10.11# dst cluster primary ip <REQUIRED>#dst_pg: '' # if defined, use this as dst dbsu pgurl instead of:# # postgres://{{ pg_admin_username }}@{{ dst_ip }}/{{ dst_db }}# # e.g. 'postgres://dbuser_dba:[email protected]:5432/test'#-----------------------------------------------------------------# PGSQL#-----------------------------------------------------------------pg_dbsu:postgrespg_replication_username:replicatorpg_replication_password:DBUser.Replicatorpg_admin_username:dbuser_dbapg_admin_password:DBUser.DBApg_monitor_username:dbuser_monitorpg_monitor_password:DBUser.Monitor#-----------------------------------------------------------------...
Generate Migration Plan
The playbook does not migrate src to dst, but it will generate everything your need to do so.
After the execution, you will find migration context dir under ~/migration/pg-meta.meta by default
Following the README.md and executing these scripts one by one, you will do the trick!
# this script will setup migration context with env vars. ~/migration/pg-meta.meta/activate
# these scripts are used for check src cluster status# and help generating new cluster definition in pigsty./check-user # check src users./check-db # check src databases./check-hba # check src hba rules./check-repl # check src replica identities./check-misc # check src special objects# these scripts are used for building logical replication# between existing src cluster and pigsty managed dst cluster# schema, data will be synced in realtime, except for sequences./copy-schema # copy schema to dest./create-pub # create publication on src./create-sub # create subscription on dst./copy-progress # print logical replication progress./copy-diff # quick src & dst diff by counting tables# these scripts will run in an online migration, which will# stop src cluster, copy sequence numbers (which is not synced with logical replication)# you have to reroute you app traffic according to your access method (dns,vip,haproxy,pgbouncer,etc...)# then perform cleanup to drop subscription and publication./copy-seq [n]# sync sequence numbers, if n is given, an additional shift will applied#./disable-src # restrict src cluster access to admin node & new cluster (YOUR IMPLEMENTATION)#./re-routing # ROUTING APPLICATION TRAFFIC FROM SRC TO DST! (YOUR IMPLEMENTATION)./drop-sub # drop subscription on dst after migration./drop-pub # drop publication on src after migration
Caveats
You can use ./copy-seq 1000 to advance all sequences by a number (e.g. 1000) after syncing sequences.
Which may prevent potential serial primary key conflict in new clusters.
You have to implement your own ./re-routing script to route your application traffic from src to dst.
Since we don’t know how your traffic is routed (e.g dns, VIP, haproxy, or pgbouncer).
Of course, you can always do that by hand…
You have to implement your own ./disable-src script to restrict the src cluster.
You can do that by changing HBA rules & reload (recommended), or just shutting down postgres, pgbouncer, or haproxy…
6.15 - Monitoring
How PostgreSQL monitoring works, and how to monitor remote (existing) PostgreSQL instances?
Overview
Pigsty uses the modern observability stack for PostgreSQL monitoring:
Grafana for metrics visualization and PostgreSQL datasource.
There are three identity labels: cls, ins, ip, which will be attached to all metrics & logs. node & haproxy will try to reuse the same identity to provide consistent metrics & logs.
Prometheus monitoring targets are defined in static files under /etc/prometheus/targets/pgsql/. Each instance will have a corresponding file. Take pg-meta-1 as an example:
When the global flag patroni_ssl_enabled is set, the patroni target will be managed as /etc/prometheus/targets/patroni/<ins>.yml because it requires a different scrape endpoint (https).
Prometheus monitoring target will be removed when a cluster is removed by bin/pgsql-rm or pgsql-rm.yml. You can use playbook subtasks, or remove them manually:
bin/pgmon-rm <ins> # remove prometheus targets from all infra nodes
Remote RDS targets are managed as /etc/prometheus/targets/pgrds/<cls>.yml. It will be created by the pgsql-monitor.yml playbook or bin/pgmon-add script.
Monitor Mode
There are three ways to monitor PostgreSQL instances in Pigsty:
Suppose the target DB node can be managed by Pigsty (accessible via ssh and sudo is available).
In that case, you can use the pg_exporter task in the pgsql.yml playbook to
deploy the monitoring component PG Exporter on the target node in the same manner as a standard deployment.
You can also deploy the connection pool and its monitoring on existing instance nodes using the pgbouncer and pgbouncer_exporter tasks
from the same playbook. Additionally, you can deploy host monitoring, load balancing, and log collection components using the
node_exporter, haproxy, and promtail tasks from the node.yml playbook, achieving a similar user experience with the native Pigsty cluster.
The definition method for existing clusters is very similar to the normal clusters managed by Pigsty.
Selectively run certain tasks from the pgsql.yml playbook instead of running the entire playbook.
./node.yml -l <cls> -t node_repo,node_pkg # Add YUM sources for INFRA nodes on host nodes and install packages../node.yml -l <cls> -t node_exporter,node_register # Configure host monitoring and add to Prometheus../node.yml -l <cls> -t promtail # Configure host log collection and send to Loki../pgsql.yml -l <cls> -t pg_exporter,pg_register # Configure PostgreSQL monitoring and register with Prometheus/Grafana.
If you can only access the target database via PGURL (database connection string), you can refer to the instructions here for configuration.
In this mode, Pigsty deploys the corresponding PG Exporter on the INFRA node to fetch metrics from the remote database, as shown below:
The monitoring system will no longer have host/pooler/load balancer metrics. But the PostgreSQL metrics & catalog info are still available.
Pigsty has two dedicated dashboards for that: PGRDS Cluster and PGRDS Instance.
Overview and Database level dashboards are reused. Since Pigsty cannot manage your RDS, you have to setup monitor on the target database in advance.
Below, we use a sandbox environment as an example: now we assume that the pg-meta cluster is an RDS instance pg-foo-1 to be monitored, and the pg-test cluster is an RDS cluster pg-bar to be monitored:
Create monitoring schemas, users, and permissions on the target. Refer to Monitor Setup for details.
Declare the cluster in the configuration list. For example, suppose we want to monitor the “remote” pg-meta & pg-test clusters:
infra:# Infra cluster for proxies, monitoring, alerts, etc.hosts:{10.10.10.10:{infra_seq:1}}vars:# Install pg_exporter on 'infra' group for remote postgres RDSpg_exporters:# List all remote instances here, assign a unique unused local port for k20001:{pg_cluster: pg-foo, pg_seq: 1, pg_host: 10.10.10.10 , pg_databases:[{name:meta }] }# Register meta database as Grafana data source20002:{pg_cluster: pg-bar, pg_seq: 1, pg_host: 10.10.10.11 , pg_port:5432}# Several different connection string concatenation methods20003:{pg_cluster: pg-bar, pg_seq: 2, pg_host: 10.10.10.12 , pg_exporter_url:'postgres://dbuser_monitor:[email protected]:5432/postgres?sslmode=disable'}20004:{pg_cluster: pg-bar, pg_seq: 3, pg_host: 10.10.10.13 , pg_monitor_username: dbuser_monitor, pg_monitor_password:DBUser.Monitor }
The databases listed in the pg_databases field will be registered in Grafana as a PostgreSQL data source, providing data support for the PGCAT monitoring panel. If you don’t want to use PGCAT and register the database in Grafana, set pg_databases to an empty array or leave it blank.
Execute the command to add monitoring: bin/pgmon-add <clsname>
bin/pgmon-add pg-foo # Bring the pg-foo cluster into monitoringbin/pgmon-add pg-bar # Bring the pg-bar cluster into monitoring
To remove a remote cluster from monitoring, use bin/pgmon-rm <clsname>
bin/pgmon-rm pg-foo # Remove pg-foo from Pigsty monitoringbin/pgmon-rm pg-bar # Remove pg-bar from Pigsty monitoring
You can use more parameters to override the default pg_exporter options. Here is an example for monitoring Aliyun RDS and PolarDB with Pigsty:
infra:# infra cluster for proxy, monitor, alert, etc..hosts:{10.10.10.10:{infra_seq:1}}vars:# install pg_exporter for remote postgres RDS on a group 'infra'pg_exporters:# list all remote instances here, alloc a unique unused local port as k20001:{pg_cluster: pg-foo, pg_seq: 1, pg_host:10.10.10.10}20002:{pg_cluster: pg-bar, pg_seq: 1, pg_host: 10.10.10.11 , pg_port:5432}20003:{pg_cluster: pg-bar, pg_seq: 2, pg_host: 10.10.10.12 , pg_exporter_url:'postgres://dbuser_monitor:[email protected]:5432/postgres?sslmode=disable'}20004:{pg_cluster: pg-bar, pg_seq: 3, pg_host: 10.10.10.13 , pg_monitor_username: dbuser_monitor, pg_monitor_password:DBUser.Monitor }20011:pg_cluster:pg-polar # RDS Cluster Name (Identity, Explicitly Assigned, used as 'cls')pg_seq:1# RDS Instance Seq (Identity, Explicitly Assigned, used as part of 'ins')pg_host:pxx.polardbpg.rds.aliyuncs.com # RDS Host Addresspg_port:1921# RDS Portpg_exporter_include_database:'test'# Only monitoring database in this listpg_monitor_username:dbuser_monitor # monitor username, overwrite defaultpg_monitor_password:DBUser_Monitor # monitor password, overwrite defaultpg_databases:[{name:test }] # database to be added to grafana datasource20012:pg_cluster:pg-polar # RDS Cluster Name (Identity, Explicitly Assigned, used as 'cls')pg_seq:2# RDS Instance Seq (Identity, Explicitly Assigned, used as part of 'ins')pg_host:pe-xx.polarpgmxs.rds.aliyuncs.com # RDS Host Addresspg_port:1521# RDS Portpg_databases:[{name:test }] # database to be added to grafana datasource20014:pg_cluster:pg-rdspg_seq:1pg_host:pgm-xx.pg.rds.aliyuncs.compg_port:5432pg_exporter_auto_discovery:truepg_exporter_include_database:'rds'pg_monitor_username:dbuser_monitorpg_monitor_password:DBUser_Monitorpg_databases:[{name:rds } ]20015:pg_cluster:pg-rdshapg_seq:1pg_host:pgm-2xx8wu.pg.rds.aliyuncs.compg_port:5432pg_exporter_auto_discovery:truepg_exporter_include_database:'rds'pg_databases:[{name:test }, {name: rds}]20016:pg_cluster:pg-rdshapg_seq:2pg_host:pgr-xx.pg.rds.aliyuncs.compg_exporter_auto_discovery:truepg_exporter_include_database:'rds'pg_databases:[{name:test }, {name: rds}]
Monitor Setup
When you want to monitor existing instances, whether it’s RDS or a self-built PostgreSQL instance, you need to make some configurations on the target database so that Pigsty can access them.
To bring an external existing PostgreSQL instance into monitoring, you need a connection string that can access that instance/cluster. Any accessible connection string (business user, superuser) can be used, but we recommend using a dedicated monitoring user to avoid permission leaks.
Monitor User: The default username used is dbuser_monitor. This user belongs to the pg_monitor group, or ensure it has the necessary view permissions.
Monitor HBA: Default password is DBUser.Monitor. You need to ensure that the HBA policy allows the monitoring user to access the database from the infra nodes.
Monitor Schema: It’s optional but recommended to create a dedicate schema monitor for monitoring views and extensions.
Monitor Extension: It is strongly recommended to enable the built-in extension pg_stat_statements.
Monitor View: Monitoring views are optional but can provide additional metrics. Which is recommended.
Monitor User
Create a monitor user on the target database cluster. For example, dbuser_monitor is used by default in Pigsty.
CREATEUSERdbuser_monitor;-- create the monitor user
COMMENTONROLEdbuser_monitorIS'system monitor user';-- comment the monitor user
GRANTpg_monitorTOdbuser_monitor;-- grant system role pg_monitor to monitor user
ALTERUSERdbuser_monitorPASSWORD'DBUser.Monitor';-- set password for monitor user
ALTERUSERdbuser_monitorSETlog_min_duration_statement=1000;-- set this to avoid log flooding
ALTERUSERdbuser_monitorSETsearch_path=monitor,public;-- set this to avoid pg_stat_statements extension not working
You also need to configure pg_hba.conf to allow monitoring user access from infra/admin nodes.
# allow local role monitor with passwordlocal all dbuser_monitor md5host all dbuser_monitor 127.0.0.1/32 md5host all dbuser_monitor <admin_ip>/32 md5host all dbuser_monitor <infra_ip>/32 md5
If your RDS does not support the RAW HBA format, add admin/infra node IP to the whitelist.
Monitor Schema
Monitor schema is optional, but we strongly recommend creating one.
CREATESCHEMAIFNOTEXISTSmonitor;-- create dedicate monitor schema
GRANTUSAGEONSCHEMAmonitorTOdbuser_monitor;-- allow monitor user to use this schema
Monitor Extension
Monitor extension is optional, but we strongly recommend enabling pg_stat_statements extension.
Note that this extension must be listed in shared_preload_libraries to take effect, and changing this parameter requires a database restart.
You should create this extension inside the admin database: postgres. If your RDS does not grant CREATE on the database postgres. You can create that extension in the default public schema:
As long as your monitor user can access pg_stat_statements view without schema qualification, it should be fine.
Monitor View
It’s recommended to create the monitor views in all databases that need to be monitored.
Monitor Schema & View Definition
----------------------------------------------------------------------
-- Table bloat estimate : monitor.pg_table_bloat
----------------------------------------------------------------------
DROPVIEWIFEXISTSmonitor.pg_table_bloatCASCADE;CREATEORREPLACEVIEWmonitor.pg_table_bloatASSELECTCURRENT_CATALOGASdatname,nspname,relname,tblid,bs*tblpagesASsize,CASEWHENtblpages-est_tblpages_ff>0THEN(tblpages-est_tblpages_ff)/tblpages::FLOATELSE0ENDASratioFROM(SELECTceil(reltuples/((bs-page_hdr)*fillfactor/(tpl_size*100)))+ceil(toasttuples/4)ASest_tblpages_ff,tblpages,fillfactor,bs,tblid,nspname,relname,is_naFROM(SELECT(4+tpl_hdr_size+tpl_data_size+(2*ma)-CASEWHENtpl_hdr_size%ma=0THENmaELSEtpl_hdr_size%maEND-CASEWHENceil(tpl_data_size)::INT%ma=0THENmaELSEceil(tpl_data_size)::INT%maEND)AStpl_size,(heappages+toastpages)AStblpages,heappages,toastpages,reltuples,toasttuples,bs,page_hdr,tblid,nspname,relname,fillfactor,is_naFROM(SELECTtbl.oidAStblid,ns.nspname,tbl.relname,tbl.reltuples,tbl.relpagesASheappages,coalesce(toast.relpages,0)AStoastpages,coalesce(toast.reltuples,0)AStoasttuples,coalesce(substring(array_to_string(tbl.reloptions,' ')FROM'fillfactor=([0-9]+)')::smallint,100)ASfillfactor,current_setting('block_size')::numericASbs,CASEWHENversion()~'mingw32'ORversion()~'64-bit|x86_64|ppc64|ia64|amd64'THEN8ELSE4ENDASma,24ASpage_hdr,23+CASEWHENMAX(coalesce(s.null_frac,0))>0THEN(7+count(s.attname))/8ELSE0::intEND+CASEWHENbool_or(att.attname='oid'andatt.attnum<0)THEN4ELSE0ENDAStpl_hdr_size,sum((1-coalesce(s.null_frac,0))*coalesce(s.avg_width,0))AStpl_data_size,bool_or(att.atttypid='pg_catalog.name'::regtype)ORsum(CASEWHENatt.attnum>0THEN1ELSE0END)<>count(s.attname)ASis_naFROMpg_attributeASattJOINpg_classAStblONatt.attrelid=tbl.oidJOINpg_namespaceASnsONns.oid=tbl.relnamespaceLEFTJOINpg_statsASsONs.schemaname=ns.nspnameANDs.tablename=tbl.relnameANDs.inherited=falseANDs.attname=att.attnameLEFTJOINpg_classAStoastONtbl.reltoastrelid=toast.oidWHERENOTatt.attisdroppedANDtbl.relkind='r'ANDnspnameNOTIN('pg_catalog','information_schema')GROUPBY1,2,3,4,5,6,7,8,9,10)ASs)ASs2)ASs3WHERENOTis_na;COMMENTONVIEWmonitor.pg_table_bloatIS'postgres table bloat estimate';GRANTSELECTONmonitor.pg_table_bloatTOpg_monitor;----------------------------------------------------------------------
-- Index bloat estimate : monitor.pg_index_bloat
----------------------------------------------------------------------
DROPVIEWIFEXISTSmonitor.pg_index_bloatCASCADE;CREATEORREPLACEVIEWmonitor.pg_index_bloatASSELECTCURRENT_CATALOGASdatname,nspname,idxnameASrelname,tblid,idxid,relpages::BIGINT*bsASsize,COALESCE((relpages-(reltuples*(6+ma-(CASEWHENindex_tuple_hdr%ma=0THENmaELSEindex_tuple_hdr%maEND)+nulldatawidth+ma-(CASEWHENnulldatawidth%ma=0THENmaELSEnulldatawidth%maEND))/(bs-pagehdr)::FLOAT+1)),0)/relpages::FLOATASratioFROM(SELECTnspname,idxname,indrelidAStblid,indexrelidASidxid,reltuples,relpages,current_setting('block_size')::INTEGERASbs,(CASEWHENversion()~'mingw32'ORversion()~'64-bit|x86_64|ppc64|ia64|amd64'THEN8ELSE4END)ASma,24ASpagehdr,(CASEWHENmax(COALESCE(pg_stats.null_frac,0))=0THEN2ELSE6END)ASindex_tuple_hdr,sum((1.0-COALESCE(pg_stats.null_frac,0.0))*COALESCE(pg_stats.avg_width,1024))::INTEGERASnulldatawidthFROMpg_attributeJOIN(SELECTpg_namespace.nspname,ic.relnameASidxname,ic.reltuples,ic.relpages,pg_index.indrelid,pg_index.indexrelid,tc.relnameAStablename,regexp_split_to_table(pg_index.indkey::TEXT,' ')::INTEGERASattnum,pg_index.indexrelidASindex_oidFROMpg_indexJOINpg_classicONpg_index.indexrelid=ic.oidJOINpg_classtcONpg_index.indrelid=tc.oidJOINpg_namespaceONpg_namespace.oid=ic.relnamespaceJOINpg_amONic.relam=pg_am.oidWHEREpg_am.amname='btree'ANDic.relpages>0ANDnspnameNOTIN('pg_catalog','information_schema'))ind_attsONpg_attribute.attrelid=ind_atts.indexrelidANDpg_attribute.attnum=ind_atts.attnumJOINpg_statsONpg_stats.schemaname=ind_atts.nspnameAND((pg_stats.tablename=ind_atts.tablenameANDpg_stats.attname=pg_get_indexdef(pg_attribute.attrelid,pg_attribute.attnum,TRUE))OR(pg_stats.tablename=ind_atts.idxnameANDpg_stats.attname=pg_attribute.attname))WHEREpg_attribute.attnum>0GROUPBY1,2,3,4,5,6)est;COMMENTONVIEWmonitor.pg_index_bloatIS'postgres index bloat estimate (btree-only)';GRANTSELECTONmonitor.pg_index_bloatTOpg_monitor;----------------------------------------------------------------------
-- Relation Bloat : monitor.pg_bloat
----------------------------------------------------------------------
DROPVIEWIFEXISTSmonitor.pg_bloatCASCADE;CREATEORREPLACEVIEWmonitor.pg_bloatASSELECTcoalesce(ib.datname,tb.datname)ASdatname,coalesce(ib.nspname,tb.nspname)ASnspname,coalesce(ib.tblid,tb.tblid)AStblid,coalesce(tb.nspname||'.'||tb.relname,ib.nspname||'.'||ib.tblid::RegClass)AStblname,tb.sizeAStbl_size,CASEWHENtb.ratio<0THEN0ELSEround(tb.ratio::NUMERIC,6)ENDAStbl_ratio,(tb.size*(CASEWHENtb.ratio<0THEN0ELSEtb.ratio::NUMERICEND))::BIGINTAStbl_wasted,ib.idxid,ib.nspname||'.'||ib.relnameASidxname,ib.sizeASidx_size,CASEWHENib.ratio<0THEN0ELSEround(ib.ratio::NUMERIC,5)ENDASidx_ratio,(ib.size*(CASEWHENib.ratio<0THEN0ELSEib.ratio::NUMERICEND))::BIGINTASidx_wastedFROMmonitor.pg_index_bloatibFULLOUTERJOINmonitor.pg_table_bloattbONib.tblid=tb.tblid;COMMENTONVIEWmonitor.pg_bloatIS'postgres relation bloat detail';GRANTSELECTONmonitor.pg_bloatTOpg_monitor;----------------------------------------------------------------------
-- monitor.pg_index_bloat_human
----------------------------------------------------------------------
DROPVIEWIFEXISTSmonitor.pg_index_bloat_humanCASCADE;CREATEORREPLACEVIEWmonitor.pg_index_bloat_humanASSELECTidxnameASname,tblname,idx_wastedASwasted,pg_size_pretty(idx_size)ASidx_size,round(100*idx_ratio::NUMERIC,2)ASidx_ratio,pg_size_pretty(idx_wasted)ASidx_wasted,pg_size_pretty(tbl_size)AStbl_size,round(100*tbl_ratio::NUMERIC,2)AStbl_ratio,pg_size_pretty(tbl_wasted)AStbl_wastedFROMmonitor.pg_bloatWHEREidxnameISNOTNULL;COMMENTONVIEWmonitor.pg_index_bloat_humanIS'postgres index bloat info in human-readable format';GRANTSELECTONmonitor.pg_index_bloat_humanTOpg_monitor;----------------------------------------------------------------------
-- monitor.pg_table_bloat_human
----------------------------------------------------------------------
DROPVIEWIFEXISTSmonitor.pg_table_bloat_humanCASCADE;CREATEORREPLACEVIEWmonitor.pg_table_bloat_humanASSELECTtblnameASname,idx_wasted+tbl_wastedASwasted,pg_size_pretty(idx_wasted+tbl_wasted)ASall_wasted,pg_size_pretty(tbl_wasted)AStbl_wasted,pg_size_pretty(tbl_size)AStbl_size,tbl_ratio,pg_size_pretty(idx_wasted)ASidx_wasted,pg_size_pretty(idx_size)ASidx_size,round(idx_wasted::NUMERIC*100.0/idx_size,2)ASidx_ratioFROM(SELECTdatname,nspname,tblname,coalesce(max(tbl_wasted),0)AStbl_wasted,coalesce(max(tbl_size),1)AStbl_size,round(100*coalesce(max(tbl_ratio),0)::NUMERIC,2)AStbl_ratio,coalesce(sum(idx_wasted),0)ASidx_wasted,coalesce(sum(idx_size),1)ASidx_sizeFROMmonitor.pg_bloatWHEREtblnameISNOTNULLGROUPBY1,2,3)d;COMMENTONVIEWmonitor.pg_table_bloat_humanIS'postgres table bloat info in human-readable format';GRANTSELECTONmonitor.pg_table_bloat_humanTOpg_monitor;----------------------------------------------------------------------
-- Activity Overview: monitor.pg_session
----------------------------------------------------------------------
DROPVIEWIFEXISTSmonitor.pg_sessionCASCADE;CREATEORREPLACEVIEWmonitor.pg_sessionASSELECTcoalesce(datname,'all')ASdatname,numbackends,active,idle,ixact,max_duration,max_tx_duration,max_conn_durationFROM(SELECTdatname,count(*)ASnumbackends,count(*)FILTER(WHEREstate='active')ASactive,count(*)FILTER(WHEREstate='idle')ASidle,count(*)FILTER(WHEREstate='idle in transaction'ORstate='idle in transaction (aborted)')ASixact,max(extract(epochfromnow()-state_change))FILTER(WHEREstate='active')ASmax_duration,max(extract(epochfromnow()-xact_start))ASmax_tx_duration,max(extract(epochfromnow()-backend_start))ASmax_conn_durationFROMpg_stat_activityWHEREbackend_type='client backend'ANDpid<>pg_backend_pid()GROUPBYROLLUP(1)ORDERBY1NULLSFIRST)t;COMMENTONVIEWmonitor.pg_sessionIS'postgres activity group by session';GRANTSELECTONmonitor.pg_sessionTOpg_monitor;----------------------------------------------------------------------
-- Sequential Scan: monitor.pg_seq_scan
----------------------------------------------------------------------
DROPVIEWIFEXISTSmonitor.pg_seq_scanCASCADE;CREATEORREPLACEVIEWmonitor.pg_seq_scanASSELECTschemanameASnspname,relname,seq_scan,seq_tup_read,seq_tup_read/seq_scanASseq_tup_avg,idx_scan,n_live_tup+n_dead_tupAStuples,round(n_live_tup*100.0::NUMERIC/(n_live_tup+n_dead_tup),2)ASlive_ratioFROMpg_stat_user_tablesWHEREseq_scan>0and(n_live_tup+n_dead_tup)>0ORDERBYseq_scanDESC;COMMENTONVIEWmonitor.pg_seq_scanIS'table that have seq scan';GRANTSELECTONmonitor.pg_seq_scanTOpg_monitor;
Shmem allocation for PostgreSQL 13+
DROPFUNCTIONIFEXISTSmonitor.pg_shmem()CASCADE;CREATEORREPLACEFUNCTIONmonitor.pg_shmem()RETURNSSETOFpg_shmem_allocationsAS$$SELECT*FROMpg_shmem_allocations;$$LANGUAGESQLSECURITYDEFINER;COMMENTONFUNCTIONmonitor.pg_shmem()IS'security wrapper for system view pg_shmem';REVOKEALLONFUNCTIONmonitor.pg_shmem()FROMPUBLIC;GRANTEXECUTEONFUNCTIONmonitor.pg_shmem()TOpg_monitor;
6.16 - Dashboards
Grafana dashboards provided by Pigsty
Grafana Dashboards for PostgreSQL clusters: Demo & Gallery.
There are 26 default grafana dashboards about PostgreSQL and categorized into 4 levels. and categorized into PGSQL, PGCAT & PGLOG by datasource.
Client connections that have sent queries but have not yet got a server connection
pgbouncer_stat_avg_query_count
gauge
datname, job, ins, ip, instance, cls
Average queries per second in last stat period
pgbouncer_stat_avg_query_time
gauge
datname, job, ins, ip, instance, cls
Average query duration, in seconds
pgbouncer_stat_avg_recv
gauge
datname, job, ins, ip, instance, cls
Average received (from clients) bytes per second
pgbouncer_stat_avg_sent
gauge
datname, job, ins, ip, instance, cls
Average sent (to clients) bytes per second
pgbouncer_stat_avg_wait_time
gauge
datname, job, ins, ip, instance, cls
Time spent by clients waiting for a server, in seconds (average per second).
pgbouncer_stat_avg_xact_count
gauge
datname, job, ins, ip, instance, cls
Average transactions per second in last stat period
pgbouncer_stat_avg_xact_time
gauge
datname, job, ins, ip, instance, cls
Average transaction duration, in seconds
pgbouncer_stat_total_query_count
gauge
datname, job, ins, ip, instance, cls
Total number of SQL queries pooled by pgbouncer
pgbouncer_stat_total_query_time
counter
datname, job, ins, ip, instance, cls
Total number of seconds spent when executing queries
pgbouncer_stat_total_received
counter
datname, job, ins, ip, instance, cls
Total volume in bytes of network traffic received by pgbouncer
pgbouncer_stat_total_sent
counter
datname, job, ins, ip, instance, cls
Total volume in bytes of network traffic sent by pgbouncer
pgbouncer_stat_total_wait_time
counter
datname, job, ins, ip, instance, cls
Time spent by clients waiting for a server, in seconds
pgbouncer_stat_total_xact_count
gauge
datname, job, ins, ip, instance, cls
Total number of SQL transactions pooled by pgbouncer
pgbouncer_stat_total_xact_time
counter
datname, job, ins, ip, instance, cls
Total number of seconds spent when in a transaction
pgbouncer_up
gauge
job, ins, ip, instance, cls
last scrape was able to connect to the server: 1 for yes, 0 for no
pgbouncer_version
gauge
job, ins, ip, instance, cls
server version number
process_cpu_seconds_total
counter
job, ins, ip, instance, cls
Total user and system CPU time spent in seconds.
process_max_fds
gauge
job, ins, ip, instance, cls
Maximum number of open file descriptors.
process_open_fds
gauge
job, ins, ip, instance, cls
Number of open file descriptors.
process_resident_memory_bytes
gauge
job, ins, ip, instance, cls
Resident memory size in bytes.
process_start_time_seconds
gauge
job, ins, ip, instance, cls
Start time of the process since unix epoch in seconds.
process_virtual_memory_bytes
gauge
job, ins, ip, instance, cls
Virtual memory size in bytes.
process_virtual_memory_max_bytes
gauge
job, ins, ip, instance, cls
Maximum amount of virtual memory available in bytes.
promhttp_metric_handler_requests_in_flight
gauge
job, ins, ip, instance, cls
Current number of scrapes being served.
promhttp_metric_handler_requests_total
counter
code, job, ins, ip, instance, cls
Total number of scrapes by HTTP status code.
scrape_duration_seconds
Unknown
job, ins, ip, instance, cls
N/A
scrape_samples_post_metric_relabeling
Unknown
job, ins, ip, instance, cls
N/A
scrape_samples_scraped
Unknown
job, ins, ip, instance, cls
N/A
scrape_series_added
Unknown
job, ins, ip, instance, cls
N/A
up
Unknown
job, ins, ip, instance, cls
N/A
6.18 - FAQ
Pigsty PGSQL module frequently asked questions
ABORT due to postgres exists
Set pg_clean = true and pg_safeguard = false to force clean postgres data during pgsql.yml
This happens when you run pgsql.yml on a node with postgres running, and pg_clean is set to false.
If pg_clean is true (and the pg_safeguard is false, too), the pgsql.yml playbook will remove the existing pgsql data and re-init it as a new one, which makes this playbook fully idempotent.
You can still purge the existing PostgreSQL data by using a special task tag pg_purge
./pgsql.yml -t pg_clean # honor pg_clean and pg_safeguard./pgsql.yml -t pg_purge # ignore pg_clean and pg_safeguard
ABORT due to pg_safeguard enabled
Disable pg_safeguard to remove the Postgres instance.
If pg_safeguard is enabled, you can not remove the running pgsql instance with bin/pgsql-rm and pgsql-rm.yml playbook.
To disable pg_safeguard, you can set pg_safeguard to false in the inventory or pass -e pg_safeguard=false as cli arg to the playbook:
./pgsql-rm.yml -e pg_safeguard=false -l <cls_to_remove> # force override pg_safeguard
Fail to wait for postgres/patroni primary
There are several possible reasons for this error, and you need to check the system logs to determine the actual cause.
This usually happens when the cluster is misconfigured, or the previous primary is improperly removed. (e.g., trash metadata in DCS with the same cluster name).
You must check /pg/log/* to find the reason.
To delete trash meta from etcd, you can use etcdctl del --prefix /pg/<cls>, do with caution!
1: Misconfiguration. Identify the incorrect parameters, modify them, and apply the changes.
2: Another cluster with the same cls name already exists in the deployment
3: The previous cluster on the node, or previous cluster with same name was not correctly removed.
To remove obsolete cluster metadata, you can use etcdctl del --prefix /pg/<cls> to manually delete the residual data.
4: The RPM packages related to your PostgreSQL or node were not successfully installed.
5: Your Watchdog kernel module was not correctly enabled or loaded, but required.
6: The locale or ctype specified pg_lc_collate and pg_lc_ctype does not exist in OS
Feel free to submit an issue or seek help from the community.
Fail to wait for postgres/patroni replica
Failed Immediately: Usually, this happens because of misconfiguration, network issues, broken DCS metadata, etc…, you have to inspect /pg/log to find out the actual reason.
Failed After a While: This may be due to source instance data corruption. Check PGSQL FAQ: How to create replicas when data is corrupted?
Timeout: If the wait for postgres replica task takes 30min or more and fails due to timeout, This is common for a huge cluster (e.g., 1TB+, which may take hours to create a replica). In this case, the underlying creating replica procedure is still proceeding. You can check cluster status with pg list <cls> and wait until the replica catches up with the primary. Then continue the following tasks:
To install PostgreSQL 12 - 15, you have to set pg_version to 12, 13, 14, or 15 in the inventory. (usually at cluster level)
pg_version:16# install pg 16 in this templatepg_libs:'pg_stat_statements, auto_explain'# remove timescaledb from pg 16 betapg_extensions:[]# missing pg16 extensions for now
How enable hugepage for PostgreSQL?
use node_hugepage_count and node_hugepage_ratio or /pg/bin/pg-tune-hugepage
If you plan to enable hugepage, consider using node_hugepage_count and node_hugepage_ratio and apply with ./node.yml -t node_tune .
It’s good to allocate enough hugepage before postgres start, and use pg_tune_hugepage to shrink them later.
If your postgres is already running, you can use /pg/bin/pg-tune-hugepage to enable hugepage on the fly. Note that this only works on PostgreSQL 15+
sync;echo3 > /proc/sys/vm/drop_caches # drop system cache (ready for performance impact)sudo /pg/bin/pg-tune-hugepage # write nr_hugepages to /etc/sysctl.d/hugepage.confpg restart <cls> # restart postgres to use hugepage
How to guarantee zero data loss during failover?
Use crit.yml template, or setting pg_rpo to 0, or config cluster with synchronous mode.
The pg_dummy_filesize is set to 64MB by default. Consider increasing it to 8GB or larger in the production environment.
It will be placed on /pg/dummy same disk as the PGSQL main data disk. You can remove that file to free some emergency space. At least you can run some shell scripts on that node.
How to create replicas when data is corrupted?
Disable clonefrom on bad instances and reload patroni config.
Pigsty sets the cloneform: true tag on all instances’ patroni config, which marks the instance available for cloning replica.
If this instance has corrupt data files, you can set clonefrom: false to avoid pulling data from the evil instance. To do so:
bin/pgmon-rm <ins> # shortcut for removing prometheus targets of pgsql instance 'ins'
7 - Kernel Forks
How to use another PostgreSQL “kernel” in Pigsty, such as Citus, Babelfish, IvorySQL, PolarDB, Neon, and Greenplum
You can use different “flavors” of PostgreSQL branches, forks and derivatives to replace the “native PG kernel” in Pigsty.
7.1 - Citus (Distributive)
Deploy native HA citus cluster with Pigsty, horizontal scaling PostgreSQL with better throughput and performance.
Beware that citus for the latest major version PostgreSQL 17 support is still WIP
Pigsty has native citus support:
Install
Citus is a standard PostgreSQL extension, which can be installed and enabled on a native PostgreSQL cluster by following the standard plugin installation process.
To install it manually, you can run the following command:
pg_primary_db has to be defined to specify the database to be managed
pg_dbsu_password has to be set to a non-empty string plain password if you want to use the pg_dbsupostgres rather than default pg_admin_username to perform admin commands
Besides, extra hba rules that allow ssl access from local & other data nodes are required. Which may looks like this
You can define each citus cluster separately within a group, like conf/dbms/citus.yml :
all:children:pg-citus0:# citus data node 0hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus0 , pg_group:0}pg-citus1:# citus data node 1hosts:{10.10.10.11:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus1 , pg_group:1}pg-citus2:# citus data node 2hosts:{10.10.10.12:{pg_seq: 1, pg_role:primary } }vars:{pg_cluster: pg-citus2 , pg_group:2}pg-citus3:# citus data node 3, with an extra replicahosts:10.10.10.13:{pg_seq: 1, pg_role:primary }10.10.10.14:{pg_seq: 2, pg_role:replica }vars:{pg_cluster: pg-citus3 , pg_group:3}vars:# global parameters for all citus clusterspg_mode: citus # pgsql cluster mode:cituspg_shard: pg-citus # citus shard name:pg-cituspatroni_citus_db:meta # citus distributed database namepg_dbsu_password:DBUser.Postgres# all dbsu password access for citus clusterpg_users:[{name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles:[dbrole_admin ] } ]pg_databases:[{name: meta ,extensions:[{name:citus }, { name: postgis }, { name: timescaledb } ] } ]pg_hba_rules:- {user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title:'all user ssl access from localhost'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'all user ssl access from intranet'}
You can also specify all citus cluster members within a group, take prod.yml for example.
#==========================================================## pg-citus: 10 node citus cluster (5 x primary-replica pair)#==========================================================#pg-citus:# citus grouphosts:10.10.10.50:{pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 0, pg_role:primary }10.10.10.51:{pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 1, pg_role:replica }10.10.10.52:{pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 0, pg_role:primary }10.10.10.53:{pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 1, pg_role:replica }10.10.10.54:{pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 0, pg_role:primary }10.10.10.55:{pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 1, pg_role:replica }10.10.10.56:{pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 0, pg_role:primary }10.10.10.57:{pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 1, pg_role:replica }10.10.10.58:{pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 0, pg_role:primary }10.10.10.59:{pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 1, pg_role:replica }vars:pg_mode: citus # pgsql cluster mode:cituspg_shard: pg-citus # citus shard name:pg-cituspg_primary_db:test # primary database used by cituspg_dbsu_password:DBUser.Postgres# all dbsu password access for citus clusterpg_vip_enabled:truepg_vip_interface:eth1pg_extensions:['citus postgis timescaledb pgvector']pg_libs:'citus, timescaledb, pg_stat_statements, auto_explain'# citus will be added by patroni automaticallypg_users:[{name: test ,password: test ,pgbouncer: true ,roles:[dbrole_admin ] } ]pg_databases:[{name: test ,owner: test ,extensions:[{name:citus }, { name: postgis } ] } ]pg_hba_rules:- {user: 'all' ,db: all ,addr: 10.10.10.0/24 ,auth: trust ,title:'trust citus cluster members'}- {user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title:'all user ssl access from localhost'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'all user ssl access from intranet'}
And you can create distributed table & reference table on the coordinator node. Any data node can be used as the coordinator node since citus 11.2.
Usage
You can access any (primary) node in the cluster as you would with a regular cluster:
And in case of primary node failure, the replica will take over with native patroni support:
test=# select * from pg_dist_node; nodeid | groupid | nodename | nodeport | noderack | hasmetadata | isactive | noderole | nodecluster | metadatasynced | shouldhaveshards
--------+---------+-------------+----------+----------+-------------+----------+----------+-------------+----------------+------------------
1|0| 10.10.10.51 |5432| default | t | t | primary | default | t | f
2|2| 10.10.10.54 |5432| default | t | t | primary | default | t | t
5|1| 10.10.10.52 |5432| default | t | t | primary | default | t | t
3|4| 10.10.10.58 |5432| default | t | t | primary | default | t | t
4|3| 10.10.10.56 |5432| default | t | t | primary | default | t | t
7.2 - WiltonDB (MSSQL)
Create SQL Server Compatible PostgreSQL cluster with WiltonDB and Babelfish (Wire Protocol Level)
Pigsty allows users to create a Microsoft SQL Server compatible PostgreSQL cluster using Babelfish and WiltonDB!
Babelfish: An open-source MSSQL (Microsoft SQL Server) compatibility extension Open Sourced by AWS
WiltonDB: A PostgreSQL kernel distribution focusing on integrating Babelfish
Babelfish is a PostgreSQL extension, but it works on a slightly modified PostgreSQL kernel Fork, WiltonDB provides compiled kernel binaries and extension binary packages on EL/Ubuntu systems.
Pigsty can replace the native PostgreSQL kernel with WiltonDB, providing an out-of-the-box MSSQL compatible cluster along with all the supported by common PostgreSQL clusters, such as HA, PITR, IaC, monitoring, etc.
WiltonDB is very similar to PostgreSQL 15, but it can not use vanilla PostgreSQL extensions directly. WiltonDB has several re-compiled extensions such as system_stats, pg_hint_plan and tds_fdw.
The cluster will listen on the default PostgreSQL port and the default MSSQL 1433 port, providing MSSQL services via the TDS WireProtocol on this port.
You can connect to the MSSQL service provided by Pigsty using any MSSQL client, such as SQL Server Management Studio, or using the sqlcmd command-line tool.
For production deployments, make sure to modify the password parameters in the pigsty.yml config before running the install playbook.
Notes
When installing and deploying the MSSQL module, please pay special attention to the following points:
WiltonDB is available on EL (7/8/9) and Ubuntu (20.04/22.04) but not available on Debian systems.
WiltonDB is currently compiled based on PostgreSQL 15, so you need to specify pg_version: 15.
On EL systems, the wiltondb binary is installed by default in the /usr/bin/ directory, while on Ubuntu systems, it is installed in the /usr/lib/postgresql/15/bin/ directory, which is different from the official PostgreSQL binary location.
In WiltonDB compatibility mode, the HBA password authentication rule needs to use md5 instead of scram-sha-256. Therefore, you need to override Pigsty’s default HBA rule set and insert the md5 authentication rule required by SQL Server before the dbrole_readonly wildcard authentication rule.
WiltonDB can only be enabled for a primary database, and you should designate a user as the Babelfish superuser, allowing Babelfish to create databases and users. The default is mssql and dbuser_myssql. If you change this, you should also modify the user in files/mssql.sql.
The WiltonDB TDS cable protocol compatibility plugin babelfishpg_tds needs to be enabled in shared_preload_libraries.
After enabling the WiltonDB extension, it listens on the default MSSQL port 1433. You can override Pigsty’s default service definitions to redirect the primary and replica services to port 1433 instead of the 5432 / 6432ports.
The following parameters need to be configured for the MSSQL database cluster:
#----------------------------------## PGSQL & MSSQL (Babelfish & Wilton)#----------------------------------## PG Installationnode_repo_modules:local,node,mssql# add mssql and os upstream repospg_mode:mssql # Microsoft SQL Server Compatible Modepg_libs:'babelfishpg_tds, pg_stat_statements, auto_explain'# add timescaledb to shared_preload_librariespg_version:15# The current WiltonDB major version is 15pg_packages:- wiltondb # install forked version of postgresql with babelfishpg support- patroni pgbouncer pgbackrest pg_exporter pgbadger vip-managerpg_extensions:[]# do not install any vanilla postgresql extensions# PG Provisionpg_default_hba_rules:# overwrite default HBA rules for babelfish cluster- {user:'${dbsu}',db: all ,addr: local ,auth: ident ,title:'dbsu access via local os user ident'}- {user:'${dbsu}',db: replication ,addr: local ,auth: ident ,title:'dbsu replication from local os ident'}- {user:'${repl}',db: replication ,addr: localhost ,auth: pwd ,title:'replicator replication from localhost'}- {user:'${repl}',db: replication ,addr: intra ,auth: pwd ,title:'replicator replication from intranet'}- {user:'${repl}',db: postgres ,addr: intra ,auth: pwd ,title:'replicator postgres db from intranet'}- {user:'${monitor}',db: all ,addr: localhost ,auth: pwd ,title:'monitor from localhost with password'}- {user:'${monitor}',db: all ,addr: infra ,auth: pwd ,title:'monitor from infra host with password'}- {user:'${admin}',db: all ,addr: infra ,auth: ssl ,title:'admin @ infra nodes with pwd & ssl'}- {user:'${admin}',db: all ,addr: world ,auth: ssl ,title:'admin @ everywhere with ssl & pwd'}- {user: dbuser_mssql ,db: mssql ,addr: intra ,auth: md5 ,title:'allow mssql dbsu intranet access'}# <--- use md5 auth method for mssql user- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: pwd ,title:'pgbouncer read/write via local socket'}- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: pwd ,title:'read/write biz user via password'}- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: pwd ,title:'allow etl offline tasks from intranet'}pg_default_services:# route primary & replica service to mssql port 1433- {name: primary ,port: 5433 ,dest: 1433 ,check: /primary ,selector:"[]"}- {name: replica ,port: 5434 ,dest: 1433 ,check: /read-only ,selector:"[]", backup:"[? pg_role == `primary` || pg_role == `offline` ]"}- {name: default ,port: 5436 ,dest: postgres ,check: /primary ,selector:"[]"}- {name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector:"[? pg_role == `offline` || pg_offline_query ]", backup:"[? pg_role == `replica` && !pg_offline_query]"}
You can define business database & users in the pg_databases and pg_users section:
#----------------------------------## pgsql (singleton on current node)#----------------------------------## this is an example single-node postgres cluster with postgis & timescaledb installed, with one biz database & two biz userspg-meta:hosts:10.10.10.10:{pg_seq: 1, pg_role:primary }# <---- primary instance with read-write capabilityvars:pg_cluster:pg-testpg_users:# create MSSQL superuser- {name: dbuser_mssql ,password: DBUser.MSSQL ,superuser: true, pgbouncer: true ,roles: [dbrole_admin], comment:superuser & owner for babelfish }pg_primary_db:mssql # use `mssql` as the primary sql server databasepg_databases:- name:mssqlbaseline:mssql.sql # init babelfish database & userextensions:- {name:uuid-ossp }- {name:babelfishpg_common }- {name:babelfishpg_tsql }- {name:babelfishpg_tds }- {name:babelfishpg_money }- {name:pg_hint_plan }- {name:system_stats }- {name:tds_fdw }owner:dbuser_mssqlparameters:{'babelfishpg_tsql.migration_mode' :'multi-db'}comment:babelfish cluster, a MSSQL compatible pg cluster
Client Access
You can use any SQL Server compatible client tool to access this database cluster.
Microsoft provides sqlcmd as the official command-line tool.
Besides, they have a go version cli tool: go-sqlcmd
Install go-sqlcmd:
curl -LO https://github.com/microsoft/go-sqlcmd/releases/download/v1.4.0/sqlcmd-v1.4.0-linux-amd64.tar.bz2
tar xjvf sqlcmd-v1.4.0-linux-amd64.tar.bz2
sudo mv sqlcmd* /usr/bin/
Get started with go-sqlcmd
$ sqlcmd -S 10.10.10.10,1433 -U dbuser_mssql -P DBUser.MSSQL
1> select @@version
2> go
version
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Babelfish for PostgreSQL with SQL Server Compatibility - 12.0.2000.8
Oct 222023 17:48:32
Copyright (c) Amazon Web Services
PostgreSQL 15.4 (EL 1:15.4.wiltondb3.3_2-2.el8) on x86_64-redhat-linux-gnu (Babelfish 3.3.0)(1 row affected)
You can route service traffic to MSSQL 1433 port instead of 5433/5434:
# route 5433 on all members to 1433 on primary sqlcmd -S 10.10.10.11,5433 -U dbuser_mssql -P DBUser.MSSQL
# route 5434 on all members to 1433 on replicassqlcmd -S 10.10.10.11,5434 -U dbuser_mssql -P DBUser.MSSQL
Install
If you have the Internet access, you can add the WiltonDB repository to the node and install it as a node package directly:
It’s OK to install vanilla PostgreSQL and WiltonDB on the same node, but you can only run one of them at a time, and this is not recommended for production environments.
Extensions
Most of the PGSQL module’s extensions (non-SQL class) cannot be used directly on the WiltonDB core of the MSSQL module and need to be recompiled.
WiltonDB currently comes with the following extension plugins:
Name
Version
Comment
dblink
1.2
connect to other PostgreSQL databases from within a database
adminpack
2.1
administrative functions for PostgreSQL
dict_int
1.0
text search dictionary template for integers
intagg
1.1
integer aggregator and enumerator (obsolete)
dict_xsyn
1.0
text search dictionary template for extended synonym processing
amcheck
1.3
functions for verifying relation integrity
autoinc
1.0
functions for autoincrementing fields
bloom
1.0
bloom access method - signature file based index
fuzzystrmatch
1.1
determine similarities and distance between strings
intarray
1.5
functions, operators, and index support for 1-D arrays of integers
btree_gin
1.3
support for indexing common datatypes in GIN
btree_gist
1.7
support for indexing common datatypes in GiST
hstore
1.8
data type for storing sets of (key, value) pairs
hstore_plperl
1.0
transform between hstore and plperl
isn
1.2
data types for international product numbering standards
hstore_plperlu
1.0
transform between hstore and plperlu
jsonb_plperl
1.0
transform between jsonb and plperl
citext
1.6
data type for case-insensitive character strings
jsonb_plperlu
1.0
transform between jsonb and plperlu
jsonb_plpython3u
1.0
transform between jsonb and plpython3u
cube
1.5
data type for multidimensional cubes
hstore_plpython3u
1.0
transform between hstore and plpython3u
earthdistance
1.1
calculate great-circle distances on the surface of the Earth
lo
1.1
Large Object maintenance
file_fdw
1.0
foreign-data wrapper for flat file access
insert_username
1.0
functions for tracking who changed a table
ltree
1.2
data type for hierarchical tree-like structures
ltree_plpython3u
1.0
transform between ltree and plpython3u
pg_walinspect
1.0
functions to inspect contents of PostgreSQL Write-Ahead Log
moddatetime
1.0
functions for tracking last modification time
old_snapshot
1.0
utilities in support of old_snapshot_threshold
pgcrypto
1.3
cryptographic functions
pgrowlocks
1.2
show row-level locking information
pageinspect
1.11
inspect the contents of database pages at a low level
pg_surgery
1.0
extension to perform surgery on a damaged relation
seg
1.4
data type for representing line segments or floating-point intervals
pgstattuple
1.5
show tuple-level statistics
pg_buffercache
1.3
examine the shared buffer cache
pg_freespacemap
1.2
examine the free space map (FSM)
postgres_fdw
1.1
foreign-data wrapper for remote PostgreSQL servers
pg_prewarm
1.2
prewarm relation data
tcn
1.0
Triggered change notifications
pg_trgm
1.6
text similarity measurement and index searching based on trigrams
xml2
1.1
XPath querying and XSLT
refint
1.0
functions for implementing referential integrity (obsolete)
pg_visibility
1.2
examine the visibility map (VM) and page-level visibility info
pg_stat_statements
1.10
track planning and execution statistics of all SQL statements executed
sslinfo
1.2
information about SSL certificates
tablefunc
1.0
functions that manipulate whole tables, including crosstab
tsm_system_rows
1.0
TABLESAMPLE method which accepts number of rows as a limit
tsm_system_time
1.0
TABLESAMPLE method which accepts time in milliseconds as a limit
unaccent
1.1
text search dictionary that removes accents
uuid-ossp
1.1
generate universally unique identifiers (UUIDs)
plpgsql
1.0
PL/pgSQL procedural language
babelfishpg_money
1.1.0
babelfishpg_money
system_stats
2.0
EnterpriseDB system statistics for PostgreSQL
tds_fdw
2.0.3
Foreign data wrapper for querying a TDS database (Sybase or Microsoft SQL Server)
babelfishpg_common
3.3.3
Transact SQL Datatype Support
babelfishpg_tds
1.0.0
TDS protocol extension
pg_hint_plan
1.5.1
babelfishpg_tsql
3.3.1
Transact SQL compatibility
Pigsty Pro offers the offline installation ability for MSSQL compatible extensions
Pigsty Pro offers MSSQL compatible extension porting services, which can port available extensions in the PGSQL module to the MSSQL cluster.
7.3 - IvorySQL (Oracle)
Run “Oracle-Compatible” PostgreSQL cluster with the IvorySQL Kernel open sourced by HighGo
IvorySQL is an open-source “Oracle-compatible” PostgreSQL kernel, developed by HighGo, licensed under Apache 2.0.
The Oracle compatibility here refers to compatibility at the PL/SQL, syntax, built-in functions, data types, system views, MERGE, and GUC parameter levels.
It’s not a wire protocol compatibility like Babelfish, openHalo, or FerretDB that allows using the original client drivers.
Users still need to use PostgreSQL client tools to access IvorySQL, but can use Oracle-compatible syntax.
Currently, IvorySQL’s latest version 4.4 maintains compatibility with PostgreSQL’s latest minor version 17.4, and provides binary RPM/DEB packages for mainstream Linux distributions.
Pigsty offers the option to replace the native PostgreSQL with the IvorySQL kernel in PG RDS.
Quick Start
Use the standard procedure to install Pigsty with the ivory configuration template:
For production deployments, you should edit the auto-generated pigsty.yml configuration file to modify parameters like passwords before executing ./install.yml for deployment.
The latest IvorySQL 4.4 is equivalent to PostgreSQL 17. Any client tool compatible with PostgreSQL’s wire protocol can access IvorySQL clusters.
By default, you can use a PostgreSQL client to access through the alternative 1521 port, which enables Oracle compatibility mode by default.
Configuration Instructions
To use the IvorySQL kernel in Pigsty, modify the following four configuration parameters:
It’s that simple - just add these four lines to the global variables in the configuration file, and Pigsty will replace the native PostgreSQL kernel with IvorySQL:
Most of the PGSQL modules’ extension (non-SQL classes) cannot be used directly on the IvorySQL kernel.
If you need to use them, you need to recompile and install from source code for the new kernel.
Currently, the IvorySQL kernel comes with the following 109 extension plugins:
IvorySQL Available Extensions
Name
Version
Description
amcheck
1.4
functions for verifying relation integrity
autoinc
1.0
functions for autoincrementing fields
bloom
1.0
bloom access method - signature file based index
bool_plperl
1.0
transform between bool and plperl
bool_plperlu
1.0
transform between bool and plperlu
btree_gin
1.3
support for indexing common datatypes in GIN
btree_gist
1.7
support for indexing common datatypes in GiST
citext
1.6
data type for case-insensitive character strings
cube
1.5
data type for multidimensional cubes
dblink
1.2
connect to other PostgreSQL databases from within a database
dict_int
1.0
text search dictionary template for integers
dict_xsyn
1.0
text search dictionary template for extended synonym processing
dummy_index_am
1.0
dummy_index_am - index access method template
dummy_seclabel
1.0
Test code for SECURITY LABEL feature
earthdistance
1.2
calculate great-circle distances on the surface of the Earth
file_fdw
1.0
foreign-data wrapper for flat file access
fuzzystrmatch
1.2
determine similarities and distance between strings
hstore
1.8
data type for storing sets of (key, value) pairs
hstore_plperl
1.0
transform between hstore and plperl
hstore_plperlu
1.0
transform between hstore and plperlu
hstore_plpython3u
1.0
transform between hstore and plpython3u
injection_points
1.0
Test code for injection points
insert_username
1.0
functions for tracking who changed a table
intagg
1.1
integer aggregator and enumerator (obsolete)
intarray
1.5
functions, operators, and index support for 1-D arrays of integers
isn
1.2
data types for international product numbering standards
ivorysql_ora
1.0
Oracle Compatible extenison on Postgres Database
jsonb_plperl
1.0
transform between jsonb and plperl
jsonb_plperlu
1.0
transform between jsonb and plperlu
jsonb_plpython3u
1.0
transform between jsonb and plpython3u
lo
1.1
Large Object maintenance
ltree
1.3
data type for hierarchical tree-like structures
ltree_plpython3u
1.0
transform between ltree and plpython3u
moddatetime
1.0
functions for tracking last modification time
ora_btree_gin
1.0
support for indexing oracle datatypes in GIN
ora_btree_gist
1.0
support for oracle indexing common datatypes in GiST
pageinspect
1.12
inspect the contents of database pages at a low level
pg_buffercache
1.5
examine the shared buffer cache
pg_freespacemap
1.2
examine the free space map (FSM)
pg_get_functiondef
1.0
Get function’s definition
pg_prewarm
1.2
prewarm relation data
pg_stat_statements
1.11
track planning and execution statistics of all SQL statements executed
pg_surgery
1.0
extension to perform surgery on a damaged relation
pg_trgm
1.6
text similarity measurement and index searching based on trigrams
pg_visibility
1.2
examine the visibility map (VM) and page-level visibility info
pg_walinspect
1.1
functions to inspect contents of PostgreSQL Write-Ahead Log
pgcrypto
1.3
cryptographic functions
pgrowlocks
1.2
show row-level locking information
pgstattuple
1.5
show tuple-level statistics
plisql
1.0
PL/iSQL procedural language
plperl
1.0
PL/Perl procedural language
plperlu
1.0
PL/PerlU untrusted procedural language
plpgsql
1.0
PL/pgSQL procedural language
plpython3u
1.0
PL/Python3U untrusted procedural language
plsample
1.0
PL/Sample
pltcl
1.0
PL/Tcl procedural language
pltclu
1.0
PL/TclU untrusted procedural language
postgres_fdw
1.1
foreign-data wrapper for remote PostgreSQL servers
refint
1.0
functions for implementing referential integrity (obsolete)
seg
1.4
data type for representing line segments or floating-point intervals
spgist_name_ops
1.0
Test opclass for SP-GiST
sslinfo
1.2
information about SSL certificates
tablefunc
1.0
functions that manipulate whole tables, including crosstab
tcn
1.0
Triggered change notifications
test_bloomfilter
1.0
Test code for Bloom filter library
test_copy_callbacks
1.0
Test code for COPY callbacks
test_custom_rmgrs
1.0
Test code for custom WAL resource managers
test_ddl_deparse
1.0
Test code for DDL deparse feature
test_dsa
1.0
Test code for dynamic shared memory areas
test_dsm_registry
1.0
Test code for the DSM registry
test_ext1
1.0
Test extension 1
test_ext2
1.0
Test extension 2
test_ext3
1.0
Test extension 3
test_ext4
1.0
Test extension 4
test_ext5
1.0
Test extension 5
test_ext6
1.0
test_ext6
test_ext7
1.0
Test extension 7
test_ext8
1.0
Test extension 8
test_ext9
1.0
test_ext9
test_ext_cine
1.0
Test extension using CREATE IF NOT EXISTS
test_ext_cor
1.0
Test extension using CREATE OR REPLACE
test_ext_cyclic1
1.0
Test extension cyclic 1
test_ext_cyclic2
1.0
Test extension cyclic 2
test_ext_evttrig
1.0
Test extension - event trigger
test_ext_extschema
1.0
test @extschema@
test_ext_req_schema1
1.0
Required extension to be referenced
test_ext_req_schema2
1.0
Test schema referencing of required extensions
test_ext_req_schema3
1.0
Test schema referencing of 2 required extensions
test_ext_set_schema
1.0
Test ALTER EXTENSION SET SCHEMA
test_ginpostinglist
1.0
Test code for ginpostinglist.c
test_integerset
1.0
Test code for integerset
test_lfind
1.0
Test code for optimized linear search functions
test_parser
1.0
example of a custom parser for full-text search
test_pg_dump
1.0
Test pg_dump with an extension
test_predtest
1.0
Test code for optimizer/util/predtest.c
test_radixtree
1.0
Test code for radix tree
test_rbtree
1.0
Test code for red-black tree library
test_regex
1.0
Test code for backend/regex/
test_resowner
1.0
Test code for ResourceOwners
test_shm_mq
1.0
Test code for shared memory message queues
test_slru
1.0
Test code for SLRU
test_tidstore
1.0
Test code for tidstore
tsm_system_rows
1.0
TABLESAMPLE method which accepts number of rows as a limit
tsm_system_time
1.0
TABLESAMPLE method which accepts time in milliseconds as a limit
unaccent
1.1
text search dictionary that removes accents
uuid-ossp
1.1
generate universally unique identifiers (UUIDs)
worker_spi
1.0
Sample background worker
xid_wraparound
1.0
Tests for XID wraparound
xml2
1.1
XPath querying and XSLT
Caveats
The IvorySQL software package is located in the pigsty-infra repository, not in pigsty-pgsql or pigsty-ivory repositories.
The default FHS of IvorySQL 4.4 has changed, please pay attention to users upgrading from older versions.
IvorySQL 4.4 requires gibc version >= 2.17, which is currently supported by Pigsty.
The last IvorySQL version supporting EL7 is 3.3, corresponding to PostgreSQL 16.3, and IvorySQL 4.x no longer supports EL7.
Pigsty does not assume any warranty for using the IvorySQL kernel, and any issues or requests should be addressed to the manufacturer.
7.4 - OpenHalo (MySQL)
The OpenHalo kernel provides a MySQL-compatible PostgreSQL kernel, which can be accessed using the MySQL client.
OpenHalo is an open-source PostgreSQL kernel that provides MySQL wire protocol compatibility.
OpenHalo is based on PostgreSQL 14.10 kernel version and provides wire protocol compatibility with MySQL 5.7.32-log / 8.0 version.
Currently, Pigsty provides deployment support for OpenHalo on EL systems, with Debian/Ubuntu system support planned for future releases.
curl -fsSL https://repo.pigsty.cc/get | bash;cd ~/pigsty
./bootstrap # Prepare Pigsty dependencies./configure -c mysql # Use MySQL (openHalo) configuration template./install.yml # Install, for production deployment please modify passwords in pigsty.yml first
For production deployment, please ensure to modify the password parameters in the pigsty.yml configuration file before running the installation playbook.
Usage
When accessing MySQL, the actual connection uses the postgres database.
Please note that the concept of “database” in MySQL actually corresponds to “Schema” in PostgreSQL.
Therefore, use mysql actually uses the mysql Schema within the postgres database.
The usernames and passwords used for MySQL are the same as those in PostgreSQL.
You can manage users and permissions using the standard PostgreSQL approach.
Client Access
OpenHalo provides MySQL wire protocol compatibility, listening on port 3306 by default, allowing direct connections from MySQL clients and drivers.
Pigsty’s conf/mysql configuration installs the mysql client tool by default.
You can access MySQL using the following command:
mysql -h 127.0.0.1 -u dbuser_dba
Currently, OpenHalo officially ensures that Navicat can access this MySQL port normally, but Intellij IDEA’s DataGrip access will result in errors.
Changed the default database name from halo0root back to postgres
Removed the 1.0. prefix from the default version number, reverting to 14.10
Modified the default configuration file to enable MySQL compatibility and listen on port 3306 by default
Please note that Pigsty does not provide any warranty for using the OpenHalo kernel. Any issues or requirements encountered while using this kernel should be addressed with the original vendor.
7.5 - OrioleDB (OLTP)
A PostgreSQL storage engine optimized for OLTP workloads, without xid wrapround & table bloat, and put data on S3
OrioleDB is a PostgreSQL storage engine extension that delivers 4x OLTP performance without xid wraparound & table bloat, and “cloud native” (data on s3) capabilities.
curl -fsSL https://repo.pigsty.cc/get | bash;cd ~/pigsty
./bootstrap # Prepare Pigsty dependencies./configure -c oriole # Use the OrioleDB configuration template./install.yml # Install Pigsty with OrioleDB
For production deployments, make sure to modify the password parameters in the pigsty.yml config before running the install playbook.
Configuration
all:children:pg-orio:vars:pg_databases:- {name: meta ,extensions:[orioledb]}vars:pg_mode:oriolepg_version:17pg_packages:[orioledb, pgsql-common ]pg_libs:'orioledb.so, pg_stat_statements, auto_explain'repo_extra_packages:[orioledb ]
Usage
To use OrioleDB, you need to install the orioledb_17 and oriolepg_17 packages (currently only available as RPMs).
Initialize TPC-B-like tables with 100 warehouses using pgbench:
pgbench -is 100 meta
pgbench -nv -P1 -c10 -S -T1000 meta
pgbench -nv -P1 -c50 -S -T1000 meta
pgbench -nv -P1 -c10 -T1000 meta
pgbench -nv -P1 -c50 -T1000 meta
Next, you can rebuild these tables using the orioledb storage engine and observe the performance differences:
-- Create OrioleDB tables
CREATETABLEpgbench_accounts_o(LIKEpgbench_accountsINCLUDINGALL)USINGorioledb;CREATETABLEpgbench_branches_o(LIKEpgbench_branchesINCLUDINGALL)USINGorioledb;CREATETABLEpgbench_history_o(LIKEpgbench_historyINCLUDINGALL)USINGorioledb;CREATETABLEpgbench_tellers_o(LIKEpgbench_tellersINCLUDINGALL)USINGorioledb;-- Copy data from regular tables to OrioleDB tables
INSERTINTOpgbench_accounts_oSELECT*FROMpgbench_accounts;INSERTINTOpgbench_branches_oSELECT*FROMpgbench_branches;INSERTINTOpgbench_history_oSELECT*FROMpgbench_history;INSERTINTOpgbench_tellers_oSELECT*FROMpgbench_tellers;-- Drop original tables and rename OrioleDB tables
DROPTABLEpgbench_accounts,pgbench_branches,pgbench_history,pgbench_tellers;ALTERTABLEpgbench_accounts_oRENAMETOpgbench_accounts;ALTERTABLEpgbench_branches_oRENAMETOpgbench_branches;ALTERTABLEpgbench_history_oRENAMETOpgbench_history;ALTERTABLEpgbench_tellers_oRENAMETOpgbench_tellers;
7.6 - PolarDB PG (RAC)
Replace vanilla PostgreSQL with PolarDB PG, which is an OSS Aurora similar to Oracle RAC
You can deploy an Aurora flavor of PostgreSQL, PolarDB, in Pigsty.
PolarDB is a distributed, shared-nothing, and high-availability database system that is compatible with PostgreSQL 15, open sourced by Aliyun.
For production deployments, make sure to modify the password parameters in the pigsty.yml config before running the install playbook.
Notes
The following parameters need to be tuned to deploy a PolarDB cluster:
#----------------------------------## PGSQL & PolarDB#----------------------------------#pg_version:15pg_packages:['polardb patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager']pg_extensions:[]# do not install any vanilla postgresql extensionspg_mode:polar # PolarDB Compatible Modepg_default_roles:# default roles and users in postgres cluster- {name: dbrole_readonly ,login: false ,comment:role for global read-only access }- {name: dbrole_offline ,login: false ,comment:role for restricted read-only access }- {name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment:role for global read-write access }- {name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment:role for object creation }- {name: postgres ,superuser: true ,comment:system superuser }- {name: replicator ,superuser: true ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment:system replicator }# <- superuser is required for replication- {name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 ,comment:pgsql admin user }- {name: dbuser_monitor ,roles: [pg_monitor] ,pgbouncer: true ,parameters:{log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment:pgsql monitor user }
Client Access
PolarDB for PostgreSQL is essentially equivalent to PostgreSQL 11, and any client tools compatible with the PostgreSQL wire protocol can access the PolarDB cluster.
Installation
If your environment has internet access, you can directly add the PolarDB repository to the node and install it as a node package:
ånd then install the PolarDB kernel pacakge with the following command:
./node.yml -t node_repo,node_pkg
Extensions
Most of the PGSQL module’s extension (non pure-SQL) cannot be used directly on the PolarDB kernel.
If you need to use them, you need to recompile and install from source code for the new kernel.
Currently, the PolarDB kernel comes with the following 61 extension plugins. In addition to Contrib extensions, the additional extensions provided include:
polar_csn 1.0 : polar_csn
polar_monitor 1.2 : examine the polardb information
polar_monitor_preload 1.1 : examine the polardb information
polar_parameter_check 1.0 : kernel extension for parameter validation
polar_px 1.0 : Parallel Execution extension
polar_stat_env 1.0 : env stat functions for PolarDB
polar_stat_sql 1.3 : Kernel statistics gathering, and sql plan nodes information gathering
polar_tde_utils 1.0 : Internal extension for TDE
polar_vfs 1.0 : polar_vfs
polar_worker 1.0 : polar_worker
timetravel 1.0 : functions for implementing time travel
vector 0.5.1 : vector data type and ivfflat and hnsw access methods
smlar 1.0 : compute similary of any one-dimensional arrays
Here is the list of extensions provided by the PolarDB kernel:
name
version
comment
hstore_plpython2u
1.0
transform between hstore and plpython2u
dict_int
1.0
text search dictionary template for integers
adminpack
2.0
administrative functions for PostgreSQL
hstore_plpython3u
1.0
transform between hstore and plpython3u
amcheck
1.1
functions for verifying relation integrity
hstore_plpythonu
1.0
transform between hstore and plpythonu
autoinc
1.0
functions for autoincrementing fields
insert_username
1.0
functions for tracking who changed a table
bloom
1.0
bloom access method - signature file based index
file_fdw
1.0
foreign-data wrapper for flat file access
dblink
1.2
connect to other PostgreSQL databases from within a database
btree_gin
1.3
support for indexing common datatypes in GIN
fuzzystrmatch
1.1
determine similarities and distance between strings
lo
1.1
Large Object maintenance
intagg
1.1
integer aggregator and enumerator (obsolete)
btree_gist
1.5
support for indexing common datatypes in GiST
hstore
1.5
data type for storing sets of (key, value) pairs
intarray
1.2
functions, operators, and index support for 1-D arrays of integers
citext
1.5
data type for case-insensitive character strings
cube
1.4
data type for multidimensional cubes
hstore_plperl
1.0
transform between hstore and plperl
isn
1.2
data types for international product numbering standards
jsonb_plperl
1.0
transform between jsonb and plperl
dict_xsyn
1.0
text search dictionary template for extended synonym processing
hstore_plperlu
1.0
transform between hstore and plperlu
earthdistance
1.1
calculate great-circle distances on the surface of the Earth
pg_prewarm
1.2
prewarm relation data
jsonb_plperlu
1.0
transform between jsonb and plperlu
pg_stat_statements
1.6
track execution statistics of all SQL statements executed
jsonb_plpython2u
1.0
transform between jsonb and plpython2u
jsonb_plpython3u
1.0
transform between jsonb and plpython3u
jsonb_plpythonu
1.0
transform between jsonb and plpythonu
pg_trgm
1.4
text similarity measurement and index searching based on trigrams
pgstattuple
1.5
show tuple-level statistics
ltree
1.1
data type for hierarchical tree-like structures
ltree_plpython2u
1.0
transform between ltree and plpython2u
pg_visibility
1.2
examine the visibility map (VM) and page-level visibility info
ltree_plpython3u
1.0
transform between ltree and plpython3u
ltree_plpythonu
1.0
transform between ltree and plpythonu
seg
1.3
data type for representing line segments or floating-point intervals
moddatetime
1.0
functions for tracking last modification time
pgcrypto
1.3
cryptographic functions
pgrowlocks
1.2
show row-level locking information
pageinspect
1.7
inspect the contents of database pages at a low level
pg_buffercache
1.3
examine the shared buffer cache
pg_freespacemap
1.2
examine the free space map (FSM)
tcn
1.0
Triggered change notifications
plperl
1.0
PL/Perl procedural language
uuid-ossp
1.1
generate universally unique identifiers (UUIDs)
plperlu
1.0
PL/PerlU untrusted procedural language
refint
1.0
functions for implementing referential integrity (obsolete)
xml2
1.1
XPath querying and XSLT
plpgsql
1.0
PL/pgSQL procedural language
plpython3u
1.0
PL/Python3U untrusted procedural language
pltcl
1.0
PL/Tcl procedural language
pltclu
1.0
PL/TclU untrusted procedural language
polar_csn
1.0
polar_csn
sslinfo
1.2
information about SSL certificates
polar_monitor
1.2
examine the polardb information
polar_monitor_preload
1.1
examine the polardb information
polar_parameter_check
1.0
kernel extension for parameter validation
polar_px
1.0
Parallel Execution extension
tablefunc
1.0
functions that manipulate whole tables, including crosstab
polar_stat_env
1.0
env stat functions for PolarDB
smlar
1.0
compute similary of any one-dimensional arrays
timetravel
1.0
functions for implementing time travel
tsm_system_rows
1.0
TABLESAMPLE method which accepts number of rows as a limit
polar_stat_sql
1.3
Kernel statistics gathering, and sql plan nodes information gathering
tsm_system_time
1.0
TABLESAMPLE method which accepts time in milliseconds as a limit
polar_tde_utils
1.0
Internal extension for TDE
polar_vfs
1.0
polar_vfs
polar_worker
1.0
polar_worker
unaccent
1.1
text search dictionary that removes accents
postgres_fdw
1.0
foreign-data wrapper for remote PostgreSQL servers
Pigsty Pro has offline installation support for PolarDB and its extensions
Pigsty has partnership with Aliyun and can provide PolarDB kernel enterprise support for enterprise users
7.7 - PolarDB O(racle)
The commercial version of PolarDB for Oracle, only available in Pigsty Enterprise Edition.
Oracle Compatible version, Fork of PolarDB PG.
This is not available in OSS version. But quite similar to the PolarDB PG kernel
7.8 - Supabase (Firebase)
How to self-host Supabase with existing managed HA PostgreSQL cluster, and launch the stateless part with docker-compose?
Supabase is the open-source Firebase alternative built upon PostgreSQL.
It provides authentication, API, edge functions, real-time subscriptions, object storage, and vector embedding capabilities out of the box.
All you need to do is to design the database schema and frontend, and you can quickly get things done without worrying about the backend development.
Supabase’s slogan is: “Build in a weekend, Scale to millions”. Supabase has great cost-effectiveness in small scales (4c8g) indeed.
But there is no doubt that when you really grow to millions of users, some may choose to self-hosting their own Supabase —— for functionality, performance, cost, and other reasons.
That’s where Pigsty comes in. Pigsty provides a complete one-click self-hosting solution for Supabase.
Self-hosted Supabase can enjoy full PostgreSQL monitoring, IaC, PITR, and high availability, the new PG 17 kernels (and 14-16),
and 400 PostgreSQL extensions ready to use, and can take full advantage of the performance and cost advantages of modern hardware.
Quick Start
First, download & install pigsty as usual, with the supa config template:
curl -fsSL https://repo.pigsty.io/get | bash
./bootstrap # install deps (ansible)./configure -c app/supa # use supa config template (IMPORTANT: CHANGE PASSWORDS!)./install.yml # install pigsty, create ha postgres & minio clusters./docker.yml
./app.yml
Please change the pigsty.yml config file according to your need before deploying Supabase. (Credentials)
Then, run the supabase.yml to launch stateless part of supabase.
./supabase.yml # launch stateless supabase containers with docker compose
You can access the supabase API / Web UI through the 80/443 infra portal,
with configured DNS for public domain, or a local /etc/hosts record with supa.pigsty pointing to the node also works.
The stateful part of this template is replaced by Pigsty’s managed HA PostgreSQL cluster and MinIO service.
And the container part are stateless, so you can launch / destroy / run multiple supabase containers on the same PGSQL/MINIO cluster simultaneously to scale out.
When running the install.yml playbook, pigsty will prepare the MinIO & PostgreSQL according to the first part of supa.yml config template:
Usually the only thing that you need to change is the password part. Don’t forget to change other passwords (haproxy, grafana, patroni) in a real prod env!
When you run the supabase.yml playbook, The resource folder app/supabase will be copy to /opt/supabase on target nodes (the supabase group).
With the default parameters file: .env and docker-compose.yml template.
# launch supabase stateless part with docker compose:# ./supabase.ymlsupabase:hosts:10.10.10.10:{supa_seq:1}# instance idvars:supa_cluster:supa # cluster namedocker_enabled:true# enable docker# use these to pull docker images via proxy and mirror registries#docker_registry_mirrors: ['https://docker.xxxxx.io']#proxy_env: # add [OPTIONAL] proxy env to /etc/docker/daemon.json configuration file# no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"# #all_proxy: http://user:pass@host:port# these configuration entries will OVERWRITE or APPEND to /opt/supabase/.env file (src template: app/supabase/.env)# check https://github.com/pgsty/pigsty/blob/main/app/supabase/.env for default valuessupa_config:# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!# https://supabase.com/docs/guides/self-hosting/docker#securing-your-servicesjwt_secret:your-super-secret-jwt-token-with-at-least-32-characters-longanon_key:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GEservice_role_key:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Qdashboard_username:supabasedashboard_password:pigsty# postgres connection string (use the correct ip and port)postgres_host:10.10.10.10postgres_port:5436# access via the 'default' service, which always route to the primary postgrespostgres_db:postgrespostgres_password:DBUser.Supa # password for supabase_admin and multiple supabase users# expose supabase via domain namesite_url:http://supa.pigstyapi_external_url:http://supa.pigstysupabase_public_url:http://supa.pigsty# if using s3/minio as file storages3_bucket:supas3_endpoint:https://sss.pigsty:9000s3_access_key:supabases3_secret_key:S3User.Supabases3_force_path_style:trues3_protocol:httpss3_region:stubminio_domain_ip:10.10.10.10# sss.pigsty domain name will resolve to this ip statically# if using SMTP (optional)#smtp_admin_email: [email protected]#smtp_host: supabase-mail#smtp_port: 2500#smtp_user: fake_mail_user#smtp_pass: fake_mail_password#smtp_sender_name: fake_sender#enable_anonymous_users: false
And the most important part is the supa_config parameter, it will be used to overwrite or append to the .env file in the /opt/supabase directory.
The most critical parameter is jwt_secret, and the corresponding anon_key and service_role_key.
For serious production use, please refer to the Supabase self-hosting guide and use their tools to generate these keys accordingly.
Pigsty uses local MinIO and PostgreSQL by default. You can overwrite the PostgreSQL connection string with postgres_host, postgres_port, postgres_db, and postgres_password.
if you want to use S3 or MinIO as file storage, you need to configure s3_bucket, s3_endpoint, s3_access_key, s3_secret_key, and other parameters accordingly.
Usually you also need to use an external SMTP service to send emails, consider using mature 3rd-party services such as Mailchimp, etc…
Expose Service
If you wish to expose service to the Internet, A public DNS will be required, please add your domain name to the infra_portal and update site_url, api_external_url, and supabase_public_url in supa_config as well:
Make sure supa.pigsty or your own domain is resolvable to the infra_portal server, and you can access the supabase studio dashboard via https://supa.pigsty.
7.9 - Greenplum (MPP)
Deploy and monitoring Greenplum/YMatrix MPP clusters with Pigsty
Pigsty has native support for Greenplum and its derivative distribution YMatrixDB.
It can deploy Greenplum clusters and monitor them with Pigsty.
To define a Greenplum cluster, you need to specify the following parameters:
Set pg_mode = gpsql and the extra identity parameters pg_shard and gp_role.
#================================================================## GPSQL Clusters ##================================================================##----------------------------------## cluster: mx-mdw (gp master)#----------------------------------#mx-mdw:hosts:10.10.10.10:{pg_seq: 1, pg_role: primary , nodename:mx-mdw-1 }vars:gp_role:master # this cluster is used as greenplum masterpg_shard:mx # pgsql sharding name & gpsql deployment namepg_cluster:mx-mdw # this master cluster name is mx-mdwpg_databases:- {name: matrixmgr , extensions:[{name:matrixdbts } ] }- {name:meta }pg_users:- {name: meta , password: DBUser.Meta , pgbouncer:true}- {name: dbuser_monitor , password: DBUser.Monitor , roles: [ dbrole_readonly ], superuser:true}pgbouncer_enabled:true# enable pgbouncer for greenplum masterpgbouncer_exporter_enabled:false# enable pgbouncer_exporter for greenplum masterpg_exporter_params:'host=127.0.0.1&sslmode=disable'# use 127.0.0.1 as local monitor host#----------------------------------## cluster: mx-sdw (gp master)#----------------------------------#mx-sdw:hosts:10.10.10.11:nodename:mx-sdw-1 # greenplum segment nodepg_instances:# greenplum segment instances6000:{pg_cluster: mx-seg1, pg_seq: 1, pg_role: primary , pg_exporter_port:9633}6001:{pg_cluster: mx-seg2, pg_seq: 2, pg_role: replica , pg_exporter_port:9634}10.10.10.12:nodename:mx-sdw-2pg_instances:6000:{pg_cluster: mx-seg2, pg_seq: 1, pg_role: primary , pg_exporter_port:9633}6001:{pg_cluster: mx-seg3, pg_seq: 2, pg_role: replica , pg_exporter_port:9634}10.10.10.13:nodename:mx-sdw-3pg_instances:6000:{pg_cluster: mx-seg3, pg_seq: 1, pg_role: primary , pg_exporter_port:9633}6001:{pg_cluster: mx-seg1, pg_seq: 2, pg_role: replica , pg_exporter_port:9634}vars:gp_role:segment # these are nodes for gp segmentspg_shard:mx # pgsql sharding name & gpsql deployment namepg_cluster:mx-sdw # these segment clusters name is mx-sdwpg_preflight_skip:true# skip preflight check (since pg_seq & pg_role & pg_cluster not exists)pg_exporter_config:pg_exporter_basic.yml # use basic config to avoid segment server crashpg_exporter_params:'options=-c%20gp_role%3Dutility&sslmode=disable'# use gp_role = utility to connect to segments
Besides, you’ll need extra parameters to connect to Greenplum Segment instances for monitoring.
Since Greenplum is no longer Open-Sourced, this feature is only available in the Professional/Enterprise version and is not open-sourced at this time.
7.10 - Cloudberry (MPP)
Deploy Cloudberry MPP cluster, which is forked from Greenplum.
Self-Hosting serverless version of PostgreSQL from Neon, which is a powerful, truly scalable, and elastic service.
Neon adopts a storage and compute separation architecture, offering seamless features such as auto-scaling, Scale to Zero, and unique capabilities like database version branching.
Due to the substantial size of Neon’s compiled binaries, they are not currently available to open-source users. If you need them, please contact Pigsty sales.
8 - Module: INFRA
Independent modules which providers infrastructure services: NTP, DNS, and the modern observability stack ——Grafana & Prometheus
Pigsty has a battery-included, production-ready INFRA module, to provide ultimate observability.
To define an infra cluster, use the hard-coded group name infra in your inventory file.
You can use multiple nodes to deploy INFRA module, but at least one is required. You have to assign a unique infra_seq to each node.
# Single infra nodeinfra:{hosts:{10.10.10.10:{infra_seq:1}}}# Two INFRA nodeinfra:hosts:10.10.10.10:{infra_seq:1}10.10.10.11:{infra_seq:2}
Then you can init INFRA module with infra.yml playbook.
Administration
Here are some administration tasks related to INFRA module:
Install/Remove Infra Module
./infra.yml # install infra/node module on `infra` group./infra-rm.yml # remove infra module from `infra` group
Manage Local Software Repo
./infra.yml -t repo # setup local yum/apt repo./infra.yml -t repo_dir # create repo directory./infra.yml -t repo_check # check repo exists./infra.yml -t repo_prepare # use existing repo if exists./infra.yml -t repo_build # build repo from upstream if not exists./infra.yml -t repo_upstream # handle upstream repo files in /etc/yum.repos.d or /etc/apt/sources.list.d./infra.yml -t repo_url_pkg # download packages from internet defined by repo_url_packages./infra.yml -t repo_cache # make upstream yum/apt cache./infra.yml -t repo_boot_pkg # install bootstrap pkg such as createrepo_c,yum-utils,... (or dpkg-dev in debian/ubuntu)./infra.yml -t repo_pkg # download packages & dependencies from upstream repo./infra.yml -t repo_create # create a local yum repo with createrepo_c & modifyrepo_c./infra.yml -t repo_use # add newly built repo./infra.yml -t repo_nginx # launch a nginx for repo if no nginx is serving
Manage Infra Component
You can use the following subtasks to manage infra components:
./infra.yml -t nginx_index # render Nginx homepage./infra.yml -t nginx_config,nginx_reload # render Nginx upstream server config./infra.yml -t prometheus_conf,prometheus_reload # render Prometheus main config and reload./infra.yml -t prometheus_rule,prometheus_reload # copy Prometheus rules & alert definition and reload./infra.yml -t grafana_plugin # download Grafana plugins from the Internet
Playbook
install.yml : Install Pigsty on all nodes in one-pass
infra.yml : Init pigsty infrastructure on infra nodes
infra-rm.yml : Remove infrastructure components from infra nodes
infra.yml
The playbook infra.yml will init pigsty infrastructure on infra nodes.
It will also install NODE module on infra nodes too.
Here are available subtasks:
# ca : create self-signed CA on localhost files/pki# - ca_dir : create CA directory# - ca_private : generate ca private key: files/pki/ca/ca.key# - ca_cert : signing ca cert: files/pki/ca/ca.crt## id : generate node identity## repo : bootstrap a local yum repo from internet or offline packages# - repo_dir : create repo directory# - repo_check : check repo exists# - repo_prepare : use existing repo if exists# - repo_build : build repo from upstream if not exists# - repo_upstream : handle upstream repo files in /etc/yum.repos.d# - repo_remove : remove existing repo file if repo_remove == true# - repo_add : add upstream repo files to /etc/yum.repos.d# - repo_url_pkg : download packages from internet defined by repo_url_packages# - repo_cache : make upstream yum cache with yum makecache# - repo_boot_pkg : install bootstrap pkg such as createrepo_c,yum-utils,...# - repo_pkg : download packages & dependencies from upstream repo# - repo_create : create a local yum repo with createrepo_c & modifyrepo_c# - repo_use : add newly built repo into /etc/yum.repos.d# - repo_nginx : launch a nginx for repo if no nginx is serving## node/haproxy/docker/monitor : setup infra node as a common node (check node.yml)# - node_name, node_hosts, node_resolv, node_firewall, node_ca, node_repo, node_pkg# - node_feature, node_kernel, node_tune, node_sysctl, node_profile, node_ulimit# - node_data, node_admin, node_timezone, node_ntp, node_crontab, node_vip# - haproxy_install, haproxy_config, haproxy_launch, haproxy_reload# - docker_install, docker_admin, docker_config, docker_launch, docker_image# - haproxy_register, node_exporter, node_register, promtail## infra : setup infra components# - infra_env : env_dir, env_pg, env_var# - infra_pkg : infra_pkg, infra_pkg_pip# - infra_user : setup infra os user group# - infra_cert : issue cert for infra components# - dns : dns_config, dns_record, dns_launch# - nginx : nginx_config, nginx_cert, nginx_static, nginx_launch, nginx_exporter# - prometheus : prometheus_clean, prometheus_dir, prometheus_config, prometheus_launch, prometheus_reload# - alertmanager : alertmanager_config, alertmanager_launch# - pushgateway : pushgateway_config, pushgateway_launch# - blackbox : blackbox_config, blackbox_launch# - grafana : grafana_clean, grafana_config, grafana_plugin, grafana_launch, grafana_provision# - loki : loki clean, loki_dir, loki_config, loki_launch# - infra_register : register infra components to prometheus
infra-rm.yml
The playbook infra-rm.yml will remove infrastructure components from infra nodes
./infra-rm.yml # remove INFRA module./infra-rm.yml -t service # stop INFRA services./infra-rm.yml -t data # remove INFRA data./infra-rm.yml -t package # uninstall INFRA packages
install.yml
The playbook install.yml will install Pigsty on all node in one-pass.
DNSMASQ: DNS resolution for Pigsty’s internal domains
Chronyd: NTP time synchronization to keep all nodes in sync
The INFRA module isn’t mandatory for HA PostgreSQL - for instance, it’s omitted in Slim Install mode.
However, since INFRA provides essential supporting services for production-grade HA PostgreSQL clusters, it’s strongly recommended for most deployments.
If you already have your own infrastructure (Nginx, local repos, monitoring, DNS, NTP), you can disable INFRA and configure Pigsty to use your existing stack instead.
Architecture Overview
INFRA module includes these components with default ports and domains:
These endpoint definitions are referenced by other services - logs go to loki endpoint, Grafana datasources register to grafana endpoint, alerts route to alertmanager endpoint.
Pigsty allows rich Nginx customization as a local file server or reverse proxy, with self-signed or real HTTPS certs.
During installation, Pigsty creates a local package repo on the INFRA node to speed up subsequent software installations.
Located at /www/pigsty and served by Nginx, it’s accessible via http://h.pigsty/pigsty.
Pigsty’s offline package is a tarball of a pre-built repo directory. If /www/pigsty exists with a /www/pigsty/repo_complete marker, Pigsty skips downloading from upstream - perfect for air-gapped environments!
Repo definition lives in /www/pigsty.repo, fetchable via http://${admin_ip}/pigsty.repo:
Prometheus, our TSDB for monitoring, listens on port 9090 (access via IP:9090 or http://p.pigsty).
Key features:
Service discovery via local static files with identity info
Metric scraping, pre-processing, and TSDB storage
Alert rule evaluation and forwarding to AlertManager
AlertManager handles alerts on port 9093 (IP:9093 or http://a.pigsty).
While it receives Prometheus alerts, you’ll need extra config (e.g., SMTP) for notifications.
Configs for Prometheus, AlertManager, PushGateway, and BlackboxExporter are in: Config: INFRA - PROMETHEUS
Grafana
Grafana, our visualization powerhouse, runs on port 3000 (IP:3000 or http://g.pigsty).
Pigsty’s monitoring is dashboard-based with URL-driven navigation. Drill down or up quickly to pinpoint issues.
Fun fact: We’ve supercharged Grafana with extra viz plugins like ECharts - it’s not just monitoring, it’s a low-code data app platform!
Loki handles logs on port 3100, with Promtail shipping logs from nodes to the mothership.
How to configure Infra nodes? How to customize Nginx servers, local repo, DNS, NTP, and observability stack?
Configuration Overview
The INFRA module primarily provides monitoring infrastructure and is optional for PostgreSQL databases.
Unless you have manually configured dependencies on DNS/NTP services from INFRA nodes elsewhere, failures in the INFRA module typically won’t affect the normal operation of PostgreSQL database clusters.
In most cases, a single INFRA node is sufficient for typical scenarios. For production environments with higher requirements, we recommend using 2-3 INFRA nodes for high availability.
To improve resource utilization, PostgreSQL high availability typically relies on the ETCD module, which can share nodes with the INFRA module.
Using more than 3 INFRA nodes provides limited benefits, but you can use more ETCD nodes (e.g., 5) to enhance the availability and reliability of DCS services.
Configuration Examples
To install the INFRA module on nodes, first add node IPs to the infra group in the inventory and assign them an Infra instance number infra_seq.
By default, a single INFRA node configuration meets most requirements. All configuration templates include a default infra group definition:
The 10.10.10.10 IP placeholder in the infra group will be replaced with the current node’s primary IP address during configuration, meaning the INFRA module will be installed on the current node.
Then use the infra.yml playbook to initialize the INFRA module on the node.
Additional Nodes
To configure two INFRA nodes, add new IPs to infra.hosts:
Most components in the Infra module are “stateless/shared-state”. For these components, high availability primarily requires addressing load balancing.
Infra component load balancing can be achieved through two methods: Keepalived L2 VIP or HAProxy Layer 4 Load Balancing.
If your network environment supports Layer 2 connectivity, you can use Keepalived L2 VIP for high availability:
This section contains some metadata of current pigsty deployments, such as version string, admin node IP address, repo mirror region and http(s) proxy when downloading pacakges.
version:v3.4.1 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default,china,europeproxy_env:# global proxy env when downloading packagesno_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"# http_proxy: # set your proxy here: e.g http://user:[email protected]# https_proxy: # set your proxy here: e.g http://user:[email protected]# all_proxy: # set your proxy here: e.g http://user:[email protected]
version
name: version, type: string, level: G
pigsty version string
default value:v3.4.0
It will be used for pigsty introspection & content rendering.
admin_ip
name: admin_ip, type: ip, level: G
admin node ip address
default value:10.10.10.10
Node with this ip address will be treated as admin node, usually point to the first node that install Pigsty.
The default value 10.10.10.10 is a placeholder which will be replaced during configure
This parameter is referenced by many other parameters, such as:
The exact string ${admin_ip} will be replaced with the actual admin_ip for above parameters.
region
name: region, type: enum, level: G
upstream mirror region: default,china,europe
default value: default
If a region other than default is set, and there’s a corresponding entry in repo_upstream.[repo].baseurl, it will be used instead of default.
For example, if china is used, pigsty will use China mirrors designated in repo_upstream if applicable.
proxy_env
name: proxy_env, type: dict, level: G
global proxy env when downloading packages
default value:
proxy_env:# global proxy env when downloading packageshttp_proxy:'http://username:[email protected]'https_proxy:'http://username:[email protected]'all_proxy:'http://username:[email protected]'no_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.aliyuncs.com,mirrors.tuna.tsinghua.edu.cn,mirrors.zju.edu.cn"
It’s quite important to use http proxy in restricted production environment, or your Internet access is blocked (e.g. Mainland China)
Please note that if the Docker module is used, the proxy server configuration will also be written to the Docker Daemon configuration file.
Please note that if the -x parameter is specified during ./configure, the proxy configuration information in the current environment will be automatically filled into the generated pigsty.yaml file.
CA
Self-Signed CA used by pigsty. It is required to support advanced security features.
ca_method:create # create,recreate,copy, create by defaultca_cn:pigsty-ca # ca common name, fixed as pigsty-cacert_validity:7300d # cert validity, 20 years by default
ca_method
name: ca_method, type: enum, level: G
available options: create,recreate,copy
default value: create
create: Create a new CA public-private key pair if not exists, use if exists
recreate: Always re-create a new CA public-private key pair
copy: Copy the existing CA public and private keys from local files/pki/ca, abort if missing
If you already have a pair of ca.crt and ca.key, put them under files/pki/ca and set ca_method to copy.
ca_cn
name: ca_cn, type: string, level: G
ca common name, not recommending to change it.
default value: pigsty-ca
you can check that with openssl x509 -text -in /etc/pki/ca.crt
cert_validity
name: cert_validity, type: interval, level: G
cert validity, 20 years by default, which is enough for most scenarios
default value: 7300d
INFRA_ID
Infrastructure identity and portal definition.
#infra_seq: 1 # infra node identity, explicitly requiredinfra_portal:# infra services exposed via portalhome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000",websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}
infra_seq
name: infra_seq, type: int, level: I
infra node identity, REQUIRED, no default value, you have to assign it explicitly.
infra_portal
name: infra_portal, type: dict, level: G
infra services exposed via portal.
default value will expose home, grafana, prometheus, alertmanager via nginx with corresponding domain names.
infra_portal:# infra services exposed via portalhome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000",websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}
Each record consists of a Key and a Value dictionary, where name is the key, representing the component name, and the value is an object that can configure the following parameters:
name: REQUIRED, specify the name of the Nginx server
Default records: home, grafana, prometheus, alertmanager, blackbox, loki are fixed names, please do not modify them.
Used as part of the Nginx configuration file name, corresponding to the configuration file: /etc/nginx/conf.d/<name>.conf
Nginx servers without the domain field will not generate configuration files, but will be used as references.
domain: OPTIONAL, when the service needs to be exposed to the outside world via Nginx, it is a REQUIRED field, specifying the domain name used
In Pigsty self-signed Nginx HTTPS certificate, the domain name will be added to the SAN field of the Nginx SSL certificate
Pigsty web page cross-references will use the default domain name here
endpoint: Usually used as an alternative to path, specifies the upstream server address. Setting endpoint indicates this is a reverse proxy server
In the configuration, ${admin_ip} can be used as a placeholder, and will be dynamically replaced with admin_ip during deployment
The default reverse proxy server uses endpoint.conf as the configuration template
The reverse proxy server can also configure the websocket and schema parameters
path: Usually used as an alternative to endpoint, specifies the local file server path. Setting path means this is a local web server
The local web server uses path.conf as the configuration template
The local web server can also configure the index parameter, whether to enable the file index page
certbot: Certbot certificate name, if configured, will use Certbot to apply for a certificate
If multiple servers specify the same certbot, Pigsty will merge the certificate application, and the final certificate name will be the name of this certbot
cert: Nginx certificate file path, if configured, will override the default certificate path
key: Nginx certificate key file path, if configured, will override the default certificate key path
websocket: Whether to enable WebSocket support
Only reverse proxy servers can configure this parameter, if enabled it will allow upstream to use WebSocket connections
schema: Protocol used by the upstream server, if configured, will override the default protocol
Default is http, if configured as https it will force HTTPS connections to the upstream server
index: Whether to enable file index page
Only local web servers can configure this parameter, if enabled it will enable the autoindex configuration to automatically generate index pages for directories
log: Nginx log file path
If specified, access logs will be written to this file, otherwise the default log file will be used according to the server type
Reverse proxy servers use /var/log/nginx/<name>.log as the default log file path
Configuration text directly injected into the Nginx Server configuration block
enforce_https: Redirect HTTP to HTTPS
Global configuration can be specified by nginx_sslmode: enforce
This configuration does not affect the default home server, which will always listen on ports 80 and 443 simultaneously to ensure compatibility.
REPO
This section is about local software repo. Pigsty will create a local software repo (APT/YUM) when init an infra node.
In the initialization process, Pigsty will download all packages and their dependencies
(specified by repo_packages) from the Internet upstream repo (specified by repo_upstream)
to {{ nginx_home }} / {{ repo_name }} (default is /www/pigsty),
and the total size of all dependent software is about 1GB or so.
When creating a local repo, Pigsty will skip the software download phase if the directory already exists and if there is a marker file named repo_complete in the dir.
If the download speed of some packages is too slow, you can set the download proxy to complete the first download by using the proxy_env
config entry or directly download the pre-packaged offline package, which is essentially a local software source built on the same operating system.
repo_enabled:true# create a yum repo on this infra node?repo_home:/www # repo home dir, `/www` by defaultrepo_name:pigsty # repo name, pigsty by defaultrepo_endpoint:http://${admin_ip}:80# access point to this repo by domain or ip:portrepo_remove:true# remove existing upstream reporepo_modules:infra,node,pgsql # install upstream repo during repo bootstrap#repo_upstream: [] # where to download#repo_packages: [] # which packages to download#repo_extra_packages: [] # extra packages to downloadrepo_url_packages:[]# extra packages from url
repo_enabled
name: repo_enabled, type: bool, level: G/I
create a yum repo on this infra node? default value: true
If you have multiple infra nodes, you can disable yum repo on other standby nodes to reduce Internet traffic.
repo_home
name: repo_home, type: path, level: G
repo home dir, /www by default
repo_name
name: repo_name, type: string, level: G
repo name, pigsty by default, it is not wise to change this value
repo_endpoint
name: repo_endpoint, type: url, level: G
access point to this repo by domain or ip:port, default value: http://${admin_ip}:80
If you have changed the nginx_port or nginx_ssl_port, or use a different infra node from admin node, please adjust this parameter accordingly.
The ${admin_ip} will be replaced with actual admin_ip during runtime.
If you want to keep existing upstream repo, set this value to false.
repo_modules
name: repo_modules, type: string, level: G/A
which repo modules are installed in repo_upstream, default value: infra,node,pgsql
This is a comma separated value string, it is used to filter entries in repo_upstream with corresponding module field.
For Ubuntu / Debian users, you can add redis to the list: infra,node,pgsql,redis
repo_upstream
name: repo_upstream, type: upstream[], level: G
This param defines the upstream software repo for Pigsty. It DOES NOT have default values, you can specify it explicitly, or leaving it empty if you want to use the default values.
When leaving it empty, Pigsty will use the default values from the repo_upstream_default defined in roles/node_id/vars according to you OS.
This param is an array os strings, each string is a list of software packages separated by space, specifying which packages to be included & downloaded.
This param DOES NOT have a default value, you can specify it explicitly, or leaving it empty if you want to use the default values.
When leaving it empty, Pigsty will use the default values from the repo_packages_default defined in roles/node_id/vars according to you OS.
Each element in repo_packages will be translated into a list of package names according to the package_map defined in the above file, for specific OS distro version.
For example, on EL systems, it will be translated into:
As a convention, repo_packages usually includes software packages that are not related to the major version of PostgreSQL (such as Infra, Node, and PGDG Common),
while software packages related to the major version of PostgreSQL (kernel, extensions) are usually specified in repo_extra_packages to facilitate switching between PG major versions.
This parameter is same as repo_packages, but it is used for the additional software packages that need to be downloaded. (Usually PG version ad hoc packages)
The default value is an empty list. You can override it at the cluster & instance level to specify additional software packages that need to be downloaded.
If this parameter is not explicitly defined, Pigsty will load the default value from the repo_extra_packages_default defined in roles/node_id/vars, which is:
[pgsql-main ]
Each element in repo_packages will be translated into a list of package names according to the package_map defined in the above file, for specific OS distro version.
For example, on EL systems, it will be translated into:
Here $v will be replaced with the actual PostgreSQL major version number pg_version, So you can add any PG version related packages here, and Pigsty will download them for you.
repo_url_packages
name: repo_url_packages, type: object[] | string[], level: G
extra packages from url, default values: []
You can use object list or string list in this parameter, in the latter case, Pigsty will use the url basename as the filename.
Beware that if the region is set to china, the pigsty.io will be replaced with pigsty.cc automatically.
INFRA_PACKAGE
These packages are installed on infra nodes only, including common rpm/deb/pip packages.
infra_packages
name: infra_packages, type: string[], level: G
This param is an array os strings, each string is a list of common software packages separated by space, specifying which packages to be installed on INFRA nodes.
This param DOES NOT have a default value, you can specify it explicitly, or leaving it empty if you want to use the default values.
When leaving it empty, Pigsty will use the default values from the repo_packages_default defined in roles/node_id/vars according to you OS.
For EL (7/8/9) system, the default values are:
infra_packages:# packages to be installed on infra nodes- grafana,loki,logcli,promtail,prometheus,alertmanager,pushgateway,grafana-plugins,restic,certbot,python3-certbot-nginx- node_exporter,blackbox_exporter,nginx_exporter,pg_exporter,pev2,nginx,dnsmasq,ansible,etcd,python3-requests,redis,mcli
For Debian (11,12) or Ubuntu (22.04, 22.04) systems, the default values are:
infra_packages:# packages to be installed on infra nodes- grafana,grafana-plugins,loki,logcli,promtail,prometheus,alertmanager,pushgateway,restic,certbot,python3-certbot-nginx- node-exporter,blackbox-exporter,nginx-exporter,pg-exporter,pev2,nginx,dnsmasq,ansible,etcd,python3-requests,redis,mcli
infra_packages_pip
name: infra_packages_pip, type: string, level: G
pip installed packages for infra nodes, default value is empty string
NGINX
Pigsty exposes all Web services through Nginx: Home Page, Grafana, Prometheus, AlertManager, etc…,
and other optional tools such as PGWe, Jupyter Lab, Pgadmin, Bytebase ,and other static resource & report such as pev, schemaspy & pgbadger
This nginx also serves as a local yum/apt repo.
nginx_enabled:true# enable nginx on this infra node?nginx_exporter_enabled:true# enable nginx_exporter on this infra node?nginx_sslmode:enable # nginx ssl mode? disable,enable,enforcenginx_home:/www # nginx content dir, `/www` by defaultnginx_port:80# nginx listen port, 80 by defaultnginx_ssl_port:443# nginx ssl listen port, 443 by defaultnginx_navbar:# nginx index page navigation links- {name: CA Cert ,url: '/ca.crt' ,desc:'pigsty self-signed ca.crt'}- {name: Package ,url: '/pigsty' ,desc:'local yum repo packages'}- {name: PG Logs ,url: '/logs' ,desc:'postgres raw csv logs'}- {name: Reports ,url: '/report' ,desc:'pgbadger summary report'}- {name: Explain ,url: '/pigsty/pev.html' ,desc:'postgres explain visualizer'}certbot_sign:false# sign nginx cert with certbot during setup?certbot_email:[email protected]# certbot email address, used for free sslcertbot_options:''# certbot extra options
nginx_enabled
name: nginx_enabled, type: bool, level: G/I
enable nginx on this infra node? default value: true
enforce: all links will be rendered as https:// by default
also redirect 80 port to 443 port for all non-default servers in nginx infra_portal
nginx_home
name: nginx_home, type: path, level: G
nginx web server static content dir, /www by default
Nginx root directory which contains static resource and repo resource. It’s wise to set this value same as repo_home so that local repo content is automatically served.
nginx_port
name: nginx_port, type: port, level: G
nginx listen port which serves the HTTP requests, 80 by default.
If your default 80 port is occupied or unavailable, you can consider using another port, and change repo_endpoint and repo_upstream (the local entry) accordingly.
Each record is rendered as a navigation link to the Pigsty home page App drop-down menu, and the apps are all optional, mounted by default on the Pigsty default server under http://h.pigsty/.
The url parameter specifies the URL PATH for the app, with the exception that if the ${grafana} string is present in the URL, it will be automatically replaced with the Grafana domain name defined in infra_portal.
certbot_sign
name: certbot_sign, type: bool, level: G/A
sign nginx cert with certbot during setup? default value: false
When set to true, Pigsty will use certbot to automatically apply for free SSL certificates from Let’s Encrypt during the execution of infra.yml and install.yml playbooks (the nginx role).
In the infra_portal defined domain, if the certbot parameter is defined, Pigsty will use certbot to apply for the domain domain certificate, and the certificate name will be the value of the certbot parameter.
If multiple servers/domains specify the same certbot parameter, Pigsty will merge and apply for a certificate for these domains, and use the value of the certbot parameter as the certificate name.
Enabling this option requires:
The current node can be accessed through the public domain name, and the DNS resolution has been correctly pointed to the public IP of the current node
The current node can access the Let’s Encrypt API interface
This option is disabled by default, you can manually execute the make cert command after installation to manually execute it, it actually calls the rendered /etc/nginx/sign-cert script, using certbot to update or apply certificates.
certbot_email
name: certbot_email, type: string, level: G/A
The email address used to receive certificate expiration reminder emails, default value: [email protected]
When certbot_sign is set to true, it is recommended to provide this parameter. Let’s Encrypt will send reminder emails to this email when the certificate is about to expire.
certbot_option
name: certbot_option, type: string, level: G/A
Additional configuration parameters passed to certbot, default value: empty string.
You can pass additional command line options to certbot through this parameter, for example --dry-run, then certbot will not actually apply for a certificate, but will preview and test it.
DNS
Pigsty will launch a default DNSMASQ server on infra nodes to serve DNS inquiry. such as h.pigstya.pigstyp.pigstyg.pigsty and sss.pigsty for optional MinIO service.
All records will be added to infra node’s /etc/hosts.d/*.
You have to add nameserver {{ admin_ip }} to your /etc/resolv to use this dns server, and node_dns_servers will do the trick.
dns_enabled:true# setup dnsmasq on this infra node?dns_port:53# dns server listen port, 53 by defaultdns_records:# dynamic dns records resolved by dnsmasq- "${admin_ip} h.pigsty a.pigsty p.pigsty g.pigsty"- "${admin_ip} api.pigsty adm.pigsty cli.pigsty ddl.pigsty lab.pigsty git.pigsty sss.pigsty wiki.pigsty"
dns_enabled
name: dns_enabled, type: bool, level: G/I
setup dnsmasq on this infra node? default value: true
If you don’t want to use the default DNS server, you can set this value to false to disable it.
And use node_default_etc_hosts and node_etc_hosts instead.
dns_port
name: dns_port, type: port, level: G
dns server listen port, 53 by default
dns_records
name: dns_records, type: string[], level: G
dynamic dns records resolved by dnsmasq, Some auxiliary domain names will be written to /etc/hosts.d/default on infra nodes by default
dns_records:# dynamic dns records resolved by dnsmasq- "${admin_ip} h.pigsty a.pigsty p.pigsty g.pigsty"- "${admin_ip} api.pigsty adm.pigsty cli.pigsty ddl.pigsty lab.pigsty git.pigsty sss.pigsty wiki.pigsty"
PROMETHEUS
Prometheus is used as time-series database for metrics scrape, storage & analysis.
prometheus_enabled:true# enable prometheus on this infra node?prometheus_clean:true# clean prometheus data during init?prometheus_data:/data/prometheus# prometheus data dir, `/data/prometheus` by defaultprometheus_sd_dir:/etc/prometheus/targets# prometheus file service discovery directoryprometheus_sd_interval:5s # prometheus target refresh interval, 5s by defaultprometheus_scrape_interval:10s # prometheus scrape & eval interval, 10s by defaultprometheus_scrape_timeout:8s # prometheus global scrape timeout, 8s by defaultprometheus_options:'--storage.tsdb.retention.time=15d'# prometheus extra server optionspushgateway_enabled:true# setup pushgateway on this infra node?pushgateway_options:'--persistence.interval=1m'# pushgateway extra server optionsblackbox_enabled:true# setup blackbox_exporter on this infra node?blackbox_options:''# blackbox_exporter extra server optionsalertmanager_enabled:true# setup alertmanager on this infra node?alertmanager_port:9093# alertmanager listen port, 9093 by defaultalertmanager_options:''# alertmanager extra server optionsexporter_metrics_path:/metrics # exporter metric path, `/metrics` by defaultexporter_install:none # how to install exporter? none,yum,binaryexporter_repo_url:''# exporter repo file url if install exporter via yum
prometheus_enabled
name: prometheus_enabled, type: bool, level: G/I
enable prometheus on this infra node?
default value: true
prometheus_clean
name: prometheus_clean, type: bool, level: G/A
clean prometheus data during init? default value: true
setup alertmanager on this infra node? default value: true
alertmanager_port
name: alertmanager_port, type: port, level: G
The listening port for AlertManager, default value is 9093.
The reason for allowing a special setting for AlertManager’s port is because Kafka’s default port also uses 9093, which can easily cause conflicts.
alertmanager_options
name: alertmanager_options, type: arg, level: G
alertmanager extra server options, default value is empty string
exporter_metrics_path
name: exporter_metrics_path, type: path, level: G
exporter metric path, /metrics by default
exporter_install
name: exporter_install, type: enum, level: G
(OBSOLETE) how to install exporter? none,yum,binary
default value: none
Specify how to install Exporter:
none: No installation, (by default, the Exporter has been previously installed by the node_pkg task)
yum: Install using yum (if yum installation is enabled, run yum to install node_exporter and pg_exporter before deploying Exporter)
binary: Install using a copy binary (copy node_exporter and pg_exporter binary directly from the meta node, not recommended)
When installing with yum, if exporter_repo_url is specified (not empty), the installation will first install the REPO file under that URL into /etc/yum.repos.d. This feature allows you to install Exporter directly without initializing the node infrastructure.
It is not recommended for regular users to use binary installation. This mode is usually used for emergency troubleshooting and temporary problem fixes.
(OBSOLETE) exporter repo file url if install exporter via yum
default value is empty string
Default is empty; when exporter_install is yum, the repo specified by this parameter will be added to the node source list.
GRAFANA
Grafana is the visualization platform for Pigsty’s monitoring system.
It can also be used as a low code data visualization environment
grafana_enabled:true# enable grafana on this infra node?grafana_clean:true# clean grafana data during init?grafana_admin_username:admin # grafana admin username, `admin` by defaultgrafana_admin_password:pigsty # grafana admin password, `pigsty` by defaultloki_enabled:true# enable loki on this infra node?loki_clean:false# whether remove existing loki data?loki_data:/data/loki # loki data dir, `/data/loki` by defaultloki_retention:15d # loki log retention period, 15d by default
grafana_enabled
name: grafana_enabled, type: bool, level: G/I
enable grafana on this infra node? default value: true
grafana_clean
name: grafana_clean, type: bool, level: G/A
clean grafana data during init? default value: true
grafana_admin_username
name: grafana_admin_username, type: username, level: G
grafana admin username, admin by default
grafana_admin_password
name: grafana_admin_password, type: password, level: G
grafana admin password, pigsty by default
default value: pigsty
WARNING: Change this to a strong password before deploying to production environment
LOKI
loki_enabled
name: loki_enabled, type: bool, level: G/I
enable loki on this infra node? default value: true
How to manage INFRA clusters using ansible playbooks, quick reference for common admin tasks.
There are three playbooks related to the INFRA module:
infra.yml: Initialize Pigsty infrastructure on infra nodes
infra-rm.yml: Remove infrastructure components from infra nodes
install.yml: Perform a complete one-time installation of Pigsty on the current node
infra.yml
The INFRA module playbook infra.yml initializes the infrastructure module on Infra nodes defined in the infra group of your config file.
This playbook performs the following tasks:
Configures directories and environment variables on Infra nodes
Downloads and creates a local software repository to accelerate subsequent installations (skipped if offline packages are used or if a local repository already exists)
Incorporates the current Infra node as a regular node managed by Pigsty
Deploys infrastructure components, including Prometheus, Grafana, Loki, Alertmanager, PushGateway, Blackbox Exporter, etc.
This playbook executes on the infra group by default:
Pigsty installs the INFRA module on the group named infra in the config file
During configure, Pigsty marks the current installation node as an Infra node and replaces the placeholder IP address 10.10.10.10 in the config template with the current node’s primary IP address
This node can initiate management tasks and hosts infrastructure components while functioning like any regular managed node
Playbook notes:
This is an idempotent playbook - repeated execution will overwrite infrastructure components on Infra nodes
Unless prometheus_clean is set to false, Prometheus time series metrics will be lost
Unless loki_clean is set to false, Loki log data will be lost
Unless grafana_clean is set to false, Grafana dashboards and configuration changes will be lost
When the local software repository /www/pigsty/repo_complete exists, this playbook skips downloading software from the internet
Complete execution takes approximately 1-3 minutes, depending on machine configuration and network conditions
Downloading software directly from the original upstream sources (without using offline packages) may take 5-10 minutes, depending on your network connection
Execution Demo
Available Tasks
Here’s the list of available tasks in the infra.yml playbook:
#--------------------------------------------------------------## Tasks#--------------------------------------------------------------## ca : create self-signed CA on localhost files/pki# - ca_dir : create CA directory# - ca_private : generate ca private key: files/pki/ca/ca.key# - ca_cert : signing ca cert: files/pki/ca/ca.crt## id : generate node identity## repo : bootstrap a local yum repo from internet or offline packages# - repo_dir : create repo directory# - repo_check : check repo exists# - repo_prepare : use existing repo if exists# - repo_build : build repo from upstream if not exists# - repo_upstream : handle upstream repo files in /etc/yum.repos.d# - repo_remove : remove existing repo file if repo_remove == true# - repo_add : add upstream repo files to /etc/yum.repos.d# - repo_url_pkg : download packages from internet defined by repo_url_packages# - repo_cache : make upstream yum cache with yum makecache# - repo_boot_pkg : install bootstrap pkg such as createrepo_c,yum-utils,...# - repo_pkg : download packages & dependencies from upstream repo# - repo_create : create a local yum repo with createrepo_c & modifyrepo_c# - repo_use : add newly built repo into /etc/yum.repos.d# - repo_nginx : launch a nginx for repo if no nginx is serving## node/haproxy/docker/monitor : setup infra node as a common node (check node.yml)# - node_name, node_hosts, node_resolv, node_firewall, node_ca, node_repo, node_pkg# - node_feature, node_kernel, node_tune, node_sysctl, node_profile, node_ulimit# - node_data, node_admin, node_timezone, node_ntp, node_crontab, node_vip# - haproxy_install, haproxy_config, haproxy_launch, haproxy_reload# - docker_install, docker_admin, docker_config, docker_launch, docker_image# - haproxy_register, node_exporter, node_register, promtail## infra : setup infra components# - infra_env : env_dir, env_pg, env_pgadmin, env_var# - infra_pkg : infra_pkg_yum, infra_pkg_pip# - infra_user : setup infra os user group# - infra_cert : issue cert for infra components# - dns : dns_config, dns_record, dns_launch# - nginx : nginx_config, nginx_cert, nginx_static, nginx_launch, nginx_certbot, nginx_reload, nginx_exporter# - prometheus : prometheus_clean, prometheus_dir, prometheus_config, prometheus_launch, prometheus_reload# - alertmanager : alertmanager_config, alertmanager_launch# - pushgateway : pushgateway_config, pushgateway_launch# - blackbox : blackbox_config, blackbox_launch# - grafana : grafana_clean, grafana_config, grafana_launch, grafana_provision# - loki : loki clean, loki_dir, loki_config, loki_launch# - infra_register : register infra components to prometheus#--------------------------------------------------------------#
infra-rm.yml
The INFRA module playbook infra-rm.yml removes Pigsty infrastructure from Infra nodes defined in the infra group of your config file.
Common subtasks include:
./infra-rm.yml # Remove the INFRA module./infra-rm.yml -t service # Stop infrastructure services on INFRA./infra-rm.yml -t data # Remove retained data on INFRA./infra-rm.yml -t package # Uninstall packages installed on INFRA
install.yml
The INFRA module playbook install.yml performs a complete one-time installation of Pigsty on all nodes.
INFRA Cluster Management SOP - Create, Destroy, Scale-out, Scale-in, and Monitor
Here are some admin tasks related to the INFRA module (because who doesn’t love infrastructure management?):
Install INFRA
Use the infra.yml playbook to install the INFRA module on Infra nodes:
./infra.yml # Install INFRA module on infra group
Remove INFRA
Use the infra-rm.yml playbook to uninstall the INFRA module from Infra nodes:
./infra-rm.yml # Uninstall INFRA module from infra group
Expand INFRA
To scale out an existing INFRA deployment, first modify the infra group by adding new node IPs and assigning unique infra_seq numbers:
all:children:infra:hosts:10.10.10.10:{infra_seq:1}# Existing node #110.10.10.11:{infra_seq:2}# New node #2 (fresh meat!)
Then use the infra.yml playbook to install INFRA on the new node:
./infra.yml -l 10.10.10.11 # Install INFRA on the new node
Local Repo
Use these playbook tasks to manage local package repositories (YUM/APT) on Infra nodes (because who doesn’t love a good package party?):
./infra.yml -t repo # Create local repo from internet or offline packages./infra.yml -t repo_dir # Create local repo directory./infra.yml -t repo_check # Check if local repo exists./infra.yml -t repo_prepare # Use existing local repo if available./infra.yml -t repo_build # Build local repo from upstream if not exists./infra.yml -t repo_upstream # Add upstream repo/list files./infra.yml -t repo_remove # Remove existing repo files if repo_remove=true./infra.yml -t repo_add # Add upstream repo files to /etc/yum.repos.d (or apt)./infra.yml -t repo_url_pkg # Download packages defined in repo_url_packages./infra.yml -t repo_cache # Create metadata cache with yum makecache / apt update./infra.yml -t repo_boot_pkg # Install bootstrap packages (createrepo_c, yum-utils, etc)./infra.yml -t repo_pkg # Download packages & deps from upstream./infra.yml -t repo_create # Create local repo with createrepo_c / dpkg-dev./infra.yml -t repo_use # Add new repo to /etc/yum.repos.d | apt sources./infra.yml -t repo_nginx # Start nginx as file server if not running
Commonly used commands (the greatest hits):
./infra.yml -t repo_upstream # Add upstream repos defined in repo_upstream./infra.yml -t repo_pkg # Download packages and their dependencies./infra.yml -t repo_create # Create/update local yum/apt repo
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which alertmanager was built, and the goos and goarch for the build.
alertmanager_cluster_alive_messages_total
counter
ins, instance, ip, peer, job, cls
Total number of received alive messages.
alertmanager_cluster_enabled
gauge
ins, instance, ip, job, cls
Indicates whether the clustering is enabled or not.
alertmanager_cluster_failed_peers
gauge
ins, instance, ip, job, cls
Number indicating the current number of failed peers in the cluster.
alertmanager_cluster_health_score
gauge
ins, instance, ip, job, cls
Health score of the cluster. Lower values are better and zero means ’totally healthy’.
alertmanager_cluster_members
gauge
ins, instance, ip, job, cls
Number indicating current number of members in cluster.
alertmanager_cluster_messages_pruned_total
counter
ins, instance, ip, job, cls
Total number of cluster messages pruned.
alertmanager_cluster_messages_queued
gauge
ins, instance, ip, job, cls
Number of cluster messages which are queued.
alertmanager_cluster_messages_received_size_total
counter
ins, instance, ip, msg_type, job, cls
Total size of cluster messages received.
alertmanager_cluster_messages_received_total
counter
ins, instance, ip, msg_type, job, cls
Total number of cluster messages received.
alertmanager_cluster_messages_sent_size_total
counter
ins, instance, ip, msg_type, job, cls
Total size of cluster messages sent.
alertmanager_cluster_messages_sent_total
counter
ins, instance, ip, msg_type, job, cls
Total number of cluster messages sent.
alertmanager_cluster_peer_info
gauge
ins, instance, ip, peer, job, cls
A metric with a constant ‘1’ value labeled by peer name.
alertmanager_cluster_peers_joined_total
counter
ins, instance, ip, job, cls
A counter of the number of peers that have joined.
alertmanager_cluster_peers_left_total
counter
ins, instance, ip, job, cls
A counter of the number of peers that have left.
alertmanager_cluster_peers_update_total
counter
ins, instance, ip, job, cls
A counter of the number of peers that have updated metadata.
alertmanager_cluster_reconnections_failed_total
counter
ins, instance, ip, job, cls
A counter of the number of failed cluster peer reconnection attempts.
alertmanager_cluster_reconnections_total
counter
ins, instance, ip, job, cls
A counter of the number of cluster peer reconnections.
alertmanager_cluster_refresh_join_failed_total
counter
ins, instance, ip, job, cls
A counter of the number of failed cluster peer joined attempts via refresh.
alertmanager_cluster_refresh_join_total
counter
ins, instance, ip, job, cls
A counter of the number of cluster peer joined via refresh.
alertmanager_config_hash
gauge
ins, instance, ip, job, cls
Hash of the currently loaded alertmanager configuration.
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which blackbox_exporter was built, and the goos and goarch for the build.
Number of schedulers this frontend is connected to.
cortex_query_frontend_queries_in_progress
gauge
ins, instance, ip, job, cls
Number of queries in progress handled by this frontend.
cortex_query_frontend_retries_bucket
Unknown
ins, instance, ip, le, job, cls
N/A
cortex_query_frontend_retries_count
Unknown
ins, instance, ip, job, cls
N/A
cortex_query_frontend_retries_sum
Unknown
ins, instance, ip, job, cls
N/A
cortex_query_scheduler_connected_frontend_clients
gauge
ins, instance, ip, job, cls
Number of query-frontend worker clients currently connected to the query-scheduler.
cortex_query_scheduler_connected_querier_clients
gauge
ins, instance, ip, job, cls
Number of querier worker clients currently connected to the query-scheduler.
cortex_query_scheduler_inflight_requests
summary
ins, instance, ip, job, cls, quantile
Number of inflight requests (either queued or processing) sampled at a regular interval. Quantile buckets keep track of inflight requests over the last 60s.
A summary of the pause duration of garbage collection cycles.
go_gc_duration_seconds_count
Unknown
ins, instance, ip, job, cls
N/A
go_gc_duration_seconds_sum
Unknown
ins, instance, ip, job, cls
N/A
go_gc_gogc_percent
gauge
ins, instance, ip, job, cls
Heap size target percentage configured by the user, otherwise 100. This value is set by the GOGC environment variable, and the runtime/debug.SetGCPercent function.
go_gc_gomemlimit_bytes
gauge
ins, instance, ip, job, cls
Go runtime memory limit configured by the user, otherwise math.MaxInt64. This value is set by the GOMEMLIMIT environment variable, and the runtime/debug.SetMemoryLimit function.
go_gc_heap_allocs_by_size_bytes_bucket
Unknown
ins, instance, ip, le, job, cls
N/A
go_gc_heap_allocs_by_size_bytes_count
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_allocs_by_size_bytes_sum
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_allocs_bytes_total
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_allocs_objects_total
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_frees_by_size_bytes_bucket
Unknown
ins, instance, ip, le, job, cls
N/A
go_gc_heap_frees_by_size_bytes_count
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_frees_by_size_bytes_sum
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_frees_bytes_total
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_frees_objects_total
Unknown
ins, instance, ip, job, cls
N/A
go_gc_heap_goal_bytes
gauge
ins, instance, ip, job, cls
Heap size target for the end of the GC cycle.
go_gc_heap_live_bytes
gauge
ins, instance, ip, job, cls
Heap memory occupied by live objects that were marked by the previous GC.
go_gc_heap_objects_objects
gauge
ins, instance, ip, job, cls
Number of objects, live or unswept, occupying heap memory.
go_gc_heap_tiny_allocs_objects_total
Unknown
ins, instance, ip, job, cls
N/A
go_gc_limiter_last_enabled_gc_cycle
gauge
ins, instance, ip, job, cls
GC cycle the last time the GC CPU limiter was enabled. This metric is useful for diagnosing the root cause of an out-of-memory error, because the limiter trades memory for CPU time when the GC’s CPU time gets too high. This is most likely to occur with use of SetMemoryLimit. The first GC cycle is cycle 1, so a value of 0 indicates that it was never enabled.
go_gc_pauses_seconds_bucket
Unknown
ins, instance, ip, le, job, cls
N/A
go_gc_pauses_seconds_count
Unknown
ins, instance, ip, job, cls
N/A
go_gc_pauses_seconds_sum
Unknown
ins, instance, ip, job, cls
N/A
go_gc_scan_globals_bytes
gauge
ins, instance, ip, job, cls
The total amount of global variable space that is scannable.
go_gc_scan_heap_bytes
gauge
ins, instance, ip, job, cls
The total amount of heap space that is scannable.
go_gc_scan_stack_bytes
gauge
ins, instance, ip, job, cls
The number of bytes of stack that were scanned last GC cycle.
go_gc_scan_total_bytes
gauge
ins, instance, ip, job, cls
The total amount space that is scannable. Sum of all metrics in /gc/scan.
Memory that is completely free and eligible to be returned to the underlying system, but has not been. This metric is the runtime’s estimate of free address space that is backed by physical memory.
go_memory_classes_heap_objects_bytes
gauge
ins, instance, ip, job, cls
Memory occupied by live objects and dead objects that have not yet been marked free by the garbage collector.
go_memory_classes_heap_released_bytes
gauge
ins, instance, ip, job, cls
Memory that is completely free and has been returned to the underlying system. This metric is the runtime’s estimate of free address space that is still mapped into the process, but is not backed by physical memory.
go_memory_classes_heap_stacks_bytes
gauge
ins, instance, ip, job, cls
Memory allocated from the heap that is reserved for stack space, whether or not it is currently in-use. Currently, this represents all stack memory for goroutines. It also includes all OS thread stacks in non-cgo programs. Note that stacks may be allocated differently in the future, and this may change.
go_memory_classes_heap_unused_bytes
gauge
ins, instance, ip, job, cls
Memory that is reserved for heap objects but is not currently used to hold heap objects.
go_memory_classes_metadata_mcache_free_bytes
gauge
ins, instance, ip, job, cls
Memory that is reserved for runtime mcache structures, but not in-use.
go_memory_classes_metadata_mcache_inuse_bytes
gauge
ins, instance, ip, job, cls
Memory that is occupied by runtime mcache structures that are currently being used.
go_memory_classes_metadata_mspan_free_bytes
gauge
ins, instance, ip, job, cls
Memory that is reserved for runtime mspan structures, but not in-use.
go_memory_classes_metadata_mspan_inuse_bytes
gauge
ins, instance, ip, job, cls
Memory that is occupied by runtime mspan structures that are currently being used.
go_memory_classes_metadata_other_bytes
gauge
ins, instance, ip, job, cls
Memory that is reserved for or used to hold runtime metadata.
go_memory_classes_os_stacks_bytes
gauge
ins, instance, ip, job, cls
Stack memory allocated by the underlying operating system. In non-cgo programs this metric is currently zero. This may change in the future.In cgo programs this metric includes OS thread stacks allocated directly from the OS. Currently, this only accounts for one stack in c-shared and c-archive build modes, and other sources of stacks from the OS are not measured. This too may change in the future.
go_memory_classes_other_bytes
gauge
ins, instance, ip, job, cls
Memory used by execution trace buffers, structures for debugging the runtime, finalizer and profiler specials, and more.
go_memory_classes_profiling_buckets_bytes
gauge
ins, instance, ip, job, cls
Memory that is used by the stack trace hash map used for profiling.
go_memory_classes_total_bytes
gauge
ins, instance, ip, job, cls
All memory mapped by the Go runtime into the current process as read-write. Note that this does not include memory mapped by code called via cgo or via the syscall package. Sum of all metrics in /memory/classes.
go_memstats_alloc_bytes
counter
ins, instance, ip, job, cls
Total number of bytes allocated, even if freed.
go_memstats_alloc_bytes_total
counter
ins, instance, ip, job, cls
Total number of bytes allocated, even if freed.
go_memstats_buck_hash_sys_bytes
gauge
ins, instance, ip, job, cls
Number of bytes used by the profiling bucket hash table.
go_memstats_frees_total
counter
ins, instance, ip, job, cls
Total number of frees.
go_memstats_gc_sys_bytes
gauge
ins, instance, ip, job, cls
Number of bytes used for garbage collection system metadata.
go_memstats_heap_alloc_bytes
gauge
ins, instance, ip, job, cls
Number of heap bytes allocated and still in use.
go_memstats_heap_idle_bytes
gauge
ins, instance, ip, job, cls
Number of heap bytes waiting to be used.
go_memstats_heap_inuse_bytes
gauge
ins, instance, ip, job, cls
Number of heap bytes that are in use.
go_memstats_heap_objects
gauge
ins, instance, ip, job, cls
Number of allocated objects.
go_memstats_heap_released_bytes
gauge
ins, instance, ip, job, cls
Number of heap bytes released to OS.
go_memstats_heap_sys_bytes
gauge
ins, instance, ip, job, cls
Number of heap bytes obtained from system.
go_memstats_last_gc_time_seconds
gauge
ins, instance, ip, job, cls
Number of seconds since 1970 of last garbage collection.
go_memstats_lookups_total
counter
ins, instance, ip, job, cls
Total number of pointer lookups.
go_memstats_mallocs_total
counter
ins, instance, ip, job, cls
Total number of mallocs.
go_memstats_mcache_inuse_bytes
gauge
ins, instance, ip, job, cls
Number of bytes in use by mcache structures.
go_memstats_mcache_sys_bytes
gauge
ins, instance, ip, job, cls
Number of bytes used for mcache structures obtained from system.
go_memstats_mspan_inuse_bytes
gauge
ins, instance, ip, job, cls
Number of bytes in use by mspan structures.
go_memstats_mspan_sys_bytes
gauge
ins, instance, ip, job, cls
Number of bytes used for mspan structures obtained from system.
go_memstats_next_gc_bytes
gauge
ins, instance, ip, job, cls
Number of heap bytes when next garbage collection will take place.
go_memstats_other_sys_bytes
gauge
ins, instance, ip, job, cls
Number of bytes used for other system allocations.
go_memstats_stack_inuse_bytes
gauge
ins, instance, ip, job, cls
Number of bytes in use by the stack allocator.
go_memstats_stack_sys_bytes
gauge
ins, instance, ip, job, cls
Number of bytes obtained from system for stack allocator.
go_memstats_sys_bytes
gauge
ins, instance, ip, job, cls
Number of bytes obtained from system.
go_sched_gomaxprocs_threads
gauge
ins, instance, ip, job, cls
The current runtime.GOMAXPROCS setting, or the number of operating system threads that can execute user-level Go code simultaneously.
go_sched_goroutines_goroutines
gauge
ins, instance, ip, job, cls
Count of live goroutines.
go_sched_latencies_seconds_bucket
Unknown
ins, instance, ip, le, job, cls
N/A
go_sched_latencies_seconds_count
Unknown
ins, instance, ip, job, cls
N/A
go_sched_latencies_seconds_sum
Unknown
ins, instance, ip, job, cls
N/A
go_sql_stats_connections_blocked_seconds
unknown
ins, instance, db_name, ip, job, cls
The total time blocked waiting for a new connection.
go_sql_stats_connections_closed_max_idle
unknown
ins, instance, db_name, ip, job, cls
The total number of connections closed due to SetMaxIdleConns.
go_sql_stats_connections_closed_max_idle_time
unknown
ins, instance, db_name, ip, job, cls
The total number of connections closed due to SetConnMaxIdleTime.
go_sql_stats_connections_closed_max_lifetime
unknown
ins, instance, db_name, ip, job, cls
The total number of connections closed due to SetConnMaxLifetime.
go_sql_stats_connections_idle
gauge
ins, instance, db_name, ip, job, cls
The number of idle connections.
go_sql_stats_connections_in_use
gauge
ins, instance, db_name, ip, job, cls
The number of connections currently in use.
go_sql_stats_connections_max_open
gauge
ins, instance, db_name, ip, job, cls
Maximum number of open connections to the database.
go_sql_stats_connections_open
gauge
ins, instance, db_name, ip, job, cls
The number of established connections both in use and idle.
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which nginx_exporter was built, and the goos and goarch for the build.
nginx_http_requests_total
counter
ins, instance, ip, job, cls
Total http requests
nginx_up
gauge
ins, instance, ip, job, cls
Status of the last metric scrape
plugins_active_instances
gauge
ins, instance, ip, job, cls
The number of active plugin instances
plugins_datasource_instances_total
Unknown
ins, instance, ip, job, cls
N/A
process_cpu_seconds_total
counter
ins, instance, ip, job, cls
Total user and system CPU time spent in seconds.
process_max_fds
gauge
ins, instance, ip, job, cls
Maximum number of open file descriptors.
process_open_fds
gauge
ins, instance, ip, job, cls
Number of open file descriptors.
process_resident_memory_bytes
gauge
ins, instance, ip, job, cls
Resident memory size in bytes.
process_start_time_seconds
gauge
ins, instance, ip, job, cls
Start time of the process since unix epoch in seconds.
process_virtual_memory_bytes
gauge
ins, instance, ip, job, cls
Virtual memory size in bytes.
process_virtual_memory_max_bytes
gauge
ins, instance, ip, job, cls
Maximum amount of virtual memory available in bytes.
prometheus_api_remote_read_queries
gauge
ins, instance, ip, job, cls
The current number of remote read queries being executed or waiting.
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which prometheus was built, and the goos and goarch for the build.
The timestamp of the oldest exemplar stored in circular storage. Useful to check for what timerange the current exemplar buffer limit allows. This usually means the last timestampfor all exemplars for a typical setup. This is not true though if one of the series timestamp is in future compared to rest series.
prometheus_tsdb_exemplar_max_exemplars
gauge
ins, instance, ip, job, cls
Total number of exemplars the exemplar storage can store, resizeable.
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which pushgateway was built, and the goos and goarch for the build.
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which pushgateway was built, and the goos and goarch for the build.
pushgateway_http_requests_total
counter
job, cls, method, code, handler, instance, ins, ip
Total HTTP requests processed by the Pushgateway, excluding scrapes.
scrape_duration_seconds
Unknown
job, cls, instance, ins, ip
N/A
scrape_samples_post_metric_relabeling
Unknown
job, cls, instance, ins, ip
N/A
scrape_samples_scraped
Unknown
job, cls, instance, ins, ip
N/A
scrape_series_added
Unknown
job, cls, instance, ins, ip
N/A
up
Unknown
job, cls, instance, ins, ip
N/A
8.8 - FAQ
Pigsty INFRA module frequently asked questions
Which components are included in INFRA
Ansible for automation, deployment, and administration;
Nginx for exposing any WebUI service and serving the yum/apt repo;
Self-Signed CA for SSL/TLS certificates;
Prometheus for monitoring metrics
Grafana for monitoring/visualization
Loki for logging collection
AlertManager for alerts aggregation
Chronyd for NTP time sync on the admin node.
DNSMasq for DNS registration and resolution.
ETCD as DCS for PGSQL HA; (dedicated module)
PostgreSQL on meta nodes as CMDB; (optional)
Docker for stateless applications & tools (optional)
How to restore Prometheus targets
If you accidentally deleted the Prometheus targets dir, you can register monitoring targets to Prometheus again with the:
./infra.yml -t register_prometheus # register all infra targets to prometheus on infra nodes./node.yml -t register_prometheus # register all node targets to prometheus on infra nodes./etcd.yml -t register_prometheus # register all etcd targets to prometheus on infra nodes./minio.yml -t register_prometheus # register all minio targets to prometheus on infra nodes./pgsql.yml -t register_prometheus # register all pgsql targets to prometheus on infra nodes
How to restore Grafana datasource
PGSQL Databases in pg_databases are registered as Grafana datasource by default.
If you accidentally deleted the registered postgres datasource in Grafana, you can register them again with
./pgsql.yml -t register_grafana # register all pgsql database (in pg_databases) as grafana datasource
How to restore the HAProxy admin page proxy
The haproxy admin page is proxied by Nginx under the default server.
If you accidentally deleted the registered haproxy proxy settings in /etc/nginx/conf.d/haproxy, you can restore them again with
./node.yml -t register_nginx # register all haproxy admin page proxy settings to nginx on infra nodes
How to restore the DNS registration
PGSQL cluster/instance domain names are registered to /etc/hosts.d/<name> on infra nodes by default.
You can restore them again with the following:
./pgsql.yml -t pg_dns # register pg DNS names to dnsmasq on infra nodes
How to expose new Nginx upstream service
If you wish to expose a new WebUI service via the Nginx portal, you can add the service definition to the infra_portal parameter.
And re-run ./infra.yml -t nginx_config,nginx_launch to update & apply the Nginx configuration.
If you wish to access with HTTPS, you must remove files/pki/csr/pigsty.csr, files/pki/nginx/pigsty.{key,crt} to force re-generating the Nginx SSL/TLS certificate to include the new upstream’s domain name.
How to expose web service through Nginx?
While you can directly access services via IP:Port, we still recommend consolidating access points by using domain names and uniformly accessing various web-based services through the Nginx portal.
This approach helps centralize access, reduce the number of exposed ports, and facilitates access control and auditing.
If you wish to expose a new WebUI service through the Nginx portal, you can add the service definition to the infra_portal parameter.
For example, here is the config used by the public demo site, which exposes several additional web services:
After completing the Nginx upstream service definition, use the following configuration and command to register the new service with Nginx.
./infra.yml -t nginx_config # regenerate Nginx config./infra.yml -t nginx_launch # update and apply nginx config# you can reload nginx with ansibleansible infra -b -a 'nginx -s reload'# reload nginx with ansible
If you wish to access via HTTPS, you must delete files/pki/csr/pigsty.csr and files/pki/nginx/pigsty.{key,crt} to force the regeneration of the Nginx SSL/TLS certificate to include the new upstream domain names. If you prefer to use an SSL certificate issued by an authoritative organization instead of a certificate issued by Pigsty’s self-signed CA, you can place it in the /etc/nginx/conf.d/cert/ directory and modify the corresponding configuration: /etc/nginx/conf.d/<name>.conf.
How to manually add upstream repo files
Pigsty has a built-in wrap script bin/repo-add, which will invoke ansible playbook node.yml to adding repo files to corresponding nodes.
bin/repo-add <selector> [modules]bin/repo-add 10.10.10.10 # add node repos for node 10.10.10.10bin/repo-add infra node,infra # add node and infra repos for group infrabin/repo-add infra node,local # add node repos and local pigsty repobin/repo-add pg-test node,pgsql # add node & pgsql repos for group pg-test
9 - Module: NODE
Tune nodes into the desired state and monitor it, manage node, VIP, HAProxy, and exporters.
The NODE module helps you manage and monitor server nodes in Pigsty. It provides:
Node initialization and configuration management
System tuning and optimization
Service exposure via HAProxy
Node monitoring via Prometheus exporters
Log collection via Promtail
Optional L2 VIP support for high availability
9.1 - Concept
Introduction to node module, admin node, infra node, pgsql node, etc…
Node is an abstraction of hardware resources, which can be bare metal, virtual machines, or even k8s pods.
The admin node is usually overlapped with the infra node, if there’s more than one infra node,
the first one is often used as the default admin node, and the rest of the infra nodes can be used as backup admin nodes.
Common Node
You can manage nodes with Pigsty, and install modules on them. The node.yml playbook will adjust the node to desired state.
Some services will be added to all nodes by default:
Component
Port
Description
Status
Node Exporter
9100
Node Monitoring Metrics Exporter
Enabled
HAProxy Admin
9101
HAProxy admin page
Enabled
Promtail
9080
Log collecting agent
Enabled
Docker Daemon
9323
Enable Container Service
Disabled
Keepalived
-
Manage Node Cluster L2 VIP
Disabled
Keepalived Exporter
9650
Monitoring Keepalived Status
Disabled
Docker & Keepalived are optional components, enabled when required.
ADMIN Node
There is one and only one admin node in a pigsty deployment, which is specified by admin_ip. It is set to the local primary IP during configure.
The node will have ssh / sudo access to all other nodes, which is critical; ensure it’s fully secured.
INFRA Node
A pigsty deployment may have one or more infra nodes, usually 2 ~ 3, in a large production environment.
The infra group specifies infra nodes in the inventory. And infra nodes will have INFRA module installed (DNS, Nginx, Prometheus, Grafana, etc…),
The admin node is also the default and first infra node, and infra nodes can be used as ‘backup’ admin nodes.
Component
Port
Domain
Description
Nginx
80
h.pigsty
Web Service Portal (YUM/APT Repo)
AlertManager
9093
a.pigsty
Alert Aggregation and delivery
Prometheus
9090
p.pigsty
Monitoring Time Series Database
Grafana
3000
g.pigsty
Visualization Platform
Loki
3100
-
Logging Collection Server
PushGateway
9091
-
Collect One-Time Job Metrics
BlackboxExporter
9115
-
Blackbox Probing
Dnsmasq
53
-
DNS Server
Chronyd
123
-
NTP Time Server
PostgreSQL
5432
-
Pigsty CMDB & default database
Ansible
-
-
Run playbooks
PGSQL Node
The node with PGSQL module installed is called a PGSQL node. The node and pg instance is 1:1 deployed.
And node instance can be borrowed from corresponding pg instances with node_id_from_pg.
Component
Port
Description
Status
PostgreSQL
5432
PostgreSQL Database
Enabled
Pgbouncer
6432
Pgbouncer Connection Pooling Service
Enabled
Patroni
8008
Patroni HA Component
Enabled
Haproxy Primary
5433
Primary connection pool: Read/Write Service
Enabled
Haproxy Replica
5434
Replica connection pool: Read-only Service
Enabled
Haproxy Default
5436
Primary Direct Connect Service
Enabled
Haproxy Offline
5438
Offline Direct Connect: Offline Read Service
Enabled
Haproxy service
543x
Customized PostgreSQL Services
On Demand
Haproxy Admin
9101
Monitoring metrics and traffic management
Enabled
PG Exporter
9630
PG Monitoring Metrics Exporter
Enabled
PGBouncer Exporter
9631
PGBouncer Monitoring Metrics Exporter
Enabled
Node Exporter
9100
Node Monitoring Metrics Exporter
Enabled
Promtail
9080
Collect Postgres, Pgbouncer, Patroni logs
Enabled
Docker Daemon
9323
Docker Container Service (disable by default)
Disabled
vip-manager
-
Bind VIP to the primary
Disabled
keepalived
-
Node Cluster L2 VIP manager (disable by default)
Disabled
Keepalived Exporter
9650
Keepalived Metrics Exporter (disable by default)
Disabled
9.2 - Configuration
Configure node identity, dns, vip, data dir, and haproxy services
Each node has identity parameters that are configured through the parameters in <cluster>.hosts and <cluster>.vars.
Pigsty uses IP as a unique identifier for database nodes. This IP must be the IP that the database instance listens to and serves externally, But it would be inappropriate to use a public IP address!
This is very important. The IP is the inventory_hostname of the host in the inventory, which is reflected as the key in the <cluster>.hosts object.
You can use ansible_* parameters to overwrite ssh behavior, e.g. connect via domain name / alias, but the primary IPv4 is still the core identity of the node.
nodename and node_cluster are not mandatory; nodename will use the node’s current hostname by default, while node_cluster will use the fixed default value: nodes.
#nodename: # [INSTANCE] # node instance identity, use hostname if missing, optionalnode_cluster:nodes # [CLUSTER]# node cluster identity, use 'nodes' if missing, optionalnodename_overwrite:true# overwrite node's hostname with nodename?nodename_exchange:false# exchange nodename among play hosts?node_id_from_pg:true# use postgres identity as node identity if applicable?
9.3 - Parameter
There are 64 parameters to customize node, monitor agent and haproxy load balancer
There are 10 sections, 66 parameters in the NODE module.
Node module are tuning target nodes into desired state and take it into the Pigsty monitor system.
NODE_ID
Each node has identity parameters that are configured through the parameters in <cluster>.hosts and <cluster>.vars. Check NODE Identity for details.
nodename
name: nodename, type: string, level: I
node instance identity, use hostname if missing, optional
no default value, Null or empty string means nodename will be set to node’s current hostname.
If node_id_from_pg is true (by default) and nodename is not explicitly defined, nodename will try to use ${pg_cluster}-${pg_seq} first, if PGSQL is not defined on this node, it will fall back to default HOSTNAME.
If nodename_overwrite is true, the node name will also be used as the HOSTNAME.
node_cluster
name: node_cluster, type: string, level: C
node cluster identity, use ’nodes’ if missing, optional
default values: nodes
If node_id_from_pg is true (by default) and node_cluster is not explicitly defined, node_cluster will try to use ${pg_cluster} first, if PGSQL is not defined on this node, it will fall back to default HOSTNAME.
nodename_overwrite
name: nodename_overwrite, type: bool, level: C
overwrite node’s hostname with nodename?
default value is true, a non-empty node name nodename will override the hostname of the current node.
When the nodename parameter is undefined or an empty string, but node_id_from_pg is true,
the node name will try to use {{ pg_cluster }}-{{ pg_seq }}, borrow identity from the 1:1 PostgreSQL Instance’s ins name.
No changes are made to the hostname if the nodename is undefined, empty, or an empty string and node_id_from_pg is false.
nodename_exchange
name: nodename_exchange, type: bool, level: C
exchange nodename among play hosts?
default value is false
When this parameter is enabled, node names are exchanged between the same group of nodes executing the node.yml playbook, written to /etc/hosts.
node_id_from_pg
name: node_id_from_pg, type: bool, level: C
use postgres identity as node identity if applicable?
default value is true
Boworrow PostgreSQL cluster & instance identity if application.
It’s useful to use same identity for postgres & node if there’s a 1:1 relationship
NODE_DNS
Pigsty configs static DNS records and dynamic DNS resolver for nodes.
If you already have a DNS server, set node_dns_method to none to disable dynamic DNS setup.
node_write_etc_hosts:true# modify `/etc/hosts` on target node?node_default_etc_hosts:# static dns records in `/etc/hosts`- "${admin_ip} h.pigsty a.pigsty p.pigsty g.pigsty"node_etc_hosts:[]# extra static dns records in `/etc/hosts`node_dns_method: add # how to handle dns servers:add,none,overwritenode_dns_servers:['${admin_ip}']# dynamic nameserver in `/etc/resolv.conf`node_dns_options:# dns resolv options in `/etc/resolv.conf`- options single-request-reopen timeout:1
node_default_etc_hosts is an array. Each element is a DNS record with format <ip> <name>.
It is used for global static DNS records. You can use node_etc_hosts for ad hoc records for each cluster.
Make sure to write a DNS record like 10.10.10.10 h.pigsty a.pigsty p.pigsty g.pigsty to /etc/hosts to ensure that the local yum repo can be accessed using the domain name before the DNS Nameserver starts.
add: Append the records in node_dns_servers to /etc/resolv.conf and keep the existing DNS servers. (default)
overwrite: Overwrite /etc/resolv.conf with the record in node_dns_servers
none: If a DNS server is provided in the production env, the DNS server config can be skipped.
node_dns_servers
name: node_dns_servers, type: string[], level: C
dynamic nameserver in /etc/resolv.conf
default values: ["${admin_ip}"] , the default nameserver on admin node will be added to /etc/resolv.conf as the first nameserver.
node_dns_options
name: node_dns_options, type: string[], level: C
dns resolv options in /etc/resolv.conf, default value:
- options single-request-reopen timeout:1
NODE_PACKAGE
This section is about upstream yum repos & packages to be installed.
node_repo_modules:local # upstream repo to be added on node, local by defaultnode_repo_remove:true# remove existing repo on node?node_packages:[openssh-server] # packages to be installed current nodes with latest version#node_default_packages: [] # default packages to be installed on infra nodes, (defaults are load from node_id/vars)
node_repo_modules
name: node_repo_modules, type: string, level: C/A
upstream repo to be added on node, default value: local
This parameter specifies the upstream repo to be added to the node. It is used to filter the repo_upstream entries
and only the entries with the same module value will be added to the node’s software source. Which is similar to the repo_modules parameter.
node_repo_remove
name: node_repo_remove, type: bool, level: C/A
remove existing repo on node?
default value is true, and thus Pigsty will move existing repo file in /etc/yum.repos.d to a backup dir: /etc/yum.repos.d/backup before adding upstream repos
On Debian/Ubuntu, Pigsty will backup & move /etc/apt/sources.list(.d) to /etc/apt/backup.
node_packages
name: node_packages, type: string[], level: C
packages to be installed current nodes, default values: [openssh-server].
Each element is a comma-separated list of package names, which will be installed on the current node in addition to node_default_packages
Packages specified in this parameter will be upgraded to the latest version, and the default value is [openssh-server], which will upgrade sshd by default to avoid SSH CVE.
This parameters is usually used to install additional software packages that is ad hoc for the current node/cluster.
node_default_packages
name: node_default_packages, type: string[], level: G
default packages to be installed on all nodes, the default values is not defined.
This param is an array os strings, each string is a comma-separated list of package names, which will be installed on all nodes by default.
This param DOES NOT have a default value, you can specify it explicitly, or leaving it empty if you want to use the default values.
When leaving it empty, Pigsty will use the default values from the node_packages_default defined in roles/node_id/vars according to you OS.
Configure tuned templates, features, kernel modules, sysctl params on node.
node_disable_firewall:true# disable node firewall? true by defaultnode_disable_selinux:true# disable node selinux? true by defaultnode_disable_numa:false# disable node numa, reboot requirednode_disable_swap:false# disable node swap, use with cautionnode_static_network:true# preserve dns resolver settings after rebootnode_disk_prefetch:false# setup disk prefetch on HDD to increase performancenode_kernel_modules:[softdog, br_netfilter, ip_vs, ip_vs_rr, ip_vs_wrr, ip_vs_sh ]node_hugepage_count:0# number of 2MB hugepage, take precedence over rationode_hugepage_ratio:0# node mem hugepage ratio, 0 disable it by defaultnode_overcommit_ratio:0# node mem overcommit ratio, 0 disable it by defaultnode_tune: oltp # node tuned profile:none,oltp,olap,crit,tinynode_sysctl_params:{}# sysctl parameters in k:v format in addition to tuned
node_disable_firewall
name: node_disable_firewall, type: bool, level: C
disable node firewall? true by default
default value is true
node_disable_selinux
name: node_disable_selinux, type: bool, level: C
disable node selinux? true by default
default value is true
node_disable_numa
name: node_disable_numa, type: bool, level: C
disable node numa, reboot required
default value is false
Boolean flag, default is not off. Note that turning off NUMA requires a reboot of the machine before it can take effect!
If you don’t know how to set the CPU affinity, it is recommended to turn off NUMA.
node_disable_swap
name: node_disable_swap, type: bool, level: C
disable node swap, use with caution
default value is false
But turning off SWAP is not recommended. But SWAP should be disabled when your node is used for a Kubernetes deployment.
If there is enough memory and the database is deployed exclusively. it may slightly improve performance
node_static_network
name: node_static_network, type: bool, level: C
preserve dns resolver settings after reboot, default value is true
Enabling static networking means that machine reboots will not overwrite your DNS Resolv config with NIC changes. It is recommended to enable it in production environment.
node_disk_prefetch
name: node_disk_prefetch, type: bool, level: C
setup disk prefetch on HDD to increase performance
default value is false, Consider enable this when using HDD.
node_kernel_modules
name: node_kernel_modules, type: string[], level: C
For example, if you have default 25% mem for postgres shard buffers, you can set this value to 0.27 ~ 0.30, Wasted hugepage can be reclaimed later with /pg/bin/pg-tune-hugepage
node_overcommit_ratio
name: node_overcommit_ratio, type: int, level: C
node mem overcommit ratio, 0 disable it by default. this is an integer from 0 to 100+ .
default values: 0, which will set vm.overcommit_memory=0, otherwise vm.overcommit_memory=2 will be used,
and this value will be used as vm.overcommit_ratio.
It is recommended to set use a vm.overcommit_ratio on dedicated pgsql nodes. e.g. 50 ~ 100.
oltp: Regular OLTP templates with optimized latency
olap : Regular OLAP templates to optimize throughput
crit: Core financial business templates, optimizing the number of dirty pages
Usually, the database tuning template pg_conf should be paired with the node tuning template: node_tune
node_sysctl_params
name: node_sysctl_params, type: dict, level: C
sysctl parameters in k:v format in addition to tuned
default values: {}
Dictionary K-V structure, Key is kernel sysctl parameter name, Value is the parameter value.
You can also define sysctl parameters with tuned profile
NODE_ADMIN
This section is about admin users and it’s credentials.
node_data:/data # node main data directory, `/data` by defaultnode_admin_enabled:true# create a admin user on target node?node_admin_uid:88# uid and gid for node admin usernode_admin_username:dba # name of node admin user, `dba` by defaultnode_admin_ssh_exchange:true# exchange admin ssh key among node clusternode_admin_pk_current:true# add current user's ssh pk to admin authorized_keysnode_admin_pk_list:[]# ssh public keys to be added to admin user
node_data
name: node_data, type: path, level: C
node main data directory, /data by default
default values: /data
If specified, this path will be used as major data disk mountpoint. And a dir will be created and throwing a warning if path not exists.
The data dir is owned by root with mode 0777.
node_admin_enabled
name: node_admin_enabled, type: bool, level: C
create a admin user on target node?
default value is true
Create an admin user on each node (password-free sudo and ssh), an admin user named dba (uid=88) will be created by default,
which can access other nodes in the env and perform sudo from the meta node via SSH password-free.
node_admin_uid
name: node_admin_uid, type: int, level: C
uid and gid for node admin user
default values: 88
node_admin_username
name: node_admin_username, type: username, level: C
name of node admin user, dba by default
default values: dba
node_admin_ssh_exchange
name: node_admin_ssh_exchange, type: bool, level: C
exchange admin ssh key among node cluster
default value is true
When enabled, Pigsty will exchange SSH public keys between members during playbook execution, allowing admins node_admin_username to access each other from different nodes.
node_admin_pk_current
name: node_admin_pk_current, type: bool, level: C
add current user’s ssh pk to admin authorized_keys
default value is true
When enabled, on the current node, the SSH public key (~/.ssh/id_rsa.pub) of the current user is copied to the authorized_keys of the target node admin user.
When deploying in a production env, be sure to pay attention to this parameter, which installs the default public key of the user currently executing the command to the admin user of all machines.
node_admin_pk_list
name: node_admin_pk_list, type: string[], level: C
ssh public keys to be added to admin user
default values: []
Each element of the array is a string containing the key written to the admin user ~/.ssh/authorized_keys, and the user with the corresponding private key can log in as an admin user.
When deploying in production envs, be sure to note this parameter and add only trusted keys to this list.
node_aliases
name: node_aliases, type: dict, level: C/I
extra aliases to be added to admin user’s shell profile
default values: {}
You can add extra shell aliases to it, pigsty will add these aliases to the /etc/profile.d/node.alias.sh file on the target node:
node_aliases:g:gitd:docker
会生成:
aliasg="git"aliasd="docker"
NODE_TIME
node_timezone:''# setup node timezone, empty string to skipnode_ntp_enabled:true# enable chronyd time sync service?node_ntp_servers:# ntp servers in `/etc/chrony.conf`- pool pool.ntp.org iburstnode_crontab_overwrite:true# overwrite or append to `/etc/crontab`?node_crontab:[]# crontab entries in `/etc/crontab`
node_timezone
name: node_timezone, type: string, level: C
setup node timezone, empty string to skip
default value is empty string, which will not change the default timezone (usually UTC)
node_ntp_enabled
name: node_ntp_enabled, type: bool, level: C
enable chronyd time sync service?
default value is true, and thus Pigsty will override the node’s /etc/chrony.conf by with node_ntp_servers.
If you already a NTP server configured, just set to false to leave it be.
node_ntp_servers
name: node_ntp_servers, type: string[], level: C
ntp servers in /etc/chrony.conf, default value: ["pool pool.ntp.org iburst"]
You can use ${admin_ip} to sync time with ntp server on admin node rather than public ntp server.
node_ntp_servers:['pool ${admin_ip} iburst']
node_crontab_overwrite
name: node_crontab_overwrite, type: bool, level: C
overwrite or append to /etc/crontab?
default value is true, and pigsty will render records in node_crontab in overwrite mode rather than appending to it.
node_crontab
name: node_crontab, type: string[], level: C
crontab entries in /etc/crontab
default values: []
NODE_VIP
You can bind an optional L2 VIP among one node cluster, which is disabled by default.
L2 VIP can only be used in same L2 LAN, which may incurs extra restrictions on your network topology.
If enabled, You have to manually assign the vip_address and vip_vrid for each node cluster.
It is user’s responsibility to ensure that the address / vrid is unique among the same LAN.
vip_enabled:false# enable vip on this node cluster?# vip_address: [IDENTITY] # node vip address in ipv4 format, required if vip is enabled# vip_vrid: [IDENTITY] # required, integer, 1-254, should be unique among same VLANvip_role:backup # optional, `master/backup`, backup by default, use as init rolevip_preempt:false# optional, `true/false`, false by default, enable vip preemptionvip_interface:eth0 # node vip network interface to listen, `eth0` by defaultvip_dns_suffix:''# node vip dns name suffix, empty string by defaultvip_exporter_port:9650# keepalived exporter listen port, 9650 by default
vip_enabled
name: vip_enabled, type: bool, level: C
enable vip on this node cluster? default value is false, means no L2 VIP is created for this node cluster.
L2 VIP can only be used in same L2 LAN, which may incurs extra restrictions on your network topology.
vip_address
name: vip_address, type: ip, level: C
node vip address in IPv4 format, required if node vip_enabled.
no default value. This parameter must be explicitly assigned and unique in your LAN.
vip_vrid
name: vip_vrid, type: int, level: C
integer, 1-254, should be unique in same VLAN, required if node vip_enabled.
no default value. This parameter must be explicitly assigned and unique in your LAN.
vip_role
name: vip_role, type: enum, level: I
node vip role, could be master or backup, will be used as initial keepalived state.
vip_preempt
name: vip_preempt, type: bool, level: C/I
optional, true/false, false by default, enable vip preemption
default value is false, means no preempt is happening when a backup have higher priority than living master.
vip_interface
name: vip_interface, type: string, level: C/I
node vip network interface to listen, eth0 by default.
It should be the same primary intranet interface of your node, which is the IP address you used in the inventory file.
If your node have different interface, you can override it on instance vars
vip_dns_suffix
name: vip_dns_suffix, type: string, level: C/I
node vip dns name suffix, empty string by default. It will be used as the DNS name of the node VIP.
vip_exporter_port
name: vip_exporter_port, type: port, level: C/I
keepalived exporter listen port, 9650 by default.
HAPROXY
HAProxy is installed on every node by default, exposing services in a NodePort manner.
haproxy_enabled:true# enable haproxy on this node?haproxy_clean:false# cleanup all existing haproxy config?haproxy_reload:true# reload haproxy after config?haproxy_auth_enabled:true# enable authentication for haproxy admin pagehaproxy_admin_username:admin # haproxy admin username, `admin` by defaulthaproxy_admin_password:pigsty # haproxy admin password, `pigsty` by defaulthaproxy_exporter_port:9101# haproxy admin/exporter port, 9101 by defaulthaproxy_client_timeout:24h # client side connection timeout, 24h by defaulthaproxy_server_timeout:24h # server side connection timeout, 24h by defaulthaproxy_services:[]# list of haproxy service to be exposed on node
haproxy_enabled
name: haproxy_enabled, type: bool, level: C
enable haproxy on this node?
default value is true
haproxy_clean
name: haproxy_clean, type: bool, level: G/C/A
cleanup all existing haproxy config?
default value is false
haproxy_reload
name: haproxy_reload, type: bool, level: A
reload haproxy after config?
default value is true, it will reload haproxy after config change.
If you wish to check before apply, you can turn off this with cli args and check it.
haproxy_auth_enabled
name: haproxy_auth_enabled, type: bool, level: G
enable authentication for haproxy admin page
default value is true, which will require a http basic auth for admin page.
disable it is not recommended, since your traffic control will be exposed
haproxy_admin_username
name: haproxy_admin_username, type: username, level: G
haproxy admin username, admin by default
haproxy_admin_password
name: haproxy_admin_password, type: password, level: G
haproxy admin password, pigsty by default
PLEASE CHANGE IT IN YOUR PRODUCTION ENVIRONMENT!
haproxy_exporter_port
name: haproxy_exporter_port, type: port, level: C
haproxy admin/exporter port, 9101 by default
haproxy_client_timeout
name: haproxy_client_timeout, type: interval, level: C
client side connection timeout, 24h by default
haproxy_server_timeout
name: haproxy_server_timeout, type: interval, level: C
server side connection timeout, 24h by default
haproxy_services
name: haproxy_services, type: service[], level: C
list of haproxy service to be exposed on node, default values: []
Each element is a service definition, here is an ad hoc haproxy service example:
haproxy_services:# list of haproxy service# expose pg-test read only replicas- name:pg-test-ro # [REQUIRED] service name, uniqueport:5440# [REQUIRED] service port, uniqueip:"*"# [OPTIONAL] service listen addr, "*" by defaultprotocol:tcp # [OPTIONAL] service protocol, 'tcp' by defaultbalance:leastconn # [OPTIONAL] load balance algorithm, roundrobin by default (or leastconn)maxconn:20000# [OPTIONAL] max allowed front-end connection, 20000 by defaultdefault:'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'options:- option httpchk- option http-keep-alive- http-check send meth OPTIONS uri /read-only- http-check expect status 200servers:- {name: pg-test-1 ,ip: 10.10.10.11 , port: 5432 , options: check port 8008 , backup:true}- {name: pg-test-2 ,ip: 10.10.10.12 , port: 5432 , options:check port 8008 }- {name: pg-test-3 ,ip: 10.10.10.13 , port: 5432 , options:check port 8008 }
It will be rendered to /etc/haproxy/<service.name>.cfg and take effect after reload.
NODE_EXPORTER
node_exporter_enabled:true# setup node_exporter on this node?node_exporter_port:9100# node exporter listen port, 9100 by defaultnode_exporter_options:'--no-collector.softnet --no-collector.nvme --collector.tcpstat --collector.processes'
node_exporter_enabled
name: node_exporter_enabled, type: bool, level: C
setup node_exporter on this node? default value is true
node_exporter_port
name: node_exporter_port, type: port, level: C
node exporter listen port, 9100 by default
node_exporter_options
name: node_exporter_options, type: arg, level: C
extra server options for node_exporter, default value: --no-collector.softnet --no-collector.nvme --collector.tcpstat --collector.processes
Pigsty enables tcpstat, processes collectors and disable nvme, softnet metrics collectors by default.
PROMTAIL
Promtail will collect logs from other modules, and send them to LOKI
INFRA: Infra logs, collected only on infra nodes.
nginx-access: /var/log/nginx/access.log
nginx-error: /var/log/nginx/error.log
grafana: /var/log/grafana/grafana.log
NODES: Host node logs, collected on all nodes.
syslog: /var/log/messages
dmesg: /var/log/dmesg
cron: /var/log/cron
PGSQL: PostgreSQL logs, collected when a node is defined with pg_cluster.
postgres: /pg/log/postgres/*
patroni: /pg/log/patroni.log
pgbouncer: /pg/log/pgbouncer/pgbouncer.log
pgbackrest: /pg/log/pgbackrest/*.log
REDIS: Redis logs, collected when a node is defined with redis_cluster.
promtail_enabled:true# enable promtail logging collector?promtail_clean:false# purge existing promtail status file during init?promtail_port:9080# promtail listen port, 9080 by defaultpromtail_positions:/var/log/positions.yaml# promtail position status file path
promtail_enabled
name: promtail_enabled, type: bool, level: C
enable promtail logging collector?
default value is true
promtail_clean
name: promtail_clean, type: bool, level: G/A
purge existing promtail status file during init?
default value is false, if you choose to clean, Pigsty will remove the existing state file defined by promtail_positions
which means that Promtail will recollect all logs on the current node and send them to Loki again.
promtail_port
name: promtail_port, type: port, level: C
promtail listen port, 9080 by default
default values: 9080
promtail_positions
name: promtail_positions, type: path, level: C
promtail position status file path
default values: /var/log/positions.yaml
Promtail records the consumption offsets of all logs, which are periodically written to the file specified by promtail_positions.
A metric with a constant ‘1’ value labeled by bios_date, bios_release, bios_vendor, bios_version, board_asset_tag, board_name, board_serial, board_vendor, board_version, chassis_asset_tag, chassis_serial, chassis_vendor, chassis_version, product_family, product_name, product_serial, product_sku, product_uuid, product_version, system_vendor if provided by DMI.
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which node_exporter was built, and the goos and goarch for the build.
A metric with a constant ‘1’ value labeled by build_id, id, id_like, image_id, image_version, name, pretty_name, variant, variant_id, version, version_codename, version_id.
node_os_version
gauge
id, ip, ins, instance, job, id_like, cls
Metric containing the major.minor part of the OS version.
node_processes_max_processes
gauge
instance, ins, job, ip, cls
Number of max PIDs limit
node_processes_max_threads
gauge
instance, ins, job, ip, cls
Limit of threads in the system
node_processes_pids
gauge
instance, ins, job, ip, cls
Number of PIDs
node_processes_state
gauge
state, instance, ins, job, ip, cls
Number of processes in each state.
node_processes_threads
gauge
instance, ins, job, ip, cls
Allocated threads in system
node_processes_threads_state
gauge
instance, ins, job, thread_state, ip, cls
Number of threads in each state.
node_procs_blocked
gauge
instance, ins, job, ip, cls
Number of processes blocked waiting for I/O to complete.
node_procs_running
gauge
instance, ins, job, ip, cls
Number of processes in runnable state.
node_schedstat_running_seconds_total
counter
ip, ins, job, cpu, instance, cls
Number of seconds CPU spent running a process.
node_schedstat_timeslices_total
counter
ip, ins, job, cpu, instance, cls
Number of timeslices executed by CPU.
node_schedstat_waiting_seconds_total
counter
ip, ins, job, cpu, instance, cls
Number of seconds spent by processing waiting for this CPU.
node_scrape_collector_duration_seconds
gauge
ip, collector, ins, job, instance, cls
node_exporter: Duration of a collector scrape.
node_scrape_collector_success
gauge
ip, collector, ins, job, instance, cls
node_exporter: Whether a collector succeeded.
node_selinux_enabled
gauge
instance, ins, job, ip, cls
SELinux is enabled, 1 is true, 0 is false
node_sockstat_FRAG6_inuse
gauge
instance, ins, job, ip, cls
Number of FRAG6 sockets in state inuse.
node_sockstat_FRAG6_memory
gauge
instance, ins, job, ip, cls
Number of FRAG6 sockets in state memory.
node_sockstat_FRAG_inuse
gauge
instance, ins, job, ip, cls
Number of FRAG sockets in state inuse.
node_sockstat_FRAG_memory
gauge
instance, ins, job, ip, cls
Number of FRAG sockets in state memory.
node_sockstat_RAW6_inuse
gauge
instance, ins, job, ip, cls
Number of RAW6 sockets in state inuse.
node_sockstat_RAW_inuse
gauge
instance, ins, job, ip, cls
Number of RAW sockets in state inuse.
node_sockstat_TCP6_inuse
gauge
instance, ins, job, ip, cls
Number of TCP6 sockets in state inuse.
node_sockstat_TCP_alloc
gauge
instance, ins, job, ip, cls
Number of TCP sockets in state alloc.
node_sockstat_TCP_inuse
gauge
instance, ins, job, ip, cls
Number of TCP sockets in state inuse.
node_sockstat_TCP_mem
gauge
instance, ins, job, ip, cls
Number of TCP sockets in state mem.
node_sockstat_TCP_mem_bytes
gauge
instance, ins, job, ip, cls
Number of TCP sockets in state mem_bytes.
node_sockstat_TCP_orphan
gauge
instance, ins, job, ip, cls
Number of TCP sockets in state orphan.
node_sockstat_TCP_tw
gauge
instance, ins, job, ip, cls
Number of TCP sockets in state tw.
node_sockstat_UDP6_inuse
gauge
instance, ins, job, ip, cls
Number of UDP6 sockets in state inuse.
node_sockstat_UDPLITE6_inuse
gauge
instance, ins, job, ip, cls
Number of UDPLITE6 sockets in state inuse.
node_sockstat_UDPLITE_inuse
gauge
instance, ins, job, ip, cls
Number of UDPLITE sockets in state inuse.
node_sockstat_UDP_inuse
gauge
instance, ins, job, ip, cls
Number of UDP sockets in state inuse.
node_sockstat_UDP_mem
gauge
instance, ins, job, ip, cls
Number of UDP sockets in state mem.
node_sockstat_UDP_mem_bytes
gauge
instance, ins, job, ip, cls
Number of UDP sockets in state mem_bytes.
node_sockstat_sockets_used
gauge
instance, ins, job, ip, cls
Number of IPv4 sockets in use.
node_tcp_connection_states
gauge
state, instance, ins, job, ip, cls
Number of connection states.
node_textfile_scrape_error
gauge
instance, ins, job, ip, cls
1 if there was an error opening or reading a file, 0 otherwise
node_time_clocksource_available_info
gauge
ip, device, ins, clocksource, job, instance, cls
Available clocksources read from ‘/sys/devices/system/clocksource’.
node_time_clocksource_current_info
gauge
ip, device, ins, clocksource, job, instance, cls
Current clocksource read from ‘/sys/devices/system/clocksource’.
node_time_seconds
gauge
instance, ins, job, ip, cls
System time in seconds since epoch (1970).
node_time_zone_offset_seconds
gauge
instance, ins, job, time_zone, ip, cls
System time zone offset in seconds.
node_timex_estimated_error_seconds
gauge
instance, ins, job, ip, cls
Estimated error in seconds.
node_timex_frequency_adjustment_ratio
gauge
instance, ins, job, ip, cls
Local clock frequency adjustment.
node_timex_loop_time_constant
gauge
instance, ins, job, ip, cls
Phase-locked loop time constant.
node_timex_maxerror_seconds
gauge
instance, ins, job, ip, cls
Maximum error in seconds.
node_timex_offset_seconds
gauge
instance, ins, job, ip, cls
Time offset in between local system and reference clock.
node_timex_pps_calibration_total
counter
instance, ins, job, ip, cls
Pulse per second count of calibration intervals.
node_timex_pps_error_total
counter
instance, ins, job, ip, cls
Pulse per second count of calibration errors.
node_timex_pps_frequency_hertz
gauge
instance, ins, job, ip, cls
Pulse per second frequency.
node_timex_pps_jitter_seconds
gauge
instance, ins, job, ip, cls
Pulse per second jitter.
node_timex_pps_jitter_total
counter
instance, ins, job, ip, cls
Pulse per second count of jitter limit exceeded events.
node_timex_pps_shift_seconds
gauge
instance, ins, job, ip, cls
Pulse per second interval duration.
node_timex_pps_stability_exceeded_total
counter
instance, ins, job, ip, cls
Pulse per second count of stability limit exceeded events.
node_timex_pps_stability_hertz
gauge
instance, ins, job, ip, cls
Pulse per second stability, average of recent frequency changes.
node_timex_status
gauge
instance, ins, job, ip, cls
Value of the status array bits.
node_timex_sync_status
gauge
instance, ins, job, ip, cls
Is clock synchronized to a reliable server (1 = yes, 0 = no).
node_timex_tai_offset_seconds
gauge
instance, ins, job, ip, cls
International Atomic Time (TAI) offset.
node_timex_tick_seconds
gauge
instance, ins, job, ip, cls
Seconds between clock ticks.
node_udp_queues
gauge
ip, queue, ins, job, exported_ip, instance, cls
Number of allocated memory in the kernel for UDP datagrams in bytes.
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which promtail was built, and the goos and goarch for the build.
promtail_config_reload_fail_total
Unknown
instance, ins, job, ip, cls
N/A
promtail_config_reload_success_total
Unknown
instance, ins, job, ip, cls
N/A
promtail_dropped_bytes_total
Unknown
host, ip, ins, job, reason, instance, cls
N/A
promtail_dropped_entries_total
Unknown
host, ip, ins, job, reason, instance, cls
N/A
promtail_encoded_bytes_total
Unknown
host, ip, ins, job, instance, cls
N/A
promtail_file_bytes_total
gauge
path, instance, ins, job, ip, cls
Number of bytes total.
promtail_files_active_total
gauge
instance, ins, job, ip, cls
Number of active files.
promtail_mutated_bytes_total
Unknown
host, ip, ins, job, reason, instance, cls
N/A
promtail_mutated_entries_total
Unknown
host, ip, ins, job, reason, instance, cls
N/A
promtail_read_bytes_total
gauge
path, instance, ins, job, ip, cls
Number of bytes read.
promtail_read_lines_total
Unknown
path, instance, ins, job, ip, cls
N/A
promtail_request_duration_seconds_bucket
Unknown
host, ip, ins, job, status_code, le, instance, cls
N/A
promtail_request_duration_seconds_count
Unknown
host, ip, ins, job, status_code, instance, cls
N/A
promtail_request_duration_seconds_sum
Unknown
host, ip, ins, job, status_code, instance, cls
N/A
promtail_sent_bytes_total
Unknown
host, ip, ins, job, instance, cls
N/A
promtail_sent_entries_total
Unknown
host, ip, ins, job, instance, cls
N/A
promtail_targets_active_total
gauge
instance, ins, job, ip, cls
Number of active total.
promtail_up
Unknown
instance, ins, job, ip, cls
N/A
request_duration_seconds_bucket
Unknown
instance, ins, job, status_code, route, ws, le, ip, cls, method
The max number of TCP connections that can be accepted (0 means no limit).
up
Unknown
instance, ins, job, ip, cls
N/A
9.8 - FAQ
Pigsty NODE module frequently asked questions
How to configure NTP service?
If NTP is not configured, use a public NTP service or sync time with the admin node.
If your nodes already have NTP configured, you can leave it there by setting node_ntp_enabled to false.
Otherwise, if you have Internet access, you can use public NTP services such as pool.ntp.org.
If you don’t have Internet access, at least you can sync time with the admin node with the following:
node_ntp_servers: # NTP servers in /etc/chrony.conf - pool cn.pool.ntp.org iburst
- pool ${admin_ip} iburst # assume non-admin nodes do not have internet access
How to force sync time on nodes?
Use chronyc to sync time. You have to configure the NTP service first.
ansible all -b -a 'chronyc -a makestep'# sync time
You can replace all with any group or host IP address to limit execution scope.
Remote nodes are not accessible via SSH commands.
Consider using Ansible connection parameters if the target machine is hidden behind an SSH springboard machine,
or if some customizations have been made that cannot be accessed directly using ssh ip.
Additional SSH ports can be specified with ansible_port or ansible_host for SSH Alias.
When performing deployments and changes, the admin user used must have ssh and sudo privileges for all nodes. Password-free is not required.
You can pass in ssh and sudo passwords via the -k|-K parameter when executing the playbook or even use another user to run the playbook via -eansible_host=<another_user>.
However, Pigsty strongly recommends configuring SSH passwordless login with passwordless sudo for the admin user.
Create an admin user with the existing admin user.
This will create an admin user specified by node_admin_username with the existing one on that node.
Pigsty will try to include all dependencies in the local yum repo on infra nodes. This repo file will be added according to node_repo_modules.
And existing repo files will be removed by default according to the default value of node_repo_remove. This will prevent the node from using the Internet repo or some stupid issues.
If you want to keep existing repo files during node init, just set node_repo_remove to false.
If you want to keep existing repo files during infra node local repo bootstrap, just set repo_remove to false.
Why my shell prompt change and how to restore it?
The pigsty prompt is defined with the environment variable PS1 in /etc/profile.d/node.sh.
To restore your existing prompt, just remove that file and login again.
Tencent OpenCloudOS Compatibility Issue
OpenCloudOS does not have softdog module, overwrite node_kernel_modules on global vars:
Pigsty use etcd as DCS: Distributed configuration storage (or distributed consensus service). Which is critical to PostgreSQL High-Availability & Auto-Failover.
You have to install ETCD module before any PGSQL modules, since patroni & vip-manager will rely on etcd to work. Unless you are using an external etcd cluster.
You don’t need NODE module to install ETCD, but it requires a valid CA on your local files/pki/ca. Check ETCD Administration SOP for more details.
10.1 - Configuration
Configure etcd clusters according to your needs, and access the service
You have to define the etcd cluster in the config inventory before deploying it.
Usually you can choose an etcd cluster with:
One Node, no high availability, just the functionality of etcd, suitable for development, testing, demonstration.
Three Nodes, basic high availability, tolerate one node failure, suitable for medium production environment.
Five Nodes, better high availability, tolerate two node failure, suitable for large production environment.
Even number of etcd nodes is meaningless, and more than five nodes is not common.
One Node
Define the group etcd in the inventory, It will create a singleton etcd instance.
# etcd cluster for ha postgresetcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }
This line exists almost in all single-node config templates, where the placeholder IP address 10.10.10.10
will be replaced with the current admin node IP.
The only necessary parameters are etcd_seq and etcd_cluster,
which uniquely identify the cluster and each instance.
Three Nodes
It’s common to use a three-node etcd cluster, which can tolerate one node failure, suitable for medium prod env.
The trio and safe config templates use a three-node etcd cluster, as shown below:
etcd:# dcs service for postgres/patroni ha consensushosts:# 1 node for testing, 3 or 5 for production10.10.10.10:{etcd_seq:1}# etcd_seq required10.10.10.11:{etcd_seq:2}# assign from 1 ~ n10.10.10.12:{etcd_seq:3}# odd number pleasevars:# cluster level parameter override roles/etcdetcd_cluster:etcd # mark etcd cluster name etcdetcd_safeguard:false# safeguard against purgingetcd_clean:true# purge etcd during init process
Five Nodes
Five nodes etcd cluster can tolerate two node failure, suitable for large prod env.
There’s a five-node etcd cluster example in the prod template:
You can use more nodes for production environment, but 3 or 5 nodes are recommended. Remember to use odd number for cluster size.
Etcd Usage
These are the services that currently use Etcd:
patroni: Use etcd as a consensus backend for PostgreSQL HA
vip-manager: Read leader info from Etcd to bind an optional L2 VIP on the PostgreSQL cluster
You’ll have to reload etcd config after any permanent change to the etcd cluster members.
e.g, update patroni reference to etcd endpoints:
./pgsql.yml -t pg_conf # generate patroni configansible all -f 1 -b -a 'systemctl reload patroni'# reload patroni config
e.g, update vip-manager reference to etcd endpoints (if you are using PGSQL L2 VIP):
./pgsql.yml -t pg_vip_config # generate vip-manager configansible all -f 1 -b -a 'systemctl restart vip-manager'# restart vip-manager to use
10.2 - Parameters
Etcd has 10 parameters to customize the etcd cluster as needed.
Etcd is a distributed, reliable key-value store used to store the most critical config/consensus data in the system.
Etcd is used as the DCS used by the HA agent Patroni, which is very important for the high availability of PostgreSQL in Pigsty.
Pigsty use the hard-coded group etcd for etcd cluster, which can be an external etcd cluster,
r a new etcd cluster created by Pigsty using the etcd.yml playbook.
#-----------------------------------------------------------------# etcd#-----------------------------------------------------------------#etcd_seq: 1 # etcd instance identifier, explicitly requiredetcd_cluster:etcd # etcd cluster & group name, etcd by defaultetcd_safeguard:false# prevent purging running etcd instance?etcd_clean:true# purging existing etcd during initialization?etcd_data:/data/etcd # etcd data directory, /data/etcd by defaultetcd_port:2379# etcd client port, 2379 by defaultetcd_peer_port:2380# etcd peer port, 2380 by defaultetcd_init:new # etcd initial cluster state, new or existingetcd_election_timeout:1000# etcd election timeout, 1000ms by defaultetcd_heartbeat_interval:100# etcd heartbeat interval, 100ms by default
etcd_seq
name: etcd_seq, type: int, level: I
etcd instance identifier, REQUIRED
no default value, you have to specify it explicitly. Here is a 3-node etcd cluster example:
etcd:# dcs service for postgres/patroni ha consensushosts:# 1 node for testing, 3 or 5 for production10.10.10.10:{etcd_seq:1}# etcd_seq required10.10.10.11:{etcd_seq:2}# assign from 1 ~ n10.10.10.12:{etcd_seq:3}# odd number pleasevars:# cluster level parameter override roles/etcdetcd_cluster:etcd # mark etcd cluster name etcdetcd_safeguard:false# safeguard against purgingetcd_clean:true# purge etcd during init process
etcd_cluster
name: etcd_cluster, type: string, level: C
etcd cluster & group name, etcd by default
default values: etcd, which is a fixed group name, can be useful when you want to use deployed some extra etcd clusters
etcd_safeguard
name: etcd_safeguard, type: bool, level: G/C/A
prevent purging running etcd instance? default value is false
If enabled, running etcd instance will not be purged by etcd.yml playbook.
etcd_clean
name: etcd_clean, type: bool, level: G/C/A
purging existing etcd during initialization? default value is true
If enabled, running etcd instance will be purged by etcd.yml playbook, which makes the playbook fully idempotent.
But if etcd_safeguard is enabled, it will still abort on any running etcd instance.
etcd_data
name: etcd_data, type: path, level: C
etcd data directory, /data/etcd by default
etcd_port
name: etcd_port, type: port, level: C
etcd client port, 2379 by default
etcd_peer_port
name: etcd_peer_port, type: port, level: C
etcd peer port, 2380 by default
etcd_init
name: etcd_init, type: enum, level: C
etcd initial cluster state, new or existing
default values: new, which will create a standalone new etcd cluster.
The value existing is used when trying to add new member to existing etcd cluster.
etcd_election_timeout
name: etcd_election_timeout, type: int, level: C
etcd election timeout, 1000 (ms) by default
etcd_heartbeat_interval
name: etcd_heartbeat_interval, type: int, level: C
etcd heartbeat interval, 100 (ms) by default
10.3 - Playbook
How to manage etcd cluster with ansible playbooks
There’s a built-in playbook: etcd.yml for installing etcd cluster. But you have to define it first.
There’s no dedicated uninstall playbook for etcd. If you want to uninstall etcd, you can use etcd_clean subtask:
./etcd.yml -t etcd_clean
Commands
Some shortcuts and common commands:
./etcd.yml # init etcd cluster ./etcd.yml -t etcd_launch # restart etcd cluster./etcd.yml -t etcd_clean # remove etcd cluster./etcd.yml -t etcd_purge # remove etcd cluster with brute force./etcd.yml -t etcd_conf # refreshing /etc/etcd/etcd.conf./etcd.yml -l 10.10.10.12 -e etcd_init=existing # add new member to existing etcd cluster./etcd.yml -l 10.10.10.12 -t etcd_purge # remove member from existing etcd cluster
Safeguard
Pigsty has safeguard mechanism for etcd module to prevent accidental purge.
etcd_clean: true by default, which will clean existing etcd instances during init
etcd_safeguard: false by default, will not prevent purge etcd cluster.
The default setting is useful for development, testing, and emergency rebuild of etcd cluster in production.
If you wish to prevent accidental purge, you can enable safeguard by setting etcd_clean to false and etcd_safeguard to true.
And you can always override this setting by using -e etcd_clean=true and -e etcd_safeguard=false in command line.
Pigsty has safeguard mechanism to prevent accidental purge. By default, etcd_clean is true, and etcd_safeguard is false,
which means the playbook will purge etcd cluster even if there are running etcd instances. In this case, etcd.yml is truly idempotent, which is useful for development, testing, and emergency rebuild of etcd cluster in production.
For provsioned etcd cluster in prod env, you can enable safeguard to prevent accidental clean.
Remove Cluster
To remove an existing etcd cluster, use the etcd_clean subtask of etcd.yml, do think before you type.
./etcd.yml -t etcd_clean # remove entire cluster, honor the etcd_safeguard./etcd.yml -t etcd_purge # purge with brutal force, omit the etcd_safeguard
The etcd_clean subtask will honor the etcd_safeguard,
while the etcd_purge subtask will ignore that and wipe out the entire etcd cluster.
./pgsql.yml -t pg_conf # regenerate patroni configansible all -f 1 -b -a 'systemctl reload patroni'# reload patroni config
To update etcd endpoints reference on vip-manager, (optional, if you are using a L2 vip)
./pgsql.yml -t pg_vip_config # regenerate vip-manager configansible all -f 1 -b -a 'systemctl restart vip-manager'# restart vip-manager to use new config
etcdctl member add <etcd-?> --learner=true --peer-urls=https://<new_ins_ip>:2380
./etcd.yml -l <new_ins_ip> -e etcd_init=existing
etcdctl member promote <new_ins_server_id>
Detail: Add member to etcd cluster
Here’s the detail, let’s start from one single etcd instance.
etcd:hosts:10.10.10.10:{etcd_seq:1}# <--- this is the existing instance10.10.10.11:{etcd_seq:2}# <--- add this new member definition to inventoryvars:{etcd_cluster:etcd }
Add a learner instance etcd-2 to cluster with etcd member add:
# tell the existing cluster that a new member etcd-2 is coming$ etcdctl member add etcd-2 --learner=true --peer-urls=https://10.10.10.11:2380
Member 33631ba6ced84cf8 added to cluster 6646fbcf5debc68f
ETCD_NAME="etcd-2"ETCD_INITIAL_CLUSTER="etcd-2=https://10.10.10.11:2380,etcd-1=https://10.10.10.10:2380"ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.10.10.11:2380"ETCD_INITIAL_CLUSTER_STATE="existing"
Check the member list with etcdctl member list (or em list), we can see an unstarted member:
$ etcdctl member promote 33631ba6ced84cf8 # promote the new learnerMember 33631ba6ced84cf8 promoted in cluster 6646fbcf5debc68f
$ em list # check again, the new member is started33631ba6ced84cf8, started, etcd-2, https://10.10.10.11:2380, https://10.10.10.11:2379, false429ee12c7fbab5c1, started, etcd-1, https://10.10.10.10:2380, https://10.10.10.10:2379, fals
The new member is added, don’t forget to reload config.
Repeat the steps above to add more members. remember to use at least 3 members for production.
Remove Member
To remove a member from existing etcd cluster, it usually takes 3 steps:
remove/uncomment it from inventory and reload config
remove it with etcdctl member remove <server_id> command and kick it out of the cluster
temporarily add it back to inventory and purge that instance, then remove it from inventory permanently
Detail: Remove member from etcd cluster
Here’s the detail, let’s start from a 3 instance etcd cluster:
etcd:hosts:10.10.10.10:{etcd_seq:1}10.10.10.11:{etcd_seq:2}10.10.10.12:{etcd_seq:3}# <---- comment this line, then reload-configvars:{etcd_cluster:etcd }
Then, you’ll have to actually kick it from cluster with etcdctl member remove command:
$ etcdctl member list
429ee12c7fbab5c1, started, etcd-1, https://10.10.10.10:2380, https://10.10.10.10:2379, false33631ba6ced84cf8, started, etcd-2, https://10.10.10.11:2380, https://10.10.10.11:2379, false93fcf23b220473fb, started, etcd-3, https://10.10.10.12:2380, https://10.10.10.12:2379, false# <--- remove this$ etcdctl member remove 93fcf23b220473fb # kick it from clusterMember 93fcf23b220473fb removed from cluster 6646fbcf5debc68f
Finally, you have to shut down the instance, and purge it from node, you have to uncomment the member in inventory temporarily, then purge it with etcd.yml playbook:
./etcd.yml -t etcd_purge -l 10.10.10.12 # purge it (the member is in inventory again)
After that, remove the member from inventory permanently, all clear!
10.5 - Monitoring
Etcd monitoring metrics, dashboards, and alerting rules
Dashboard
The ETCD module provides a monitoring dashboard: Etcd Overview.
This dashboard provides key information about the ETCD status, with the most notable being ETCD Aliveness, which displays the overall service status of the ETCD cluster.
Red bands indicate periods when instances are unavailable, while the blue-gray bands below show when the entire cluster is unavailable.
Start time of the process since unix epoch in seconds.
process_virtual_memory_bytes
gauge
cls, ins, instance, job, ip
Virtual memory size in bytes.
process_virtual_memory_max_bytes
gauge
cls, ins, instance, job, ip
Maximum amount of virtual memory available in bytes.
promhttp_metric_handler_requests_in_flight
gauge
cls, ins, instance, job, ip
Current number of scrapes being served.
promhttp_metric_handler_requests_total
counter
cls, ins, instance, job, ip, code
Total number of scrapes by HTTP status code.
scrape_duration_seconds
Unknown
cls, ins, instance, job, ip
N/A
scrape_samples_post_metric_relabeling
Unknown
cls, ins, instance, job, ip
N/A
scrape_samples_scraped
Unknown
cls, ins, instance, job, ip
N/A
scrape_series_added
Unknown
cls, ins, instance, job, ip
N/A
up
Unknown
cls, ins, instance, job, ip
N/A
10.7 - FAQ
Pigsty ETCD dcs module frequently asked questions
What is the role of the etcd in pigsty?
etcd is a distributed, reliable key-value store used to store the most critical config / consensus data in the deployment.
Pigsty uses etcd as the DCS (Distributed Configuration Store) service for Patroni, which will store the high availability status information of the PostgreSQL cluster.
How many etcd instance should I choose?
If more than (include) half of the etcd instances are down, the etcd cluster and its service will be unavailable.
For example, a 3-node etcd cluster can tolerate at most one node failure, and the other two nodes can still work normally; while a 5-node etcd cluster can tolerate 2 node failures.
Beware that the learner instances in the etcd cluster do not count in the member number, so in a 3-node etcd cluster, if there is a learner instance, the actual member count is 2, so no node failure can be tolerated.
It is advisable to choose an odd number of etcd instances to avoid split-brain scenarios. It is recommended to use 3 or 5 nodes for the production environment.
What is the impact of etcd failure?
If etcd cluster is unavailable, it will affect the control plane of Pigsty, but not the data plane - the existing PostgreSQL cluster will continue to serve, but admin operations through Patroni will not work.
During etcd failure, PostgreSQL HA is unable to perform automatic failover, and most of the Patroni operations will be blocked, such as edit-config, restart, switchover, etc…
Admin tasks through Ansible playbooks are usually not affected by etcd failure, such as create database, create user, reload HBA and Service, etc…, And you can always operate the PostgreSQL cluster directly to achieve most of the patroni functions.
Beware that the above description is only applicable to newer versions of Patroni (>=3.0, Pigsty >= 2.0). If you are using an older version of Patroni (<3.0, corresponding to Pigsty version 1.x), etcd / consul failure will cause a serious impact:
All PostgreSQL clusters will be demoted and reject write requests, and etcd failure will be amplified as a global PostgreSQL failure. After Patroni 3.0’s DCS Failsafe feature, this situation has been significantly improved.
What data is stored in the etcd cluster?
etcd is only used for PostgreSQL HA consensus in Pigsty, no other data is stored in etcd by default.
These consensus data are managed by Patroni, and when these data are lost in etcd, Patroni will automatically rebuild them.
Thus, by default, the etcd in Pigsty can be regarded as a “stateless service” that is disposable, which brings great convenience to maintenance work.
If you use etcd for other purposes, such as storing metadata for Kubernetes, or storing other data, you need to back up the etcd data yourself and restore the data after the etcd cluster is restored.
How to recover from etcd failure?
Since etcd is disposable in Pigsty, you can quickly stop the bleeding by “restarting” or “redeploying” etcd in case of failure.
To Restart the etcd cluster, you can use the following Ansible command (or systemctl restart etcd):
./etcd.yml -t etcd_launch
To Reset the etcd cluster, you can run this playbook, it will nuke the etcd cluster and redeploy it:
./etcd.yml
Beware that if you use etcd to store other data, don’t forget to backup etcd data before nuking the etcd cluster.
Is any maintenance work for etcd cluster?
In short: do not use all the quota of etcd.
etcd has a default quota for database size of 2GB, if your etcd database size exceeds this limit, etcd will reject write requests.
Meanwhile, as etcd’s data model illustrates, each write will generate a new version (a.k.a. revision),
so if your etcd cluster writes frequently, even with very few keys, the etcd database size may continue to grow, and may fail when it reaches the quota limit.
You can achieve this by Auto Compact, Manual Compact, Defragmentation, and Quota Increase, etc., please refer to the etcd official maintenance guide.
Pigsty has auto compact enabled by default since v2.6, so you usually don’t have to worry about etcd full.
For versions before v2.6, we strongly recommend enabling etcd’s auto compact feature in the production environment.
Fill etcd may lead to PostgreSQL failure!
For Pigsty v2.0 - v2.5 users, we strongly recommend upgrading to a newer version, or following the instructions below to enable etcd auto compaction!
How to enable etcd auto compaction?
If you are using an earlier version of Pigsty (v2.0 - v2.5), we strongly recommend that you enable etcd’s auto compaction feature in the production environment.
You can set all the PostgreSQL cluster to maintenance mode and then redeploy the etcd cluster with ./etcd.yml to apply the these changes.
It will increase the etcd default quota from 2 GiB to 16 GiB, and ensure that only the most recent day’s write history is retained, avoiding the infinite growth of the etcd database size.
Where does the PostgreSQL HA data stored in etcd?
Patroni will use the pg_namespace (default is /pg) as the prefix for all metadata keys in etcd, followed by the PostgreSQL cluster name.
For example, a PG cluster named pg-meta, its metadata keys will be stored under /pg/pg-meta, which may look like this:
The hard-coded group, etcd, will be used as DCS servers for PGSQL. You can initialize them with etcd.yml or assume it is an existing external etcd cluster.
To use an existing external etcd cluster, define them as usual and make sure your current etcd cluster certificate is signed by the same CA as your self-signed CA for PGSQL.
How to add a new member to the existing etcd cluster?
MinIO is an S3-compatible object storage server. It’s designed to be scalable, secure, and easy to use.
It has native multi-node multi-driver HA support and can store documents, pictures, videos, and backups.
Pigsty uses MinIO as an optional PostgreSQL backup storage repo, in addition to the default local posix FS repo.
If the MinIO repo is used, the MINIO module should be installed before any PGSQL modules.
MinIO requires a trusted CA to work, so you have to install it in addition to NODE module.
11.1 - Usage
Get started with MinIO and MCli, how to access the MinIO service?
After MinIO cluster is configured and deployed with the playbook,
you can start using and accessing the MinIO cluster by following the instructions here.
Deploy Cluster
It is straightforward to deploy a single-node MinIO instance with Pigsty.
The install.yml playbook will automatically create the MinIO cluster defined in the inventory,
so you don’t need to run the minio.yml playbook manually, if you choose the default one-pass installation.
If you plan to deploy a production-grade large-scale multi-node MinIO cluster,
we strongly recommend you to read the Pigsty MinIO configuration document
and the MinIO document before proceeding.
Access Cluster
You have to access MinIO via HTTPS, so make sure the default minio service domain (sss.pigsty) point to the right place:
You can add static resolution records in node_etc_hosts or manually modify the /etc/hosts file
You can add a record on the internal DNS server if you are using an DNS service
You can add a record in dns_records if you are using the DNSMASQ on infra nodes
It is recommended to use the first method: static DNS resolution records to avoid MinIO’s additional dependency on DNS in production environments.
You have to point the MinIO service domain to the IP address and service port of the MinIO server node, or the IP address and service port of the load balancer.
Pigsty will use the default domain name sss.pigsty and default port 9000.
For example, if you are using haproxy to expose MinIO service like this, the port may be 9002.
Adding Alias
To access the MinIO server cluster using the mcli client, you need to configure the server alias first:
mcli alias ls # list minio alias (the default is sss)mcli aliasset sss https://sss.pigsty:9000 minioadmin minioadmin # root usermcli aliasset sss https://sss.pigsty:9002 minioadmin minioadmin # root user, on load balancer port 9002mcli aliasset pgbackrest https://sss.pigsty:9000 pgbackrest S3User.Backup # use another user
There’s a pre-configured MinIO alias named sss on the admin user of the admin node, you can use it directly.
For the full functionality of the MinIO client tool mcli, please refer to the documentation: MinIO Client.
Manage User
You can manage biz users in MinIO using mcli, for example, you can create the two default biz users using the command line:
mcli admin user list sss # list all users set +o history# hide shell historymcli admin user add sss dba S3User.DBA
mcli admin user add sss pgbackrest S3User.Backup
set -o history
Manage Bucket
You can manage bucket with mcli:
mcli ls sss/ # list all bucket on 'sss'mcli mb --ignore-existing sss/hello # create a bucket named 'hello'mcli rb --force sss/hello # delete the 'hello' bucket
Mange Object
You can perform object CRUD with cli, for example:
mcli cp /www/pigsty/* sss/infra/ # upload local repo content to infra bucket mcli cp sss/infra/plugins.tgz /tmp/ # download file to local from miniomcli ls sss/infra # list all files in the infra bucketmcli rm sss/infra/plugins.tgz # delete file in infra bucket mcli cat sss/infra/repo_complete # output the content of
Pigsty repo has rclone available, a convenient cloud object storage client that you can use to access MinIO services.
yum install rclone;# el compatiblednf install rclone;# debian/ubuntumkdir -p ~/.config/rclone/;tee ~/.config/rclone/rclone.conf > /dev/null <<EOF
[sss]
type = s3
access_key_id = minioadmin
secret_access_key = minioadmin
endpoint = sss.pigsty:9000
EOFrclone ls sss:/
Backup Repo
The MinIO is used as a backup repository for pgBackRest by default in Pigsty.
When you modify the pgbackrest_method to minio, the PGSQL module will automatically switch the backup repository to MinIO.
pgbackrest_method: local # pgbackrest repo method:local,minio,[user-defined...]pgbackrest_repo: # pgbackrest repo:https://pgbackrest.org/configuration.html#section-repositorylocal:# default pgbackrest repo with local posix fspath:/pg/backup # local backup directory, `/pg/backup` by defaultretention_full_type:count # retention full backups by countretention_full:2# keep 2, at most 3 full backup when using local fs repominio:# optional minio repo for pgbackresttype:s3 # minio is s3-compatible, so s3 is useds3_endpoint:sss.pigsty # minio endpoint domain name, `sss.pigsty` by defaults3_region:us-east-1 # minio region, us-east-1 by default, useless for minios3_bucket:pgsql # minio bucket name, `pgsql` by defaults3_key:pgbackrest # minio user access key for pgbackrests3_key_secret:S3User.Backup # minio user secret key for pgbackrests3_uri_style:path # use path style uri for minio rather than host stylepath:/pgbackrest # minio backup path, default is `/pgbackrest`storage_port:9000# minio port, 9000 by defaultstorage_ca_file:/pg/cert/ca.crt # minio ca file path, `/pg/cert/ca.crt` by defaultbundle:y# bundle small files into a single filecipher_type:aes-256-cbc # enable AES encryption for remote backup repocipher_pass:pgBackRest # AES encryption password, default is 'pgBackRest'retention_full_type:time # retention full backup by time on minio reporetention_full:14# keep full backup for last 14 days
Beware that if you are using MinIO through load balancer, you should use the corresponding domain name and port number here.
11.2 - Configuration
Configure MinIO clusters according to your needs, and access service through LB & Proxy
Configuration
You have to define a MinIO cluster in the config inventory before deploying it.
There are 3 major deployment modes for MinIO clusters:
SNMD: Single-Node Multi-Drive: a compromise mode, use multiple disks (>=2) on a single server, only when resources are extremely limited.
MNMD: Multi-Node Multi-Drive: standard production deployment with the best reliability, but requires multiple servers and real drivers.
We recommend using SNSD and MNMD for development and production deployment, respectively, and SNMD only when resources are extremely limited (only one server).
When using a multi-node MinIO cluster, you can access the service from any node, so the best practice is to use a load balancer and HA access.
Core Param
There’s one and only one core param for MinIO deployment, which is MINIO_VOLUMES, which specify the nodes, drivers, pools of a minio cluster
Pigsty will auto-generate MINIO_VOLUMES according to the config inventory for you, but you can always override it directly.
If not explicitly specified, Pigsty will generate it according to the following rules:
SNSD: MINIO_VOLUMES is point to any dir on local node, from minio_data
SNMD: MINIO_VOLUMES is point to a series of real driver on local node, from minio_data
MNMD: MINIO_VOLUMES is point to multiple node & multiple drivers, according to minio_data and minio_node
Use minio_data to specify drivers on each node, such as /data{1...4}
Use minio_node to specify node name pattern, such as ${minio_cluster}-${minio_seq}.pigsty
Multi-Pool: MINIO_VOLUMES need to be explicitly specified
The only required params are minio_seq and minio_cluster, which generate a unique identity for each MinIO instance.
Single-Node Single-Driver mode is for dev purposes, so you can use a common dir as the data dir.
The default data dir for SNSD minio is specified by minio_data, which is /data/minio by default.
Beware that in multi-driver or multi-node mode, MinIO will refuse to start if using a common dir as the data dir rather than a mount point.
We strongly recommend using a static domain name record to access MinIO. For example, the default sss.pigsty if minio_domain can be added to all nodes through:
node_etc_hosts:["10.10.10.10 sss.pigsty"]# domain name to access minio from all nodes (required)
To use multiple disks on a single node, you have to specify the minio_data in the format of {{ prefix }}{x...y},
which defines a series of disk mount points.
minio:hosts:{10.10.10.10:{minio_seq:1}}vars:minio_cluster:minio # minio cluster name, minio by defaultminio_data:'/data{1...4}'# minio data dir(s), use {x...y} to specify multi drivers
Use real drivers and mountpoint
Beware that in multi-driver or multi-node mode, MinIO will refuse to start if using a common dir as the data dir rather than a mount point.
This example defines a single-node MinIO cluster with 4 drivers: /data1, /data2, /data3, /data4. You have to mount them properly before launching MinIO:
The vagrant MinIO sandbox has pre-defined 4-node MinIO cluster with 4 drivers.
You have to properly mount them before starting MinIO (be sure to format disks with xfs):
mkfs.xfs /dev/vdb; mkdir /data1; mount -t xfs /dev/sdb /data1;mkfs.xfs /dev/vdc; mkdir /data2; mount -t xfs /dev/sdb /data2;mkfs.xfs /dev/vdd; mkdir /data3; mount -t xfs /dev/sdb /data3;mkfs.xfs /dev/vde; mkdir /data4; mount -t xfs /dev/sdb /data4;
Disk management is beyond this topic, just make sure your /etc/fstab is properly configured to auto-mount disks after reboot.
SNMD mode can utilize multiple disks on a single server to provide higher performance and capacity, and tolerate partial disk failures.
But it can do nothing with node failure, and you can’t add new nodes at runtime, so we don’t recommend using SNMD mode in production unless you have a special reason.
The minio_node param specifies the MinIO node name pattern, which is ${minio_cluster}-${minio_seq}.pigsty by default.
The server name is very important for MinIO to identify and access other nodes in the cluster.
It will be populated with minio_cluster and minio_seq, and write to /etc/hosts of all minio cluster members.
In this case, the MINIO_VOLUMES will be set to https://minio-{1...4}.pigsty/data{1...4} to identify the 16 disks on 4 nodes.
Multi-Pool
MinIO’s architecture allows for cluster expansion by adding new storage pools.
In Pigsty, you can achieve this by explicitly specifying the minio_volumes param to specify nodes/disks for each pool.
For example, suppose you have already created a MinIO cluster as defined in the Multi-Node Multi-Disk example,
and now you want to add a new storage pool consisting of four nodes.
You can specify minio_volumes here to allocate nodes for each pool to scale out the cluster.
Please note that by default, Pigsty allows only one MinIO cluster per deployment.
If you need to deploy multiple MinIO clusters, some parameters with default values need to be explicitly set and cannot be omitted to avoid naming conflicts, as shown above.
Expose Service
MinIO will serve on port 9000 by default. If a multi-node MinIO cluster is deployed, you can access its service via any node.
It would be better to expose MinIO service via a load balancer, such as the default haproxy on NODE, or use the L2 vip.
To expose MinIO service with haproxy, you have to define an extra service with haproxy_services:
minio:hosts:10.10.10.10:{minio_seq: 1 , nodename:minio-1 }10.10.10.11:{minio_seq: 2 , nodename:minio-2 }10.10.10.12:{minio_seq: 3 , nodename:minio-3 }vars:minio_cluster:minionode_cluster:miniominio_data:'/data{1...2}'# use two disk per nodeminio_node:'${minio_cluster}-${minio_seq}.pigsty'# minio node name patternhaproxy_services:# EXPOSING MINIO SERVICE WITH HAPROXY- name:minio # [REQUIRED] service name, uniqueport:9002# [REQUIRED] service port, uniqueoptions:# [OPTIONAL] minio health check- option httpchk- option http-keep-alive- http-check send meth OPTIONS uri /minio/health/live- http-check expect status 200servers:- {name: minio-1 ,ip: 10.10.10.10 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-2 ,ip: 10.10.10.11 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-3 ,ip: 10.10.10.12 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}
MinIO uses port 9000 by default. A multi-node MinIO cluster can be accessed by connecting to any one of its nodes.
Service access falls under the scope of the NODE module, and we’ll provide only a basic introduction here.
High-availability access to a multi-node MinIO cluster can be achieved using an L2 VIP or HAProxy.
For example, you can use Keepalived to bind an L2 VIP to the MinIO cluster,
or use the haproxy component provided by the NODE module to expose MinIO services through a load balancer.
# minio cluster with 4 nodes and 4 drivers per nodeminio:hosts:10.10.10.10:{minio_seq: 1 , nodename:minio-1 }10.10.10.11:{minio_seq: 2 , nodename:minio-2 }10.10.10.12:{minio_seq: 3 , nodename:minio-3 }10.10.10.13:{minio_seq: 4 , nodename:minio-4 }vars:minio_cluster:miniominio_data:'/data{1...4}'minio_buckets:[{name:pgsql }, { name: infra }, { name: redis } ]minio_users:- {access_key: dba , secret_key: S3User.DBA, policy:consoleAdmin }- {access_key: pgbackrest , secret_key: S3User.SomeNewPassWord , policy:readwrite }# bind a node l2 vip (10.10.10.9) to minio cluster (optional)node_cluster:miniovip_enabled:truevip_vrid:128vip_address:10.10.10.9vip_interface:eth1# expose minio service with haproxy on all nodeshaproxy_services:- name:minio # [REQUIRED] service name, uniqueport:9002# [REQUIRED] service port, uniquebalance:leastconn # [OPTIONAL] load balancer algorithmoptions:# [OPTIONAL] minio health check- option httpchk- option http-keep-alive- http-check send meth OPTIONS uri /minio/health/live- http-check expect status 200servers:- {name: minio-1 ,ip: 10.10.10.10 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-2 ,ip: 10.10.10.11 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-3 ,ip: 10.10.10.12 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-4 ,ip: 10.10.10.13 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}
In the configuration above, HAProxy is enabled on all nodes of the MinIO cluster, exposing MinIO services on port 9002, and a Layer 2 VIP is bound to the cluster.
When in use, users should point the sss.pigsty domain name to the VIP address 10.10.10.9 and access MinIO services using port 9002.
This ensures high availability, as the VIP will automatically switch to another node if any node fails.
In this scenario, you may also need to globally modify the destination of domain name resolution and adjust the minio_endpoint parameter to change the endpoint address corresponding to the MinIO alias on the management node:
minio_endpoint:https://sss.pigsty:9002 # Override the default https://sss.pigsty:9000node_etc_hosts:["10.10.10.9 sss.pigsty"]# Other nodes will use the sss.pigsty domain
Dedicate Proxies
Pigsty allow using dedicate load balancer cluster instead of the node cluster itself to run VIP & HAProxy.
proxy:hosts:10.10.10.18 :{nodename: proxy1 ,node_cluster: proxy ,vip_interface: eth1 ,vip_role:master }10.10.10.19 :{nodename: proxy2 ,node_cluster: proxy ,vip_interface: eth1 ,vip_role:backup }vars:vip_enabled:truevip_address:10.10.10.20vip_vrid:20haproxy_services: # expose minio service :sss.pigsty:9000- name:minio # [REQUIRED] service name, uniqueport:9000# [REQUIRED] service port, uniquebalance:leastconn# Use leastconn algorithm and minio health checkoptions:["option httpchk","option http-keep-alive","http-check send meth OPTIONS uri /minio/health/live","http-check expect status 200"]servers:# reload service with ./node.yml -t haproxy_config,haproxy_reload- {name: minio-1 ,ip: 10.10.10.21 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-2 ,ip: 10.10.10.22 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-3 ,ip: 10.10.10.23 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-4 ,ip: 10.10.10.24 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-5 ,ip: 10.10.10.25 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}
In this case, you need to manually configure the DNS resolution to point sss.pigsty to the VIP address of dedicate proxies cluster
minio_endpoint: https://sss.pigsty:9002 # overwrite the defaults:https://sss.pigsty:9000node_etc_hosts:["10.10.10.20 sss.pigsty"]# domain name to access minio from all nodes (required)
# This is the newly added HA MinIO Repo definition, USE THIS INSTEAD!minio_ha:type:s3s3_endpoint: minio-1.pigsty # s3_endpoint could be any load balancer:10.10.10.1{0,1,2},or domain names point to any of the 3 nodess3_region: us-east-1 # you could use external domain name:sss.pigsty , which resolve to any members (`minio_domain`)s3_bucket: pgsql # instance & nodename can be used :minio-1.pigsty minio-1.pigsty minio-1.pigsty minio-1 minio-2 minio-3s3_key:pgbackrest # Better using a new password for MinIO pgbackrest users3_key_secret:S3User.SomeNewPassWords3_uri_style:pathpath:/pgbackreststorage_port:9002# Use the load balancer port 9002 instead of default 9000 (direct access)storage_ca_file:/etc/pki/ca.crtbundle:ycipher_type:aes-256-cbc # Better using a new cipher password for your production environmentcipher_pass:pgBackRest.With.Some.Extra.PassWord.And.Salt.${pg_cluster}retention_full_type:timeretention_full:14
Expose Console
MinIO has a built-in console that can be accessed via HTTPS @ minio_admin_port.
If you want to expose the MinIO console to the outside world, you can add MinIO to infra_portal.
Beware that MinIO console should be accessed via HTTPS, please DO NOT expose MinIO console without encryption in production.
Which means you usually need to add m.pigsty resolution to your DNS server, or /etc/hosts on your local host, to access the MinIO console.
Meanwhile, if you are using Pigsty’s self-signed CA rather than a regular public CA,
you usually need to manually trust the CA or certificate to skip the “insecure” warning in the browser.
11.3 - Parameter
MinIO has 15 parameters to customize the cluster as needed.
MinIO is a S3 compatible object storage service.
Which is used as an optional central backup storage repo for PostgreSQL.
You may also use it for other purposes, such as storing large files, documents, pictures & videos.
#-----------------------------------------------------------------# MINIO#-----------------------------------------------------------------#minio_seq: 1 # minio instance identifier, REQUIREDminio_cluster:minio # minio cluster identifier, REQUIREDminio_clean:false# cleanup minio during init?, false by defaultminio_user:minio # minio os user, `minio` by defaultminio_node:'${minio_cluster}-${minio_seq}.pigsty'# minio node name patternminio_data:'/data/minio'# minio data dir(s), use {x...y} to specify multi drivers#minio_volumes: # minio data volumes, override defaults if specifiedminio_domain:sss.pigsty # minio external domain name, `sss.pigsty` by defaultminio_port:9000# minio service port, 9000 by defaultminio_admin_port:9001# minio console port, 9001 by defaultminio_access_key:minioadmin # root access key, `minioadmin` by defaultminio_secret_key:minioadmin # root secret key, `minioadmin` by defaultminio_extra_vars:''# extra environment variablesminio_alias:sss # alias name for local minio deployment#minio_endpoint: https://sss.pigsty:9000 # if not specified, overwritten by defaultsminio_buckets:[{name:pgsql }, { name: infra }, { name: redis } ]minio_users:- {access_key: dba , secret_key: S3User.DBA, policy:consoleAdmin }- {access_key: pgbackrest , secret_key: S3User.Backup, policy:readwrite }
minio_seq
name: minio_seq, type: int, level: I
minio instance identifier, REQUIRED identity parameters. no default value, you have to assign it manually
minio_cluster
name: minio_cluster, type: string, level: C
minio cluster name, minio by default. This is useful when deploying multiple MinIO clusters
minio_clean
name: minio_clean, type: bool, level: G/C/A
cleanup minio during init?, false by default
minio_user
name: minio_user, type: username, level: C
minio os user name, minio by default
minio_node
name: minio_node, type: string, level: C
minio node name pattern, this is used for multi-node deployment
Minio has a safeguard to prevent accidental deletion. Control by the following parameter:
minio_clean, false by default, which means Pigsty will not remove existing MinIO data by default
If you wish to remove existing minio data during init, please set this parameter to true in the config file, or override it with command-line parameter -e minio_clean=true.
./minio.yml -l <cls> -e minio_clean=true
If you just want to clean existing MinIO data without installing a new instance, simply execute the minio_clean subtask:
The minio_cluster param mark this cluster as a MinIO cluster, and the minio_seq is the sequence number of the MinIO node, which is used to generate MinIO node name like minio-1, minio-2, etc.
This snippet defines a single-node MinIO cluster, using the following command to create the MinIO cluster:
./minio.yml -l minio # init MinIO module on the minio group
Remove Cluster
To destroy an existing MinIO cluster, use the minio_clean subtask of minio.yml, DO THINK before you type.
./minio.yml -l minio -t minio_clean -e minio_clean=true# Stop MinIO and Remove Data Dir
If you wish to remove prometheus monitor target too:
ansible infra -b -a 'rm -rf /etc/prometheus/targets/minio/minio-1.yml'# delete the minio monitoring target
You can not scale MinIO at node/disk level, but you can scale at storage pool (multiple nodes) level.
Assume you have a 4-node MinIO cluster and want to double the capacity by adding another four-node storage pool.
minio:hosts:10.10.10.10:{minio_seq: 1 , nodename:minio-1 }10.10.10.11:{minio_seq: 2 , nodename:minio-2 }10.10.10.12:{minio_seq: 3 , nodename:minio-3 }10.10.10.13:{minio_seq: 4 , nodename:minio-4 }vars:minio_cluster:miniominio_data:'/data{1...4}'minio_buckets:[{name:pgsql }, { name: infra }, { name: redis } ]minio_users:- {access_key: dba , secret_key: S3User.DBA, policy:consoleAdmin }- {access_key: pgbackrest , secret_key: S3User.SomeNewPassWord , policy:readwrite }# bind a node l2 vip (10.10.10.9) to minio cluster (optional)node_cluster:miniovip_enabled:truevip_vrid:128vip_address:10.10.10.9vip_interface:eth1# expose minio service with haproxy on all nodeshaproxy_services:- name:minio # [REQUIRED] service name, uniqueport:9002# [REQUIRED] service port, uniquebalance:leastconn # [OPTIONAL] load balancer algorithmoptions:# [OPTIONAL] minio health check- option httpchk- option http-keep-alive- http-check send meth OPTIONS uri /minio/health/live- http-check expect status 200servers:- {name: minio-1 ,ip: 10.10.10.10 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-2 ,ip: 10.10.10.11 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-3 ,ip: 10.10.10.12 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}- {name: minio-4 ,ip: 10.10.10.13 ,port: 9000 ,options:'check-ssl ca-file /etc/pki/ca.crt check port 9000'}
Step 1, add 4 node definition in the group, allocate sequence number 5 to 8.
The key step is to modify the minio_volumes param, assign the new 4 nodes to a new storage pool.
MinIO cannot scale down at the node/disk level, but you can retire at the storage pool (multiple nodes) level ——
Add a new storage pool, drain the old storage pool, migrate to the new storage pool, and then retire the old storage pool.
# 1. remove failure nodebin/node-rm <your_old_node_ip>
# 2. replace failure node with the same name (modify the inventory in case of IP change)bin/node-add <your_new_node_ip>
# 3. provisioning MinIO on new node./minio.yml -l <your_new_node_ip>
# 4. instruct MinIO to perform heal actionmc admin heal
Pigsty has built-in Redis support, which is a high-performance data-structure server. Deploy redis in standalone, cluster or sentinel mode.
12.1 - Configuration
Configure Redis clusters according to your needs
The entity model of Redis is almost the same as that of PostgreSQL, which also includes the concepts of Cluster and Instance. The Cluster here does not refer to the native Redis Cluster mode.
The core difference between the REDIS module and the PGSQL module is that Redis uses a single-node multi-instance deployment rather than the 1:1 deployment: multiple Redis instances are typically deployed on a physical/virtual machine node to utilize multi-core CPUs fully. Therefore, the ways to configure and administer Redis instances are slightly different from PGSQL.
In Redis managed by Pigsty, nodes are entirely subordinate to the cluster, which means that currently, it is not allowed to deploy Redis instances of two different clusters on one node. However, this does not affect deploying multiple independent Redis primary replica instances on one node.
Configuration
Redis Identity
Redis identity parameters are required parameters when defining a Redis cluster.
A Redis node can only belong to one Redis cluster, which means you cannot assign a node to two different Redis clusters simultaneously.
On each Redis node, you need to assign a unique port number to the Redis instance to avoid port conflicts.
Typically, the same Redis cluster will use the same password, but multiple Redis instances on a Redis node cannot set different passwords (because redis_exporter only allows one password).
Redis Cluster has built-in HA, while standalone HA requires manually configured in Sentinel because we are unsure if you have any sentinels available. Fortunately, configuring standalone Redis HA is straightforward: Configure HA with sentinel.
#redis_cluster: <CLUSTER> # redis cluster name, required identity parameter#redis_node: 1 <NODE> # redis node sequence number, node int id required#redis_instances: {} <NODE> # redis instances definition on this redis noderedis_fs_main:/data # redis main data mountpoint, `/data` by defaultredis_exporter_enabled:true# install redis exporter on redis nodes?redis_exporter_port:9121# redis exporter listen port, 9121 by defaultredis_exporter_options:''# cli args and extra options for redis exporterredis_safeguard:false# prevent purging running redis instance?redis_clean:true# purging existing redis during init?redis_rmdata:true# remove redis data when purging redis server?redis_mode: standalone # redis mode:standalone,cluster,sentinelredis_conf:redis.conf # redis config template path, except sentinelredis_bind_address:'0.0.0.0'# redis bind address, empty string will use host ipredis_max_memory:1GB # max memory used by each redis instanceredis_mem_policy:allkeys-lru # redis memory eviction policyredis_password:''# redis password, empty string will disable passwordredis_rdb_save:['1200 1']# redis rdb save directives, disable with empty listredis_aof_enabled:false# enable redis append only file?redis_rename_commands:{}# rename redis dangerous commandsredis_cluster_replicas:1# replica number for one master in redis clusterredis_sentinel_monitor:[]# sentinel master list, works on sentinel cluster only
REDIS
#redis_cluster: <CLUSTER> # redis cluster name, required identity parameter#redis_node: 1 <NODE> # redis node sequence number, node int id required#redis_instances: {} <NODE> # redis instances definition on this redis noderedis_fs_main:/data # redis main data mountpoint, `/data` by defaultredis_exporter_enabled:true# install redis exporter on redis nodes?redis_exporter_port:9121# redis exporter listen port, 9121 by defaultredis_exporter_options:''# cli args and extra options for redis exporterredis_safeguard:false# prevent purging running redis instance?redis_clean:true# purging existing redis during init?redis_rmdata:true# remove redis data when purging redis server?redis_mode: standalone # redis mode:standalone,cluster,sentinelredis_conf:redis.conf # redis config template path, except sentinelredis_bind_address:'0.0.0.0'# redis bind address, empty string will use host ipredis_max_memory:1GB # max memory used by each redis instanceredis_mem_policy:allkeys-lru # redis memory eviction policyredis_password:''# redis password, empty string will disable passwordredis_rdb_save:['1200 1']# redis rdb save directives, disable with empty listredis_aof_enabled:false# enable redis append only file?redis_rename_commands:{}# rename redis dangerous commandsredis_cluster_replicas:1# replica number for one master in redis clusterredis_sentinel_monitor:[]# sentinel master list, works on sentinel cluster only
redis_cluster
name: redis_cluster, type: string, level: C
redis cluster name, required identity parameter.
no default value, you have to define it explicitly.
Comply with regexp [a-z][a-z0-9-]*, it is recommended to use the same name as the group name and start with redis-
redis_node
name: redis_node, type: int, level: I
redis node sequence number, unique integer among redis cluster is required
You have to explicitly define the node id for each redis node. integer start from 0 or 1.
redis_instances
name: redis_instances, type: dict, level: I
redis instances definition on this redis node
no default value, you have to define redis instances on each redis node using this parameter explicitly.
Here is an example for a native redis cluster definition
redis bind address, empty string will use inventory hostname
default values: 0.0.0.0, which will bind to all available IPv4 address on this host
PLEASE bind to intranet IP only in production environment, i.e. set this value to ''
redis_max_memory
name: redis_max_memory, type: size, level: C/I
max memory used by each redis instance, default values: 1GB
redis_mem_policy
name: redis_mem_policy, type: enum, level: C
redis memory eviction policy
default values: allkeys-lru, check redis eviction policy for more details
noeviction: New values aren’t saved when memory limit is reached. When a database uses replication, this applies to the primary database
allkeys-lru: Keeps most recently used keys; removes least recently used (LRU) keys
allkeys-lfu: Keeps frequently used keys; removes least frequently used (LFU) keys
volatile-lru: Removes least recently used keys with the expire field set to true.
volatile-lfu: Removes least frequently used keys with the expire field set to true.
allkeys-random: Randomly removes keys to make space for the new data added.
volatile-random: Randomly removes keys with expire field set to true.
volatile-ttl: Removes keys with expire field set to true and the shortest remaining time-to-live (TTL) value.
redis_password
name: redis_password, type: password, level: C/N
redis password, empty string will disable password, which is the default behavior
Note that due to the implementation limitation of redis_exporter, you can only set one redis_password per node.
This is usually not a problem, because pigsty does not allow deploying two different redis cluster on the same node.
PLEASE use a strong password in production environment
redis_rdb_save
name: redis_rdb_save, type: string[], level: C
redis rdb save directives, disable with empty list, check redis persist for details.
the default value is ["1200 1"]: dump the dataset to disk every 20 minutes if at least 1 key changed:
redis_aof_enabled
name: redis_aof_enabled, type: bool, level: C
enable redis append only file? default value is false.
redis_rename_commands
name: redis_rename_commands, type: dict, level: C
rename redis dangerous commands, which is a dict of k:v old: new
default values: {}, you can hide dangerous commands like FLUSHDB and FLUSHALL by setting this value, here’s an example:
replica number for one master/primary in redis cluster, default values: 1
redis_sentinel_monitor
name: redis_sentinel_monitor, type: master[], level: C
This can only be used when redis_mode is set to sentinel.
List of redis master to be monitored by this sentinel cluster. each master is defined as a dict with name, host, port, password, quorum keys.
redis_sentinel_monitor:# primary list for redis sentinel, use cls as name, primary ip:port- {name: redis-src, host: 10.10.10.45, port: 6379 ,password: redis.src, quorum:1}- {name: redis-dst, host: 10.10.10.48, port: 6379 ,password: redis.dst, quorum:1}
The name and host are mandatory, port, password, quorum are optional, quorum is used to set the quorum for this master, usually large than half of the sentinel instances.
Beware that redis can not be reload online, you have to restart redis to make config effective.
Use Redis Client Tools
Access redis instance with redis-cli:
$ redis-cli -h 10.10.10.10 -p 6379# <--- connect with host and port10.10.10.10:6379> auth redis.ms # <--- auth with passwordOK
10.10.10.10:6379> set a 10# <--- set a keyOK
10.10.10.10:6379> get a # <--- get a key back"10"
Redis also has a redis-benchmark which can be used for benchmark and generate load on redis server:
# promote a redis instance to primary> REPLICAOF NO ONE
"OK"# make a redis instance replica of another instance> REPLICAOF 127.0.0.1 6799"OK"
Configure HA with Sentinel
You have to enable HA for redis standalone m-s cluster manually with your redis sentinel.
Take the 4-node sandbox as an example, a redis sentinel cluster redis-meta is used manage the redis-ms standalone cluster.
# for each sentinel, add redis master to the sentinel with:$ redis-cli -h 10.10.10.11 -p 26379 -a redis.meta
10.10.10.11:26379> SENTINEL MONITOR redis-ms 10.10.10.10 6379110.10.10.11:26379> SENTINEL SET redis-ms auth-pass redis.ms # if auth enabled, password has to be configured
If you wish to remove a redis master from sentinel, use SENTINEL REMOVE <name>.
You can configure multiple redis master on sentinel cluster with redis_sentinel_monitor.
redis_sentinel_monitor:# primary list for redis sentinel, use cls as name, primary ip:port- {name: redis-src, host: 10.10.10.45, port: 6379 ,password: redis.src, quorum:1}- {name: redis-dst, host: 10.10.10.48, port: 6379 ,password: redis.dst, quorum:1}
And refresh master list on sentinel cluster with:
./redis.yml -l redis-meta -t redis-ha # replace redis-meta if your sentinel cluster has different name
Start time of the Redis instance since unix epoch in seconds.
redis_target_scrape_request_errors_total
counter
cls, ip, instance, ins, job
Errors in requests to the exporter
redis_total_error_replies
counter
cls, ip, instance, ins, job
total_error_replies metric
redis_total_reads_processed
counter
cls, ip, instance, ins, job
total_reads_processed metric
redis_total_system_memory_bytes
gauge
cls, ip, instance, ins, job
total_system_memory_bytes metric
redis_total_writes_processed
counter
cls, ip, instance, ins, job
total_writes_processed metric
redis_tracking_clients
gauge
cls, ip, instance, ins, job
tracking_clients metric
redis_tracking_total_items
gauge
cls, ip, instance, ins, job
tracking_total_items metric
redis_tracking_total_keys
gauge
cls, ip, instance, ins, job
tracking_total_keys metric
redis_tracking_total_prefixes
gauge
cls, ip, instance, ins, job
tracking_total_prefixes metric
redis_unexpected_error_replies
counter
cls, ip, instance, ins, job
unexpected_error_replies metric
redis_up
gauge
cls, ip, instance, ins, job
Information about the Redis instance
redis_uptime_in_seconds
gauge
cls, ip, instance, ins, job
uptime_in_seconds metric
scrape_duration_seconds
Unknown
cls, ip, instance, ins, job
N/A
scrape_samples_post_metric_relabeling
Unknown
cls, ip, instance, ins, job
N/A
scrape_samples_scraped
Unknown
cls, ip, instance, ins, job
N/A
scrape_series_added
Unknown
cls, ip, instance, ins, job
N/A
up
Unknown
cls, ip, instance, ins, job
N/A
12.7 - FAQ
Pigsty REDIS module frequently asked questions
ABORT due to existing redis instance
use redis_clean = true and redis_safeguard = false to force clean redis data
This happens when you run redis.yml to init a redis instance that is already running, and redis_clean is set to false.
If redis_clean is set to true (and the redis_safeguard is set to false, too), the redis.yml playbook will remove the existing redis instance and re-init it as a new one, which makes the redis.yml playbook fully idempotent.
ABORT due to redis_safeguard enabled
This happens when removing a redis instance with redis_safeguard set to true.
You can disable redis_safeguard to remove the Redis instance. This is redis_safeguard is what it is for.
How to add a single new redis instance on this node?
Use bin/redis-add <ip> <port> to deploy a new redis instance on node.
How to remove a single redis instance from the node?
bin/redis-rm <ip> <port> to remove a single redis instance from node
13 - Module: FERRET
Pigsty has built-in FerretDB support, which is a MongoDB compatiable middleware based on PostgreSQL.
MongoDB was once a stunning technology,
allowing developers to cast aside the “schema constraints” of relational databases and quickly build applications.
However, over time, MongoDB abandoned its open-source nature, changing its license to SSPL, which made it unusable for many open-source projects and early commercial projects.
Most MongoDB users actually do not need the advanced features provided by MongoDB, but they do need an easy-to-use open-source document database solution. To fill this gap, FerretDB was born.
PostgreSQL’s JSON functionality is already well-rounded: binary storage JSONB, GIN arbitrary field indexing, various JSON processing functions, JSON PATH, and JSON Schema,
it has long been a fully-featured, high-performance document database. However, providing alternative functionality and direct emulation are not the same.
FerretDB can provide a smooth transition to PostgreSQL for applications driven by MongoDB drivers.
Pigsty provided a Docker-Compose support for FerretDB in 1.x,
and native deployment support since v2.3. As an optional feature, it greatly benefits the enrichment of the PostgreSQL ecosystem.
The Pigsty community has already become a partner with the FerretDB community, and we shall find more opportunities to work together in the future.
Currently, FerretDB 2.0 provides a new version based on the Microsoft DocumentDB extension plugin, which is now officially supported in Pigsty v3.3.
13.1 - Usage
Quick start guide for FerretDB - how to get started, connect reliably, and use the mongosh client tool
Install Client Tools
You can use MongoDB’s command-line tool MongoSH to access FerretDB.
Use the pig command to add MongoDB repository, then install mongosh using yum or apt:
You can access FerretDB using MongoDB connection strings with any MongoDB driver in any language. Here’s an example using the mongosh CLI tool:
$ mongosh
Current Mongosh Log ID: 67ba8c1fe551f042bf51e943
Connecting to: mongodb://127.0.0.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+2.4.0
Using MongoDB: 7.0.77
Using Mongosh: 2.4.0
For mongosh info see: https://www.mongodb.com/docs/mongodb-shell/
test>
mongosh 'mongodb://dbuser_meta:[email protected]:27017/meta'# Business admin usermongosh 'mongodb://dbuser_view:[email protected]:27017/meta'# Read-only user
Quick Start
You can connect to FerretDB and use it as if it were a MongoDB cluster.
Configure FerretDB cluster and its required PostgreSQL cluster
FerretDB Cluster
Before deploying a Mongo (FerretDB) cluster, you need to define it in the inventory using the relevant parameters.
The following example uses the default single-node pg-meta cluster’s meta database as FerretDB’s underlying storage:
all:children:#----------------------------------## ferretdb for mongodb on postgresql#----------------------------------## ./mongo.yml -l ferretferret:hosts:10.10.10.10:{mongo_seq:1}vars:mongo_cluster:ferretmongo_pgurl:'postgres://mongod:[email protected]:5432/meta'
Here, mongo_cluster and mongo_seq are essential identity parameters. For FerretDB, mongo_pgurl is also required to specify the underlying PG location.
Note that the mongo_pgurl parameter requires a PostgreSQL superuser. In this example, a dedicated mongod superuser is defined for FerretDB.
Note that FerretDB’s authentication is entirely based on PostgreSQL.
You can create other regular users using either FerretDB or PostgreSQL.
PostgreSQL Cluster
FerretDB 2.0+ requires an extension: DocumentDB, which depends on several other extensions. Here’s a template for creating a PostgreSQL cluster for FerretDB:
all:children:#----------------------------------## pgsql (singleton on current node)#----------------------------------## postgres cluster: pg-metapg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-metapg_users:- {name: mongod ,password: DBUser.Mongo ,pgbouncer: true ,roles: [dbrole_admin ] ,superuser: true ,comment:ferretdb super user }- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment:pigsty admin user }- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment:read-only viewer for meta database }pg_databases:- {name: meta, owner: mongod ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions:[documentdb, postgis, vector, pg_cron, rum ]}pg_hba_rules:- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}- {user: mongod , db: all ,addr: world ,auth: pwd ,title:'mongodb password access from everywhere'}pg_extensions:- documentdb, citus, postgis, pgvector, pg_cron, rumpg_parameters:cron.database_name:metapg_libs:'pg_documentdb, pg_documentdb_core, pg_cron, pg_stat_statements, auto_explain'# add timescaledb to shared_preload_libraries
High Availability
You can use Services to connect to a highly available PostgreSQL cluster and deploy multiple FerretDB instance replicas with L2 VIP binding for FerretDB layer high availability.
Get started with Docker in pigsty: install, uninstall, download, mirror, proxy, images and more.
Pigsty includes built-in Docker support, allowing you to quickly deploy containerized applications.
Getting Started
Docker is an optional module and is not enabled by default in most Pigsty configuration templates. Users must explicitly download and configure Docker to use it within Pigsty.
For instance, in the default meta template, Docker is not installed. However, the rich single-node template will download and install Docker.
The key differences between these configurations are the repo_modules and repo_packages parameters:
To download Docker during Pigsty installation, enable Docker repositories by modifying repo_modules and specifying Docker packages in repo_packages or repo_extra_packages:
Packages defined here (docker-ce, docker-compose-plugin) are automatically downloaded during the default install.yml run, becoming available via local repositories.
After Pigsty installation, update repositories by running ./infra.yml -t repo_build.
Docker installation requires enabling the Docker module in repo_modules.
Repository
Docker requires external repositories, pre-configured under repo_upstream with the module name docker:
Pigsty provides ready-to-use software templates based on Docker Compose to deploy external applications seamlessly integrated with Pigsty-managed database clusters.
14.2 - Parameter
5 parameters to customize the Docker module as needed.
docker_enabled:false# enable docker on this node?docker_data:/var/lib/docker # docker data directory, /var/lib/docker by defaultdocker_storage_driver:overlay2 # docker storage driver, can be zfs, btrfsdocker_cgroups_driver: systemd # docker cgroup fs driver:cgroupfs,systemddocker_registry_mirrors:[]# docker registry mirror listdocker_exporter_port:9323# docker metrics exporter port, 9323 by defaultdocker_image:[]# docker image to be pulled after bootstrapdocker_image_cache:/tmp/docker/*.tgz# docker image cache glob pattern
docker_enabled
name: docker_enabled, type: bool, level: G/C/I
enable docker on this node? default value is false
docker_data
name: docker_data, type: path, level: C
Docker data directory, /var/lib/docker by default.
Run this playbook on any host will install docker-ce and docker-compose-plugin on target node with docker_enabled: true flag.
Here are the available subtasks in the docker.yml playbook:
docker_install: Install Docker and Docker Compose packages on the node.
docker_admin: Add specified users to the Docker administrator user group.
docker_config: Generate Docker daemon service configuration file.
docker_launch: Start the Docker daemon service.
docker_register: Register Docker daemon as a Prometheus monitoring target.
docker_image: Attempt to load prepackaged Docker images from /tmp/docker/*.tgz if present.
The Docker module does not provide a dedicated playbook for uninstalling Docker. If you need to uninstall Docker, you can manually stop the Docker service and then uninstall it:
systemctl stop docker # Stop Docker daemon serviceyum remove docker-ce docker-compose-plugin # Uninstall Docker on EL systemsapt remove docker-ce docker-compose-plugin # Uninstall Docker on Debian systems
Here are some basic MySQL cluster management operations:
Create MySQL cluster with mysql.yml:
./mysql.yml -l my-test
Playbook
Pigsty has the following playbooks related to the MYSQL module:
mysql.yml: Deploy MySQL according to the inventory
mysql.yml
The playbook mysql.yml contains the following subtasks:
mysql-id : generate mysql instance identity
mysql_clean : remove existing mysql instance (DANGEROUS)mysql_dbsu : create os user mysql
mysql_install : install mysql rpm/deb packages
mysql_dir : create mysql data & conf dir
mysql_config : generate mysql config file
mysql_boot : bootstrap mysql cluster
mysql_launch : launch mysql service
mysql_pass : write mysql password
mysql_db : create mysql biz database
mysql_user : create mysql biz user
mysql_exporter : launch mysql exporter
mysql_register : register mysql service to prometheus
#-----------------------------------------------------------------# MYSQL_IDENTITY#-----------------------------------------------------------------# mysql_cluster: #CLUSTER # mysql cluster name, required identity parameter# mysql_role: replica #INSTANCE # mysql role, required, could be primary,replica# mysql_seq: 0 #INSTANCE # mysql instance seq number, required identity parameter#-----------------------------------------------------------------# MYSQL_BUSINESS#-----------------------------------------------------------------# mysql business object definition, overwrite in group varsmysql_users:[]# mysql business usersmysql_databases:[]# mysql business databasesmysql_services:[]# mysql business services# global credentials, overwrite in global varsmysql_root_username:rootmysql_root_password:DBUser.Rootmysql_replication_username:replicatormysql_replication_password:DBUser.Replicatormysql_admin_username:dbuser_dbamysql_admin_password:DBUser.DBAmysql_monitor_username:dbuser_monitormysql_monitor_password:DBUser.Monitor#-----------------------------------------------------------------# MYSQL_INSTALL#-----------------------------------------------------------------# - install - #mysql_dbsu:mysql # os dbsu name, mysql by default, better not change itmysql_dbsu_uid:27# os dbsu uid and gid, 306 for default mysql users and groupsmysql_dbsu_home:/var/lib/mysql # mysql home directory, `/var/lib/mysql` by defaultmysql_dbsu_ssh_exchange:true# exchange mysql dbsu ssh key among same mysql clustermysql_packages:# mysql packages to be installed, `mysql-community*` by default- mysql-community*- mysqld_exporter# - bootstrap - #mysql_data:/data/mysql # mysql data directory, `/data/mysql` by defaultmysql_listen:'0.0.0.0'# mysql listen addresses, comma separated IP listmysql_port:3306# mysql listen port, 3306 by defaultmysql_sock:/var/lib/mysql/mysql.sock# mysql socket dir, `/var/lib/mysql/mysql.sock` by defaultmysql_pid:/var/run/mysqld/mysqld.pid# mysql pid file, `/var/run/mysqld/mysqld.pid` by defaultmysql_conf:/etc/my.cnf # mysql config file, `/etc/my.cnf` by defaultmysql_log_dir:/var/log # mysql log dir, `/var/log/mysql` by defaultmysql_exporter_port:9104# mysqld_exporter listen port, 9104 by defaultmysql_parameters:{}# extra parameters for mysqldmysql_default_parameters:# default parameters for mysqld
15.2 - Module: Kafka
Deploy kafka with pigsty: open-source distributed event streaming platform
Kafka module is currently available in Pigsty Pro as a Beta Preview.
Kafka requires a Java runtime, so you need to install an available JDK when installing Kafka (OpenJDK 17 is used by default, but other JDKs and versions, such as 8 and 11, can also be used).
Single node Kafka configuration example, please note that in Pigsty single machine deployment mode.
the Kafka Peer 9093 port is already occupied by AlertManager, it is recommended to use other ports, such as (9095).
kf-main:hosts:10.10.10.10:{kafka_seq: 1, kafka_role:controller }vars:kafka_cluster:kf-mainkafka_data:/data/kafkakafka_peer_port:9095# 9093 is already hold by alertmanager
TigerBeetle Requires Linux Kernel Version 5.5 or Higher!
Please note that TigerBeetle supports only Linux kernel version 5.5 or higher, making it incompatible by default with EL7 (3.10) and EL8 (4.18) systems.
To install TigerBeetle, please use EL9 (5.14), Ubuntu 22.04 (5.15), Debian 12 (6.1), Debian 11 (5.10), or another supported system.
15.5 - Module: Kubernetes
Deploy kubernetes, the Production-Grade Container Orchestration Platform
Kubernetes is a production-grade, open-source container orchestration platform. It helps you automate, deploy, scale, and manage containerized applications.
Overview
Pigsty has native support for [ETCD] clusters, which can be used by Kubernetes. Therefore, the pro version also provides the KUBE module for deploying production-grade Kubernetes clusters.
The KUBE module is currently in Beta status and only available for Pro edition customers.
SealOS
SealOS is a lightweight, high-performance, and easy-to-use Kubernetes distribution.
It is designed to simplify the deployment and management of Kubernetes clusters.
Pigsty provides SealOS 5.0 RPM and DEB packages in the Infra repository, which can be downloaded and installed directly.
Kubernetes support multiple container runtimes, if you want to use Containerd as container runtime, please make sure Containerd is installed on the node.
#kube_cluster: #IDENTITY# # define kubernetes cluster name kube_role:node # default kubernetes role (master|node)kube_version:1.31.0# kubernetes versionkube_registry:registry.aliyuncs.com/google_containers # kubernetes version aliyun k8s miiror repositorykube_pod_cidr:"10.11.0.0/16"# kubernetes pod network cidrkube_service_cidr:"10.12.0.0/16"# kubernetes service network cidrkube_dashboard_admin_user:dashboard-admin-sa # kubernetes dashboard admin user name
15.6 - Module: Consul
Deploy consul, the alternative of Etcd, with Pigsty.
In the old version (1.x) of Pigsty, Consul was used as the default high-availability DCS. Now this support has been removed, but it will be provided as a separate module in the future.
#-----------------------------------------------------------------# CONSUL#-----------------------------------------------------------------consul_role:node # consul role, node or server, node by defaultconsul_dc:pigsty # consul data center name, `pigsty` by defaultconsul_data:/data/consul # consul data dir, `/data/consul`consul_clean:true# consul purge flag, if true, clean consul during initconsul_ui:false# enable consul ui, the default value for consul server is true
15.7 - Module: Victoria
Deploy VictoriaMetrics & VictoriaLogs, the in-place replacement for Prometheus & Loki.
VictoriaMetrics is the in-place replacement for Prometheus, offering better performance and compression ratio.
Overview
Victoria is currently only available in the Pigsty Professional Edition Beta preview.
It includes the deployment and management of VictoriaMetrics and VictoriaLogs components.
Installation
Pigsty Infra Repo has the RPM / DEB packages for VictoriaMetrics, use the following command to install:
For common users, installing the standalone version of VictoriaMetrics is sufficient.
If you need to deploy a cluster, you can install the victoria-metrics-cluster package.
15.8 - Module: Jupyter
Launch Jupyter notebook server with Pigsty, a web-based interactive scientific notebook.
Run jupyter notebook with docker, you have to:
change the default password in .env: JUPYTER_TOKEN
create data dir with proper permission: make dir, owned by 1000:100
make up to pull up jupyter with docker compose
cd ~/pigsty/app/jupyter ; make dir up
Visit http://lab.pigsty or http://10.10.10.10:8888, the default password is pigsty
importpsycopg2conn=psycopg2.connect('postgres://dbuser_dba:[email protected]:5432/meta')cursor=conn.cursor()cursor.execute('SELECT * FROM pg_stat_activity')foriincursor.fetchall():print(i)
Alias
make up # pull up jupyter with docker composemake dir # create required /data/jupyter and set ownermake run # launch jupyter with dockermake view # print jupyter access pointmake log # tail -f jupyter logsmake info # introspect jupyter with jqmake stop # stop jupyter containermake clean # remove jupyter containermake pull # pull latest jupyter imagemake rmi # remove jupyter imagemake save # save jupyter image to /tmp/docker/jupyter.tgzmake load # load jupyter image from /tmp/docker/jupyter.tgz
16 - Tasks
Look up common tasks and how to perform them using a short sequence of steps
16.1 - DNS: Access Pigsty Web Services with Domain Names
How to configure DNS records to access Pigsty web services using domain names?
After installing Pigsty, users can access most Infra components’ web interfaces via IP + Port.
Let’s say your node’s internal IP is 10.10.10.10, then by default:
While IP + Port works fine for dev/test environments (hey, we’re all lazy sometimes!), for more serious deployments, I strongly recommend accessing these services via domain names.
Using domains has numerous advantages, doesn’t cost extra, and requires just one simple config line.
If you access Nginx directly through the ip:port, it will route to h.pigsty, which is the Pigsty homepage (/www/ directory, served as software repo).
Because Nginx provides multiple services through the same port, it must be distinguished by the domain name (HOST header by the browser). Therefore, by default, Nginx only exposes services with the domain parameter.
And Pigsty will expose grafana, prometheus, and alertmanager services by default in addition to the home server.
How to configure nginx upstream?
Pigsty has a built-in configuration template full.yml, could be used as a reference, and also exposes some Web services in addition to the default services.
Each record in infra_portal is a key-value pair, where the key is the name of the service, and the value is a dictionary.
Currently, there are four available configuration items in the configuration dictionary:
endpoint: REQUIRED, specifies the address of the upstream service, which can be IP:PORT or DOMAIN:PORT.
In this parameter, you can use the placeholder ${admin_ip}, and Pigsty will fill in the value of admin_ip.
domain: OPTIONAL, specifies the domain name of the proxy. If not filled in, Nginx will not expose this service.
For services that need to know the endpoint address but do not want to expose them (such as Loki, Blackbox Exporter), you can leave the domain blank.
scheme: OPTIONAL, specifies the protocol (http/https) when forwarding, leave it blank to default to http.
For services that require HTTPS access (such as the MinIO management interface), you need to specify scheme: https.
websocket: OPTIONAL, specifies whether to enable WebSocket, leave it blank to default to off.
Services that require WebSocket (such as Grafana, Jupyter) need to be set to true to work properly.
If you need to add a new Web service exposed by Nginx, you need to add the corresponding record in the infra_portal parameter in the pigsty.yml file, and then execute the playbook to take effect:
./infra.yml -t nginx # Tune nginx into desired state
To avoid service interruption, you can also execute the following tasks separately:
./infra.yml -t nginx_config # re-generate nginx upstream config in /etc/nginx/conf.d./infra.yml -t nginx_cert # re-generate nginx ssl cert to include new domain namesnginx -s reload # online reload nginx configuration
Nginx distinguishes between different services using the domain name in the HOST header set by the browser. Thus, by default, except for the software repository, you need to access services via domain name.
You can directly access these services via IP address + port, but we recommend accessing all components through Nginx on ports 80/443 using domain names.
When accessing the Pigsty WebUI via domain name, you need to configure DNS resolution or modify the local /etc/hosts file for static resolution. There are several typical methods:
If your service needs to be publicly accessible, you should resolve the internet domain name via a DNS provider (Cloudflare, Aliyun DNS, etc.). Note that in this case, you usually need to modify the Pigsty infra_portalparameter, as the default *.pigsty is not suitable for public use.
If your service needs to be shared within an office network, you should resolve the internal domain name via an internal DNS provider (company internal DNS server) and point it to the IP of the Nginx server. You can request the network administrator to add the appropriate resolution records in the internal DNS server, or ask the system users to manually configure static DNS resolution records.
If your service is only for personal use or a few users (e.g., DBA), you can ask these users to use static domain name resolution records. On Linux/MacOS systems, modify the /etc/hosts file (requires sudo permissions) or C:\Windows\System32\drivers\etc\hosts (Windows) file.
We recommend ordinary single-machine users use the third method, adding the following resolution records on the machine used to access the web system via a browser:
The IP address here is the public IP address where the Pigsty service is installed, and then you can access Pigsty subsystems in the browser via a domain like: http://g.pigsty.
Other web services and custom domains can be added similarly. For example, the following are possible domain resolution records for the Pigsty sandbox demo:
If nginx_sslmode is set to enabled or enforced, you can trust self-signed ca: files/pki/ca/ca.crt to use https in your browser.
Pigsty will generate self-signed certs for Nginx, if you wish to access via HTTPS without “Warning”, here are some options:
Apply & add real certs from trusted CA: such as Let’s Encrypt
Trust your generated CA crt as root ca in your OS and browser
Type thisisunsafe in Chrome will supress the warning
You can access these web UI directly via IP + port. While the common best practice would be access them through Nginx and distinguish via domain names. You’ll need configure DNS records, or use the local static records (/etc/hosts) for that.
How to access Pigsty Web UI by domain name?
There are several options:
Resolve internet domain names through a DNS service provider, suitable for systems accessible from the public internet.
Configure internal network DNS server resolution records for internal domain name resolution.
Modify the local machine’s /etc/hosts file to add static resolution records. (For Windows, it’s located at:)
We recommend the third method for common users. On the machine (which runs the browser), add the following record into /etc/hosts (sudo required) or C:\Windows\System32\drivers\etc\hosts in Windows:
You have to use the external IP address of the node here.
How to configure server side domain names?
The server-side domain name is configured with Nginx. If you want to replace the default domain name, simply enter the domain you wish to use in the parameter infra_portal. When you access the Grafana monitoring homepage via http://g.pigsty, it is actually accessed through the Nginx proxy to Grafana’s WebUI:
How to apply free Let’s Encrypt HTTPS certificates with certbot?
Pigsty comes with the Certbot tool pre-installed and enabled by default on the Infra node.
This means you can directly use the certbot command-line tool to request a genuine Let’s Encrypt free HTTPS certificate for your Nginx server and public domain, instead of using the self-signed HTTPS certificates provided by Pigsty.
To achieve this, you need to:
Determine which domains require certificates
Point these domains to your server
Use Certbot to apply for certificates
Configure a scheduled task to renew the certificates
Be aware of some important considerations when applying for certificates
Here are the detailed steps:
Determine Which Domains Need Certificates
First, decide which “upstream services” need genuine public certificates.
For example, in infra_portal, suppose we need to expose the following five services:
Grafana monitoring dashboard at g.pigsty.cc
Prometheus time-series database at p.pigsty.cc
AlertManager alert dashboard at a.pigsty.cc
Pigsty documentation site at pigsty.cc, pointing to the local documentation directory
Pigsty software repository at repo.pigsty.cc, pointing to the software repository
In this example, we intentionally did not choose to apply for a genuine Let’s Encrypt certificate for the home page. The reason will be explained in the last section.
Point These Domains to Your Server
Next, you need to point the selected domains to your server’s public IP address.
For example, if the Pigsty CC site’s IP address is 47.83.172.23, you can set the following A records for domain resolution in your domain registrar’s DNS control panel (e.g., Alibaba Cloud DNS Console):
The first time you apply, certbot will prompt you to enter your email and agree to the terms of service. Just follow the instructions.
$ certbot --nginx -d pigsty.cc -d repo.pigsty.cc -d g.pigsty.cc -d p.pigsty.cc -d a.pigsty.cc
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Enter email address (used for urgent renewal and security notices)(Enter 'c' to cancel): [email protected]- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Please read the Terms of Service at
https://letsencrypt.org/documents/LE-SA-v1.4-April-3-2024.pdf. You must agree in
order to register with the ACME server. Do you agree?
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o: Y
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Would you be willing, once your first certificate is successfully issued, to
share your email address with the Electronic Frontier Foundation, a founding
partner of the Let's Encrypt project and the non-profit organization that
develops Certbot? We'd like to send you email about our work encrypting the web,
EFF news, campaigns, and ways to support digital freedom.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o: N
Account registered.
Requesting a certificate for pigsty.cc and 4 more domains
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/pigsty.cc/fullchain.pem
Key is saved at: /etc/letsencrypt/live/pigsty.cc/privkey.pem
This certificate expires on 2025-05-18.
These files will be updated when the certificate renews.
Certbot has set up a scheduled task to automatically renew this certificate in the background.
Deploying certificate
Successfully deployed certificate for pigsty.cc to /etc/nginx/conf.d/web.conf
Successfully deployed certificate for repo.pigsty.cc to /etc/nginx/conf.d/repo.conf
Successfully deployed certificate for g.pigsty.cc to /etc/nginx/conf.d/grafana.conf
Successfully deployed certificate for p.pigsty.cc to /etc/nginx/conf.d/prometheus.conf
Successfully deployed certificate for a.pigsty.cc to /etc/nginx/conf.d/alertmanager.conf
Congratulations! You have successfully enabled HTTPS on https://pigsty.cc, https://repo.pigsty.cc, https://g.pigsty.cc, https://p.pigsty.cc, and https://a.pigsty.cc
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
If you like Certbot, please consider supporting our work by:
* Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate
* Donating to EFF: https://eff.org/donate-le
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
After the first application, you can skip these steps and use the command directly for future applications.
Configure a Scheduled Task to Renew the Certificate
By default, certificates are valid for three months, so you should renew them before they expire by using certbot renew.
To renew the certificate, run the following command:
certbot renew
Before executing for real, you can use the DryRun mode to test if the renewal works correctly:
certbot renew --dry-run
If you’ve modified the Nginx configuration file, make sure that Certbot’s changes do not interfere with your configuration.
You can set this command as a crontab job to run on the first day of each month at midnight to renew the certificate and print the log.
Caveats
Special attention should be paid to the SSL certificate for home. When you apply for a certificate for it, Certbot will modify the Nginx configuration file to redirect HTTP on port 80 to HTTPS on port 443. However, this will affect the default repo_upstream local software repository unless you make corresponding adjustments.
16.4 - Docker: Setup & Proxy
How to configure container support in Pigsty? and how to configure mirror & proxy for DockerHub?
Pigsty has a DOCKER module, which provides a set of playbooks to install and manage Docker on the target nodes.
This document will guide you through how to enable Docker support in Pigsty, and how to configure a proxy server for DockerHub.
Install Docker
To install docker on specified nodes, you can use the docker.yml playbook:
./docker.yml -l <ip|group|cls>
That’s it.
Proxy 101
Assuming you have a working HTTP(s) proxy server, if you wish to connect to docker hub or other registry sites via the proxy server:
You proxy service should provide you with something like
If you wish to use a proxy server when Docker pulls images, you should specify the proxy_env parameter in the global variables of the pigsty.yml configuration file:
all:vars:proxy_env:# global proxy env when downloading packagesno_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.myqcloud.com,*.tsinghua.edu.cn"http_proxy:http://192.168.0.106:8118all_proxy:http://192.168.0.106:8118https_proxy:http://192.168.0.106:8118
And when the Docker playbook is executed, these configurations will be rendered as proxy configurations in /etc/docker/daemon.json:
Please note that Docker Daemon does not use the all_proxy parameter
If you wish to manually specify a proxy server, you can directly modify the proxies configuration in /etc/docker/daemon.json;
Or you can modify the service definition in /lib/systemd/system/docker.service (Debian/Ubuntu) and /usr/lib/systemd/system/docker.service to add environment variable declarations in the [Service] section
You can also log in to other mirror sites, such as quay.io, by executing:
docker login quay.io
username #> # input your usernamepassword #> # input your password
16.5 - Use PostgreSQL as Ansible Config Inventory CMDB
Use PostgreSQL instead of static YAML config file as Ansible config inventory
You can use PostgreSQL as a configuration source for Pigsty, replacing the static YAML configuration file.
There are some advantages to using CMDB as a dynamic inventory: metadata is presented in a highly structured way in the form of data tables,
and consistency is ensured through database constraints. At the same time, using CMDB allows you to use third-party tools to edit and manage Pigsty metadata, making it easier to integrate with external systems.
Ansible Inventory
Pigsty’s default configuration file path is specified in ansible.cfg as inventory = pigsty.yml.
Changing this parameter will change the default configuration file path used by Ansible.
If you point it to an executable script file, Ansible will use the dynamic inventory mechanism, execute the script, and expect the script to return a configuration file.
Using CMDB is implemented by editing the ansible.cfg in the Pigsty directory:
We can define a new database grafana on pg-meta.
A Grafana-specific database cluster can also be created on a new machine node: pg-grafana.
Define Cluster
To create a new dedicated database cluster pg-grafana on two bare nodes 10.10.10.11, 10.10.10.12, define it in the config file.
pg-grafana:hosts:10.10.10.11:{pg_seq: 1, pg_role:primary}10.10.10.12:{pg_seq: 2, pg_role:replica}vars:pg_cluster:pg-grafanapg_databases:- name:grafanaowner:dbuser_grafanarevokeconn:truecomment:grafana primary databasepg_users:- name:dbuser_grafanapassword:DBUser.Grafanapgbouncer:trueroles:[dbrole_admin]comment:admin user for grafana database
Create Cluster
Complete the creation of the database cluster pg-grafana with the following command: pgsql.yml.
bin/createpg pg-grafana # Initialize the pg-grafana cluster
This command calls Ansible Playbook pgsql.yml to create the database cluster.
. /pgsql.yml -l pg-grafana # The actual equivalent Ansible playbook command executed
The business users and databases defined in pg_users and pg_databases are created automatically when the cluster is initialized. After creating the cluster using this configuration, the following connection string access database can be used.
postgres://dbuser_grafana:[email protected]:5432/grafana # direct connection to the primarypostgres://dbuser_grafana:[email protected]:5436/grafana # direct connection to the default servicepostgres://dbuser_grafana:[email protected]:5433/grafana # Connect to the string read/write servicepostgres://dbuser_grafana:[email protected]:5432/grafana # direct connection to the primarypostgres://dbuser_grafana:[email protected]:5436/grafana # Direct connection to default servicepostgres://dbuser_grafana:[email protected]:5433/grafana # Connected string read/write service
By default, Pigsty is installed on a single meta node. Then the required users and databases for Grafana are created on the existing pg-meta database cluster instead of using the pg-grafana cluster.
Create Biz User
The convention for business object management is to create users first and then create the database.
Define User
To create a user dbuser_grafana on a pg-meta cluster, add the following user definition to pg-meta’s cluster definition.
Add location: all.children.pg-meta.vars.pg_users.
- name:dbuser_grafanapassword:DBUser.Grafanacomment:admin user for grafana databasepgbouncer:trueroles:[dbrole_admin ]
If you have defined a different password here, replace the corresponding parameter with the new password.
Create User
Complete the creation of the dbuser_grafana user with the following command.
bin/pgsql-user pg-meta dbuser_grafana # Create the `dbuser_grafana` user on the pg-meta cluster
Calls Ansible Playbook pgsql-user.yml to create the user
The dbrole_admin role has the privilege to perform DDL changes in the database, which is precisely what Grafana needs.
Create Biz Database
Define database
Create business databases in the same way as business users. First, add the definition of the new database grafana to the cluster definition of pg-meta.
Use the following command to complete the creation of the grafana database.
bin/pgsql-db pg-meta grafana # Create the `grafana` database on the `pg-meta` cluster
Calls Ansible Playbook pgsql-db.yml to create the database.
. /pgsql-db.yml -l pg-meta -e pg_database=grafana # The actual Ansible playbook to execute
Access Database
Check Connectivity
You can access the database using different services or access methods.
postgres://dbuser_grafana:DBUser.Grafana@meta:5432/grafana # Direct connectionpostgres://dbuser_grafana:DBUser.Grafana@meta:5436/grafana # default servicepostgres://dbuser_grafana:DBUser.Grafana@meta:5433/grafana # primary service
We will use the default service that accesses the database directly from the primary through the LB.
First, check if the connection string is reachable and if you have privileges to execute DDL commands.
psql postgres://dbuser_grafana:DBUser.Grafana@meta:5436/grafana -c \
'CREATE TABLE t(); DROP TABLE t;'
Config Grafana
For Grafana to use the Postgres data source, you need to edit /etc/grafana/grafana.ini and modify the config entries.
[database];type = sqlite3;host = 127.0.0.1:3306;name = grafana;user = root# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;""";password =;url =
See from the monitor system that the new grafana database is already active, then Grafana has started using Postgres as the primary backend database. However, the original Dashboards and Datasources in Grafana have disappeared. You need to re-import Dashboards and Postgres Datasources.
Manage Dashboard
You can reload the Pigsty monitor dashboard by going to the files/ui dir in the Pigsty dir using the admin user and executing grafana.py init.
cd ~/pigsty/files/ui
. /grafana.py init # Initialize the Grafana monitor dashboard using the Dashboards in the current directory
This script detects the current environment (defined at ~/pigsty during installation), gets Grafana access information, and replaces the URL connection placeholder domain name (*.pigsty) in the monitor dashboard with the real one in use.
As a reminder, using grafana.py clean will clear the target monitor dashboard, and using grafana.py load will load all the monitor dashboards in the current dir. When Pigsty’s monitor dashboard changes, you can use these two commands to upgrade all the monitor dashboards.
Manage DataSources
When creating a new PostgreSQL cluster with pgsql.yml or a new business database with pgsql-db.yml, Pigsty will register the new PostgreSQL data source in Grafana, and you can access the target database instance directly through Grafana using the default admin user. Most of the functionality of the application pgcat relies on this.
To register a Postgres database, you can use the register_grafana task in pgsql.yml.
./pgsql.yml -t register_grafana # Re-register all Postgres data sources in the current environment./pgsql.yml -t register_grafana -l pg-test # Re-register all the databases in the pg-test cluster
Update Grafana Database
You can directly change the backend data source used by Grafana by modifying the Pigsty config file. Edit the grafana_database and grafana_pgurl parameters in pigsty.yml and change them.
Then re-execute the grafana task in infral.yml to complete the Grafana upgrade.
./infra.yml -t grafana
16.7 - Use PG as Prometheus Backend
Persist prometheus metrics with PostgreSQL + TimescaleDB through Promscale
It is not recommended to use PostgreSQL as a backend for Prometheus, but it is a good opportunity to understand the
Pigsty deployment system.
Postgres Preparation
vi pigsty.yml # dbuser_prometheus prometheuspg_databases: # define business users/roles on this cluster, array of user definition - { name: prometheus, owner: dbuser_prometheus , revokeconn: true, comment: prometheus primary database }pg_users: # define business users/roles on this cluster, array of user definition - {name: dbuser_prometheus , password: DBUser.Prometheus ,pgbouncer: true , createrole: true, roles: [dbrole_admin], comment: admin user for prometheus database }
Beware that pg_vip_address must be a valid IP address with subnet and available in the current L2 network.
Beware that pg_vip_interface must be a valid network interface name and should be the same as the one using IPv4 address in the inventory.
If the network interface name is different among cluster members, users should explicitly specify the pg_vip_interface parameter for each instance, for example:
Additional configuration and maintenance complexity
Locked huge page memory, less flexibility for systems requiring high resource elasticity
Limited benefits in small memory scenarios, potentially counterproductive
Note: Huge Pages and Transparent Huge Pages (THP) are different concepts. Pigsty will force disable Transparent Huge Pages to follow database best practices.
When to Enable Huge Pages?
We recommend enabling huge pages if your scenario meets the following conditions:
OLAP analytical workloads
Memory exceeding several tens of GB
PostgreSQL 15+
Linux kernel version > 3.10 (> EL7, > Ubuntu 16)
Pigsty does not enable huge pages by default, but you can easily enable them through configuration and dedicate them to PostgreSQL.
Allocate Node Huge Pages
To enable huge pages on a node, users can use these two parameters:
node_hugepage_count: Precisely specify the number of 2MB huge pages to allocate
node_hugepage_ratio: Specify a percentage to allocate a portion of memory as huge pages
Choose one of these parameters. You can either specify the exact number of (2MB) huge pages or the memory ratio to be allocated as huge pages (0.00 - 0.90), with the former having higher priority.
node_hugepage_count:0# Precisely specify number of 2MB huge pages, higher prioritynode_hugepage_ratio:0# Memory ratio allocated as 2MB huge pages, lower priority
Apply changes:
./node.yml -t node_tune
Essentially, this writes the vm.nr_hugepages parameter to /etc/sysctl.d/hugepage.conf and executes sysctl -p to apply changes.
Note: These parameters enable huge pages for the entire node, not just PostgreSQL.
PostgreSQL server attempts to use huge pages by default at startup. If insufficient huge pages are available, PostgreSQL will continue to start using regular pages.
When reducing huge page count, only unused and free huge pages will be released. Used huge pages will be released after process termination.
Pigsty allows allocating up to 90% of memory as huge pages, but for PostgreSQL databases, a reasonable range is typically 25% - 40% of memory.
We recommend setting: node_hugepage_ratio=0.30 and further adjusting huge page count after PostgreSQL startup as needed.
Monitor Huge Page Status
The most intuitive way is to use Pigsty’s monitoring system. Here’s a sample monitoring chart when adjusting huge pages:
If we add some load to PostgreSQL, like pgbench -is10, PostgreSQL will start using more huge pages (Alloc = Total - Free).
Note: Once huge pages are (allocated or reserved), even if you reduce the system’s vm.nr_hugepages parameter, these pages will remain reserved until used up.
Therefore, to truly reclaim these huge pages, you need to restart the PostgreSQL service.
Before PostgreSQL starts, you need to allocate sufficient huge pages, otherwise PostgreSQL won’t be able to use them.
In Pigsty, the default SharedBuffer doesn’t exceed 25% of memory, so you can allocate 26% ~ 27% of memory as huge pages to ensure PostgreSQL can use them.
node_hugepage_ratio:0.27# Allocate 27% of memory as huge pages, definitely enough for PG
If you don’t mind slight resource waste, you can directly allocate around 27% of memory as huge pages.
Reclamation Script
After PG starts, you can query the actual number of huge pages PostgreSQL uses with this SQL:
SHOWshared_memory_size_in_huge_pages;
Finally, you can precisely specify the required number of huge pages:
However, to precisely count the required number of huge pages without missing any, you typically need to wait until the PostgreSQL server starts.
A compromise approach is to:
Initially over-allocate huge pages
Start PostgreSQL
Query the exact required number from PG
Then precisely modify the huge page count
Dedicate Huge Pages to PG
By default, all processes can use huge pages. If you want to restrict huge page usage to PostgreSQL only, you can modify the vm.hugetlb_shm_group kernel parameter.
You can adjust the node_sysctl_params parameter to include PostgreSQL’s GID.
node_sysctl_params:vm.hugetlb_shm_group:26
node_sysctl_params:vm.hugetlb_shm_group:543
Note: Default PostgreSQL UID/GID values differ between EL/Debian, being 26 and 543 respectively (can be explicitly modified via pg_dbsu_uid)
To remove this change:
sysctl -p /etc/sysctl.d/hugepage.conf
Quick Adjustment Script
The pg-tune-hugepage script can reclaim wasted huge pages, but it’s only available for PostgreSQL 15+.
If your PostgreSQL is already running, you can enable huge pages (PG15+ only) using:
sync;echo3 > /proc/sys/vm/drop_caches # Flush disk, free system cache (be prepared for performance impact)sudo /pg/bin/pg-tune-hugepage # Write nr_hugepages to /etc/sysctl.d/hugepage.confpg restart <cls> # Restart postgres to use hugepage
How to deploy a native HA citus cluster with Pigsty & Patroni?
Citus is a PostgreSQL extension that transforms PostgreSQL into a distributed database, enabling horizontal scaling across multiple nodes to handle large amounts of data and queries.
Since Patroni v3.0, native support for Citus high availability has been provided, simplifying the setup of Citus clusters. Pigsty also offers native support for this.
Note: The latest version of Citus (12.1.6) supports PostgreSQL versions 16, 15, and 14, but does not support PostgreSQL 17 and lacks official ARM64 support. Pigsty’s extension repository provides ARM64 packages for Citus, but caution is advised when using it on ARM architecture.
Citus Cluster
Pigsty natively supports Citus. Refer to conf/citus.yml.
This example uses a four-node sandbox with a Citus cluster named pg-citus, consisting of a two-node coordinator cluster pg-citus0 and two worker clusters pg-citus1 and pg-citus2.
pg-citus:hosts:10.10.10.10:{pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.2/24 ,pg_seq: 1, pg_role:primary }10.10.10.11:{pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.2/24 ,pg_seq: 2, pg_role:replica }10.10.10.12:{pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.3/24 ,pg_seq: 1, pg_role:primary }10.10.10.13:{pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.4/24 ,pg_seq: 1, pg_role:primary }vars:pg_mode: citus # pgsql cluster mode:cituspg_version:16# Citus does not support pg16 yetpg_shard: pg-citus # Citus shard name:pg-cituspg_primary_db:citus # primary database used by Cituspg_vip_enabled:true# enable VIP for Citus clusterpg_vip_interface:eth1 # VIP interface for all memberspg_dbsu_password:DBUser.Postgres # all DBSU passwords for Citus clusterpg_extensions:[citus, postgis, pgvector, topn, pg_cron, hll ] # install these extensionspg_libs:'citus, pg_cron, pg_stat_statements'# Citus will be added automatically by Patronipg_users:[{name: dbuser_citus ,password: DBUser.Citus ,pgbouncer: true ,roles:[dbrole_admin ] }]pg_databases:[{name: citus ,owner: dbuser_citus ,extensions:[citus, vector, topn, pg_cron, hll ] }]pg_parameters:cron.database_name:cituscitus.node_conninfo:'sslmode=require sslrootcert=/pg/cert/ca.crt sslmode=verify-full'pg_hba_rules:- {user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title:'all user ssl access from localhost'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'all user ssl access from intranet'}
Compared to a standard PostgreSQL cluster, Citus cluster configuration has some specific requirements. First, ensure that the Citus extension is downloaded, installed, loaded, and enabled. This involves the following four parameters:
repo_packages: Must include the citus extension, or you need to use a PostgreSQL offline package with the Citus extension.
pg_extensions: Must include the citus extension, meaning you need to install the citus extension on each node.
pg_libs: Must include the citus extension, and it must be first in the list, but now Patroni will automatically handle this.
pg_databases: Define a primary database with the citus extension installed.
Additionally, ensure the configuration for the Citus cluster is correct:
pg_mode: Must be set to citus to inform Patroni to use the Citus mode.
pg_primary_db: Specify the primary database name, which must have the citus extension (named citus here).
pg_shard: Specify a unified name as a prefix for all horizontal shard PG clusters (e.g., pg-citus).
pg_group: Specify a shard number, starting from zero for the coordinator cluster and incrementing for worker clusters.
pg_cluster: Must match the combination of [pg_shard] and [pg_group].
pg_dbsu_password: Set a non-empty plain-text password for proper Citus functionality.
pg_parameters: It is recommended to set the citus.node_conninfo parameter, which enforces SSL access and requires node-to-node client certificate verification.
Once configured, deploy the Citus cluster just like a regular PostgreSQL cluster using pgsql.yml.
Managing Citus Clusters
After defining the Citus cluster, use the same playbook pgsql.yml to deploy the Citus cluster:
./pgsql.yml -l pg-citus # Deploy Citus cluster pg-citus
Any DBSU user (postgres) can use patronictl (alias: pg) to list the status of the Citus cluster:
Each horizontal shard cluster can be treated as a separate PGSQL cluster, managed with the pg (patronictl) command. Note that when using pg to manage the Citus cluster, the --group parameter must be used to specify the cluster shard number:
pg list pg-citus --group 0# Use --group 0 to specify the shard number
Citus has a system table called pg_dist_node to record node information, which Patroni automatically maintains.
PGURL=postgres://postgres:[email protected]/citus
psql $PGURL -c 'SELECT * FROM pg_dist_node;'# View node information
Additionally, you can view user authentication information (restricted to superusers):
$ psql $PGURL -c 'SELECT * FROM pg_dist_authinfo;'# View node authentication info (superuser only)
You can then access the Citus cluster with regular business users (e.g., dbuser_citus with DDL permissions):
psql postgres://dbuser_citus:[email protected]/citus -c 'SELECT * FROM pg_dist_node;'
Using the Citus Cluster
When using a Citus cluster, we highly recommend reading the Citus Official Documentation to understand its architecture and core concepts.
Key to this is understanding the five types of tables in Citus, their characteristics, and use cases:
Distributed Table
Reference Table
Local Table
Local Management Table
Schema Table
On the coordinator node, you can create distributed and reference tables and query them from any data node. Since version 11.2, any Citus database node can act as a coordinator.
We can use pgbench to create some tables, distributing the main table (pgbench_accounts) across the nodes, and using other smaller tables as reference tables:
Production citus deployment usually requires physical replication for both coordinator and each worker cluster.
For example, in simu.yml there’s a 10-node cluster cluster:
pg-citus:# citus grouphosts:10.10.10.50:{pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 0, pg_role:primary }10.10.10.51:{pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 1, pg_role:replica }10.10.10.52:{pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 0, pg_role:primary }10.10.10.53:{pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 1, pg_role:replica }10.10.10.54:{pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 0, pg_role:primary }10.10.10.55:{pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 1, pg_role:replica }10.10.10.56:{pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 0, pg_role:primary }10.10.10.57:{pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 1, pg_role:replica }10.10.10.58:{pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 0, pg_role:primary }10.10.10.59:{pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 1, pg_role:replica }vars:pg_mode: citus # pgsql cluster mode:cituspg_version:16# citus does not have pg16 availablepg_shard: pg-citus # citus shard name:pg-cituspg_primary_db:citus # primary database used by cituspg_vip_enabled:true# enable vip for citus clusterpg_vip_interface:eth1 # vip interface for all memberspg_dbsu_password:DBUser.Postgres # enable dbsu password access for cituspg_extensions:[citus, postgis, pgvector, topn, pg_cron, hll ] # install these extensionspg_libs:'citus, pg_cron, pg_stat_statements'# citus will be added by patroni automaticallypg_users:[{name: dbuser_citus ,password: DBUser.Citus ,pgbouncer: true ,roles:[dbrole_admin ] }]pg_databases:[{name: citus ,owner: dbuser_citus ,extensions:[citus, vector, topn, pg_cron, hll ] }]pg_parameters:cron.database_name:cituscitus.node_conninfo:'sslrootcert=/pg/cert/ca.crt sslmode=verify-full'pg_hba_rules:- {user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title:'all user ssl access from localhost'}- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title:'all user ssl access from intranet'}
We’ll cover a range of advanced topics in subsequent tutorials:
Read-write separation
Failover handling
Consistent backup and restore
Advanced monitoring and troubleshooting
Connection pool
16.12 - HA Drill: 2/3 Failure
How to recover from emergency scenario with 2-node broken in a 3-node setup?
When two nodes (majority) in a classic 3-node HA deployment fail simultaneously, automatic failover becomes impossible. Time for some manual intervention - let’s roll up our sleeves!
First, assess the status of the failed nodes. If they can be restored quickly, prioritize bringing them back online. Otherwise, initiate the Emergency Response Protocol.
The Emergency Response Protocol assumes your management node is down, leaving only a single database node alive. In this “last man standing” scenario, here’s the fastest recovery path:
Adjust HAProxy configuration to direct traffic to the primary
Stop Patroni and manually promote the PostgreSQL replica to primary
Adjusting HAProxy Configuration
If you’re accessing the cluster through means other than HAProxy, you can skip this part (lucky you!).
If you’re using HAProxy to access your database cluster, you’ll need to adjust the load balancer configuration to manually direct read/write traffic to the primary.
Edit /etc/haproxy/<pg_cluster>-primary.cfg, where <pg_cluster> is your PostgreSQL cluster name (e.g., pg-meta)
Comment out health check configurations
Comment out the server entries for the two failed nodes, keeping only the current primary
listen pg-meta-primarybind *:5433mode tcpmaxconn 5000balance roundrobin# Comment out these four health check lines#option httpchk # <---- remove this#option http-keep-alive # <---- remove this#http-check send meth OPTIONS uri /primary # <---- remove this#http-check expect status 200 # <---- remove thisdefault-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100server pg-meta-1 10.10.10.10:6432 check port 8008 weight 100# Comment out the failed nodes#server pg-meta-2 10.10.10.11:6432 check port 8008 weight 100 <---- comment this#server pg-meta-3 10.10.10.12:6432 check port 8008 weight 100 <---- comment this
Don’t rush to systemctl reload haproxy just yet - we’ll do that after promoting the primary.
This configuration bypasses Patroni’s health checks and directs write traffic straight to our soon-to-be primary.
Manual Replica Promotion
SSH into the target server, switch to dbsu user, execute a CHECKPOINT to flush disk buffers, stop Patroni, restart PostgreSQL, and perform the promotion:
sudo su - postgres # Switch to database dbsu userpsql -c 'checkpoint; checkpoint;'# Double CHECKPOINT for good luck (and clean buffers)sudo systemctl stop patroni # Bid farewell to Patronipg-restart # Restart PostgreSQLpg-promote # Time for a promotion! psql -c 'SELECT pg_is_in_recovery();'# 'f' means we're primary - mission accomplished!
If you modified the HAProxy config earlier, now’s the time to systemctl reload haproxy and direct traffic to our new primary.
systemctl reload haproxy # Route write traffic to our new primary
Preventing Split-Brain
After stopping the bleeding, priority #2 is: Prevent Split-Brain. We need to ensure the other two servers don’t come back online and start a civil war with our current primary.
The simple approach:
Pull the plug (power/network) on the other two servers - ensure they can’t surprise us with an unexpected comeback
Update application connection strings to point directly to our lone survivor primary
Next steps depend on your situation:
A: The two servers have temporary issues (network/power outage) and can be restored in place
B: The two servers are permanently dead (hardware failure) and need to be decommissioned
Recovery from Temporary Failure
If the other two servers can be restored, follow these steps:
Handle one failed server at a time, prioritizing the management/INFRA node
Start the failed server and immediately stop Patroni
Once ETCD quorum is restored, start Patroni on the surviving server (current primary) to take control of PostgreSQL and reclaim cluster leadership.
Put Patroni in maintenance mode:
systemctl restart patroni
pg pause <pg_cluster>
On the other two instances, create a touch /pg/data/standby.signal file as postgres user to mark them as replicas, then start Patroni:
systemctl restart patroni
After confirming Patroni cluster identity/roles are correct, exit maintenance mode:
pg resume <pg_cluster>
Recovery from Permanent Failure
After permanent failure, first recover the ~/pigsty directory on the management node - particularly the crucial pigsty.yml and files/pki/ca/ca.key files.
No backup of these files? You might need to deploy a fresh Pigsty and migrate your existing cluster via backup cluster.
Pro tip: Keep your pigsty directory under version control (Git). Learn from this experience - future you will thank present you.
Config Repair
Use your surviving node as the new management node. Copy the ~/pigsty directory there and adjust the configuration.
For example, replace the default management node 10.10.10.10 with the surviving node 10.10.10.12:
all:vars:admin_ip:10.10.10.12# New management node IPnode_etc_hosts:[10.10.10.12h.pigsty a.pigsty p.pigsty g.pigsty sss.pigsty]infra_portal:{}# Update other configs referencing old admin_ipchildren:infra:# Adjust Infra clusterhosts:# 10.10.10.10: { infra_seq: 1 } # Old Infra node10.10.10.12:{infra_seq:3}# New Infra nodeetcd:# Adjust ETCD clusterhosts:#10.10.10.10: { etcd_seq: 1 } # Comment out failed node#10.10.10.11: { etcd_seq: 2 } # Comment out failed node10.10.10.12:{etcd_seq:3}# Keep survivorvars:etcd_cluster:etcdpg-meta:# Adjust PGSQL cluster confighosts:#10.10.10.10: { pg_seq: 1, pg_role: primary }#10.10.10.11: { pg_seq: 2, pg_role: replica }#10.10.10.12: { pg_seq: 3, pg_role: replica , pg_offline_query: true }10.10.10.12:{pg_seq: 3, pg_role: primary , pg_offline_query:true}vars:pg_cluster:pg-meta
After module repairs, follow the standard scale-out procedure to add new nodes and restore HA.
16.13 - Restic: FS Backup/Recovery
How to use Restic for regular file system backup and recovery
While Pigsty handles PostgreSQL database backup and recovery, how do we handle backup and recovery for regular files and directories?
For various business applications using PostgreSQL (such as Odoo, GitLab), you can use Restic to regularly backup file system data (e.g., /data/odoo).
Restic is an excellent open-source backup tool that supports snapshots, incremental backups, encryption, compression, and can use various services including S3/MinIO as backup repositories.
For detailed information, please refer to the restic documentation.
Quick Start
Pigsty Infra repository provides ready-to-use latest Restic RPM/DEB packages, while most Linux distributions’ official repositories offer older versions.
yum install -y restic
apt install -y restic
For demonstration purposes, we’ll use a local directory as the backup repository. Repository initialization only needs to be done once:
exportAWS_ACCESS_KEY_ID=minioadmin # Default MinIO accountexportAWS_SECRET_ACCESS_KEY=minioadmin # Default MinIO passwordrestic -r s3:http://sss.pigsty:9000/infra init # Use the default infra bucket as backup destination
16.14 - JuiceFS: S3FS & PGFS
How to build a distributed cloud-native filesystem JuiceFS using PostgreSQL and MinIO provided by Pigsty.
JuiceFS is a high-performance, cloud-native distributed filesystem.
This guide demonstrates how to build a production-grade JuiceFS cluster using PostgreSQL as the metadata engine and MinIO as the object storage engine, both provided by Pigsty.
juicefs mount sqlite3:///tmp/jfs.db ~/jfs # Foreground mount, auto-unmounts on exitjuicefs mount sqlite3:///tmp/jfs.db ~/jfs -d # Daemon mount, requires manual unmountjuicefs umount ~/jfs # Unmount and exit process
Data Cleanup
Clear JuiceFS metadata from PostgreSQL using:
DROP TABLE IF EXISTS jfs_acl,jfs_chunk,jfs_chunk_ref,jfs_counter,jfs_delfile,jfs_delslices,jfs_detached_node,jfs_dir_quota,jfs_dir_stats,jfs_edge,jfs_flock,jfs_node,jfs_plock,jfs_session2,jfs_setting,jfs_sustained,jfs_symlink,jfs_xattr CASCADE;
Clear object storage bucket using:
mcli rm --recursive --force infra/jfs
PGFS Performance Summary
Benchmark results on second-hand physical hardware:
METAURL=postgres://dbuser_meta:DBUser.Meta@:5432/meta
OPTIONS=( --storage postgres
--bucket :5432/meta
--access-key dbuser_meta
--secret-key DBUser.Meta
${METAURL} jfs
)juicefs format "${OPTIONS[@]}"juicefs mount ${METAURL} ~/jfs -d # Mount in backgroundjuicefs bench ~/jfs # Run benchmarkjuicefs umount ~/jfs # Unmount
Out-of-the-box config templates to launch application use PostgreSQL as the core database.
PostgreSQL is the most popular database in the world, with countless classic software built on top of it. Pigsty provides ready-to-use provisioning templates for it.
Pigsty’s template utilizes external PostgreSQL, MinIO, and Etcd services managed and created by Pigsty,
including full backup and recovery, high availability, monitoring and alerting, Infrastructure as Code (IaC),
connection pooling, load balancing, and more. It also addresses “last mile” issues like infrastructure,
Nginx forwarding, and certificate application. Compared to using Docker to launch an entire software stack,
including the database, in a “toy mode,” it provides the capabilities needed for “enterprise-grade” solutions.
17.1 - Self-Hosting Dify
How to use Pigsty to build an AI Workflow LLMOps platform — Dify, and use external PostgreSQL, PGVector, Redis as storage?
Dify is a generative AI application innovation engine and open-source LLM application development platform. It provides capabilities from Agent construction to AI workflow orchestration, RAG retrieval, and model management, helping users easily build and operate generative AI-native applications.
Pigsty provides support for self-hosting Dify, allowing you to deploy Dify with a single command while storing critical state in externally managed PostgreSQL. You can use pgvector in the same PostgreSQL instance as a vector database, further simplifying deployment.
Dify listens on port 5001 by default. You can access it via browser at http://<ip>:5001 and set up your initial user credentials to log in.
After Dify starts, you can install various extensions, configure system models, and begin using it!
Why Self-Host
There are many reasons to self-host Dify, but the primary motivation is data security.
The DockerCompose template provided by Dify uses basic default database images, lacking enterprise-grade features like high availability, disaster recovery, monitoring, IaC, and PITR capabilities.
Pigsty elegantly solves these issues for Dify, deploying all components with a single command based on configuration files, and using mirrors to resolve China region access challenges. This makes Dify deployment and delivery incredibly smooth. It handles PostgreSQL master database, PGVector vector database, MinIO object storage, Redis, Prometheus monitoring, Grafana visualization, Nginx reverse proxy, and free HTTPS certificates in one go.
Pigsty ensures all Dify state is stored in externally managed services, including metadata in PostgreSQL and other data in the filesystem. Therefore, the Dify instance launched via Docker Compose becomes a stateless application that can be destroyed and rebuilt at any time, greatly simplifying operations.
Installation
Let’s start with single-node Dify deployment. We’ll cover production high-availability deployment methods later.
curl -fsSL https://repo.pigsty.cc/get | bash;cd ~/pigsty
./bootstrap # Prepare Pigsty dependencies./configure -c app/supa # Use Supabase application templatevi pigsty.yml # Edit config file, modify domain and passwords./install.yml # Install Pigsty and various databases
When you use the ./configure -c app/dify command, Pigsty automatically generates the configuration file based on the conf/app/dify.yml template and your current environment. You should modify passwords, domain, and other relevant parameters in the generated pigsty.yml configuration file according to your actual needs, then use ./install.yml to execute the standard installation process.
Next, run docker.yml to install Docker and Docker Compose, then use app.yml to complete Dify deployment:
./docker.yml # Install Docker and Docker Compose./app.yml # Deploy Dify stateless components using Docker
You can access the Dify Web management interface at http://<your_ip_address>:5001 on your local network.
Default username, email, and password will be prompted for setup on first login.
You can also use the locally resolved placeholder domain dify.pigsty, or follow the configuration below to use a real domain with HTTPS certificates.
Configuration
When you use the ./configure -c app/dify command for configuration, Pigsty automatically generates the configuration file based on the conf/app/dify.yml template and your current environment. Here’s a detailed explanation of the default configuration:
all:children:# the dify applicationdify:hosts:{10.10.10.10:{}}vars:app:dify # specify app name to be installed (in the apps)apps:# define all applicationsdify:# app name, should have corresponding ~/pigsty/app/dify folderfile:# data directory to be created- {path: /data/dify ,state: directory ,mode:0755}conf:# override /opt/dify/.env config file# change domain, mirror, proxy, secret keyNGINX_SERVER_NAME:dify.pigsty# A secret key for signing and encryption, gen with `openssl rand -base64 42` (CHANGE PASSWORD!)SECRET_KEY:sk-9f73s3ljTXVcMT3Blb3ljTqtsKiGHXVcMT3BlbkFJLK7U# expose DIFY nginx service with port 5001 by defaultDIFY_PORT:5001# where to store dify files? the default is ./volume, we'll use another volume created aboveDIFY_DATA:/data/dify# proxy and mirror settings#PIP_MIRROR_URL: https://pypi.tuna.tsinghua.edu.cn/simple#SANDBOX_HTTP_PROXY: http://10.10.10.10:12345#SANDBOX_HTTPS_PROXY: http://10.10.10.10:12345# database credentialsDB_USERNAME:difyDB_PASSWORD:difyai123456DB_HOST:10.10.10.10DB_PORT:5432DB_DATABASE:difyVECTOR_STORE:pgvectorPGVECTOR_HOST:10.10.10.10PGVECTOR_PORT:5432PGVECTOR_USER:difyPGVECTOR_PASSWORD:difyai123456PGVECTOR_DATABASE:difyPGVECTOR_MIN_CONNECTION:2PGVECTOR_MAX_CONNECTION:10pg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-metapg_users:- {name: dify ,password: difyai123456 ,pgbouncer: true ,roles: [ dbrole_admin ] ,superuser: true ,comment:dify superuser }pg_databases:- {name: dify ,owner: dify ,revokeconn: true ,comment:dify main database }pg_hba_rules:- {user: dify ,db: all ,addr: 172.17.0.0/16 ,auth: pwd ,title:'allow dify access from local docker network'}node_crontab:['00 01 * * * postgres /pg/bin/pg-backup full']# make a full backup every 1aminfra:{hosts:{10.10.10.10:{infra_seq:1}}}etcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }#minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }vars:# global variablesversion:v3.4.1 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymldocker_enabled:true# enable docker on app group#docker_registry_mirrors: ["https://docker.1ms.run"] # use mirror in mainland chinaproxy_env:# global proxy env when downloading packages & pull docker imagesno_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.tsinghua.edu.cn"#http_proxy: 127.0.0.1:12345 # add your proxy env here for downloading packages or pull images#https_proxy: 127.0.0.1:12345 # usually the proxy is format as http://user:[email protected]#all_proxy: 127.0.0.1:12345infra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}#minio : { domain: m.pigsty ,endpoint: "${admin_ip}:9001" ,scheme: https ,websocket: true }dify:# nginx server config for difydomain:dify.pigsty # REPLACE WITH YOUR OWN DOMAIN!endpoint:"10.10.10.10:5001"# dify service endpoint: IP:PORTwebsocket:true# add websocket supportcertbot:dify.pigsty # certbot cert name, apply with `make cert`#----------------------------------## Credential: CHANGE THESE PASSWORDS#----------------------------------##grafana_admin_username: admingrafana_admin_password:pigsty#pg_admin_username: dbuser_dbapg_admin_password:DBUser.DBA#pg_monitor_username: dbuser_monitorpg_monitor_password:DBUser.Monitor#pg_replication_username: replicatorpg_replication_password:DBUser.Replicator#patroni_username: postgrespatroni_password:Patroni.API#haproxy_admin_username: adminhaproxy_admin_password:pigsty#minio_access_key: minioadminminio_secret_key:minioadmin # minio root secret key, `minioadmin` by defaultrepo_extra_packages:[pg17-main ]pg_version:17
Checklist
Here’s a checklist of configuration items you need to focus on:
Best to specify an email address certbot_email for receiving certificate expiration notifications
Configure Dify’s NGINX_SERVER_NAME parameter to specify your actual domain
all:children:# Cluster definitiondify:# Dify groupvars:# Dify group variablesapps:# Application configurationdify:# Dify application definitionconf:# Dify application configurationNGINX_SERVER_NAME:dify.pigstyvars:# Global parameters#certbot_sign: true # Use Certbot to apply for free HTTPS certificatecertbot_email:[email protected]# Email for certificate application, used for expiration notifications, optionalinfra_portal:# Configure Nginx serverdify:# Dify server definitiondomain:dify.pigsty # Please replace with your own domain here!endpoint:"10.10.10.10:5001"# Please specify Dify's IP and port here (default auto-configured)websocket:true# Dify needs websocket enabled certbot:dify.pigsty # Specify Certbot certificate name
Use the following command to apply for Nginx certificates:
# Apply for certificates, can also manually execute /etc/nginx/sign-cert scriptmake cert
# The above Makefile shortcut command actually executes the following playbook tasks:./infra.yml -t nginx_certbot,nginx_reload -e certbot_sign=true
Execute app.yml playbook to redeploy Dify service to make NGINX_SERVER_NAME configuration take effect.
./app.yml
File Backup
You can use restic to backup Dify’s filesystem. Dify’s data files are in the /data/dify directory. You can use the following commands to backup:
Odoo is an open-source enterprise resource planning (ERP) software
that provides a full suite of business applications, including CRM, sales, purchasing, inventory, production, accounting, and other management functions. Odoo is a typical web application that uses PostgreSQL as the underlying database.
All your business on one platform, Simple, efficient, yet affordable
Get Started
curl -fsSL https://repo.pigsty.io/get | bash;cd ~/pigsty
./bootstrap # install ansible./configure -c app/odoo # use odoo config (please CHANGE CREDENTIALS in pigsty.yml)./install.yml # install pigsty./docker.yml # install docker compose./app.yml # launch odoo stateless part with docker
Config Template
The conf/app/odoo.yml defines a template configuration file that defines the resources required for a single Odoo instance.
all:children:# the odoo application (default username & password: admin/admin)odoo:hosts:{10.10.10.10:{}}vars:app:odoo # specify app name to be installed (in the apps)apps:# define all applicationsodoo:# app name, should have corresponding ~/app/odoo folderfile:# optional directory to be created- {path: /data/odoo ,state: directory, owner: 100, group:101}- {path: /data/odoo/webdata ,state: directory, owner: 100, group:101}- {path: /data/odoo/addons ,state: directory, owner: 100, group:101}conf:# override /opt/<app>/.env config filePG_HOST:10.10.10.10# postgres hostPG_PORT:5432# postgres portPG_USERNAME:odoo # postgres userPG_PASSWORD:DBUser.Odoo # postgres passwordODOO_PORT:8069# odoo app portODOO_DATA:/data/odoo/webdata # odoo webdataODOO_ADDONS:/data/odoo/addons # odoo pluginsODOO_DBNAME:odoo # odoo database nameODOO_VERSION:18.0# odoo image version# the odoo databasepg-odoo:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-odoopg_users:- {name: odoo ,password: DBUser.Odoo ,pgbouncer: true ,roles: [ dbrole_admin ] ,createdb: true ,comment:admin user for odoo service }- {name: odoo_ro ,password: DBUser.Odoo ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment:read only user for odoo service }- {name: odoo_rw ,password: DBUser.Odoo ,pgbouncer: true ,roles: [ dbrole_readwrite ] ,comment:read write user for odoo service }pg_databases:- {name: odoo ,owner: odoo ,revokeconn: true ,comment:odoo main database }pg_hba_rules:- {user: all ,db: all ,addr: 172.17.0.0/16 ,auth: pwd ,title:'allow access from local docker network'}- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title:'allow grafana dashboard access cmdb from infra nodes'}infra:{hosts:{10.10.10.10:{infra_seq:1}}}etcd:{hosts:{10.10.10.10:{etcd_seq: 1 } }, vars:{etcd_cluster:etcd } }#minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }vars:# global variablesversion:v3.3.0 # pigsty version stringadmin_ip:10.10.10.10# admin node ip addressregion: default # upstream mirror region:default|china|europenode_tune: oltp # node tuning specs:oltp,olap,tiny,critpg_conf: oltp.yml # pgsql tuning specs:{oltp,olap,tiny,crit}.ymldocker_enabled:true# enable docker on app group#docker_registry_mirrors: ["https://docker.m.daocloud.io"] # use dao cloud mirror in mainland chinaproxy_env:# global proxy env when downloading packages & pull docker imagesno_proxy:"localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.tsinghua.edu.cn"#http_proxy: 127.0.0.1:12345 # add your proxy env here for downloading packages or pull images#https_proxy: 127.0.0.1:12345 # usually the proxy is format as http://user:[email protected]#all_proxy: 127.0.0.1:12345infra_portal:# domain names and upstream servershome :{domain:h.pigsty }grafana :{domain: g.pigsty ,endpoint:"${admin_ip}:3000", websocket:true}prometheus :{domain: p.pigsty ,endpoint:"${admin_ip}:9090"}alertmanager :{domain: a.pigsty ,endpoint:"${admin_ip}:9093"}blackbox :{endpoint:"${admin_ip}:9115"}loki :{endpoint:"${admin_ip}:3100"}minio :{domain: m.pigsty ,endpoint:"${admin_ip}:9001",scheme: https ,websocket:true}odoo :{domain: odoo.pigsty, endpoint:"127.0.0.1:8069",websocket: true } #cert: /path/to/crt ,key:/path/to/key# setup your own domain name here ^^^, or use default domain name, or ip + 8069 port direct access# certbot --nginx --agree-tos --email [email protected] -n -d odoo.your.domain # replace with your email & odoo domain#----------------------------------## Credential: CHANGE THESE PASSWORDS#----------------------------------##grafana_admin_username: admingrafana_admin_password:pigsty#pg_admin_username: dbuser_dbapg_admin_password:DBUser.DBA#pg_monitor_username: dbuser_monitorpg_monitor_password:DBUser.Monitor#pg_replication_username: replicatorpg_replication_password:DBUser.Replicator#patroni_username: postgrespatroni_password:Patroni.API#haproxy_admin_username: adminhaproxy_admin_password:pigstyrepo_modules:infra,node,pgsql,dockerrepo_packages:[node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility, docker ]repo_extra_packages:[pg17-main ]pg_version:17
Get Started
Check .env file for configurable environment variables:
make up # pull up odoo with docker compose in minimal modemake run # launch odoo with docker , local data dir and external PostgreSQLmake view # print odoo access pointmake log # tail -f odoo logsmake info # introspect odoo with jqmake stop # stop odoo containermake clean # remove odoo containermake pull # pull latest odoo imagemake rmi # remove odoo imagemake save # save odoo image to /tmp/docker/odoo.tgzmake load # load odoo image from /tmp/docker/odoo.tgz
Use External PostgreSQL
You can use external PostgreSQL for Odoo. Odoo will create its own database during setup, so you don’t need to do that
If you want to access odoo through SSL, you have to trust files/pki/ca/ca.crt on your browser (or use the dirty hack thisisunsafe in chrome)
17.3 - Self-Hosting Supabase on PostgreSQL
A tutorial for self-hosting production-grade supabase on local/cloud VM/BMs.
Supabase is great, own your own Supabase is even better.
Here’s a comprehensive tutorial for self-hosting production-grade supabase on local/cloud VM/BMs.
Supabase is an open-source Firebase alternative, a Backend as a Service (BaaS).
Supabase wraps PostgreSQL kernel and vector extensions, alone with authentication, realtime subscriptions, edge functions, object storage, and instant REST and GraphQL APIs from your postgres schema.
It let you skip most backend work, requiring only database design and frontend skills to ship quickly.
Currently, Supabase may be the most popular open-source project in the PostgreSQL ecosystem, boasting over 74,000 stars on GitHub.
And become quite popular among developers, and startups, since they have a generous free plan, just like cloudflare & neon.
Why Self-Hosting?
Supabase’s slogan is: “Build in a weekend, Scale to millions”. It has great cost-effectiveness in small scales (4c8g) indeed.
But there is no doubt that when you really grow to millions of users, some may choose to self-hosting their own Supabase —— for functionality, performance, cost, and other reasons.
That’s where Pigsty comes in. Pigsty provides a complete one-click self-hosting solution for Supabase.
Self-hosted Supabase can enjoy full PostgreSQL monitoring, IaC, PITR, and high availability capability,
You can run the latest PostgreSQL 17(,16,15) kernels, (supabase is using the 15 currently), alone with 404 PostgreSQL extensions out-of-the-box.
Run on mainstream Linus OS distros with production grade HAPostgreSQL, MinIO, Prometheus & Grafana Stack for observability, and Nginx for reverse proxy.
Since most of the supabase maintained extensions are not available in the official PGDG repo,
we have compiled all the RPM/DEBs for these extensions and put them in the Pigsty repo:
pg_graphql: GraphQL support in PostgreSQL (Rust extension via PIGSTY)
pg_jsonschema: JSON Schema validation (Rust extension via PIGSTY)
wrappers: Supabase’s foreign data source wrappers bundle (Rust extension via PIGSTY)
index_advisor: Query index advisor (SQL extension via PIGSTY)
pg_net: Async non-blocking HTTP/HTTPS requests in SQL (C extension via PIGSTY)
vault: Store encrypted credentials in Vault (C extension via PIGSTY)
pgjwt: PostgreSQL implementation of JSON Web Token API (SQL extension via PIGSTY)
pgsodium: Table data encryption storage TDE (C extension via PIGSTY)
supautils: Secure database clusters in cloud environments (C extension via PIGSTY)
pg_plan_filter: Block specific queries using execution plan cost filtering (C extension via PIGSTY)
Everything is under your control, you have the ability and freedom to scale PGSQL, MinIO, and Supabase itself.
And take full advantage of the performance and cost advantages of modern hardware like Gen5 NVMe SSD.
All you need is prepare a VM with several commands and wait for 10 minutes….
Get Started
First, download & install pigsty as usual, with the supa config template:
Please change the pigsty.yml config file according to your need before deploying Supabase. (Credentials)
For dev/test/demo purposes, we will just skip that, and comes back later.
Then, run the docker.yml & app.yml to launch stateless part of supabase.
./docker.yml # install docker compose./app.yml # launch dify stateless part with docker
You can access the supabase API / Web UI through the 8000/8443 directly.
with configured DNS, or a local /etc/hosts entry, you can also use the default supa.pigsty domain name via the 80/443 infra portal.
Credentials for Supabase Studio: supabase : pigsty
The stateful part of this template is replaced by Pigsty’s managed PostgreSQL cluster and MinIO cluster.
The container part are stateless, so you can launch / destroy / run multiple supabase containers on the same stateful PGSQL / MINIO cluster simultaneously to scale out.
If you’re using Supabase on your local machine or within a LAN, you can directly connect to Supabase via IP:Port through Kong’s exposed HTTP port 8000.
You can use a locally resolved domain name, but for serious production deployments, we recommend using a real domain name + HTTPS to access Supabase. In this case, you typically need to prepare the following:
Your server should have a public IP address
Purchase a domain name, use the DNS resolution services provided by cloud/DNS/CDN providers to point it to your installation node’s public IP (lower alternative: local /etc/hosts)
Apply for a certificate, using free HTTPS certificates issued by certificate authorities like Let’s Encrypt for encrypted communication (lower alternative: default self-signed certificates, manually trusted)
You can refer to the certbot tutorial to apply for a free HTTPS certificate. Here we assume your custom domain name is: supa.pigsty.cc, then you should modify the supa domain in infra_portal like this:
all:vars:infra_portal:supa :domain:supa.pigsty.cc # replace with your own domain!endpoint:"10.10.10.10:8000"websocket:truecertbot:supa.pigsty.cc # certificate name, usually the same as the domain name
If the domain name has been resolved to your server’s public IP, then you can automatically complete the certificate application and application in the Pigsty directory by executing the following command:
Configure them to your custom domain name, for example: supa.pigsty.cc, then apply the configuration again:
./app.yml -t app_config,app_launch
As a lower alternative, you can use a local domain name to access Supabase.
When using a local domain name, you can configure the resolution of supa.pigsty in the browser’s /etc/hosts or LAN DNS, pointing it to the public IP address of the installation node.
The Nginx on the Pigsty management node will apply for a self-signed certificate for this domain name (the browser will display Unsecure), and forward the request to the 8000 port of Kong, which is processed by Supabase.
MinIO or External S3
Pigsty’s self-hosting supabase will use a local SNSD MinIO server,
which is used by Supabase itself for object storage, and by PostgreSQL for backups.
For production use, you should consider using a HA MNMD MinIO cluster or an external S3 compatible service instead.
We recommend using an external S3 when:
you just have one single server available, then external s3 gives you a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
you are operating in the cloud, then using S3 directly is recommended rather than wrap expensively EBS with MinIO
To use an external S3 compatible service, you’ll have to update two related references in the pigsty.yml config.
First, let’s update the S3 related configurations in all.children.supa.vars.apps.[supabase].conf, pointing it to the external S3 compatible service:
# if using s3/minio as file storageS3_BUCKET:supaS3_ENDPOINT:https://sss.pigsty:9000S3_ACCESS_KEY:supabaseS3_SECRET_KEY:S3User.SupabaseS3_FORCE_PATH_STYLE:trueS3_PROTOCOL:httpsS3_REGION:stubMINIO_DOMAIN_IP:10.10.10.10# sss.pigsty domain name will resolve to this ip statically
Then, reload the supabase service with the following command:
./app.yml -t app_config,app_launch
You can also use S3 as the backup repository for PostgreSQL, in all.vars.pgbackrest_repo add a new aliyun backup repository definition:
all:vars:pgbackrest_method: aliyun # pgbackrest backup method:local,minio,[other user-defined repositories...]pgbackrest_repo: # pgbackrest backup repository:https://pgbackrest.org/configuration.html#section-repositoryaliyun:# define a new backup repository aliyuntype:s3 # aliyun oss is s3-compatible object storages3_endpoint:oss-cn-beijing-internal.aliyuncs.coms3_region:oss-cn-beijing s3_bucket:pigsty-osss3_key:xxxxxxxxxxxxxxs3_key_secret:xxxxxxxxs3_uri_style:hostpath:/pgbackrestbundle:ycipher_type:aes-256-cbccipher_pass:PG.${pg_cluster} # set a cipher password bound to the cluster nameretention_full_type:time retention_full:14
Then, specify the use of the aliyun backup repository in all.vars.pgbackrest_mehod, and reset the pgBackrest backup:
./pgsql.yml -t pgbackrest
Pigsty will switch the backup repository to the external object storage.
Sending Mail with SMTP
Some Supabase features require email. For production use, I’d recommend using an external SMTP service.
Since self-hosted SMTP servers often result in rejected or spam-flagged emails.
To do this, modify the Supabase configuration and add SMTP credentials:
all:children:supa:# supa groupvars:# supa group varsapps:# supa group app listsupabase:# the supabase appconf:# the supabase app conf entriesSMTP_HOST:smtpdm.aliyun.com:80SMTP_PORT:80SMTP_USER:[email protected]SMTP_PASS:your_email_user_passwordSMTP_SENDER_NAME:MySupabaseSMTP_ADMIN_EMAIL:[email protected]ENABLE_ANONYMOUS_USERS:false
And don’t forget to reload the supabase service with ./app.yml -t app_config,app_launch
Backup Strategy
In the supabase template, Pigsty has already used a daily full backup at 01:00 AM,
you can refer to the backup/restore to modify the backup strategy.
all:children:pg-meta:hosts:{10.10.10.10:{pg_seq: 1, pg_role:primary } }vars:pg_cluster:pg-meta # daily full backup at 01:00 AMnode_crontab:['00 01 * * * postgres /pg/bin/pg-backup full']
Then, apply the Crontab configuration to the nodes with the following command:
The default single-node deployment (with external S3) provide a minimal disaster recovery guarantee, with RTO in hours and RPO in MBs.
To achieve RTO < 30s and zero data loss, you need a multi-node high availability cluster with at least 3-nodes.
Which involves high availability for these components:
ETCD: DCS requires at least three nodes to tolerate one node failure.
PGSQL: PGSQL synchronous commit mode recommends at least three nodes.
INFRA: It’s good to have two or three copies of observability stack.
Supabase itself can also have multiple replicas to achieve high availability.
We recommend you to refer to the trio and safe config to upgrade your cluster to three nodes or more.
In this case, you also need to modify the access points for PostgreSQL and MinIO to use the DNS / L2 VIP / HAProxy HA access points.
18 - Software
Software and tools that use PostgreSQL can be managed by the docker daemon
PostgreSQL is the most popular database in the world, and countless software is built on PostgreSQL, around PostgreSQL, or serves PostgreSQL itself, such as
“Application software” that uses PostgreSQL as the preferred database
“Tooling software” that serves PostgreSQL software development and management
“Database software” that derives, wraps, forks, modifies, or extends PostgreSQL
And Pigsty just have a series of Docker Compose templates for these software, application and databases:
Expose PostgreSQL & Pgbouncer Metrics for Prometheus
How to prepare Docker?
To run docker compose templates, you need to install the DOCKER module on the node,
If you don’t have the Internet access or having firewall issues, you may need to configure a DockerHub proxy, check the tutorial.
18.1 - Kong: the Nginx API Gateway
Learn how to deploy Kong, the API gateway, with Docker Compose and use external PostgreSQL as the backend database
TL;DR
cd app/kong ; docker-compose up -d
make up # pull up kong with docker-composemake ui # run swagger ui containermake log # tail -f kong logsmake info # introspect kong with jqmake stop # stop kong containermake clean # remove kong containermake rmui # remove swagger ui containermake pull # pull latest kong imagemake rmi # remove kong imagemake save # save kong image to /tmp/kong.tgzmake load # load kong image from /tmp
importpsycopg2conn=psycopg2.connect('postgres://dbuser_dba:[email protected]:5432/meta')cursor=conn.cursor()cursor.execute('SELECT * FROM pg_stat_activity')foriincursor.fetchall():print(i)
Alias
make up # pull up jupyter with docker composemake dir # create required /data/jupyter and set ownermake run # launch jupyter with dockermake view # print jupyter access pointmake log # tail -f jupyter logsmake info # introspect jupyter with jqmake stop # stop jupyter containermake clean # remove jupyter containermake pull # pull latest jupyter imagemake rmi # remove jupyter imagemake save # save jupyter image to /tmp/docker/jupyter.tgzmake load # load jupyter image from /tmp/docker/jupyter.tgz
18.3 - Gitea: Simple Self-Hosting Git Service
Launch the self-hosting Git service with Gitea and Pigsty managed PostgreSQL
make up # pull up gitea with docker-compose in minimal modemake run # launch gitea with docker , local data dir and external PostgreSQLmake view # print gitea access pointmake log # tail -f gitea logsmake info # introspect gitea with jqmake stop # stop gitea containermake clean # remove gitea containermake pull # pull latest gitea imagemake rmi # remove gitea imagemake save # save gitea image to /tmp/gitea.tgzmake load # load gitea image from /tmp
PostgreSQL Preparation
Gitea use built-in SQLite as default metadata storage, you can let Gitea use external PostgreSQL by setting connection string environment variable
docker run -p 9000:9000 -p 9001:9001 \
-e "MINIO_ROOT_USER=admin"\
-e "MINIO_ROOT_PASSWORD=pigsty.minio"\
minio/minio server /data --console-address ":9001"
visit http://10.10.10.10:9000 with user admin and password pigsty.minio
make up # pull up minio with docker-composemake run # launch minio with dockermake view # print minio access pointmake log # tail -f minio logsmake info # introspect minio with jqmake stop # stop minio containermake clean # remove minio containermake pull # pull latest minio imagemake rmi # remove minio imagemake save # save minio image to /tmp/minio.tgzmake load # load minio image from /tmp
18.6 - ByteBase: PG Schema Migration
Self-hosting bytebase with PostgreSQL managed by Pigsty
ByteBase
ByteBase is a database schema change management tool, which is a tool for database schema changes. The following command will start a ByteBase on the meta node 8887 port by default.
Then visit http://10.10.10.10:8887/ 或 http://ddl.pigsty to access bytebase console. You have to “Create Project”, “Env”, “Instance”, “Database” to perform schema migration.
make up # pull up bytebase with docker-compose in minimal modemake run # launch bytebase with docker , local data dir and external PostgreSQLmake view # print bytebase access pointmake log # tail -f bytebase logsmake info # introspect bytebase with jqmake stop # stop bytebase containermake clean # remove bytebase containermake pull # pull latest bytebase imagemake rmi # remove bytebase imagemake save # save bytebase image to /tmp/bytebase.tgzmake load # load bytebase image from /tmp
PostgreSQL Preparation
Bytebase use its internal PostgreSQL database by default, You can use external PostgreSQL for higher durability.
If you wish to perform CRUD operations and design more fine-grained permission control, please refer
to Tutorial 1 - The Golden Key to generate a signed JWT.
This is an example of creating pigsty cmdb API with PostgREST
cd ~/pigsty/app/postgrest ; docker-compose up -d
http://10.10.10.10:8884 is the default endpoint for PostgREST
http://10.10.10.10:8883 is the default api docs for PostgREST
make up # pull up postgrest with docker-composemake run # launch postgrest with dockermake ui # run swagger ui containermake view # print postgrest access pointmake log # tail -f postgrest logsmake info # introspect postgrest with jqmake stop # stop postgrest containermake clean # remove postgrest containermake rmui # remove swagger ui containermake pull # pull latest postgrest imagemake rmi # remove postgrest imagemake save # save postgrest image to /tmp/postgrest.tgzmake load # load postgrest image from /tmp
Swagger UI
Launch a swagger OpenAPI UI and visualize PostgREST API on 8883 with:
covid: Visualizes WHO COVID-19 data and allows you to check pandemic data by country.
isd: NOAA ISD, which provides access to meteorological observation records from 30,000 surface weather stations worldwide since 1901.
Structure
A Pigsty applet provides an installation script in its root directory: install or a related shortcut. You need to run this script as an admin user on the admin node to execute the installation. The installation script will detect the current environment (fetching METADB_URL, PIGSTY_HOME, GRAFANA_ENDPOINT, etc.) to complete the installation.
Typically, dashboards with the APP tag will be listed in the Pigsty Grafana homepage navigation under the Apps dropdown menu, and dashboards with both APP and OVERVIEW tags will be listed in the homepage panel navigation.
19.1 - Analyse CSVLOG Sample with the built-in PGLOG
Analyse CSVLOG Sample with the built-in PGLOG
PGLOG is a sample application included with Pigsty that uses the pglog.sample table in MetaDB as the data source.
Simply populate this table with logs and access the corresponding Dashboard.
Pigsty provides some handy commands to fetch CSV logs and load them into the sample table. The following shortcut commands are available on the master node by default:
catlog [node=localhost][date=today]# Print CSV logs to standard outputpglog # Load CSVLOG from standard inputpglog12 # Load CSVLOG in PG12 formatpglog13 # Load CSVLOG in PG13 formatpglog14 # Load CSVLOG in PG14 format (=pglog)catlog | pglog # Analyze logs of the current node for todaycatlog node-1 '2021-07-15'| pglog # Analyze CSV logs of node-1 for 2021-07-15
Next, you can visit the following links to view sample log analysis dashboards:
The catlog command fetches CSV database logs from a specific node for a specific date and writes them to stdout.
By default, catlog fetches logs of the current node for today, but you can specify the node and date via parameters.
By combining pglog and catlog, you can quickly fetch and analyze database CSV logs.
catlog | pglog # Analyze logs of the current node for todaycatlog node-1 '2021-07-15'| pglog # Analyze CSV logs of node-1 for 2021-07-15
19.2 - NOAA ISD Station
Fetch, Parse, Analyze, and Visualize Integrated Surface Weather Station Dataset
Including 30000 meteorology station, daily, sub-hourly observation records, from 1900-2023. https://github.com/Vonng/isd
It is recommended to use with Pigsty, the battery-included PostgreSQL distribution with Grafana & echarts for visualization. It will setup everything for your with make all;
Otherwise, you’ll have to provide your own PostgreSQL instance, and setup grafana dashboards manually.
Export PGURL in your environment to specify the target postgres database:
# the default PGURL for pigsty's meta database, change that accordinglyexportPGURL=postgres://dbuser_dba:[email protected]:5432/meta?sslmode=disable
psql "${PGURL}" -c 'SELECT 1'# check if connection is ok
make sql # setup postgres schema on target database
Get isd station metadata
The basic station metadata can be downloaded and loaded with:
make reload-station # equivalent to get-station + load-station
Fetch and load isd.daily
To load isd.daily dataset, which is organized by yearly tarball files.
You can download the raw data from noaa and parse with isd parser
make get-parser # download parser binary from github, you can just build with: make buildmake reload-daily # download and reload latest daily data and re-calculates monthly/yearly data
Load Parsed Stable CSV Data
Or just load the pre-parsed stable part from GitHub.
Which is well-formatted CSV that does not require an isd parser.
make get-stable # download stable isd.daily dataset from Githubmake load-stable # load downloaded stable isd.daily dataset into database
More Data
There are two parts of isd datasets needs to be regularly updated: station metadata & isd.daily of the latest year, you can reload them with:
make reload # reload-station + reload-daily
You can download and load isd.daily in a specific year with:
bin/get-daily 2022# get daily observation summary of a specific year (1900-2023)bin/load-daily "${PGURL}"2022# load daily data of a specific year
You can also download and load isd.hourly in a specific year with:
bin/get-hourly 2022# get hourly observation record of a specific year (1900-2023)bin/load-hourly "${PGURL}"2022# load hourly data of a specific year
CREATETABLEIFNOTEXISTSisd.daily(stationVARCHAR(12)NOTNULL,-- station number 6USAF+5WBAN
tsDATENOTNULL,-- observation date
-- temperature & dew point
temp_meanNUMERIC(3,1),-- mean temperature ℃
temp_minNUMERIC(3,1),-- min temperature ℃
temp_maxNUMERIC(3,1),-- max temperature ℃
dewp_meanNUMERIC(3,1),-- mean dew point ℃
-- pressure
slp_meanNUMERIC(5,1),-- sea level pressure (hPa)
stp_meanNUMERIC(5,1),-- station pressure (hPa)
-- visible distance
vis_meanNUMERIC(6),-- visible distance (m)
-- wind speed
wdsp_meanNUMERIC(4,1),-- average wind speed (m/s)
wdsp_maxNUMERIC(4,1),-- max wind speed (m/s)
gustNUMERIC(4,1),-- max wind gust (m/s)
-- precipitation / snow depth
prcp_meanNUMERIC(5,1),-- precipitation (mm)
prcpNUMERIC(5,1),-- rectified precipitation (mm)
sndpNuMERIC(5,1),-- snow depth (mm)
-- FRSHTT (Fog/Rain/Snow/Hail/Thunder/Tornado)
is_foggyBOOLEAN,-- (F)og
is_rainyBOOLEAN,-- (R)ain or Drizzle
is_snowyBOOLEAN,-- (S)now or pellets
is_hailBOOLEAN,-- (H)ail
is_thunderBOOLEAN,-- (T)hunder
is_tornadoBOOLEAN,-- (T)ornado or Funnel Cloud
-- record count
temp_countSMALLINT,-- record count for temp
dewp_countSMALLINT,-- record count for dew point
slp_countSMALLINT,-- record count for sea level pressure
stp_countSMALLINT,-- record count for station pressure
wdsp_countSMALLINT,-- record count for wind speed
visib_countSMALLINT,-- record count for visible distance
-- temp marks
temp_min_fBOOLEAN,-- aggregate min temperature
temp_max_fBOOLEAN,-- aggregate max temperature
prcp_flagCHAR,-- precipitation flag: ABCDEFGHI
PRIMARYKEY(station,ts));-- PARTITION BY RANGE (ts);
ISD Hourly
CREATETABLEIFNOTEXISTSisd.hourly(stationVARCHAR(12)NOTNULL,-- station id
tsTIMESTAMPNOTNULL,-- timestamp
-- air
tempNUMERIC(3,1),-- [-93.2,+61.8]
dewpNUMERIC(3,1),-- [-98.2,+36.8]
slpNUMERIC(5,1),-- [8600,10900]
stpNUMERIC(5,1),-- [4500,10900]
visNUMERIC(6),-- [0,160000]
-- wind
wd_angleNUMERIC(3),-- [1,360]
wd_speedNUMERIC(4,1),-- [0,90]
wd_gustNUMERIC(4,1),-- [0,110]
wd_codeVARCHAR(1),-- code that denotes the character of the WIND-OBSERVATION.
-- cloud
cld_heightNUMERIC(5),-- [0,22000]
cld_codeVARCHAR(2),-- cloud code
-- water
sndpNUMERIC(5,1),-- mm snow
prcpNUMERIC(5,1),-- mm precipitation
prcp_hourNUMERIC(2),-- precipitation duration in hour
prcp_codeVARCHAR(1),-- precipitation type code
-- sky
mw_codeVARCHAR(2),-- manual weather observation code
aw_codeVARCHAR(2),-- auto weather observation code
pw_codeVARCHAR(1),-- weather code of past period of time
pw_hourNUMERIC(2),-- duration of pw_code period
-- misc
-- remark TEXT,
-- eqd TEXT,
dataJSONB-- extra data
)PARTITIONBYRANGE(ts);
Parser
There are two parsers: isdd and isdh, which takes noaa original yearly tarball as input, generate CSV as output (which could be directly consumed by PostgreSQL COPY command).
NAME
isd -- Intergrated Surface Dataset Parser
SYNOPSIS
isd daily [-i <input|stdin>][-o <output|stout>][-v] isd hourly [-i <input|stdin>][-o <output|stout>][-v][-d raw|ts-first|hour-first]DESCRIPTION
The isd program takes noaa isd daily/hourly raw tarball data as input.
and generate parsed data in csv format as output. Works in pipe mode
cat data/daily/2023.tar.gz | bin/isd daily -v | psql ${PGURL} -AXtwqc "COPY isd.daily FROM STDIN CSV;" isd daily -v -i data/daily/2023.tar.gz | psql ${PGURL} -AXtwqc "COPY isd.daily FROM STDIN CSV;" isd hourly -v -i data/hourly/2023.tar.gz | psql ${PGURL} -AXtwqc "COPY isd.hourly FROM STDIN CSV;"OPTIONS
-i <input> input file, stdin by default
-o <output> output file, stdout by default
-p <profpath> pprof file path, enableif specified
-d de-duplicate rows for hourly dataset (raw, ts-first, hour-first) -v verbose mode
-h print help
UI
ISD Overview
Show all stations on a world map.
ISD Country
Show all stations among a country.
ISD Station
Visualize station metadata and daily/monthly/yearly summary
Enter the app folder and run make to perform the installation:
make # if local data is viablemake all # download data from WHOmakd reload # re-download the latest data
Other subtasks:
make reload # download latest data and pour it againmake ui # install grafana dashboardsmake sql # install database schemasmake download # download latest datamake load # load downloaded data into databasemake reload # download latest data and pour it into database
Added new pgBackRest backup monitoring metrics and dashboards
Enhanced Nginx server configuration options, with support for automated Certbot issuance
Now prioritizing PostgreSQL’s built-in C/C.UTF-8 locale settings
IvorySQL 4.4 is now fully supported across all platforms (RPM/DEB on x86/ARM)
Added new software packages: Juicefs, Restic, TimescaleDB EventStreamer
The Apache AGE graph database extension now fully supports PostgreSQL 13–17 on EL
Improved the app.yml playbook: launch standard Docker app without extra config
Bump Supabase, Dify, and Odoo app templates, bump to their latest versions
Add electric app template, local-first PostgreSQL Sync Engine
Infra Packages
+restic 0.17.3
+juicefs 1.2.3
+timescaledb-event-streamer 0.12.0
Prometheus 3.2.1
AlertManager 0.28.1
blackbox_exporter 0.26.0
node_exporter 1.9.0
mysqld_exporter 0.17.2
kafka_exporter 1.9.0
redis_exporter 1.69.0
pgbackrest_exporter 0.19.0-2
DuckDB 1.2.1
etcd 3.5.20
FerretDB 2.0.0
tigerbeetle 0.16.31
vector 0.45.0
VictoriaMetrics 1.113.0
VictoriaLogs 1.17.0
rclone 1.69.1
pev2 1.14.0
grafana-victorialogs-ds 0.16.0
grafana-victoriametrics-ds 0.14.0
grafana-infinity-ds 3.0.0
PostgreSQL Related
Patroni 4.0.5
PolarDB 15.12.3.0-e1e6d85b
IvorySQL 4.4
pgbackrest 2.54.2
pev2 1.14
WiltonDB 13.17
PostgreSQL Extensions
pgspider_ext 1.3.0 (new extension)
apache age 13–17 el rpm (1.5.0)
timescaledb 2.18.2 → 2.19.0
citus 13.0.1 → 13.0.2
documentdb 1.101-0 → 1.102-0
pg_analytics 0.3.4 → 0.3.7
pg_search 0.15.2 → 0.15.8
pg_ivm 1.9 → 1.10
emaj 4.4.0 → 4.6.0
pgsql_tweaks 0.10.0 → 0.11.0
pgvectorscale 0.4.0 → 0.6.0 (pgrx 0.12.5)
pg_session_jwt 0.1.2 → 0.2.0 (pgrx 0.12.6)
wrappers 0.4.4 → 0.4.5 (pgrx 0.12.9)
pg_parquet 0.2.0 → 0.3.1 (pgrx 0.13.1)
vchord 0.2.1 → 0.2.2 (pgrx 0.13.1)
pg_tle 1.2.0 → 1.5.0
supautils 2.5.0 → 2.6.0
sslutils 1.3 → 1.4
pg_profile 4.7 → 4.8
pg_snakeoil 1.3 → 1.4
pg_jsonschema 0.3.2 → 0.3.3
pg_incremental 1.1.1 → 1.2.0
pg_stat_monitor 2.1.0 → 2.1.1
ddl_historization 0.7 → 0.0.7 (bug fix)
pg_sqlog 3.1.7 → 1.6 (bug fix)
pg_random removed development suffix (bug fix)
asn1oid 1.5 → 1.6
table_log 0.6.1 → 0.6.4
Interface Changes
Added new Docker parameters: docker_data and docker_storage_driver (#521 by @waitingsong)
Added new Infra parameter: alertmanager_port, which lets you specify the AlertManager port
Added new Infra parameter: certbot_sign, apply for cert during nginx init? (false by default)
Added new Infra parameter: certbot_email, specifying the email used when requesting certificates via Certbot
Added new Infra parameter: certbot_options, specifying additional parameters for Certbot
Updated IvorySQL to place its default binary under /usr/ivory-4 starting in IvorySQL 4.4
Changed the default for pg_lc_ctype and other locale-related parameters from en_US.UTF-8 to C
For PostgreSQL 17, if using UTF8 encoding with C or C.UTF-8 locales, PostgreSQL’s built-in localization rules now take priority
configure automatically detects whether C.utf8 is supported by both the PG version and the environment, and adjusts locale-related options accordingly
Set the default IvorySQL binary path to /usr/ivory-4
Updated the default value of pg_packages to pgsql-main patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager
Updated the default value of repo_packages to [node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility, extra-modules]
Removed LANG and LC_ALL environment variable settings from /etc/profile.d/node.sh
Now using bento/rockylinux-8 and bento/rockylinux-9 as the Vagrant box images for EL
Added a new alias, extra_modules, which includes additional optional modules
curl -fsSL https://repo.pigsty.io/get | bash
cd ~/pigsty; ./bootstrap; ./configure; ./install.yml
Highlight Features
Extension Exploding:
Pigsty now has an unprecedented 390 available extensions for PostgreSQL. This includes 121 extension RPM packages and 133DEB packages, surpassing the total number of extensions provided by the PGDG official repository (135 RPM/109 DEB).
Pigsty has ported unique PG extensions from the EL/DEB system to each other, achieving a great alignment of extension ecosystems between the two major distributions.
A crude list of the extension ecosystem is as follows:
Pigsty v3 allows you to replace the PostgreSQL kernel, currently supporting Babelfish (SQL Server compatible, with wire protocol emulation), IvorySQL (Oracle compatible), and RAC PolarDB for PostgreSQL.
Additionally, self-hosted Supabase is now available on Debian systems. You can emulate MSSQL (via WiltonDB), Oracle (via IvorySQL), Oracle RAC (via PolarDB), MongoDB (via FerretDB), and Firebase (via Supabase) in Pigsty
with production-grade PostgreSQL clusters featuring HA, IaC, PITR, and monitoring.
Pro Edition:
We now offer PGSTY Pro, a professional edition that provides value-added services on top of the open-source features.
The professional edition includes additional modules: MSSQL, Oracle, Mongo, K8S, Victoria, Kafka, etc., and offers broader support for PG major versions, operating systems, and chip architectures.
It provides offline installation packages customized for precise minor versions of all operating systems, and support for legacy systems like EL7, Debian 11, Ubuntu 20.04.
Major Changes
This Pigsty release updates the major version number from 2.x to 3.0, with several significant changes:
Primary supported operating systems updated to: EL 8 / EL 9 / Debian 12 / Ubuntu 22.04
EL7 / Debian 11 / Ubuntu 20.04 systems are now deprecated and no longer supported.
Default to online installation, offline packages are no longer provided to resolve minor OS version compatibility issues.
The bootstrap process will no longer prompt for downloading offline packages, but if /tmp/pkg.tgz exists, it will still use the offline package automatically.
For offline installation needs, please create offline packages yourself or consider our subscription service.
Unified adjustment of upstream software repositories used by Pigsty, address changes, and GPG signing and verification for all packages.
Standard repository: https://repo.pigsty.io/{apt/yum}
Domestic mirror: https://repo.pigsty.cc/{apt/yum}
API parameter changes and configuration template changes
Configuration templates for EL and Debian systems are now consolidated, with differing parameters managed in the roles/node_id/vars/ directory.
Configuration directory changes, all configuration file templates are now placed in the conf directory and categorized into default, dbms, demo, build.
Docker is now completely treated as a separate module, and will not be downloaded by default
New beta module: KAFKA
New beta module: KUBE
Other New Features
Epic enhancement of PG OLAP analysis capabilities: DuckDB 1.0.0, DuckDB FDW, and PG Lakehouse, Hydra have been ported to the Debian system.
Resolved package build issues for ParadeDB, now available on Debian/Ubuntu.
All required extensions for Supabase are now available on Debian/Ubuntu, making Supabase self-hostable across all OSes.
Provided capability for scenario-based pre-configured extension stacks. If you’re unsure which extensions to install, we offer extension recommendation packages (Stacks) tailored for specific application scenarios.
Created metadata tables, documentation, indexes, and name mappings for all PostgreSQL ecosystem extensions, ensuring alignment and usability for both EL and Debian systems.
Enhanced proxy_env parameter functionality to mitigate DockerHub ban issues, simplifying configuration.
Established a new dedicated software repository offering all extension plugins for versions 12-17, with the PG16 extension repository implemented by default in Pigsty.
Upgraded existing software repositories, employing standard signing and verification mechanisms to ensure package integrity and security. The APT repository adopts a new standard layout built through reprepro.
Provided sandbox environments for 1, 2, 3, 4, 43 nodes: meta, dual, trio, full, prod, and quick configuration templates for 7 major OS Distros.
Add PostgreSQL 17 and pgBouncer 1.23 metrics support in pg_exporter config, adding related dashboard panels.
Add logs panel for PGSQL Pgbouncer / PGSQL Patroni Dashboard
Add new playbook cache.yml to make offline packages, instead of bash bin/cache and bin/release-pkg
API Changes
New parameter option: pg_mode now have several new options:
pgsql: Standard PostgreSQL high availability cluster.
citus: Citus horizontally distributed PostgreSQL native high availability cluster.
gpsql: Monitoring for Greenplum and GP compatible databases (Pro edition).
mssql: Install WiltonDB / Babelfish to provide Microsoft SQL Server compatibility mode for standard PostgreSQL high availability clusters, with wire protocol level support, extensions unavailable.
ivory: Install IvorySQL to provide Oracle compatibility for PostgreSQL high availability clusters, supporting Oracle syntax/data types/functions/stored procedures, extensions unavailable (Pro edition).
polar: Install PolarDB for PostgreSQL (PG RAC) open-source version to support localization database capabilities, extensions unavailable (Pro edition).
New parameter: pg_parameters, used to specify parameters in postgresql.auto.conf at the instance level, overriding cluster configurations for personalized settings on different instance members.
New parameter: pg_files, used to specify additional files to be written to the PostgreSQL data directory, to support license feature required by some kernel forks.
New parameter: repo_extra_packages, used to specify additional packages to download, to be used in conjunction with repo_packages, facilitating the specification of extension lists unique to OS versions.
Parameter renaming: patroni_citus_db renamed to pg_primary_db, used to specify the primary database in the cluster (used in Citus mode).
Parameter enhancement: Proxy server configurations in proxy_env will be written to the Docker Daemon to address internet access issues, and the configure -x option will automatically write the proxy server configuration of the current environment.
Parameter enhancement: Allow using path item in infra_portal entries, to expose local dir as web service rather than proxy to another upstream.
Parameter enhancement: The repo_url_packages in repo.pigsty.io will automatically switch to repo.pigsty.cc when the region is China, addressing internet access issues. Additionally, the downloaded file name can now be specified.
Parameter enhancement: The extension field in pg_databases.extensions now supports both dictionary and extension name string modes. The dictionary mode offers version support, allowing the installation of specific extension versions.
Parameter enhancement: If the repo_upstream parameter is not explicitly overridden, it will extract the default value for the corresponding system from rpm.yml or deb.yml.
Parameter enhancement: If the repo_packages parameter is not explicitly overridden, it will extract the default value for the corresponding system from rpm.yml or deb.yml.
Parameter enhancement: If the infra_packages parameter is not explicitly overridden, it will extract the default value for the corresponding system from rpm.yml or deb.yml.
Parameter enhancement: If the node_default_packages parameter is not explicitly overridden, it will extract the default value for the corresponding system from rpm.yml or deb.yml.
Parameter enhancement: The extensions specified in pg_packages and pg_extensions will now perform a lookup and translation from the pg_package_map defined in rpm.yml or deb.yml.
Parameter enhancement: Packages specified in node_packages and pg_extensions will be upgraded to the latest version upon installation. The default value in node_packages is now [openssh-server], helping to fix the OpenSSH CVE.
Parameter enhancement: pg_dbsu_uid will automatically adjust to 26 (EL) or 543 (Debian) based on the operating system type, avoiding manual adjustments.
pgBouncer Parameter update, max_prepared_statements = 128 enabled prepared statement support in transaction pooling mode, and set server_lifetime to 600.
Patroni template parameter update, uniformly increase max_worker_processes +8 available backend processes, increase max_wal_senders and max_replication_slots to 50, and increase the OLAP template temporary file size limit to 1/5 of the main disk.
Software Upgrade
The main components of Pigsty are upgraded to the following versions (as of the release time):
Get the latest source with bash -c "$(curl -fsSL http://get.pigsty.cc/latest)"
Download & Extract packages with new download script.
Monitor Enhancement
Split monitoring system into 5 major categories: INFRA, NODES, REDIS, PGSQL, APP
Logging enabled by default
now loki and promtail are enabled by default. with prebuilt loki-rpm
Models & Labels
A hidden ds prometheus datasource variable is added for all dashboards, so you can easily switch different datasource simply by select a new one rather than modifying Grafana Datasources & Dashboards
An ip label is added for all metrics, and will be used as join key between database metrics & nodes metrics
INFRA Monitoring
Home dashboard for infra: INFRA Overview
Add logging Dashboards : Logs Instance
PGLOG Analysis & PGLOG Session now treated as an example Pigsty APP.
NODES Monitoring Application
If you don’t care database at all, Pigsty now can be used as host monitoring software alone!
New Panels: PGSQL Cluster, add 10 key metrics panel (toggled by default)
New Panels: PGSQL Instance, add 10 key metrics panel (toggled by default)
Simplify & Redesign: PGSQL Service
Add cross-references between PGCAT & PGSL dashboards
[ENHANCEMENT] monitor deploy
Now grafana datasource is automatically registered during monly deployment
[ENHANCEMENT] software upgrade
add PostgreSQL 13 to default package list
upgrade to PostgreSQL 14.1 by default
add greenplum rpm and dependencies
add redis rpm & source packages
add perf as default packages
v1.2.0
[ENHANCEMENT] Use PostgreSQL 14 as default version
[ENHANCEMENT] Use TimescaleDB 2.5 as default extension
now timescaledb & postgis are enabled in cmdb by default
[ENHANCEMENT] new monitor-only mode:
you can use pigsty to monitor existing pg instances with a connectable url only
pg_exporter will be deployed on meta node locally
new dashboard PGSQL Cluster Monly for remote clusters
[ENHANCEMENT] Software upgrade
grafana to 8.2.2
pev2 to v0.11.9
promscale to 0.6.2
pgweb to 0.11.9
Add new extensions: pglogical pg_stat_monitor orafce
[ENHANCEMENT] Automatic detect machine spec and use proper node_tune and pg_conf templates
[ENHANCEMENT] Rework on bloat related views, now more information are exposed
[ENHANCEMENT] Remove timescale & citus internal monitoring
[ENHANCEMENT] New playbook pgsql-audit.yml to create audit report.
[BUG FIX] now pgbouncer_exporter resource owner are {{ pg_dbsu }} instead of postgres
[BUG FIX] fix pg_exporter duplicate metrics on pg_table pg_index while executing REINDEX TABLE CONCURRENTLY
[CHANGE] now all config templates are minimize into two: auto & demo. (removed: pub4, pg14, demo4, tiny, oltp )
pigsty-demo is configured if vagrant is the default user, otherwise pigsty-auto is used.
How to upgrade from v1.1.1
There’s no API change in 1.2.0 You can still use old pigsty.yml configuration files (PG13).
For the infrastructure part. Re-execution of repo will do most of the parts
As for the database. You can still use the existing PG13 instances. In-place upgrade is quite
tricky especially when involving extensions such as PostGIS & Timescale. I would highly recommend
performing a database migration with logical replication.
The new playbook pgsql-migration.yml will make this a lot easier. It will create a series of
scripts which will help you to migrate your cluster with near-zero downtime.
v1.1.1
[ENHANCEMENT] replace timescaledb apache version with timescale version
[ENHANCEMENT] upgrade prometheus to 2.30
[BUG FIX] now pg_exporter config dir’s owner are {{ pg_dbsu }} instead of prometheus
How to upgrade from v1.1.0
The major change in this release is timescaledb. Which replace old apache license version with timescale license version
promtail_clean remove existing promtail status during init?
promtail_port default port used by promtail, 9080 by default
promtail_status_file location of promtail status file
promtail_send_url endpoint of loki service which receives log data
v0.8.0
Service Provisioning support is added in this release
New Features
Service provision.
full locale support.
API Changes
Role vip and haproxy are merged into service.
#------------------------------------------------------------------------------# SERVICE PROVISION#------------------------------------------------------------------------------pg_weight:100# default load balance weight (instance level)# - service - #pg_services:# how to expose postgres service in cluster?# primary service will route {ip|name}:5433 to primary pgbouncer (5433->6432 rw)- name:primary # service name {{ pg_cluster }}_primarysrc_ip:"*"src_port:5433dst_port:pgbouncer # 5433 route to pgbouncercheck_url:/primary # primary health check, success when instance is primaryselector:"[]"# select all instance as primary service candidate# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)- name:replica # service name {{ pg_cluster }}_replicasrc_ip:"*"src_port:5434dst_port:pgbouncercheck_url:/read-only # read-only health check. (including primary)selector:"[]"# select all instance as replica service candidateselector_backup:"[? pg_role == `primary`]"# primary are used as backup server in replica service# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)- name:default # service's actual name is {{ pg_cluster }}-{{ service.name }}src_ip:"*"# service bind ip address, * for all, vip for cluster virtual ip addresssrc_port:5436# bind port, mandatorydst_port: postgres # target port:postgres|pgbouncer|port_number , pgbouncer(6432) by defaultcheck_method: http # health check method:only http is available for nowcheck_port: patroni # health check port:patroni|pg_exporter|port_number , patroni by defaultcheck_url:/primary # health check url path, / as defaultcheck_code:200# health check http code, 200 as defaultselector:"[]"# instance selectorhaproxy:# haproxy specific fieldsmaxconn:3000# default front-end connectionbalance:roundrobin # load balance algorithm (roundrobin by default)default_server_options:'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)- name:offline # service name {{ pg_cluster }}_replicasrc_ip:"*"src_port:5438dst_port:postgrescheck_url:/replica # offline MUST be a replicaselector:"[? pg_role == `offline` || pg_offline_query ]"# instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'selector_backup:"[? pg_role == `replica` && !pg_offline_query]"# replica are used as backup server in offline servicepg_services_extra:[]# extra services to be added# - haproxy - #haproxy_enabled:true# enable haproxy among every cluster membershaproxy_reload:true# reload haproxy after confighaproxy_policy:roundrobin # roundrobin, leastconnhaproxy_admin_auth_enabled:false# enable authentication for haproxy admin?haproxy_admin_username:admin # default haproxy admin usernamehaproxy_admin_password:admin # default haproxy admin passwordhaproxy_exporter_port:9101# default admin/exporter porthaproxy_client_timeout:3h # client side connection timeouthaproxy_server_timeout:3h # server side connection timeout# - vip - #vip_mode:none # none | l2 | l4vip_reload:true# whether reload service after config# vip_address: 127.0.0.1 # virtual ip address ip (l2 or l4)# vip_cidrmask: 24 # virtual ip address cidr mask (l2 only)# vip_interface: eth0 # virtual ip network interface (l2 only)
New Options
# - localization - #pg_encoding:UTF8 # default to UTF8pg_locale:C # default to Cpg_lc_collate:C # default to Cpg_lc_ctype:en_US.UTF8 # default to en_US.UTF8pg_reload:true# reload postgres after hba changesvip_mode:none # none | l2 | l4vip_reload:true# whether reload service after config
Remove Options
haproxy_check_port # covered by service options
haproxy_primary_port
haproxy_replica_port
haproxy_backend_port
haproxy_weight
haproxy_weight_fallback
vip_enabled # replace by vip_mode
Service
pg_services and pg_services_extra Defines the services in cluster:
A service has some mandatory fields:
name: service’s name
src_port: which port to listen and expose service?
selector: which instances belonging to this service?
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)- name:default # service's actual name is {{ pg_cluster }}-{{ service.name }}src_ip:"*"# service bind ip address, * for all, vip for cluster virtual ip addresssrc_port:5436# bind port, mandatorydst_port: postgres # target port:postgres|pgbouncer|port_number , pgbouncer(6432) by defaultcheck_method: http # health check method:only http is available for nowcheck_port: patroni # health check port:patroni|pg_exporter|port_number , patroni by defaultcheck_url:/primary # health check url path, / as defaultcheck_code:200# health check http code, 200 as defaultselector:"[]"# instance selectorhaproxy:# haproxy specific fieldsmaxconn:3000# default front-end connectionbalance:roundrobin # load balance algorithm (roundrobin by default)default_server_options:'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
Database
Add additional locale support: lc_ctype and lc_collate.
It’s mainly because of pg_trgm ’s weird behavior on i18n characters.
pg_databases:- name:meta # name is the only required field for a database# owner: postgres # optional, database owner# template: template1 # optional, template1 by default# encoding: UTF8 # optional, UTF8 by default , must same as template database, leave blank to set to db default# locale: C # optional, C by default , must same as template database, leave blank to set to db default# lc_collate: C # optional, C by default , must same as template database, leave blank to set to db default# lc_ctype: C # optional, C by default , must same as template database, leave blank to set to db defaultallowconn:true# optional, true by default, false disable connect at allrevokeconn:false# optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)# tablespace: pg_default # optional, 'pg_default' is the default tablespaceconnlimit:-1# optional, connection limit, -1 or none disable limit (default)extensions:# optional, extension name and where to create- {name: postgis, schema:public}parameters:# optional, extra parameters with ALTER DATABASEenable_partitionwise_join:truepgbouncer:true# optional, add this database to pgbouncer list? true by defaultcomment:pigsty meta database # optional, comment string for database
v0.7.0
Monitor only deployment support
Overview
Monitor Only Deployment
Now you can monitoring existing postgres clusters without Pigsty provisioning solution.
Intergration with other provisioning solution is available and under further test.
Database/User Management
Update user/database definition schema to cover more usecases.
Add pgsql-createdb.yml and pgsql-user.yml to mange user/db on running clusters.
service_registry:consul # none | consul | etcd | bothprometheus_options:'--storage.tsdb.retention=30d'# prometheus cli optsprometheus_sd_method: consul # Prometheus service discovery method:static|consulprometheus_sd_interval:2s # Prometheus service discovery refresh intervalpg_offline_query:false# set to true to allow offline queries on this instancenode_exporter_enabled:true# enabling Node Exporterpg_exporter_enabled:true# enabling PG Exporterpgbouncer_exporter_enabled:true# enabling Pgbouncer Exporterexport_binary_install:false# install Node/PG Exporter via copy binarydcs_disable_purge:false# force dcs_exists_action = abort to avoid dcs purgepg_disable_purge:false# force pg_exists_action = abort to avoid pg purgehaproxy_weight:100# relative lb weight for backend instancehaproxy_weight_fallback:1# primary server weight in replica service group
Obsolete Config Entries
prometheus_metrics_path # duplicate with exporter_metrics_path prometheus_retention # covered by `prometheus_options`
pg_databases:# create a business database 'meta'- name:metaschemas:[meta] # create extra schema named 'meta'extensions:[{name:postgis}] # create extra extension postgisparameters:# overwrite database meta's default search_pathsearch_path:public, monitor
New Schema
pg_databases:- name:meta # name is the only required field for a databaseowner:postgres # optional, database ownertemplate:template1 # optional, template1 by defaultencoding:UTF8 # optional, UTF8 by defaultlocale:C # optional, C by defaultallowconn:true# optional, true by default, false disable connect at allrevokeconn:false# optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)tablespace:pg_default # optional, 'pg_default' is the default tablespaceconnlimit:-1# optional, connection limit, -1 or none disable limit (default)extensions:# optional, extension name and where to create- {name: postgis, schema:public}parameters:# optional, extra parameters with ALTER DATABASEenable_partitionwise_join:truepgbouncer:true# optional, add this database to pgbouncer list? true by defaultcomment:pigsty meta database # optional, comment string for database
Changes
Add new options: template , encoding, locale, allowconn, tablespace, connlimit
Add new option revokeconn, which revoke connect privileges from public for this database
Add comment field for database
Apply Changes
You can create new database on running postgres clusters with pgsql-createdb.yml playbook.
Define your new database in config files
Pass new database.name with option pg_database to playbook.
pg_users:- username:test # example production user have read-write accesspassword:test # example user's passwordoptions:LOGIN # extra optionsgroups:[dbrole_readwrite ] # dborole_admin|dbrole_readwrite|dbrole_readonlycomment:default test user for production usagepgbouncer:true# add to pgbouncer
New Schema
pg_users:# complete example of user/role definition for production user- name:dbuser_meta # example production user have read-write accesspassword:DBUser.Meta # example user's password, can be encryptedlogin:true# can login, true by default (should be false for role)superuser:false# is superuser? false by defaultcreatedb:false# can create database? false by defaultcreaterole:false# can create role? false by defaultinherit:true# can this role use inherited privileges?replication:false# can this role do replication? false by defaultbypassrls:false# can this role bypass row level security? false by defaultconnlimit:-1# connection limit, -1 disable limitexpire_at:'2030-12-31'# 'timestamp' when this role is expiredexpire_in:365# now + n days when this role is expired (OVERWRITE expire_at)roles:[dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonlypgbouncer:true# add this user to pgbouncer? false by default (true for production user)parameters:# user's default search pathsearch_path:publiccomment:test user
Changes
username field rename to name
groups field rename to roles
options now split into separated configration entries:
login, superuser, createdb, createrole, inherit, replication,bypassrls,connlimit
expire_at and expire_in options
pgbouncer option for user is now false by default
Apply Changes
You can create new users on running postgres clusters with pgsql-createuser.yml playbook.
Define your new users in config files (pg_users)
Pass new user.name with option pg_user to playbook.
service_registry:consul # none | consul | etcd | bothprometheus_options:'--storage.tsdb.retention=30d'# prometheus cli optsprometheus_sd_method: consul # Prometheus service discovery method:static|consulprometheus_sd_interval:2s # Prometheus service discovery refresh intervalpg_offline_query:false# set to true to allow offline queries on this instancenode_exporter_enabled:true# enabling Node Exporterpg_exporter_enabled:true# enabling PG Exporterpgbouncer_exporter_enabled:true# enabling Pgbouncer Exporterexport_binary_install:false# install Node/PG Exporter via copy binarydcs_disable_purge:false# force dcs_exists_action = abort to avoid dcs purgepg_disable_purge:false# force pg_exists_action = abort to avoid pg purgehaproxy_weight:100# relative lb weight for backend instancehaproxy_weight_fallback:1# primary server weight in replica service group
Obsolete Config Entries
prometheus_metrics_path # duplicate with exporter_metrics_path prometheus_retention # covered by `prometheus_options`
you can customize default role system, schemas, extensions, privileges with variables now:
Template Configuration
# - system roles - #pg_replication_username:replicator # system replication userpg_replication_password:DBUser.Replicator # system replication passwordpg_monitor_username:dbuser_monitor # system monitor userpg_monitor_password:DBUser.Monitor # system monitor passwordpg_admin_username:dbuser_admin # system admin userpg_admin_password:DBUser.Admin # system admin password# - default roles - #pg_default_roles:- username:dbrole_readonly # sample user:options:NOLOGIN # role can not logincomment:role for readonly access # comment string- username: dbrole_readwrite # sample user:one object for each useroptions:NOLOGINcomment:role for read-write accessgroups:[dbrole_readonly ] # read-write includes read-only access- username: dbrole_admin # sample user:one object for each useroptions:NOLOGIN BYPASSRLS # admin can bypass row level securitycomment:role for object creationgroups:[dbrole_readwrite,pg_monitor,pg_signal_backend]# NOTE: replicator, monitor, admin password are overwritten by separated config entry- username:postgres # reset dbsu password to NULL (if dbsu is not postgres)options:SUPERUSER LOGINcomment:system superuser- username:replicatoroptions:REPLICATION LOGINgroups:[pg_monitor, dbrole_readonly]comment:system replicator- username:dbuser_monitoroptions:LOGIN CONNECTION LIMIT 10comment:system monitor usergroups:[pg_monitor, dbrole_readonly]- username:dbuser_adminoptions:LOGIN BYPASSRLScomment:system admin usergroups:[dbrole_admin]- username:dbuser_statspassword:DBUser.Statsoptions:LOGINcomment:business read-only user for statisticsgroups:[dbrole_readonly]# object created by dbsu and admin will have their privileges properly setpg_default_privilegs:- GRANT USAGE ON SCHEMAS TO dbrole_readonly- GRANT SELECT ON TABLES TO dbrole_readonly- GRANT SELECT ON SEQUENCES TO dbrole_readonly- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly- GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite- GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite- GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin- GRANT CREATE ON SCHEMAS TO dbrole_admin- GRANT USAGE ON TYPES TO dbrole_admin# schemaspg_default_schemas:[monitor]# extensionpg_default_extensions:- {name: 'pg_stat_statements', schema:'monitor'}- {name: 'pgstattuple', schema:'monitor'}- {name: 'pg_qualstats', schema:'monitor'}- {name: 'pg_buffercache', schema:'monitor'}- {name: 'pageinspect', schema:'monitor'}- {name: 'pg_prewarm', schema:'monitor'}- {name: 'pg_visibility', schema:'monitor'}- {name: 'pg_freespacemap', schema:'monitor'}- {name: 'pg_repack', schema:'monitor'}- name:postgres_fdw- name:file_fdw- name:btree_gist- name:btree_gin- name:pg_trgm- name:intagg- name:intarray# postgres host-based authentication rulespg_hba_rules:- title:allow meta node password accessrole:commonrules:- host all all 10.10.10.10/32 md5- title:allow intranet admin password accessrole:commonrules:- host all +dbrole_admin 10.0.0.0/8 md5- host all +dbrole_admin 172.16.0.0/12 md5- host all +dbrole_admin 192.168.0.0/16 md5- title:allow intranet password accessrole:commonrules:- host all all 10.0.0.0/8 md5- host all all 172.16.0.0/12 md5- host all all 192.168.0.0/16 md5- title:allow local read-write access (local production user via pgbouncer)role:commonrules:- local all +dbrole_readwrite md5- host all +dbrole_readwrite 127.0.0.1/32 md5- title:allow read-only user (stats, personal) password directly accessrole:replicarules:- local all +dbrole_readonly md5- host all +dbrole_readonly 127.0.0.1/32 md5pg_hba_rules_extra:[]# pgbouncer host-based authentication rulespgbouncer_hba_rules:- title:local password accessrole:commonrules:- local all all md5- host all all 127.0.0.1/32 md5- title:intranet password accessrole:commonrules:- host all all 10.0.0.0/8 md5- host all all 172.16.0.0/12 md5- host all all 192.168.0.0/16 md5pgbouncer_hba_rules_extra:[]
v0.4.0
The second public beta (v0.4.0) of pigsty is available now ! 🎉
Monitoring System
Skim version of monitoring system consist of 10 essential dashboards:
PG Overview
PG Cluster
PG Service
PG Instance
PG Database
PG Query
PG Table
PG Table Catalog
PG Table Detail
Node
Software upgrade
Upgrade to PostgreSQL 13.1, Patroni 2.0.1-4, add citus to repo.
Case Number: PIGSTY-20231201 etcd filled up (no auto-compaction) causing PG HA unavailabile
Severity Level: Critical, Please arrange fix ASAP
Affected Versions: Pigsty v2.0.0 - v2.5.1, fixed in Pigsty v2.6.0
Description: etcd has a default 2GB database capacity limit. If your etcd database exceeds this limit, etcd will reject write requests, which may cause PostgreSQL high availability mechanisms that depend on etcd to fail.
At the same time, etcd’s data model creates a new version with each write, so even if you have only a few keys, frequent writes to your etcd cluster can cause the etcd database size to continuously grow and eventually fail when it reaches the capacity limit.
Solution: Update Pigsty to v2.6.0 or above, or update the code in the roles/etcd section and re-execute ./etcd.yml to force reset the etcd cluster to implement the fix.
As you can see, this doc site is hosted on Claw CloudClaw Cloud, a Singapore-based “Aliyun Youth Edition”.
I’m using a China-optimized cloud server with 4-core 8GB RAM / 200GB disk, 1Gbps bandwidth, and 2TB monthly traffic, priced at $18/month, hosted in the HK availability zone.
Compared to EC2 instances sold by Alibaba Cloud/Tencent Cloud/AWS, this is much cheaper - especially for bandwidth. The domestic price of 0.8¥ per GB is practically daylight robbery.
This thing actually has decent speed for Mainland China access, with ping around 50ms from Hong Kong. That’s why I’m using it to host this site, along with running Pigsty’s Demo.
If you want to set up a site or build a personal VPN/proxy, consider this option. The following referral link gives you 10% off, and helps me earn commission to offset server costs:
Hetzner
Besides, Hetzner is also a good option, $188/mo for 80Core/128G / 2TB NVMe SSD powerful server. What can I say?

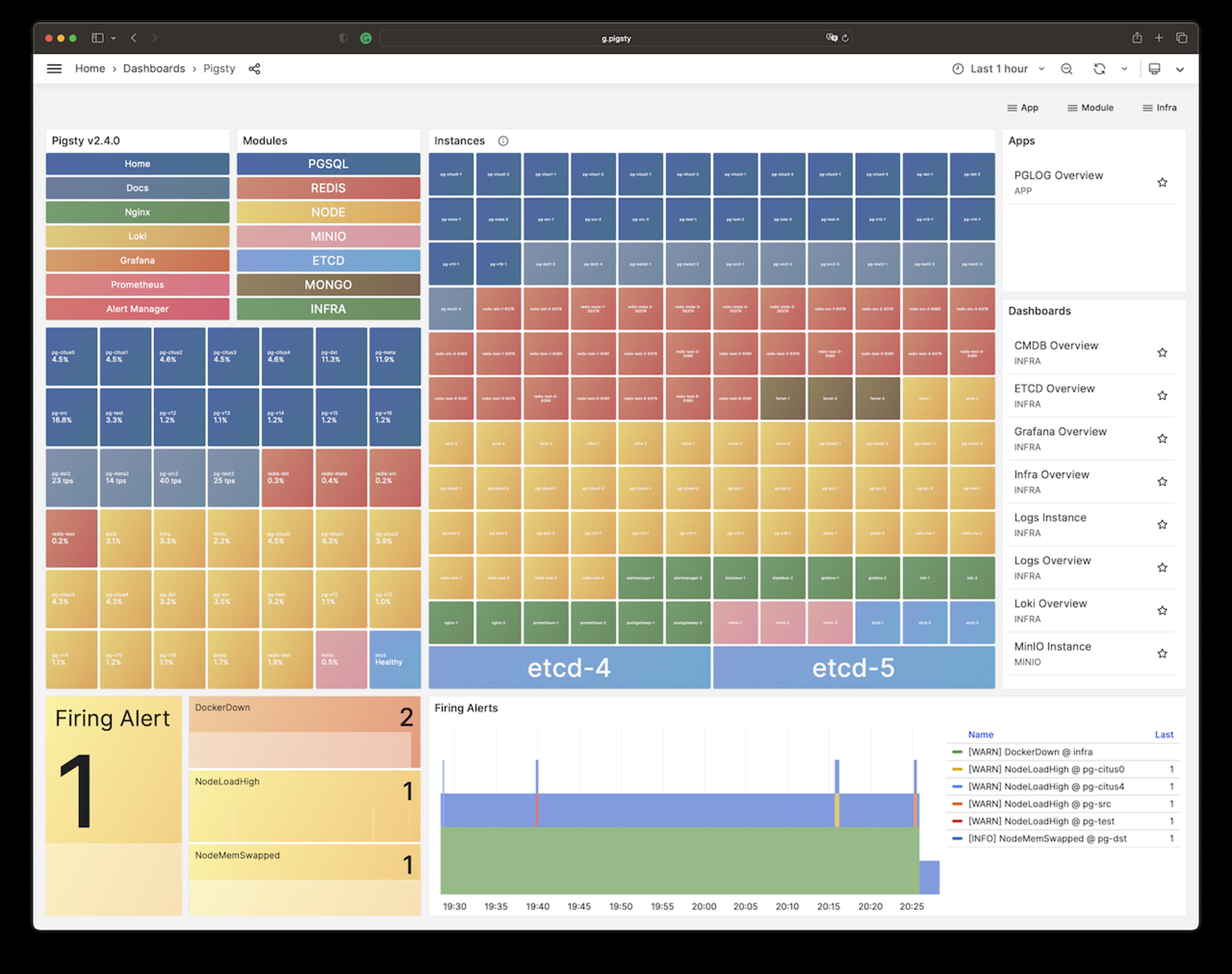
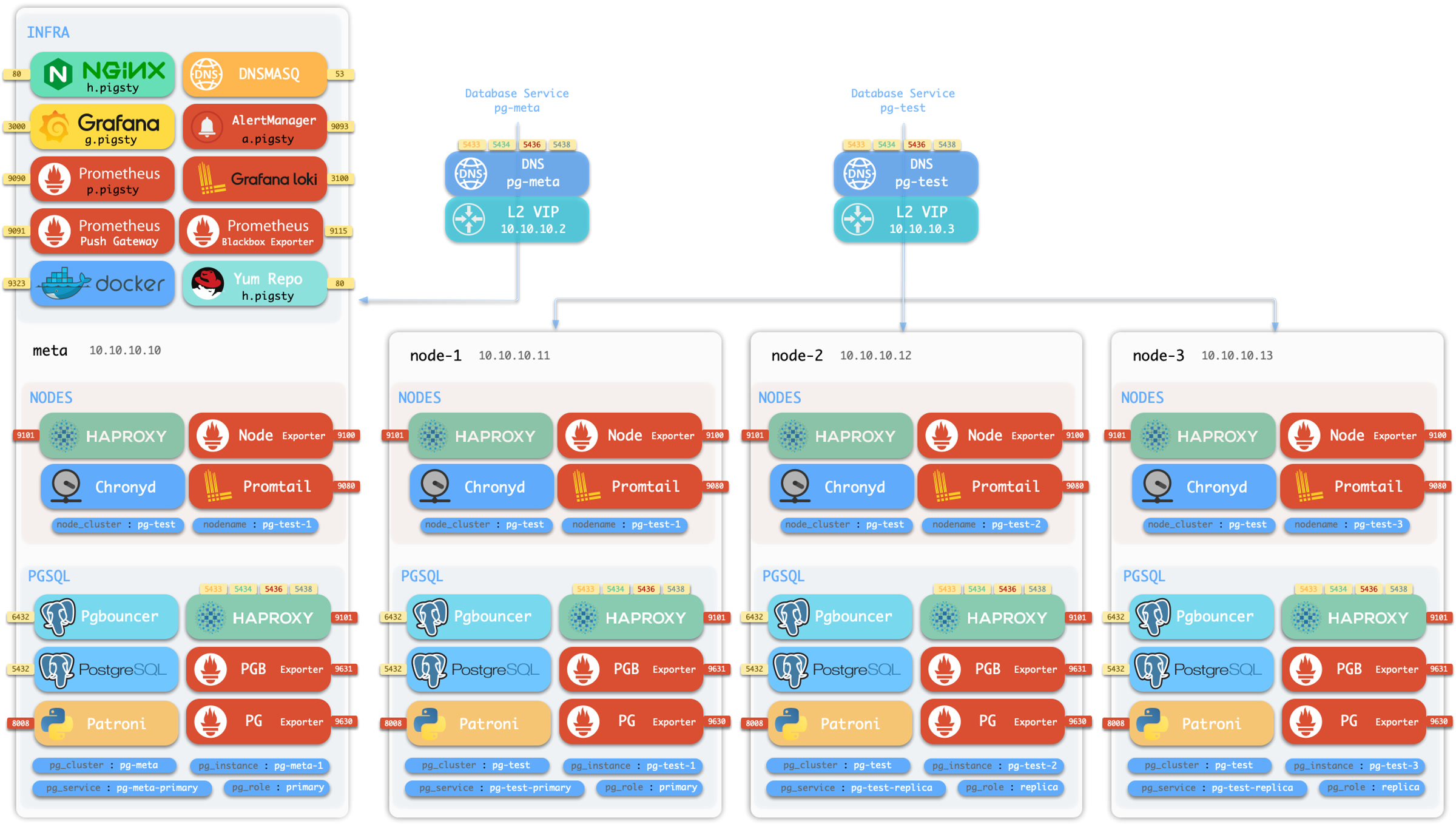
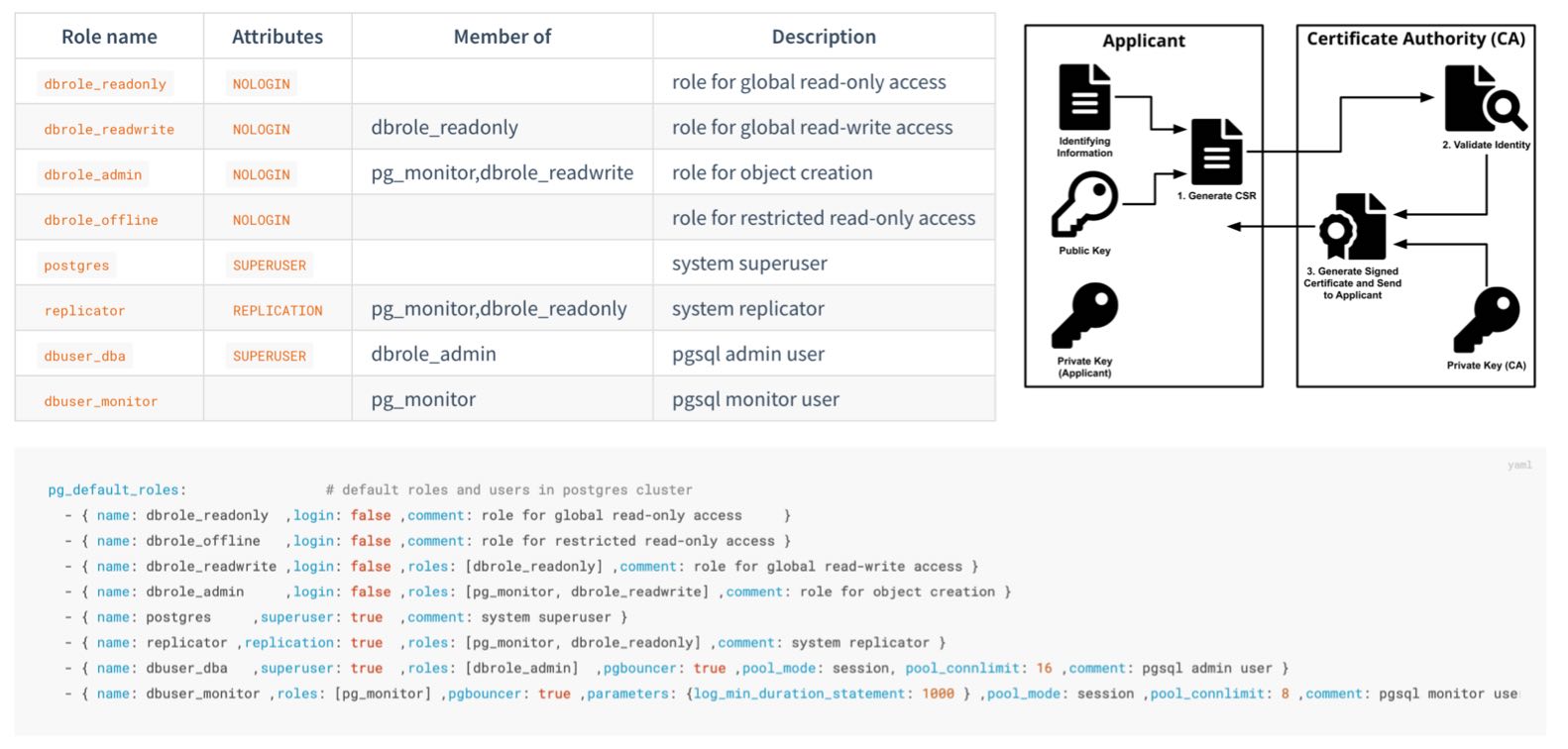
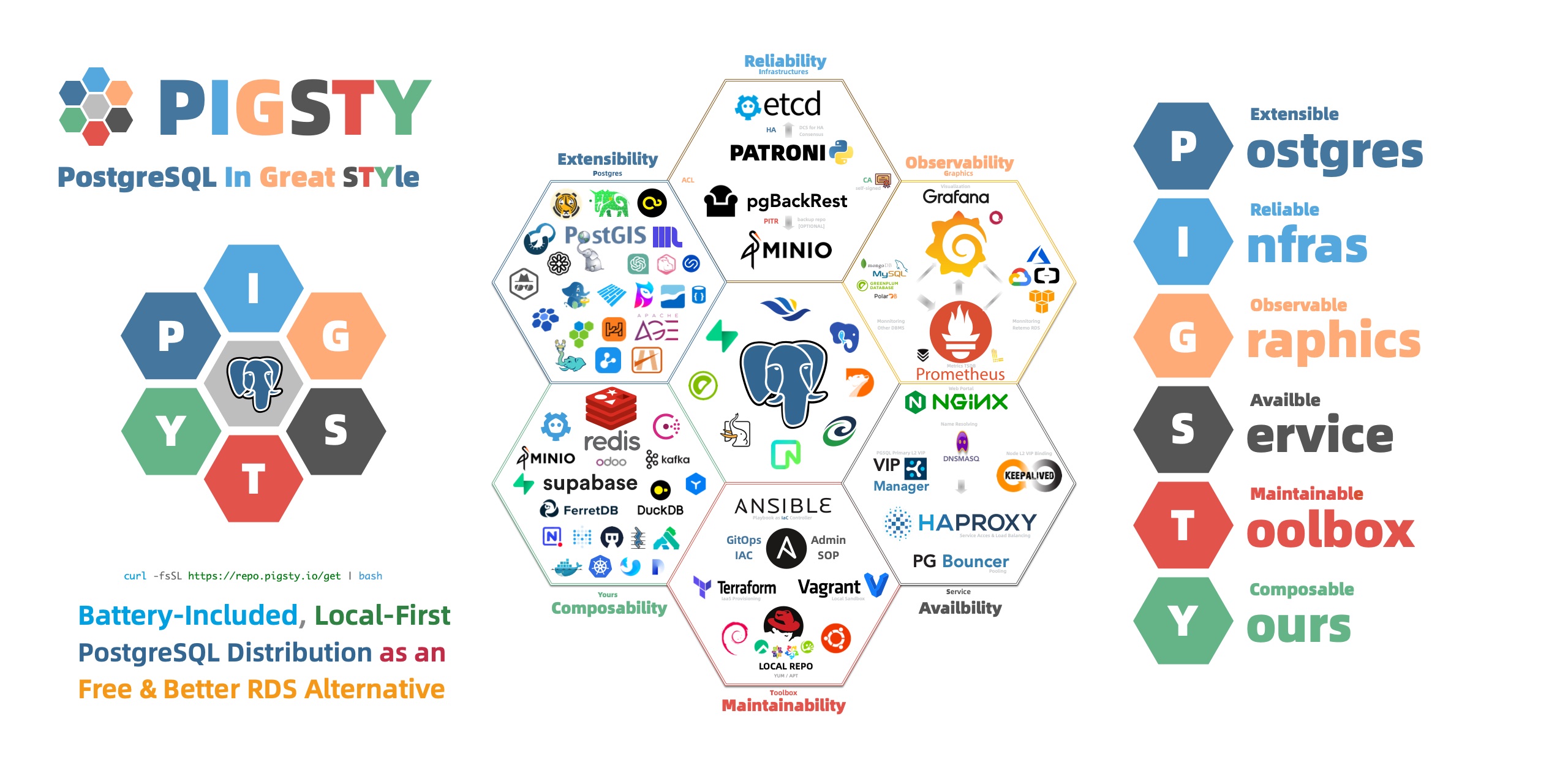
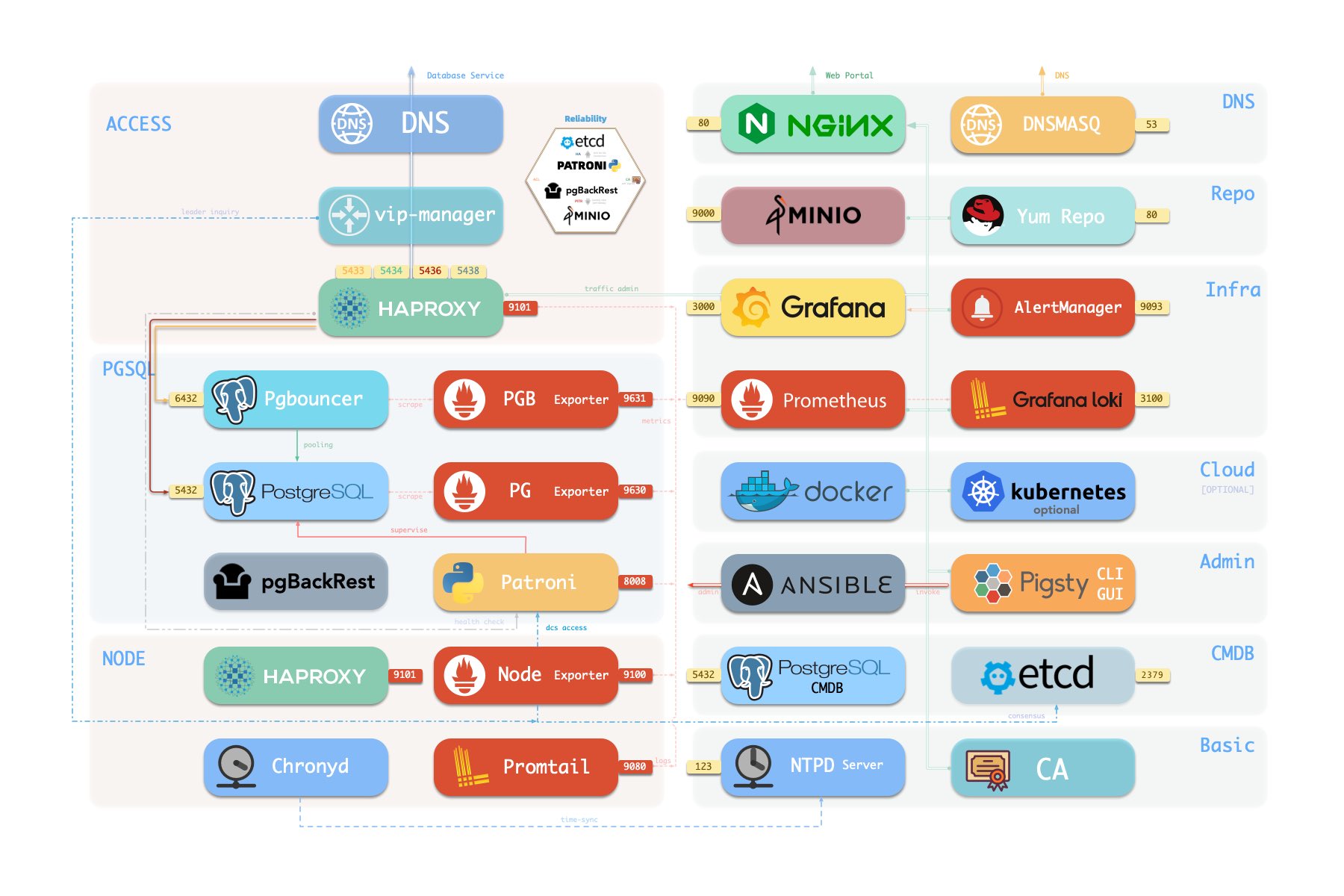
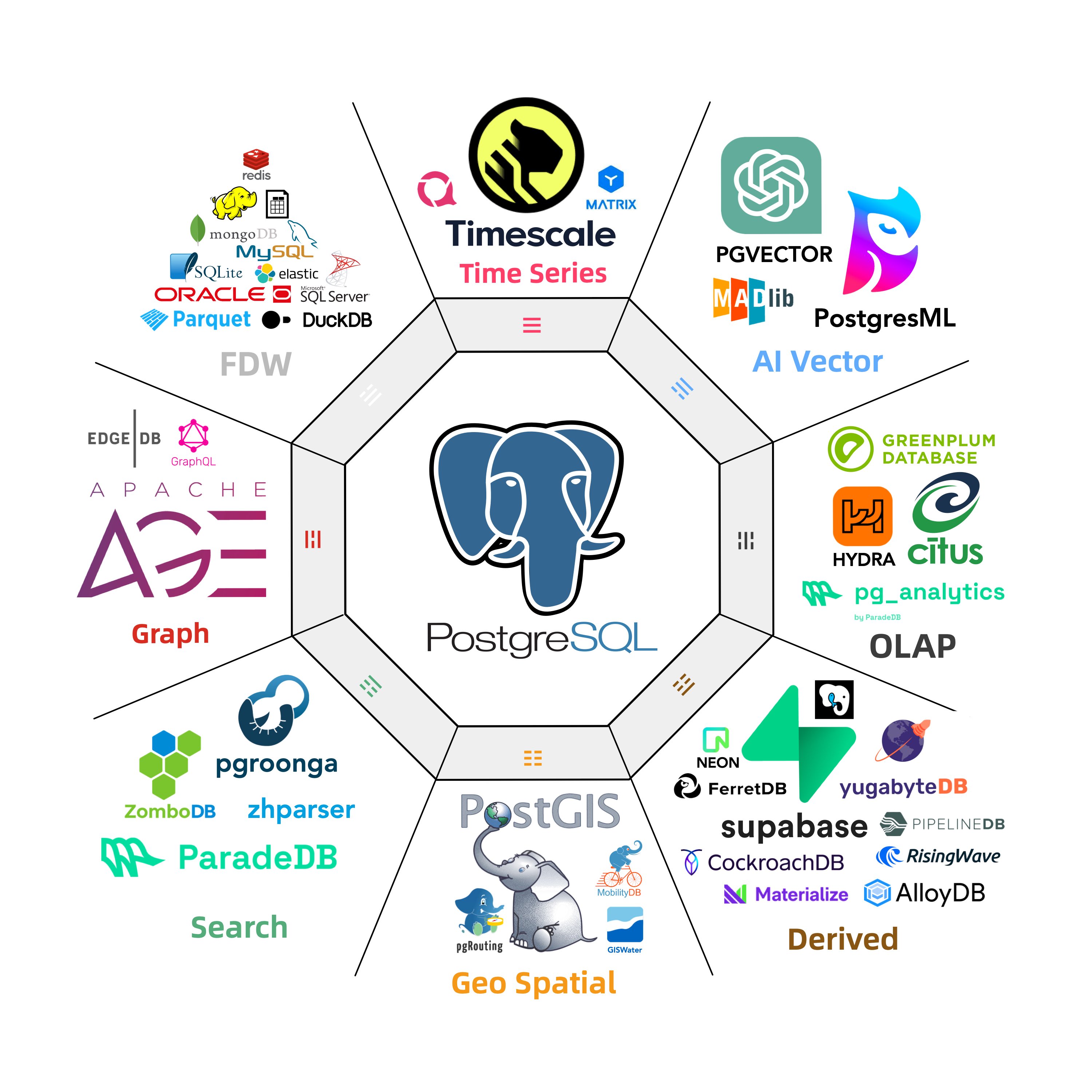

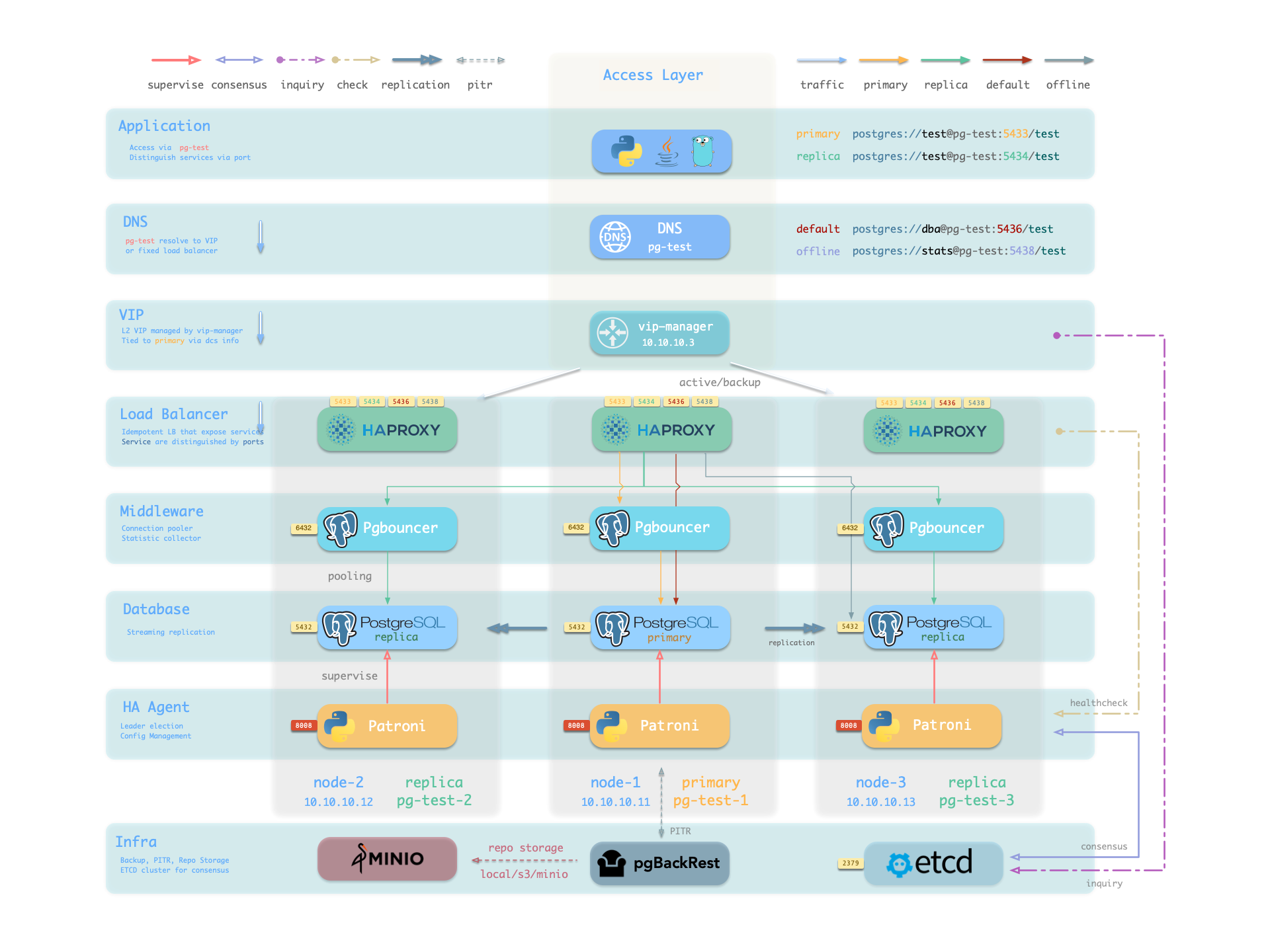

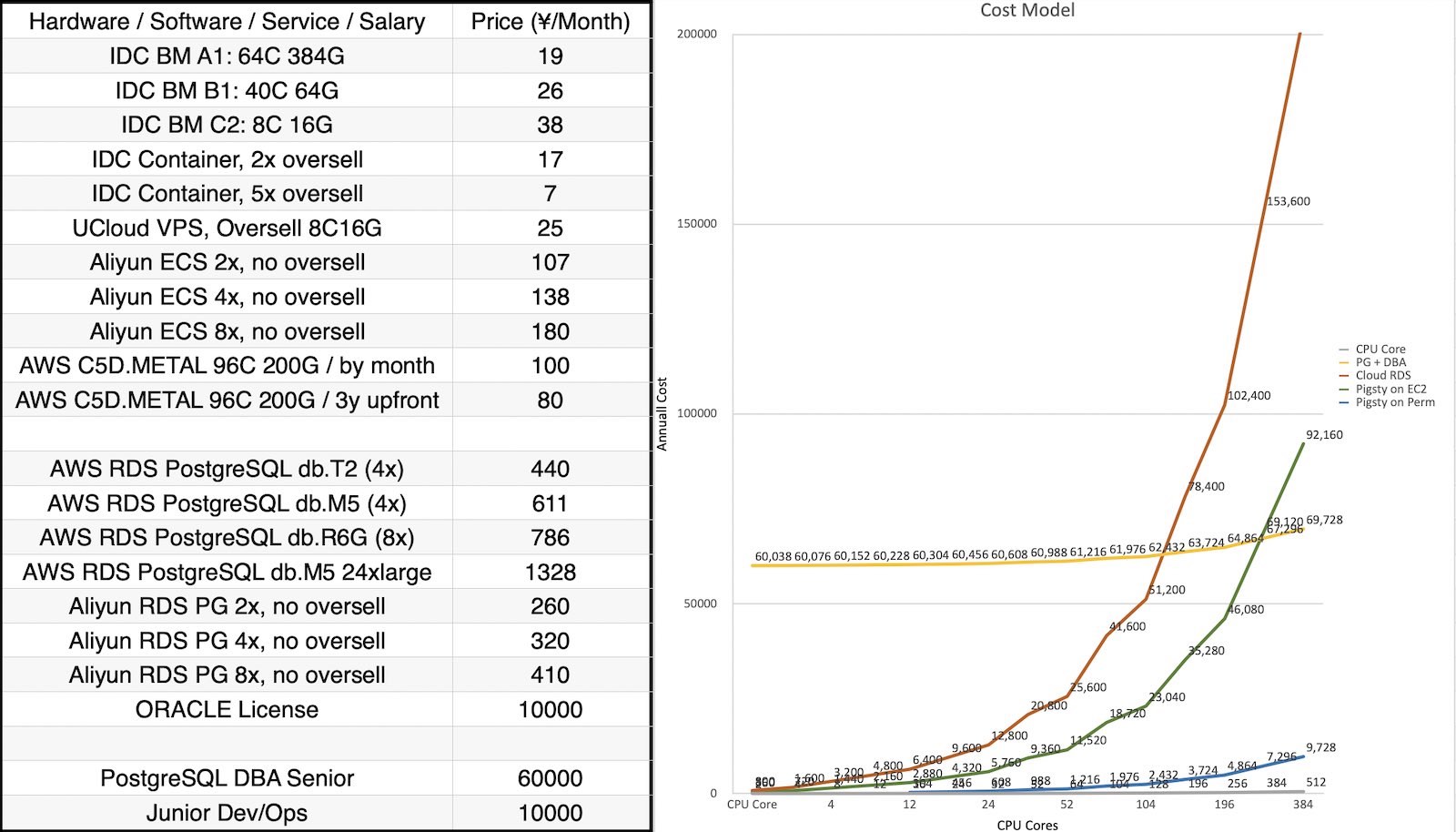


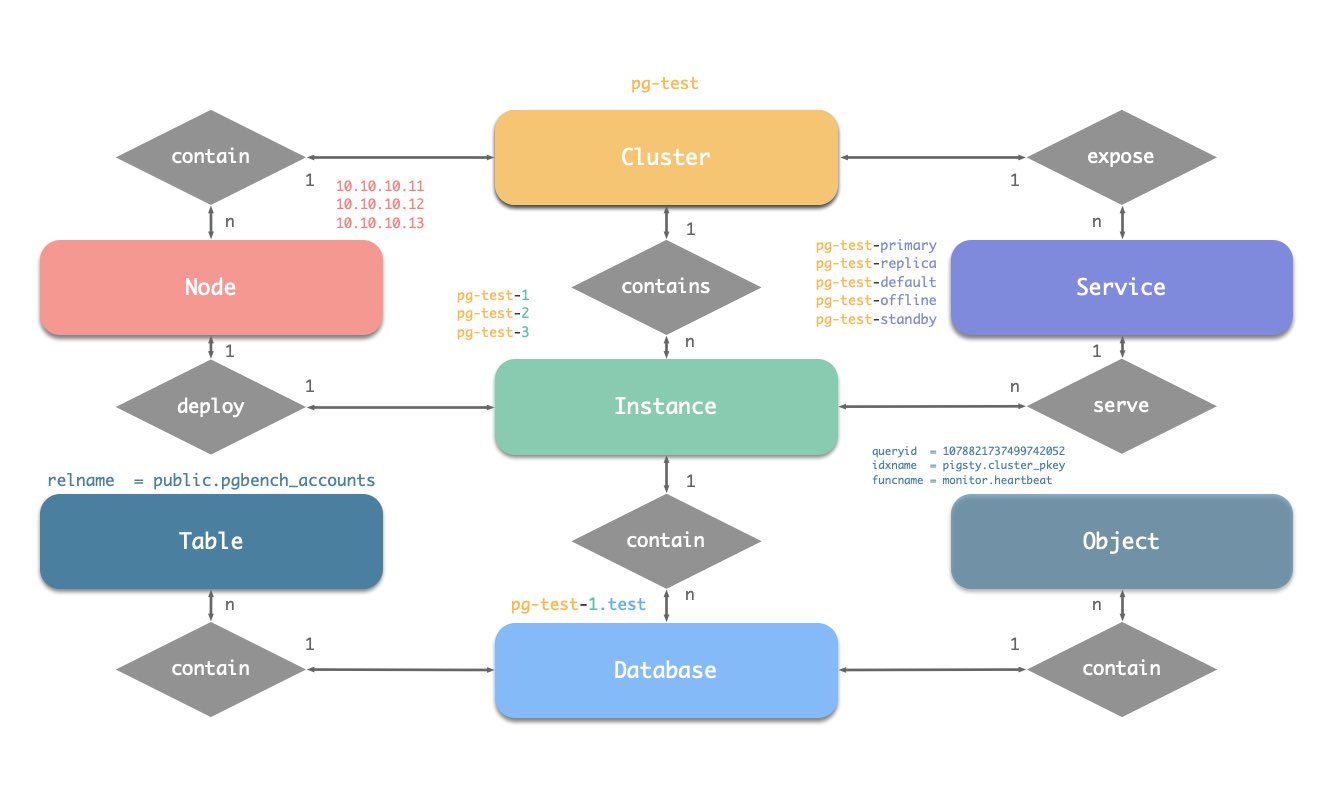
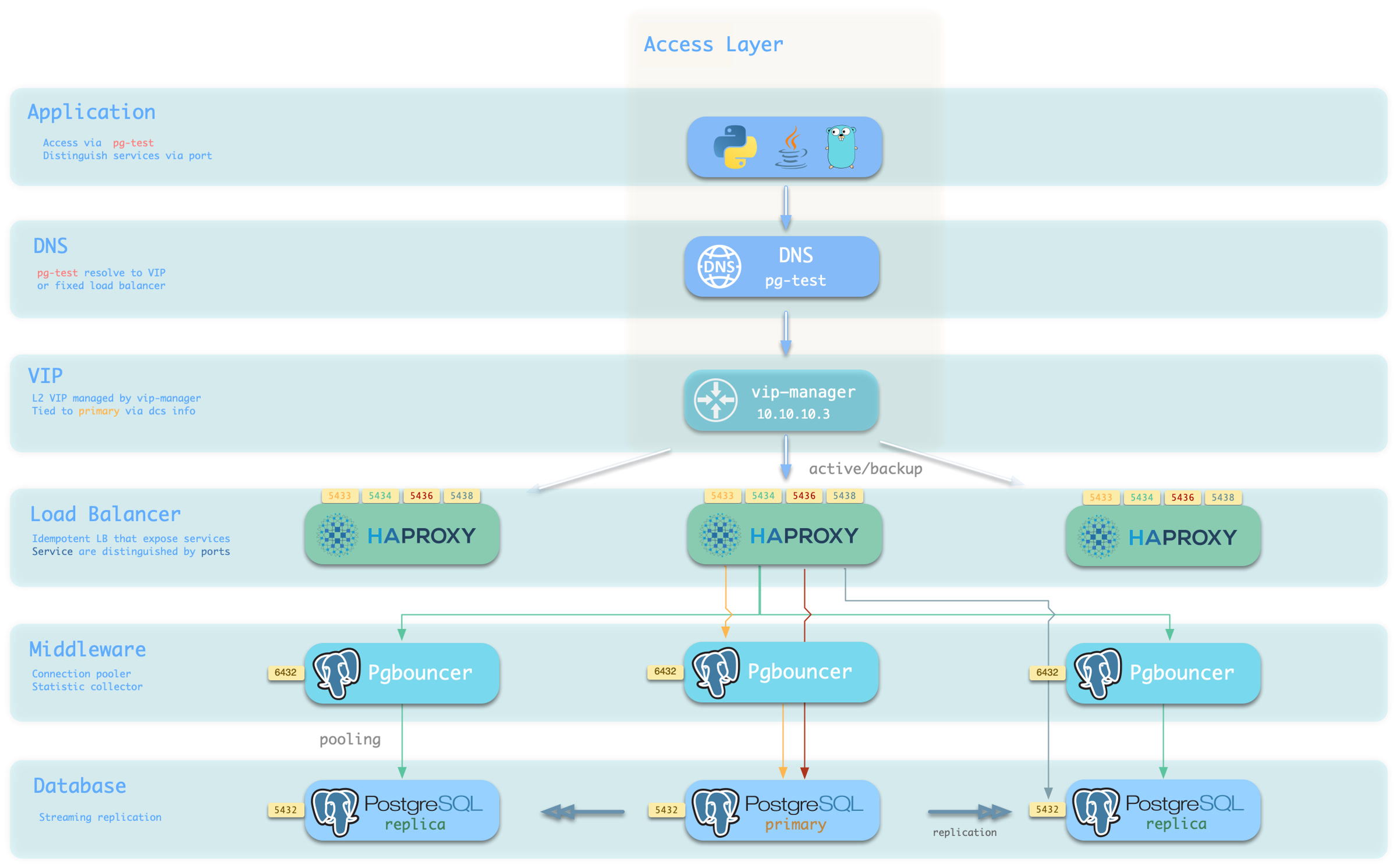












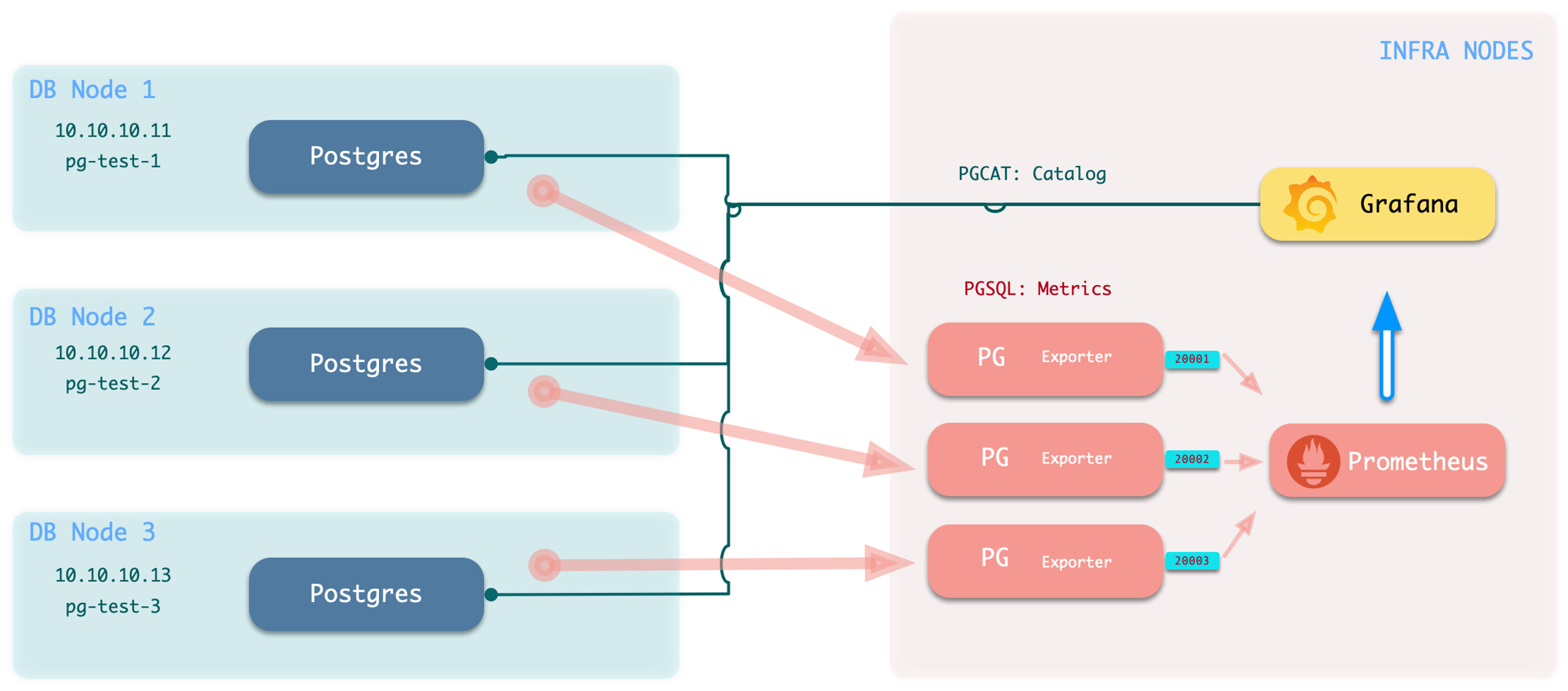
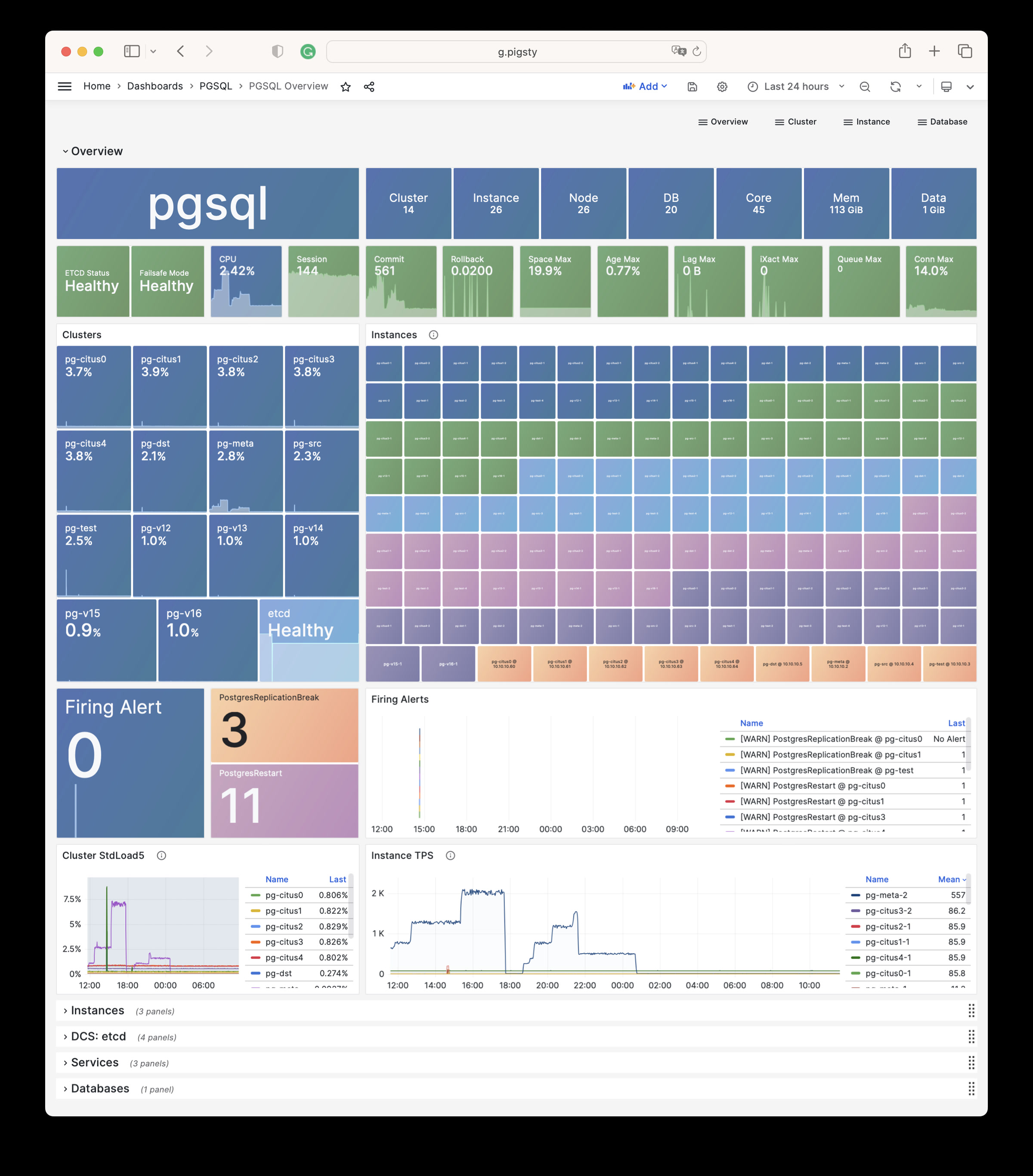
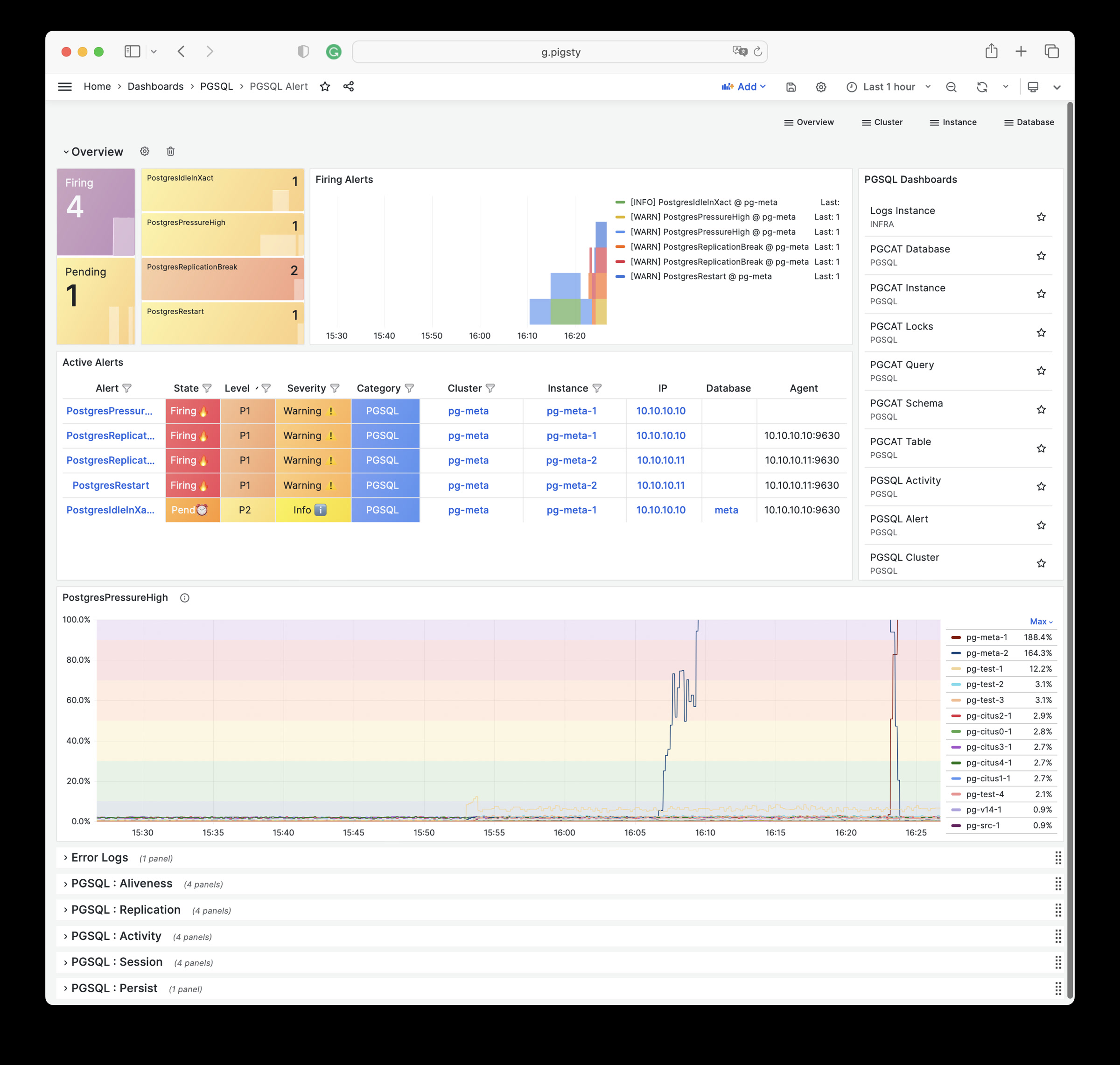
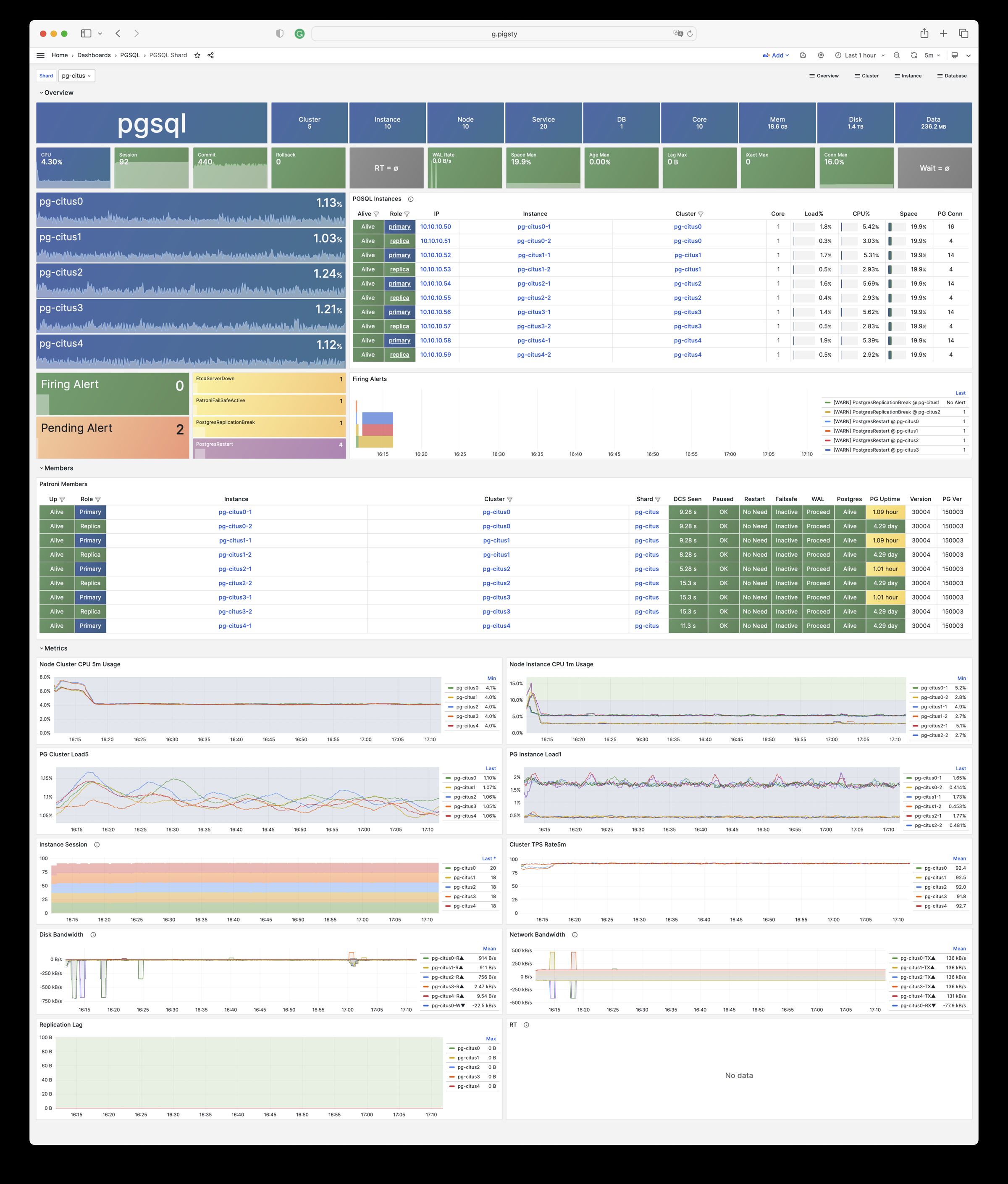
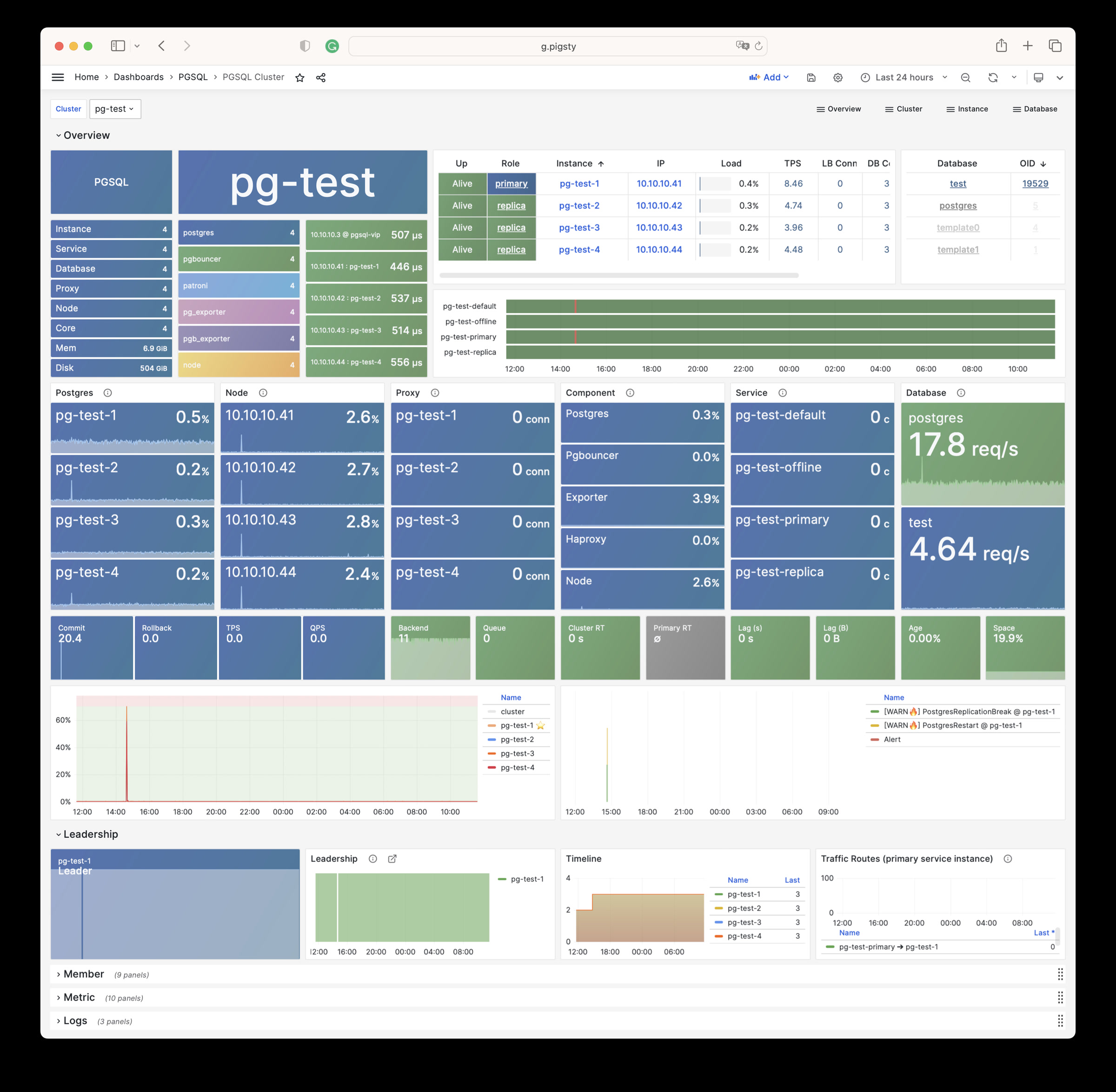
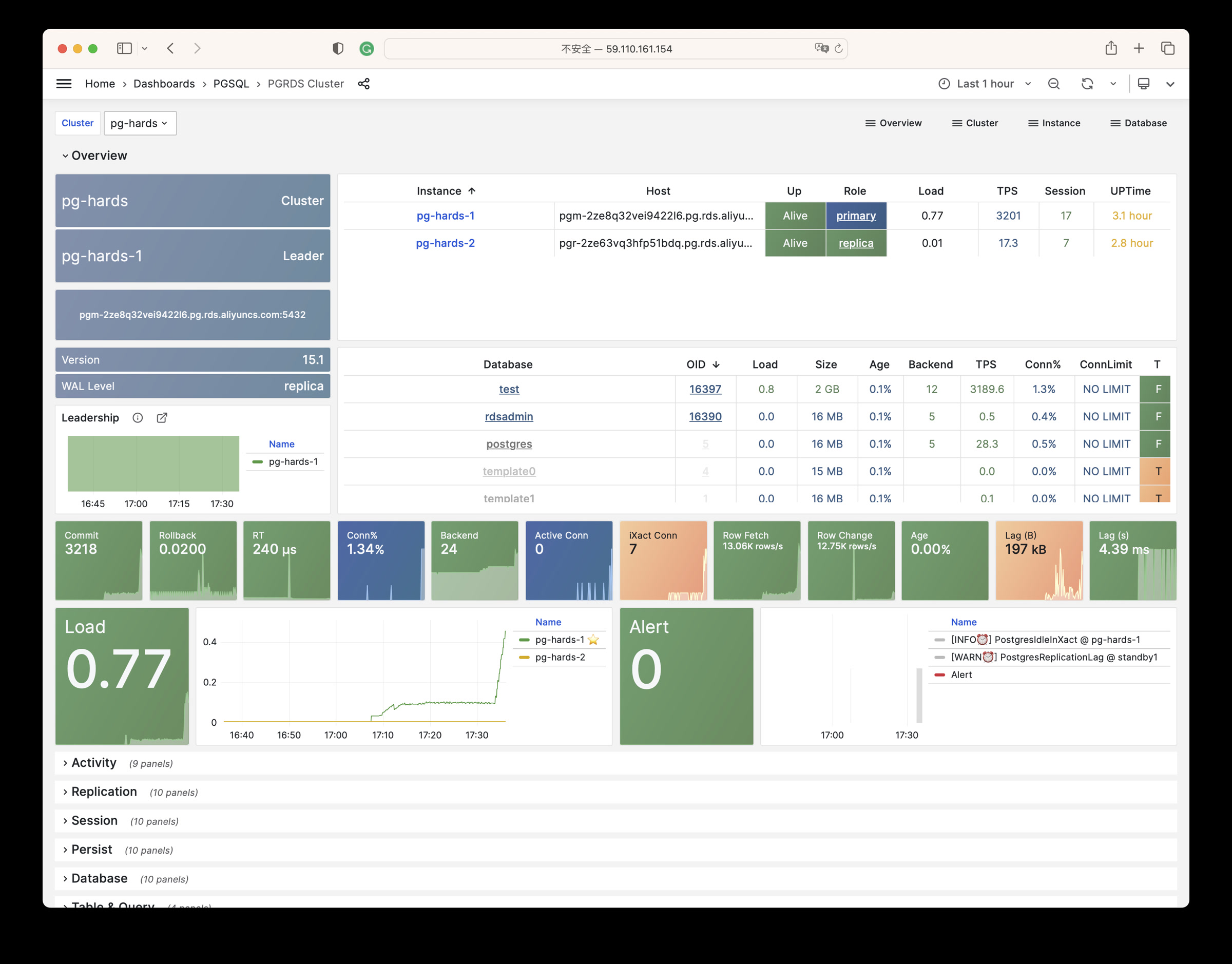
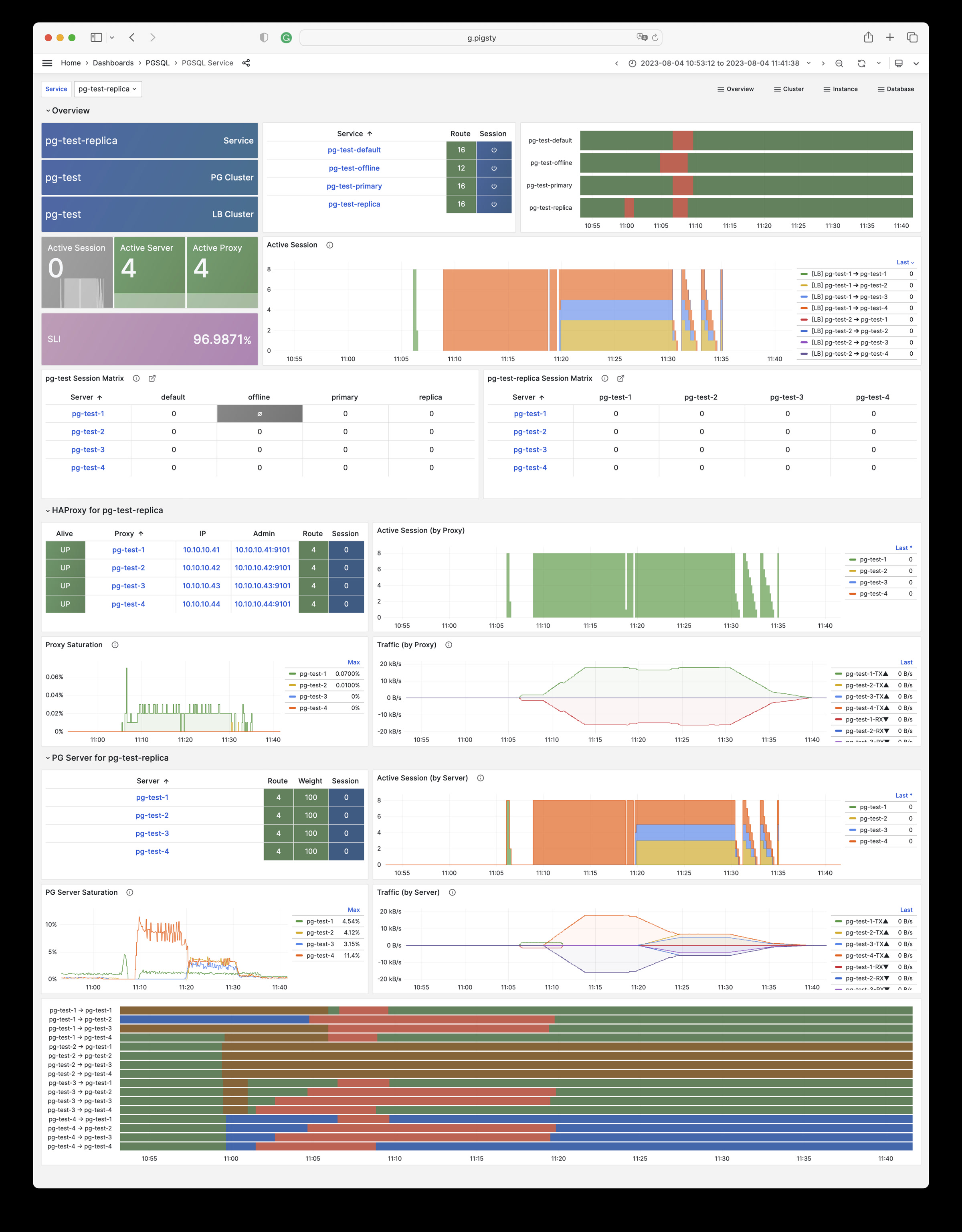
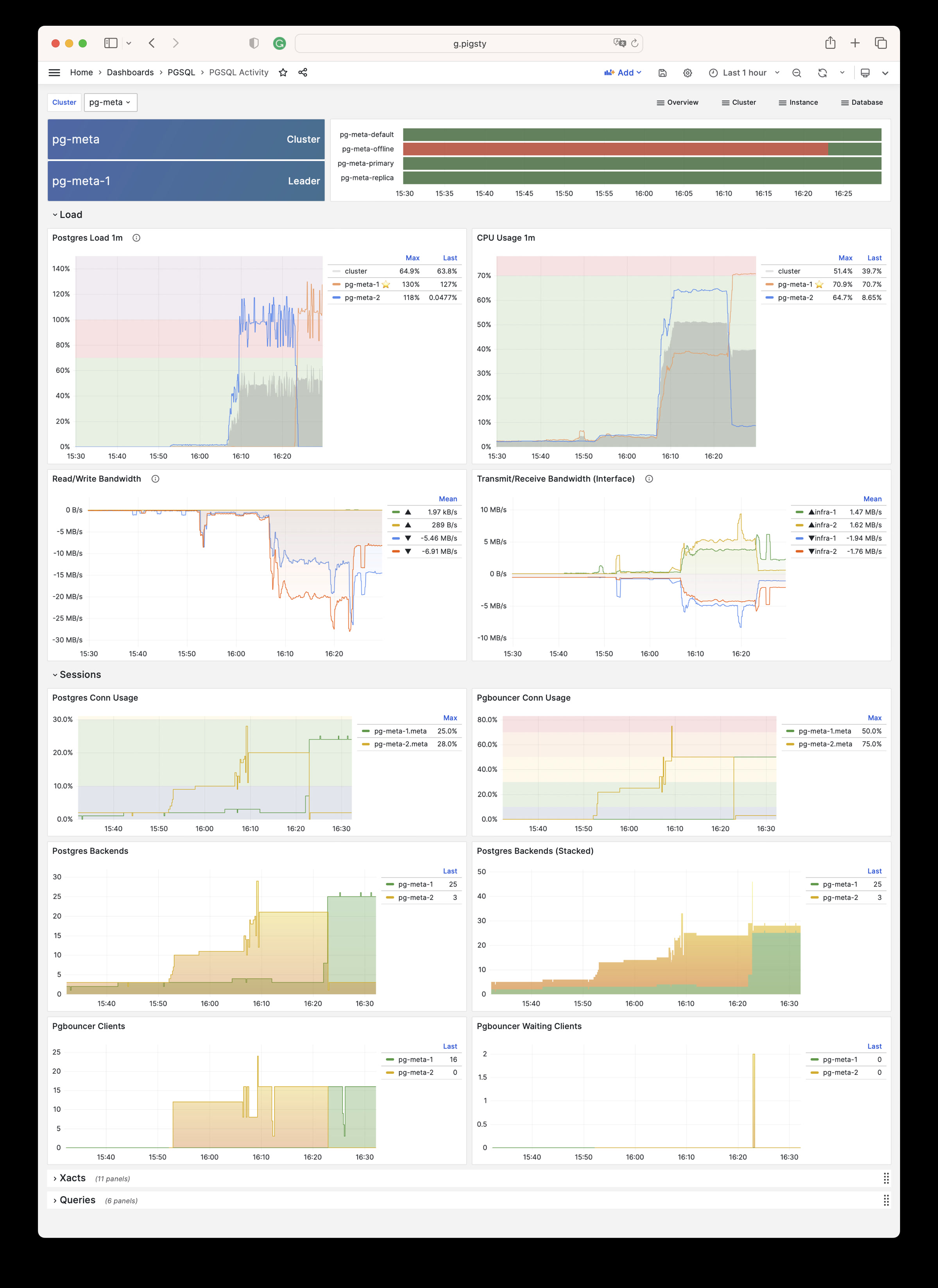
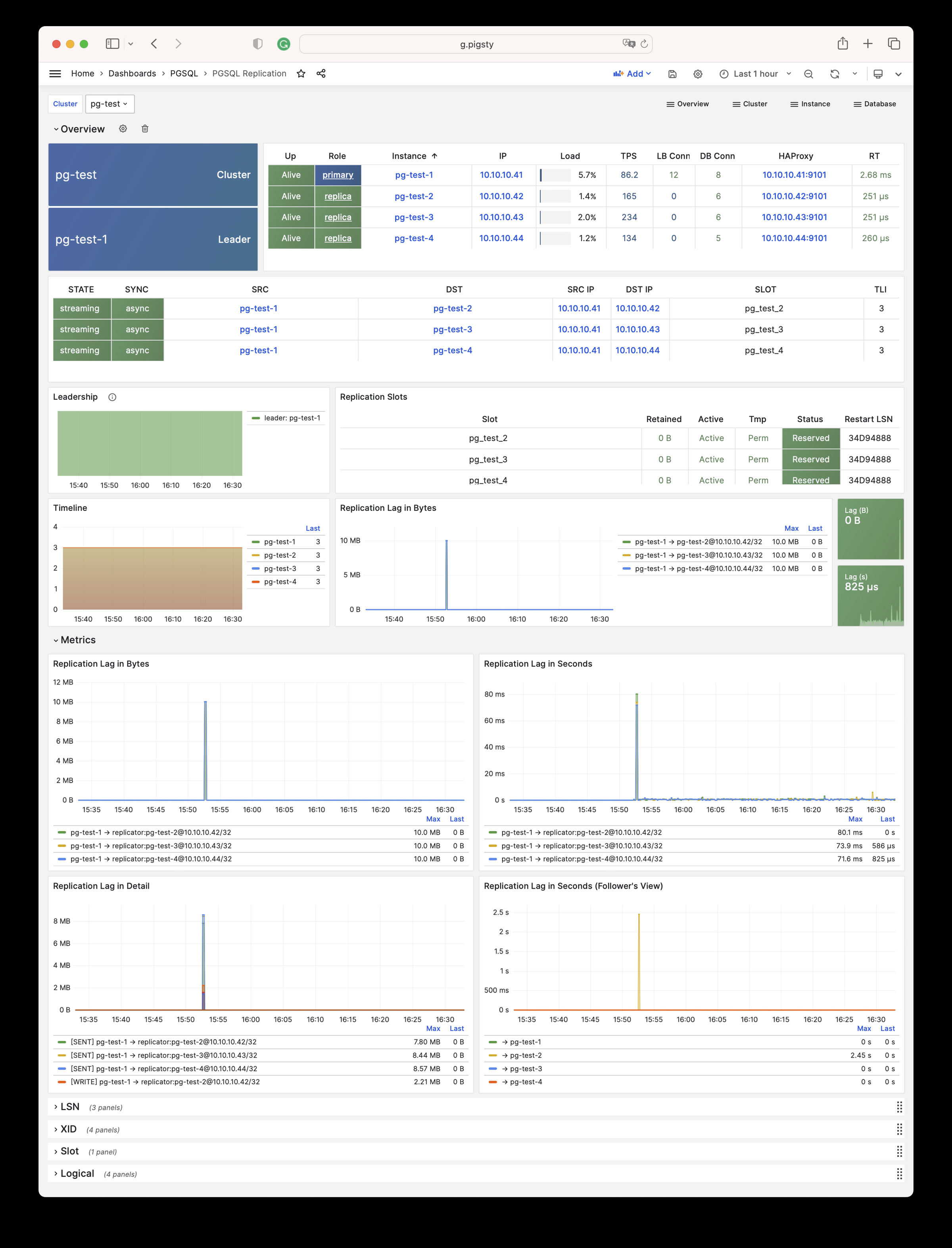
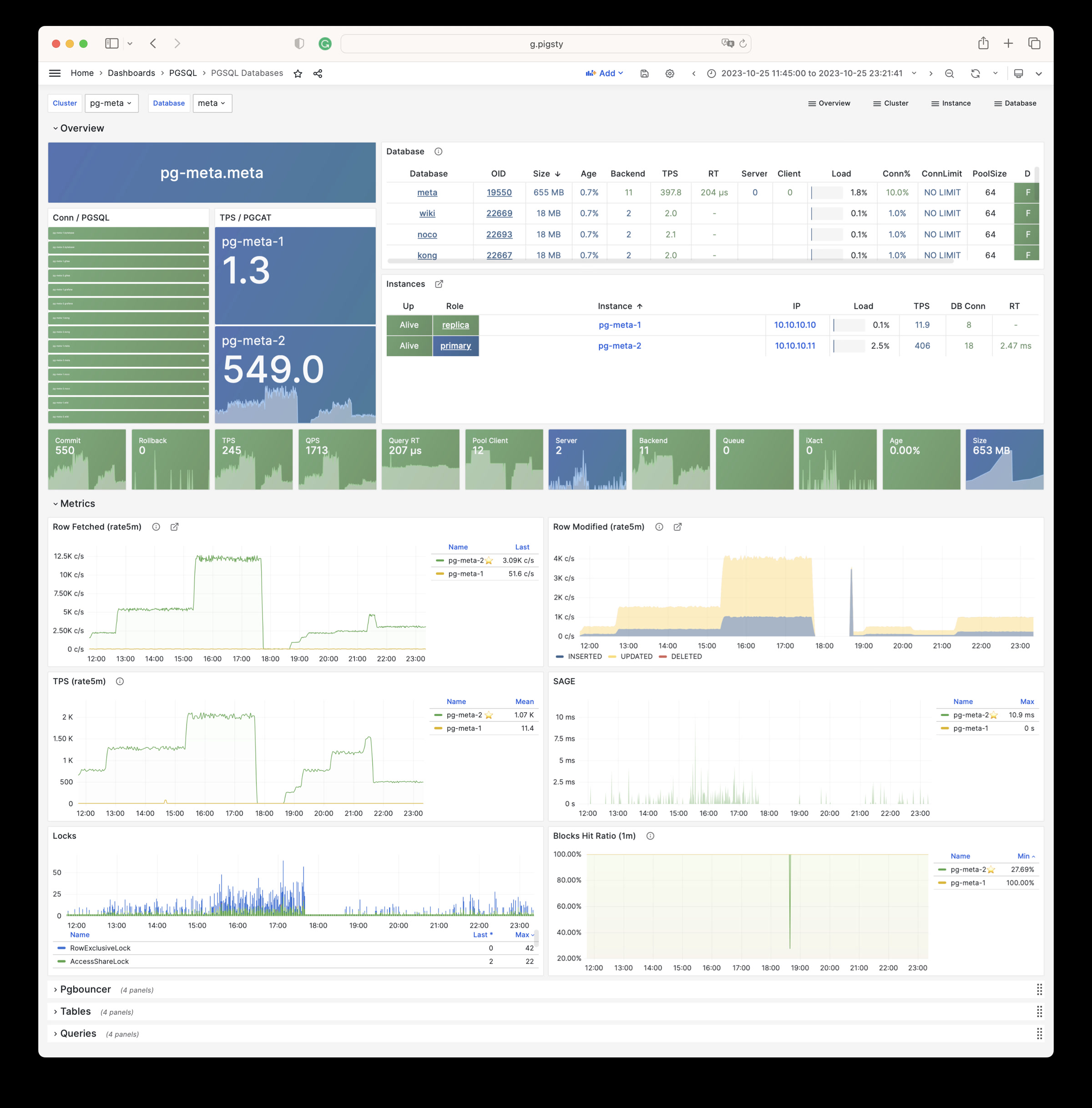
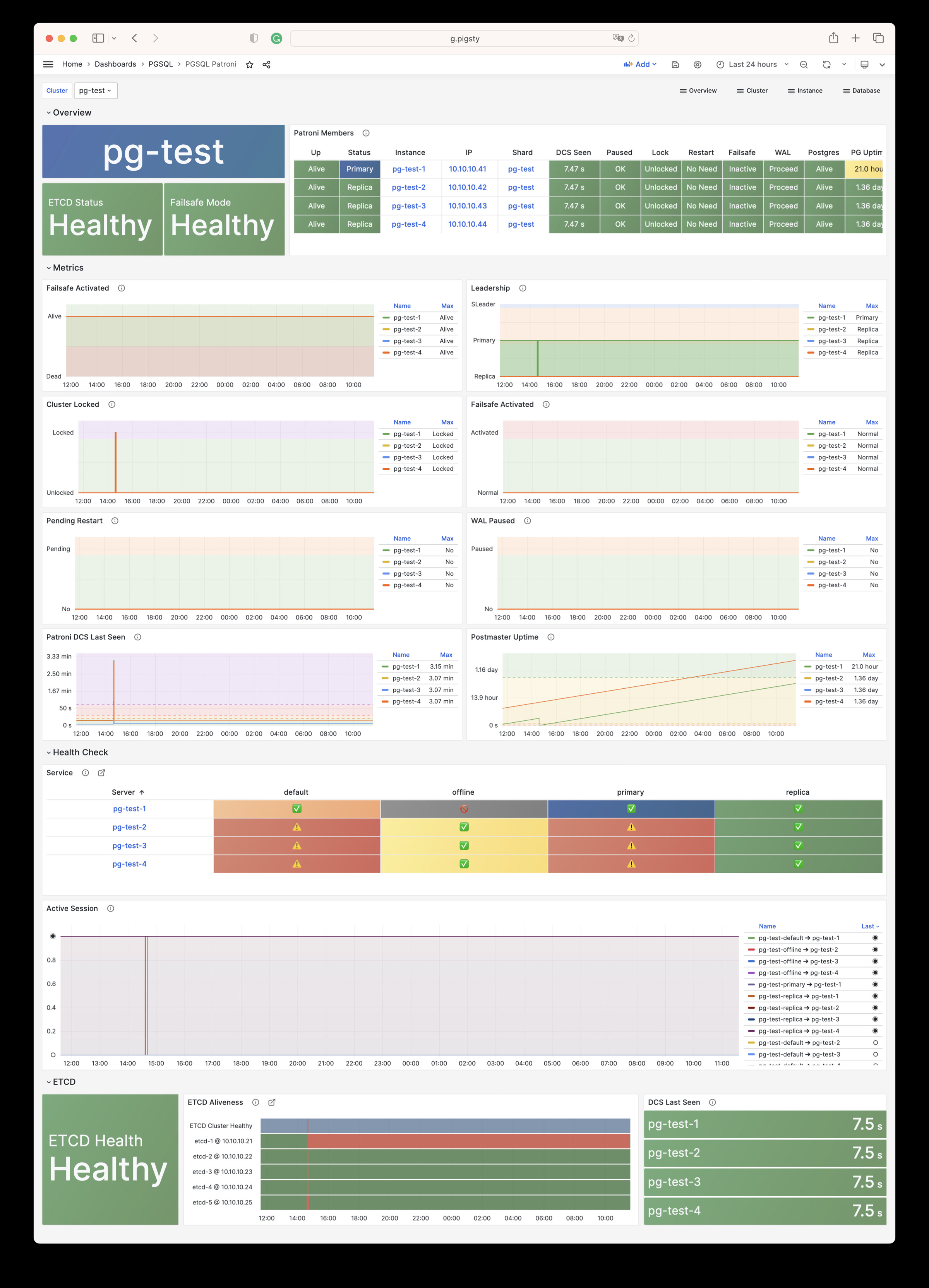
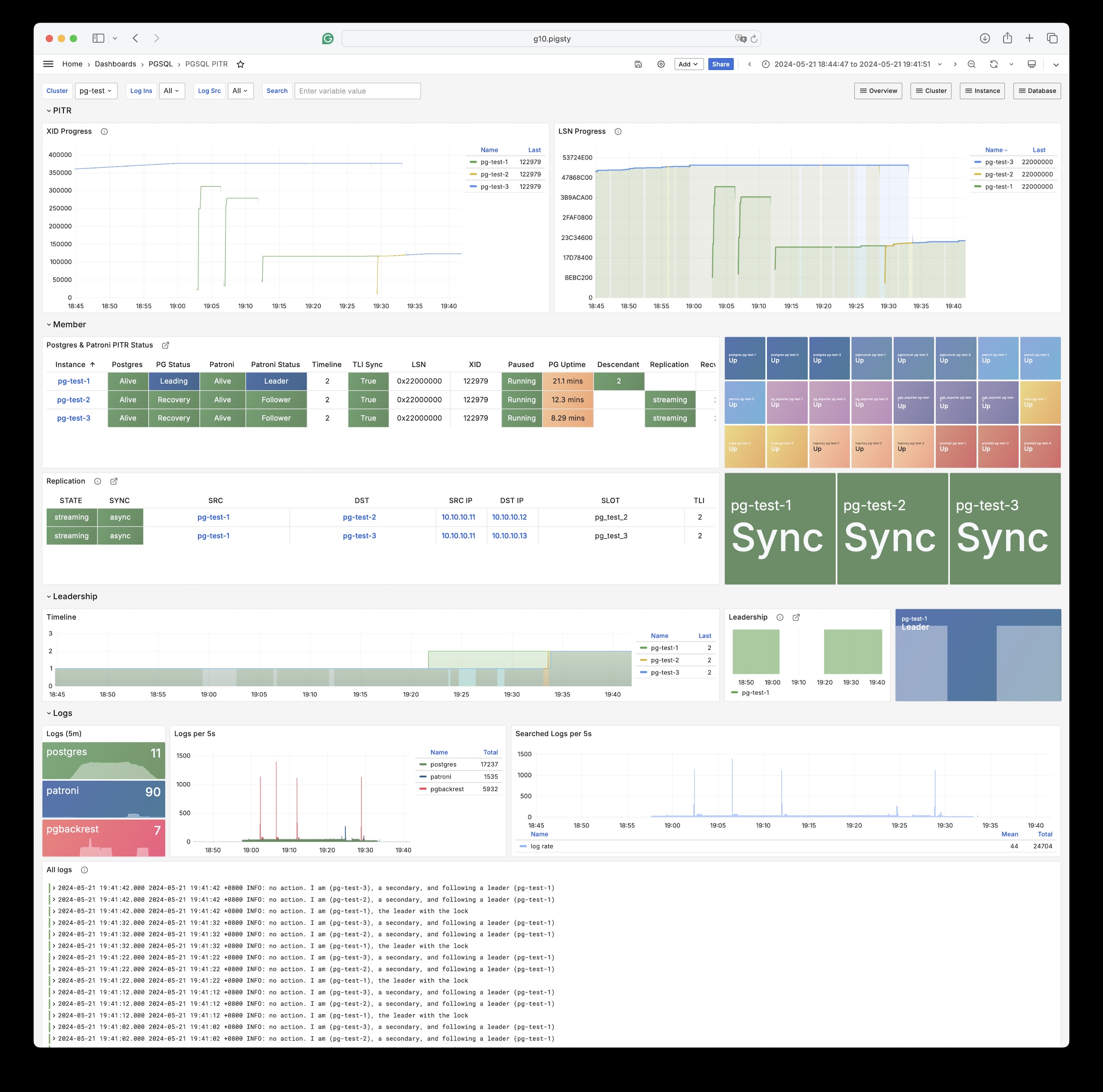
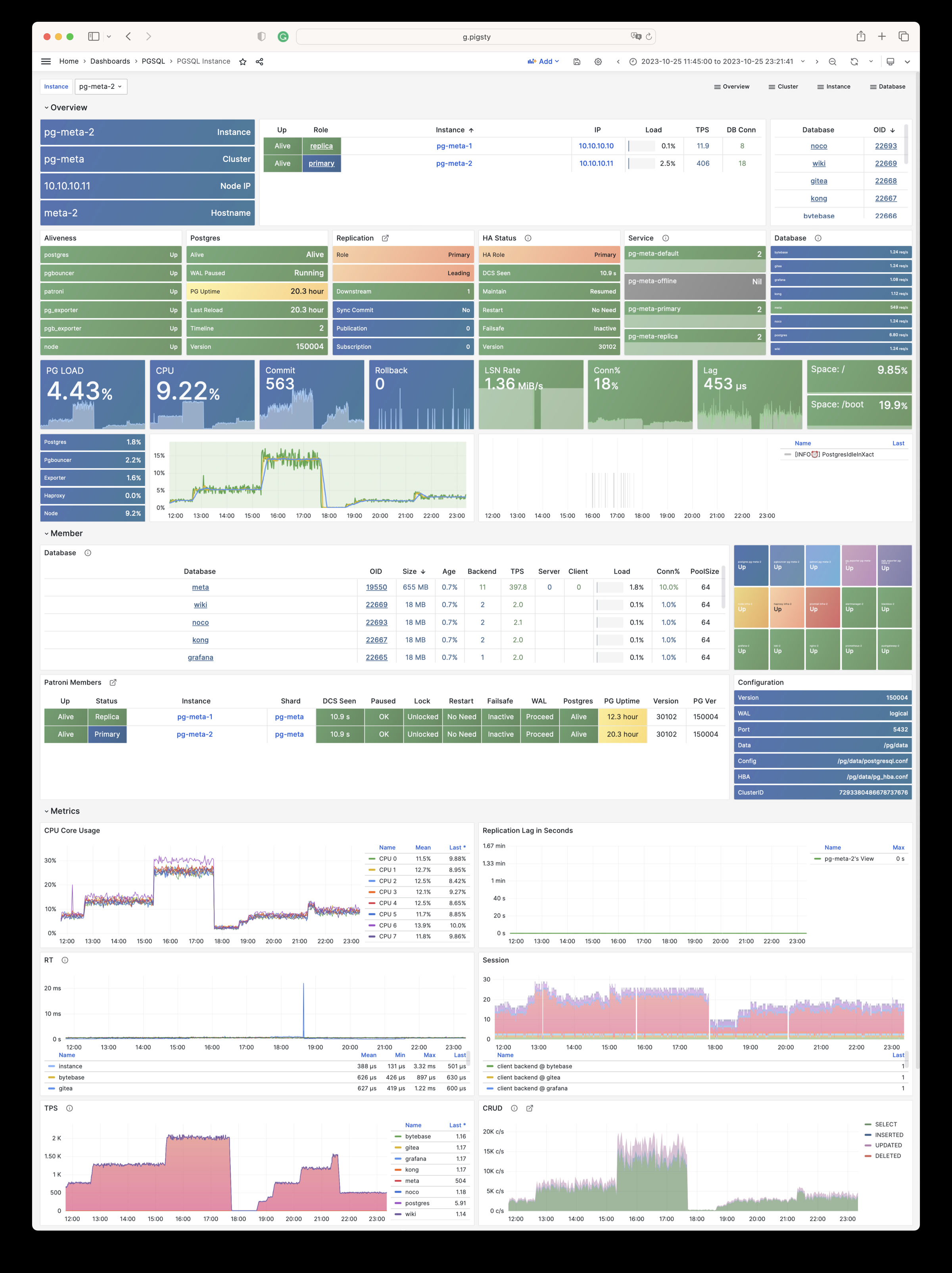
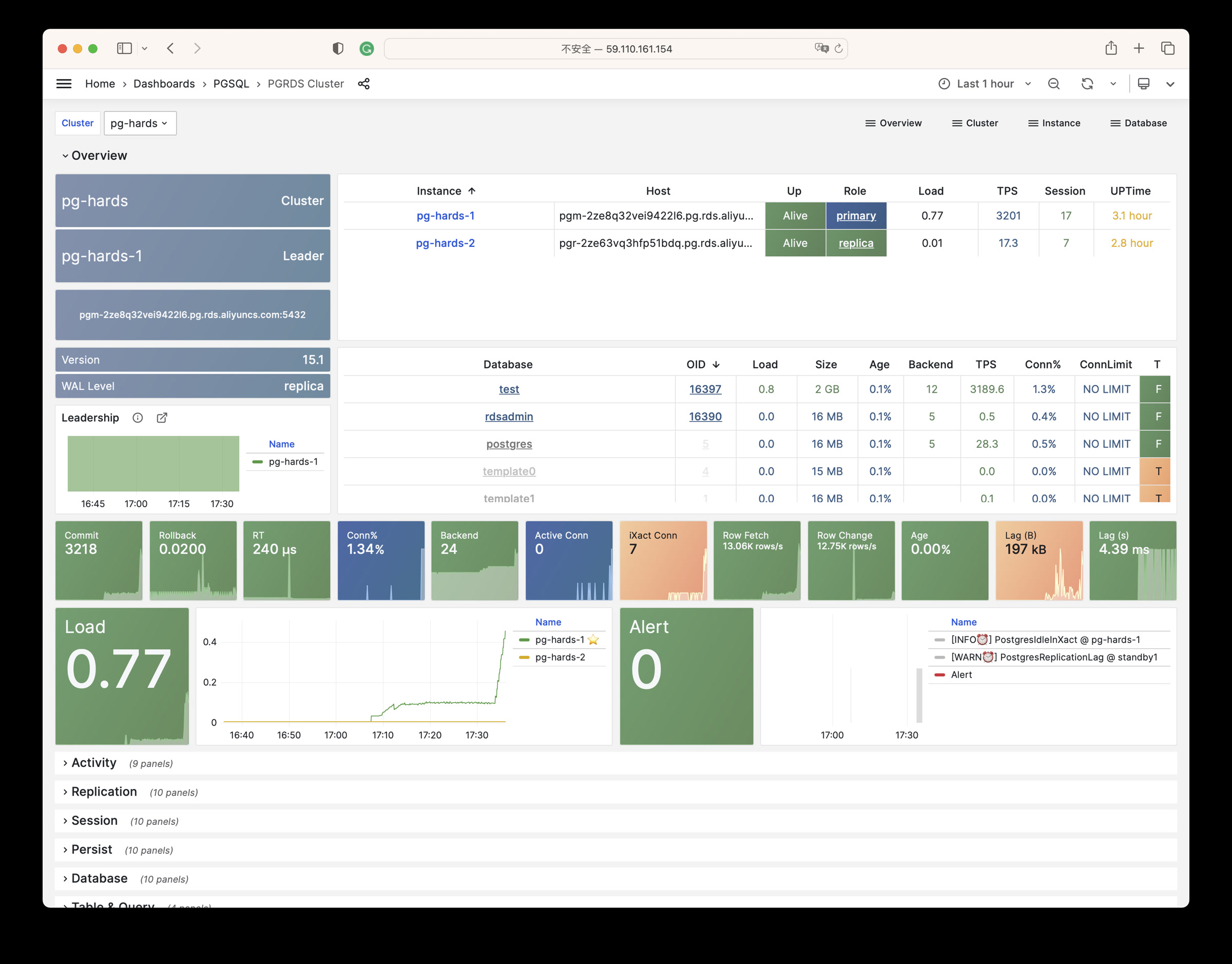
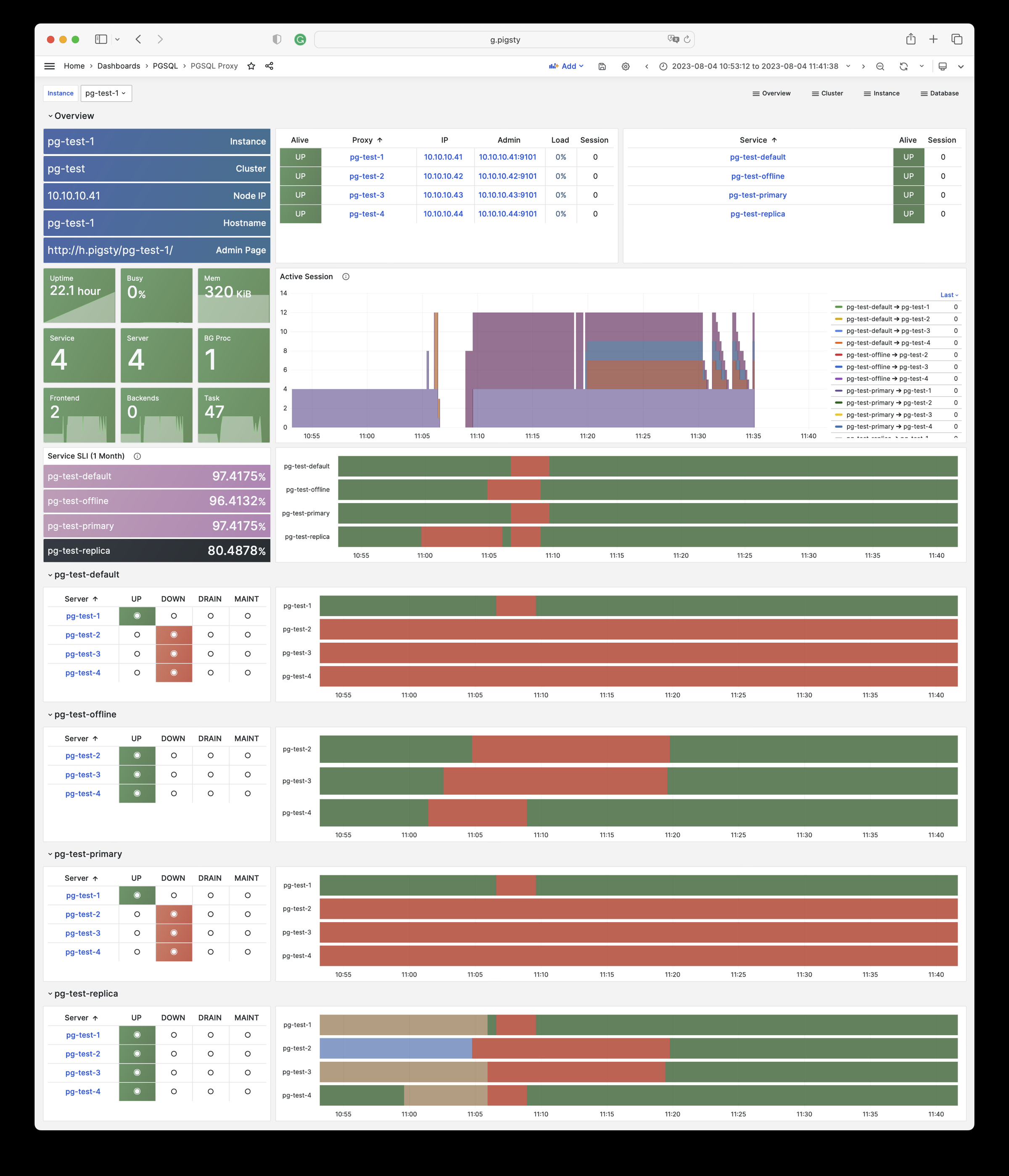
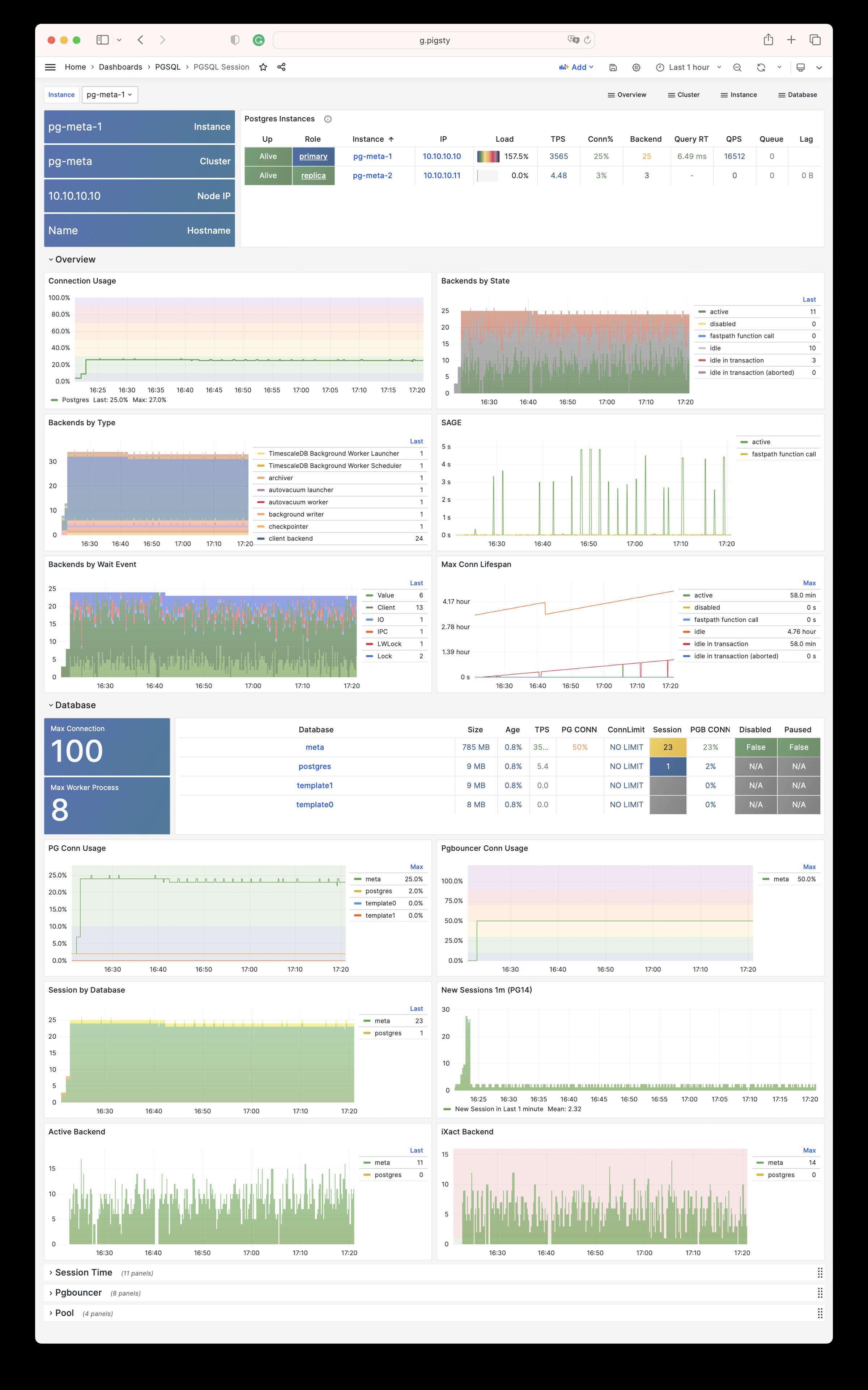
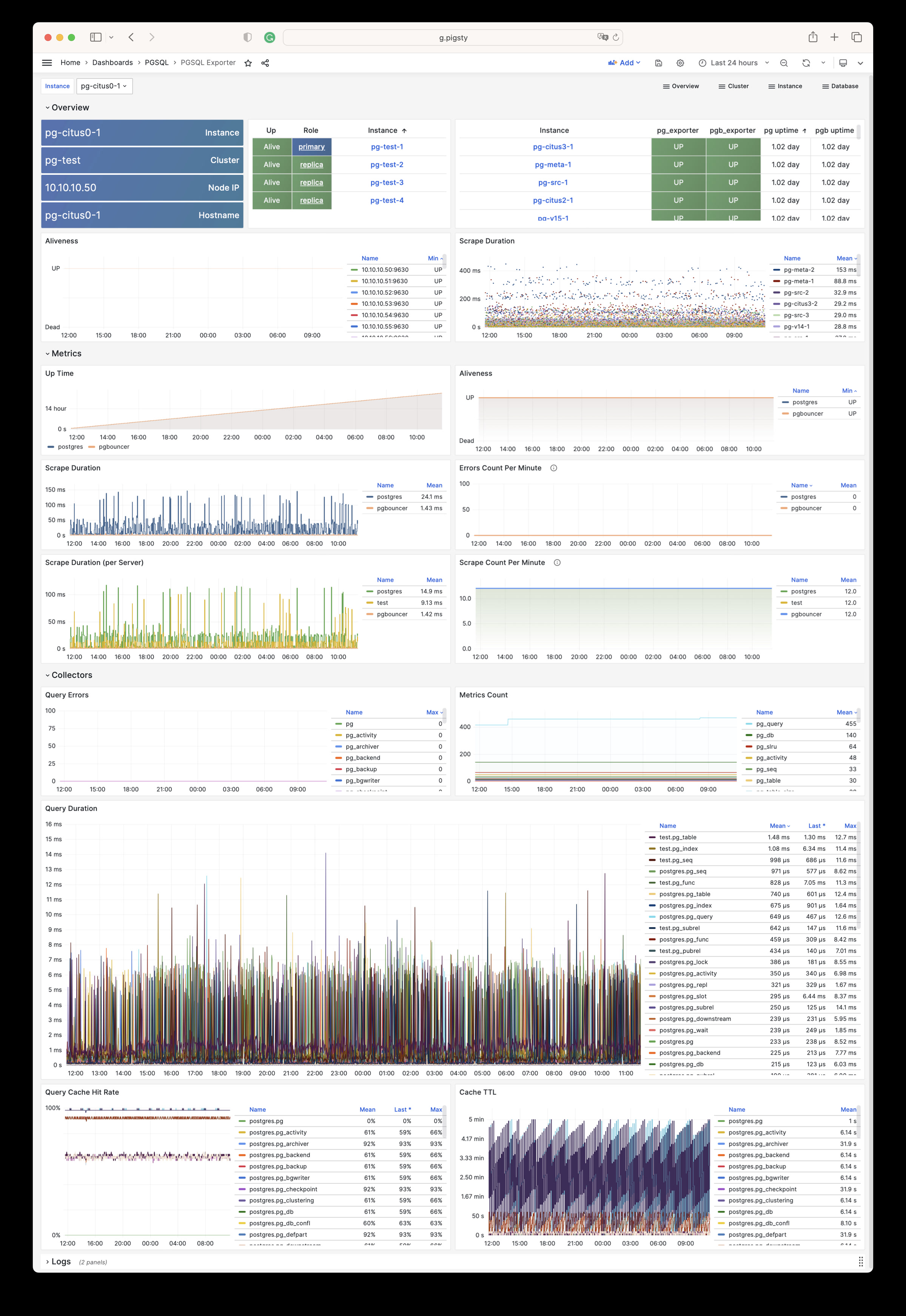
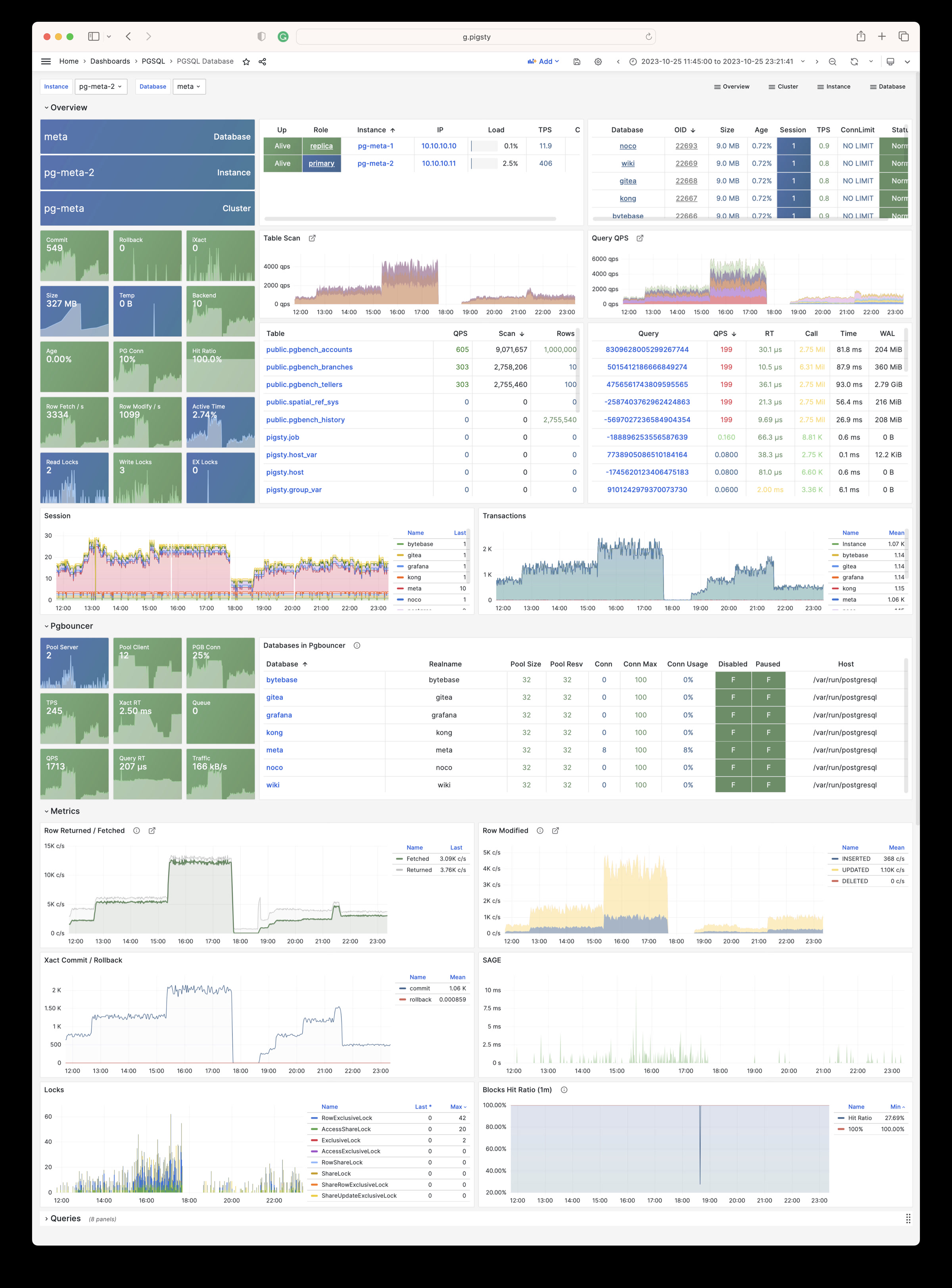
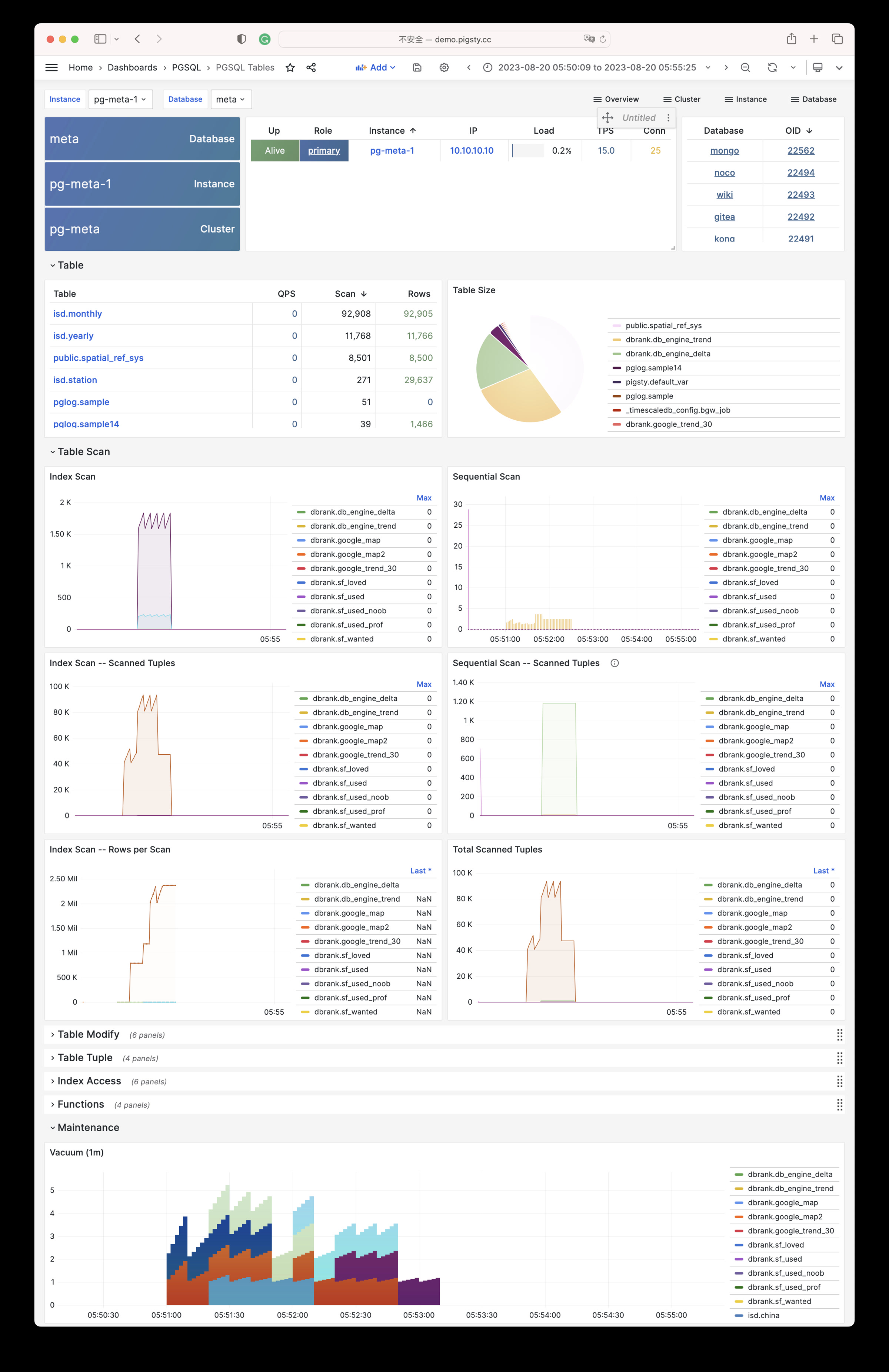
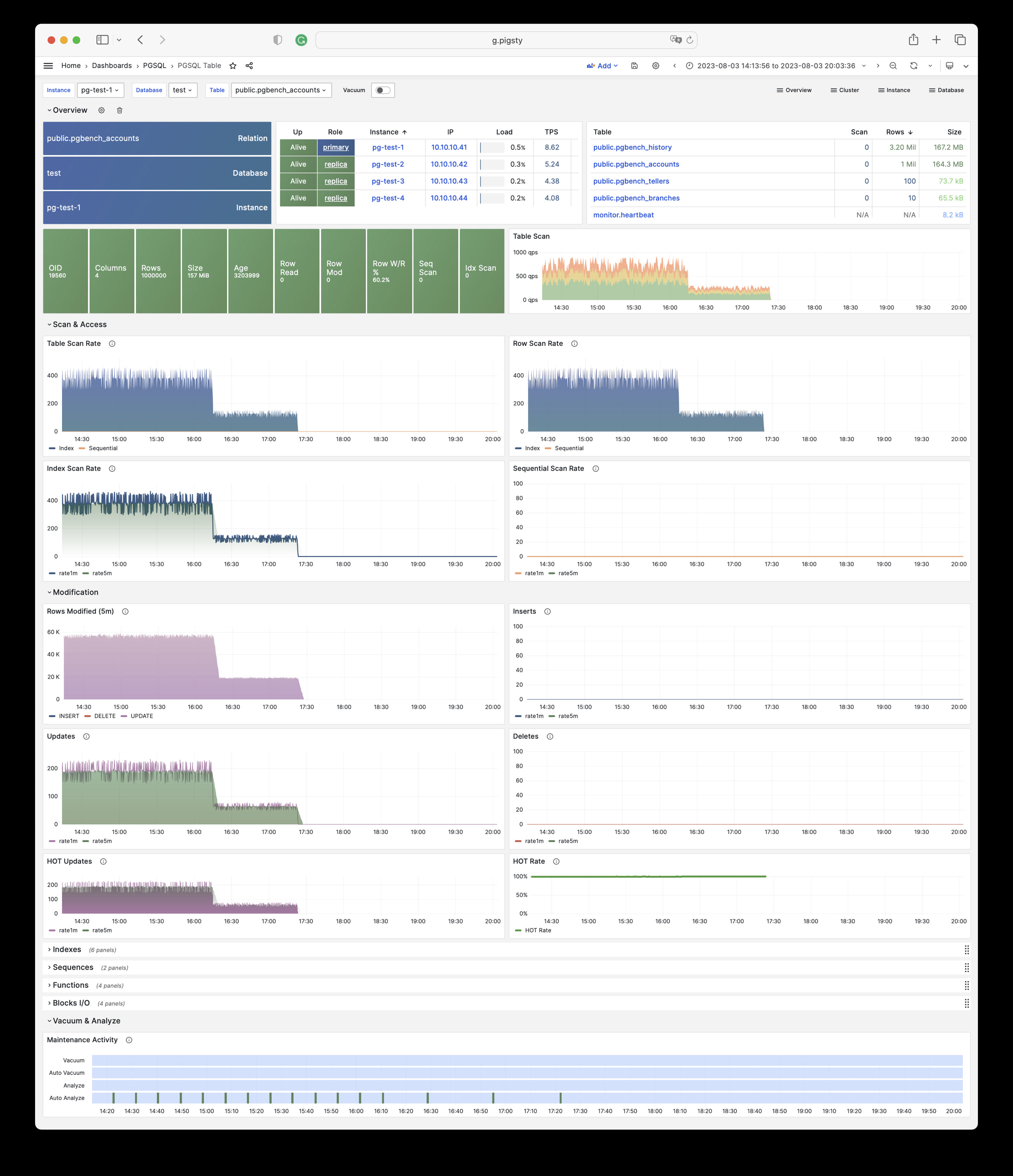
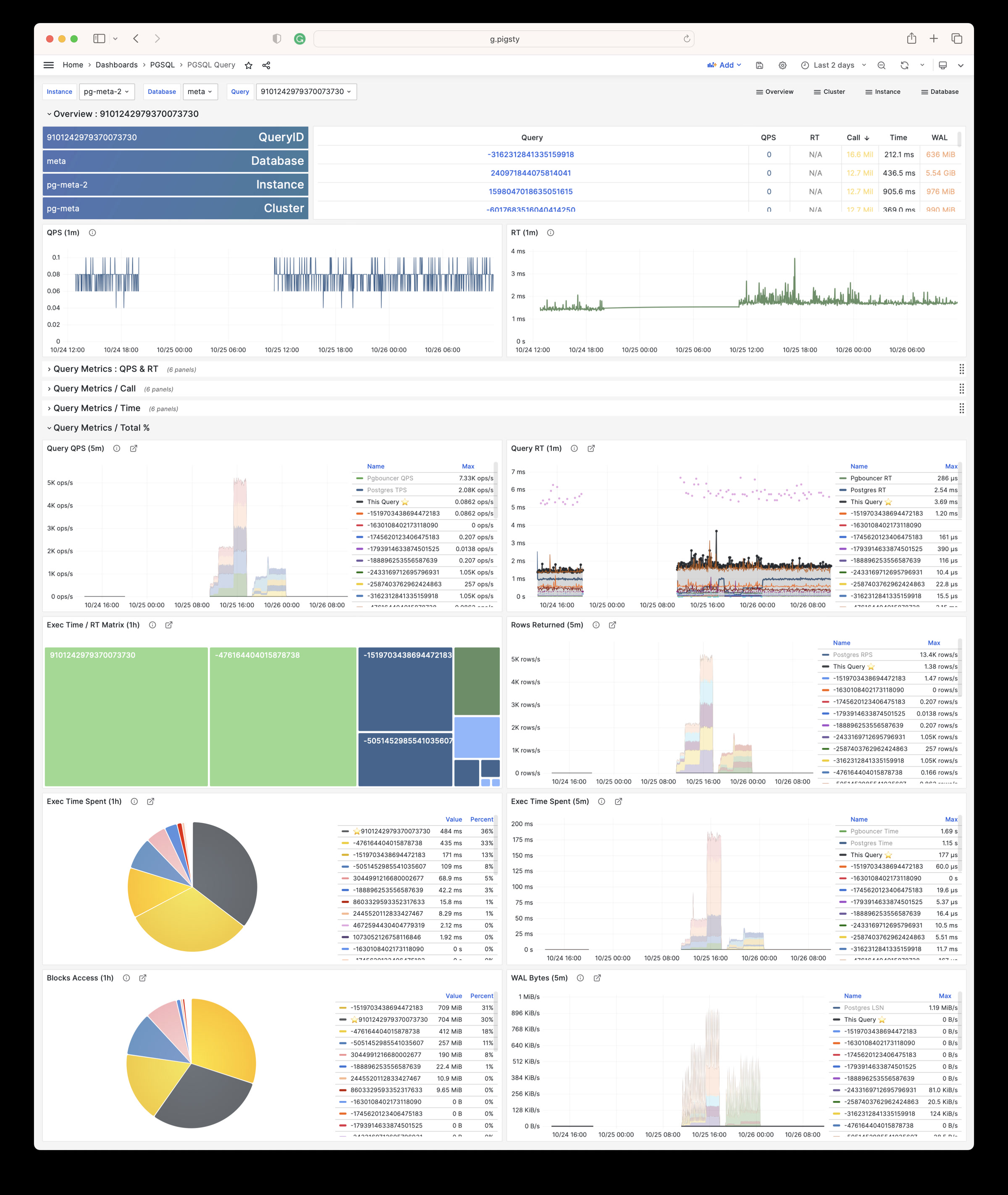
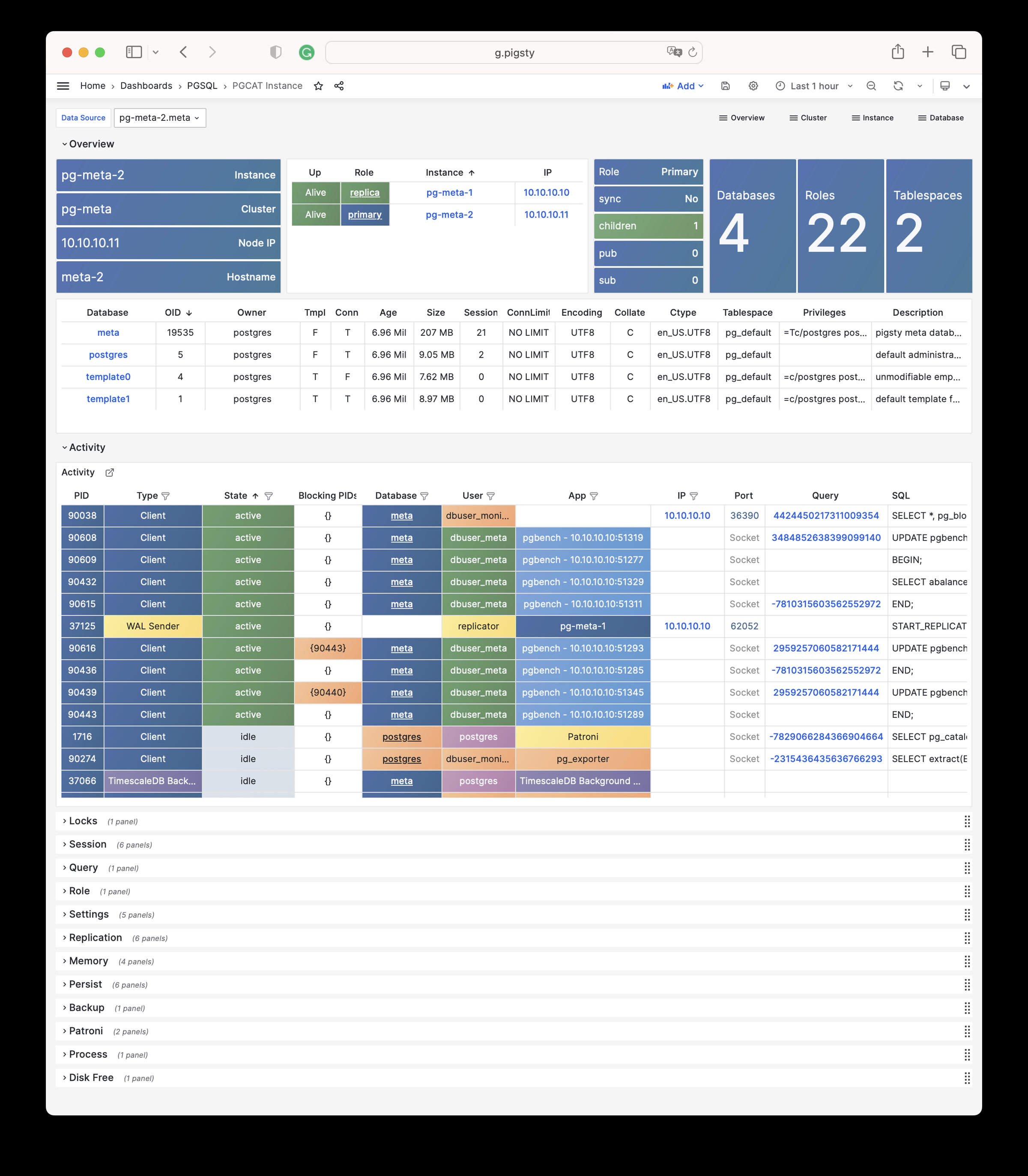
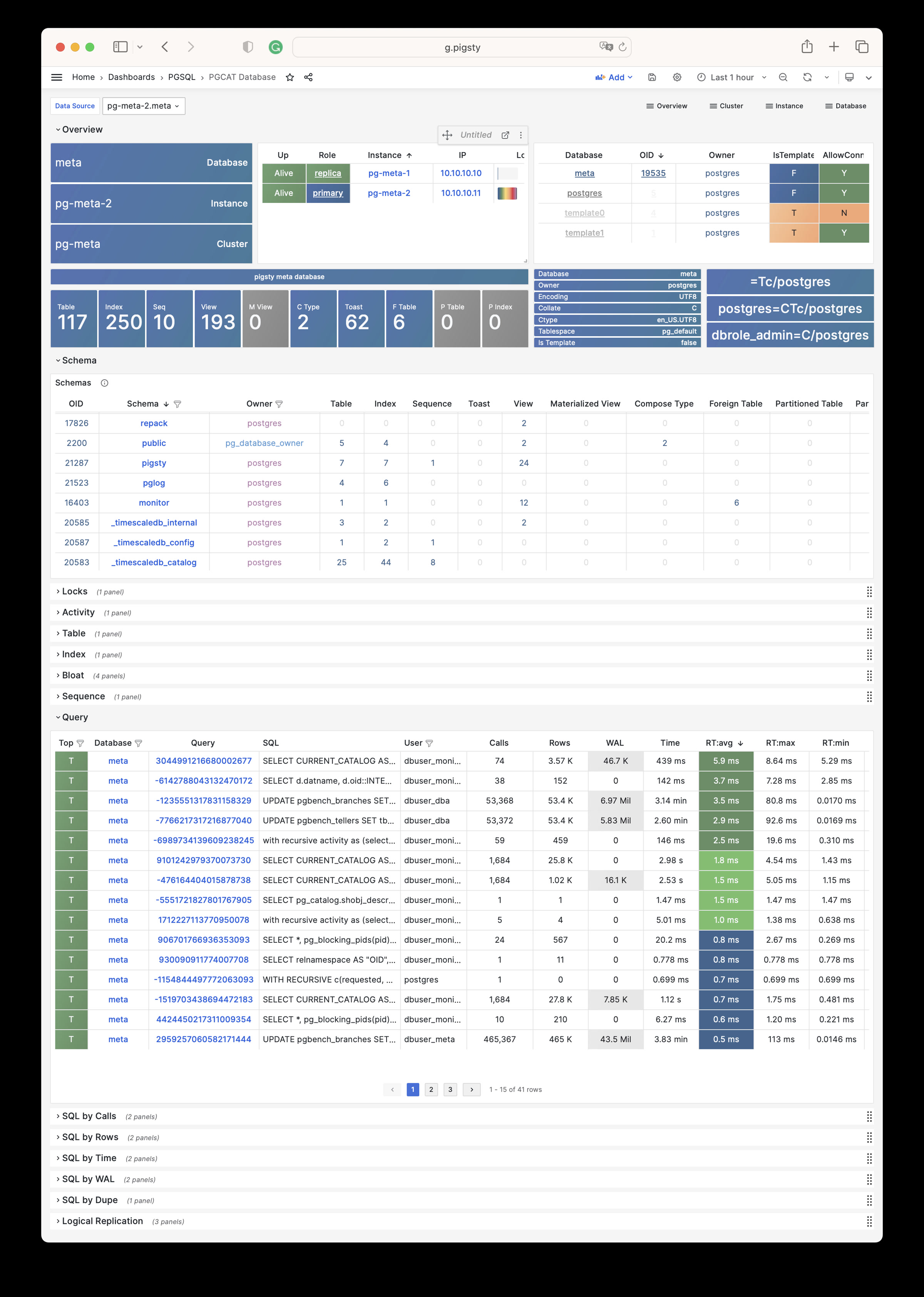
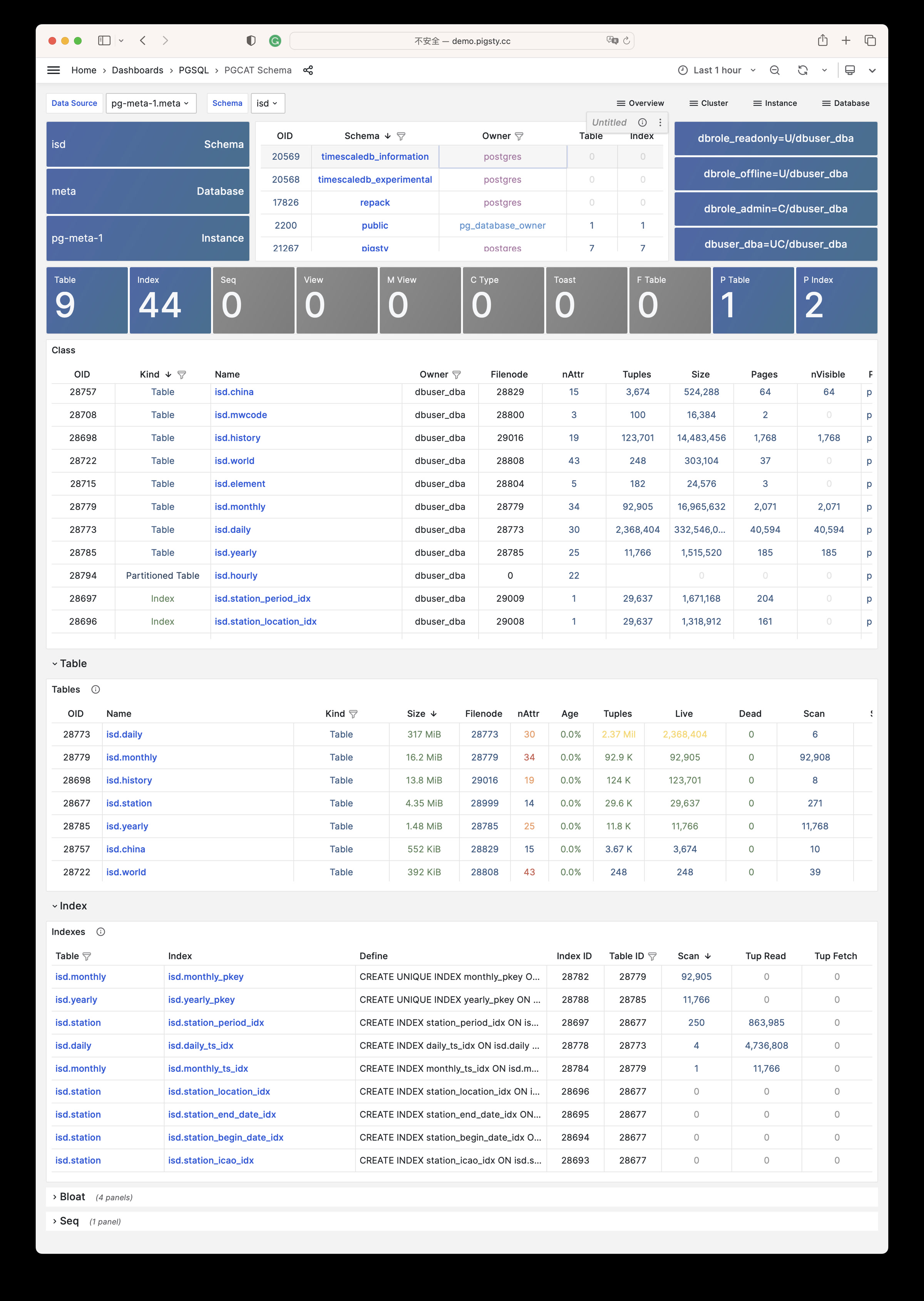

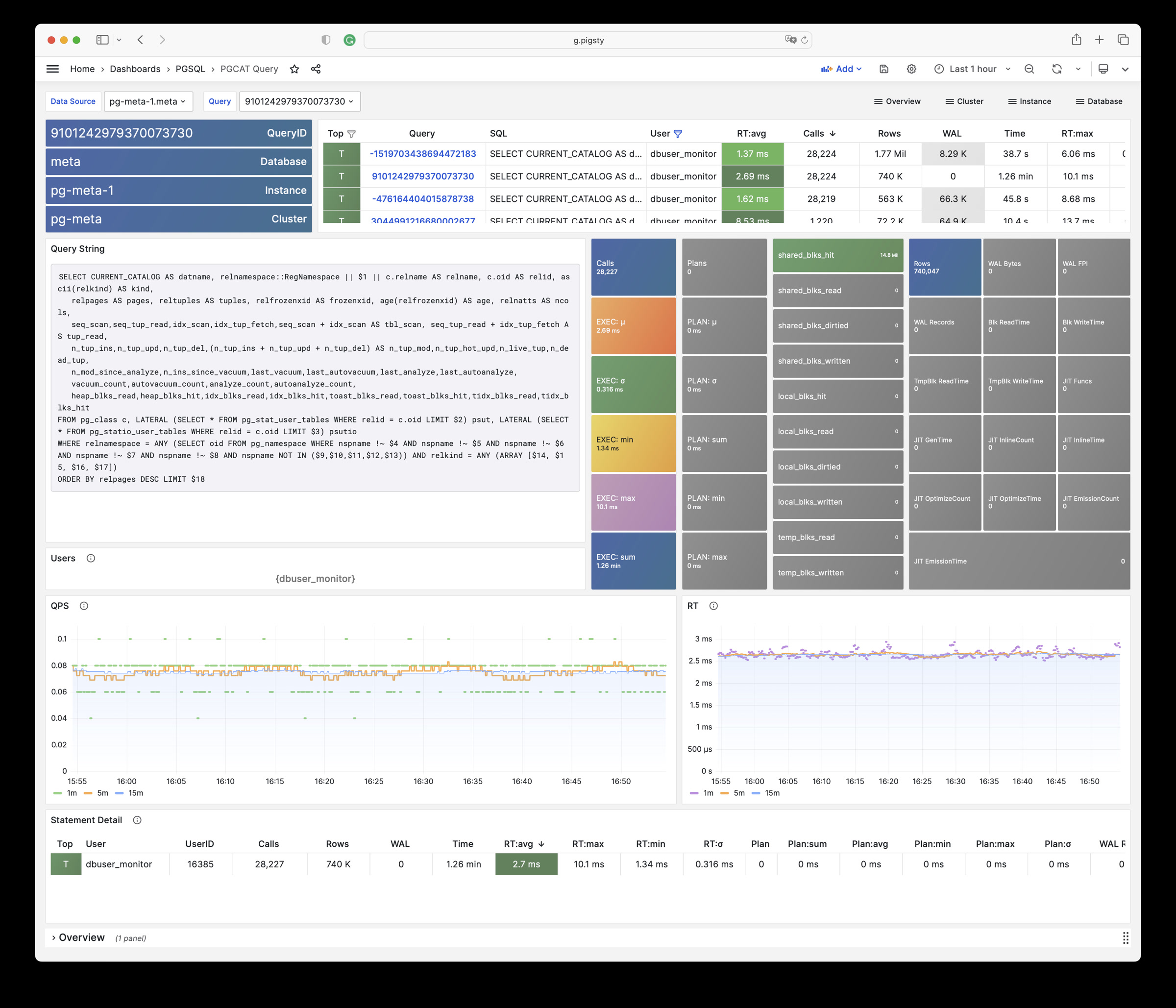
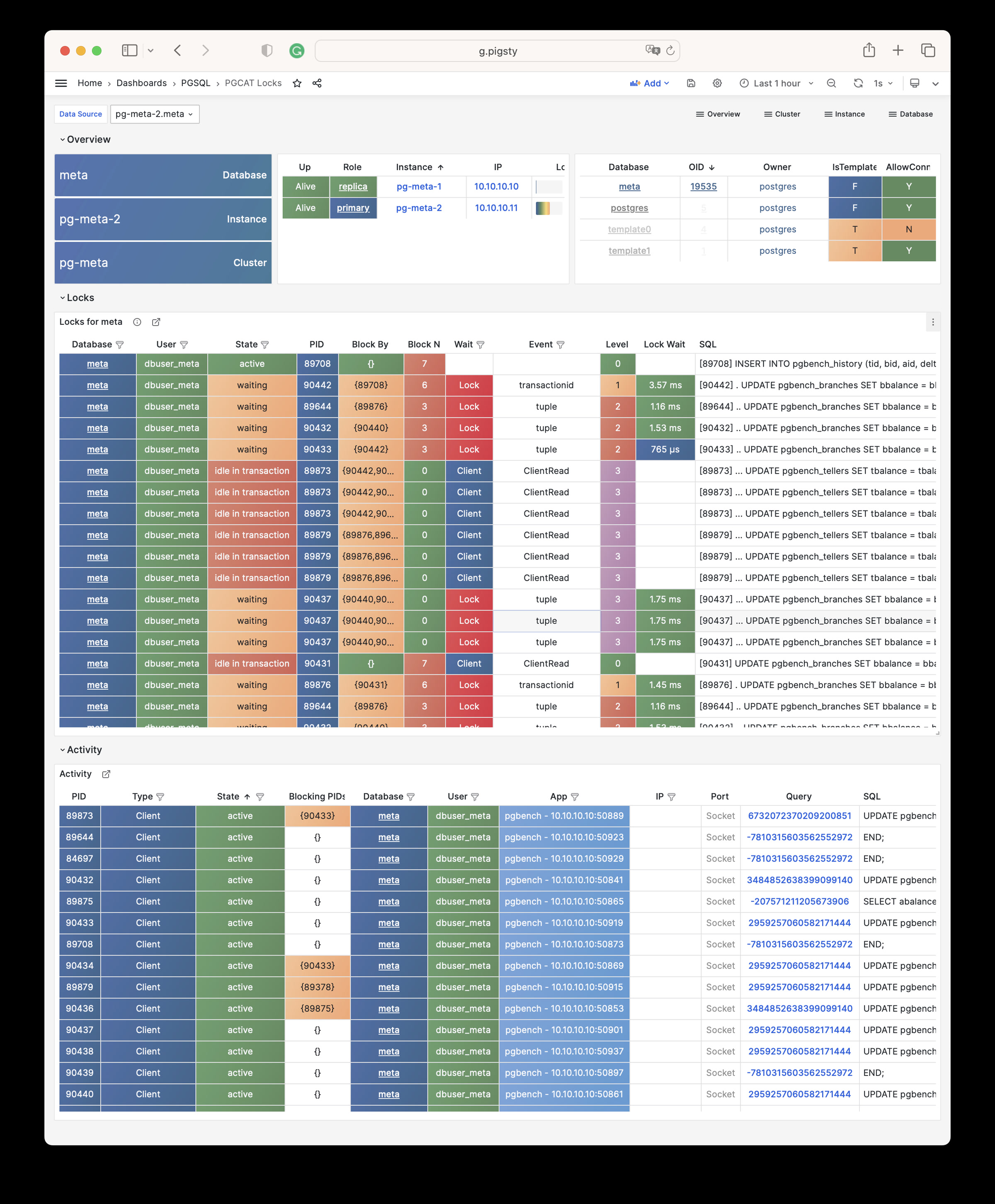
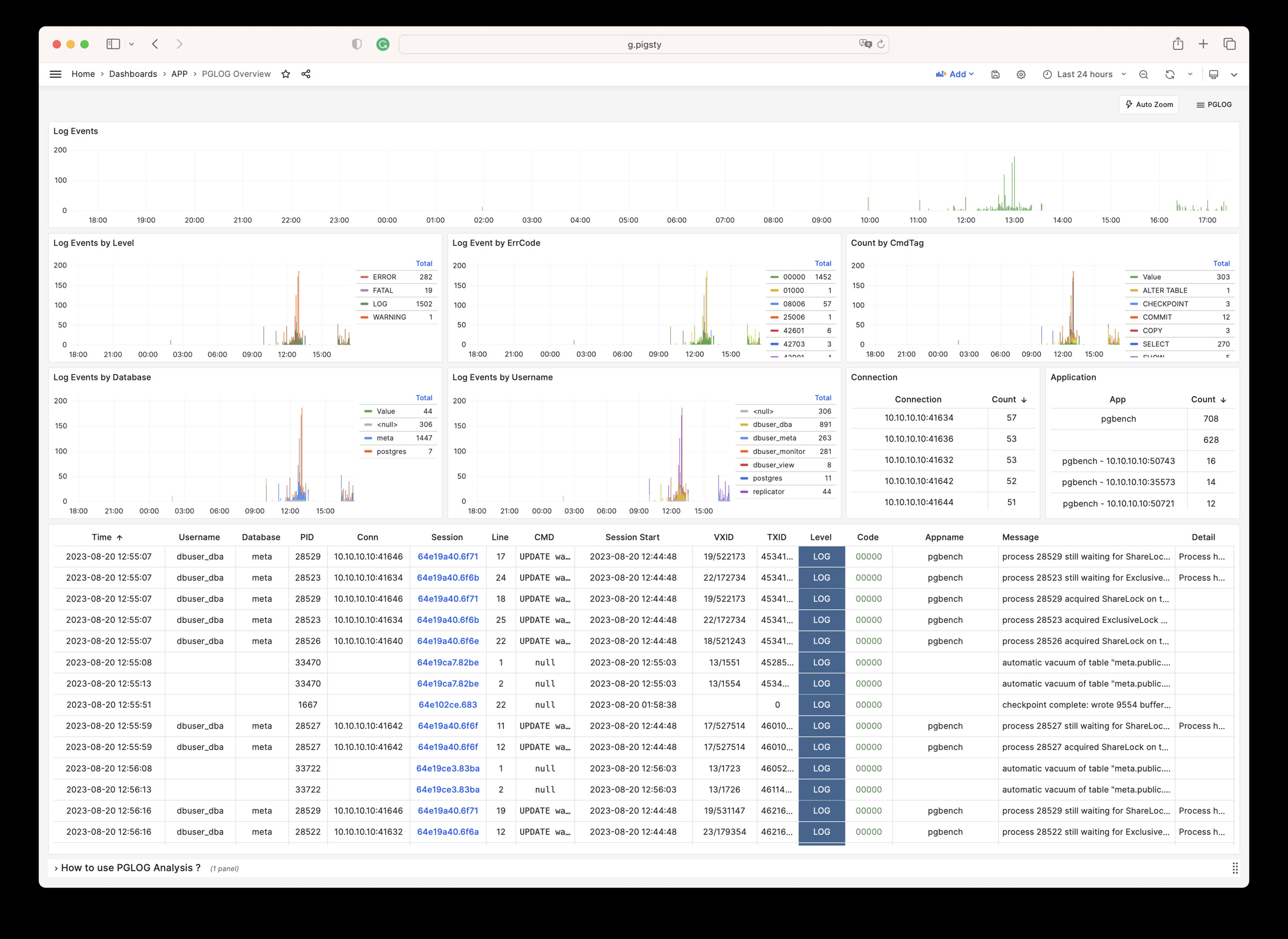
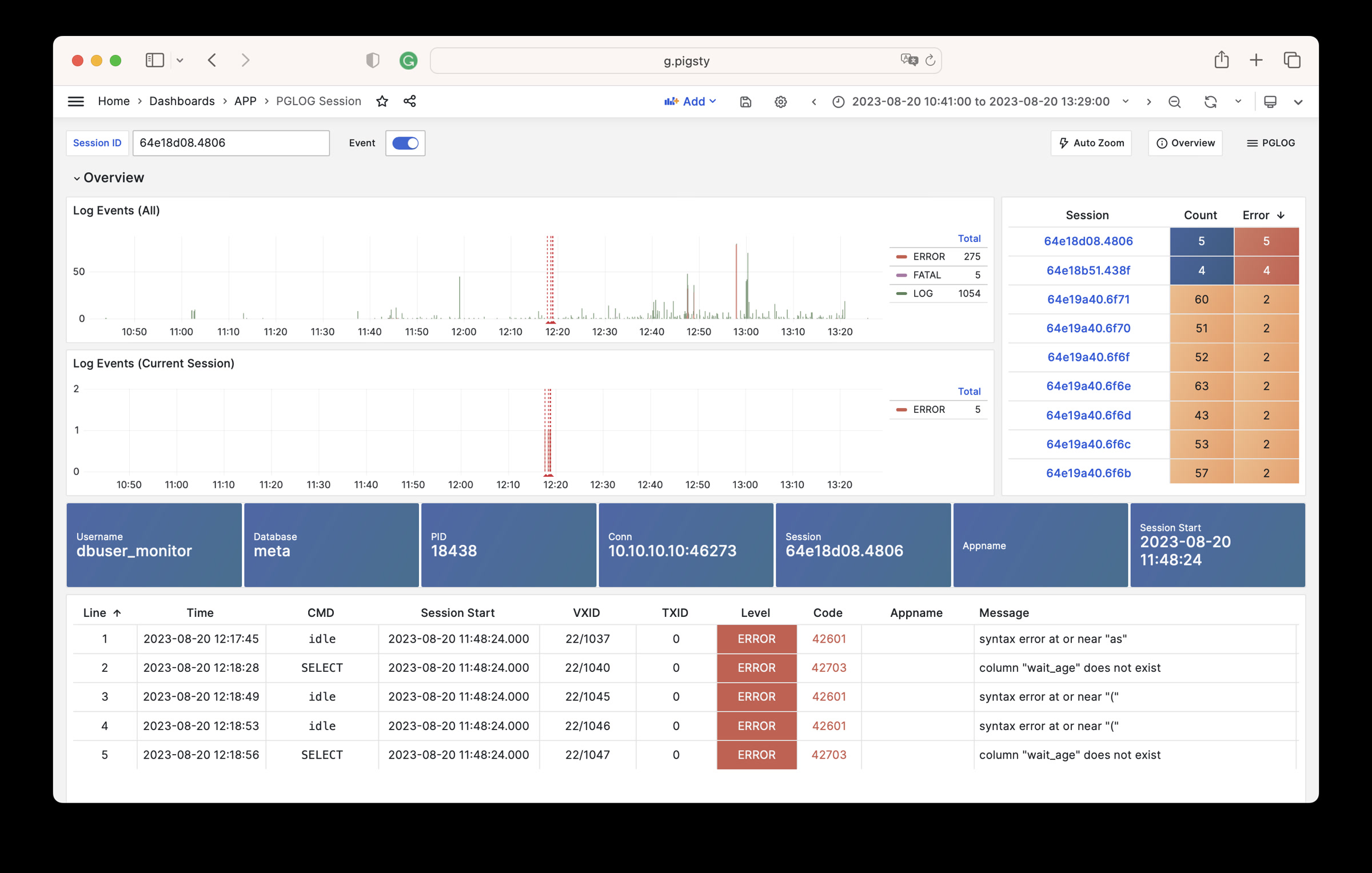
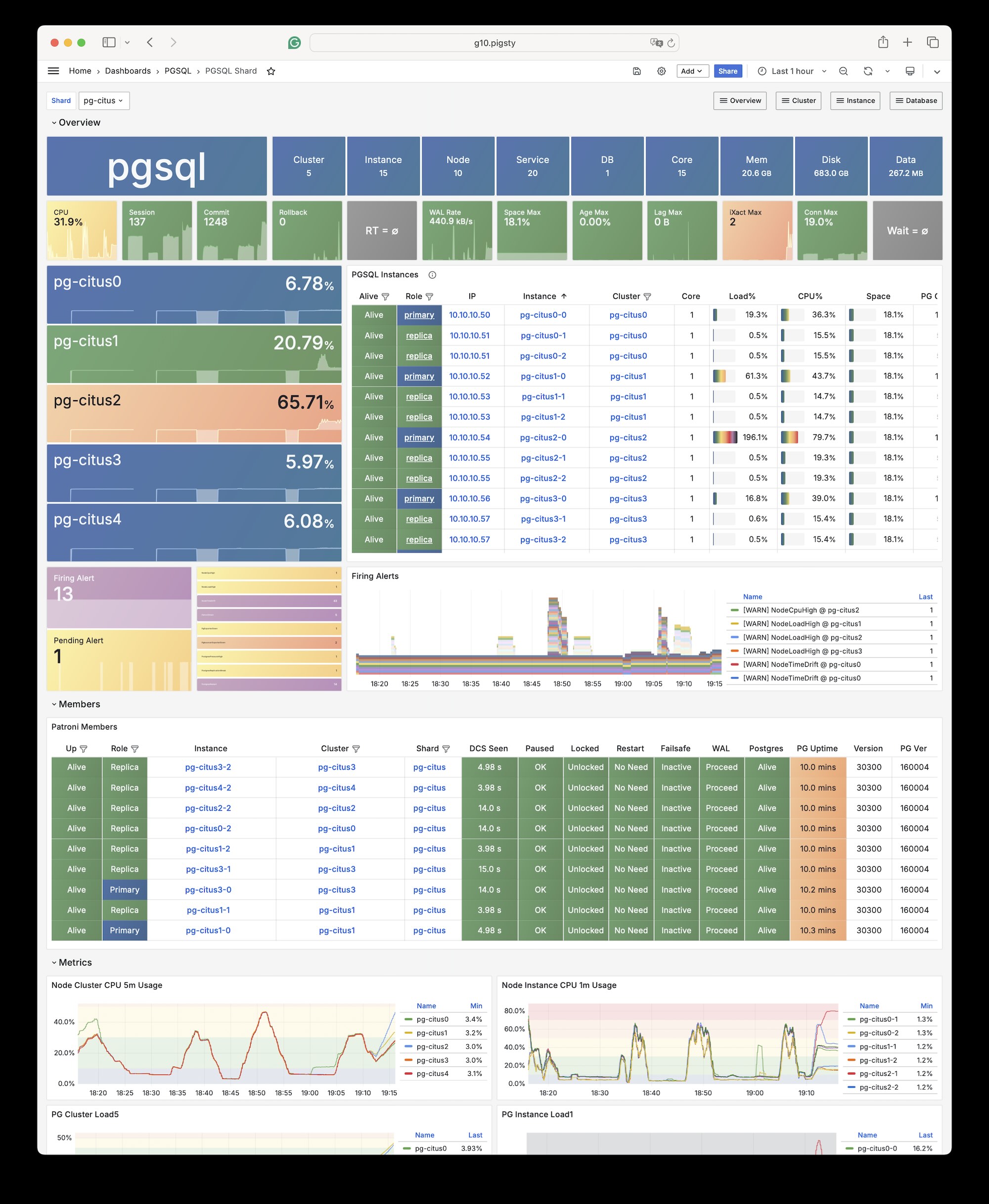
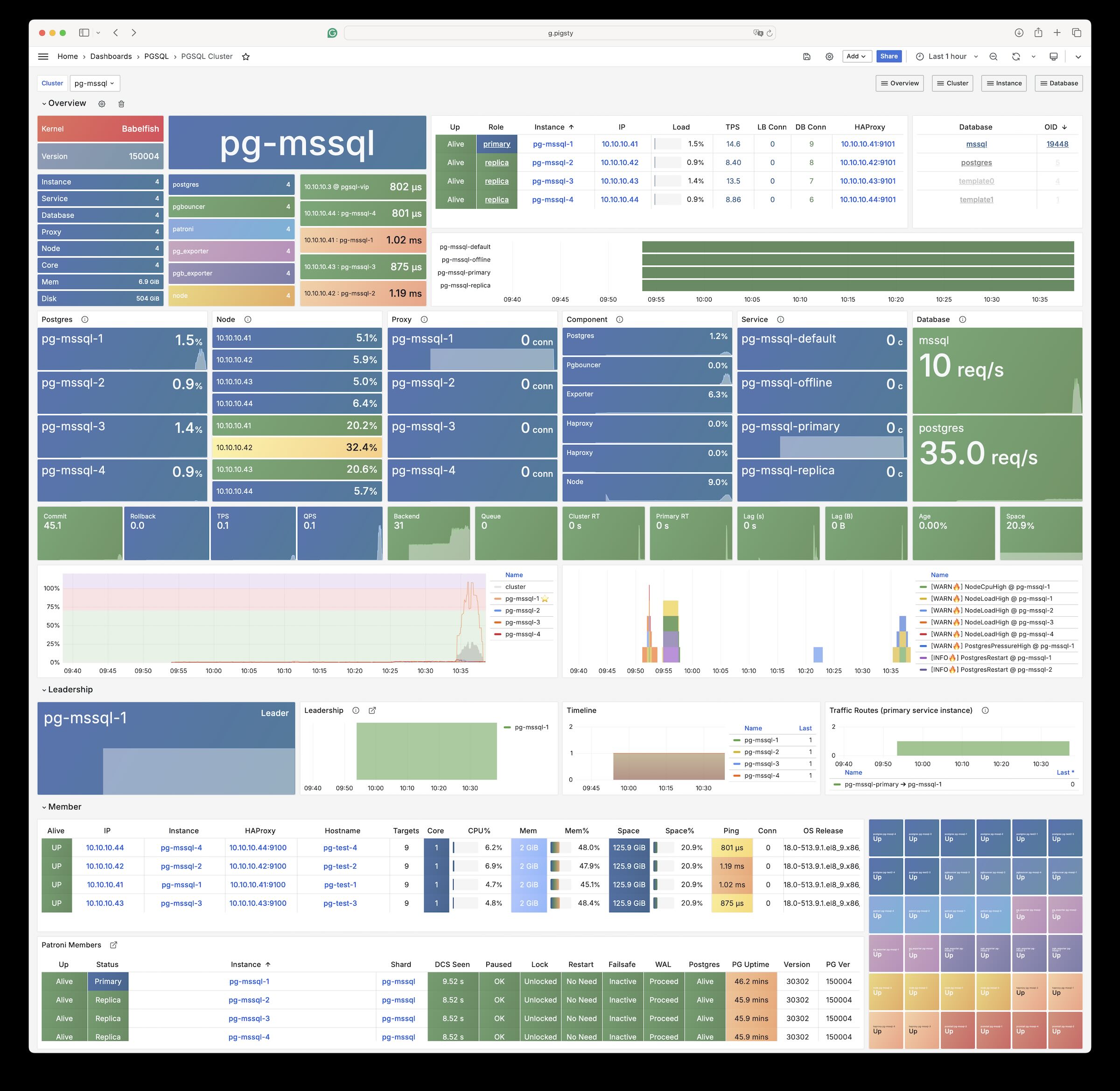
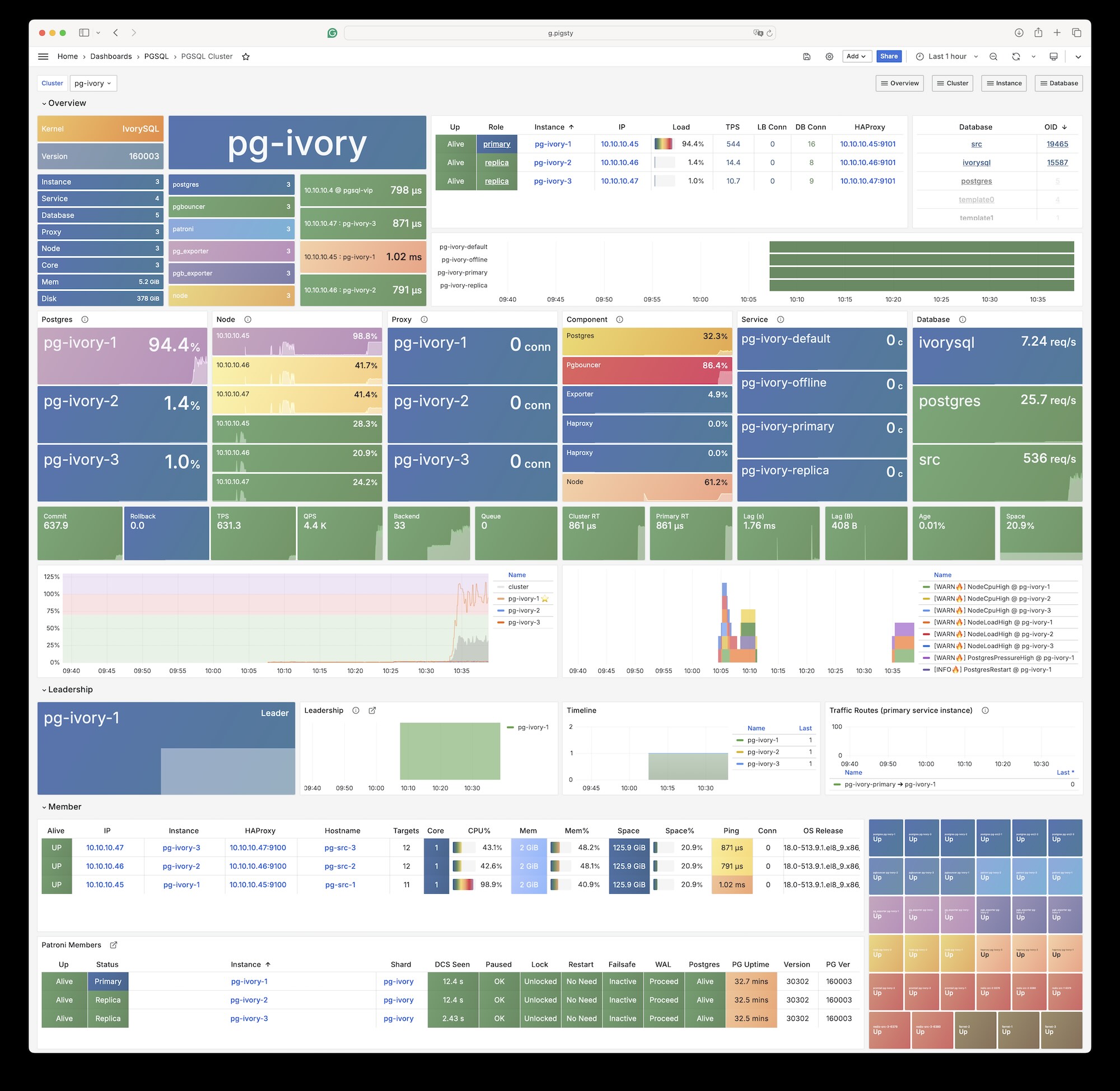
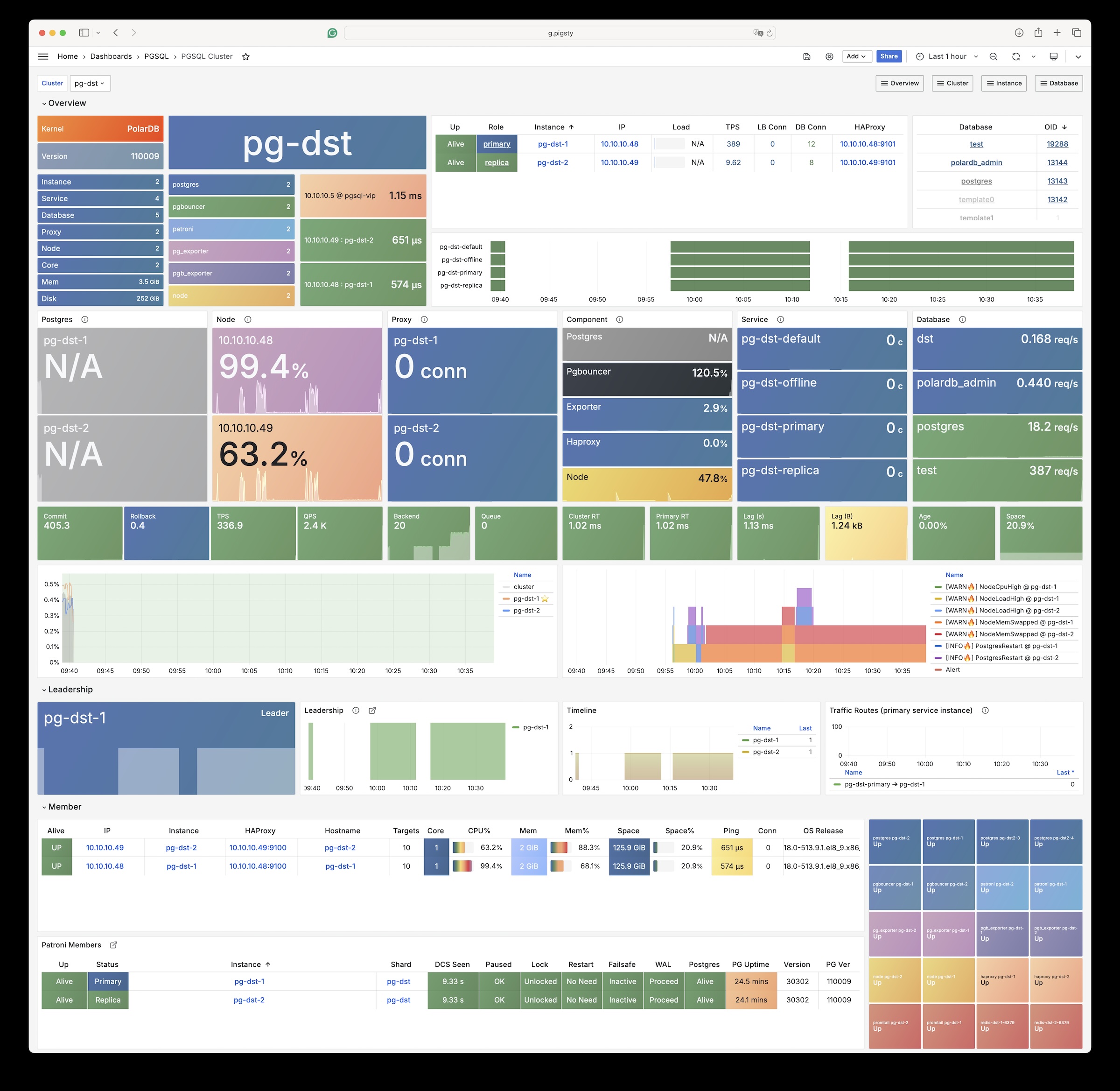



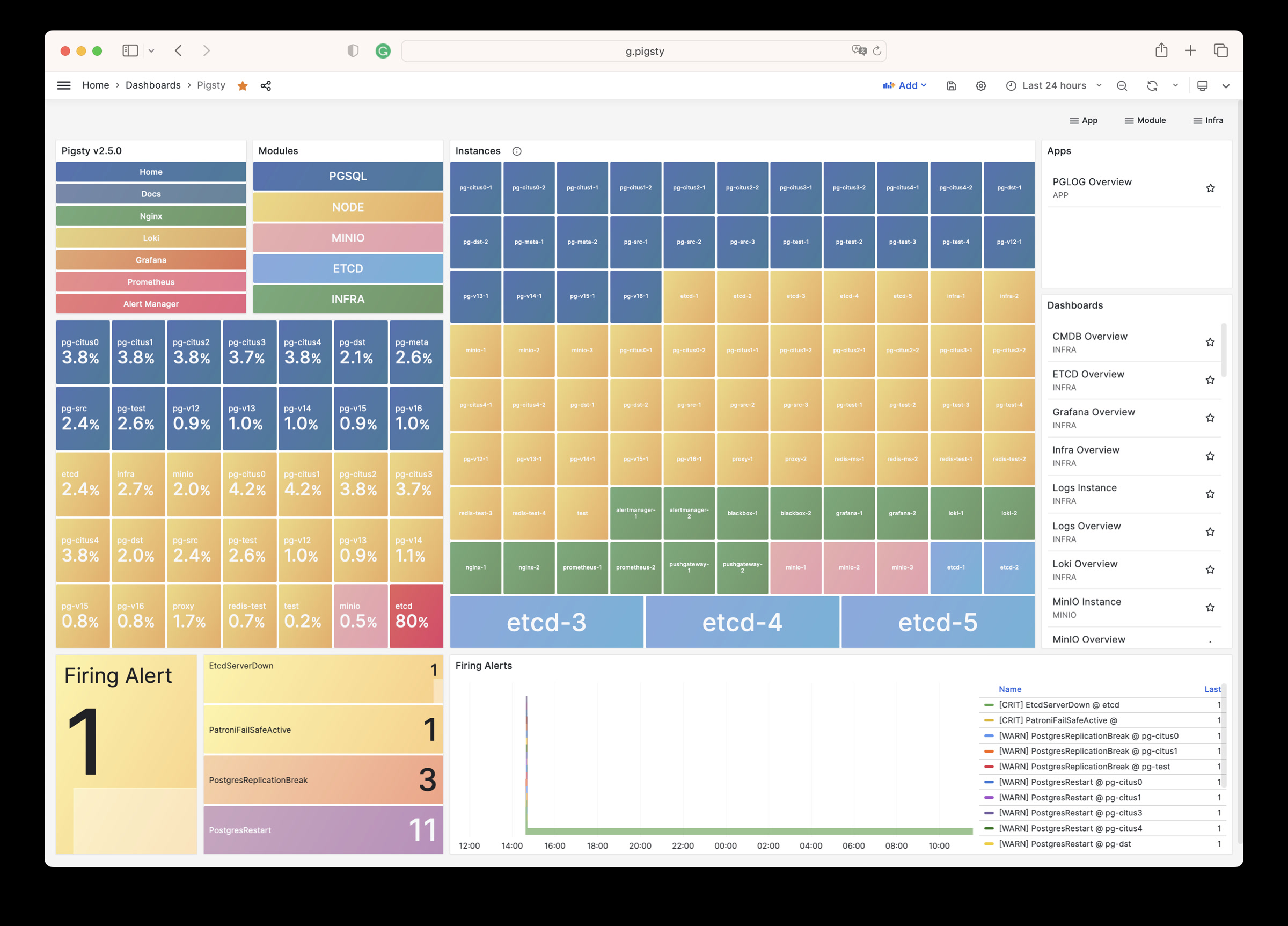

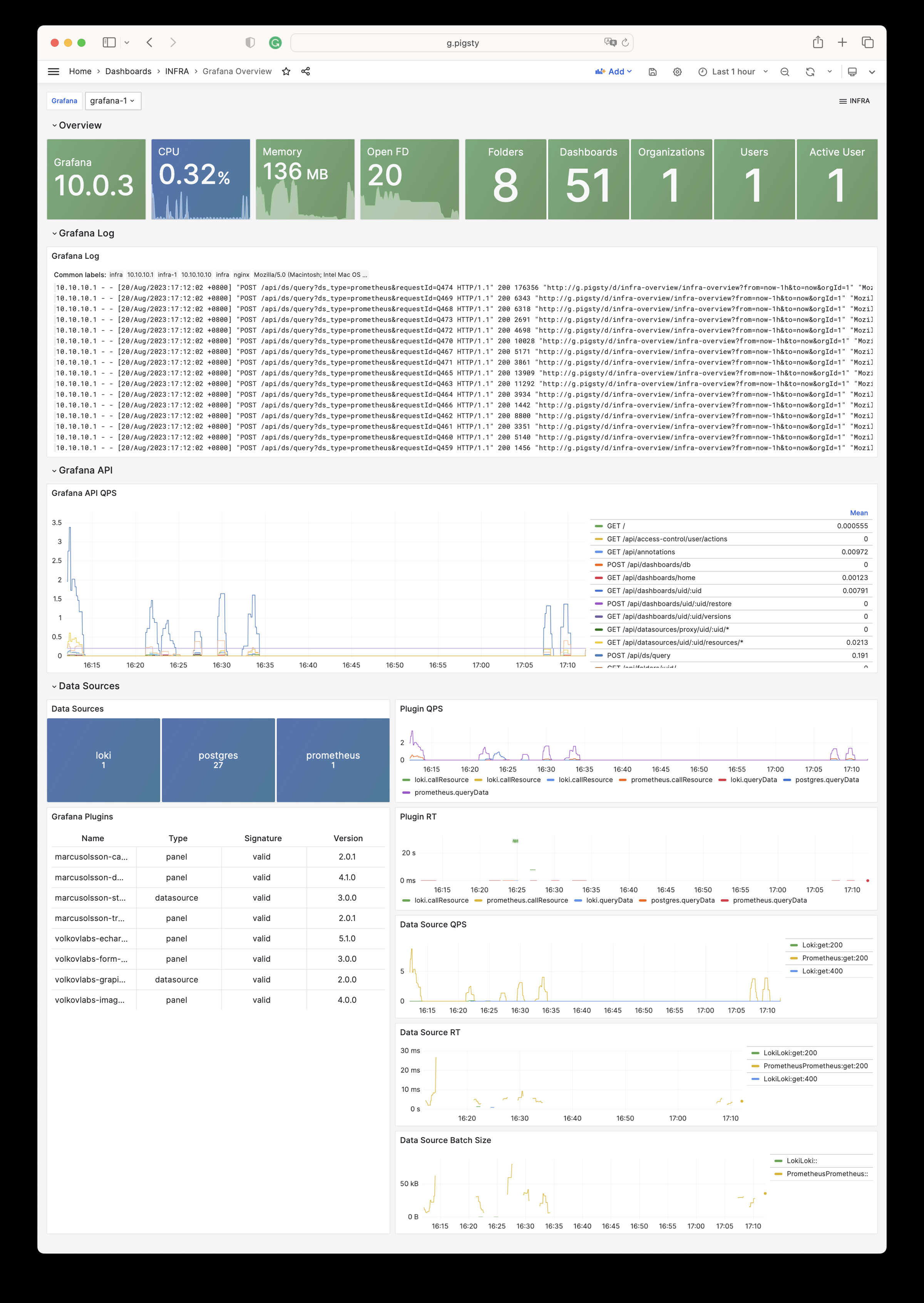
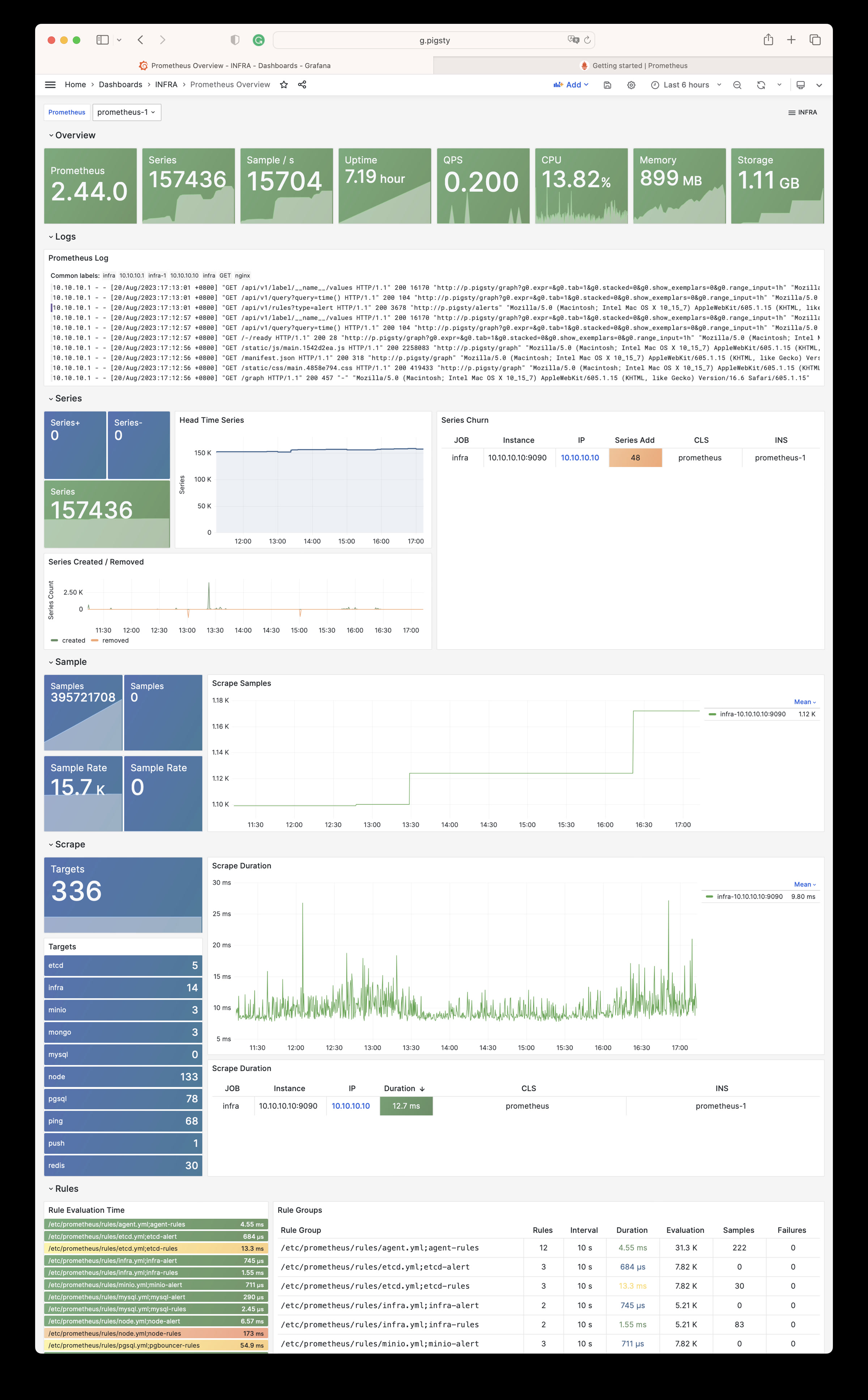
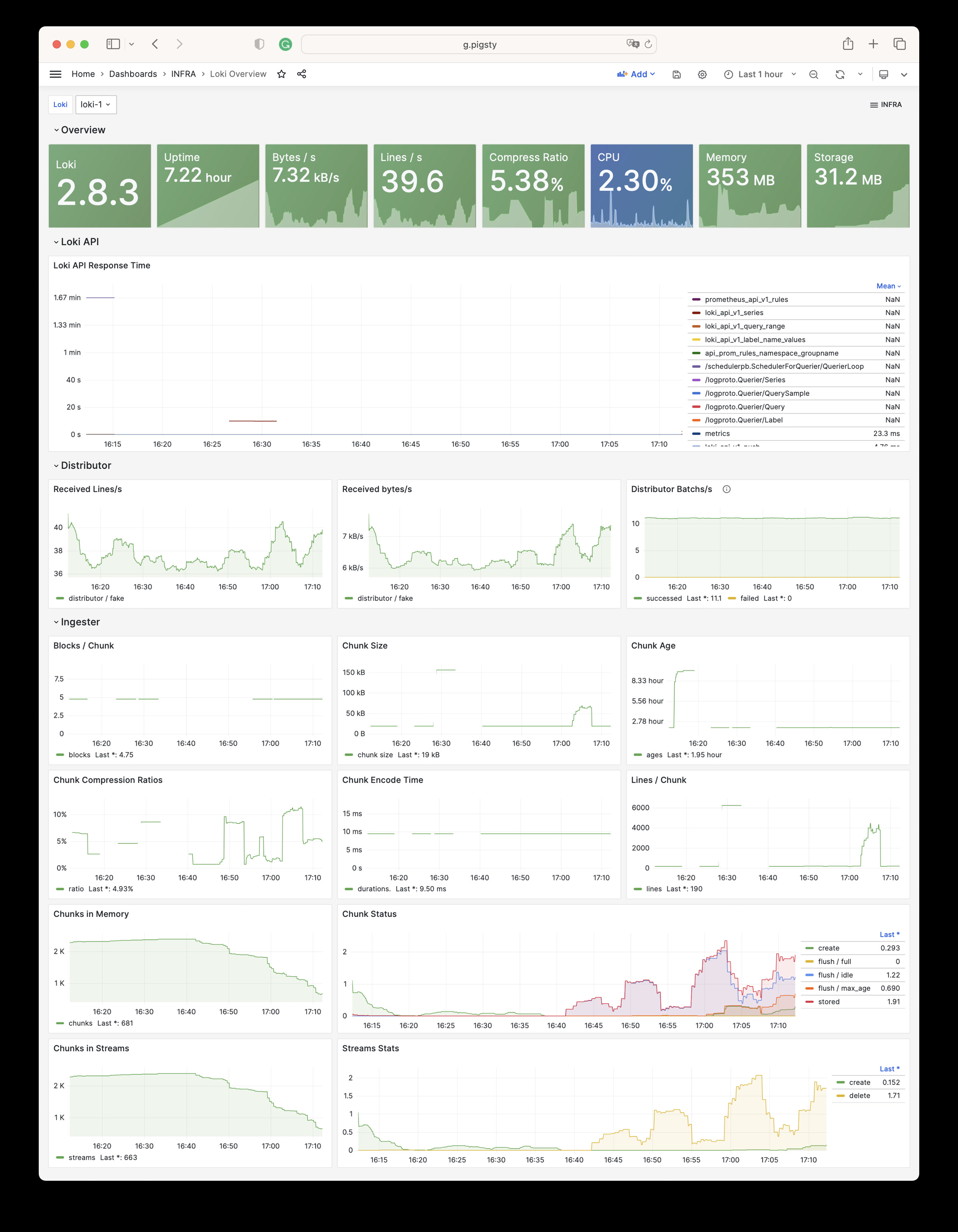
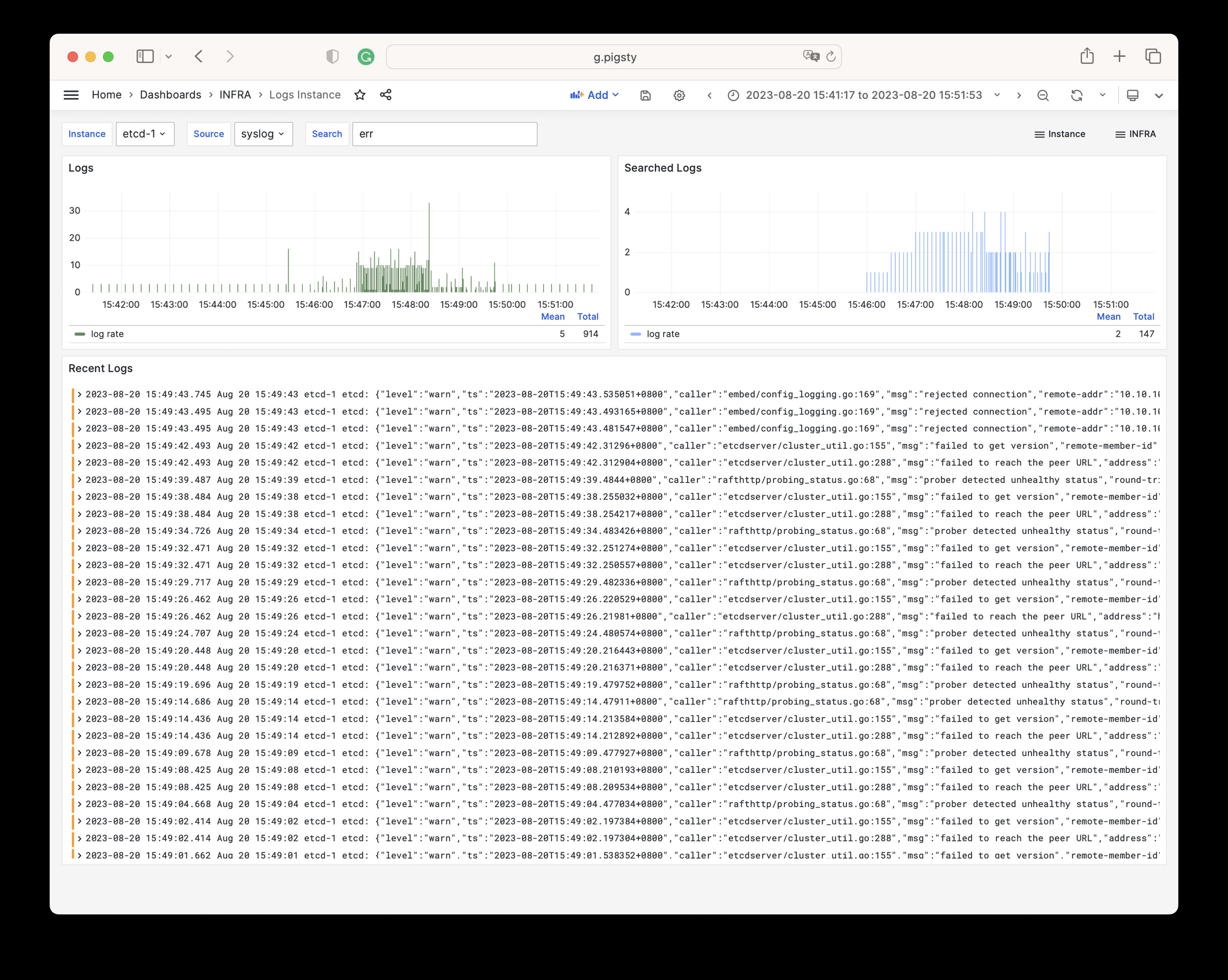
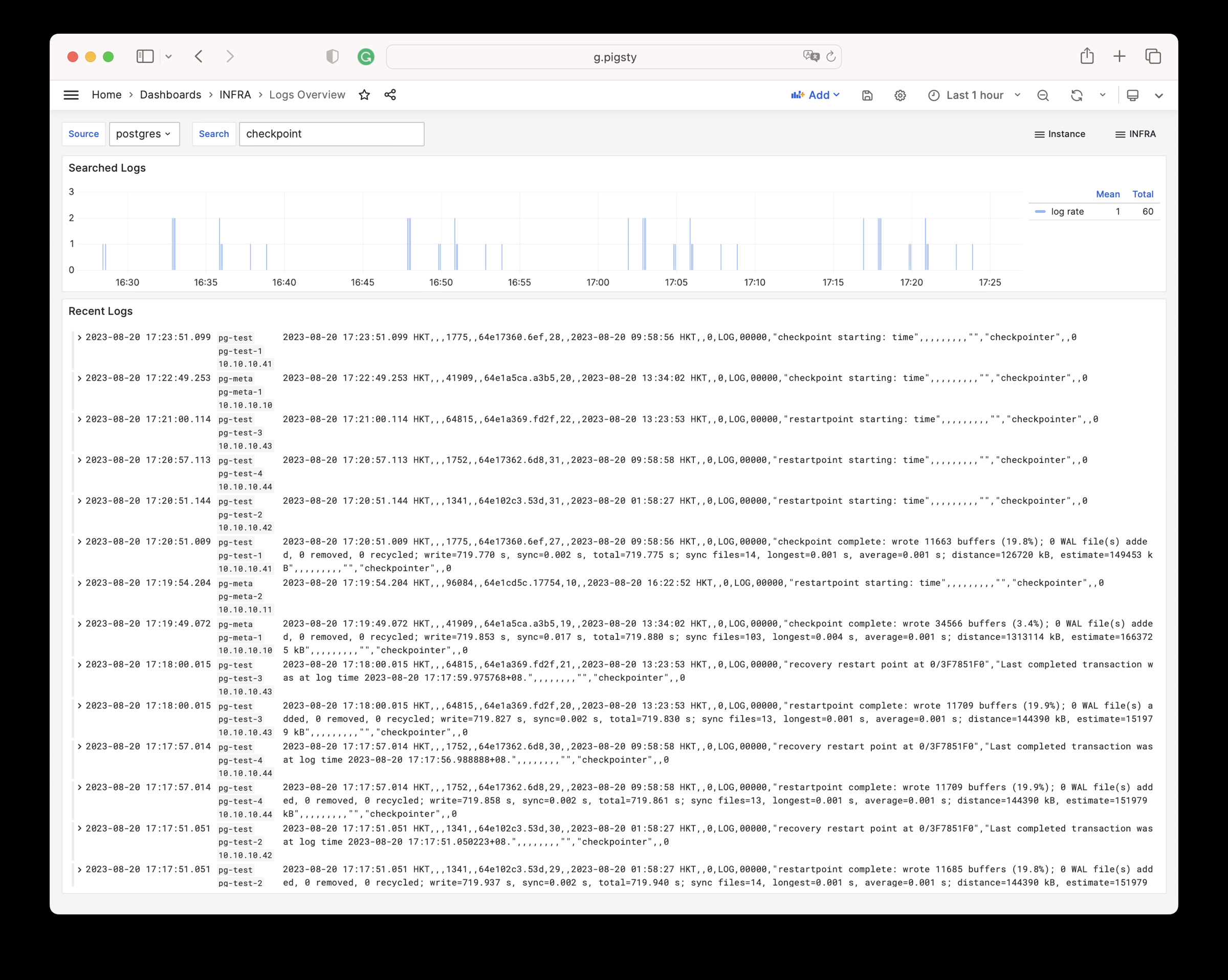
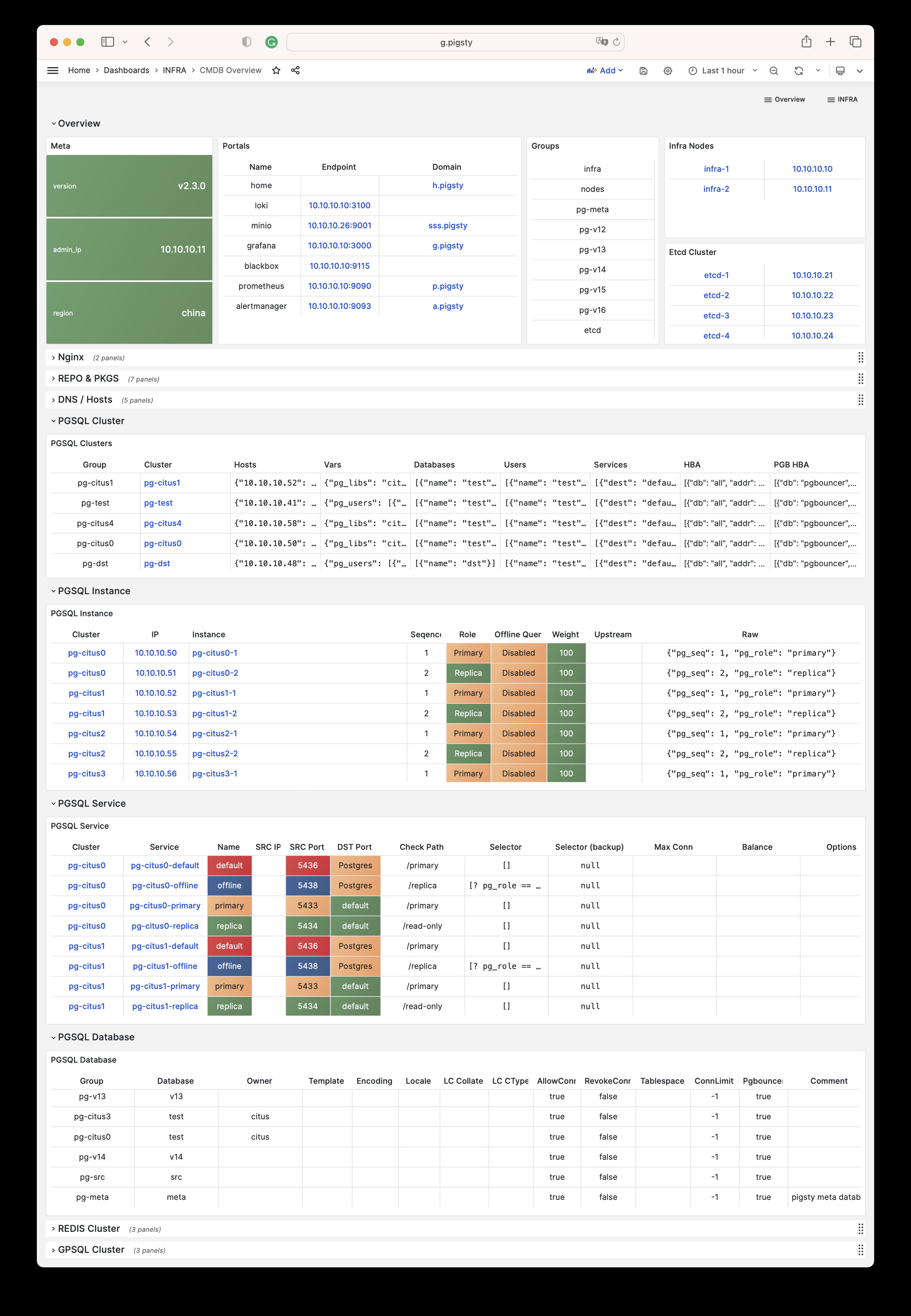
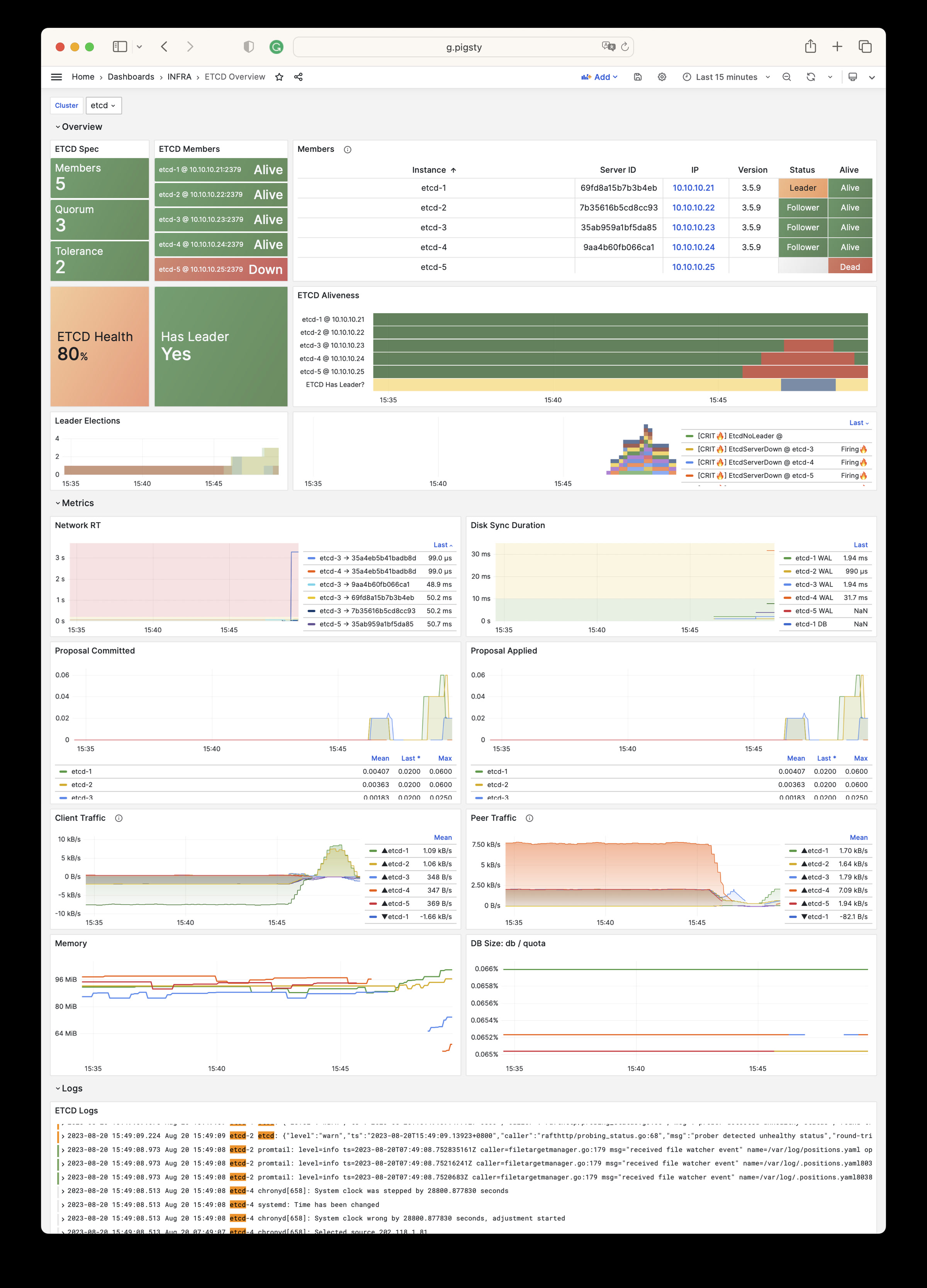

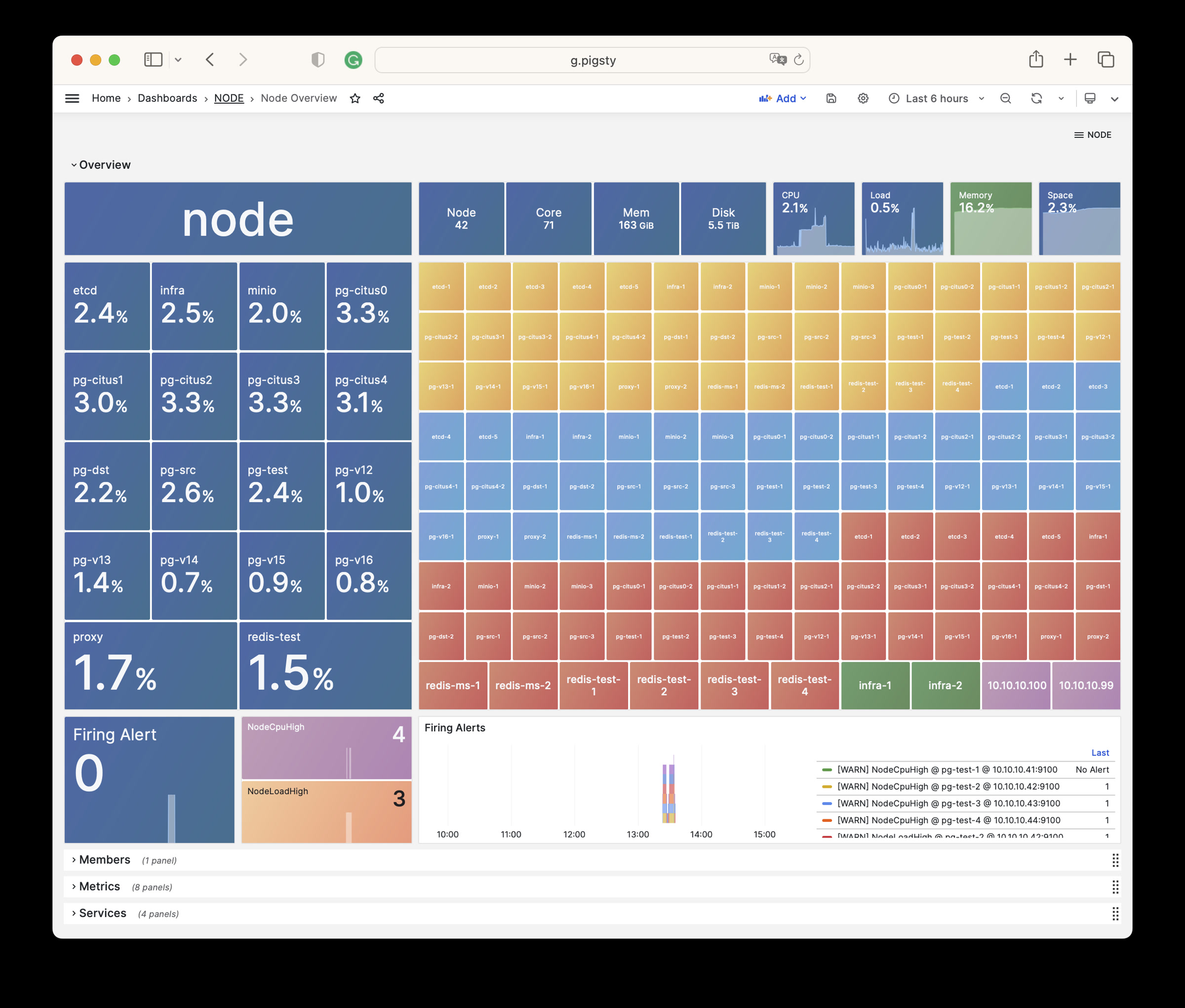
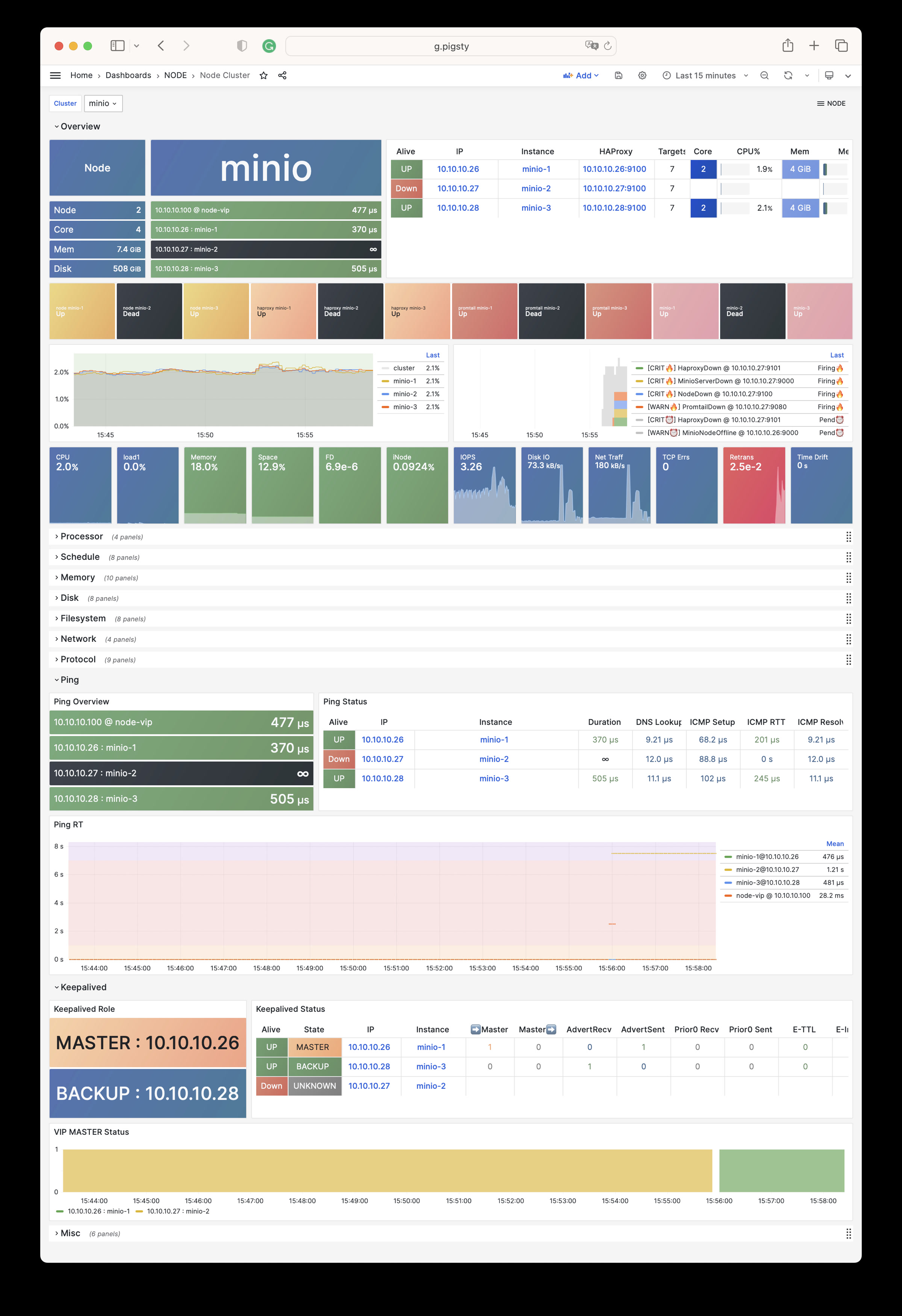
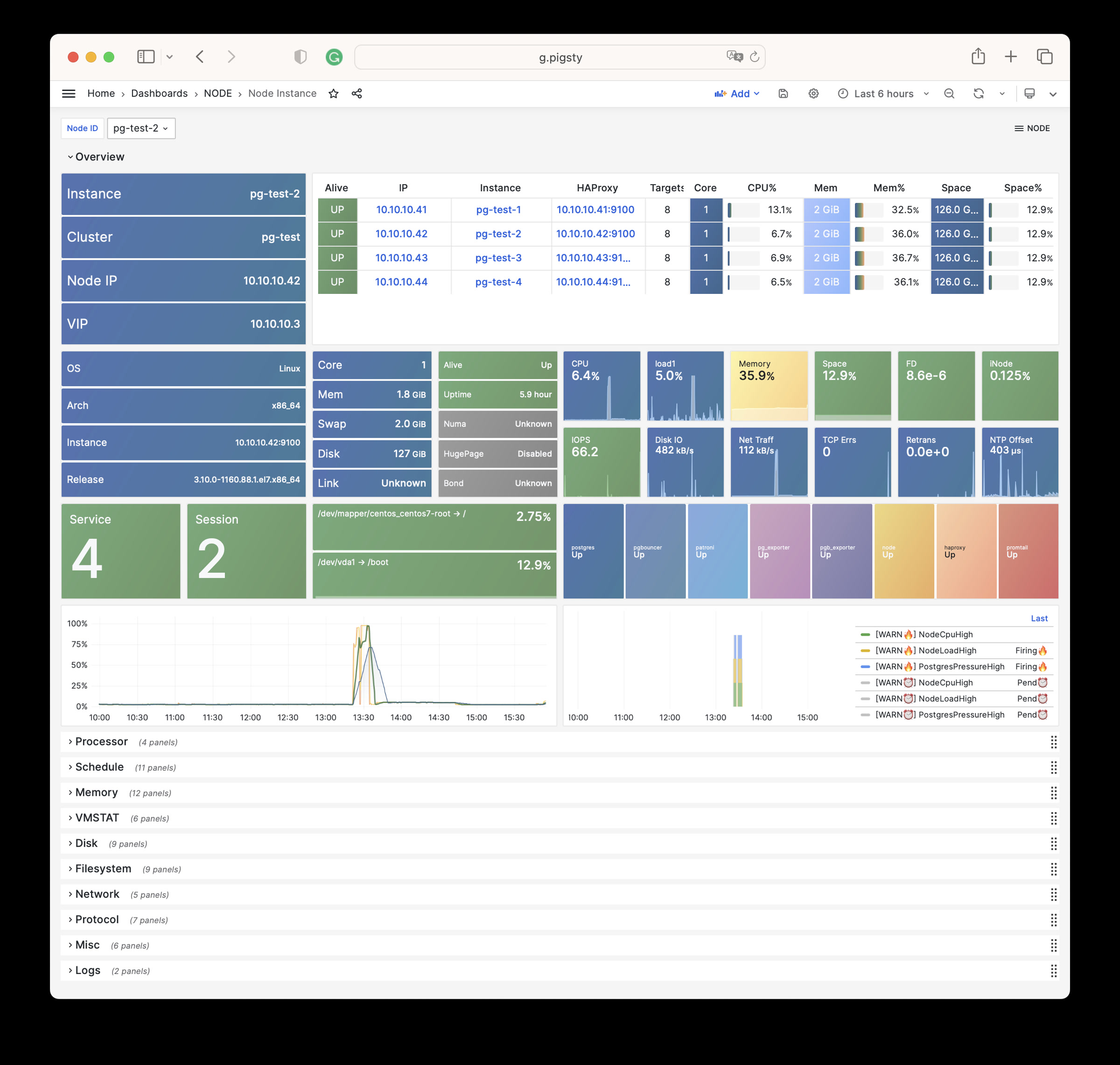
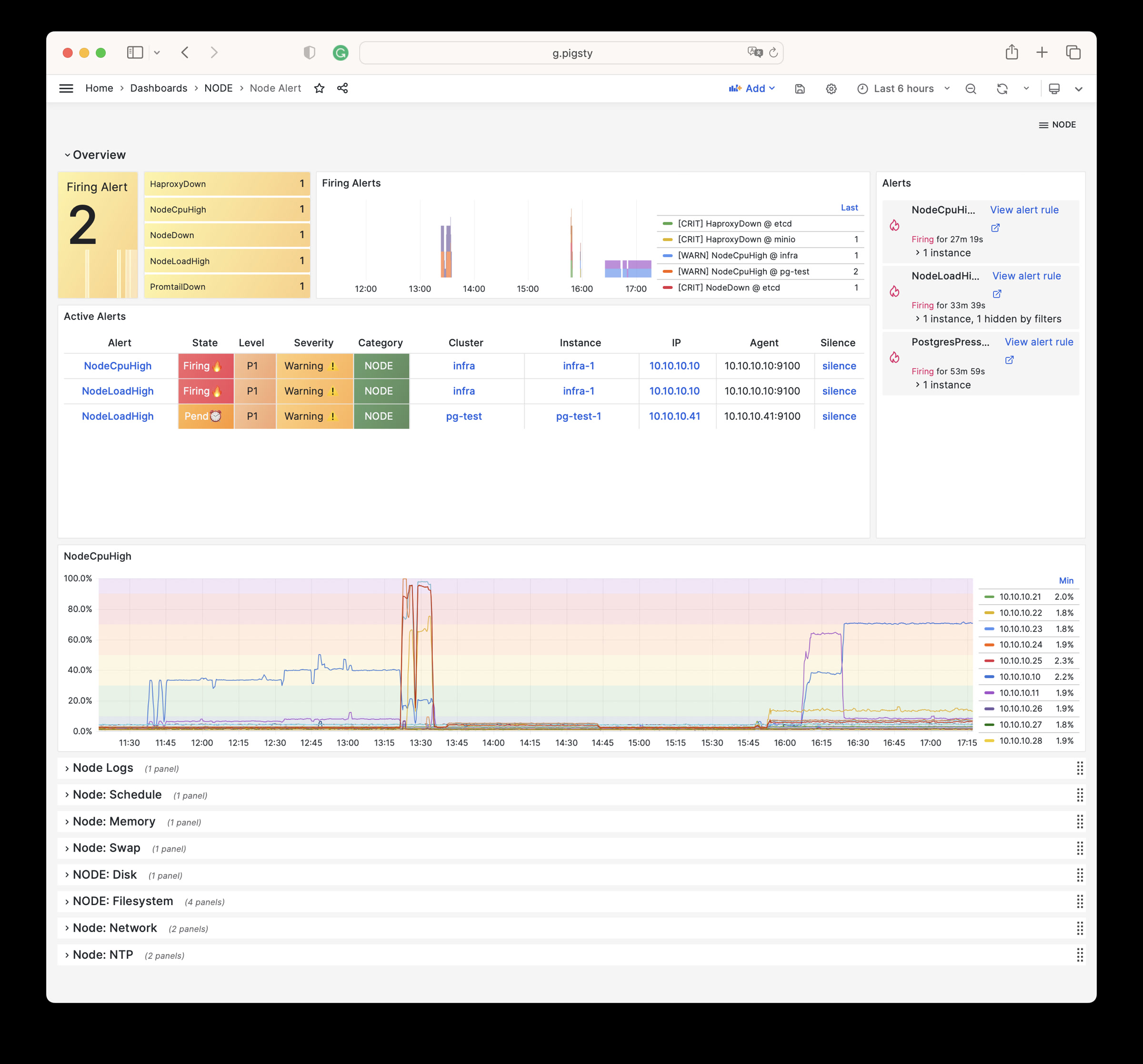
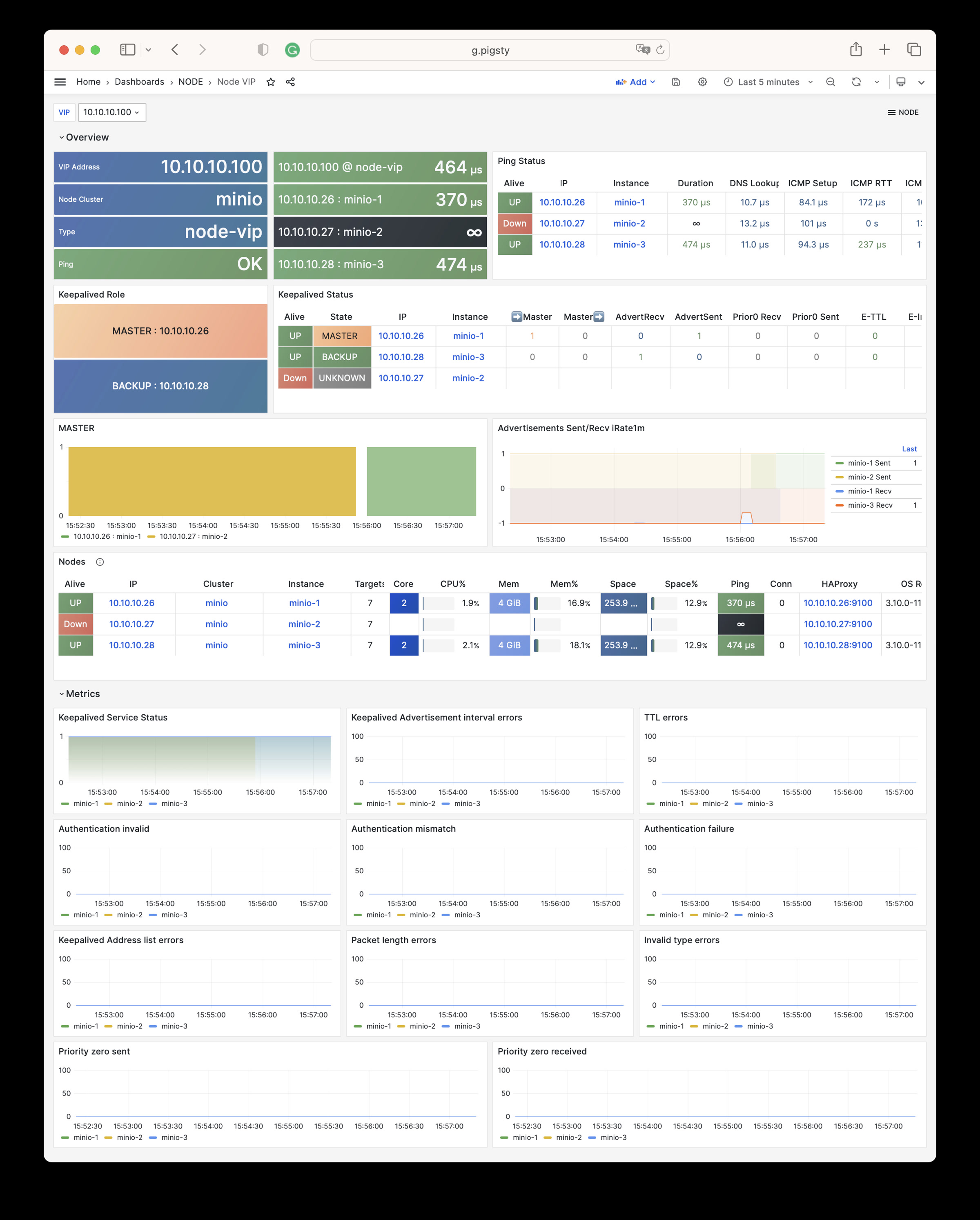
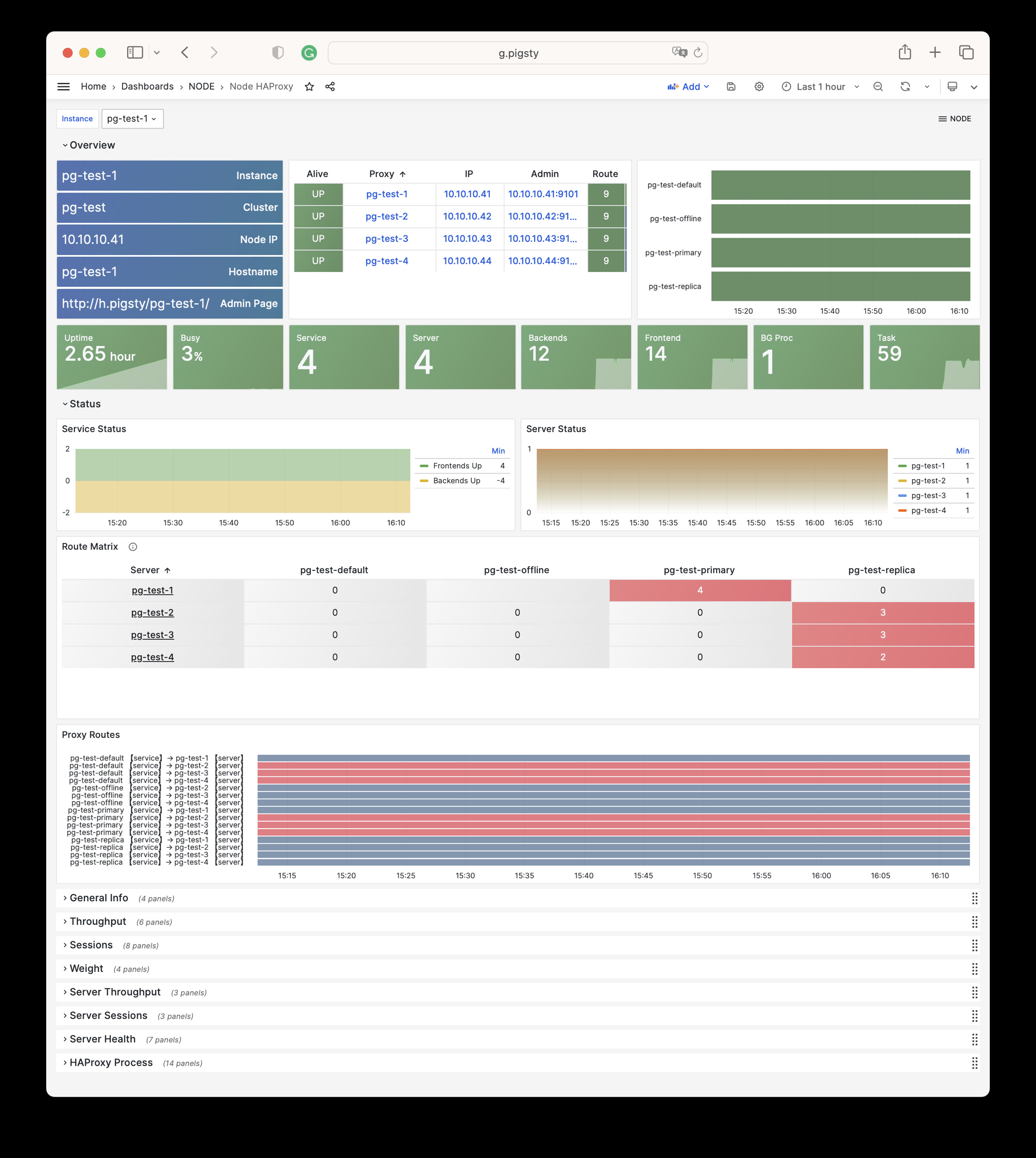


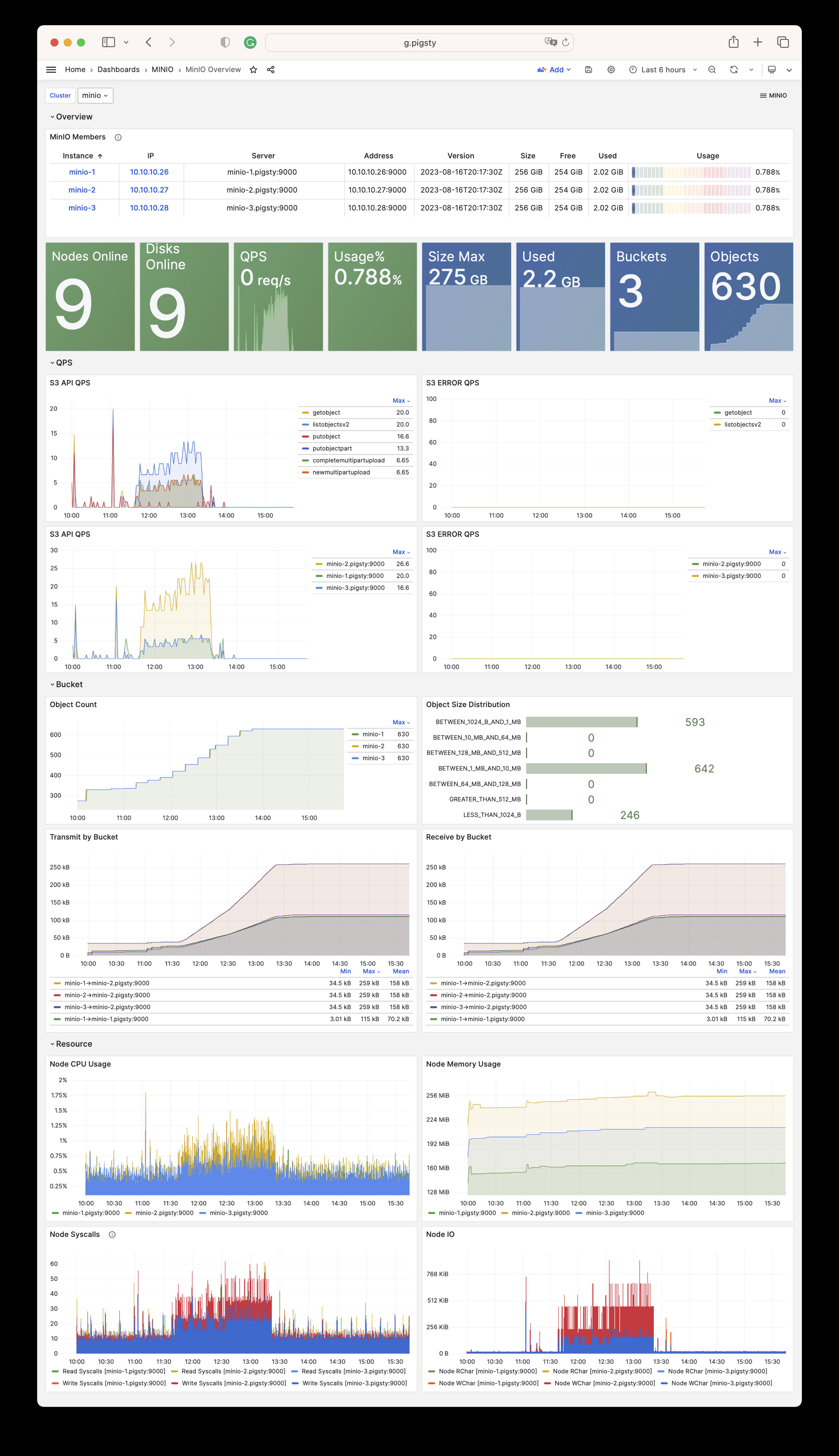

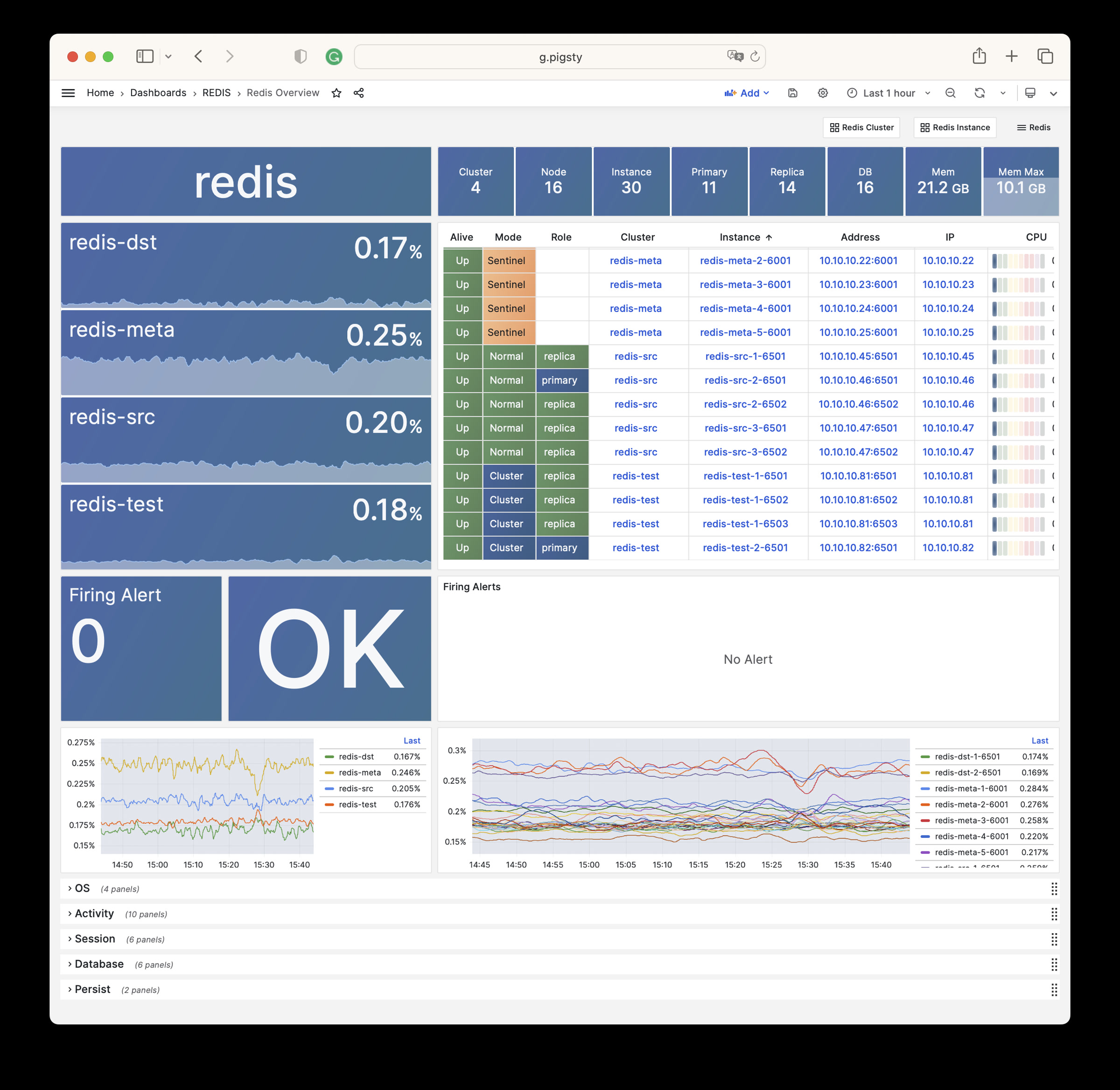
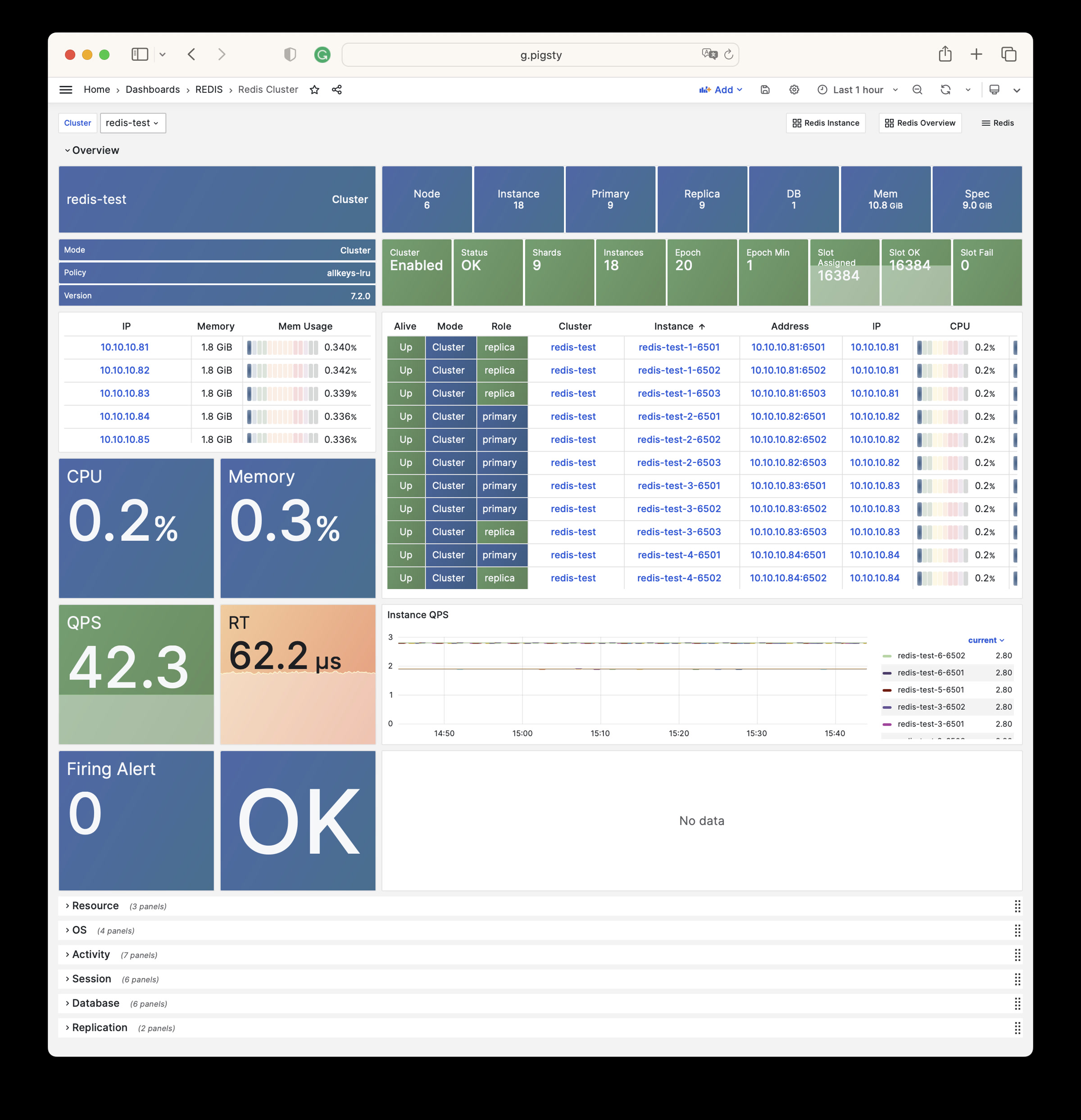
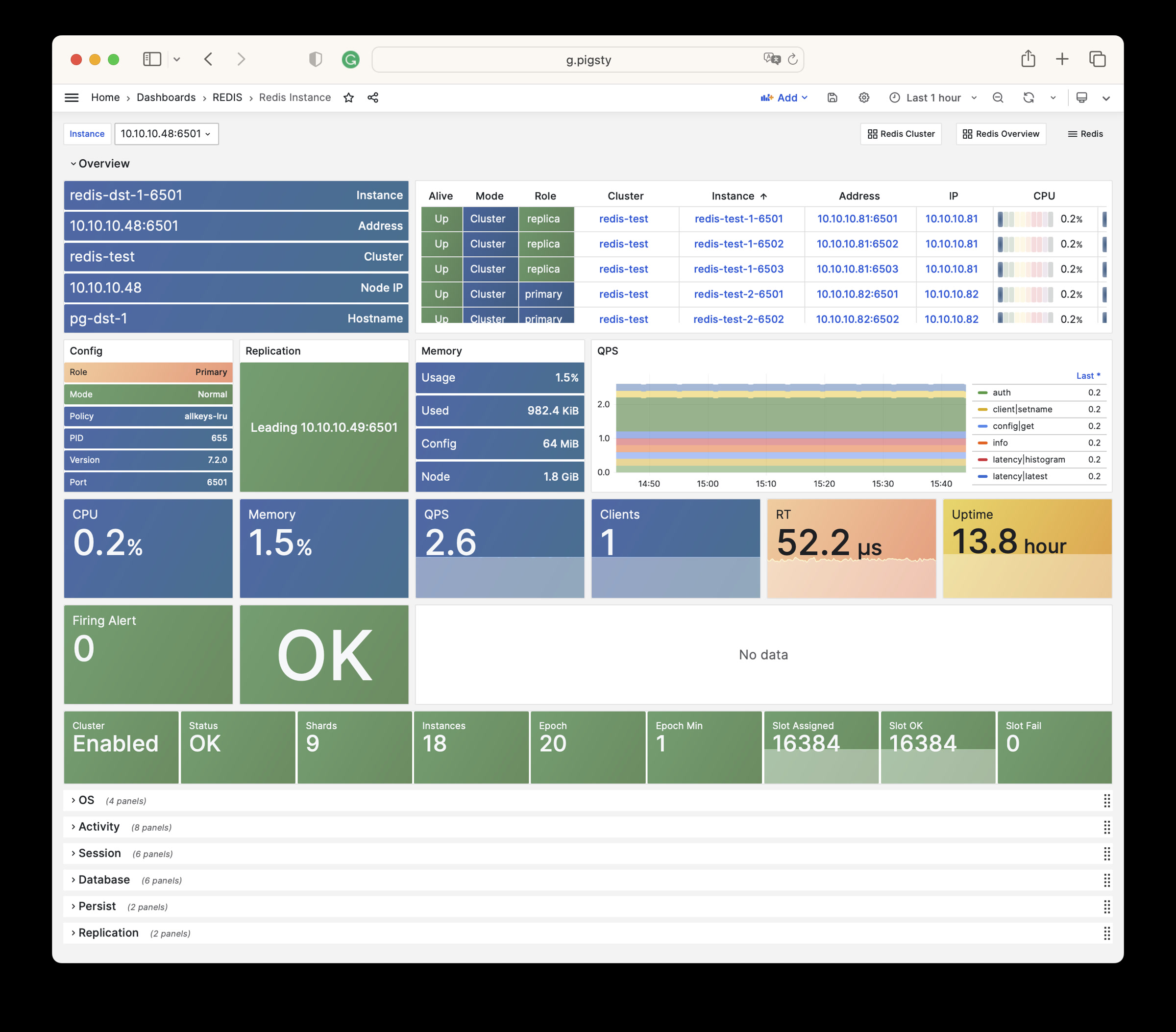


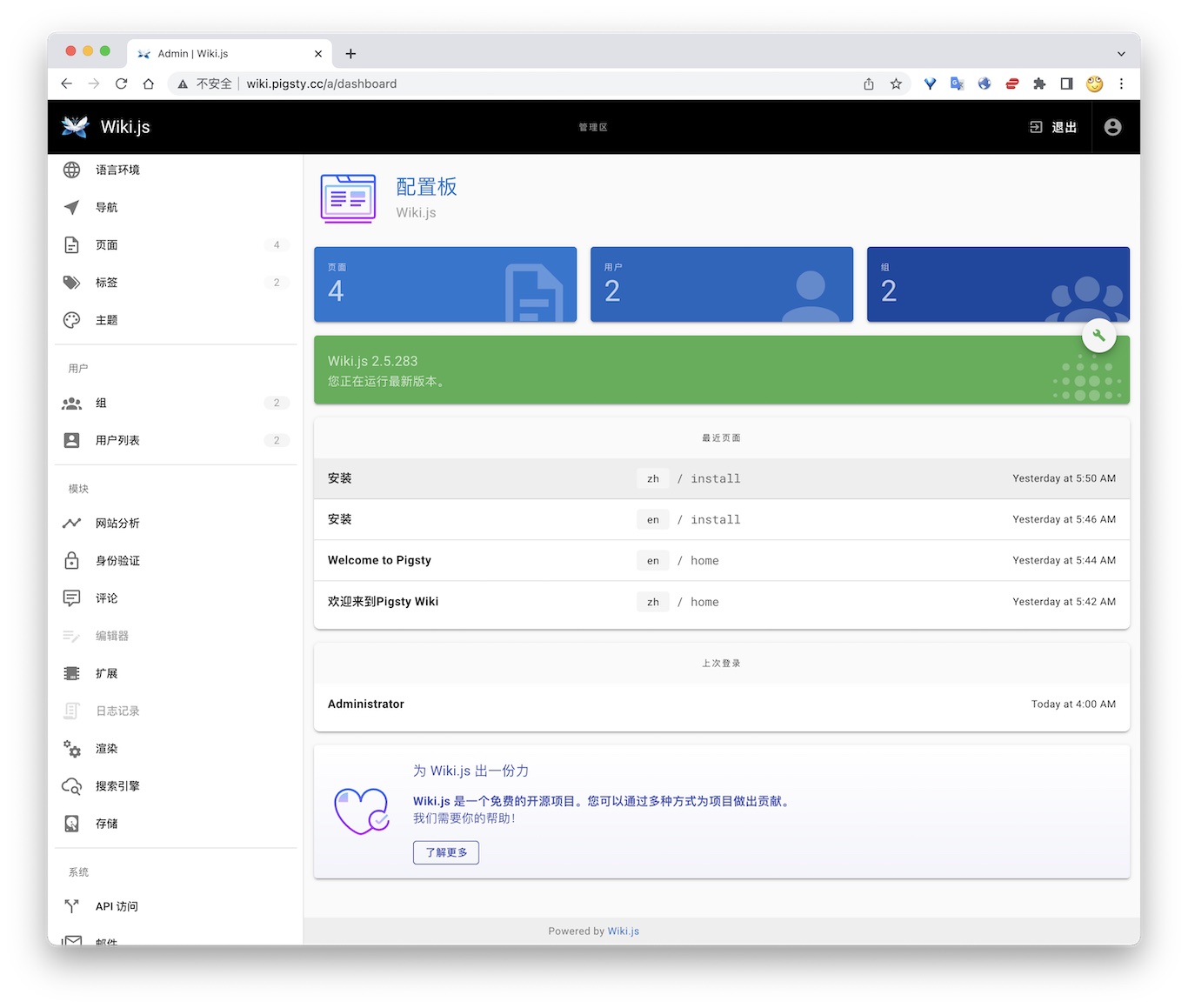
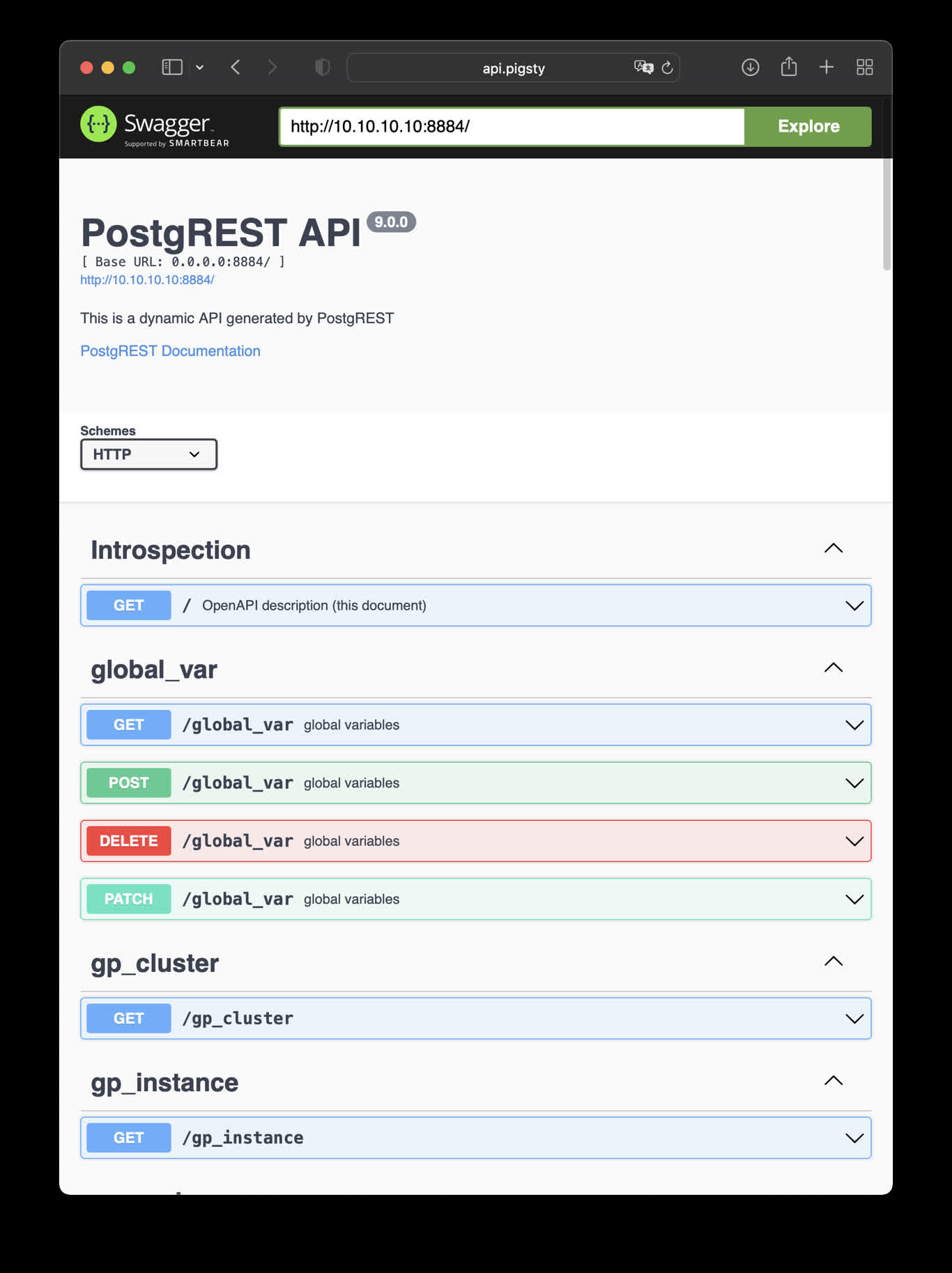
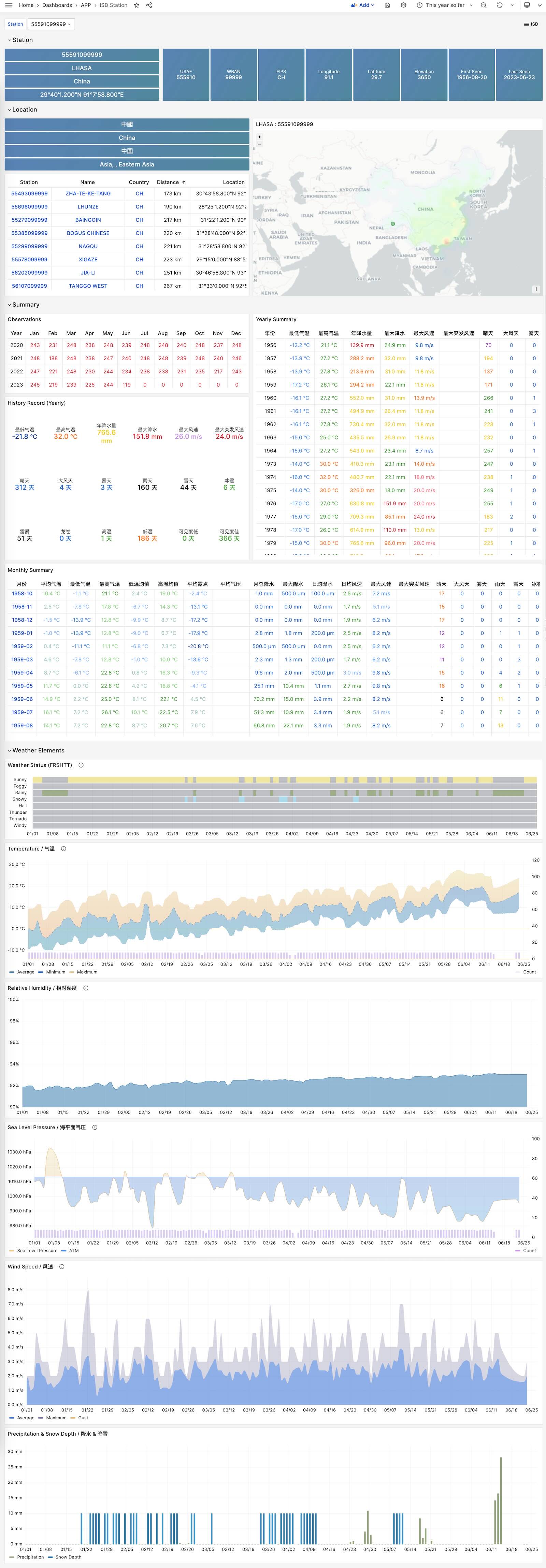
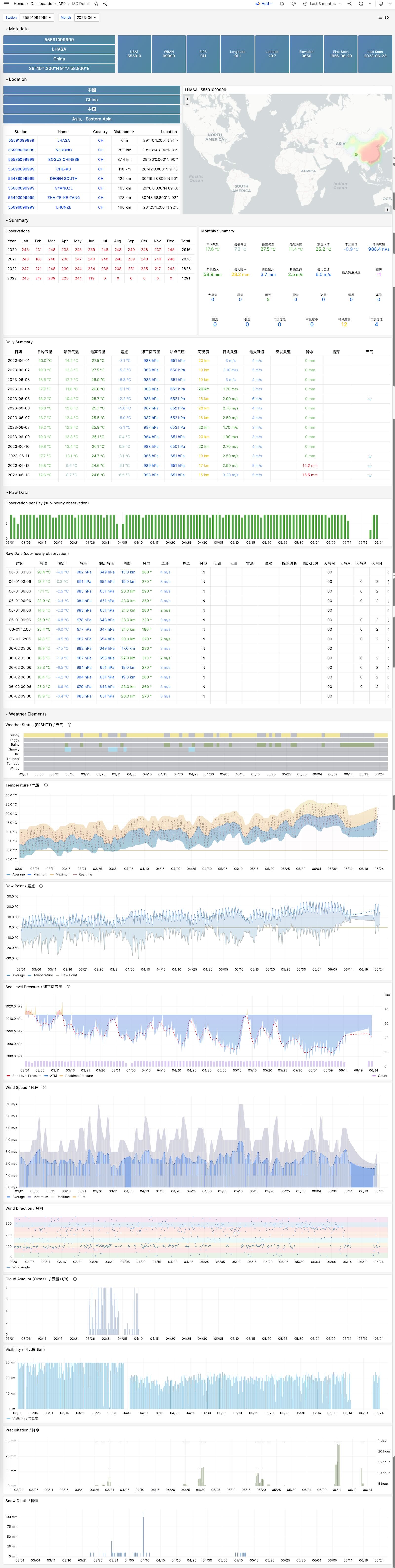
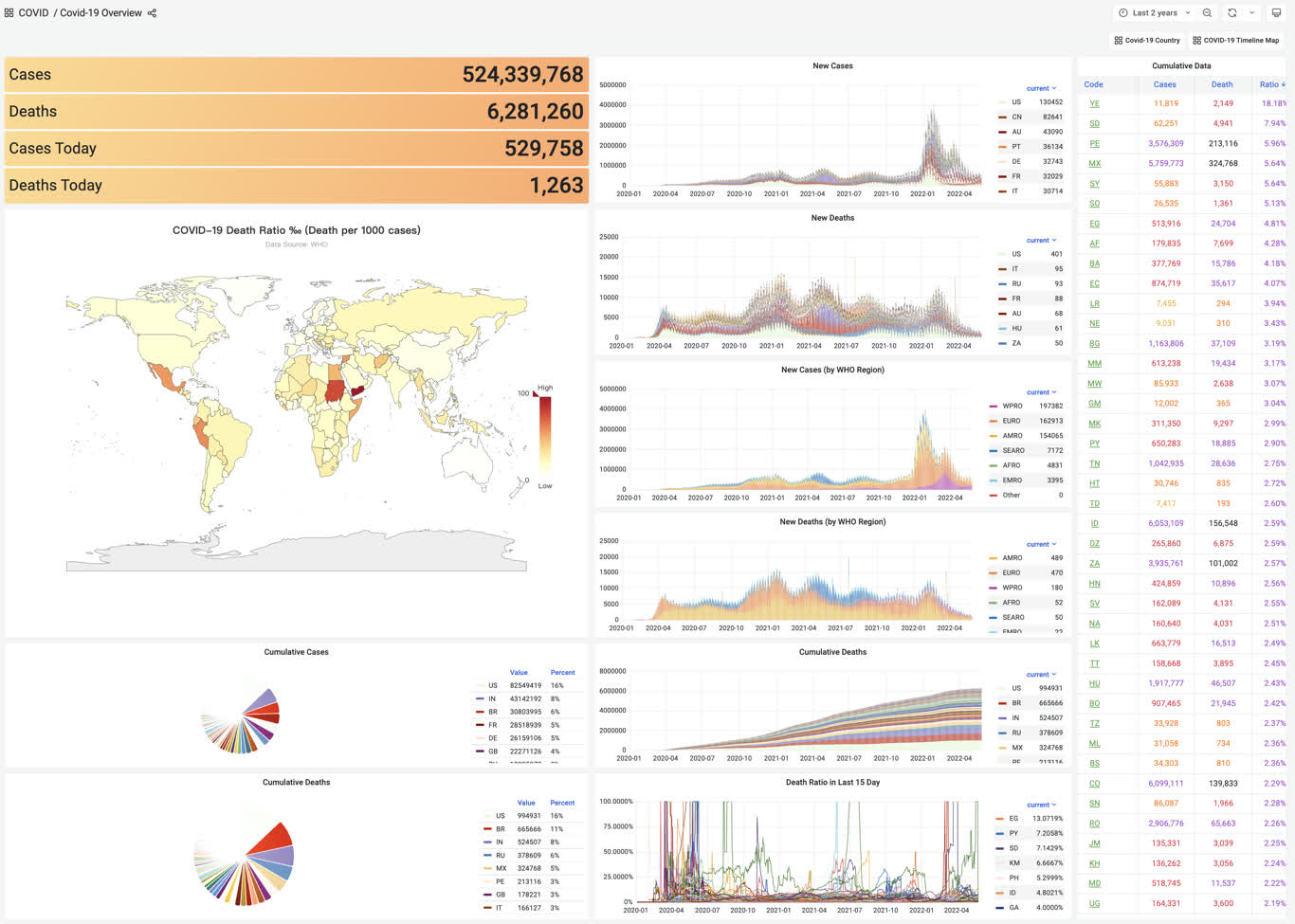
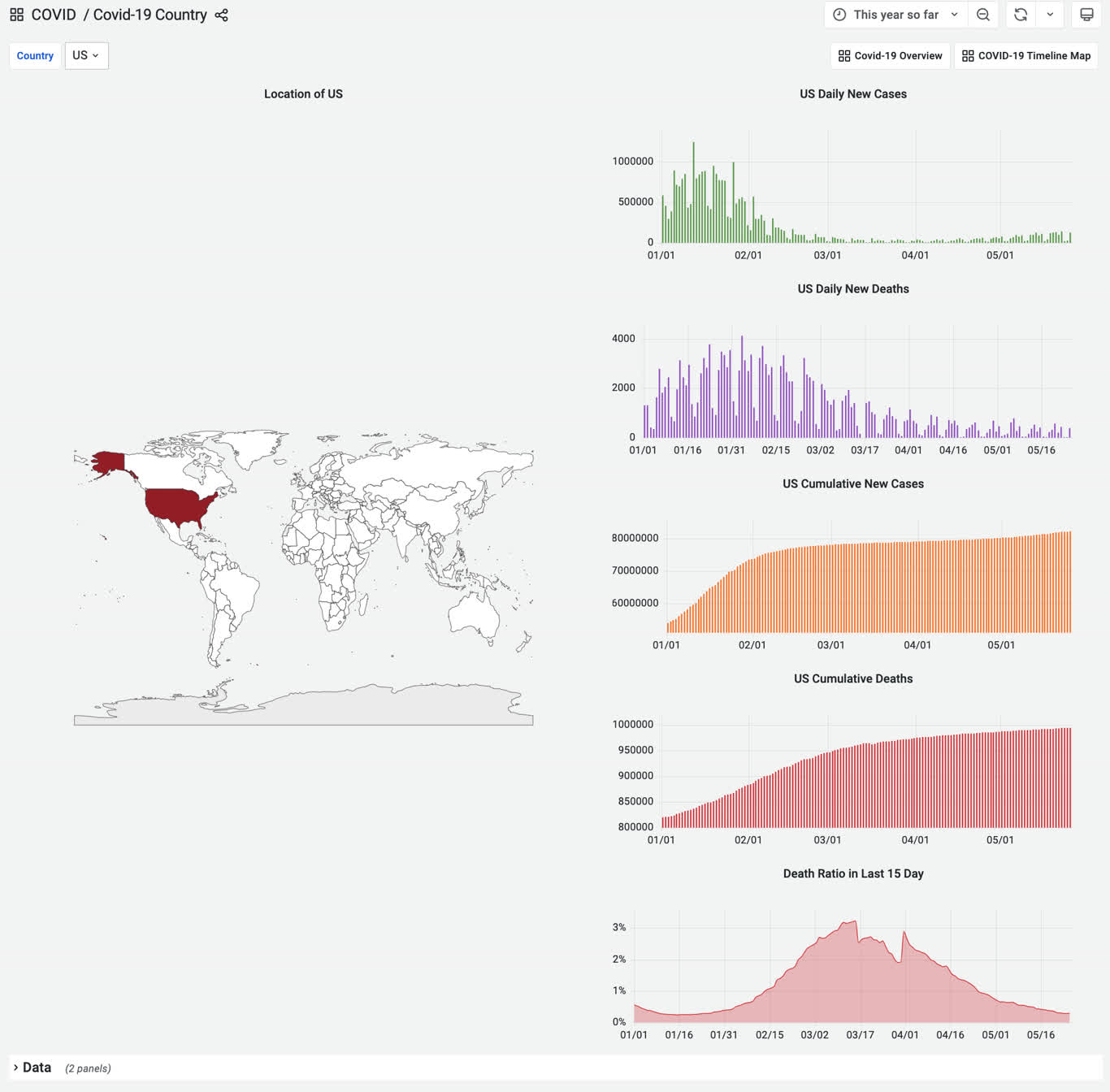
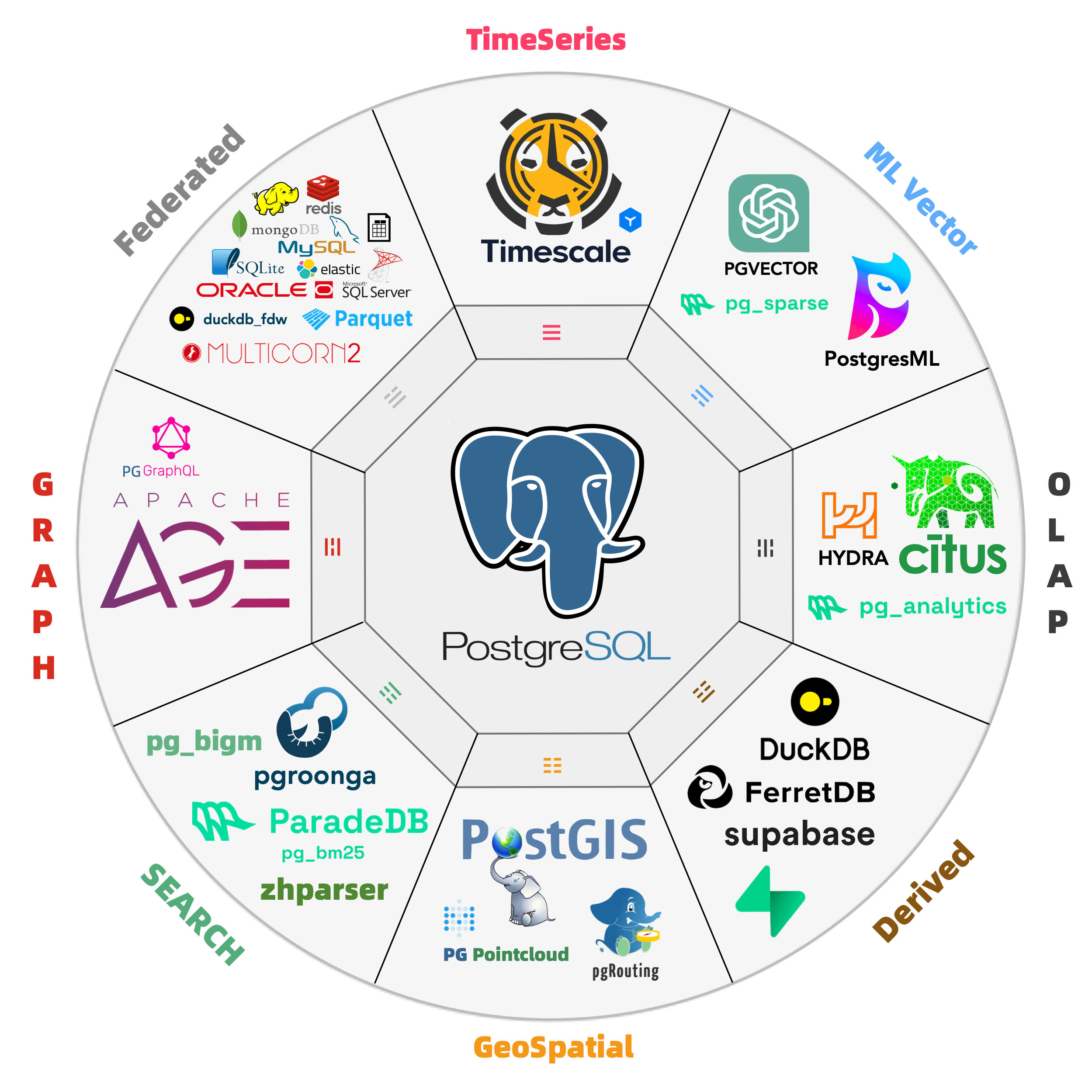{kind=link}