Concept
Module:
Categories:
PGSQL for production environments is organized in clusters, which clusters are logical entities consisting of a set of database instances associated by primary-replica. Each database cluster is an autonomous serving unit consisting of at least one database instance (primary).
ER Diagram
Let’s get started with ER diagram. There are four types of core entities in Pigsty’s PGSQL module:
- PGSQL Cluster: An autonomous PostgreSQL business unit, used as the top-level namespace for other entities.
- PGSQL Service: A named abstraction of cluster ability, route traffics, and expose postgres services with node ports.
- PGSQL Instance: A single postgres server which is a group of running processes & database files on a single node.
- PGSQL Node: An abstraction of hardware resources, which can be bare metal, virtual machine, or even k8s pods.
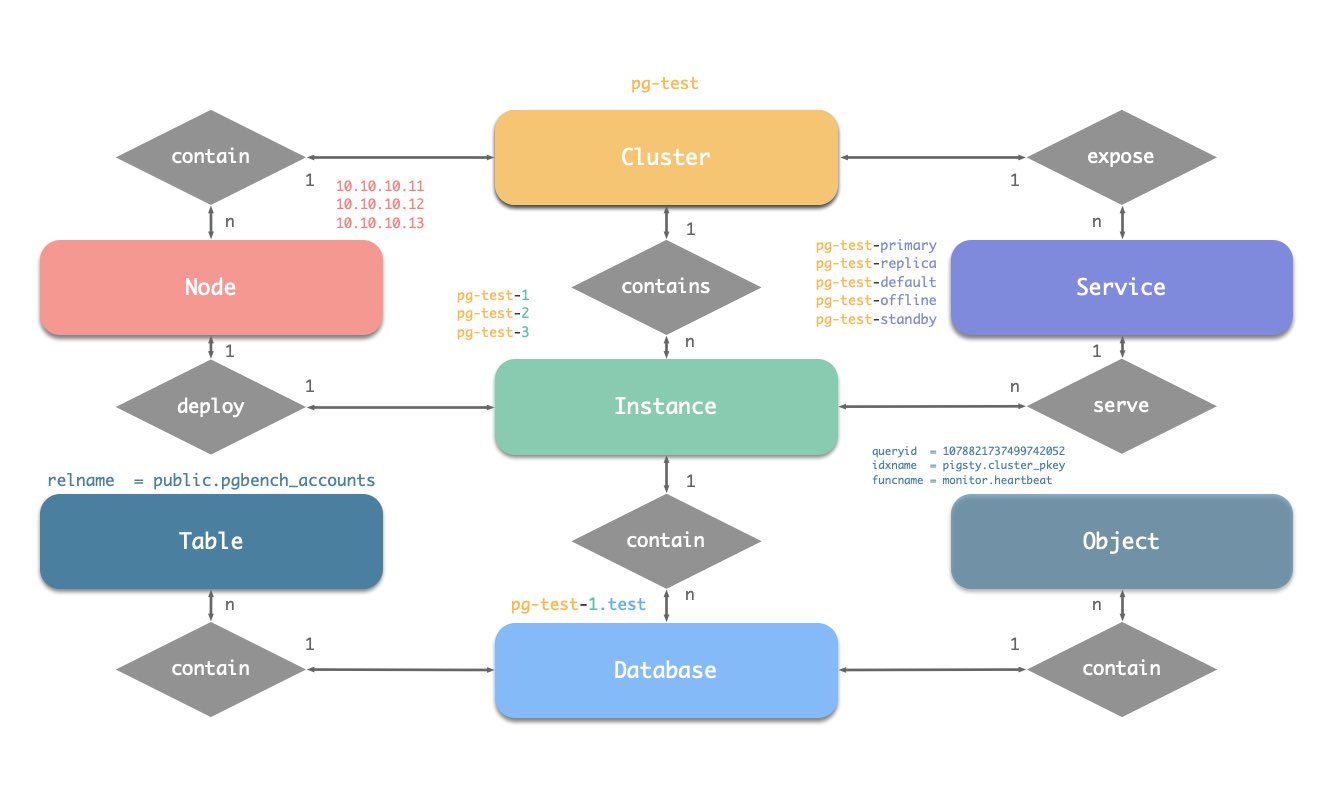
Naming Convention
- The cluster name should be a valid domain name, without any dot:
[a-zA-Z0-9-]+ - Service name should be prefixed with cluster name, and suffixed with a single word: such as
primary,replica,offline,delayed, join by- - Instance name is prefixed with cluster name and suffixed with an integer, join by
-, e.g.,${cluster}-${seq}. - Node is identified by its IP address, and its hostname is usually the same as the instance name since they are 1:1 deployed.
Identity Parameters
Here are some common parameters used to identify PGSQL entities: instance, service, etc…
# pg_cluster: #CLUSTER # pgsql cluster name, required identity parameter
# pg_seq: 0 #INSTANCE # pgsql instance seq number, required identity parameter
# pg_role: replica #INSTANCE # pgsql role, required, could be primary,replica,offline
# pg_instances: {} #INSTANCE # define multiple pg instances on node in `{port:ins_vars}` format
# pg_upstream: #INSTANCE # repl upstream ip addr for standby cluster or cascade replica
# pg_shard: #CLUSTER # pgsql shard name, optional identity for sharding clusters
# pg_group: 0 #CLUSTER # pgsql shard index number, optional identity for sharding clusters
# gp_role: master #CLUSTER # greenplum role of this cluster, could be master or segment
pg_offline_query: false #INSTANCE # set to true to enable offline query on this instance
You have to assign these identity parameters explicitly, there’s no default value for them.
| Name | Type | Level | Description |
|---|---|---|---|
pg_cluster |
string |
C | PG database cluster name |
pg_seq |
number |
I | PG database instance id |
pg_role |
enum |
I | PG database instance role |
pg_shard |
string |
C | PG database shard name of cluster |
pg_group |
number |
C | PG database shard index of cluster |
pg_cluster: It identifies the name of the cluster, which is configured at the cluster level.pg_role: Configured at the instance level, identifies the role of the ins. Only theprimaryrole will be handled specially. If not filled in, the default is thereplicarole and the specialdelayedandofflineroles.pg_seq: Used to identify the ins within the cluster, usually with an integer number incremented from 0 or 1, which is not changed once it is assigned.{{ pg_cluster }}-{{ pg_seq }}is used to uniquely identify the ins, i.e.pg_instance.{{ pg_cluster }}-{{ pg_role }}is used to identify the services within the cluster, i.e.pg_service.pg_shardandpg_groupare used for horizontally sharding clusters, for citus & greenplum only.
pg_cluster, pg_role, pg_seq are core identity params,
which are required for any Postgres cluster, and must be explicitly specified. Here’s an example:
pg-test:
hosts:
10.10.10.11: {pg_seq: 1, pg_role: replica}
10.10.10.12: {pg_seq: 2, pg_role: primary}
10.10.10.13: {pg_seq: 3, pg_role: replica}
vars:
pg_cluster: pg-test
Here are entities & resources in this cluster
- one cluster:
pg-test - two roles:
primary&replica - three instances:
pg-test-1,pg-test-2,pg-test-3 - three nodes:
10.10.10.11,10.10.10.12,10.10.10.13 - four services:
pg-test-primary: Read-Write Servicepg-test-replica: Read-Only Servicepg-test-default: Direct RW Servicepg-test-offline: Offline Read Service
And the corresponding metrics will be labeled with these identity parameters in the monitoring system (Prometheus/Grafana/Loki):
pg_up{cls="pg-meta", ins="pg-meta-1", ip="10.10.10.10", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", job="pgsql"}
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.